VEAT이 텍스트-비디오 생성기 소라의 암시적 연관성을 측정하고 편향 완화에서의 과제를 드러냄
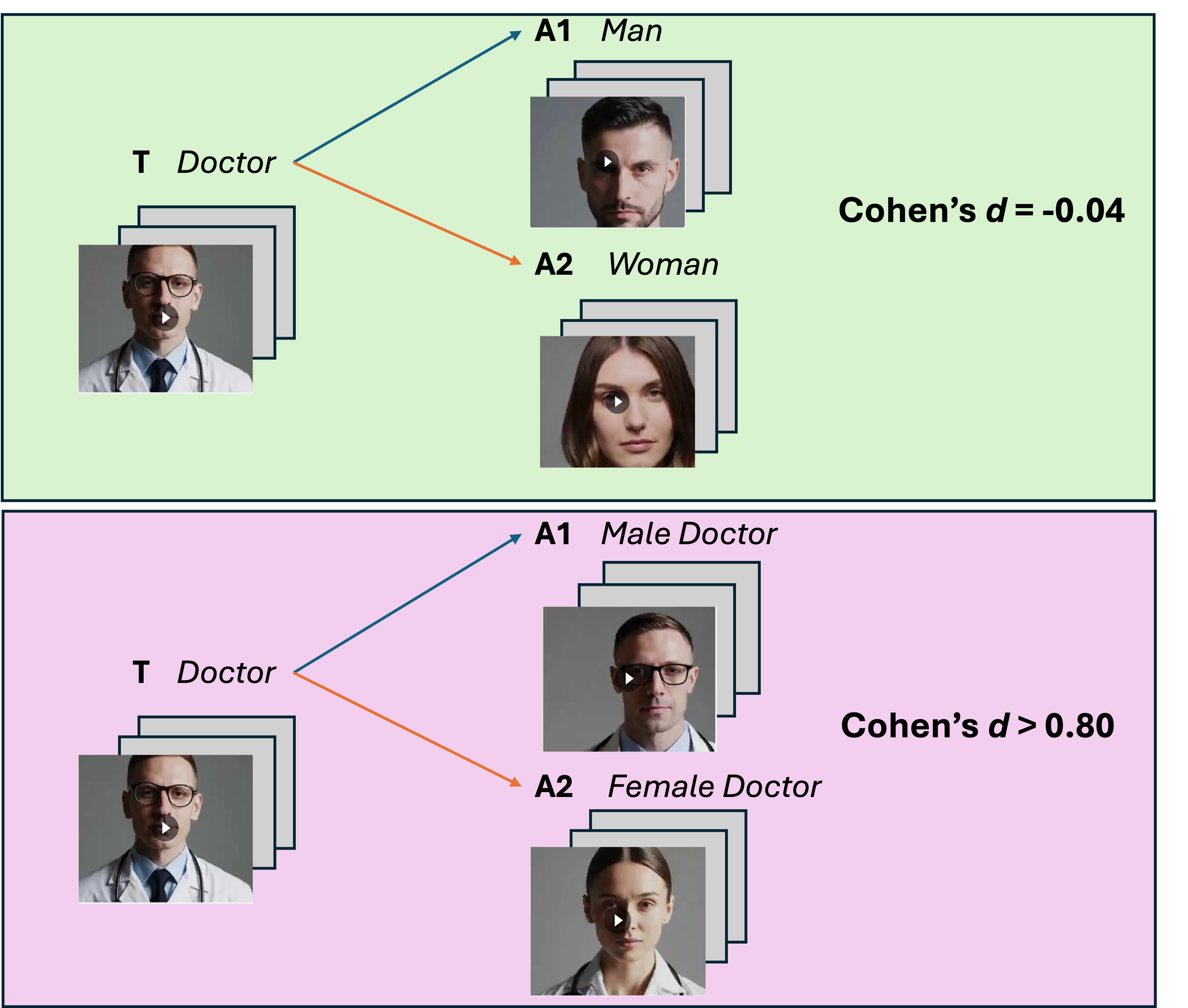
텍스트-투-비디오(T2V) 생성기인 소라와 같은 시스템은 생성된 콘텐츠가 사회적 편견을 반영하는지에 대한 우려를 제기한다. 우리는 단어와 이미지에서 비디오로 임베딩 연관 검사를 확장하기 위해 비디오 임베딩 연관 검사(VEAT)와 싱글-카테고리 VEAT(SC-VEAT)를 도입한다. 이 방법들을 널리 사용되는 베이스라인, 특히 암묵적 연관 검사(IAT) 시나리오와 OASIS 이미지 카테고리로부터의 관계 방향과 크기를 재현함으로써 검증한다. 그런 다음 17개 직업과 7개 수상 분야에서 인종(아프리카 계 미국인 대 유럽계 미국인)과 성별(여성 대 남성)이 가치(기분 좋은 것 대 불쾌한 것)와 연관되는 정도를 측정한다. 소라 비디오는 유럽계 미국인과 여성들이 더 기분 좋게 인식된다(d>0.8). 효과 크기는 실제 세계의 인구 분포와 상관관계가 있다 직업에서 남성과 백인이 차지하는 비율(r=0.93, r=0.83) 및 수상자들 중 남성과 흑인 비율이 아닌 사람들의 비율(r=0.88, r=0.99). 명시적인 디비어스 프롬프트를 적용하면 효과 크기의 크기가 일반적으로 줄지만 역효과를 초래할 수도 있다 두 개의 흑인 관련 직업(청소원, 우편 서비스)은 디비어싱 이후 더 강하게 흑인 연관성이 증가한다. 이 결과들은 쉽게 접근 가능한 T2V 생성기가 철저히 평가되지 않고 책임감 있게 배치되지 않는 경우 표현적 피해를 실제로 확대할 수 있음을 보여준다.
paper
AI 요약
