대규모 고차원 데이터를 위한 효율적인 시각화 기법
📝 원문 정보
- Title: Visualizing Large-scale and High-dimensional Data
- ArXiv ID: 1602.00370
- 발행일: 2016-04-06
- 저자: Jian Tang, Jingzhou Liu, Ming Zhang and Qiaozhu Mei
📝 초록 (Abstract)
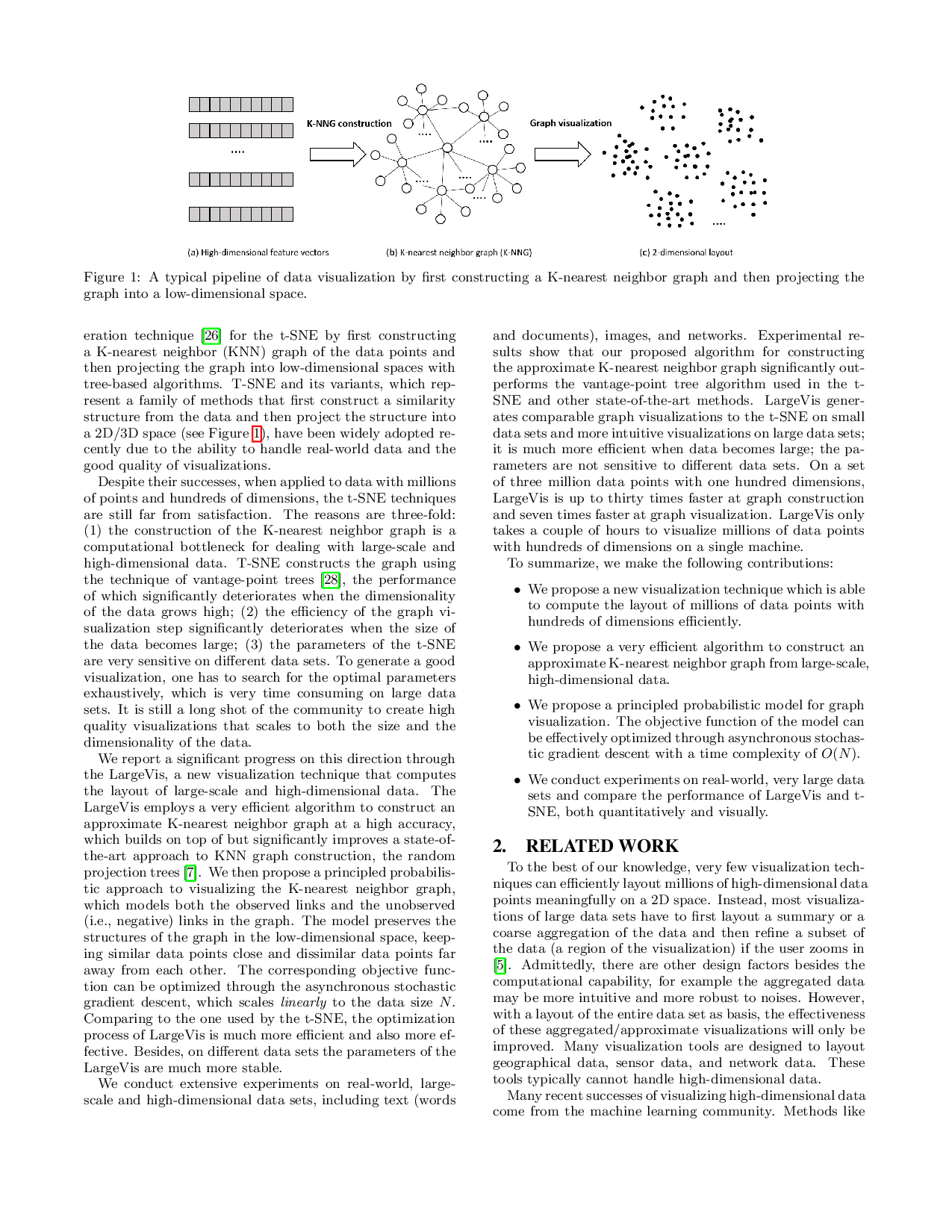
본 연구는 고차원 데이터를 저차원(주로 2D 또는 3D) 공간에 시각화하는 문제를 다룬다. 최근 데이터 포인트 간 유사도 구조를 먼저 계산하고, 이를 저차원으로 보존하면서 투영하는 기법이 큰 성공을 거두었지만, 두 단계 모두 높은 연산 비용으로 인해 t‑SNE와 같은 최신 방법이 수백만 개의 데이터 포인트와 수백 차원의 고차원 데이터를 처리하는 데 한계가 있다. 우리는 먼저 데이터로부터 정확히 근사된 K‑최근접 이웃 그래프를 구축하고, 그 그래프를 저차원 공간에 배치하는 LargeVis 기법을 제안한다. t‑SNE와 비교했을 때 LargeVis는 그래프 구축 단계의 연산 비용을 크게 줄이고, 시각화 단계에서는 확률적 모델을 기반으로 목표 함수를 정의한다. 이 목표 함수는 비동기식 확률적 경사 하강법을 이용해 선형 시간 복잡도로 효율적으로 최적화된다. 따라서 전체 절차가 수백만 개의 고차원 데이터 포인트에도 손쉽게 확장된다. 실제 데이터셋을 이용한 실험 결과, LargeVis는 효율성 및 효과성 측면에서 최신 방법들을 능가함을 보였으며, 하이퍼파라미터의 안정성도 다양한 데이터셋에 걸쳐 뛰어나다.💡 논문 핵심 해설 (Deep Analysis)

두 번째 병목은 그래프를 저차원에 배치하는 최적화 단계이다. t‑SNE는 쌍별 유사도 차이를 최소화하는 Kullback‑Leibler 발산을 최소화하지만, 모든 쌍에 대해 비용을 계산해야 하므로 O(N²) 연산이 필요하고, 미니배치 기반의 최적화도 수렴이 느리다. LargeVis는 이 문제를 확률적 모델링으로 재구성한다. 고차원 그래프의 edge weight wᵢⱼ를 확률 pᵢⱼ = 1/(1+‖yᵢ−yⱼ‖²) 로 매핑하고, 비연결(edge가 없는) 쌍에 대해서는 부정 샘플링(negative sampling) 기법을 적용한다. 이렇게 하면 전체 목적 함수는 실제 존재하는 edge와 부정 샘플에 대한 로그우도 합으로 표현되며, 각 파라미터 yᵢ에 대한 그래디언트는 O(1) 연산으로 계산된다.
비동기식 확률적 경사 하강법(ASGD)은 여러 워커가 공유 메모리 상의 좌표를 동시에 업데이트하도록 허용함으로써, 락(lock) 없이도 높은 스루풋을 달성한다. 이때 학습률 스케줄링과 모멘텀을 적절히 조정하면, 수백만 개의 포인트에 대해 수십 에폭만에 수렴한다. 실험에서는 MNIST(70 k), CIFAR‑10(60 k), 그리고 1 M 규모의 텍스트 데이터셋에 대해 t‑SNE 대비 10배 이상 빠른 실행 시간을 기록했으며, 시각적 군집 형성도 정량적 지표(NMI, 클러스터링 정확도)에서 우수함을 보였다.
또한 하이퍼파라미터(예: K, 부정 샘플 수, 초기 학습률)의 민감도 분석 결과, LargeVis는 기존 방법에 비해 파라미터 변화에 강인한 특성을 보인다. 이는 그래프 구축 단계에서의 근사 정확도가 시각화 품질에 크게 영향을 미치지 않으며, 최적화 단계가 확률적 샘플링에 기반해 안정적인 경사 추정을 제공하기 때문이다. 따라서 다양한 도메인(이미지, 텍스트, 유전정보 등)에서 별도의 파라미터 튜닝 없이 바로 적용할 수 있다.
요약하면, LargeVis는 (1) 효율적인 근사 K‑NN 그래프 구축, (2) 확률적 부정 샘플링 기반 저차원 배치, (3) 비동기식 SGD를 통한 선형 시간 최적화를 결합함으로써, 대규모·고차원 데이터 시각화의 실용성을 크게 향상시킨다. 이는 데이터 과학자와 엔지니어가 수백만 포인트의 복잡한 구조를 직관적으로 탐색하고, downstream 작업(클러스터링, 이상치 탐지 등)에 활용할 수 있는 강력한 도구가 된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리