MORE 음성 인식의 다목적 적대적 공격
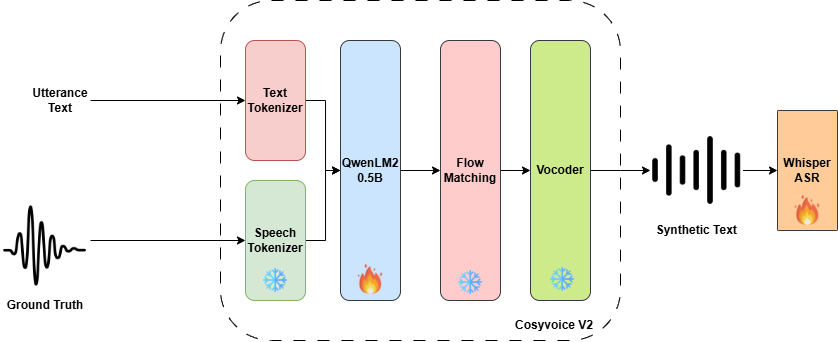
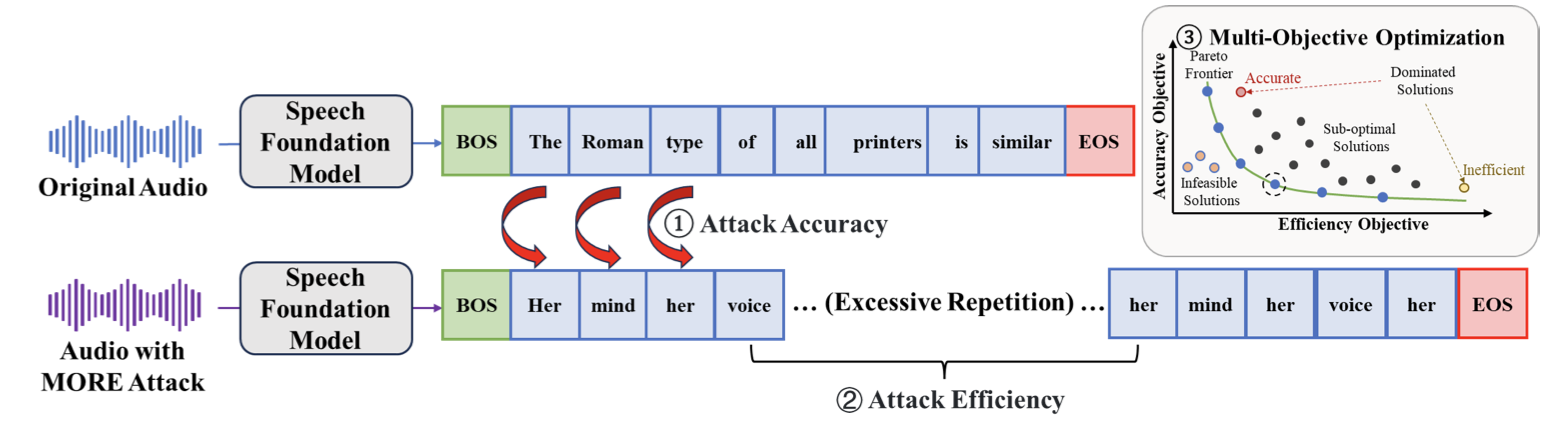
오토메이티드 스피치 인식(ASR) 모델은 가상 어시스턴트, 실시간 자막 생성, 임상 기록 작성 등 다양한 분야에서 중요한 역할을 하고 있습니다. 그러나 이러한 시스템들은 적대적 공격에 취약하며, 이로 인해 인식 정확도나 추론 효율성이 크게 저하될 수 있습니다. 본 논문에서는 대표적인 ASR 모델인 Whisper 가족의 안정성을 평가하기 위해 새로운 공격 방법 **MORE**를 제안합니다. **MORE**는 정확성과 효율성을 동시에 해치는 다목적 공격 방법으로, 이전 연구들이 주로 정확도에만 초점을 맞춘 것과 달리, 더 종합적인 모델 취약점 평가를 가능하게 합니다.
paper
AI 요약