Title: Using Structured Input and Modularity for Improved Learning
ArXiv ID: 1903.12366
발행일: 2019-04-01
저자: Zehra Sura, Tong Chen, and Hyojin Sung
📝 초록 (Abstract)
본 논문에서는 입력 데이터의 알려진 구조를 활용하여 학습을 더 효율적으로 만드는 방법을 설명합니다. 우리의 연구 분야는 프로그래밍 언어이며, 우리는 딥 뉴럴 네트워크를 사용하여 프로그램 분석을 수행합니다. 컴퓨터 프로그램에는 루프 중첩, 조건부 블록 및 데이터 범위와 같은 구조적 정보가 포함되어 있으며 이는 프로그램 분석에 중요합니다. 이 경우, 신경망은 이러한 구조를 인식하고 문제에 대한 목표 함수도 학습해야 합니다. 그러나 컴파일러 도구와 잘 정의된 프로그래밍 언어용 파서가 사용 가능함으로써, 이 영역에서 구조적 정보는 소프트웨어로 쉽게 접근할 수 있습니다.
입력 데이터의 알려진 구조를 활용하는 우리의 방법은 다음과 같습니다: (1) 입력 데이터를 전처리하여 관련 구조를 노출시키고, (2) 신경망을 구성하되, 입력 데이터의 구조를 네트워크 설계의 일부로 통합합니다. 이 방법은 신경망을 모듈화함으로써 복잡성을 분해하고 전체 네트워크의 학습 효율성을 높이는 효과가 있습니다. 우리는 예제 코드 분석 문제에 이 방법을 적용하였고, 더 작은 네트워크 크기와 적은 학습 샘플로 더 높은 정확도를 달성할 수 있음을 보여주었습니다. 또한, 입력 데이터의 다른 분포에서 동일한 성능을 제공하는 견고한 방법입니다.
💡 논문 핵심 해설 (Deep Analysis)
This paper discusses a method for improving the learning efficiency of deep neural networks by utilizing structural information from program code. The authors aim to enhance the effectiveness of machine learning in analyzing and optimizing complex programs. Traditional methods often struggle with capturing intricate structures within code, leading to suboptimal performance. By leveraging compiler tools and parsers, this study pre-processes input data to explicitly represent structural elements such as loop nests, conditional blocks, and statement scopes. This approach simplifies the learning process for neural networks, enabling them to achieve higher accuracy with less training data and smaller network sizes.
The proposed method involves modularizing neural networks based on domain knowledge about program structures. Each structure type corresponds to a component neural network within the larger architecture. The authors demonstrate that their modular design can handle more complex problems than traditional monolithic networks, showing improved performance across various experiments. This work holds significant implications for advancing machine learning techniques in software engineering and potentially extends to other domains with structured data.
📄 논문 본문 발췌 (Translation)
본 논문에서는 컴퓨터 프로그램 분석 및 코드 최적화를 위한 딥 뉴럴 네트워크의 활용에 초점을 맞추고 있습니다. 이는 성능을 달성하는 데 중요한 기술입니다. 응용 프로그램이 고성능을 달성하기 위해서는 복잡한 알고리즘이 필요하며, 오늘날 사용되는 다양한 하드웨어 플랫폼은 이러한 복잡성을 더욱 증가시킵니다. 컴파일러와 런타임 시스템과 같은 소프트웨어 도구들은 이 복잡성을 관리하기 위해 사용됩니다. 이러한 도구들은 정확한 프로그램 분석을 통해 코드를 최적화하고 성능을 제공합니다. 일부 분석 및 최적화 결정은 간단하며 효율적인 계산 모델이 존재하지만, 다른 경우는 복잡하거나 알려져 있지 않은 경우가 많습니다 (즉, 분석 모델이 없는 경우). 이 경우, 하드웨어 특성과 애플리케이션 도메인에 대한 지식을 바탕으로 휴리스틱 모델을 개발해야 합니다. 그러나 성능에 영향을 미치는 요소와 시스템 상호작용의 수가 많아서, 좋은 휴리스틱을 개발하는 것이 비용이 많이 들거나 불가능할 수 있습니다. 대신, 기계학습 기술을 사용하여 프로그램 분석 및 최적화에 데이터 중심 접근 방식을 도입할 수 있습니다.
기존 연구에서는 프로그램 분석과 최적화를 위한 다양한 기계학습 기법들이 제시되었습니다. 예를 들어, 루프 최적화와 병렬화 전략 및 매개변수 선택, 코드 배치 및 스케줄링 결정, 적용할 변환 집합 및 순서 선택 등에 대한 연구가 이루어졌습니다. 이 논문에서는 이러한 기계학습 기법들의 종류와 사용된 프로그램/시스템의 특징을 고려한 문헌 조사를 실시하였습니다. 또한, 컴파일러 최적화를 위한 기계학습 분야에서 이루어진 연구 진전도 조사하였습니다.
기존 대부분의 연구는 정적 및 동적인 프로그램 특성 목록 또는 문자열 형태의 프로그램 코드를 직접 사용하여 입력 데이터로 활용하였습니다. 본 논문에서는 다른 접근 방식을 취합니다: 도메인 지식을 이용해 코드 내에서 관련 구조 (예: 루프, 기본 블록, 문장 등)를 결정하고 이를 기계학습에 적용합니다. 이러한 구조적 정보는 토큰 시퀀스로 인코딩되어 입력 데이터에 포함됩니다. 이를 위해 이미 프로그램 내에서 구조적 정보를 추출하는 데 능한 컴파일러 도구체의 기능을 재사용하였습니다. 구조적 정보를 학습 데이터에 명시적으로 인코딩함으로써, 자동화된 기계학습이 이를 더 쉽게 학습할 수 있습니다.
데이터 표현은 다음과 같은 여러 가지 장점을 가지고 있습니다:
코드 구조로 직접 제공되는 입력 데이터는 코드에서 파생된 2차 특성 목록이 아닙니다.
표현력: 인코딩된 구조는 프로그램 코드로부터 사용자 정의 규칙을 통해 도출되며, 반드시 기존 프로그래밍 언어에 정의된 구조와 일치할 필요가 없습니다.
추가적인 속성 정보를 다양한 구조와 관련하여 유연하게 인코딩하고 입력 데이터 시퀀스 내에서 적절한 문맥 포인트에 내장할 수 있습니다.
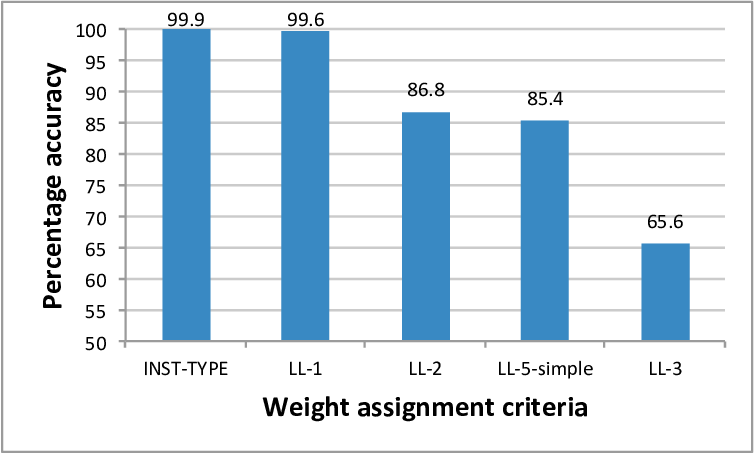
우리는 기계학습이 복잡한 프로그램 분석 및 코드 최적화 문제에도 적용될 수 있는지 탐구하려 합니다. 이를 위해, 딥 러닝이라는 강력한 기계학습 기법을 사용하였습니다. 예를 들어, 프로그램의 동적 명령어 카운트를 추정하는 문제를 고려해 보겠습니다. 명령어 카운트는 다양한 작업 유형에 따라 다릅니다: 스칼라 산술 연산, 벡터 계산 또는 메모리 액세스 작업 등이 있습니다. 입력 프로그램이 제어 흐름 없이 연속된 작업의 시퀀스인 경우, 시퀀스 내에서 로컬 속성 (즉, 작업 유형)만 명령어 카운트에 기여하며 현재 딥 러닝 방법은 이러한 경우 매우 잘 작동합니다. 마찬가지로, 입력 프로그램이 단일 중첩 루프를 가진 간단한 제어 흐름을 가지면, 가장 가까운 포함 루프의 반복 횟수와 같은 명령어 카운트 계산에 필요한 정보는 프로그램 시퀀스 내에서 쉽게 찾을 수 있습니다. 그러나 프로그램 구조가 복잡해지면 관련 문맥 정보를 프로그램 시퀀스로부터 추출하기가 더 어려워집니다. 이 경우, 현재 LSTM 기반 딥 러닝 방법은 성능이 저하되고 학습된 모델의 정확도가 낮아집니다.
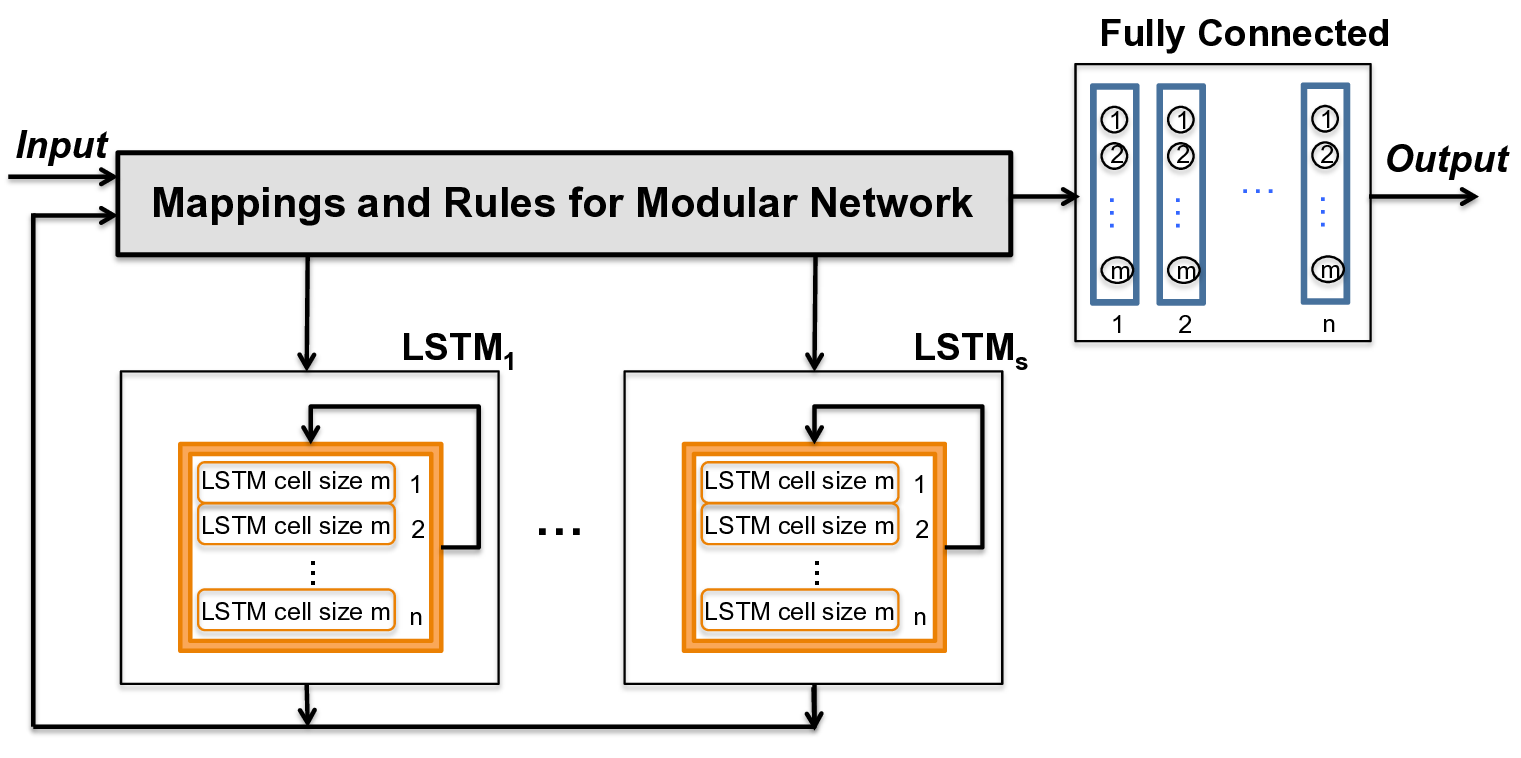
[IMG_PROTECT_1]
본 논문에서는 문제 도메인에 대한 고수준 지식을 딥 뉴럴 네트워크 설계 (레이아웃)으로 전환하는 방법을 제시합니다. 각 학습 데이터 항목은 토큰 시퀀스로 구성되며, 각 토큰은 문제 도메인 내에서 고수준 의미 구조에 해당합니다. 예를 들어 프로그램 분석의 경우, 구조 유형은 루프 시작, 루프 종료 또는 문장 블록과 같은 것들일 수 있습니다. 모듈화된 신경망은 여러 개의 구성 요소 신경망으로 구성되며 각각의 구성 요소 신경망은 각 구조 유형에 해당합니다. 모듈화된 신경망에는 입력 시퀀스 내의 개인 토큰을 적절한 구성 요소 신경망으로 라우팅하는 제어 논리가 포함됩니다. 이 제어 논리는 개별 토큰 처리 전후에 신경망 상태를 업데이트하기 위해 도메인 지식을 사용하여 연결 규칙을 결정합니다.
본 논문에서는 다음과 같은 기여를 소개합니다:
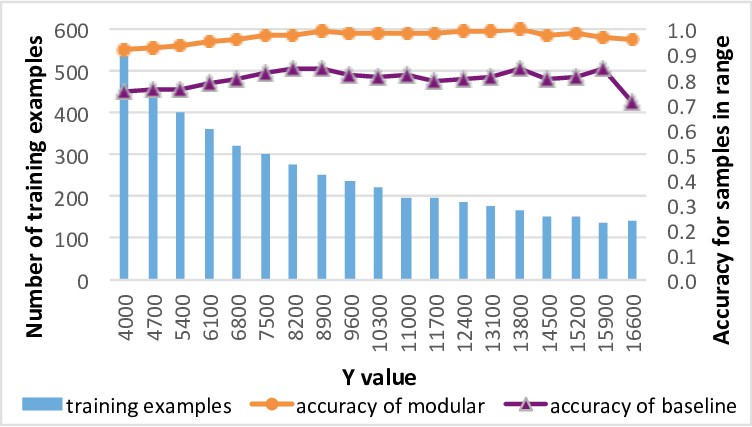
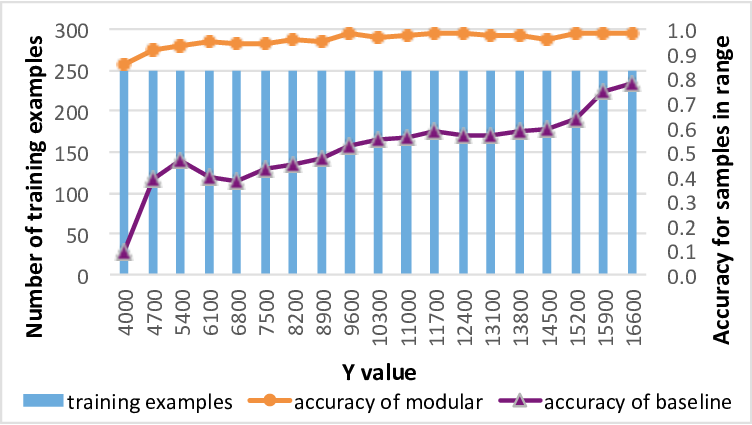
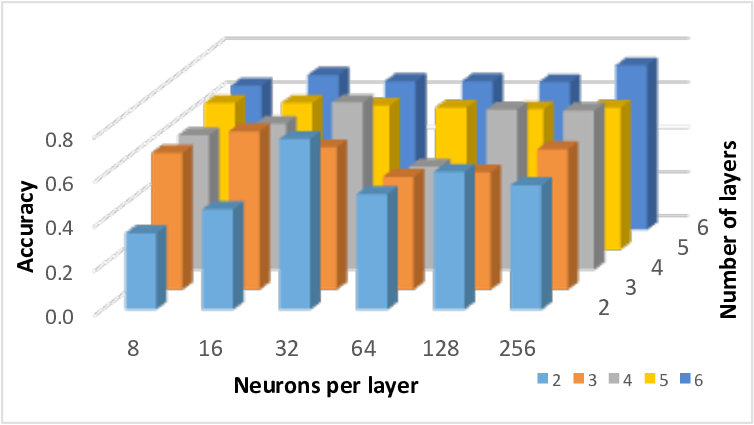
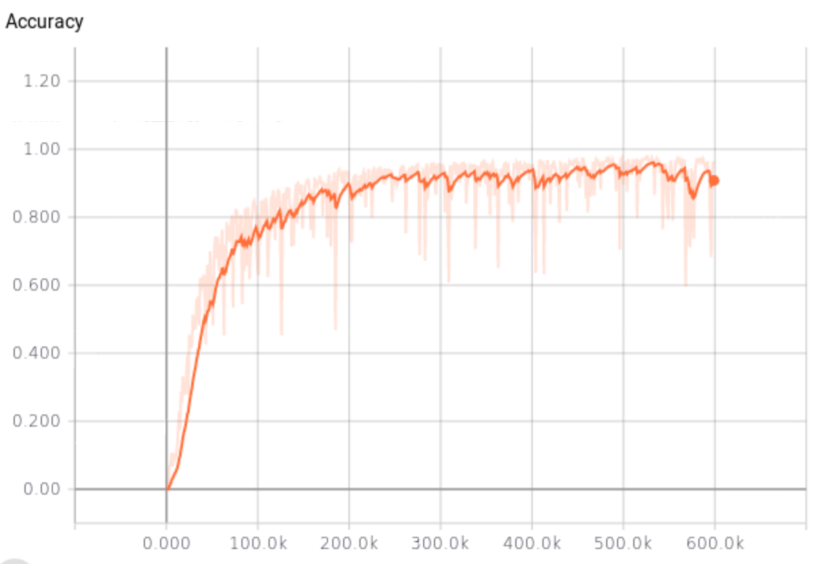
우리는 딥 뉴럴 네트워크를 설계하는 새로운 방법, 즉 모듈화된 신경망을 제시하였습니다. 우리의 방법은 프로그램 구조에 대한 관련 정보 (도메인 지식)을 신경망의 설계 자체에 자연스럽게 통합합니다. 결과적으로 생성된 네트워크는 현재 기법으로 설계된 동등하거나 더 큰 크기의 단일 블록 네트워크보다 복잡한 학습 문제를 처리할 수 있습니다.
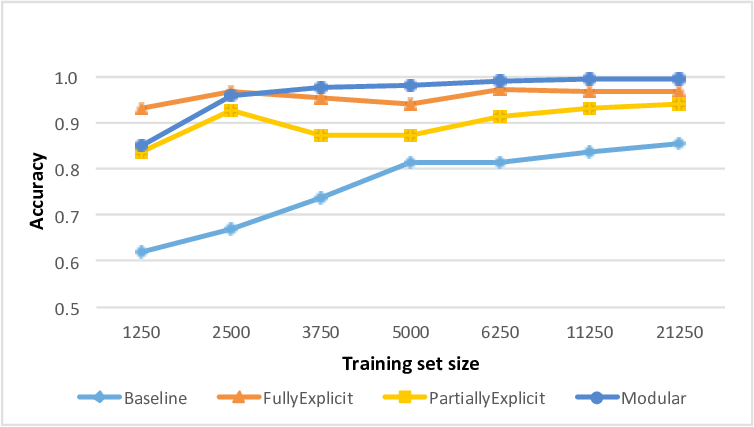
우리는 예제 코드 분석 문제에 대한 모듈화된 신경망을 설계하여, 현재 최신 기술로 설계된 LSTM 기반 딥 뉴럴 네트워크와 비교하였습니다. 우리의 방법은 더 작은 네트워크 크기와 더 적은 학습 샘플로 더 높은 정확도를 달성할 수 있음을 보여주었습니다.