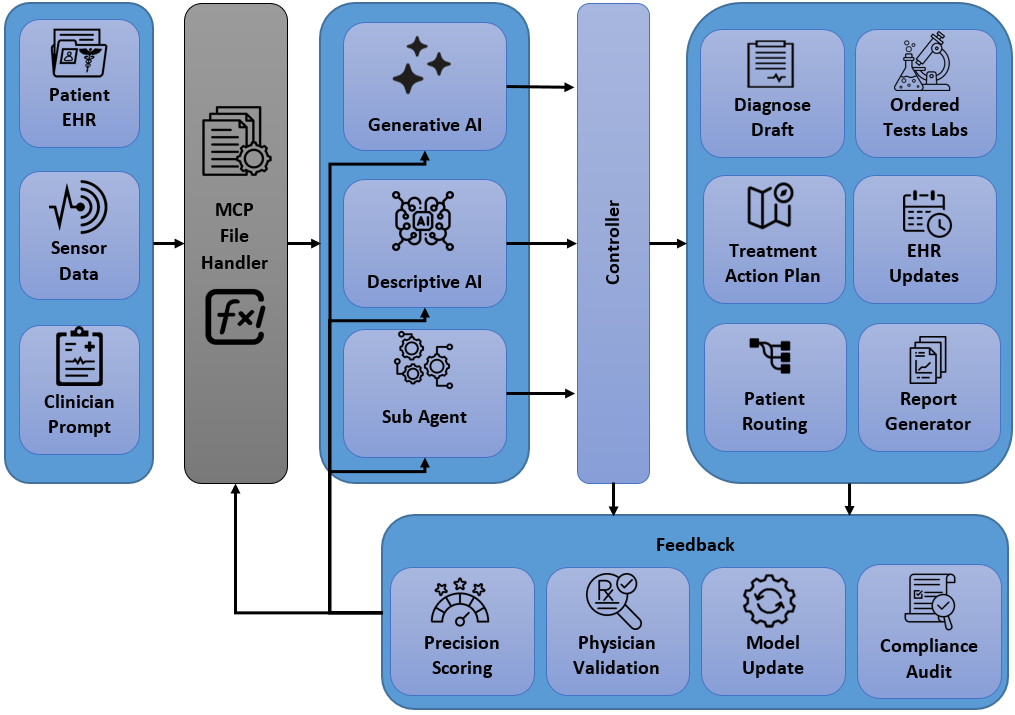
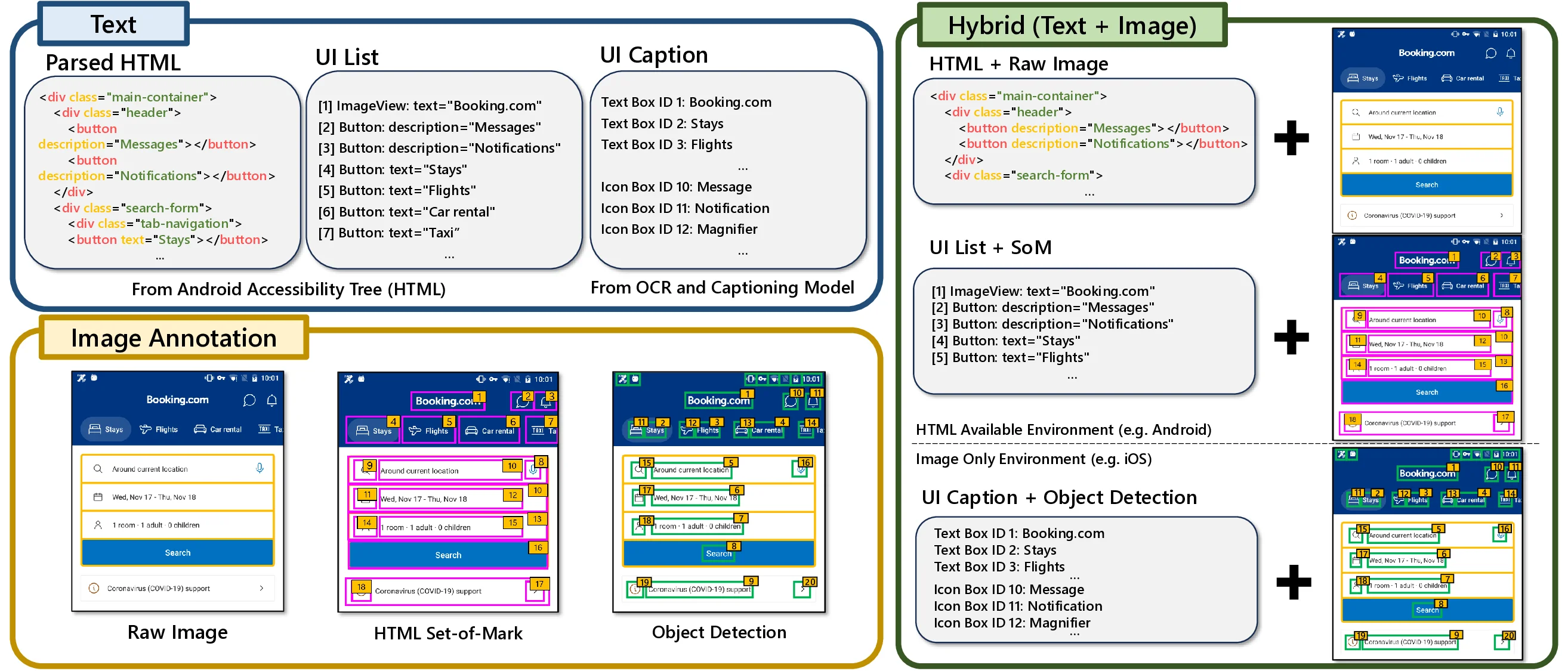
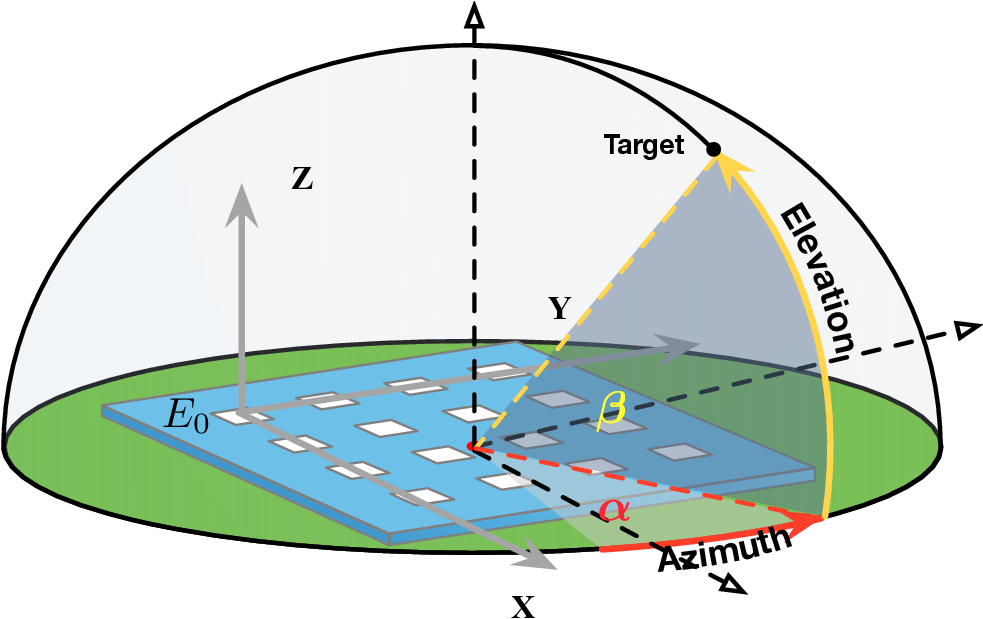
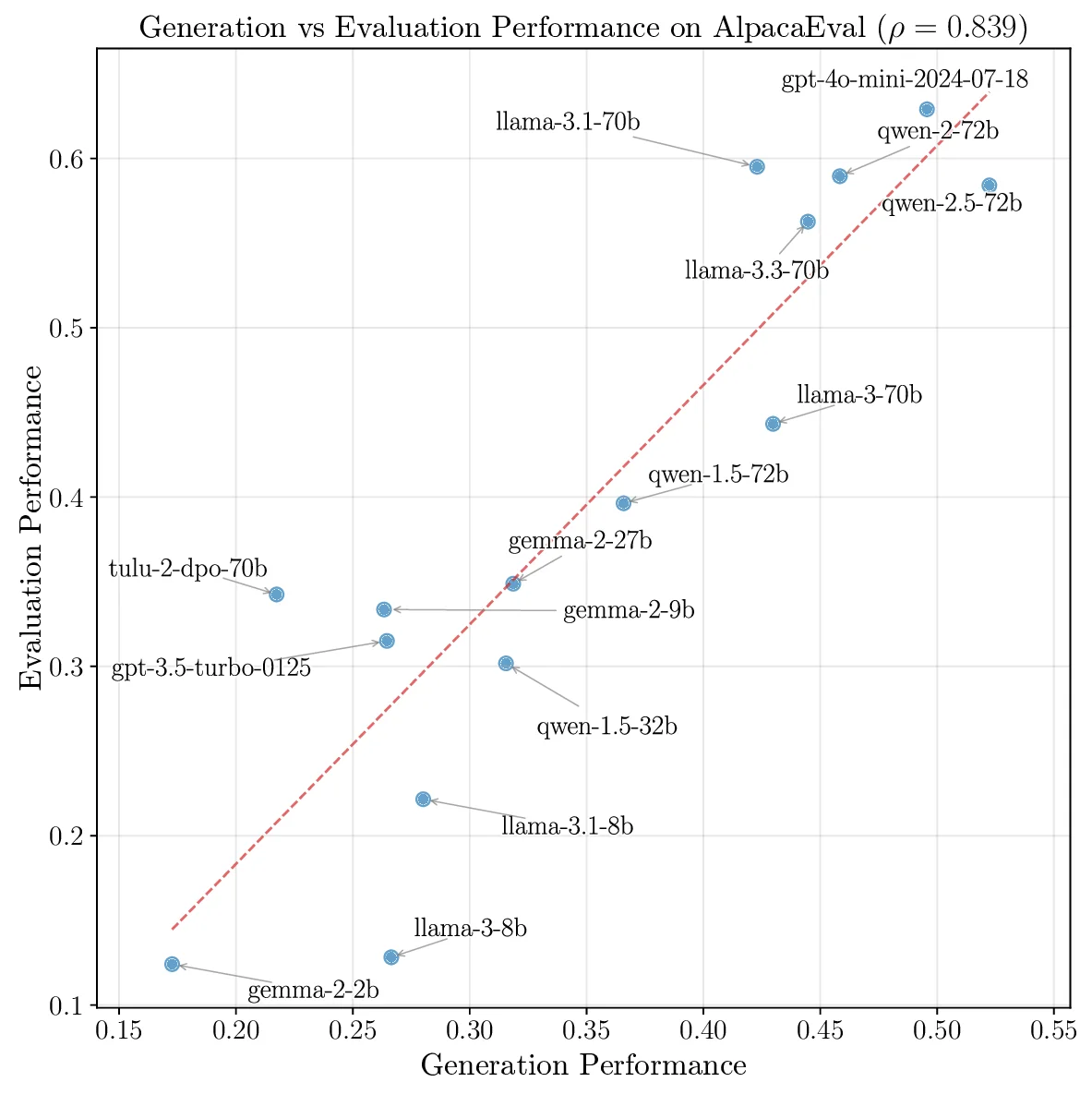
멀티모달 단일 롤아웃 학습 효율성 향상: MSSR (Multimodal Stabilized Single‑Rollout) 소개
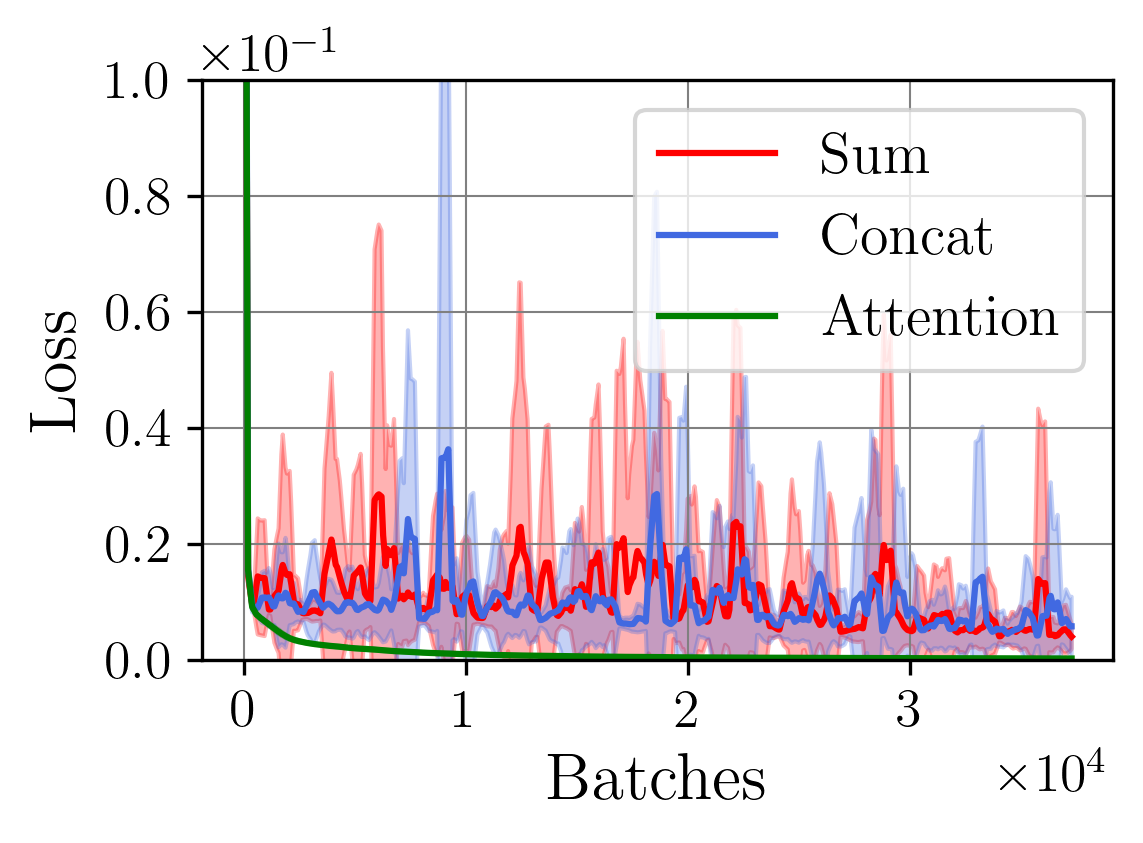
1. 연구 배경 및 동기 - RLVR 은 인간 피드백 대신 자동 검증 가능한 정답 신호를 사용해 LLM/MLLM을 정렬한다는 점에서 비용‑효율적인 학습 방법으로 주목받고 있다. - 멀티모달 환경에서는 시각‑언어 인코더 가 무거워, 다중 롤아웃 (그룹 기반) 방식이 연산량을 급증시킨다. - 기존 텍스트‑전용 단일 롤아웃 연구(