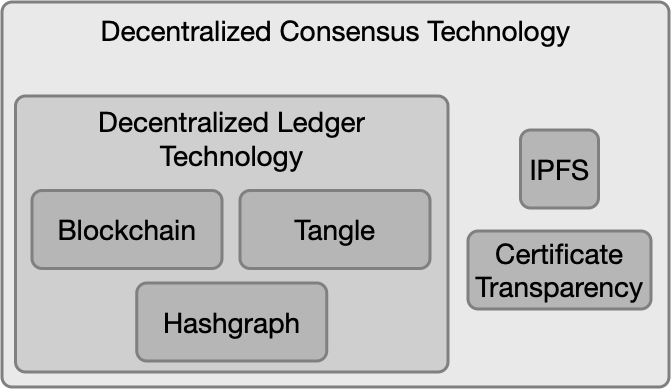
메트릭 제약 최적화를 위한 평행 투영 방법
기계 학습과 데이터 마이닝의 많은 클러스터링 응용 프로그램은 메트릭 제약 최적화 문제를 해결하는 데 의존하고 있습니다. 이러한 문제는 큰 데이터셋에서 n 개체에 대한 거리 변수 간 삼각 부등식을 강제하는 O(n^3)의 제약 조건으로 특징지어집니다. 이 방법은 유용하지만, 세제곱 수준의 제약 조건과 표준 최적화 소프트웨어의 높은 메모리 요구 사항 때문에 실제 사용에서 어려움이 따릅니다. 최근 연구에서는 반복적인 투영법을 통해 이전보다 더 큰 규모의 문제를 해결할 수 있음을 보여주었지만, 이러한 방법의 주요 제한점은 느린 수렴 속도입니다. 본 논문에서는 메트릭 제약 최적화에 대한 병렬 투영 방법을 제시하여 실제 사용에서 수렴 속도를 높였습니다. 우리의 접근 방식의 핵심은 여러 메트릭 제약 조건에 대해 동시에 투영을 수행할 수 있도록 하는 새로운 병렬 실행 스케줄입니다. 우리는 상관 클러스터링 문제의 메트릭 제약 선형 계획법 이완을 해결하는 데 이러한 실행 스케줄을 구현하고 실험한 결과를 보여줍니다. 실험에서는 2.9조 개의 제약 조건을 포함하는 문제에 대한 다양한 실험적 결과가 나왔습니다.
paper
AI 요약

![[한글 번역 중] Viability and Performance of a Private LLM Server for SMBs A Benchmark Analysis of Qwen3-30B on Consumer-Grade Hardware](https://koineu.com/posts/2025/12/2025-12-28-191036-viability_and_performance_of_a_private_llm_server_/aime_2025_model_scores.png)