AI 기반 다중 클러스터 환경의 클라우드 리소스 최적화
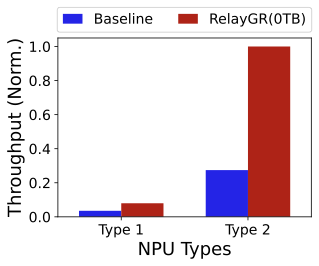
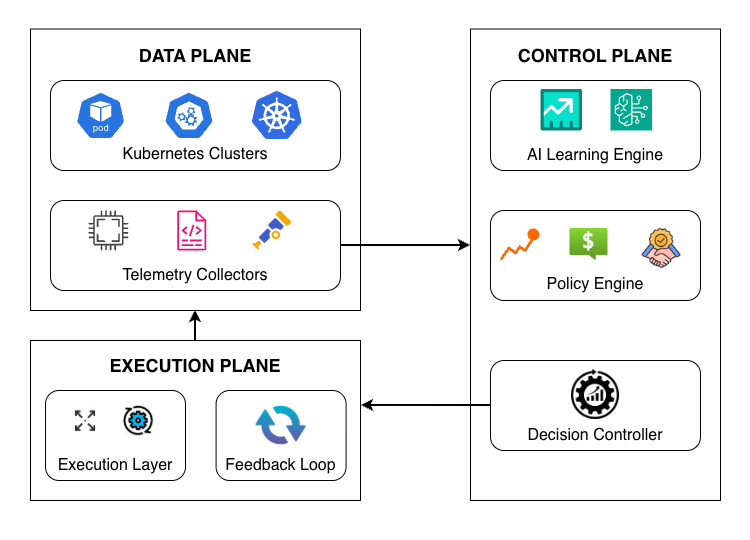
현대의 클라우드 네이티브 시스템은 확장성, 견고성 및 지리적 분산을 지원하기 위해 다중 클러스터 배포에 점점 더 의존하고 있습니다. 그러나 기존의 리소스 관리 접근 방식은 여전히 대응형이고 클러스터 중심적이어서 동적인 워크로드 하에서 시스템 전체의 행동을 최적화하는 능력이 제한됩니다. 이러한 한계는 분산 환경에 걸쳐서 효율적인 리소스 활용, 지연된 적응 및 증가된 운영 부담으로 이어집니다. 본 논문은 다중 클러스터 클라우드 시스템에서 적응형 리소스 최적화를 위한 AI 기반 프레임워크를 제시합니다. 제안된 접근 방식은 예측 학습, 정책 인식 결정 및 지속적인 피드백을 통합하여 클러스터 간에 능동적이고 조율된 리소스 관리를 가능하게 합니다. 이 프레임워크는 클러스터 간 텔리미트리와 역사적 실행 패턴을 분석하여 성능, 비용 및 신뢰성 목표를 균형 있게 맞추기 위해 리소스 할당을 동적으로 조정합니다. 프로토타입 구현은 전통적인 대응형 접근 방식에 비해 개선된 리소스 효율성, 워크로드 변동 시 더 빠른 안정화 및 성능 변화의 감소를 보여줍니다. 결과는 확장적이고 견고한 클라우드 플랫폼을 위한 핵심 요인으로서 지능형 자가 적응 인프라 관리의 효과성을 강조합니다.
paper
AI 요약