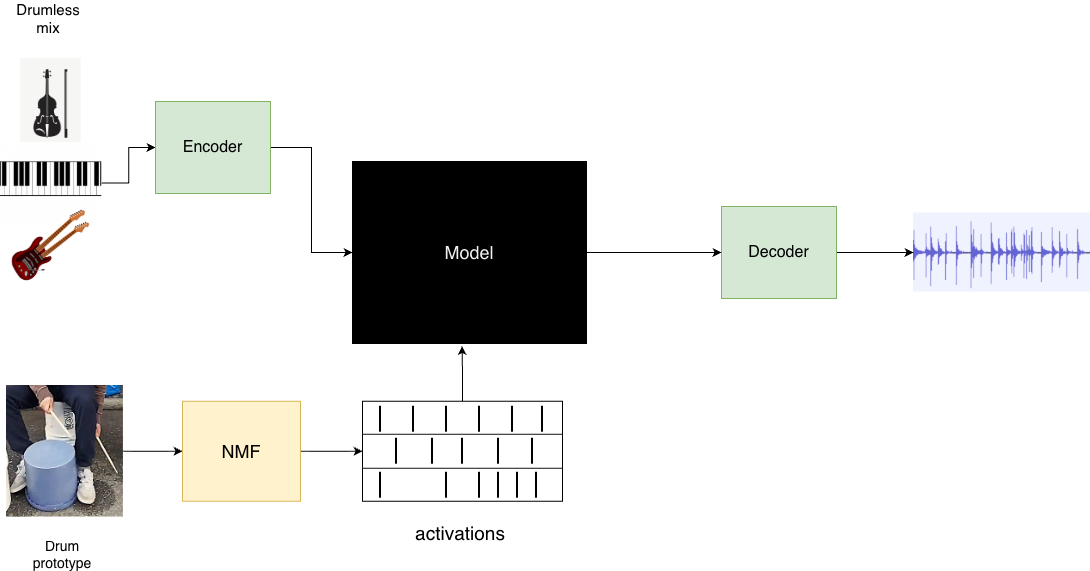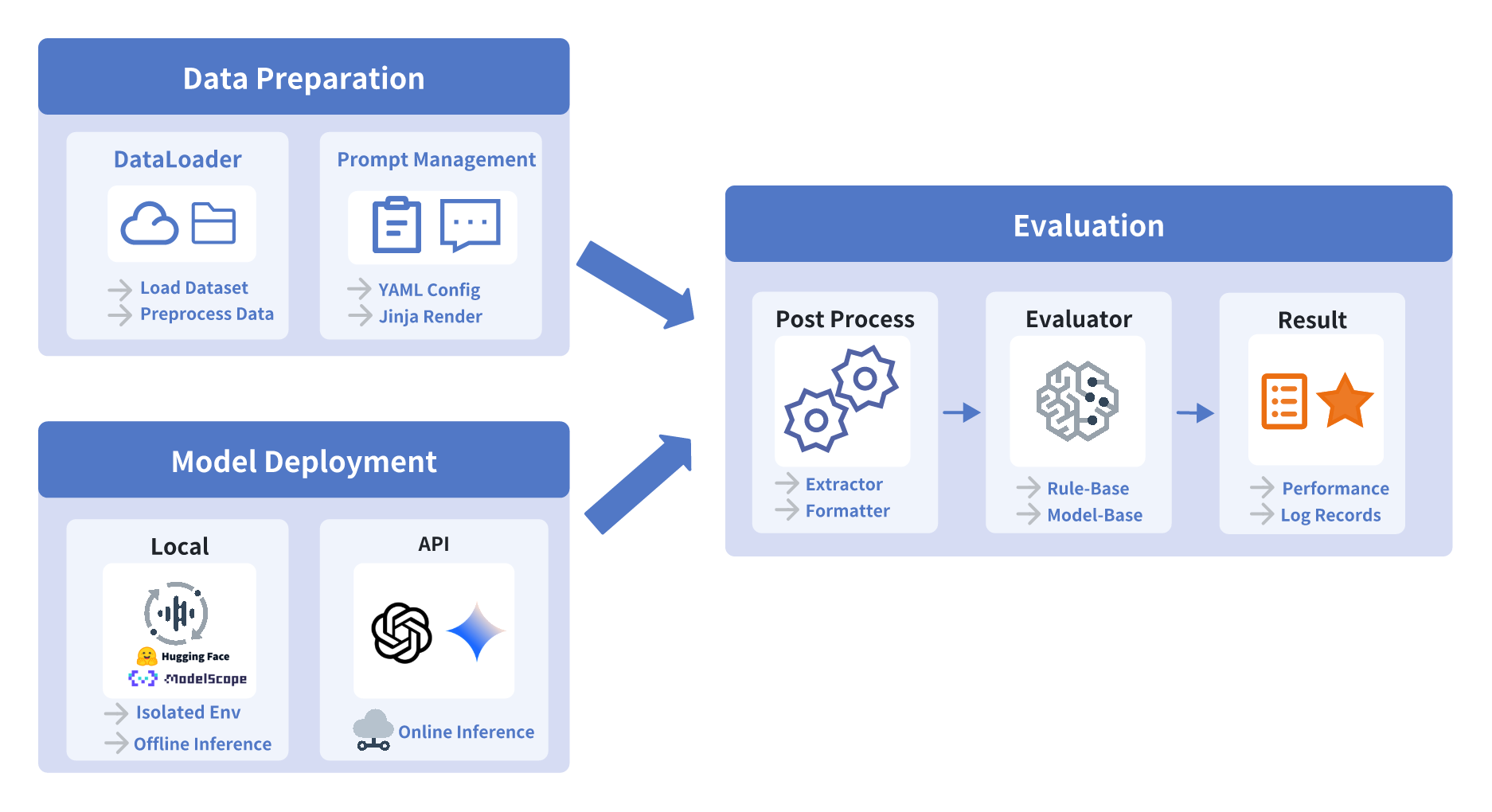
UltraEval-오디오 오디오 기초 모델의 종합적인 평가를 위한 통일된 프레임워크
오디오 기반 모델의 폭발적인 발전과 함께, 오디오 모델을 객관적이고 체계적으로 평가하기 위한 통합 평가 프레임워크인 **UltraEval-Audio**를 제안합니다. 이 프레임워크는 데이터 로딩부터 추론 파라미터 조정까지 다양한 과정을 분리하여 연구자들이 실험의 재현성을 높이고, 빠르게 적응하고 확장할 수 있도록 설계되었습니다.
paper
AI 요약