- Title: The demise of the filesystem and multi level service architecture
- ArXiv ID: 1907.13060
- 발행일: 2019-08-01
- 저자: William O Mullane, Niall Gaffney, Frossie Economou, Arfon M. Smith, J. Ross Thomson, Tim Jenness
📝 초록
천문학 데이터 센터는 여전히 파일 시스템에 의존하고 있습니다. 그러나 산업계에서는 이미 이러한 상황을 벗어났습니다. 현재 컴퓨팅 인프라의 표준은 POSIX 파일 시스템 대신 대규모 데이터 처리의 확장성을 달성하기 위해 객체 저장소를 사용하는 것입니다. 이는 소프트웨어의 포터빌리티와 재사용 가능성을 높이는 기회를 제공하지만, 현재 센터에 있는 고유한 구현 방식과 호환되지 않아 문제가 발생합니다.
💡 논문 해설
**핵심 요약**: 이 논문은 천문학 분야에서 데이터 처리의 확장성을 위해 POSIX 파일 시스템 대신 객체 저장소를 사용하는 것이 필요하다는 것을 주장하고 있습니다. 현재 천문학 센터들이 여전히 고유한 구현 방식을 유지하고 있어, 이 논문은 이를 통일화하여 효율적인 데이터 처리와 액세스 방법을 제시합니다.
문제 제기: 천문학 데이터의 증가로 인해 기존 POSIX 파일 시스템이 데이터 접근과 확장성에 한계를 보이고 있습니다. 이는 데이터 처리와 저장에 있어 많은 시간과 리소스를 낭비하게 됩니다. 또한, 다양한 포맷과 저장 방식을 사용함으로써 상호 운용성이 저하되고 있습니다.
해결 방안 (핵심 기술): 이 논문은 천문학 분야에서도 객체 저장소와 API를 통해 데이터 접근성을 높이고, 이를 위해 표준화된 인터페이스를 제시합니다. 또한, 데이터와 메타데이터의 변환 서비스를 개발하여 상호 운용성을 향상시키고자 합니다.
주요 성과: 이 논문은 천문학 분야에서 이미 객체 저장소가 사용되었던 예제를 제공하고 있으며, 이를 통해 POSIX 파일 시스템보다 높은 확장성과 효율적인 데이터 처리가 가능함을 보여줍니다. 특히, 다양한 클라우드 서비스와 통합된 인프라 구조를 제시하여 미래의 천문학 연구에 큰 도움이 될 것입니다.
의미 및 활용: 이 논문은 천문학 분야에서 데이터 처리와 저장 방식을 표준화함으로써, 상호 운용성을 높이고 효율적인 데이터 관리가 가능하게 합니다. 또한, 클라우드 기반 서비스를 통해 대규모 데이터 처리의 확장성과 효과성을 크게 향상시키며, 연구자들이 더 많은 시간을 실제 과학적 분석에 집중할 수 있게 됩니다.
📄 논문 발췌 (ArXiv Source)
# 서론
요약: 파일 시스템 개념은 처리를 확장하는 데 제한적이며, 산업계에서는 이미 이 개념을 버렸습니다. 천문학도 새로운 아키텍처로 나아가야 합니다.
객체 저장소는 천문학에 새로운 것이 아닙니다. FITS와 IRAF 테이프는 파일 시스템이 생성되는 데이터의 양을 처리할 수 없었을 때 사용되었던 객체 저장소의 예입니다. 당시에는 객체 저장소에서 파일 시스템으로 이동하는 표준이 만들어져, 객체가 디스크에 정의된 네임스페이스로 가져와질 수 있었습니다. POSIX 디스크 용량과 POSIX 유사 파일 시스템의 폭발적인 성장은 객체 저장소를 사용한 세대의 연구자들을 생성하지 않았습니다. 이 성장은 지금까지 데이터 시스템을 지원해왔지만, 조사 및 지향형 망원경 아카이브에서 생성되는 데이터의 크기와 복잡성은 POSIX 표준에 의해 파일 액세스에 대한 요구 사항이 우리의 데이터 작업 능력을 크게 제한하는 수준으로 도달하고 있습니다. 다른 병렬 파일 시스템에는 강점과 약점이 있습니다.
대규모에서는 드롭박스와 AWS 같은 데이터 서비스 제공자가 POSIX 시스템에서 파일을 저장하지 않습니다. 대신, 대규모 객체 저장소 위에 디렉토리 구조의 환영을 제공합니다. 이를 통해 더 빠른 파일 액세스가 가능하며, 각 개체에 대해 CRUD 스타일의 기능만 수행됩니다. 또한, 의사 파일 시스템 계층은 일반적으로 그래프 데이터베이스에서 제공되는 구조의 보기일 뿐이며, 사용자는 실제 시간 쿼리로 파일 조직을 구성하거나 현재와 같이 중첩된 심볼릭 링크를 통해 많은 데이터를 구성하는 방법을 제거할 수 있습니다. 일부는 의사 파일 시스템의 사용자 뷰에 대한 POSIX 캐시를 제공하여 fopen, fscan 및 fclose 표준 명령으로 POSIX 스타일 애플리케이션이 파일에 액세스할 수 있습니다. 또한 이러한 제공자는 데이터가 어떻게 저장되는지 사용자에게 보여주지 않습니다. 필요한 형식(예: 엑셀, CSV 또는 웹 앱이 시트를 위해 사용하는 JSON 형식)으로 데이터를 요청할 수 있습니다.
천문학 데이터 연구원들이 이 곡선을 따르는 때가 왔습니다. 사용자가 노트북에 있는 도구에서 협업을 지원하면서 개개인의 시스템 관리 필요성을 줄이는 것(Jupyter Hubs, Overleaf, Google Slides)처럼 천문학 데이터 처리 및 분석도 이와 같이 나아갈 수 있습니다.
제안사항
모든 과학 연구를 지원하는 커뮤니티 전체의 아키텍처 개발을 위해 산업 표준 계층화된 아키텍처를 천문학 처리 및 데이터 액세스에 적용합니다.
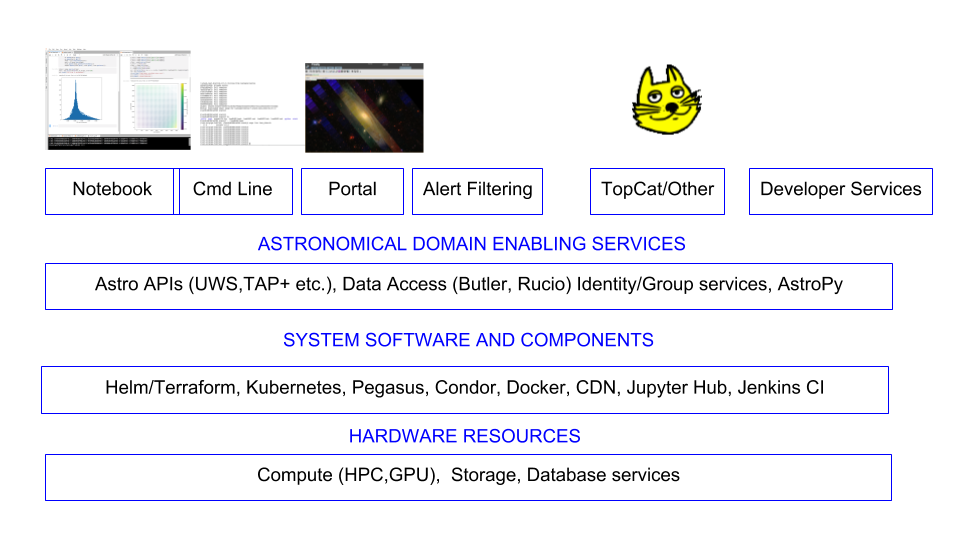
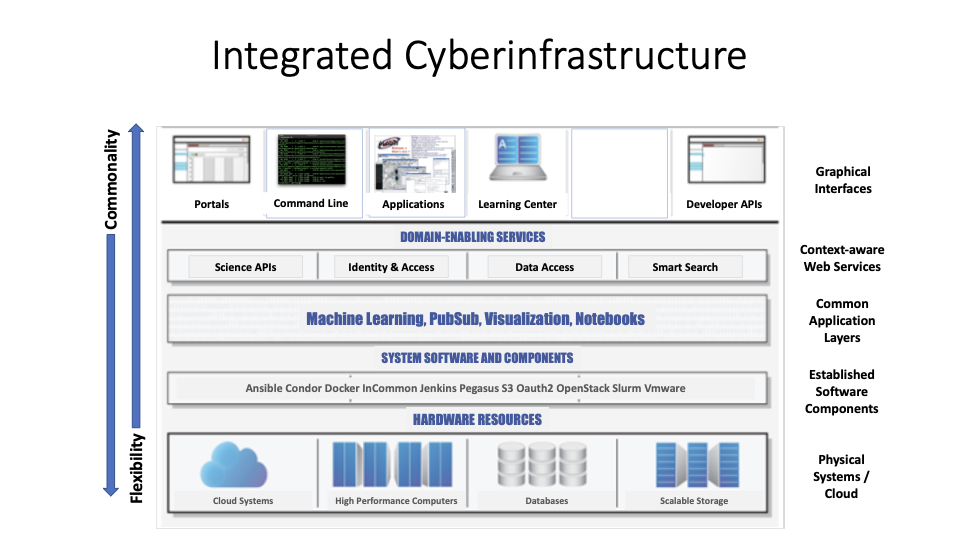
style="width:49.0%" />
산업 표준 사이버 인프라 모델(왼쪽)과 천문학의 그러한 모델의 구현(오른쪽)
모든 자금 지원 천문학 프로젝트에는 소프트웨어 전달물이 있어야 하며, 이는 아키텍처 및 데이터 액세스 API를 활용해야 합니다.
공통 API 계층을 지원하기 위한 데이터와 메타데이터 변환 서비스 개발.
대부분의 대학과 연구 기관에서 지원하는 InCommon 또는 Globus Auth 등의 공동 연방 인증 서비스를 채택하고 구독합니다.
상품화된 서비스 및 소프트웨어 기반 커뮤니티 아키텍처
천문학 및 천체물리학 커뮤니티는 과거에 데이터 관리와 분석에 관련된 문제를 해결하기 위해 특수한 소프트웨어와 하드웨어 인프라를 개발하고 사용해 왔습니다. 이러한 요구 사항은 이제 더 이상 독특하지 않으며, 우리는 산업이나 다른 과학 도메인에서 찾기 어려웠던 규모의 데이터셋을 처리하는 데 필요한 오픈 소스 소프트웨어, 상품화된 하드웨어 및 관리 클라우드 서비스에 대한 풍부한 자원에 접근할 수 있습니다. 이러한 기술을 사용하여 “천문학 스택"의 문서와 참조 구현을 제공하고 연구자들과 임무가 클라우드 컴퓨팅 서비스에 액세스하는 것을 더 쉽게 만들면, 운영 비용을 줄이고 과학으로의 시간을 가속화하며 천문학과 천체물리학 분야에서 연방 자금 지원 연구의 과학적 수익성을 높일 수 있습니다.
이 그림은 인터페이스를 위한 서비스 액세스, 공통 도메인 전체로 활성화된 서비스 및 상위 수준의 CI를 지원하는 시스템 수준 구성 요소의 컬렉션을 나타내는 CI 계층입니다. 이 그림 하단에는 잘 정립되고 지원되는 구성 요소에 기반한 상품화 계층이 있습니다. 이러한 계층 위로 옮길수록 도메인 또는 매우 특정한 서브도메인 수준의 인터페이스를 노출하는 데 더 많은 추상화가 가능합니다. 이러한 추상화를 통해 보다 일반적인 서비스를 개발할 수 있으며 전체 CI에 대해 더 널리 적용될 수 있습니다.
이러한 구조는 또한 이러한 시스템 서비스 기반의 잘 지원되는 소프트웨어 구성 요소로 구성된 참조 아키텍처와 함께 제공함으로써 공급자가 이러한 일반적인 서비스를 배포하고 지원할 수 있도록 합니다. 이를 통해 교차 임무 및 센터 상호 운용성을 가능하게 합니다.
이러한 인프라 구조는 천문학 분야 외부에서 개발된 많은 표준화된 소프트웨어(예: CILogon과 같은 공통 인증 메커니즘)를 사용해야 합니다. 또한 표준 API 인터페이스가 이러한 구성 요소를 상위 수준의 API에 노출시켜야 합니다. 데이터 포맷팅 및 메타데이터 구조는 서비스 레벨에서 노출되어 더 많은 데이터와 메타데이터 재사용이 가능합니다.