EntropyDB 확률적 접근을 통한 근사 질의 처리 방법
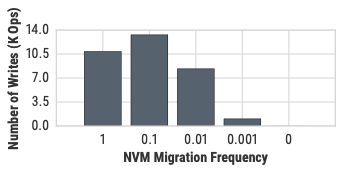
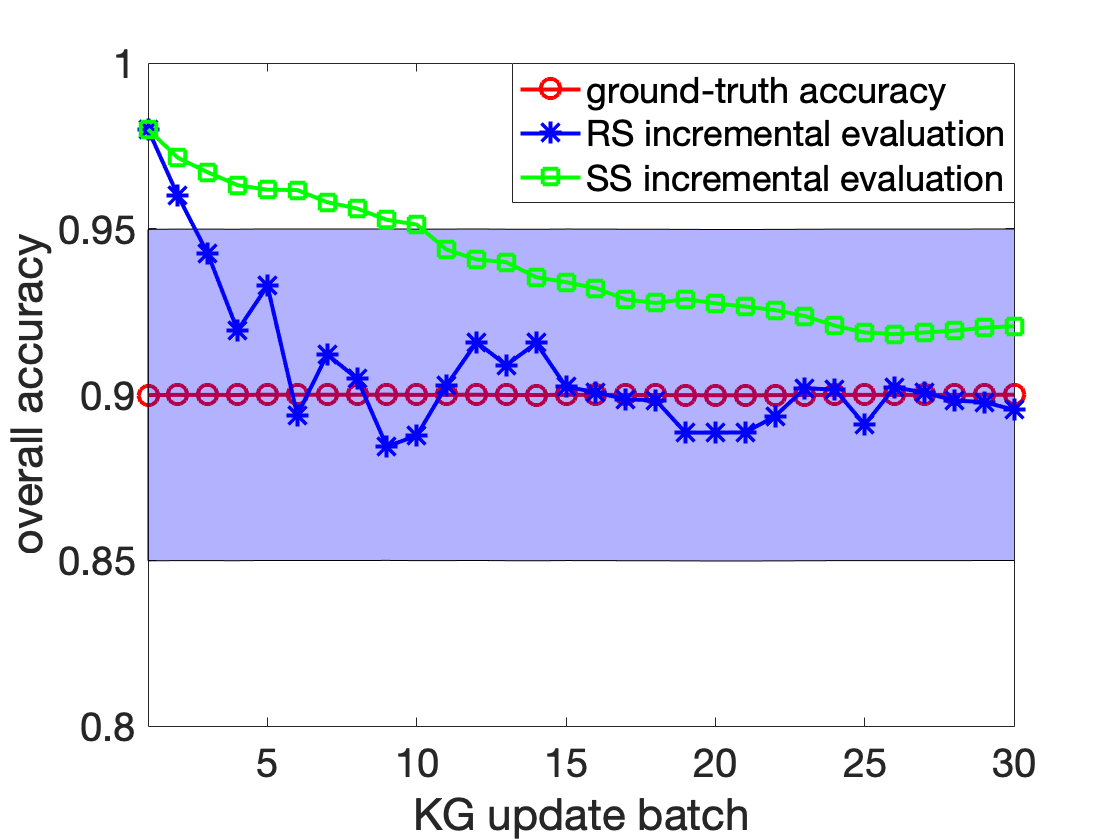
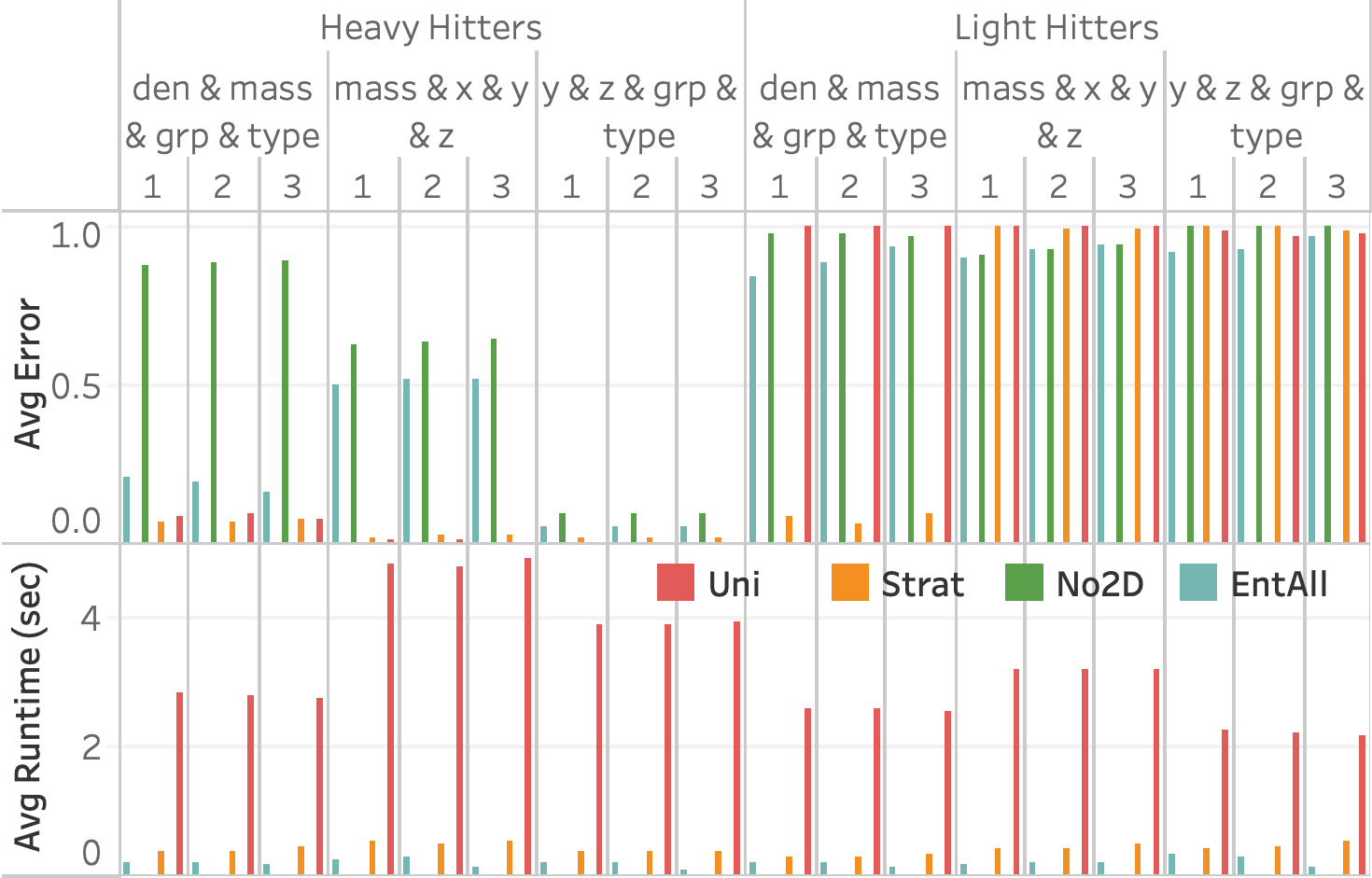
본 논문에서는 EntropyDB라는 상호작용형 데이터 탐색 시스템을 제시합니다. 이 시스템은 확률적 접근법을 사용하여 데이터셋의 작은 쿼리 가능한 요약을 생성합니다. 기존의 요약 기술과 달리 우리는 최대 엔트로피 원칙을 사용하여 데이터의 확률적 표현을 생성하고 이를 이용해 근사적인 쿼리 답변을 제공합니다. 우리 팀은 확률적 표현의 이론적 프레임워크와 공식화를 개발하고, 이를 어떻게 쿼리를 처리하는지 설명합니다. 우리는 해결 기법과 전처리 시간 및 쿼리 실행 시간을 개선하기 위한 두 가지 중요한 최적화 방법을 제시하며, 쿼리 오류를 줄이는 방법도 탐구합니다. 마지막으로, 미국 내 비행기 데이터로 구성된 5GB 크기의 데이터셋과 데이터 정리 작업을 수행한 결과를 바탕으로 실험을 실시했습니다. 본 연구에서는 n = 1일 때 튜플의 기대 횟수와 마진 확률이 동일하다는 것을 증명하였습니다.
paper
AI 요약