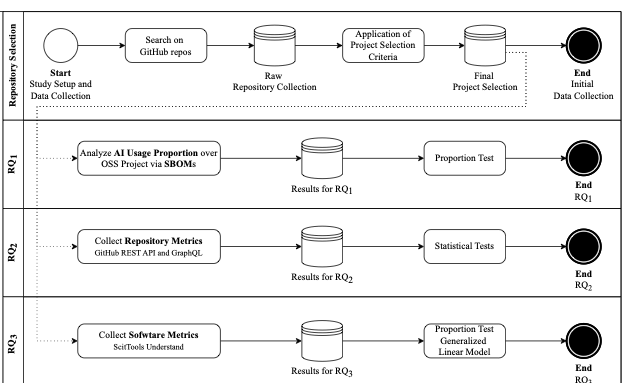
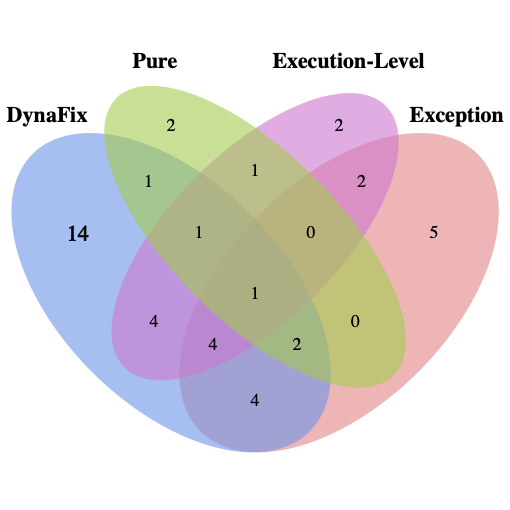
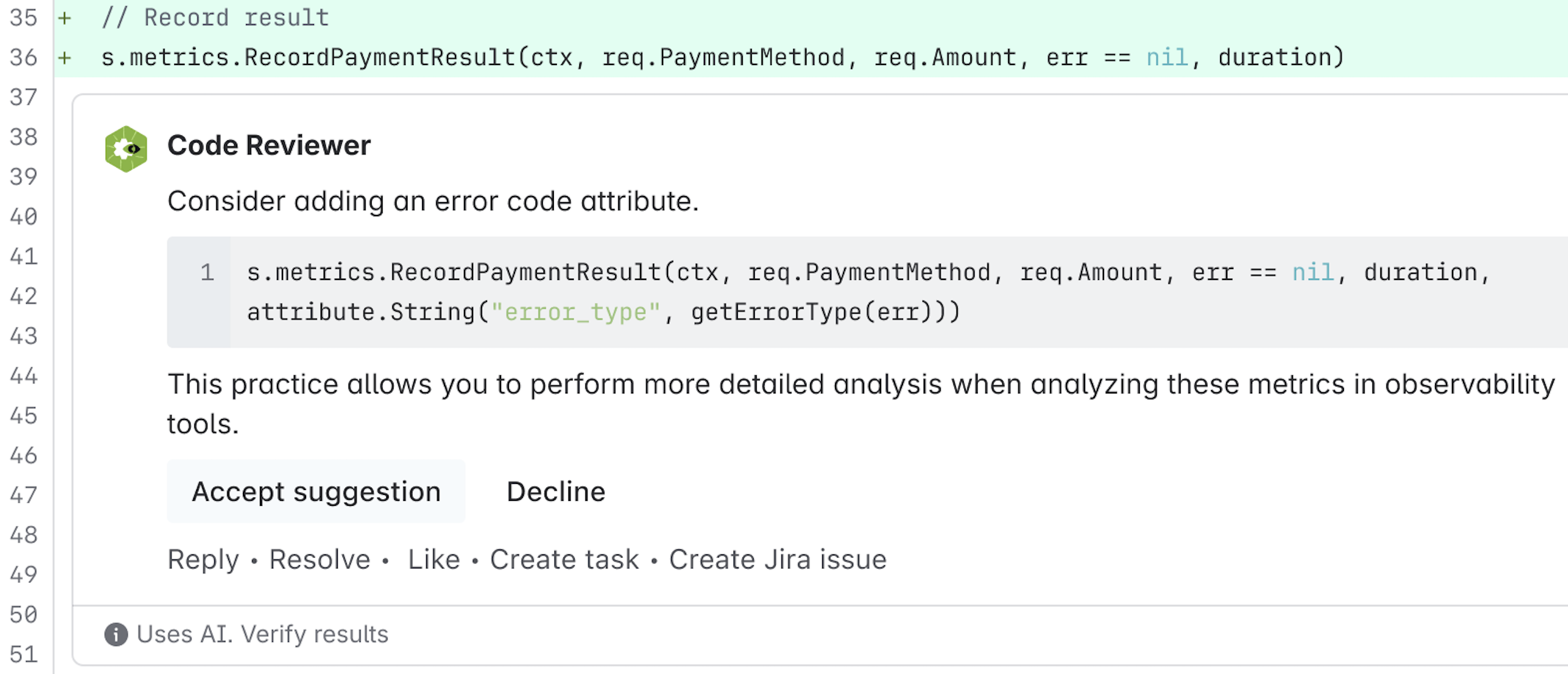
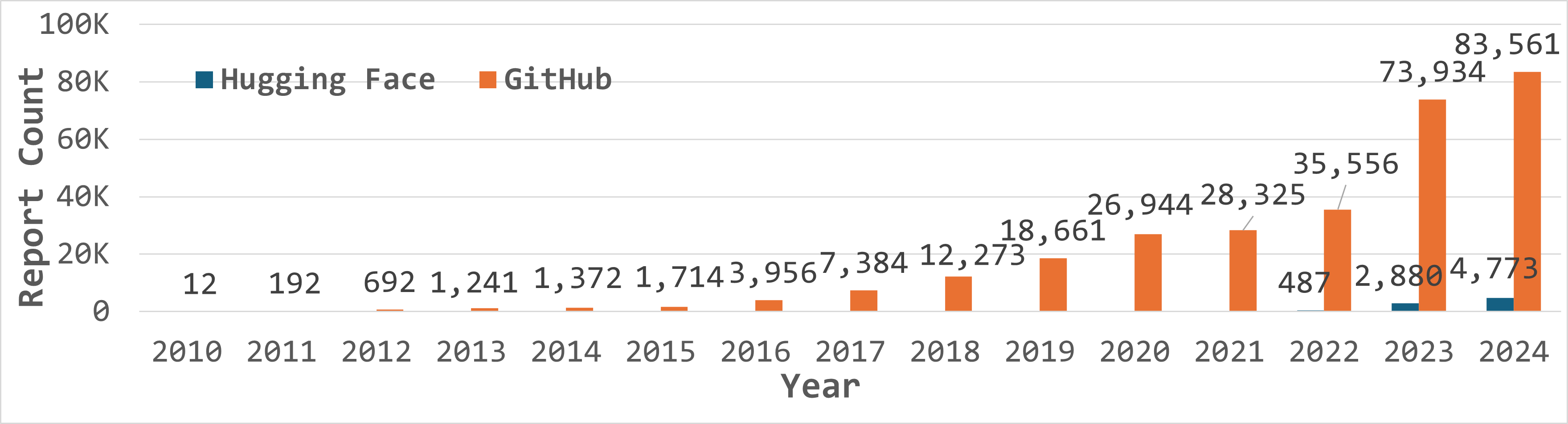No Image
대응형 계층적 평가를 통한 LLM과 SAST 도구의 Python CWE 예측 성능 분석
대형 언어 모델(Large Language Models, LLMs)은 소프트웨어 개발에 필수적이지만 자주 취약한 코드를 생성합니다. 현재의 코드 취약점 탐지 벤치마크는 이진 분류를 사용하고 있어 CWE 수준의 구체성이 부족하여 반복적인 수정 시스템에서 실질적인 피드백이 어렵습니다. 우리는 LLMs과 SAST 도구를 평가하기 위해 계층화에 대한 인식을 갖춘, CWE 특수 패널티를 사용하는 함수 레벨의 Python 벤치마크인 ALPHA(Adaptive Learning via Penalty in Hierarchical Assessment)를 제시합니다. ALPHA는 과도한 일반화, 과도한 구체화 및 횡단 오류를 구분하여 진단 도구로서 실제 차이점을 반영합니다. 7개의 LLMs과 2개의 SAST 도구를 평가한 결과, LLMs은 전체적으로 SAST보다 훨씬 높은 성능을 보였지만, SAST는 감지가 이루어질 때 더 높은 정확도를 나타냈습니다. 중요한 점은 예측 일관성이 모델 간에 매우 다름(8.26%~81.87%의 일치율)으로, 피드백 주도 시스템에 대한 의미가 큽니다. 우리는 향후 작업을 위해 ALPHA 패널티를 감독 학습 세분화에 통합하는 경로를 제시하며, 이는 원칙적인 계층 인식 취약점 탐지의 가능성을 열어놓습니다.
paper
AI 요약