지능형 지식 분배 리소스 인식 다중 에이전트 통신을 위한 제약 행동 POMDPs
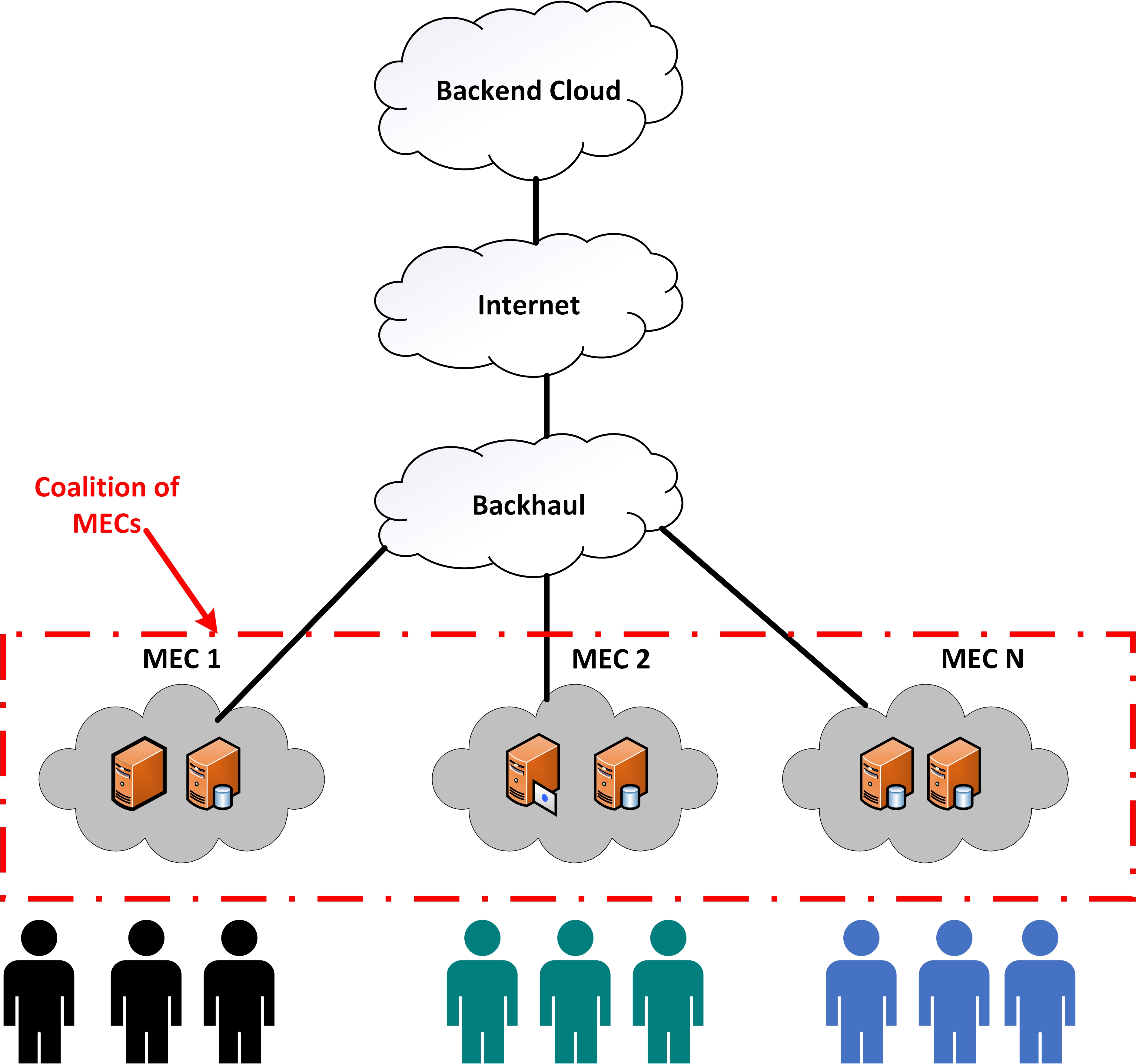
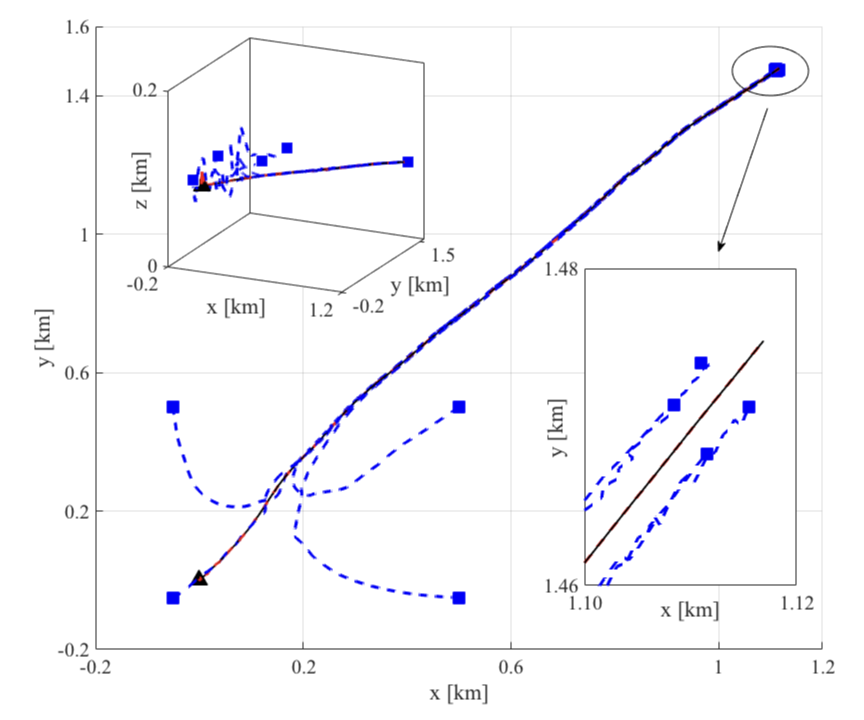
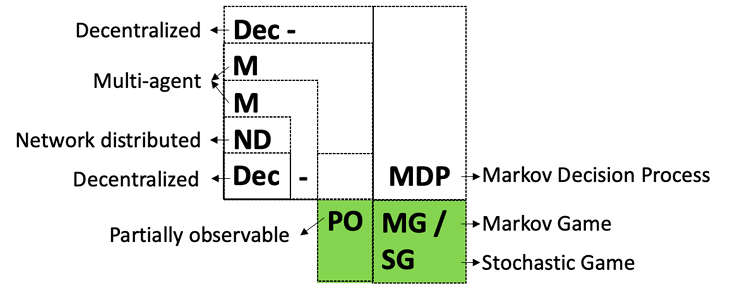
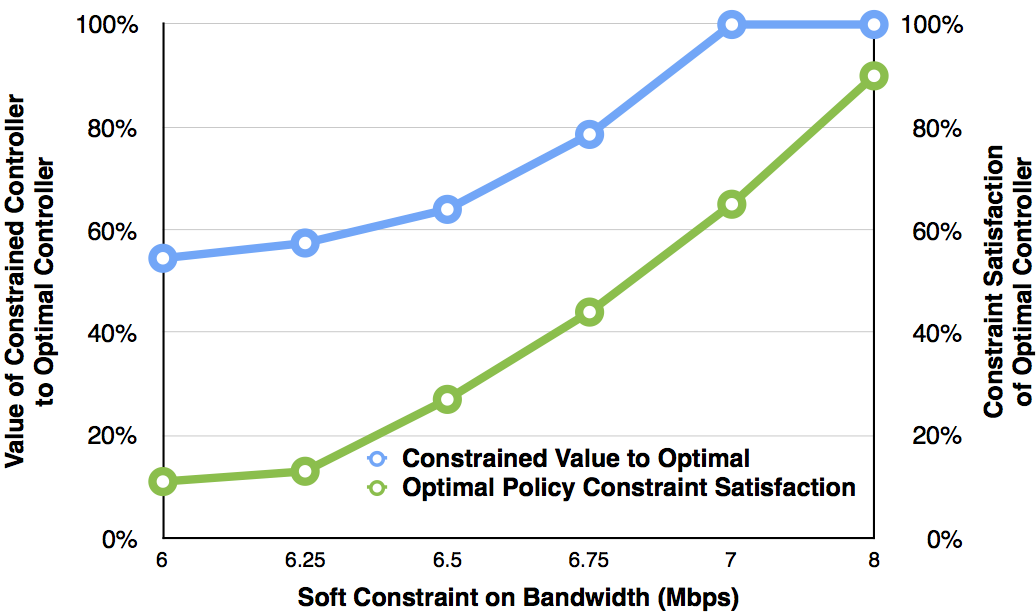
이 논문은 다중 에이전트 지식 분배의 기본적인 문제를 다룹니다. 각 에이전트에게 제한된 자원이 있을 때 어떤 정보가 누구에게 언제 전송되어야 하는지에 대한 문제입니다. 다중 에이전트 시스템의 통신 요구사항은 정확한 환경 상태와 다른 에이전트들의 상태를 유지해야 할 때 매우 높을 수 있습니다. 네트워크 시스템, 예를 들어 전력과 대역폭에 미치는 다중 에이전트 조정의 영향을 줄이기 위해 이 논문은 부분적으로 관찰 가능한 마코프 결정 과정(POMDPs)에 두 가지 개념을 도입합니다 1) 액션 기반 제약조건으로 인해 제약된 액션 POMDPs(CA-POMDPs); 및 2) 결과 무한 수평 컨트롤러의 부드러운 확률적 제약 조건 충족. 무한 수평 분석을 가능하게 하기 위해 먼저 제약이 없는 정책은 유한 상태 컨트롤러(FSC)로 표현되고 정책 반복으로 최적화됩니다. FSC 표현을 통해 마코프 체인 몬테카를로와 이산 최적화의 조합을 사용하여 제어기의 확률적 제약 조건 충족을 개선하고 가치 함수에 미치는 영향을 최소화할 수 있습니다. CA-POMDP 프레임워크 내에서 우리는 에이전트 간 지식 분배를 위한 제약 조건 하에서 각 에이전트의 정책을 제공하는 지능형 지식 분배(IKD)를 제안합니다. 마지막으로, CA-POMDP 및 IKD 개념은 여러 무인 항공기(UAVs)가 이질적인 센서로 협력하여 재난 지역에서 보이지 않는 장애물을 피하기 위해 지상 자산을 정위화하는 자산 추적 문제를 사용하여 검증됩니다. IKD 모델은 다중 에이전트 통신을 통해 자산 추적을 유지하면서 소프트 전력 및 대역폭 제약 조건을 3%만 위반했지만, 그리디와 나이브 접근법은 제약 조건을 60% 이상 위반했습니다.