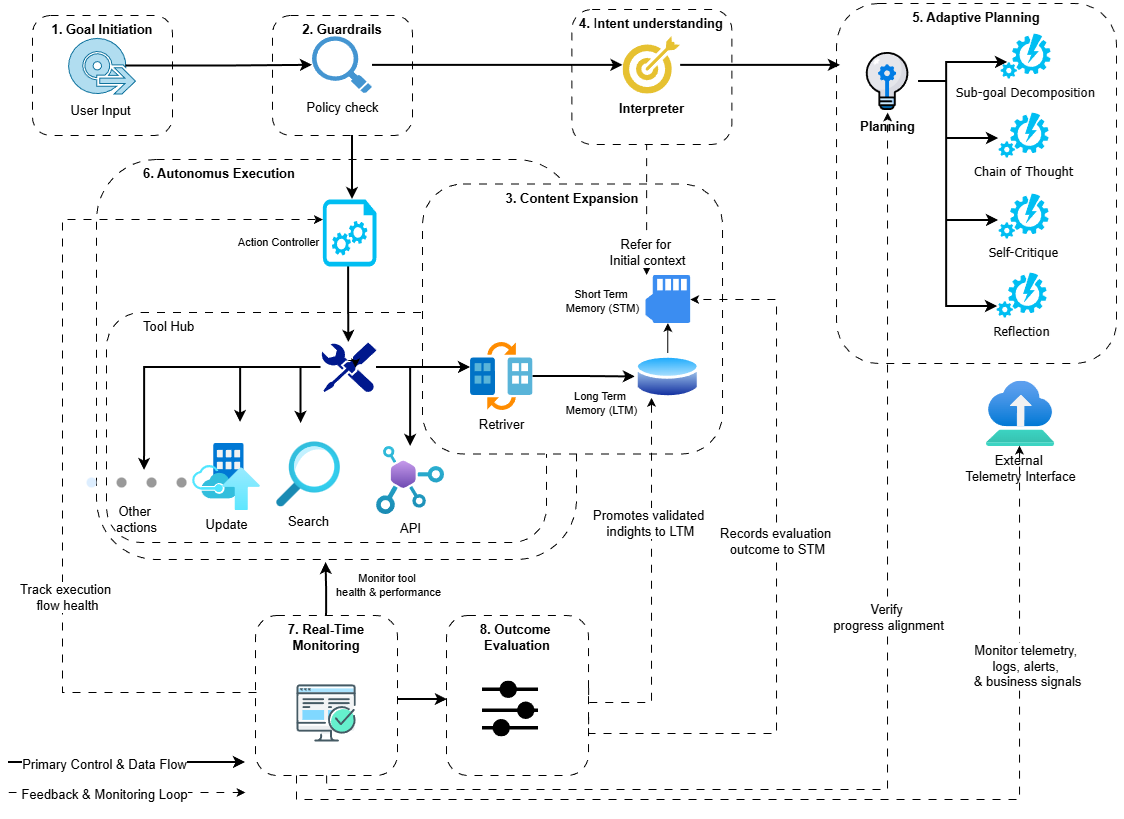
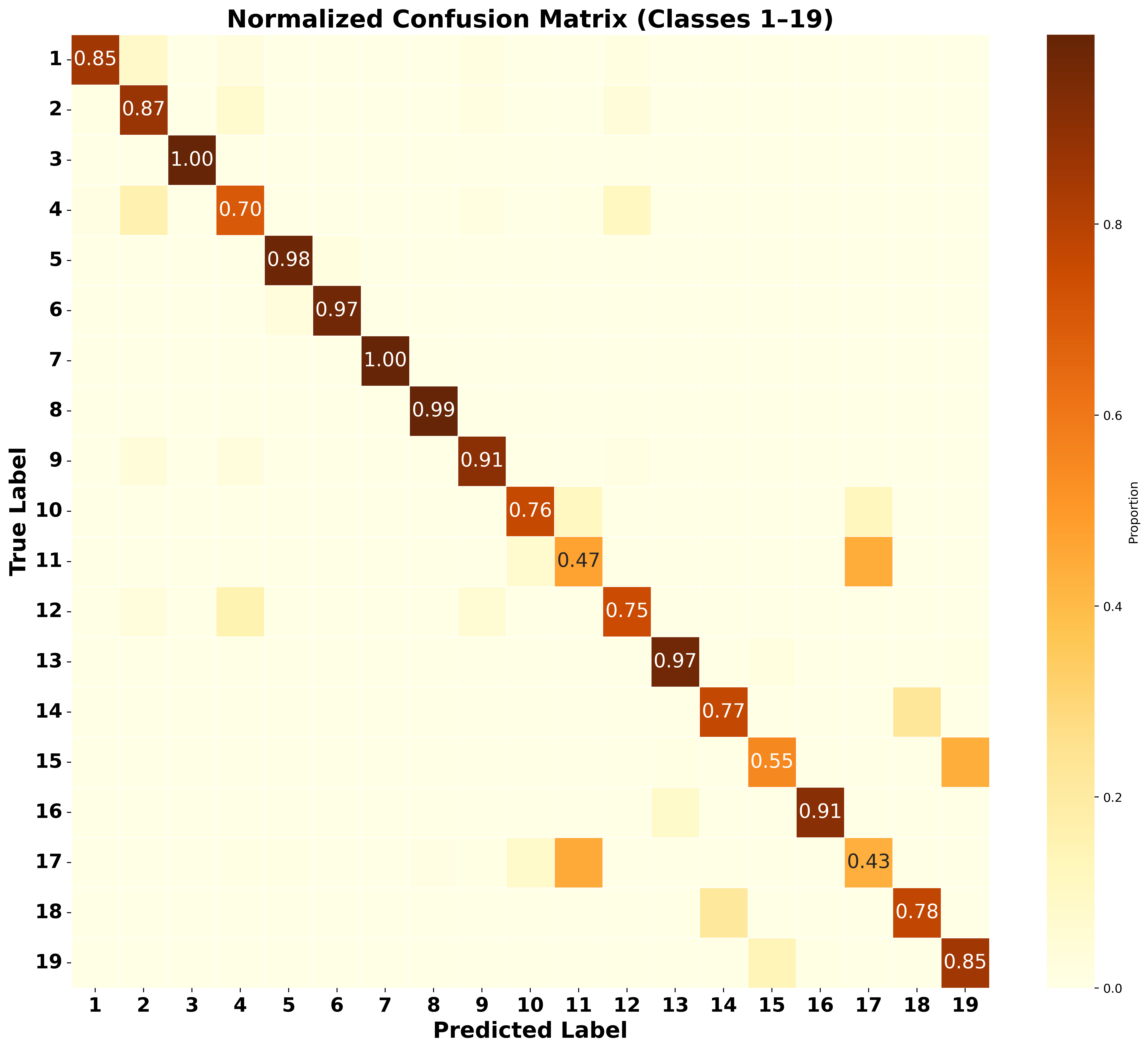
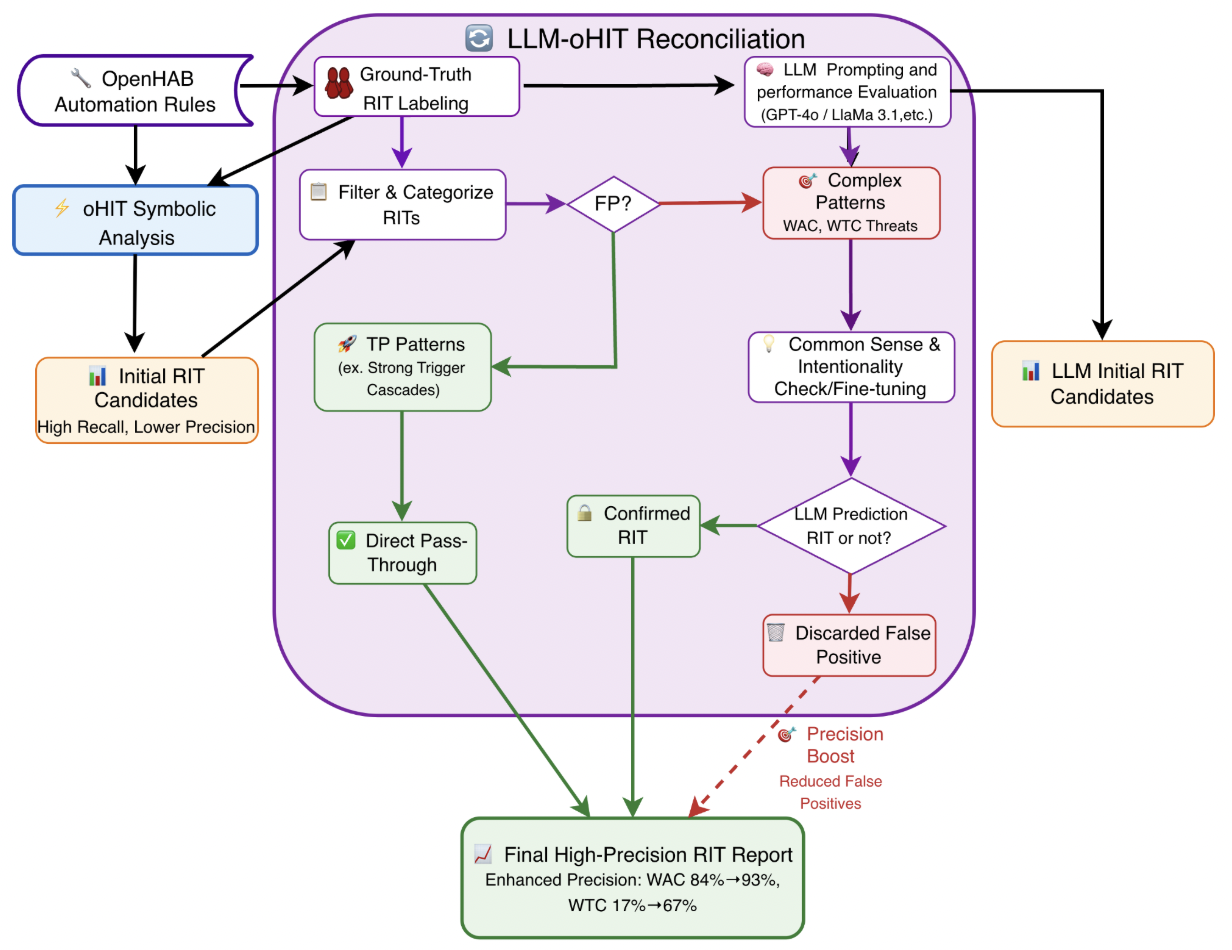
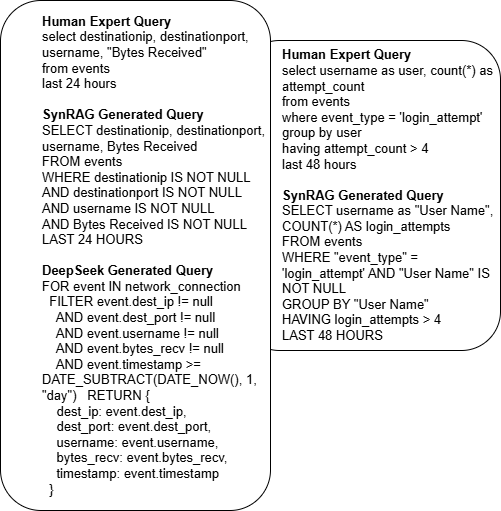
SynRAG 이질적인 SIEM 시스템용 실행 가능한 쿼리 생성 대형 언어 모델 프레임워크
보안 정보 및 이벤트 관리(SIEM) 시스템은 대규모 기업들이 매일 수백만 개의 로그와 이벤트를 수집하고 분석하여 IT 인프라스트럭처를 모니터링하는 데 필수적입니다. 보안 운영 센터(SOC) 분석가는 이러한 방대한 데이터를 모니터링하고 분석하여 잠재적인 위협을 식별하고 기업 자산을 보호하기 위한 예방 조치를 취해야 합니다. 하지만 Palo Alto Networks Qradar, Google SecOps, Splunk, Microsoft Sentinel 및 Elastic Stack과 같은 SIEM 플랫폼들 간의 다양성은 상당한 도전 과제를 제기합니다. 이러한 시스템들은 속성, 아키텍처, 쿼리 언어에서 차이점이 있어 분석가들이 광범위한 훈련을 받지 않으면 여러 플랫폼을 효과적으로 모니터링하기 어렵고 기업은 인력을 확대해야 하는 상황입니다. 이 문제를 해결하기 위해 우리는 플랫폼에 무관한 사양에서 다중 SIEM 플랫폼용 위협 탐지 또는 사건 조사 쿼리를 자동으로 생성하는 통합 프레임워크인 SynRAG을 도입합니다. SynRAG은 분석가가 작성한 단일 고수준 사양으로 특정 플랫폼에 맞는 쿼리를 생성할 수 있습니다. SynRAG 없이 분석가는 시스템 간에 크게 차이가 나는 쿼리 언어 때문에 각 SIEM 플랫폼별로 별도의 쿼리를 수작업으로 작성해야 합니다. 이 프레임워크는 다양한 SIEM 환경에서 위협 탐지와 사건 조사를 원활하게 진행할 수 있도록 하여 전문적인 훈련과 수동 쿼리 번역에 대한 필요성을 줄입니다. 우리는 Qradar 및 SecOps를 대표적인 SIEM 시스템으로 사용하여 GPT, Llama, DeepSeek, Gemma, Claude와 같은 최첨단 언어 모델들과 SynRAG을 비교 평가하였습니다. 우리의 결과는 SynRAG이 위협 탐지와 사건 조사에 있어 다양한 SIEM 환경에서 최첨단 기본 모델보다 훨씬 더 좋은 쿼리를 생성한다는 것을 보여줍니다.