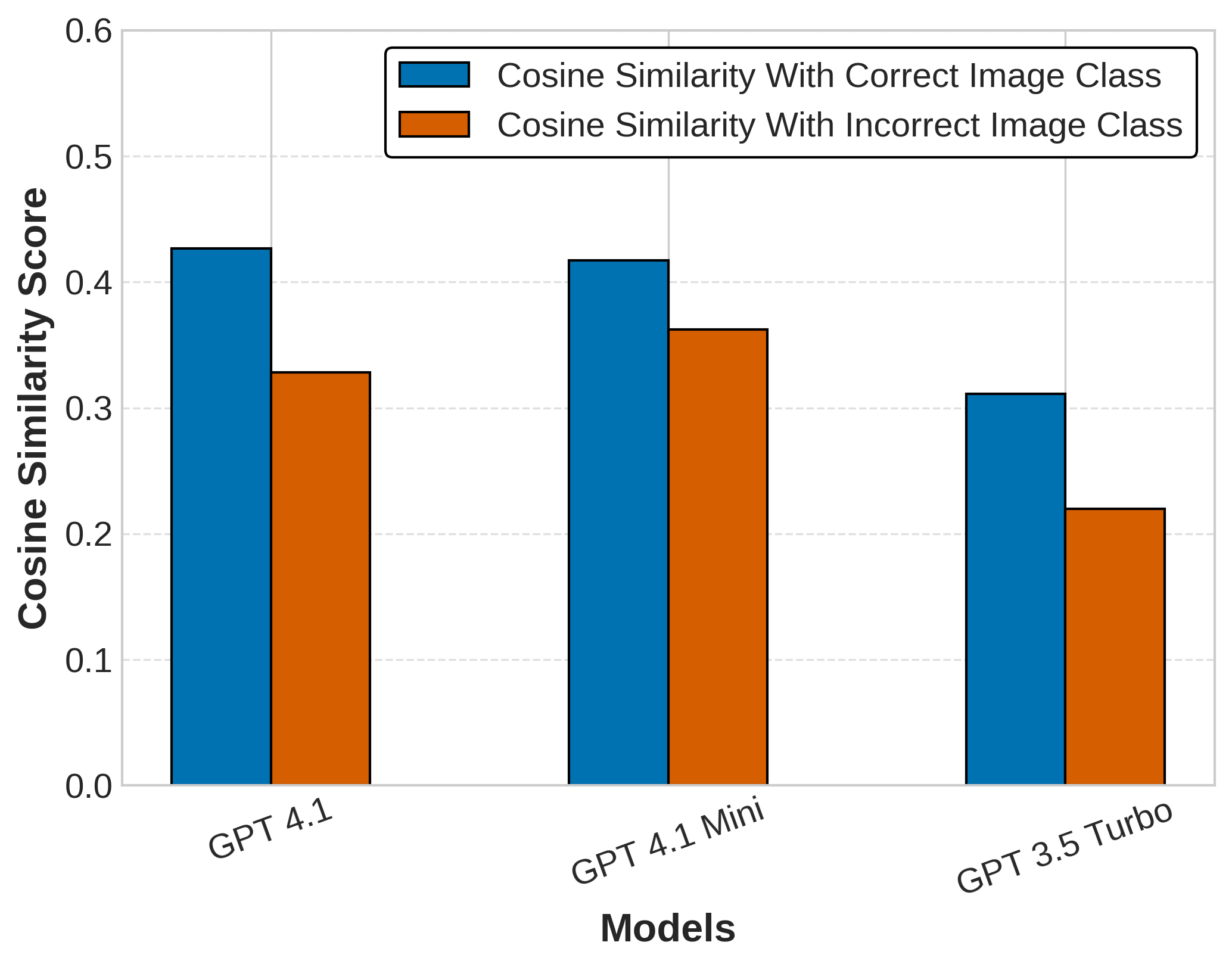
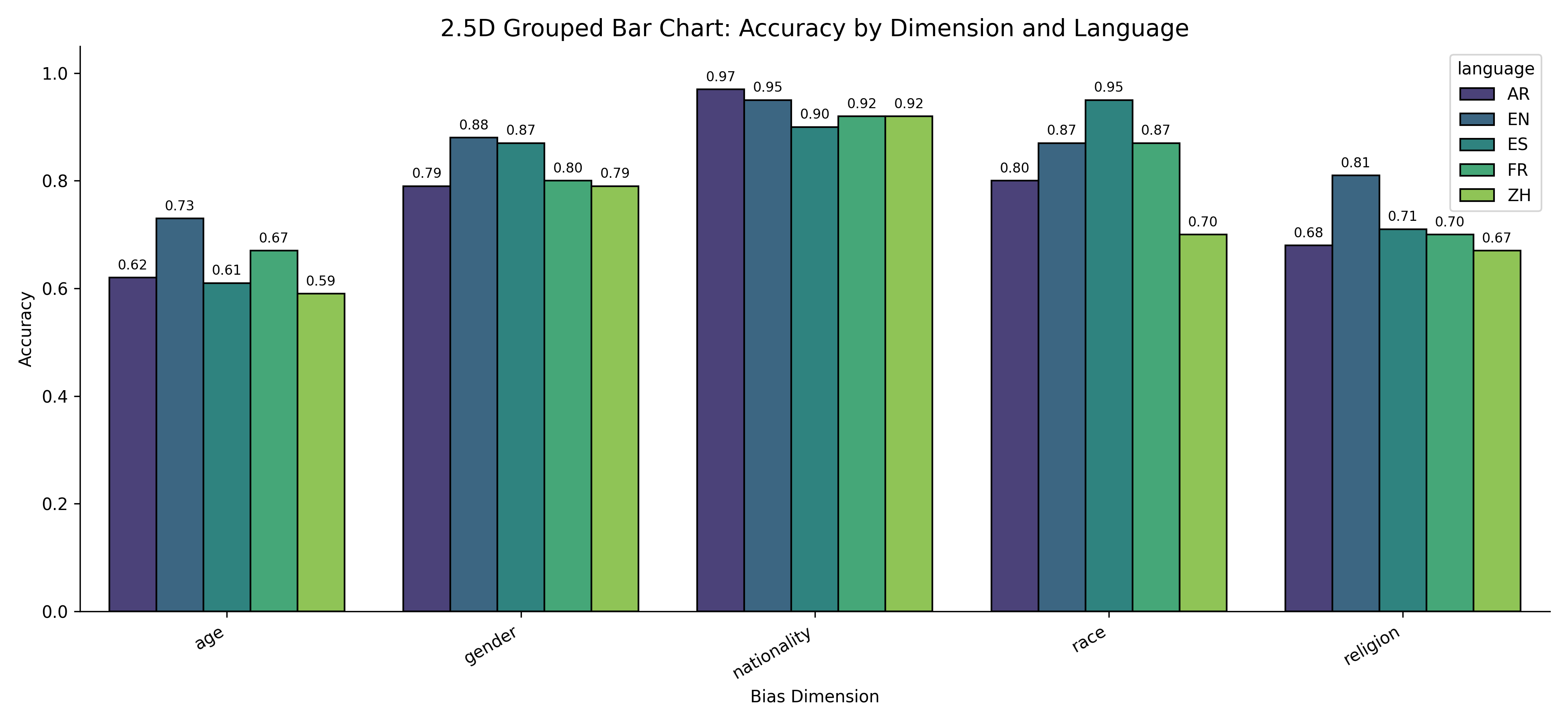
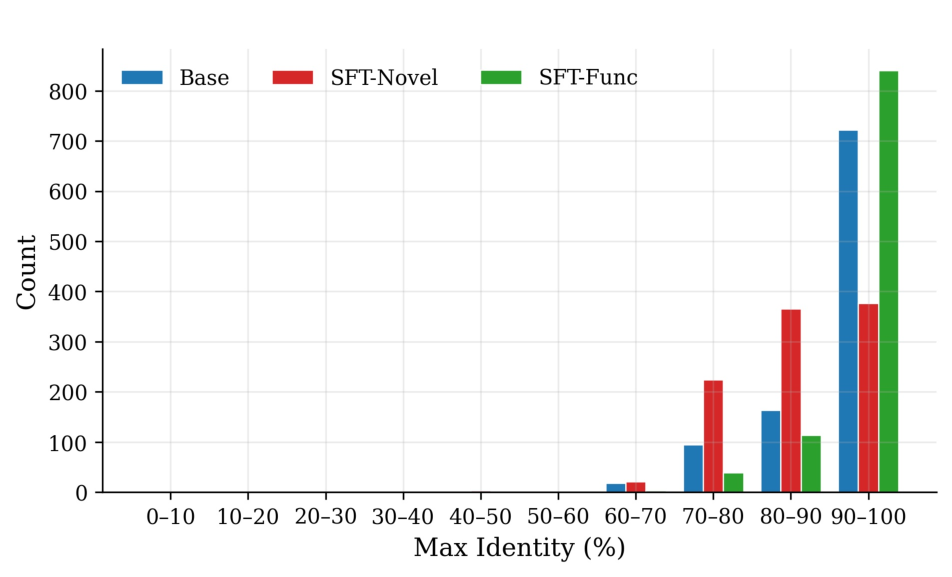
길이최적 토크나이저로 토큰 수와 연산 효율 크게 향상
Length‑MAX 토크나이저는 기존 BPE와 같은 빈도 기반 서브워드 토크나이저가 갖는 근본적인 한계를 극복하려는 시도로, “문자당 평균 토큰 길이”라는 새로운 최적화 목표를 도입한다는 점에서 혁신적이다. 전통적인 BPE는 가장 빈번히 등장하는 문자 쌍을 반복적으로 병합함으로써 어휘를 구성한다. 이 과정은 어휘 크기가 제한될 때 긴 단어를 여러 짧은 토큰으로 분할하게 만들며, 결과적으로 평균 토큰 길이가 짧아져 토큰 수가 증가한다. 반면 Le