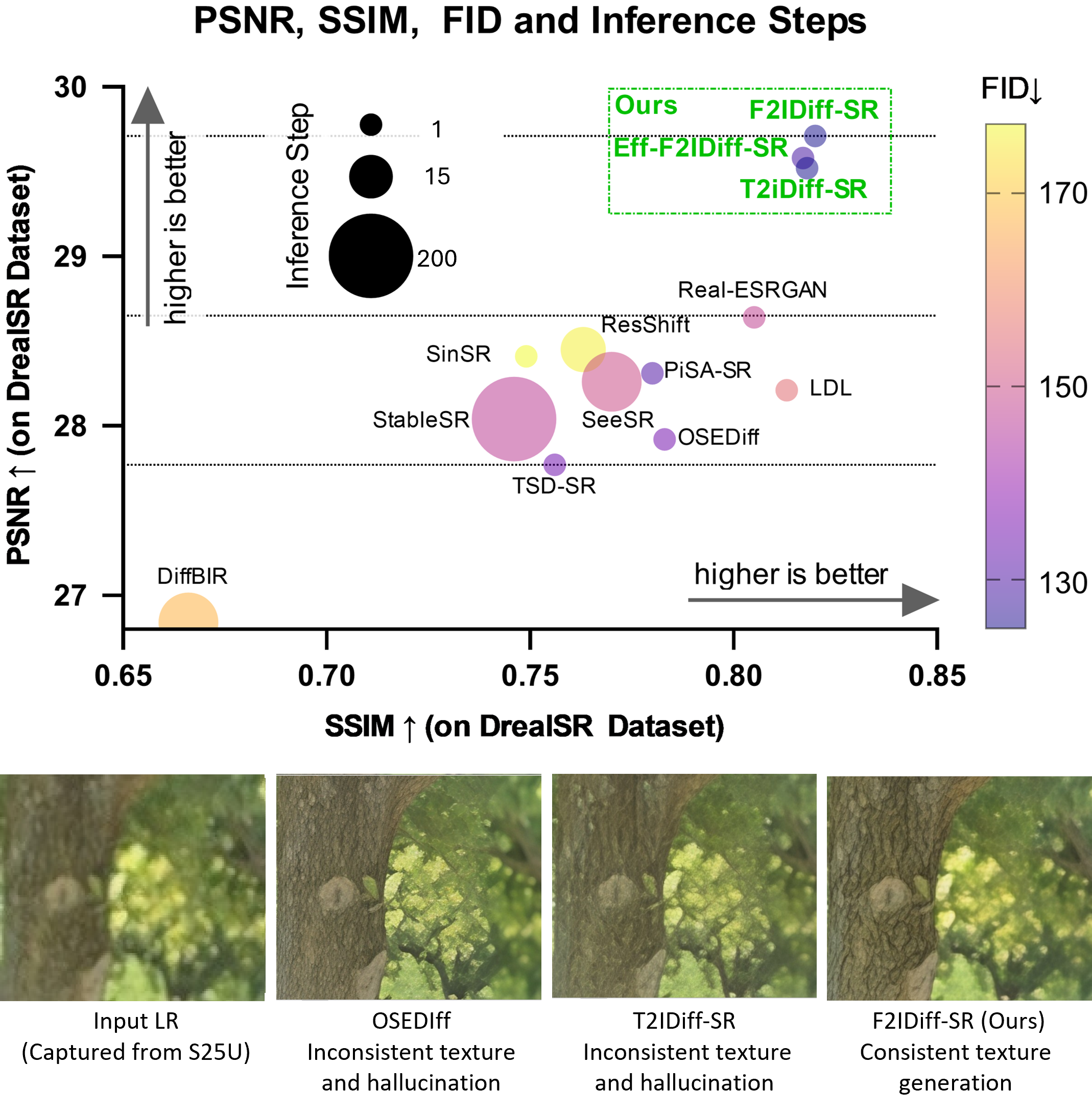
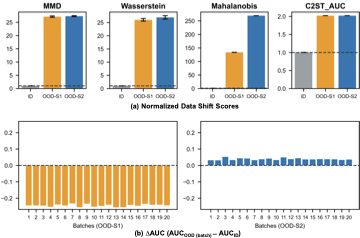
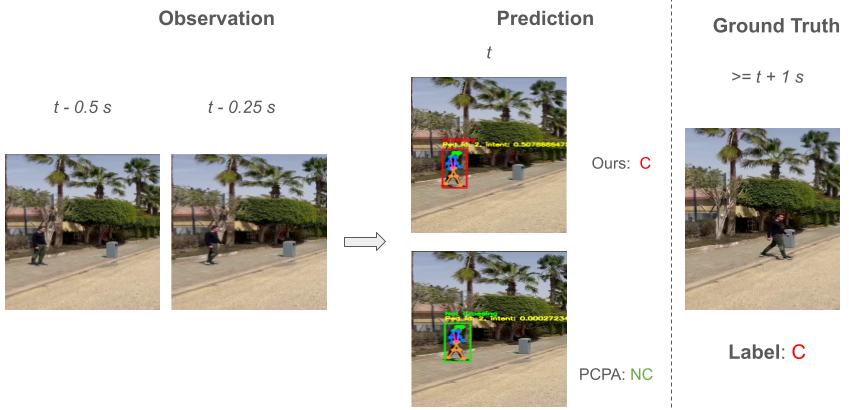
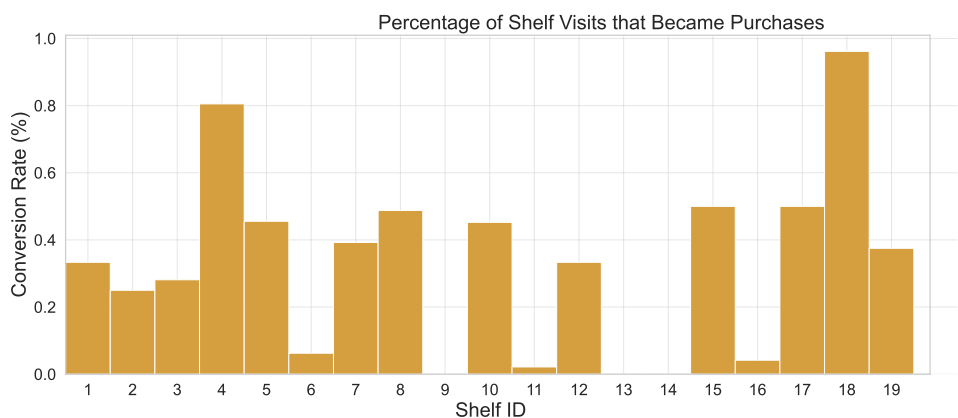
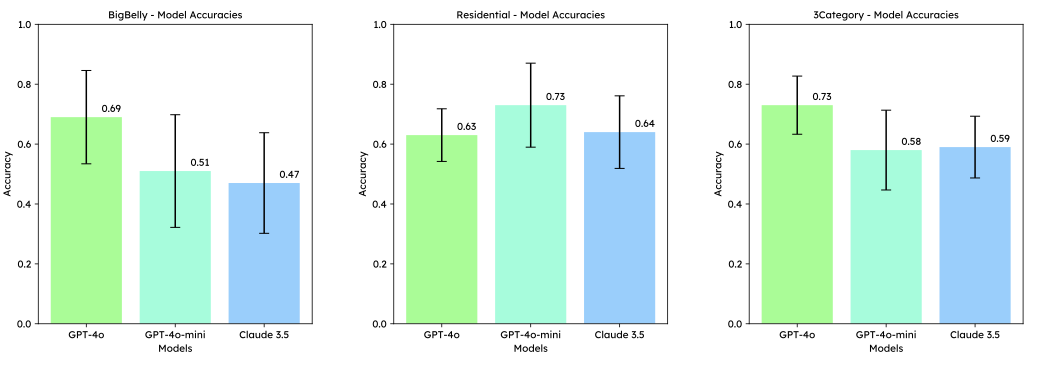
위상 각도 융합을 통한 개선된 객체 추적
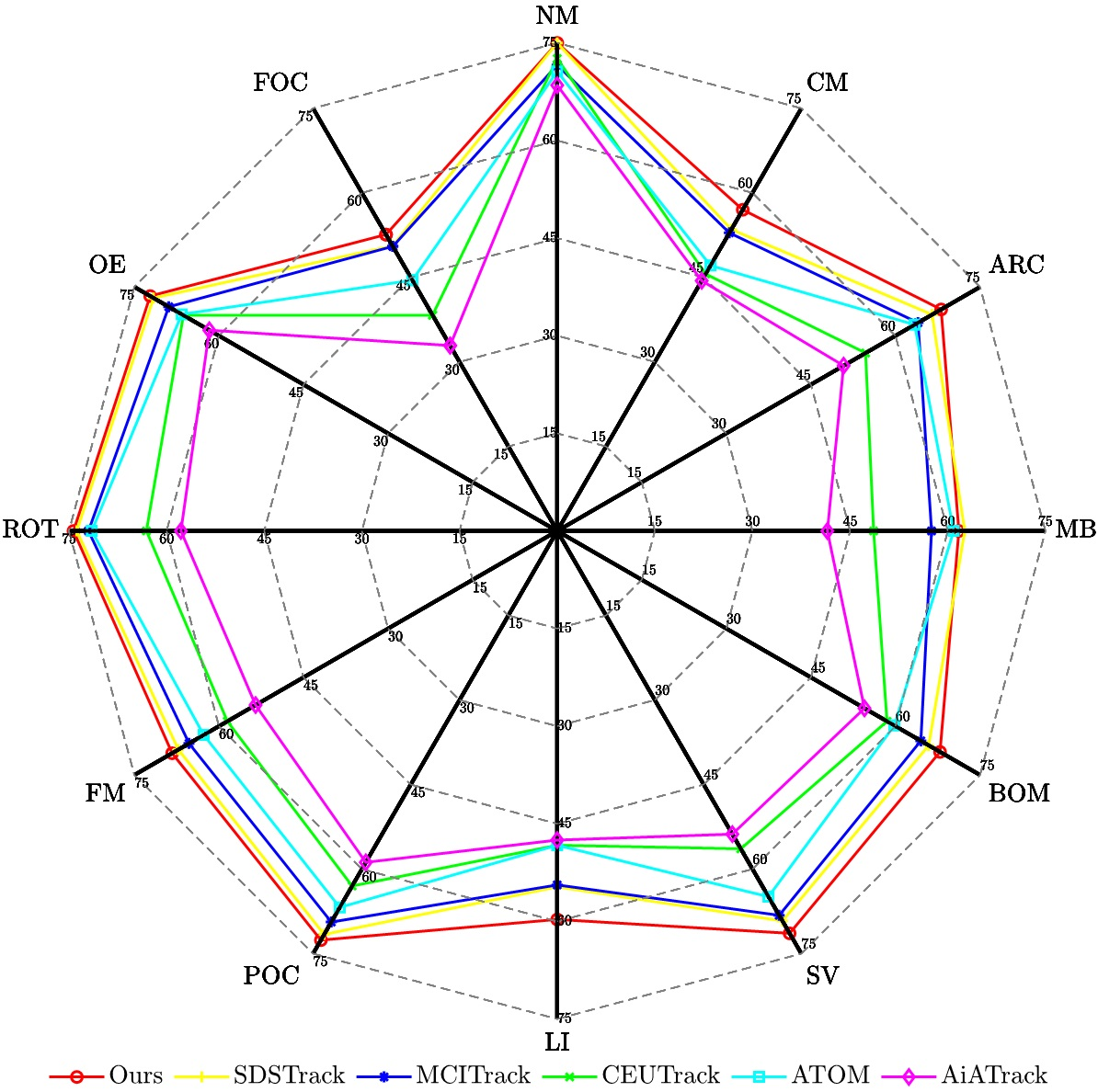
기존의 RGB-이벤트 시각적 객체 추적 접근법은 주로 기존의 피처 레벨 융합에 의존하며, 이는 이벤트 카메라의 고유한 장점을 완전히 활용하지 못합니다. 특히, 이벤트 카메라는 높은 동적인 범위와 움직임에 민감한 특성이 간과되며, 정보가 적은 영역도 일정하게 처리되어 백본 네트워크의 불필요한 계산 부담이 발생합니다. 이러한 문제를 해결하기 위해, 우리의 접근법은 주파수 도메인에서 조기 융합을 수행하는 새로운 추적 프레임워크를 제안합니다. 이를 통해 이벤트 모달리티로부터 고주파 정보의 효과적인 집약화가 가능해집니다. 구체적으로, RGB와 이벤트 모달리티는 빠른 푸리에 변환을 통해 공간 도메인에서 주파수 도메인으로 변환되며, 그들의 진폭과 위상 성분은 분리됩니다. 고주파 이벤트 정보는 진폭 및 위상 주의를 통한 선택적 융합을 통해 RGB 모달리티에 통합되어 피처 표현을 향상시키고 백본 계산을 크게 줄입니다. 또한, 움직임 가이드 스페이셜 스파시피케이션 모듈은 이벤트 카메라의 움직임 민감성 특성을 활용하여 대상 움직임 큐와 공간 확률 분포 간의 관계를 포착하고, 정보가 적은 영역을 필터링하며 대상 관련 피처를 강화합니다. 마지막으로, 대상 관련 피처 집합이 백본 네트워크에 학습용으로 입력되며 추적 헤드는 최종 대상 위치를 예측합니다. FE108, FELT 및 COESOT 등 널리 사용되는 세 가지 RGB-이벤트 추적 벤치마크 데이터셋에서의 광범위한 실험은 우리의 방법의 높은 성능과 효율성을 입증합니다. 이 논문의 소스 코드는 https //github.com/Event-AHU/OpenEvTracking 에서 공개될 예정입니다.