합성 이미지로 이상 탐지 최적화
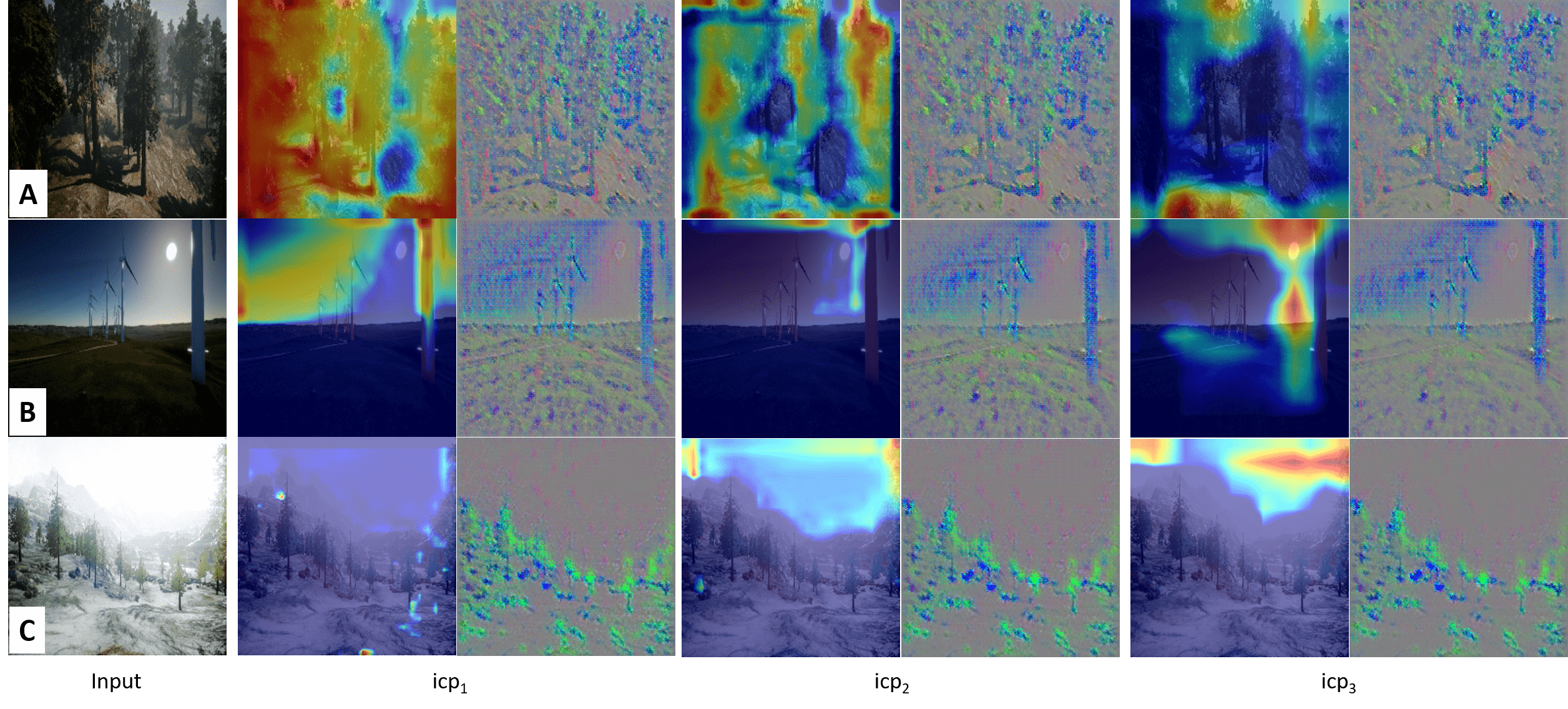
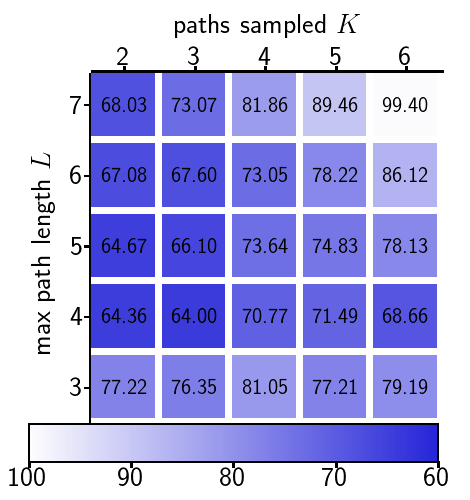
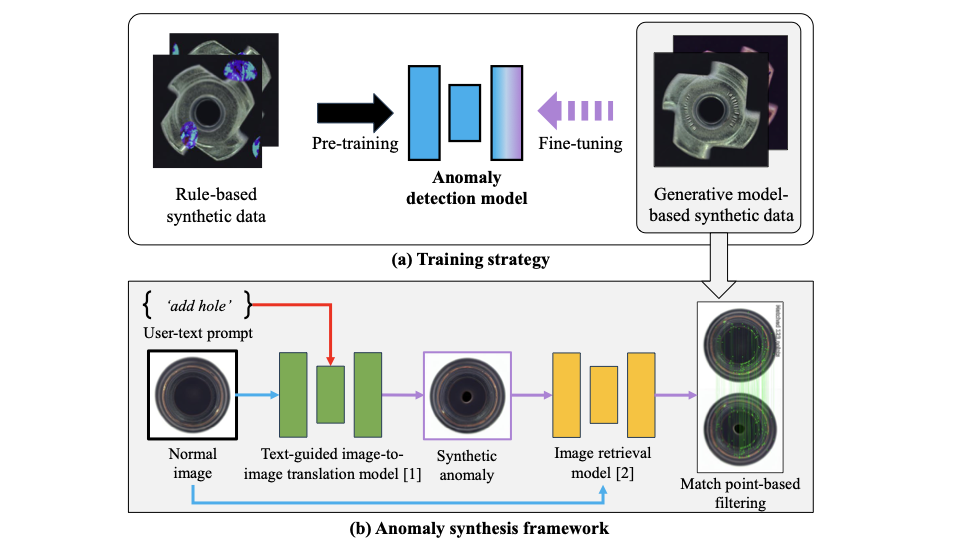
Anomaly detection plays a vital role in industrial manufacturing. Due to the scarcity of real defect images, unsupervised approaches that rely solely on normal images have been extensively studied. Recently, diffusion-based generative models brought attention to training data synthesis as an alternative solution. In this work, we focus on a strategy to effectively leverage synthetic images to maximize the anomaly detection performance. Previous synthesis strategies are broadly categorized into two groups, presenting a clear trade-off. Rule-based synthesis, such as injecting noise or pasting patches, is cost-effective but often fails to produce realistic defect images. On the other hand, generative model-based synthesis can create high-quality defect images but requires substantial cost. To address this problem, we propose a novel framework that leverages a pre-trained text-guided image-to-image translation model and image retrieval model to efficiently generate synthetic defect images. Specifically, the image retrieval model assesses the similarity of the generated images to real normal images and filters out irrelevant outputs, thereby enhancing the quality and relevance of the generated defect images. To effectively leverage synthetic images, we also introduce a two stage training strategy. In this strategy, the model is first pre-trained on a large volume of images from rule-based synthesis and then fine-tuned on a smaller set of high-quality images. This method significantly reduces the cost for data collection while improving the anomaly detection performance. Experiments on the MVTec AD dataset demonstrate the effectiveness of our approach.