- Title: A Survey of Autonomous Driving Common Practices and Emerging Technologies
- ArXiv ID: 1906.05113
- 발행일: 2020-04-06
- 저자: Ekim Yurtsever, Jacob Lambert, Alexander Carballo, Kazuya Takeda
📝 초록
자율 주행 시스템(ADS)은 안전하고 편안하며 효율적인 운전 경험을 약속합니다. 그러나 ADS를 장착한 차량에 관련된 사망자가 증가하고 있습니다. 최신 기술의 강건성을 더욱 개선하지 않으면 ADS의 전체 잠재력은 실현될 수 없습니다. 이 논문에서는 미해결 문제들을 논의하고 자율 주행의 기술적 측면을 조사합니다. 현재 도전 과제, 고수준 시스템 아키텍처, 신규 메소드 및 핵심 기능(위치 추정, 맵핑, 인식, 계획, 인간-기계 인터페이스)에 대한 연구가 철저히 검토되었습니다. 또한 최신 기술을 자체 플랫폼에서 구현하고 다양한 알고리즘들을 실제 운전 환경에서 비교하였습니다. 논문은 ADS 개발을 위한 사용 가능한 데이터 세트와 도구들에 대한 개요로 마무리됩니다.
💡 논문 해설
**핵심 요약**: 이 논문은 자율 주행 시스템(ADS)의 기술적 측면과 미해결 문제들을 조사하고, 그 해결 방법을 제시합니다. ADS의 강건성을 향상시키기 위한 다양한 핵심 기능과 알고리즘들에 대한 철저한 검토가 이루어졌습니다.
문제 제기: 자율 주행 시스템은 안전하고 효율적인 운전 경험을 제공해야 하지만, 최근 사망자가 증가하면서 그 강건성에 대한 의구심이 생겼습니다. 이 논문에서는 ADS의 기술적 측면을 조사하고 미해결 문제들을 찾아 해결하려고 합니다.
해결 방안 (핵심 기술):ADS는 다양한 핵심 기능으로 구성되며, 각각의 기능이 서로 상호작용하여 안전한 자율 주행을 가능하게 합니다. 논문에서는 위치 추정, 맵핑, 인식(주변 환경에 대한 정보 수집), 계획, 그리고 인간-기계 인터페이스 등의 핵심 기술들을 분석하고 개선 방안을 제시합니다.
주요 성과: 이 연구는 ADS의 미해결 문제를 체계적으로 조사하고, 각각의 핵심 기능에 대한 최신 알고리즘들을 비교하여 그 강점과 약점을 정확하게 파악하였습니다. 또한 실제 운전 환경에서 다양한 알고리즘들의 성능을 평가했습니다.
의의 및 활용: 이 연구는 ADS의 개발을 위한 중요한 가이드라인을 제공하며, 이를 통해 안전하고 효율적인 자율 주행 시스템을 실현할 수 있습니다. 특히 강건성을 향상시키기 위한 다양한 알고리즘들의 비교와 분석은 미래의 연구 및 개발에 큰 도움이 될 것입니다.
📄 논문 발췌 (ArXiv Source)
# 결론
본 논문에서는 자율 주행 시스템에 대한 조사를 통해 몇 가지 핵심 혁신과 기존 시스템을 소개하였습니다. 자율 주행의 가능성은 이미 소비자들에게 마케팅되고 있지만, 이 조사는 여전히 명확한 연구 격차가 있음을 보여줍니다. 완전 모듈형부터 완전 엔드-투-엔드까지 다양한 아키텍처 모델이 제안되었지만 각각은 단점이 있습니다. 정확성과 효율성이 여전히 부족한 알고리즘들이 있으며, 온라인 평가의 필요성을 인식하게 되었습니다. 불량한 도로 조건 및 혹독한 날씨에 대한 대응도 여전히 개선이 필요한 문제입니다. 차량 간 통신은 아직 초기 단계이며, 중앙화된 클라우드 기반 정보 관리 시스템은 복잡한 인프라가 필요하기 때문에 구현되지 않았습니다. 또한 인간-기계 상호 작용 분야는 여전히 미개척 영역입니다.
자율 주행 시스템의 개발은 과학 분야와 신기술의 발전에 의존합니다. 그러므로, 이 논문에서는 기존 방법의 약점을 극복하거나 대안을 제시하는 최근 연구 동향들을 논의하였습니다. 이번 조사는 다양한 학술 협력과 산업계 및 일반 대중의 지원을 통해 남아 있는 과제를 해결할 수 있음을 보여줍니다. 자율 주행 시스템 전반에 걸친 강건성 향상을 위한 집중적인 노력으로 안전하고 효율적인 도로는 바로 눈앞에 있습니다.
인식
주변 환경을 인지하고 안전한 탐색을 위해 필요한 정보를 추출하는 것은 ADS의 중요한 목표입니다. 다양한 작업들이 다양한 감지 모달리티를 사용하며, 이러한 작업들은 인식 범주의 일부로 분류됩니다. 컴퓨터 비전 연구의 몇십 년 동안 카메라는 가장 많이 사용되는 센서였으며, 3D 비전은 강력한 대체 또는 보완 수단으로 자리잡았습니다.
이 절의 나머지 부분은 핵심 인식 작업을 다룹니다. 이미지 기반 물체 탐지를 7.1.1에서, 세분화를 7.1.2에서, 3D 물체 탐지를 7.1.3에서, 도로 및 차선 탐지를 7.3, 물체 추적을 7.2에서 논의합니다.
탐지
이미지 기반 물체 탐지
Architecture
파라미터 수
층수
ImageNet1K Top 5 오류 %
Incept.ResNet v2
30
95
4.9
Inception v4
41
75
5
ResNet101
45
100
6.05
DenseNet201
18
200
6.34
YOLOv3-608
63
53+1
6.2
ResNet50
26
49
6.7
GoogLeNet
6
22
6.7
VGGNet16
134
13+2
6.8
AlexNet
57
5+2
15.3
ImageNet1K 테스트 세트에서 2D 경계 상자 추정 아키텍처 비교, Top 5% 오류 순서대로 정렬되었습니다. 파라미터 수 (Num. Params)와 층수 (Num. Layers), 알고리즘의 계산 비용을 암시합니다.
물체 탐지는 관심 있는 물체의 위치와 크기를 식별하는 것을 의미합니다. 교통 신호, 표지판, 횡단보도 등 정적 물체부터 다른 차량, 보행자 또는 자전거 운전자까지 동적인 물체 모두가 ADS에 중요합니다. 일반화된 물체 탐지는 컴퓨터 비전 분야의 중심 문제로 오랫동안 연구되어 왔으며, 특정 클래스의 객체가 이미지 내에 존재하는지를 판단한 다음 사각형 경계 상자를 통해 그 크기를 결정하는 것을 목표로 합니다. 본 절에서는 ADS 파이프라인에서 여러 다른 작업의 출발점으로 작용하는 최신 물체 탐지 방법을 주로 논의합니다.
물체 인식 연구는 50년 이상 되었지만, 성능이 드라이빙 자동화에 의미 있는 수준까지 도달한 것은 비교적 최근인 1990년대 말과 2000년대 초반부터입니다. 2012년에는 DCNN AlexNet이 ImageNet 이미지 인식 챌린지를 뒤집었습니다. 이 결과는 집중적인 관심을 슈퍼바이즈드 학습, 특히 딥러닝에 향하게 하였습니다. 일반적인 이미지 기반 물체 탐지에 대한 광범위한 조사가 존재하지만 여기에서는 ADS에 적용할 수 있는 최신 방법에 초점을 맞춥니다.
현재 모든 최신 방법은 DCNN을 사용하지만, 명확한 구분이 있습니다:
단일 단계 탐지 프레임워크는 객체 위치와 클래스 예측을 동시에 생성하는 단일 네트워크를 사용합니다.
영역 제안 탐지 프레임워크에서는 일반적인 관심 영역이 먼저 제안되고, 분류기 네트워크에 의해 분류됩니다.
영역 제안 방법은 현재 탐지 벤치마크에서 선두를 달리고 있지만, 높은 계산 비용과 일반적으로 구현, 학습 및 조정이 어려운 단점을 가지고 있습니다. 반면 단일 단계 탐지 알고리즘은 추론 시간이 빠르고 메모리 비용이 낮아 실시간 운전 자동화에 적합합니다. YOLO (You Only Look Once)는 인기 있는 단일 단계 감지기를 나타내며 지속적으로 개선되었습니다. 그들의 네트워크는 입력 이미지의 해상도를 크게 줄이는 과정에서 이미지 특징을 추출하는 DCNN을 사용합니다. 완전 연결 신경망은 각 그리드 셀과 클래스에 대한 클래스 확률 및 경계 상자 매개변수를 예측합니다. 이 설계는 YOLO를 매우 빠르게 만듭니다. 전체 모델은 45 FPS에서 작동하며, 정확도를 약간 희생하면서 작은 모델은 155 FPS에서 작동합니다. YOLOv2, YOLO9000 및 YOLOv3는 PASCAL VOC와 MS COCO 벤치마크를 잠시 리드하며 낮은 계산 비용과 메모리 비용을 유지했습니다. 다른 널리 사용되는 알고리즘인 Single Shot Detector (SSD)는 VGGNet과 같은 표준 DCNN 아키텍처를 사용하여 공개 벤치마크에서 경쟁력을 가지며, YOLO보다 더 빠릅니다.
ADS의 탐지에 있어 정확성과 계산 비용을 모두 고려하는 것이 중요합니다. 탐지 결과는 신뢰할 수 있어야 하며, 계획 및 제어 모듈이 이러한 물체에 반응하기 위해 가능한 한 많은 시간을 가져야 합니다. 따라서 단일 단계 감지기는 종종 ADS의 탐지 알고리즘으로 선택됩니다. 그러나 1 표에 보여듯이, 두 단계 감지 프레임워크에서 사용되는 영역 제안 네트워크(RPN)는 물체 인식 및 위치 추정 정확도 측면에서 뛰어나며 최근 몇 년 동안 계산 비용이 크게 개선되었습니다. RPN은 세분화와 같은 탐지 관련 작업에도 더 적합합니다. 이전 섹션에서 논의되었듯이, 전이 학습을 통해 여러 인식 작업을 동시에 수행하는 RPN은 온라인 응용 프로그램에 점점 더 가능해지고 있습니다. RPN은 가까운 미래에 ADS 응용 프로그램에서 단일 단계 감지 네트워크를 대체할 수 있습니다.
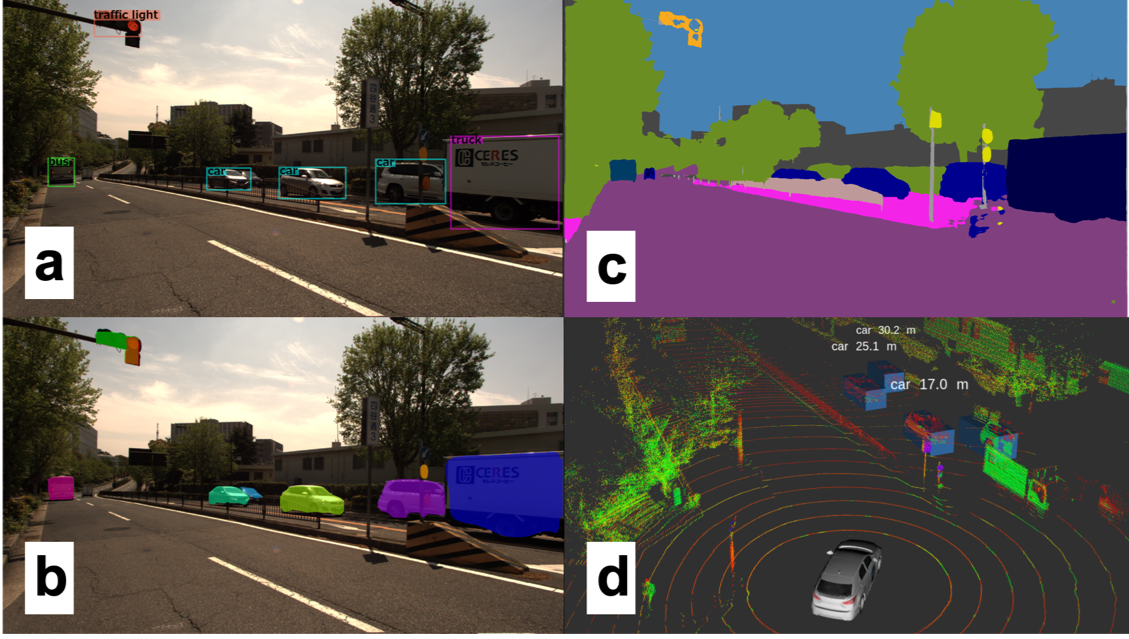
나고야 대학교 근처의 도시 풍경, 우리의 실험 차량이 촬영한 카메라 및 라이다 데이터와 최신 인식 알고리즘의 탐지 결과. (a) YOLOv3에서 생성된 경계 상자 결과를 보여주는 전면 카메라의 화각, (b) MaskRCNN에서 생성된 인스턴스 세그멘테이션 결과. (c) DeepLabv3에서 생성된 세분화 마스크. (d) 객체 탐지 결과를 가진 3D 라이다 데이터. 이 네 가지 중 3D 인식 알고리즘만이 탐지된 물체의 거리를 출력합니다.
전방위 및 이벤트 카메라 기반 인식: 자동화 수준을 향상시키기 위해서는 360도 화상, 또는 적어도 팬오멘틱 비전이 필요합니다. 이를 위해 여러 카메라 배열을 사용할 수 있지만, 각 카메라 간의 정밀한 외부 교정은 이미지 스티칭이 가능하도록 해야 합니다. 대안으로는 전체 방향 카메라를 사용하거나 매우 넓은 각도의 피시아이 렌즈가 장착된 작은 배열을 사용할 수 있습니다. 그러나 이러한 방법들은 본질적으로 교정하기 어렵습니다; 구형 이미지는 크게 왜곡되어 있으며, 구형 이미지를 생성하는 카메라 모델에 따라 거울 반사 또는 피시아이 렌즈 왜곡을 고려해야 합니다. 모델 및 교정의 정확도는 왜곡되지 않은 이미지의 품질을 결정하며, 여기에서 앞서 언급한 2D 비전 알고리즘을 사용합니다. [그림: ricoh] 에는 피시아이 렌즈로 생성된 두 개의 구형 이미지가 하나의 팬오멘틱 이미지로 결합되는 예가 나와 있습니다. 일부 왜곡은 여전히 남지만, 이러한 교정 과제에도 불구하고 전체 방향 카메라는 SLAM 및 3D 재구성과 같은 다양한 응용 프로그램에 사용되었습니다.
이벤트 카메라는 비교적 새로운 모달리티로 관찰된 장면의 움직임으로 인해 발생하는 비동기 이벤트를 출력합니다. 이는 동적인 물체 탐지에 흥미로운 감지 모달리티입니다. 다른 매력적인 요인은 그들의 응답 시간이 마이크로초 단위라는 점이며, 높은 속도의 주행에서는 프레임률이 한계가 됩니다. 센서 해상도는 여전히 문제가 되지만 새로운 모델들이 급속하게 개선되고 있습니다. 이들은 ADS와 밀접한 관련이 있는 다양한 응용 분야에 사용되었습니다. 최근 조사는 자세 추정 및 SLAM, 시각-인성 오도미터, 3D 재구성을 비롯한 여러 애플리케이션의 진전을 요약합니다. 특히 이벤트 카메라를 이용한 엔드 투 엔드 주행에 대한 개방 소스 프레임워크가 제안되었습니다.
Metadata
Title_Easy_KO: 자율주행 시스템의 핵심 기술과 미해결 문제
Title_Easy_EN: Core Technologies and Unresolved Issues in Autonomous Driving Systems