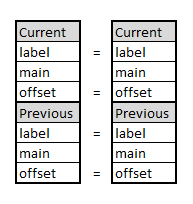
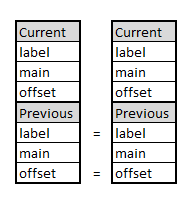
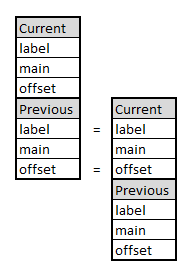
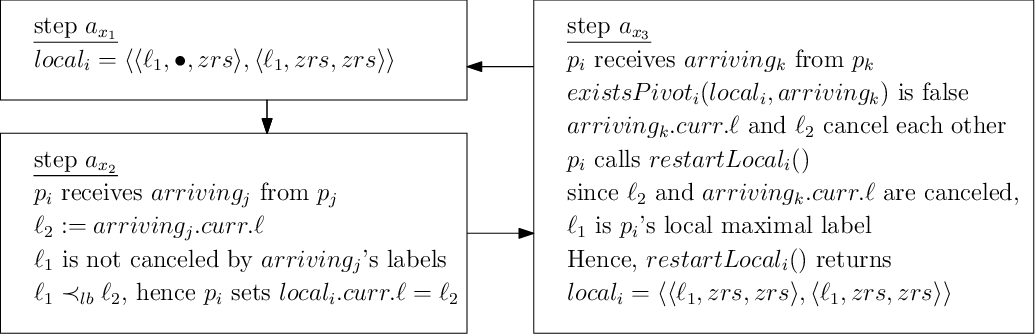
벡터 클록 알고리즘은 인과적 순서를 구현하는 기초적인 대기 자유(building blocks) 요소입니다. 대기 자유 알고리즘으로, 이들은 유한한 수의 단계 내에서 작업을 완료할 것을 보장합니다. 안정화 알고리즘은 소프트 오류와 설계에 따른 가정의 임의적인 위반과 같은 일시적 고장을 통해 시스템이 회복될 수 있게 합니다. 우리는 최초로, 알고리즘이 비동기 중단 가능 메시지 패싱 시스템에서 일시적 고장 후 대기 자유 방식으로 복구하는 안정화 벡터 클록 알고리즘을 제안합니다. 이 설정에서는 (통신과 중단 실패 및) 일시적인 고장에 대한 유한하고 대기 자유 회복을 입증, 메시지와 저장 크기를 제한하고, 모든 오래된 정보를 제거하면서 블로킹 없이 처리하며, 동일 시점에서 여러 네트워크 노드에서 발생하는 카운터 오버플로 이벤트를 처리하는 것이 어렵습니다. 우리의 알고리즘은 일시적 고장이 없는 경우 안전을 위반하지 않으며, 마지막 일시적 고장 후 공정한 실행 중에는 회복 시간을 제한합니다. 핵심 포인트는 실행의 공정성이 없는 상황에서도 시스템이 안전을 위반할 수 있는 횟수를 제한한다는 것입니다(기존 알고리즘은 일시적인 고장과 중단 실패로 인해 영원히 블로킹될 가능성이 있습니다). 벡터 클록은 원격 복제 동기화가 필요 없는 비동기 시스템에서 기본 동기화 빌딩 블록을 구현하므로, 우리의 연구 결과는 실행 공정성을 보장할 수 없는 다른 시스템의 설계에 유용합니다.
시스템 설정
이 시스템은 프로세서 집합 $`P = \{p_1, \ldots, p_N\}`$을 포함합니다. 각각의 프로세서는 유한 상태 머신으로 모델링되는 계산 및 통신 엔티티입니다. 프로세서 $`p_i`$는 시스템 내에서 고유한 식별자인 $`i`$를 가지고 있습니다. 활성화된 두 개의 프로세서는 각각의 양방향 통신 채널을 통해 직접 통신할 수 있으며, 각 방향당 유한한 용량($`\capacity \in \N`$, 예를 들어 최대 한 개의 메시지를 저장 가능)이 있습니다. 즉, 네트워크의 위상은 완전 연결 그래프이며, 각 $`p_i \in P`$는 수신 프로세서로부터 메시지를 저장하는 유한 용량의 버퍼($`\capacity`$)를 가지고 있습니다. 만약 버퍼가 꽉 차면, 보내는 프로세서는 받는 프로세서의 버퍼를 덮어씁니다. 우리는 임의의 $`p_i, p_j \in P`$가 $`channel_{i,j}`$, 즉 패킷 누락, 재정렬 및 중복을 허용하는 비-FIFO 채널 위에서 신뢰할 수 있는 FIFO 메시지 전송 프로토콜을 통해 $`p_i`$로부터 $`p_j`$까지 패킷을 전송하는 것으로 가정합니다. 이러한 프로토콜은 안정화를 보장하며, 네트워크 채널이 비-FIFO일 경우에도 신뢰할 수 있는 FIFO 메시지 전달을 제공합니다.
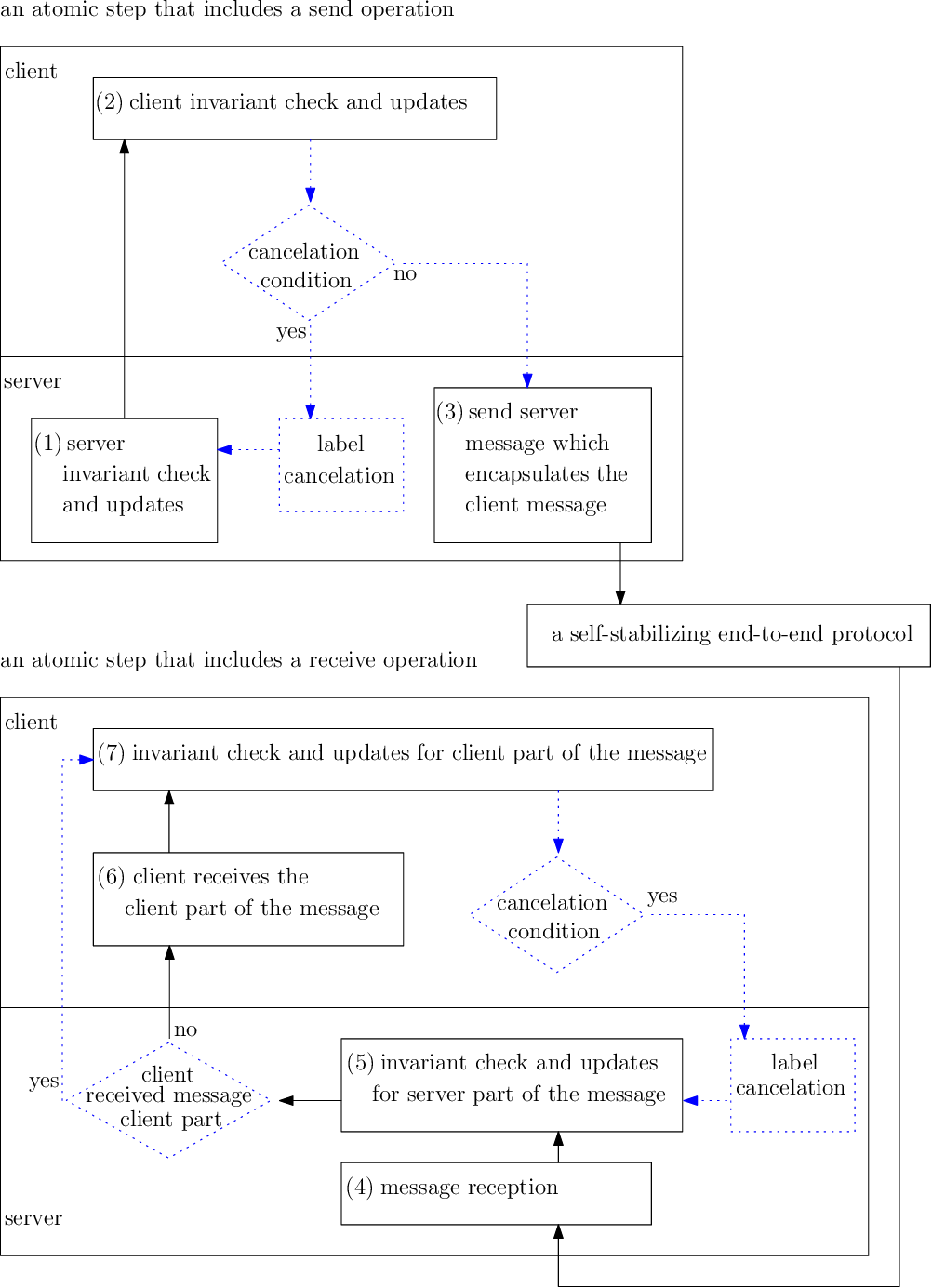
프로세서의 프로그램은 (원자적) 단계의 시퀀스입니다. 각 단계는 내부 계산으로 시작하여 단일 통신 작업(즉, 패킷 $`send`$ 또는 $`receive`$)으로 끝납니다. 우리는 교차 실행 모델을 가정하며, 이는 한 번에 하나의 단계만 원자적으로 실행되는 방식입니다. 입력 이벤트는 패킷 수신이나 주기적인 타이머로 구성되며, 예를 들어 프로세서가 메시지를 방송하도록 트리거할 수 있습니다. 시스템은 비동기이며 각 프로세서의 실행 알고리즘이 타이머 속도에 무관합니다. 스케줄러는 적대적으로 작용할 수 있지만, 우리는 각 프로세서의 로컬 스케줄러가 공정하다고 가정합니다. 즉, 프로세서는 전송 및 수신 작업을 번갈아가며 수행하며(프로세서의 통신 채널이 비어 있지 않은 경우). 프로세서 $`p_i`$가 이웃에게 메시지를 보낼 때 각 단계에는 최대 한 개의 send 또는 receive 작업만 포함될 수 있습니다.
프로세서 $`p_i \in P`$의 상태, $`s_i`$,는 $`p_i`$의 모든 변수와 $`p_i`$의 입력 통신 채널에 있는 모든 메시지 집합을 포함합니다. 즉, $`p_i`$의 단계는 $`s_i`$를 변경하거나($`channel_{j,i}`$에서 메시지를 제거) 또는($`channel_{i,j}`$에 메시지를 큐에 넣음) 메시지가 도착했을 때나 메시지가 보낼 때 변경될 수 있습니다. 우리는 $`p_i`$가 무한히 많이 $`p_j`$에게 메시지를 보내면, 프로세서 $`p_j`$는 그 메시지를 무한히 많이 받게 된다고 가정합니다, 즉 통신 채널은 공평합니다. 시스템 상태는 각각의 $`s_i`$(전송 중인 메시지 포함)를 포함하는 튜플 형태입니다: $`c = (s_1, s_2, \cdots, s_N)`$. 우리는 *실행(또는 실행)*을 다음과 같이 정의합니다: $`R={c_0,a_0,c_1,a_1,\ldots}`$, 여기서 각 시스템 상태 $`c_{x+1}`$은 (초기 시스템 상태 $`c_0`$ 제외) 단계 $`a_x`$의 실행을 통해 이전 시스템 상태 $`c_x`$로부터 얻어집니다.
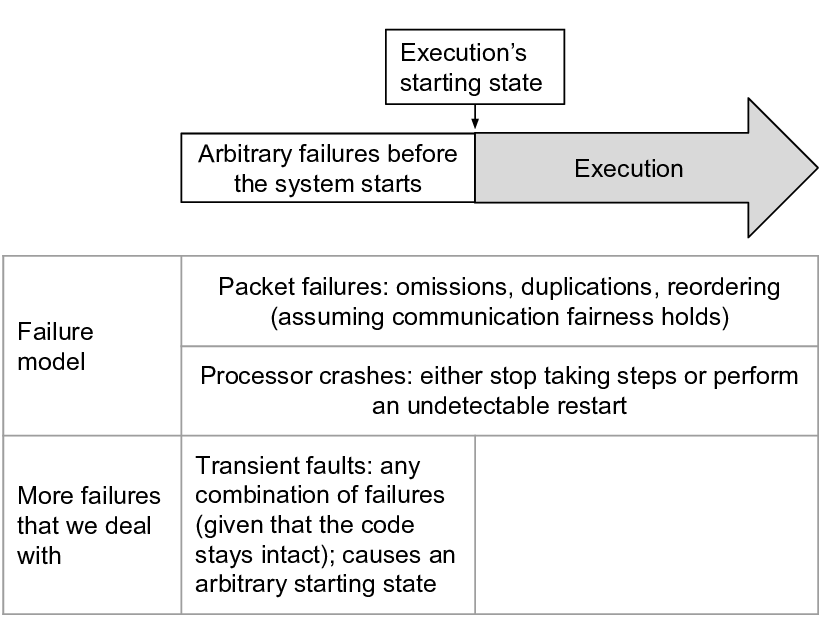
어떤 순간에도 프로세서 $`p_i`$는 경고 없이 중단 실패를 겪을 수 있습니다. 즉, 무한히 멈추거나 다른 프로세서가 중단을 감지할 수 없는 상태에서 다시 시작될 수 있습니다. 만약 프로세서 $`p_i`$가 무감각하게 재시작하면, 그것은 중단 직전의 동일한 상태를 가진 채 단계를 계속 수행하지만, 다른 프로세서가 중단과 재시작 사이에 보낸 메시지를 잃을 수 있습니다. 프로세서는 집합 $`P`$를 알고 있지만, 무한히 작동하는 프로세서의 수나 식별자는 모릅니다.
우리는 일시적인 고장이 시작 시스템 상태 $`c_0`$ 이전에만 발생한다고 가정하고, 따라서 $`c_0`$는 임의적입니다. 프로세서가 $`c_0`$ 이후에 중단될 수 있으므로 우리가 고려하는 실행은 공평하지 않습니다.
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.