Title: Social Media Text Processing and Semantic Analysis for Smart Cities
ArXiv ID: 1709.03406
발행일: 2017-09-12
저자: Jo~ao Filipe Figueiredo Pereira
📝 초록 (Abstract)
사회 미디어의 등장으로 사람들은 24시간 내내 정보를 즉시 얻고 공유하는 것이 가능해졌습니다. 많은 연구 영역에서 이러한 방대한 양의 사용자 생성 콘텐츠로부터 유용한 통찰력을 얻으려는 시도가 이루어져 왔습니다. 이 논문은 지능형 교통 시스템과 스마트시티의 맥락에서 사회 미디어 스트림으로부터 지식을 추출하는 것을 목표로, 여러 도시나 지역에 대한 병렬 수집 기능을 제공하는 프레임워크를 설계하고 개발했습니다. 이 프레임워크는 언어별 텍스트 전처리, 주제 모델링 및 교통 관련 텍스트 분류기, 그리고 데이터 집계와 시각화 기능을 포함합니다. 또한 5개 도시 - 리우데자네이루, 상파울루, 뉴욕, 런던, 멜버른에서 수집된 총 4300만 개 이상의 위치 정보가 달린 트윗에 대한 탐색적 데이터 분석을 수행했습니다. 또한 리우데자네이루와 상파울루 사이에서 대규모 주제 모델링 비교를 실시하여 두 도시 간 공통된 많은 주제를 확인할 수 있었습니다.
💡 논문 핵심 해설 (Deep Analysis)
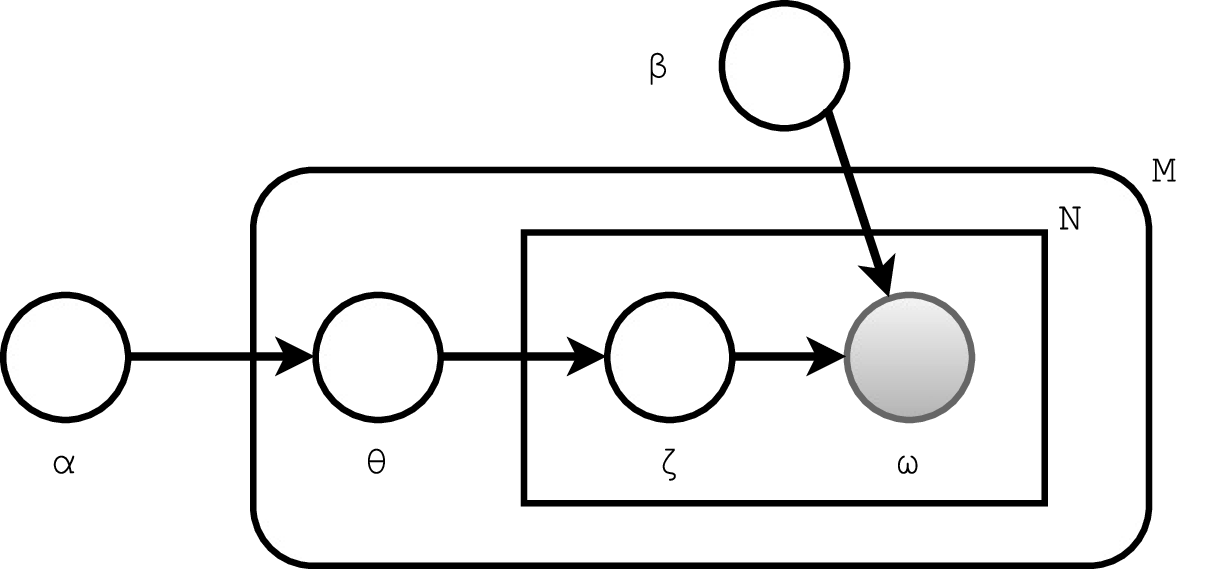
This paper focuses on social media text processing and semantic analysis in the context of smart cities and intelligent transportation systems. The authors developed a framework for collecting, filtering, preprocessing, topic modeling, and classifying location-tagged tweets from multiple pre-defined regions or cities. This framework aims to extract valuable knowledge from unstructured social media data for decision-making processes related to city services.
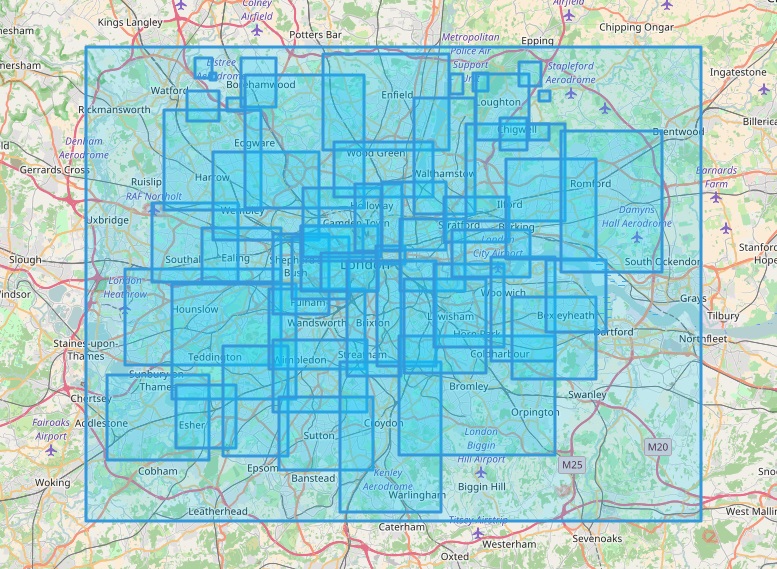
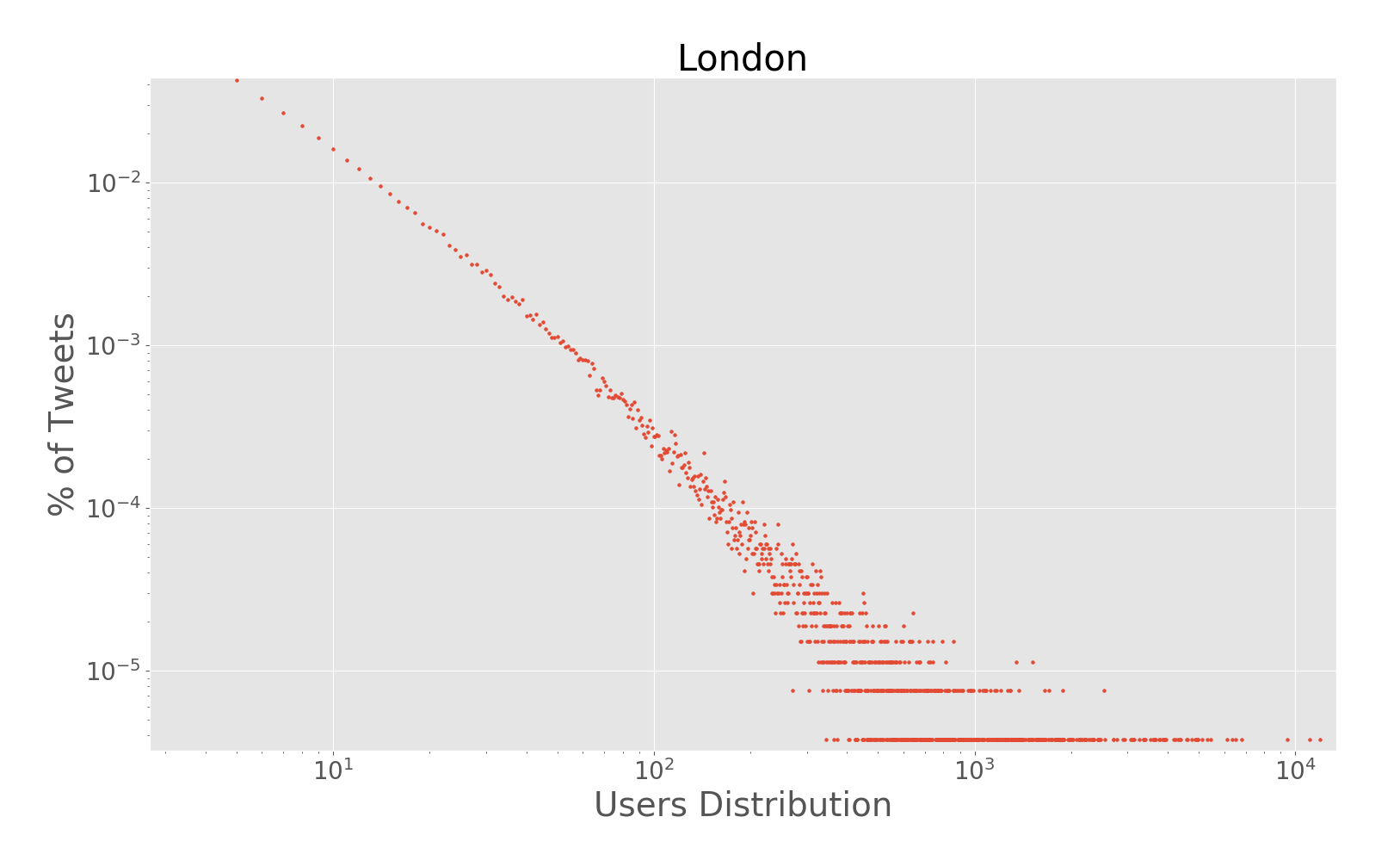
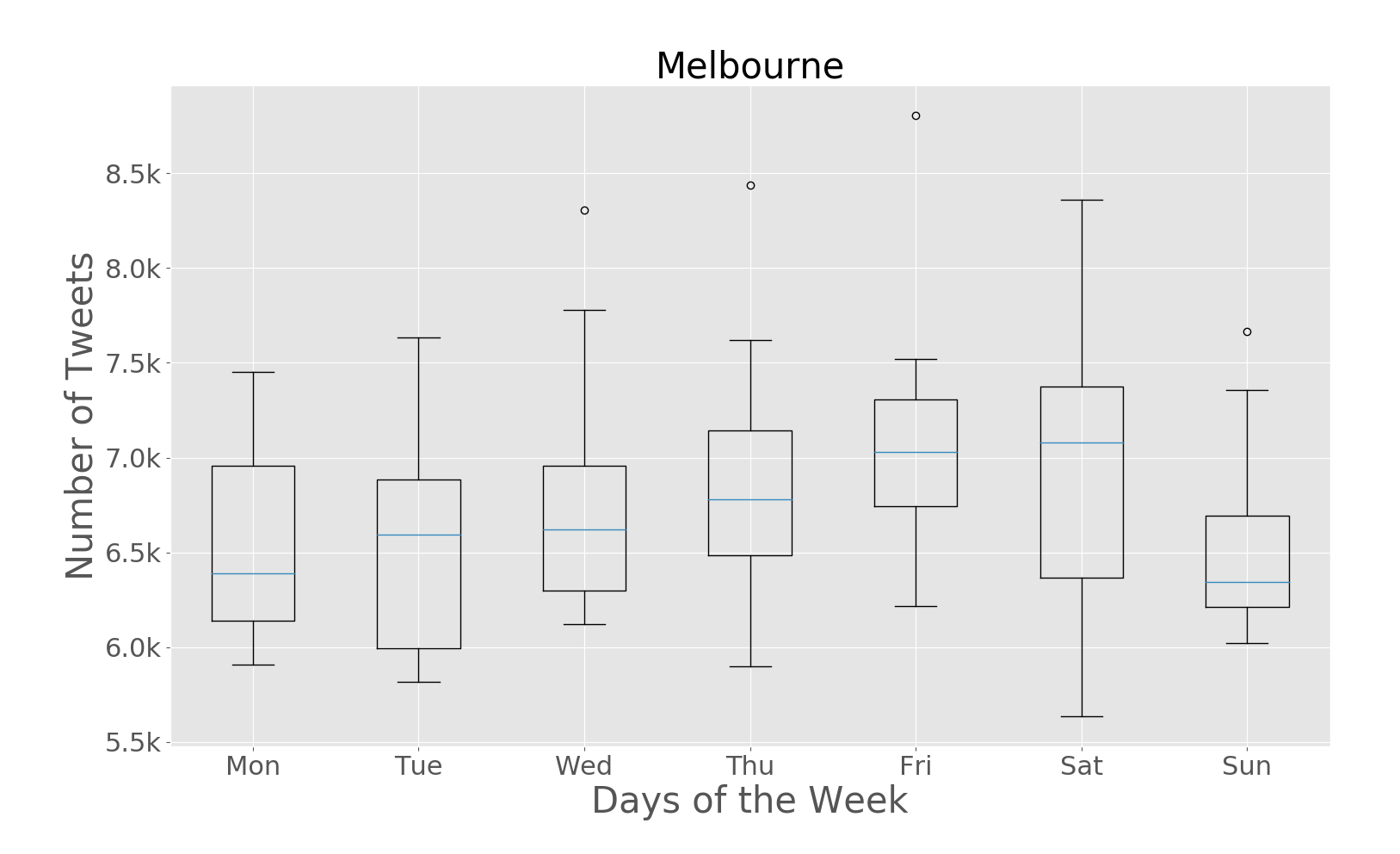
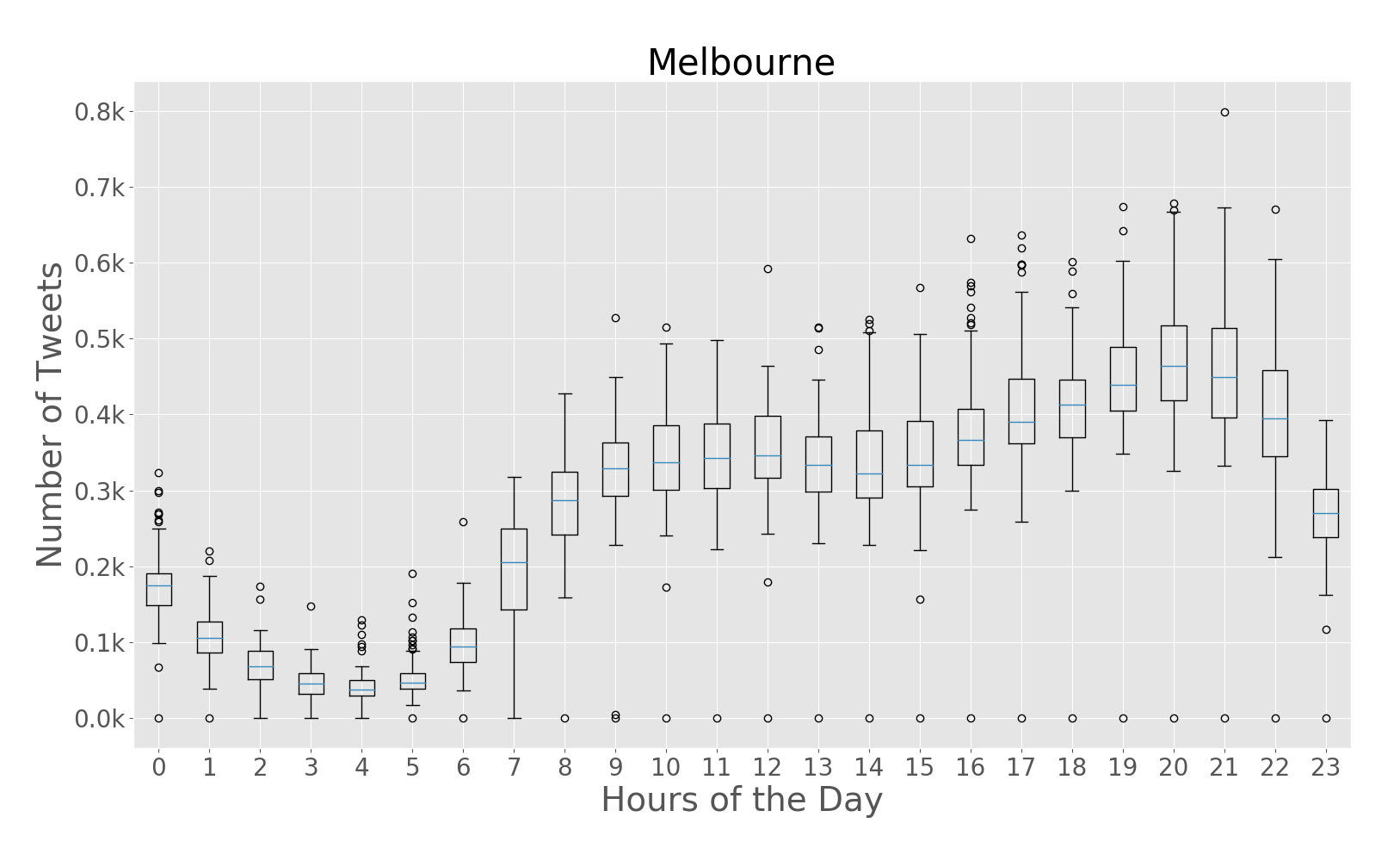
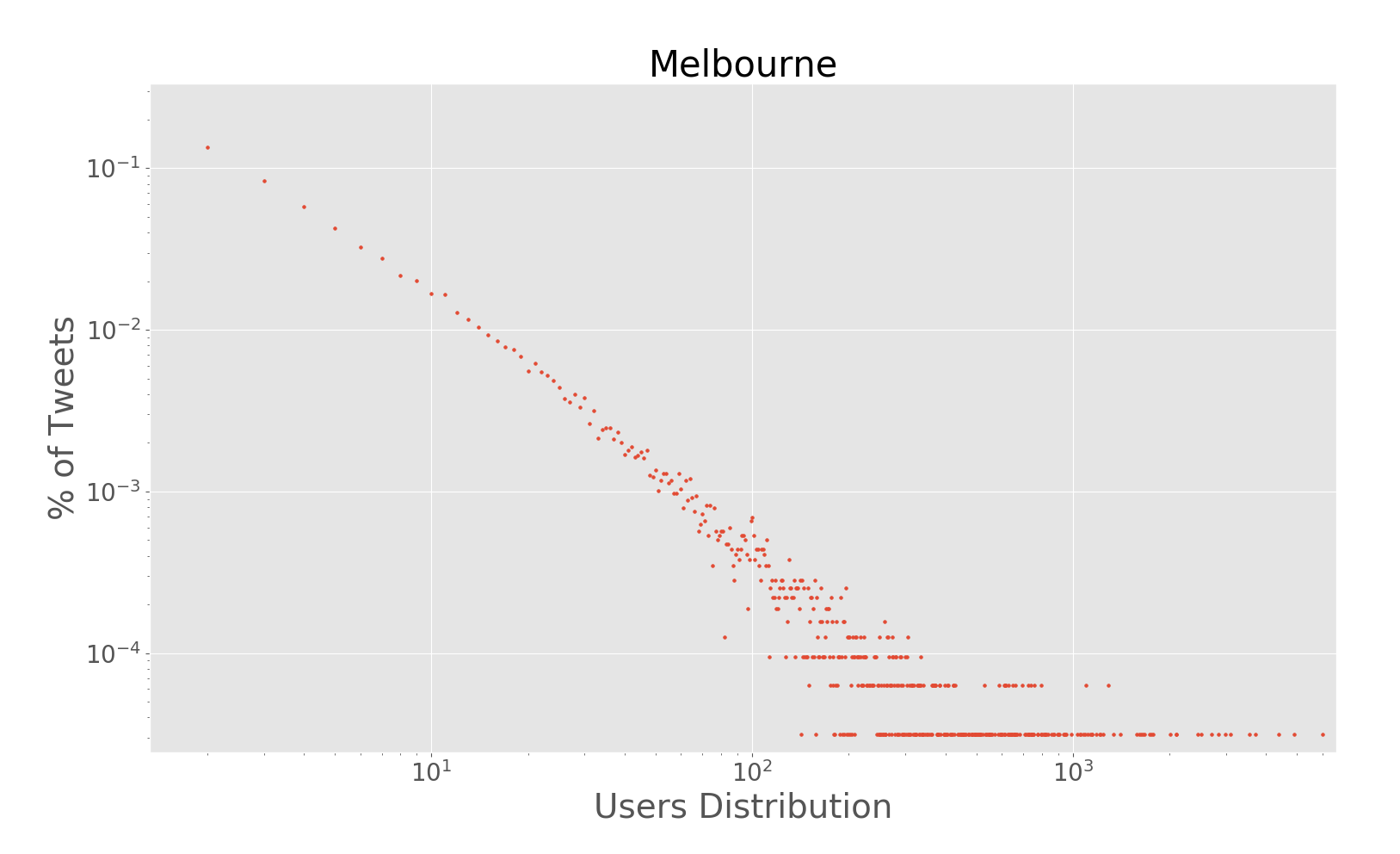
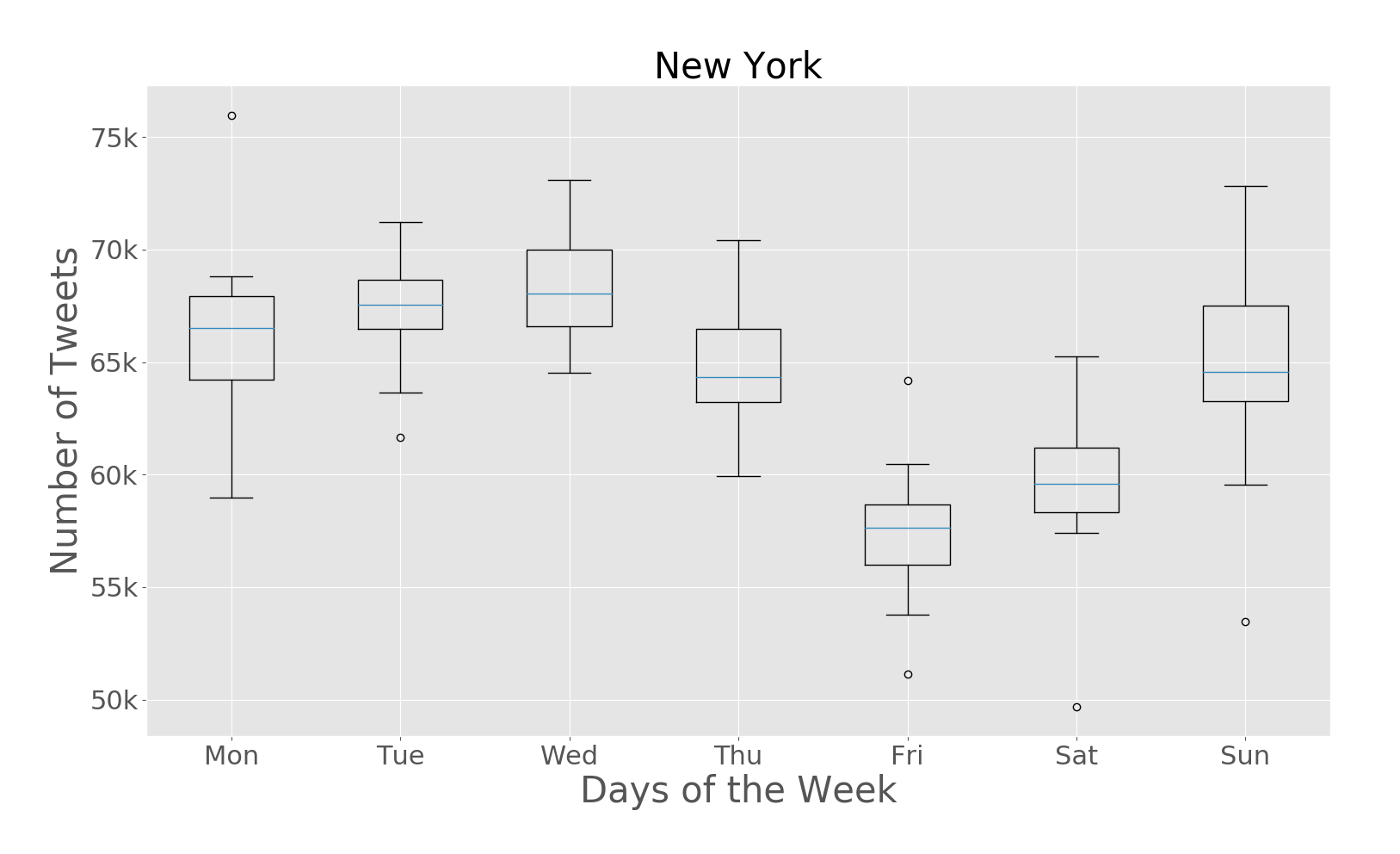
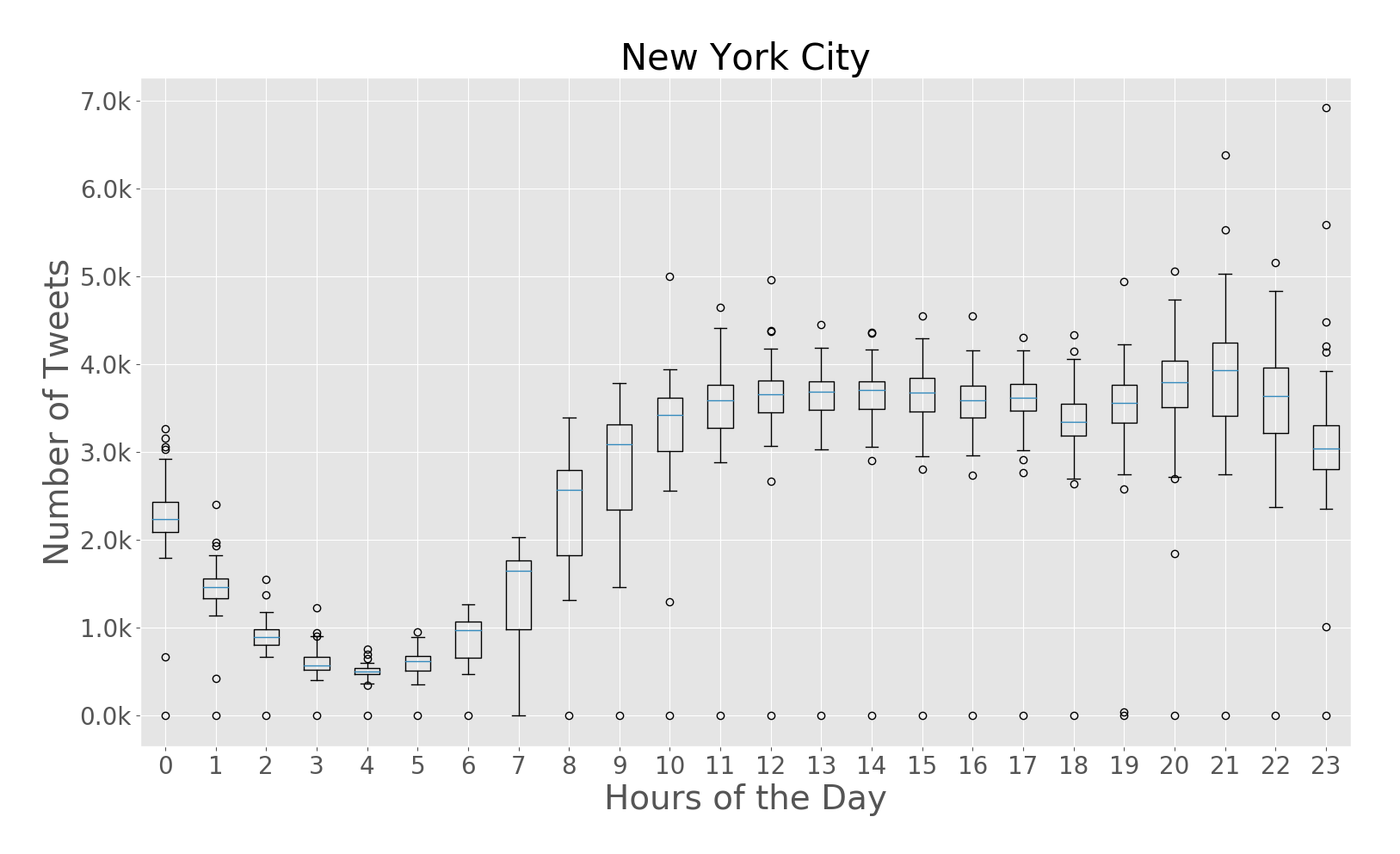
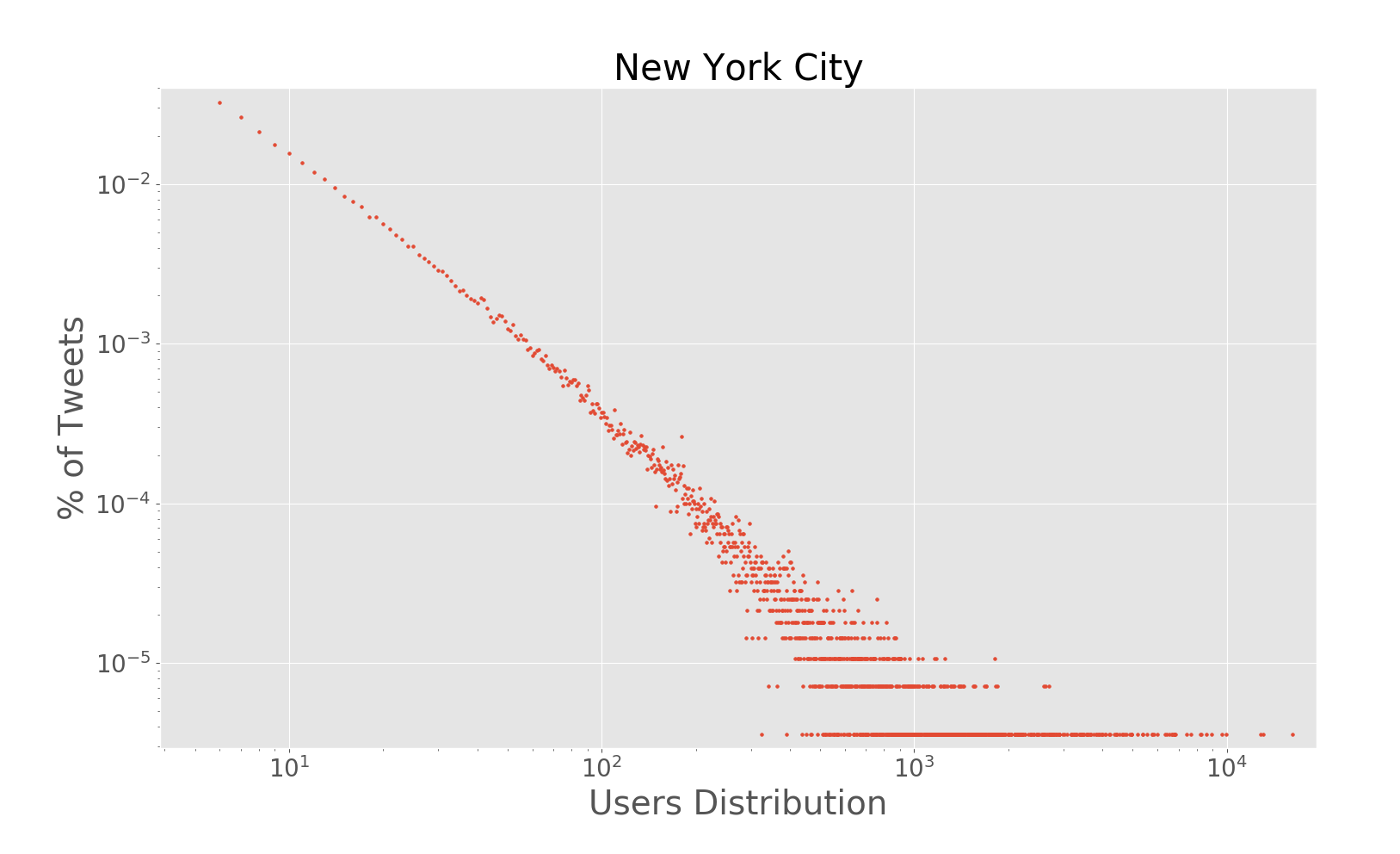
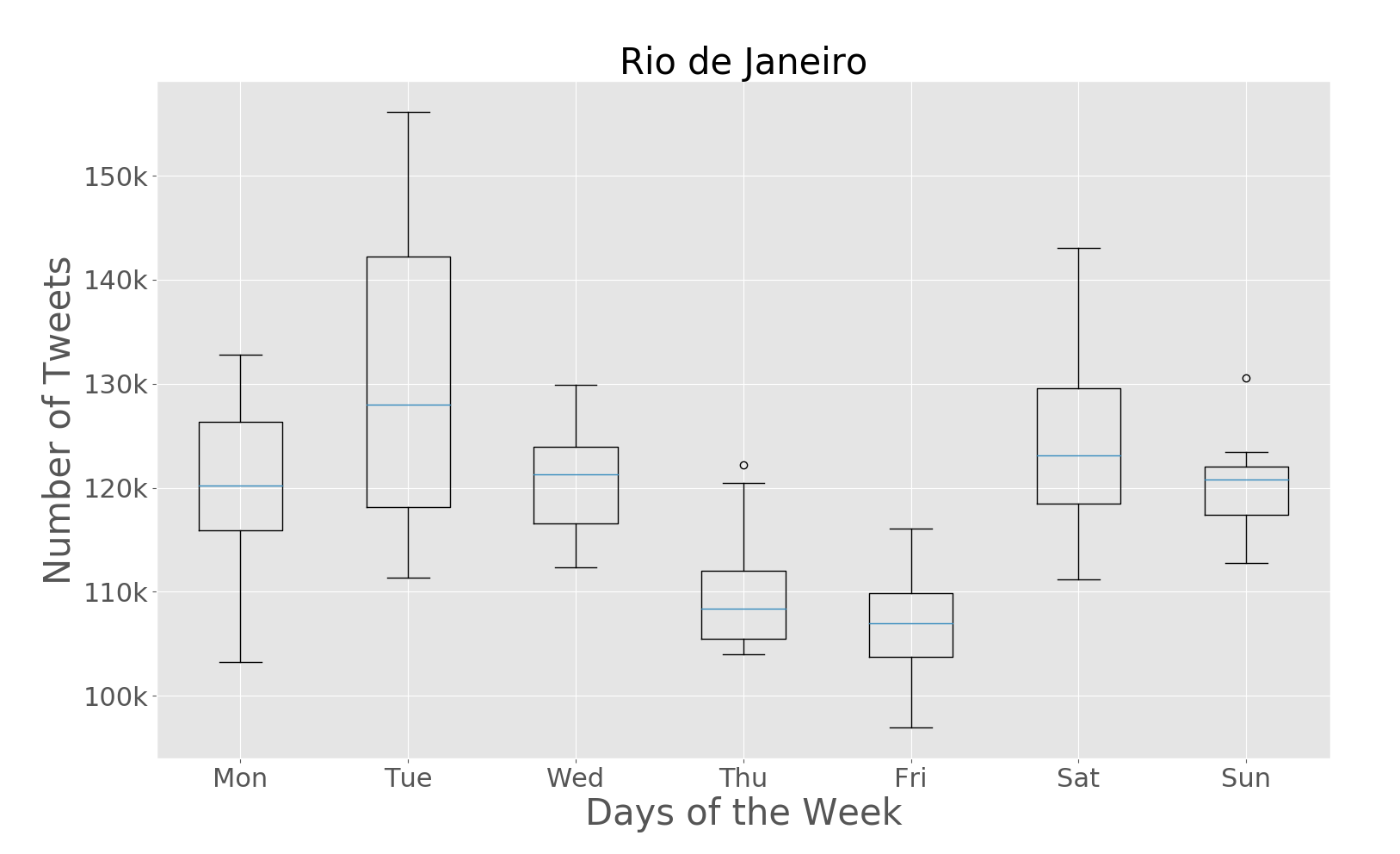
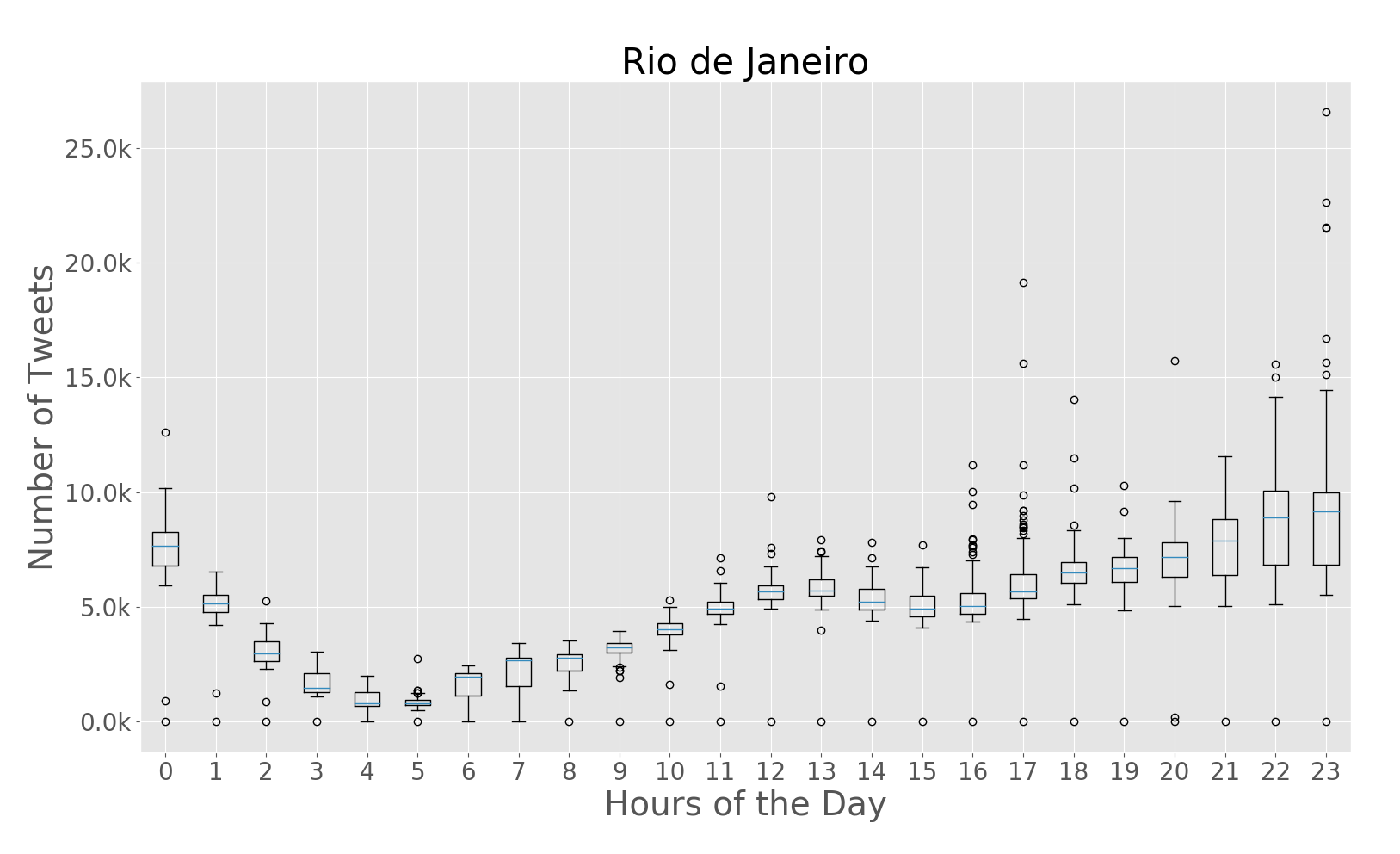
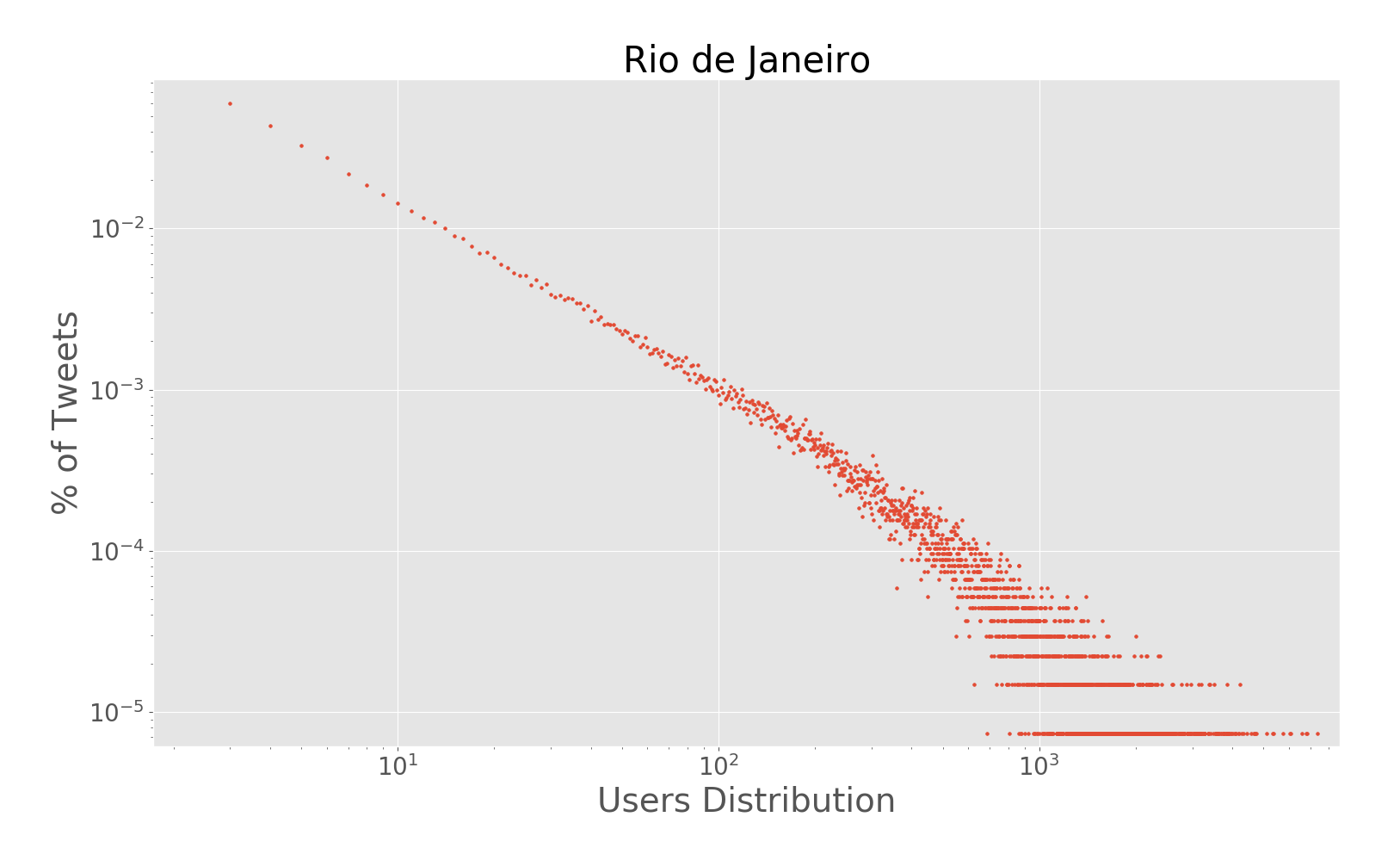
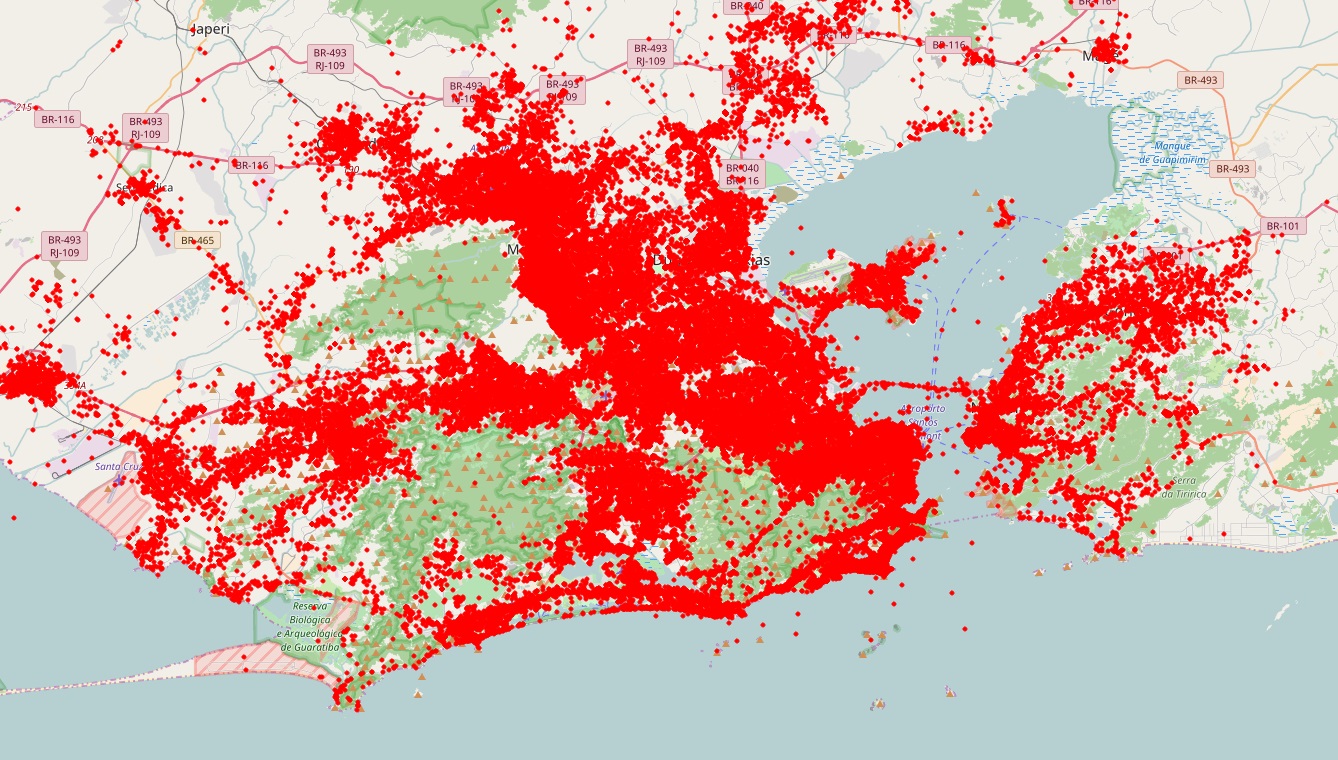
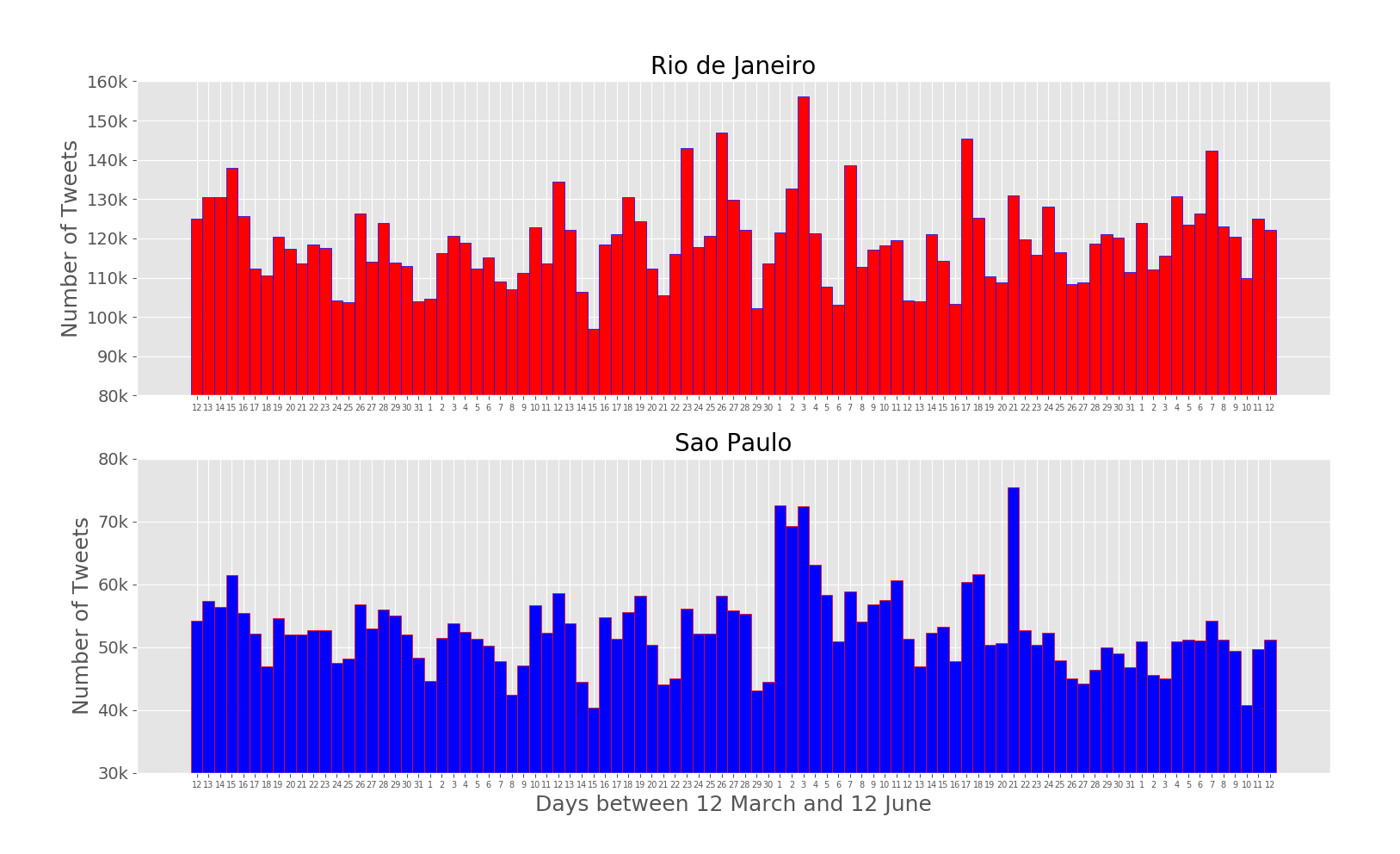
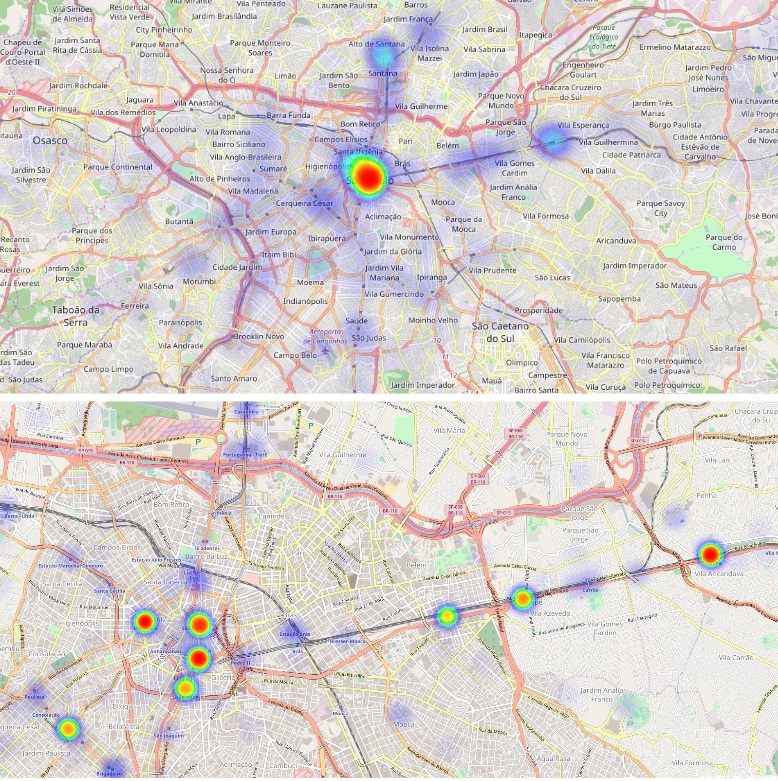
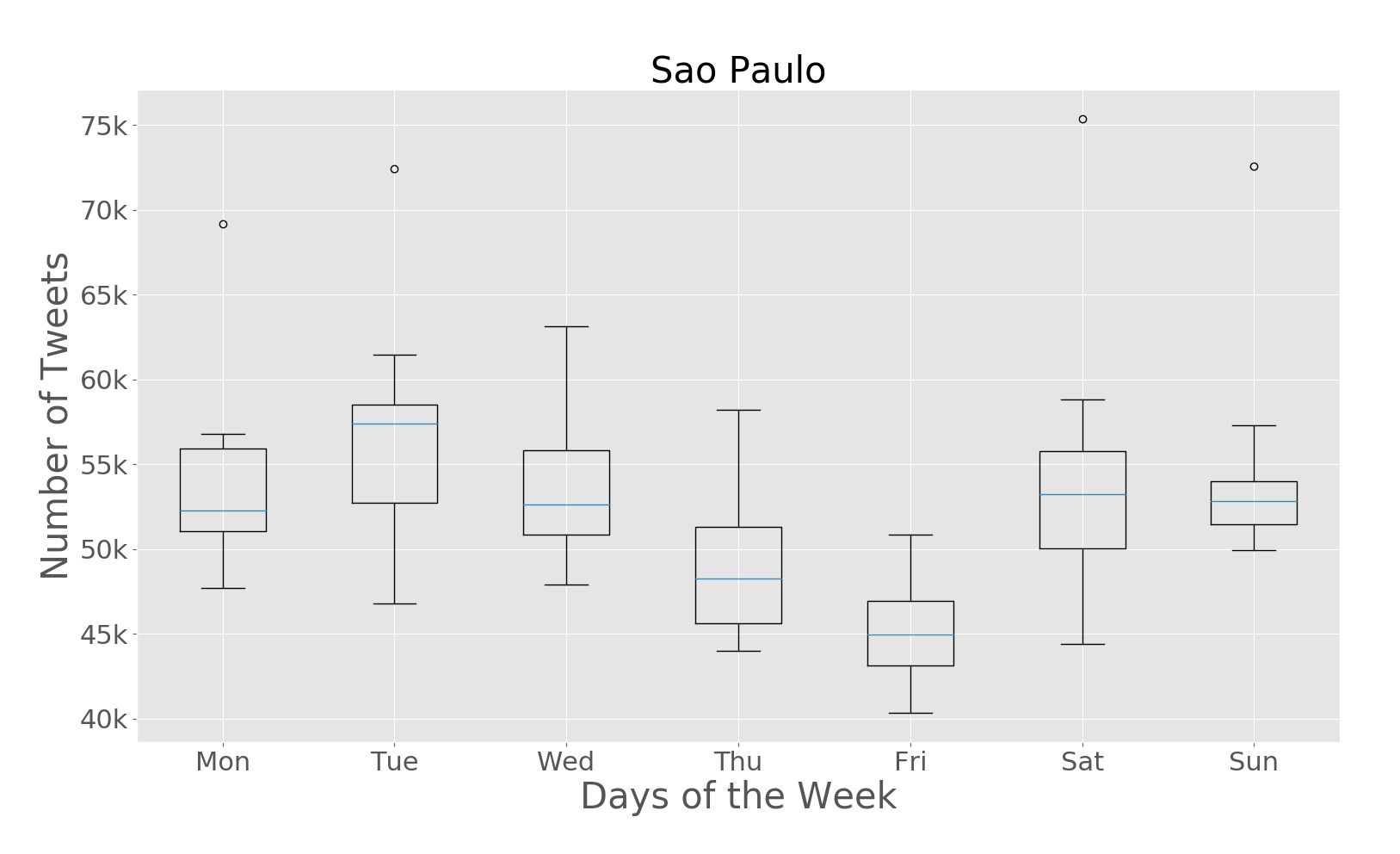
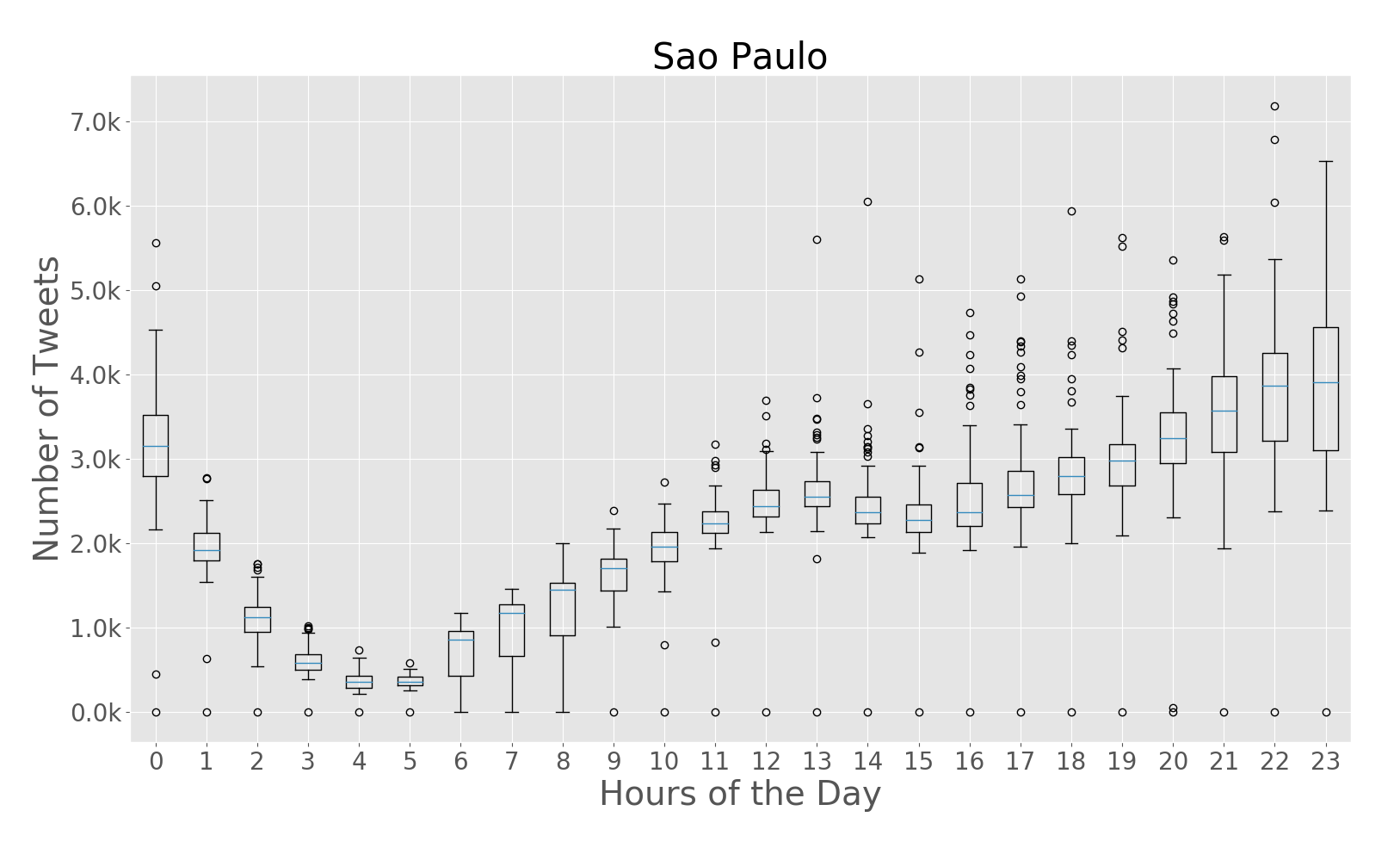
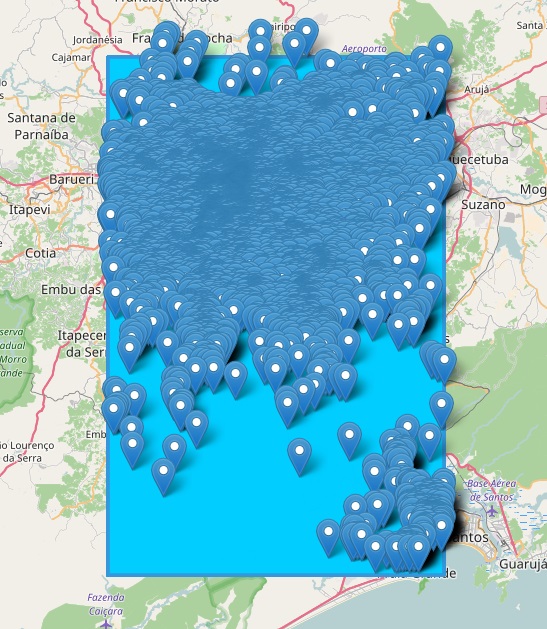
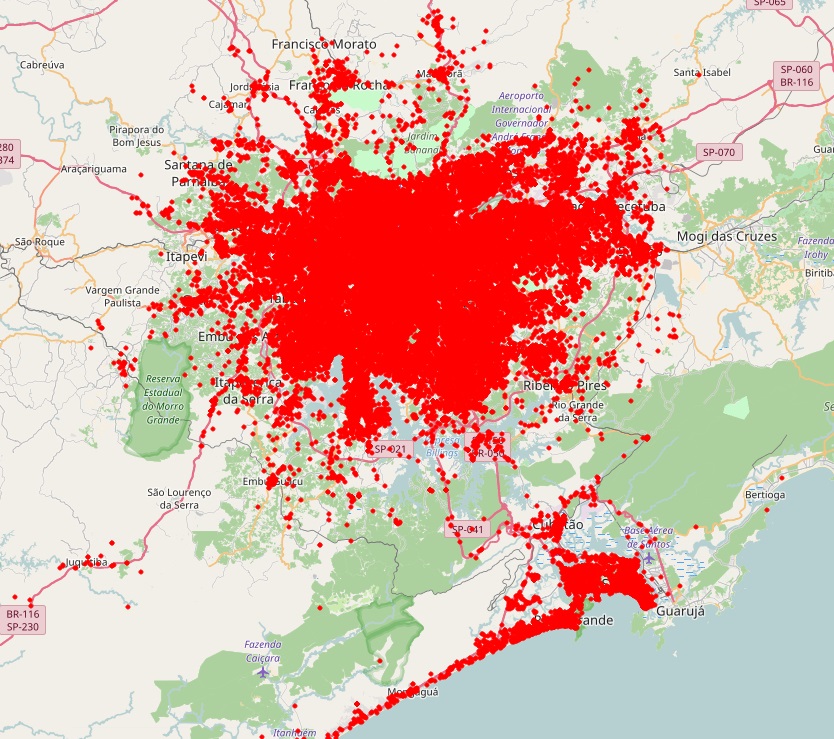
The paper addresses the challenge of extracting meaningful insights from vast amounts of user-generated content on social media platforms like Twitter. The authors designed a system that can collect, process, and analyze location-tagged tweets in real-time, providing useful aggregated data visualizations. They performed extensive experiments with over 43 million tweets collected from five cities: Rio de Janeiro, São Paulo, New York City, London, and Melbourne.
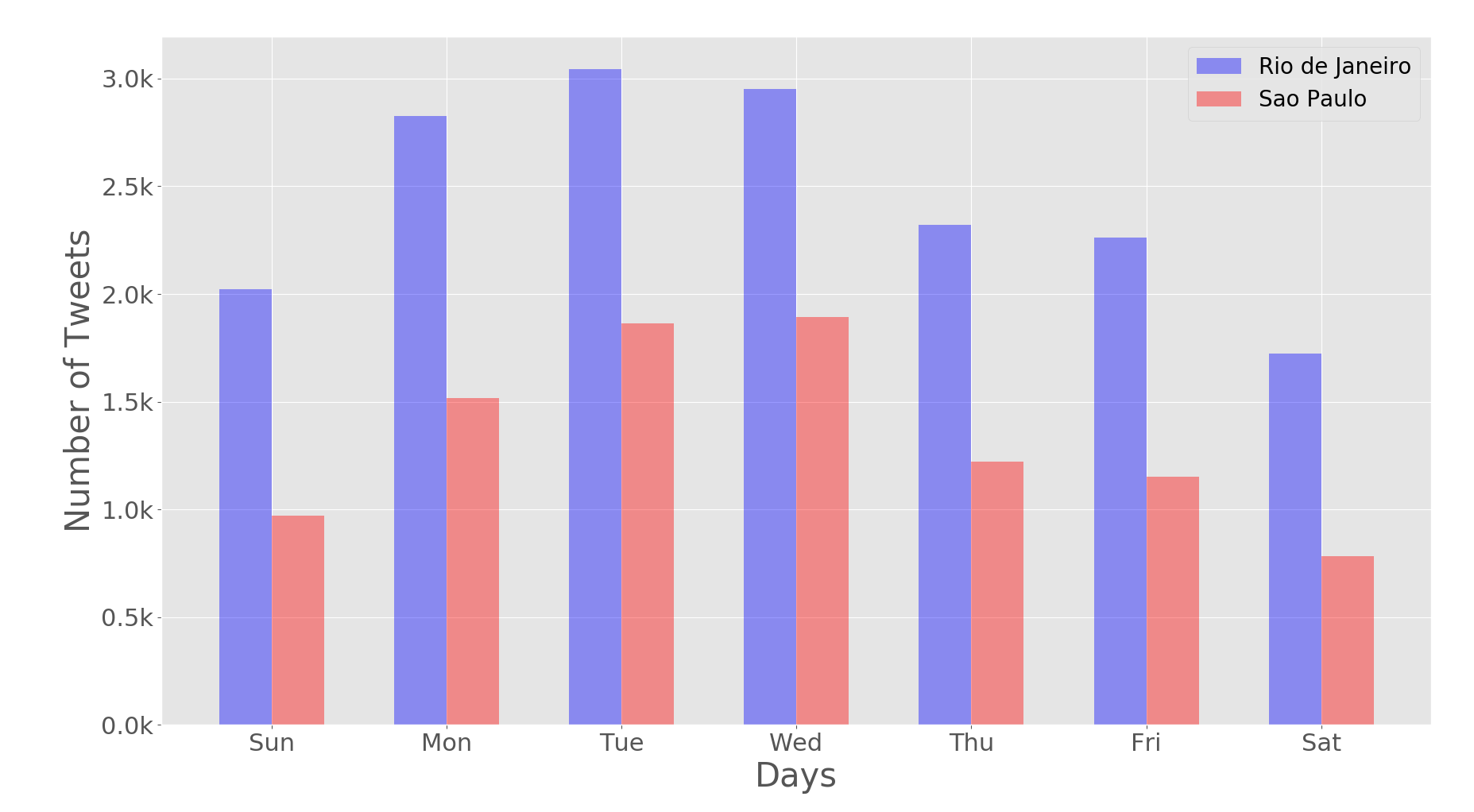
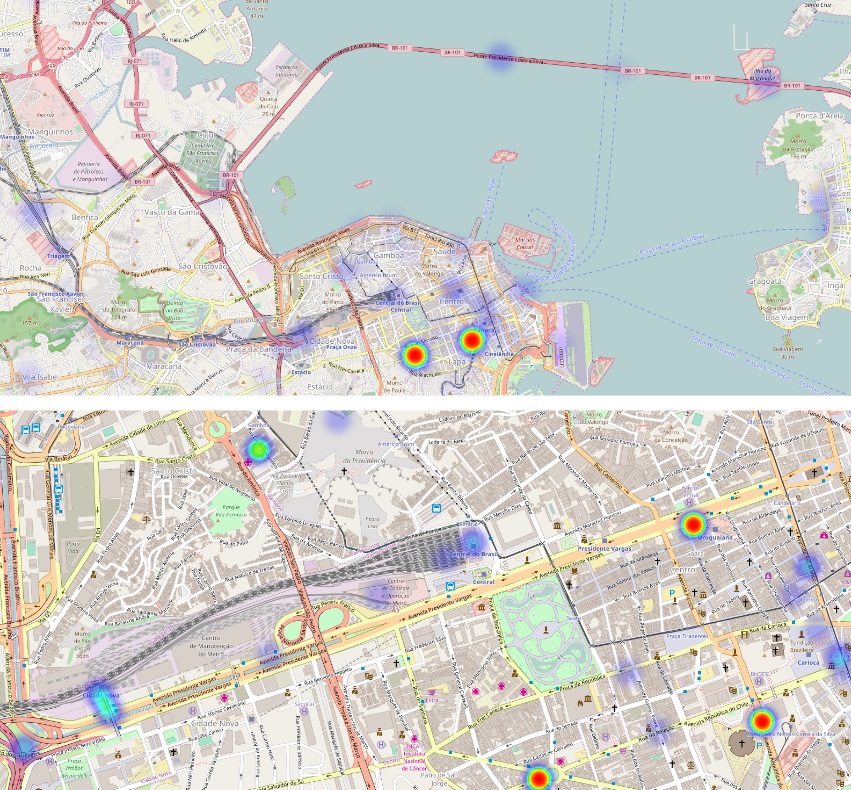
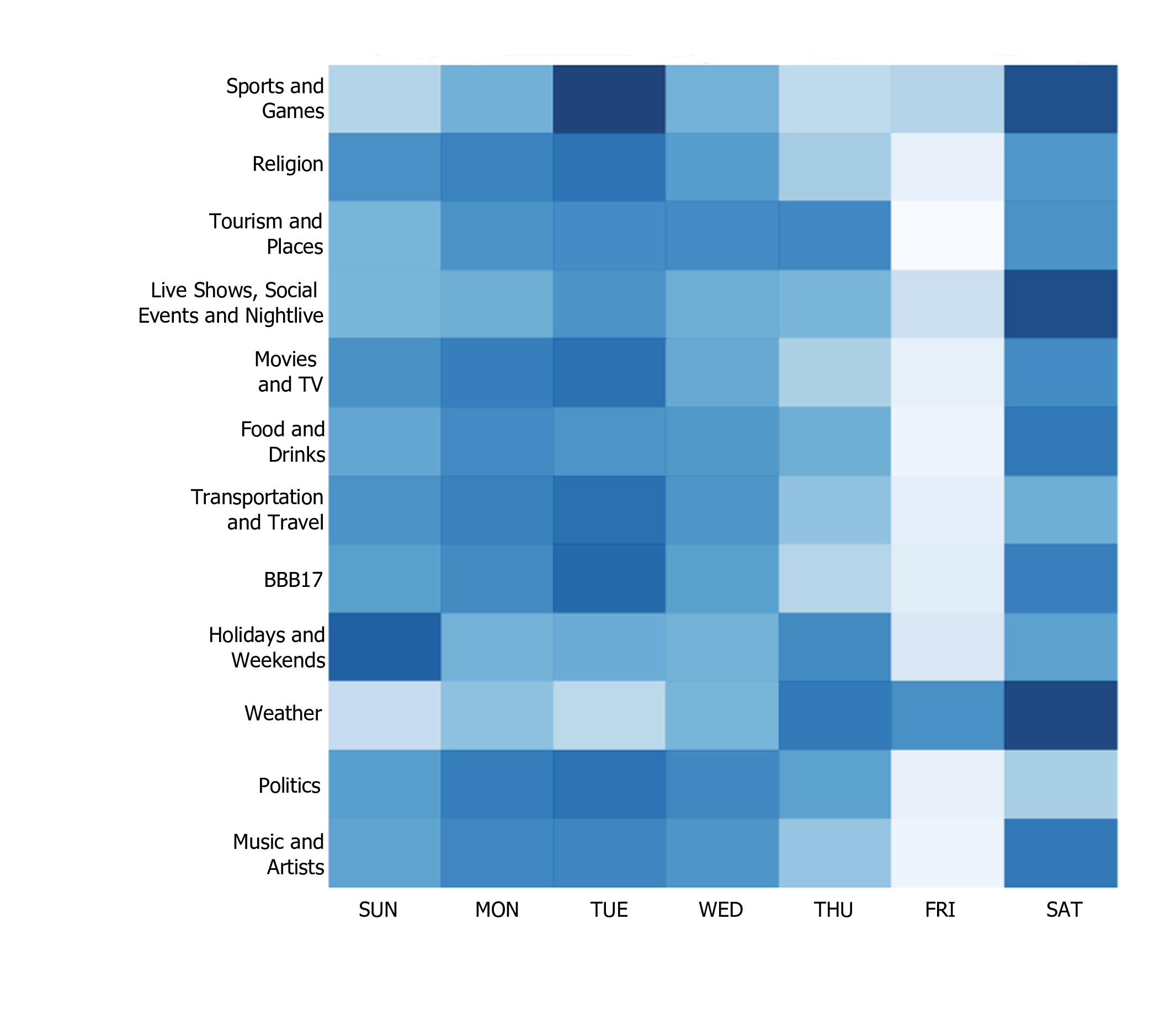
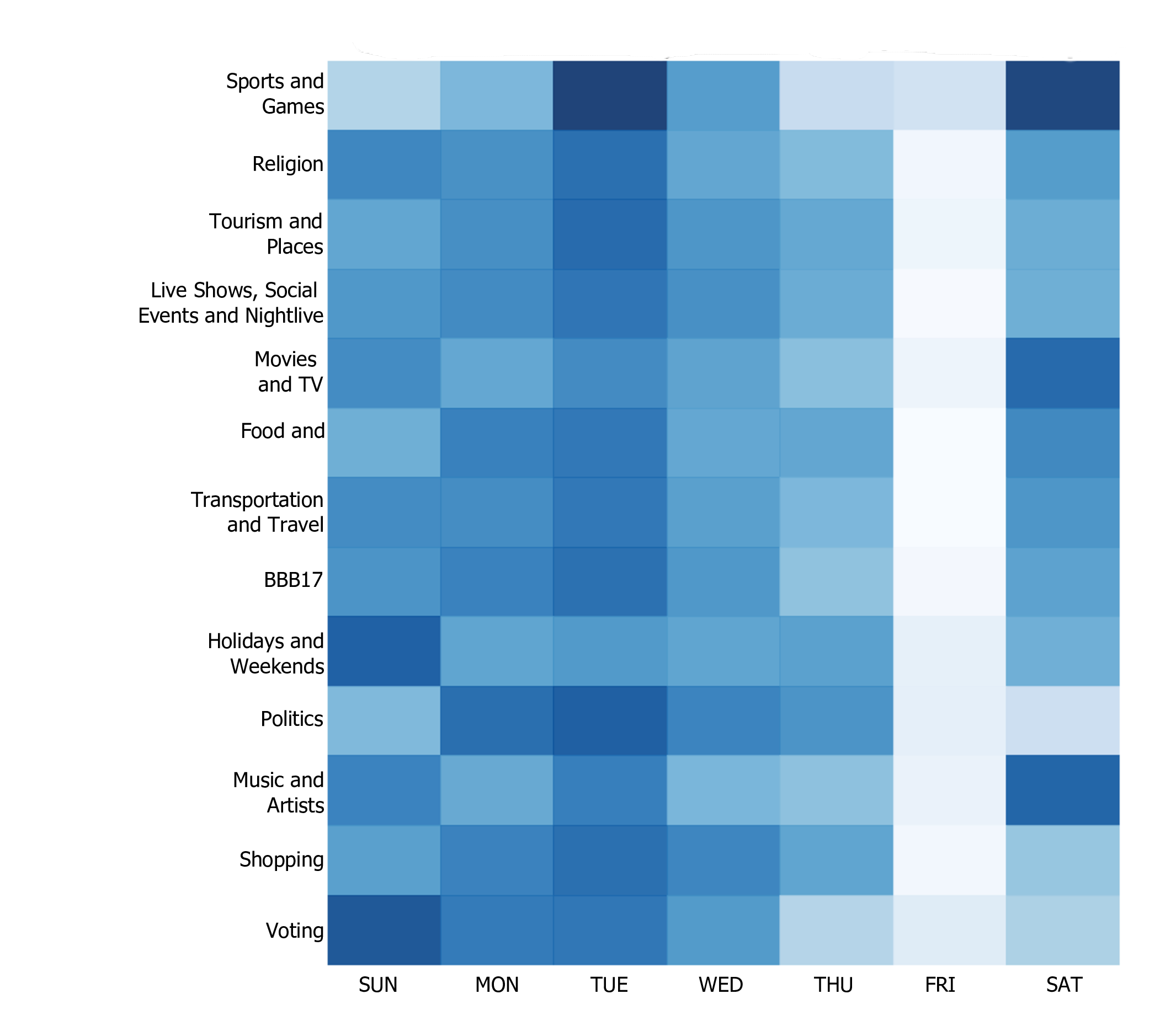
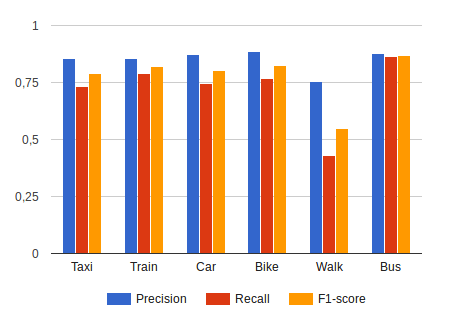
One of the significant findings is that despite being geographically close but culturally distinct, both Rio de Janeiro and São Paulo share many common topics in their social media conversations. The authors also demonstrated the effectiveness of using word embeddings for classifying travel-related tweets in Portuguese and English.
This research is important because it provides a practical framework for leveraging social media data to monitor and improve urban transportation services. It can help city managers understand public sentiment and make informed decisions based on real-time feedback from citizens.
📄 논문 본문 발췌 (Translation)
# 서론
맥락과 동기
최근 몇 년간 사회 미디어 서비스의 등장으로 인해 일반 대중이 온라인에 방대한 양의 정보를 게시하기 시작했습니다. 이러한 종류의 정보를 활용하려는 필요성이 꾸준히 증가하고 있으며, 마케팅, 비즈니스 또는 심지어 정치 분야에서도 가치를 창출할 수 있습니다. 미니 블로깅 플랫폼인 트위터에서 매일 5억 개 이상의 메시지를 다양한 주제에 대해 공개적으로 공유하고 있으며, 이는 그들의 의견과 감정을 표현하는 과정입니다. 이러한 이유로, 일부 도시에서 수행되는 기술 프로젝트에서는 사회 미디어 스트림을 지식 추출의 잠재적 자원으로 보고 있습니다. 예를 들어, 도시 내부 서비스에 대한 시민들의 만족도를 파악하는 것과 같은 목적으로 활용됩니다.
사회 미디어 스트림에서 정보를 추출하는 것은 어려운 작업입니다. 트윗은 텍스트 메시지이므로 비구조화된 데이터의 특성을 가지고 있습니다. 또한 제한된 길이(140자), 비표준 언어 사용, 철자가 잘못된 단어, 약어, 모호성 및 특수 링크나 해시태그와 같은 요소가 포함되어 있습니다.
많은 연구 프로젝트는 텍스트 마이닝 기법을 통해 의견에 나타난 감정을 추출하기 위해 수행되었습니다. 감성 분석은 이러한 작업에 중점을 둔 분야입니다. 시민들이 생성한 메시지에서 특정 측면 또는 일반적인 수준의 감성 극성을 탐지하는 것은 기업이나 일반 시민에게 도시 서비스 문제를 식별하고 품질 인식 센서로 활용할 가능성을 제공합니다.
문제 제기 및 목표
이 논문에서 다루는 문제는 특히 트위터에서 특정 시나리오에 대한 사회 미디어 스트림의 연속적인 분석입니다. 예를 들어, 포르투의 도시 교통 서비스 품질과 관련된 주제입니다. 따라서 다음과 같은 다섯 가지 서로 다른 점을 구분할 필요가 있습니다:
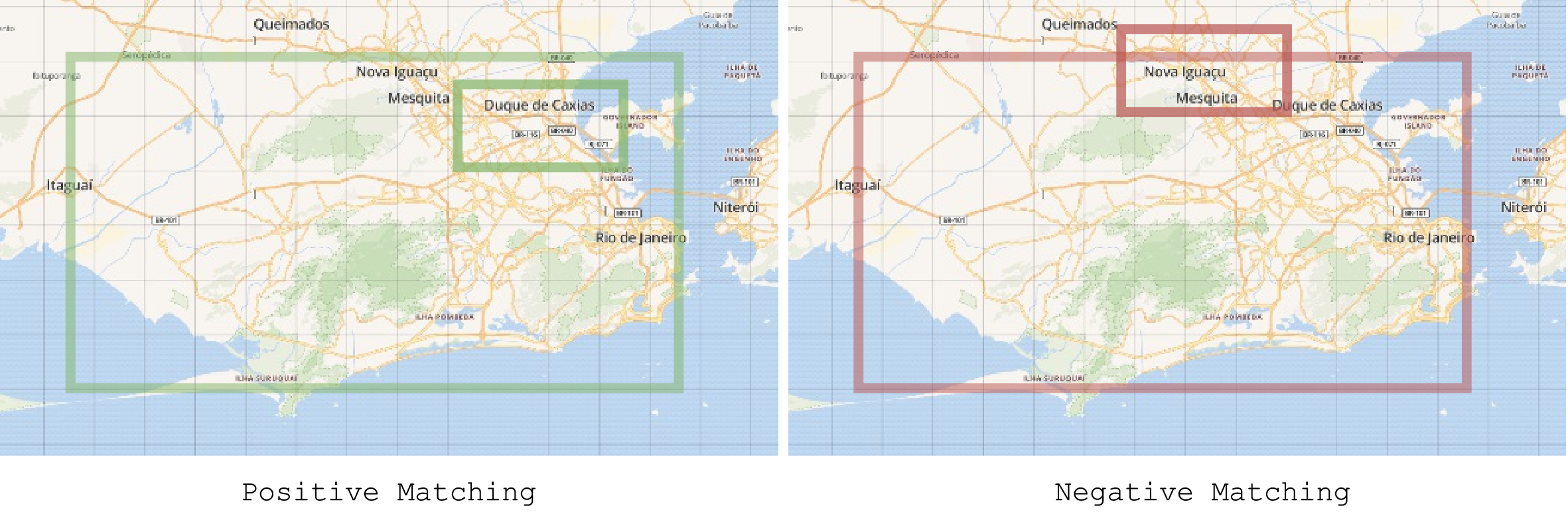
타겟 시나리오에 대한 데이터 수집
실제 시나리오를 선택하여 사례 연구를 수행합니다.
이름 인식 및 내용 필터링
메시지 내의 엔티티를 식별하는 것은 필터링 작업을 용이하게 하기 위해 중요하며, 최종 데이터 세트에 포함되어야 하는 관련 메시지만 나타나게 합니다.
트위터 메시지에서 측면/주제 인식
각 의견은 일반적으로 엔티티 또는 도시의 서비스에 대한 특정 주제를 가지고 있으므로 이러한 주제를 인식하는 것은 중요합니다.
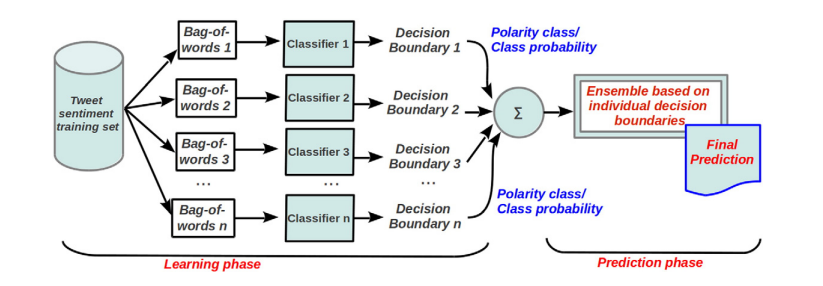
감성 극성 분류
감성 극성은 긍정, 부정 및 중립 세 가지 유형이 될 수 있습니다. 이 단계에서는 메시지 내에서 표현된 극성을 추정해야 합니다.
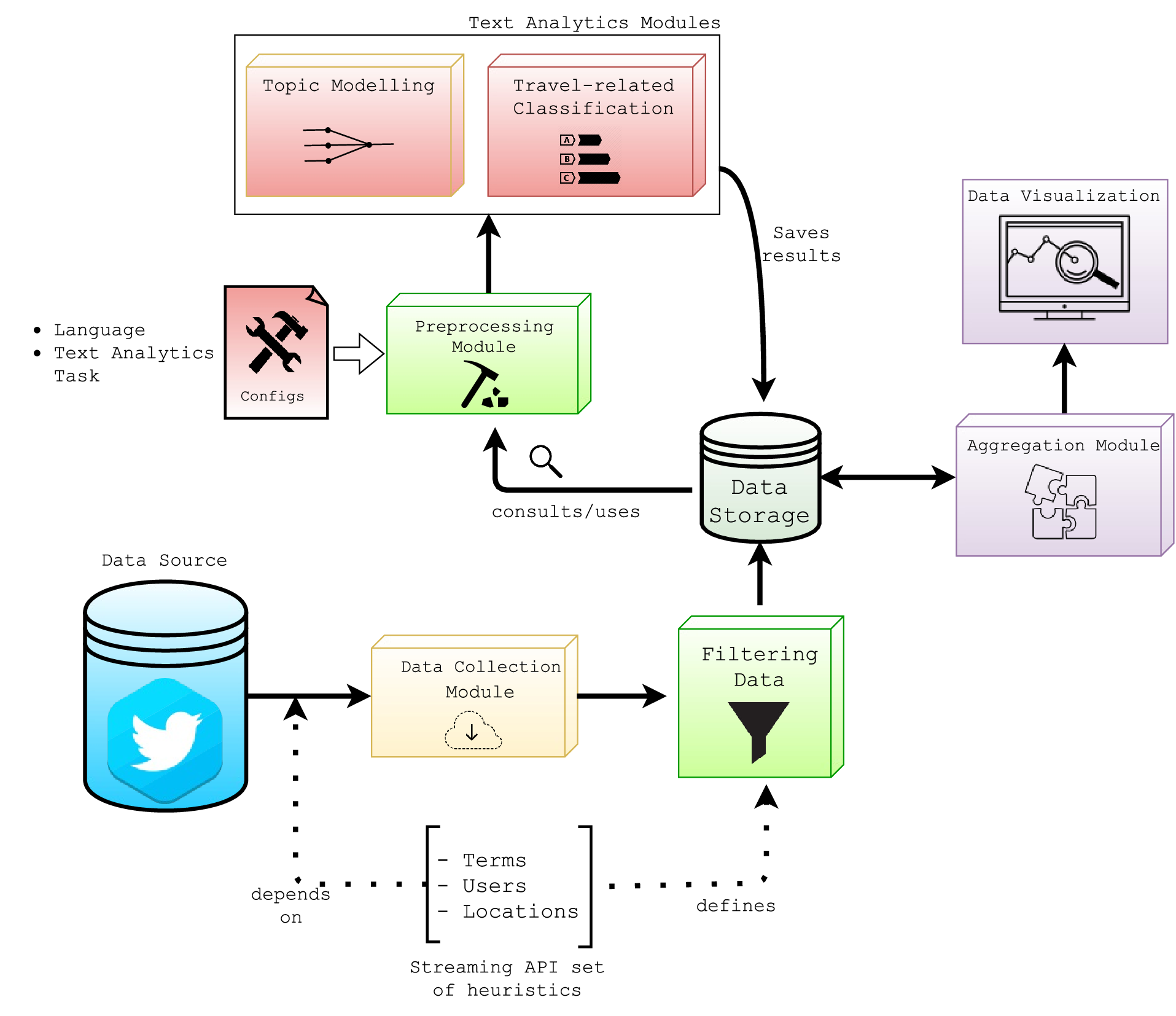
데이터 집계와 시각화
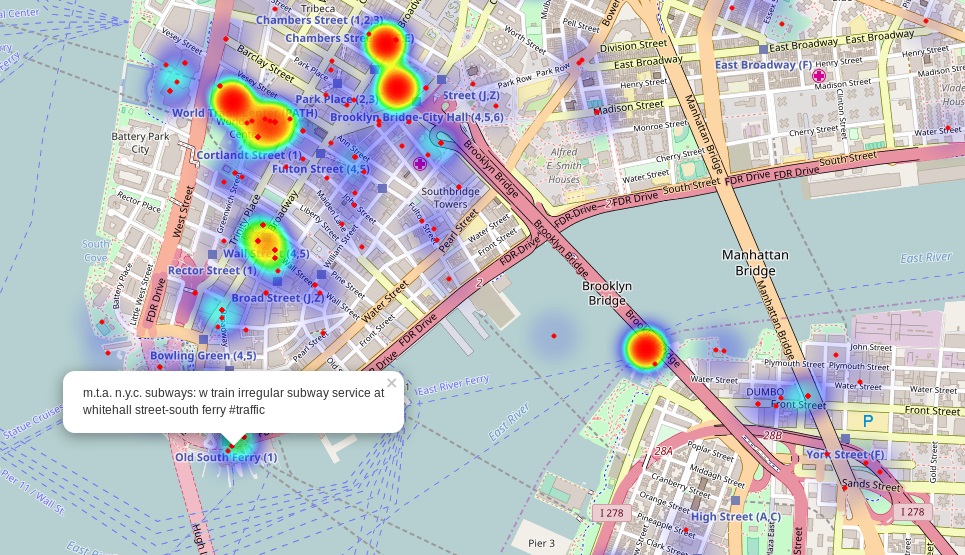
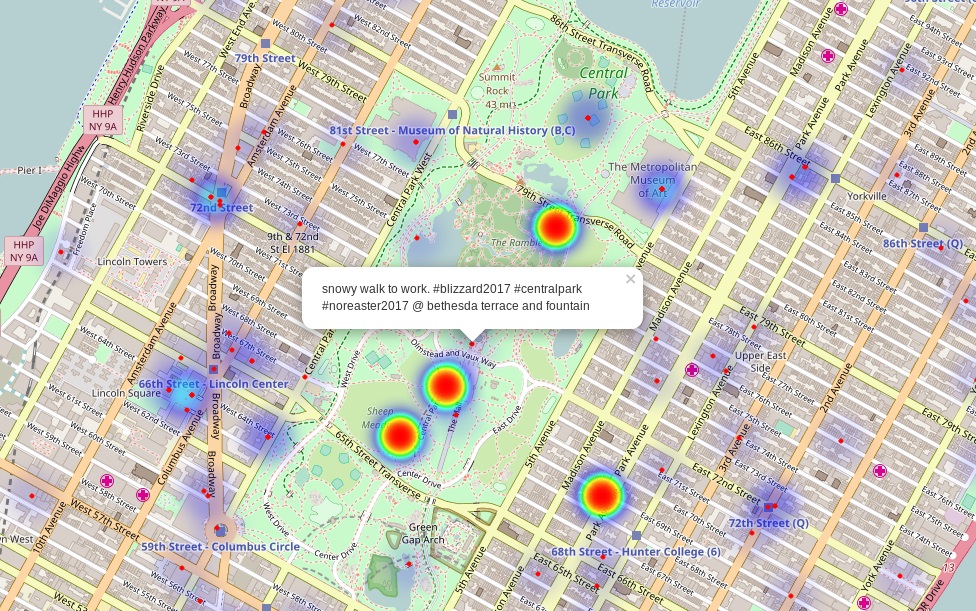
모든 작업의 결과를 집계하는 것이 필요합니다. 일부 메시지는 다른 방식으로 동일한 측면을 참조할 수 있으므로 이러한 특징이 있는 메시지를 결합하는 것이 필요합니다. 또한 사용자가 분석 UI에 액세스할 때 즉시 결과가 표시되도록 연속적으로 계산해야 합니다. 결과의 시각화에서는 사용자에게 분석을 용이하게 하는 양적 및 질적 지표를 제공할 수 있습니다.
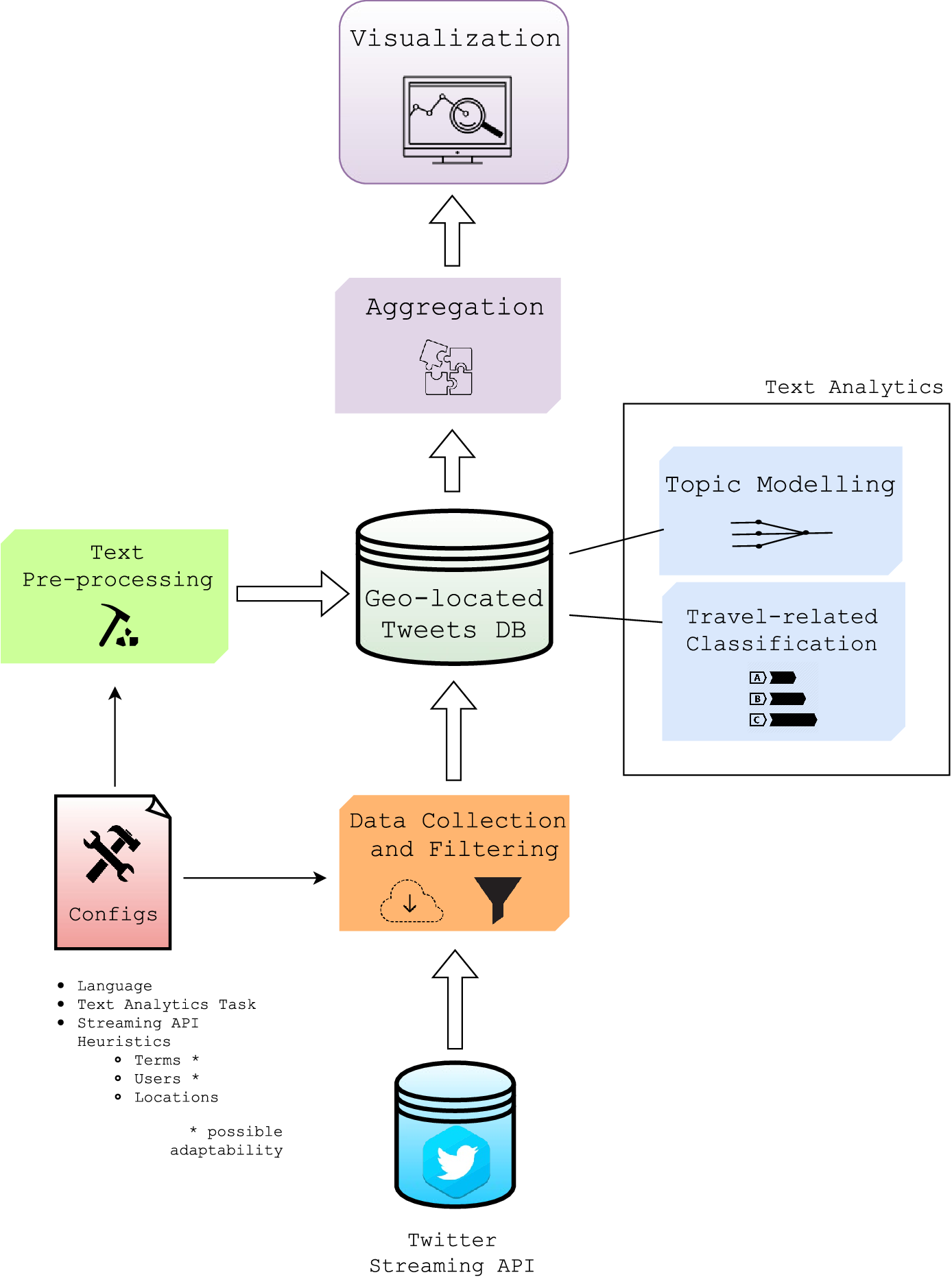
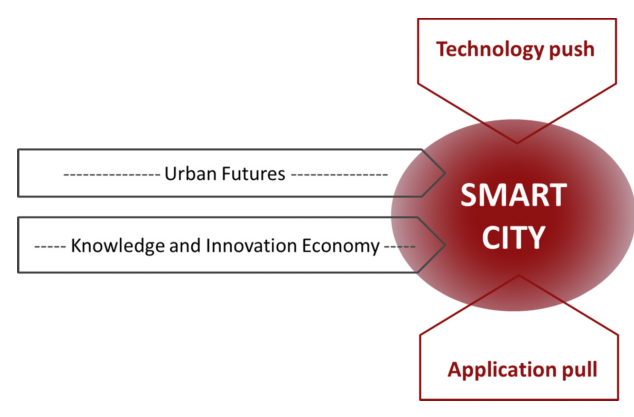
상기한 모든 점을 고려할 때, 이 논문의 최종 목표는 사회 미디어 텍스트에 대한 자동 처리를 위한 프레임워크를 생성하는 것입니다. 이 프레임워크는 의미 처리, 주제 탐지 및 감성 분석 기능을 제공합니다. 사용자 인터페이스를 통해 사용자는 질적 및 양적 지표의 세트를 시각화하여 분석할 수 있습니다. 이러한 지식은 특정 서비스를 이용하는 사용자나 해당 엔티티에게 의사결정 과정을 개선하는 데 중요합니다.
논문 구조
이 보고서는 다양한 주제를 다루며, 그에 따라 세 가지 다른 섹션으로 구성되어 있습니다.
첫 번째 섹션은 스마트시티와 지능형 교통 시스템 분야에서의 맥락을 간략하게 설명합니다. 또한 소셜 미디어 분석, 특히 트위터에 대한 연구를 개괄하며, 그 정보 탐색이 문명에 제공하는 이점을 설명합니다. 트윗 메시지에서 정보를 탐색하기 위해 텍스트 마이닝 영역, 특히 정보 추출, 주제 모델링 및 감성 분석의 다양한 분야에 대한 심도 있는 연구가 이루어졌습니다.
두 번째 섹션에서는 제안된 솔루션과 방법론을 다룹니다. 마지막으로 결론 섹션에서는 학습한 작업들에 대한 결론과 우리 솔루션이 가지는 이점과 위험 요소를 다룹니다.