VLA-RAIL VLA 모델과 로봇을 위한 실시간 비동기 추론 링커
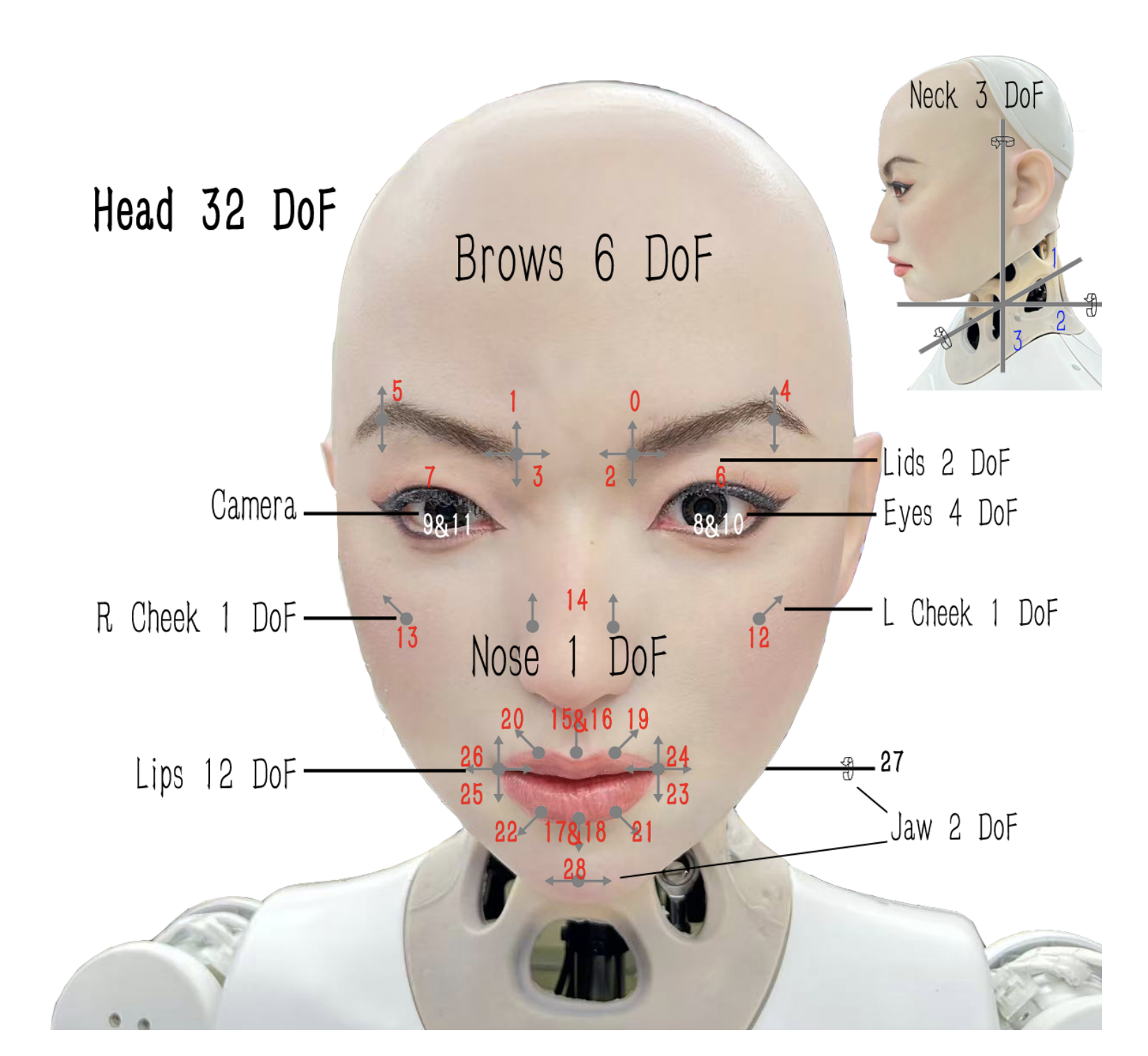
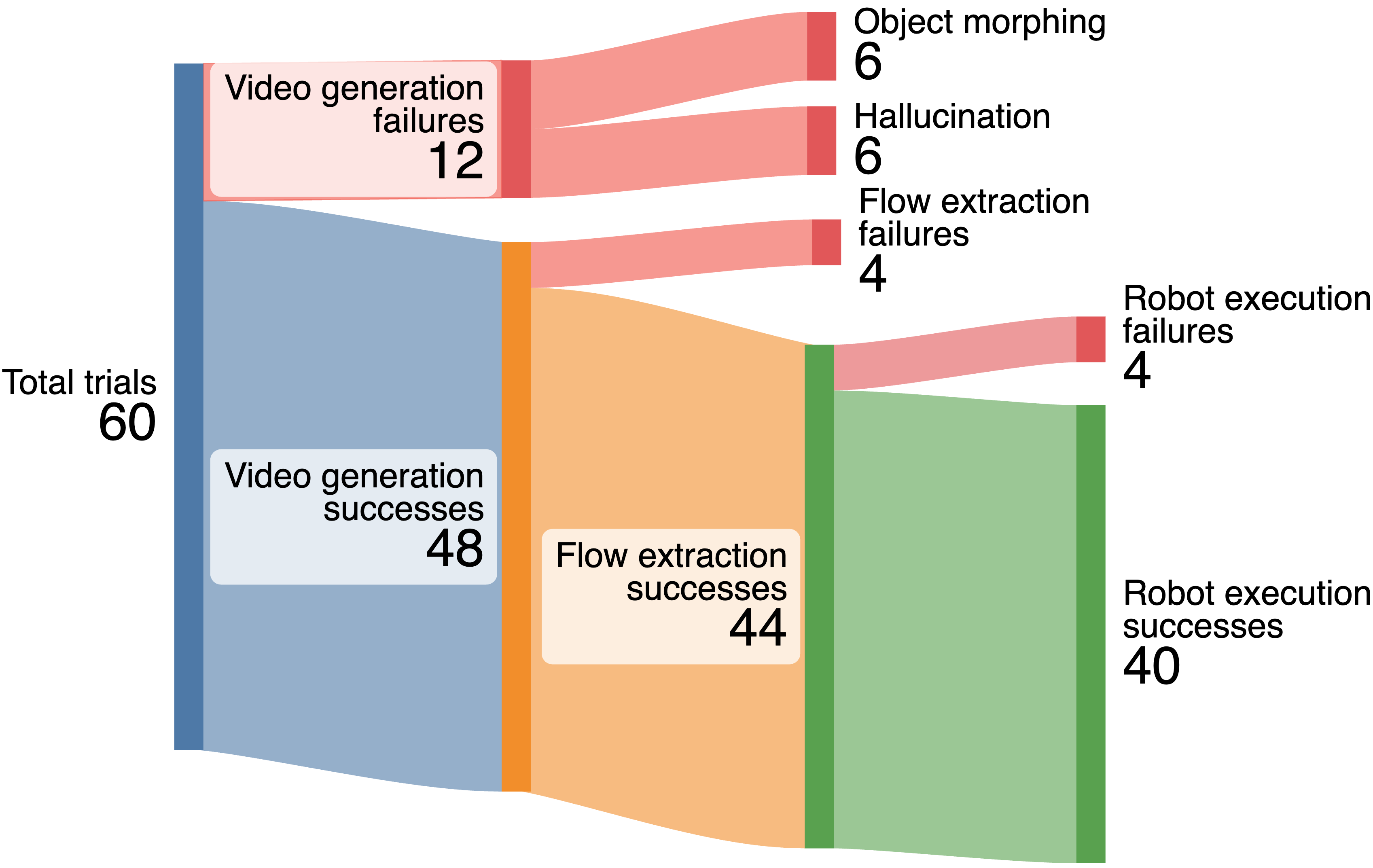
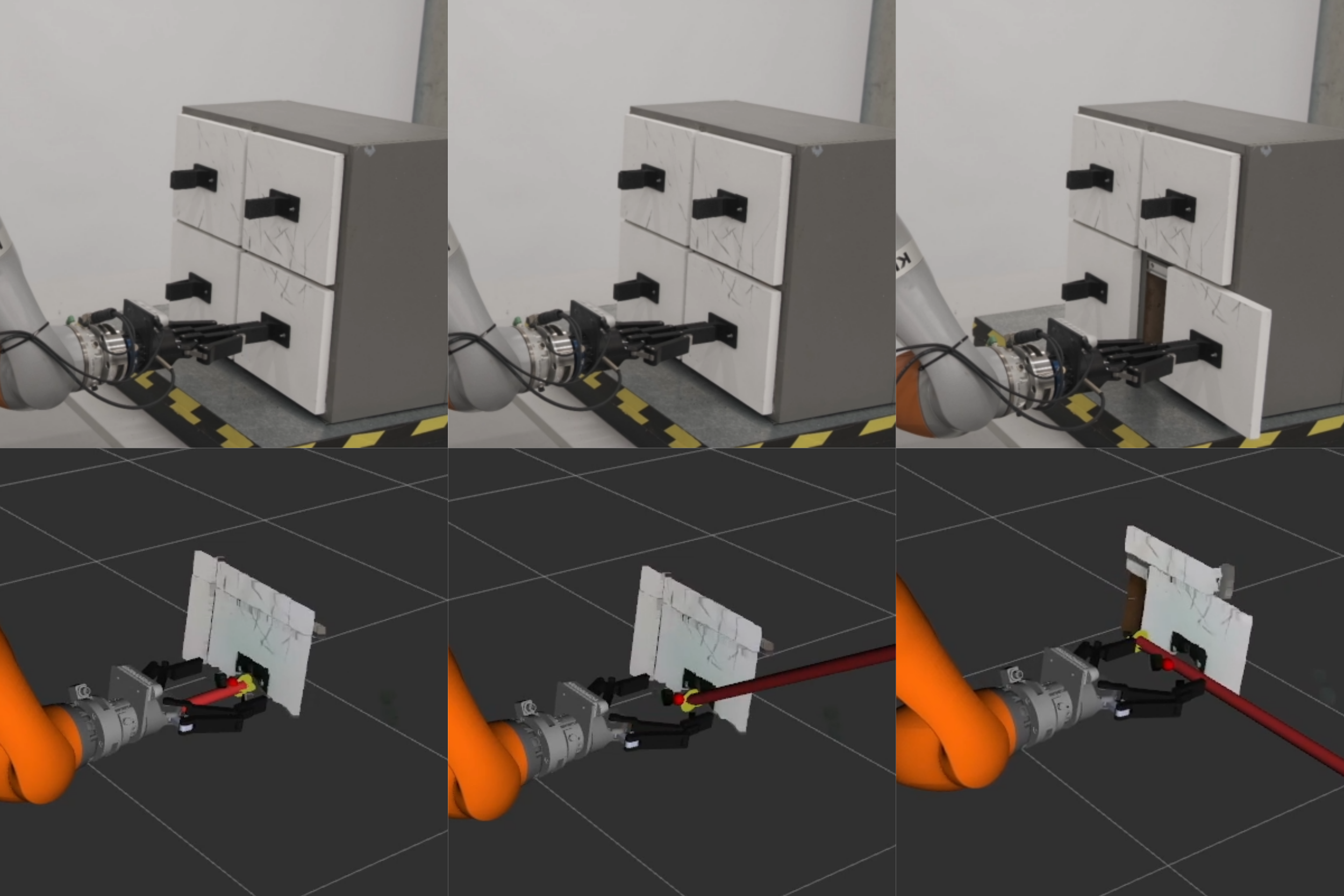
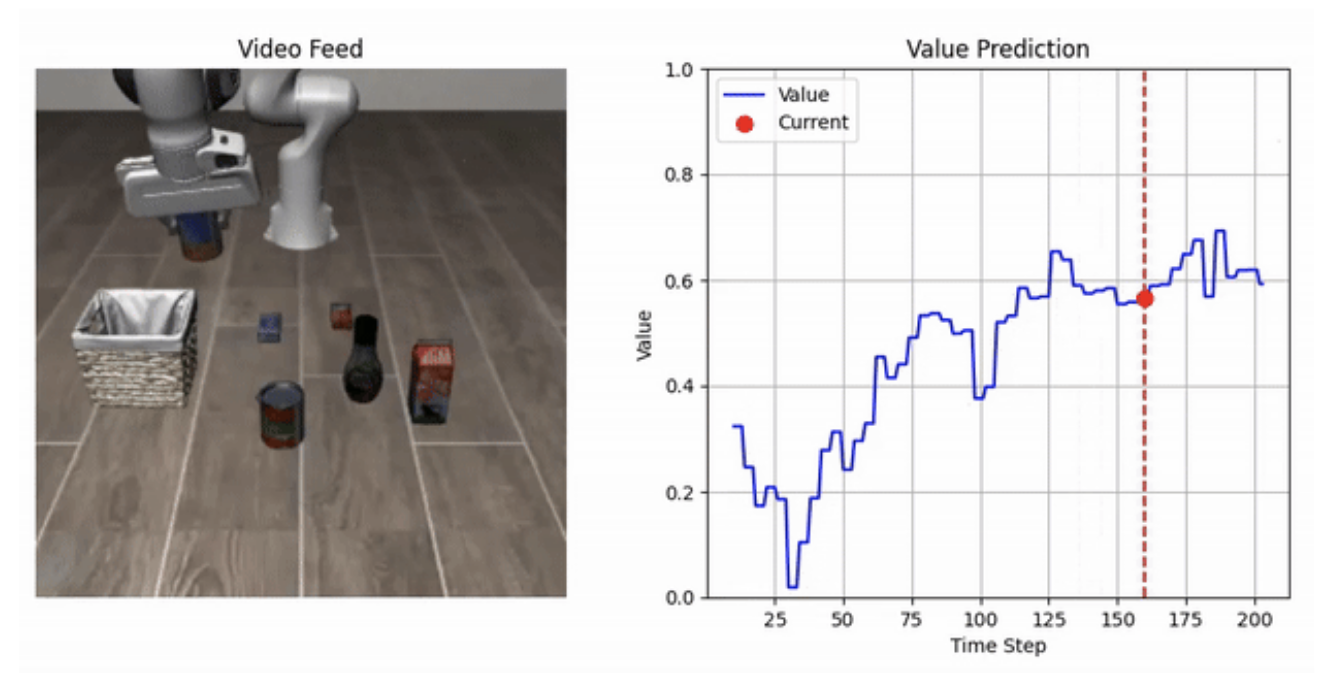
비전-언어-행동(VLA) 모델은 로봇이 자연 언어 명령을 이해하고, 공간-시각적 의미를 추출하며, 열린 세계 조작 작업에 적합한 행동을 생성할 수 있게 합니다. 그러나 VLA 모델의 배포는 다양한 하드웨어 구성과 소프트웨어 인터페이스로 인해 한정되어 있습니다. 본 논문에서는 이러한 문제를 해결하기 위해 실시간 비동기 추론 프레임워크인 VLA-RAIL을 제안합니다.
paper
AI 요약