Computer Science / Systems and Control
Computer Science / Machine Learning
Electrical Engineering and Systems Science / Systems and Control
Mathematics / Information Theory
Computer Science / Information Theory
분산 가설 검정 및 비베이지안 학습을 위한 새로운 접근 방식 개선된 학습 속도와 바이잔틴 저항성
📝 원문 정보
- Title: A New Approach to Distributed Hypothesis Testing and Non-Bayesian Learning Improved Learning Rate and Byzantine-Resilience- ArXiv ID: 1907.03588
- 발행일: 2019-07-09
- 저자: Aritra Mitra, John A. Richards and Shreyas Sundaram
📝 초록
우리는 각각 부분적으로 정보가 있는 개인 신호를 받는 에이전트 그룹이 공동으로 학습하려고 하는 상황을 연구합니다. 이들은 세상의 진정한 기저 상태(유한한 가설 집합 중 하나)를 파악하고자 합니다. 이를 해결하기 위해, 우리는 기존 접근 방법과 본질적으로 다른 분산 학습 규칙을 제안합니다. 이 새로운 접근법은 어떠한 형태의 "신념 평균화"도 사용하지 않습니다. 대신 에이전트들은 최소값 규칙에 근거해 자신의 신념을 업데이트합니다. 관찰 모델과 네트워크 구조에 대한 표준 가정 하에서, 각 에이전트가 거의 확실히 진실을 학습한다는 것을 증명했습니다. 주요 기여로는, 각 허위 가설이 모든 에이전트에 의해 확률 1의 속도로 지수적으로 빠르게 배제된다는 것입니다. 또한 우리는 계산 효율적인 변형 규칙을 개발하여 예상치 못한 행동을 보이는 에이전트(바이잔틴 적대자 모델로 표현)가 의도적으로 오해를 퍼뜨리려고 할 때에도 증명 가능한 탄력성을 제공합니다.💡 논문 해설
**핵심 요약**: 이 논문은 각각 부분적인 정보만을 가진 여러 에이전트가 공동으로 진실을 찾아내는 방법론을 제시하고 있습니다. 기존의 신념 평균화 방식과 달리, 이들은 최소값 규칙을 사용하여 학습합니다.문제 제기: 각각의 에이전트는 부분적으로 정보가 있는 개인 신호를 받고, 이러한 정보들로부터 세상의 진정한 상태(가설 중 하나)를 공동으로 찾아내려고 합니다. 문제는 여러 에이전트들이 서로 다른 정보를 가진 채로 어떻게 협력하여 정확하게 진실을 학습할 수 있는지입니다.
해결 방안 (핵심 기술): 이 연구에서는 기존의 신념 평균화 방법 대신, 각 에이전트가 자신의 정보와 네트워크에서 얻은 정보를 바탕으로 최소값 규칙을 사용하여 학습하는 새로운 분산 학습 규칙을 제안합니다. 이를 통해 에이전트들은 허위 가설들을 빠르게 배제하고 진실에 도달할 수 있습니다.
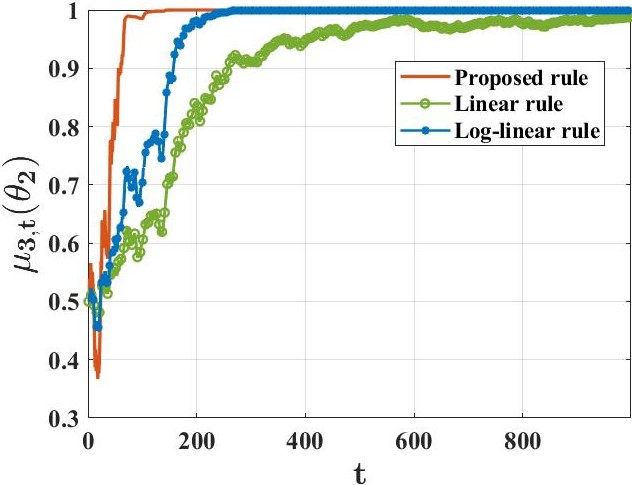
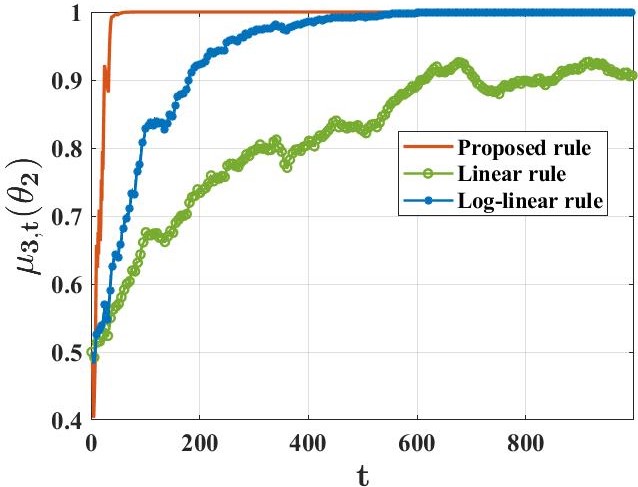
주요 성과: 이 논문은 각 에이전트가 거의 확실히 진실을 학습한다는 것을 증명하였습니다. 특히, 모든 에이전트는 허위 가설들을 지수적으로 빠르게 배제할 수 있으며, 이러한 속도는 기존의 방법보다 더 빠릅니다.
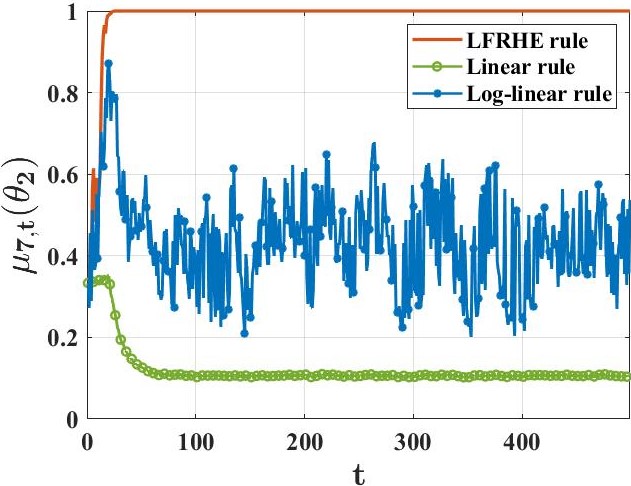
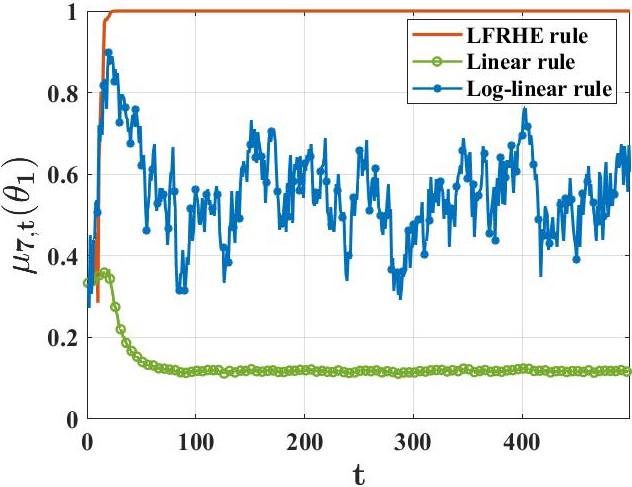
의미 및 활용: 이 연구는 분산 시스템에서 정보를 효과적으로 공유하고 학습하는 새로운 방법을 제시하여, 특히 바이잔틴 적대자 모델로 표현되는 에이전트가 의도적으로 오해를 퍼뜨리는 상황에서도 탄력적인 성능을 보장합니다. 이는 안정적이고 신뢰할 수 있는 분산 학습 시스템의 설계에 중요한 기여를 합니다.
📄 논문 발췌 (ArXiv Source)
📊 논문 시각자료 (Figures)