경제 데이터의 증분 도메인 지식 모델링 및 시각화 세브리나
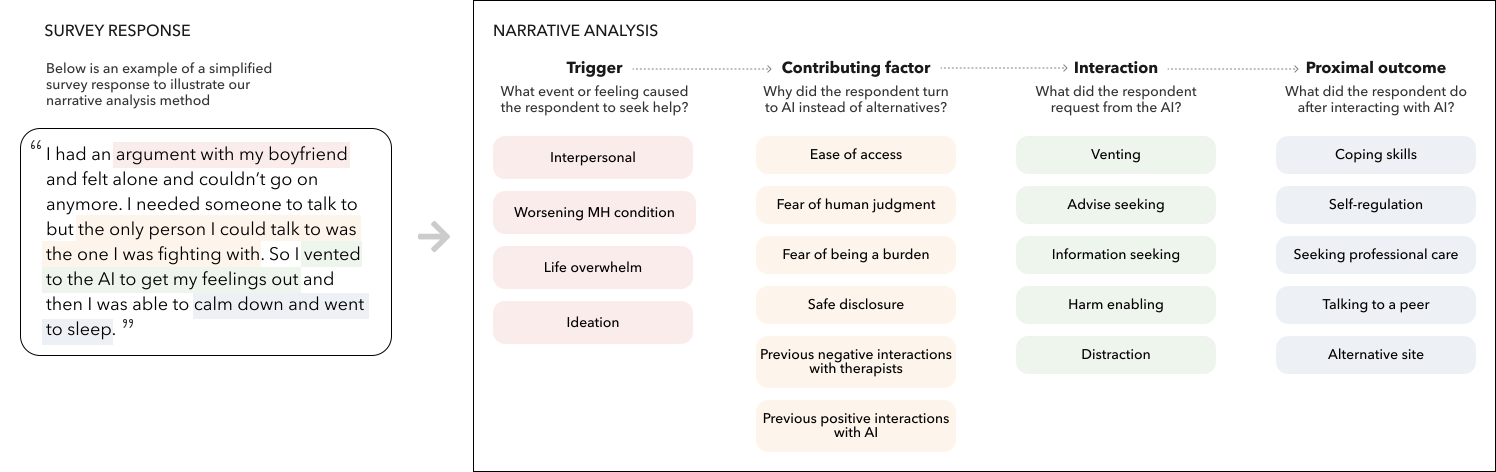
투자 계획은 지역과 산업 분야별로 확장된 금융 풍경에 대한 지식이 필요하다. 데이터는 충분히 있지만, 신문, 오픈 데이터 등 다양한 출처에서 분산되어 있어 금융 분석가들이 전체적인 그림을 이해하는 것이 어렵다. 본 논문에서는 Sabrina라는 접근법을 소개한다. 이 접근법은 회사 간 금융 거래 네트워크 생성을 위한 파이프라인을 포함하며, 지역 내 개별 기업의 실제 정보와 경제의 일반적인 매크로적 측면에 대한 (증분적) 도메인 지식을 통합한다. Sabrina는 다양한 데이터 출처를 일관된 시각화 인터페이스에서 결합하여 분석 과정을 시각적으로 지원한다. 세 명의 전문가를 대상으로 한 사용자 연구를 통해 Sabrina의 유용성을 보여준다.
paper
AI 요약