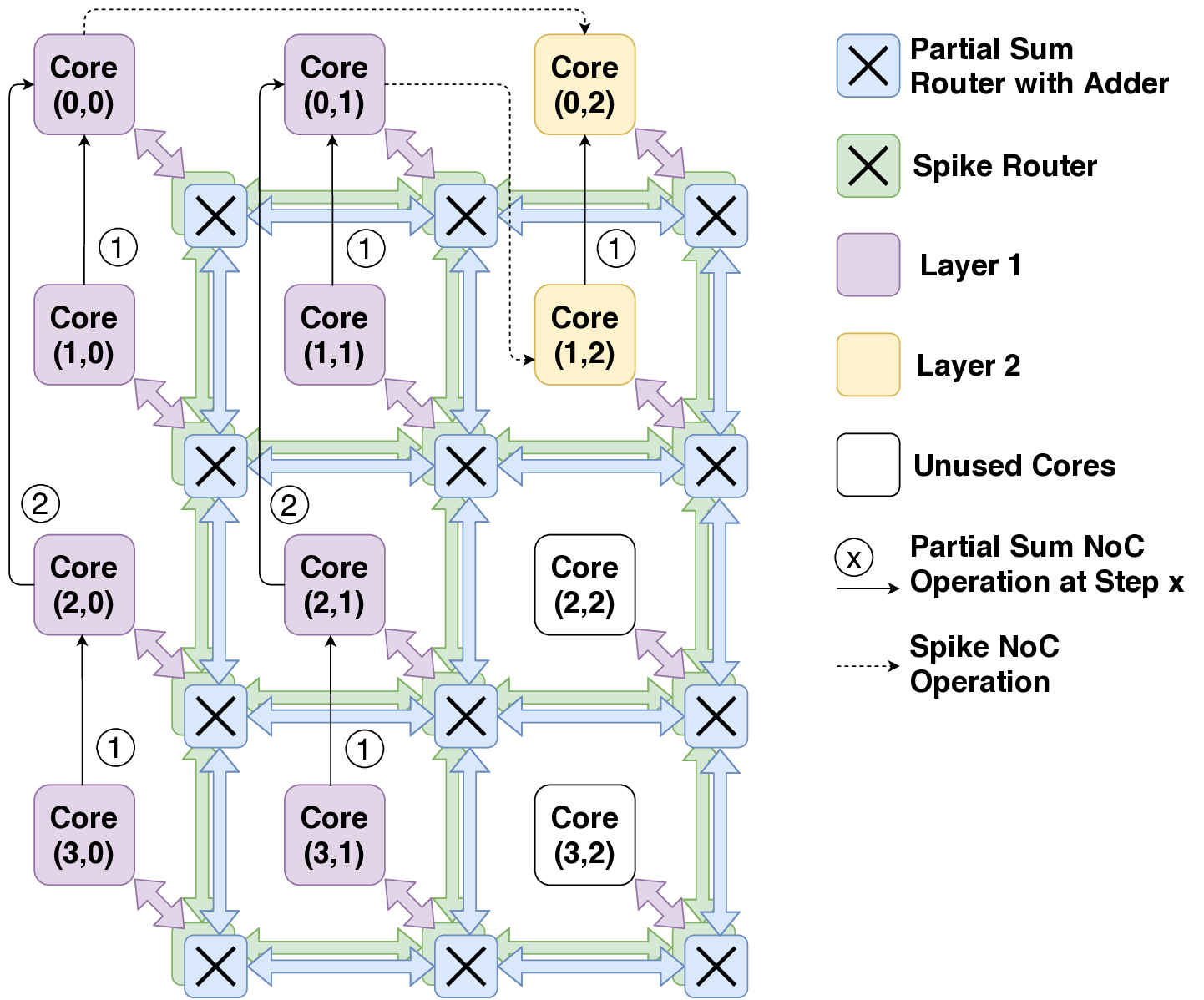
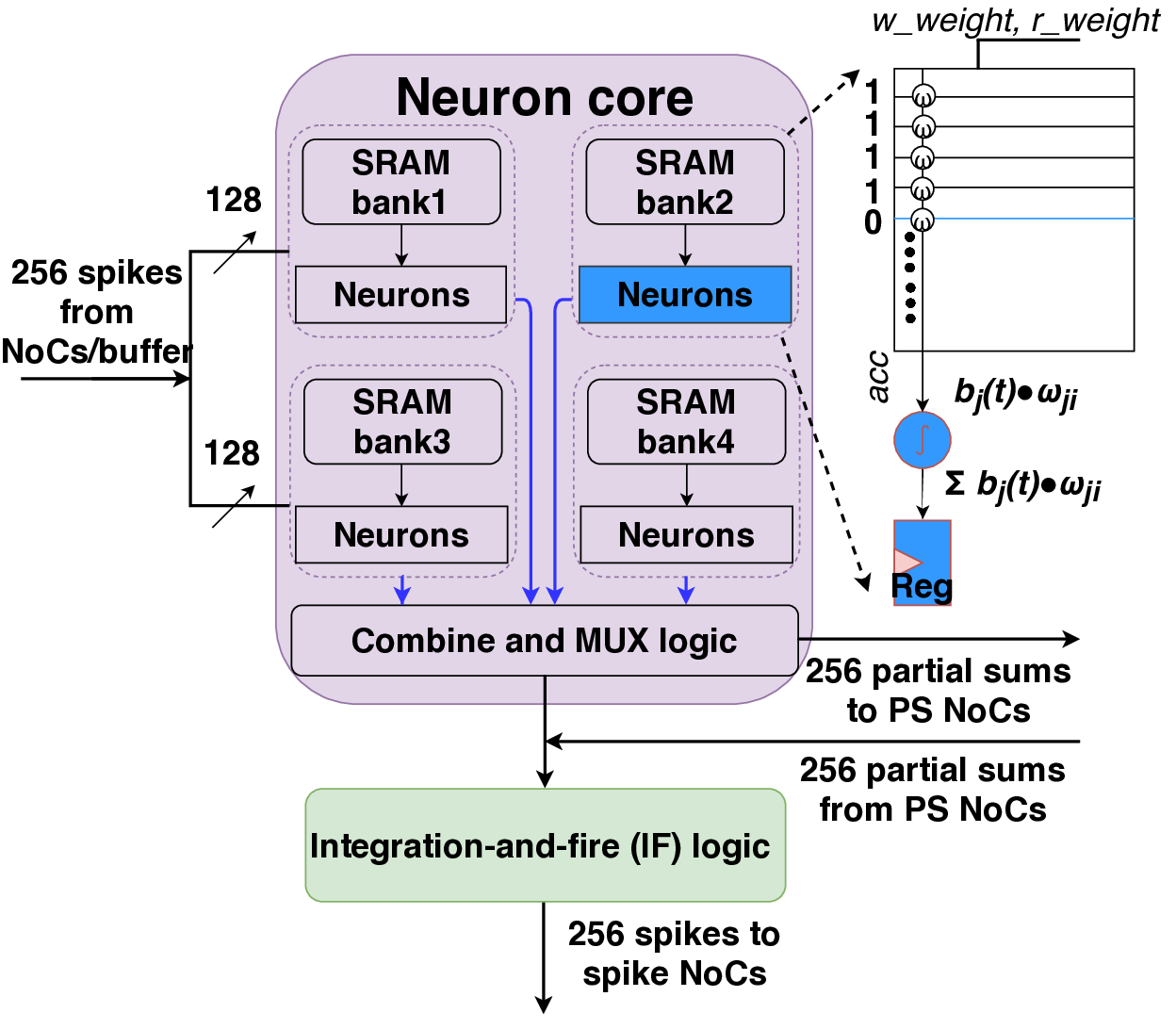
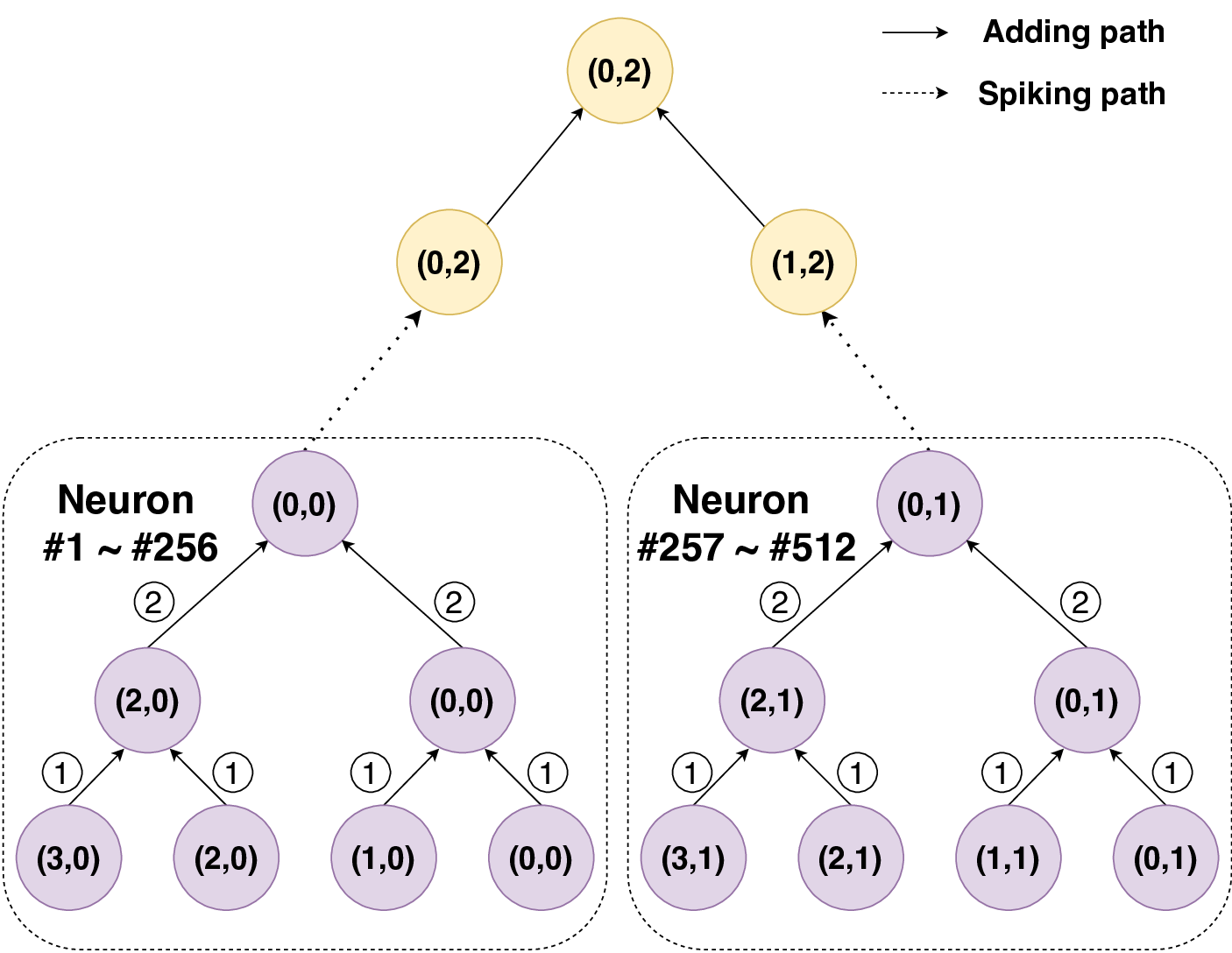
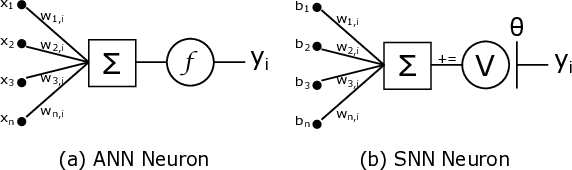
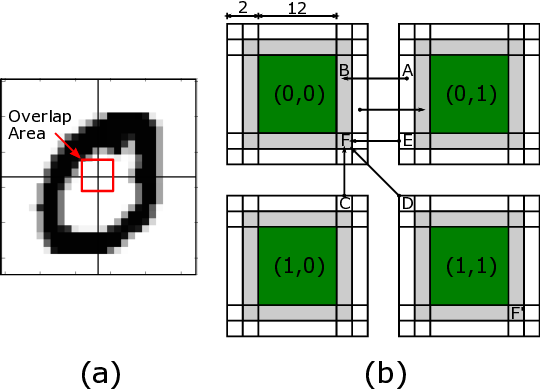
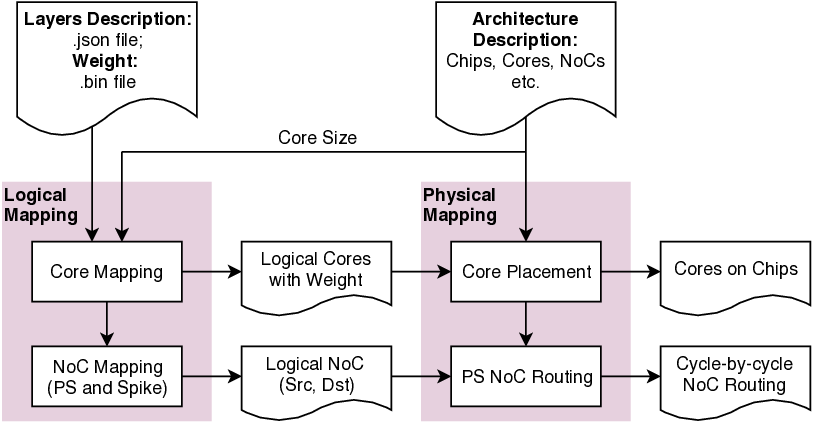
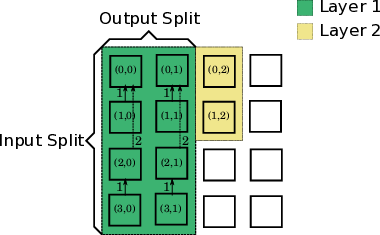
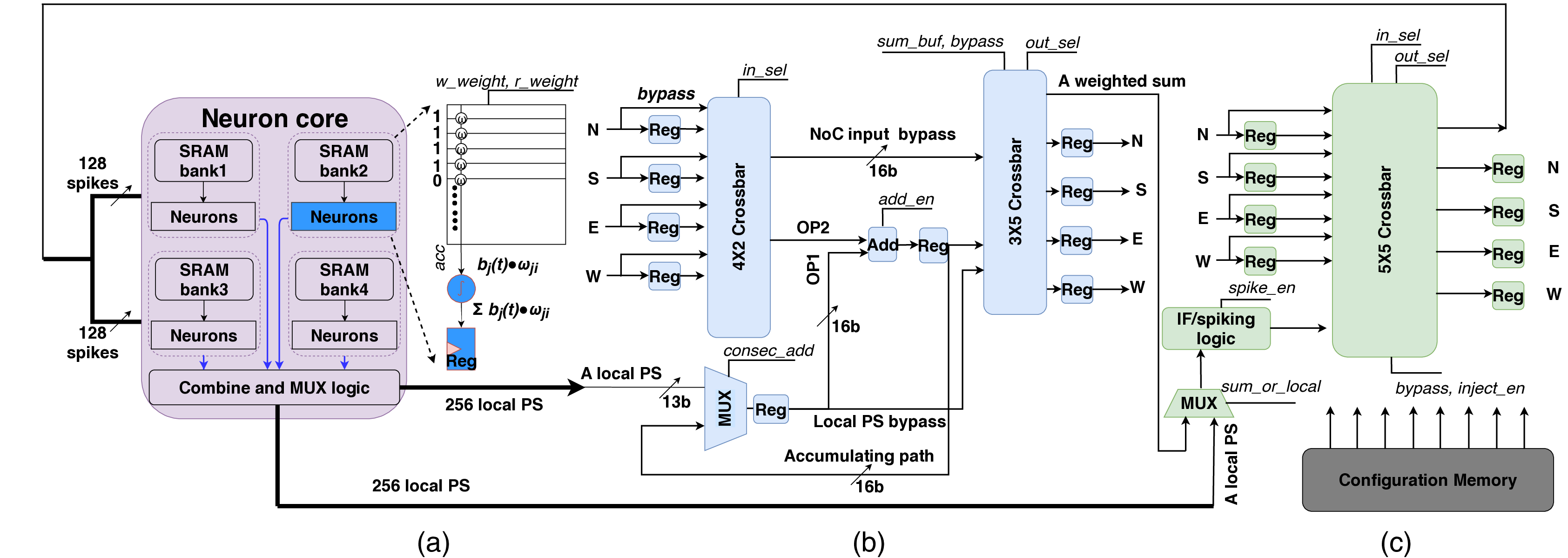
신경: 부분 합과 스파이크 네트워크 온 칩을 갖춘 저전력 재구성형 뉴로모픽 가속기
📝 원문 정보
- Title: Shenjing: A low power reconfigurable neuromorphic accelerator with partial-sum and spike networks-on-chip
- ArXiv ID: 1911.10741
- 발행일: 2019-12-02
- 저자: Bo Wang, Jun Zhou, Weng-Fai Wong, and Li-Shiuan Peh
📝 초록 (Abstract)
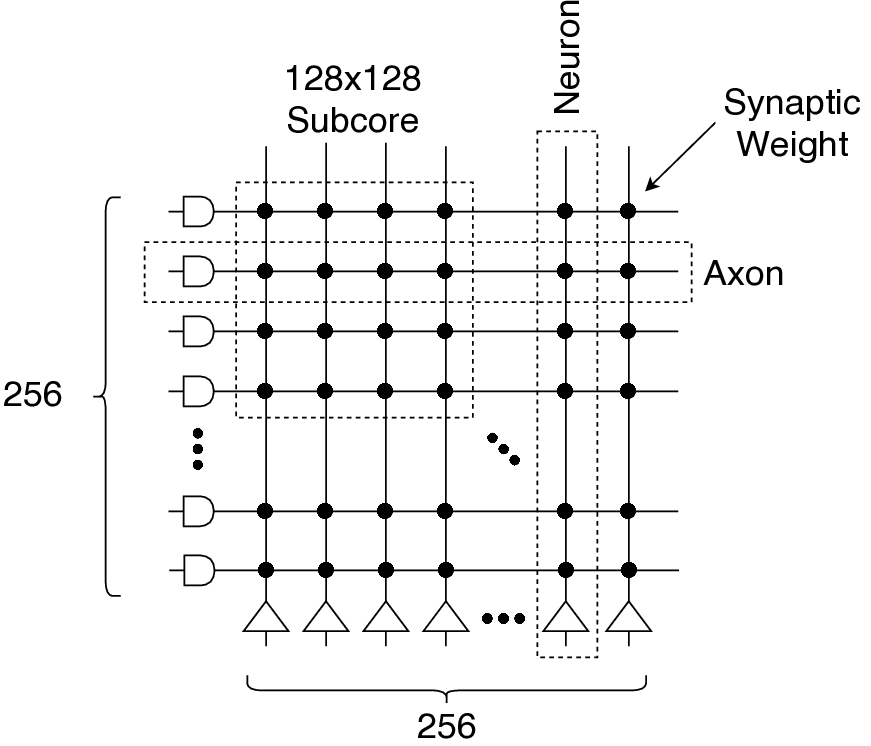
다음 세대의 장치 내 AI는 에너지 효율적인 딥 뉴럴 네트워크가 필요할 것으로 예상된다. 뇌에서 착안한 스팽킹 뉴럴 네트워크(SNN)이 유망한 후보로 식별되었다. 곱셈의 필요성을 없애는 것만으로도 에너지를 크게 절약할 수 있다. 장치 내 응용 프로그램에서는 계산뿐만 아니라 통신에도 많은 양의 에너지와 시간이 소요된다. 본 논문에서 우리는 Shenjing이라는 구성 가능한 SNN 아키텍처를 제안한다. 이는 모든 온칩 통신을 소프트웨어에 완전히 노출시키며, 저 전력에서도 높은 정확도로 SNN 모델을 매핑할 수 있게 한다. TrueNorth와 같은 이전의 SNN 아키텍처들과 달리 Shenjing은 매핑을 위해 모델 수정과 재학습이 필요하지 않다. 우리는 기존 인공 신경망(ANN)인 멀티레이어 퍼셉트론, 컨볼루셔널 뉴럴 네트워크, 그리고 최신의 잔차 네트워크를 Shenjing에 성공적으로 매핑하여 SNN의 에너지 효율성을 실현할 수 있음을 보여준다. MNIST 추론 문제에서 멀티레이어 퍼셉트론을 사용해 96%의 정확도로 10개의 Shenjing 코어를 이용하여 단 1.26mW만 소비하는 것을 달성하였다.💡 논문 핵심 해설 (Deep Analysis)
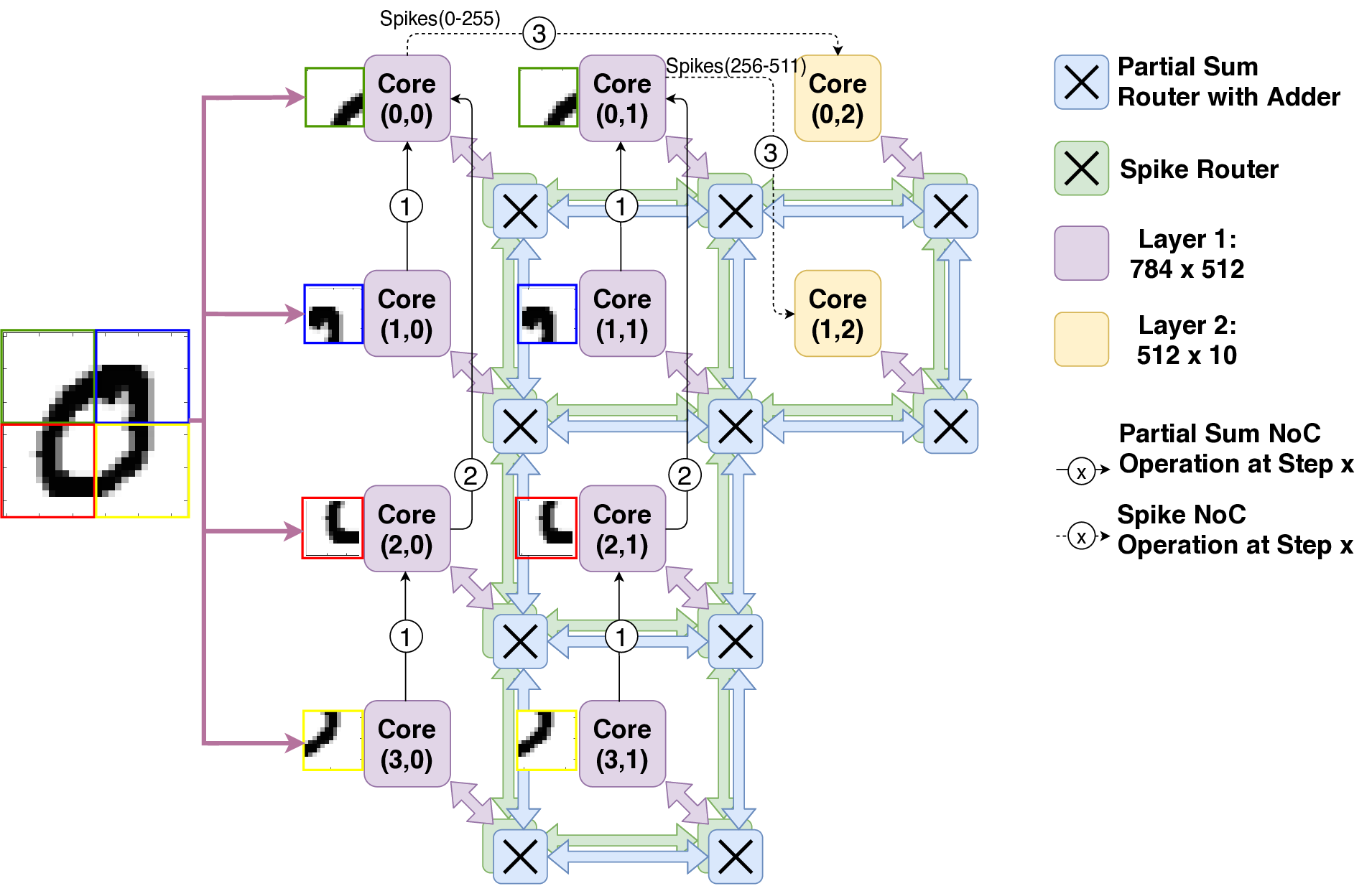
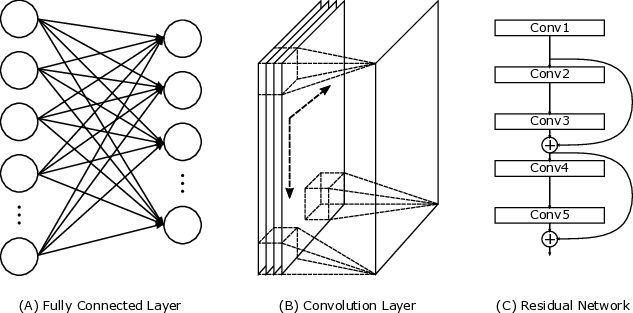
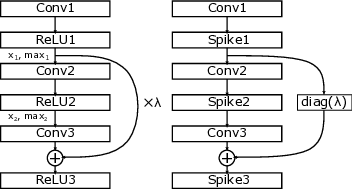
The key technical contribution is the design of Shenjing’s configurable SNN framework that supports a wide range of ANN architectures including multilayer perceptrons (MLP), convolutional neural networks (CNN), and residual networks (RN). This versatility allows for efficient mapping of these models onto the Shenjing architecture, achieving high accuracy with low power consumption. For instance, in MNIST inference using MLP, Shenjing achieved 96% accuracy while consuming only 1.26mW.
The significance of this work lies in its potential to enhance on-device AI applications by providing a highly energy-efficient platform that can support various types of neural networks without compromising performance or requiring extensive retraining efforts. This makes Shenjing particularly suitable for devices with limited power resources, such as smartphones and wearable technology, where low-power consumption is critical.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리