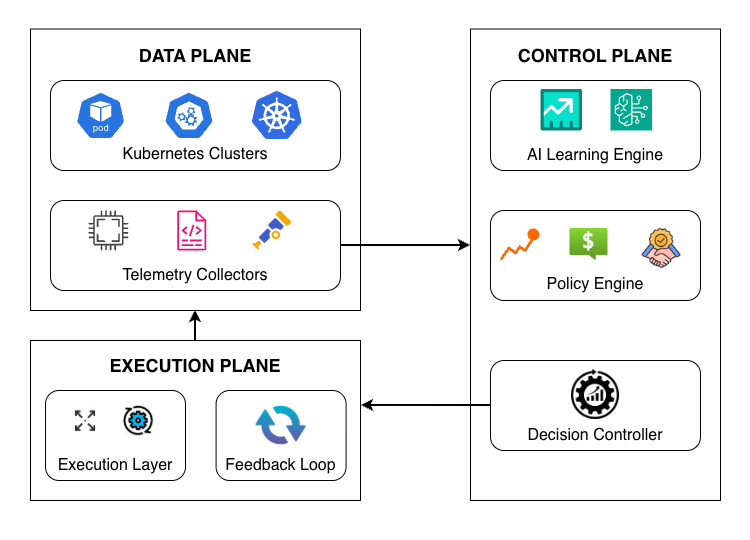
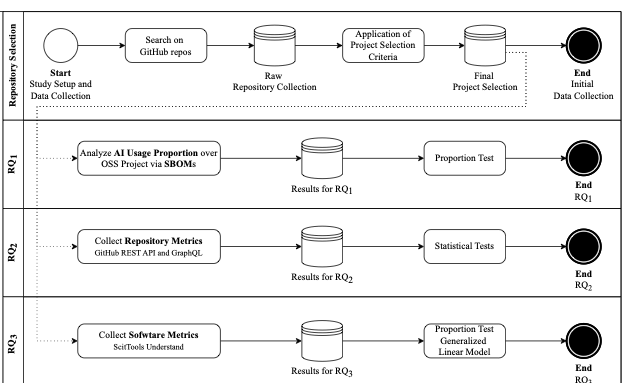
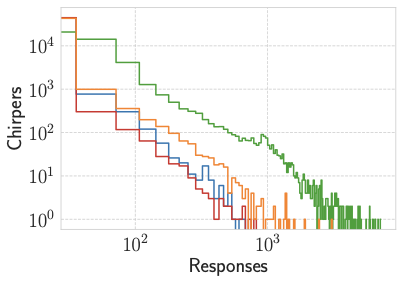
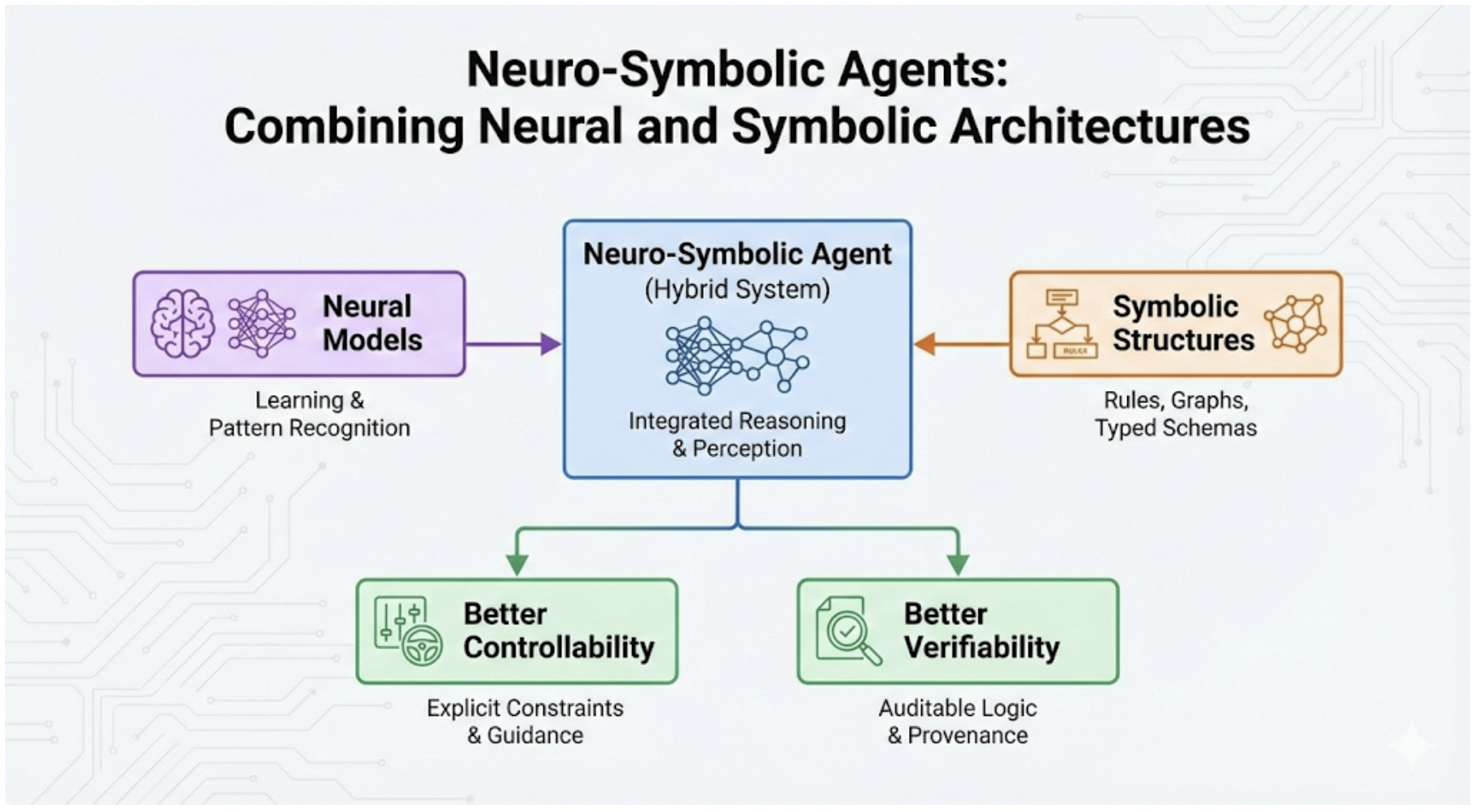
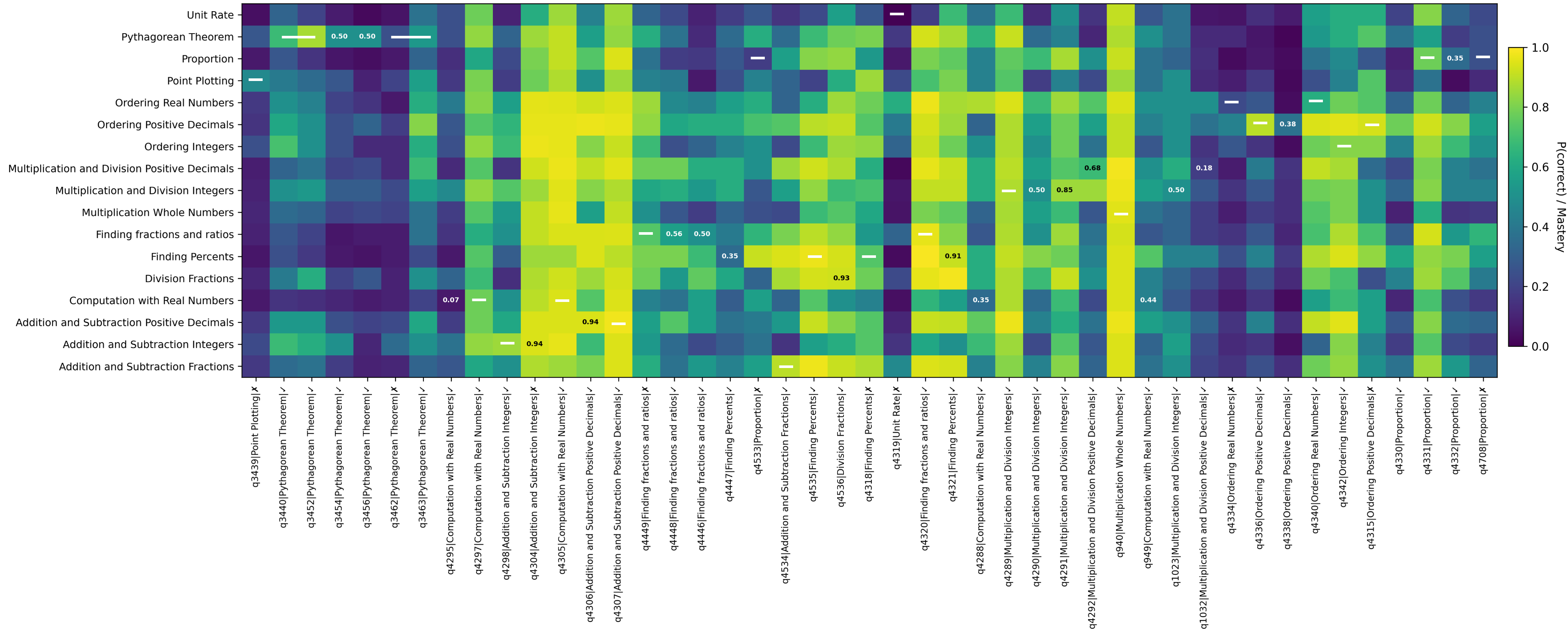
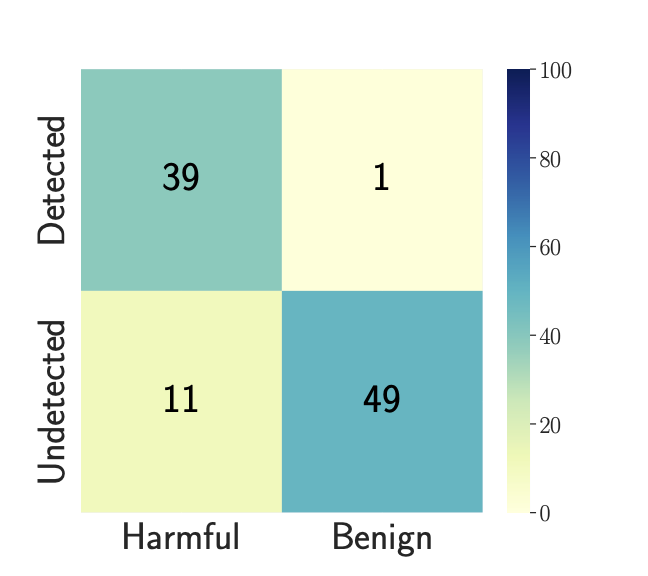
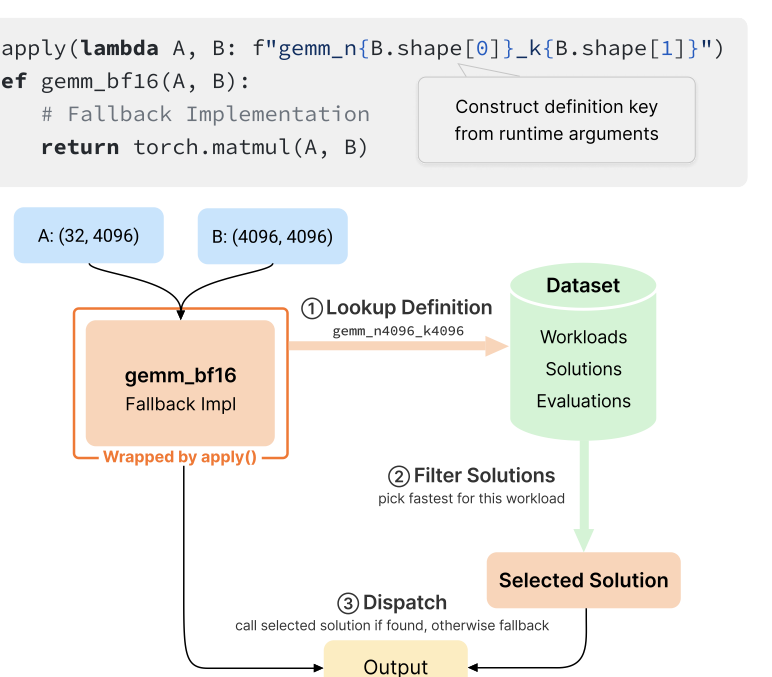
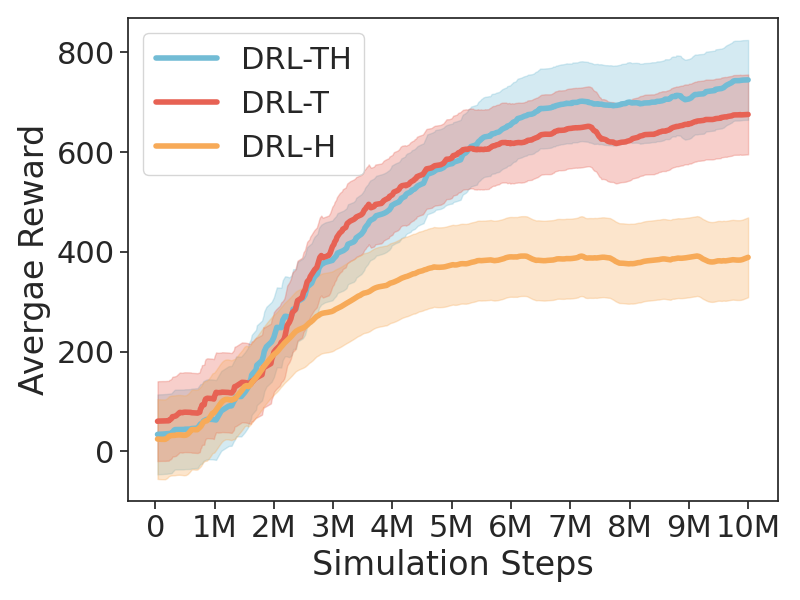
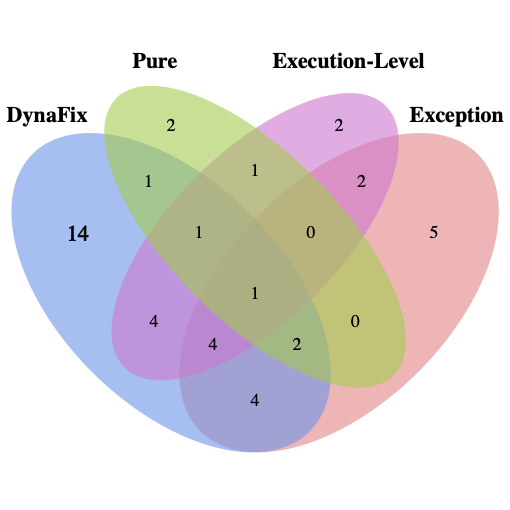
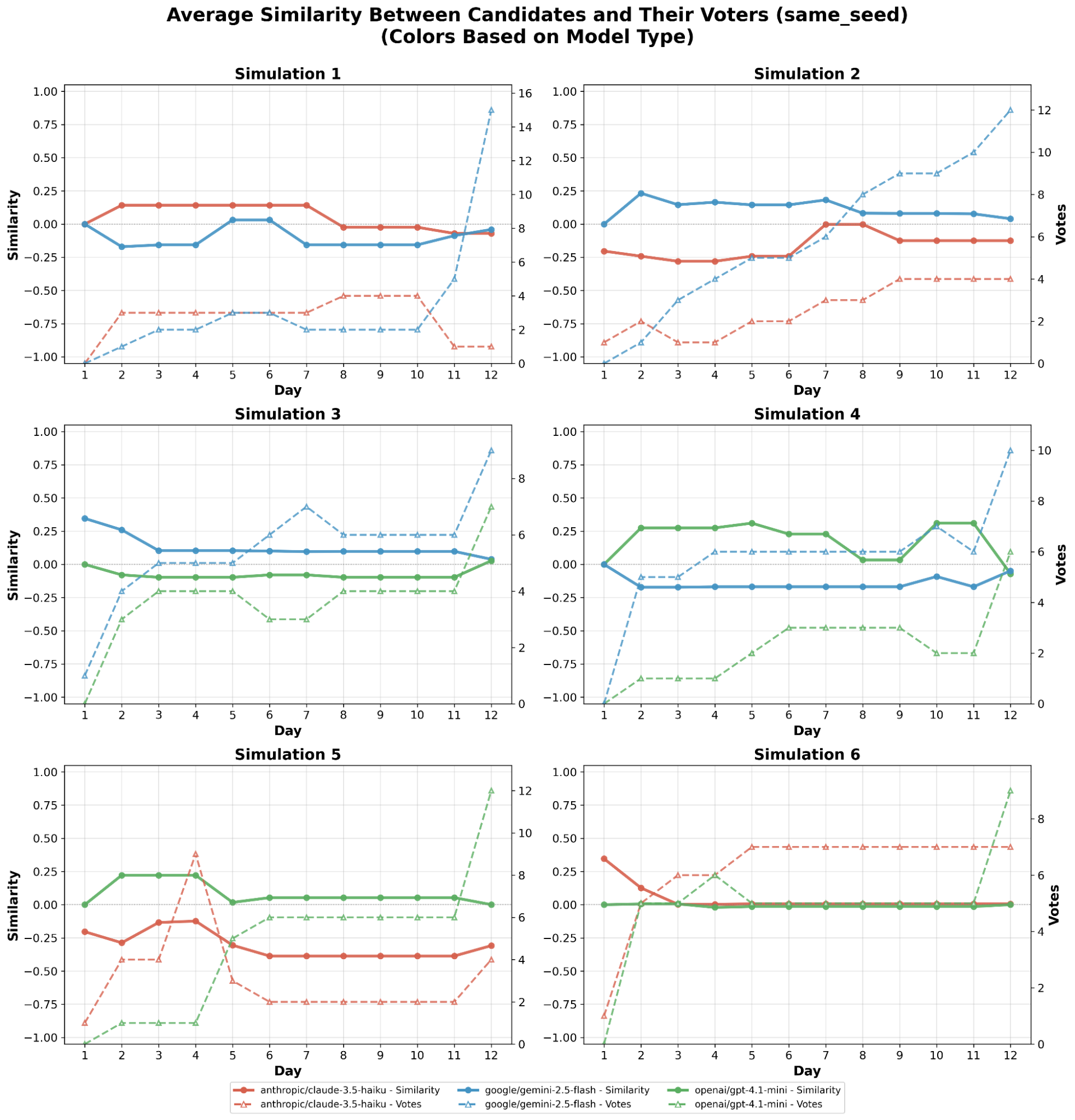
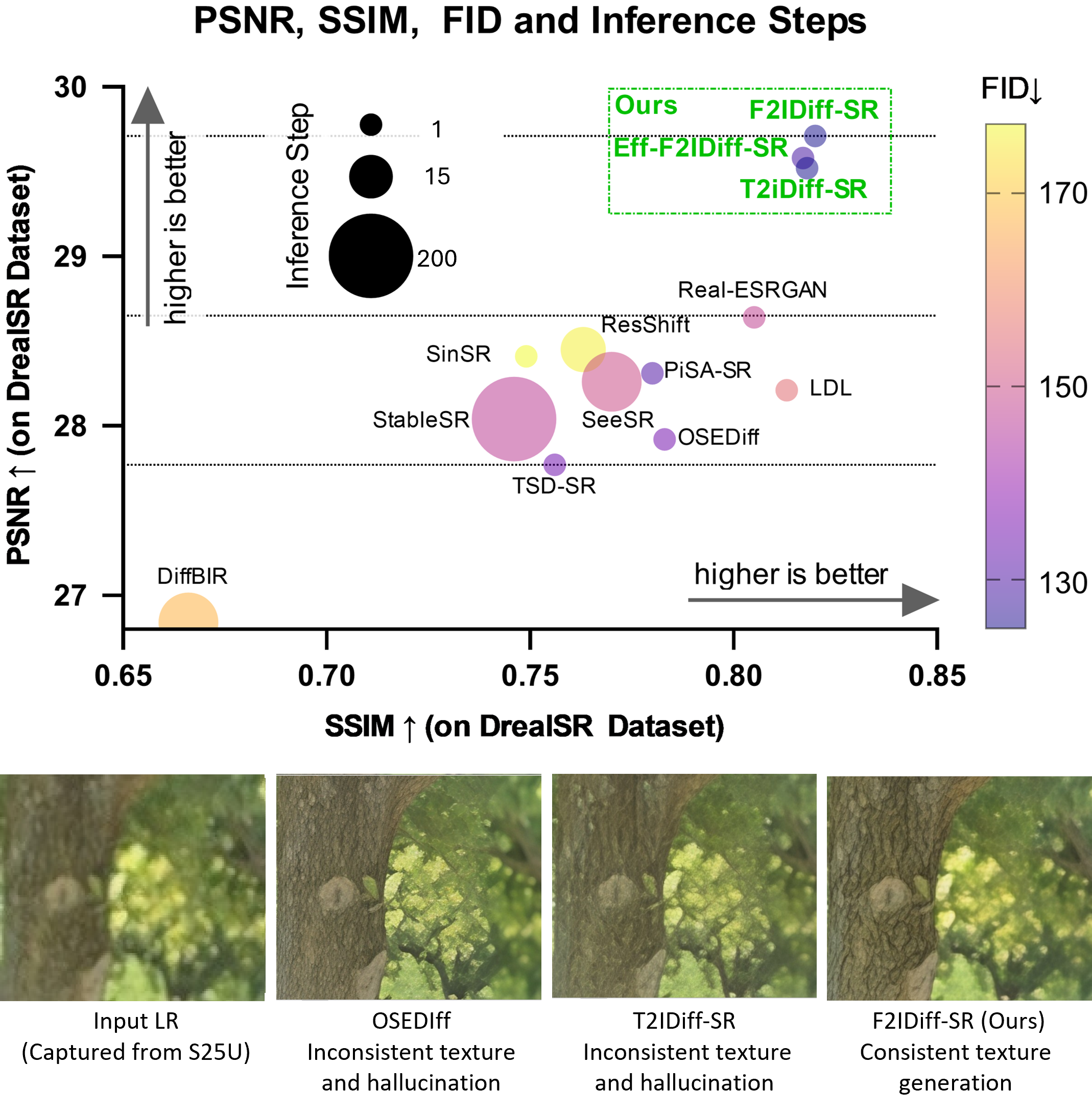
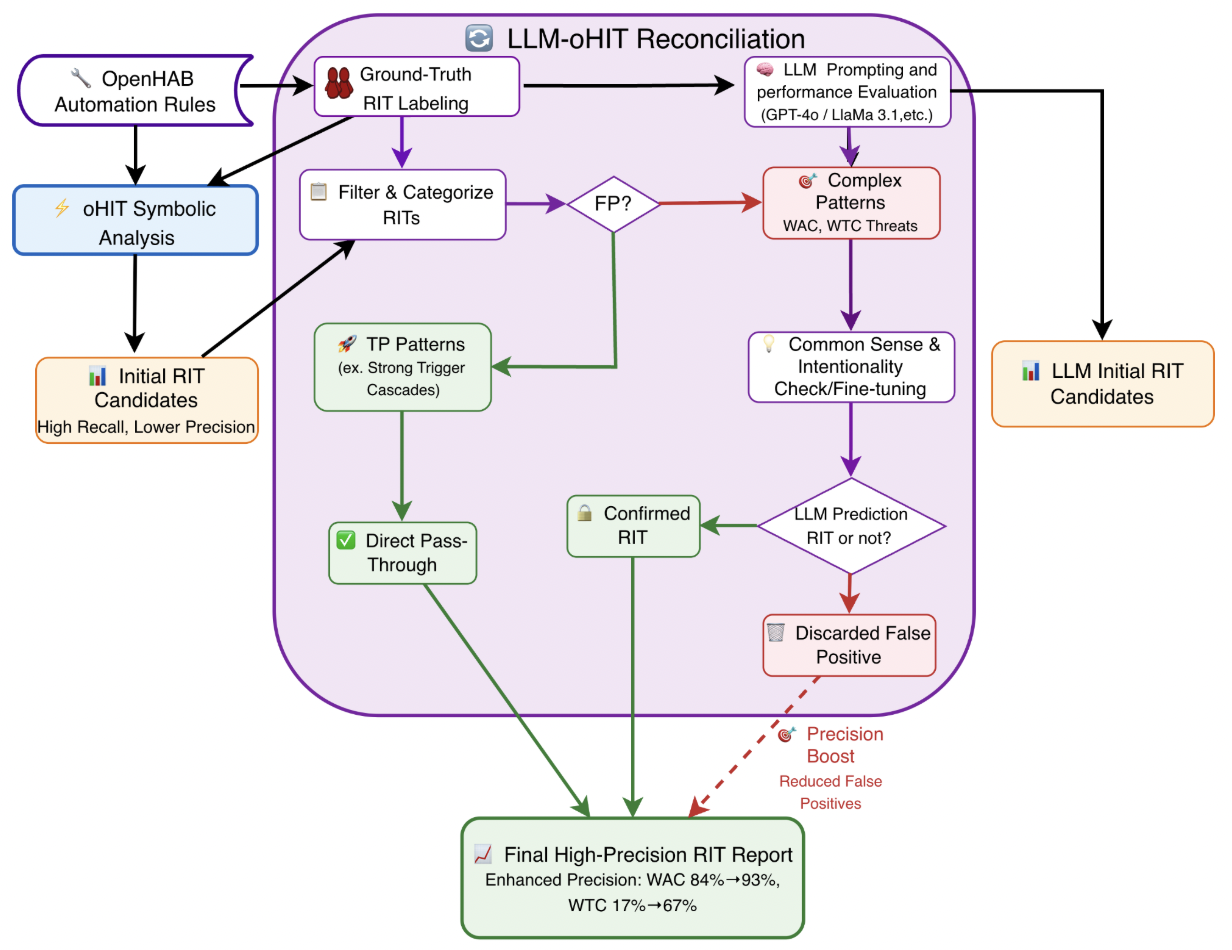
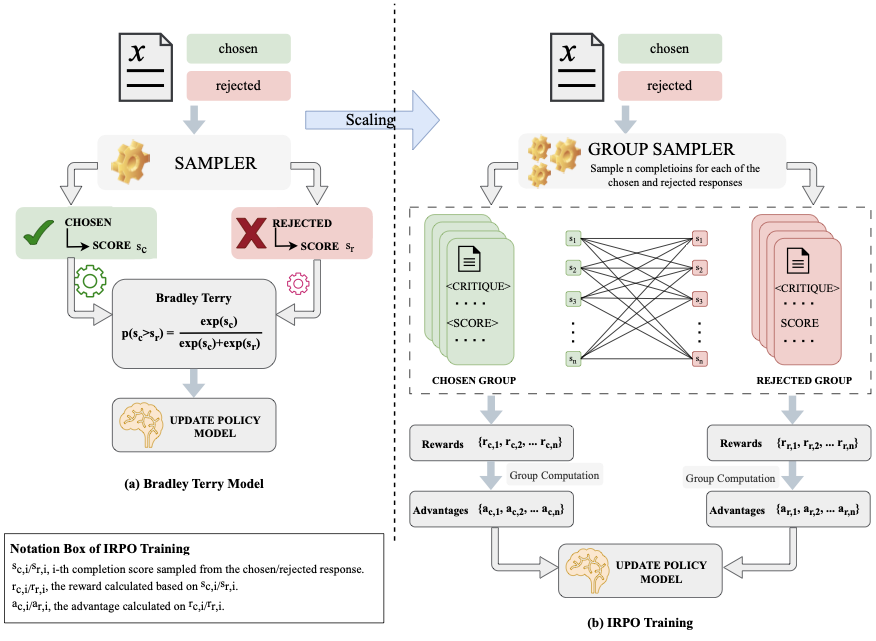
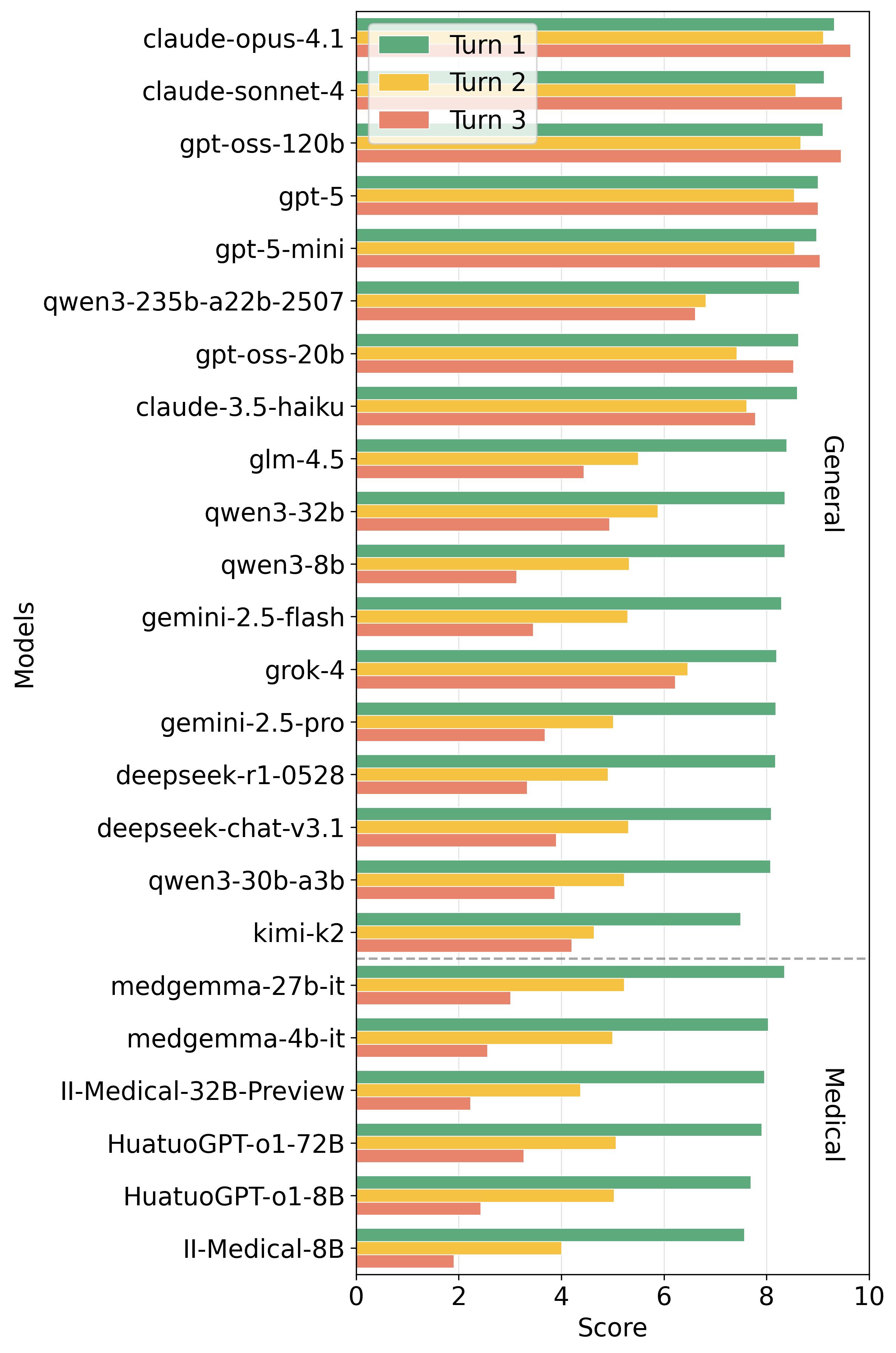
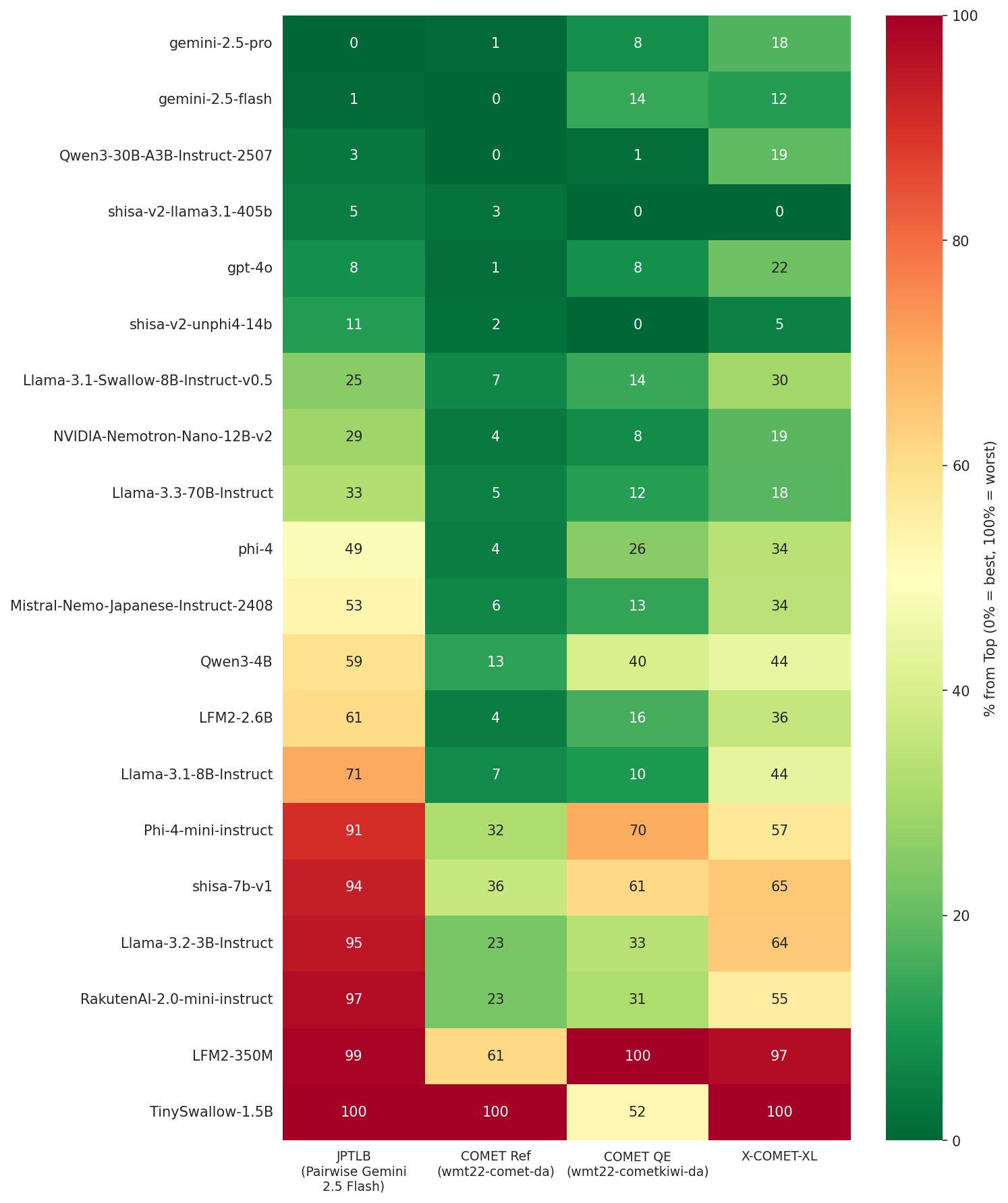
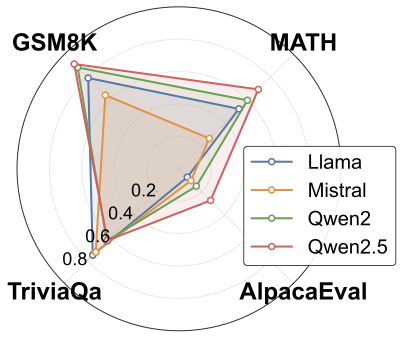
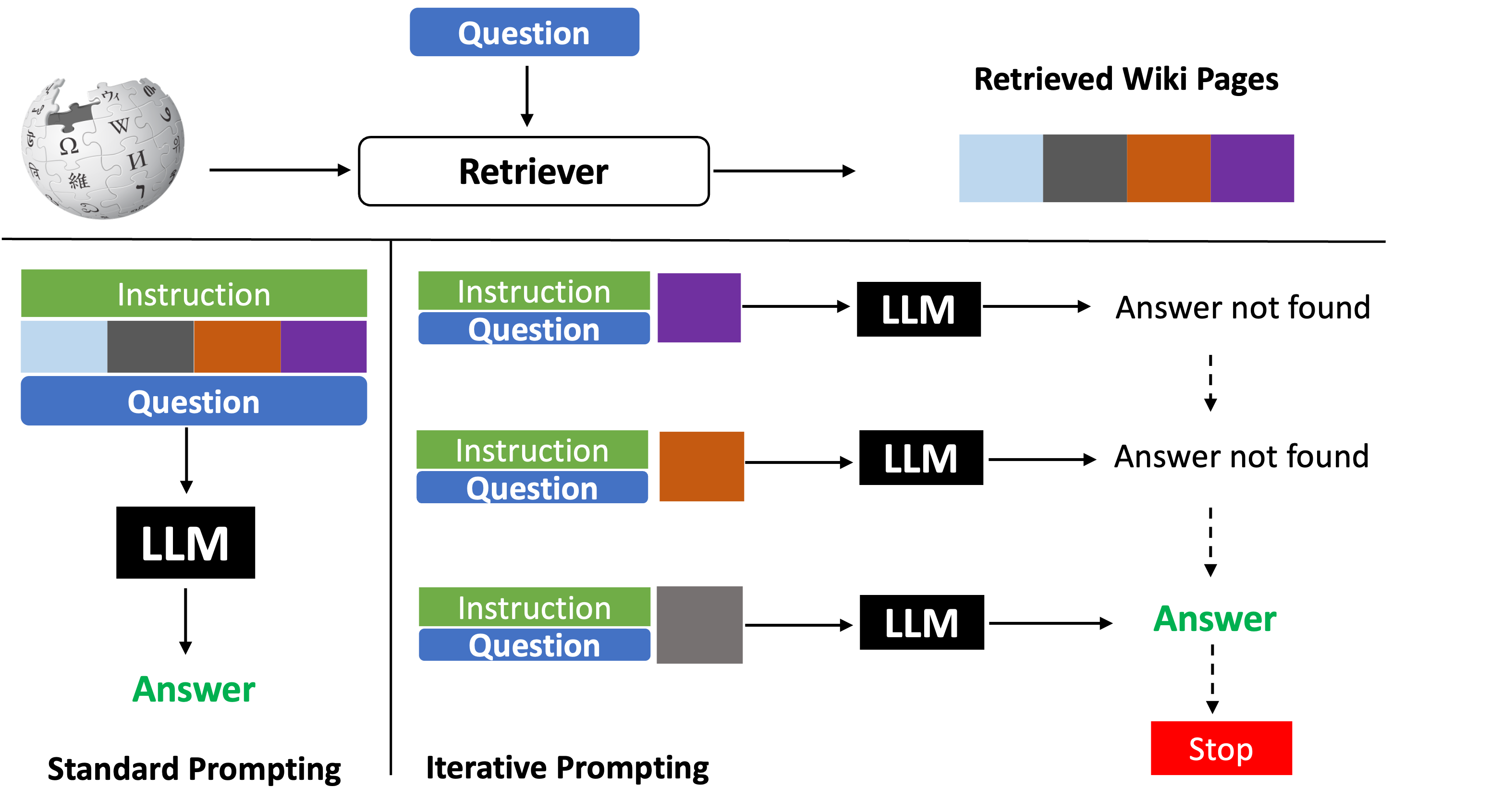
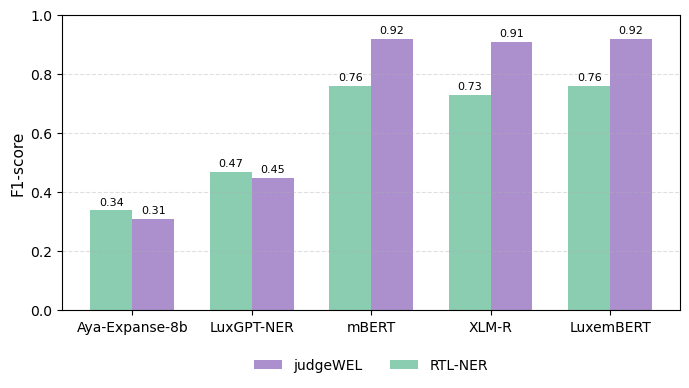
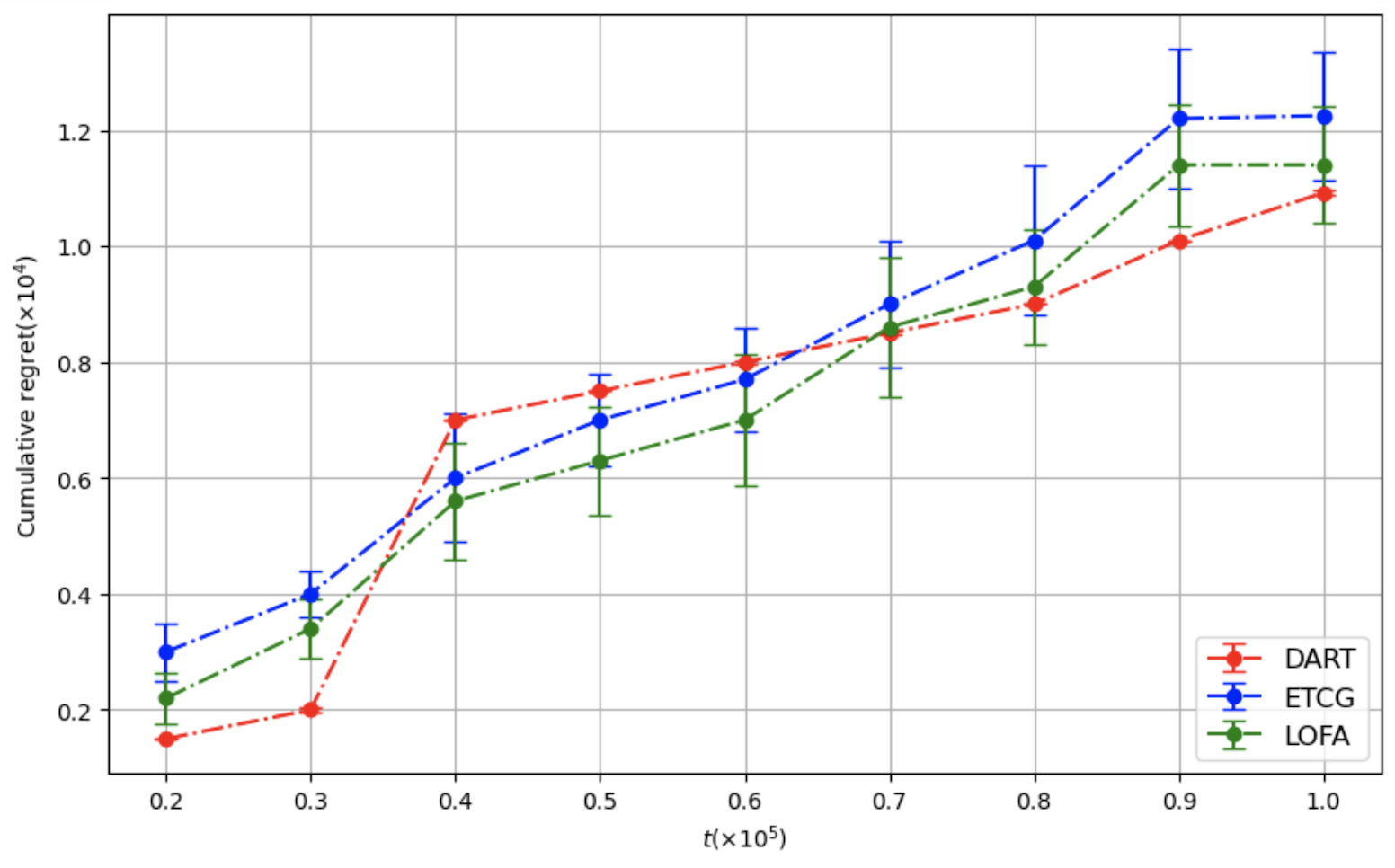
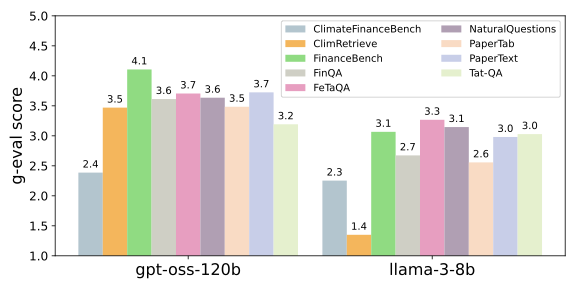
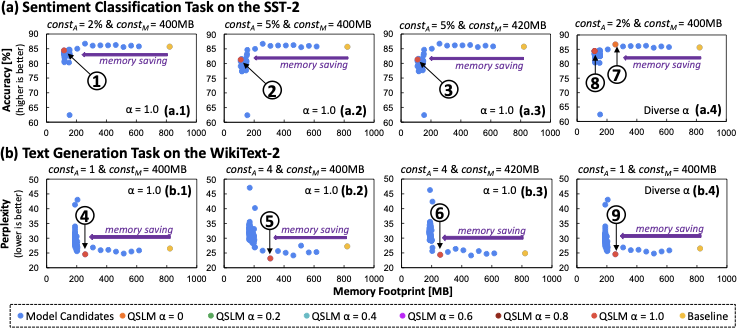
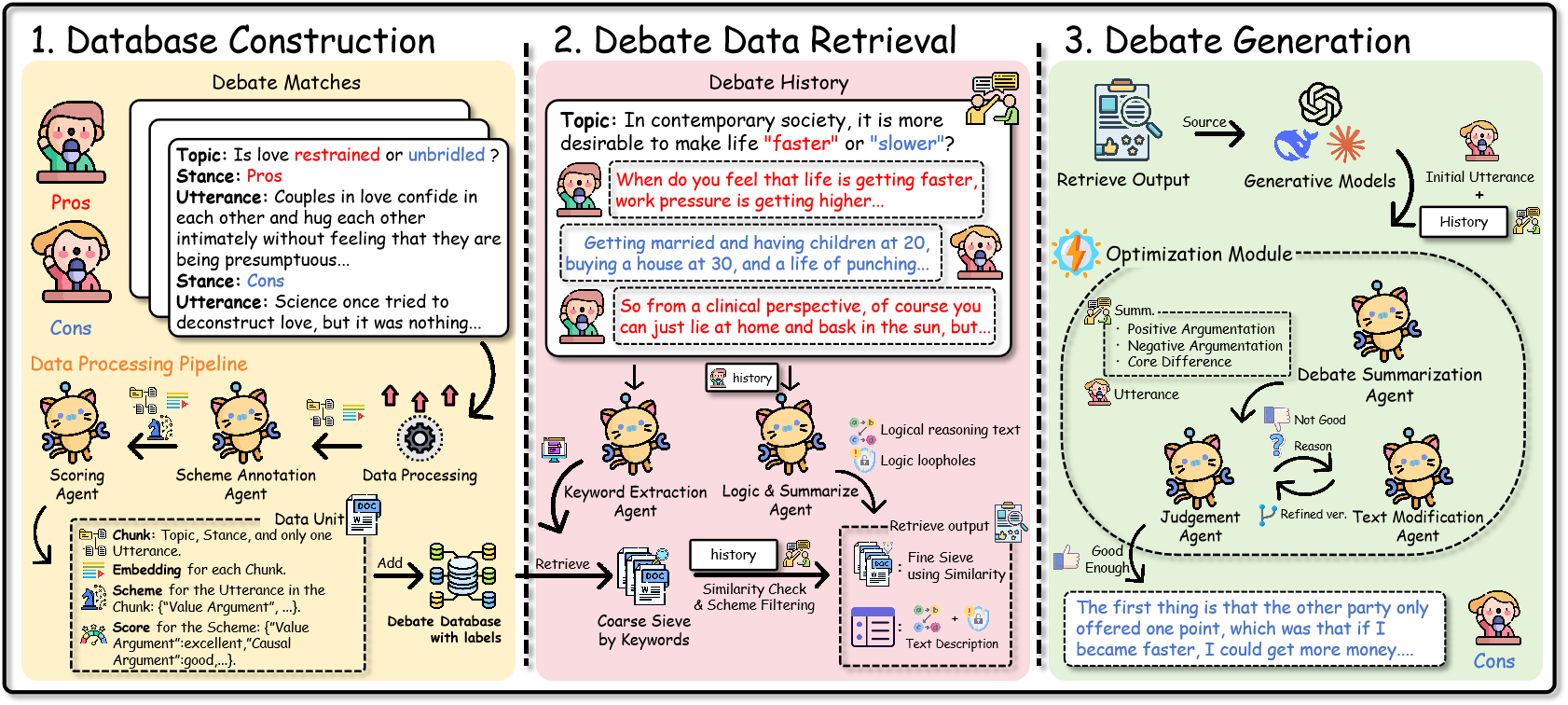
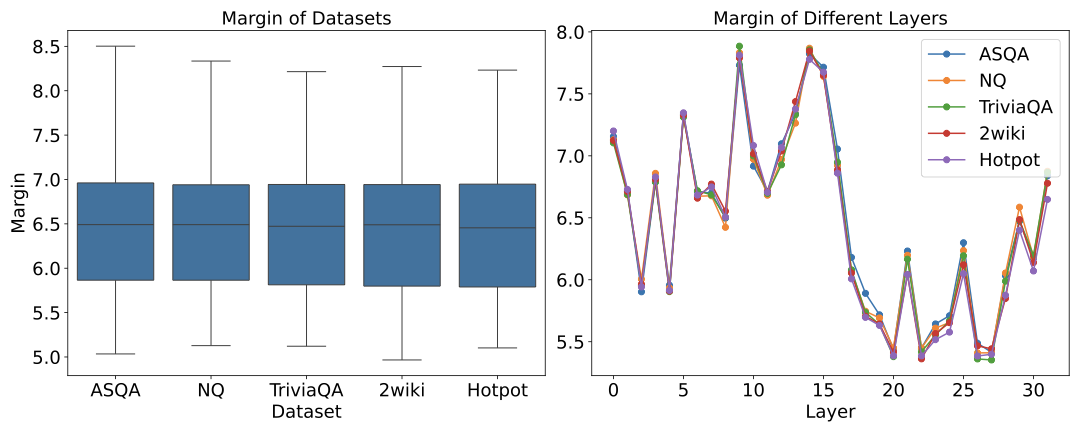
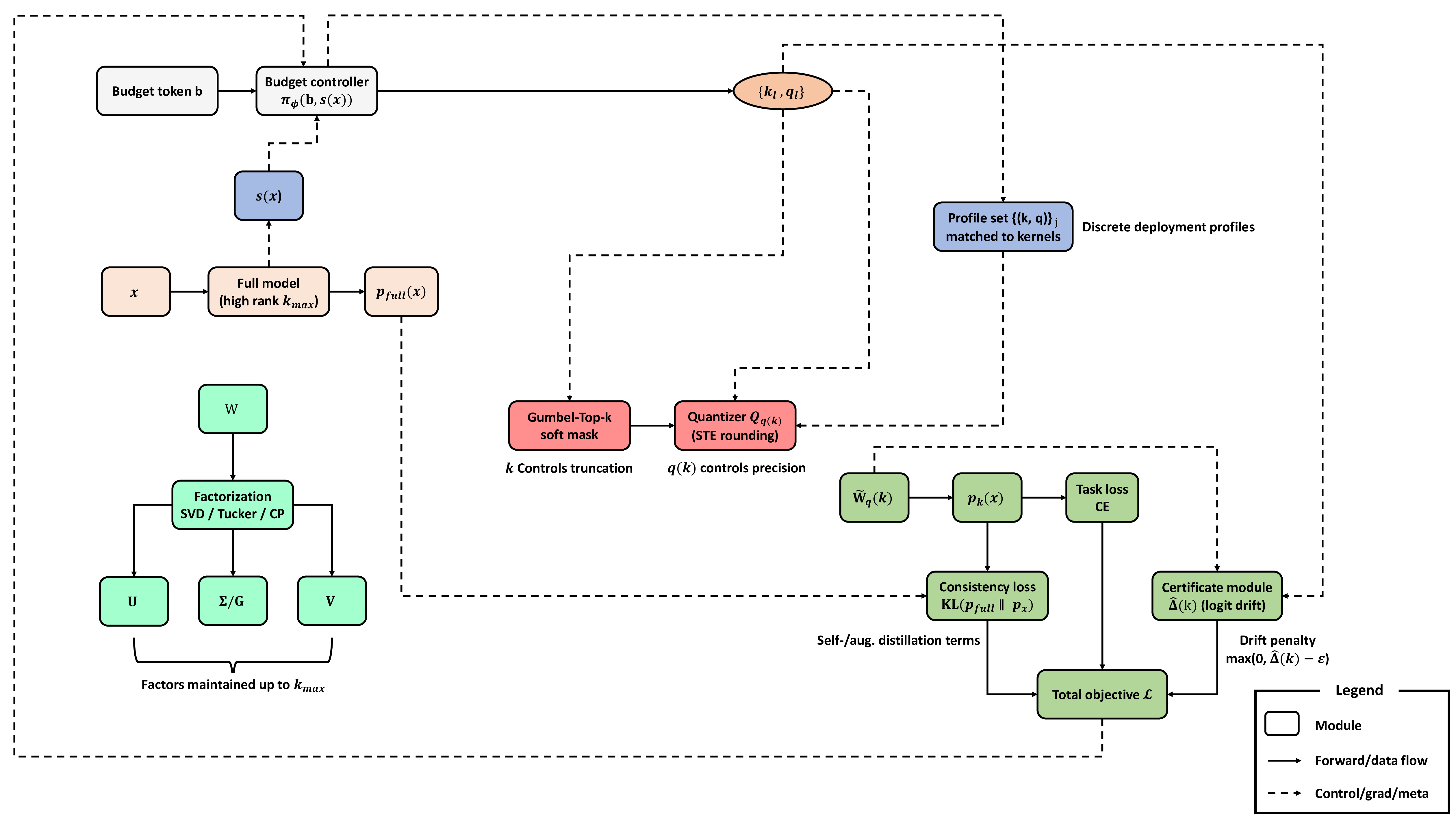
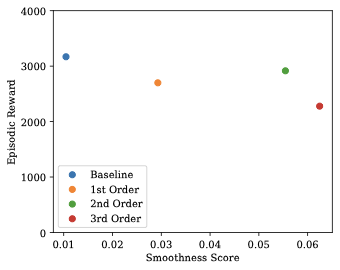
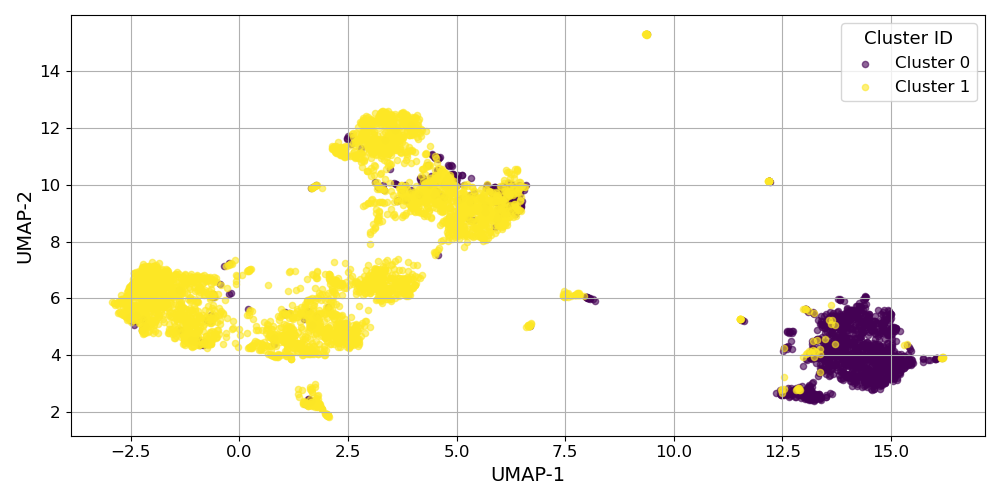
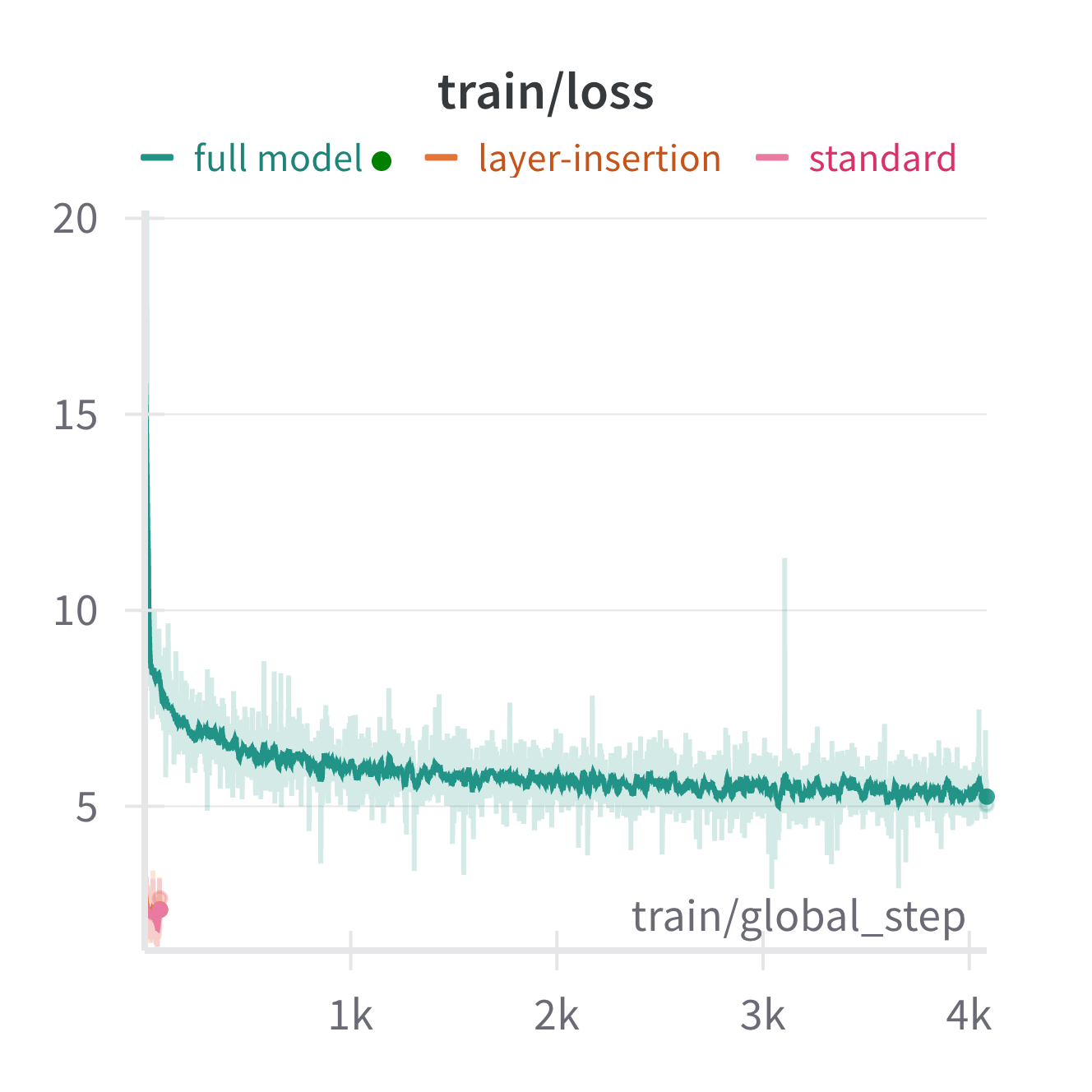
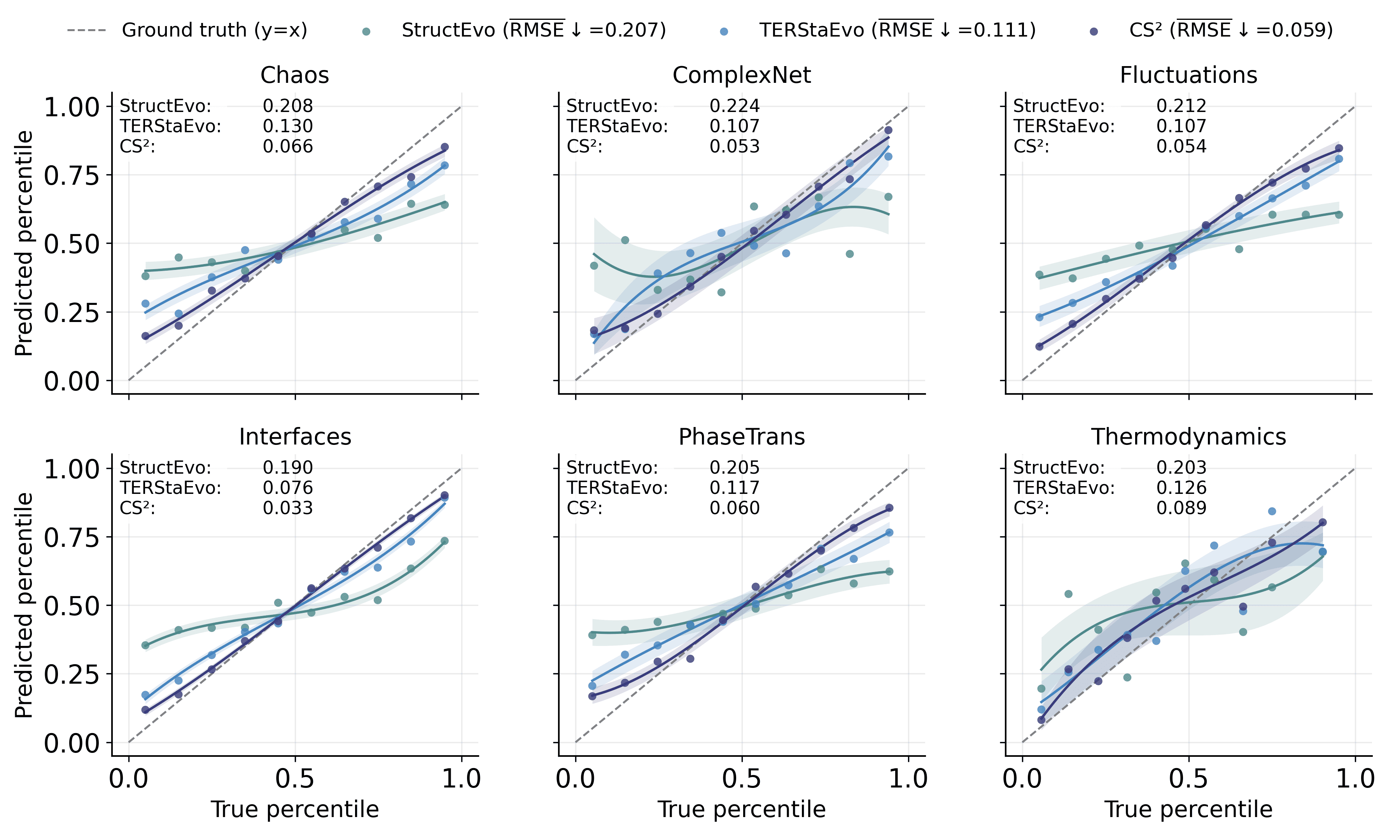
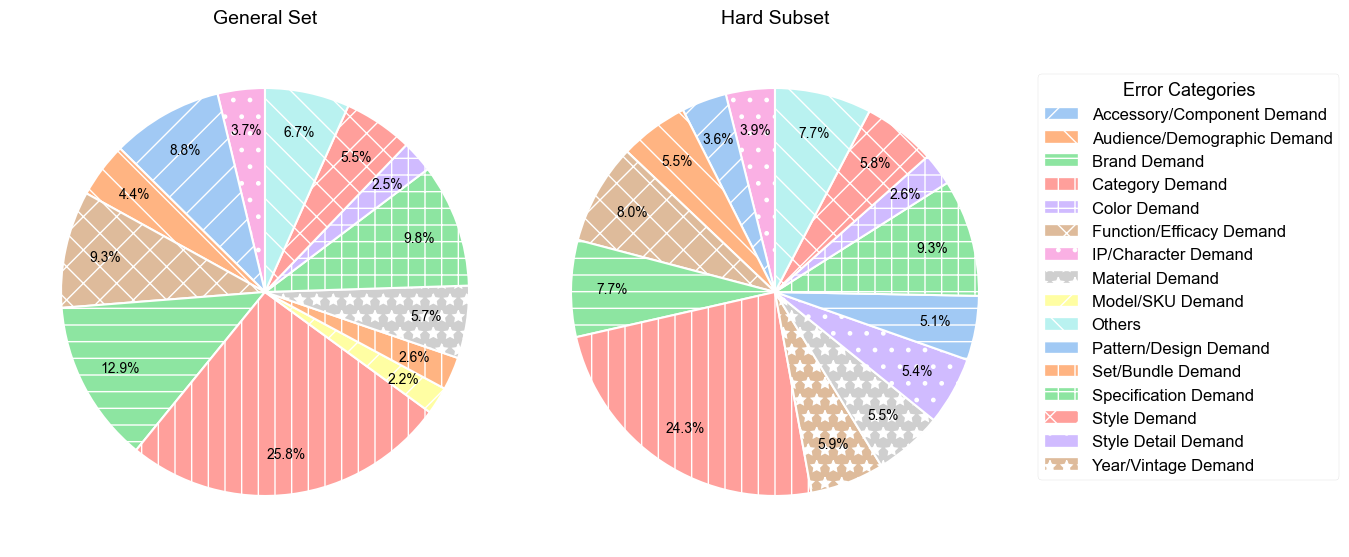
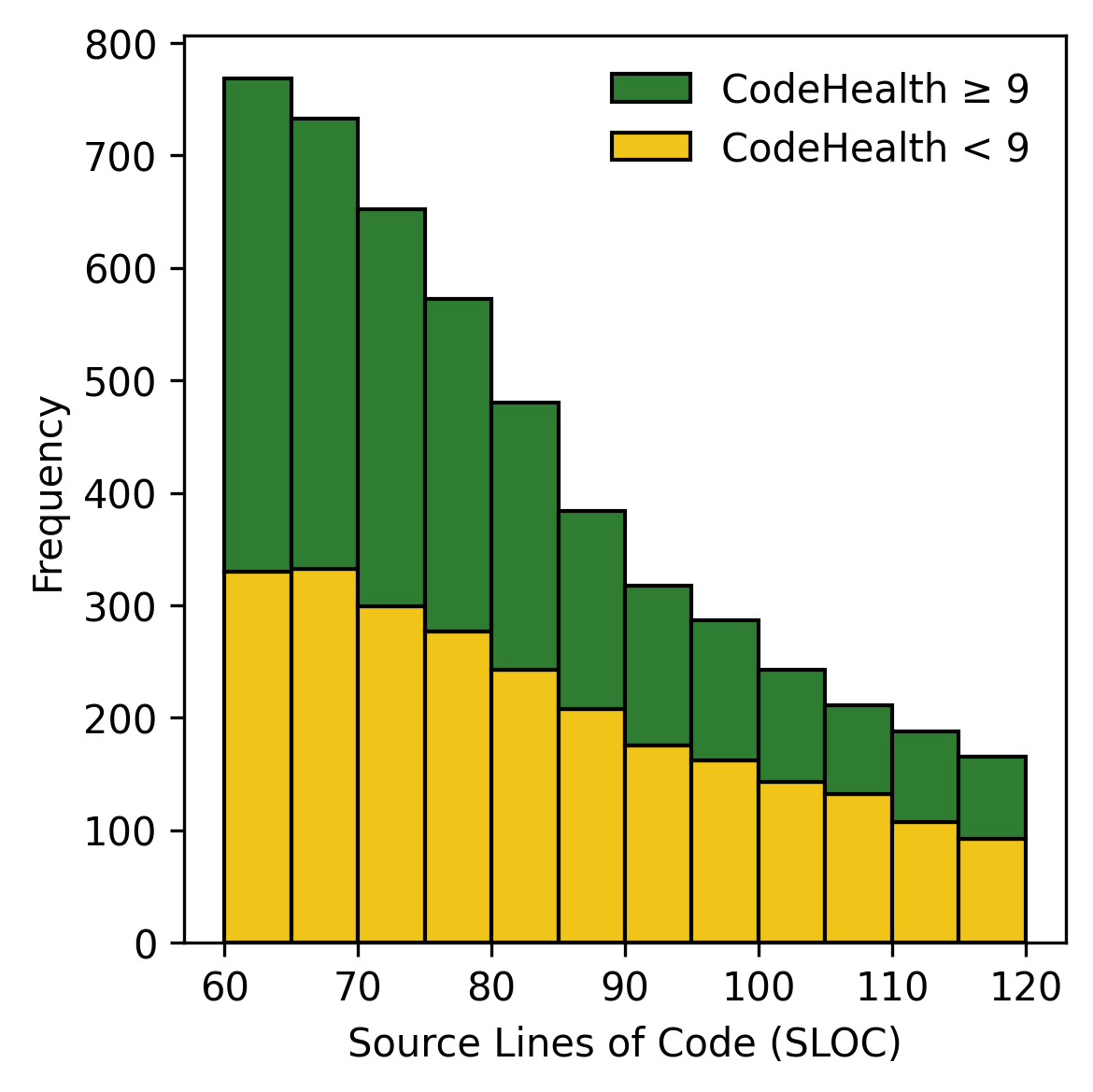
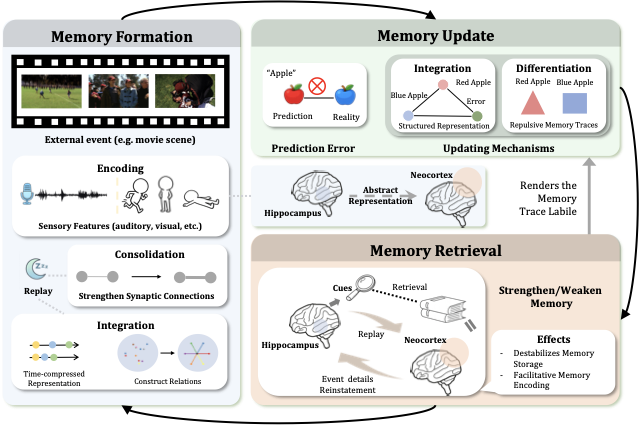
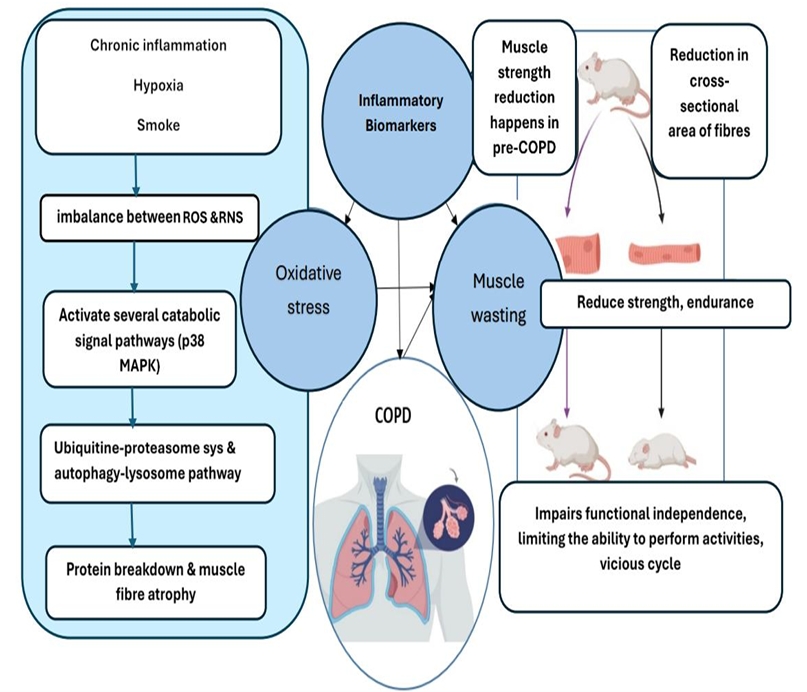
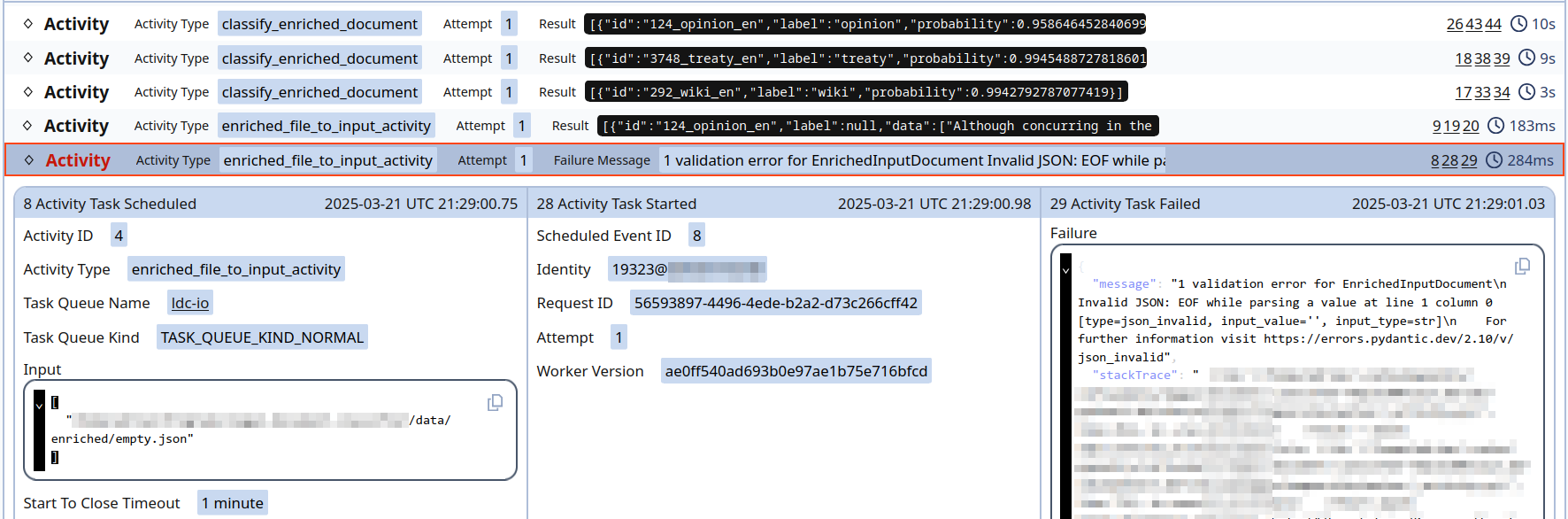
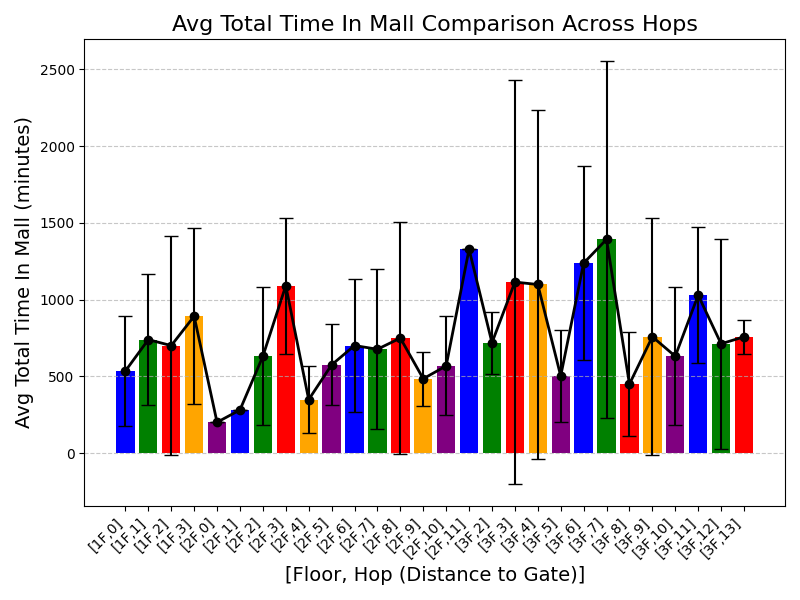
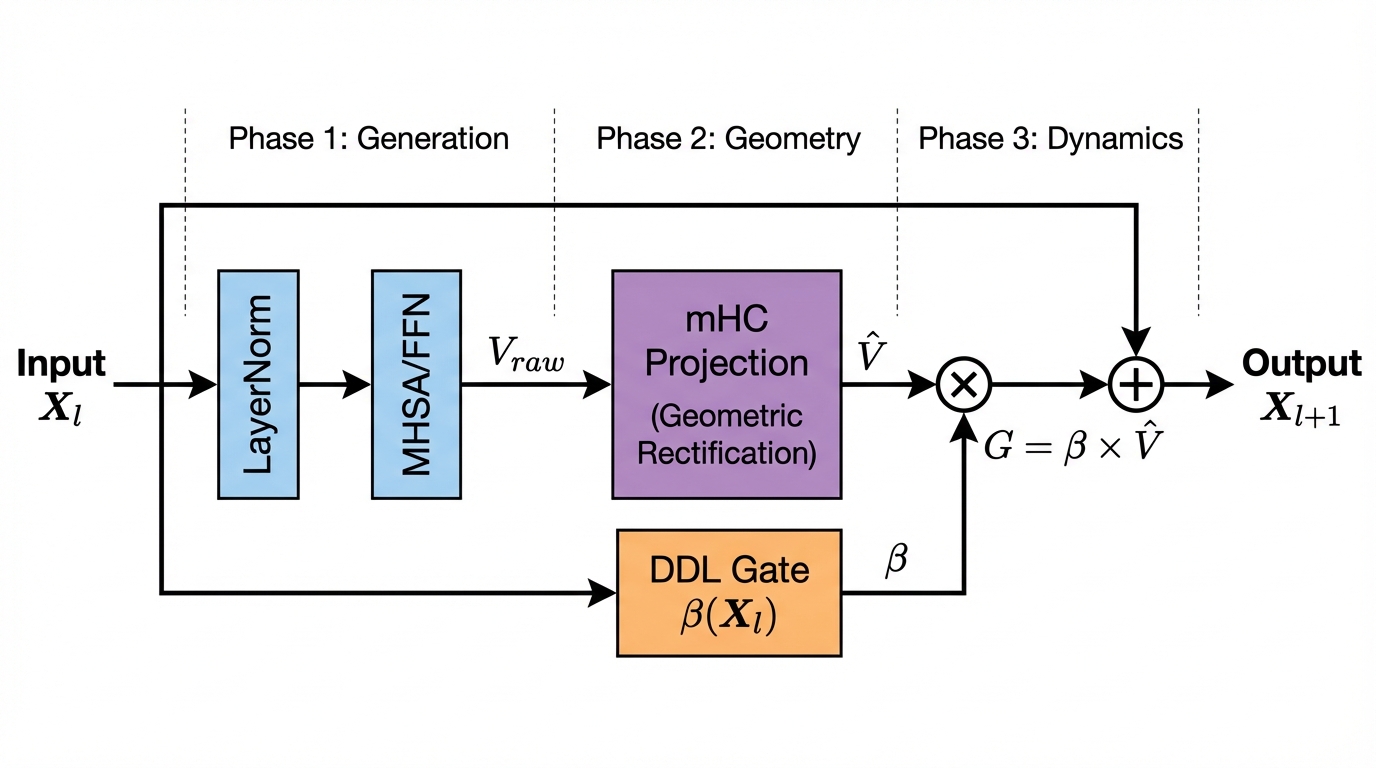
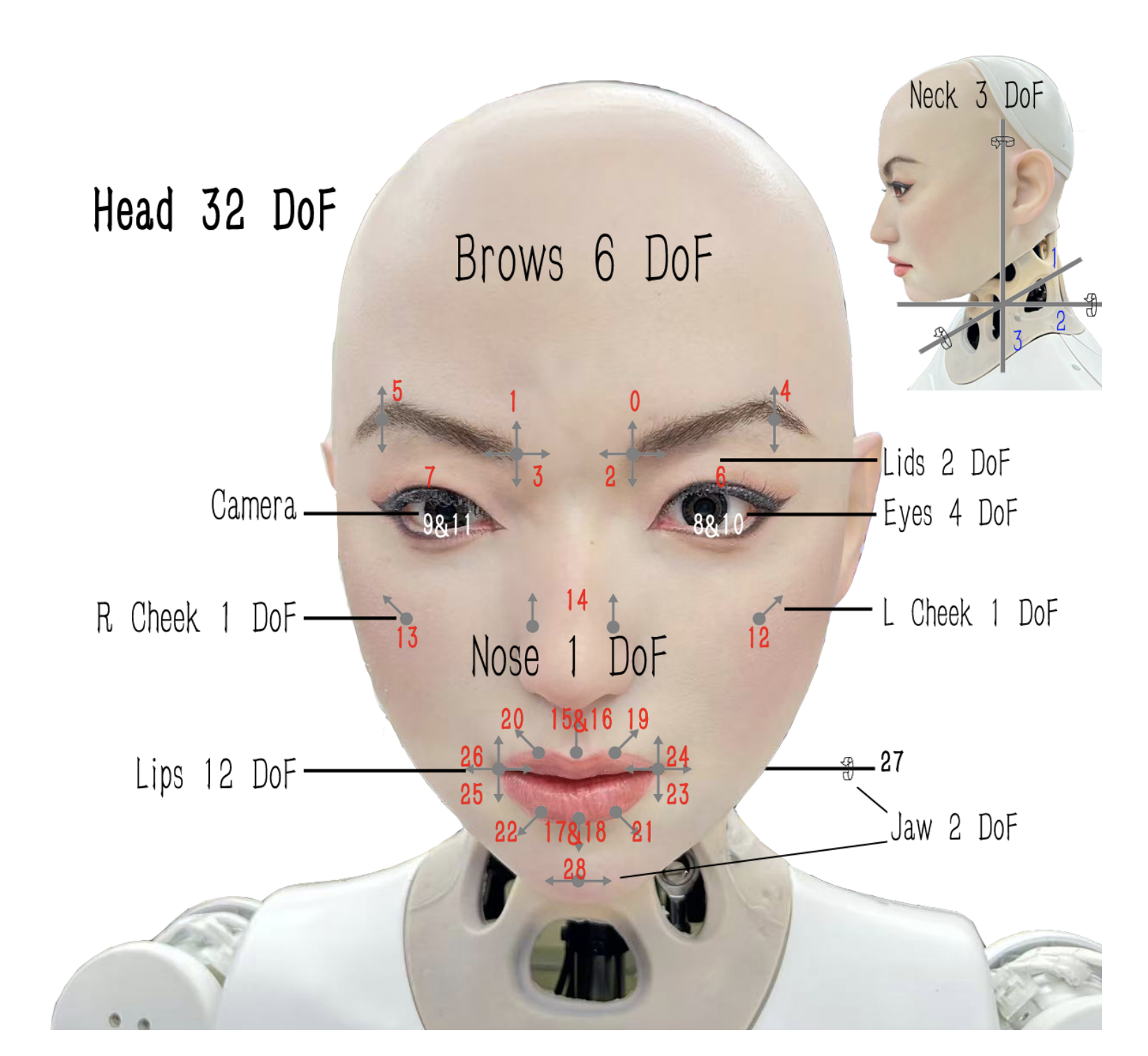
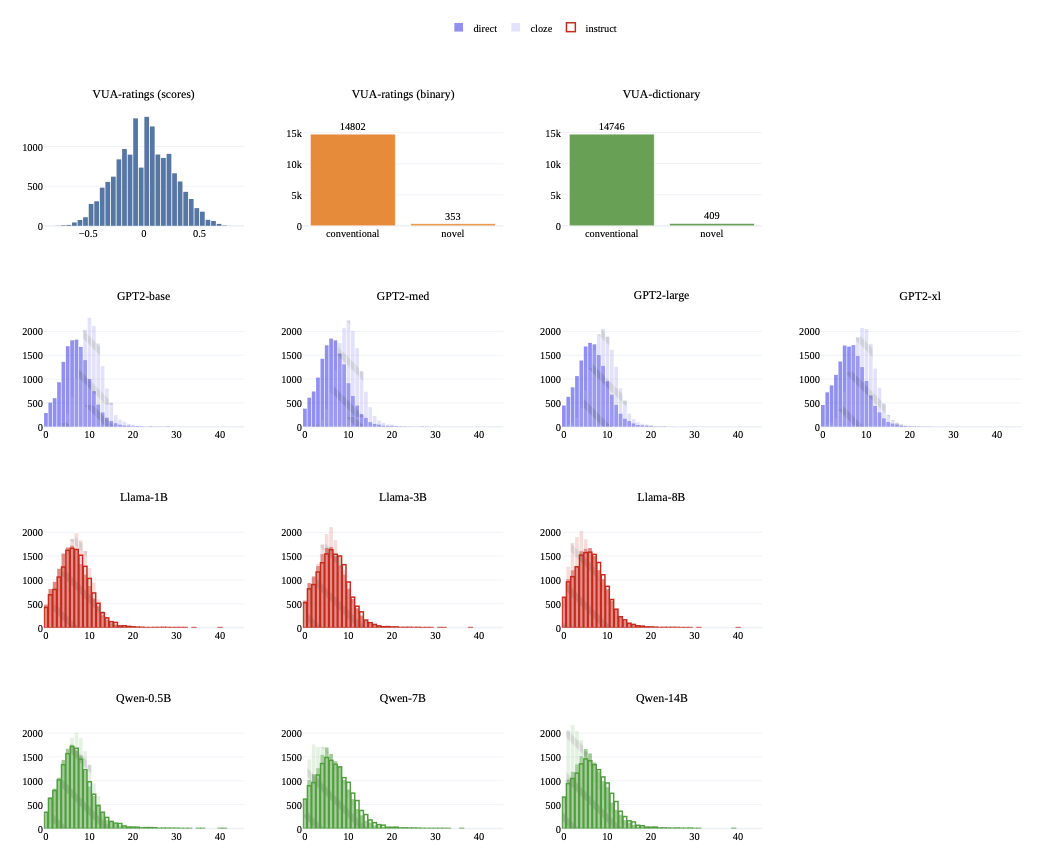
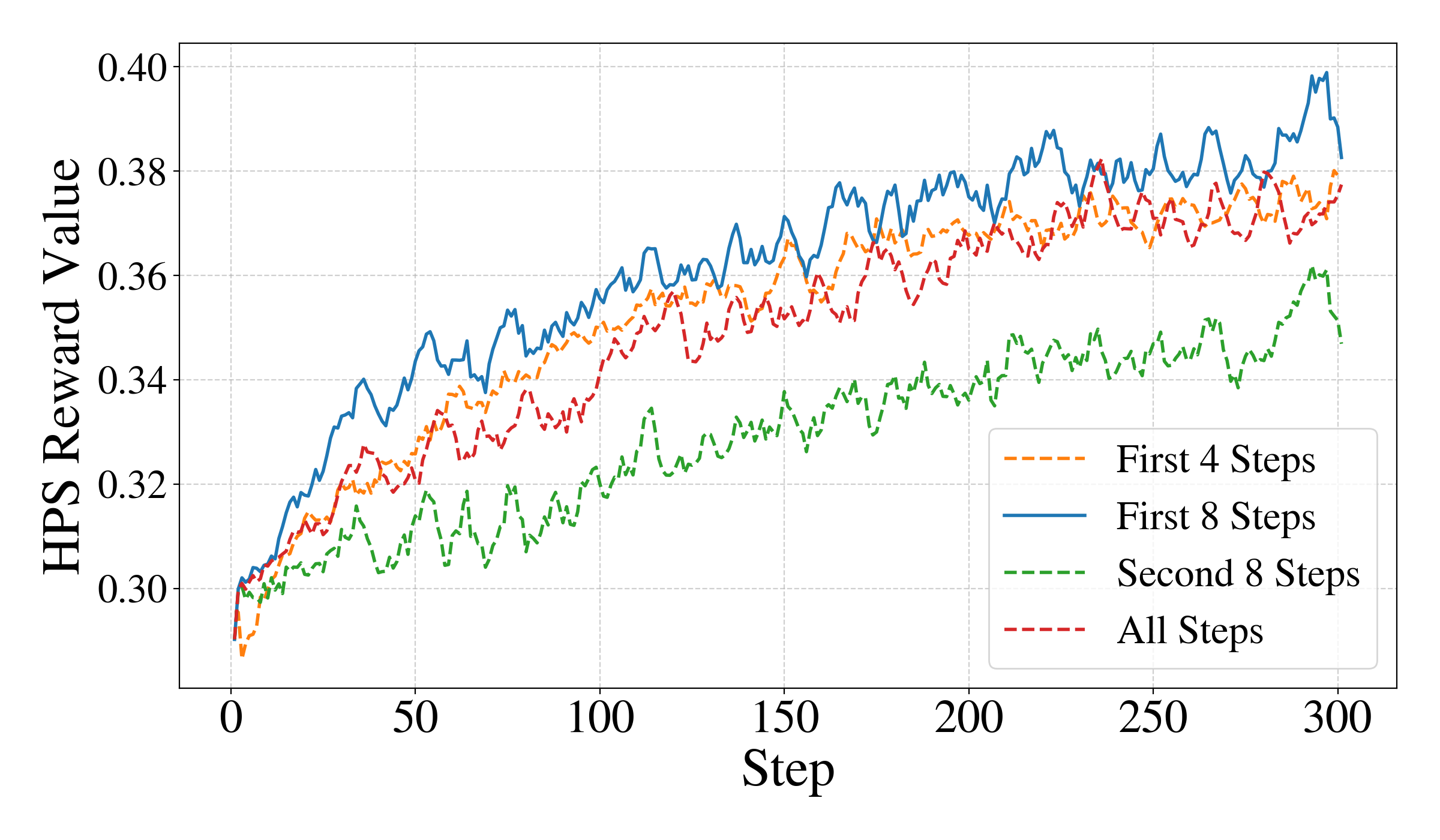
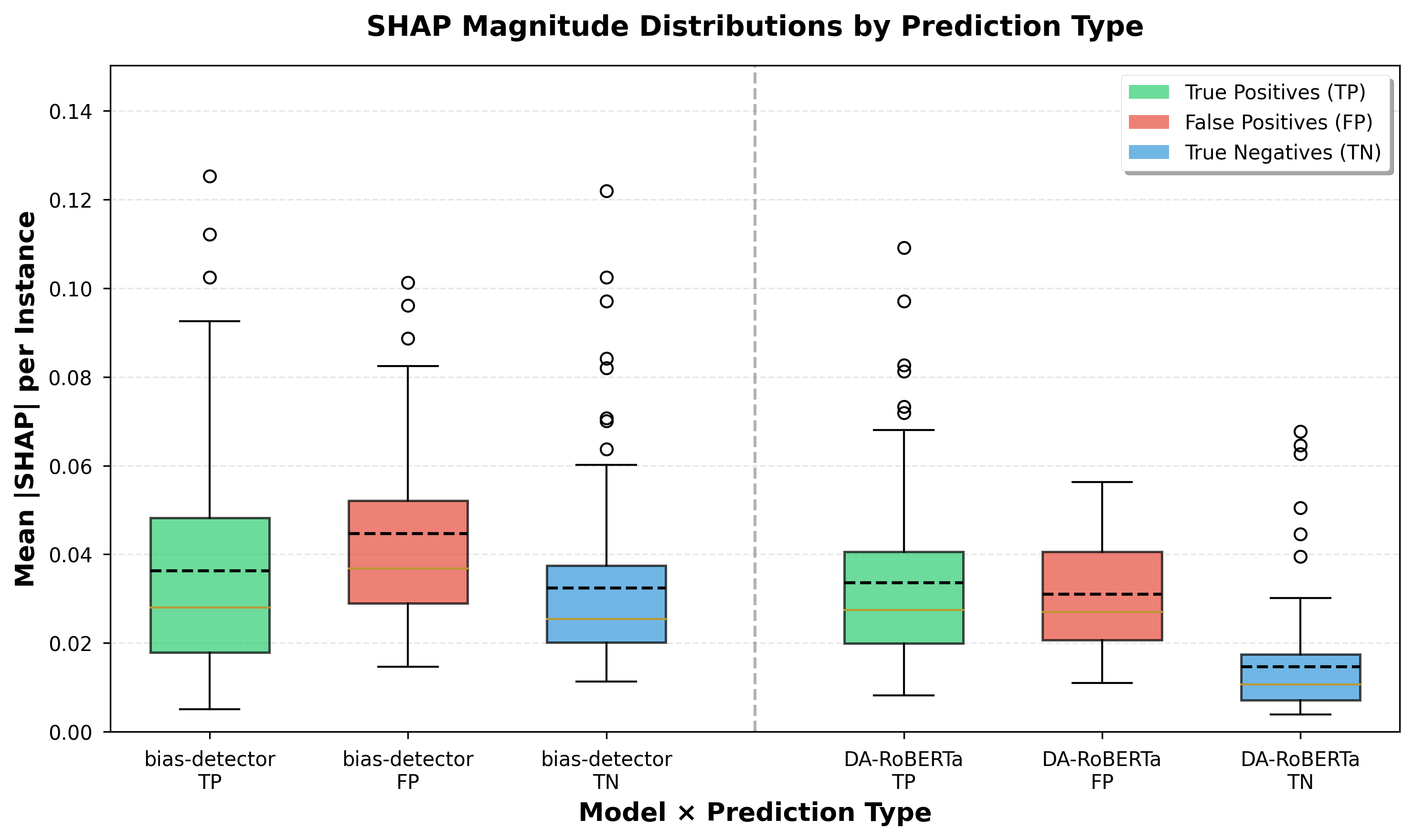
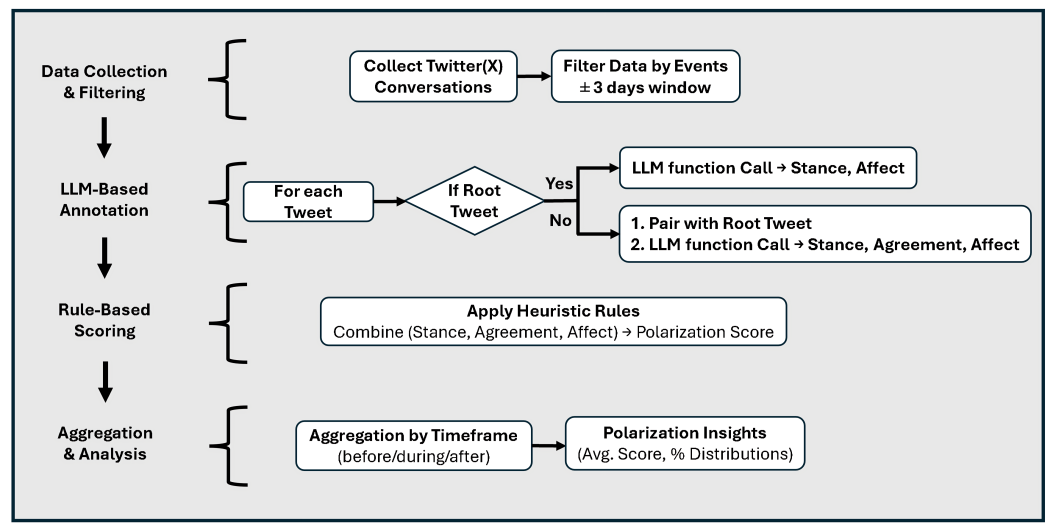
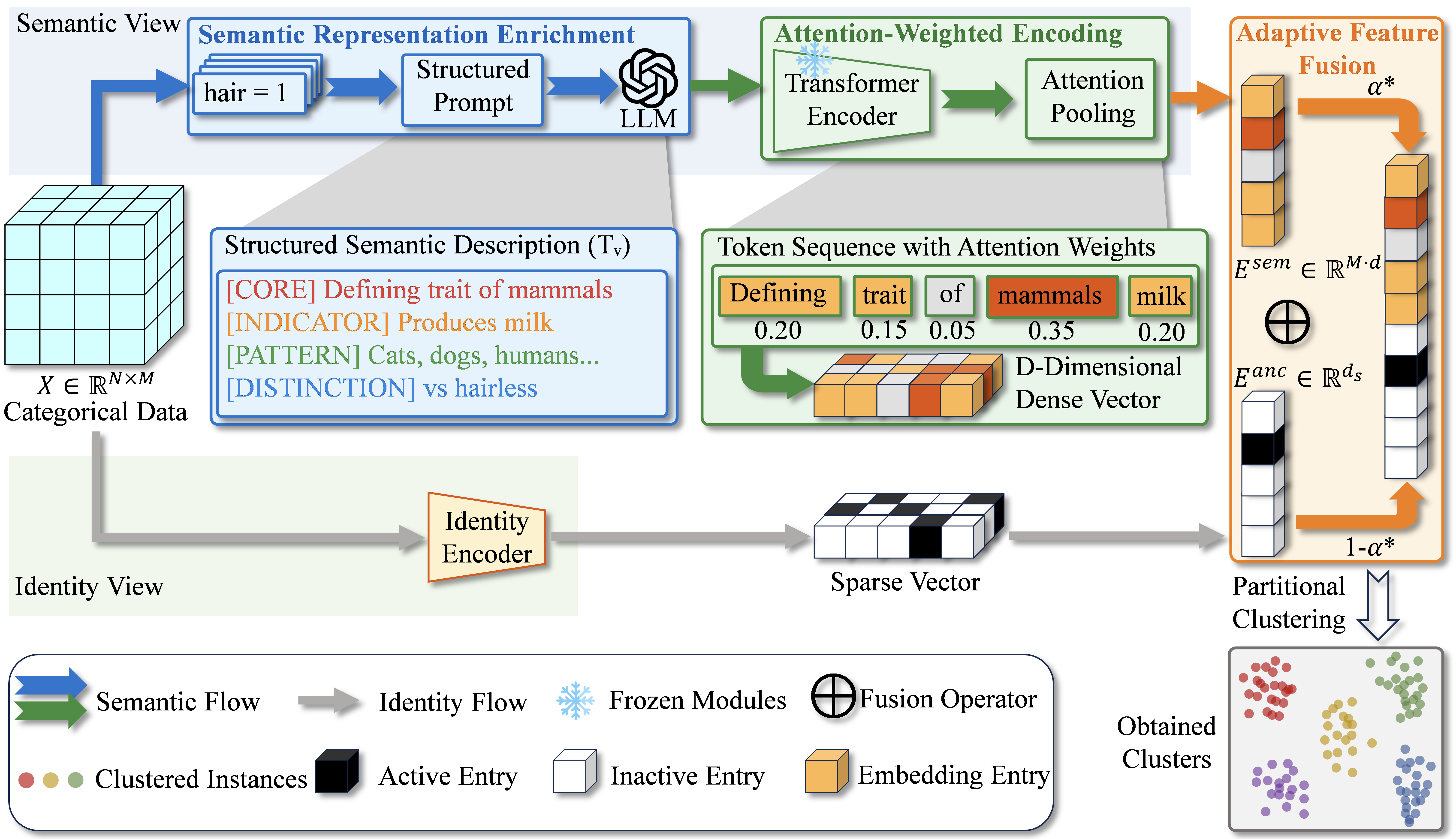
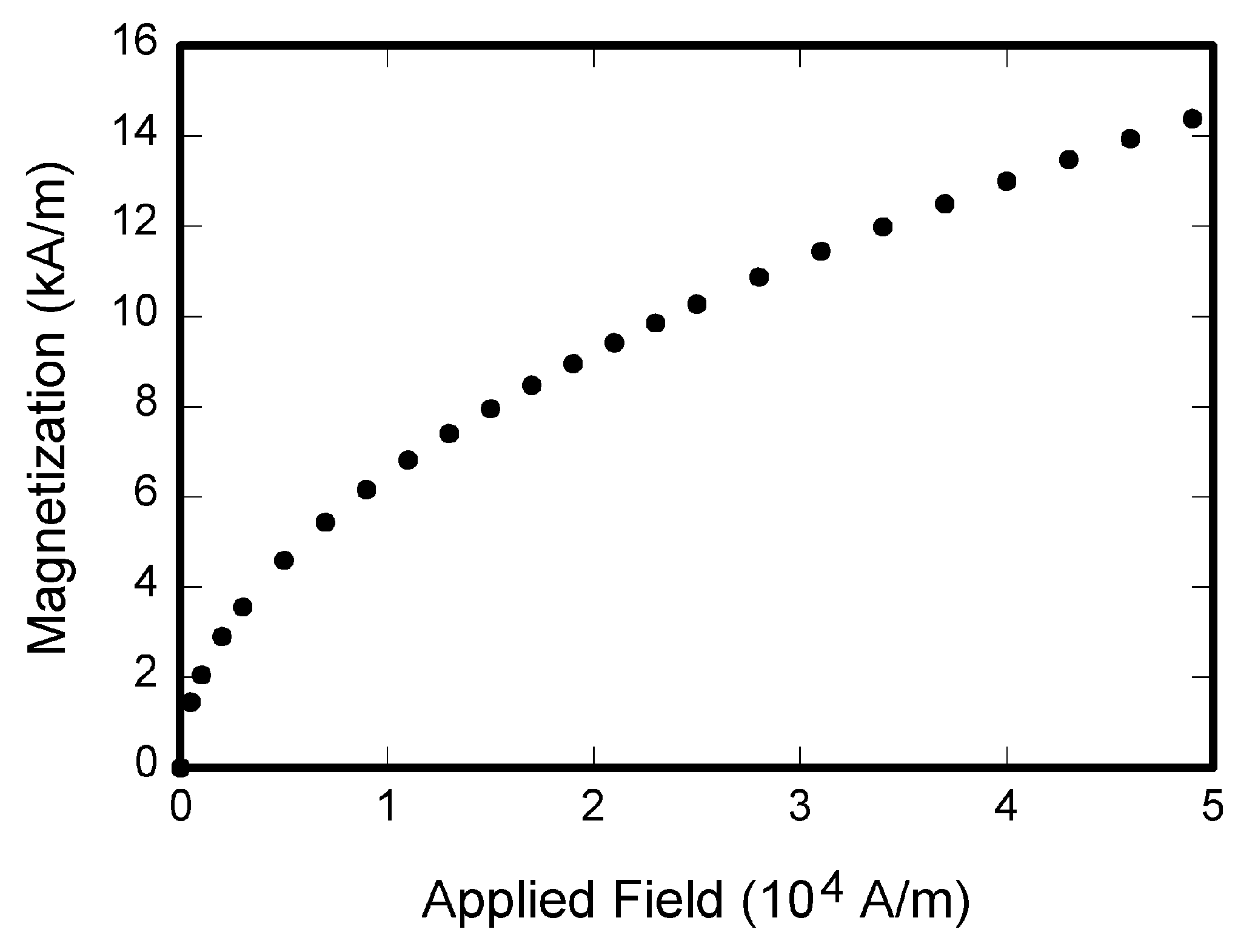
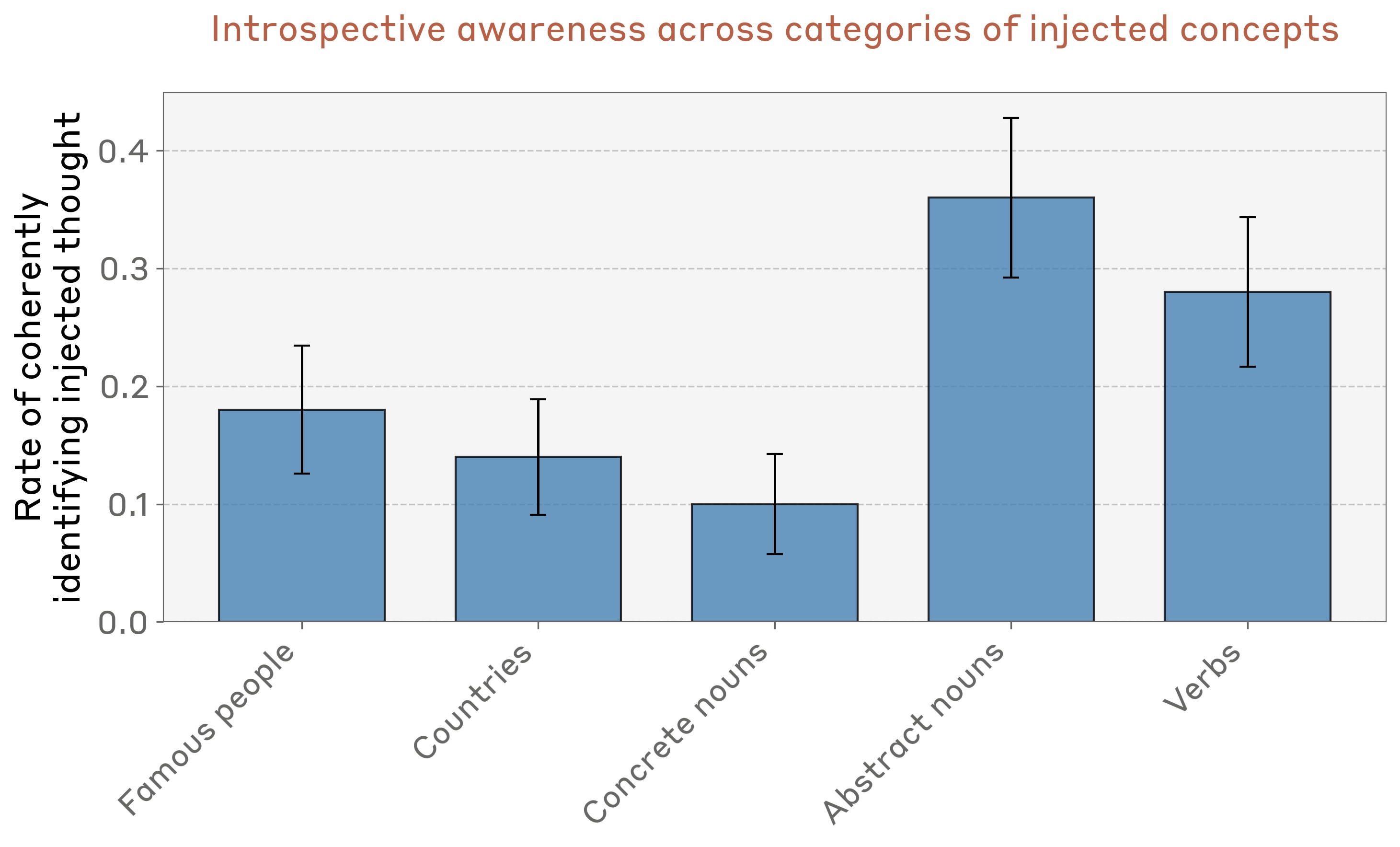
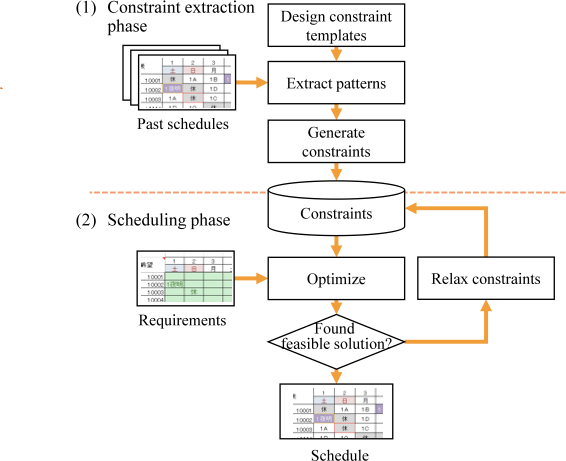
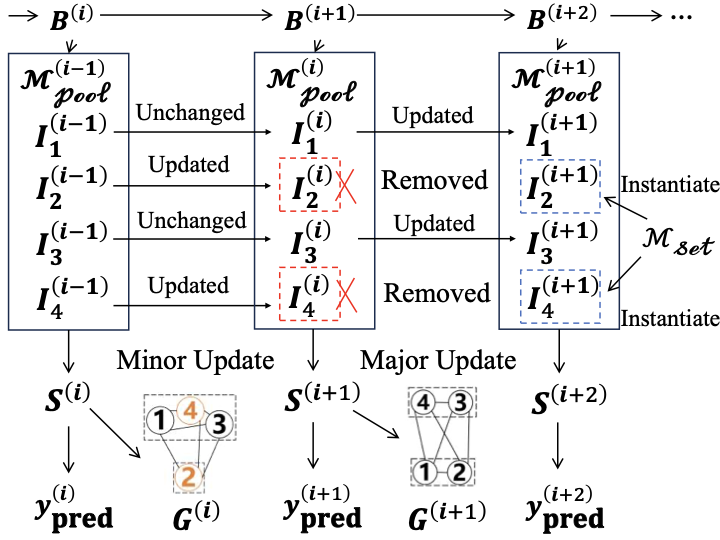
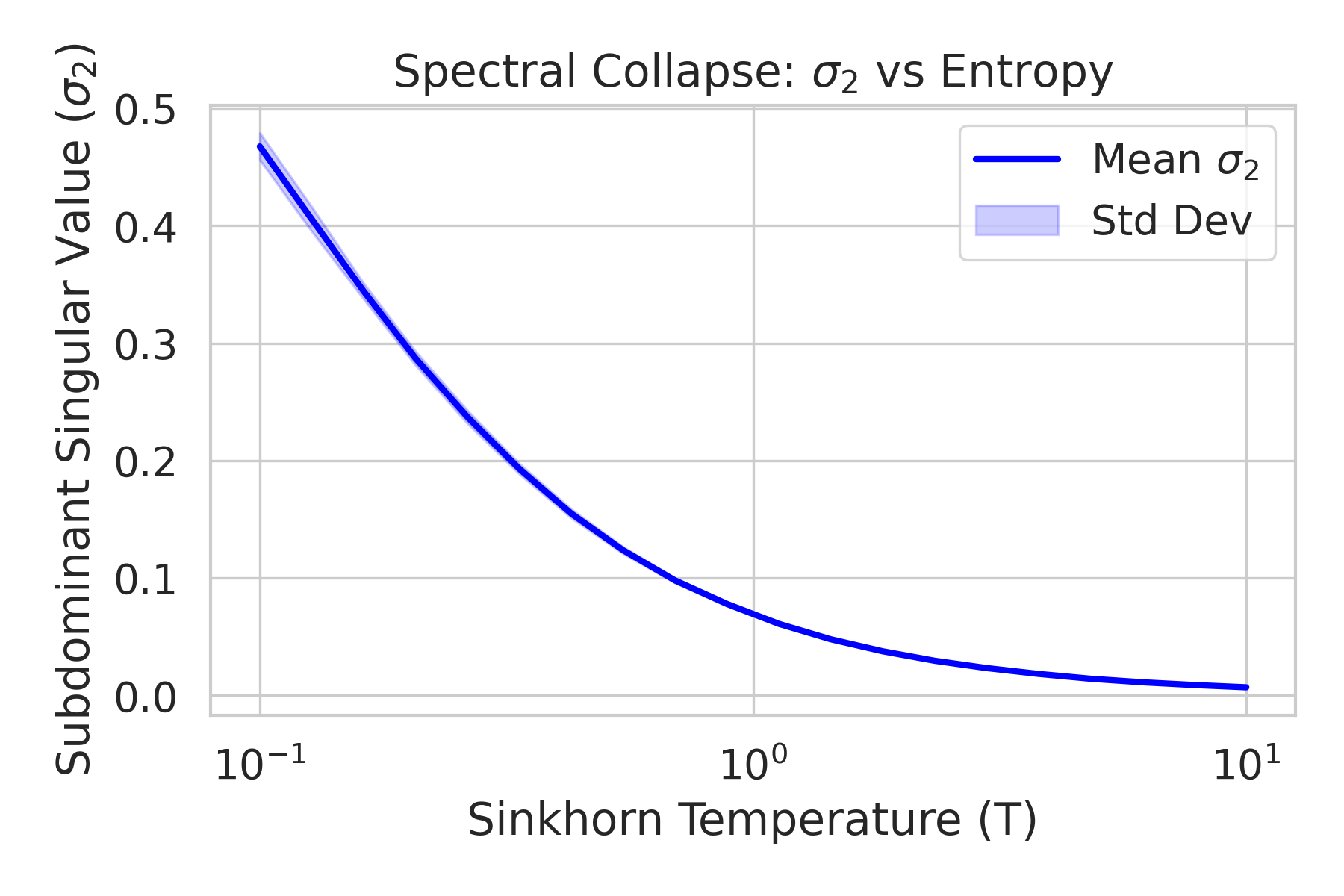
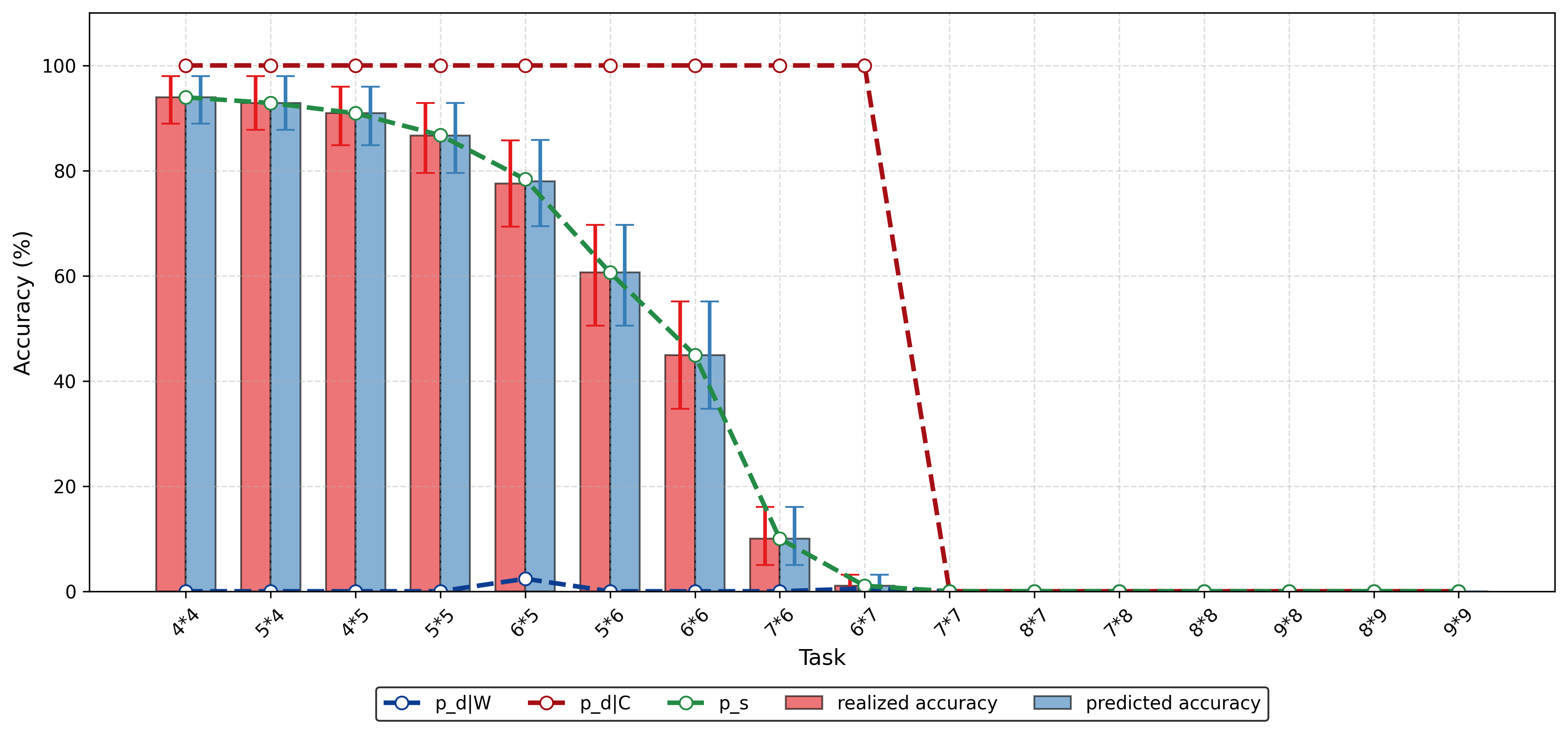
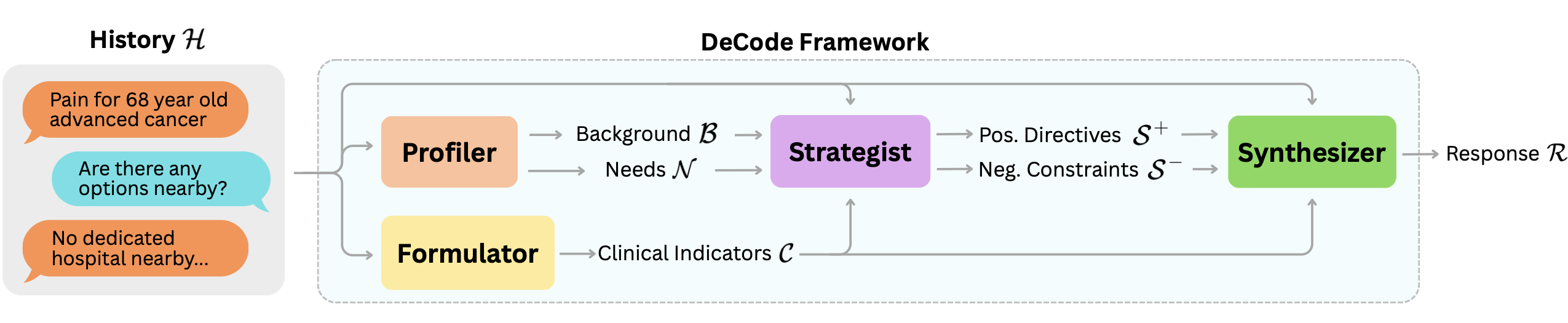
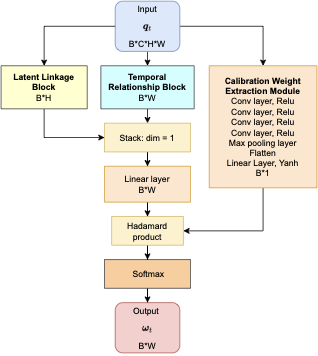
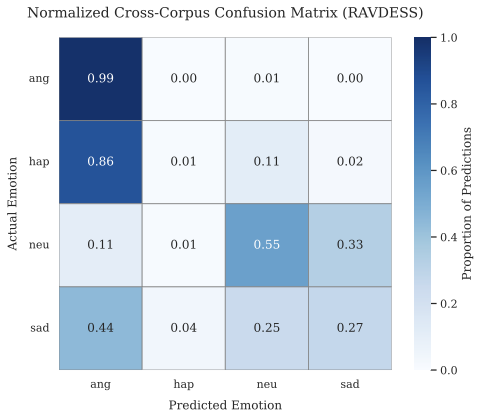
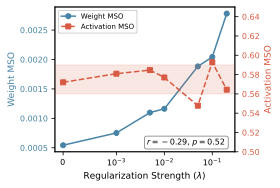
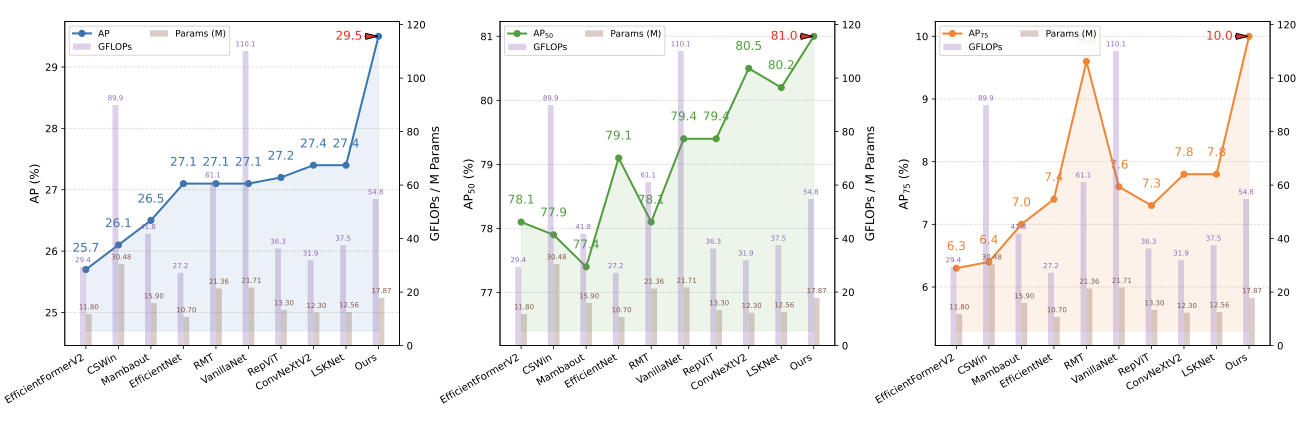
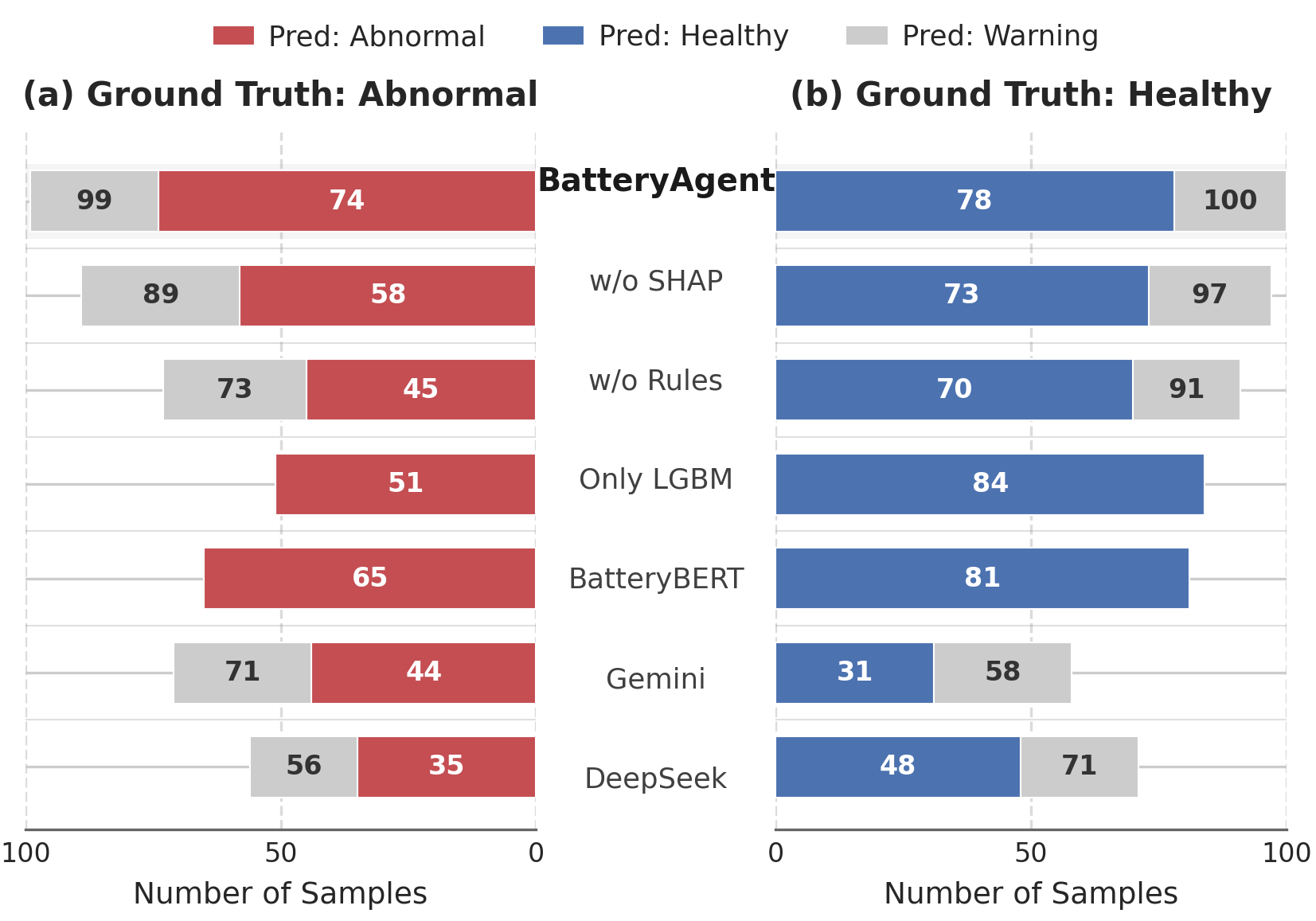
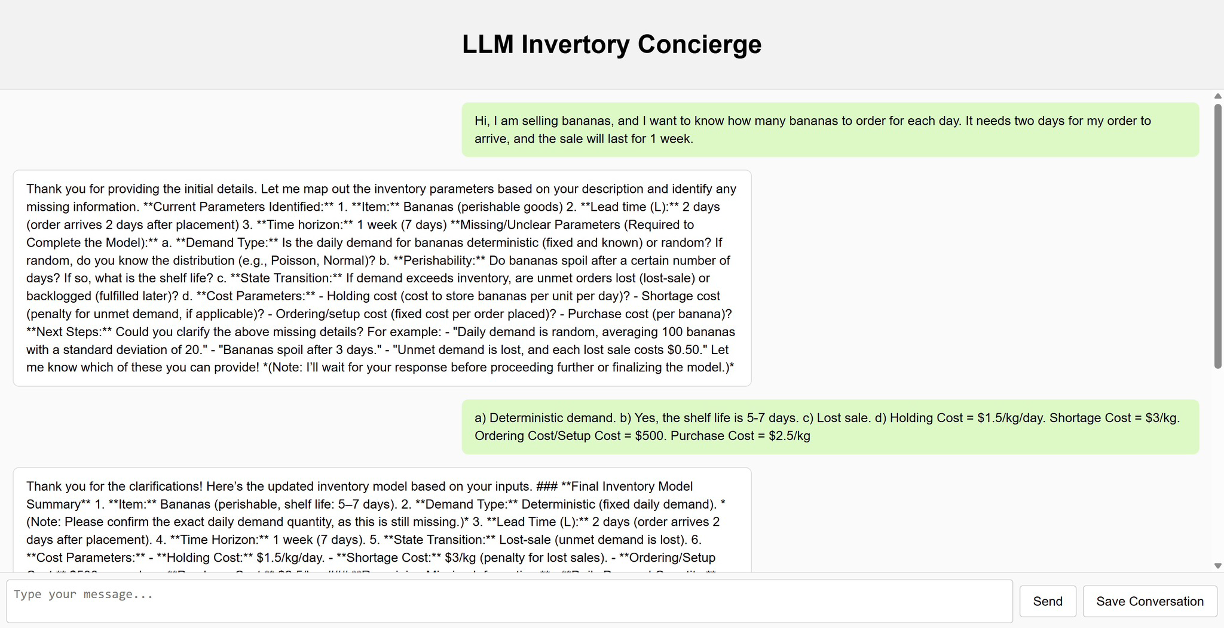
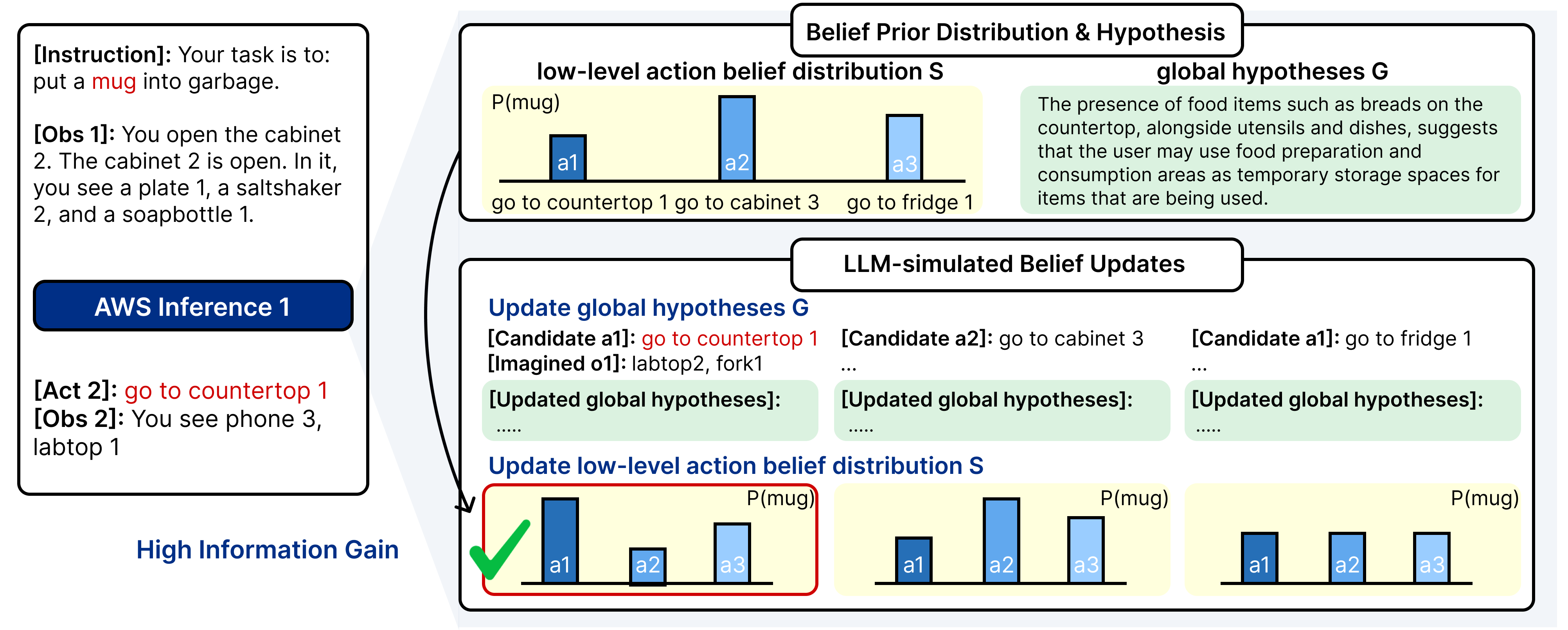
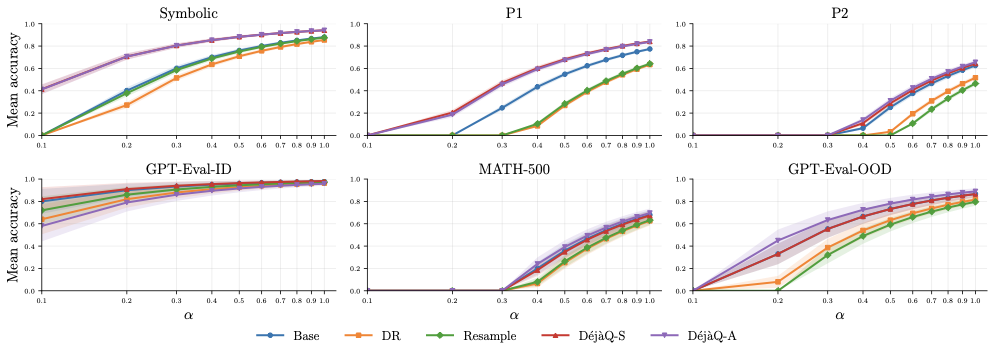
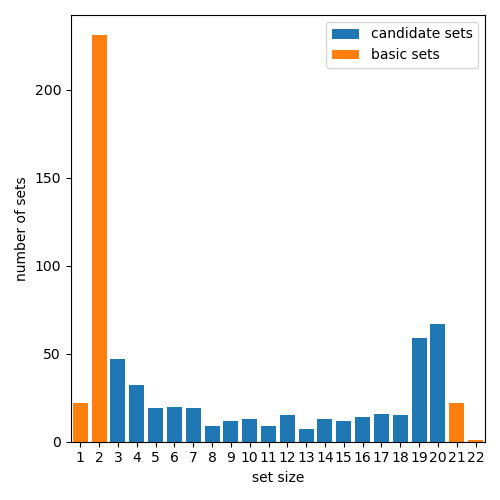
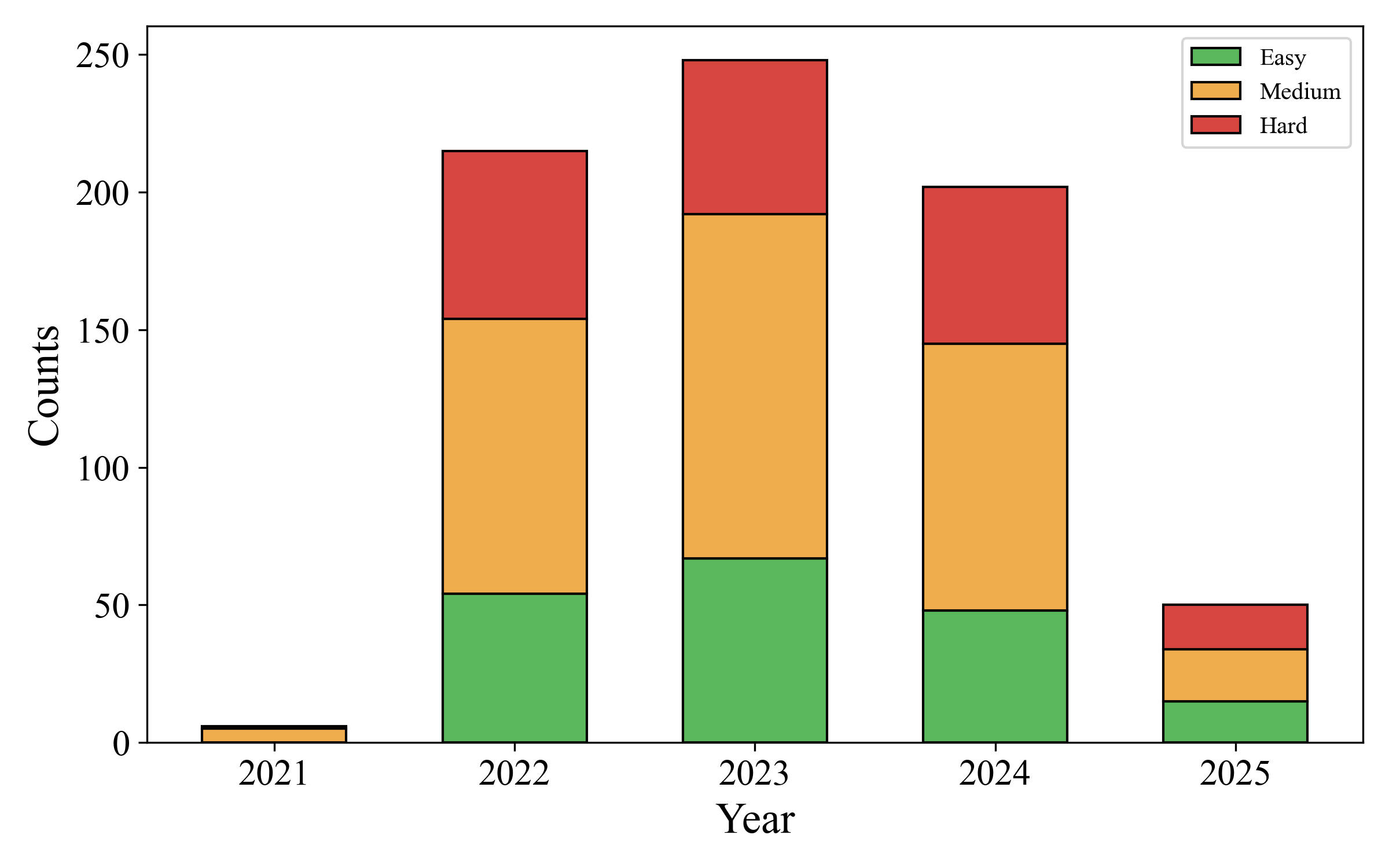
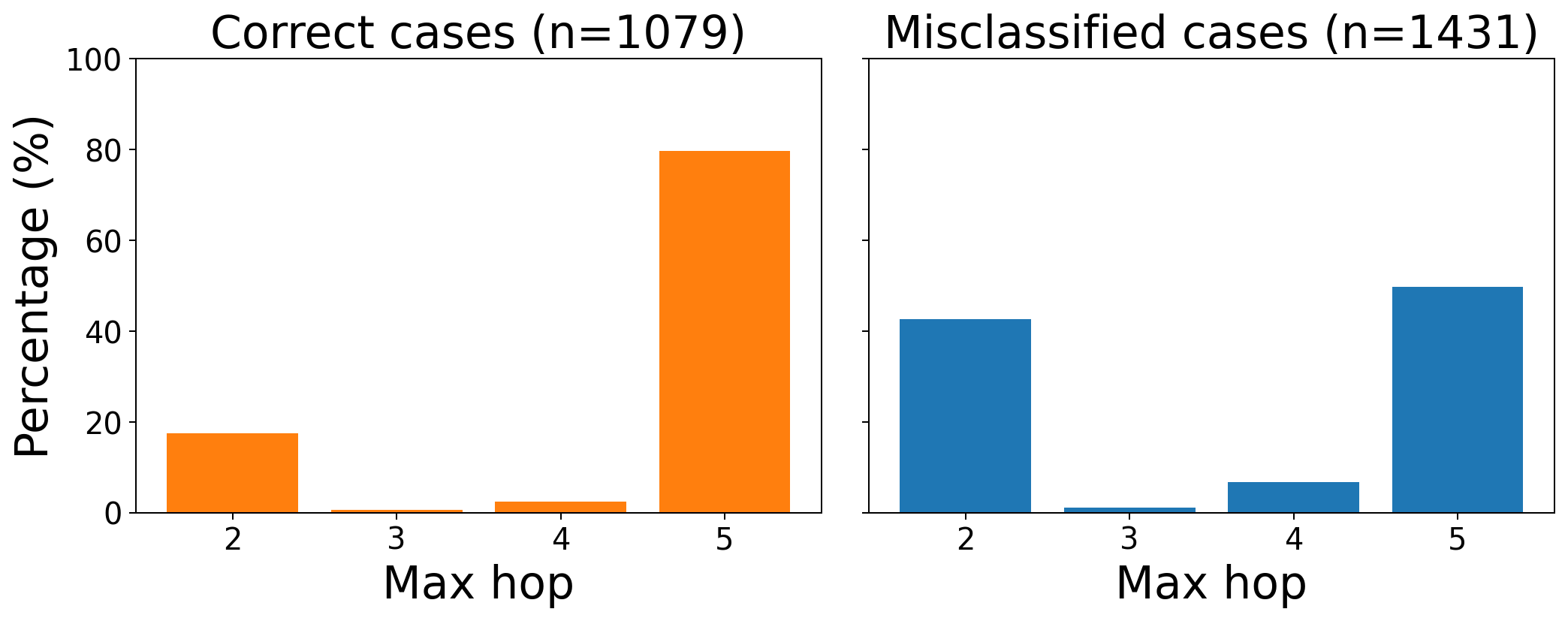
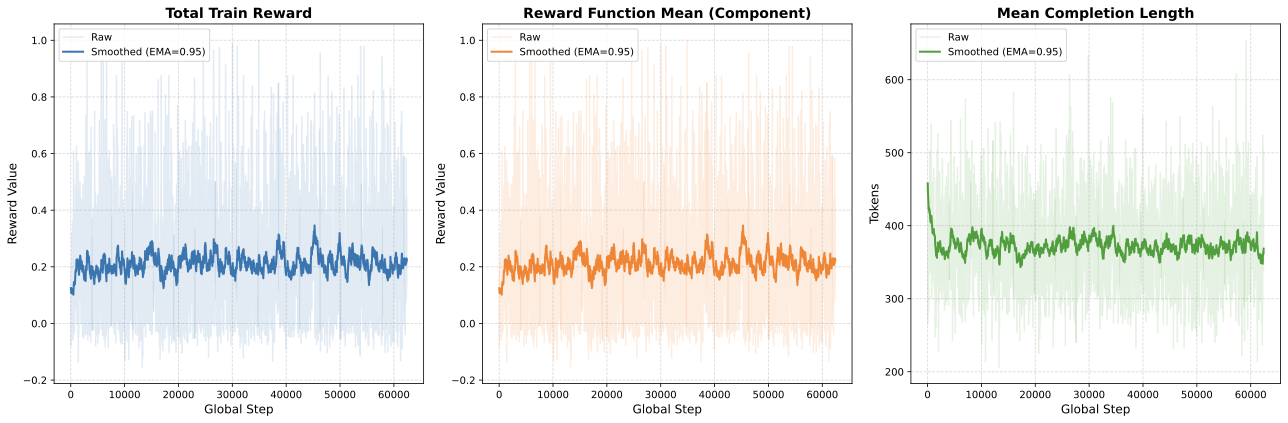
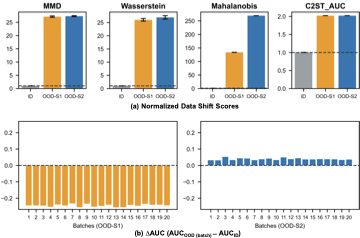
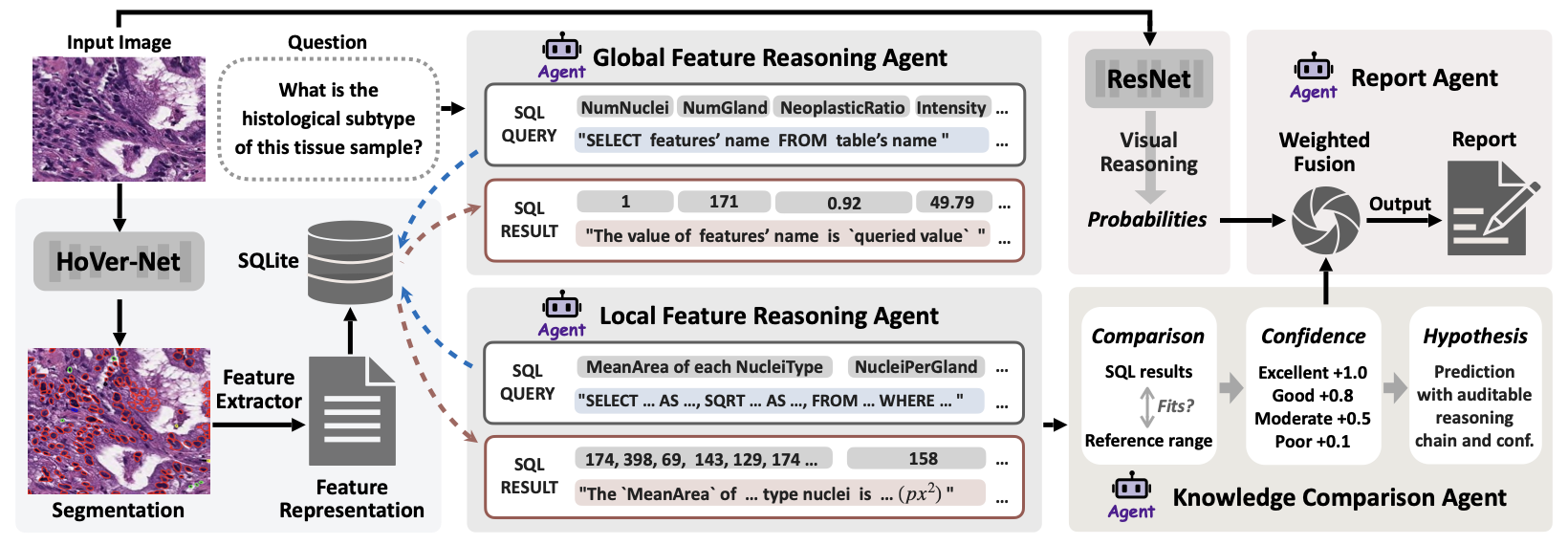
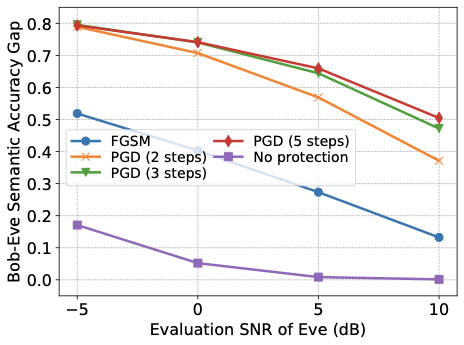
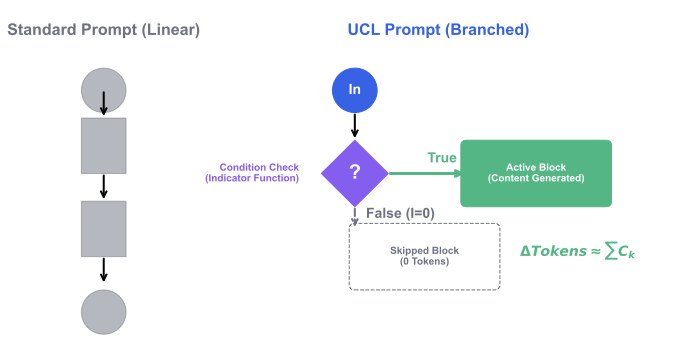
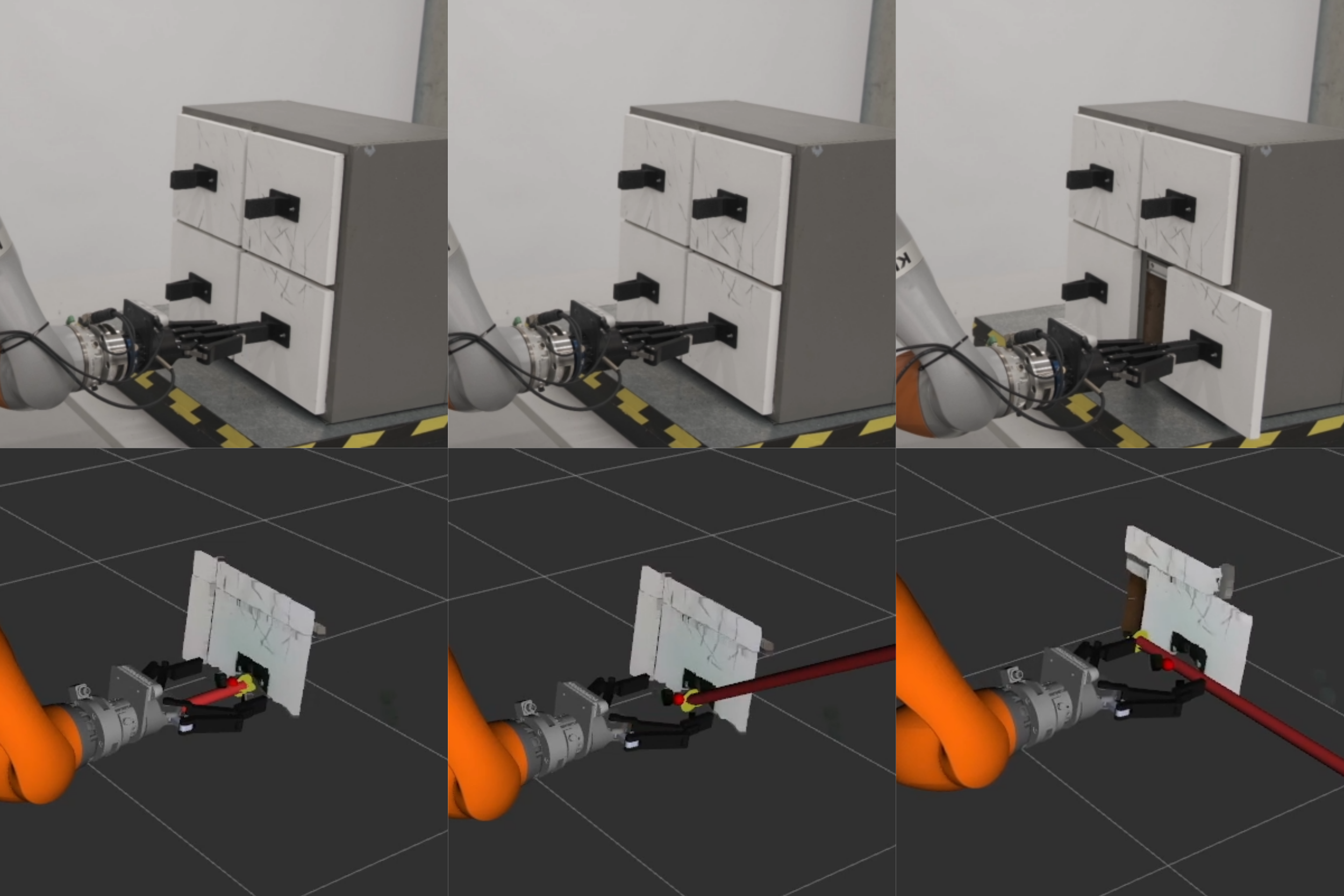
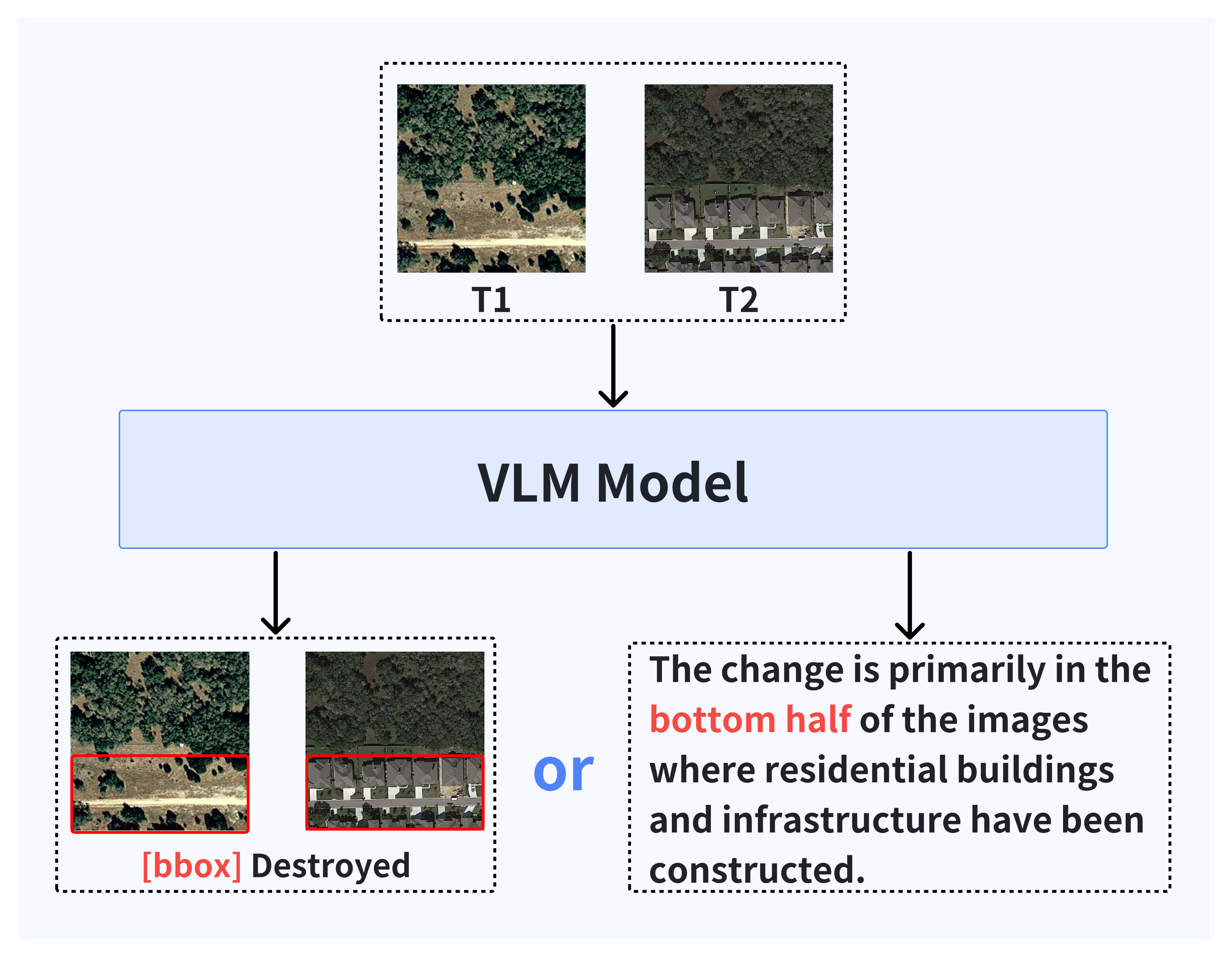
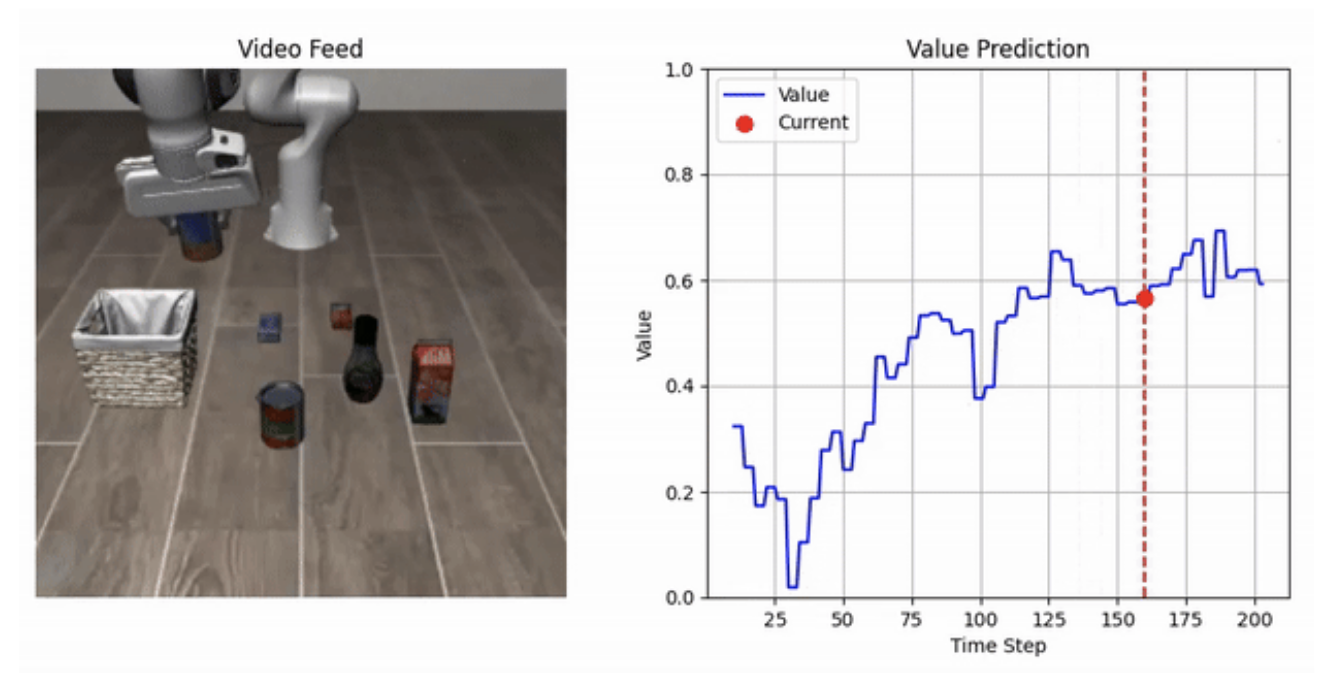
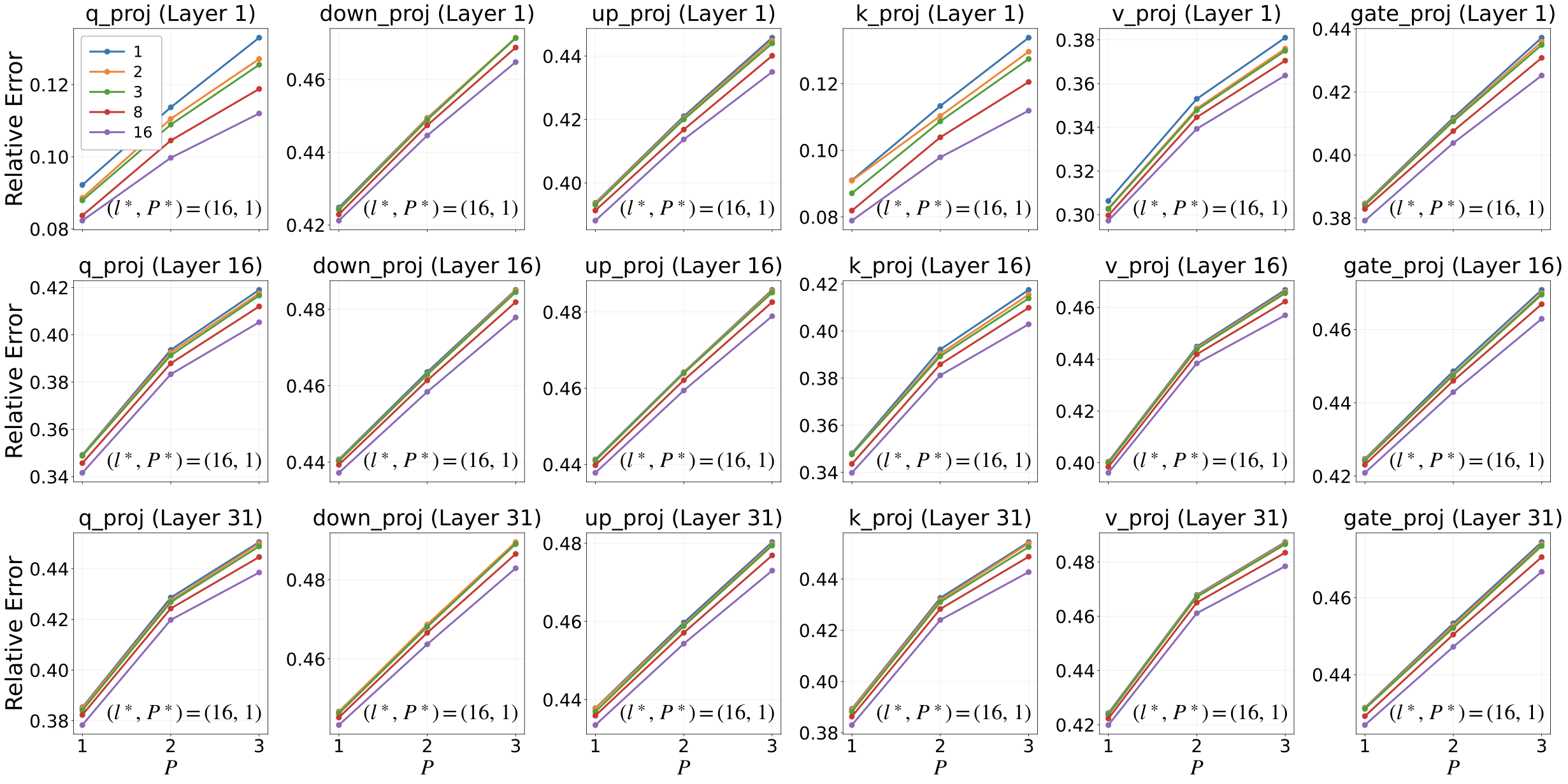
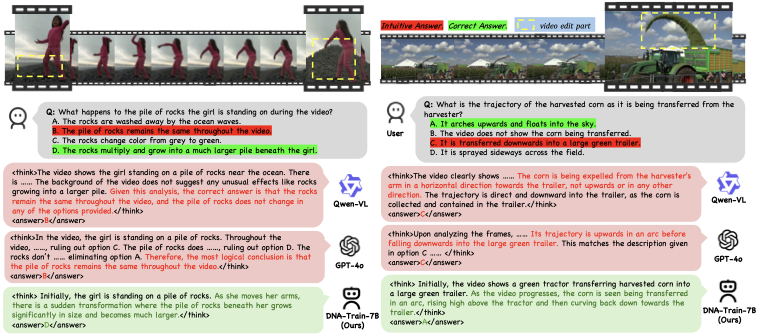
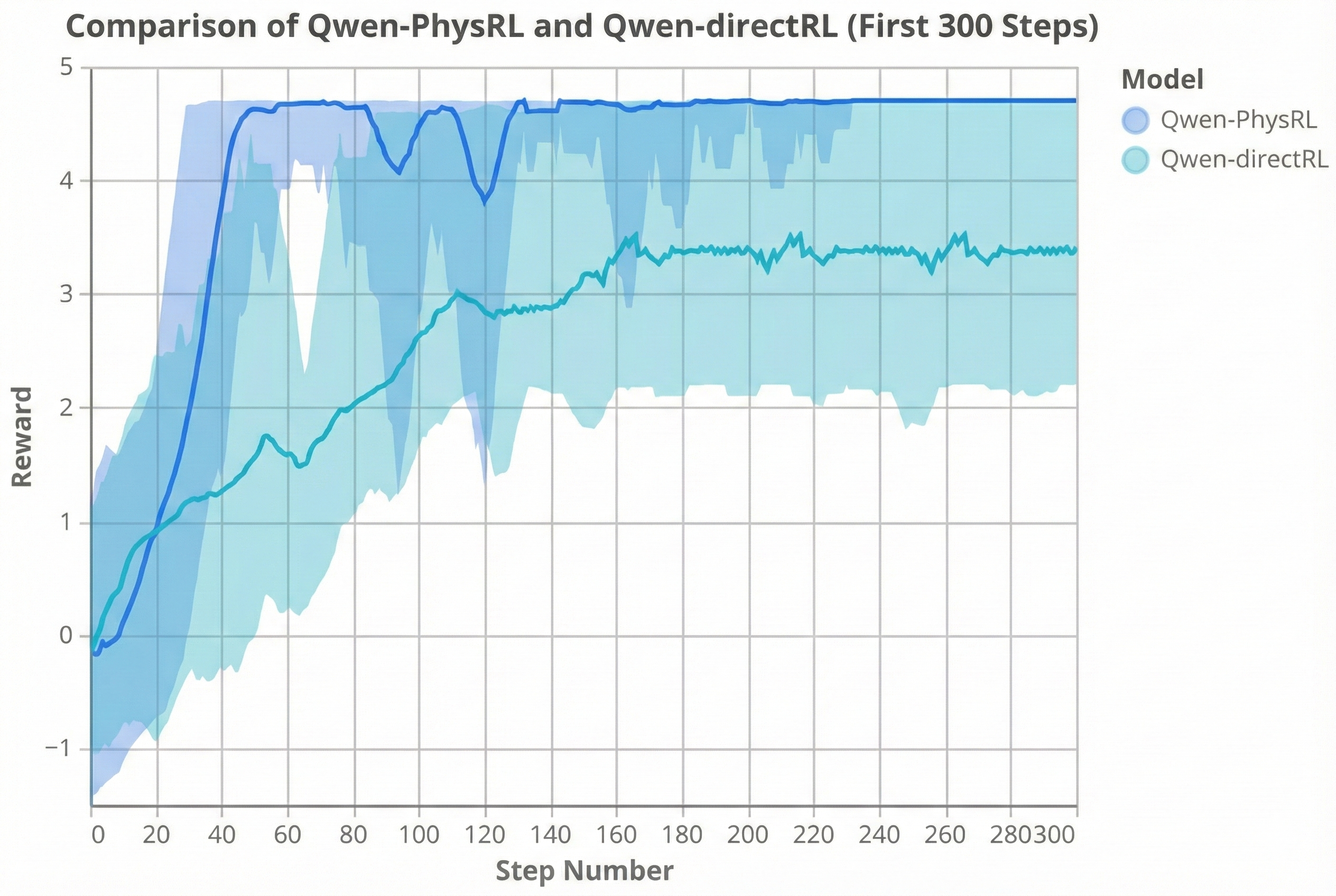
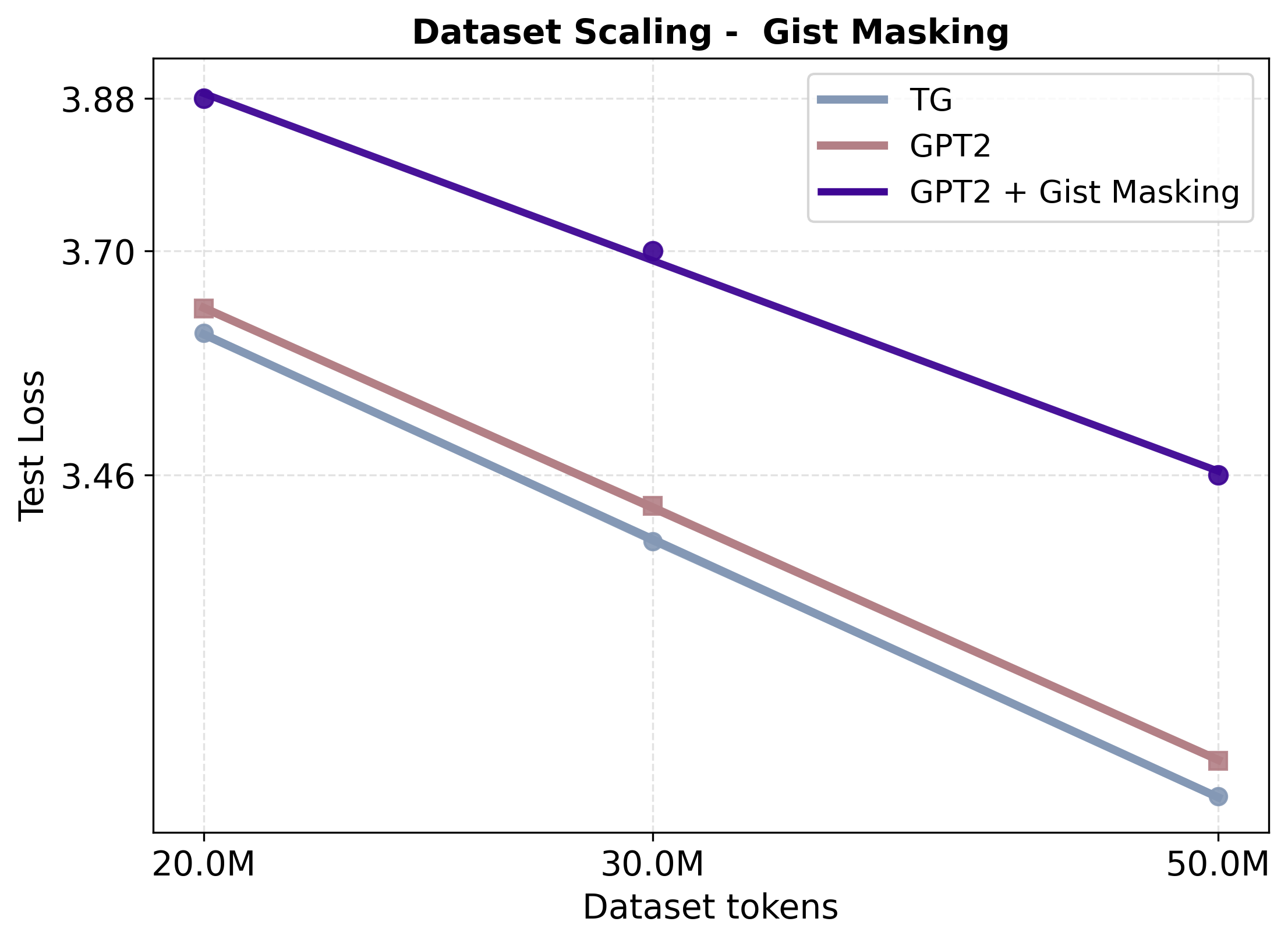
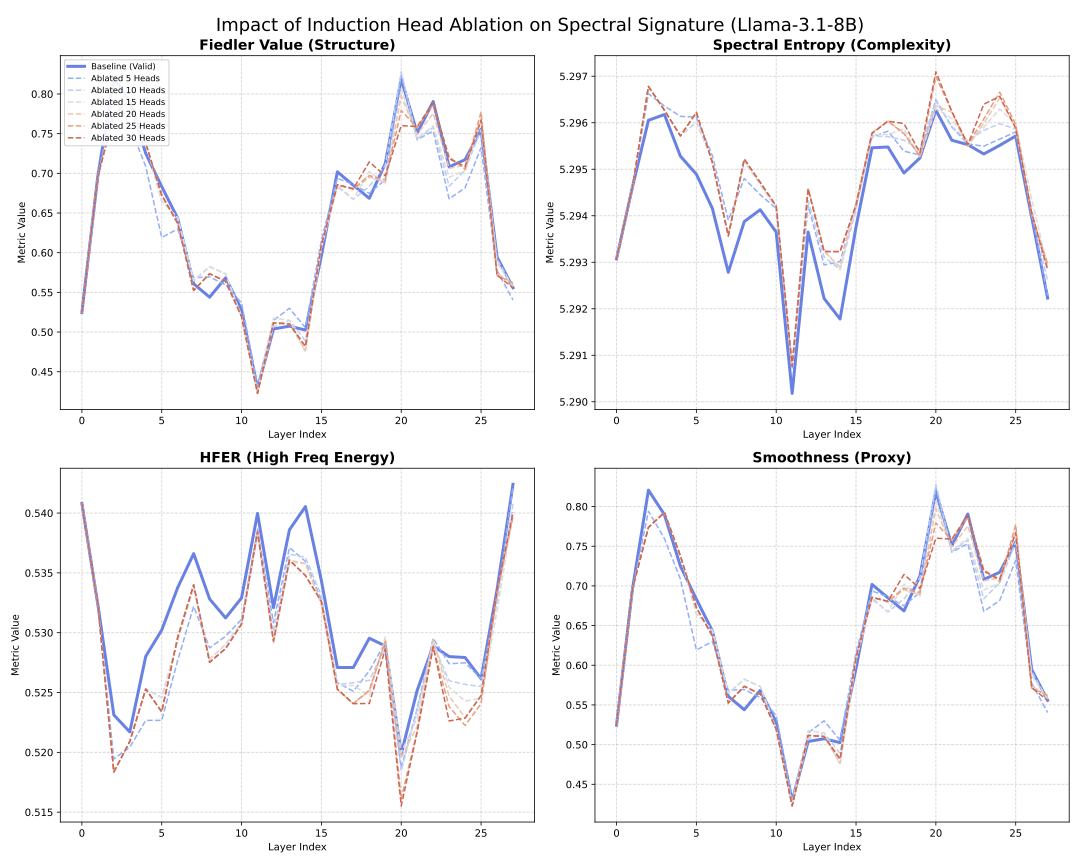
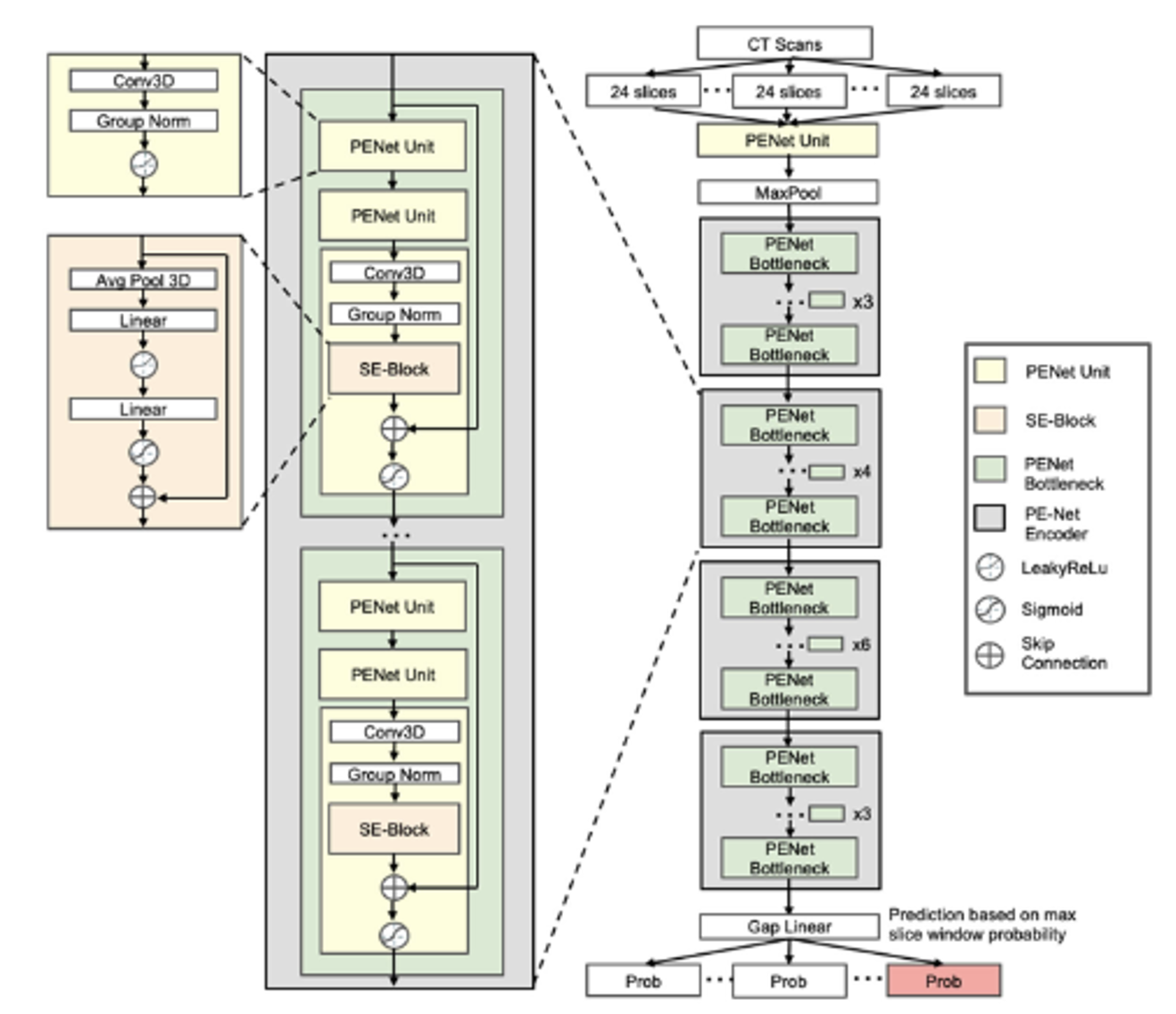
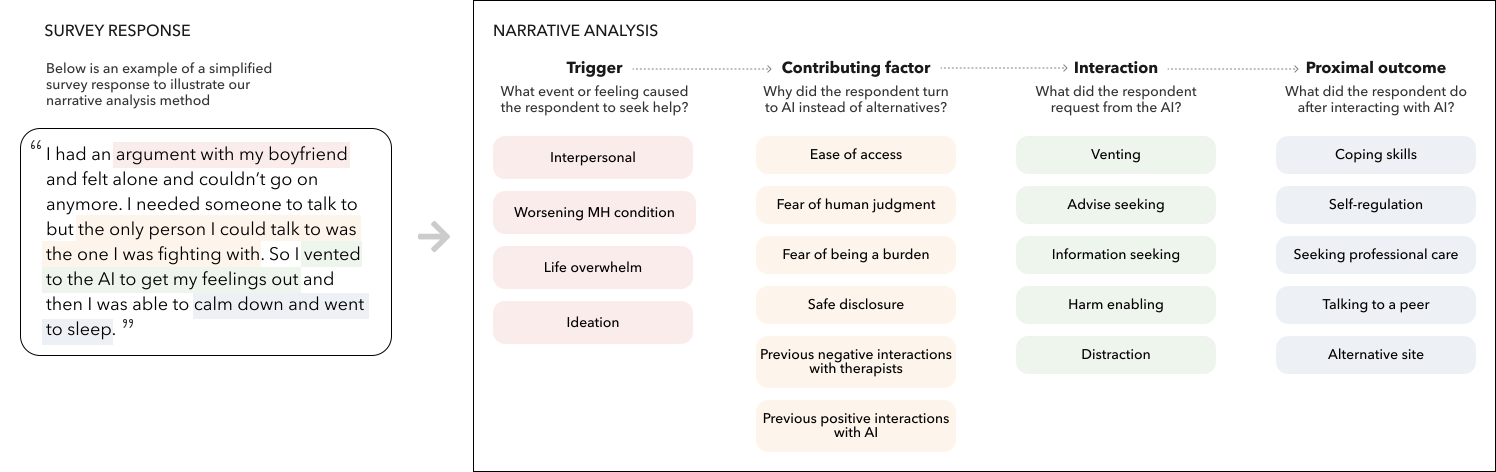
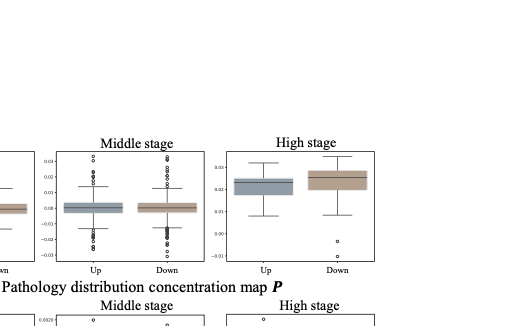
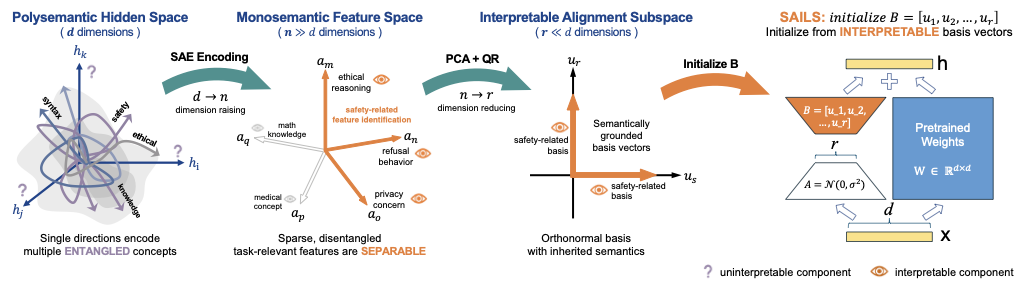
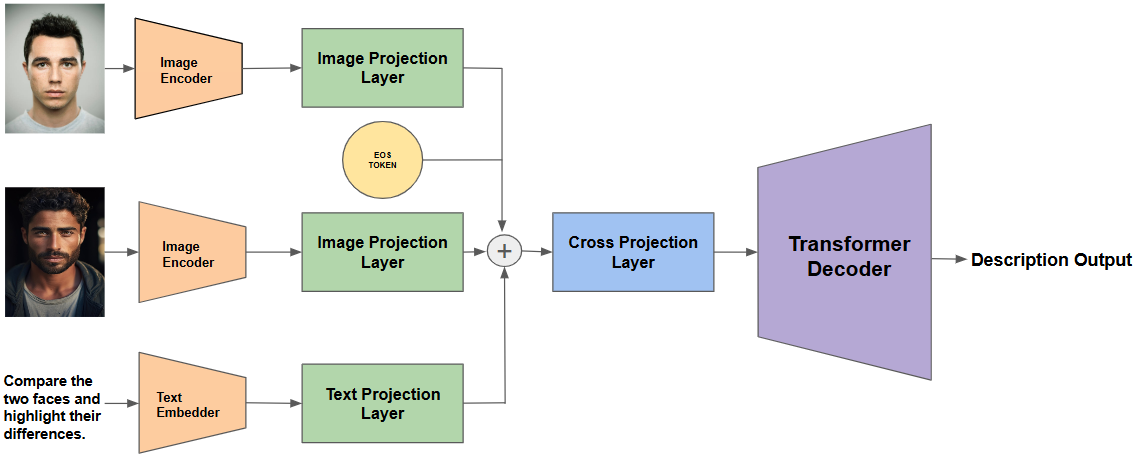
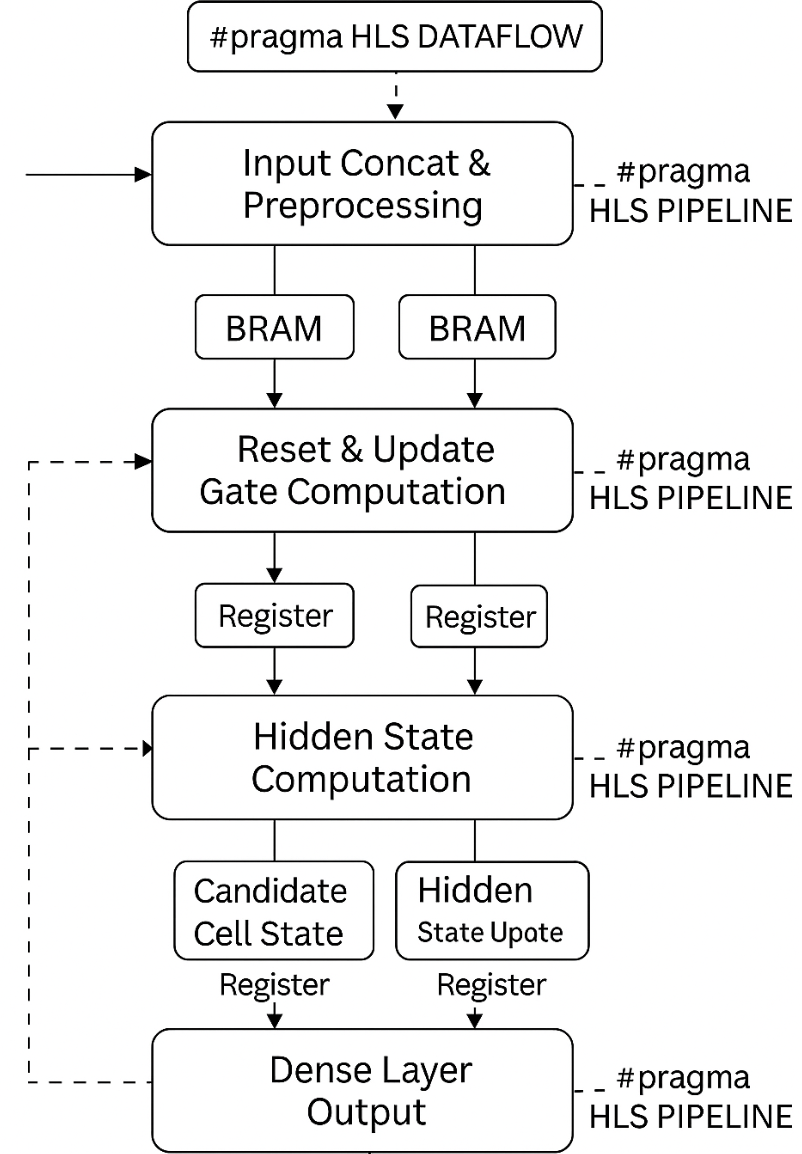
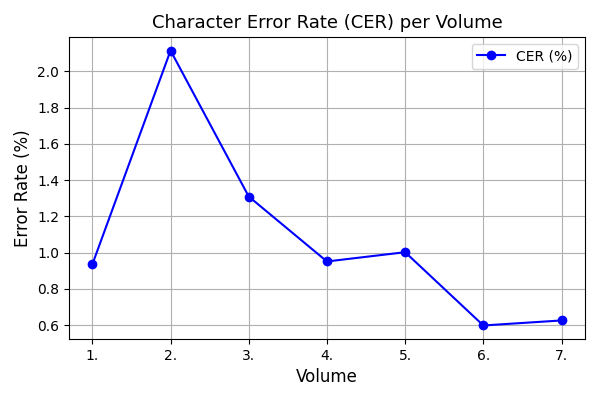
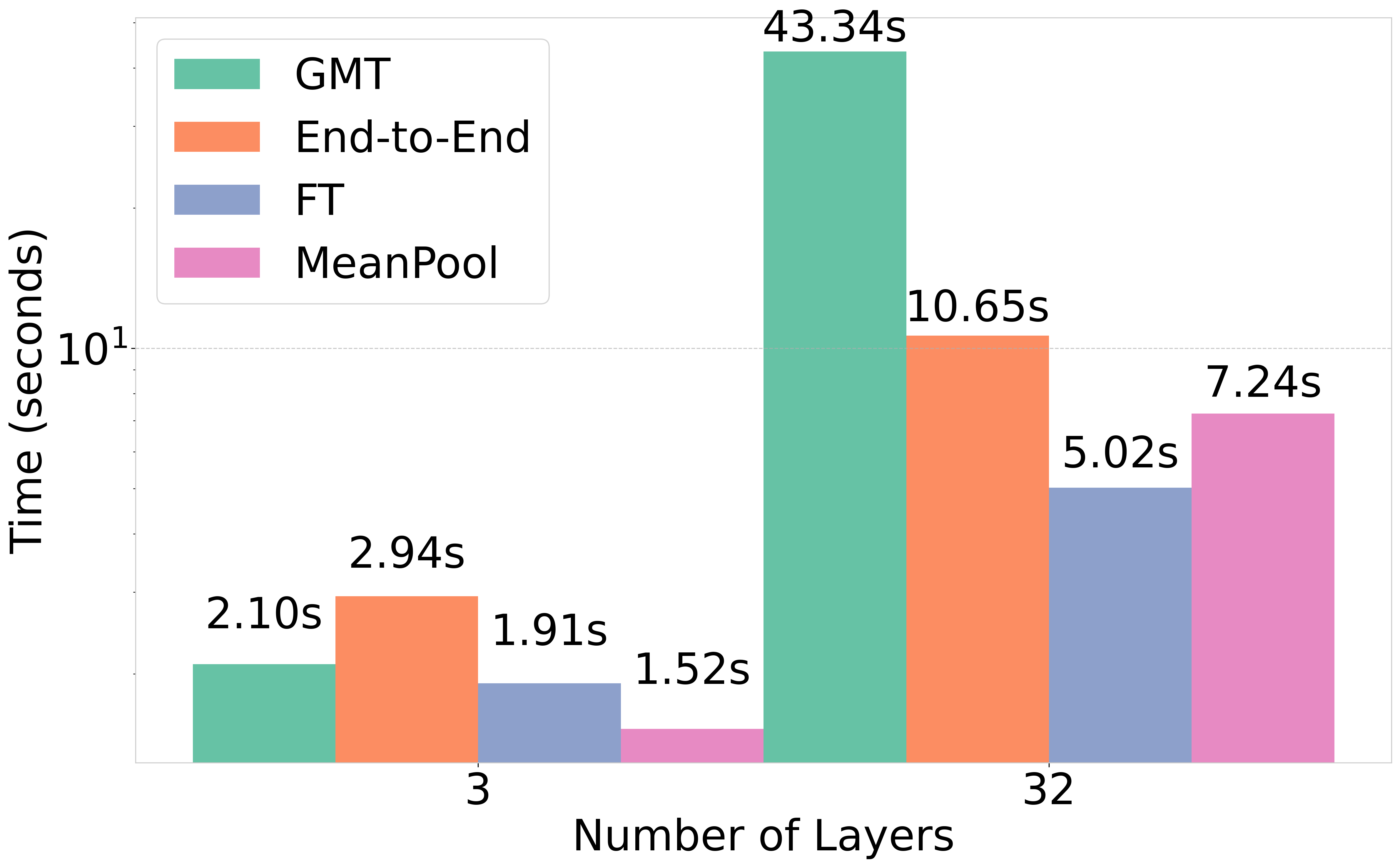
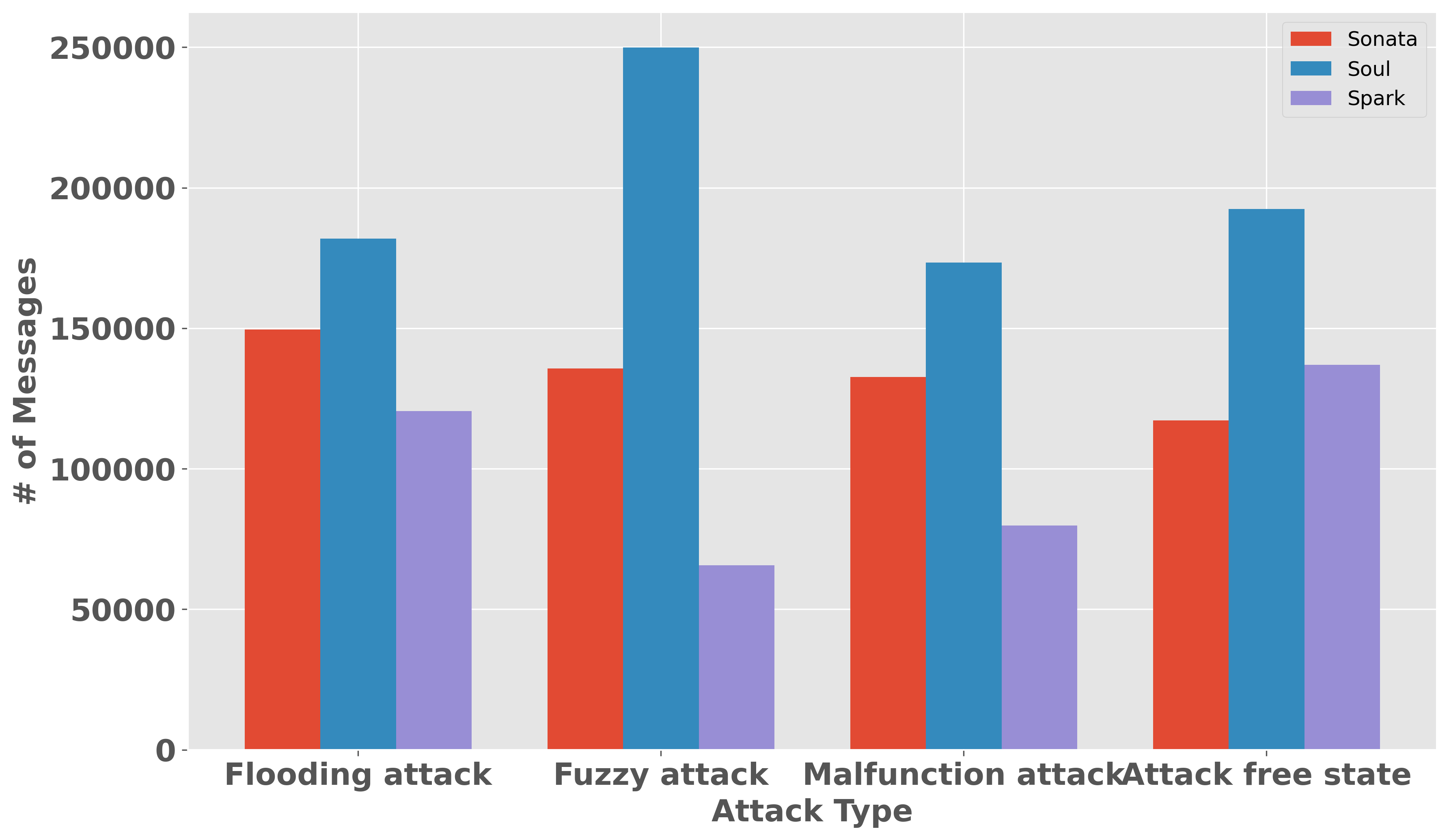
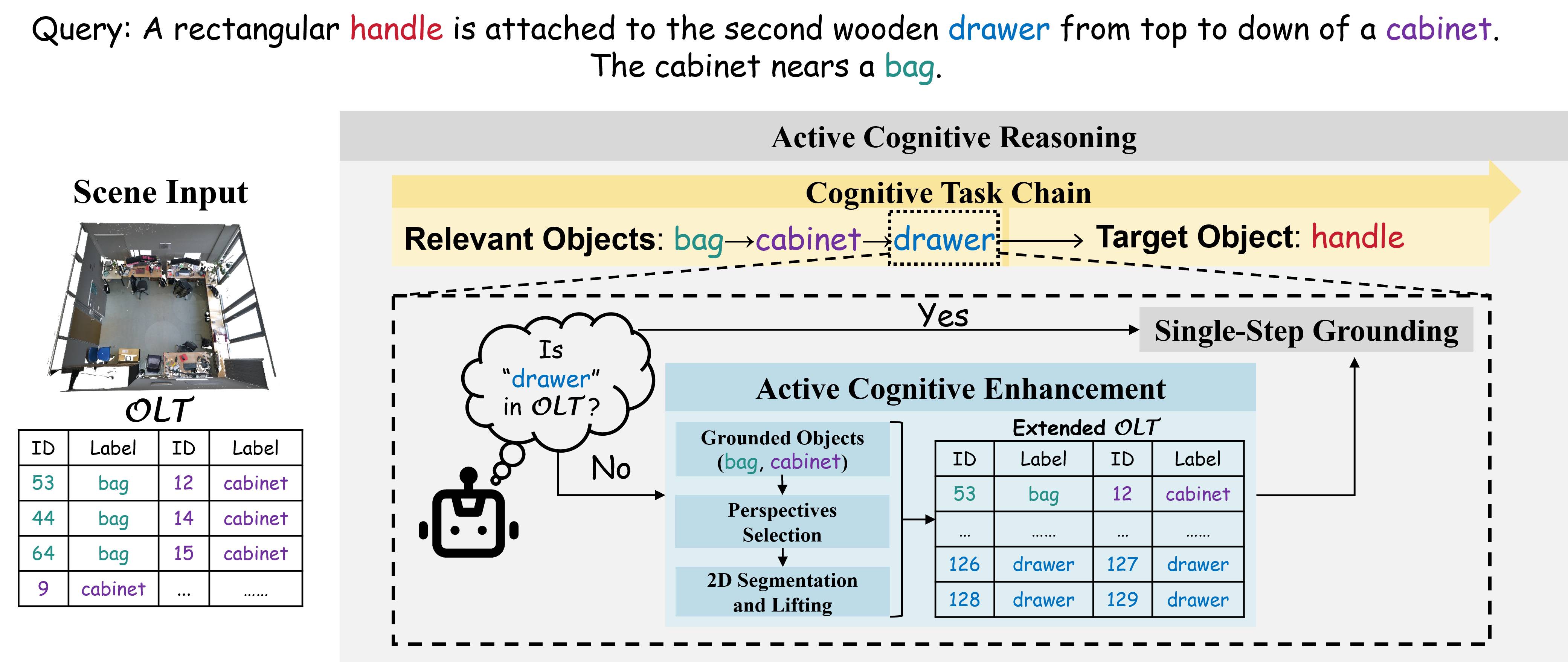
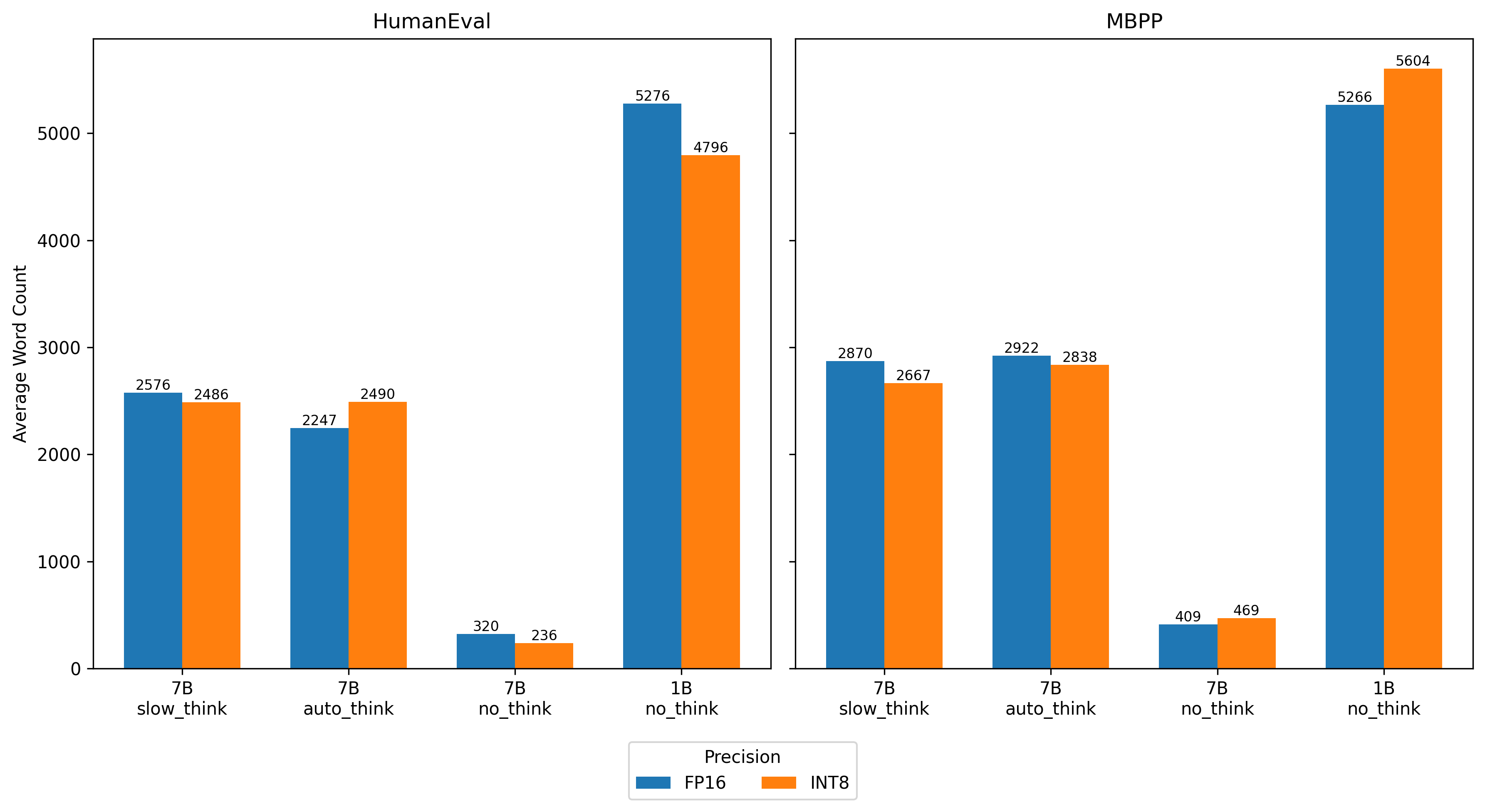
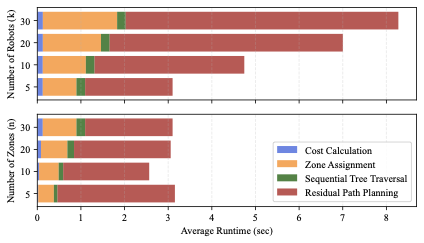
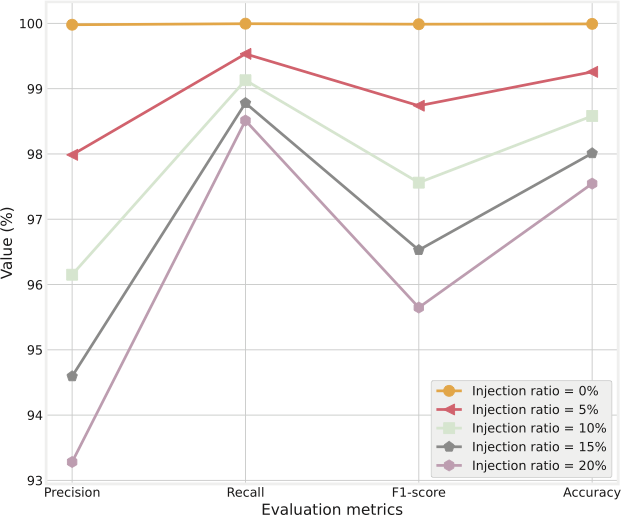
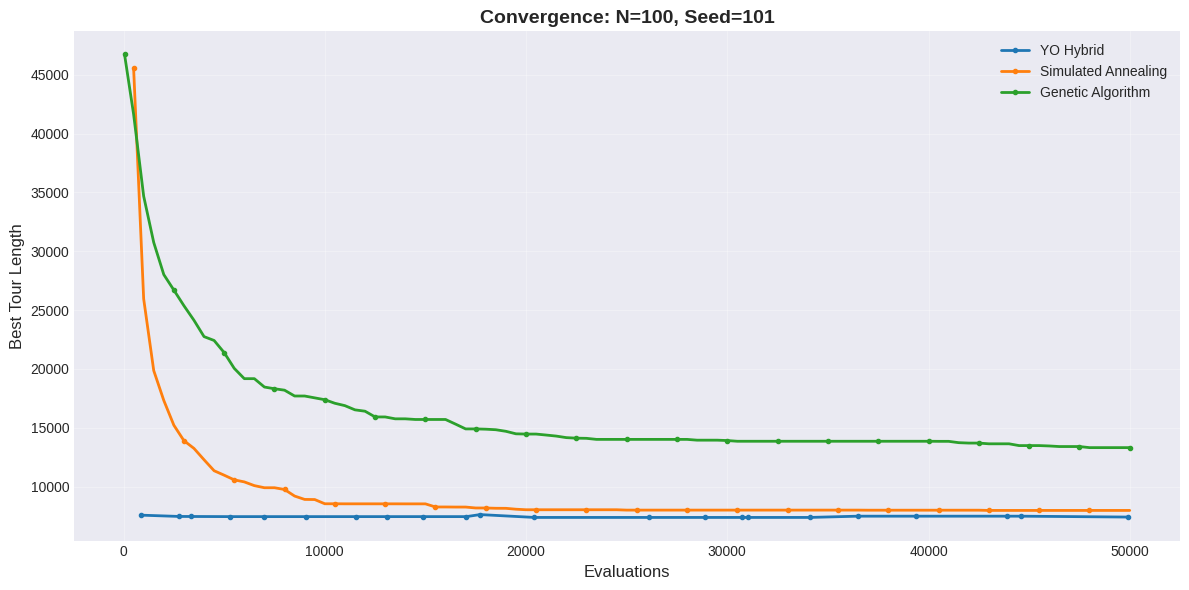
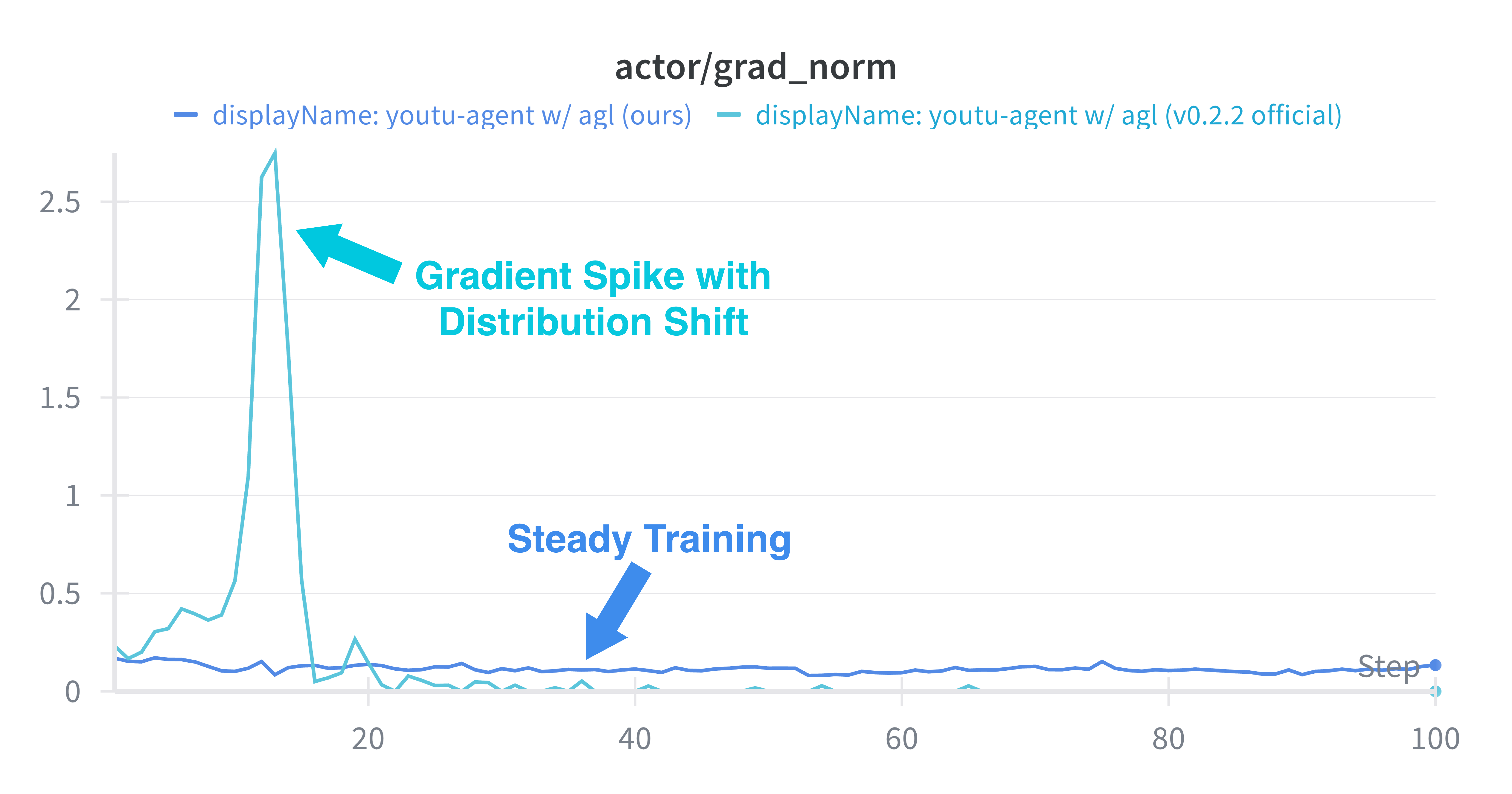
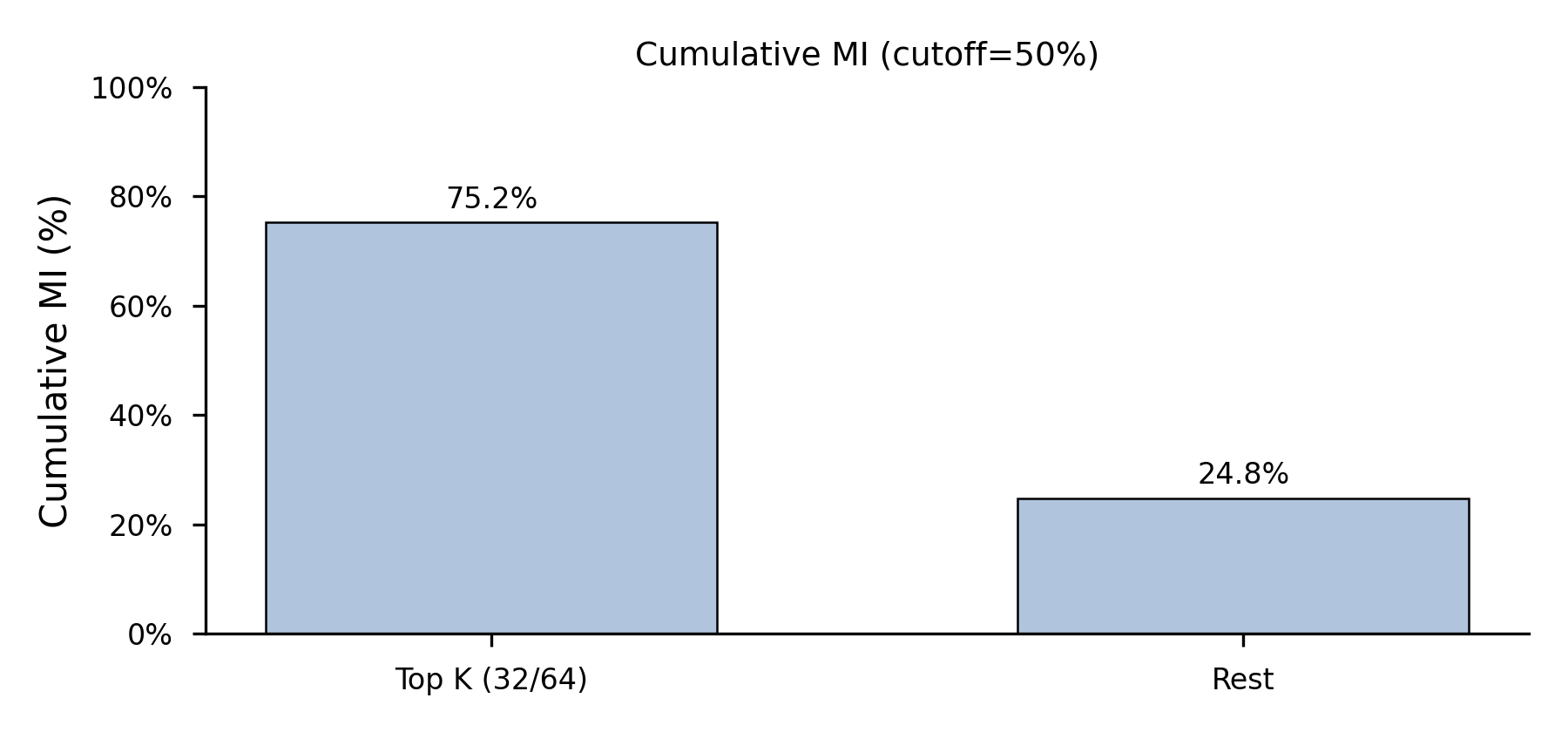
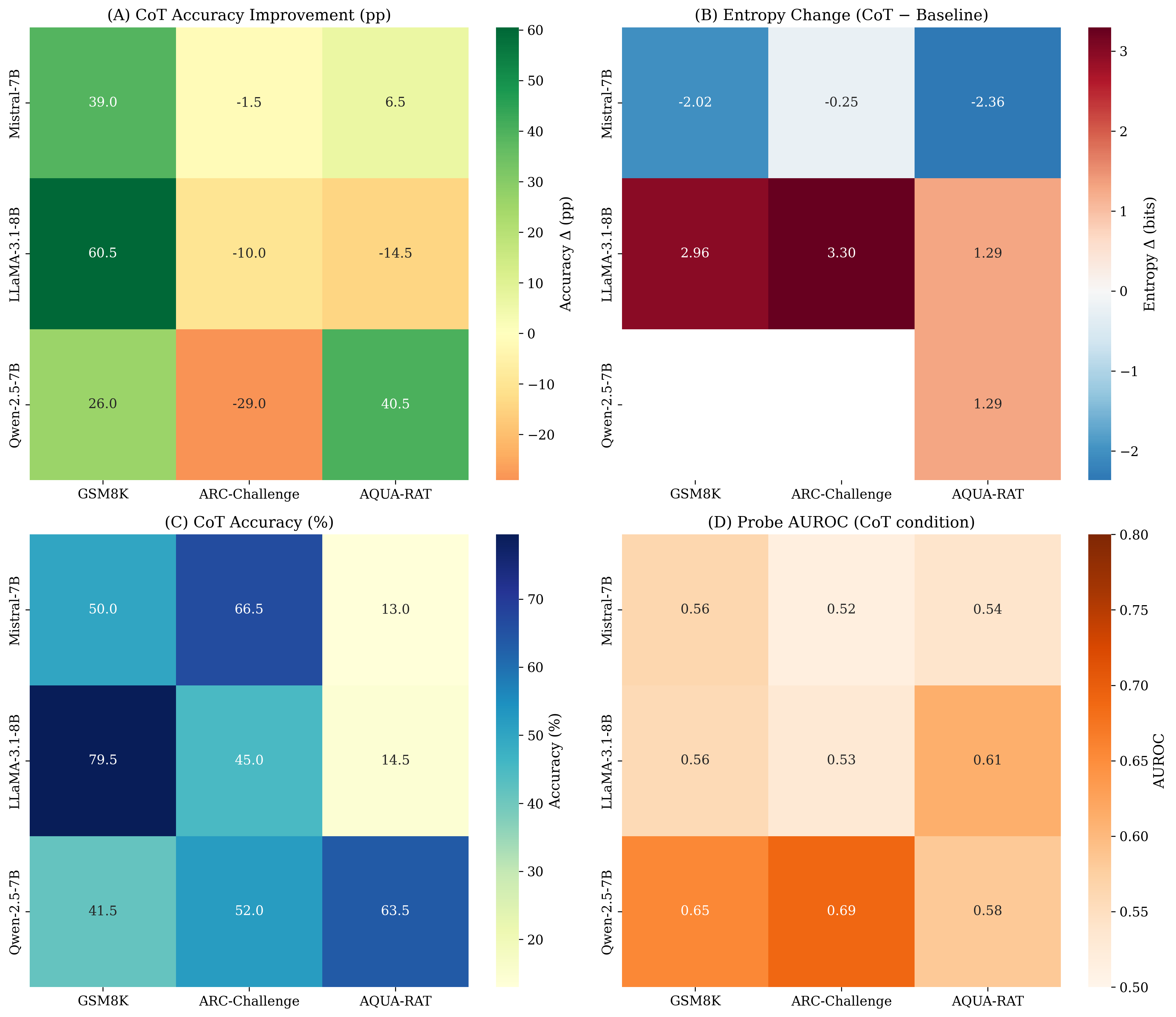
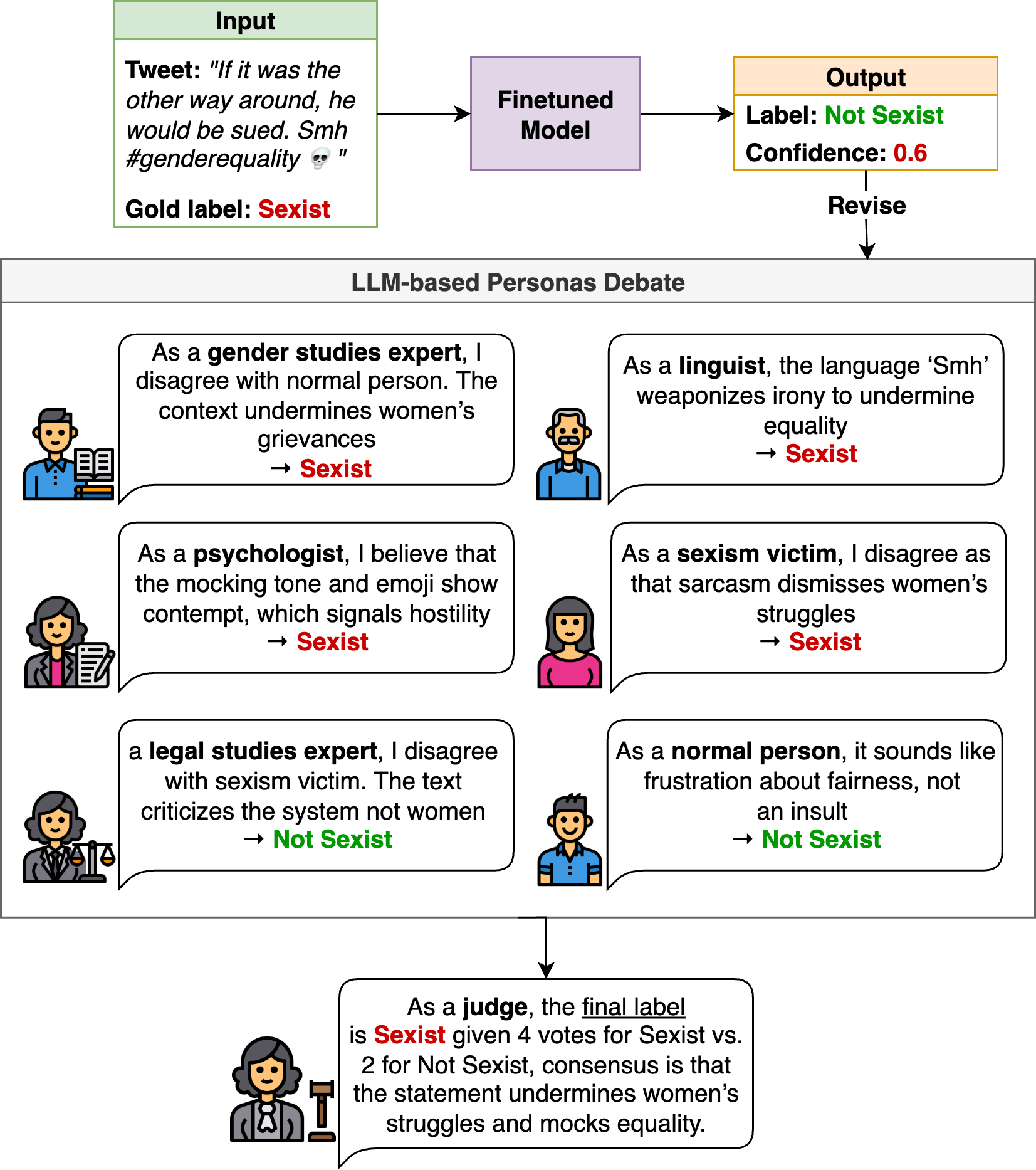
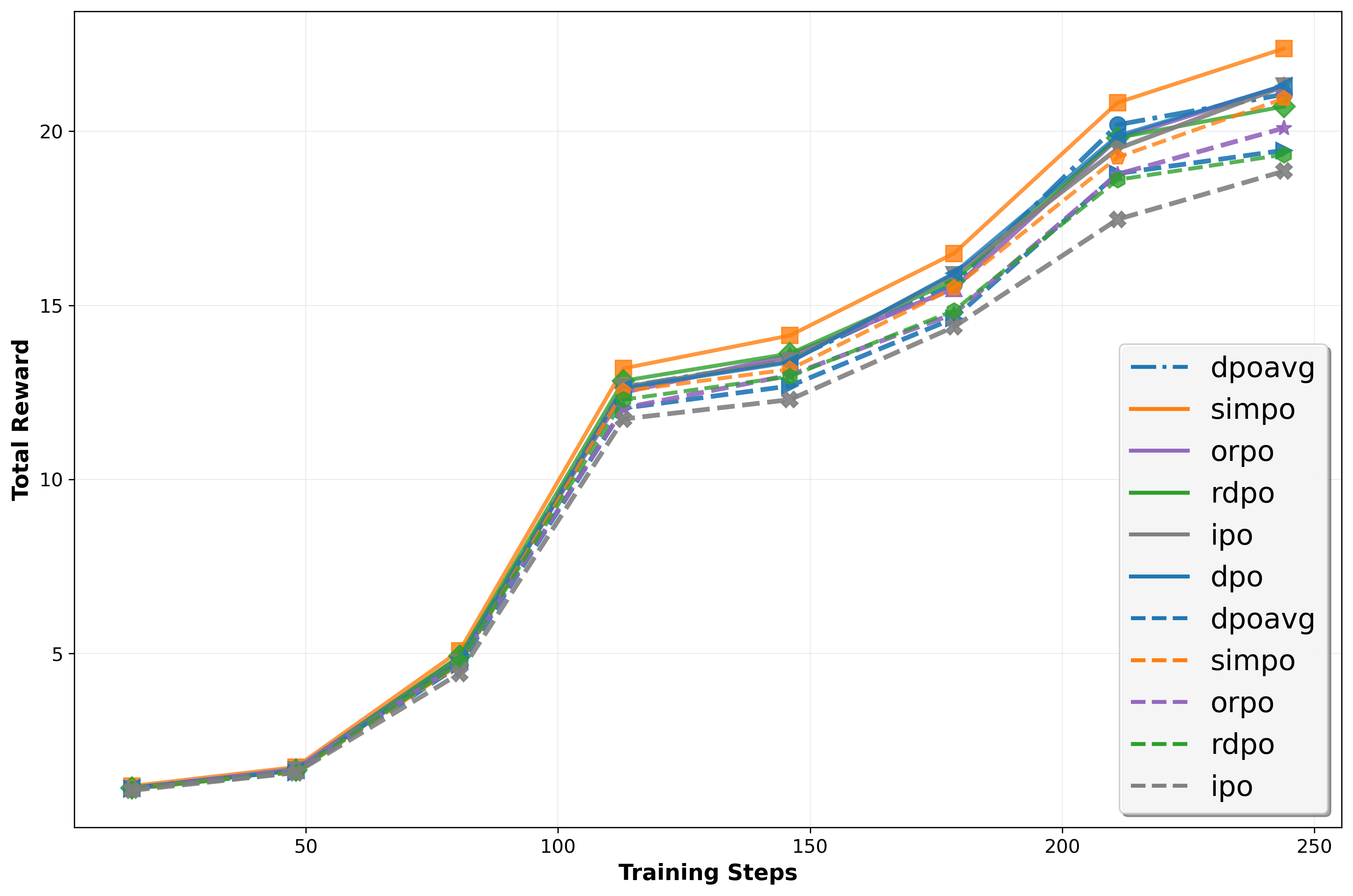
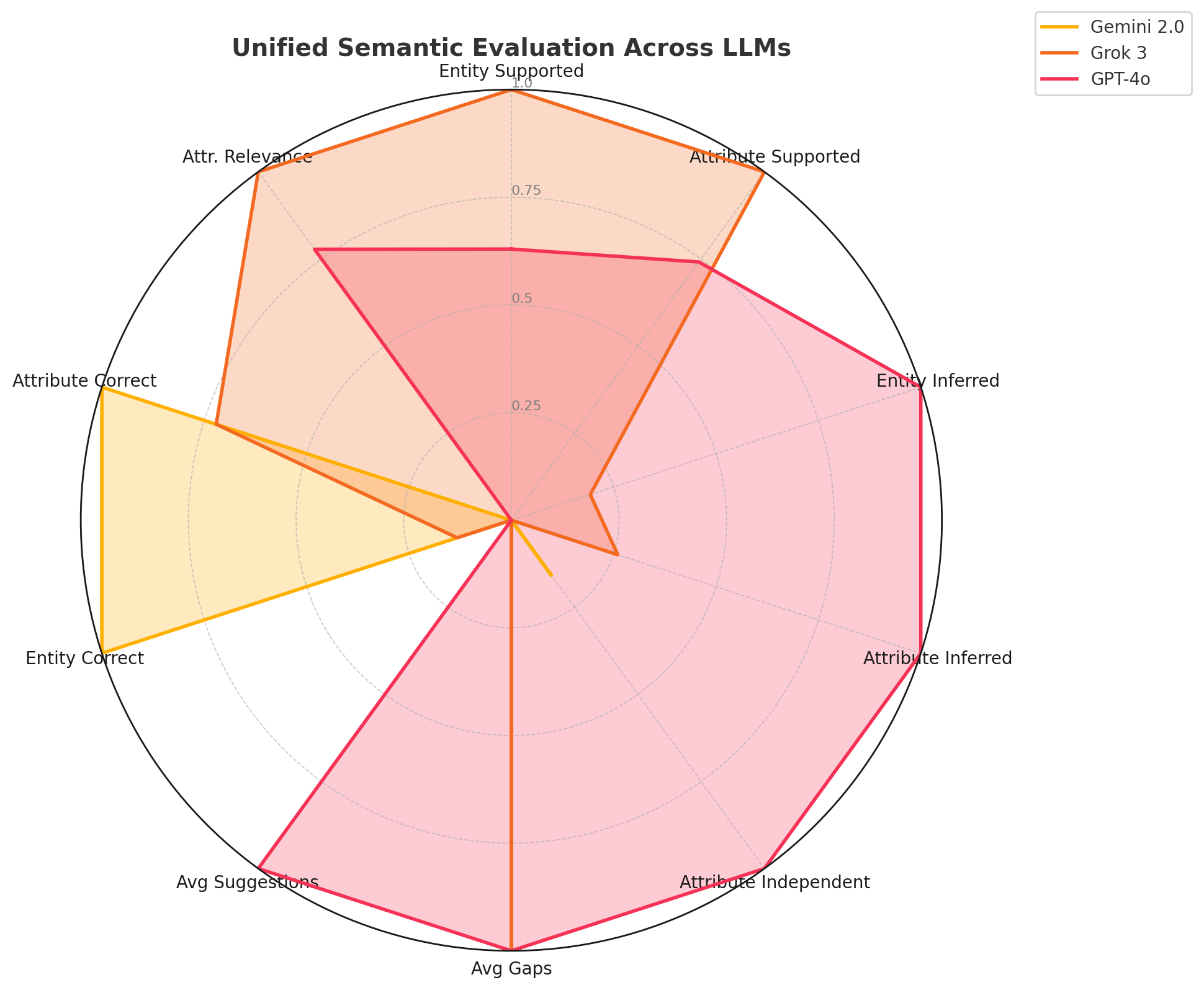
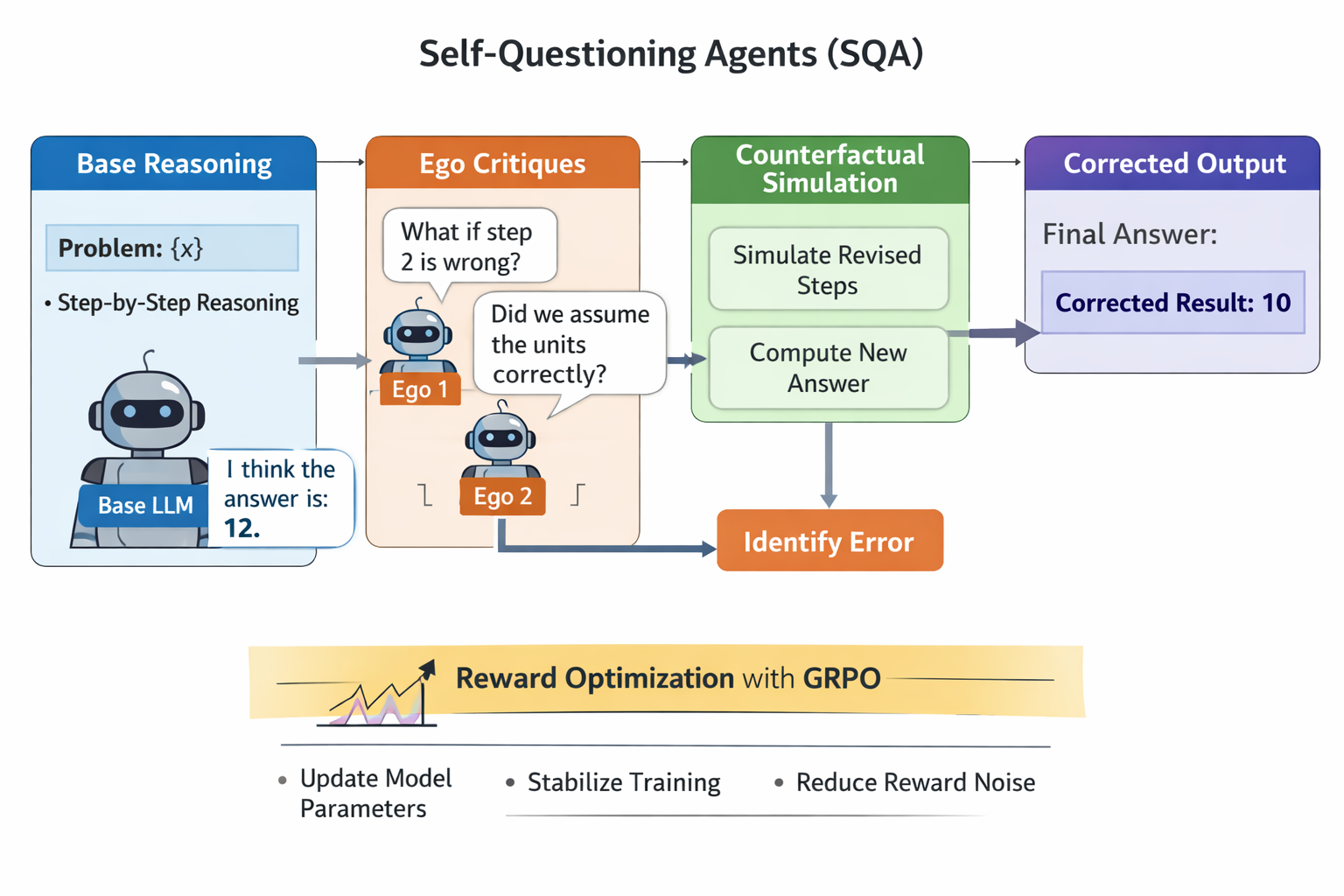
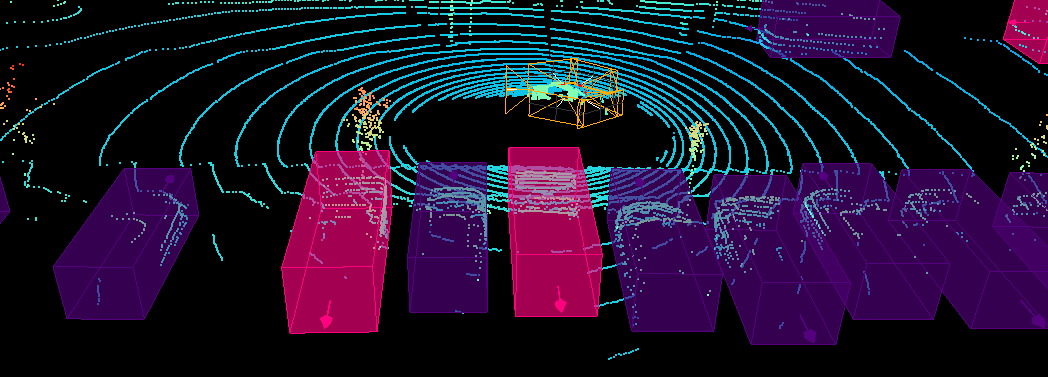
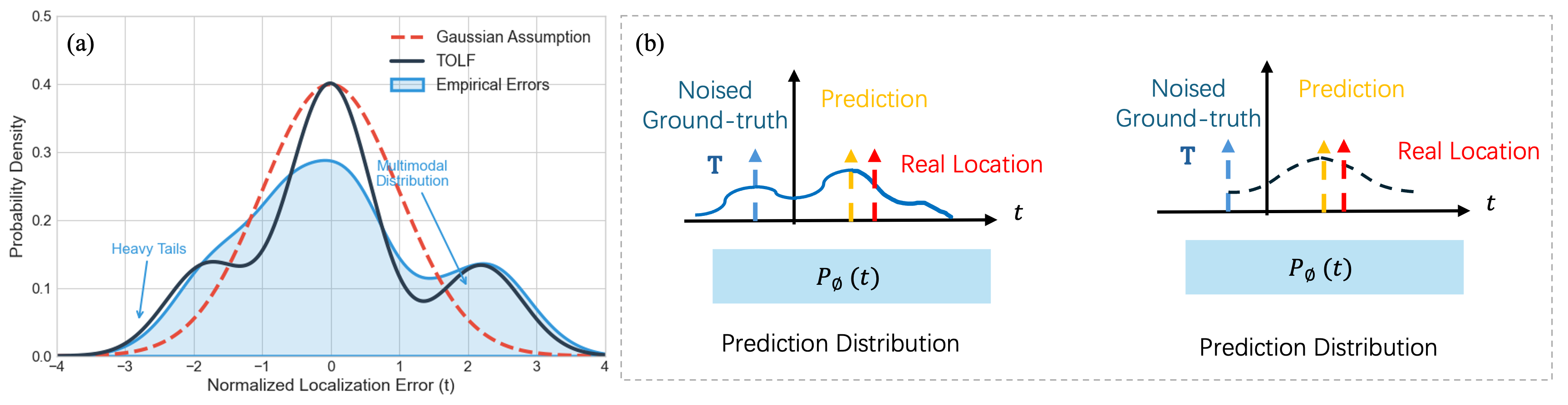
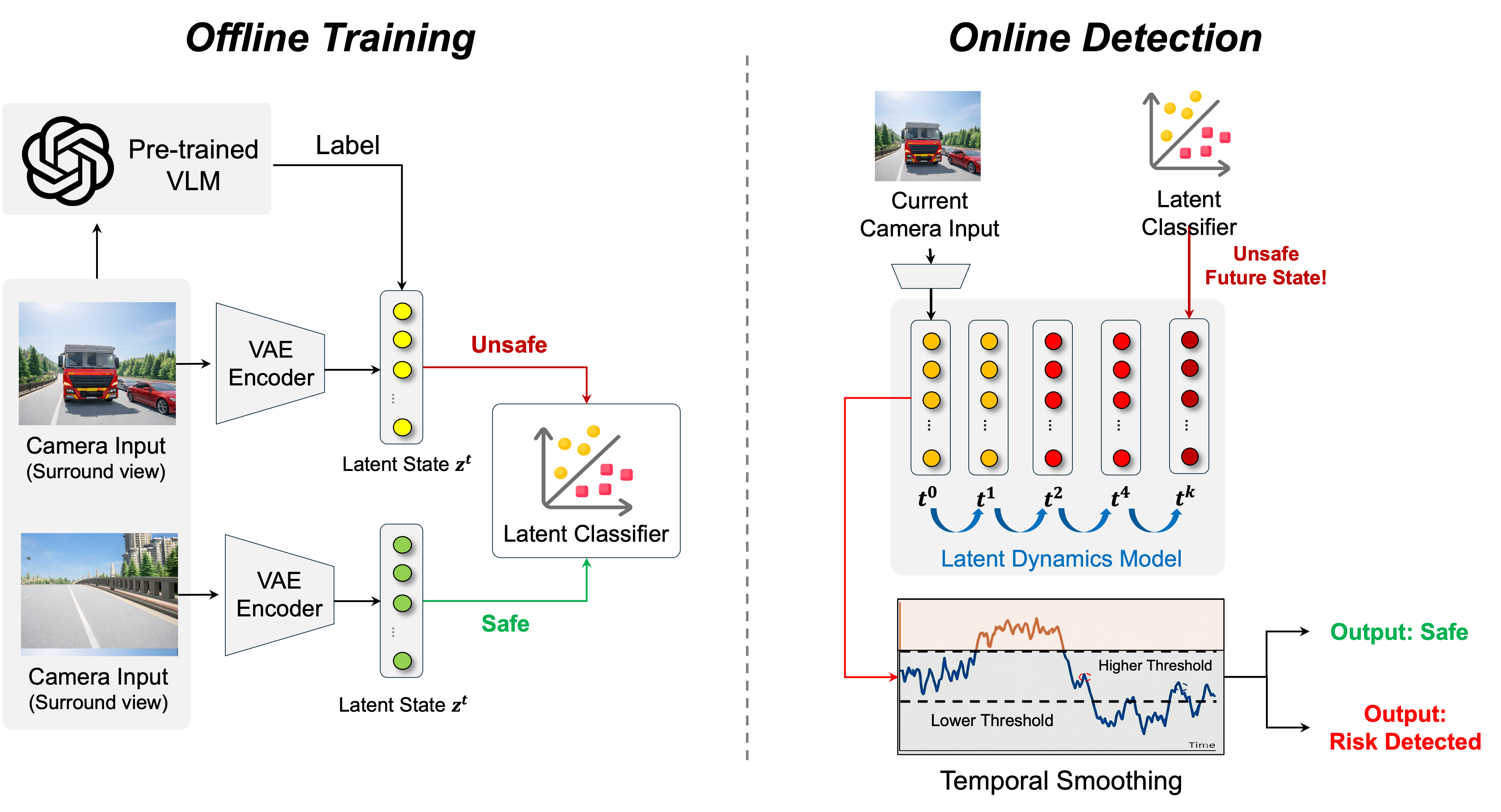
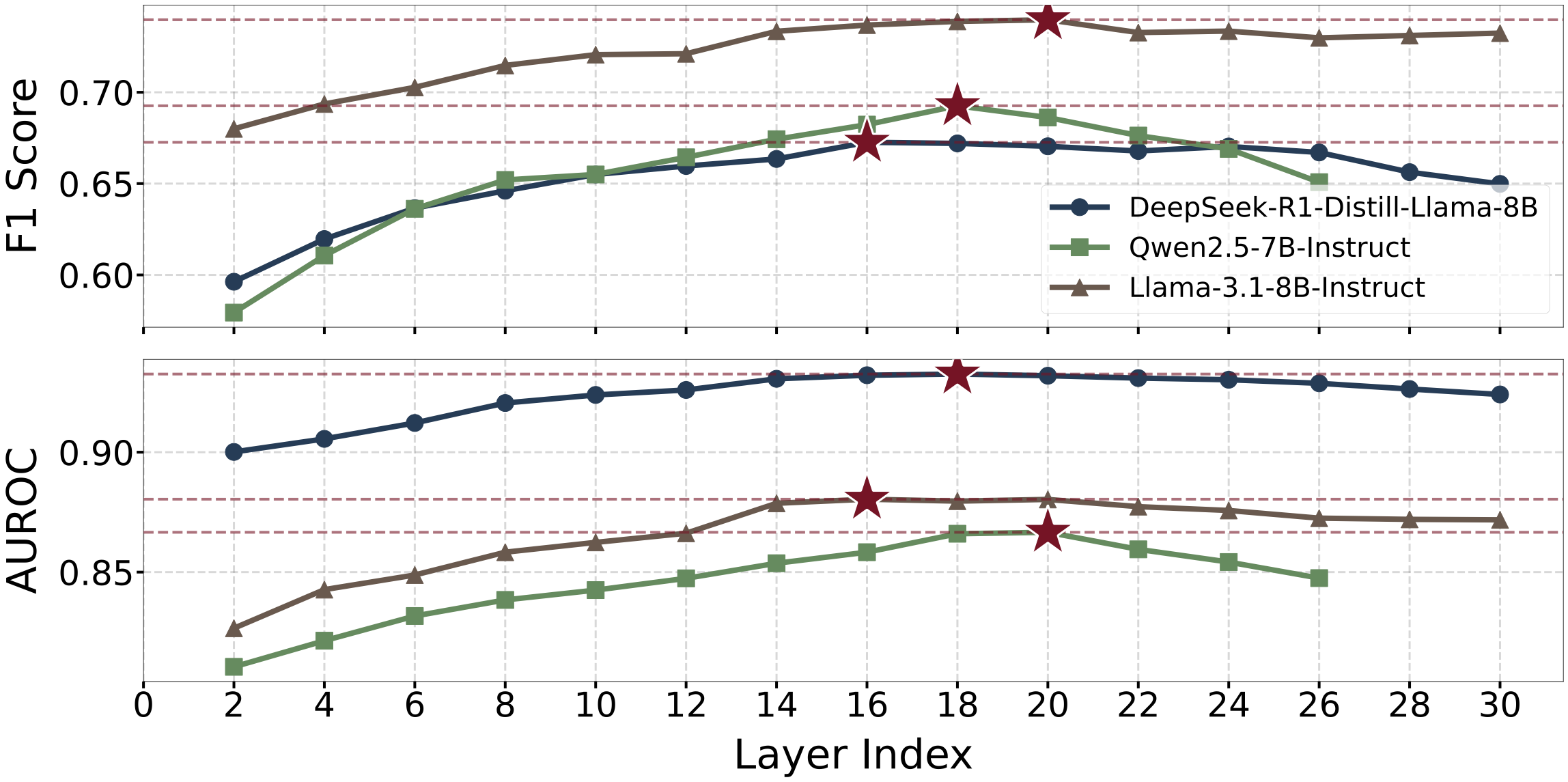
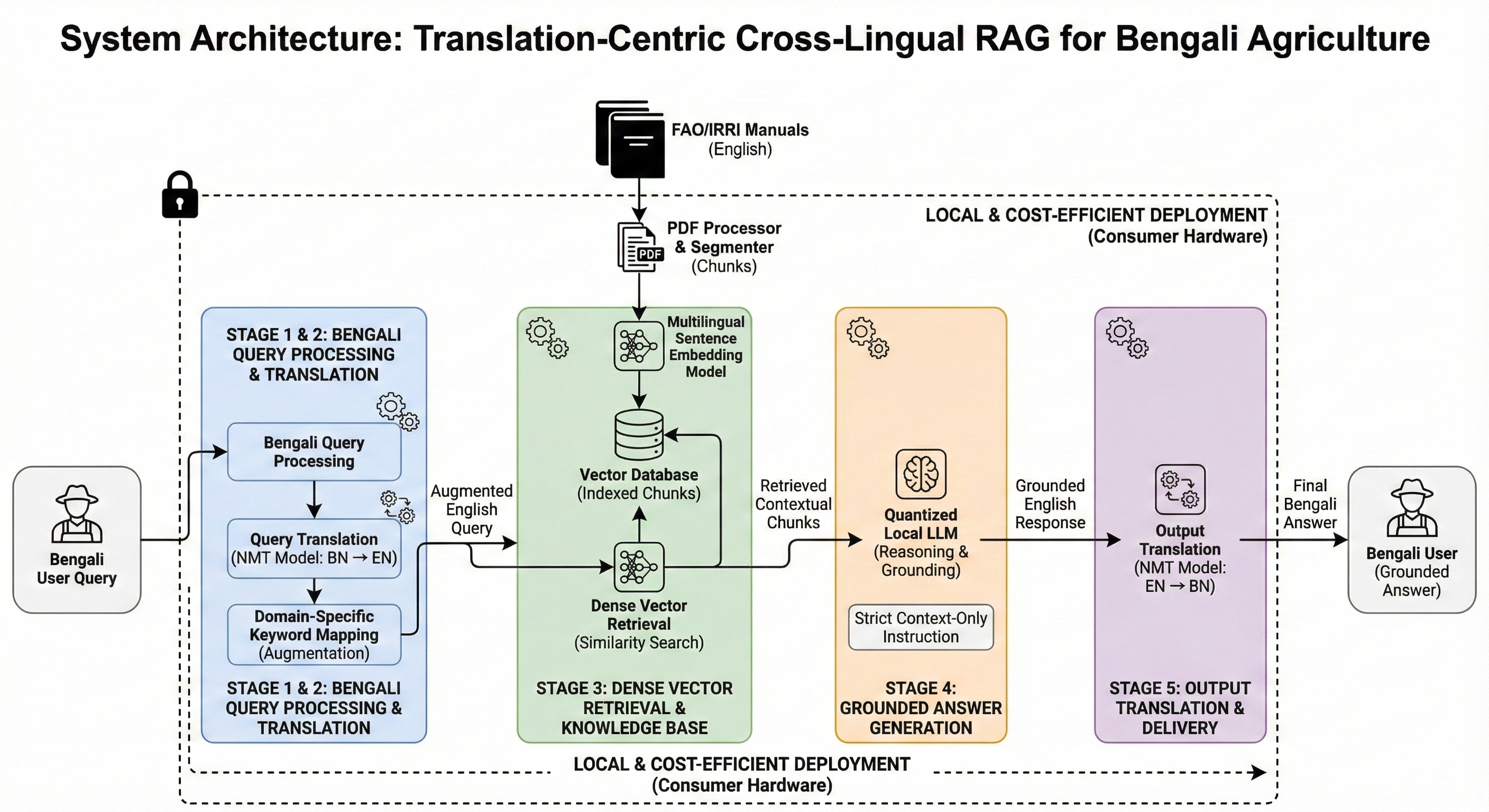
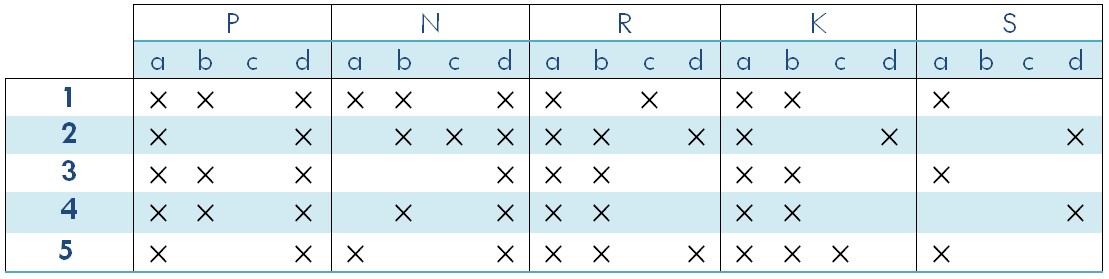
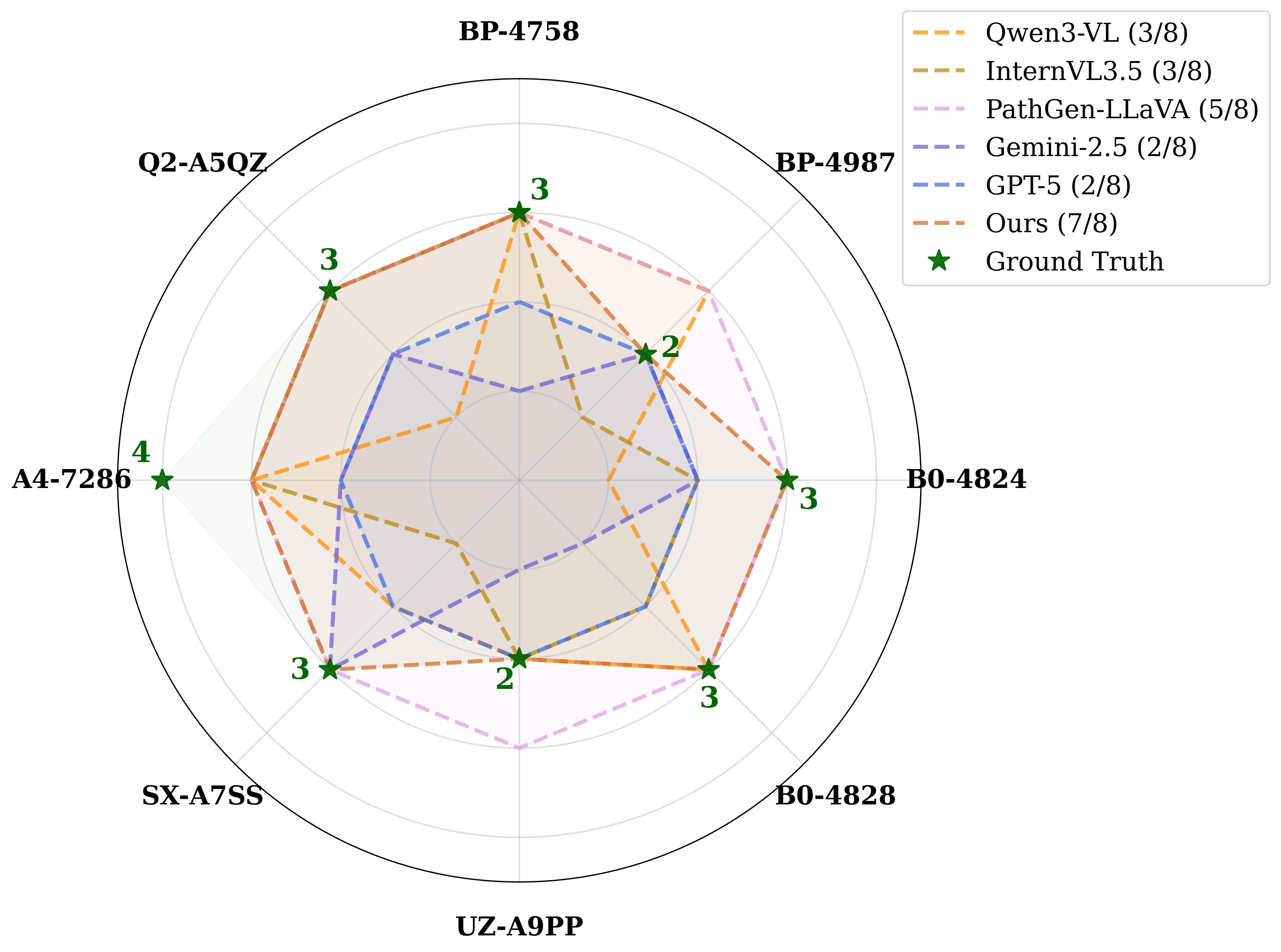
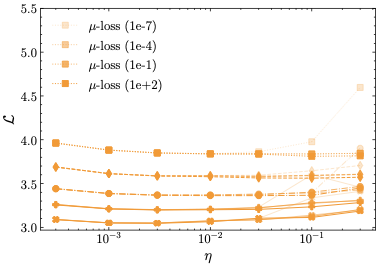
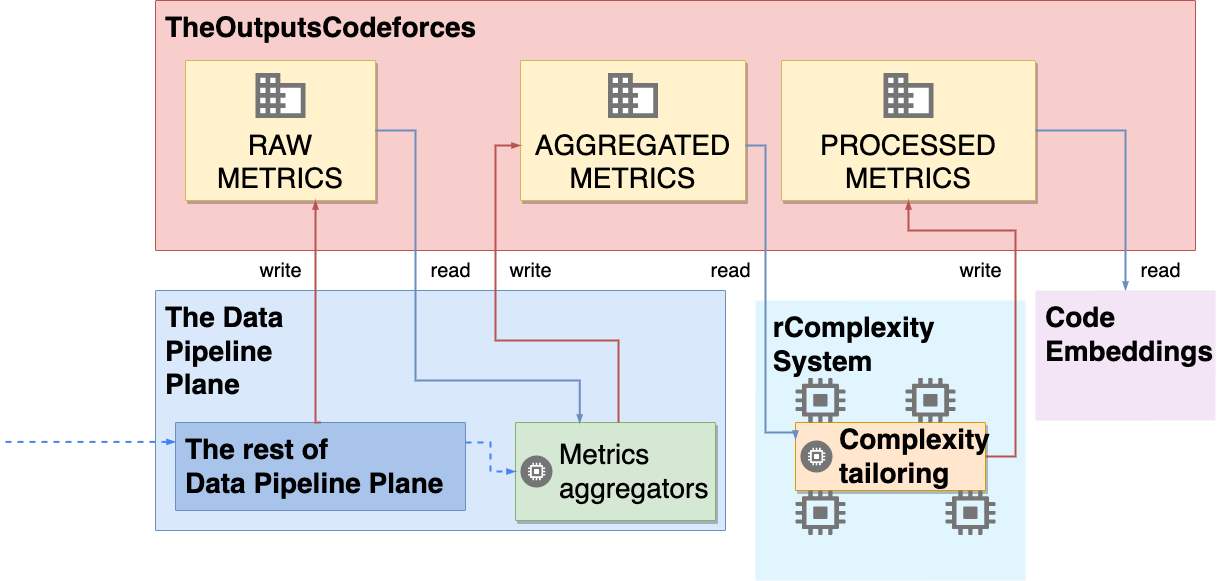
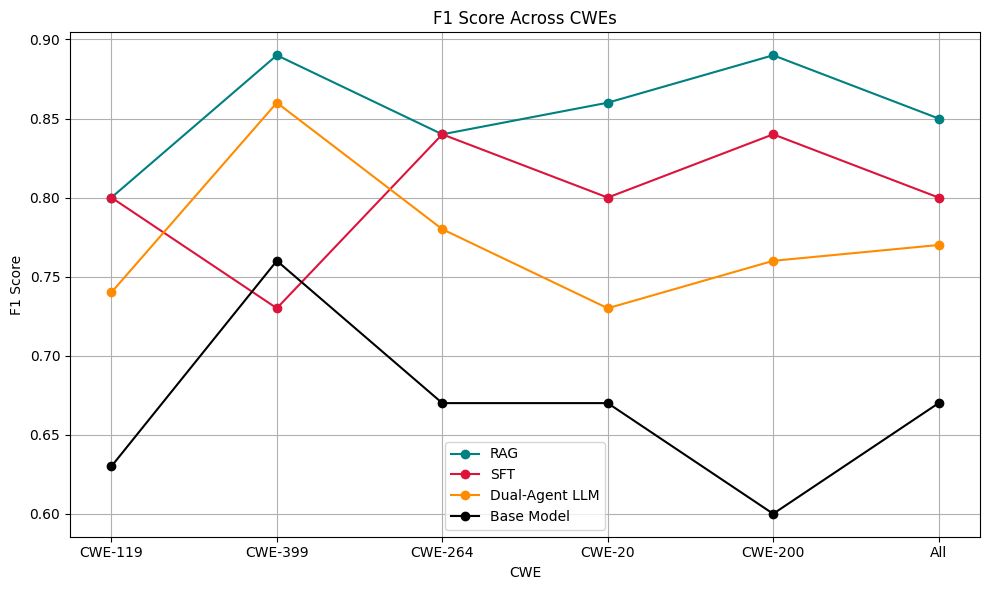
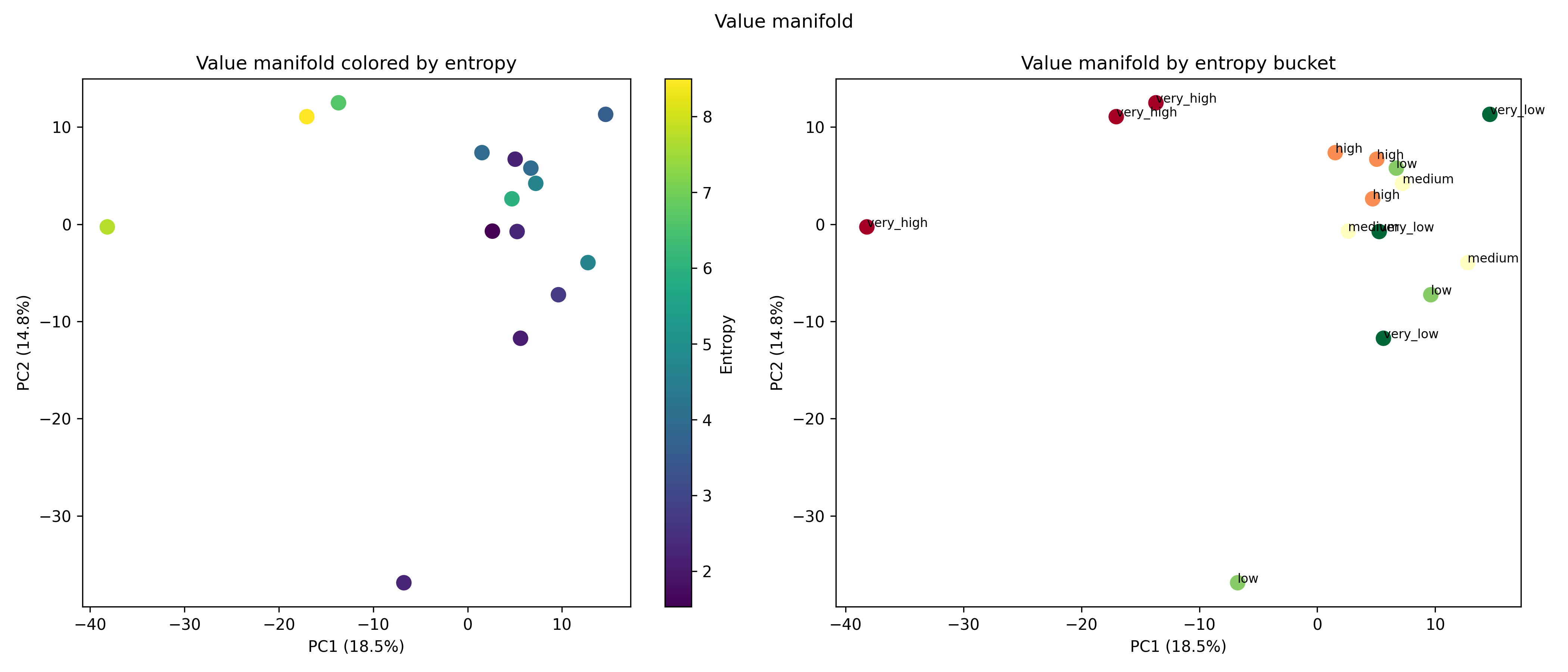
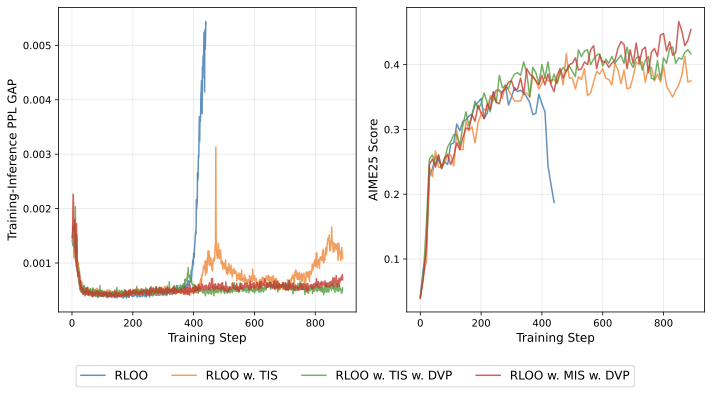
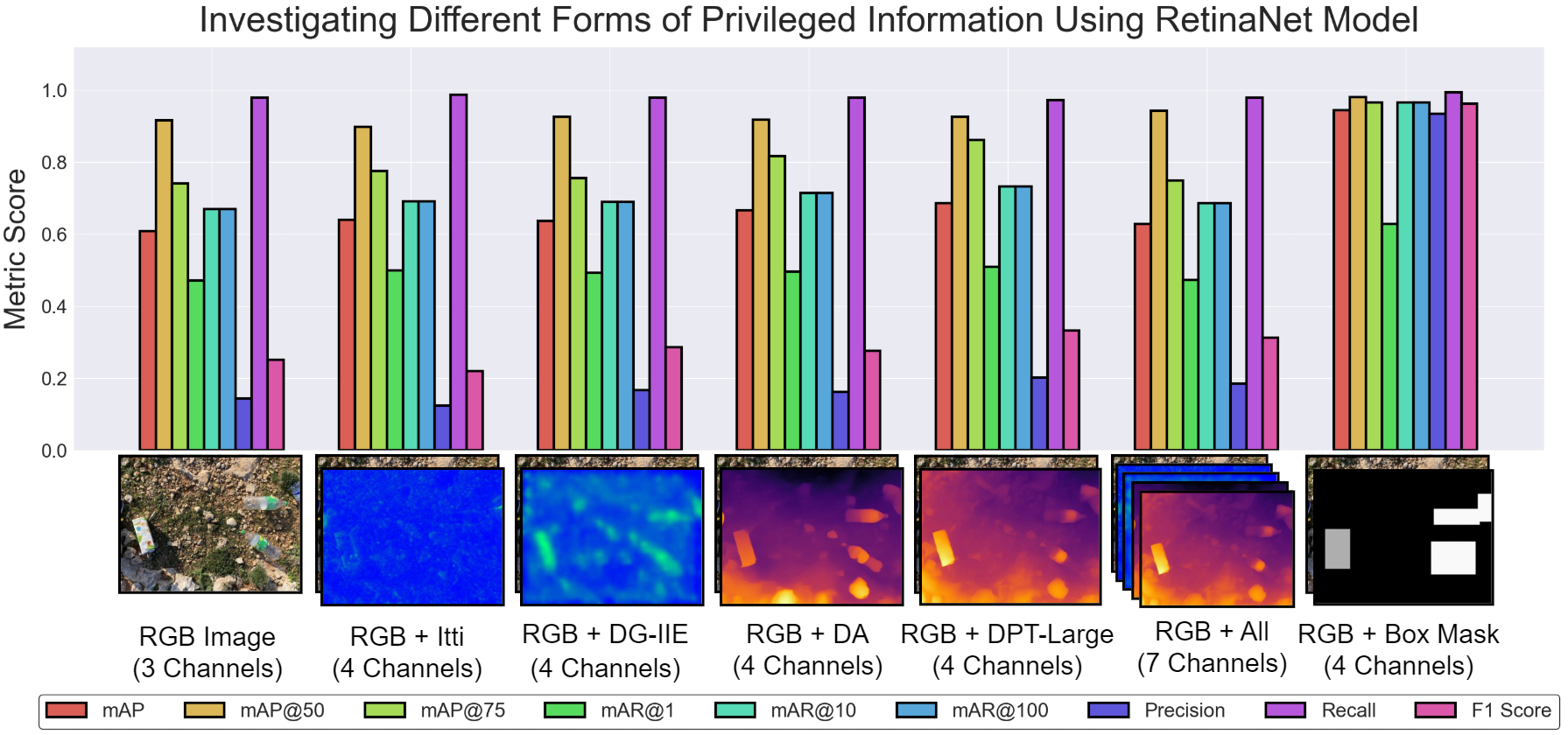
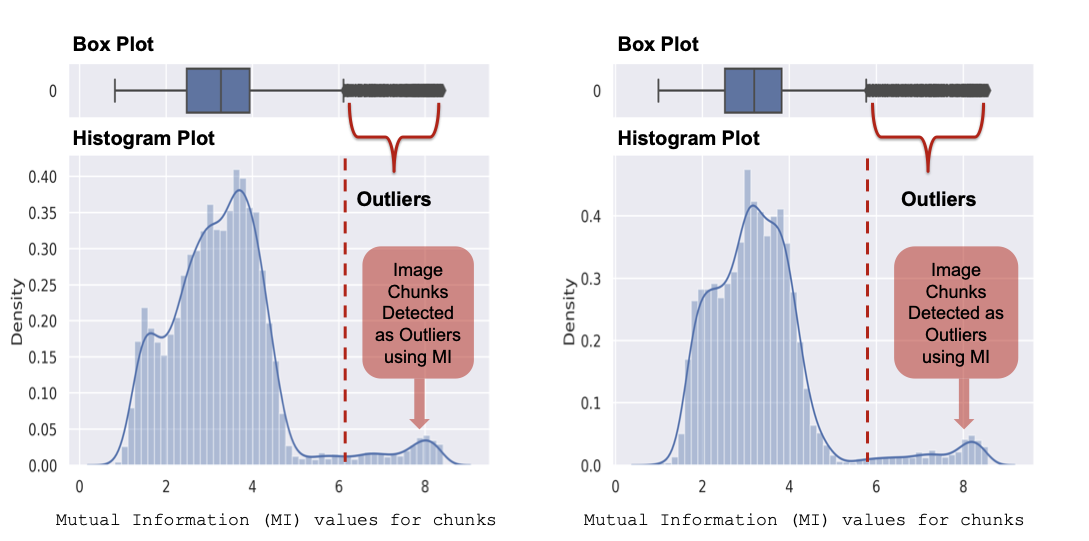
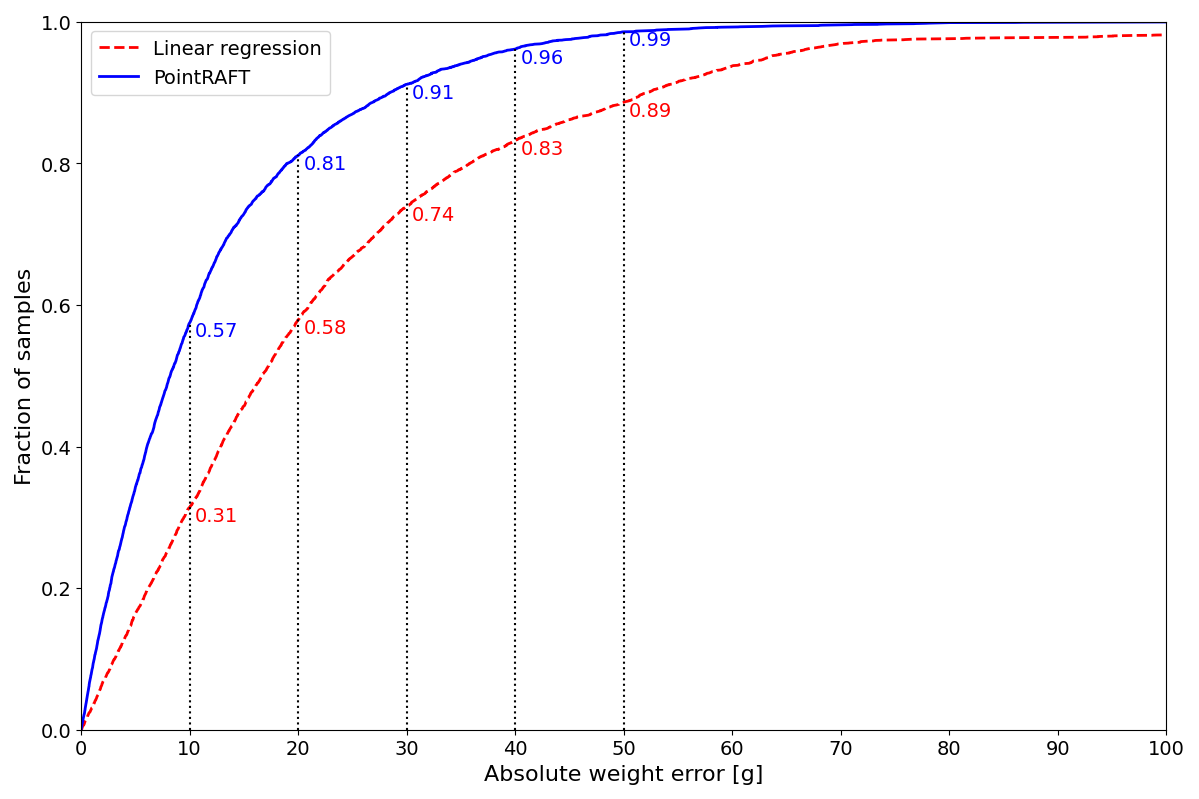
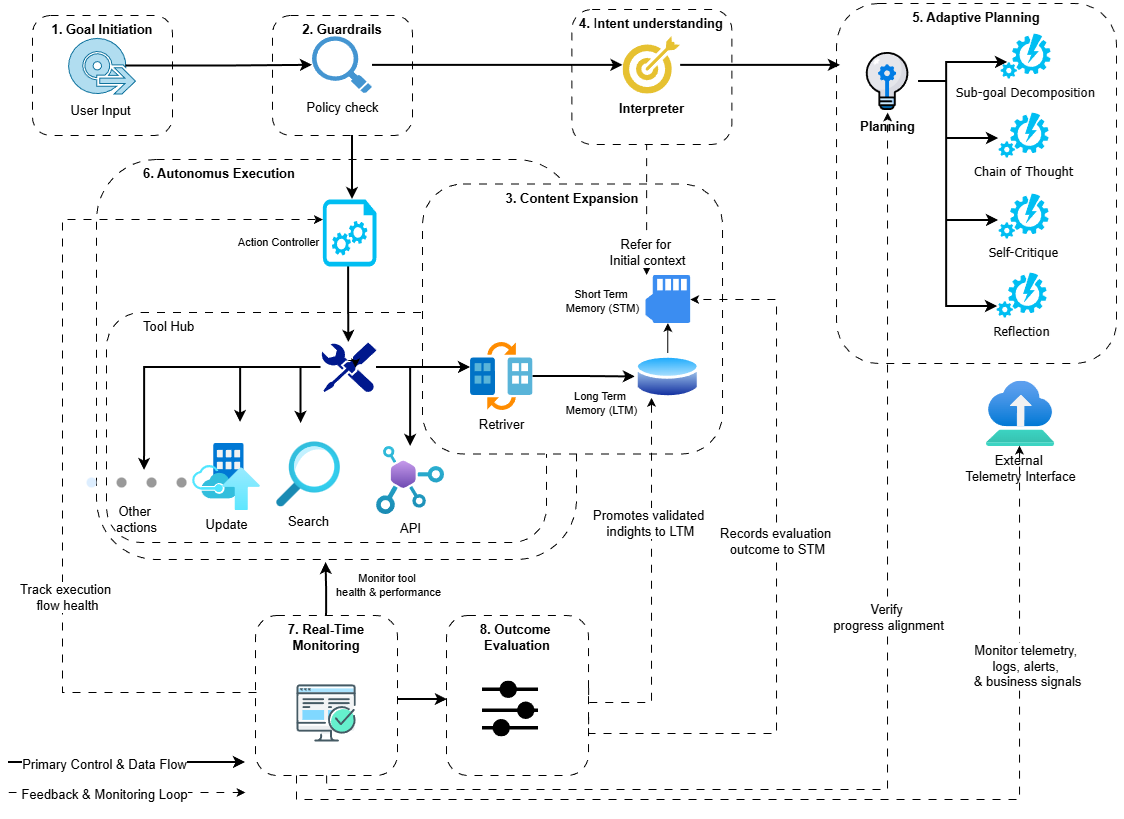
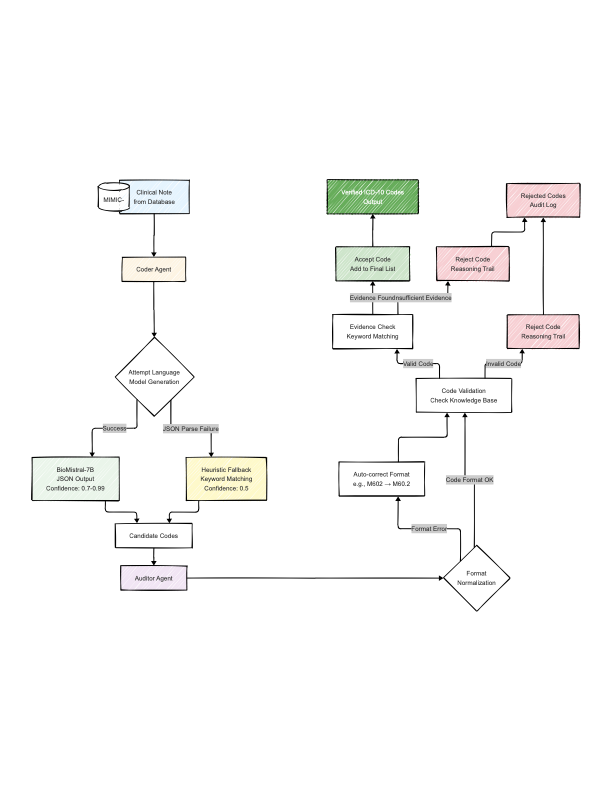
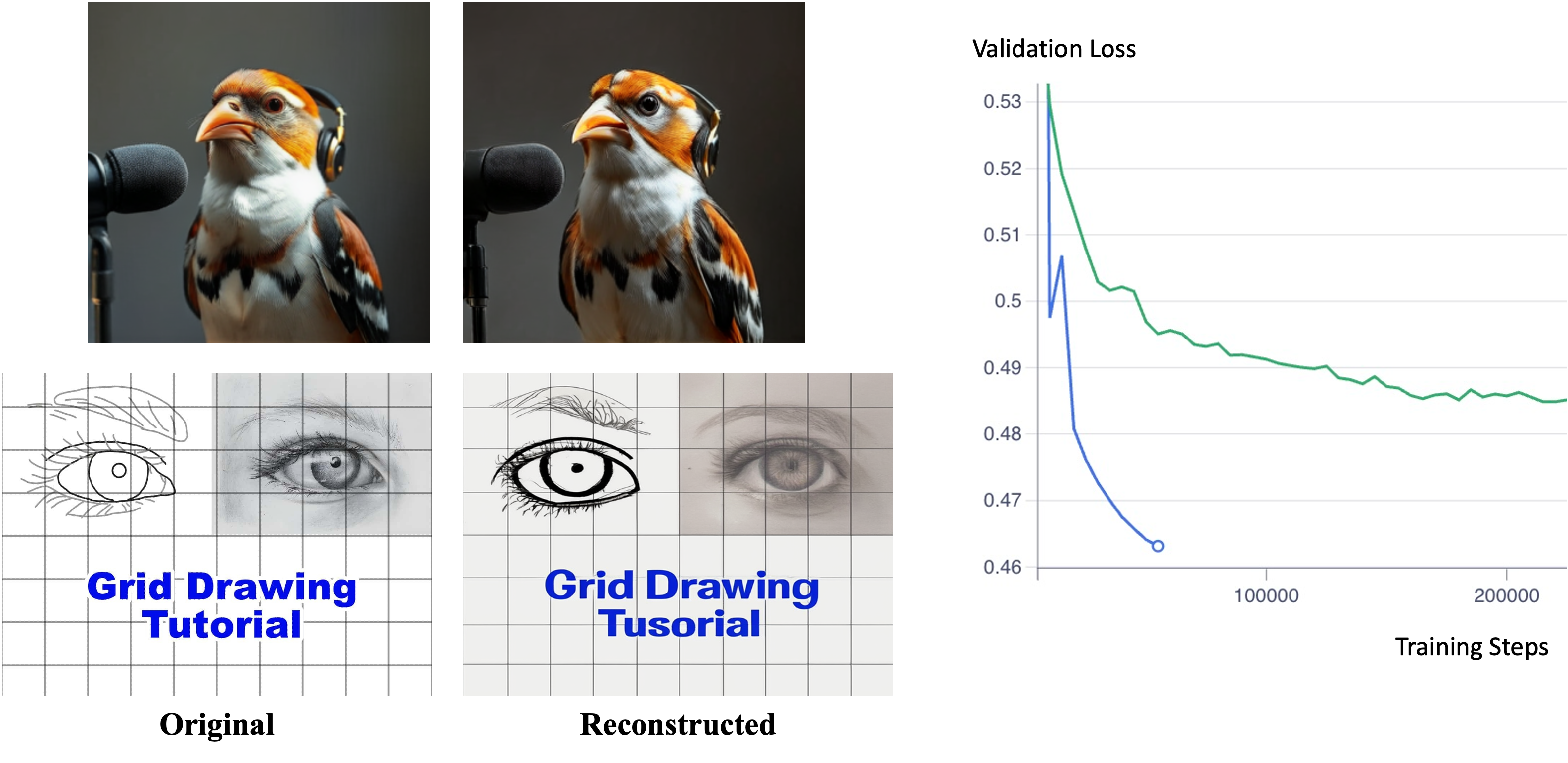
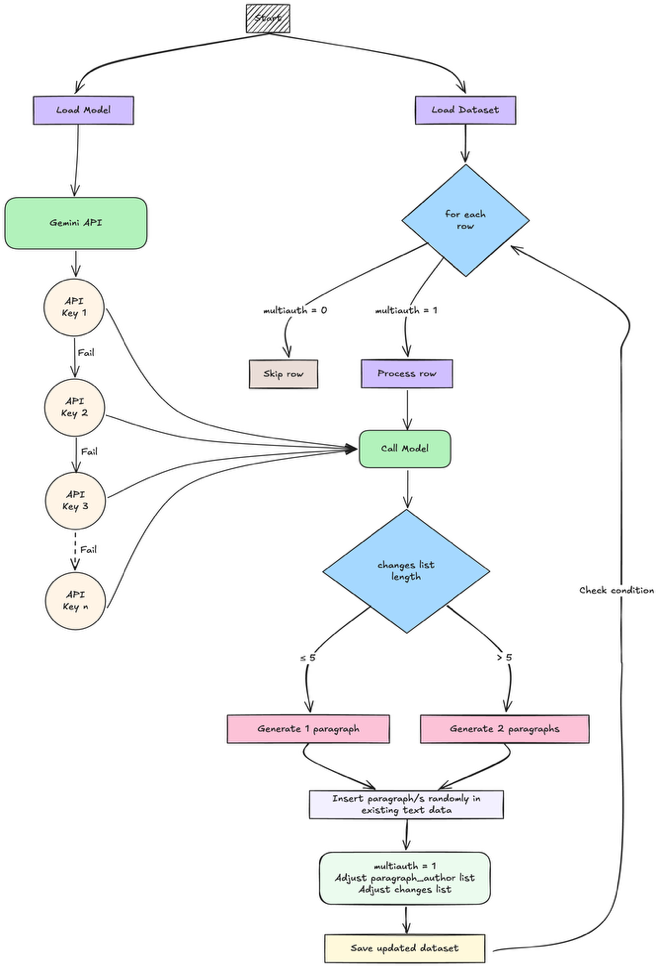
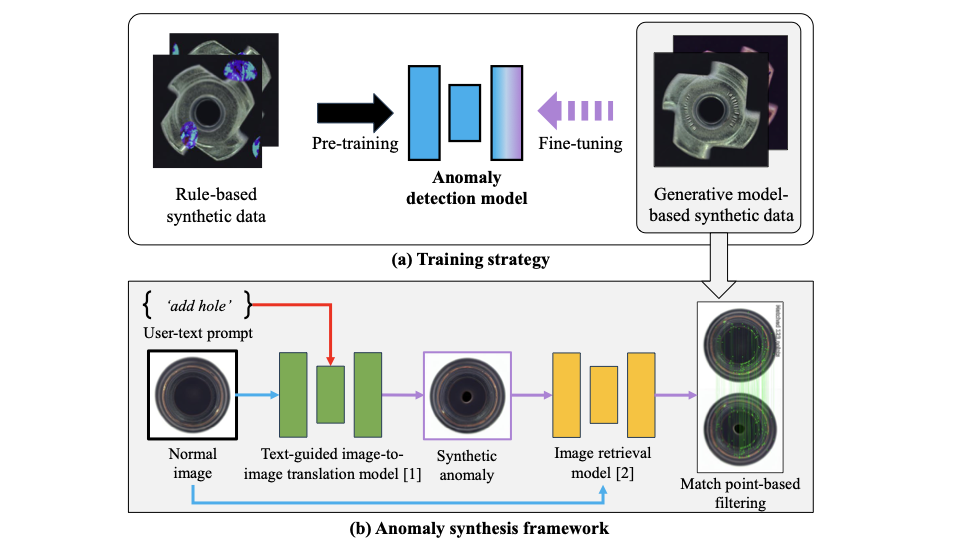
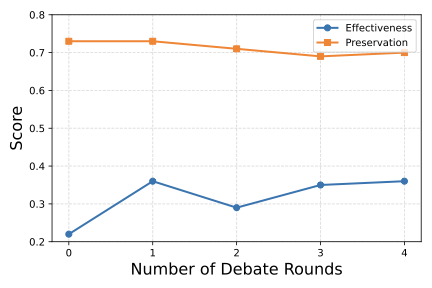
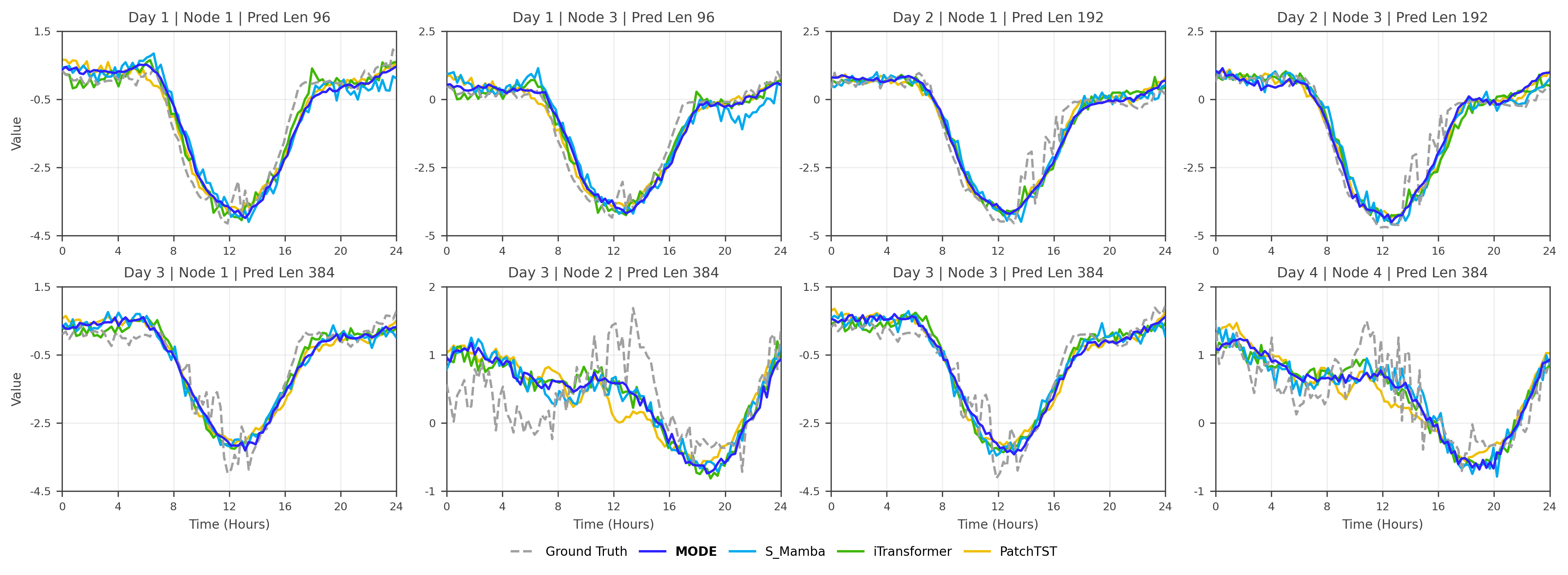
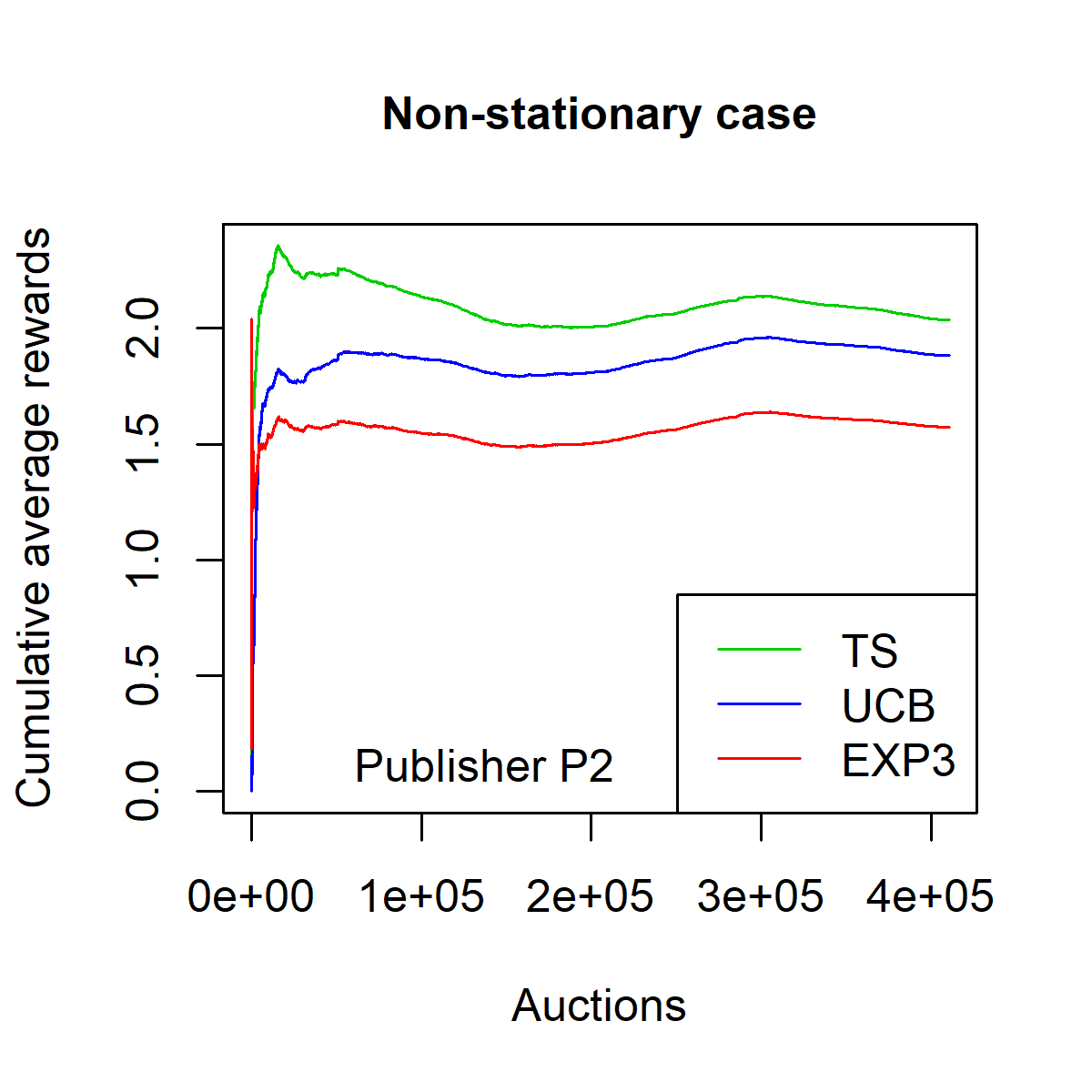
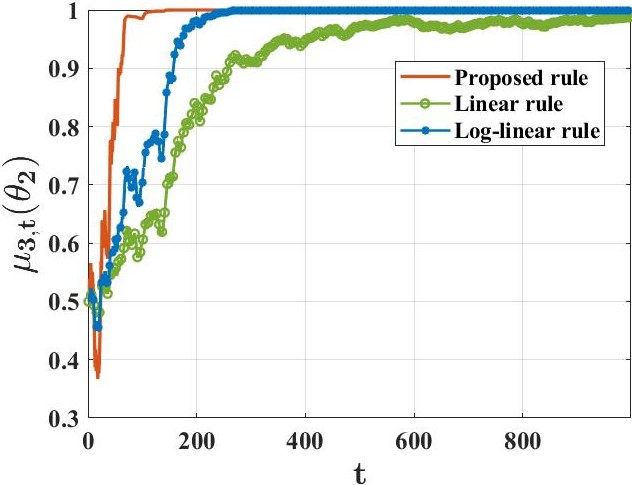
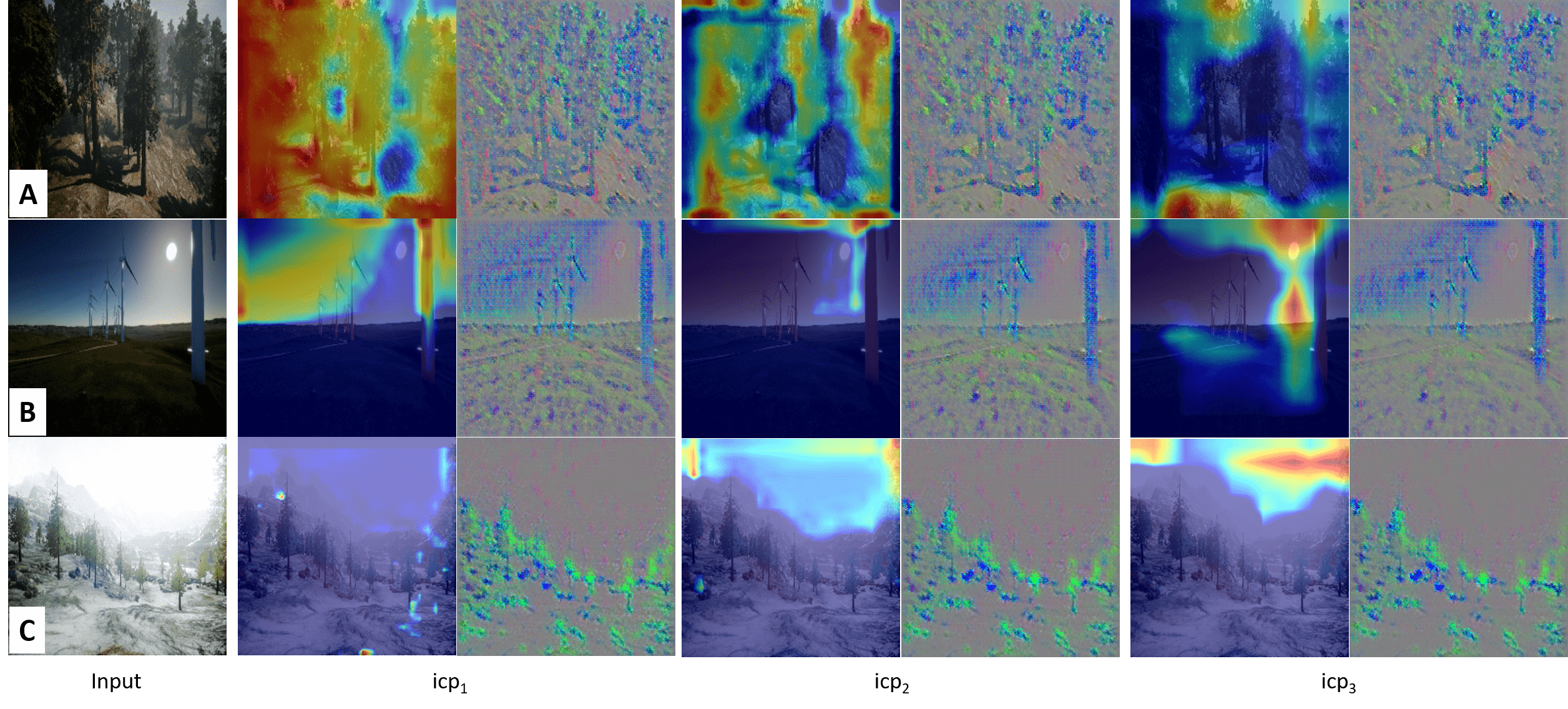
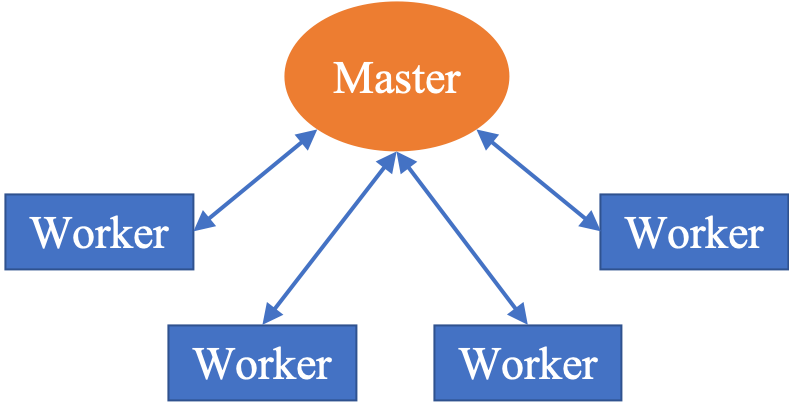
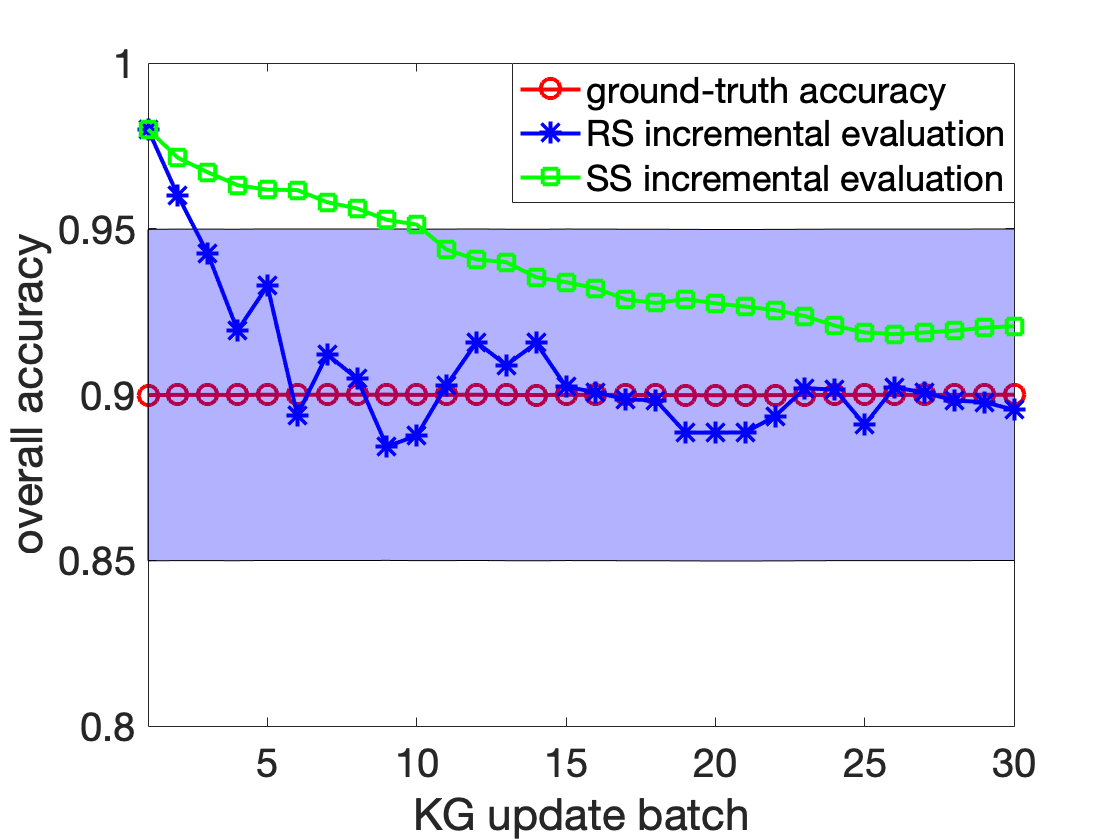
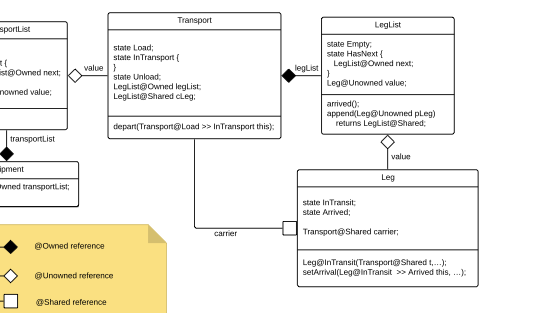
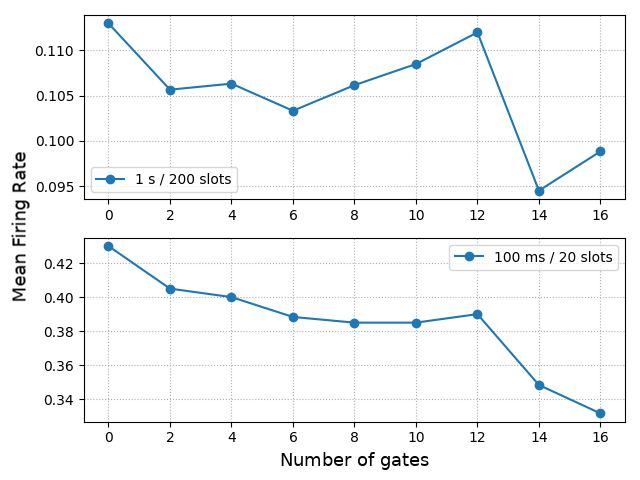
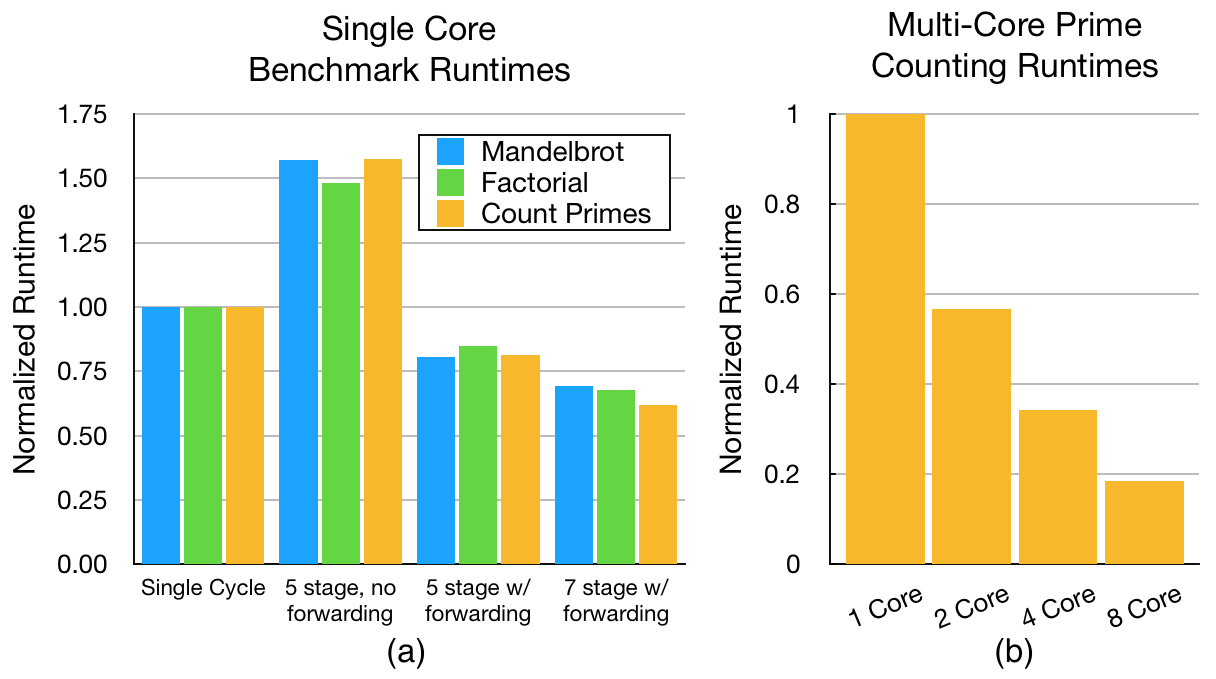
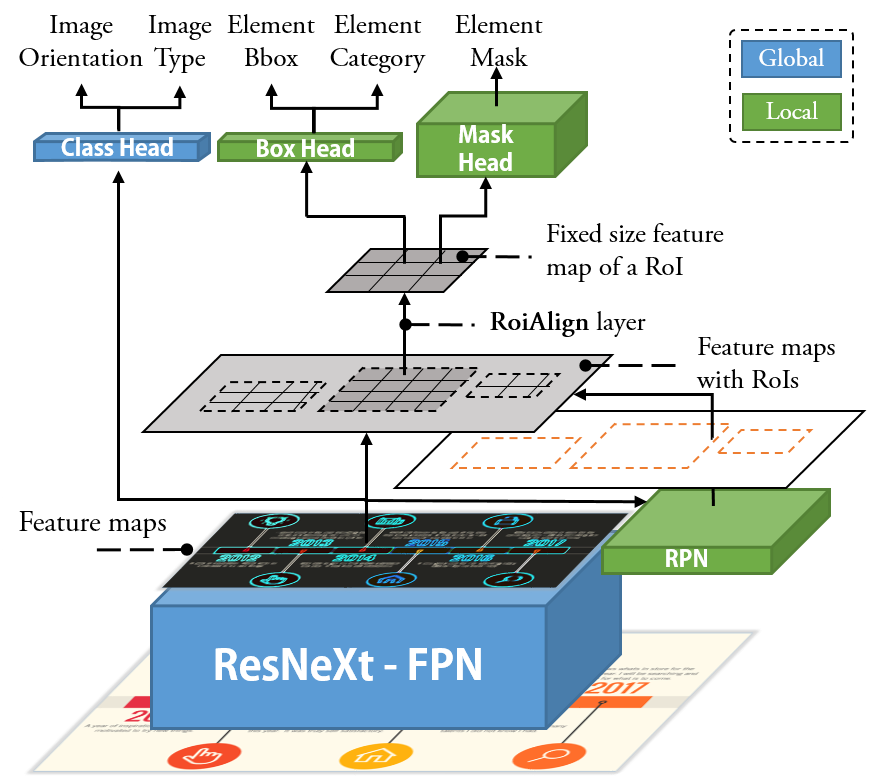
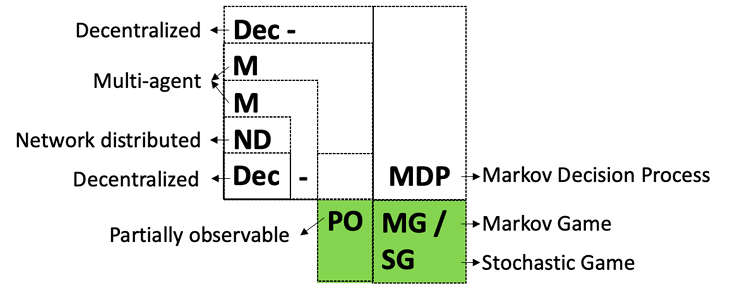
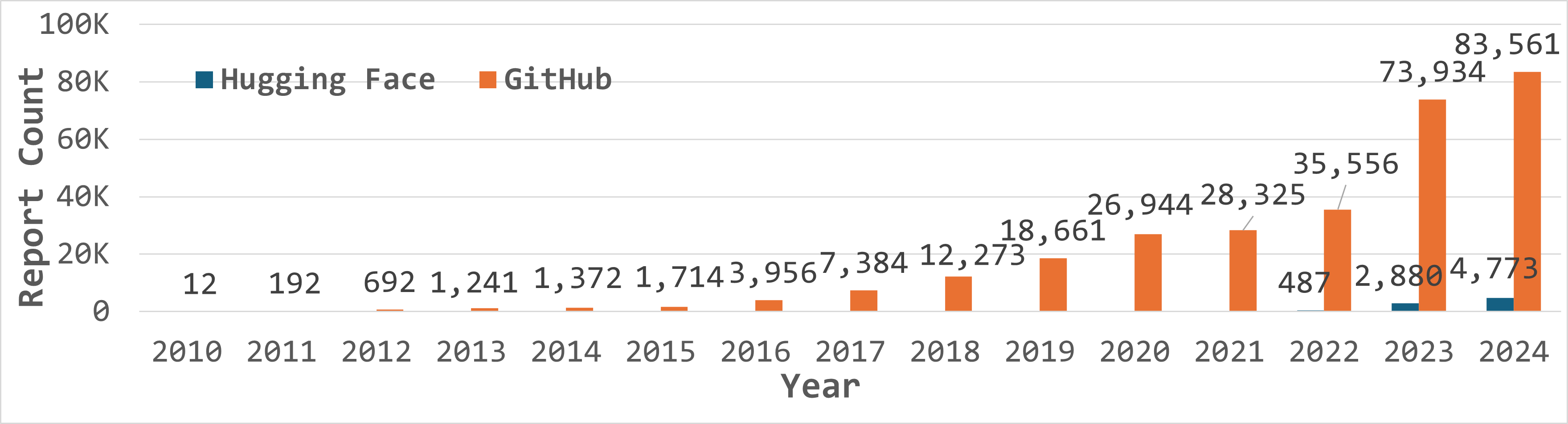양자 조언을 사용한 함수 역원의 하한값
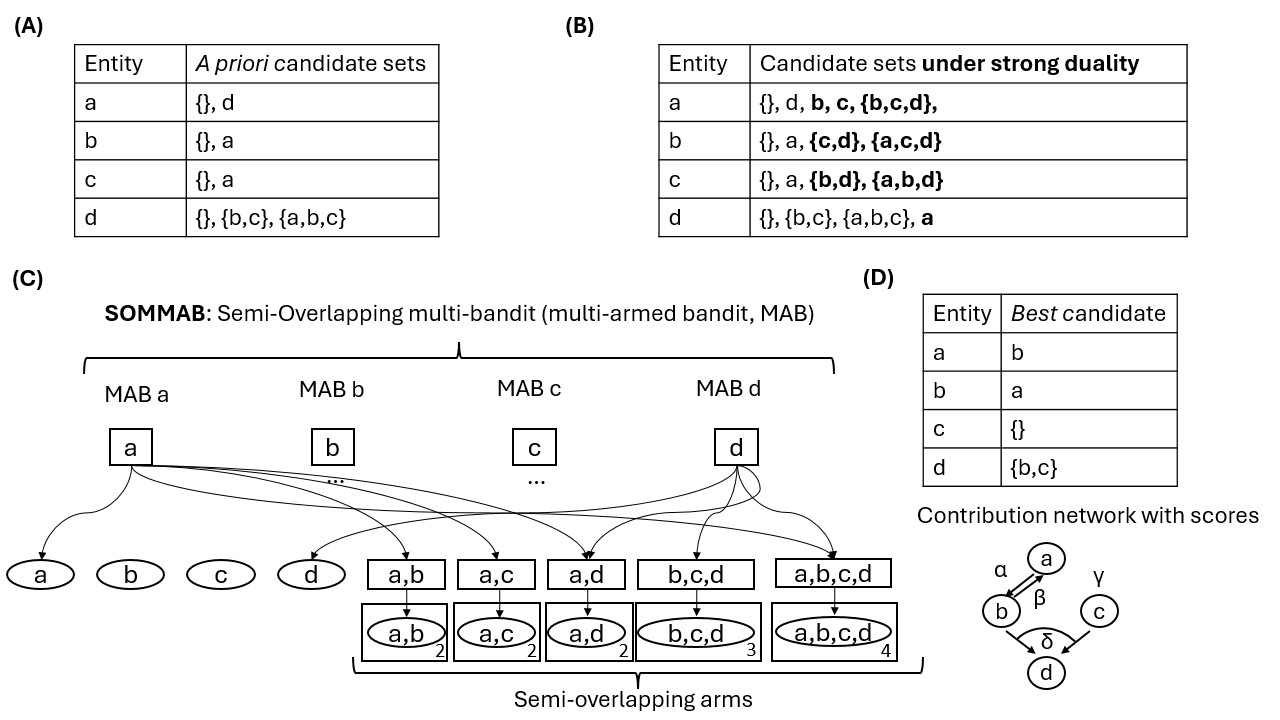
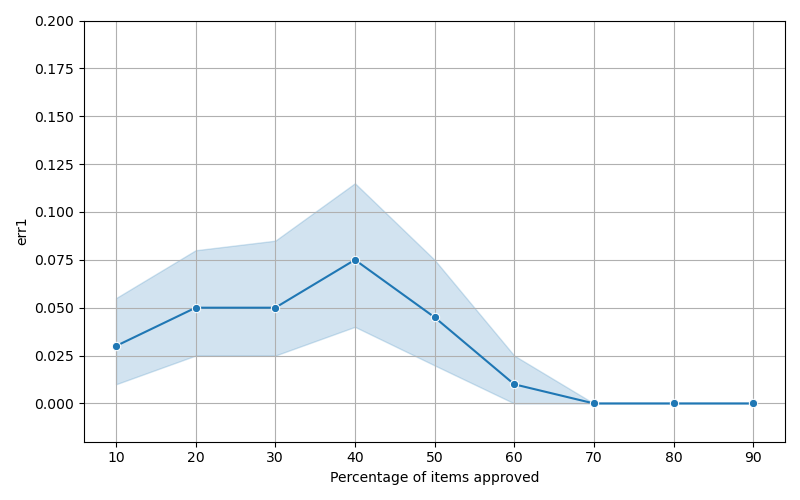
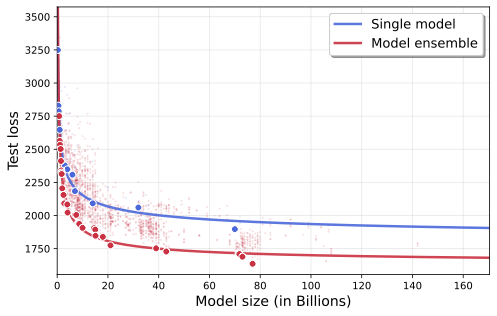
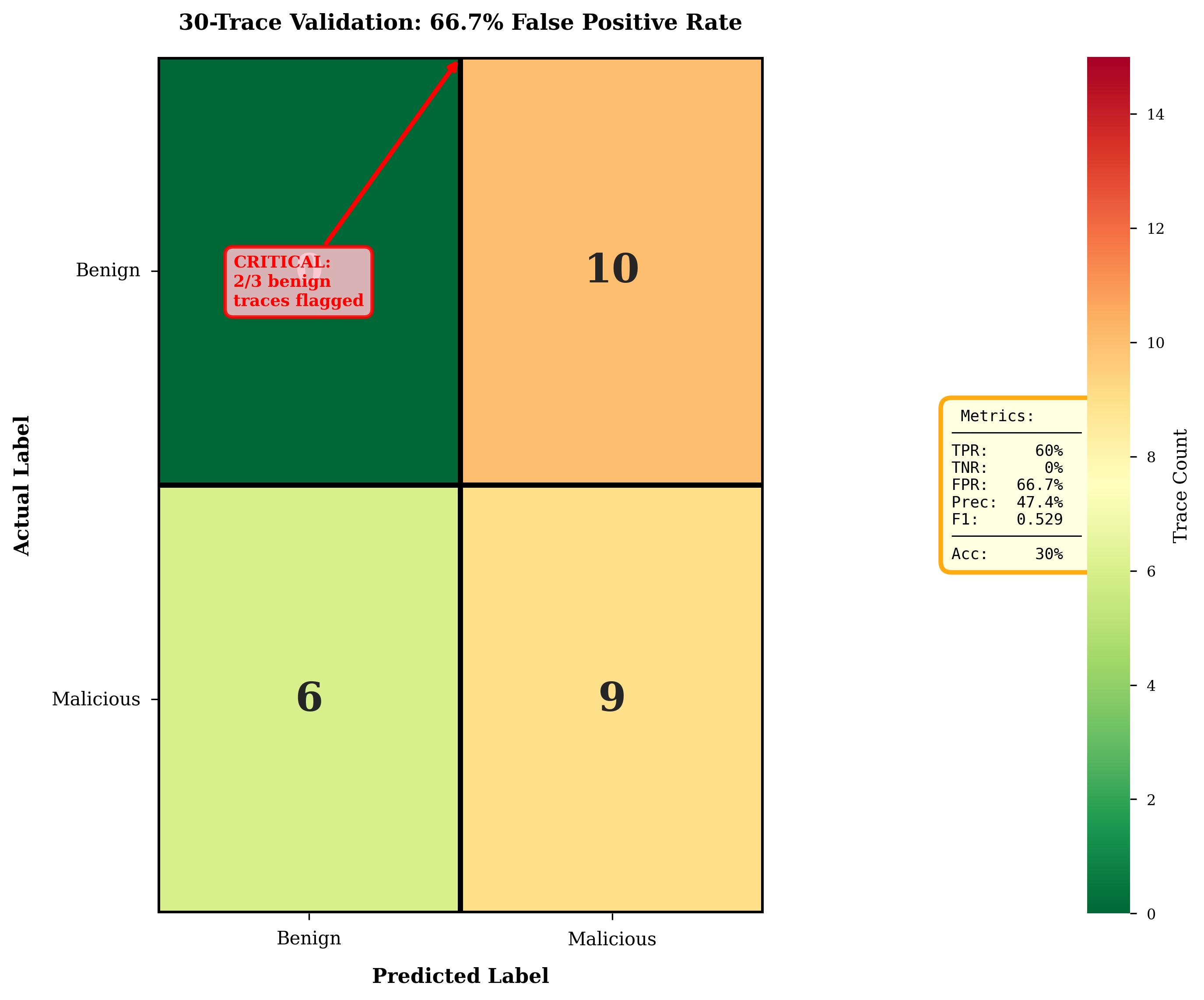
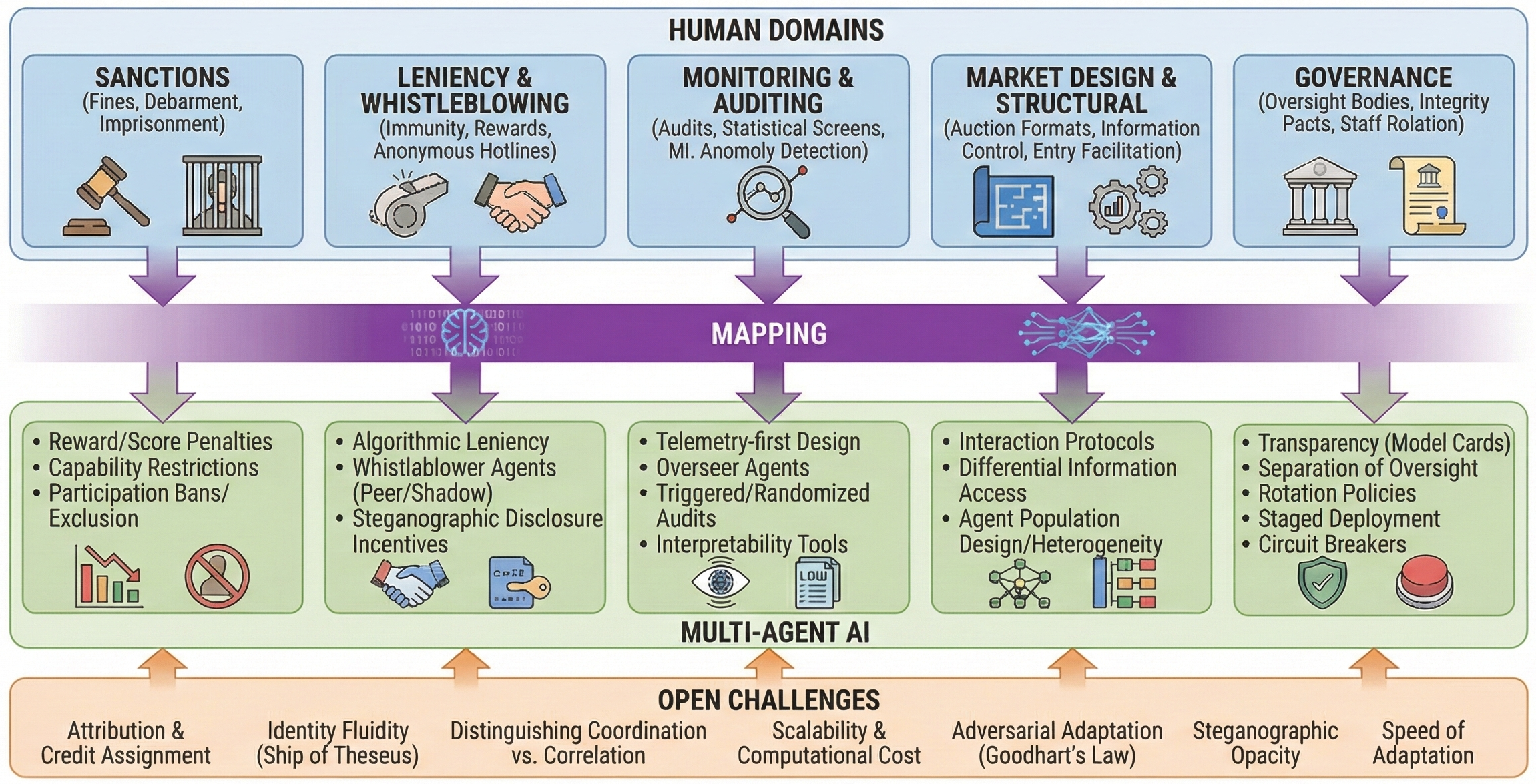
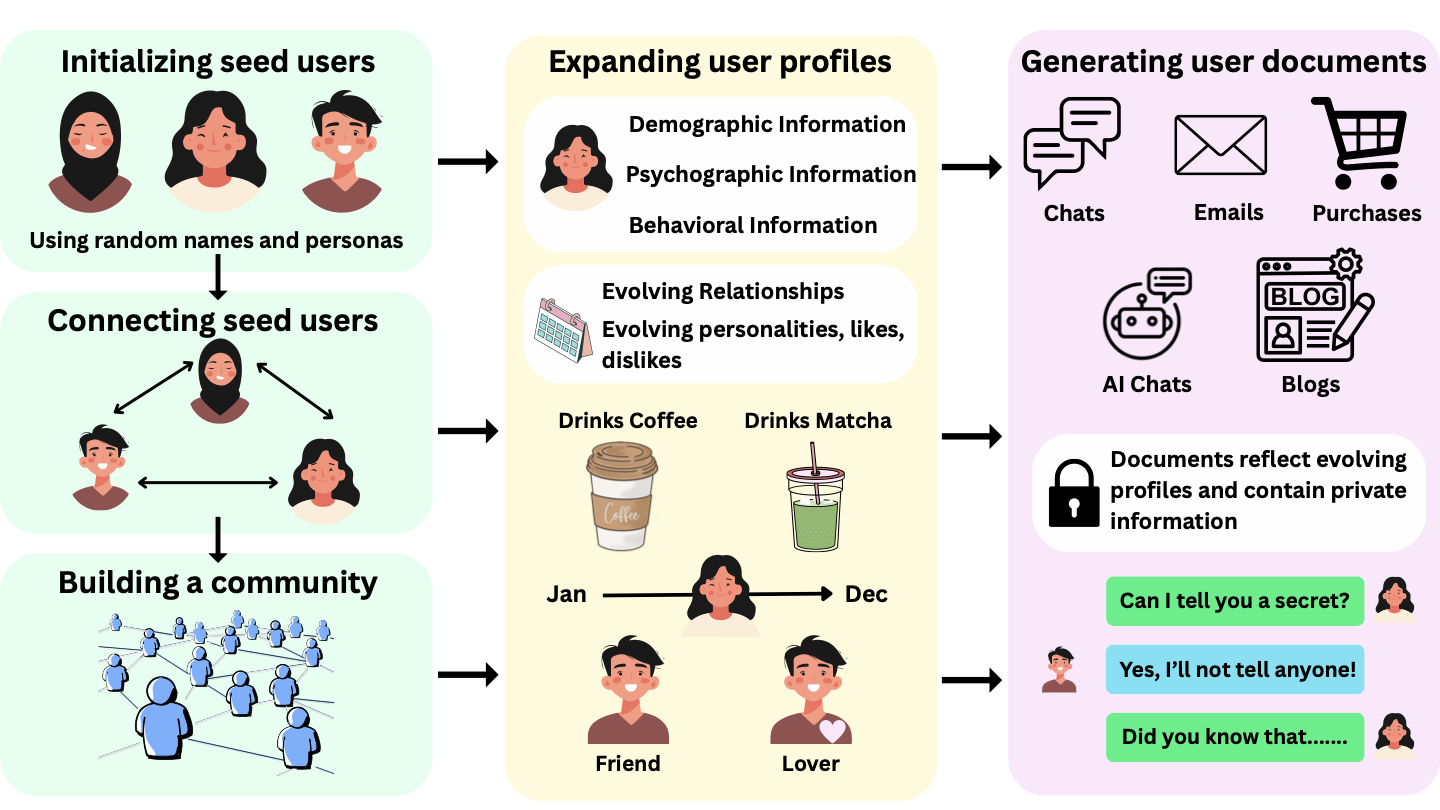
함수 역산은 임의의 함수 $f [M] to [N]$가 주어졌을 때, 이미지 $y$의 사전 영상(pre-image) $f^{-1}(y)$를 찾는 문제입니다. 이 연구에서는 예처리 모델에서 이 문제를 재검토합니다. 이 모델에서는 함수 $f$에만 의존하는 보조 정보 또는 조언(advice) 크기 $S$를 계산할 수 있습니다. 이것은 고전적인 설정에서 잘 연구된 문제지만, 양자 알고리즘이 어떻게 더 나은 성능을 내는지 명확하지 않습니다. 특히 Grover의 알고리즘 외에는 예처리의 힘을 활용하지 못합니다. Nayebi 등은 $ST^2 ge tilde Omega(N)$에 대한 하한 값을 양자 알고리즘이 역순열(permutation)을 역산하는 데 사용되는 하한 값으로 증명했습니다. 그러나 이들은 조언이 고전적인 경우만 고려했습니다. Hhan 등은 그 결과를 완전히 양자 알고리즘에 대한 결과로 확장했습니다. 본 연구에서는 $M = O(N)$인 범위에서 함수 역산을 위한 완전히 양자 알고리즘에 대해 동일한 점근적 하한 값을 제공합니다. 이러한 경계를 증명하기 위해 Ambainis 등이 처음으로 소개했던 양자 랜덤 액세스 코드의 개념을 일반화하여, 우리가 주어진 (필연적으로 독립적이지 않은) 임의 변수 목록을 길이가 가변적인 인코딩으로 압축하고 이 인코딩만으로 임의의 요소를 높은 확률로 검색할 수 있도록 합니다. 우리의 주요 기술적 업적 중 하나는 이러한 일반화된 양자 랜덤 액세스 코드에 대한 거의 최하한 값을 (넓은 매개변수 범위에서) 증명하는 것입니다.








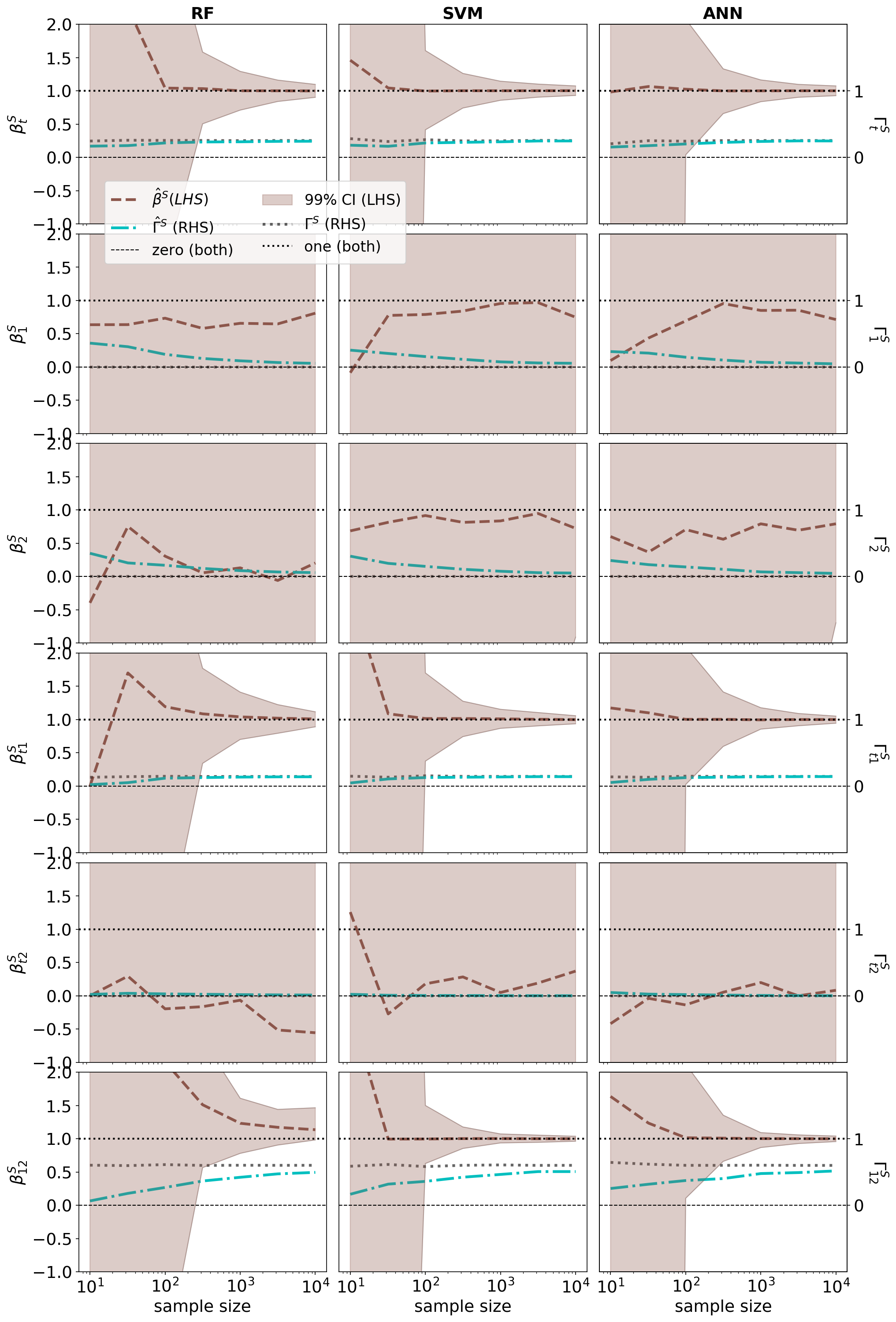
![[한글 번역 중] Analysis of the $( mu/ mu_I, lambda)$-CSA-ES with Repair by Projection Applied to a Conically Constrained Problem](https://koineu.com/posts/2019/08/2019-08-12-129250-analysis_of_the____mu__mu_i__lambda___csa_es_with_/out_dynamics_projection_commaes_nd_csa_0017_p1_100_00_p2_3_16_xi_10_sigma_0_00010_c_0_05000_D_20_00000_lambda_10_mu_3_dim_00400_r2.png)



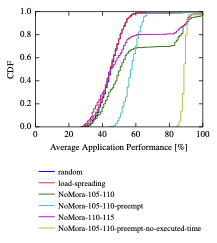
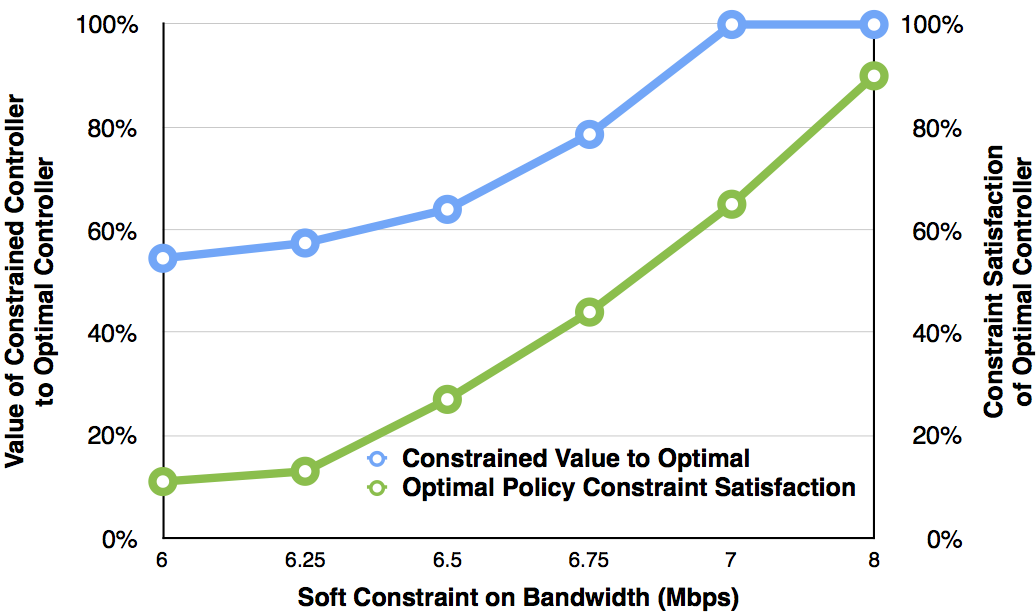
![[한글 번역 중] Viability and Performance of a Private LLM Server for SMBs A Benchmark Analysis of Qwen3-30B on Consumer-Grade Hardware](https://koineu.com/posts/2025/12/2025-12-28-191036-viability_and_performance_of_a_private_llm_server_/aime_2025_model_scores.png)
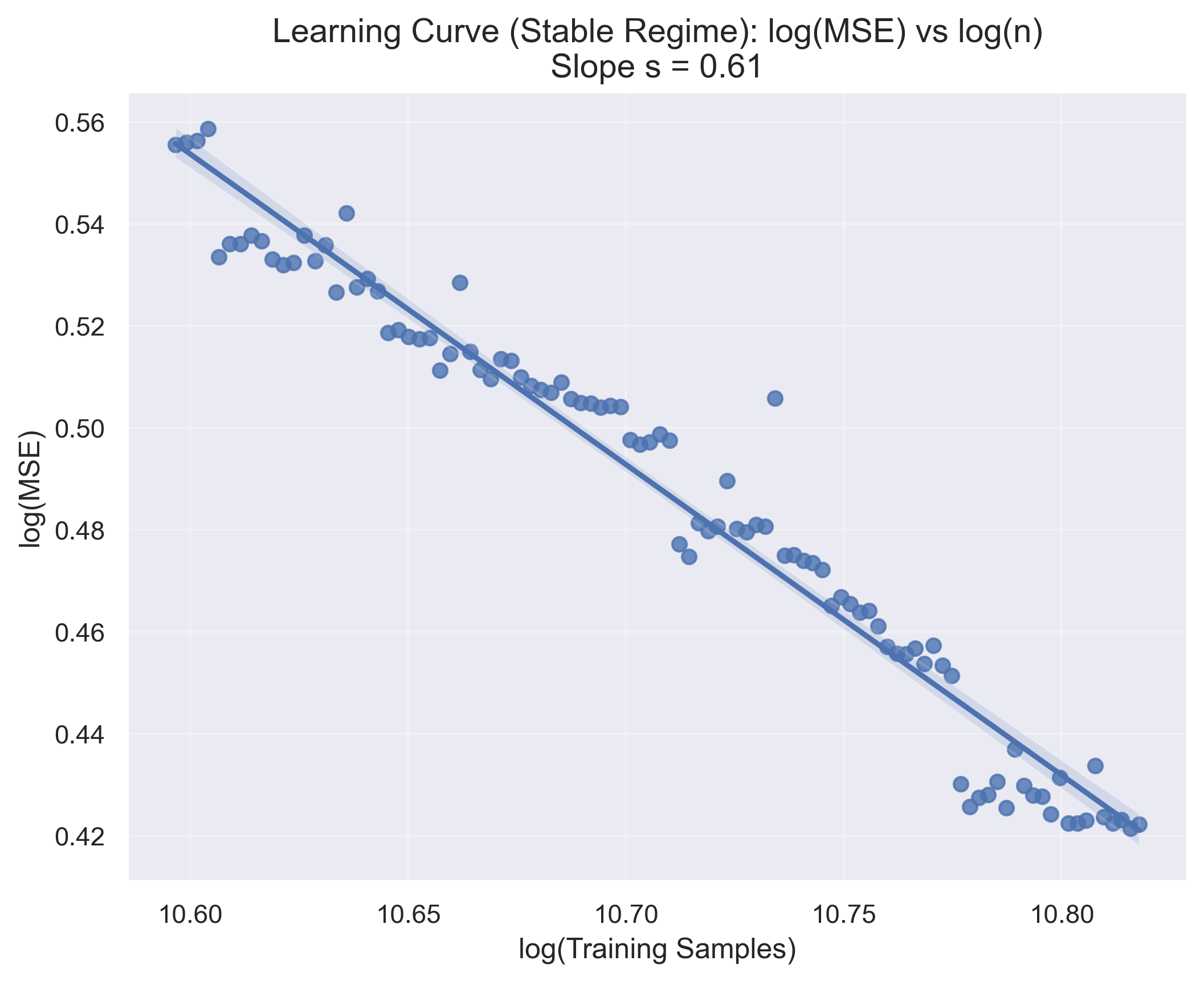
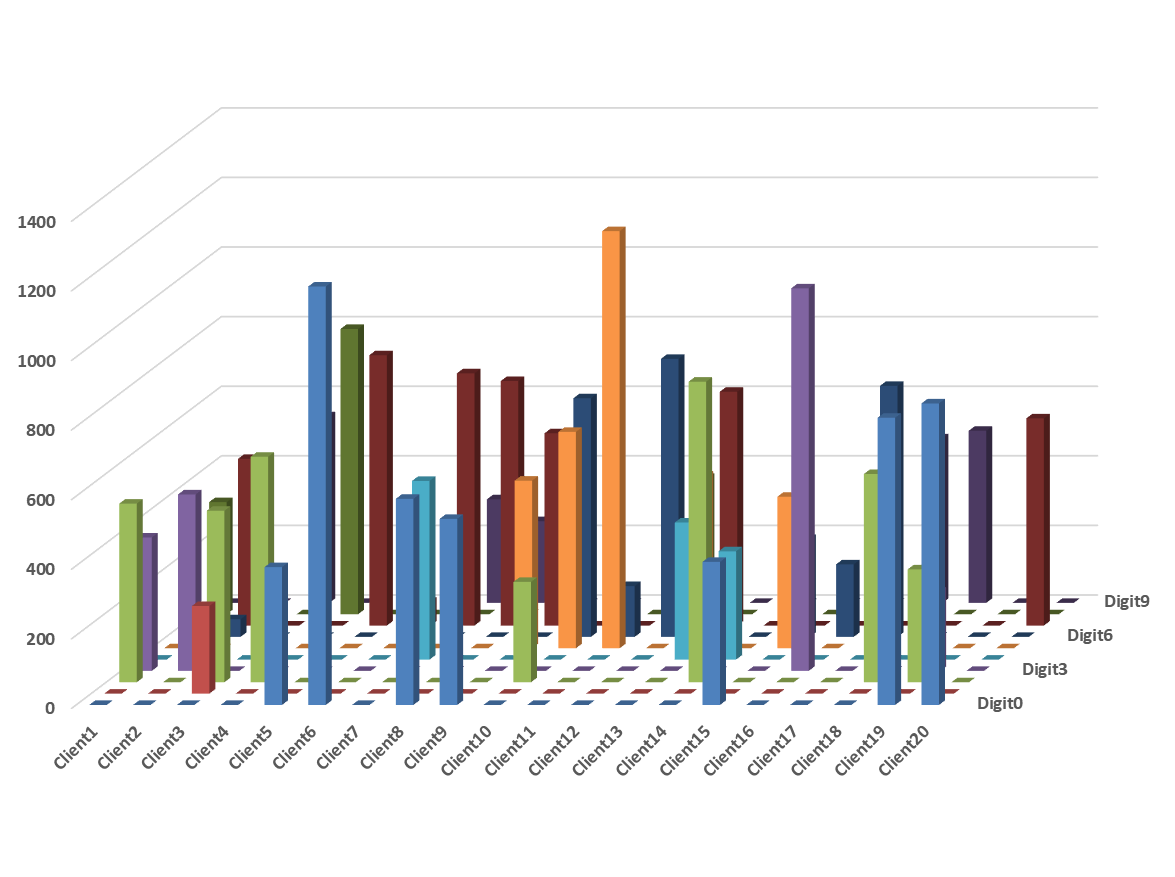
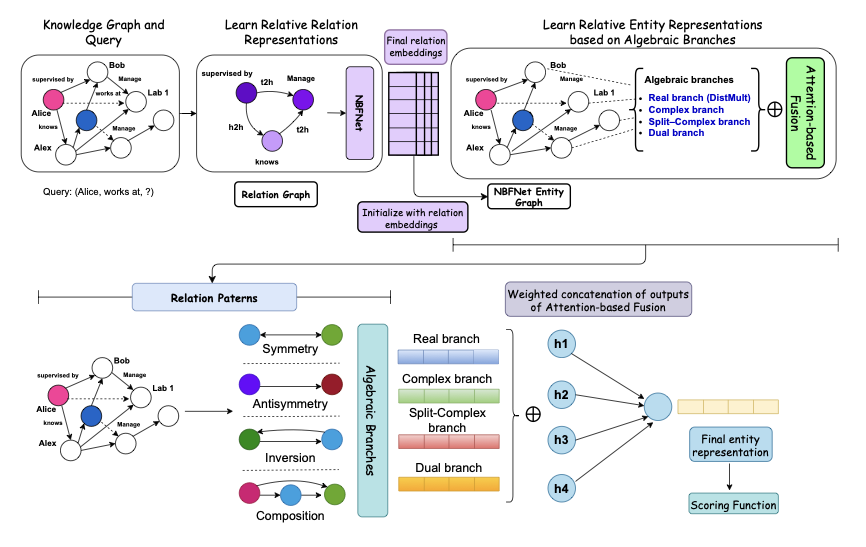
![[한글 번역 중] Can Small Training Runs Reliably Guide Data Curation? Rethinking Proxy-Model Practice](https://koineu.com/posts/2025/12/2025-12-30-190824-can_small_training_runs_reliably_guide_data_curati/benchmark_all_gpt2_gpt2large.png)
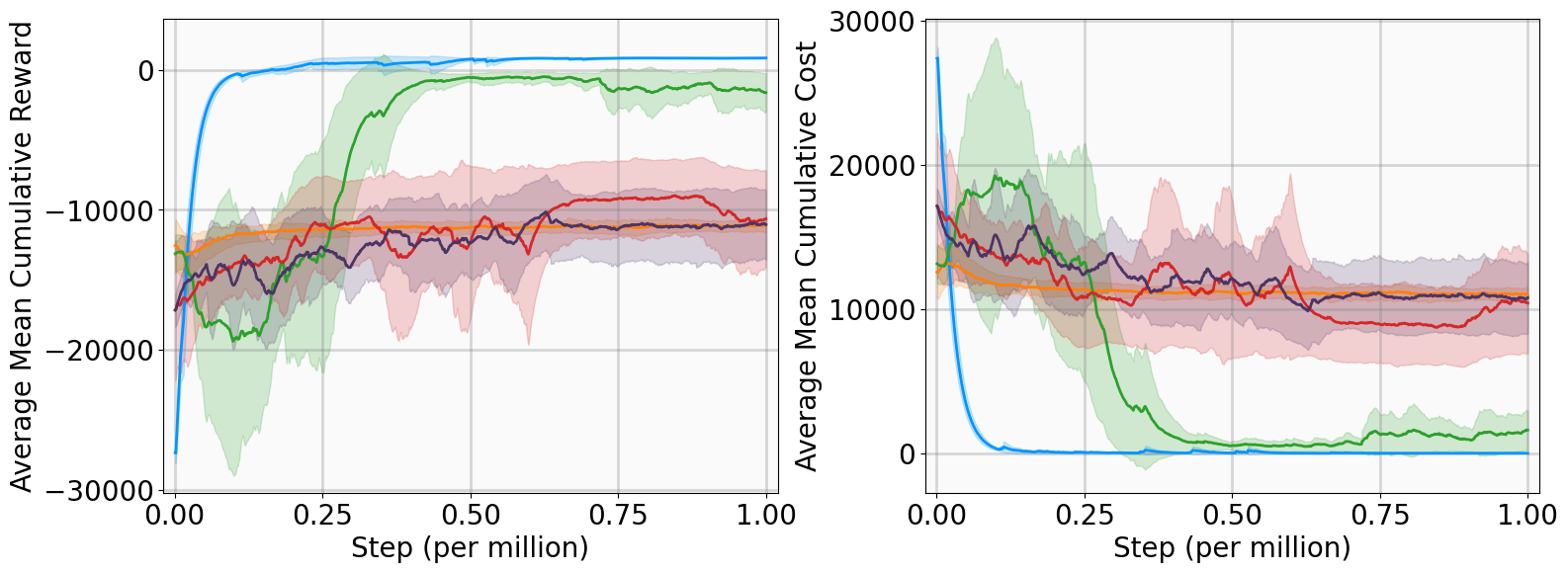

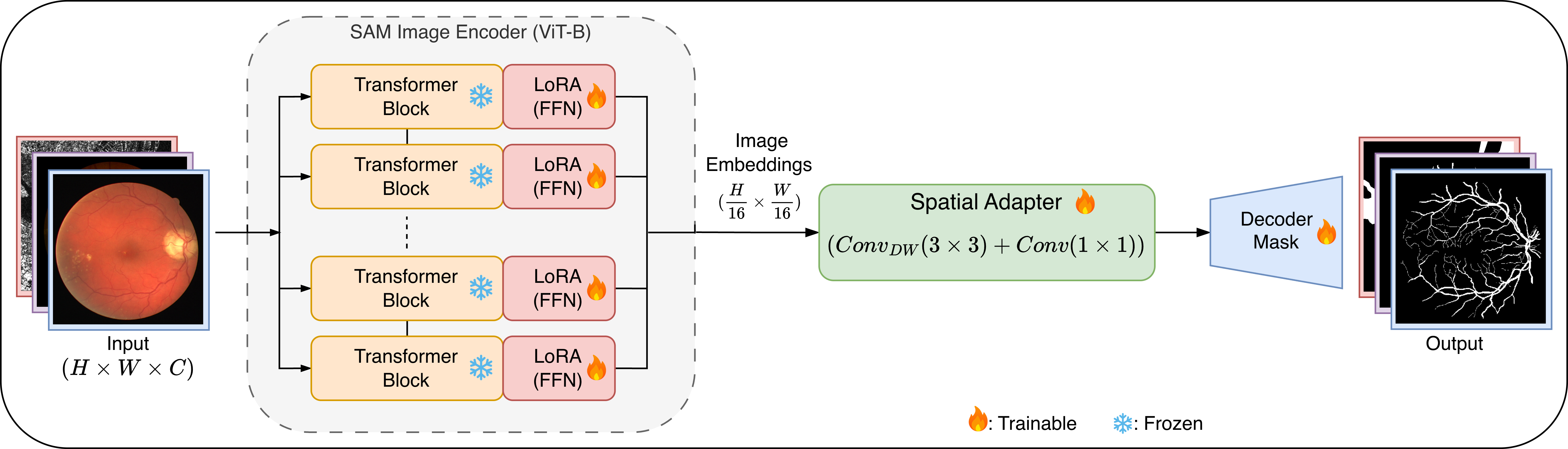
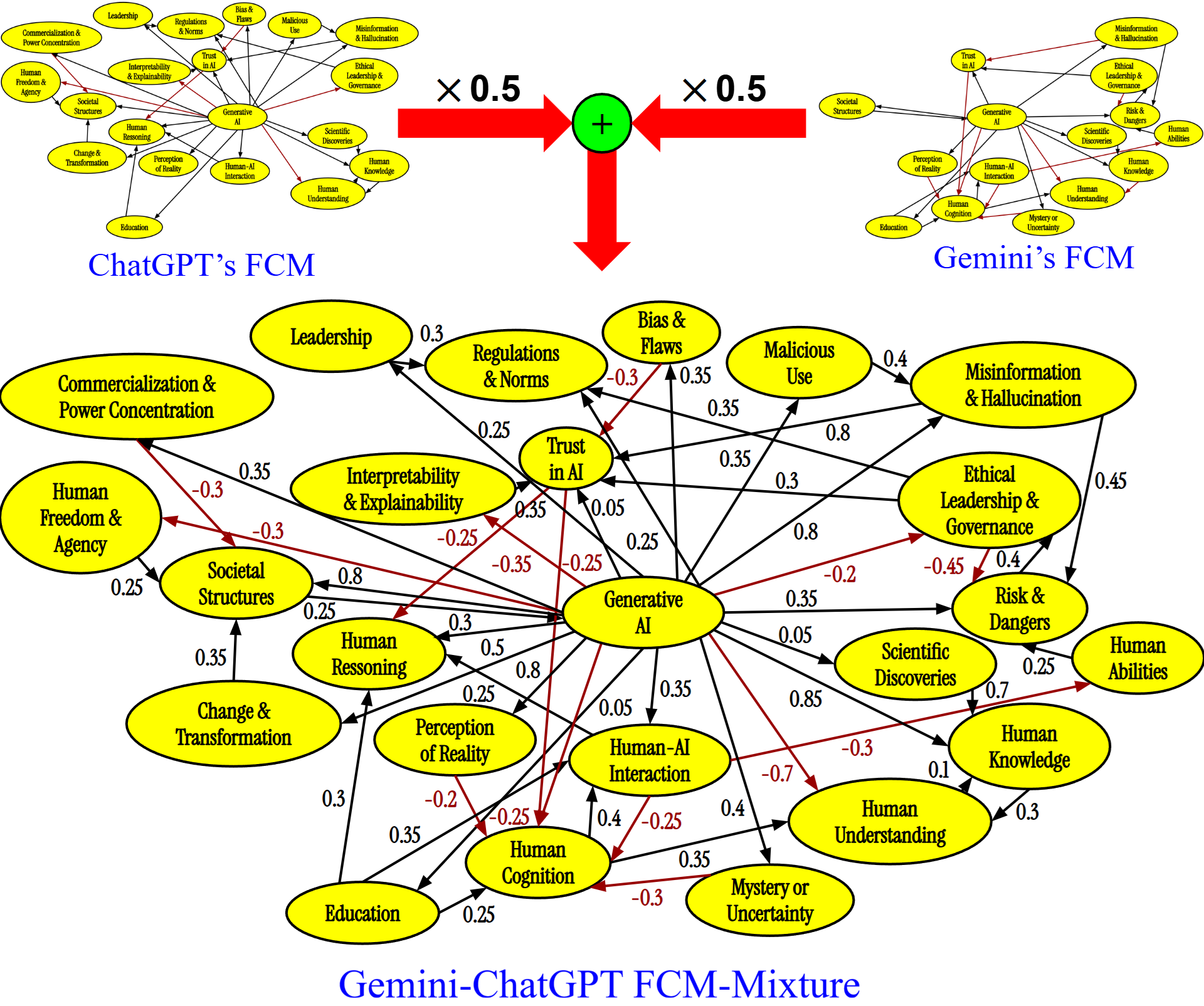
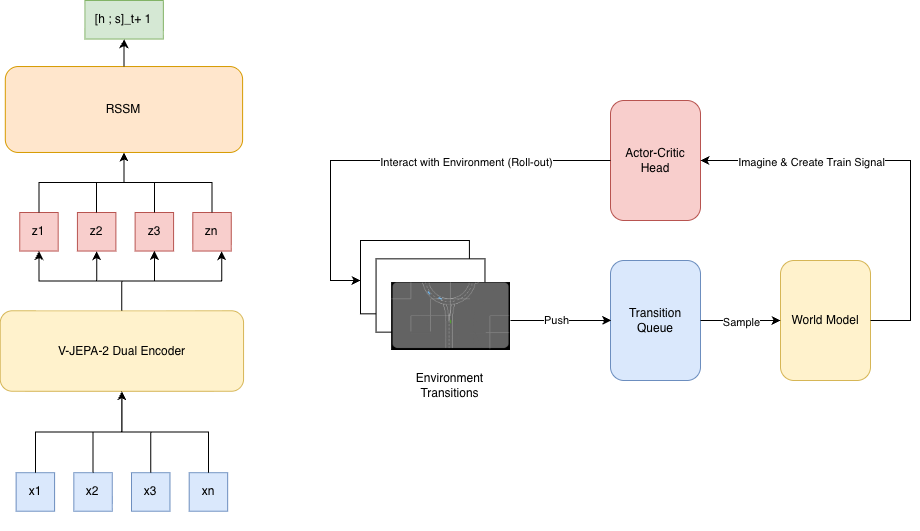
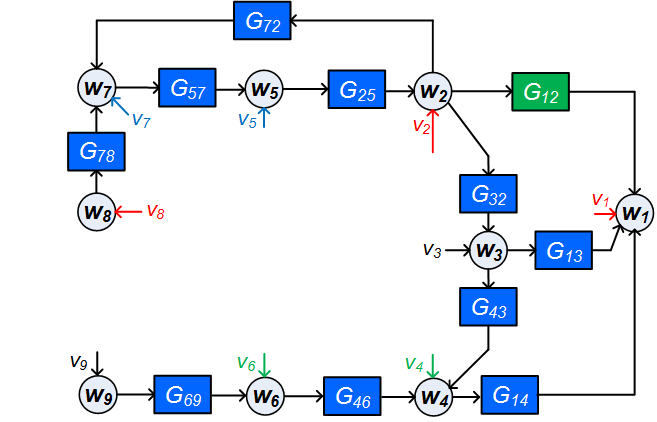
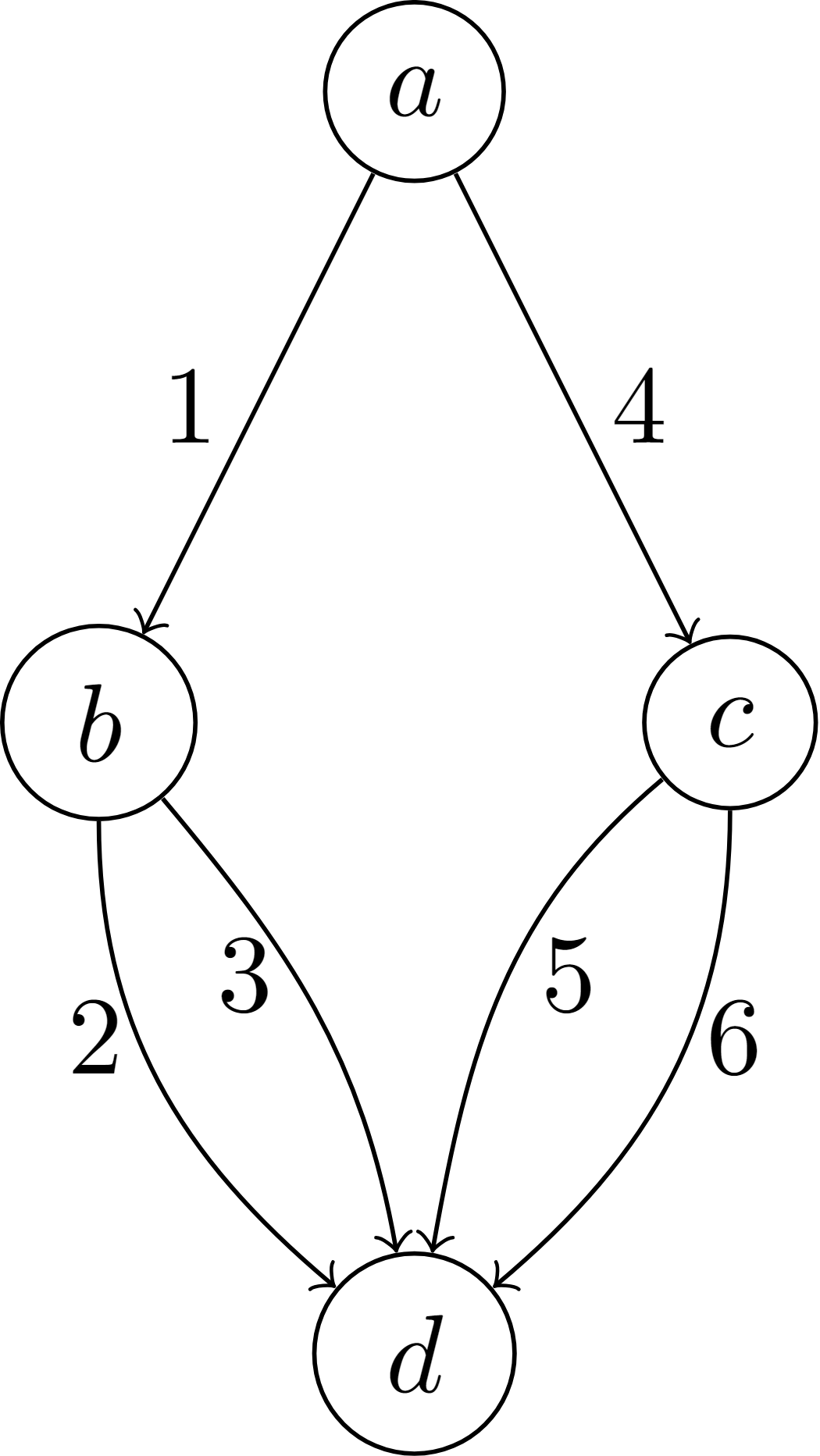
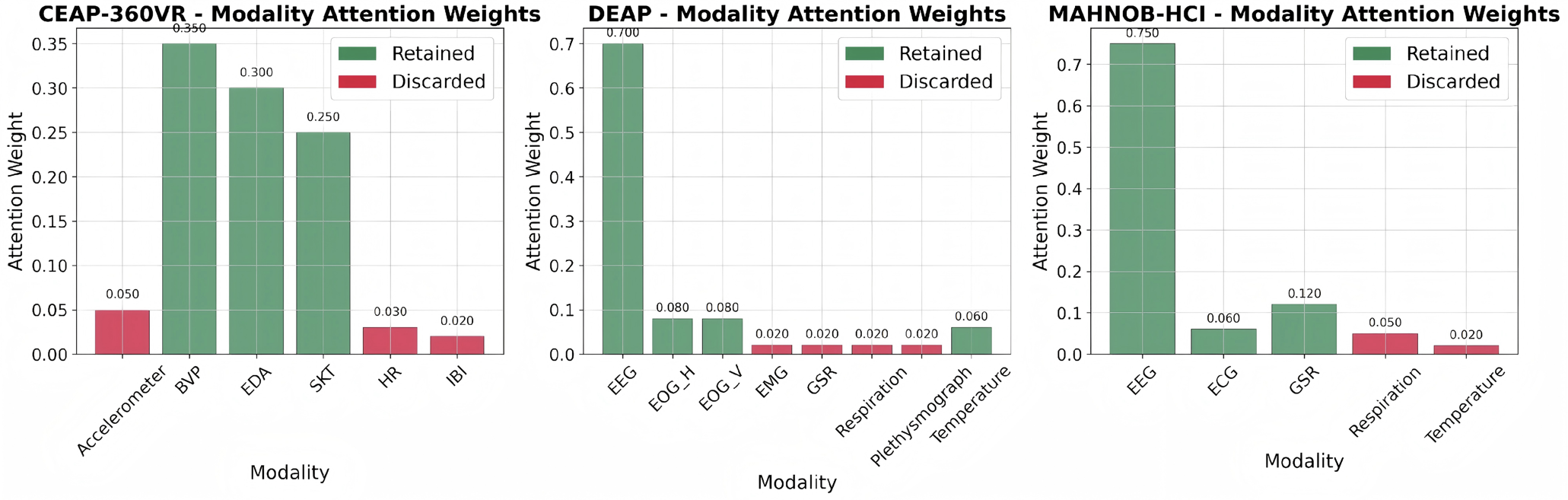
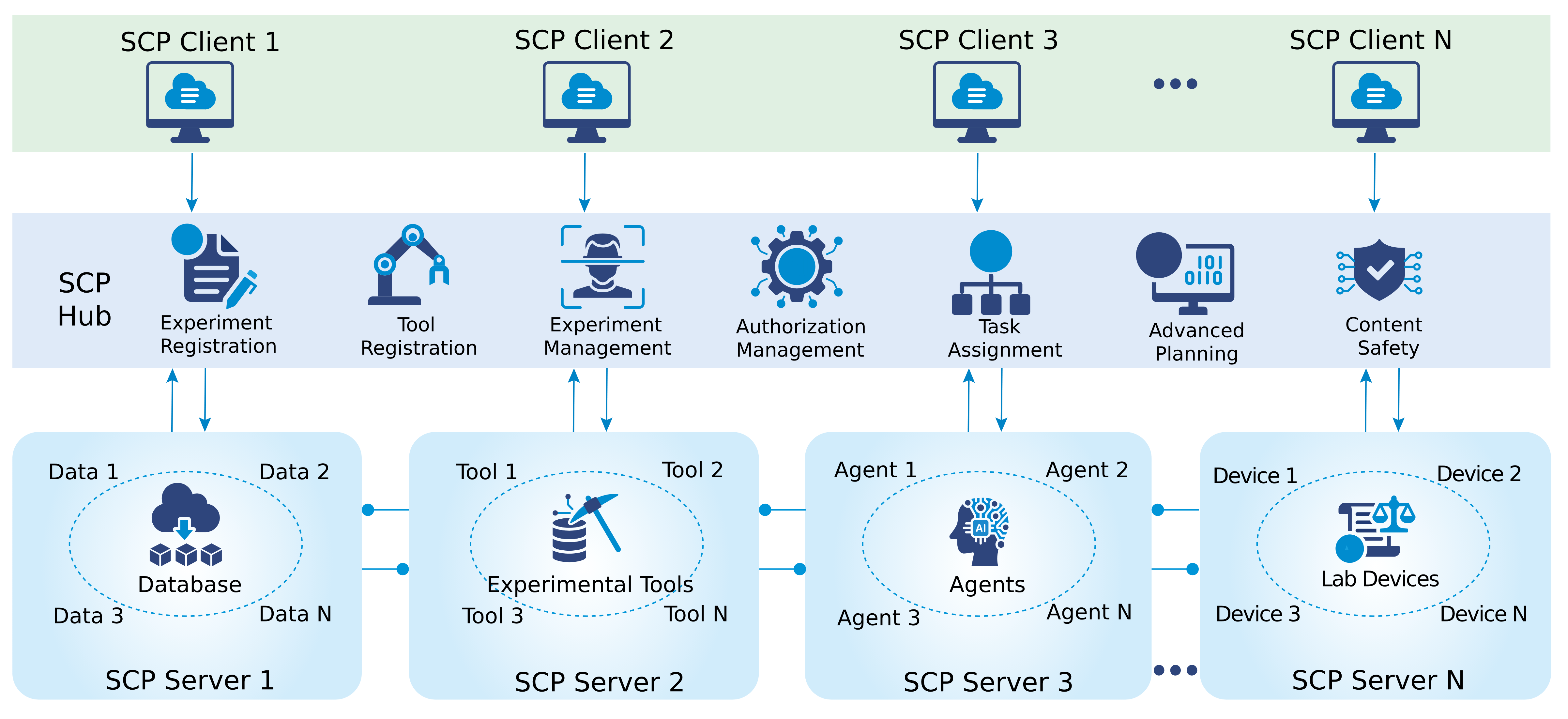
![[한글 번역 중] Bio-inspired Agentic Self-healing Framework for Resilient Distributed Computing Continuum Systems](https://koineu.com/posts/2026/01/2026-01-01-190751-bio_inspired_agentic_self_healing_framework_for_re/framework.png)
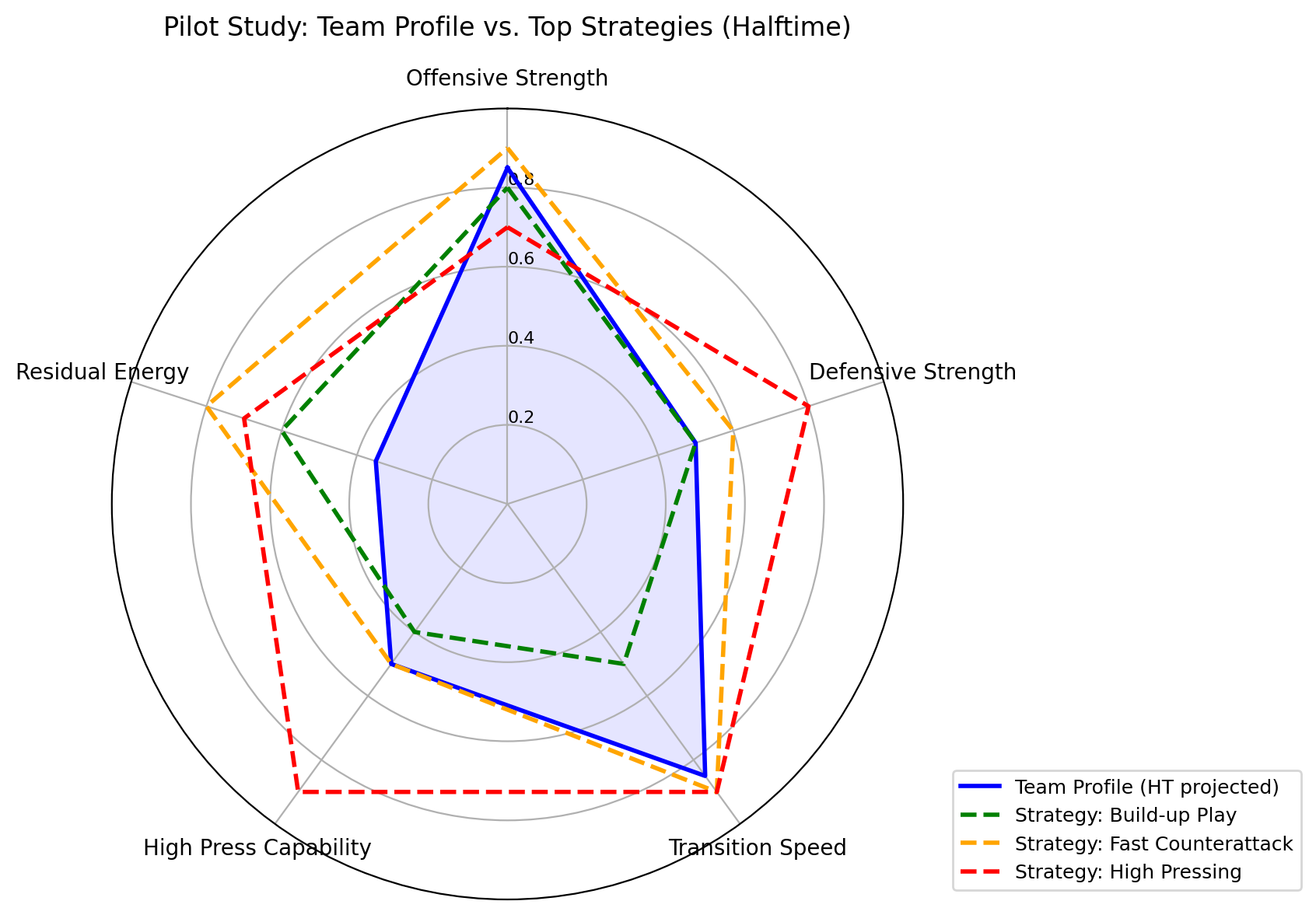

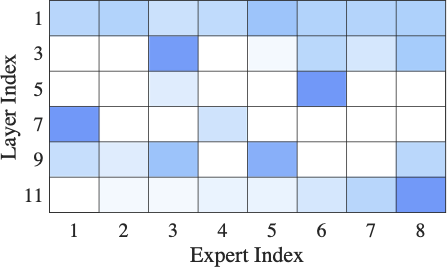
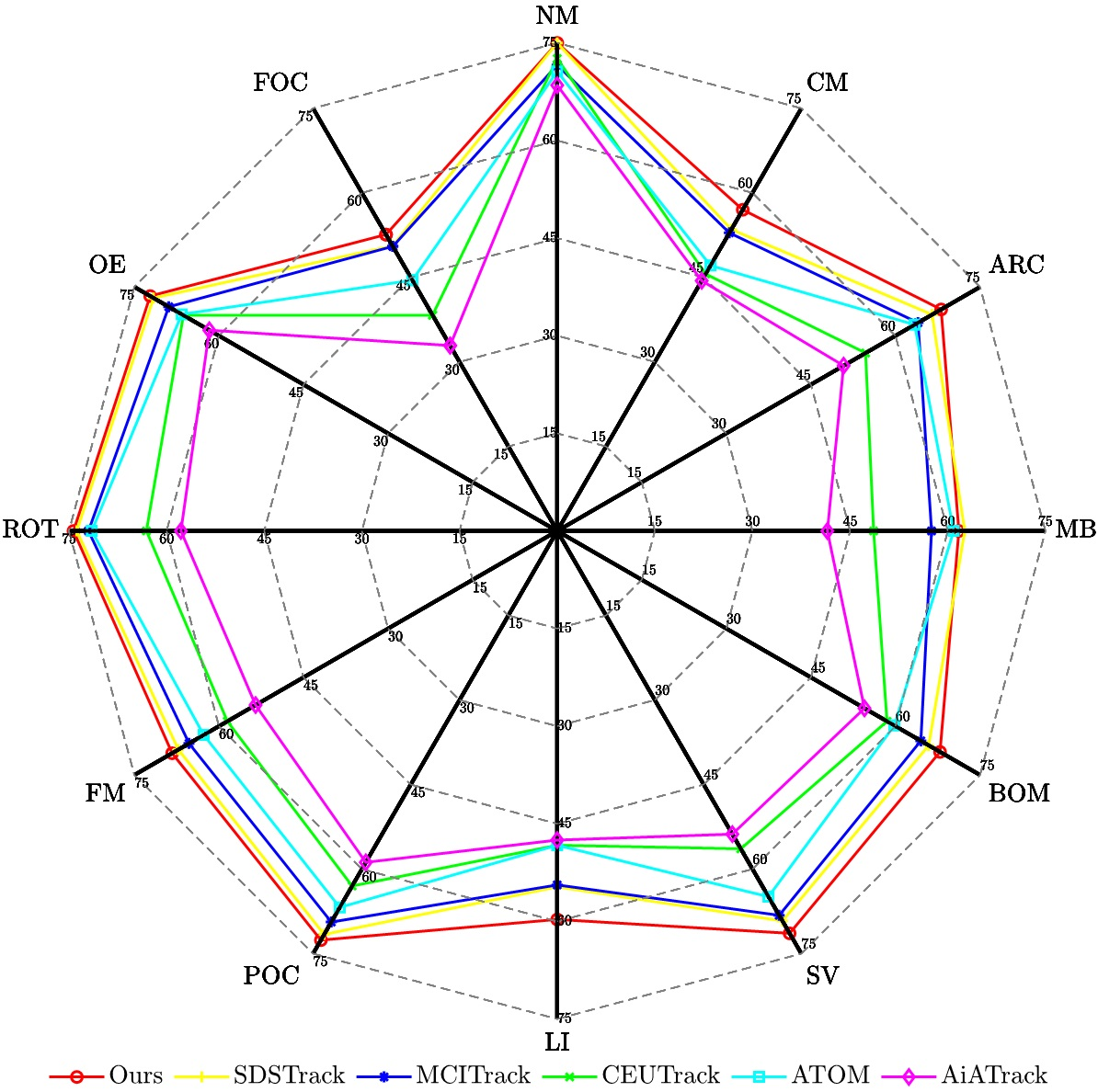
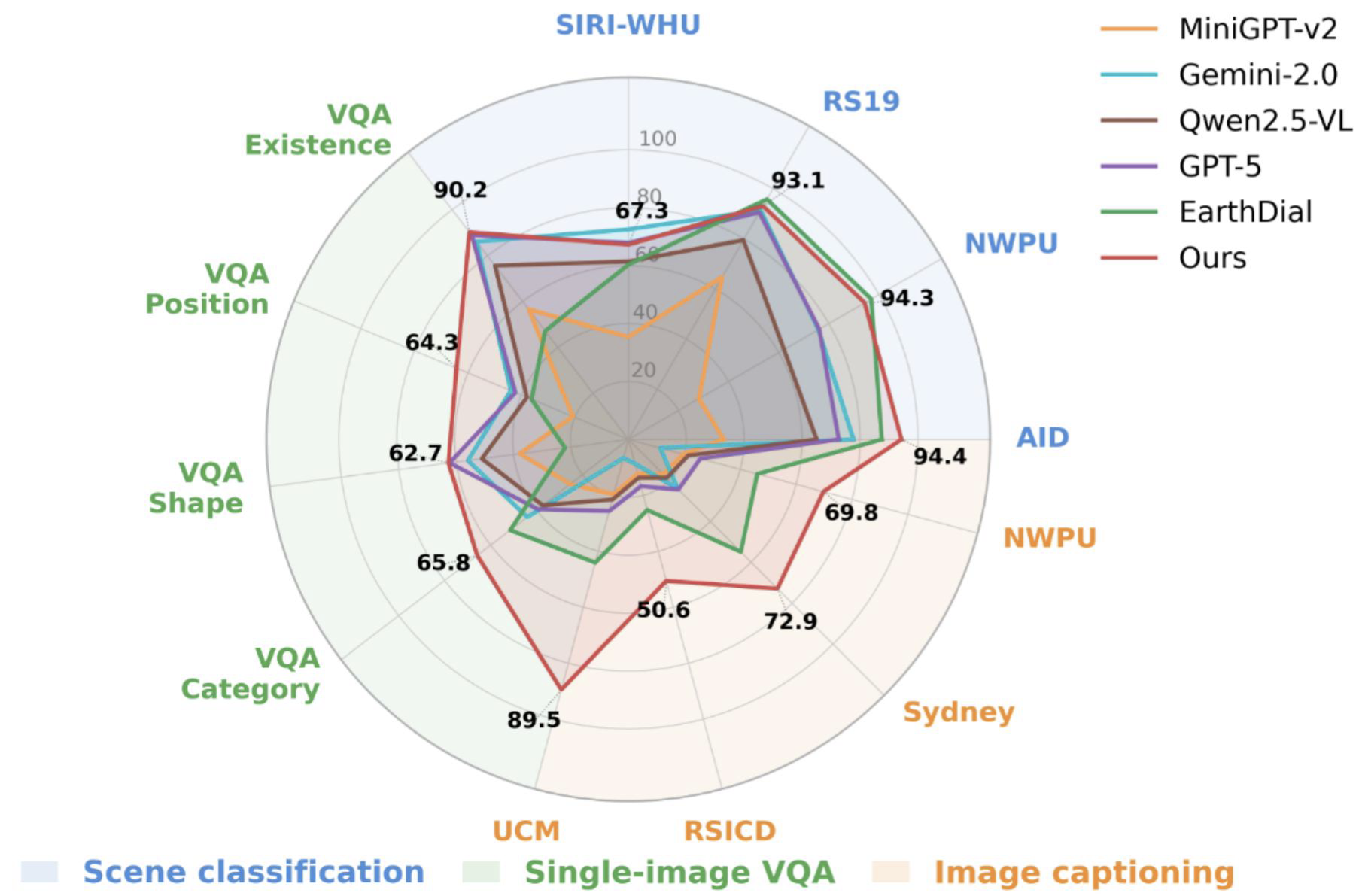
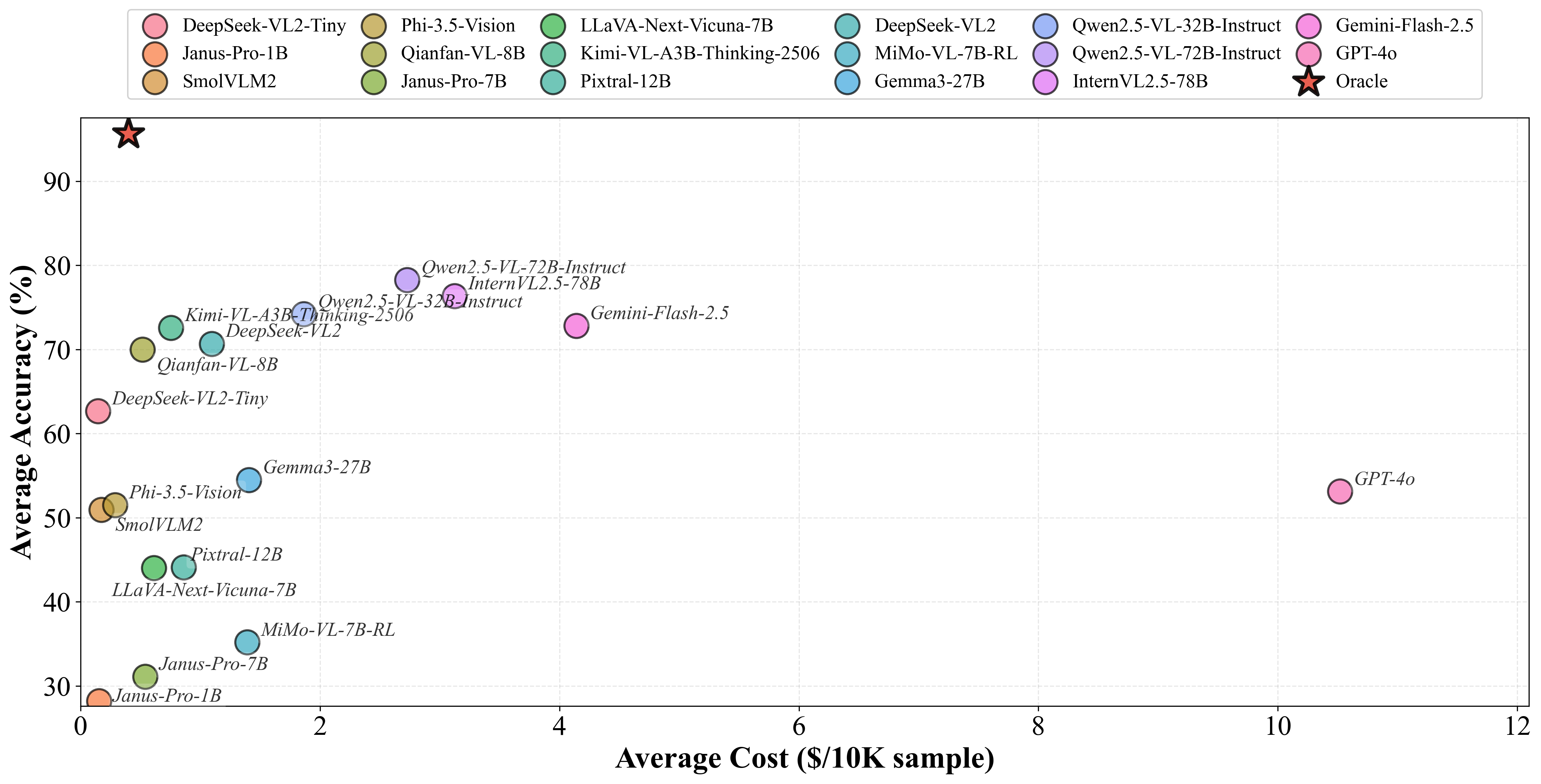
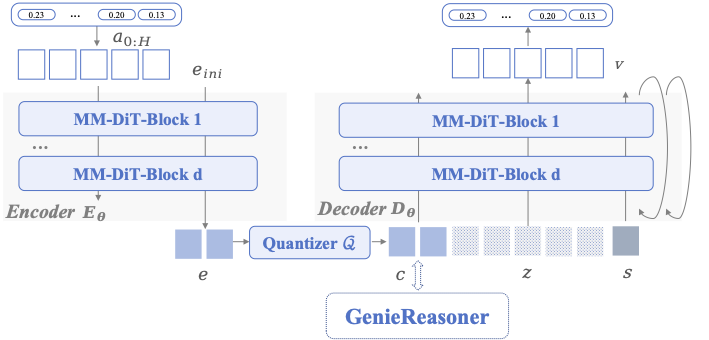
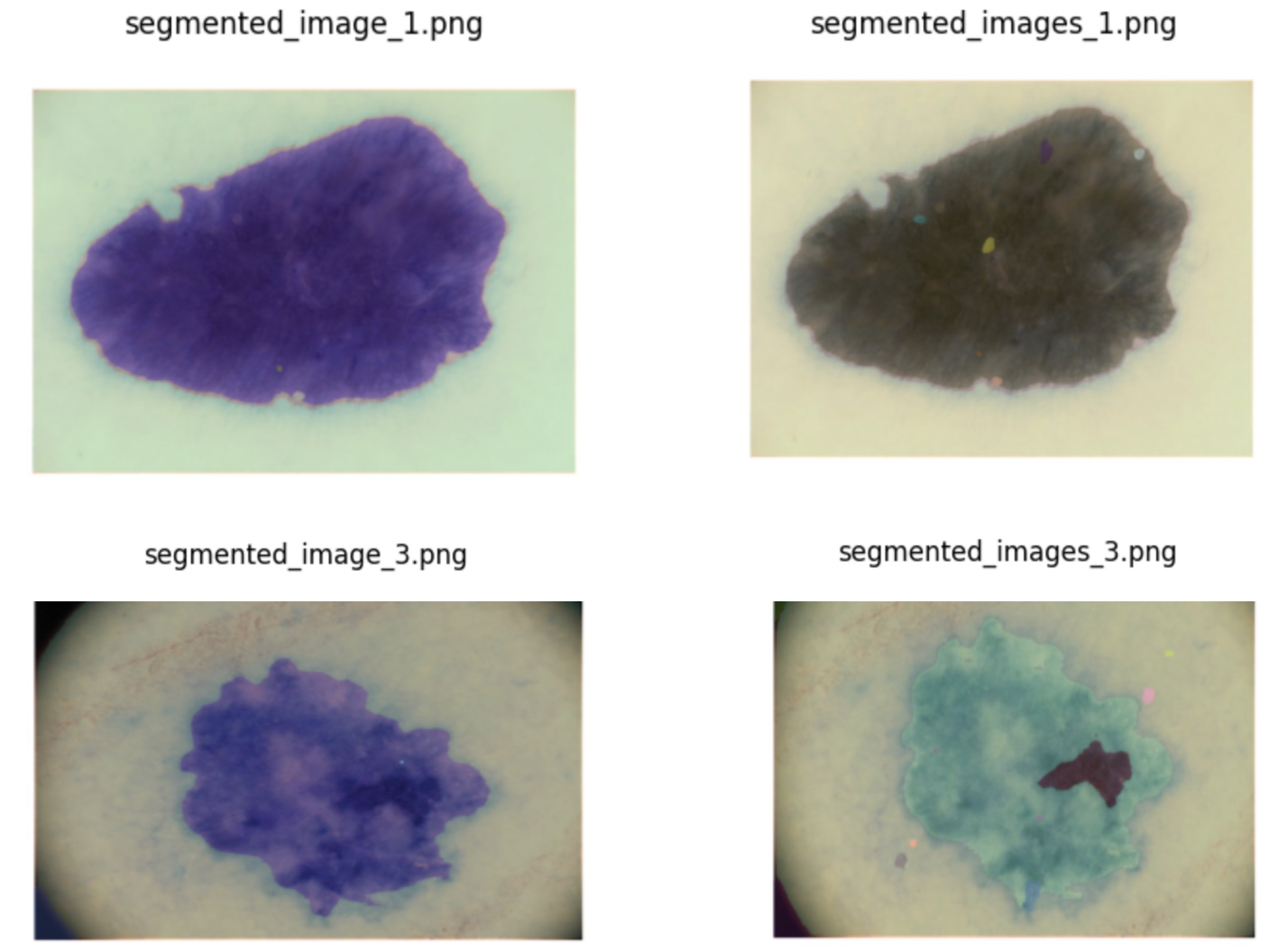
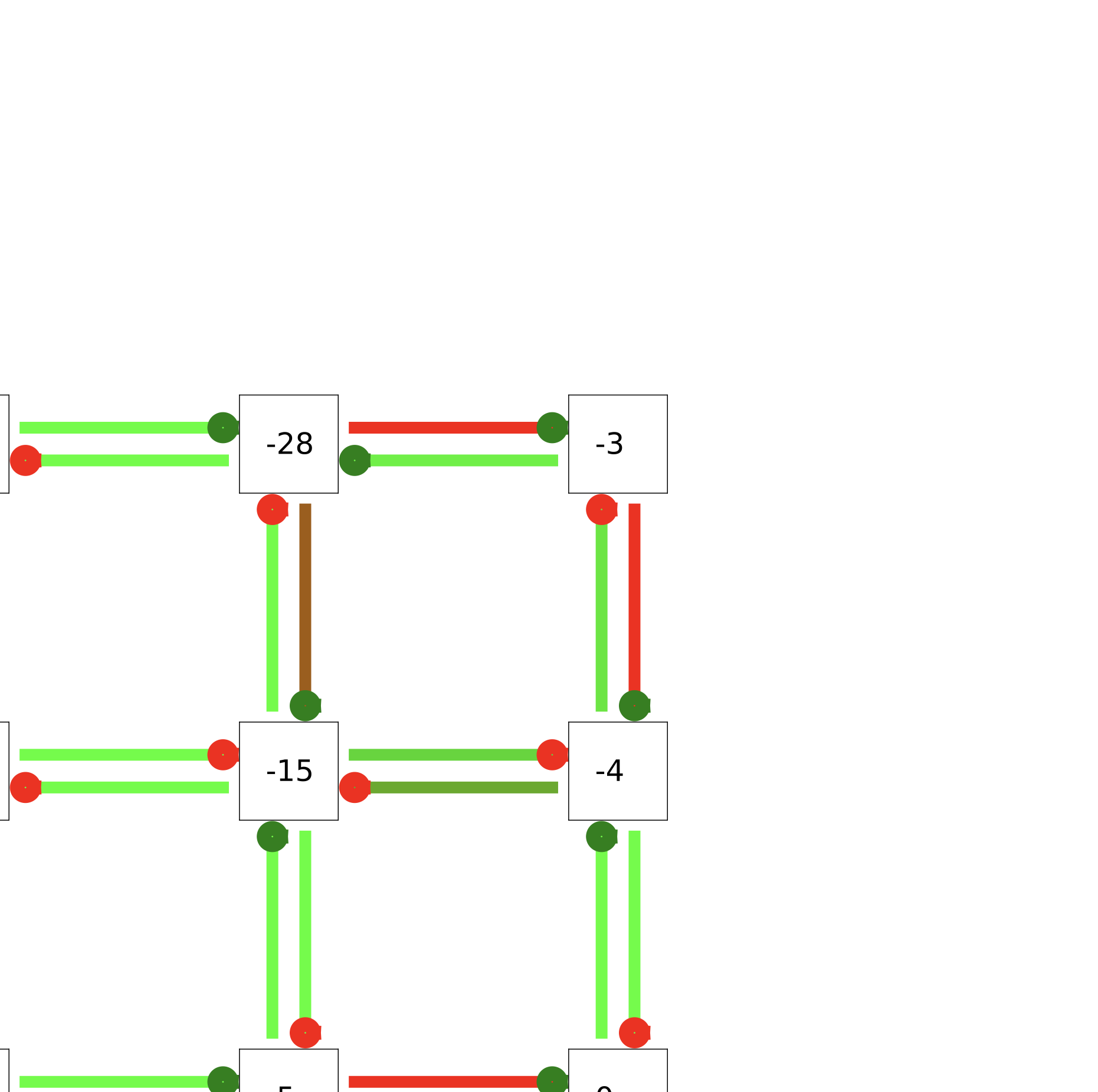
![[한글 번역 중] KGCE Knowledge-Augmented Dual-Graph Evaluator for Cross-Platform Educational Agent Benchmarking with Multimodal Language Models](https://koineu.com/posts/2026/01/2026-01-04-190607-kgce__knowledge_augmented_dual_graph_evaluator_for/model_avg.png)

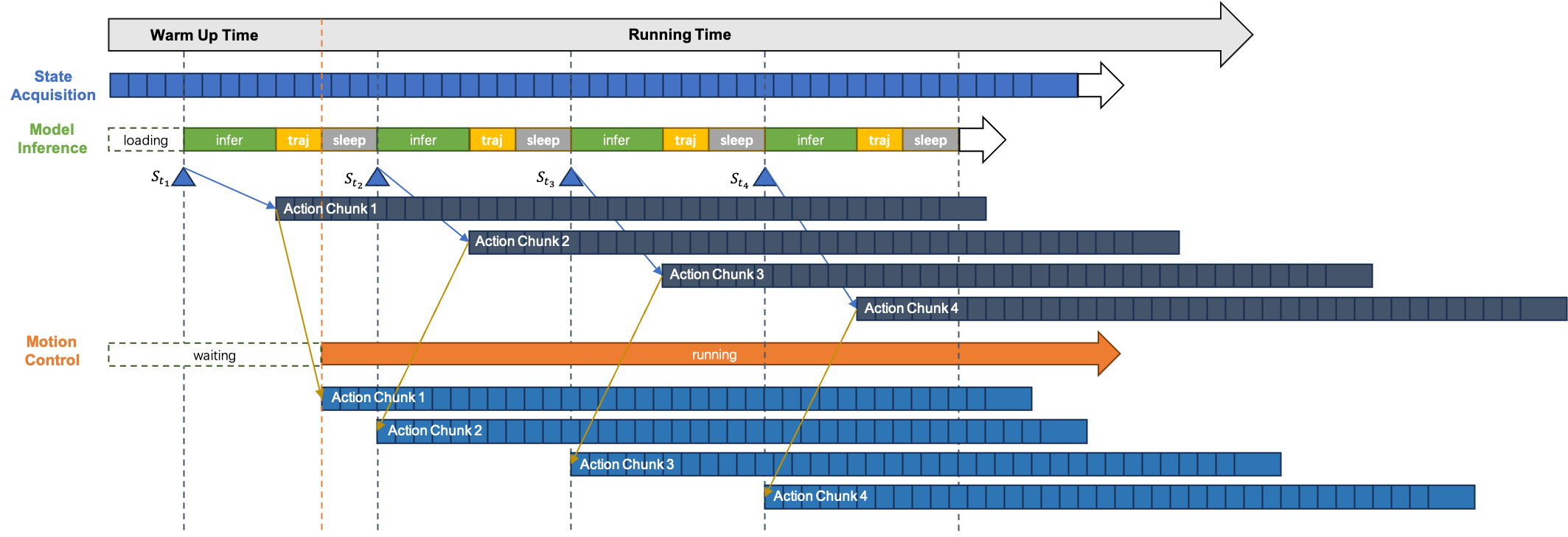
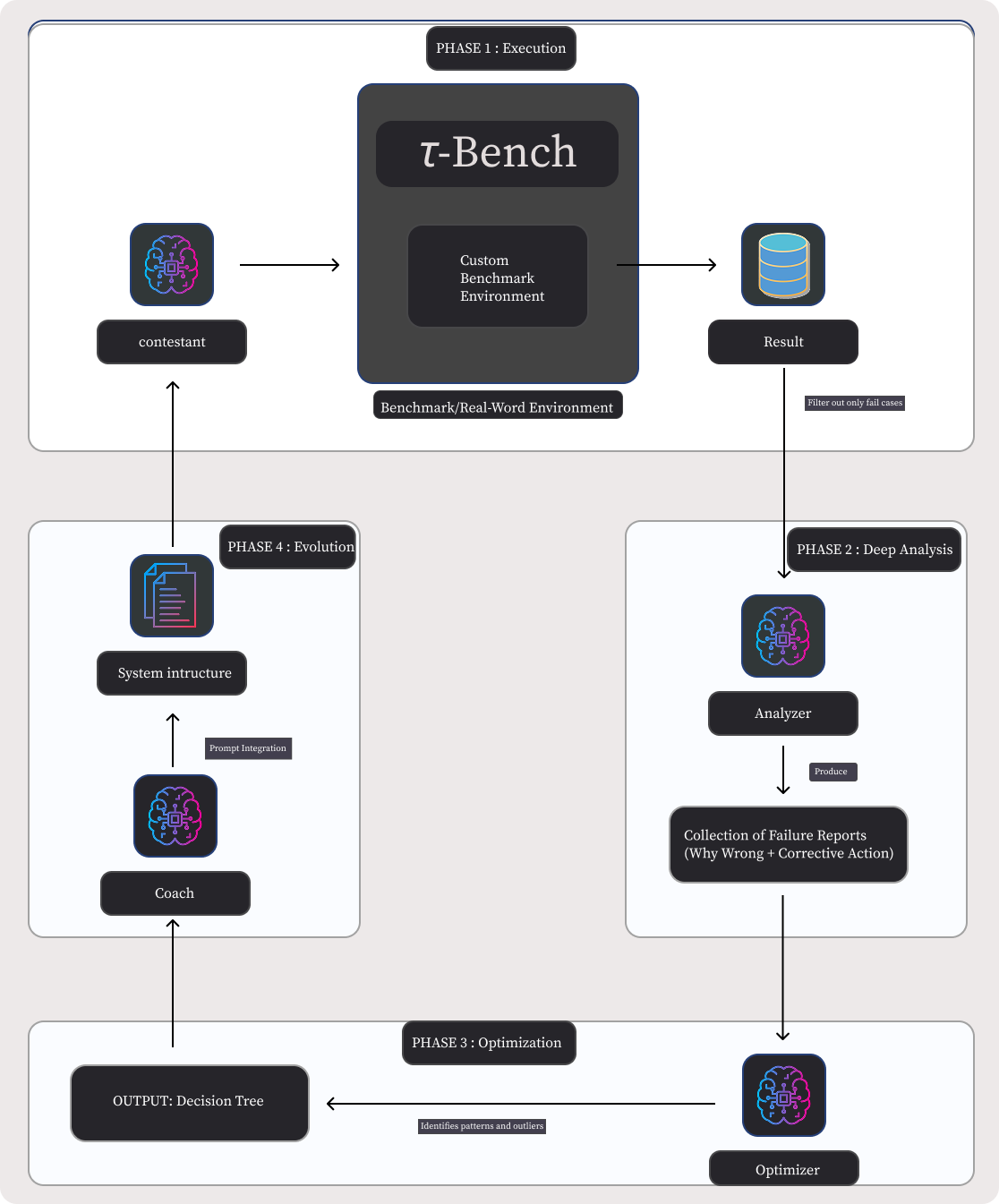
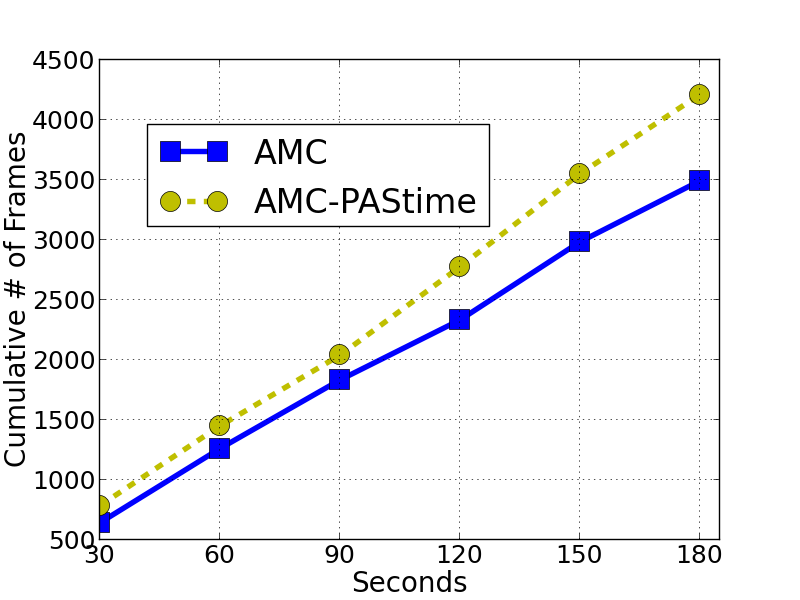
![[한글 번역 중] REE-TTT Highly Adaptive Radar Echo Extrapolation Based on Test-Time Training](https://koineu.com/posts/2026/01/2026-01-04-190573-ree_ttt__highly_adaptive_radar_echo_extrapolation_/fig7.png)

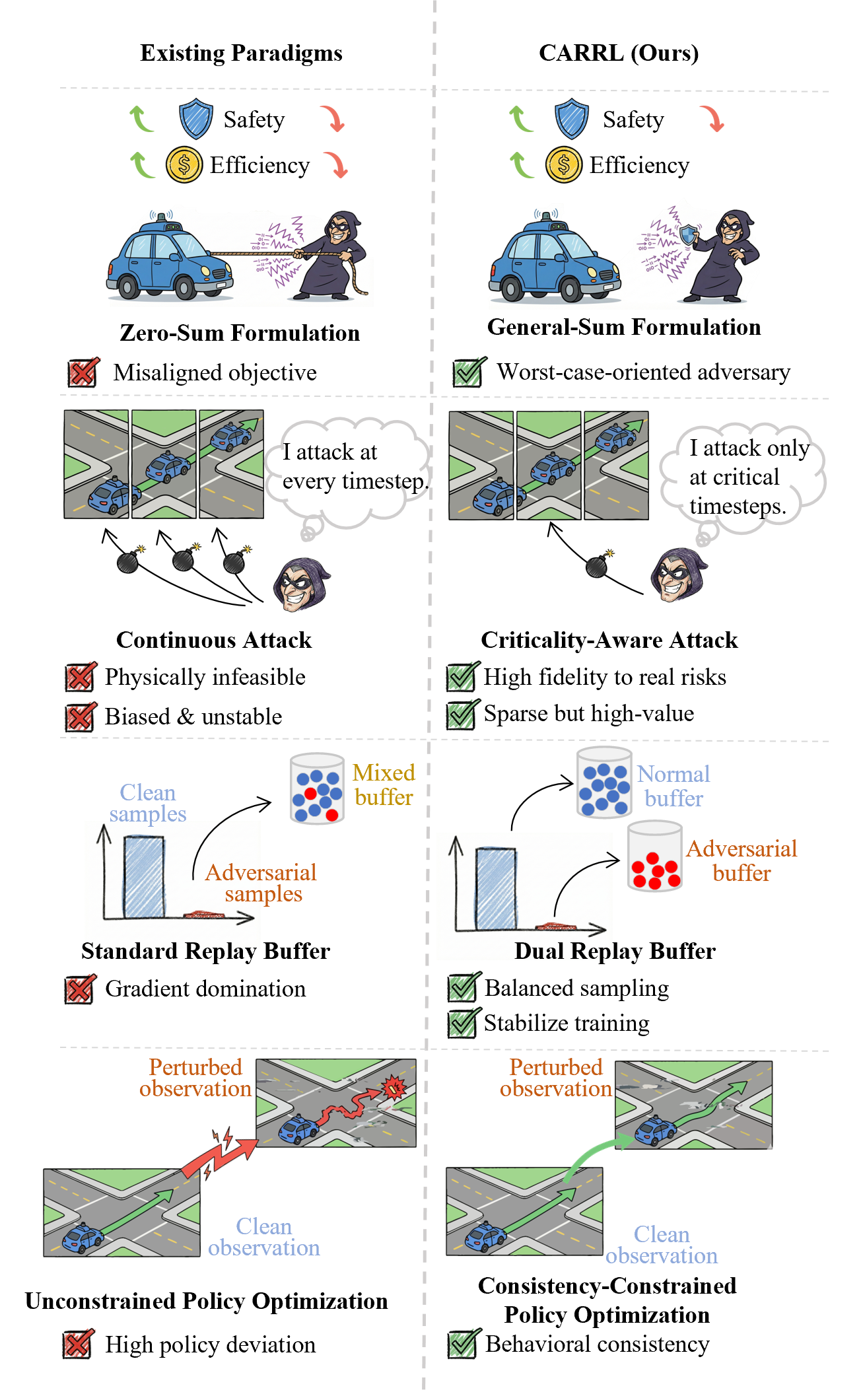











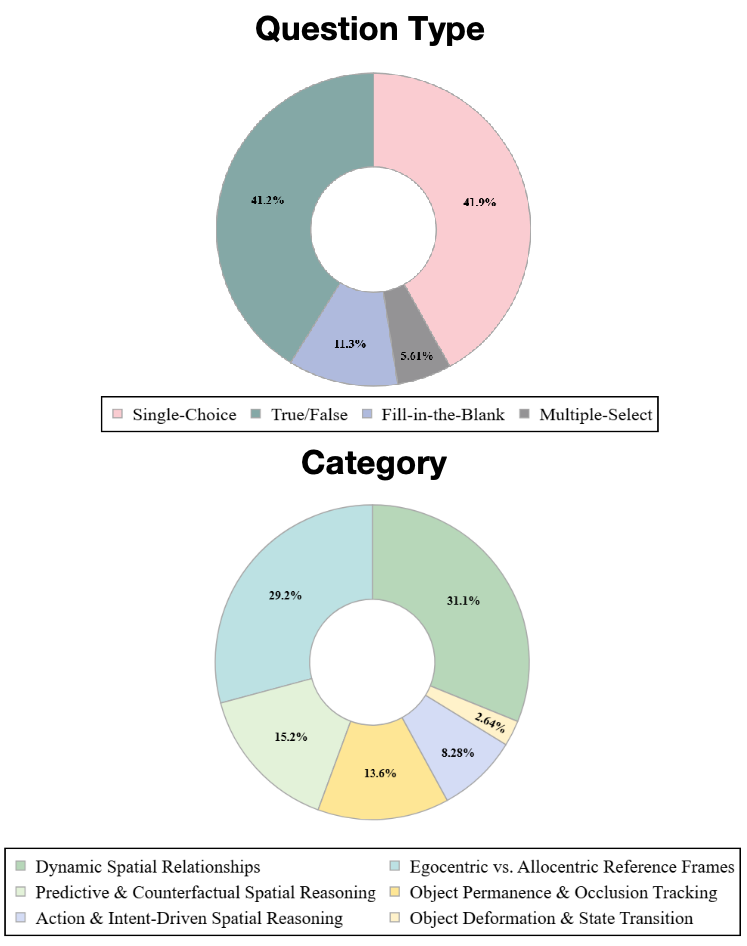
![[한글 번역 중] CubeBench Diagnosing Interactive, Long-Horizon Spatial Reasoning Under Partial Observations](https://koineu.com/posts/2025/12/2025-12-29-191003-cubebench__diagnosing_interactive__long_horizon_sp/news.png)
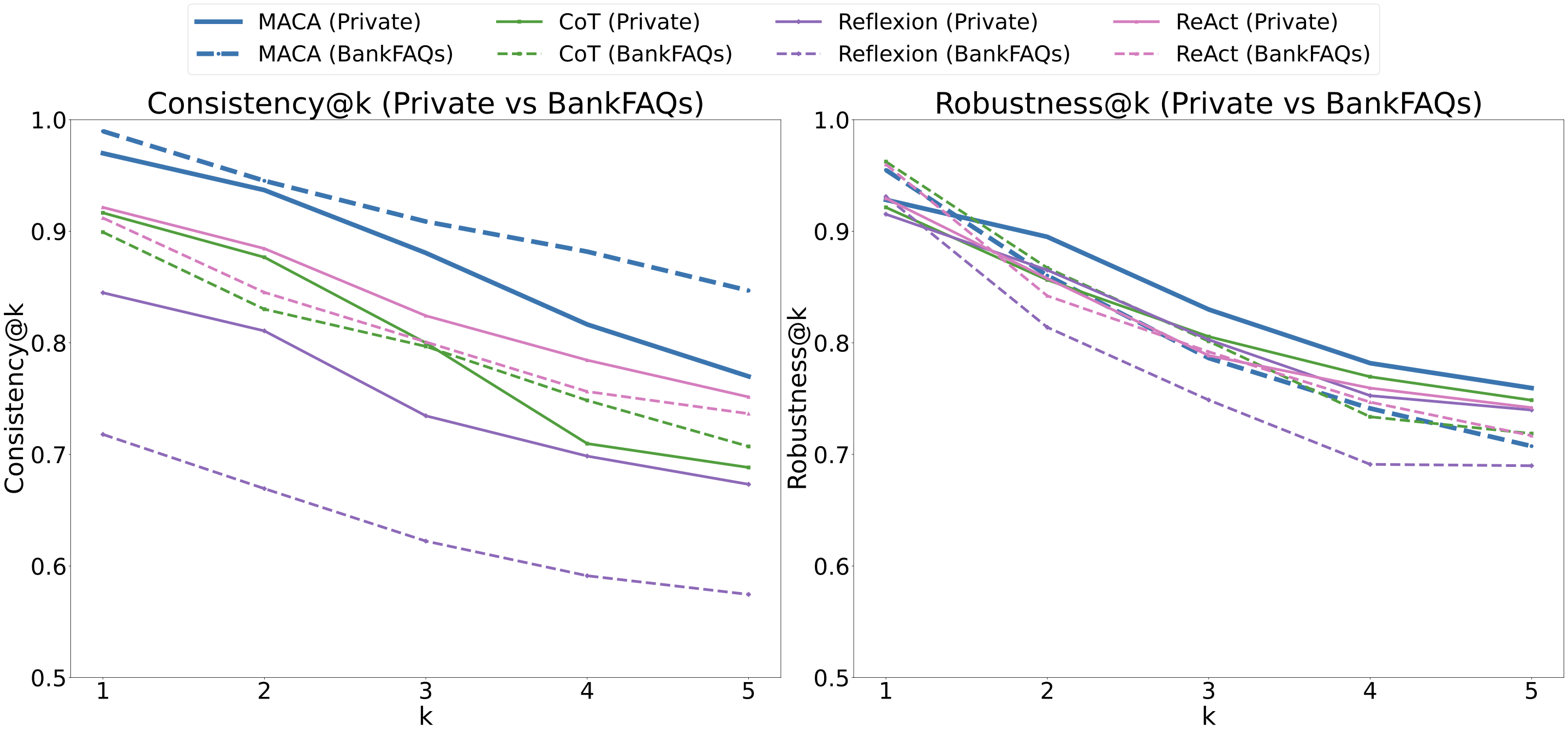
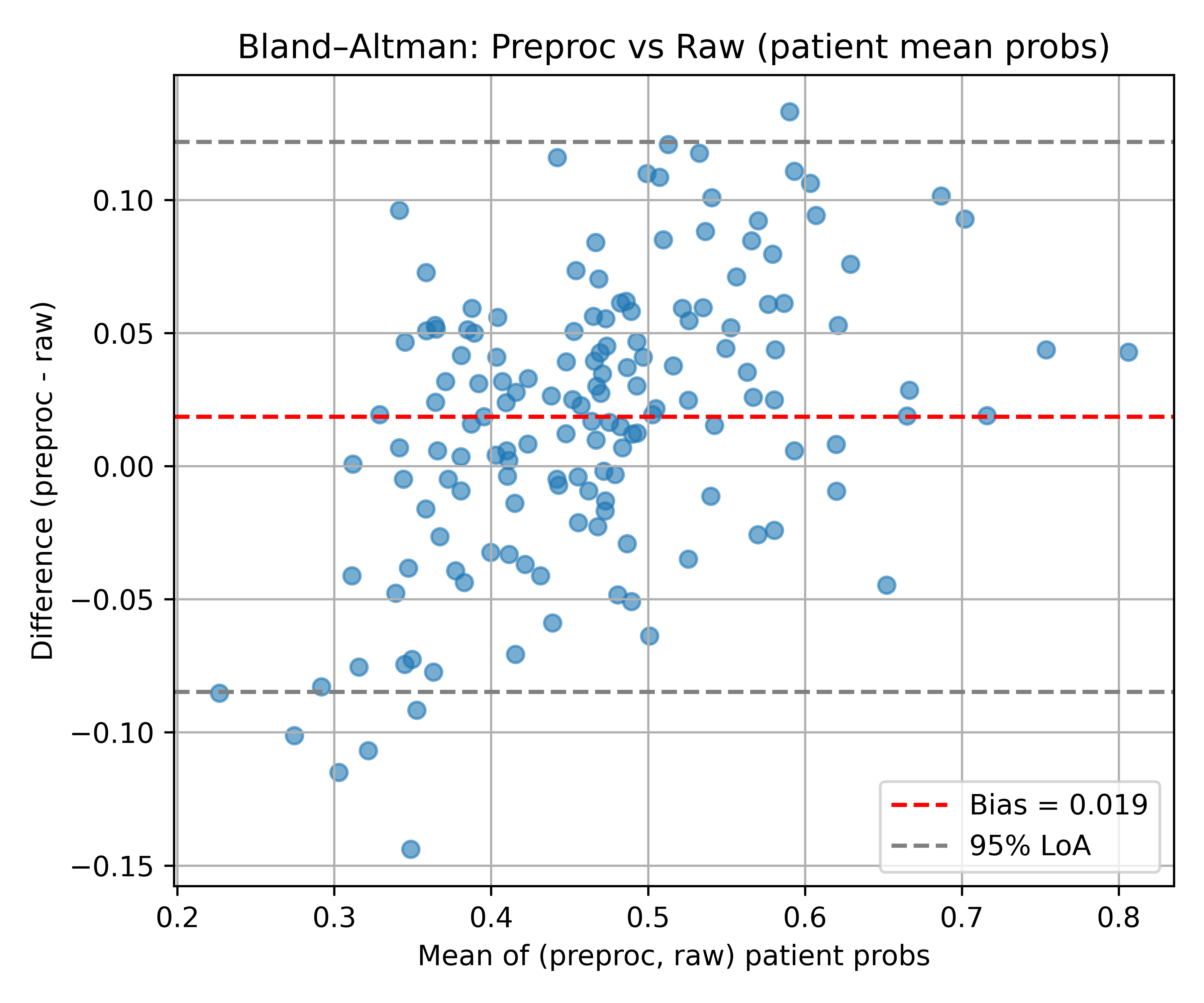
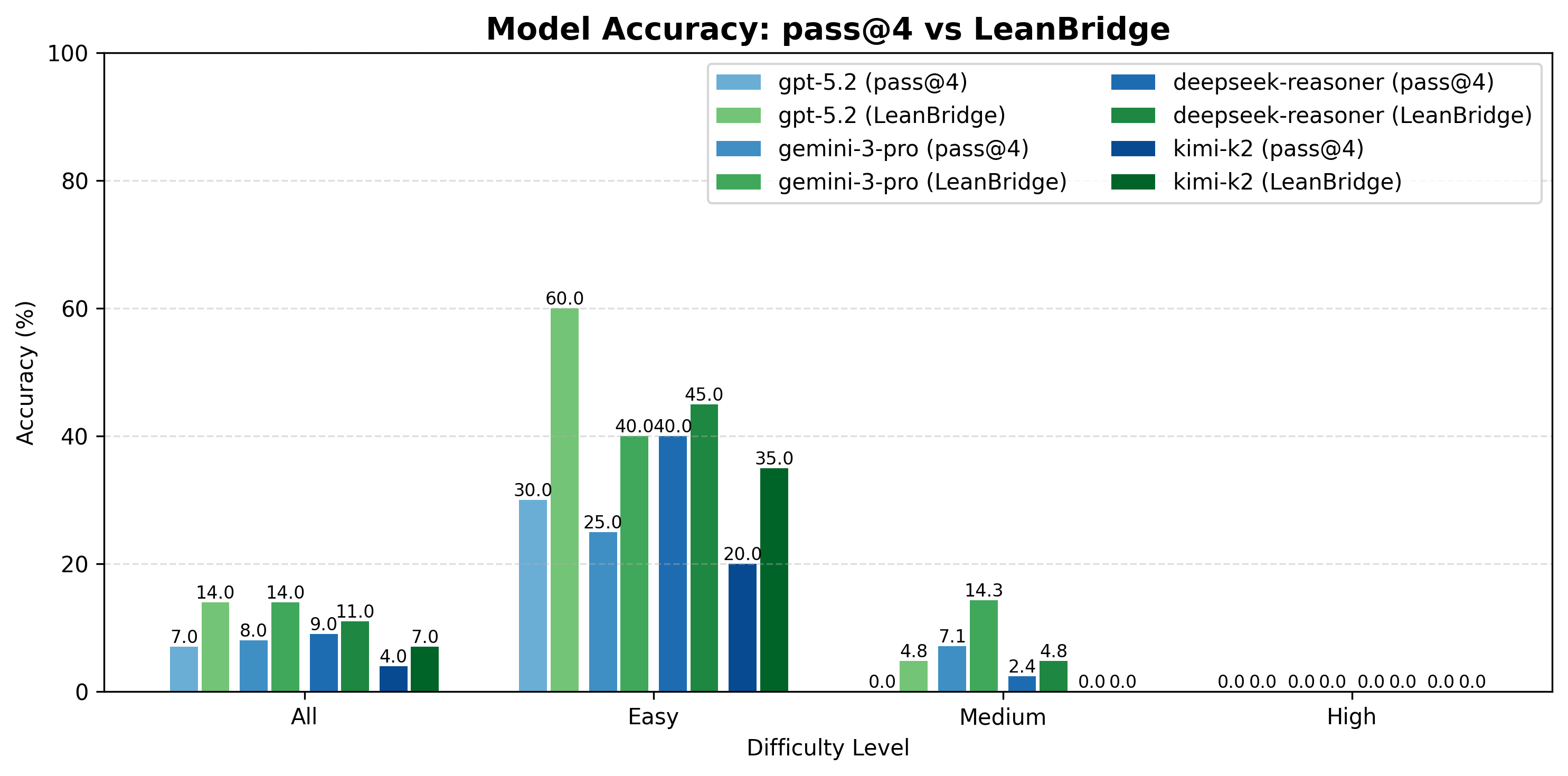
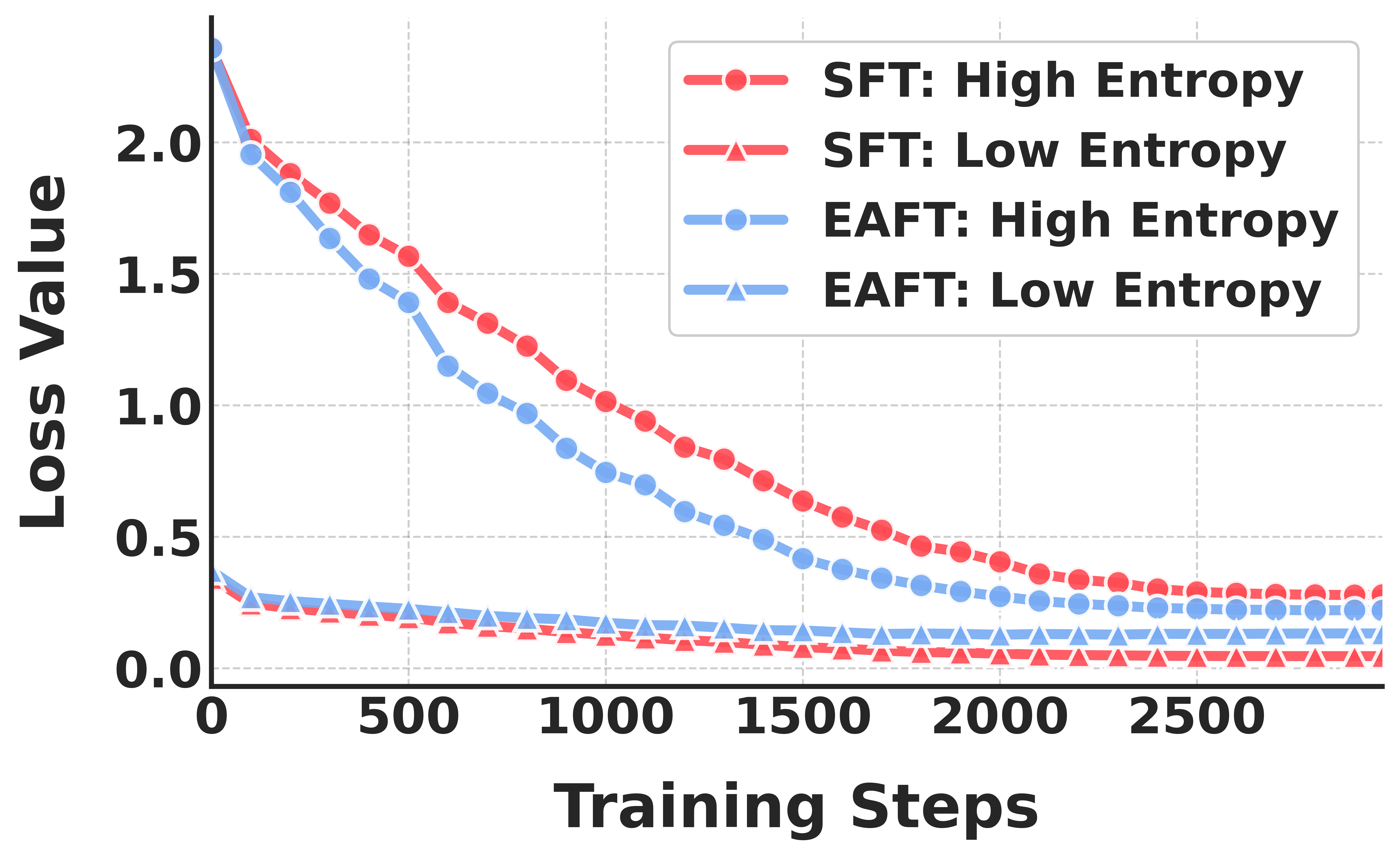
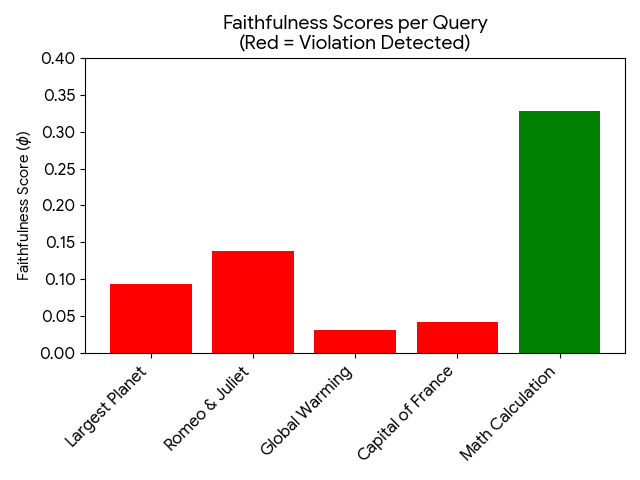
![[한글 번역 중] Is Chain-of-Thought Really Not Explainability? Chain-of-Thought Can Be Faithful without Hint Verbalization](https://koineu.com/posts/2025/12/2025-12-28-191035-is_chain_of_thought_really_not_explainability__cha/pass_at_k_all.png)