건강·웰니스용 대형 언어 모델 개발·평가를 위한 원칙 기반 프레임워크
📝 원문 정보
- Title: A Principle-based Framework for the Development and Evaluation of Large Language Models for Health and Wellness
- ArXiv ID: 2512.08936
- 발행일: 2025-10-23
- 저자: Brent Winslow, Jacqueline Shreibati, Javier Perez, Hao-Wei Su, Nichole Young-Lin, Nova Hammerquist, Daniel McDuff, Jason Guss, Jenny Vafeiadou, Nick Cain, Alex Lin, Erik Schenck, Shiva Rajagopal, Jia-Ru Chung, Anusha Venkatakrishnan, Amy Armento Lee, Maryam Karimzadehgan, Qingyou Meng, Rythm Agarwal, Aravind Natarajan, Tracy Giest
📝 초록 (Abstract)
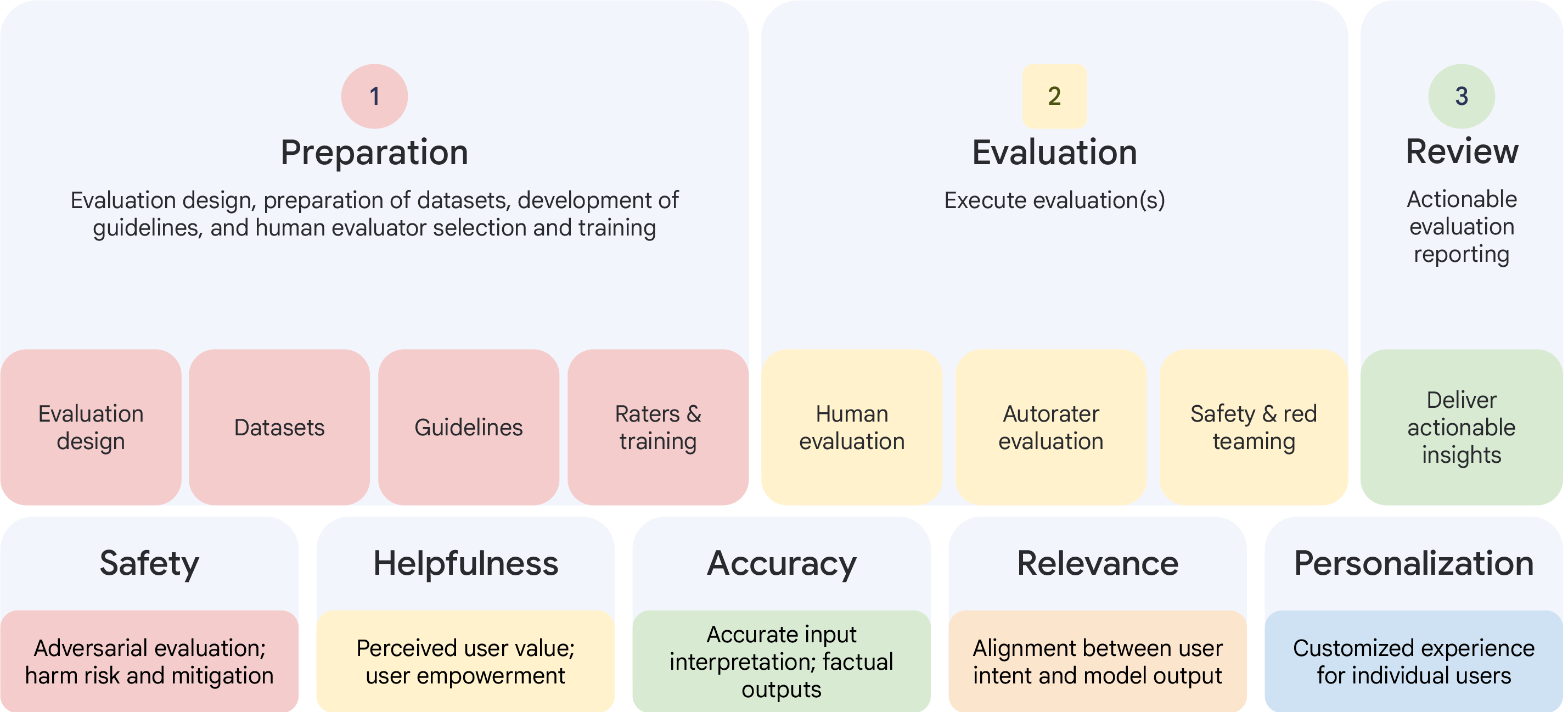
생성형 인공지능을 개인 건강 애플리케이션에 적용하면 맞춤형·데이터 기반의 건강·피트니스 안내가 가능해지는 동시에 사용자 안전, 모델 정확도, 개인정보 보호와 같은 문제도 발생한다. 이를 해결하고자 본 연구에서는 개인 건강·웰니스 분야에 적용되는 대형 언어 모델(LLM)의 체계적인 평가를 위해 새로운 원칙 기반 프레임워크를 개발·검증하였다. 먼저 개인 건강 데이터를 해석하도록 설계된 LLM 기반 시스템인 “Fitbit Insights Explorer”의 개발 과정을 소개한다. 이어서 안전성·유용성·정확성·관련성·개인화(SHARP) 원칙을 중심으로, 일반 사용자와 임상 전문가의 인간 평가, 자동 평점기(autorater) 평가, 적대적 테스트 등을 포함한 종합 평가 기법을 통합한 전 과정 운영 방법론을 제시한다. 이 프레임워크를 13,000명 이상의 사전 동의 사용자를 대상으로 단계적 배포한 결과, 초기 테스트에서는 드러나지 않았던 문제들을 체계적으로 발견하고, 이를 기반으로 시스템을 개선함으로써 기술적 평가와 실제 사용자 피드백을 결합하는 필요성을 입증하였다. 최종적으로 본 연구는 LLM 기반 건강 애플리케이션의 책임 있는 개발·배포를 위한 실용적이고 표준화된 접근법을 제공하여, 혁신을 촉진하면서도 안전하고 효과적이며 신뢰할 수 있는 기술 구현을 지원한다.💡 논문 핵심 해설 (Deep Analysis)
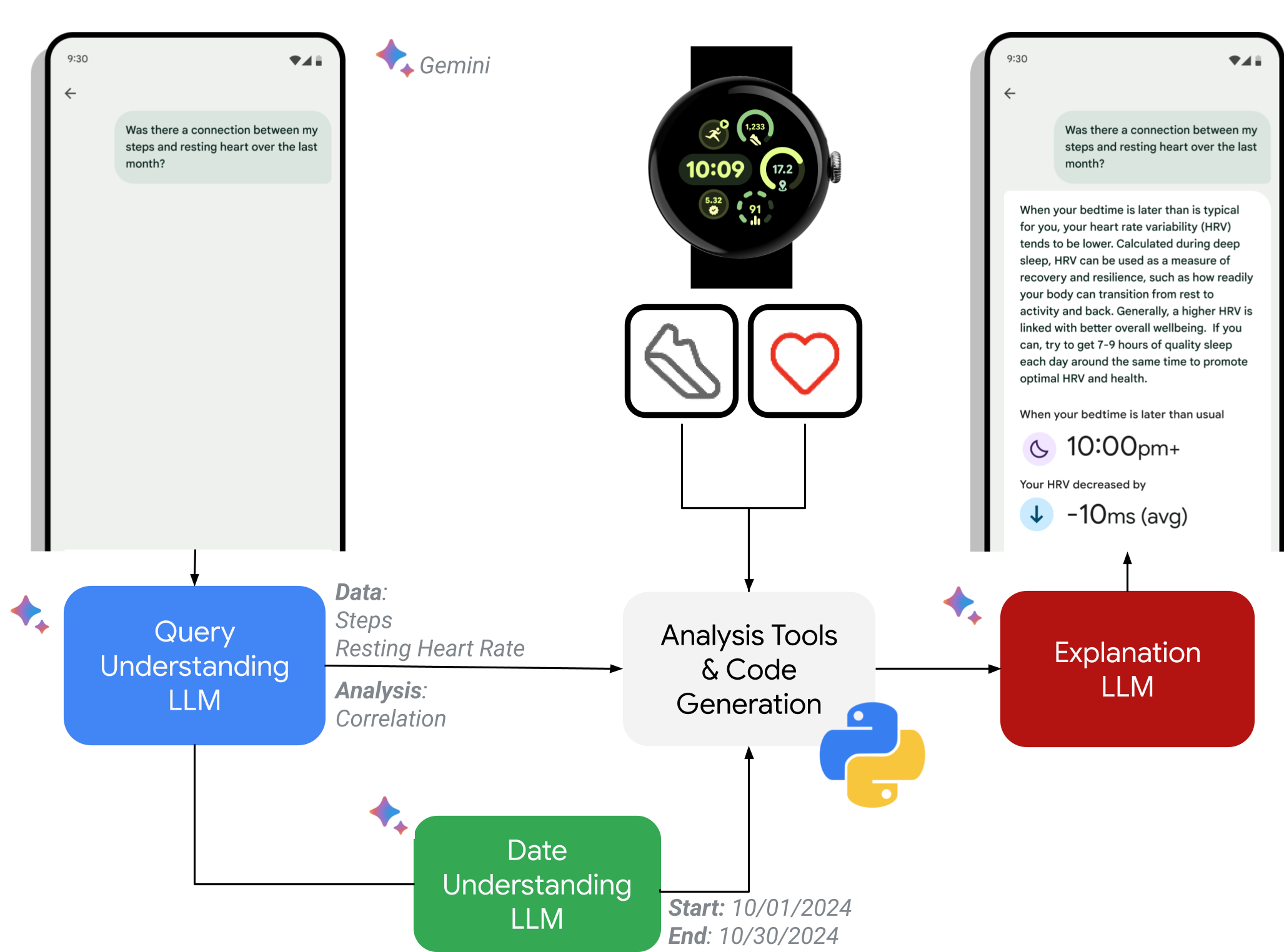
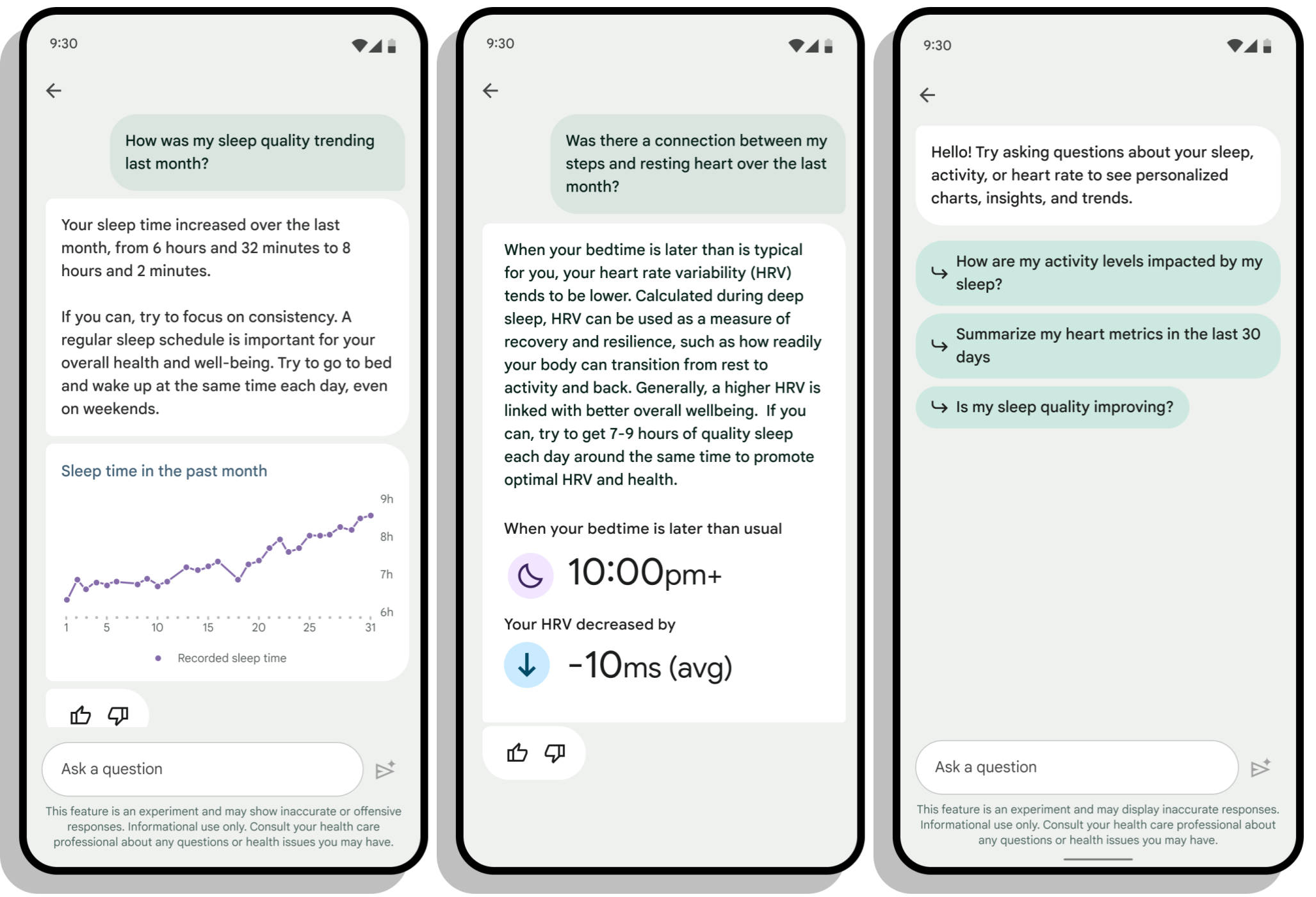
‘Fitbit Insights Explorer’는 실제 웨어러블 데이터(심박수, 걸음 수, 수면 패턴 등)를 LLM에 입력해 사용자가 이해하기 쉬운 언어로 해석해 주는 서비스이다. 논문은 이 시스템을 개발 단계에서부터 SHARP 프레임워크를 적용해 반복적인 피드백 루프를 운영했으며, 13 000명 이상의 사전 동의 사용자를 대상으로 단계적 배포(베타 → 파일럿 → 정식)하면서 실사용 데이터를 수집했다. 특히 초기 베타 테스트에서는 발견되지 않았던 ‘프라이버시 누출 위험’이나 ‘잘못된 건강 조언’ 같은 문제를 적대적 테스트와 임상 전문가 리뷰를 통해 식별하고, 모델 프롬프트 조정·추가 검증 레이어 도입 등 구체적인 개선 조치를 취했다.
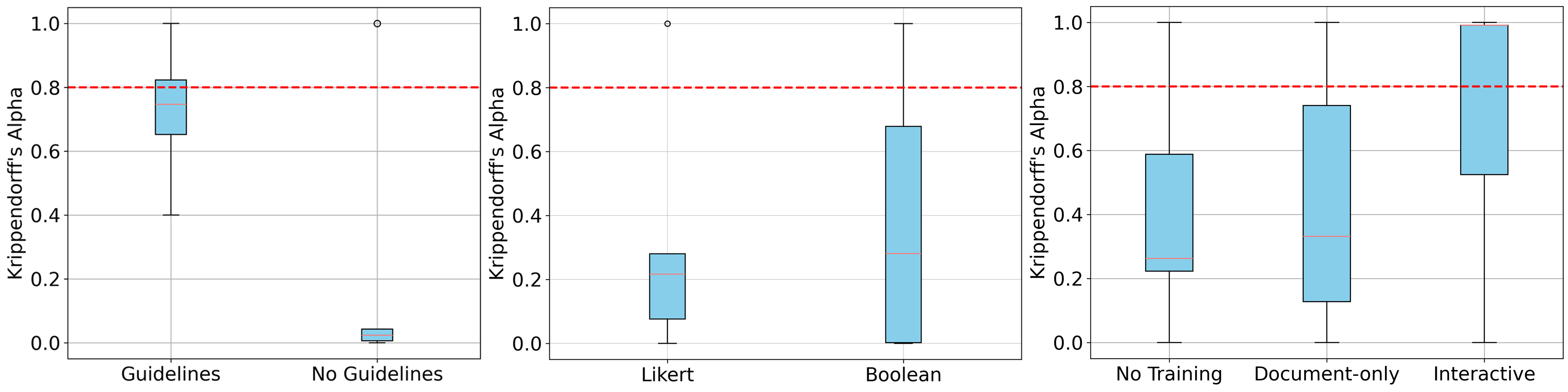
이러한 실증적 접근은 두 가지 중요한 시사점을 제공한다. 첫째, 기술적 성능(예: perplexity, BLEU 등)만으로는 건강 분야 LLM의 안전성을 보장할 수 없으며, 실제 사용자와 전문가의 질적 피드백이 필수적이다. 둘째, 프레임워크를 개발·배포 전후에 일관되게 적용함으로써 문제 발견·수정 주기가 짧아져, 제품이 시장에 나가기 전 위험을 최소화한다.
한계점도 존재한다. 연구는 Fitbit 데이터에 국한되어 있어 다른 종류의 생리 데이터(예: 혈당, 혈압)나 비웨어러블 기반 데이터에 대한 일반화 가능성을 검증하지 못했다. 또한 ‘일반 사용자’ 평가가 주로 영미권 사용자에 의존했을 가능성이 있어 문화·언어적 다양성을 충분히 반영하지 못했을 수 있다. 향후 연구에서는 다국어·다문화 사용자 집단을 포함한 확장된 파일럿을 진행하고, 의료 규제(예: FDA, CE)와 연계된 인증 절차를 프레임워크에 통합하는 방안을 모색해야 한다.
결론적으로, 이 논문은 LLM을 건강·웰니스 서비스에 적용할 때 필요한 ‘안전·유용·정확·관련·개인화’라는 다차원 평가 기준을 제시하고, 이를 실제 제품 개발에 적용한 사례를 통해 프레임워크의 실효성을 입증했다. 이는 향후 AI 기반 디지털 헬스케어 솔루션이 책임감 있게 상용화되는 데 중요한 청사진이 될 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리