- Title: Towards Automated Infographic Design Deep Learning-based Auto-Extraction of Extensible Timeline
- ArXiv ID: 1907.13550
- 발행일: 2023-10-10
- 저자: Chen Zhu-Tian, Yun Wang, Qianwen Wang, Yong Wang, and Huamin Qu
📝 초록
디자이너들은 정보그래픽을 만들 때 효과적인 인지성과 시각적 스타일 모두를 고려해야 합니다. 이 과정은 전문 디자이너에게도 어렵고 시간이 많이 소요되며, 초보 사용자는 더욱 어려울 수 있습니다. 따라서 자동화된 정보그래픽 설계에 대한 수요가 있습니다. 본 연구에서는 타임라인 정보그래픽을 자동으로 추출하는 종단 간 접근법을 제안합니다. 우리의 접근 방법은 분해와 재구성의 패러다임을 채택하고, 분해 단계에서 다중 작업 딥 뉴럴 네트워크를 사용하여 비트맵 이미지 타임라인에서 두 가지 유형의 정보를 동시에 해석합니다. 하나는 전체적인 정보, 즉 타임라인의 표현, 척도, 레이아웃 및 방향성이고, 다른 하나는 각 시각 요소의 위치, 범주 및 픽셀입니다. 재구성 단계에서는 비트맵 이미지에서 확장 가능한 템플릿을 추출하기 위해 세 가지 기법인 Non-Maximum Merging, Redundancy Recover, 그리고 DL GrabCut를 사용하는 파이프라인을 제안합니다. 우리의 접근 방법의 효과를 평가하기 위해 합성 타임라인 데이터셋(4296개 이미지)과 인터넷에서 수집한 실제 타임라인 데이터셋(393개 이미지)을 작성하였습니다. 우리는 두 데이터셋에 대한 양적 평가 결과를 보고하고, 자동으로 추출된 템플릿 및 이러한 템플릿을 기반으로 생성된 자동 타임라인의 예제를 제시하여 성능을 질적으로 입증합니다. 결과는 우리의 접근 방법이 실제 타임라인 정보그래픽에서 확장 가능한 템플릿을 효과적으로 추출할 수 있음을 확인합니다.
💡 논문 해설
**핵심 요약**: 이 논문은 디지털 이미지를 이용해 자동으로 타임라인 정보그래픽의 템플릿을 생성하는 방법에 대해 설명합니다. 이를 통해 디자이너는 복잡한 과정 없이도 일관성 있고 효과적인 시각화를 만들 수 있습니다.
문제 제기: 정보그래픽은 데이터를 쉽게 이해할 수 있도록 보여주는 데 매우 중요하지만, 이러한 그래픽을 만들어내는 것은 전문가에게조차 어렵고 시간이 많이 소요됩니다. 특히 타임라인은 역사적 사건이나 과정을 표현하는 데 널리 사용되지만, 디자인과 데이터를 동시에 고려해야 하는 복잡성이 있습니다.
해결 방안 (핵심 기술): 이 논문에서는 비트맵 이미지를 분석하여 타임라인 정보그래픽의 구조적 요소를 추출하는 알고리즘을 제시합니다. 이를 위해 ‘분해’와 ‘재구성’ 단계가 있습니다. ‘분해’ 단계에서 다중 작업 딥 러닝 모델이 이미지에서 전반적인 타임라인의 구조와 각 요소의 위치 및 범주를 분석합니다. ‘재구성’ 단계에서는 이 정보를 이용하여 기존 그래픽을 새로운 데이터로 쉽게 업데이트할 수 있는 확장 가능한 템플릿을 생성하는 방법을 제시합니다.
주요 성과: 논문은 합성된 타임라인 이미지와 실제 웹에서 수집한 이미지를 이용해 알고리즘의 효과를 평가하였습니다. 이는 자동으로 추출된 템플릿이 실제 사용에 적합하다는 것을 보여주었습니다.
의의 및 활용: 이 연구는 정보그래픽 디자인의 자동화를 촉진하여 전문가와 초보자가 쉽게 시각적으로 효과적인 타임라인을 만들 수 있도록 해줍니다. 특히, 이 방법은 데이터 분석이나 스토리텔링에서 중요한 역할을 하는 타임라인 정보그래픽의 제작 과정을 간소화시킵니다.
📄 논문 발췌 (ArXiv Source)
**[도입]**
이 섹션에서는 타임라인 정보그래픽의 배경과 문제를 소개하고, 제안된 접근 방법 및 데이터셋을 개괄합니다.
타임라인 정보그래픽은 최근 Brehmer 등에 의해 연구되었습니다. 다음과 같이 간략히 설명할 수 있습니다:
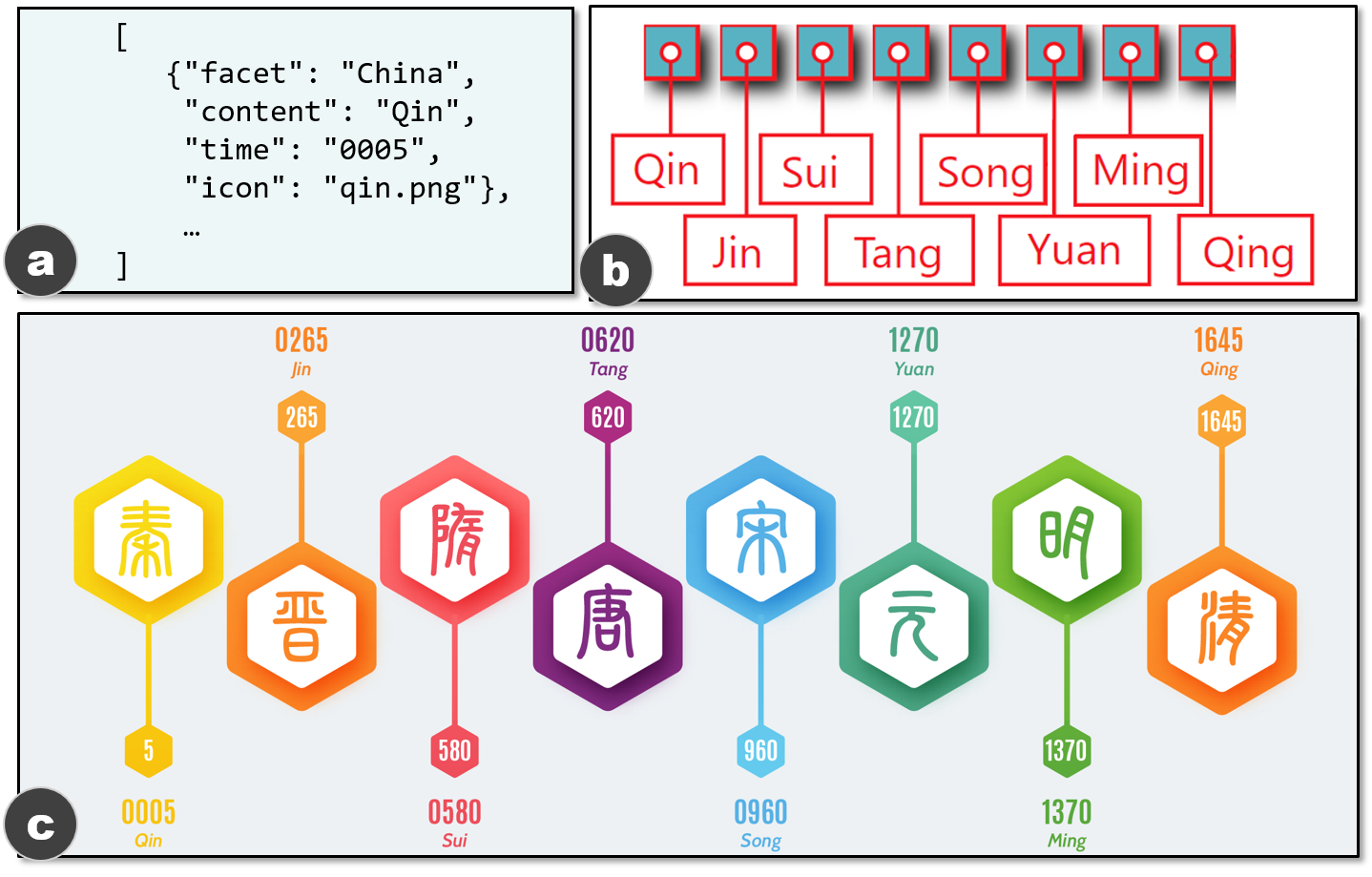
타임라인 데이터: 타임라인은 사건의 구간 데이터(즉, 이벤트 시퀀스)를 표시하며, 연속적인 양적 시간 시리즈 데이터와 다릅니다. 스토리텔링을 위한 타임라인 정보그래픽에는 보통 작은 기본 데이터셋이 사용되며, 이것은 이야기의 핵심 포인트가 이미 원본 데이터셋에서 추출되었다고 가정하기 때문입니다.
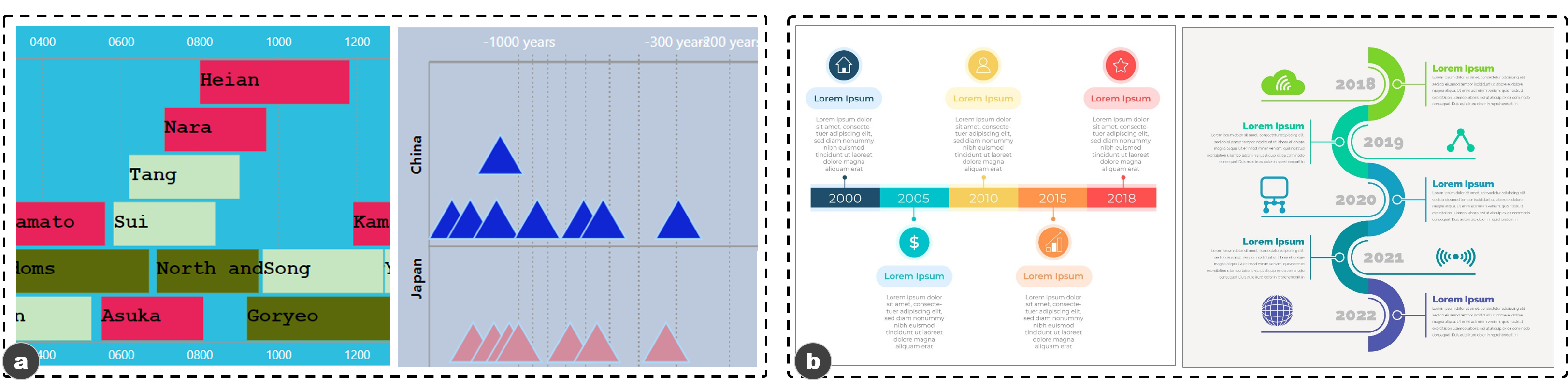
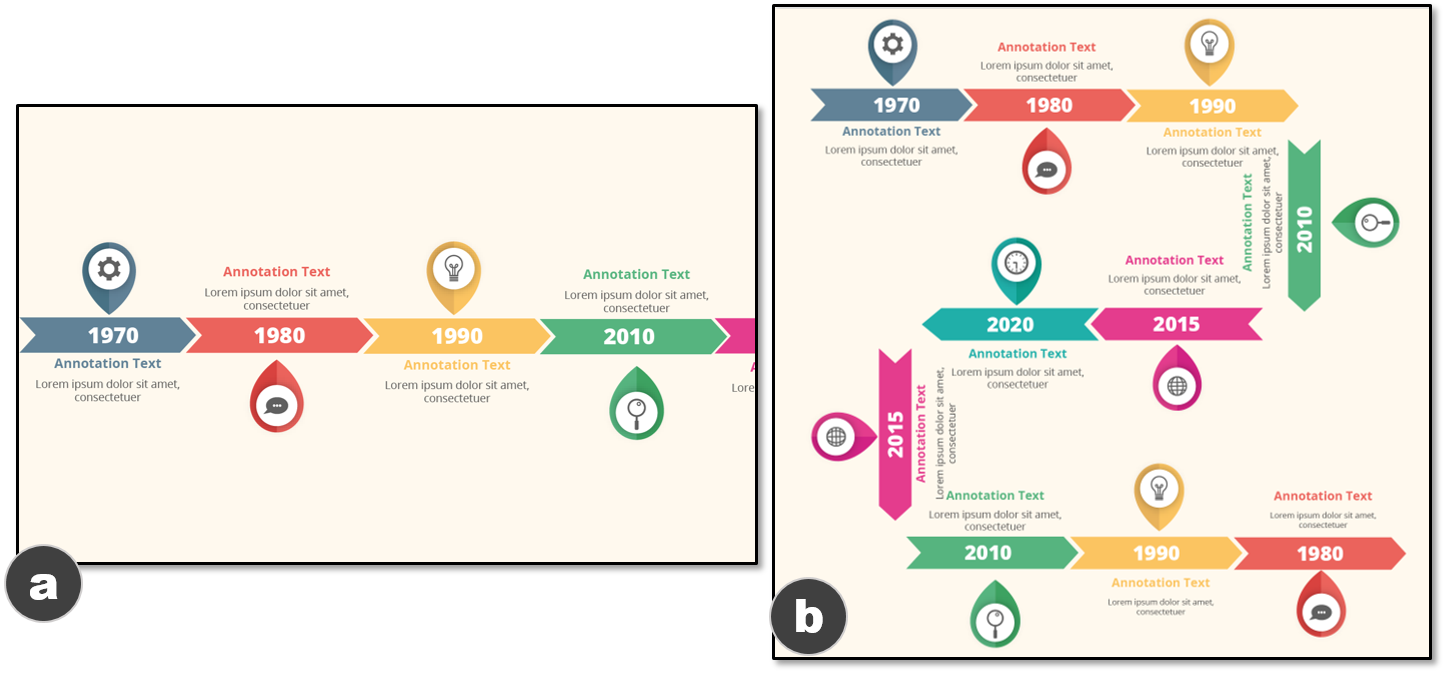
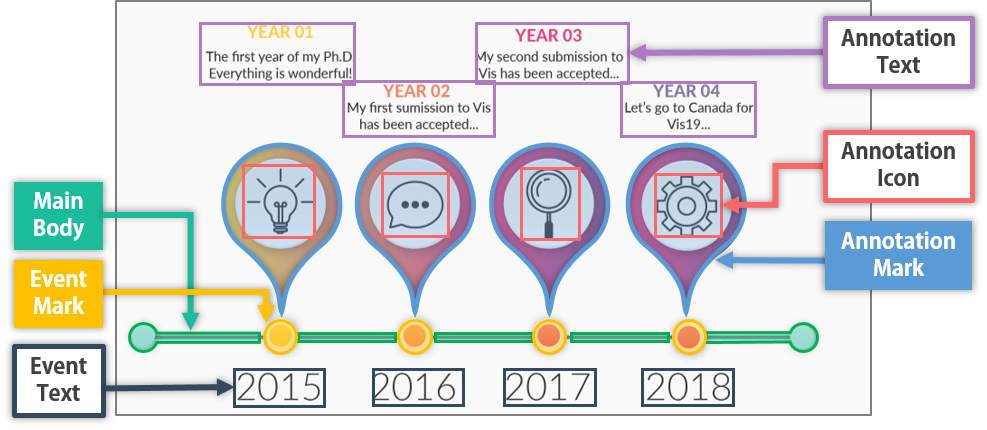
타임라인 디자인: 타임라인은 각 차원에 대해 5개 이하의 옵션만 사용할 수 있습니다(표 참조). 이러한 차원들은 타임라인 내에서 사건들이 어떻게 구성되는지 나타냅니다. 예를 들어, 선형 표현에서는 사건이 직선 위에 배치되며, 이것은 가장 일반적인 타임라인 표현 방법입니다. 보통 이벤트는 그래픽 마크(예: 사각형)로 시각적으로 인코딩됩니다. 이러한 마크의 위치는 해당 이벤트가 발생한 시간을 나타냅니다. 추가적인 주석(예: 텍스트나 아이콘)은 일반적으로 이벤트 마크 옆에 배치되어 이벤트의 세부 정보를 설명합니다.
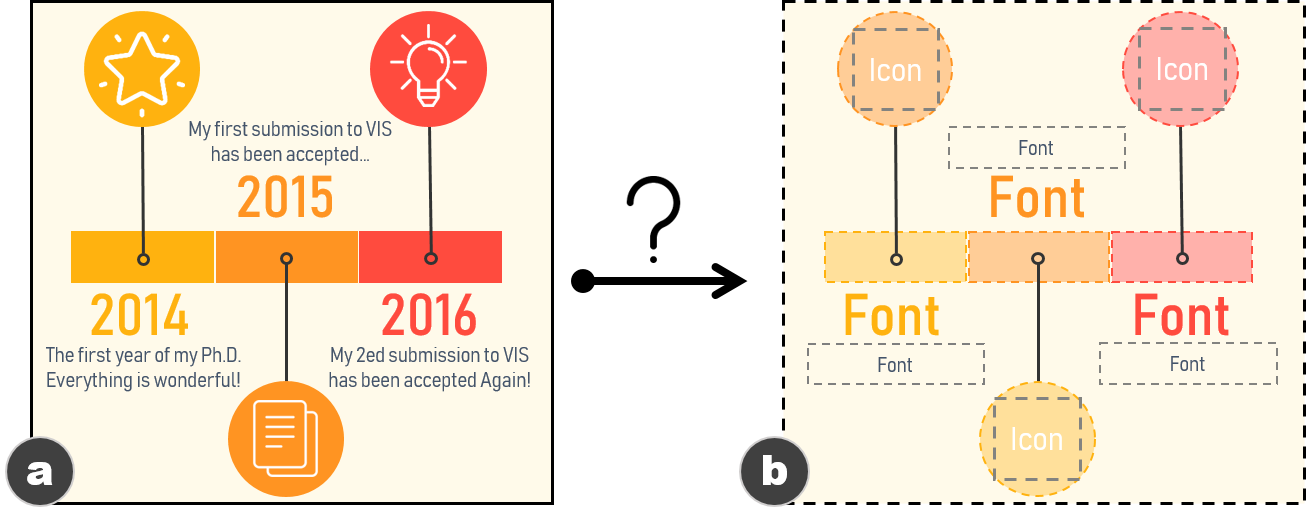
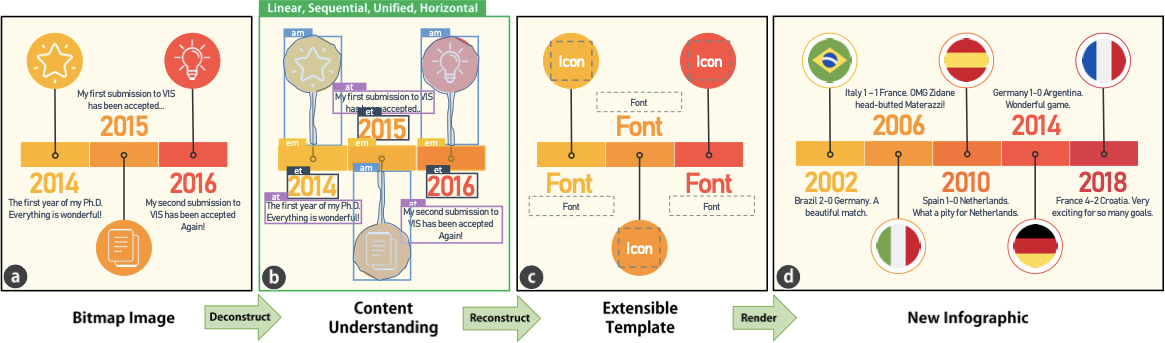
타임라인 정보그래픽은 비트맵 이미지 형태로 널리 사용됩니다. 그러나 이러한 그래픽을 재생산하는 것은 쉽지 않습니다. 따라서, 주어진 비트맵 타임라인이 자동으로 그 확장 가능한 템플릿을 추출할 수 있는 방법을 제안합니다(그림 참조). 이를 위해 다음 두 가지 요구 사항이 충족되어야 합니다:
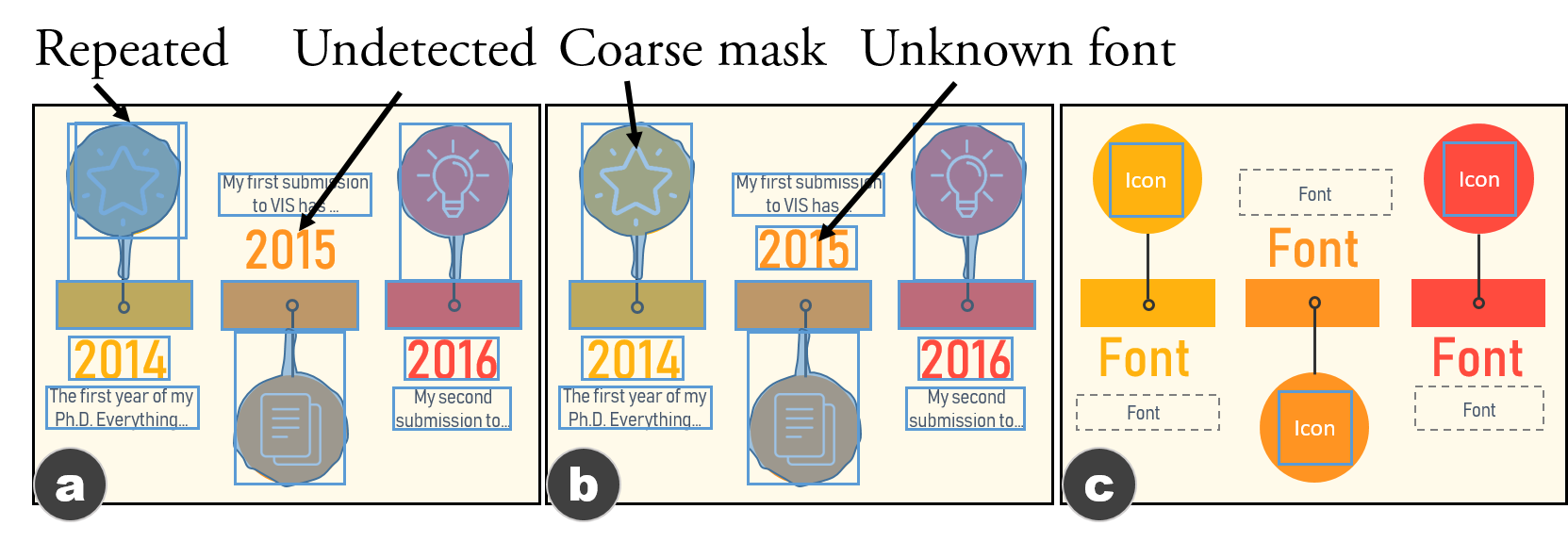
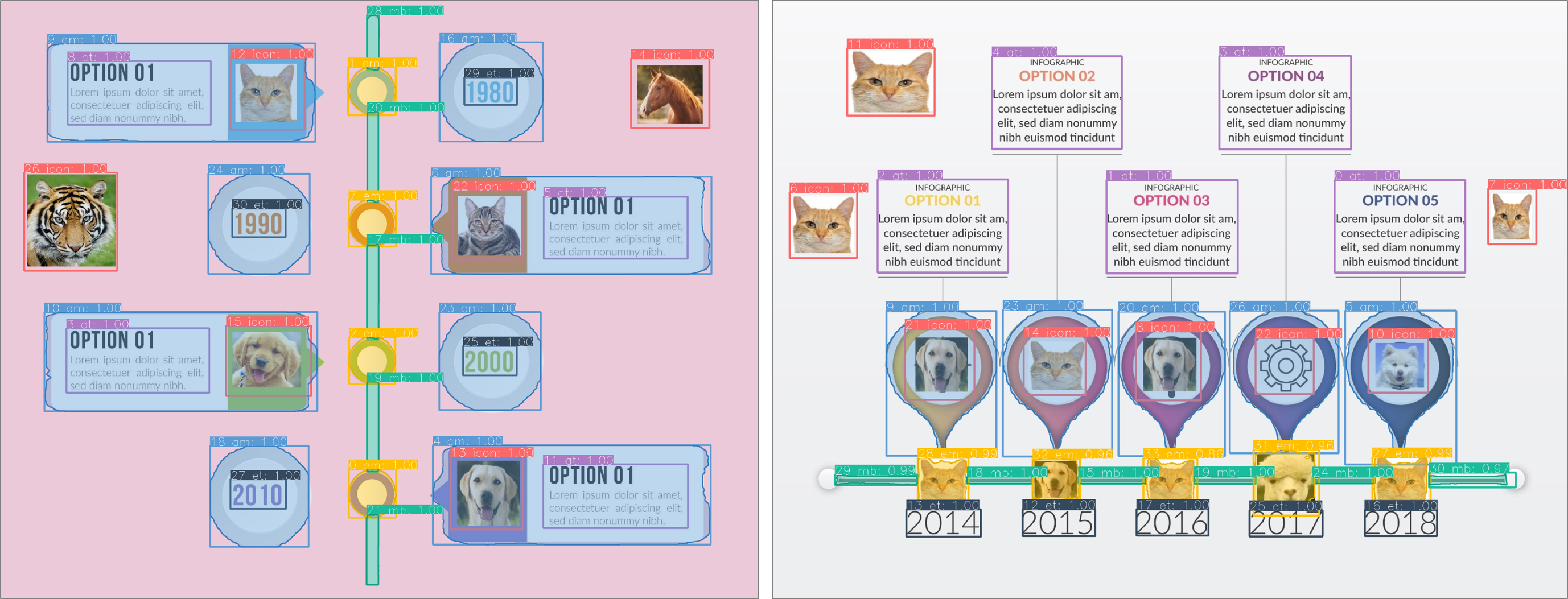
내용 파싱: 기계는 먼저 이미지의 내용을 해석해야 합니다. 이미지를 계산적으로 이해하는 것은 구조적 정보로 표현될 수 있으며, 이는 자동화 과정에서 필수적입니다. 그러나 정보그래픽 이미지는 픽셀 단위로만 접근할 수 있습니다. 따라서 비트맵 이미지를 입력으로 받아 구조적 정보를 출력하는 프로세스가 필요합니다.
템플릿 구성: 이미지의 구조적 정보를 기반으로, 기계는 이를 자동으로 확장 가능한 템플릿으로 생성해야 합니다. 이 템플릿에는 재사용할 요소와 업데이트할 요소에 대한 세부 정보(예: 위치, 색상, 폰트, 형태 등)가 포함되어야 합니다.
[방법 개요]
이 두 가지 요구 사항을 충족시키기 위해, 우리는 두 단계로 구성된 접근 방법을 설계하였습니다. 각 단계의 입력 및 출력을 정의합니다.
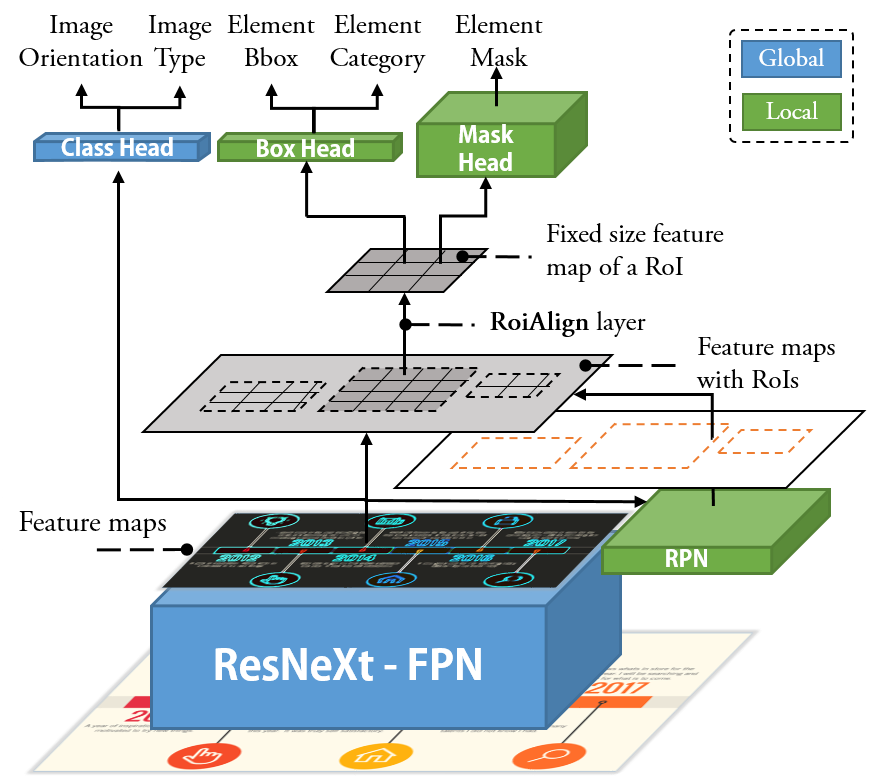
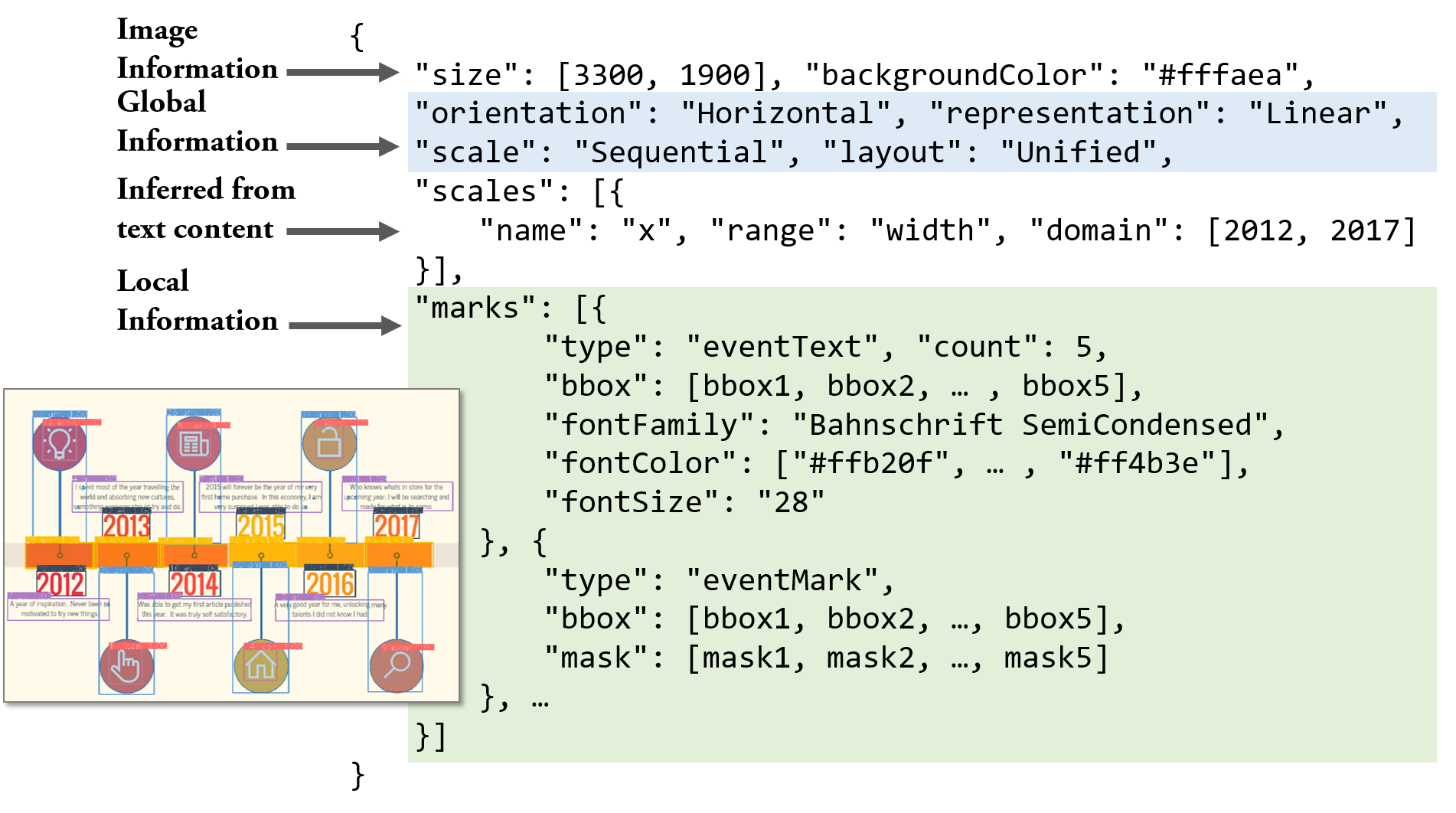
분해: 첫 번째 단계의 목표는 비트맵 타임라인 정보그래픽 $I$에서 구조적 정보를 해석하는 것입니다(그림 참조). 출력으로 두 가지 유형의 정보, 즉 글로벌 정보 $G$와 로컬 정보 $L$을 정의합니다. 글로벌 정보는 전체 타임라인에 대한 내용을 포함하며, 이에는 방향성이 포함됩니다. 로컬 정보는 각 개별 요소에 대한 내용을 포함하며, 여기에는 범주(무엇), 위치(어디), 픽셀 단위 마스크(어느 픽셀)가 포함됩니다. 따라서 첫 번째 단계의 이상적인 프로세스는 다음과 같은 맵핑 함수 $f$를 통해 표현할 수 있습니다:
MATH
\begin{equation}
f: I \rightarrow (G, L)
\end{equation}
클릭하여 더 보기
우리는 이러한 함수 $f$를 딥 뉴럴 네트워크(DNN) 모델 $h \approx f$로 근사화합니다. 이 DNN 모델은 매개변수 집합 $\Theta$를 가지고 있으며, 코퍼스 $\mathbb{C} = \{(I_i: (G_i, L_i))\}_{i=1}^n$에서 학습할 수 있습니다. 각 항목 $(I_i: (G_i, L_i))$는 그림과 관련된 글로벌 및 로컬 정보를 나타냅니다. 따라서 우리는 $(G, L) = h(I | \Theta)$를 통해 출력을 얻을 수 있습니다.
재구성: 확장 가능한 템플릿을 재구성하기 위해 함수 $g$는 비트맵 정보그래픽 $I$, 글로벌 및 로컬 정보 $G$, $L$을 입력으로 받아, 재사용 요소 $E_r$(예: 그림 참조)과 업데이트 요소 $E_u$(예: 텍스트와 아이콘을 포함한 그림 참조)에 대한 세부 정보를 반환해야 합니다. 즉,
MATH
\begin{equation}
g: (I, G, L) \rightarrow (E_r, E_u)
\end{equation}
``
$E$는 각각의 요소가 속성 집합으로 표현되는 집합입니다, 즉,
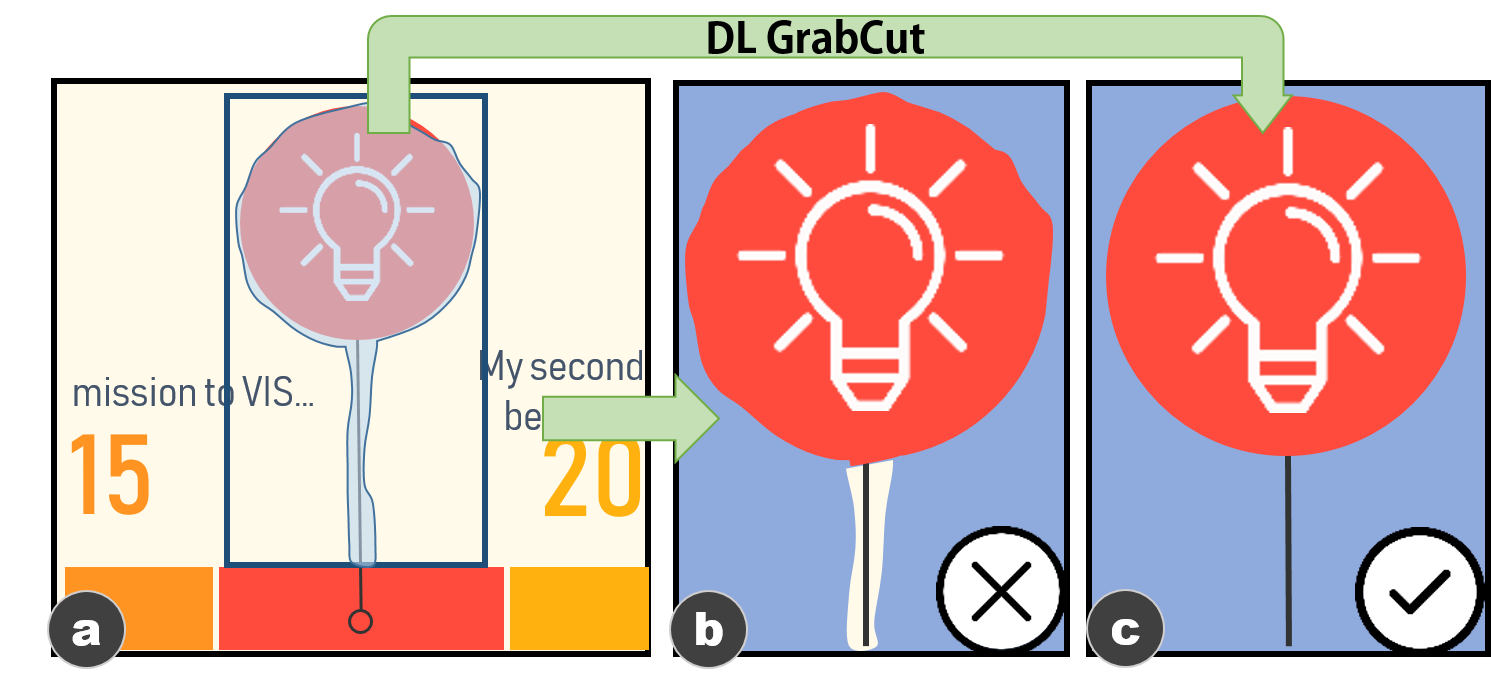
$`E = \{ \textbf{$e$}^i := (a^1, a^2, ..., a^m)\}_{i=1}^n`$. $G$와 $L$에 따라, 우리는 $E_r$과 $E_u$ 내 요소의 속성(예: 크기, 형태, 색상, 위치, 다른 것들에 대한 오프셋)을 추론할 수 있습니다. 확장 가능한 템플릿을 가능하게 하는 필수적인 속성을 강조합니다. $E_r$의 기본 속성은 재사용할 그래픽 마크(예: 그림 참조)입니다. 따라서, 우리는 원본 이미지에서 $E_r$의 픽셀을 분리해야 합니다. $E_u$의 경우, 업데이트 내용의 스타일을 유지하기 위해 텍스트와 관련된 속성(예: 폰트 패밀리, 크기, 색상)이 식별되어야 합니다.
**[데이터셋]**
우리는 모델 $h$를 학습하고 접근 방법을 평가하기 위해 두 가지 데이터셋을 사용합니다. 첫 번째는 합성 데이터셋(이하 $D_1$)입니다. 우리는 타임라인 제작 도구인 TimelineStoryteller(TS)를 확장하여 모든 유형의 타임라인이 포함된 $D_1$을 생성했습니다. 두 번째 데이터셋(이하 $D_2$)은 실제 웹에서 수집한 타임라인으로 구성되어 있습니다. 이는 Google Image, Pinterest, FreePicker에서 *타임라인 정보그래픽* 및 *정보그래픽 타임라인*을 검색어로 사용하여 수집되었습니다. $D_2$에는 다양한 스타일이 포함되며 특히 마크에 있어서 다양성이 큽니다. 또한 가장 일반적인 타입의 타임라인이 포함되어 있습니다.
</div>
<div style="margin-top: 20px;"><a href="https://arxiv.org/pdf/1907.13550.pdf" target="_blank" style="display: inline-block; padding: 12px 25px; background-color: #007bff; color: white !important; text-decoration: none; border-radius: 8px; font-weight: 600; margin-top: 10px; margin-bottom: 10px; box-shadow: 0 4px 6px rgba(0,0,0,0.1); transition: all 0.3s ease;">📄 ArXiv 원문 PDF 보기</a></div>
<div class="mobile-ad w-full my-6 text-center" style="border: 2px dashed red; background: #ffe6e6;"><ins class="adsbygoogle" style="display:block" data-ad-client="ca-pub-1873718820012422" data-ad-slot="auto"></ins><script>(adsbygoogle = window.adsbygoogle || []).push({});</script></div>
<br>
<h4>📊 논문 시각자료 (Figures)</h4>
<br>
<br>

<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>

<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>

<br>
<br>
<br>
<br>
<br>
<br>
<br>
<br>

<br>
<br>

<br>
<br>
<br>
<br>
<h4 style="margin-top: 3rem; margin-bottom: 1rem; border-bottom: 1px solid #e5e7eb; padding-bottom: 0.5rem;">감사의 말씀</h4>
이 글의 저작권은 연구하신 과학자분들께 있으며, 인류 문명 발전에 공헌해주신 노고에 감사를 드립니다.