거시경제의 위상 매핑
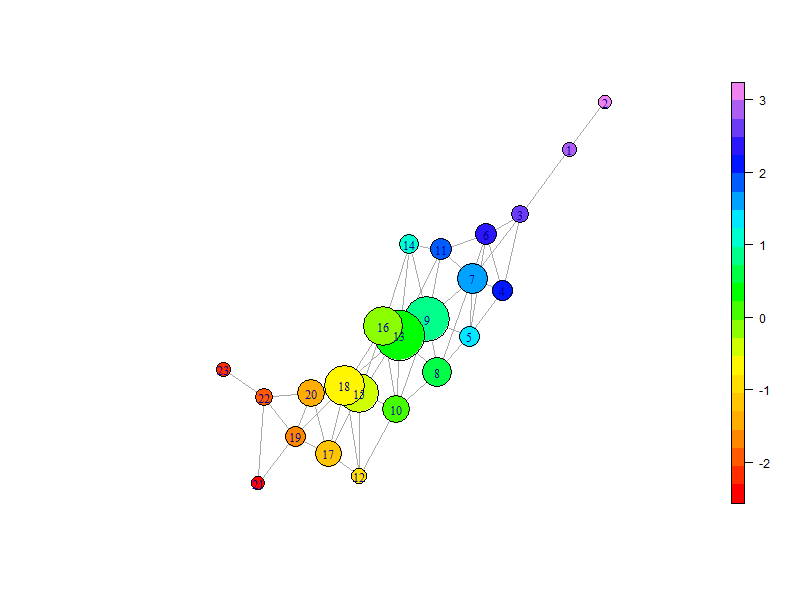
An understanding of the economic landscape in a world of ever increasing data necessitates representations of data that can inform policy, deepen understanding and guide future research. Topological Data Analysis offers a set of tools which deliver on all three calls. Abstract two-dimensional snapshots of multi-dimensional space readily capture non-monotonic relationships, inform of similarity between points of interest in parameter space, mapping such to outcomes. Specific examples show how some, but not all, countries have returned to Great Depression levels, and reappraise the links between real private capital growth and the performance of the economy. Theoretical and empirical expositions alike remind on the dangers of assuming monotonic relationships and discounting combinations of factors as determinants of outcomes; both dangers Topological Data Analysis addresses. Policy-makers can look at outcomes and target areas of the input space where such are not satisfactory, academics may additionally find evidence to motivate theoretical development, and practitioners can gain a rapid and robust base for decision making.