- Title: Learning Multilingual Embeddings for Cross-Lingual Information Retrieval in the Presence of Topically Aligned Corpora
- ArXiv ID: 1804.04475
- 발행일: 2018-04-13
- 저자: Mitodru Niyogi, Kripabandhu Ghosh, Arnab Bhattacharya
📝 초록
다국어 정보 검색은 정렬된 병렬 코퍼스가 없는 경우에 어려운 과제입니다. 본 논문에서는 평가를 위한 IR 시나리오 설계로 구성된 주제별로 정렬된 코퍼스를 고려하여 이 문제를 해결합니다. 우리는 문장 단위로 정렬된 코퍼스, 문서 단위로 정렬된 코퍼스 또는 사전, 통사론 규칙과 같은 언어 특정 자원을 사용하지 않습니다. 대신 공통 공간으로 임베딩하고 그로부터 직접 단어 간의 대응 관계를 학습합니다. 우리의 접근 방식은 표준 FIRE 데이터셋에 대해 벵갈리어, 힌디어 및 영어로 이중 언어 IR을 시험하였습니다. 제안된 방법은 검색 평가 지표뿐만 아니라 시간 요구사항 측면에서도 최신 기술을 능가합니다. 우리는 또한 우리의 방법을 성공적으로 삼국어 환경으로 확장시켰습니다.
💡 논문 해설
**핵심 요약**: 이 논문은 다국어 정보 검색에서 병렬 코퍼스 없이도 효과적인 결과를 얻는 방법을 제안합니다. 공통의 임베딩 공간을 통해 언어 간 단어 대응 관계를 학습하고 이를 이용하여 정보 검색의 성능을 향상시킵니다.
문제 제기: 다국어 정보 검색은 여러 언어로 된 문서에서 원하는 정보를 찾아내는 과제입니다. 이 과정에서 병렬 코퍼스가 필요하지만, 이런 자원이 항상 존재하지 않는 경우가 많습니다. 따라서 기존의 방법들은 제약을 받게 되며 특히 리소스가 부족한 언어들에서는 더욱 어려움을 겪습니다.
해결 방안 (핵심 기술): 이 연구에서 제안하는 해결 방안은 병렬 코퍼스 없이도 효과적인 정보 검색을 가능하게 하는 방법입니다. 공통의 임베딩 공간을 사용하여 각 언어의 단어를 같은 공간에 위치시킵니다. 이를 통해 서로 다른 언어 간의 단어 대응 관계를 학습하고, 이를 이용해 쿼리와 문서를 비교할 수 있습니다. 예를 들어 영어로 작성된 쿼리를 벵갈리어나 힌디어로 된 문서에서 검색하는 것이 가능합니다.
주요 성과: 제안한 방법은 표준 데이터셋에 대해 이중 언어 및 삼국어 정보 검색 환경에서 우수한 성능을 보였습니다. 또한 시간 요구사항 측면에서도 기존 방법보다 효율적입니다. 다양한 평가 지표를 통해 이를 확인할 수 있습니다.
의의 및 활용: 이 연구는 병렬 코퍼스 없이도 효과적인 다국어 정보 검색을 가능하게 하므로, 리소스가 부족한 언어들에서도 정보 검색 성능 향상에 큰 도움이 될 것입니다. 특히 인도와 같은 여러 언어를 공식적으로 사용하는 국가에서는 디지털 기술의 활용을 크게 진전시킬 수 있습니다.
📄 논문 발췌 (ArXiv Source)
# 서론
다국어 정보 검색은 여러 언어가 동시에 사용되는 정보 검색 (IR) 작업의 한 분야로, 연구의 중요한 부분입니다. 인터넷을 통해 처리되는 비영어 데이터의 증가와 현대 IR/NLP (자연어 처리) 작업에 의해 다국어 IR의 중요성이 더욱 부각되었습니다. 특히 우리는 일반적인 정보 검색 작업을 다룹니다. 여기서 쿼리는 여러 언어 중 하나로 작성되고, 문서는 나머지 언어들에서 추출됩니다.
이러한 쿼리들은 상당히 흔합니다. 예를 들어 전국 단위의 이벤트인 일반 선거나 비상 사태, 스포츠 행사 등에서는 “파티 X가 주 Y에서 몇 개의 의석을 얻었는가?“와 같은 쿼리들이 여러 언어로 작성되곤 합니다. 제안된 시스템은 이러한 질문에 대한 답변을 어느 언어로 작성된 문서들에서도 찾아내야 할 수 있습니다.
이전 연구 대부분에서는 문장 단위로 정렬된 병렬 데이터와 사전, 통사론 규칙 등의 언어 특정 자원을 필요로 했습니다. Vulic 등은 이러한 제약 요소를 없애고, 문서 단위로 정렬된 비교 코퍼스만을 사용하여 이중 언어 단어 임베딩을 학습했습니다. 하지만 그러한 정렬된 코퍼스는 항상 쉽게 얻을 수 있는 것은 아니며, 이를 만드는데 상당한 노력이 필요합니다. 특히 인도의 여러 언어처럼 리소스가 부족한 언어들은 이런 문제에 더욱 크게 영향을 받습니다.
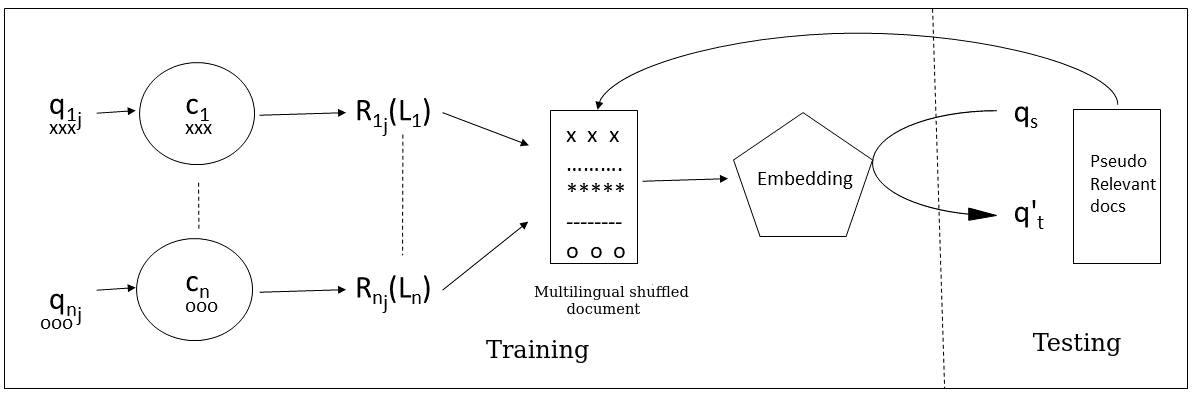
따라서 우리는 병렬 코퍼스나 언어 특정 자원 없이 다국어 IR 시스템을 구축하는 방법을 제안합니다. 이는 단순히 TREC 스타일의 테스트 컬렉션만 사용하여 교차 언어 임베딩을 자동으로 학습합니다. 또한 이 설정에서 다국어 임베딩을 구축하는 것을 제안합니다. 이를 통해 교차 언어 검색 패러다임에서 콜렉션 쌍별로 임베딩을 만들 필요가 없으며, 모든 가능한 언어 쌍에 대해 이중 언어 임베딩을 학습할 필요도 없습니다. 대신 이 단일 다국어 임베딩은 어떤 두 개의 언어 사이에서도 자동으로 교차 언어 검색을 수행할 수 있습니다.
이 연구는 특히 인도와 같은 다언어 국가에서 온라인 상황에 매우 유용합니다. 또한, 이는 세계 각국 정부가 적극적으로 추진하고 있는 많은 디지털 이니셔티브를 위한 게임 체인저가 될 수 있습니다.
검색 시에는 쿼리의 제목 필드만 사용했습니다. 불용어 제거가 수행되었습니다. 모든 검색 실험에서는 Terrier IR 툴킷 (http://terrier.org/
)에서 제공하는 디리클레 언어 모델을 기본값으로 사용하였습니다.
베이스라인: 우리는 Vulic 등과의 이중 언어 임베딩 방법을 비교합니다. 셔플링 코드는 저자로부터 얻었습니다.
단일 언어: 단일 언어 설정에서는 실제 목표 언어 쿼리를 사용하여 검색하고 이를 통해 다국어 설정에서 달성할 수 있는 성능의 상한선을 설정합니다.
실험
학습
Gensim의 Word2Vec 구현 (https://radimrehurek.com/gensim/models/word2vec.html
)를 사용했습니다. skip-gram 모델은 다음과 같은 파라미터로 학습되었습니다: (i) 벡터 차원: 100, (ii) 학습률: 0.01, (iii) 최소 단어 수: 1. 컨텍스트 윈도우 크기는 5에서 50까지 5씩 증가시켰습니다. 이중 언어 임베딩에서는 훈련 세트에서 가장 좋은 성능을 보인 50을 사용했습니다. 또한 다양한 파라미터 값을 시도하여 최적의 모델을 찾았습니다.
분석
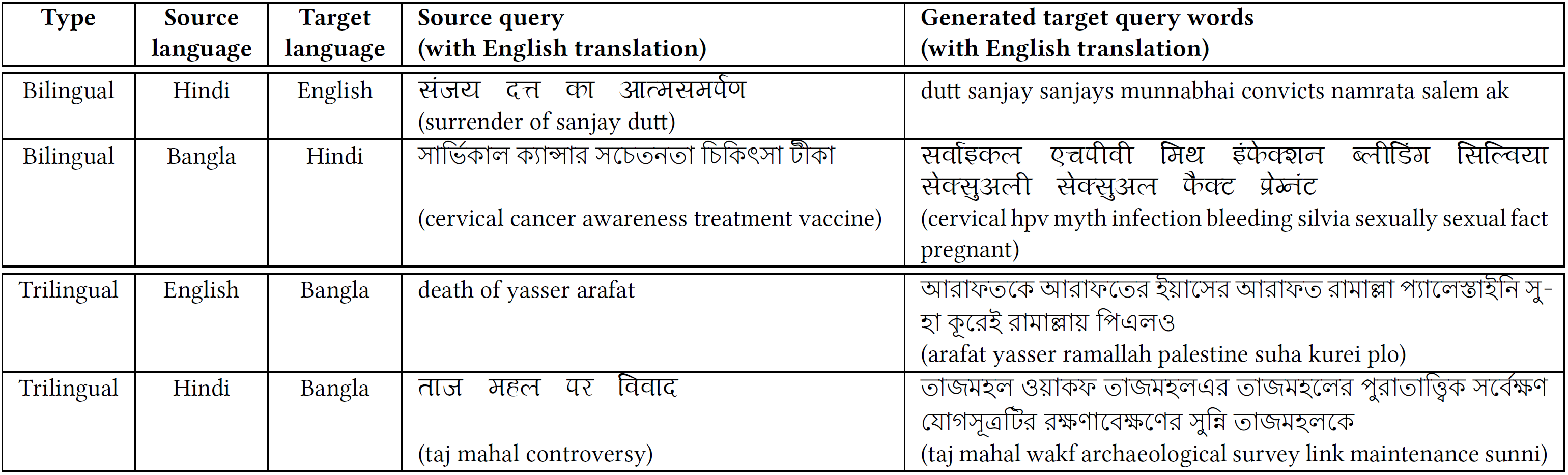
그림 [IMG_PROTECT_0]은 우리의 제안된 방법이 이중 언어 및 삼국어 임베딩을 이용해 생성한 일부 예시 쿼리를 보여줍니다. “sanjay dutt의 항복” (1993년 폭탄 테러 사건과 관련하여 영화 배우 Sanjay Dutt가 유죄 판결을 받은 것에 대한 내용)에 대한 생성된 쿼리는 중요 단어들인 sanjay, dutt, salem (Abu Salem, 테러리스트), ak (AK-47, 소총), munnabhai (Sanjay의 인기 있는 스크린 이름)를 포함합니다. “자궁 경부암 인식 및 치료 백신"에 대한 생성된 쿼리는 유용한 용어들인 cervical, hpv (Human papillomavirus), infection, pregnant, silvia (Silvia De Sanjose, 암 역학 연구의 선두 연구자)를 포함합니다. “Yasser Arafat의 사망"에 대한 생성된 쿼리는 arafat, yasser, ramallah (Yasser의 본부), palestine, suha (Suha Arafat, Yasser Arafat의 아내) 및 plo (팔레스타인 해방기구)와 같은 용어를 포함합니다. “Taj Mahal 논란"에 대한 생성된 쿼리는 중요한 단어들인 taj, mahal, wakf, archaeological 및 sunni를 포함하고 있습니다. 이러한 예시들은 우리의 목표 쿼리 생성의 효과성을 명확히 보여줍니다.