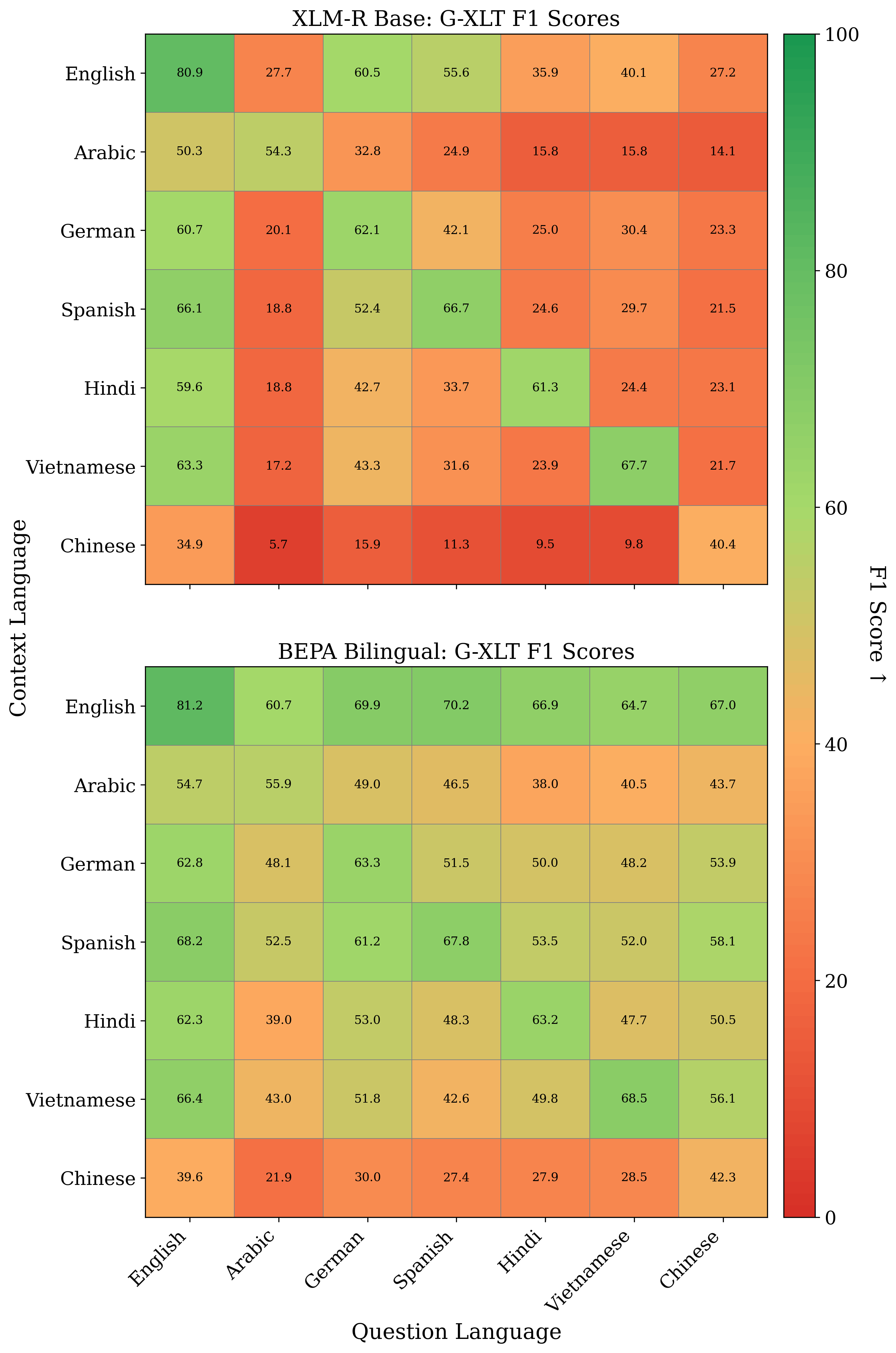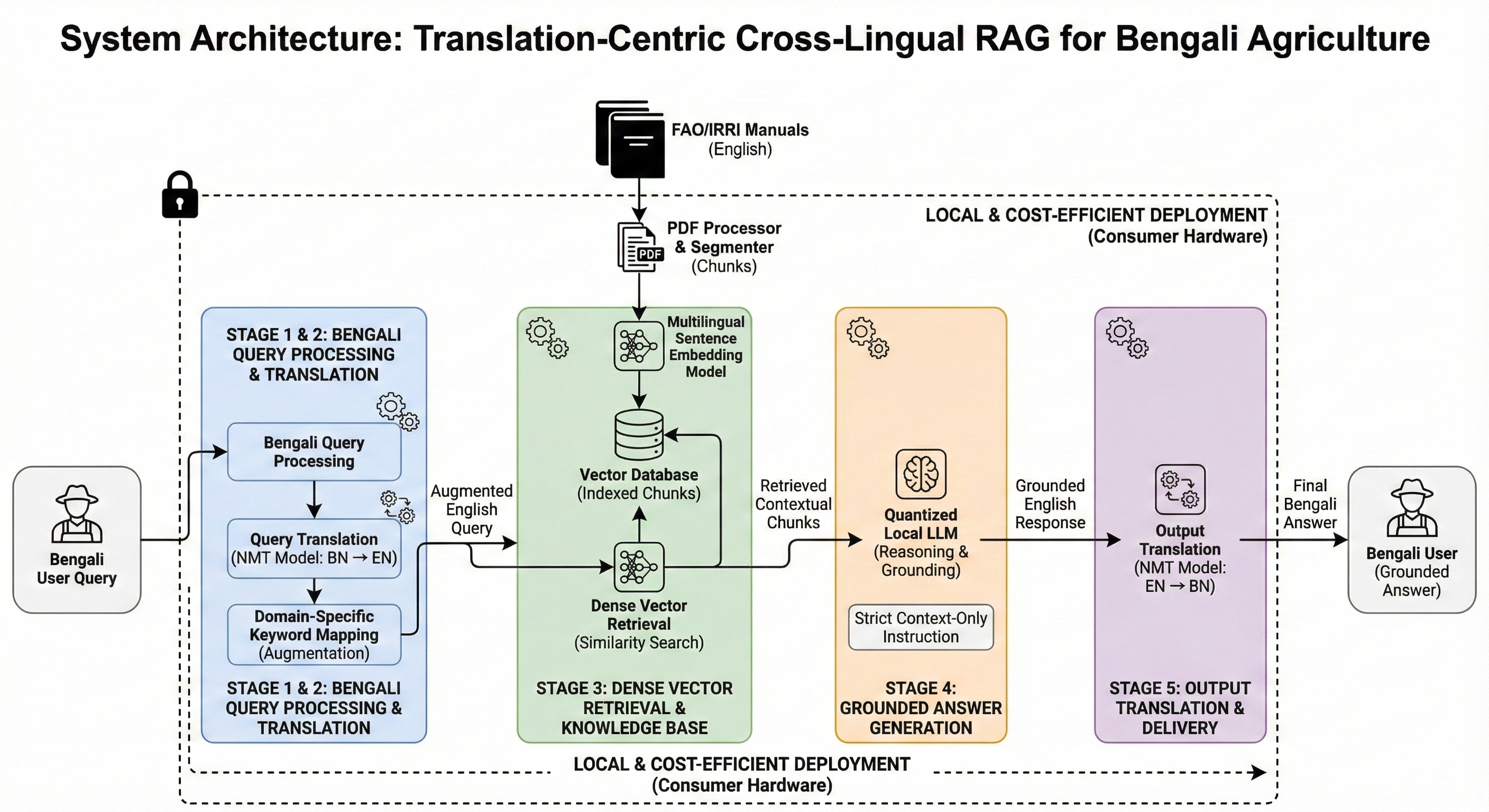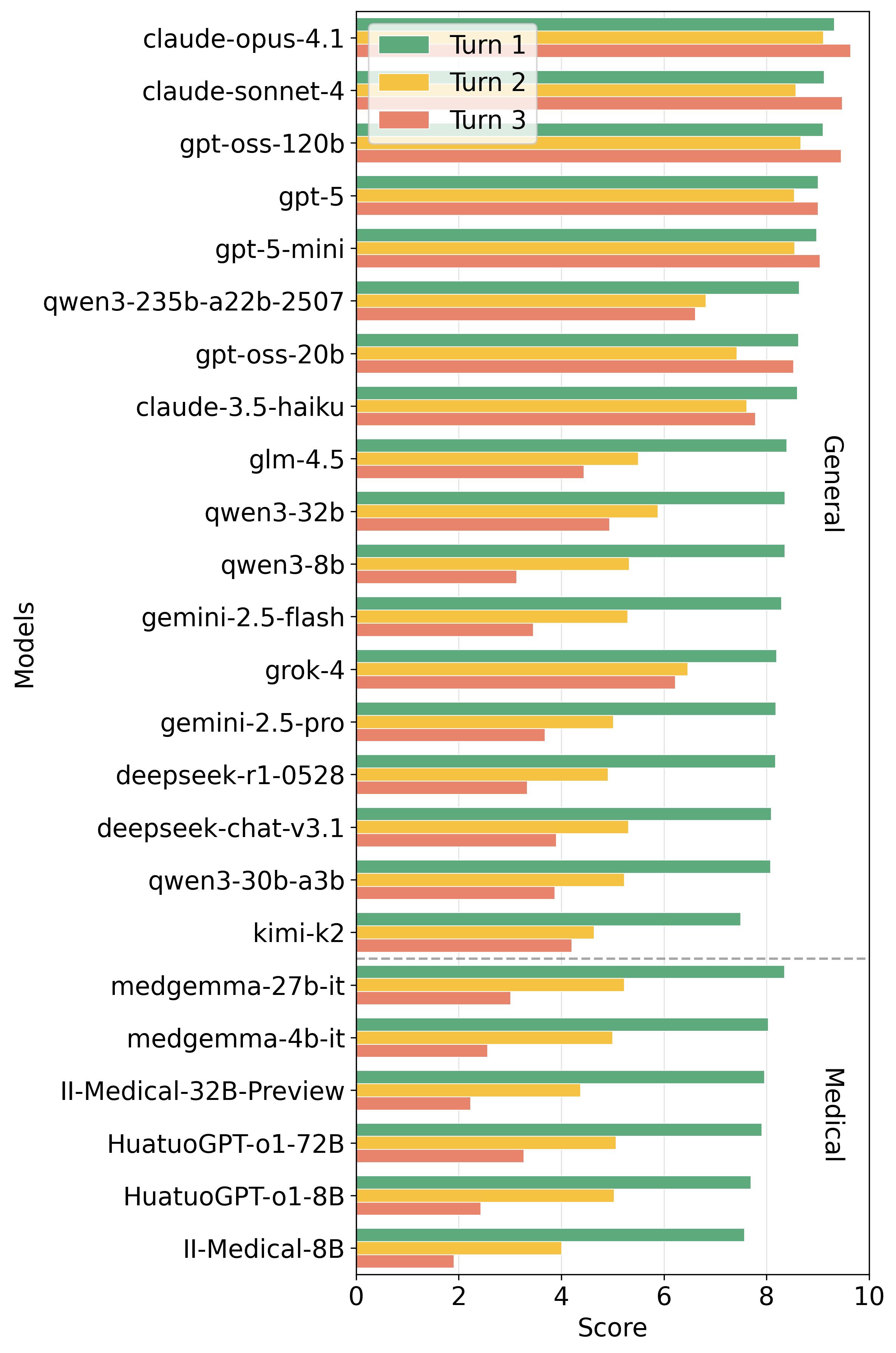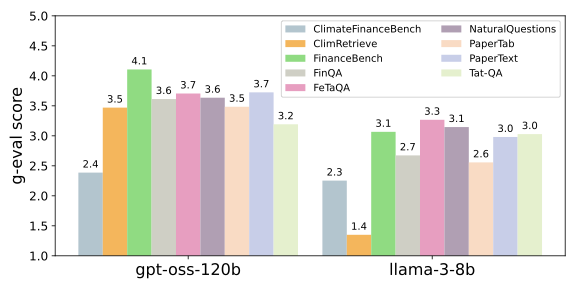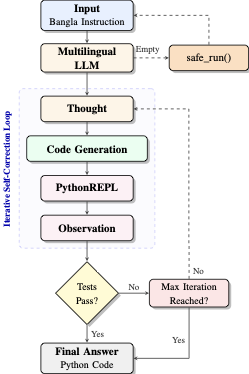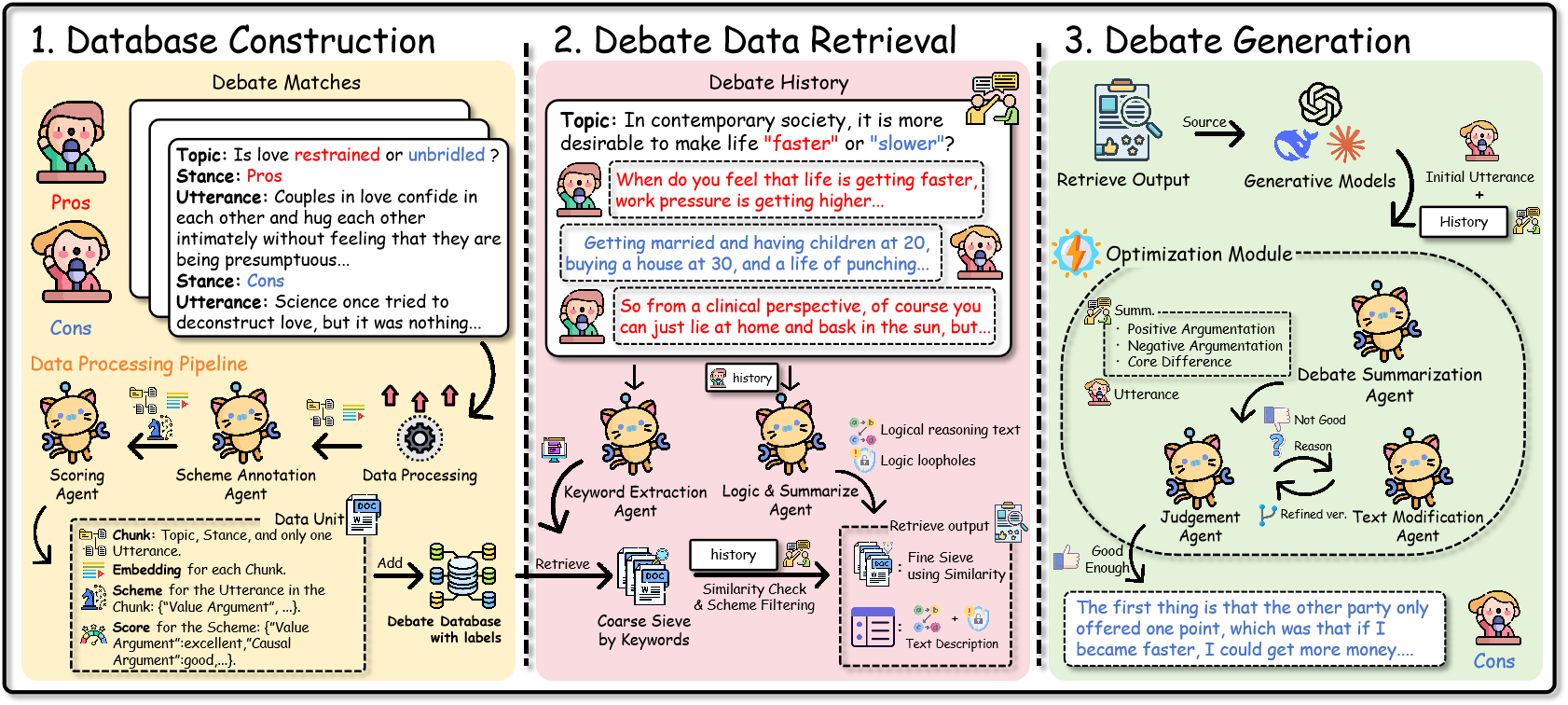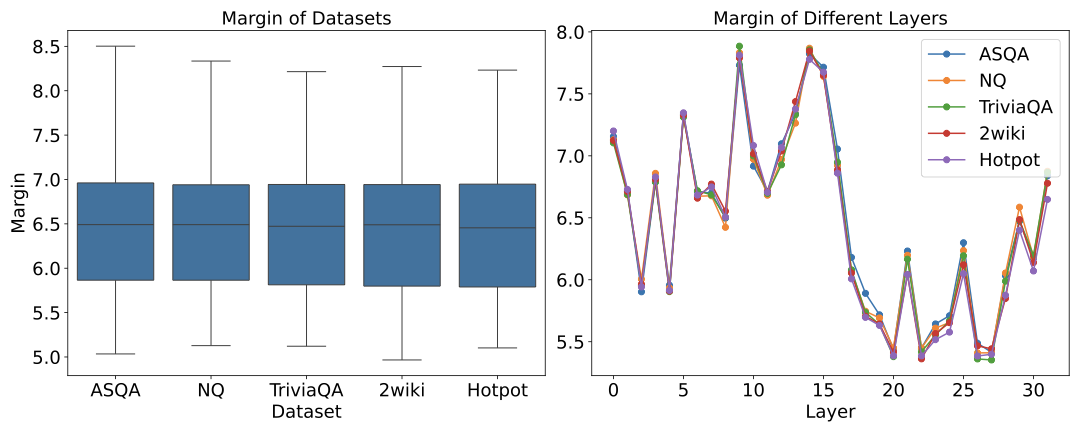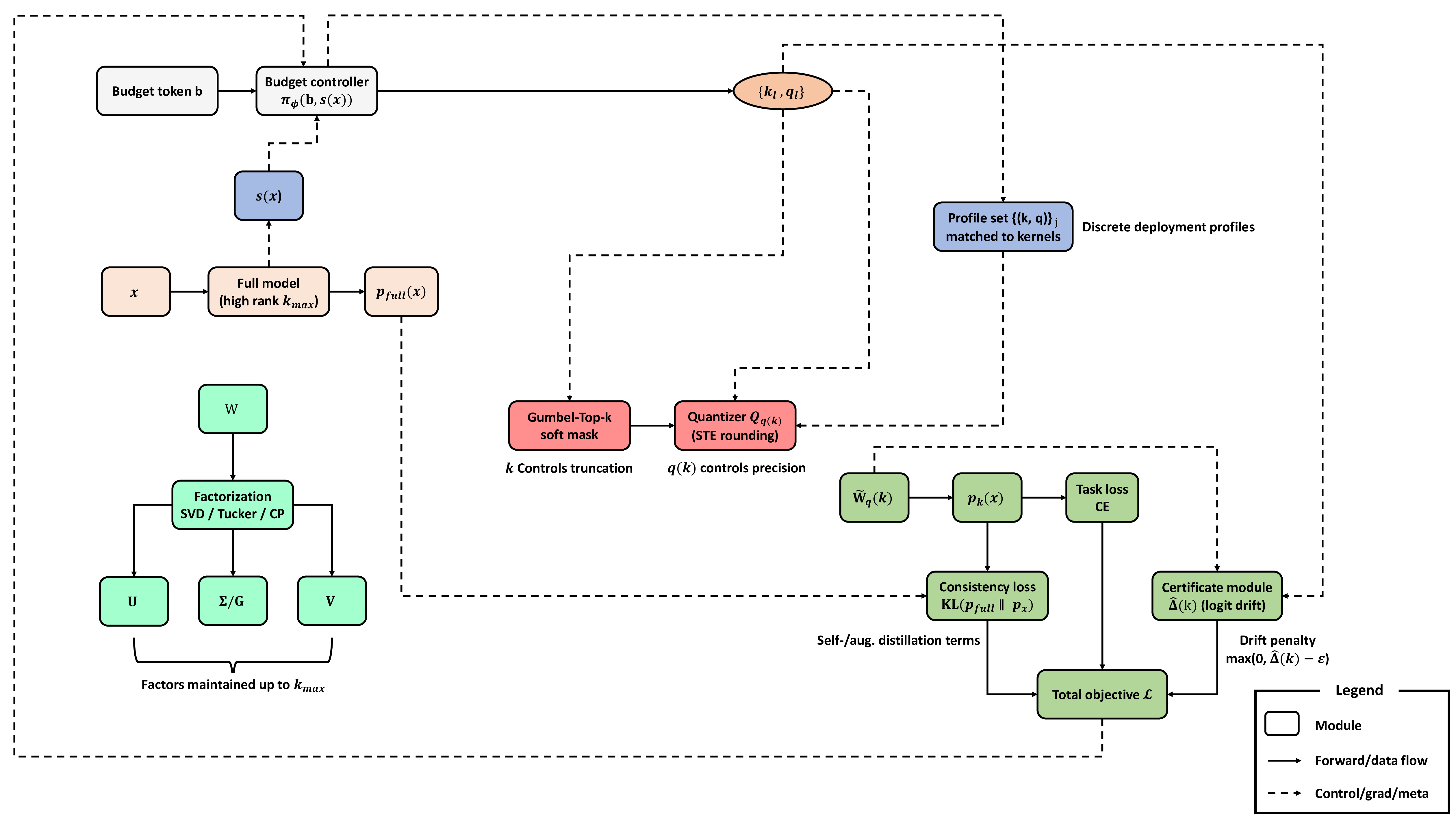
AdaGReS 토큰 예산에 적응하는 중복 고려 스코어링을 통한 선욕적 문맥 선택
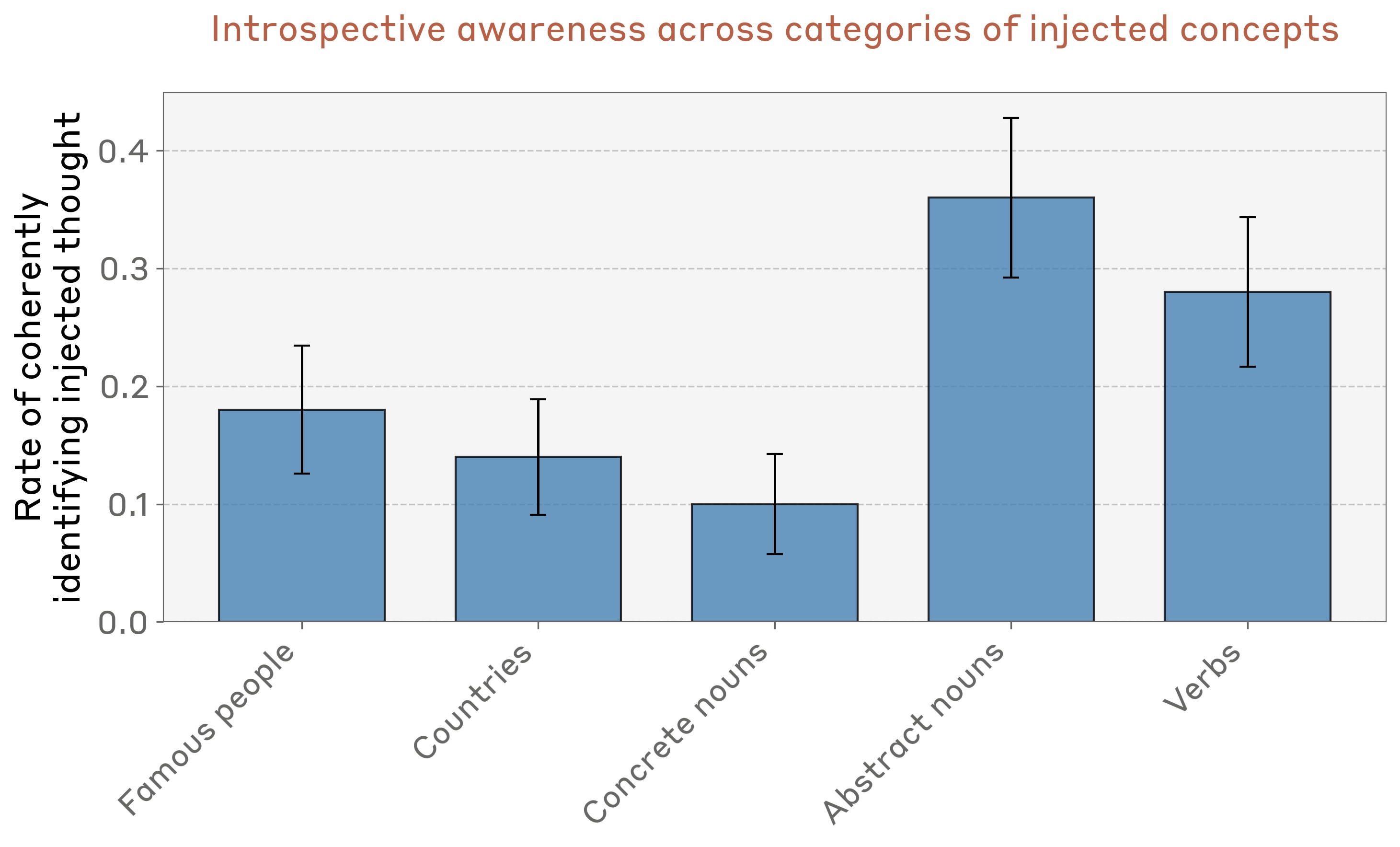
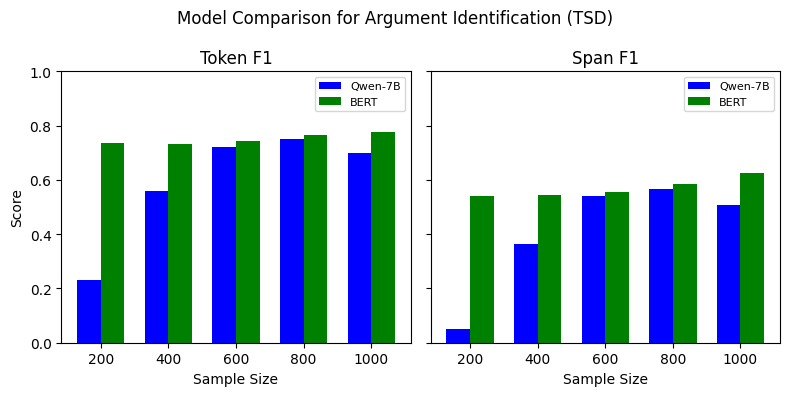
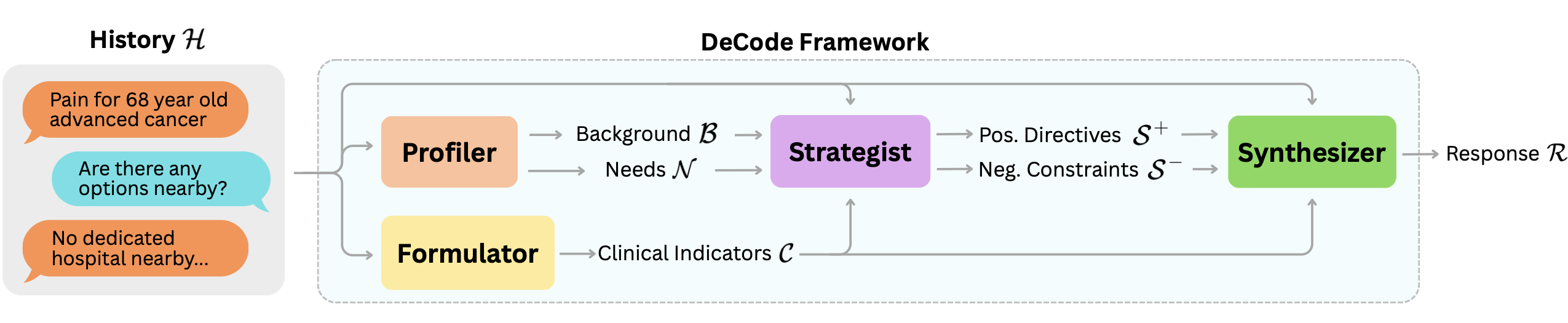
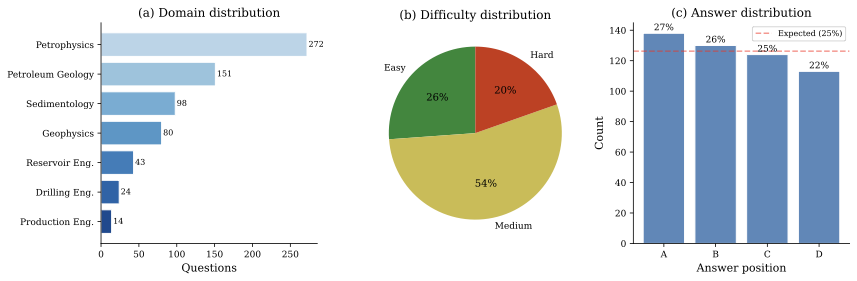
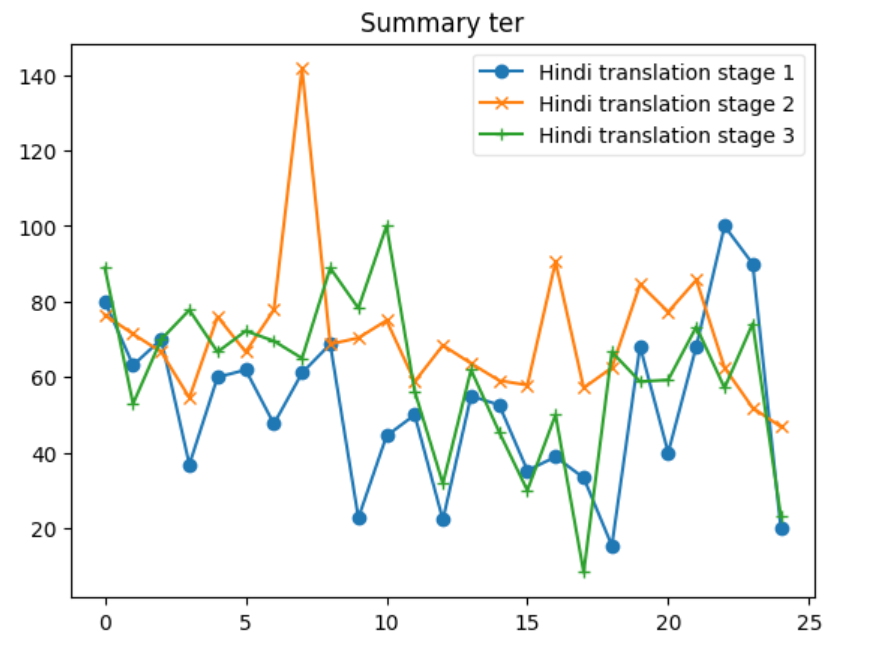
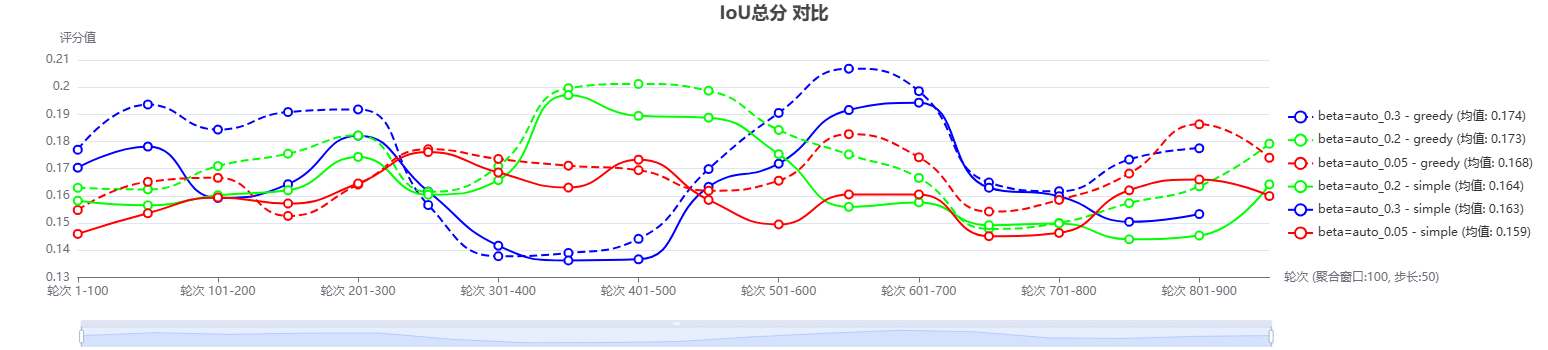
RAG(Retrieval-Augmented Generation)는 대형 언어 모델(LLM)이 외부 지식을 통합하고, 지식 집약적인 작업 성능을 향상시키는 주요 기술로 발전했습니다. 그러나 RAG 시스템은 검색된 결과의 다양성과 관련성을 균형 있게 유지하는 데 어려움을 겪습니다. 본 논문에서는 이러한 문제를 해결하기 위해 새로운 맥락 점수화 및 선택 메커니즘을 제안하고 이를 구현합니다.
paper
AI 요약