- Title: Efficient Knowledge Graph Accuracy Evaluation
- ArXiv ID: 1907.09657
- 발행일: 2019-07-24
- 저자: Junyang Gao, Xian Li, Yifan Ethan Xu, Bunyamin Sisman, Xin Luna Dong, Jun Yang
📝 초록
지대한 규모의 지식 그래프(KG) 정확도를 추정하려면 그래프에서 샘플을 선택하여 인간이 주석을 달아야 합니다. KG 개발 사이클과 실용적인 응용 프로그램에 중요한 역할을 하는 동시에 인력 주석 비용을 최소화하면서 통계적으로 의미 있는 정확도 평가를 얻는 방법은 이전 연구에서 크게 간과되어 왔습니다. 이를 해결하기 위해 본 논문에서는 품질이 높고 통계적 보장이 강력한 정확도 평가를 제공하면서 인력 노력을 최소화하는 효율적인 샘플링 및 평가 프레임워크를 제안합니다. 실제 주석 비용 함수의 속성을 근거로 클러스터 샘플링을 사용하여 전체 비용을 줄이는 것을 제안하였습니다. 또한 가중치와 단계별 샘플링, 계층화 등을 적용하여 더 나은 샘플링 설계를 수행했습니다. 또한 진화하는 KG에 대한 효율적인 증분 평가를 가능하게 하기 위해 계층화 샘플링과 가중치 변형 리저버 샘플링을 기반으로 하는 두 가지 솔루션을 도입하였습니다. 실제 데이터 세트에서 진행된 광범위한 실험은 제안된 솔루션의 효과성과 효율성을 입증합니다. 기본 접근법과 비교했을 때, 우리의 최적 솔루션은 정정 KG 평가에 대해 60%까지 비용을 절감하고 진화하는 KG 평가에는 80%까지 비용을 줄일 수 있습니다. 이 모든 것이 평가 품질의 손실 없이 이루어집니다.
💡 논문 해설
**핵심 요약**: 본 논문은 지대한 규모의 지식 그래프(KG)를 정확하게 평가하기 위해 효율적인 샘플링 및 주석 방법을 제안합니다. 기존 방법들과 비교해 봤을 때, 이 접근법은 인력 노력을 최소화하면서도 정확도 평가의 품질과 통계적 신뢰성을 유지할 수 있습니다.
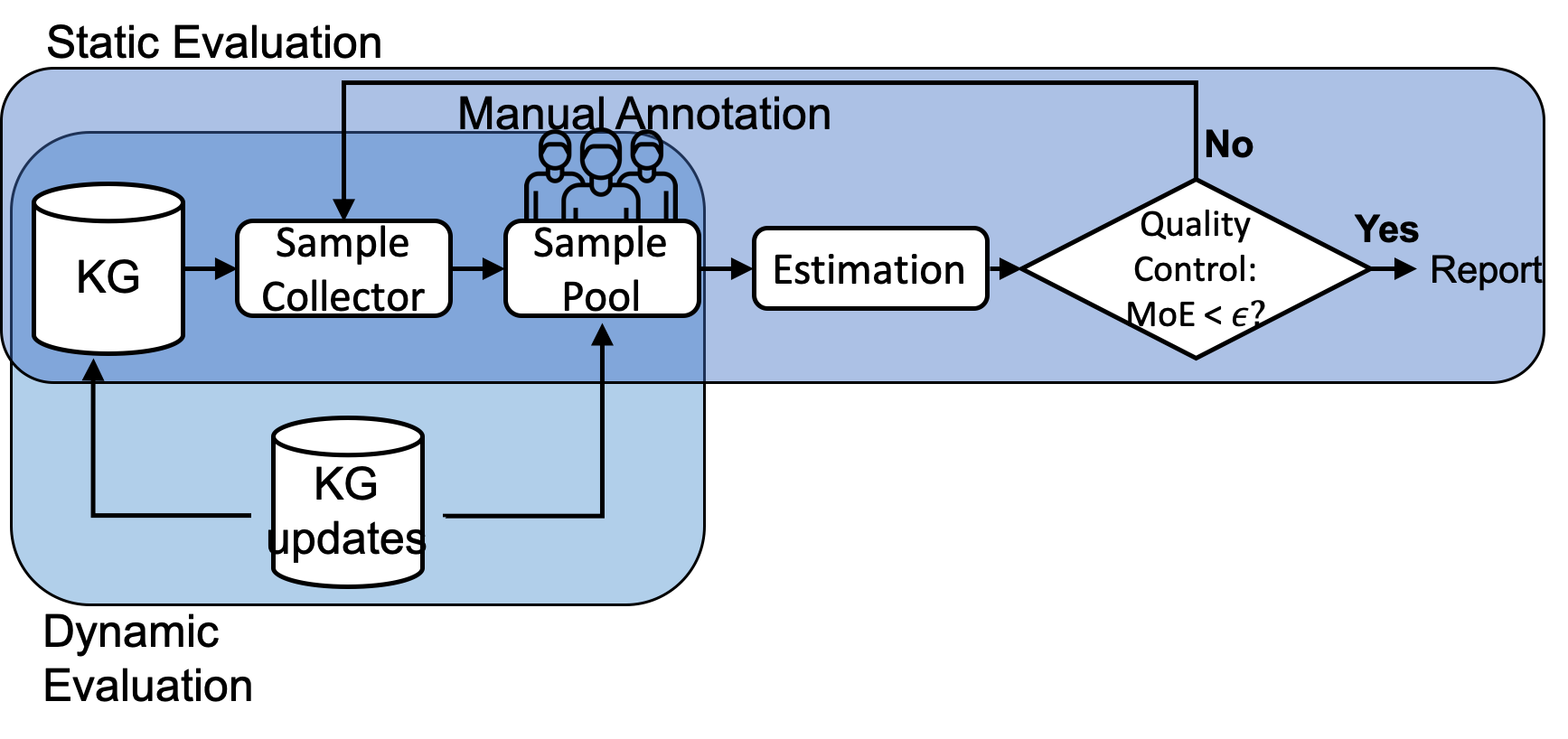
문제 제기: 지식 그래프(KG)는 많은 양의 정보를 포함하고 있지만, 그 안에 잘못된 사실들이 있을 가능성이 큽니다. 이러한 KG의 정확도를 평가하려면 많은 양의 주석 작업이 필요하지만, 이는 비용과 시간 측면에서 큰 부담을 초래합니다. 특히, KG가 계속 진화하면서 새로운 정보가 추가될 때마다 그 정확성을 다시 평가해야 하는 문제도 있습니다.
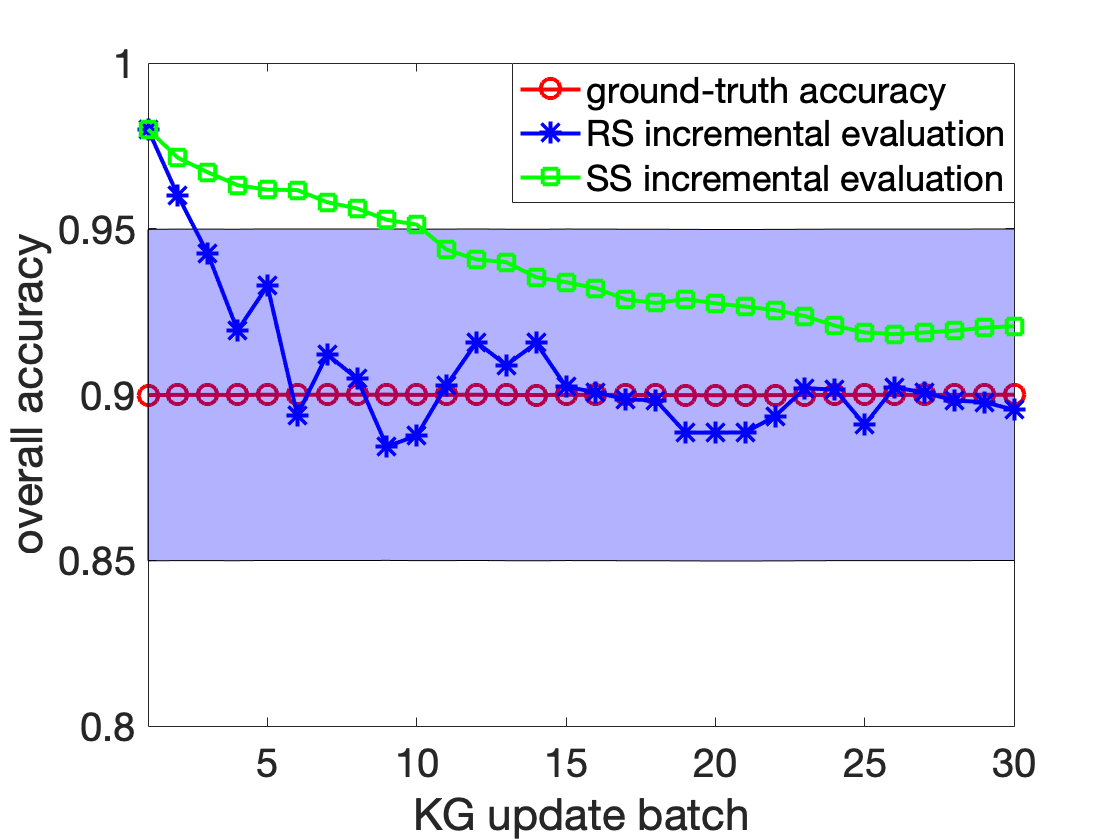
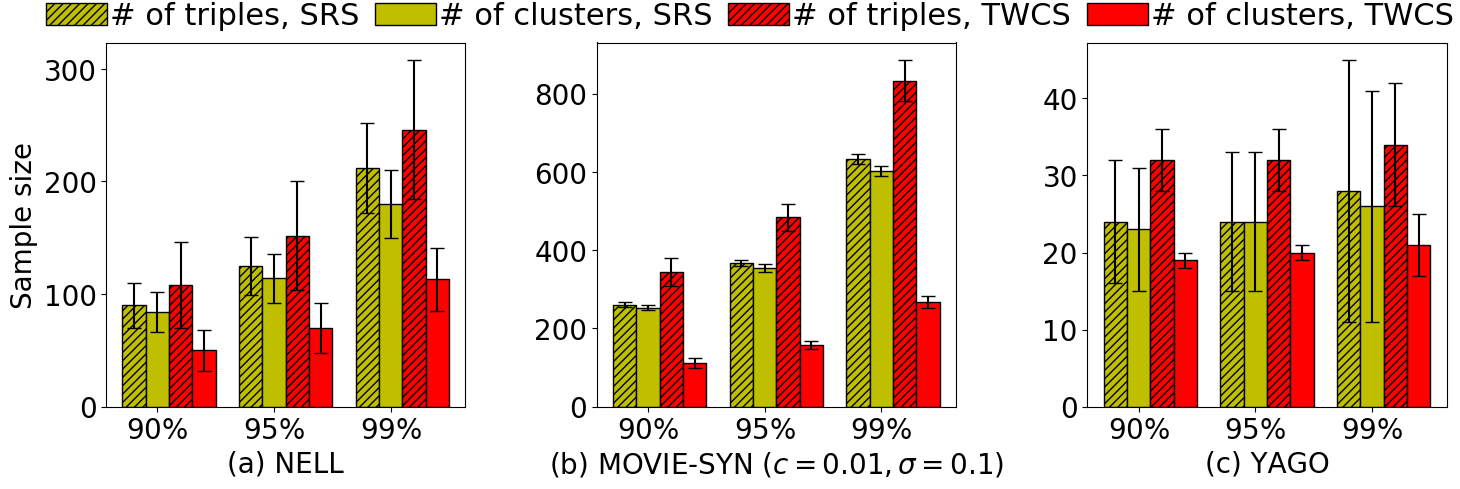
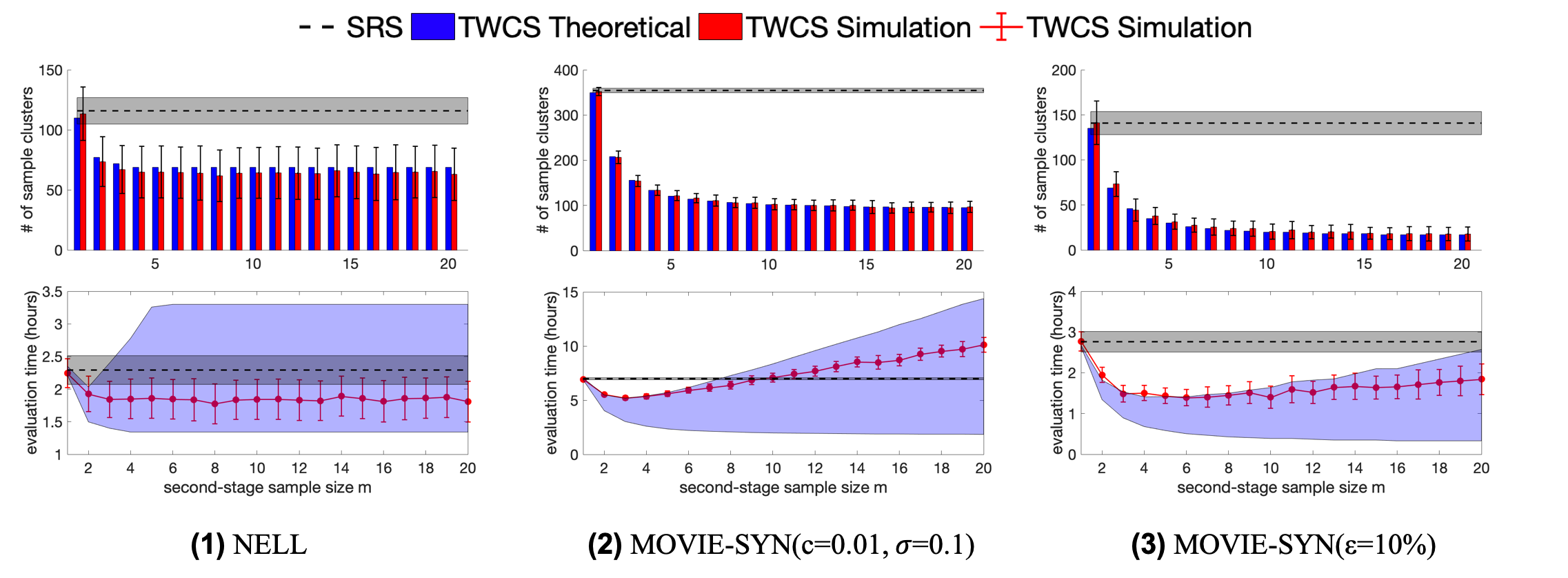
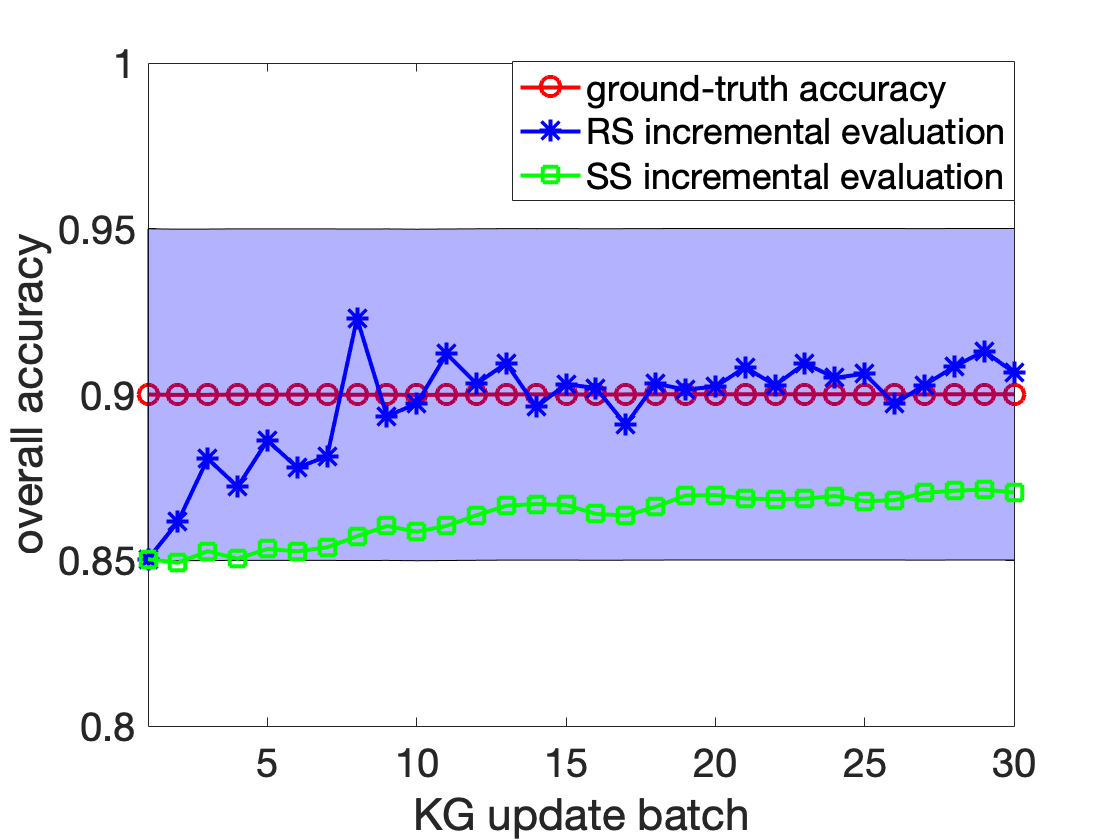
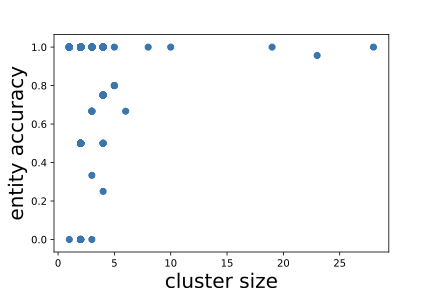
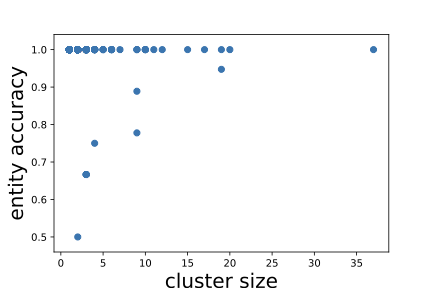
해결 방안 (핵심 기술): 본 논문에서는 이 문제를 해결하기 위해 효율적인 샘플링 및 주석 방법을 제안합니다. 이를 통해 KG의 일부만을 샘플링하여 그 정확성을 평가함으로써 전체적인 작업 비용과 시간을 크게 줄일 수 있습니다. 특히, 클러스터 샘플링, 가중치 샘플링, 계층화 샘플링 등 다양한 기법을 활용하였습니다. 이러한 방법들은 KG 내에서 동일한 엔티티에 대한 정보를 함께 평가함으로써 주석 작업의 효율성을 크게 높입니다.
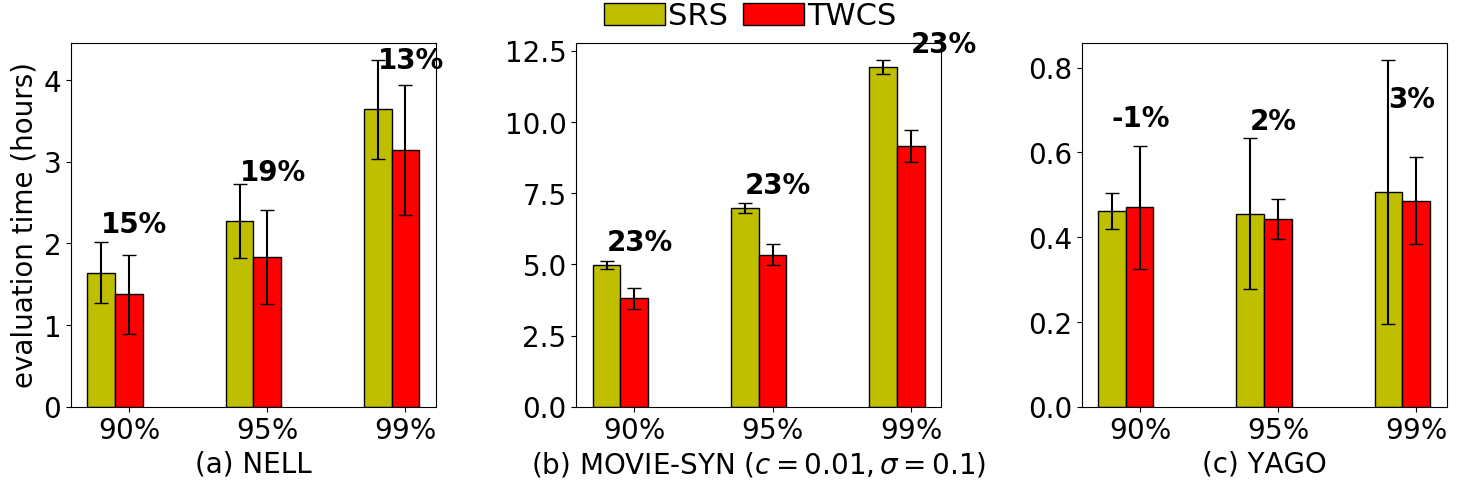
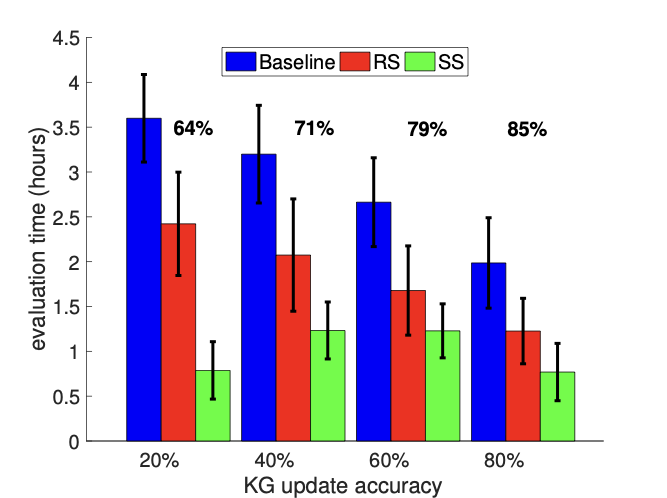
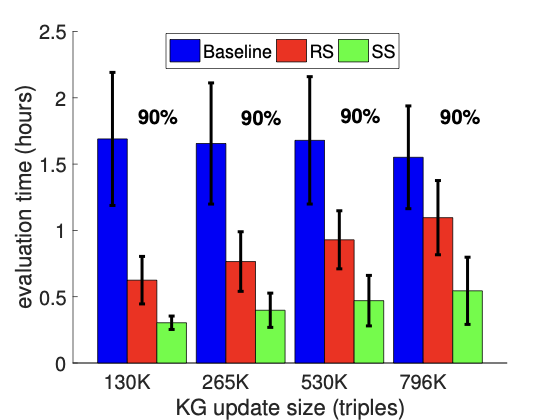
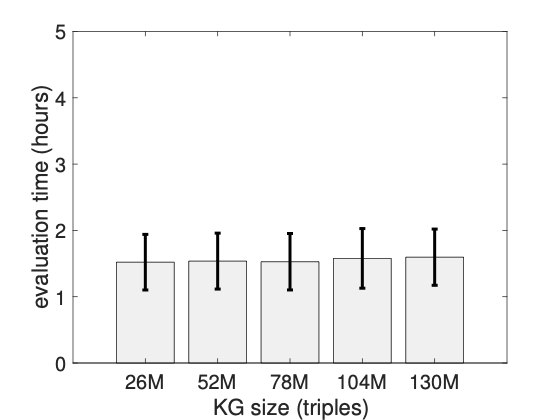
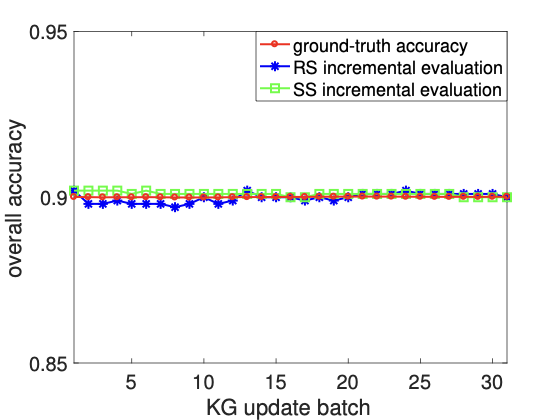
주요 성과: 제안된 접근법은 정적 KG에 대해 최대 60%, 진화하는 KG에 대해서는 최대 80%까지 비용을 절감하였습니다. 이로 인해 평가 결과의 품질이 저하되지 않으면서도 주석 작업의 효율성이 크게 향상되었습니다.
의의 및 활용: 이 연구는 큰 규모의 KG를 효과적으로 평가할 수 있는 방법을 제공함으로써, KG 개발과 실용적인 응용 프로그램에 중요한 역할을 합니다. 특히, KG가 계속 진화하고 새로운 정보가 추가되는 상황에서도 그 정확성을 효율적으로 유지할 수 있게 됩니다.
📄 논문 발췌 (ArXiv Source)
지난 몇 년 동안 RDF 형식의 *(주체, 관계, 대상)*로 수백만 개의 관계적 사실을 포함하는 대규모 지식 그래프(KG)가 증가하고 있습니다. DBPedia, YAGO, NELL, Knowledge-Vault 등의 예를 들 수 있습니다. 그러나 KG 구축 과정은 완벽하지 않기 때문에 이러한 KG에는 많은 잘못된 사실이 있을 수 있습니다. KG의 정확도를 알기는 KG의 구축 과정을 개선하는 데 중요합니다(예: 데이터 품질과 다양한 처리 단계에서 발생할 수 있는 결함에 대한 더 나은 이해), 그리고 하류 애플리케이션에게 데이터 품질의 불확실성을 알리고 이를 대처하도록 합니다. 이러한 중요성에도 불구하고, KG 정확도를 효율적이고 신뢰성 있게 평가하는 문제는 이전 학술 연구에서 대부분 간과되어 왔습니다.
KG의 정확도는 KG 내에 있는 triple 중 올바른 triple의 비율로 정의할 수 있습니다. 여기서 우리는 대응 관계가 실제 사실과 일치하면 triple을 올바르다고 고려합니다. 일반적으로 인간 판단을 기반으로 triple의 정확성을 평가합니다. 현대 KG 규모에 맞는 수동 평가는 금전적으로 비용이 매우 높습니다. 따라서 가장 일반적인 관행은 KG에서 (비교적 작은) 샘플을 선택하여 수동 주석을 수행하고 해당 샘플 기반으로 KG 정확도의 추정치를 계산하는 것입니다. 단순하고 인기 있는 접근법 중 하나는 KG에서 triple을 무작위로 샘플링하여 수동 주석을 수행하는 것입니다. 작은 샘플 집합은 주석 비용이 낮아지지만, 실제 정확도와 크게 다를 가능성이 있습니다. 통계적으로 의미 있는 추정치를 얻기 위해서는 충분한 수의 triple을 샘플링해야 하므로 추가적인 주석 비용이 발생합니다.
Task1
Task2
(Michael Jordan, graduatedFrom, UNC)
(Michael Jordan, wasBornIn, LA)
(Vanessa Williams, performedIn, Soul Food)
(Michael Jordan, birthDate, February 17, 1963)
(Twilight, releaseDate, 2008)
(Michael Jordan, performedIn, Space Jam)
(Friends, directedBy, Lewis Gilbert)
(Michael Jordan, graduatedFrom, UNC)
(The Walking Dead, duration, 1h 6min)
(Michael Jordan, hasChild, Marcus Jordan)
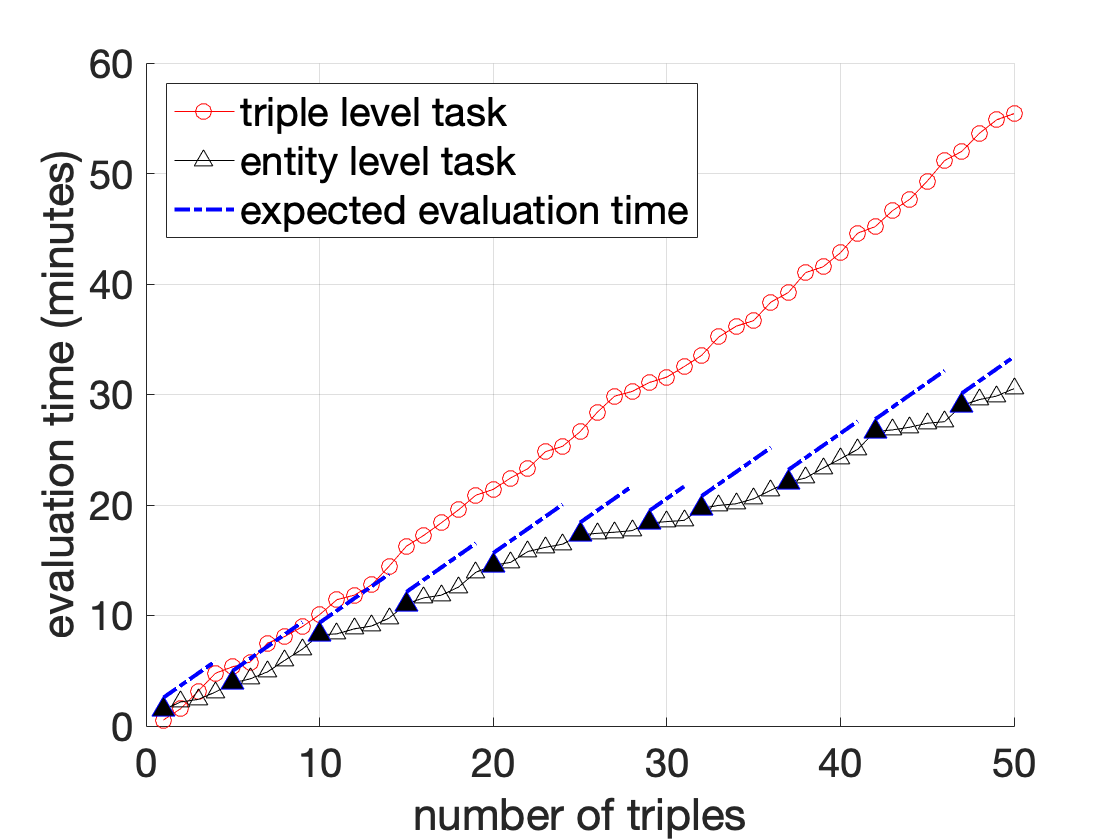
해결책을 동기부여하기 위해 수동 주석 과정이 어떻게 이루어지는지 자세히 살펴보겠습니다. 여기서는 [fig:motivating-example]에 표시된 두 가지 주석 작업을 예로 사용하겠습니다.
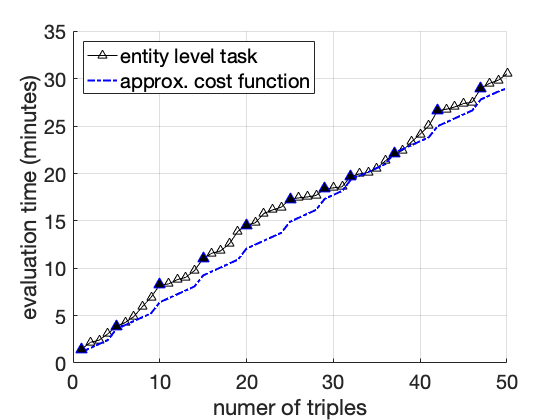
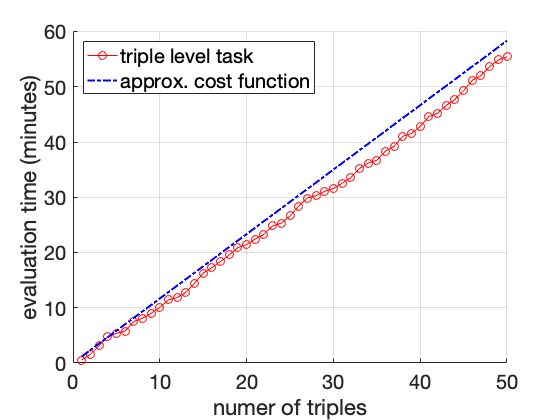
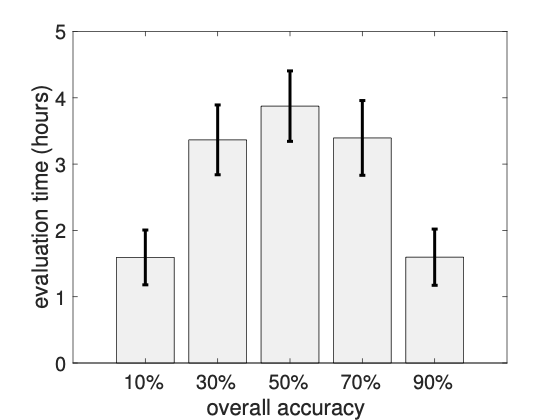
실제 엔터티의 언급은 모호할 수 있습니다. 예를 들어, Task1에서 첫 번째 triple인 “Michael Jordan"이라는 이름은 다른 사람들을 가리킬 수 있습니다 — NBA 명예의 전당에 입성한 농구 선수 Michael Jordan 또는 컴퓨터 과학자 Michael Jordan입니다. 이 중 먼저 출생지는 New York이고, 나중에는 Los Angeles에서 태어났습니다. 우리는 주체와 대상 간 관계를 확인하기 전에 각 엔티티를 식별해야 합니다.[^1] 새 triple을 이미 식별한 엔티티에 대해 평가하면 총 주석 비용이 더 낮아집니다. Task2의 경우, 모든 triple은 동일한 엔티티인 Michael Jordan에 대한 정보입니다. 이 Michael Jordan을 농구 선수로 식별한 후에는 주석자가 각각의 triple에 대해 추가적인 식별 작업 없이 그 정확성을 쉽게 평가할 수 있습니다. 반면, Task1에서는 다섯 개의 서로 다른 엔티티에 대한 다섯 개의 다른 triple을 포함하고 있습니다. 각 triple의 주석 과정은 독립적이며, 주석자가 각각의 엔티티를 식별하기 위해 추가적인 노력을 기울여야 합니다. 예를 들어, “Friends"는 TV 시리즈인지 영화인가? “Twilight"는 2008년에 나온 영화인지 아니면 1998년에 나온 것인가? 동일한 수의 triple로 주석 작업을 수행하더라도 Task2는 더 적은 시간이 걸립니다.
핵심 요약: 본 논문에서는 지대한 규모의 지식 그래프(KG)를 정확하게 평가하기 위해 효율적인 샘플링 및 주석 방법을 제안합니다. 기존 방법들과 비교해 봤을 때, 이 접근법은 인력 노력을 최소화하면서도 정확도 평가의 품질과 통계적 신뢰성을 유지할 수 있습니다.
문제 제기: 지식 그래프(KG)는 많은 양의 정보를 포함하고 있지만, 그 안에 잘못된 사실들이 있을 가능성이 큽니다. 이러한 KG의 정확도를 평가하려면 많은 양의 주석 작업이 필요하지만, 이는 비용과 시간 측면에서 큰 부담을 초래합니다. 특히, KG가 계속 진화하면서 새로운 정보가 추가될 때마다 그 정확성을 다시 평가해야 하는 문제도 있습니다.
해결 방안 (핵심 기술): 본 논문에서는 이 문제를 해결하기 위해 효율적인 샘플링 및 주석 방법을 제안합니다. 이를 통해 KG의 일부만을 샘플링하여 그 정확성을 평가함으로써 전체적인 작업 비용과 시간을 크게 줄일 수 있습니다. 특히, 클러스터 샘플링, 가중치 샘플링, 계층화 샘플링 등 다양한 기법을 활용하였습니다. 이러한 방법들은 KG 내에서 동일한 엔티티에 대한 정보를 함께 평가함으로써 주석 작업의 효율성을 크게 높입니다.
주요 성과: 제안된 접근법은 정적 KG에 대해 최대 60%, 진화하는 KG에 대해서는 최대 80%까지 비용을 절감하였습니다. 이로 인해 평가 결과의 품질이 저하되지 않으면서도 주석 작업의 효율성이 크게 향상되었습니다.
의의 및 활용: 이 연구는 큰 규모의 KG를 효과적으로 평가할 수 있는 방법을 제공함으로써, KG 개발과 실용적인 응용 프로그램에 중요한 역할을 합니다. 특히, KG가 계속 진화하고 새로운 정보가 추가되는 상황에서도 그 정확성을 효율적으로 유지할 수 있게 됩니다.