Label-efficient Training Updates for Malware Detection over Time
Machine Learning (ML)-based detectors are becoming essential to counter the proliferation of malware. However, common ML algorithms are not designed to cope with the dynamic nature of real-world settings, where both legitimate and malicious software …
Authors: Luca Minnei, Cristian Manca, Giorgio Piras
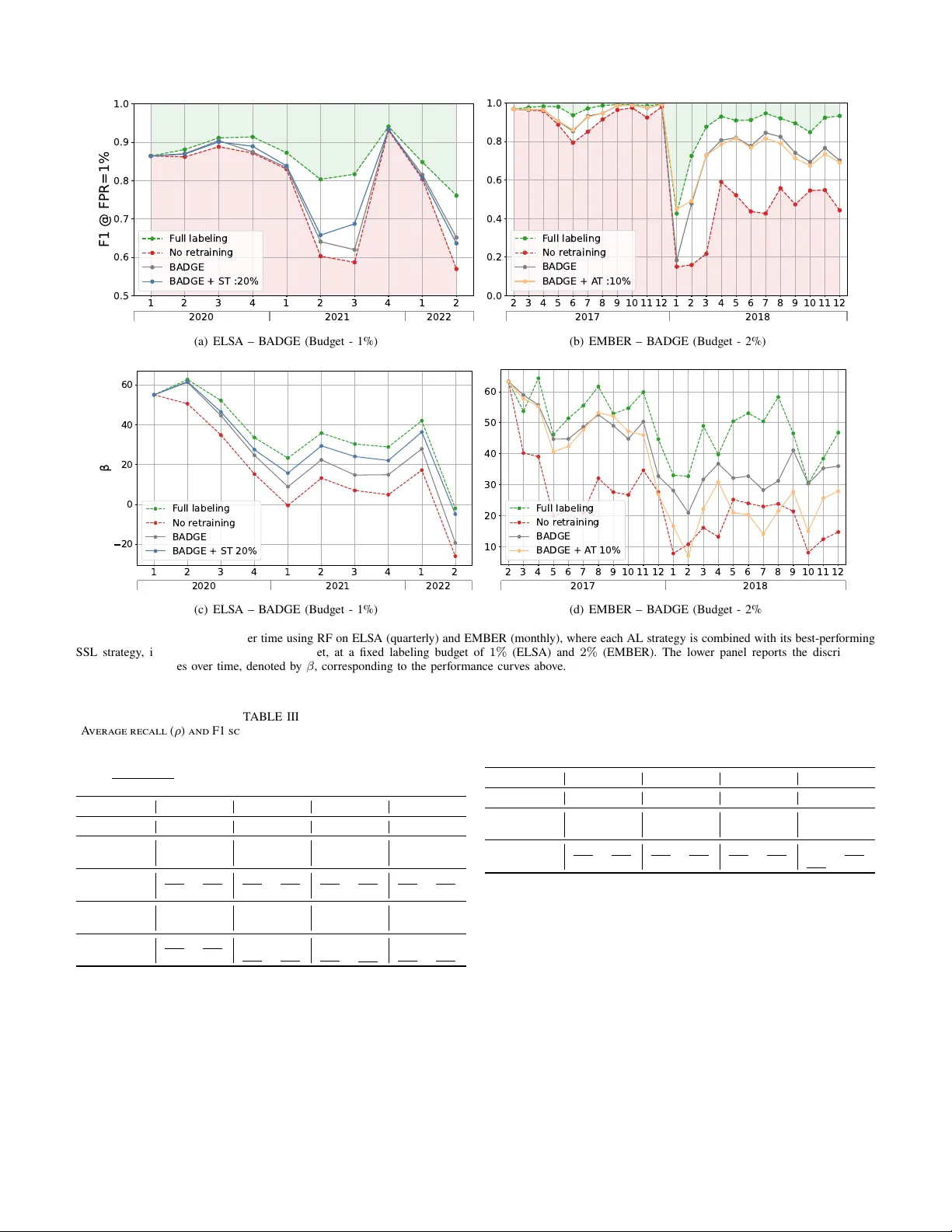
1 Label-efficient T raining U pdates f or Malw are Detection o v er Time Luca Minnei 1 , Cristian Manca 1 , Giorgio Piras 1 , Ang elo Sotgiu 1 , Maura Pintor , Member , IEEE 1 , Daniele Ghiani 1,2 , Da vide Maiorca, Member , IEEE 1 , Giorgio Giacinto, Senior Member , IEEE 1,3 , and Battista Biggio, F ellow , IEEE 1,3 1 Depar tment of Electrical and Electronic Engineering, U niv ersity of Cagliari, Italy 2 Depar tment of Computer , Control and Management Engineer ing, Sapienza U niv ersity , Rome, Italy 3 CINI, Rome, Italy Abstract —Machine Learning (ML)-based detectors are becom- ing essential to counter the proliferation of malware. How ev er , common ML algorithms are not designed to cope with the dynamic nature of real-w orld settings, where bo th legitimate and malicious software ev olv e. This distr ibution drift causes models trained under static assumptions to degrade o ver time unless the y are continuously updated. R egularl y retraining these models, ho w ev er , is expensiv e, since labeling new acq uired data requires costly manual anal ysis by security experts. T o reduce labeling costs and address distribution drift in malware detection, prior w ork e xplored activ e learning (AL) and semi-supervised learning (SSL) techniques. Y et, existing studies (i) are tightly coupled to specific detector arc hitectures and restricted to a specific malwar e domain, r esulting in non-unif orm com parisons; and (ii) lack a consistent methodology for analyzing the distribution drift, despite the critical sensitivity of the malware domain to temporal chang es. In this w ork, we bridge this gap by proposing a model- agnostic framew ork that ev aluates an extensiv e set of AL and SSL techniq ues, isolated and combined, for Android and Windo ws malwar e detection. W e show that these techniq ues, when com- bined, can reduce manual annotation costs by up to 90% across both domains while achieving comparable detection perf ormance to full-labeling retraining. W e also introduce a methodology for f eature-le vel drift analy sis that measures f eature stability o v er time, showing its correlation with the detector per formance. Ov erall, our study pro vides a detailed understanding of ho w AL and SSL beha v e under distribution drift and how the y can be successfully combined, offering practical insights for the design of effectiv e detectors o v er time. Index T erms —Malw are Detection, Machine Learning, Activ e Learning, Semi-Supervised Learning, Distribution Drift I. Intr oduction Android and Windo ws dominate mobile and desktop ecosy s- tems, making them prime targets f or malwar e , malicious software that can infiltrate and compromise devices. Machine Learning (ML) algor ithms enable automatic and effectiv e malware detection [1], [2]. How e v er , such detectors are often ev aluated under stationar y conditions, with train and test data dra wn from the same underl ying dis tr ibution. This f ails to reflect real-w orld settings where both malware and benign samples continuously e v ol v e, inducing significant shifts in data distributions. This is commonl y referred to as distribution drift , which leads to progressive detector per f ormance decay when tested in the wild [3]. A common counter measure is to continuall y retrain detectors on updated data. Ho w ev er, labeling ne w l y collected samples can be resource- and time- consuming, as it often requires expert inspection [4]. There- f ore, traditional fully super vised training is unrealistic in real- w orld scenar ios. T o reduce labeling costs, pr ior w ork explored activ e lear ning (AL) [5], which selects informativ e samples f or labeling, and semi-super vised learning (SSL) [6], which assigns pseudo-labels to unlabeled data. While promising, both hav e sev eral drawbac ks when applied in isolation: AL is constrained by the high annotation cos t, resulting in small annotation budgets that may not capture the rapidl y changing data dis tr ibution, while SSL can easil y reinf orce e xisting biases and propag ate errors when pseudo-labels are incorrect [7]. These limitations motiv ate their combination: AL f ocuses the limited labeling budget on a fe w highl y inf or mativ e samples, while SSL adds many pseudo-labeled samples from already observed distributions. Existing w ork combining AL and SSL f or distribution drift in malware detection s till suffers from sev eral limitations. First, many implementations are tightly coupled to specific ML algorithms [8] or ad hoc pipelines [9], limiting their generalizability across different models and settings. Second, e valuations are typically confined to a single platf orm or domain (e.g., Android or Window s) [10], [11], [12] and with different baselines and setups, leaving it unclear whether their performance can be replicated across different en vironments. Finall y , while framed as distribution-dr ift reme- dies, pr ior w ork provides limited anal ysis and insights on drift and its causes. In this w ork, we address these issues b y proposing a model-agnostic framew ork combining AL and SSL for label-efficient retraining of malware detectors under distribution dr ift. W e conduct a sys tematic ev aluation of 8 AL and 2 SSL techniques, analyzing their individual and combined effects under dis tr ibution drift across Android and Windo w s malware datasets. T o inter pret the results, w e introduce a f eature-lev el stability analy sis that captures ho w discriminative features ev olv e ov er time. Our findings show that combining AL and SSL achiev es performance comparable to full retraining while reducing labeling costs by up to 90% . The proposed dr ift anal ysis fur ther explains these results, highlighting wh y different retraining s trategies e xhibit different performance ov er time. 2 II. B a ck gr ound This section provides essential background on ML f or malware detection and on AL and SSL methodologies. A. Mac hine Lear ning f or Malwar e Detection ML techniques hav e been increasingly adopted f or malw are detection [13], [14]. In this work, we focus on methods that e xtract f eatures b y running static analy sis on in put programs (e.g., Android apps or W indo ws PE files) and con verting the output into a suitable numer ical representation. Each sample, associated with a label y ∈ { 0 , 1 } (respectivel y , benign and malware), is mapped to a d -dimensional feature v ector x ∈ X ⊆ R d . The ML detector f is then trained on ( x , y ) pairs to perform malw are classification. At inference time, the classifier takes as input a ne w sample x and outputs a confidence score f ( x ) ∈ [0 , 1] , representing the estimated probability that it belongs to the malware class; a predicted label ˆ y is then obtained b y applying a decision rule ˆ y ( x ) = I [ f ( x ) > τ ] , where I is the indicator function and τ a decision threshold. T raining U pdates for Malware Classifiers. In realistic de- plo yment settings, detectors are per iodically updated as new data is collected to cope with ev olving distributions. W e model malware detection o v er a temporally ordered sequence of data batches index ed by t ∈ { 0 , . . . , T } . At step t , D ( t ) denotes the labeled training set, and U ( t ) denotes the new ly collected batch of samples whose labels are unknown at acquisition time. The detector trained at step t is denoted as f ( t ) and outputs a malware score f ( t ) ( x ) ∈ [0 , 1] . For each update, AL selects a set to be labeled D ( t ) AL ⊆ U ( t ) , while SSL produces a pseudo-labeled set D ( t ) SSL ⊆ U ( t ) . The training set D ( t ) is then augmented with these new l y-labeled samples, yielding D ( t +1) . B. Activ e Learning Str ategies AL selects a small number of unlabeled samples e xpected to pro vide the g reatest benefit when updating the detector . W e f ocus on pool-based approaches, where models access large pools of unlabeled samples and select the most inf ormative ones f or labeling, aligning with operational malware analy - sis, where suspicious software is continuously collected and selectiv ely labeled offline under a cons trained e xpert budget. W e ex clude str eam-based AL methods, where data comes sequentiall y and needs immediate labeling. Similarly , we do not consider quer y synthesis AL techniques that request labels f or both real and synthetically generated data, as synthetic samples ma y not cor respond to valid samples in input space, potentially wasting oracle effor t. An AL strategy uses the prediction scores f ( x ) to rank the samples in U ( t ) according to its selection cr iterion and queries the top k samples f or oracle labeling, yielding D ( t ) AL . W e define a query function q ( t ) : X → { 0 , 1 } that selects the samples to be labeled: D ( t ) AL = n ( x , y ) x ∈ U ( t ) , q ( t ) ( x ) = 1 o , (1) where y ref ers to the label provided b y the anal ys t. The function q is generall y assigned through a method-specific score function, which is thresholded to obtain the selection: Random Sampling (RS). In RS, instances are selected uni- f ormly at random. Despite its simplicity , it ser v es as a baseline f or e v aluating the effectiv eness of more adv anced AL strate- gies. Formally , given a query rate π , the query function f or RS is defined using the Ber noulli distribution: q ( t ) RS ( x ) ∼ Bernoulli( π ) . (2) Margin Sampling (MS) [5]. MS selects the sample with the smallest difference betw een the top two predicted class prob- abilities. In binar y classification, the query function becomes: q ( t ) MS ( x ) = I h 2 f ( t ) ( x ) − 1 ≤ m MS i , (3) where m MS is the margin betw een the two class predictions. Least-Confident Sampling (LCS) [5]. LCS selects the in- stances with the lo w est prediction confidence, such as: q ( t ) LCS ( x ) = I h max f ( t ) ( x ) , 1 − f ( t ) ( x ) ≤ m LCS i , (4) where m LCS is the margin for the minimum confidence. This function tar gets samples where the classifier is less confident in its decision, f ocusing on instances near the decision boundary . Entrop y Sampling (ES) [5]. ES selects the sample with the highest predictiv e entropy H . Its query function is defined as: q ( t ) ES ( x ) = I h H f ( t ) ( x ) ≥ m ES i , (5) where m ES is a threshold f or the entrop y . Entropy measures the total uncer tainty of the model across all classes. For binar y linear classifiers, MS, LCS, and ES are equivalent, as they all select samples closest to the decision boundar y f ( x ) = τ ; consequentl y , they induce identical query rankings. Expected A v erage Precision (EAP) [15]. EAP estimates, f or each sample, the expected improv ement in A v erage Precision (AP) after retraining if the label is provided: q ( t ) EAP ( x ) = I X y ∈{ 0 , 1 } f ( t ) y ( x ) AP f ( t +1) | ( x , y ) ≥ m EAP (6) This strategy may become computationally cos tly due to the repeated retraining required to estimate impro v ement in AP . CLustering with Uncertainty -w eighted Embeddings (CL UE) [16]. CL UE clusters samples in the model’s embedding space and weights them based on their uncer tainty , selecting the nearest samples to centroid clusters. W e apply it in feature space, defining the query function as: q ( t ) CLUE ( x ) = I h H f ( t ) ( x ) · x − µ c ( x ) 2 ≥ m CLUE i , (7) where µ c ( x ) is the centroid of the cluster to which x is assigned, the predictive entrop y H ( f ( t ) ( x )) defines each sample ’ s contr ibution to cluster f ormation, and m CLUE is a threshold on the distance from the centroid. CoreSet Selection (CoreSet) [17]. CoreSet selects a represen- tativ e subset that minimizes the distance between each sample and the selected set in embedding space (in our setting, the f eature space). It constructs a batch S ( t ) CS ⊂ U ( t ) b y iterativ ely 3 Unlabeled pool AL query SSL pseudo-labeling Updated detector Unlabeled Queried Pseudo-labeled benign Pseudo-labeled malware Benign Malware annotate retrain & annotate retrain (1) (2) (3) Fig. 1. Ov erview of our proposed pipeline combining AL and SSL. The dash-dot line represents the detector’ s decision boundary . Given a set of new ly collected unlabeled samples (left), AL queries a small set of inf ormative samples for e xpert annotation (center), while SSL automaticall y assigns pseudo-labels to high-confidence samples (r ight), enabling efficient model retraining with reduced labeling cost. selecting samples that maximize their minimum distance to the already selected set, f ollo wing a farthest-firs t cr iter ion: x ∗ = arg max x ∈ U ( t ) \ S min z ∈ S ∥ x − z ∥ 2 , (8) where S is initialized either with the labeled set D ( t ) or with an empty set. The process is repeated until the desired number of samples is selected. The quer y function is defined as: q ( t ) CoreSet ( x ) = I h x ∈ S ( t ) CS i . (9) Batch A ctiv e Learning b y Div erse Gradient Embeddings (B ADGE) [18]. B ADGE is a batch active learning strategy that selects inf or mative and div erse samples b y operating in the gradient embedding space. It computes the gradient embedding f or each unlabeled sample x ∈ U ( t ) as the gradients of the cross-entropy loss with respect to the model embeddings, using the label ˆ y ( x ) predicted by the cur rent detector f ( t ) . W e extend it to non-differentiable models by computing appro ximate gradient embeddings in the model f eature space using a sur rogate softmax linear classifier . For the i -th class, g radient embeddings can thus be computed as: ψ i ( x ) = f ( t ) i ( x ) − I ( ˆ y ( x ) = i ) x . (10) B ADGE then selects a batch S ( t ) BADGE ⊂ U ( t ) b y applying k - means++ seeding to the set of gradient embeddings. The quer y function is then defined as: q ( t ) BADGE ( x ) = I h x ∈ S ( t ) BADGE i . (11) C. Semi-super vised Lear ning Strat egies SSL aims to reduce labeling cost by automatically assigning labels to a subset of new ly collected samples bef ore incor po- rating them into the training set. W e adopt two SSL techniques relying on pseudo-labels to iterativ ely update the model, which are fully model-agnostic and require no modifications to the underl ying detector, making them par ticularl y suitable f or our setting. W e build the SSL dataset through a pseudo-labeling function g ( t ) : X → { 0 , 1 , ⊥} , where ⊥ means that no pseudo label is assigned and the sample is ex cluded from the set: D ( t ) SSL = n x , g ( t ) ( x ) x ∈ U ( t ) , g ( t ) ( x ) = ⊥ o . (12) Self- T raining with Symmetric Thresholding (ST) [19]. ST builds the pseudo-labeled set by selecting high-confidence predictions from the unlabeled pool U ( t ) using the cur rent detector score f ( t ) . It defines the pseudo-labeling function as: g ( t ) ST ( x ) = 1 if f ( t ) ( x ) ≥ γ , 0 if f ( t ) ( x ) ≤ 1 − γ , ⊥ otherwise , (13) assigning a pseudo-label to eac h x ∈ U ( t ) whose prediction confidence e x ceeds a fixed threshold γ , equal f or both classes. ST’ s main limitation is its inability to address class imbalance, common in malware detection, because a single threshold tends to fa v or the ma jority class (goodware), worsening the imbalance and reducing the detection of rare malware. Self- T raining with Asymmetric Thresholding (A T) [20]. A T is a variant of ST that addresses class imbalance using class- specific confidence thresholds. Its pseudo-labeling function is: g ( t ) A T ( x ) = 1 if f ( t ) ( x ) ≥ γ + , 0 if f ( t ) ( x ) ≤ γ − , ⊥ otherwise , (14) which pseudo-labels each sample using tw o different thresh- olds γ − and γ + f or goodware and malware, respectiv ely . By properl y tuning them, A T can increase the fraction of pseudo- labeled malw are and prev ent D ( t ) SSL from being dominated by goodware, improving sensitivity to rare malicious beha viors. III. Label -efficient Mal w are Detector Upd ates This section details our framew ork for label-efficient de- tector updates and introduces a f eature-le v el drift analy sis to measure the stability of discr iminative features o v er time. A. Combining AL and SSL W e adopt a two-s tage update procedure, sho wn in Fig. 1, in which AL is applied bef ore SSL, interlea v ed with a retraining step. AL uses a limited labeling budget to select inf ormativ e samples, while SSL subsequentl y enlarges the update set at negligible cost by pseudo-labeling high-confidence samples. W e apply AL bef ore SSL so that pseudo-labeling relies on a partially adapted detector , reducing the r isk of early er rors being propagated and amplified ov er time. At time step t , the detector f ( t ) is trained on the av ailable labeled dataset D ( t ) and applied to a new ly collected unlabeled batch U ( t ) . AL is first applied to U ( t ) to identify a subset of samples 4 to label, yielding D ( t ) AL . W e then update the training set with these new ly labeled samples, ˜ D ( t ) = D ( t ) ∪ D ( t ) AL , and retrain the detector to obtain an intermediate model ˜ f ( t ) . SSL is then applied to the remaining unlabeled set, ˜ U ( t ) = U ( t ) \ D ( t ) AL , using the intermediate detector ˜ f ( t ) to assign pseudo-labels to high-confidence instances, yielding a pseudo-labeled set D ( t ) SSL . By construction, AL and SSL operate on disjoint subsets of samples, with AL allocating the e xpensiv e labeling budget to inf ormative samples and SSL suppor ting the update with lo w-cos t pseudo-labels. Finall y , the updated model f ( t +1) is obtained by training f on the enr iched training set, defined as: D ( t +1) = D ( t ) ∪ D ( t ) AL ∪ D ( t ) SSL . (15) This update procedure is then repeated ov er successiv e time steps, enabling the detector to adapt to ev olving malw are distributions while limiting manual labeling effor t. Practical Implications. This design jointly achie v es ro- bustness to distribution dr ift, label efficiency , and model- agnosticity . Our pipeline is compatible with both full-history and sliding-windo w updates. In long-running deployments, D ( t ) ma y be maintained as a sliding windo w , discarding the oldest samples and retaining onl y the most recent ones. This keeps retraining scalable and a v oids older retained samples from accumulating and numerically dominating the training set. As the data v olume in our experiments is manag eable, w e retain the full history when updating the detector (i.e., no samples are discarded). Our approach is label-efficient: lo w AL labeling budgets reduce the need for time-consuming analy sis, whereas SSL pseudo-labels can be generated at scale at negli- gible cost. W e also recall that the pipeline is model-agnostic: the AL and SSL components use onl y the detector outputs (and, f or some AL strategies, feature-space representations) without modifying their architecture or training procedure. B. Drift Analysis W e analyze the distribution dr ift based on the temporal stability of detector -agnostic f eature–class associations. Motiv ation. Unlik e anal yses based on model-specific latent spaces or architecture-dependent signals, w e operate on f eature values and class labels, enabling comparisons across different detectors with the same f eature representation. Our goal is to quantify whether f eatures that are discr iminative on the current training set, i.e., significantly associated with one class (goodware or malware), remain stable o v er time, i.e., preserve the same class association in subsequent batches (e.g., in the next month f or EMBER or in the ne xt quarter f or ELS A). Intuitivel y , if a detector is trained using feature–class associations that no longer hold ov er time, then its predictions rely on stale cues, and per f ormance is expected to degrade. Methodology . T o quantify feature–class association, we ana- lyze each f eature j separately , compar ing their values in both classes by applying the Wilco x on–Mann–Whitne y (WMW) test and computing its nor malized U statis tic, equiv alently the R OC A UC, defined as A UC j . W e use WMW as it provides (i) a measure of statistical significance through the p -value p j , assessing whether the obser v ed association is due to random variation, and (ii) an association direction, indicating whether a f eature can be associated with a class. Based on that, w e define f or each f eature the class-association indicat or , encoding the direction of the association only when statis tically significant: a j = ( sgn(2A UC j − 1) , if p j < 0 . 05 , 0 , otherwise . (16) Thus, for statisticall y significant associations, a j encodes their direction, i.e., +1 f or malware and − 1 f or goodware, respec- tiv ely . Other wise, a j = 0 indicates that no reliable association is f ound, either because it is not statisticall y significant or no clear direction emer ges ( AUC j ≈ 0 . 5 ). At each time step t , we compute the indicator on train and test data under the same f eature representation, obtaining a ( t ) tr,j and a ( t ) ts,j f or each f eature j , respectiv ely . Discrepancy between train and test association directions rev eals the presence of distribution drift, while preser vation sho ws its absence. On the other hand, no assumption can be made when the association cannot be determined in both the train and test features. Based on those assumptions, we compute the stability score metr ic as: β ( t ) = 1 d d X j =1 a ( t ) tr,j · a ( t ) ts,j − I h a ( t ) tr,j + a ( t ) ts,j = 1 i . (17) Features whose class association is statisticall y significant and is preser ved betw een train and tes t data contr ibute positivel y to β ( t ) through the first summation ter m, as their presence is desirable. Conv ersely , f eatures that chang e association direc- tion contribute negativ el y , through the first (if the associations ha v e opposite directions) and the second (if one of the tw o indicators is zero) summation ter ms. Consequently , larg er β ( t ) indicates g reater stability , whereas low er v alues indicate misalignment between the detectors’ feature representations and the discr iminativ e features characterizing the cur rent data distribution. This also provides a detector -agnos tic wa y to interpret AL/SSL updates: successful sample selection should increase the fraction of stable discr iminativ e features, thereby mitigating per f or mance decay under distr ibution dr ift. IV . Experiments W e first descr ibe the e xper imental setup and e valuation protocol, then present and discuss the results. A. Experimental Setup Datasets. W e consider the EMBER Windo w s dataset [2] and the Android ELS A dataset [21]. EMBER pro vides 2 , 381 fea- tures e xtracted from PE files. W e combine the 2017 and 2018 releases and e x clude unlabeled samples, obtaining 1 , 500 , 000 PE files that are approximatel y balanced ov erall. How ev er , under the temporal split, the class prior varies across months, inducing batch-le v el imbalance. Moreo ver , concatenating tw o releases introduces an additional distr ibution chang e at the y ear boundar y , due to different sampling strategies. T o emulate a realistic deplo yment setting, we adopt a monthly stream: samples from the first month are used f or training only , while samples from subsequent months f or m consecutiv e incoming unlabeled batches U ( t ) . Each U ( t ) is first used to ev aluate f ( t ) and then processed b y the AL –SSL pipeline to obtain 5 D ( t +1) . The ELSA dataset compr ises applications collected from AndroZoo [22] with pre-e xtracted Drebin f eatures [1]. The dataset is strongl y imbalanced, with a 9:1 benign-to- malware ratio. W e use data from 2017 to 2021 f or training (75,000 applications). The remaining 137,500 applications, sampled betw een Jan. 2020 and Jun. 2022, are reser ved f or ev aluation and split into quarterl y batches. As in [10], we retain the 10 , 000 most frequent features to reduce computational o v erhead; despite the fixed representation, the set of activ e (non-zero) f eatures and their discriminative patterns vary ov er time, reflecting the ev olution of app behaviors. Models. On ELSA, we rely on a linear Suppor t V ector Machine (SVM) with C = 0 . 1 , and a Random F orest (RF) with 80 trees and maximum depth 30 . On EMBER, w e use only RF , as training an SVM is not feasible in se v eral of the considered settings due to memor y cons traints. As AL strategies rely on probability estimates, w e appl y Platt scaling to the SVM, thereb y facilitating uncer tainty-based active lear ning methods. Evaluation Protocol. T o assess the effectiv eness of the consid- ered retraining strategies, we use the F1 score and the Recall score when fixing the False P ositiv e Rate (FPR) to 1% . W e compare them against two baselines: a no-r etr aining (NR) model trained only once on the initial set D (0) and nev er updated; and a full-labeling (FL) model retrained at each step t using the fully labeled dataset D ( t ) ∪ x , y x ∈ U ( t ) . All the tested AL and SSL methods are trained with full labeling only on D (0) and are retrained after w ards using the dataset (with labels) obtained via the selected strategies at time t . Label budgets. W e control the labeling budget as a percentage of the unlabeled set. For each method, thresholds and selection criter ia are tuned to meet the cor responding budget, ensur ing that all approaches label an equal number of samples per step. B. Experimental Results on AL, SSL, and AL+SSL AL Analy sis. W e first ev aluate AL in isolation to assess whether selective labeling can suppor t detector updates under temporal dr ift with limited annotation budgets. W e compare the strategies described in Sect. II-B across f our label budgets, appro ximately 1% , 2% , 5% , and 10% of the incoming batch. Higher budgets are not considered, as our goal is to focus on the low -label regime, where annotations are constrained, and the benefit of selective quer ying is most informativ e. W e e x clude EAP from EMBER ev aluation as it requires retraining per sample and cannot scale to larg e datasets due to time and memory constraints. Figs. 2(a) and 2(b) sho w the F1-score ev olution f or the AL techniques in both datasets with a fixed labeling budg et of 10% of the total samples. The results clear ly indicate that detectors can be effectiv ely retrained without la- beling all av ailable samples, repor ting consistent per f or mance across both datasets. Specifically , when fixing a budget of 10% , most techniques exhibit a trend that closely matches the per f ormance of FL, which uses the entire dataset f or retraining. This demonstrates that AL techniques can reduce the amount of labels required b y 90% , helping to counteract the per formance decline caused by distribution drift in both ELS A and EMBER datasets, and are generall y effectiv e and not limited to specific models, in contrast to prior claims [10]. T ABLE I A vera ge recall ( ρ ) and F1 score acr oss different AL strategies and label budgets, a t fixed FPR of 1%, for SVM and RF models on ELSA. Best overall resul ts are in bold , the top AL method is underlined , and v alues below the NR b aseline are in red . AL Strategy 1% Budget 2% Budget 5% Budget 10% Budget ρ F1 ρ F1 ρ F1 ρ F1 SVM + NR 74.9 80.0 74.9 80.0 74.9 80.0 74.9 80.0 SVM + FL 82.2 85.4 82.2 85.4 82.2 85.4 82.2 85.4 SVM + RS 72.9 78.5 74.5 79.9 76.0 81.2 76.6 81.6 SVM + B ADGE 78.6 82.9 80.2 84.0 81.5 85.0 83.5 86.3 SVM + CLUE 78.1 82.6 80.4 84.2 82.2 85.4 82.5 85.6 SVM + CoreSet 74.8 79.9 76.1 81.0 75.6 80.6 79.0 83.2 SVM + EAP 77.9 82.4 80.0 84.0 81.7 85.1 82.9 86.0 SVM + ES 76.0 80.9 78.6 82.9 80.6 84.4 82.3 85.5 SVM + LCS 76.0 80.9 78.6 82.9 80.6 84.4 82.3 85.5 SVM + MS 76.0 80.9 78.6 82.9 80.6 84.4 82.3 85.5 RF + NR 71.9 78.1 71.9 78.1 71.9 78.1 71.9 78.1 RF + FL 83.1 86.1 83.1 86.1 83.1 86.1 83.1 86.1 RF + RS 71.6 78.0 74.3 80.1 75.1 80.7 76.0 81.4 RF + BADGE 74.4 80.1 78.6 83.1 79.8 84.0 80.6 84.4 RF + CLUE 75.2 80.8 77.0 82.1 78.4 83.0 80.6 84.5 RF + CoreSet 69.1 76.0 68.9 75.6 73.7 79.5 76.7 81.8 RF + EAP 73.3 79.2 75.9 81.2 78.6 83.1 79.8 83.9 RF + ES 72.5 78.4 72.4 78.5 77.1 82.1 79.3 83.6 RF + LCS 72.3 78.5 74.3 80.0 76.4 81.5 79.5 83.7 RF + MS 69.5 76.3 72.9 78.9 77.2 82.2 79.4 83.6 T ABLE II Comp arison of AL strategies for different label budgets on EMBER (RF). Refer to T able I caption for metrics and formatting. AL Strategy 1% Budget 2% Budget 5% Budget 10% Budget ρ F1 ρ F1 ρ F1 ρ F1 RF + NR 56.6 66.3 56.6 66.3 56.6 66.3 56.6 66.3 RF + FL 86.7 91.4 86.7 91.4 86.7 91.4 86.7 91.4 RF + RS 67.0 76.7 72.4 81.4 75.1 83.1 79.0 86.5 RF + Badge 69.0 78.3 73.5 81.9 79.6 86.5 84.8 90.3 RF + CLUE 61.7 71.3 67.6 76.8 74.9 83.1 80.7 87.6 RF + CoreSet 55.7 64.8 56.0 64.8 64.7 74.1 73.2 82.1 RF + ES 59.4 68.3 63.0 71.4 78.2 85.3 85.5 90.4 RF + LCS 59.8 69.0 63.3 71.4 78.1 84.9 84.2 89.6 RF + MS 58.9 67.6 63.6 72.2 77.1 83.8 84.2 89.6 T ables I and II repor t detailed metr ics across different budgets, sho wing that the data selection method in AL significantly affects per f or mance, par ticularl y with smaller budgets. Both datasets repor t the same trends. B ADGE is the o v erall best- performing method, especially in low -budg et regimes, where more sophisticated strategies outper f or m simpler ones such as LSC or ES. As the budget increases, the gap between different strategies nar ro w s, and ev en RS progressivel y approaches FL, since most methods hav e already queried enough samples to achie v e high per f ormance. At v er y lo w budgets, retraining can be high-variance: with only a f ew queried points, some AL strategies may select an unrepresentative batch (often dominated by the majority class or containing outliers). In- corporating these labels can per turb the decision function, resulting in lo w er perf or mance than the NR baseline. AL can significantly reduce labeling costs while still achie v - ing per f ormance comparable to full labeling. SSL Analy sis. W e ne xt e v aluate SSL in isolation to assess whether pseudo-labeling alone can suppor t detector updates 6 No r etraining F ull labeling RS MS LCS ES EAP CL UE Cor eSet BADGE 1 2 3 4 1 2 3 4 1 2 0.5 0.6 0.7 0.8 0.9 1.0 F1 @ FPR=1% 2020 2021 2022 (a) ELSA – AL Compar ison (Budget - 10%) 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12 0.0 0.2 0.4 0.6 0.8 1.0 F1 @ FPR=1% 2017 2018 (b) EMBER – AL Comparison (Budget - 10%) No r etraining F ull labeling ST 10% A T 10% 1 2 3 4 1 2 3 4 1 2 0.5 0.6 0.7 0.8 0.9 1.0 F1 @ FPR=1% 2020 2021 2022 (c) ELSA – SSL Compar ison (Budget - 10%) 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12 0.0 0.2 0.4 0.6 0.8 1.0 F1 @ FPR=1% 2017 2018 (d) EMBER – SSL Compar ison (Budget - 10%) Fig. 2. F1 score at FPR = 1% ov er time for RF on ELSA (quarterl y) and EMBER (monthly) with a 10% labeling budget. T op: comparison of AL strategies, alongside NR and FL ref erences. Bottom: compar ison of SSL strategies under the same budget, with the same references. under temporal drift. W e compare the strategies descr ibed in Sect. II-C across pseudo-label budg ets of 10% , 20% , 60% , and 80% . Higher budgets are e x cluded to prev ent er ror accumulation from misclassified pseudo-labels. In A T , we meet desired budgets by first pseudo-labeling the top 80% most confident samples as malware and filling the remain- ing with the most confident goodware to obtain ( γ + , γ − ) . Figs. 2(c) and 2(d) repor t the F1-score ev olution for each method in both datasets, under a pseudo-labeling budget of 10% . W e obser v e that SSL techniques generall y do not impro v e perf or mance and ev en perf orm worse than the NR baseline, and are far from matching FL per f or mance. Fur ther insights can be dra wn from T ables III and IV, whic h sum- marize av erag e per f ormance metr ics across different budgets. The results confir m the limited effectiveness of these strategies in both datasets. Fur thermore, w e observe a consistent trend: increasing the budget often raises the r isk of misclassification, decreasing ov erall effectiveness. On ELS A, with SVM, A T uses class-specific thresholds, as described in Sect. II-C, which can be ov er ly permissive when malware scores o v erlap with benign scores, injecting noisy positive pseudo-labels. This is particularly harmful at (FPR = 1%) and can shift the linear decision boundar y farther than S T . RF is more robus t, so A T can help relative to S T , although SSL remains belo w the baselines on both datasets. On EMBER, A T and ST perform similarl y with RF , but still under per f orm the baseline. Ov erall, these results demonstrate the limitations of relying solely on SSL: the quality of pseudo-labels is constrained by the reliability of models ’ predictions on ne w samples, which, in turn, deteriorates when these pseudo-labels are f ed back into the retraining process. This reinforces e xisting biases and propagates er rors, under mining the models ’ per f ormance. U nder distribution dr ift, using SSL alone yields w orse results than not retraining at all. Combining AL and SSL. W e now anal yze the impact of com- bining AL with SSL using the pipeline descr ibed in Sect. III-A. For each AL –SSL pair ing, w e consider multiple budgets f or AL (1%, 2%, 5%, 10%) and SSL (10%, 20%, 40%, 80%), and compare each h ybr id configuration against the cor responding AL-only baseline to isolate the contribution of pseudo-labeling after selective labeling. Due to space constraints, w e do not report the entire resulting compar ison g rid, but summarize the observed dominant trends f or representativ e lo w-budg et configurations, where interaction between AL and SSL is most 7 1 2 3 4 1 2 3 4 1 2 0.5 0.6 0.7 0.8 0.9 1.0 F1 @ FPR=1% 2020 2021 2022 F ull labeling No r etraining BADGE BADGE + ST :20% (a) ELSA – B ADGE (Budget - 1%) 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12 0.0 0.2 0.4 0.6 0.8 1.0 F1 @ FPR=1% 2017 2018 F ull labeling No r etraining BADGE BADGE + A T :10% (b) EMBER – B ADGE (Budget - 2%) 1 2 3 4 1 2 3 4 1 2 20 0 20 40 60 2020 2021 2022 F ull labeling No r etraining BADGE BADGE + ST 20% (c) ELSA – B ADGE (Budget - 1%) 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12 10 20 30 40 50 60 2017 2018 F ull labeling No r etraining BADGE BADGE + A T 10% (d) EMBER – B ADGE (Budget - 2%) Fig. 3. F1 score at FPR = 1% o ver time using RF on ELS A (quarterly) and EMBER (monthly), where each AL strategy is combined with its best-performing SSL strategy , including the optimal SSL budget, at a fixed labeling budget of 1% (ELSA) and 2% (EMBER). The low er panel repor ts the discriminant percentage of features o ver time, denoted b y β , cor responding to the per formance curves abo ve. T ABLE III A vera ge recall ( ρ ) and F1 score acr oss different SSL strategies and pseudo-label budgets, a t fixed FPR of 1%, for SVM and RF models on ELS A. Best o verall resul ts are in bold , the top SSL method is underlined, and v alues below the NR b aseline are in red . SSL strategy 10% Budget 20% Budget 60% Budget 80% Budget ρ F1 ρ F1 ρ F1 ρ F1 SVM + NR 74.9 80.0 74.9 80.0 74.9 80.0 74.9 80.0 SVM + FL 82.2 85.4 82.2 85.4 82.2 85.4 82.2 85.4 SVM + ST 73.8 79.1 73.7 79.0 73.5 78.9 73.9 79.3 SVM + A T 72.1 77.9 71.0 76.9 66.0 71.7 65.3 70.7 RF + NR 71.9 78.1 71.9 78.1 71.9 78.1 71.9 78.1 RF + FL 83.1 86.1 83.1 86.1 83.1 86.1 83.1 86.1 RF + ST 71.8 78.0 69.0 75.8 70.9 77.1 67.9 75.0 RF + AT 71.4 77.6 71.4 77.6 71.7 77.9 70.8 77.3 inf ormative. In par ticular , Figs. 3(a) and 3(b) sho w the F1 score o v er time, with the AL budget fixed to 1% on ELSA and 2% on EMBER. For each dataset, w e repor t only the SSL con- figuration that maximizes F1 at that budget, including both the selected SSL method and its pseudo-label budget. This enables a direct compar ison between the best AL+SSL configuration and the cor responding AL -only baseline, thereb y isolating SSL ’ s contribution. At low AL budg ets, adding SSL yields T ABLE IV Comp arison of SSL strategies for different pseudo-label budgets on EMBER (RF). Refer to T able III caption for metrics and formatting. SSL strategy 10% Budget 20% Budget 60% Budget 80% Budget ρ F1 ρ F1 ρ F1 ρ F1 RF + NR 56.6 66.3 56.6 66.3 56.6 66.3 56.6 66.3 RF + FL 86.7 91.4 86.7 91.4 86.7 91.4 86.7 91.4 RF + ST 52.1 60.3 52.3 60.9 48.1 55.7 48.1 56.1 RF + AT 50.8 58.5 51.6 59.8 47.4 54.6 48.3 56.0 clear gains. On ELSA, with AL budget fixed to 1% , the best- performing h ybr id configuration combines B ADGE with ST using a 20% pseudo-label budget. On EMBER, with a to 2% AL budget, the bes t-performing h ybrid configuration combines B ADGE with A T using a 10% pseudo-label budg et. In both cases, the hybrid s trategy impro ves ov er the corresponding AL- only baseline and nar row s the gap to FL, indicating that a small amount of ne w l y acquired labels can make subsequent pseudo-labeling sufficientl y reliable. Notabl y , the bes t results are obtained with relativel y small pseudo-label budg ets, sug- ges ting that, in this lo w-budg et regime, modest SSL updates are preferable to more aggressive pseudo-labeling, as they pro vide additional co v erage while limiting er ror propagation. 8 20 0 20 40 60 0.6 0.7 0.8 0.9 F1 @ FPR=1% r = 0 . 5 7 9 , p = 2 . 0 0 e - 0 4 = 0 . 3 3 8 , p = 3 . 2 0 e - 0 3 vs. F1 scor e - ELS A 20 40 60 0.2 0.4 0.6 0.8 1.0 F1 @ FPR=1% r = 0 . 7 2 1 , p = 2 . 0 0 e - 0 4 = 0 . 5 4 2 , p = 2 . 0 0 e - 0 4 vs. F1 scor e - EMBER Fig. 4. Scatter plots of F1 score versus β of the cur ve in Fig. 3 for ELSA (right plot) and EMBER (left plot). The insets report Pearson r and Kendall τ cor relations with two-sided per mutation-test p-values (10,000 resamples). As the AL budget increases, the benefits of SSL diminish, as AL alone already acquires enough inf ormative labeled samples to effectiv ely update the detector, approaching the FL baseline upper bound. In this regime, the marginal benefit of SSL depends on the configuration and ma y be offset b y the noise introduced b y incor rect pseudo-labels. This sugges ts that the main contr ibution of SSL is concentrated in the most label-constrained regimes, whereas with larg er AL budgets, selectiv e labeling alone is often sufficient to achie v e near - optimal adaptation. These results rev eal a consistent pattern: SSL is most beneficial when the labeling budg et is limited, reducing the amount of labeled data needed to approach a targ et performance. As the AL budget increases, the AL -only baseline approaches the performance of full-retraining, and SSL pseudo-labeling does not pro vide significant gains. Combining AL and SSL is most effectiv e in low -budget labeling regimes ( < 2% ). C. Experimental Results on Distribution Drif t While pre vious results quantify the effectiv eness of AL and SSL in terms of detection per f ormance, the y do not explain wh y some retraining strategies adapt better to distribution drift than others. W e therefore complement the per formance analy sis with a feature-le v el dr ift diagnosis. The datasets e xhibit heterog eneous drift conditions: EMBER sho ws batch- lev el class-pr ior fluctuations and a discontinuity across the 2017/2018 release boundary , whereas ELS A is strongl y im- balanced and e xhibits time-v arying f eature activity patter ns. T o enable a unified diagnosis across these settings, we rel y on the feature-le v el stability indicator introduced in Sect. III-B. In par ticular , at each time step t we compute the stability score β ( t ) , i.e., the percentage of features that preser v e their signed class association (if statisticall y significant) minus the percentage of features that change association direction from the cur rent training set to the subsequent ev aluation batch. W e then compare how each β ( t ) relates to the cor responding F1 ( t ) analyzing the same retraining policies shown in Fig. 3. Specif- ically , for both datasets we consider the tw o baselines (FL and NR), the best-perf orming AL configuration in each domain (B ADGE at 1% on ELSA and B ADGE at 2% on EMBER), and their best SSL -augmented variants (B ADGE+ ST with a 20% SSL budget on ELSA and B ADGE+ A T with a 10% SSL budget on EMBER). The cor responding stability scores β ( t ) are plotted in Figs. 3(c) and 3(d), directl y beneath the asso- ciated F1 cur v es, so that temporal chang es in f eature stability can be visually compared with the cor responding per f ormance dynamics. Results show a common pattern: temporal drops in β ( t ) are often accompanied by drops in the cor responding F1 ( t ) curves, and both tend to reco v er when adaptation is more effectiv e. NR generall y exhibits lo wer stability and low er performance, whereas AL increases β ( t ) and AL+SSL often narrow s the gap to FL, which remains the most s table and best- performing ref erence. The effect is more pronounced on ELS A, where both β ( t ) and F1 e xhibit larg er temporal swings, while EMBER show s smoother dynamics. N otably , on EMBER, B ADGE+ A T is in some batches slightly belo w B ADGE alone, likel y because AL already pro vides a strong update and the additional pseudo-labels introduce mild noise. This visual co- variation sugges ts that retraining strategies that better preserve discriminative feature–class associations also tend to maintain higher detection performance ov er time. T o assess this effect more rigorously , w e aggregate obser vations across retraining policies and compute the cor relation between { β ( t ) } T t =1 and { F1 ( t ) } T t =1 using paired permutation tests f or Pearson ’ s r and Kendall’ s τ . This agg regation is par ticularly required f or ELS A, which contains onl y 10 quarterl y time points and would otherwise make per-policy tests under po w ered. In this setting, w e obser v e, in Fig. 4 a statisticall y significant positive associ- ation in both datasets: on ELSA, r = 0 . 579 ( p = 2 . 0 × 10 − 4 ) and τ = 0 . 338 ( p = 3 . 20 × 10 − 3 ); on EMBER, r = 0 . 721 ( p = 2 . 0 × 10 − 4 ) and τ = 0 . 542 ( p = 2 . 0 × 10 − 4 ). Overall, these results support the effectiv eness of β ( t ) as a drift- sensitiv e diagnostic: higher stability is generally associated with better detection perf ormance, although the relationship is not one-to-one. Indeed, configurations with similar β ( t ) can still yield different F1 scores, indicating that stability is inf ormative, but not sufficient by itself to full y predict performance. This highlights the influence of the specific retraining policy , since performance depends not only on ho w much discriminative structure is refreshed, but also on which f eature–class associations are updated. Higher stability of discr iminant f eatures ov er time is asso- ciated with better detection performance. V . Related W ork AL f or Malwar e Detection. AL f or malware detection un- der distribution dr ift remains a larg ely undere xplored area. A ctDroid [23] is an online learning framew ork that employ s a single uncer tainty sampling strategy based on prediction confidence thresholds, specificall y designed to detect Android malware. In contrast, the work presented in [10] proposes a technique that combines contrastiv e lear ning with a pseudo- loss uncer tainty score to facilitate active sample selection in a continuous Android malware detection pipeline. Existing studies sho w AL ’ s potential f or distribution drift but lack sy stematic comparisons across AL strategies and malware domains. Our framew ork addresses this gap with a unified ev aluation using consistent budg ets and models. SSL for Malware Detection. The role of SSL in malware detection under distribution drift has receiv ed limited attention. 9 DroidEv ol v er [24] employ s an ensemble of classifiers incre- mentally updated via pseudo labeling. DroidEvol ver++ [25] impro v es robustness to distribution dr ift by refining pseudo labeling, stabilizing label assignments, and adapting detec- tion thresholds. Both are limited to the Android domain. MORPH [8], instead, uses per iodic self-training with asym- metric pseudo-labeling tailored for neural netw orks, while AD APT [26] applies adaptiv e confidence-based self-training. Existing methods often yield unfair compar isons by ev aluating SSL strategies under inconsistent model architectures and labeling budgets, leading to biased results. Our framew ork enables controlled compar isons within a unified setup, varying labeling budgets, and cov ering multiple malware domains. Combining AL and SSL. A small body of pr ior w ork has e xplored combining AL and SSL techniq ues in the malw are domain. MalOSDF [9] combines opcode-slice feature extrac- tion with SSEAL, a semi-supervised ensemble that lev erag es an AL algor ithm to reduce labeling cost b y pseudo-labeling confident samples and querying uncertain ones f or annotation. Ho w ev er, this approac h is not e valuated under dis tribution dr ift and is limited to Windo ws malware, lacking compar ison with alternative AL or SSL methodologies. LDCDroid [11] miti- gates model aging in Android malware detection by selecting samples f or retraining based on distribution dr ift measured in model-specific latent f eatures. Ne v er theless, it remains tied to a single neural architecture, it is limited to the Android domain, and it explores only a limited set of AL strategies. In contrast, our work adopts a model-agnostic and modular per - spectiv e, enabling a sys tematic ev aluation of standard AL and SSL strategies—both individually and in combination—under realistic temporal ev olution. Moreov er, we complement per - f ormance e valuation with a dedicated analy sis of distribution drift to inspect how different retraining s trategies update the model ov er time, an aspect largel y une xplored in pr ior work. VI. Concl usion and Future Work This w ork addresses the problem of efficiently updating malware classifiers while reducing reliance on costl y anno- tations. W e introduce a model-agnostic retraining pipeline with modular components combining AL and SSL techniq ues. A cross Android and Windo w s domains, we sho w that AL can approach the effectiveness of full labeling while requiring only 10% of the labels, and that the proposed hybrid AL+SSL strat- egy fur ther impro v es o v er AL alone b y complementing sparse oracle quer ies with high-confidence pseudo-labels. W e also introduce a feature-le v el analy sis of distribution drift based on the stability of discriminative f eature beha vior o ver time. The proposed metr ic closely tracks detection perf or mance o v er time and sho ws that effectiv e retraining policies are those that better preser v e (or refresh) discr iminative features, nar rowing the gap to full labeling; moreov er, retraining strategies can differ in per f or mance ev en at comparable s tability , indicating that the techniq ues that select the bes t samples with the best f eatures matter . Our ev aluation does not incor porate r icher representation lear ning (e.g., transf ormer -based) or more ad- vanced query strategies be y ond the examined AL heur istics. Future work will extend the framew ork to include such meth- ods and inv estigate strong er AL and SSL schemes tailored to adv ersarially ev olving data. A promising direction is to couple the retraining pipeline with adaptiv e, feature-s tability policies that dynamicall y decide when to retrain and the labeling budget, improving automation and annotation efficiency of malware detectors in rapidly -changing threat environments. A ckno wledgements This research was par tially suppor ted b y the Horizon Europe projects ELSA (GA no. 101070617) and CoEvolu- tion (101168560), and by SERICS (PE00000014) and F AIR (PE00000013) under the MUR NRRP (EU-NGEU). This w ork was conducted while D. Ghiani was enrolled in the Italian National Doctorate on AI r un by the Sapienza Univ . of Rome in collaboration with the U niv . of Cagliar i. References [1] D. Ar p, M. Spreitzenbarth, M. Hubner, H. Gascon, K. Rieck, and C. Siemens, “Drebin: Effectiv e and e xplainable detection of android malware in your pock et., ” in Ndss , 2014. [2] H. S. Anderson and P . Roth, “Ember: An open dataset f or training s tatic pe malware machine lear ning models, ” 2018. [3] F . Pendlebury , F . Pierazzi, R. Jordaney , J. Kinder, and L. Cav allaro, “TESSERA CT: Eliminating e xperimental bias in malware classification across space and time,” in 28th USENIX Security Symposium , 2019. [4] R. J. Joy ce, D. Amlani, C. Nicholas, and E. Raff, “Motif: A malware ref- erence dataset with ground tr uth famil y labels, ” Computers & Security , 2023. [5] B. Settles, “ Activ e lear ning literature surve y , ” tech. rep., Univ ersity of Wisconsin–Madison, 2009. [6] J. E. van Engelen and H. H. Hoos, “ A surve y on semi-supervised learning, ” Machine Learning , 2020. [7] B. Chen, J. Jiang, X. W ang, P . W an, J. W ang, and M. Long, “Debiased self-training for semi-supervised learning, ” Advances in N eur al Inf orma- tion Processing Systems , 2022. [8] M. T . Alam, R. Fiebling er , A. Mahara, and N. Rastogi, “Mor ph: T ow ards automated concept dr ift adaptation for malware detection, ” 2024. [9] W . Guo, J. X ue, W . Meng, W . Han, Z. Liu, Y . W ang, and Z. Li, “Malosdf: An opcode slice-based malware detection framew ork using active and ensemble learning,” Electronics , 2024. [10] Y . Chen, Z. Ding, and D. W agner , “Continuous lear ning f or android malware detection, ” in 32nd USENIX Security Symposium , 2023. [11] Z. Liu, R. W ang, B. Peng, L. Qiu, Q. Gan, C. W ang, and W . Zhang, “Ldcdroid: Learning data drift character istics f or handling the model aging problem in android malware detection,” Computers & Security , 2025. [12] L. Minnei, G. Piras, A. Sotgiu, M. Pintor, A. Demontis, D. Maiorca, B. Biggio, et al. , “ An e xperimental analy sis of semi-supervised lear ning f or malware detection, ” in CEUR W ORKSHOP PROCEEDINGS , 2025. [13] A. Muzaffar , H. Ragab Hassen, M. A. Lones, and H. Zantout, “ An in- depth revie w of mac hine lear ning based android malware detection, ” Computers & Security , 2022. [14] P . Manir iho, A. N. Mahmood, and M. J. M. Cho wdhury , “ A sys tematic literature revie w on window s malware detection: T echniques, research issues, and future directions,” Jour nal of Systems and Sof twar e , 2024. [15] H. W ang, X. Chang, L. Shi, Y . Y ang, and Y .-D. Shen, “U ncer tainty sam- pling for action recognition via maximizing e xpected av erage precision, ” in IJCAI international joint confer ence on ar tificial intellig ence , 2018. [16] V . Prabhu, A. Chandrasekaran, K. Saenko, and J. Hoffman, “ Activ e domain adaptation via clustering uncertainty-w eighted embeddings, ” in 2021 IEEE/CVF International Confer ence on Computer Vision , 2021. [17] O. Sener and S. Sav arese, “ Activ e learning f or conv olutional neural netw orks: A core-set approach, ” in Int’l Conf. Learn. Repr . (ICLR) , 2018. [18] J. T . Ash, C. Zhang, A. Krishnamur thy , J. Langf ord, and A. Agar - wal, “Deep batch active learning b y diverse, uncertain gradient low er bounds, ” in 8th Int’l Conf. Learn. Repr . (ICLR) , 2020. [19] D. Y aro w sky , “U nsupervised word sense disambiguation rivaling su- pervised methods, ” in 33rd annual meeting of the association for computational linguistics , 1995. [20] A. Stanescu and D. Caragea, “Semi-super vised self-training approaches f or imbalanced splice site datasets, ” in Proc. of the 6th Int’l Conf erence on Bioinformatics and Computational Biology, BICoB , 2014. 10 [21] “R obust android malware detection competition.” https: //ramd- competition.github.io/. Accessed on May 2025. [22] K. Allix, T . F . Bissyand ´ e, J. Klein, and Y . Le T raon, “ Androzoo: Collecting millions of android apps f or the researc h community ,” in Proceedings of the 13th Int’l Conf. on Mining Sof twar e Repositories , MSR ’16, 2016. [23] A. Muzaffar , H. R. Hassen, H. Zantout, and M. A. Lones, “ Actdroid: An activ e lear ning framew ork for android malware detection, ” Computers & Security , 2025. [24] K. Xu, Y . Li, R. Deng, K. Chen, and J. X u, “Droide vol ver: Self-ev olving android malw are detection system, ” in 2019 IEEE Eur opean Symposium on Security and Privacy (EuroS&P) , 2019. [25] Z. Kan, F . Pendlebury , F . Pierazzi, and L. Cav allaro, “Inv estig ating labelless dr ift adaptation for malware detection, ” in Proc. 14th A CM W orkshop on AI and Security (AISec) , 2021. [26] M. T . Alam, A. Piplai, and N. Rastogi, “ Adapt: A pseudo-labeling approach to combat concept drift in malware detection, ” arXiv preprint arXiv :2507.08597 , 2025. Luca Minnei is a Ph.D. student in Inf or matics, Elec- tronics, and Computer Engineer ing at the U niv ersity of Cagliar i, Ital y , he earned a B.Sc. in Computer Science in 2022 and an M.Sc. in Computer En- gineering, Cybersecur ity , and Artificial Intelligence in 2024, both with honors. His research focuses on malware detection and concept drift in machine learning secur ity . Cristian Manca is a Master ’ s student in Computer Engineering, Cybersecurity , and Artificial Intelli- gence. He earned his B.Sc. in Electr ical, Electronic, and Computer Engineer ing in 2023, with a thesis on the identification and rejection of ev asiv e samples with Neural Rejection Defense. Maura Pintor is an Assistant Professor at the Univ ersity of Cagliari, Italy . She received her PhD in Electronic and Computer Engineer ing (with honors) in 2022 from the U niv ersity of Cagliari. Her research interests include adv ersar ial mac hine learning and trustworth y security e valuations of ML models, with applications in cybersecur ity . She ser ves as an A C f or NeurIPS, and as AE f or Pattern Recognition. Giorgio Piras is a Postdoctoral Researcher at the Univ ersity of Cagliari. He received his PhD in Ar ti- ficial Intelligence in January 2025 from the Sapienza Univ ersity of Rome (with honors). His research mainly f ocuses on adv ersarial machine learning, with a particular attention to neural netw ork pruning, e xplainable AI, and LLM security . He ser v es as a revie w er for jour nals and conferences, including Pattern Recognition and Neurocomputing jour nals. Angelo Sotgiu is an Assistant Professor at the Univ ersity of Cagliar i. He received from the Uni- v ersity of Cagliari (Italy) the PhD in Electronic and Computer Engineer ing in F ebruar y 2023. His research mainly focuses on the security of machine learning, also consider ing practical applications like malware detection. He ser ves as a review er f or sev eral journals and conf erences. Daniele Ghiani receiv ed his BSc in Computer Engi- neering (2021) and MSc in Computer Engineering, Cybersecurity , and AI (2024) from the Univ ersity of Cagliar i. He is currently a PhD student in the Italian national PhD programme in AI at Sapienza Univ ersity , co-located at the Univ ersity of Cagliari. His research addresses Continual Learning and re- gression issues in Android malware detection. Da vide Maiorca received the Ph.D. in 2016 from the Univ ersity of Cagliari. He is an Associate Pro- f essor of Computer Engineer ing at the Univ ersity of Cagliari and a member of the PRA Lab. His research f ocuses on x86/Android malware analysis and de- tection, malicious documents (e.g., PDF, Microsoft Office), and adversarial mac hine lear ning. He earned the Italian National Scientific Qualification (ASN) in 2021 and has authored 25+ papers. Giorgio Giacinto is a Professor of Computer En- gineering at the Univ ersity of Cagliar i, Italy . He leads Cybersecurity research within the sAIfer Lab research group. His main contr ibutions lie in ma- chine lear ning approaches to cybersecurity , includ- ing threat analysis and detection, and are supported by funding from national and inter national projects. He has published nearl y 200 papers in international conf erences and journals and regularl y ser v es as a member of the Editor ial Board and Program Com- mittee for sev eral of them. He is a Fello w of the IAPR and a Senior Member of the IEEE Computer Society and A CM. Battista Biggio (MSc 2006, PhD 2010) is Full Prof essor of Computer Engineering at the Univ er - sity of Cagliari, Italy . He has provided pioneer - ing contr ibutions to machine lear ning secur ity . His paper “P oisoning Attac ks against Suppor t V ector Machines ” w on the prestigious 2022 ICML T est of Time A ward. He chaired IAPR TC1 (2016-2020), and serv ed as Associate Editor f or IEEE TNNLS and IEEE CIM. He is now Associate Editor-in-Chief f or Pattern R ecognition and ser ves as Area Chair for NeurIPS and IEEE Symp. SP . He is F ellow of IEEE and AAIA, ACM Senior Member , and Member of IAPR, AAAI, and ELLIS.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment