아날로그 NVM 크로스바에 배포를 위한 DNN IoT 애플리케이션 훈련
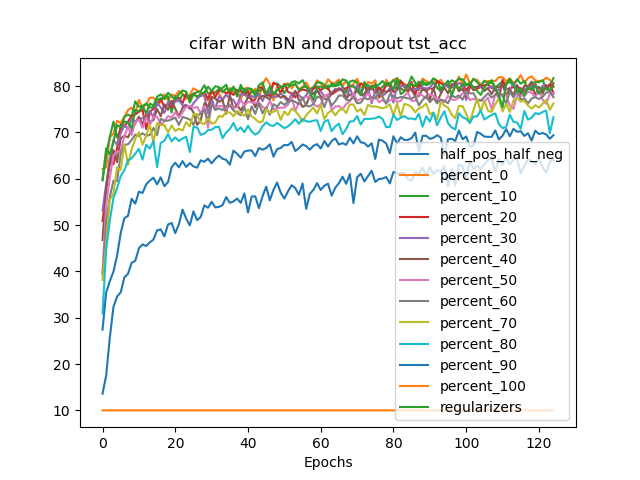
에너지 효율성, 보안 및 프라이버시에 대한 추세는 최근 딥러닝 네트워크(DNNs)를 마이크로컨트롤러에 배포하는 데 초점을 맞추게 되었습니다. 그러나 계산 및 메모리 자원의 제약으로 인해 이러한 시스템에서 배포 가능한 ML 모델의 크기와 복잡성이 제한됩니다. 저항성 비휘발성 메모리(NVM) 기술을 기반으로 하는 컴퓨테이션-인-메모리(CIM) 아키텍처는 현대 DNN에 내재된 고성능 및 저전력 요구사항을 충족시키는 데 큰 희망을 제공합니다. 그러나 이러한 기술들은 여전히 미숙하고, 본질적인 아날로그 영역 노이즈 문제와 NVM 구조에서 음수 가중치를 표현할 수 없는 문제가 있습니다. 이로 인해 크로스바의 크기가 커지고, ADC와 DAC에 부정적 영향을 미칩니다. 본 논문에서는 이러한 과제들을 해결하기 위한 훈련 프레임워크를 제공하고 회로 수준에서 얻어진 효율성 증가를 정량적으로 평가합니다. 두 가지 기여를 제안합니다 첫째, 개별 DNN 계층의 튜닝을 필요로 하지 않는 훈련 알고리즘으로 각 계층의 가중치와 활성화에 일관성을 보장하여 아날로그 블록 재사용과 주변 하드웨어를 크게 줄입니다. 둘째, NAS 방법론을 사용하여 단극 가중치(모두 양수 또는 모두 음수) 행렬/서브행렬의 사용을 제안합니다. 가중치 단극성은 크로스바 영역을 두 배로 늘릴 필요를 없애고 아날로그 주변 장비를 간소화합니다. CIFAR10과 HAR 애플리케이션에 대한 검증 결과, 4비트 및 2비트 장치를 사용하여 크로스바로 매핑했을 때 95%의 부동소수점 정확도에서 2비트 양수 가중치만으로 92.91%의 정확도를 달성했습니다. 제안된 기법의 조합은 80%의 면적 개선과 최대 45%의 에너지 감소를 가져왔습니다.