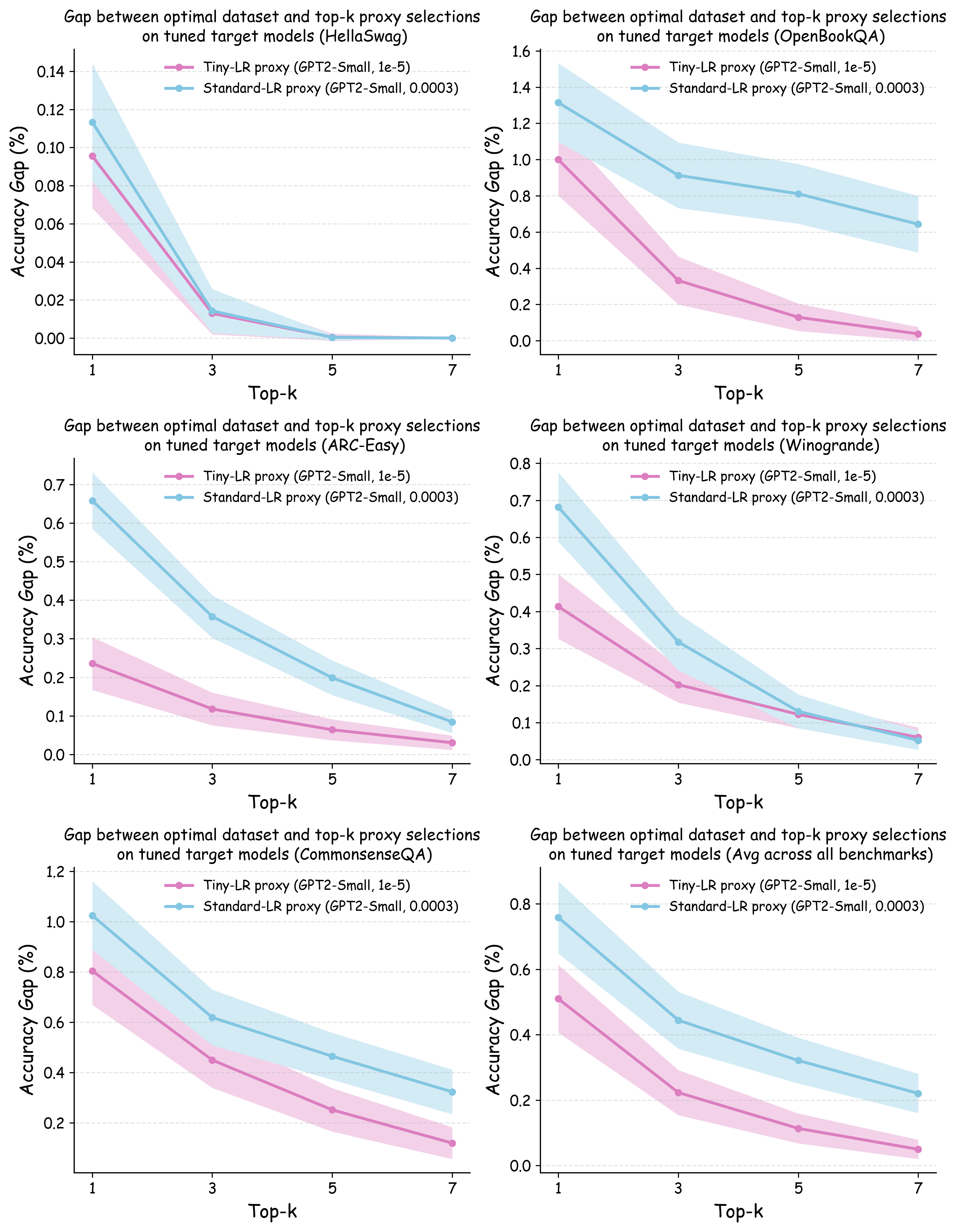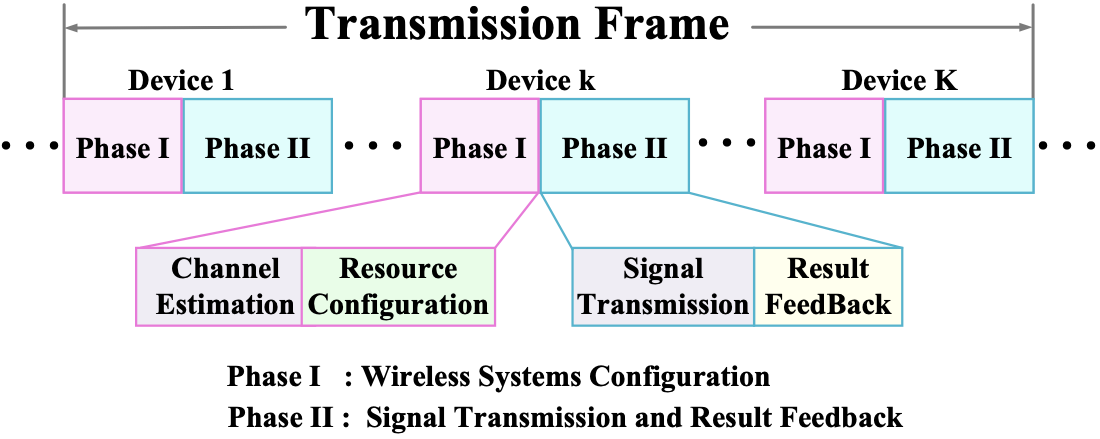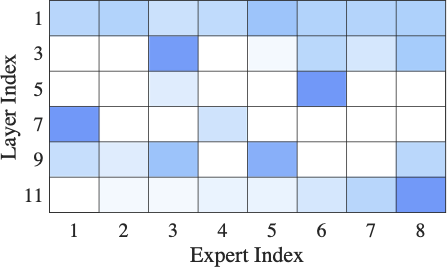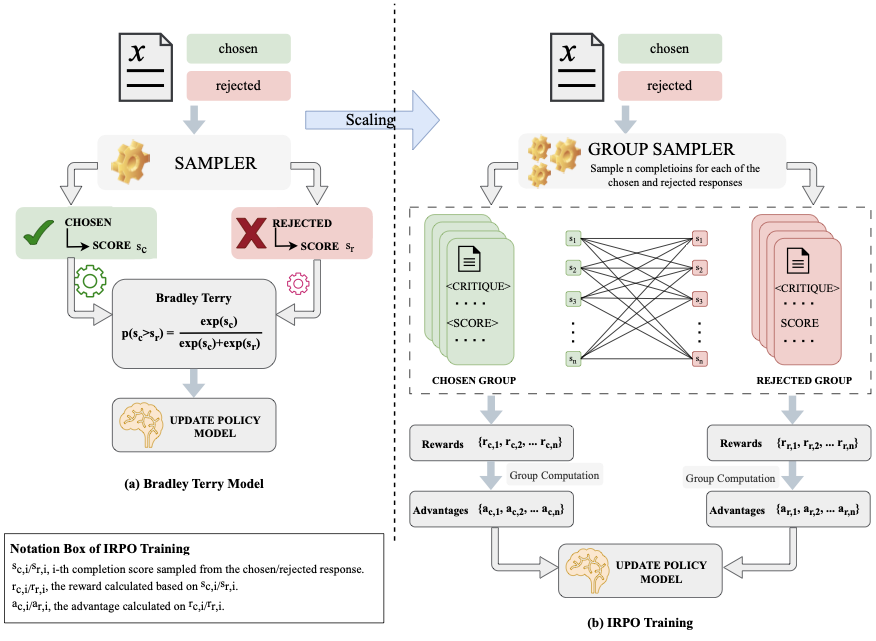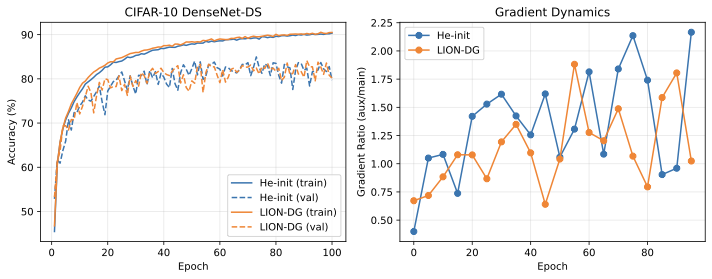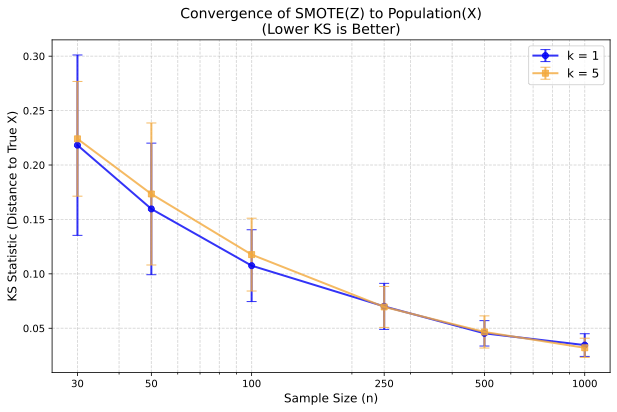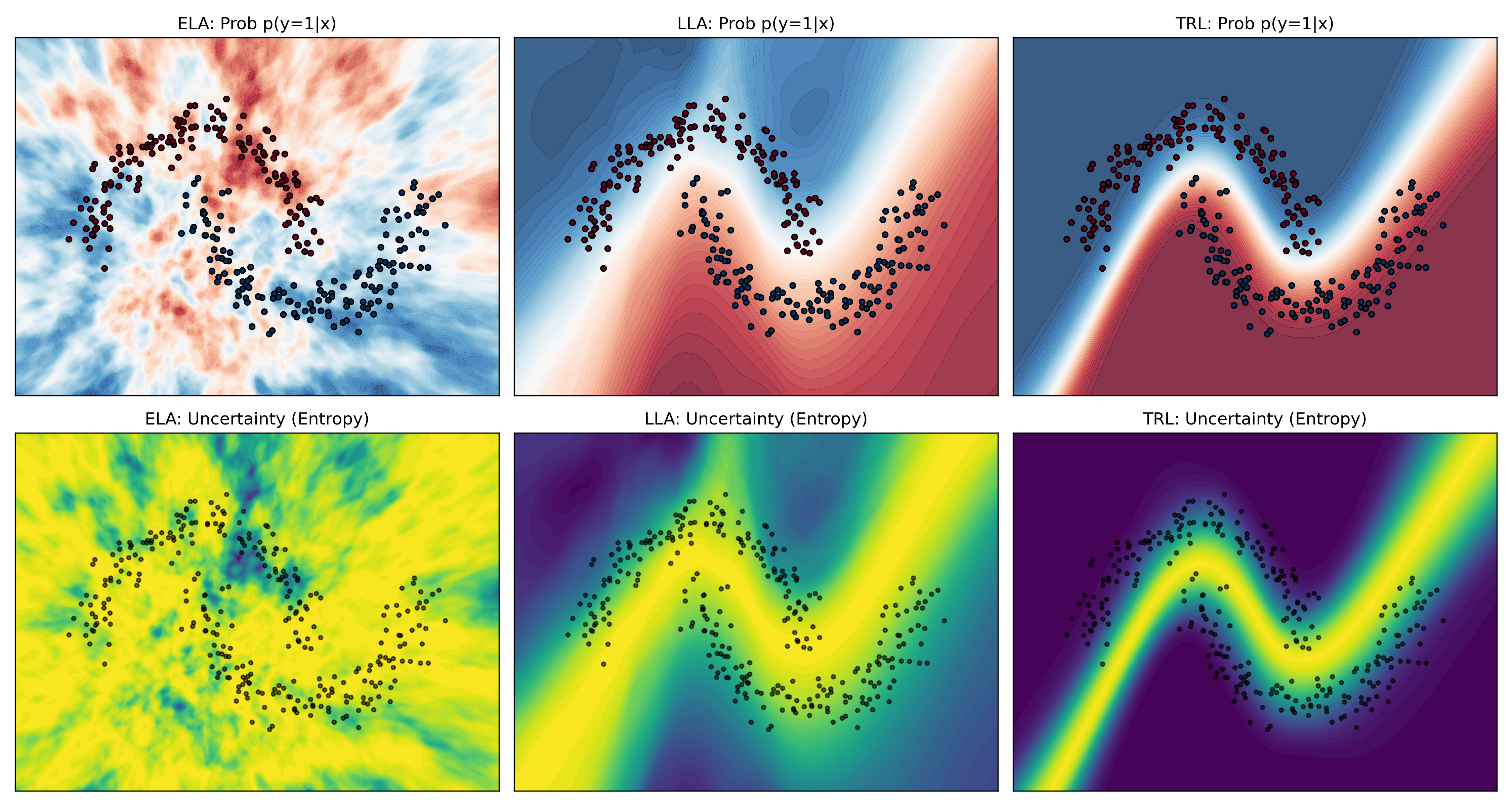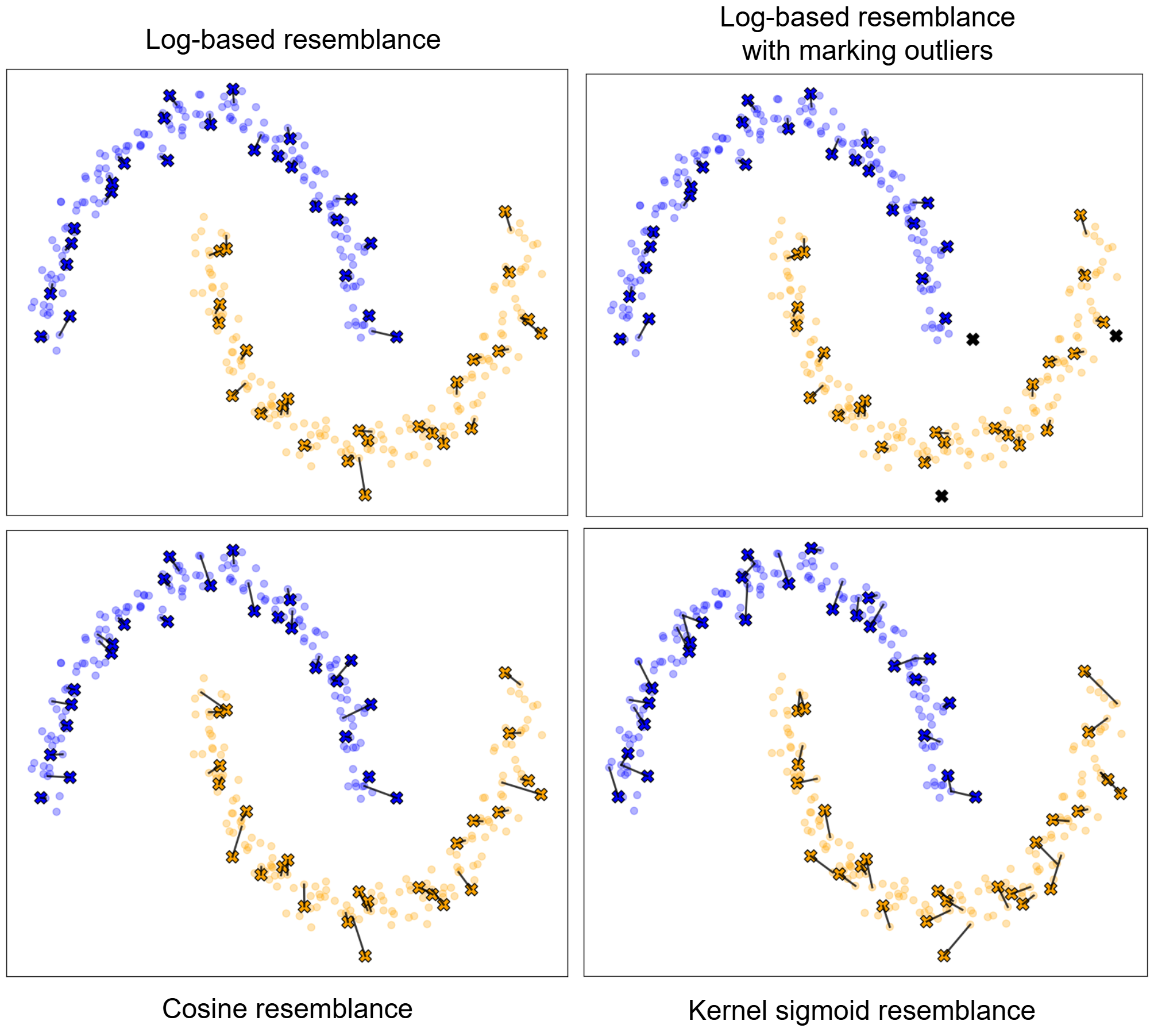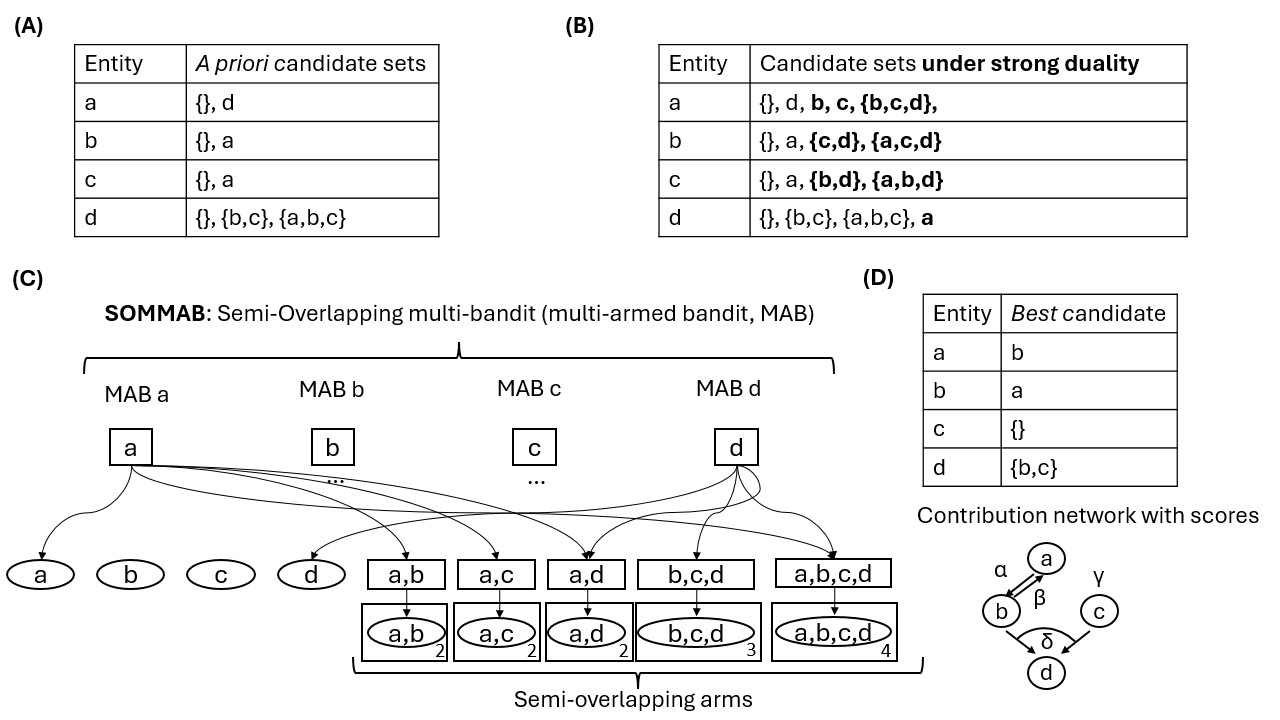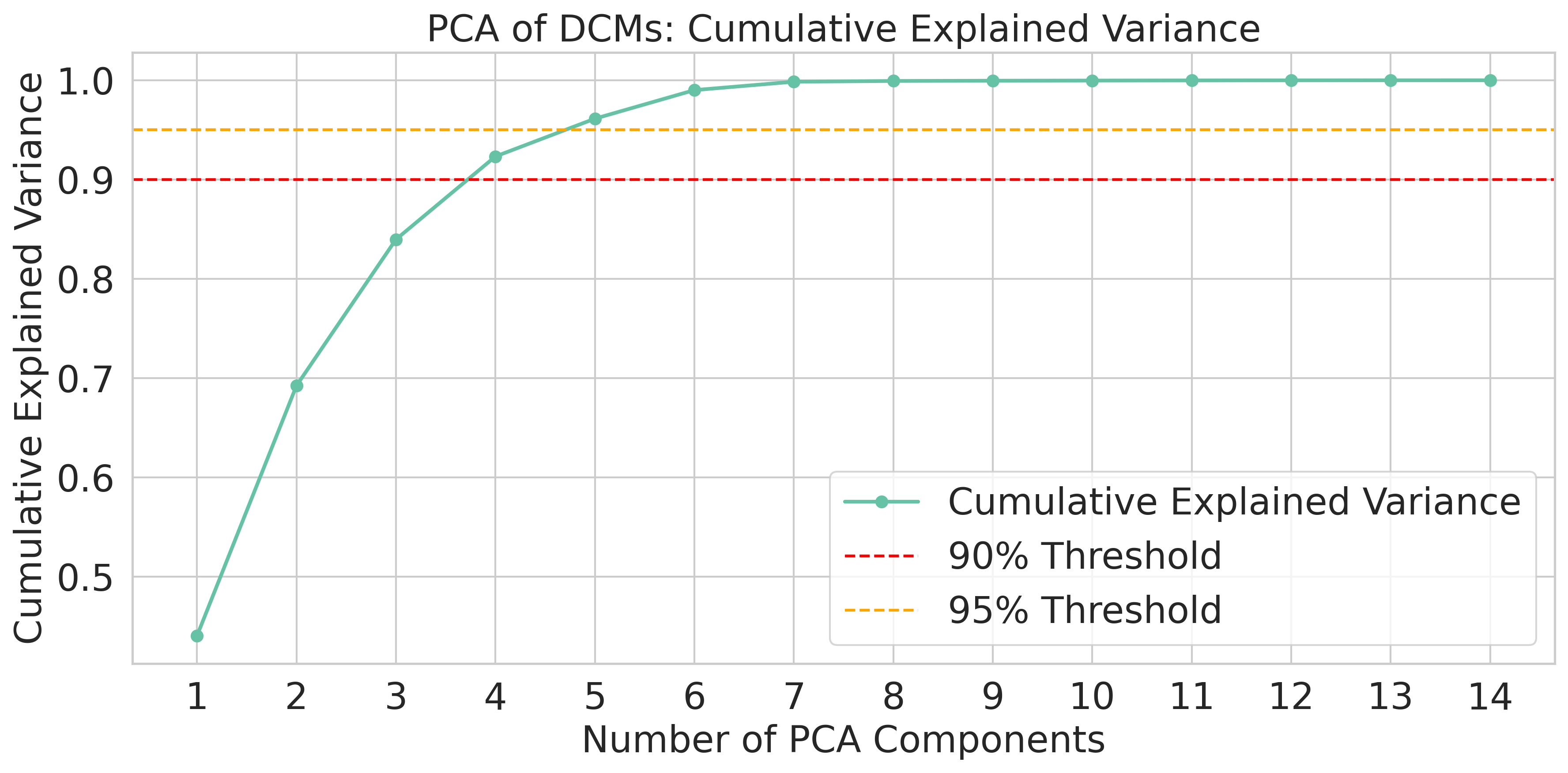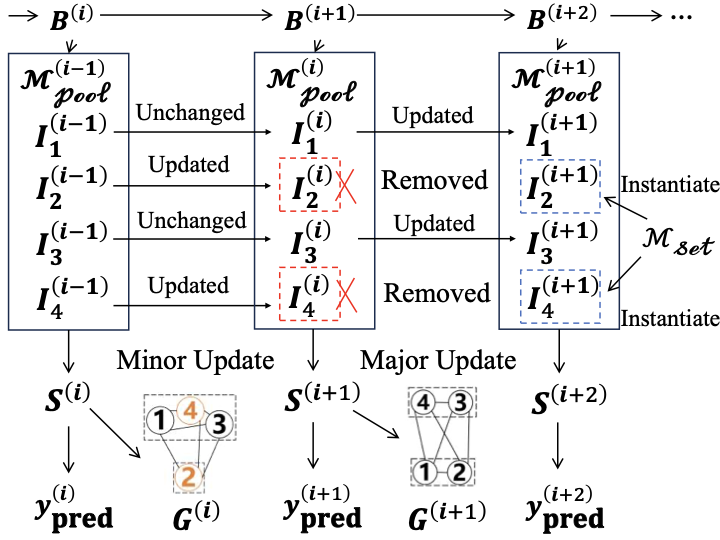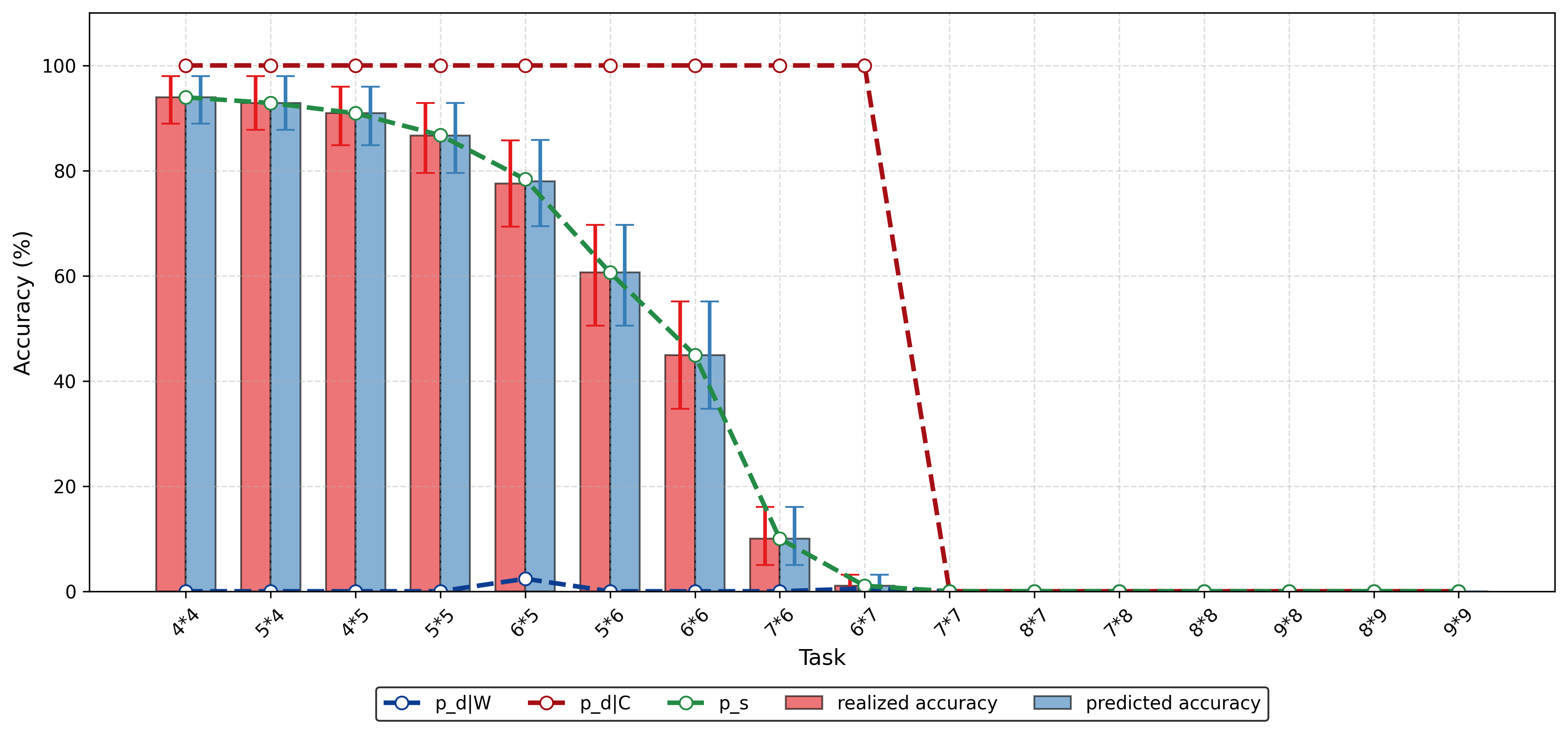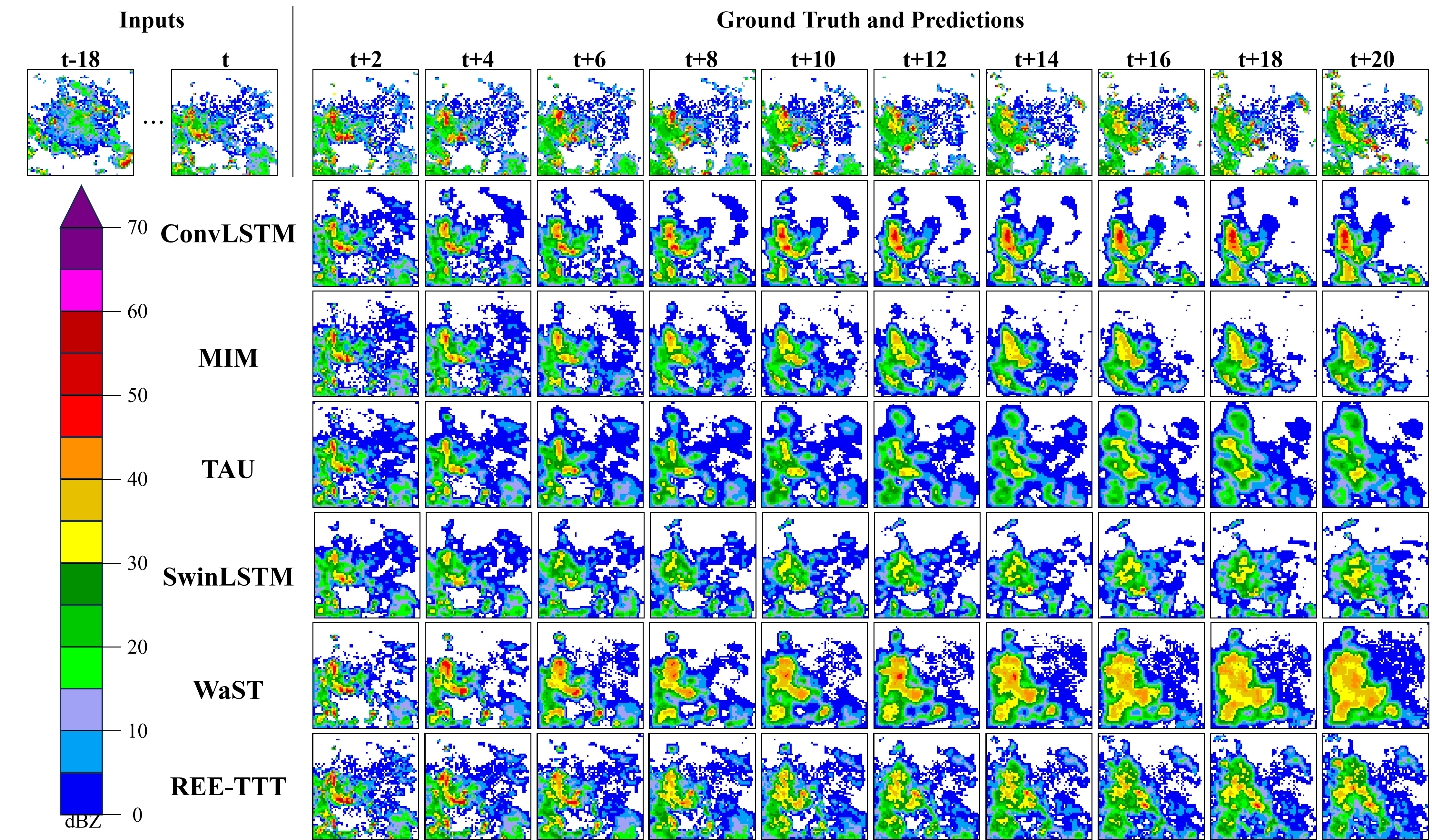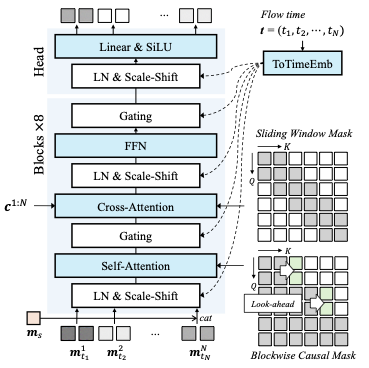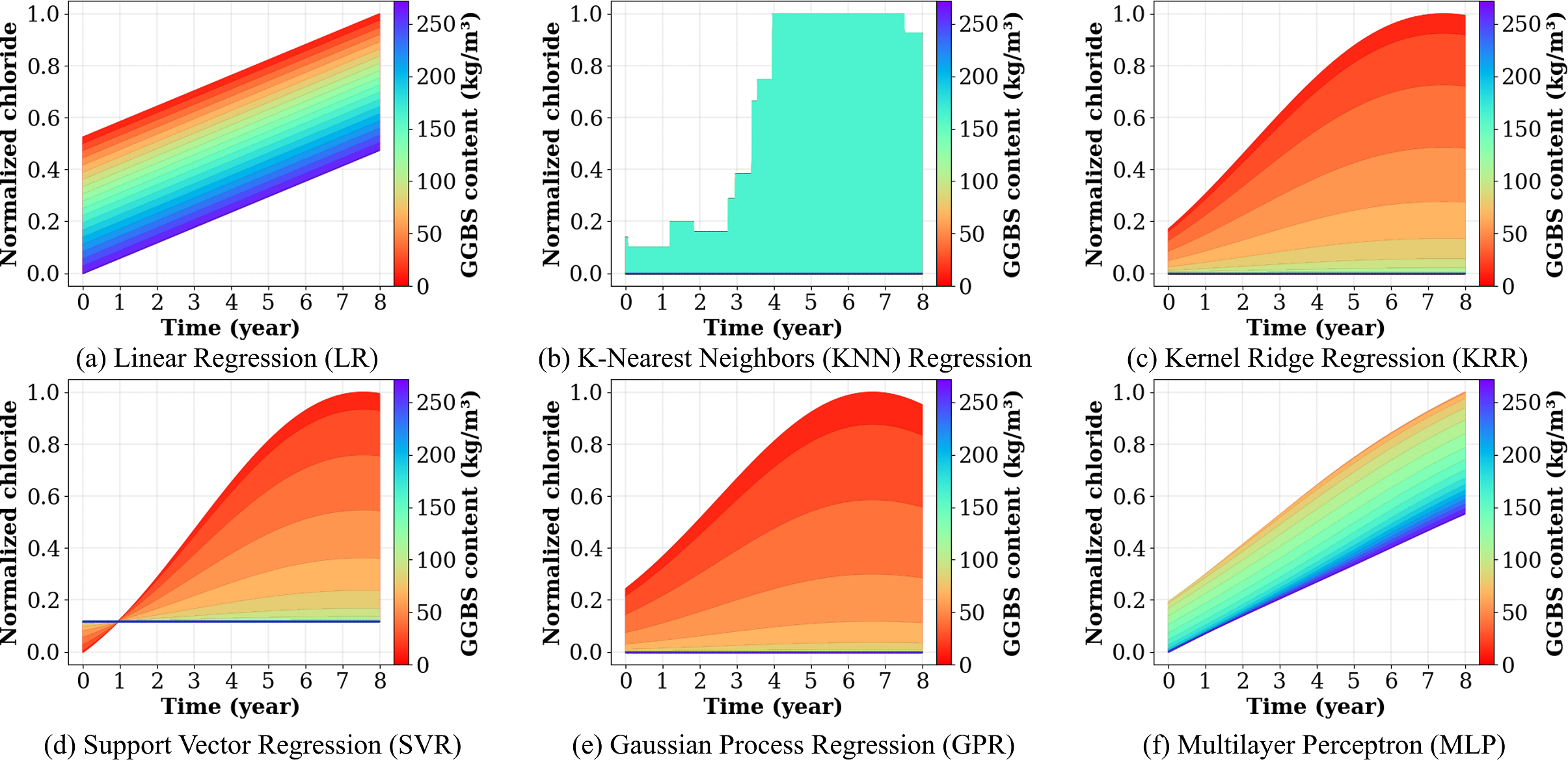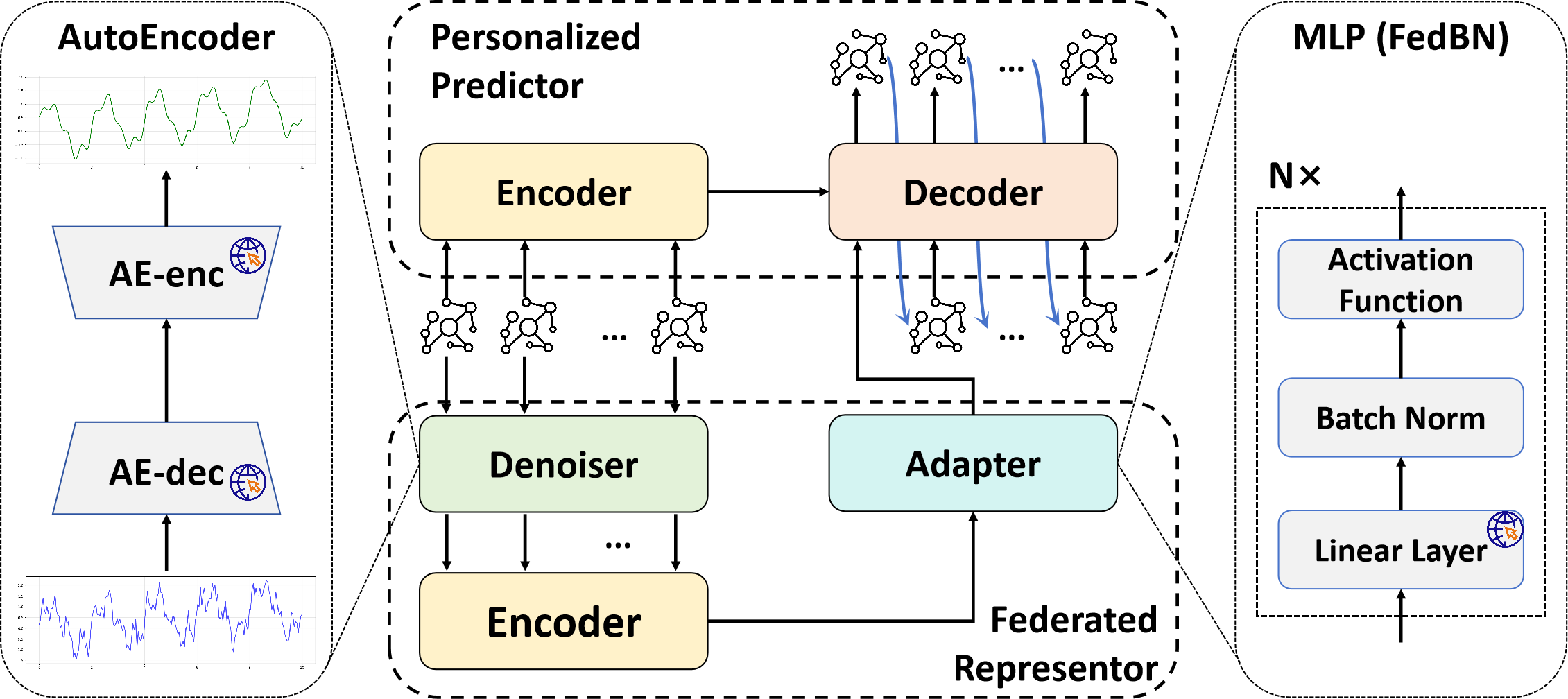
AutoFed 개인화 프롬프트를 활용한 수동 없는 연방 교통 예측
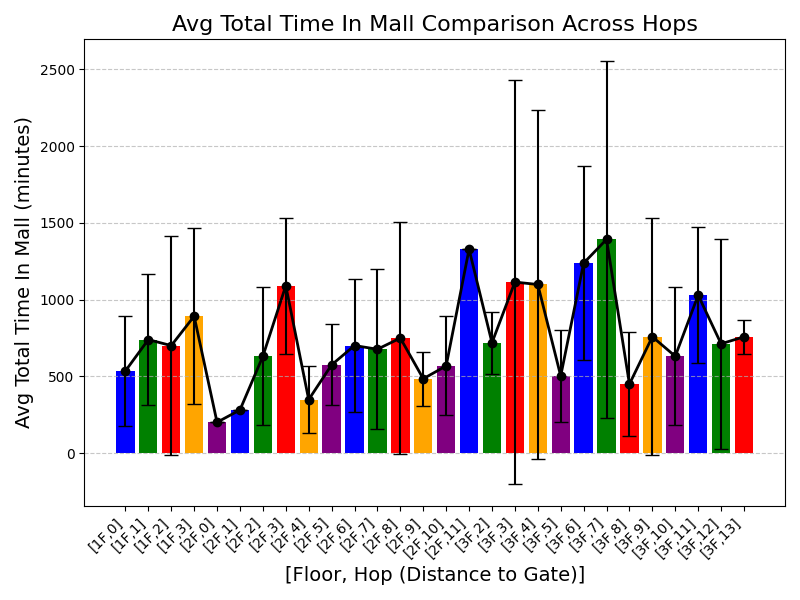
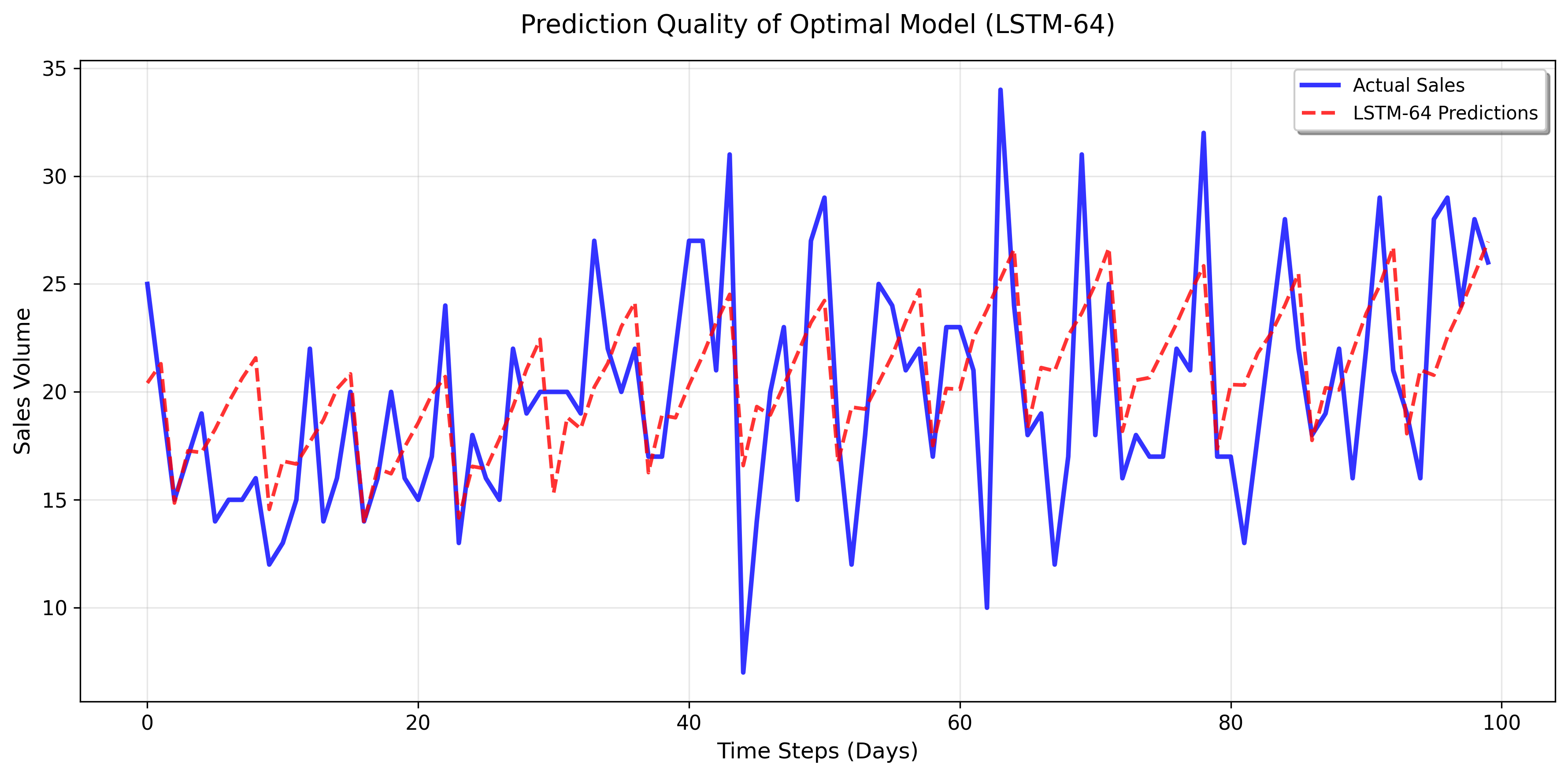
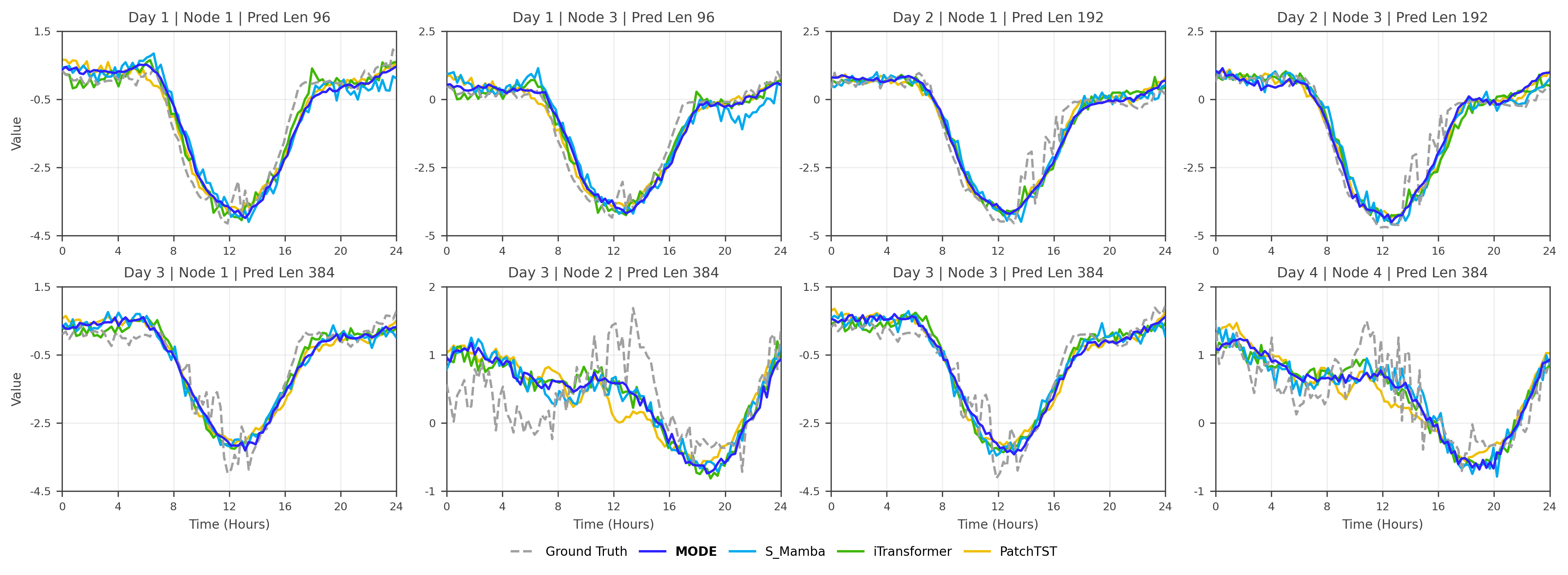
정확한 교통 예측은 라이드해링, 도시 도로 계획, 차량 페리 관리 등 지능형 교통 시스템에 필수적입니다. 하지만 교통 데이터 주변의 중요한 프라이버시 문제로 인해 대부분의 기존 방법은 로컬 트레이닝에 의존하여 데이터 실로와 제한적인 지식 공유가 발생합니다. 연방 학습(FL)은 개인정보 보호 협업 훈련을 통해 효율적인 해결책을 제공하지만, 표준 FL은 클라이언트 간의 독립적이지 않고 동일하게 분포되지 않은(non-IID) 문제에 어려움을 겪습니다. 이挑战组合中包含了韩文和中文,最后的部分没有完全翻译成韩文。以下是完整的韩文翻译: 정확한 교통 예측은 라이드해링, 도시 도로 계획, 차량 페리 관리 등 지능형 교통 시스템에 필수적입니다. 하지만 교통 데이터 주변의 중요한 프라이버시 문제로 인해 대부분의 기존 방법은 로컬 트레이닝에 의존하여 데이터 실로와 제한적인 지식 공유가 발생합니다. 연방 학습(FL)은 개인정보 보호 협업 훈련을 통해 효율적인 해결책을 제공하지만, 표준 FL은 클라이언트 간의 독립적이지 않고 동일하게 분포되지 않은(non-IID) 문제에 어려움을 겪습니다. 이 어려움은 개인화 연방 학습(PFL)이 유망한 패러다임으로 등장하는 원인이 되었습니다. 그럼에도 불구하고 현재의 PFL 프레임워크는 교통 예측 작업에 대한 전문적인 그래프 특징 공학, 데이터 처리 및 네트워크 아키텍처 설계가 필요합니다. 많은 이전 연구들의 주목할 만한 제한점 중 하나는 실세계 시나리오에서 자주 사용 불가능한 데이터셋 간의 하이퍼파라미터 최적화에 의존하는 것입니다. 이를 해결하기 위해 AutoFed라는 새로운 PFL 프레임워크를 제안합니다. 이는 개인화된 예측자에게 교차 클라이언트 지식을 활용하면서도 로컬 특이성을 유지하도록 하여 자동 조정을 통해 인공적인 하이퍼파라미터 튜닝의 필요성을 제거합니다. 프롬프트 학습에서 영감을 받아, AutoFed는 클라이언트 맞춤형 어댑터를 사용하여 로컬 데이터를 축소된 글로벌 공유 프롬프트 행렬에 응축하는 연방 표현자를 도입하였습니다. 이 프롬프트는 개인화 예측자에게 조건을 제공합니다. 실제 데이터셋에서의 광범위한 실험은 AutoFed가 다양한 시나리오에서 일관되게 우수한 성능을 달성한다는 것을 보여주었습니다. 본 논문의 코드는 https //github.com/RS2002/AutoFed 에서 제공됩니다.