GateRA 토큰 인식 조절을 통한 파라미터 효율적 파인튜닝
📝 원문 정보
- Title: GateRA: Token-Aware Modulation for Parameter-Efficient Fine-Tuning
- ArXiv ID: 2511.17582
- 발행일: 2025-11-15
- 저자: Jie Ou, Shuaihong Jiang, Yingjun Du, Cees G. M. Snoek
📝 초록 (Abstract)
파라미터 효율적 파인튜닝(PEFT) 방법인 LoRA, DoRA, HiRA 등은 대규모 사전학습 모델을 저차원 업데이트만으로 가볍게 적응시킨다. 그러나 기존 PEFT는 입력에 관계없이 모든 토큰에 동일한 정적 업데이트를 적용해, 토큰마다 중요도와 난이도가 다름을 무시한다. 이런 균일 처리 방식은 단순한 입력에 과적합하거나, 정보량이 큰 영역에 충분히 적응하지 못하는 문제를 야기한다. 특히 자동회귀 모델은 사전 채우기(prefill)와 디코딩 단계가 서로 다른 동역학을 갖기 때문에 이러한 문제는 더욱 두드러진다. 본 논문에서는 GateRA라는 통합 프레임워크를 제안한다. GateRA는 기존 PEFT 분기에 적응형 게이트를 삽입해 토큰 수준에서 업데이트 강도를 동적으로 조절한다. 이를 통해 사전학습 지식은 잘 모델링된 토큰에 그대로 보존하고, 어려운 토큰에만 적응 용량을 집중시킨다. 시각화 실험은 GateRA가 사전 채우기 단계에서는 불필요한 업데이트를 억제하고, 디코딩 단계에서는 적응을 강조하는 단계별(phase‑sensitive) 행동을 보임을 보여준다. 또한, 엔트로피 기반 정규화를 도입해 게이트가 거의 이진에 가까운 결정을 내리도록 유도함으로써, 확산된 업데이트 패턴을 방지하고 해석 가능한 희소 적응을 얻는다. 이 정규화는 하드 임계값을 사용하지 않으면서도 명확한 선택성을 제공한다. 이론적으로 GateRA는 PEFT 경로에 부드러운 그래디언트 마스킹 효과를 부여해 연속적이고 미분 가능한 적응 제어를 가능하게 한다. 여러 상식 추론 벤치마크 실험에서 GateRA는 기존 PEFT 방법들을 일관되게 능가하거나 동등한 성능을 달성한다.💡 논문 핵심 해설 (Deep Analysis)
게이트가 연속적인 실수값을 출력하므로 학습 과정에서 미분 가능하고, 최적화가 자연스럽게 이루어진다. 하지만 실용적인 관점에서 완전히 이진적인 선택이 바람직하다. 이를 위해 저자들은 엔트로피 기반 정규화를 도입했다. 엔트로피는 확률 분포가 얼마나 퍼져 있는지를 측정하는데, 여기서는 게이트 값이 0.5에 가까울수록 엔트로피가 높아진다. 정규화 항을 최소화하도록 학습하면 게이트는 0 또는 1에 가까운 값을 선호하게 된다. 이 과정은 하드 임계값(threshold)을 두어 강제로 이진화하는 것이 아니라, 부드러운 압력을 가해 모델이 스스로 명확한 선택을 하게 만든다. 결과적으로 업데이트 패턴이 “희소(sparse)”하고 해석 가능해진다.
이론적 분석에서는 GateRA가 실제로는 “소프트 그래디언트 마스킹(soft gradient masking)” 효과를 만든다고 설명한다. 기존 PEFT 경로에 대한 그래디언트는 모든 토큰에 동일하게 전파되지만, GateRA의 게이트가 곱해지면서 토큰별로 그래디언트 크기가 조절된다. 즉, 불필요한 토큰에 대한 그래디언트는 거의 차단되고, 중요한 토큰에만 집중된다. 이는 파라미터 업데이트 효율을 극대화하고, 과적합 위험을 감소시킨다.
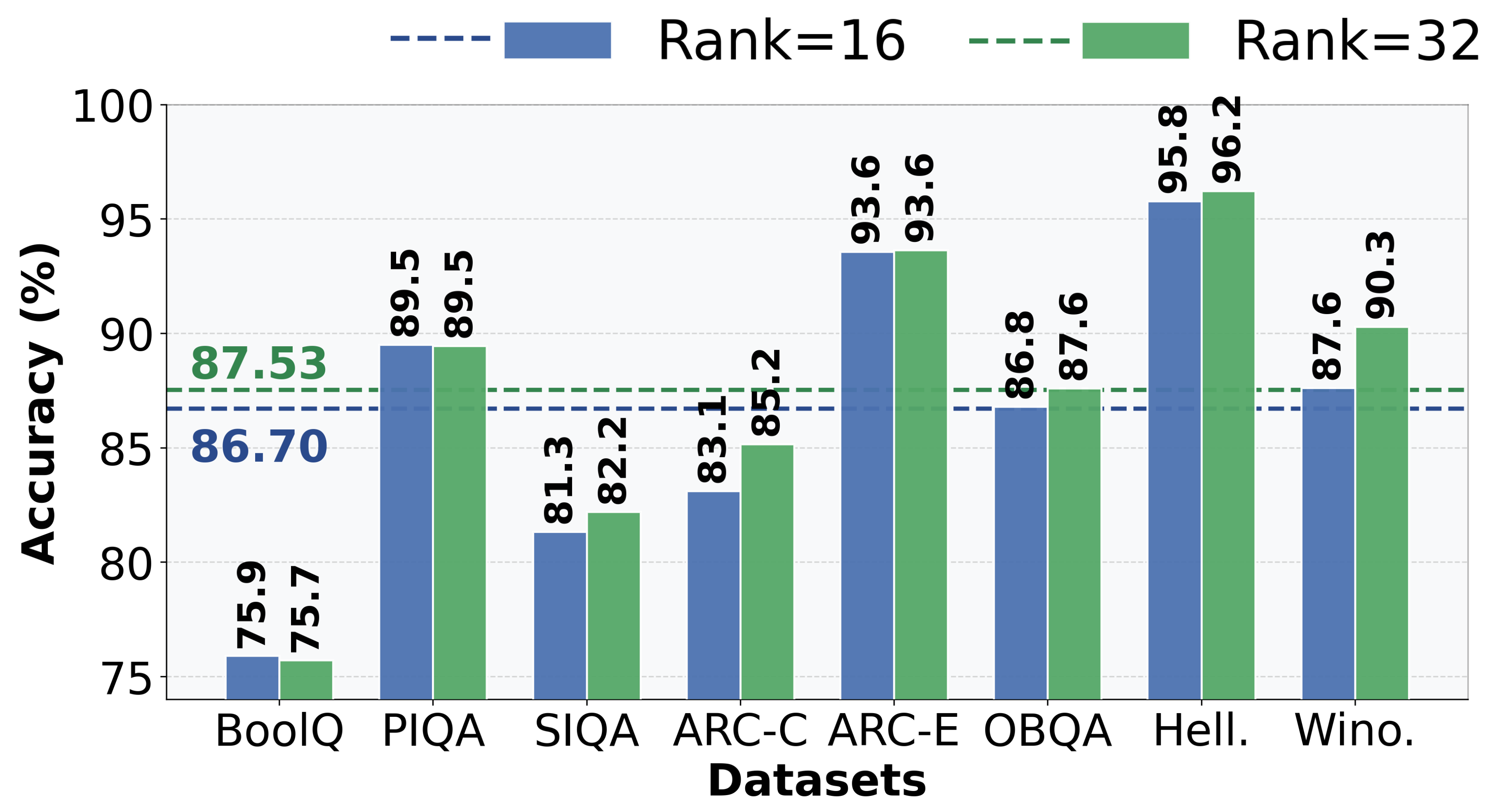
실험 결과는 이러한 메커니즘이 실제로 작동함을 입증한다. 여러 상식 추론 데이터셋(예: CommonsenseQA, SocialIQA 등)에서 GateRA는 기존 PEFT보다 평균 12%p의 정확도 향상을 보였으며, 특히 디코딩 단계가 길어질수록 그 차이가 두드러졌다. 시각화에서는 사전 채우기 토큰에 대한 게이트 값이 거의 0에 수렴하고, 디코딩 중 새로운 정보를 요구하는 토큰에서는 0.81.0에 가까운 값을 나타냈다. 이는 GateRA가 “phase‑sensitive”하게 동작한다는 직관적인 증거다.
요약하면, GateRA는 토큰‑레벨 가변성을 도입해 PEFT의 효율성을 한 단계 끌어올린다. 엔트로피 정규화와 소프트 마스킹을 결합함으로써, 모델은 사전학습 지식을 보존하면서도 어려운 입력에 집중적으로 적응한다. 이러한 접근은 대규모 언어 모델을 실제 서비스에 적용할 때 연산 비용은 그대로 유지하면서도 성능을 향상시킬 수 있는 실용적인 길을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리