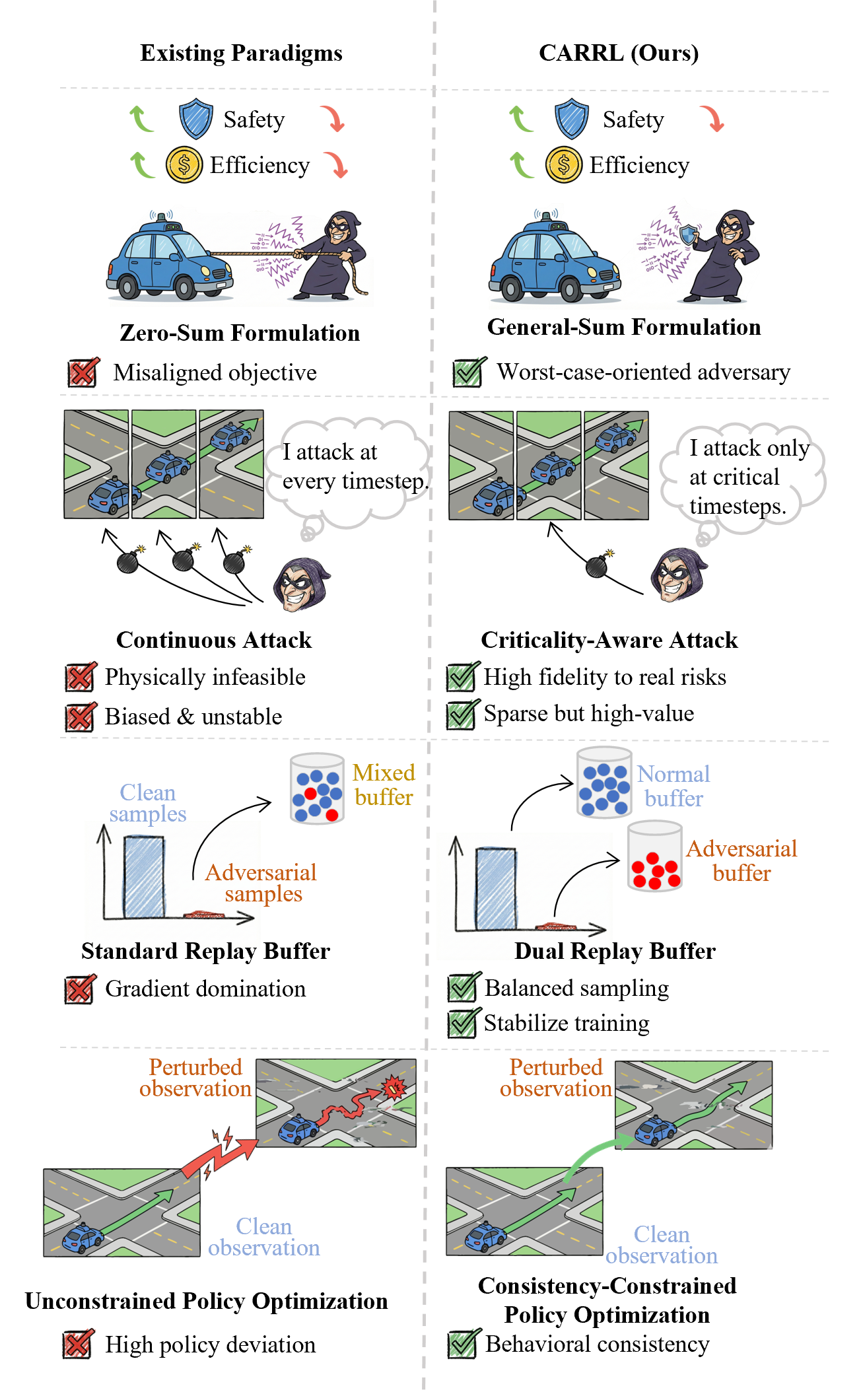
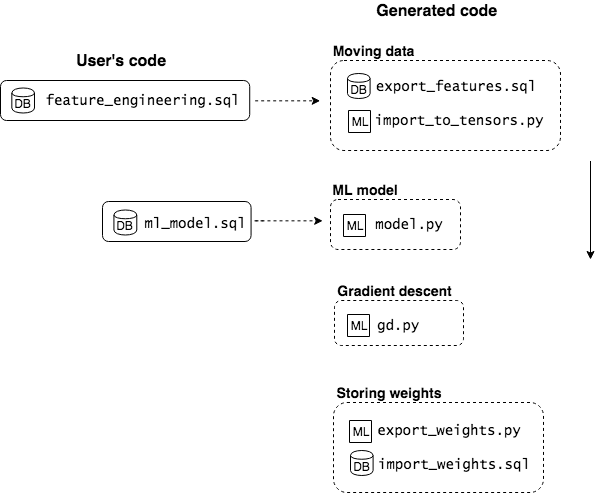
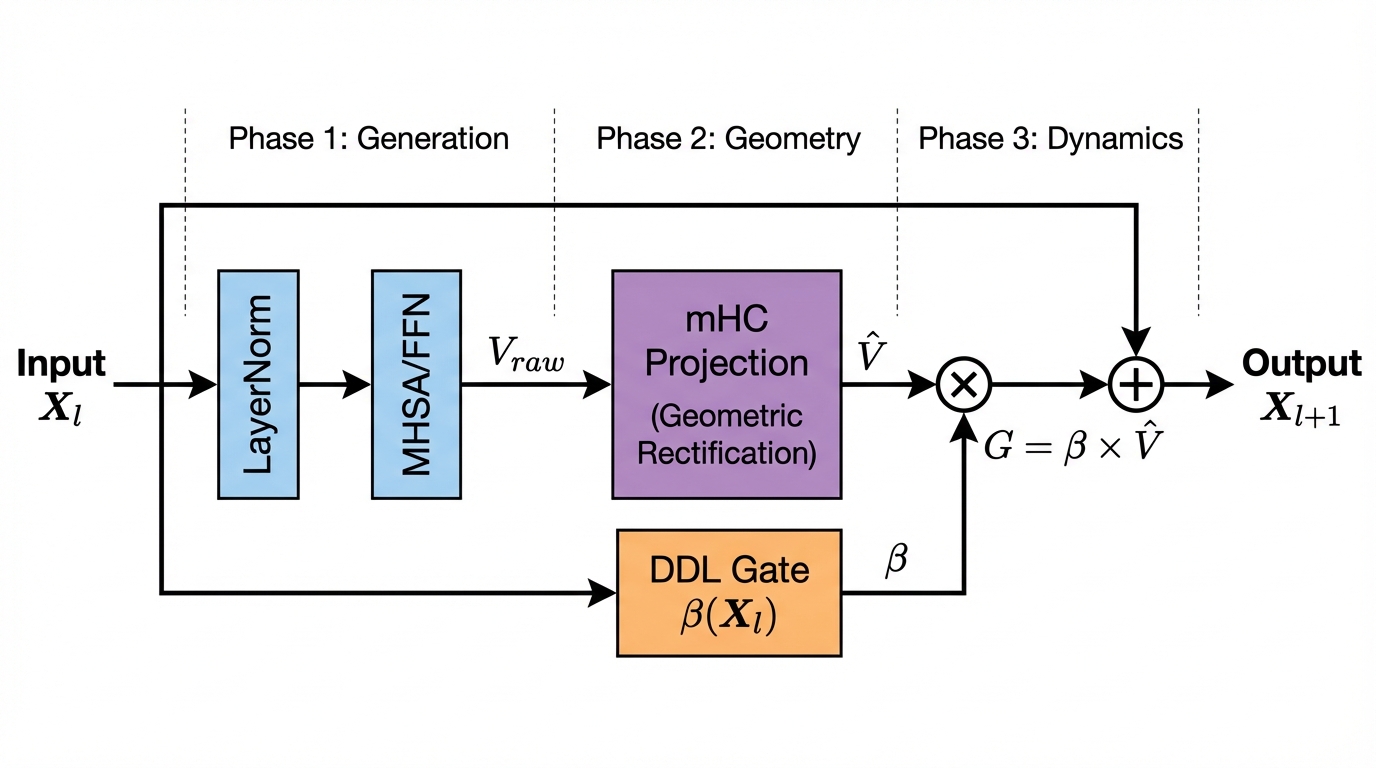
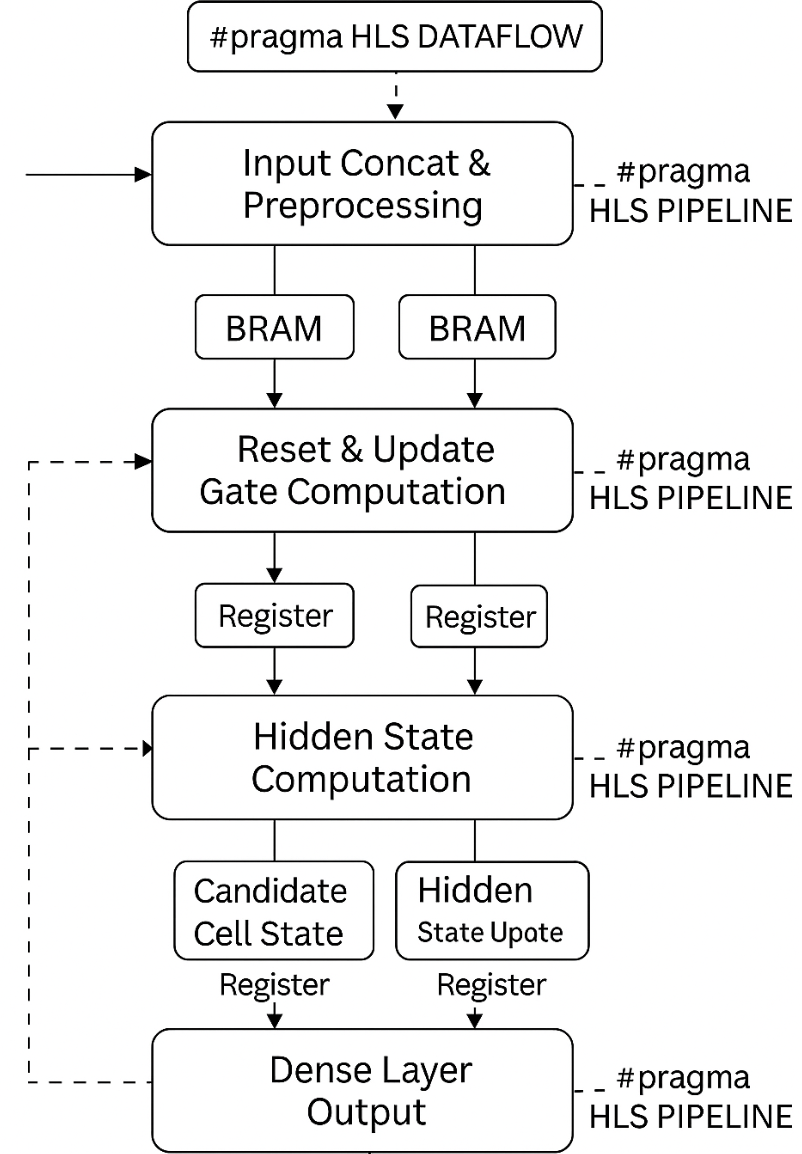
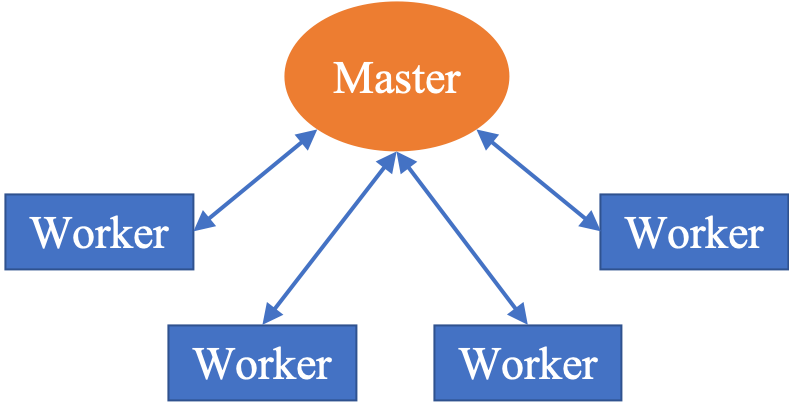
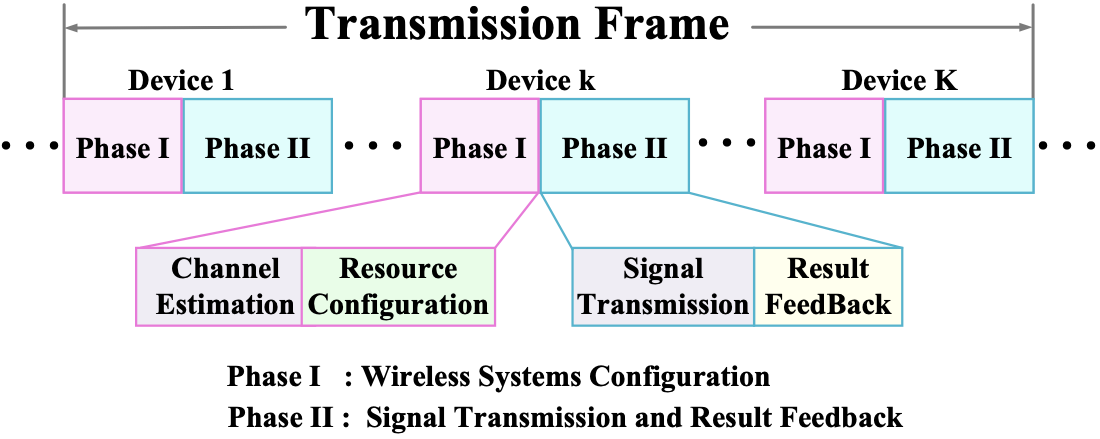
산업 IoT를 위한 디지털 트윈 기반 통신 효율적 연방 이상 감지
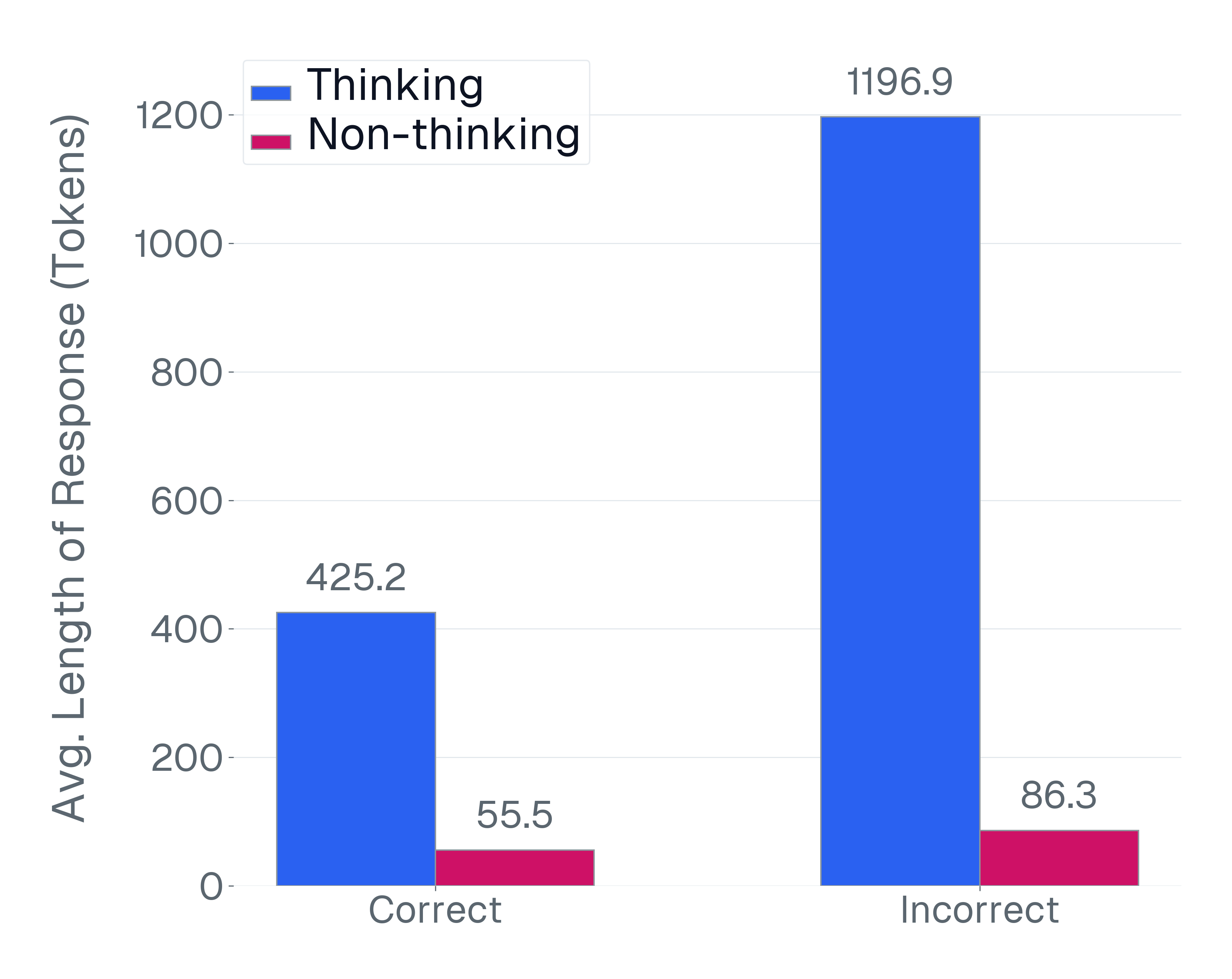
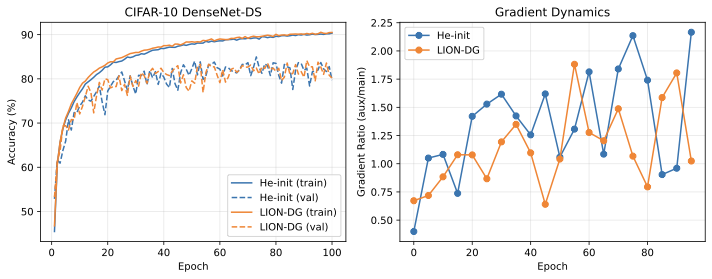
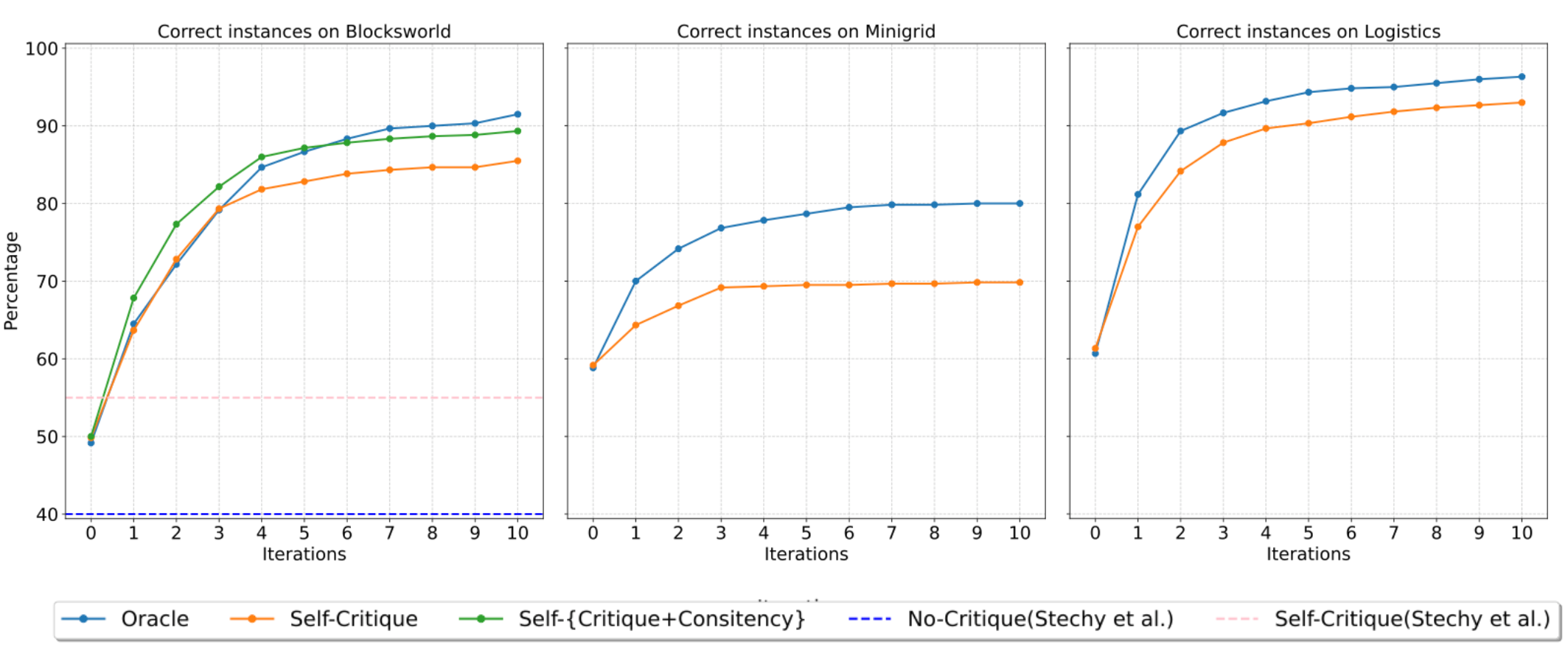
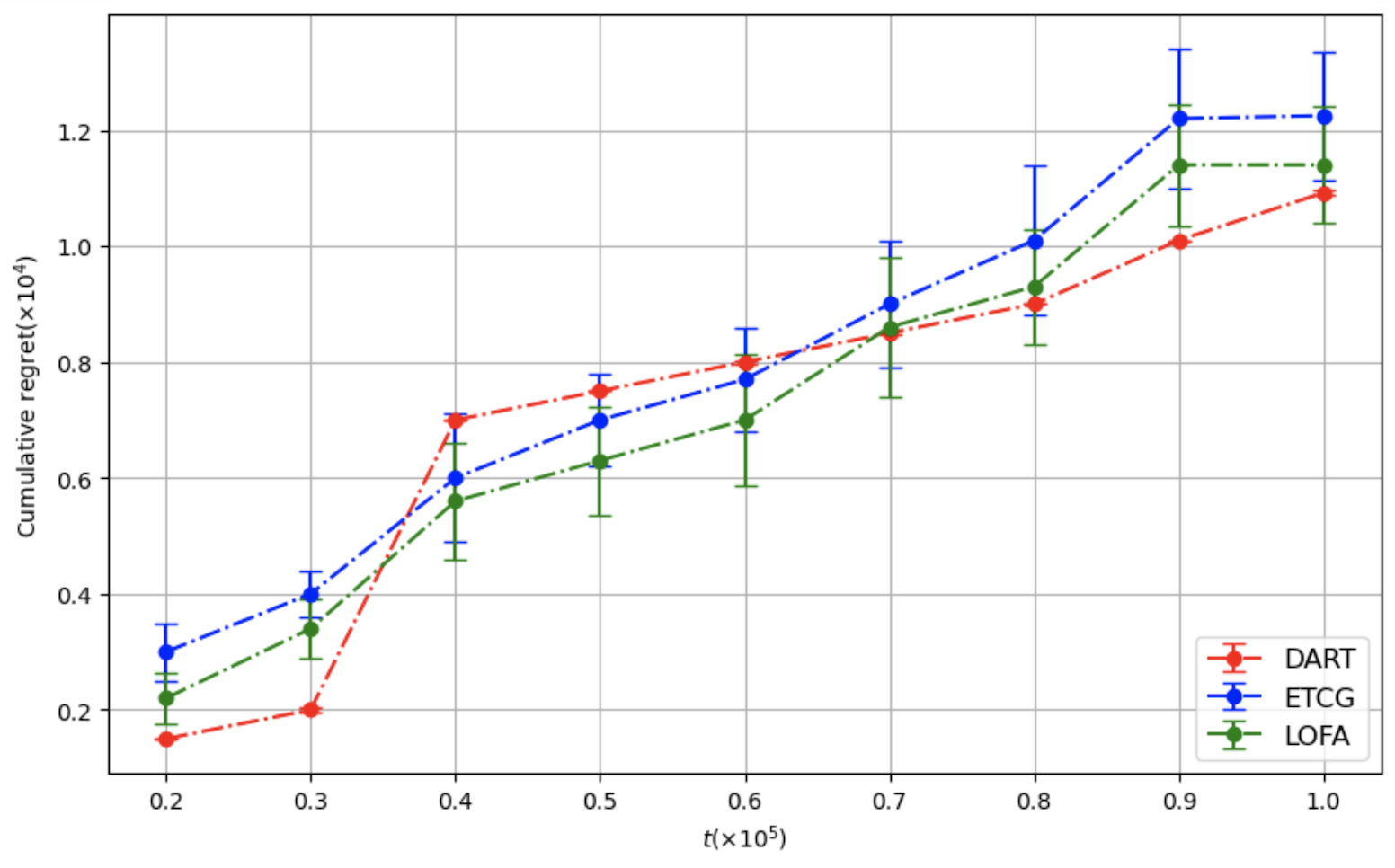
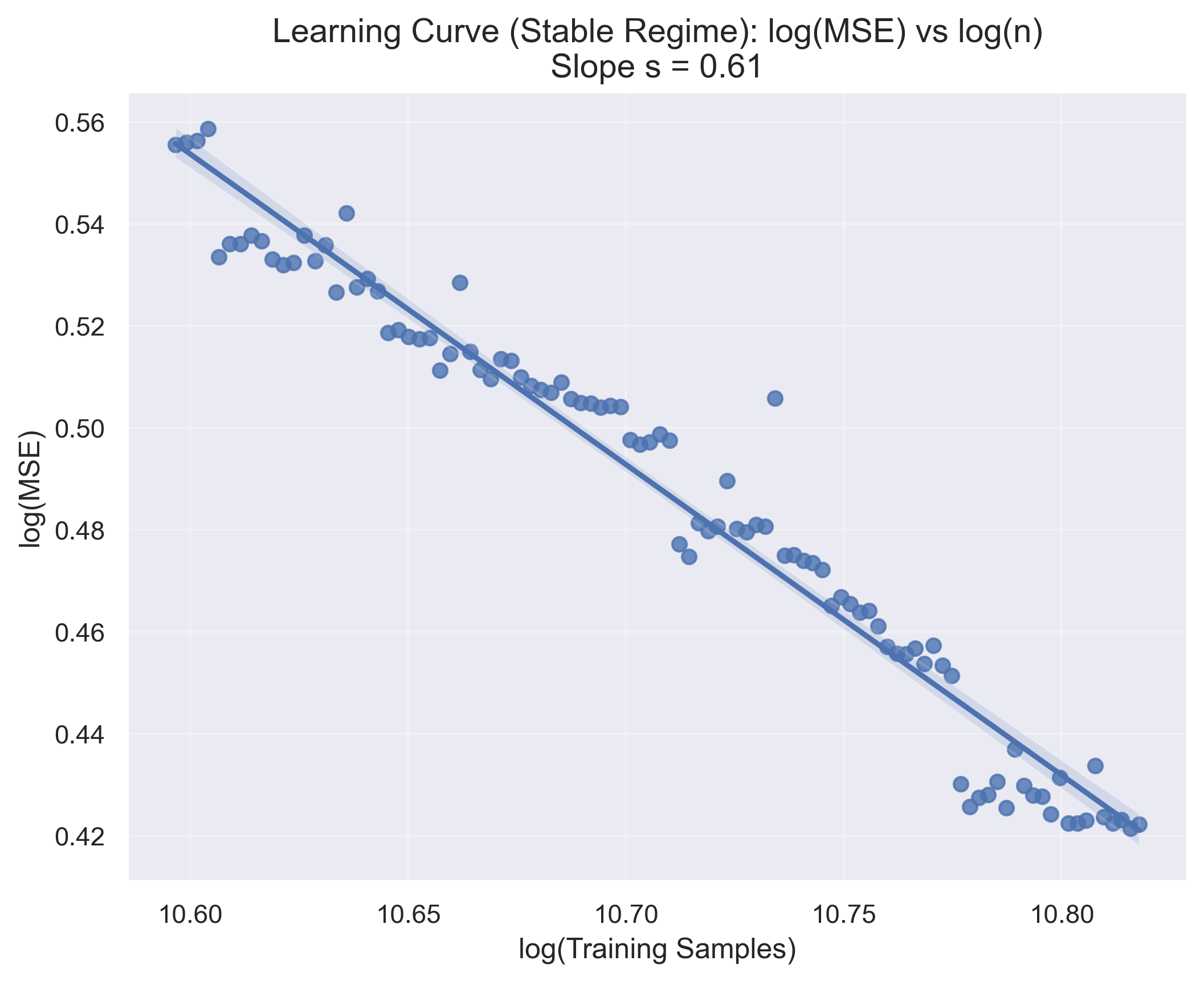
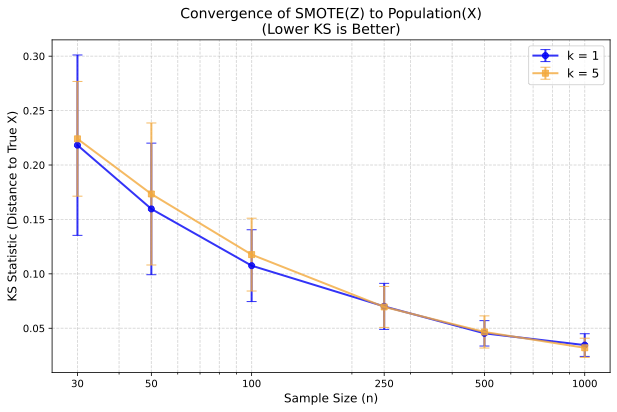
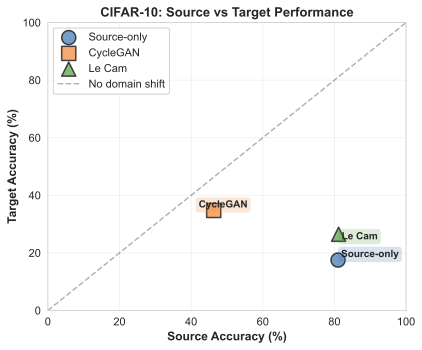
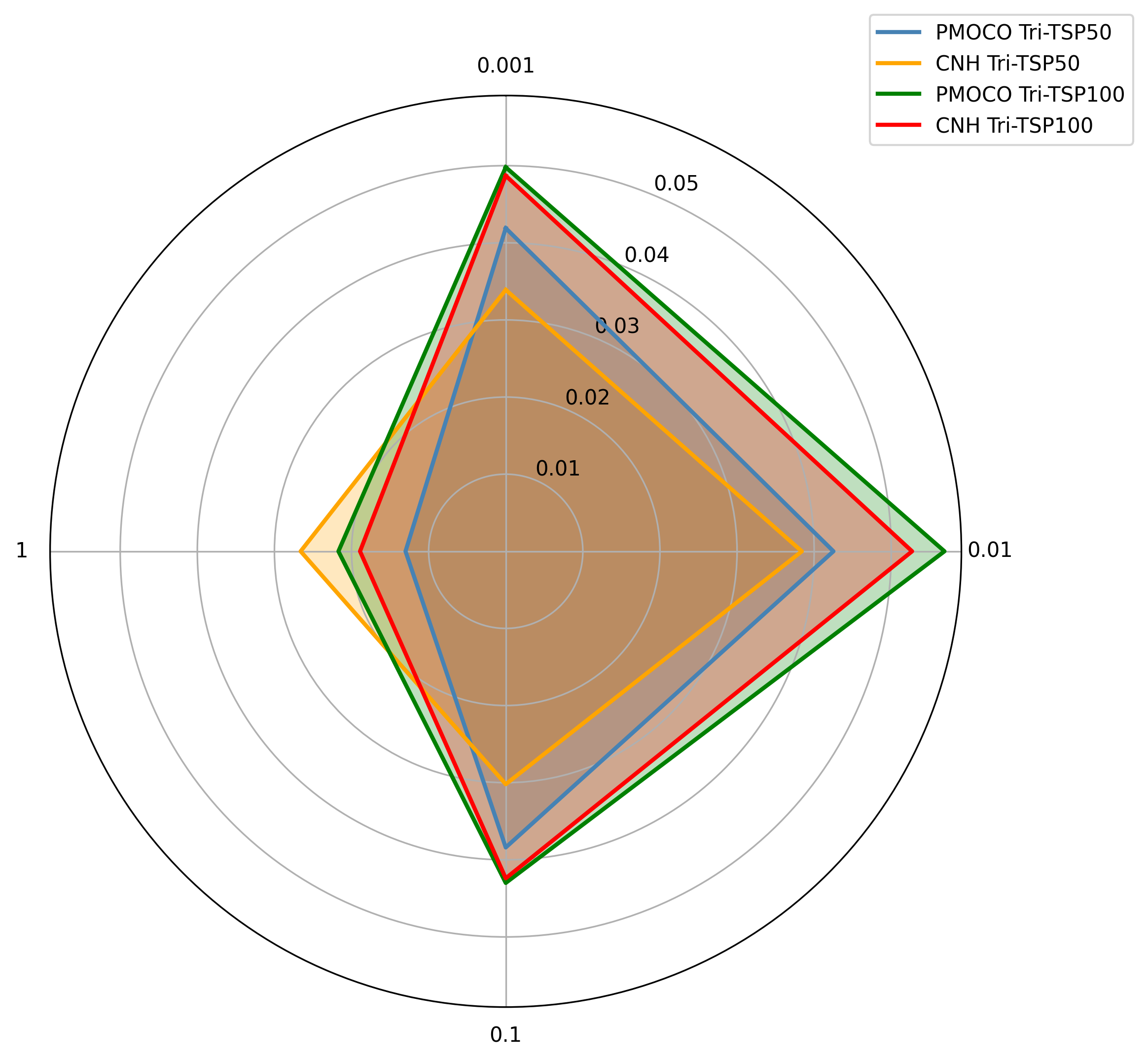
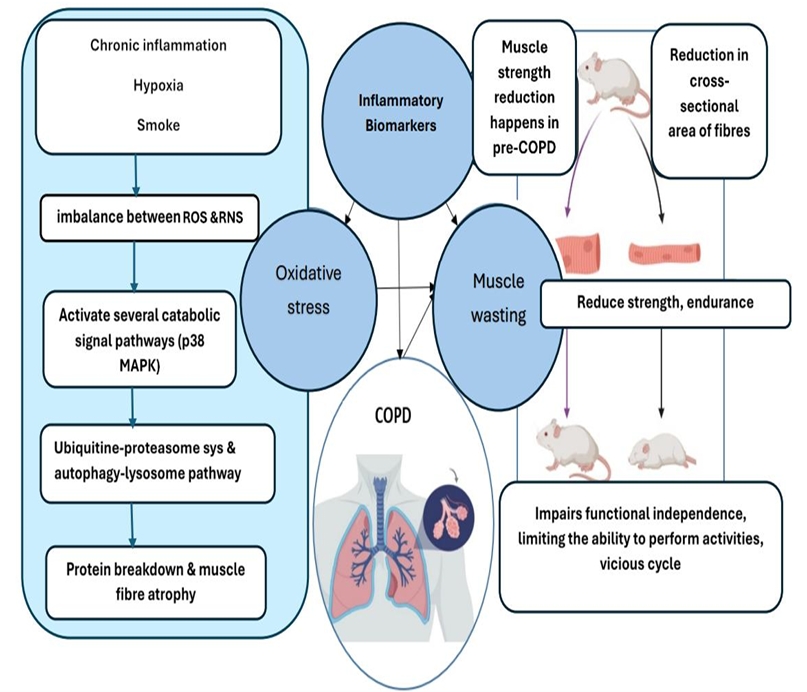
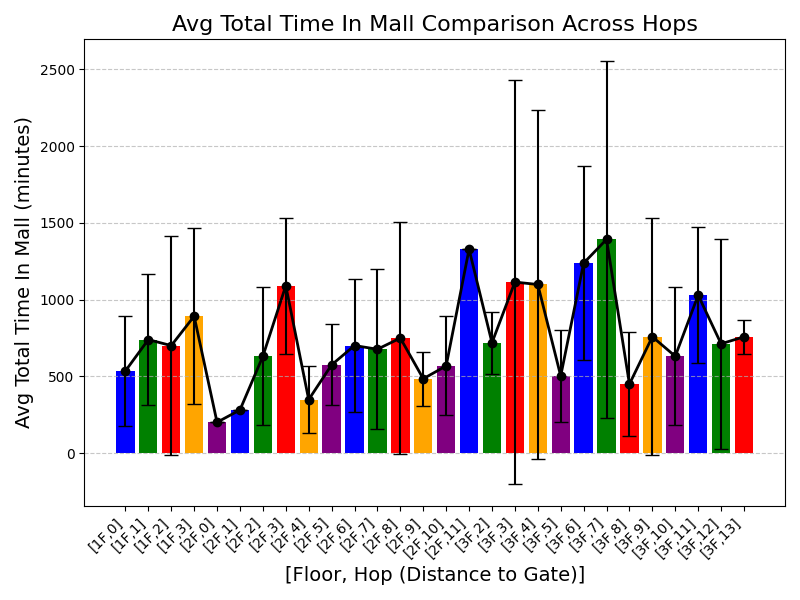
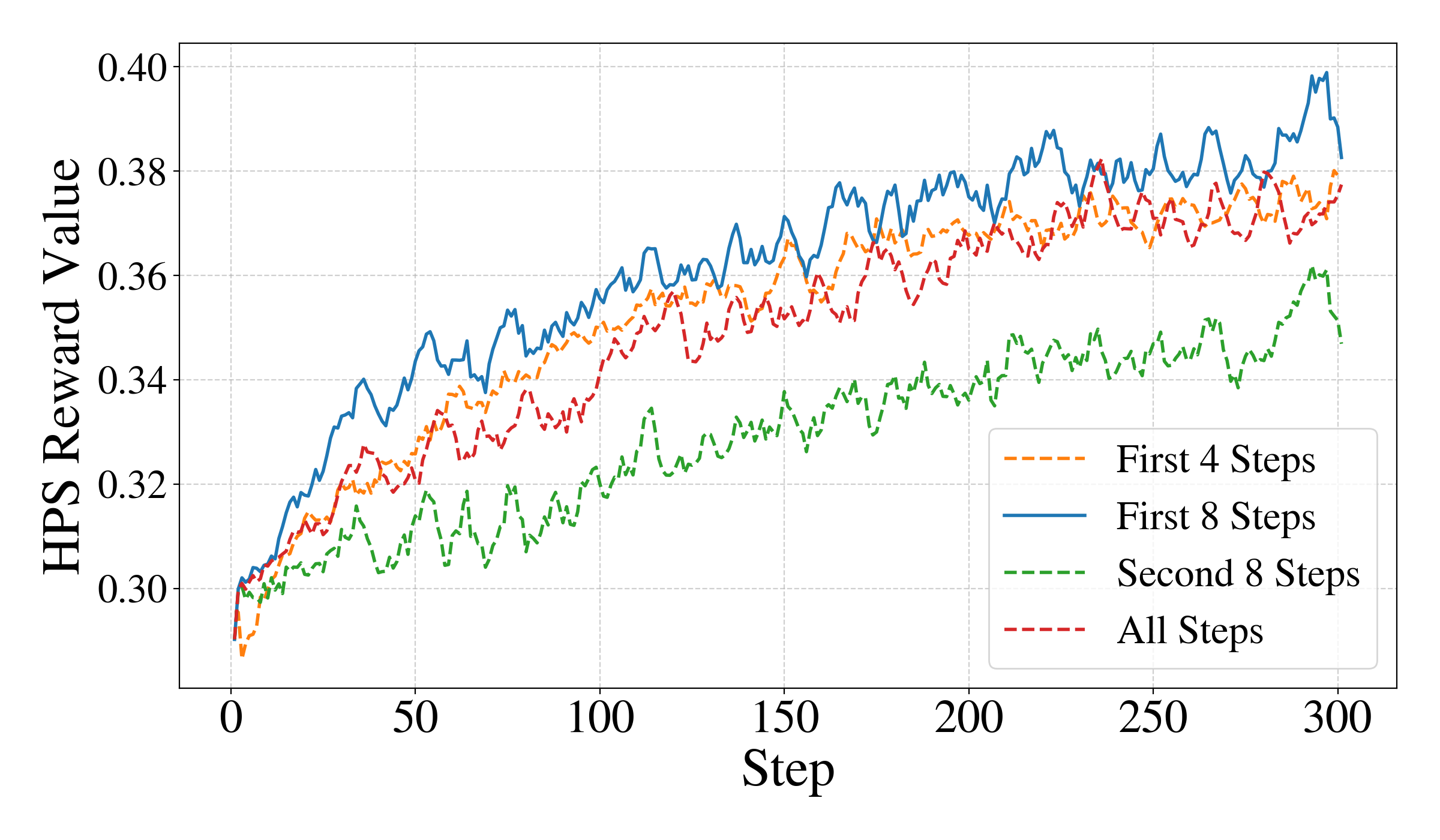
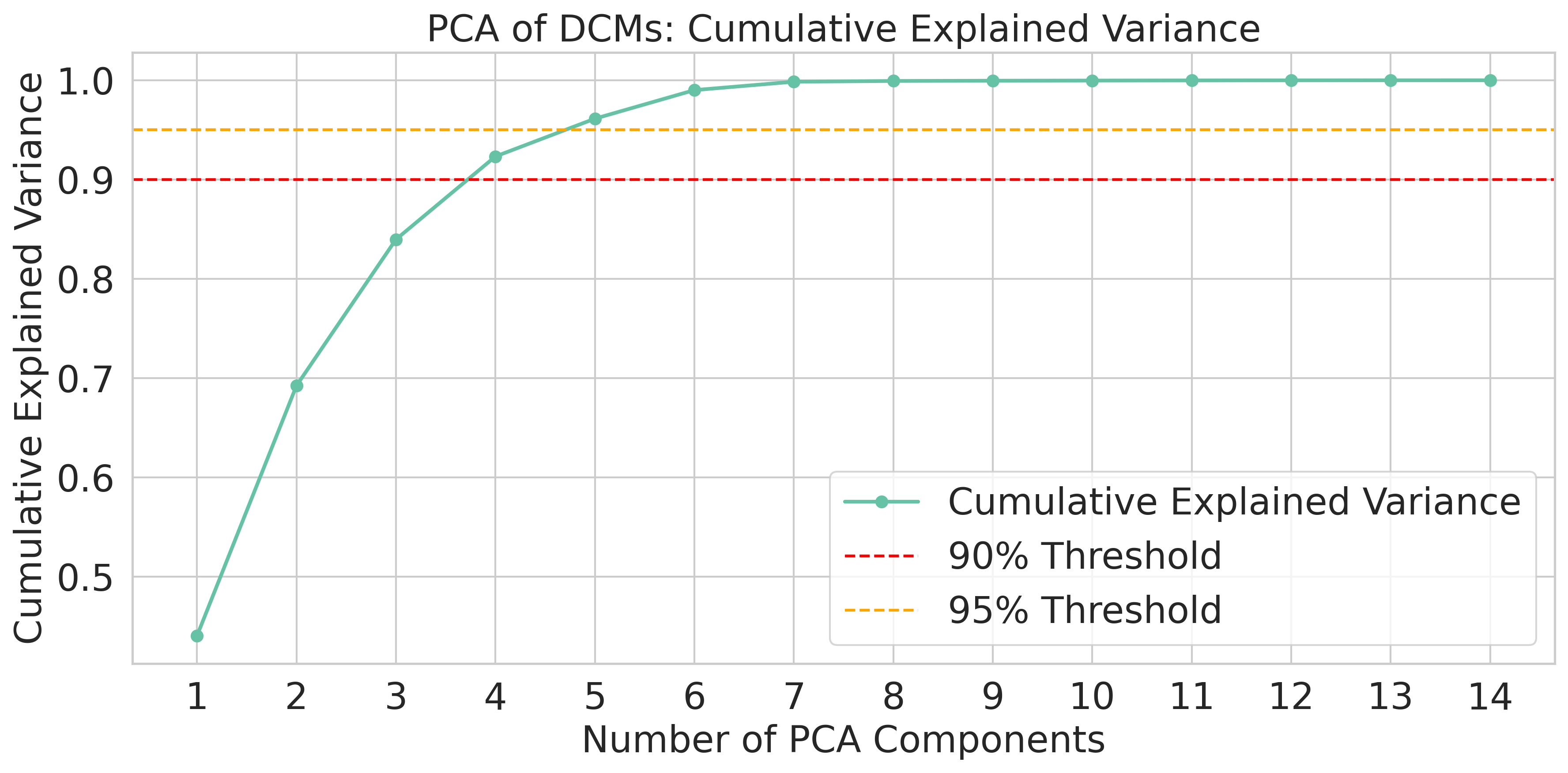
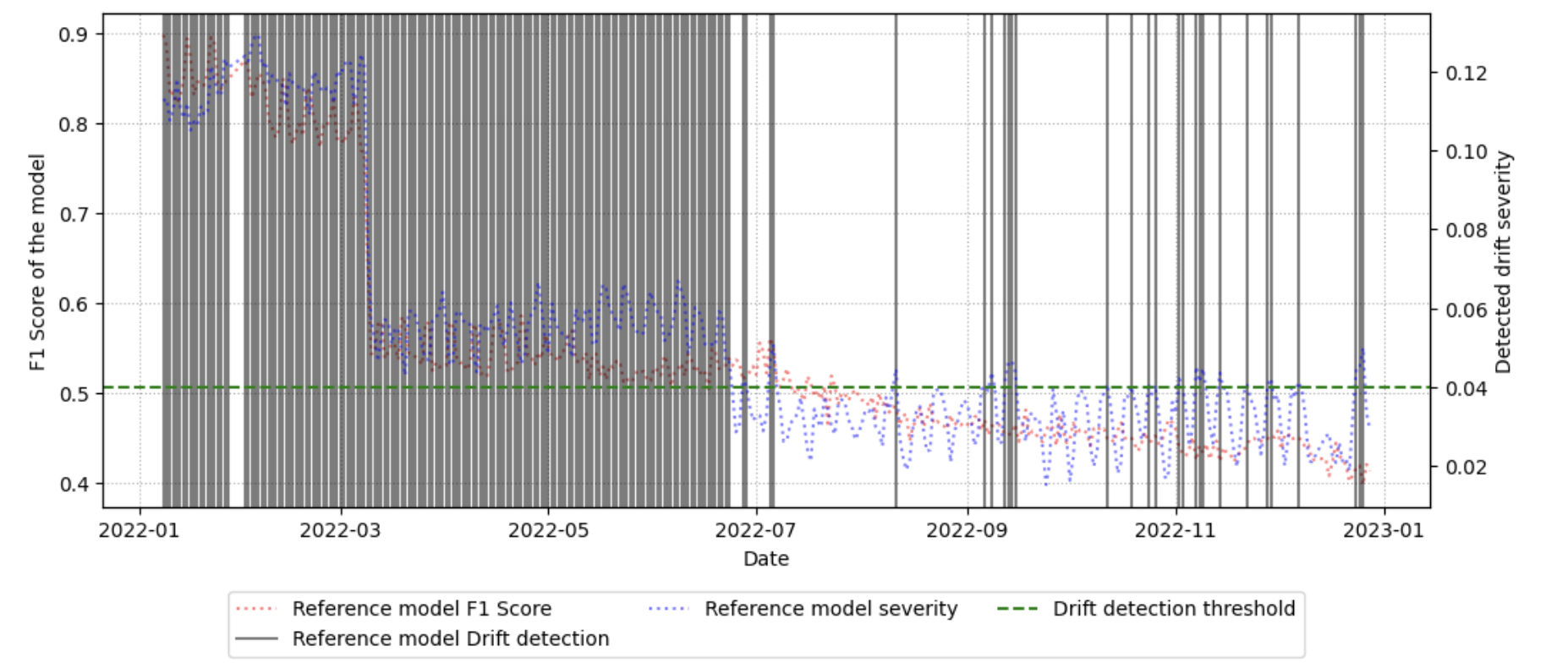
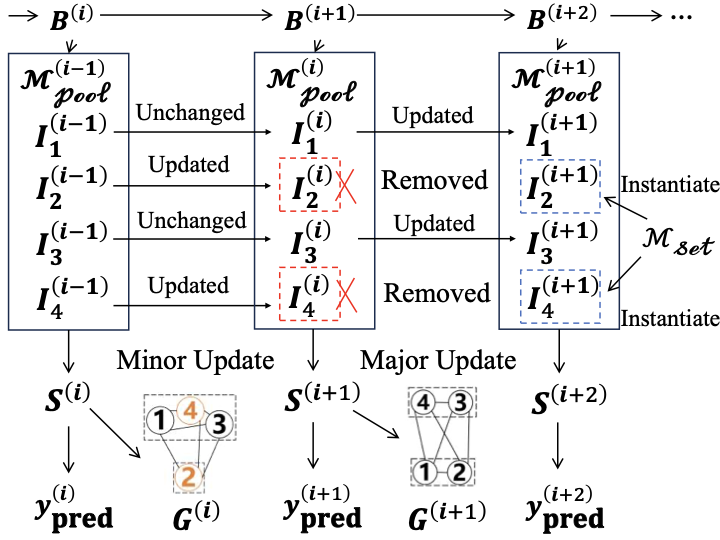
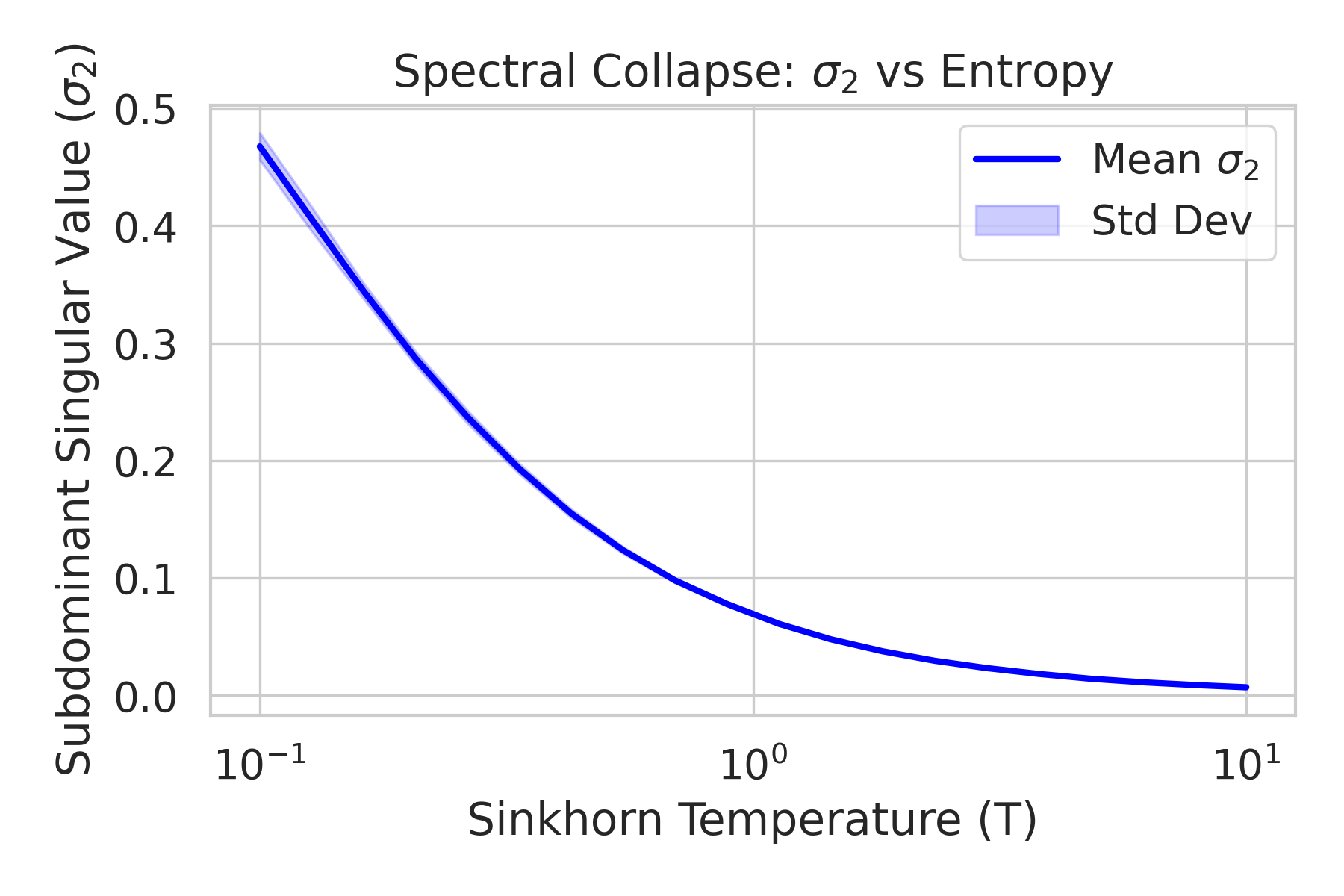
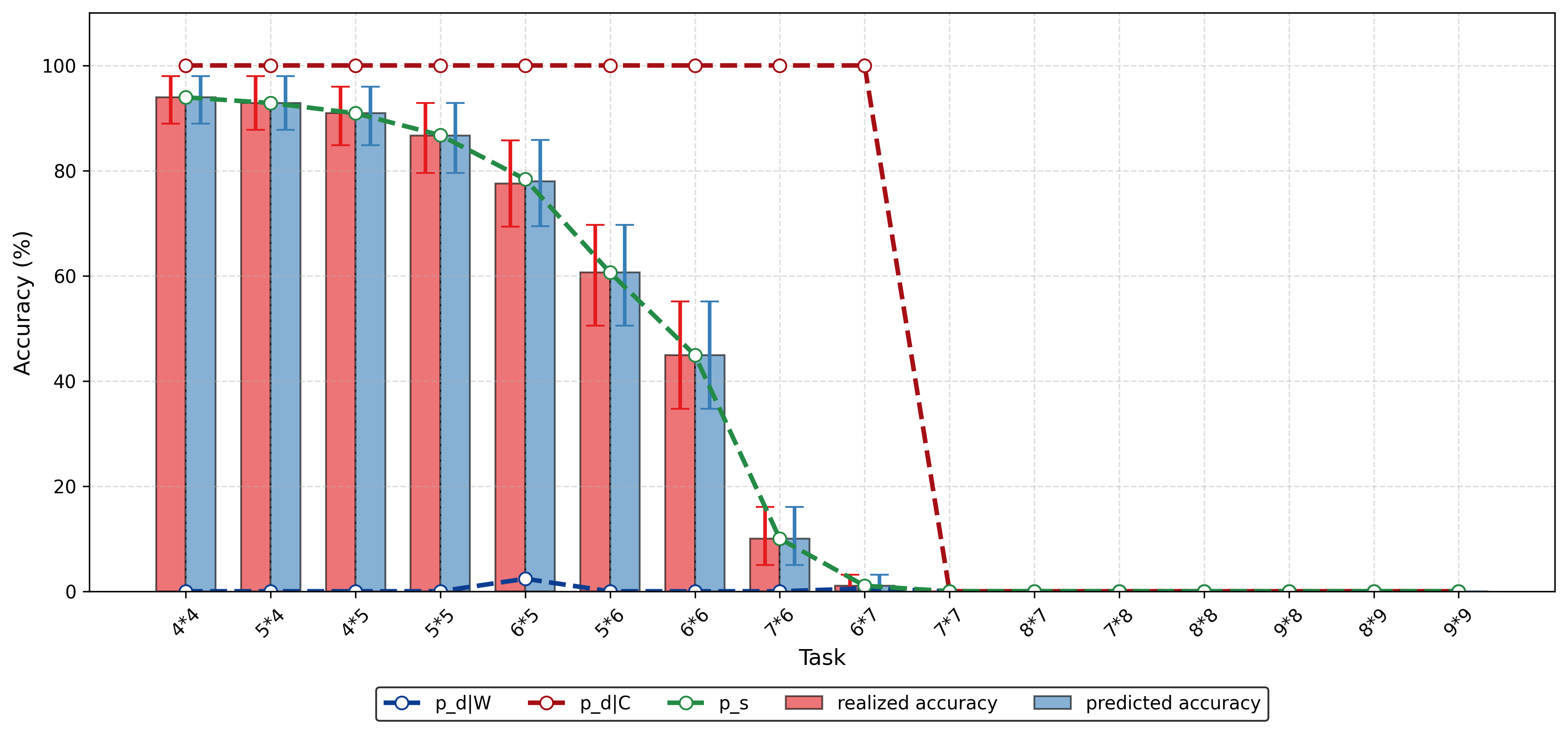
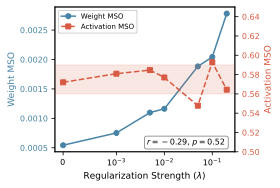
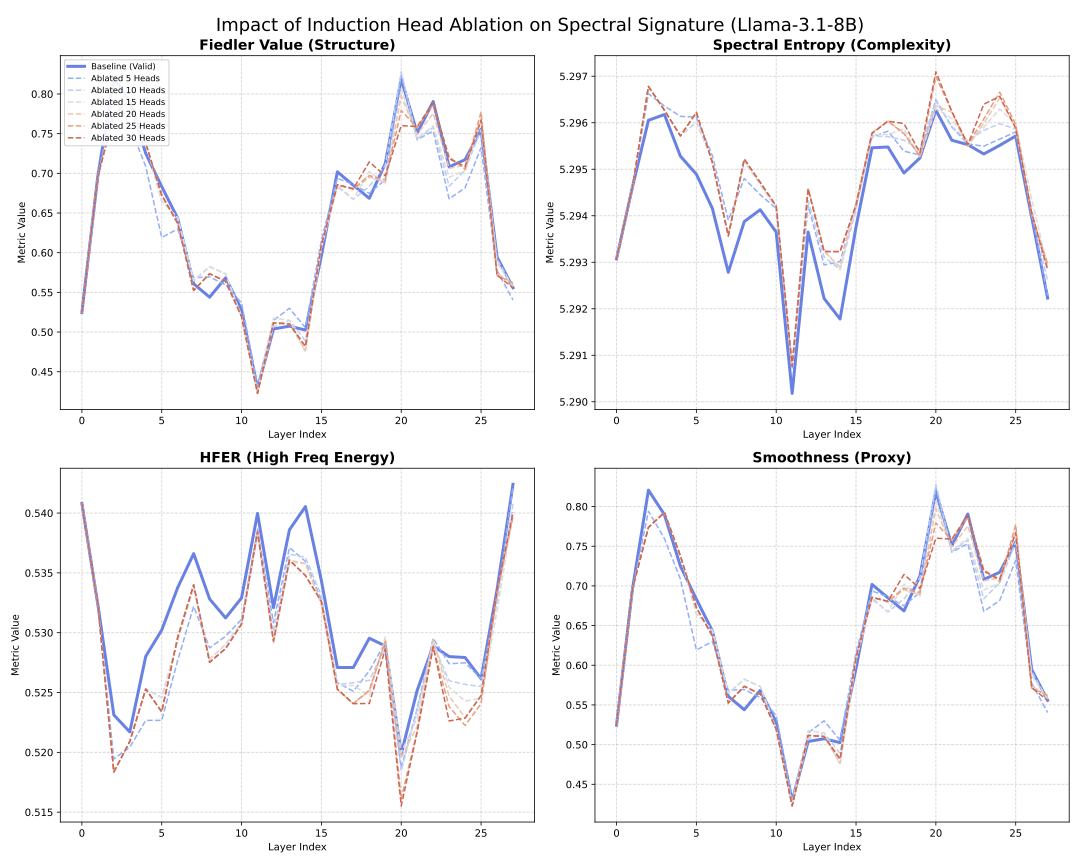
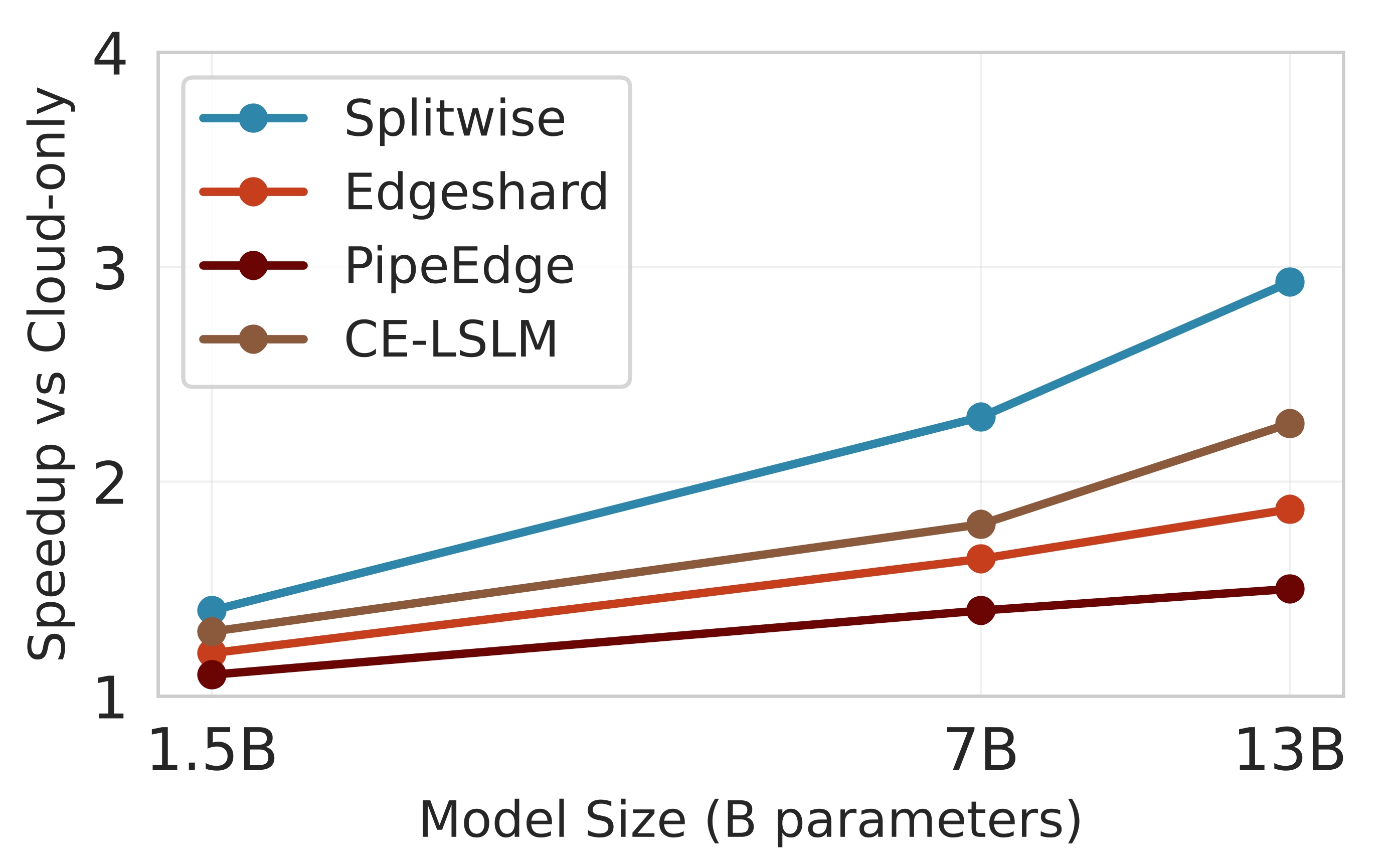
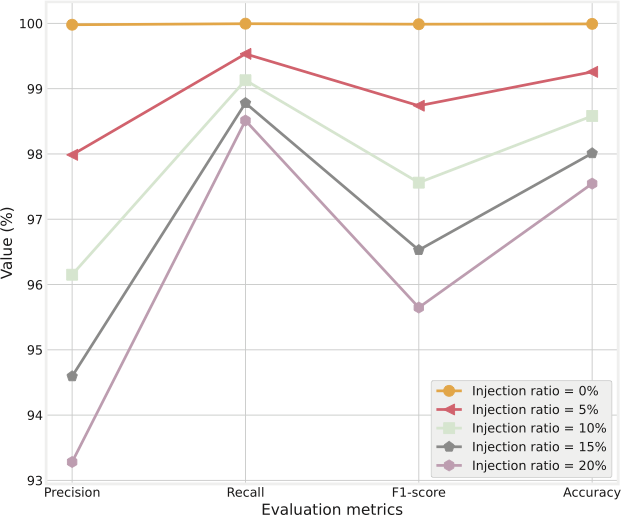
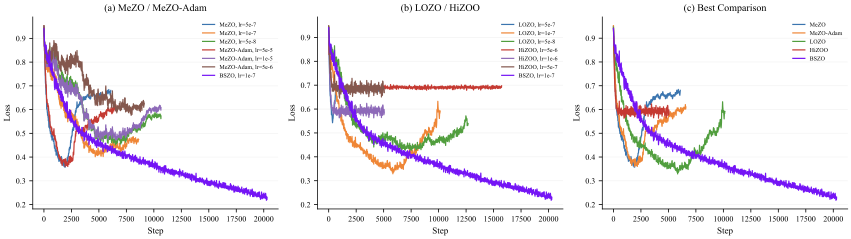
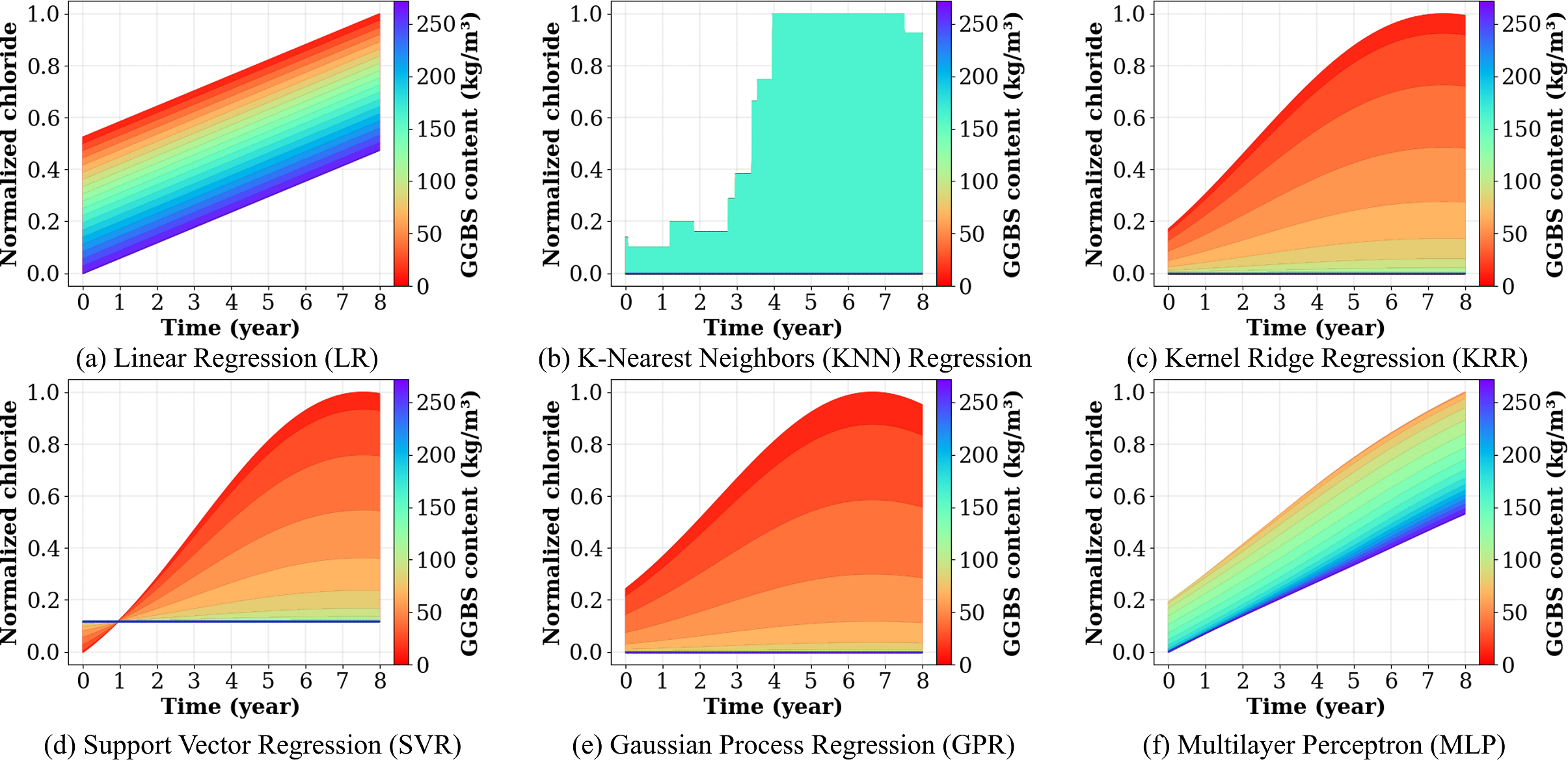
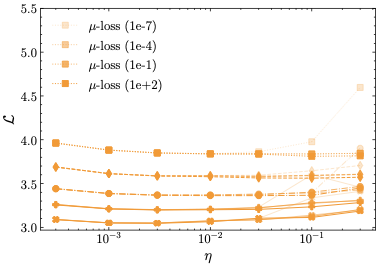
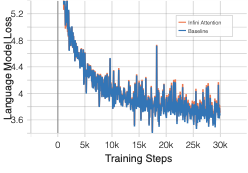
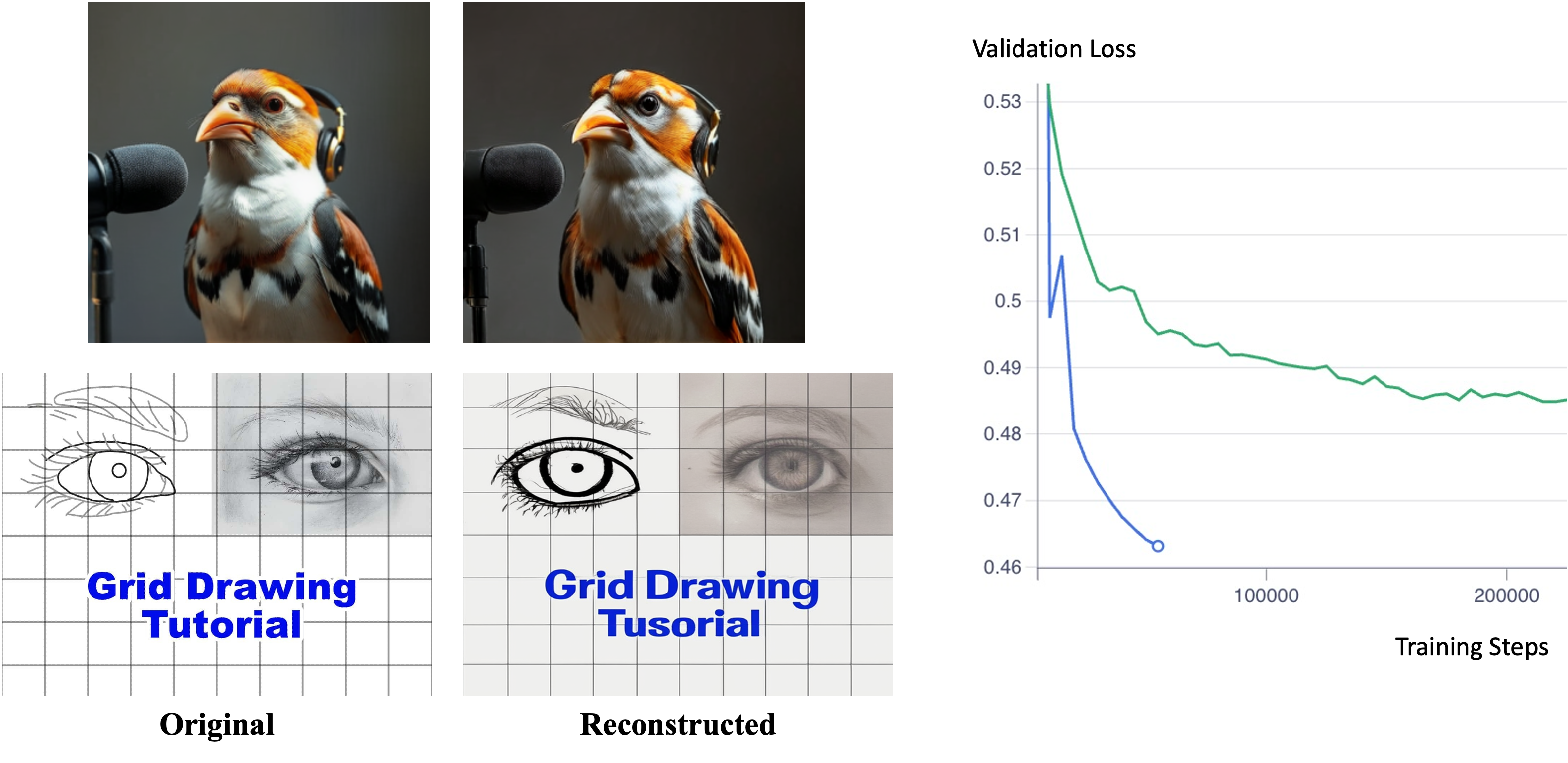
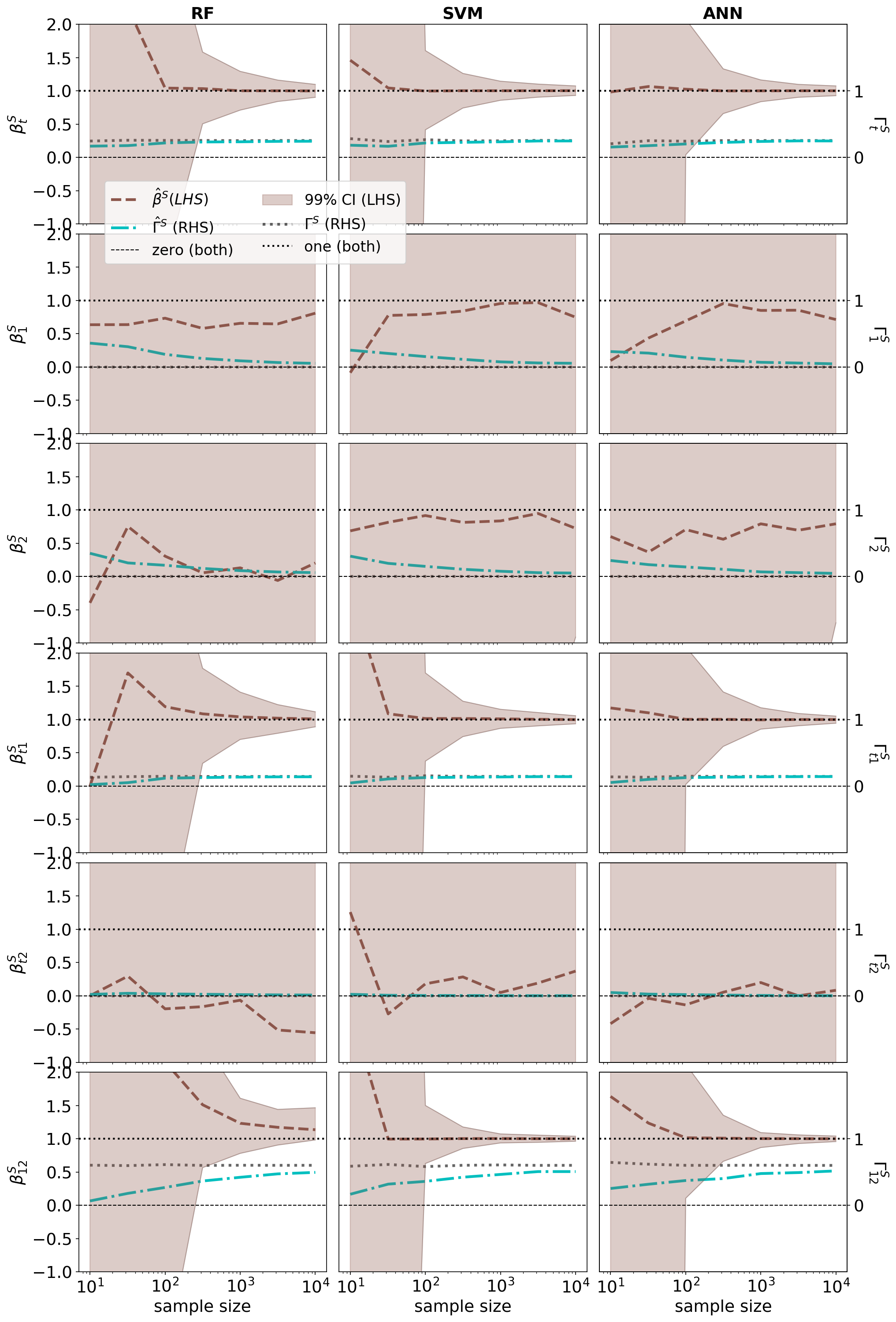
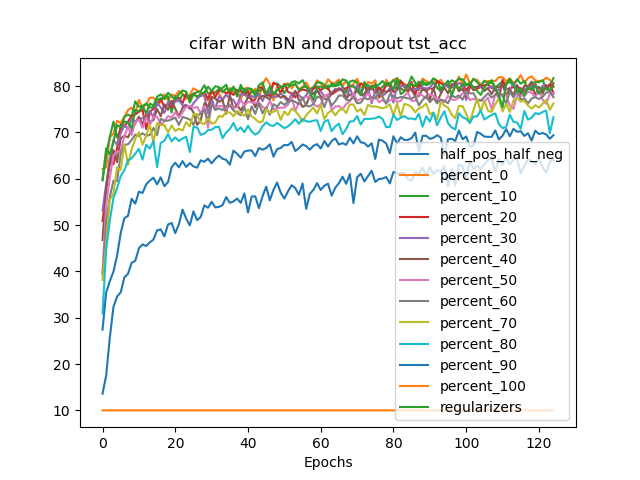
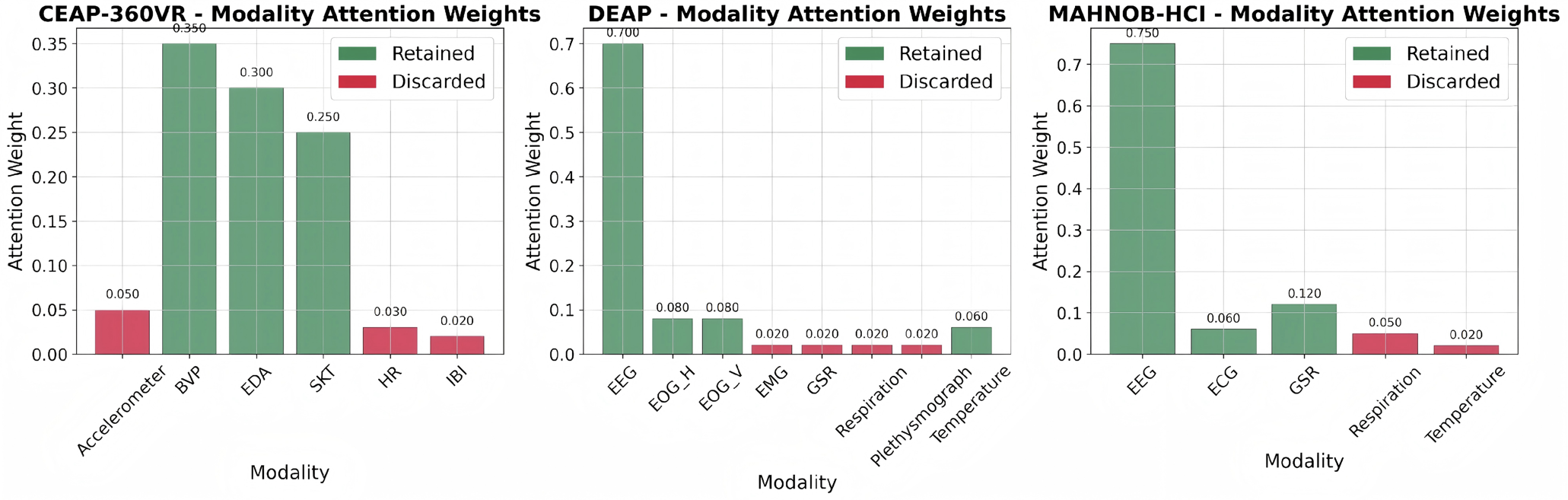
이상 감지는 산업 시스템의 안전성, 신뢰성 및 효율성을 유지하는 데 점점 더 중요한 역할을 하고 있습니다. 최근 디지털 트윈과 데이터 기반 의사결정의 도입으로 여러 통계적이고 머신러닝 방법이 제안되었습니다. 그러나 이러한 방법들은 실제 센서 데이터셋에만 의존하거나, 라벨링된 데이터 부족, 높은 거짓 경보율 및 프라이버시 문제와 같은 여러 가지 곤란을 겪고 있습니다. 이 문제를 해결하기 위해 우리는 전역 모델 성능을 향상시키면서도 데이터 프라이버시와 통신 효율성을 유지하는 디지털 트윈 통합 연방 학습 (DTFL) 방법의 일련을 제안합니다. 구체적으로, 다섯 가지 새로운 접근법을 제시합니다 디지털 트윈 기반 메타러닝(DTML), 연방 파라미터 융합(FPF), 계층별 파라미터 교환(LPE), 순환 가중치 적응(CWA) 및 디지털 트윈 지식 증산(DTKD). 각 방법은 합성과 실제 세계의 지식을 결합하는 고유한 메커니즘을 소개합니다. 일반화와 통신 오버헤드를 균형있게 조절합니다. 우리는 공개 가능 데이터셋을 사용하여 광범위한 실험을 수행했습니다. 80% 정확도 목표에 도달하는 데 CWA는 33라운드, FPF는 41라운드, LPE는 48라운드, DTML은 87라운드가 걸렸으며, 표준 FedAvg 기준선 및 DTKD는 100라운드 내에 목표를 달성하지 못했습니다. 이러한 결과는 통신 효율성 향상 (DTML보다 최대 62% 적은 라운드, LPE 보다 31% 적음)을 강조하고 DT 지식을 FL에 통합하면 IIoT 이상 감지의 운영적으로 의미있는 정확도 임계치로 수렴하는 속도를 가속화한다는 것을 입증합니다.



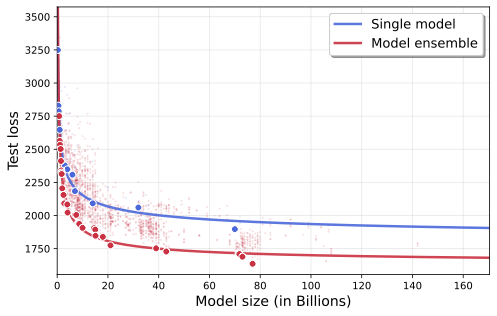
![[한글 번역 중] Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice](https://koineu.com/posts/2025/12/2025-12-30-190824-can_small_training_runs_reliably_guide_data_curati/benchmark_all_gpt2_gpt2large.png)

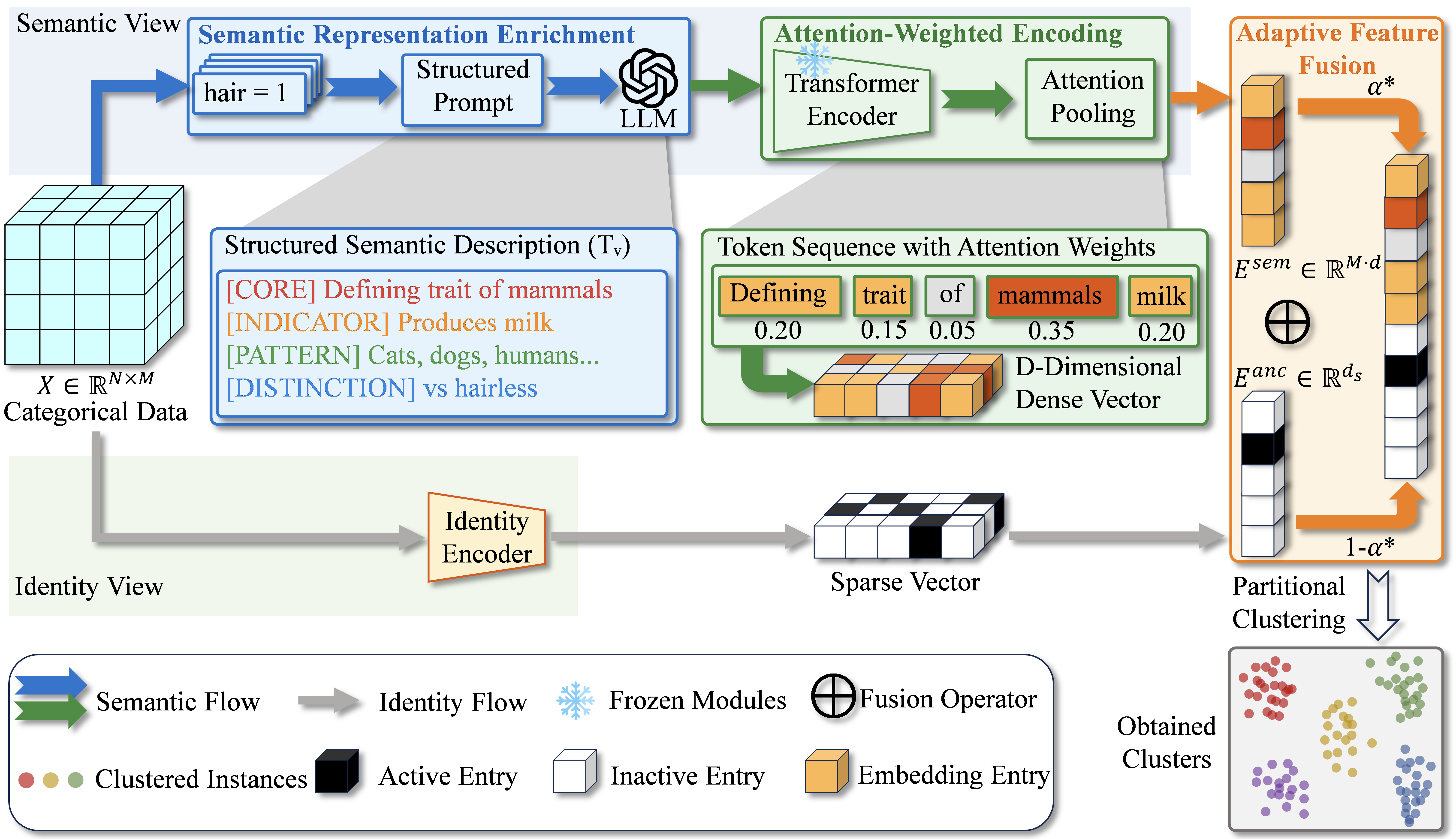
![[한글 번역 중] REE-TTT Highly Adaptive Radar Echo Extrapolation Based on Test-Time Training](https://koineu.com/posts/2026/01/2026-01-04-190573-ree_ttt__highly_adaptive_radar_echo_extrapolation_/fig7.png)