The Surprising Effectiveness of Noise Pretraining for Implicit Neural Representations
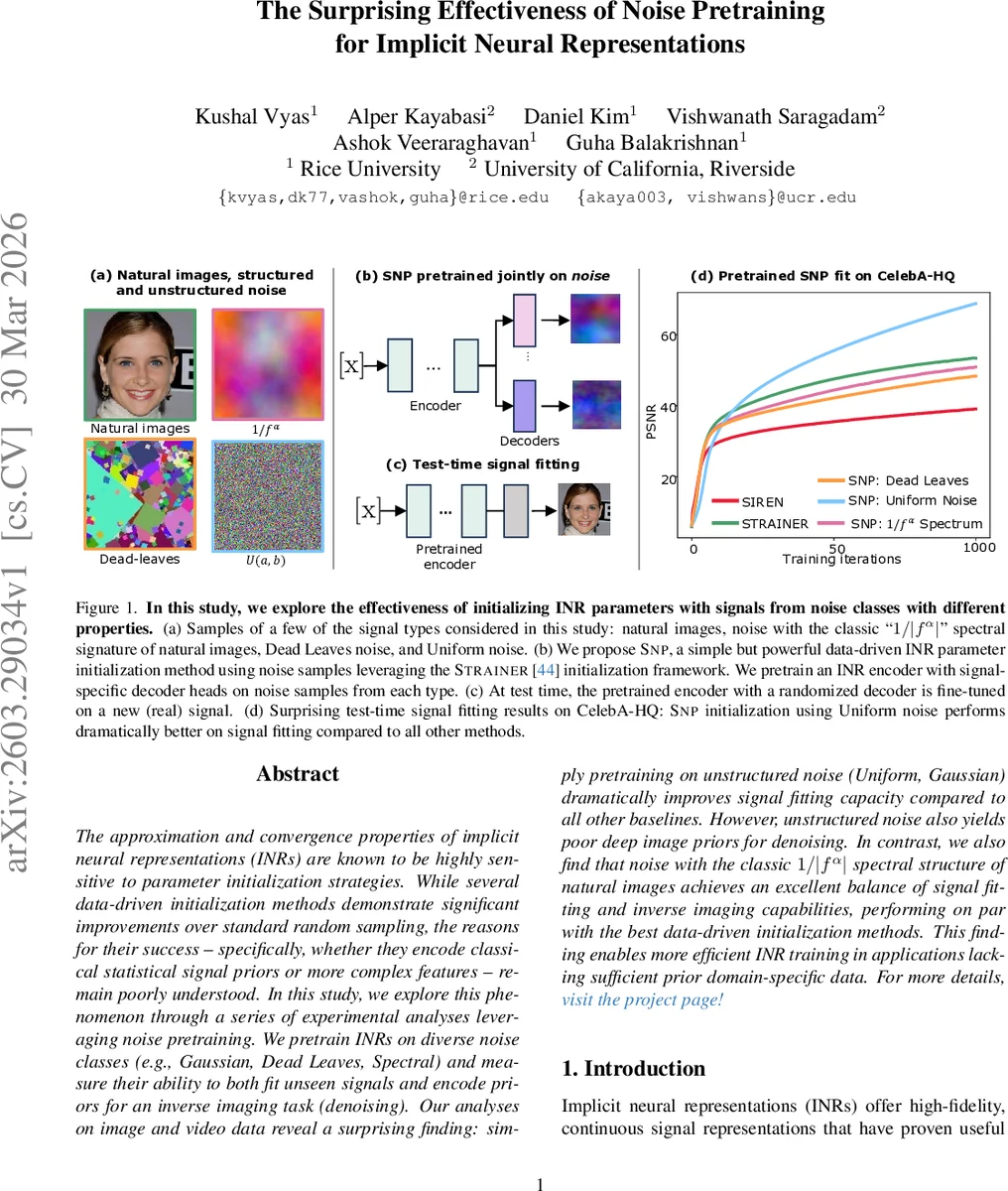
The approximation and convergence properties of implicit neural representations (INRs) are known to be highly sensitive to parameter initialization strategies. While several data-driven initialization methods demonstrate significant improvements over standard random sampling, the reasons for their success – specifically, whether they encode classical statistical signal priors or more complex features – remain poorly understood. In this study, we explore this phenomenon through a series of experimental analyses leveraging noise pretraining. We pretrain INRs on diverse noise classes (e.g., Gaussian, Dead Leaves, Spectral) and measure their ability to both fit unseen signals and encode priors for an inverse imaging task (denoising). Our analyses on image and video data reveal a surprising finding: simply pretraining on unstructured noise (Uniform, Gaussian) dramatically improves signal fitting capacity compared to all other baselines. However, unstructured noise also yields poor deep image priors for denoising. In contrast, we also find that noise with the classic $1/|f^α|$ spectral structure of natural images achieves an excellent balance of signal fitting and inverse imaging capabilities, performing on par with the best data-driven initialization methods. This finding enables more efficient INR training in applications lacking sufficient prior domain-specific data. For more details, visit project page at https://kushalvyas.github.io/noisepretraining.html
💡 Research Summary
The paper investigates why data‑driven initialization methods dramatically improve the convergence and performance of implicit neural representations (INRs). While prior work has shown that meta‑learning, hyper‑networks, and transfer learning can provide strong “deep image priors” for tasks such as denoising, it remains unclear whether these gains stem from encoding high‑level semantic features or from more basic statistical regularities of natural images. To disentangle these possibilities, the authors adopt an empirical strategy inspired by recent work that pretrains vision models on synthetic noise.
They build on the STRAINER framework, which splits a sinusoidal‑activated MLP (six layers, ω=30) into a shared encoder and multiple signal‑specific decoder heads. Instead of training the encoder on real images, they pretrain it on various noise classes, creating a variant they call SNP (STRAINER Noise Pretraining). The noise families include: (1) unstructured Uniform (U(0,1)) and Gaussian (N(0.5,0.2)) noise, (2) structured “Dead‑Leaves” noise that mimics strong edges and texture patches, and (3) noise with a 1/|f^α| power‑spectrum, i.e., the classic spectral signature of natural images. During pretraining, ten noise samples are jointly optimized for 5 000 iterations; at test time, the encoder weights are frozen, a fresh decoder is randomly initialized, and the whole network is fine‑tuned on a new real signal for 2 000 iterations using an L2 loss.
The authors evaluate on three image datasets (CelebA‑HQ faces, AFHQ animal images, OASIS‑MRI scans) and a set of ten diverse video clips. Baselines include vanilla SIREN (random initialization), STRAINER trained on real data, meta‑learned initializations, TransINR, and Implicit Pattern Composers (IPC). Performance is measured with PSNR, SSIM, and LPIPS, focusing on PSNR for signal‑fitting because all methods reach >50 dB.
Key findings:
- Unstructured noise excels at signal fitting. SNP models pretrained on Uniform or Gaussian noise achieve astonishing PSNR values (≈80 dB) and converge far faster than any data‑driven baseline. The encoder appears to capture a very generic low‑frequency bias that makes subsequent fitting trivial.
- Unstructured noise lacks deep priors. Despite their fitting prowess, these models perform poorly on denoising tasks; PSNR/SSIM are substantially lower than those of SIREN, STRAINER, or meta‑learned initializations. This indicates that the encoder has not learned the higher‑order statistical regularities needed for a useful image prior.
- Structured spectral noise provides a balanced trade‑off. Pretraining on noise with a 1/|f^α| spectrum yields performance comparable to STRAINER on both signal fitting and denoising, while requiring no real images for pretraining. The spectral bias aligns with the natural image power‑law, allowing the encoder to represent both low‑ and high‑frequency components effectively.
- Dead‑Leaves noise is intermediate. It improves over random initialization but falls short of both unstructured and spectral noise in both metrics, suggesting that edge‑patch statistics alone are insufficient.
The authors conclude that the success of data‑driven INR initialization can be largely attributed to low‑level statistical priors—particularly the natural image power‑law—rather than complex semantic features. Consequently, generating simple spectral noise offers a practical, data‑free way to obtain strong INR initializations, especially valuable in scientific imaging domains where labeled data are scarce. The paper also outlines future directions: exploring different α values, extending to 3‑D or video‑specific architectures, and combining spectral noise pretraining with alternative activation functions or deeper encoder designs.
Comments & Academic Discussion
Loading comments...
Leave a Comment