COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game
A central challenge in building continually improving agents is that training environments are typically static or manually constructed. This restricts continual learning and generalization beyond the training distribution. We address this with COvol…
Authors: Alkis Sygkounas, Rishi Hazra, Andreas Persson
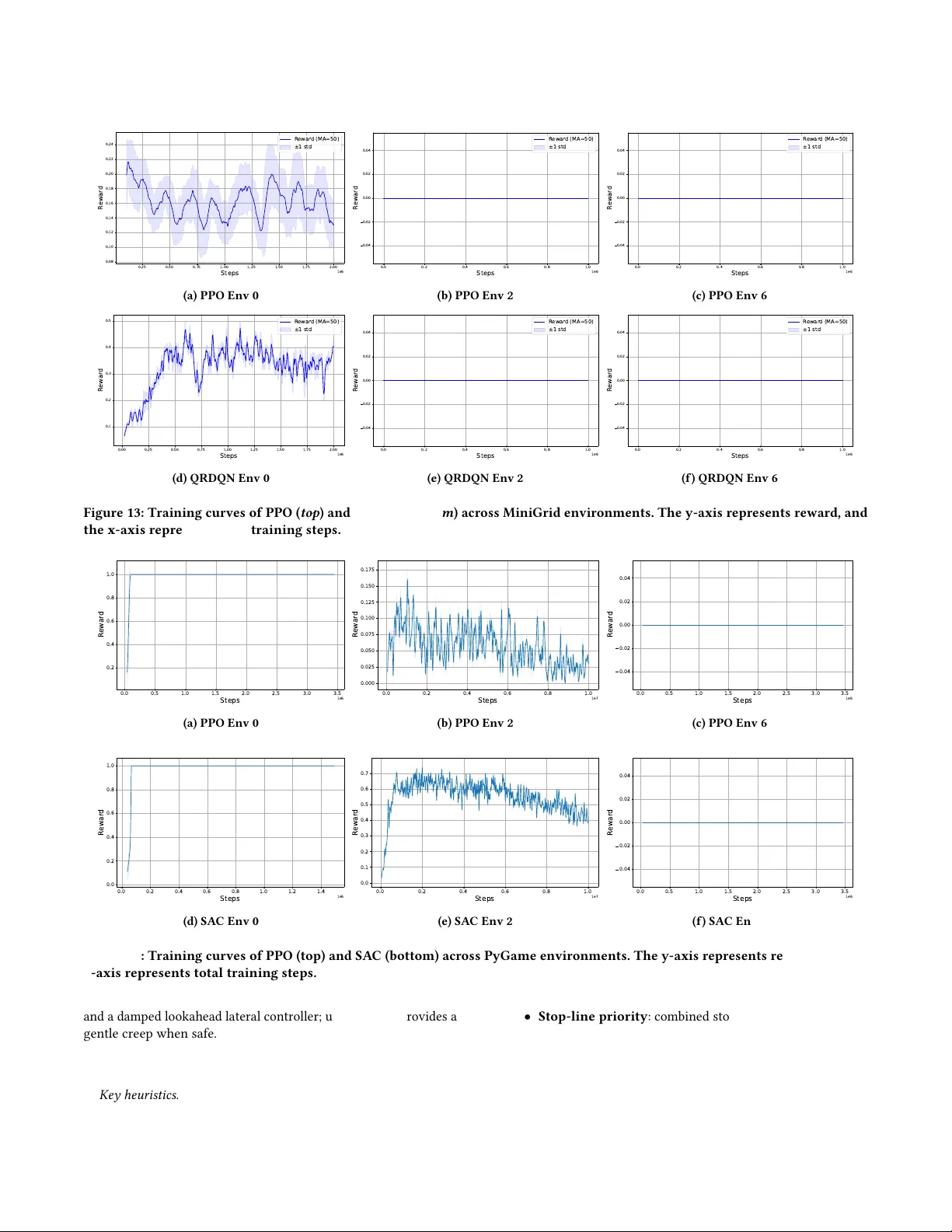
COvolve: Adv ersarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via T wo-Player Zero-Sum Game Alkis Sygkounas Machine Perception and Interaction Lab, Ör ebro University Sweden alkis.sygkounas@oru.se Rishi Hazra Machine Perception and Interaction Lab, Ör ebro University Sweden rishi.hazra@oru.se Andreas Persson Machine Perception and Interaction Lab, Ör ebro University Sweden andreas.persson@oru.se Pedro Zuidberg Dos Martires Machine Perception and Interaction Lab, Ör ebro University Sweden pedro.zuidberg- dos- martires@oru.se Amy Lout Machine Perception and Interaction Lab, Ör ebro University Sweden amy .lout@oru.se Abstract A central challenge in building continually improving agents is that training environments are typically static or manually con- structed. This restricts continual learning and generalization be- yond the training distribution. W e address this with COvolve , a co-evolutionary framework that lev erages large language models (LLMs) to generate both environments and agent policies, expressed as executable Python code. W e model the interaction between en- vironment and policy designers as a two-player zero-sum game, ensuring adversarial co-ev olution in which environments expose policy weaknesses and policies adapt in response. This process in- duces an automated curriculum in which environments and policies co-evolve to ward increasing complexity . T o guarantee robustness and prevent forgetting as the curriculum progresses, w e compute the mixed-strategy Nash equilibrium (MSNE) of the zero-sum game, thereby yielding a meta-policy . This MSNE meta-policy ensures that the agent does not forget to solve previously seen environ- ments while learning to solve previously unseen ones. Experiments in urban driving, symbolic maze-solving, and ge ometric navigation showcase that COvolve produces progressively more complex en- vironments. Our results demonstrate the potential of LLM-driv en co-evolution to achie ve open-ended learning without predened task distributions or manual intervention. Ke ywords Co-evolution, Unsupervised Environment Design, Mixed-strategy Nash Equilibrium, Large Language Models 1 Introduction Developing agents that continually acquire new skills in dynamic and unpredictable settings remains a core challenge in AI. Most current training pipelines still depend on large amounts of human- curated data, which is costly and often produces agents that gen- eralize poorly beyond their training distribution [ 47 ]. While rein- forcement learning (RL) oers an appealing alternative by allowing agents to learn through extensive interaction in a simulator [ 41 ], it inherits a fundamental limitation: the environments used for train- ing are either xed and/or manually designed. Constructing an environment distribution that captures the diversity and variability of r eal-world conditions is inherently dicult [ 5 ], and RL agents of- ten fail to generalize beyond the narrow distribution they encounter during training [ 15 , 22 , 23 ]. Achieving robustness and transferabil- ity , therefore, requires exposing agents to a diverse and con tinually evolving curriculum of environments that adapt to their capabilities and expand the range of behaviors they must master [6, 23]. 1 ch Unsupervise d environment design (UED) [ 9 , 21 ] addresses these limitations in training environments by automatically generating a curriculum of environments that adapts in diculty based on the agent’s p erformance. By dynamically tailoring environments to expose and challenge the agent’s weaknesses, UED encourages con- tinual learning. Howev er , UED typically generates envir onments via randomization or simple heuristics, which limits the diversity and relevance of the resulting tasks. W e overcome this by intro- ducing COvolve , a co-evolutionary framework that frames UED as a two-player zero-sum game . COvolve leverages LLM-based code generation with rich priors to imaginatively design both environ- ments and policies. In COvolve , an LLM-powered environment designer and policy designer compete adversarially to co-evolve more challenging levels and more capable policies, respectively , as conceptually illustrated in Figure 1. Previous research has explor ed LLM-driven environment gener- ation [ 12 ] and policy design [ 25 ] using code-based outputs, where both environments and p olicies are represented directly as exe- cutable programs. Such programmatic repr esentations provide ad- vantages over neural encodings, including improved generalizabil- ity to unseen scenarios [ 19 , 45 ], greater modularity and reuse of behavioral components [ 11 , 48 ], and stronger v eriability and in- terpretability [ 2 , 46 ]. They also allow Python to express arbitrarily complex environment and policy logic, while LLMs contribute pri- ors that enable the automatic synthesis of diverse tasks without hand-crafted templates [ 12 ]. However , existing approaches typically address either environment generation without promoting r obust 1 Illustrative videos are available at: https://anonymous.4open.science/r/covolve- 6187/. Code will be released upon acceptance. Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi Environment Population ( 𝓛 ) Policy Population ( 𝓟 ) Player 1 Player 2 argmax( 𝓹* ) Policy Designer Environment Designer Mixed Strategy Nash Equilibrium ( 𝓹* ) > > Figure 1: A conceptual ov erview of the pr oposed COvolve , comprise d of an Environment Designer and a Policy Designer that co-evolve by playing a two-player zero-sum game. The Environment Designer generates increasingly challenging environments (as code), while the Policy Designer creates policies (as code) to solve them. A mixed-strategy Nash e quilibrium enables robust, open-ended learning through continual adaptation. agent learning [ 12 ], or policy design without continual adaptation to new challenges [ 26 ]. In contrast, COvolve integrates both asp ects into a closed-loop LLM-driven co-ev olution process that simulta- neously advances environment complexity and policy capability . Concretely , we make the following contributions: (1) Game-theoretic Framework for Robust Policy Design. W e frame the co-evolution as a two-play er zero-sum game between a policy player and an environment player , where the payo is the policy’s success rate in each environment. At each iteration, COvolve main- tains populations of policies and environments, evaluates all pairs to form an empirical payo matrix, and computes the mixe d-strategy Nash equilibrium of this matrix game. The resulting meta-policy distribution solves the max–min objective within the empirical meta-game [ 32 ], improving worst-case performance against the current environment set and guiding the environment player to generate levels that exploit weaknesses of the equilibrium distri- bution [ 24 ]. In contrast, prior approaches [ 50 ] train independent policies per environment, thereby compromising population-level robustness and causing catastrophic forgetting. (2) Empirical Evidence of Emergent Curriculum and Generalization. W e empirically demonstrate that COvolve produces increasingly challenging environments across diverse domains (urban driving, maze-solving, and 2D navigation), with generate d levels exhibit- ing escalating complexity and diversity over time. Crucially , our evaluation shows that computing the MSNE is essential to prevent catastrophic forgetting, unlike approaches such as Eurekaverse [ 26 ], which retain only the latest best policy and netune on new envi- ronments, leading to forgetting. 2 Related W orks Domain randomization (DR) exposes agents to a broad distribution of environments [ 20 , 44 ] but lacks adaptivity and often pr oduces trivial or unsolvable tasks [ 9 ]. Unsupervised environment design (UED) addresses this by automatically generating curricula tailored to agent performance. For instance, minimax adv ersarial training selects environments that minimize the agent’s reward [ 31 , 35 , 39 ]. Howev er , it can produce overly dicult tasks unless constrained [ 9 ]. Regret-based methods like P AIRED [ 9 ] address this by dening re- gret relative to an approximated optimal policy to ensure solvability . While our work uses a minimax adversary , future directions could also incorporate regret-based strategies to avoid generating un- solvable levels. Crucially , our LLM-driven co-evolution introduces data-driven priors that enable the design of more challenging and relevant environments than classical, heuristic-based UED . Recent work uses LLMs to generate and automate environment design [ 12 , 49 ], world model generation [ 8 , 43 ], and reward speci- cation in RL [ 17 , 29 ]. Howev er , most frame works either decouple environment and agent learning or focus only on environment generation, limiting agent robustness. Our framework enables fully closed-loop co-evolution, automatically generating a curriculum that adapts to both the agent and the environment. W e use game- theoretic principles to maintain a div erse policy population via a mixed-strategy Nash equilibrium, yielding a meta-policy that is ro- bust across the evolving set of generated environments and provides a principled population-level objective for continual adaptation. In parallel with environmental design, LLMs have been used to synthesize modular , generalizable, and interpretable code-based policies. Approaches like Code-as-Policies[ 25 ], RL-GPT[ 28 ], and ProgPrompt[ 42 ] leverage LLMs to generate executable plans or combine code with RL controllers, but are typically limited to nar- row task distributions. In contrast, our approach constructs robust, continually adaptive policies that learn within an open-ended, co- evolving curriculum. Our work is also related to the self-play paradigm, in which models play dual roles to create a self-improvement loop. Here, LLMs create copies of themselv es with dierent roles to impro ve without relying on human data. This has b een used in domains like coding (Coder- T ester Agents) [ 27 , 51 ] and reasoning ( Challenger- Solver Agents) [ 3 , 18 ]. The improvement step is directly applied to the LLMs, which can b e inecient for domains where solutions can COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game be represented by compact policies rather than large , monolithic models. In contrast, COvolve harnesses LLMs to drive the design of specialized agents that are modular , interpretable, and easier to deploy . A more concurrent work is Bachrach et al . [1] where LLMs produce strategies as code for playing against a Nash equilibrium mixture over the curr ent population of strategies. 3 Preliminaries 3.1 Unsupervise d Environment Design (UED) Formally , a UED is dene d over an underspecied partially obser v- able Markov decision process ( UPOMDP) [ 9 ], given by the 8 -tuple M = ( Θ , S , A , O , 𝑇 , 𝑂 , 𝑅, 𝛾 ) , with the last seven elements having the same meaning as in a standard POMDP: S , A , and O are the sets of states, actions, and observations, respectively , 𝑇 and 𝑂 denote the transition and observation functions, 𝑅 is the reward function, and 𝛾 ∈ [ 0 , 1 ] the discount factor . The rst element Θ of a UPOMDP M denotes the space of un- derspecied environment parameters (e.g., number and position of obstacles, size of the grid). Picking a sp ecic 𝜃 ∈ Θ material- izes a concrete POMDP . A UPOMDP can hence be viewed as a set of POMDPs. A concrete set of parameters 𝜃 ∈ Θ is also referred to as a level . The choice of 𝜃 may inuence the reward function 𝑅 : S × A × Θ → R , the transition function 𝑇 : S × A × Θ → Δ ( S ) , and the obser vation function 𝑂 : S × Θ → O , where Δ ( 𝑆 ) is the set of all probability distributions over S . Given a level 𝜃 ∈ Θ , the expected discounted return (i.e. utility) of a policy 𝜋 and a level 𝜃 is denoted as 𝑈 𝜃 ( 𝜋 ) = E 𝜏 ∼ ( 𝜋 ,𝜃 ) [ 𝐺 𝜏 ] , with 𝜏 denoting trajectories sampled under the p olicy 𝜋 at level 𝜃 . 𝐺 𝜏 is the sum of discounted rewards for each trajectory: Í 𝑇 𝑡 = 0 𝛾 𝑡 𝑟 𝑡 , with 𝑟 𝑡 being the reward collected at time step 𝑡 . The optimal policy for level 𝜃 is then given by 𝜋 ★ 𝜃 = arg max 𝜋 𝑈 𝜃 ( 𝜋 ) . The goal of UED is to train a policy that performs well across a broad distribution of envir onments. T o this end, UED is typically framed as a two-player game, with an adversary Λ from which we can sample levels given a policy: 𝜃 ∼ Λ ( 𝜋 ) . The adversary’s goal is to identify levels that challenge the policy 𝜋 by optimizing the utility function 𝑈 𝜃 ( 𝜋 ) that exposes its weaknesses. A simple example is that of a minimax adversary [ 31 , 35 , 39 ], which is a point distribution Λ ( 𝜋 ) = arg min 𝜃 ∈ Θ 𝑈 𝜃 ( 𝜋 ) and pro- poses new le vels to minimize the policy performance. In response, a maximin policy is one that tries to perform well under the most ad- versarial lev el 𝜋 ∗ = arg max 𝜋 ∈ Π min 𝜃 ∈ Θ 𝑈 𝜃 ( 𝜋 ) . Howev er , solving this exactly is computationally intractable. In the following section, we introduce an ecient approximation method. 3.2 Policy Space Response Oracles (PSRO) PSRO [ 24 ] is a general framework for multi-agent learning that addresses the fundamental challenge of non-stationarity in multi- agent environments. In such settings, the optimal policy for one agent depends on the policies of other agents, cr eating a moving target that makes traditional single-agent reinforcement learning approaches ineective. Rather than attempting to learn a single “best" p olicy , PSRO builds and maintains a diverse population of policies over time. This approach pro vides robustness against vari- ous opponent strategies and reduces exploitability in competitive scenarios. In a 2-player setting, the PSRO framework operates through the following four-step iterative process: (1) Each player 𝑖 ∈ { 1 , 2 } maintains a growing set of p olicies P 𝑖 = { 𝜋 𝑖 1 , 𝜋 𝑖 2 , . . . , 𝜋 𝑖 𝑡 } , creating a library of strategies for that player . (2) PSRO constructs a payo matrix M ∈ R | P 1 | × | P 2 | by evaluating all pairwise policy combina- tions, where each entry represents the expected payos for players 1 when player 1 uses policy 𝜋 1 𝑖 and player 2 uses policy 𝜋 2 𝑗 . (3) The framework computes a meta-policy for player 1 that determines how to mix the existing policies in the population. (4) For player 2, a new best response policy 𝜋 2 𝑡 + 1 is trained to maximize perfor- mance against the player 1 meta-policy , and is subsequently added to the policy population P 2 of player 2. This iterative process con- tinues until convergence, resulting in a diverse and robust policy population. 4 Methodology W e adapt PSRO to UED by formulating environment and policy generation as a co-evolutionary process between an Environment Designer and a Policy Designer . The tw o designers iteratively gener- ate, evaluate, and r etain populations of environments and policies. At each iteration, new candidates are produced via structural pro- gram mutations [ 14 , 52 ] of previously generated envir onments and policies, followed by tness-based selection. This interaction is governed by a minimax objective, yielding a two-play er zero-sum game summarized in Algorithm 1, with additional algorithmic de- tails pr ovided in Appendix A. Since both envir onments and policies are represented as executable Python code, Figure 2 illustrates their co-evolution across successiv e iterations. Algorithm 1 COvolve 1: Require: Initial environment 𝜃 0 2: Hyperparameters: T otal iterations 𝑇 , candidate generated per level 𝐾 3: Initialize environment levels L ← { 𝜃 0 } , policy sequence P ← ( ) , Payo Matrix M = [ ] ⊲ Initialize co-evolving populations 4: for 𝑡 = 0 to 𝑇 do 5: # 1. Policy Design (structural mutation + selection) 6: Generate 𝐾 candidates: { ˜ 𝜋 1 , . . . , ˜ 𝜋 𝐾 } = Ψ ( 𝜋 𝑡 − 1 , O 𝜃 𝑡 − 1 , A 𝜃 𝑡 − 1 ) 7: 𝜋 𝑡 = arg max 𝑗 𝑈 𝜃 𝑡 − 1 ( ˜ 𝜋 𝑗 ) 8: Append P ← 𝜋 𝑡 9: # 2. Update Payoff Matrix M (fitness evaluation) 10: for 𝑖 , 𝑗 = 0 to 𝑡 do 11: 𝑚 𝑖 𝑗 ← 𝑈 𝜃 𝑗 ( 𝜋 𝑖 ) 12: end for ⊲ Cross-population tness computation 13: # 3. Recompute MSNE (population-level update) 14: 𝑝 ★ ← SolveNash ( 𝑀 ) ⊲ Eq. 1 ⊲ Mixture over evolv ed policies 15: # 4. Best Response Environment Design (structural mutation + selection) 16: Generate 𝐾 candidates: { ˜ 𝜃 1 , . . . , ˜ 𝜃 𝐾 } = Λ ( 𝜃 𝑡 − 1 , 𝑝 ★ ) 17: 𝜃 𝑡 + 1 = arg min 𝑗 { E 𝜋 𝑖 ∼ 𝑝 ★ [ 𝑈 ˜ 𝜃 𝑗 ( 𝜋 𝑖 ) ] } 18: Add L ← 𝜃 𝑡 + 1 19: end for 20: Return: MSNE Policy distribution 𝑝 ★ , environment levels L Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi from minigrid.core.world_object import Goal,Door,Key,Wall from minigrid.core.grid import Grid from minigrid.minigrid_env import MiniGridEnv from minigrid.core.mission import MissionSpace import numpy as np , random from collections import deque VALID_COLORS = [ "red" , "green" , "blue" , "purple" , "yellow" , "grey" ] #--------------------BFSutils-------------------- def _passable (env,x,y,keys): cell = env . grid . get(x,y) if cell is None : return True if isinstance (cell,Wall): return False if isinstance (cell,Door) and cell . is_locked and (cell . color not in keys): return False return True def flood_reachable (env,start,keys): """4-neighborhoodfloodrespectingwalls/lockeddoors.""" q,vis = deque([start]),{start} while q: x,y = q . popleft() for dx,dy in (( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )): nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height and (nx,ny) not in vis: if _passable(env,nx,ny,keys): vis . add((nx,ny));q . append((nx,ny)) return vis def shortest_path (env,start,goal,keys): """BFSshortestpath(listof(x,y))orNone.""" q,par = deque([start]),{start: None } while q: x,y = q . popleft() if (x,y) == goal: path,cur = [],(x,y) while cur is not None : path . append(cur);cur = par[cur] return list ( reversed (path)) for dx,dy in (( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )): nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height and (nx,ny) not in par: if _passable(env,nx,ny,keys): par[(nx,ny)] = (x,y);q . append((nx,ny)) return None def bfs_ignore_doors (env,start,goal): """Scaffoldpathignoringlocks(doorspassable,wallsblock).""" def pass_ign (cell): if cell is None : return True return not isinstance (cell,Wall) q,par = deque([start]),{start: None } while q: x,y = q . popleft() if (x,y) == goal: path,cur = [],(x,y) while cur is not None :path . append(cur);cur = par[cur] return list ( reversed (path)) for dx,dy in (( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )): nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height and (nx,ny) not in par: if pass_ign(env . grid . get(nx,ny)): par[(nx,ny)] = (x,y);q . append((nx,ny)) return None #--------------------smallhelpers-------------------- def find_random_empty (env,exclude = None ): ex = set (exclude or []) choices = [(x,y) for x in range ( 1 ,env . width -1 ) for y in range ( 1 ,env . height -1 ) if env . grid . get(x,y) is None and (x,y) not in ex] return random . choice(choices) if choices else None def manhattan (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) #--------------------Environment-------------------- class CustomEnv (MiniGridEnv): """ Relaxedchokepoints+robustkeyplacement. Knobs: -num_doors(int):numberoflockeddoorsonthemainpath -fraction_hard(float):fractionofdoorsastruechokepoints -soft_wing_len(int):softdoorwinglength(0=nowings) -complexity(float):randomobstacledensity[0..1] Fixes: -EachkeyiisplacedontheAGENTSIDEofdoori. -Werequire:path(agent->key_i)andpath(key_i->door_i_side). -Wereservethosecorridors(witha1-cellhalo)solaterobstaclescannotblockthem. """ def __init__ ( self , size =28 , max_steps = None , complexity =0.55 , num_doors =6 , fraction_hard =0.25 , soft_wing_len =1 ): self . size = size self . complexity = complexity self . num_doors = num_doors self . fraction_hard = fraction_hard self . soft_wing_len = soft_wing_len if max_steps is None : max_steps = 5 * (size ** 2 ) mission_space = MissionSpace( lambda : "Reachthegreengoal." ) import gymnasium as gym self . observation_space = gym . spaces . Box( low =0.0 ,high =1.0 ,shape = ( self . size * self . size * 3 ,),dtype = np . float32 ) super () . __init__ (mission_space = mission_space, grid_size = self . size, see_through_walls = True , max_steps = max_steps) self . failure_feedback = "" #--------------------generation-------------------- def _gen_grid ( self ,width,height): if self . num_doors > len (VALID_COLORS): self . failure_feedback = f"Requested { self . num_doors } doors>availablecolors" return max_tries,solved = 800 , False for _ in range (max_tries): #cleargrid self . grid = Grid(width,height) self . grid . wall_rect( 0 , 0 ,width,height) for x in range ( 1 ,width -1 ): for y in range ( 1 ,height -1 ): self . grid . set(x,y, None ) #agent/goal agent_pos = find_random_empty( self ) goal_pos = find_random_empty( self ,exclude = [agent_pos]) if not agent_pos or not goal_pos or agent_pos == goal_pos: continue self . agent_pos = agent_pos self . agent_dir = random . randint( 0 , 3 ) self . put_obj(Goal(),goal_pos[ 0 ],goal_pos[ 1 ]) #scaffoldpath main_path = bfs_ignore_doors( self ,agent_pos,goal_pos) if not main_path or len (main_path) < ( 2 * self . num_doors + 5 ): continue path_set = set (main_path) #doorslots&colors door_idxs = self . _choose_sequential_door_indices(main_path, self . num_doors) colors = random . sample(VALID_COLORS,k = self . num_doors) #pickhardvssoftdoors n_hard = max ( 1 , min ( self . num_doors, int ( round ( self . fraction_hard * self . num_doors)))) hard_mask = set (random . sample( range ( self . num_doors),k = n_hard)) #placedoors+structures door_positions = [] for i,idx in enumerate (door_idxs): x,y = main_path[idx] if self . grid . get(x,y) is not None : break self . put_obj(Door(colors[i],is_locked = True ),x,y) door_positions . append((x,y)) orient = self . _local_path_orient(main_path,idx) if i in hard_mask: self . _add_barrier_line(x,y,orient) self . _add_door_jamb(x,y,orient) else : self . _add_soft_wings(x,y,orient, self . soft_wing_len) self . _add_door_jamb(x,y,orient) else : #successplacingdoors #---KEYPLACEMENTwithcorridorprotection--- reserve = set (path_set) | {agent_pos,goal_pos} | set (door_positions) protected = set () key_positions = [] for i,(dx,dy) in enumerate (door_positions): unlocked = set (colors[:i]) #colorsbeforedooriareusable #regionreachablebeforeopeningdoori region = flood_reachable( self ,agent_pos,unlocked) #door-sideanchors(neighborsthatareinregion) side_neighbors = [(nx,ny) for (nx,ny) in self . _neighbors(dx,dy) if ( 0 <= nx < self . width and 0 <= ny < self . height) and _passable( self ,nx,ny,unlocked) and (nx,ny) in region] if not side_neighbors: break #noapproachside→rejectlayout #candidatecells=regionminusreserves;biasoff-pathandnotcramped candidates = [c for c in region if c not in reserve and self . grid . get( * c) is None and self . _free_neighbors_count( * c,keys = unlocked) >= 2 ] if not candidates: break #preferoff-path far = [c for c in candidates if self . _dist_to_set(c,path_set) >= 2 ] pool = far if far else candidates random . shuffle(pool) #pickacandidatethatvalidatesbothpathsandprotectcorridors placed = False for cx,cy in pool: p1 = shortest_path( self ,agent_pos,(cx,cy),unlocked) if not p1: continue #pathfromkeytoANYdoor-sideneighbor p2 = None for s in side_neighbors: p2 = shortest_path( self ,(cx,cy),s,unlocked) if p2: break if not p2: continue #accept;placekeyandprotectbothcorridors(with1-cellhalo) self . put_obj(Key(colors[i]),cx,cy) key_positions . append((cx,cy)) for cell in p1 + p2: protected . add(cell) for nb in self . _neighbors( * cell): if 1 <= nb[ 0 ] < self . width -1 and 1 <= nb[ 1 ] < self . height -1 : protected . add(nb) reserve |= set (p1) | set (p2) | set (key_positions) placed = True break if not placed: break #failplacingavalid,reachablekey else : #scatterobstaclesbutNEVERonprotected/reserve self . _place_obstacles(reserve | protected,door_positions,key_positions) #finalsolvabilitycheck(collectingkeysinorder) if self . _check_solvable_ordered(agent_pos,goal_pos,colors,door_positions,key_positions): solved = True if solved: break #ifanystepfailed,tryagain continue if not solved: self . failure_feedback = "Nosolvablelayoutfound.Lowercomplexityordoors,orreducefraction_hard." def gen_obs ( self ): return self . grid . encode() . astype(np . float32) #--------------------internals-------------------- def _neighbors ( self ,x,y): return [(x +1 ,y),(x -1 ,y),(x,y +1 ),(x,y -1 )] def _free_neighbors_count ( self ,x,y,keys = frozenset ()): cnt = 0 for nx,ny in self . _neighbors(x,y): if 0 <= nx < self . width and 0 <= ny < self . height and _passable( self ,nx,ny,keys): cnt += 1 return cnt def _dist_to_set ( self ,c,S): #ManhattandistancetoclosestelementinS(boundedsmallloop) x,y = c best = 1e9 for px,py in S: d = abs (px - x) + abs (py - y) if d < best:best = d if best == 0 : break return best def _check_solvable_ordered ( self ,start,goal,colors,door_positions,key_positions): """Simulatepickingkeysinorder;ateachstageverifyreachabilitytonextkeyandfinallygoal.""" pos = start have = set () for i,color in enumerate (colors): kpos = key_positions[i] p = shortest_path( self ,pos,kpos,have) if not p: return False have . add(color) #pickkeyi pos = kpos #Afterpicking,verifywecanreachtheapproachsideofdoori(andthuspassit) dpos = door_positions[i] #passthroughdoorcellisallowednow p2 = shortest_path( self ,pos,dpos,have) if not p2: return False pos = dpos #finallytogoal p_last = shortest_path( self ,pos,goal,have) return p_last is not None def _choose_sequential_door_indices ( self ,path,k): n = len (path);start,end = 2 ,n -3 if end - start + 1 < k: step = max ( 1 ,(end - start + 1 ) // k) idxs = [ min (end,start + i * step) for i in range (k)] return sorted ( set (idxs))[:k] base = [start + (i +1 ) * (end - start) // (k +1 ) for i in range (k)] out,last = [],start -1 for b in base: j = max (last +1 ,b + random . randint( -2 , 2 )) j = min (j,end - (k - len (out) - 1 )) out . append(j);last = j return out def _local_path_orient ( self ,path,idx): a = path[ max ( 0 ,idx -1 )];c = path[ min ( len (path) -1 ,idx +1 )] dx,dy = c[ 0 ] - a[ 0 ],c[ 1 ] - a[ 1 ] return 'x' if abs (dx) >= abs (dy) else 'y' def _add_barrier_line ( self ,x,y,orient): if orient == 'x' : for yy in range ( 1 , self . height -1 ): if yy == y: continue if self . grid . get(x,yy) is None : self . put_obj(Wall(),x,yy) else : for xx in range ( 1 , self . width -1 ): if xx == x: continue if self . grid . get(xx,y) is None : self . put_obj(Wall(),xx,y) def _add_soft_wings ( self ,x,y,orient,wing_len =2 ): wing_len = max ( 0 , int (wing_len)) if wing_len == 0 : return if orient == 'x' : for d in range ( 1 ,wing_len +1 ): for yy in (y - d,y + d): if 1 <= yy < self . height -1 and self . grid . get(x,yy) is None : self . put_obj(Wall(),x,yy) else : for d in range ( 1 ,wing_len +1 ): for xx in (x - d,x + d): if 1 <= xx < self . width -1 and self . grid . get(xx,y) is None : self . put_obj(Wall(),xx,y) def _add_door_jamb ( self ,x,y,orient): sides = [(x,y -1 ),(x,y +1 )] if orient == 'x' else [(x -1 ,y),(x +1 ,y)] for sx,sy in sides: if 1 <= sx < self . width -1 and 1 <= sy < self . height -1 : if self . grid . get(sx,sy) is None : self . put_obj(Wall(),sx,sy) def _place_obstacles ( self ,reserved,doors,keys): """Scatterobstacleswithdensityself.complexity,neveronreservedoradjacenttodoors/keys.""" reserved = set (reserved) | set (doors) | set (keys) #1-cellhaloarounddoors/keys for d in doors + keys: for nb in self . _neighbors( * d): if 1 <= nb[ 0 ] < self . width -1 and 1 <= nb[ 1 ] < self . height -1 : reserved . add(nb) free = [(x,y) for x in range ( 1 , self . width -1 ) for y in range ( 1 , self . height -1 ) if (x,y) not in reserved and self . grid . get(x,y) is None ] n_obs = int ( len (free) * self . complexity) random . shuffle(free) placed = 0 for (x,y) in free: if placed >= n_obs: break #avoidsealingnarrow1-widecorridors:keepatleast2passableneighbors if self . _free_neighbors_count(x,y,keys = frozenset ()) <= 1 : continue self . put_obj(Wall(),x,y);placed += 1 from minigrid.core.world_object import Goal,Door,Key,Wall from minigrid.core.grid import Grid from minigrid.minigrid_env import MiniGridEnv from minigrid.core.mission import MissionSpace import numpy as np , random from collections import deque VALID_COLORS = [ "red" , "green" , "blue" , "purple" , "yellow" , "grey" ] #--------------------BFSutils-------------------- def _passable (env,x,y,keys): cell = env . grid . get(x,y) if cell is None : return True if isinstance (cell,Wall): return False if isinstance (cell,Door) and cell . is_locked and (cell . color not in keys): return False return True def flood_reachable (env,start,keys): """4-neighborhoodfloodrespectingwalls/lockeddoors.""" q,vis = deque([start]),{start} while q: x,y = q . popleft() for dx,dy in (( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )): nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height and (nx,ny) not in vis: if _passable(env,nx,ny,keys): vis . add((nx,ny));q . append((nx,ny)) return vis def shortest_path (env,start,goal,keys): """BFSshortestpath(listof(x,y))orNone.""" q,par = deque([start]),{start: None } while q: x,y = q . popleft() if (x,y) == goal: path,cur = [],(x,y) while cur is not None : path . append(cur);cur = par[cur] return list ( reversed (path)) for dx,dy in (( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )): nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height and (nx,ny) not in par: if _passable(env,nx,ny,keys): par[(nx,ny)] = (x,y);q . append((nx,ny)) return None def bfs_ignore_doors (env,start,goal): """Scaffoldpathignoringlocks(doorspassable,wallsblock).""" def pass_ign (cell): if cell is None : return True return not isinstance (cell,Wall) q,par = deque([start]),{start: None } while q: x,y = q . popleft() if (x,y) == goal: path,cur = [],(x,y) while cur is not None :path . append(cur);cur = par[cur] return list ( reversed (path)) for dx,dy in (( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )): nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height and (nx,ny) not in par: if pass_ign(env . grid . get(nx,ny)): par[(nx,ny)] = (x,y);q . append((nx,ny)) return None #--------------------smallhelpers-------------------- def find_random_empty (env,exclude = None ): ex = set (exclude or []) choices = [(x,y) for x in range ( 1 ,env . width -1 ) for y in range ( 1 ,env . height -1 ) if env . grid . get(x,y) is None and (x,y) not in ex] return random . choice(choices) if choices else None def manhattan (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) #--------------------Environment-------------------- class CustomEnv (MiniGridEnv): """ Relaxedchokepoints+robustkeyplacement. Knobs: -num_doors(int):numberoflockeddoorsonthemainpath -fraction_hard(float):fractionofdoorsastruechokepoints -soft_wing_len(int):softdoorwinglength(0=nowings) -complexity(float):randomobstacledensity[0..1] Fixes: -EachkeyiisplacedontheAGENTSIDEofdoori. -Werequire:path(agent->key_i)andpath(key_i->door_i_side). -Wereservethosecorridors(witha1-cellhalo)solaterobstaclescannotblockthem. """ def __init__ ( self , size =28 , max_steps = None , complexity =0.55 , num_doors =6 , fraction_hard =0.25 , soft_wing_len =1 ): self . size = size self . complexity = complexity self . num_doors = num_doors self . fraction_hard = fraction_hard self . soft_wing_len = soft_wing_len if max_steps is None : max_steps = 5 * (size ** 2 ) mission_space = MissionSpace( lambda : "Reachthegreengoal." ) import gymnasium as gym self . observation_space = gym . spaces . Box( low =0.0 ,high =1.0 ,shape = ( self . size * self . size * 3 ,),dtype = np . float32 ) super () . __init__ (mission_space = mission_space, grid_size = self . size, see_through_walls = True , max_steps = max_steps) self . failure_feedback = "" #--------------------generation-------------------- def _gen_grid ( self ,width,height): if self . num_doors > len (VALID_COLORS): self . failure_feedback = f"Requested { self . num_doors } doors>availablecolors" return max_tries,solved = 800 , False for _ in range (max_tries): #cleargrid self . grid = Grid(width,height) self . grid . wall_rect( 0 , 0 ,width,height) for x in range ( 1 ,width -1 ): for y in range ( 1 ,height -1 ): self . grid . set(x,y, None ) #agent/goal agent_pos = find_random_empty( self ) goal_pos = find_random_empty( self ,exclude = [agent_pos]) if not agent_pos or not goal_pos or agent_pos == goal_pos: continue self . agent_pos = agent_pos self . agent_dir = random . randint( 0 , 3 ) self . put_obj(Goal(),goal_pos[ 0 ],goal_pos[ 1 ]) #scaffoldpath main_path = bfs_ignore_doors( self ,agent_pos,goal_pos) if not main_path or len (main_path) < ( 2 * self . num_doors + 5 ): continue path_set = set (main_path) #doorslots&colors door_idxs = self . _choose_sequential_door_indices(main_path, self . num_doors) colors = random . sample(VALID_COLORS,k = self . num_doors) #pickhardvssoftdoors n_hard = max ( 1 , min ( self . num_doors, int ( round ( self . fraction_hard * self . num_doors)))) hard_mask = set (random . sample( range ( self . num_doors),k = n_hard)) #placedoors+structures door_positions = [] for i,idx in enumerate (door_idxs): x,y = main_path[idx] if self . grid . get(x,y) is not None : break self . put_obj(Door(colors[i],is_locked = True ),x,y) door_positions . append((x,y)) orient = self . _local_path_orient(main_path,idx) if i in hard_mask: self . _add_barrier_line(x,y,orient) self . _add_door_jamb(x,y,orient) else : self . _add_soft_wings(x,y,orient, self . soft_wing_len) self . _add_door_jamb(x,y,orient) else : #successplacingdoors #---KEYPLACEMENTwithcorridorprotection--- reserve = set (path_set) | {agent_pos,goal_pos} | set (door_positions) protected = set () key_positions = [] for i,(dx,dy) in enumerate (door_positions): unlocked = set (colors[:i]) #colorsbeforedooriareusable #regionreachablebeforeopeningdoori region = flood_reachable( self ,agent_pos,unlocked) #door-sideanchors(neighborsthatareinregion) side_neighbors = [(nx,ny) for (nx,ny) in self . _neighbors(dx,dy) if ( 0 <= nx < self . width and 0 <= ny < self . height) and _passable( self ,nx,ny,unlocked) and (nx,ny) in region] if not side_neighbors: break #noapproachside→rejectlayout #candidatecells=regionminusreserves;biasoff-pathandnotcramped candidates = [c for c in region if c not in reserve and self . grid . get( * c) is None and self . _free_neighbors_count( * c,keys = unlocked) >= 2 ] if not candidates: break #preferoff-path far = [c for c in candidates if self . _dist_to_set(c,path_set) >= 2 ] pool = far if far else candidates random . shuffle(pool) #pickacandidatethatvalidatesbothpathsandprotectcorridors placed = False for cx,cy in pool: p1 = shortest_path( self ,agent_pos,(cx,cy),unlocked) if not p1: continue #pathfromkeytoANYdoor-sideneighbor p2 = None for s in side_neighbors: p2 = shortest_path( self ,(cx,cy),s,unlocked) if p2: break if not p2: continue #accept;placekeyandprotectbothcorridors(with1-cellhalo) self . put_obj(Key(colors[i]),cx,cy) key_positions . append((cx,cy)) for cell in p1 + p2: protected . add(cell) for nb in self . _neighbors( * cell): if 1 <= nb[ 0 ] < self . width -1 and 1 <= nb[ 1 ] < self . height -1 : protected . add(nb) reserve |= set (p1) | set (p2) | set (key_positions) placed = True break if not placed: break #failplacingavalid,reachablekey else : #scatterobstaclesbutNEVERonprotected/reserve self . _place_obstacles(reserve | protected,door_positions,key_positions) #finalsolvabilitycheck(collectingkeysinorder) if self . _check_solvable_ordered(agent_pos,goal_pos,colors,door_positions,key_positions): solved = True if solved: break #ifanystepfailed,tryagain continue if not solved: self . failure_feedback = "Nosolvablelayoutfound.Lowercomplexityordoors,orreducefraction_hard." def gen_obs ( self ): return self . grid . encode() . astype(np . float32) #--------------------internals-------------------- def _neighbors ( self ,x,y): return [(x +1 ,y),(x -1 ,y),(x,y +1 ),(x,y -1 )] def _free_neighbors_count ( self ,x,y,keys = frozenset ()): cnt = 0 for nx,ny in self . _neighbors(x,y): if 0 <= nx < self . width and 0 <= ny < self . height and _passable( self ,nx,ny,keys): cnt += 1 return cnt def _dist_to_set ( self ,c,S): #ManhattandistancetoclosestelementinS(boundedsmallloop) x,y = c best = 1e9 for px,py in S: d = abs (px - x) + abs (py - y) if d < best:best = d if best == 0 : break return best def _check_solvable_ordered ( self ,start,goal,colors,door_positions,key_positions): """Simulatepickingkeysinorder;ateachstageverifyreachabilitytonextkeyandfinallygoal.""" pos = start have = set () for i,color in enumerate (colors): kpos = key_positions[i] p = shortest_path( self ,pos,kpos,have) if not p: return False have . add(color) #pickkeyi pos = kpos #Afterpicking,verifywecanreachtheapproachsideofdoori(andthuspassit) dpos = door_positions[i] #passthroughdoorcellisallowednow p2 = shortest_path( self ,pos,dpos,have) if not p2: return False pos = dpos #finallytogoal p_last = shortest_path( self ,pos,goal,have) return p_last is not None def _choose_sequential_door_indices ( self ,path,k): n = len (path);start,end = 2 ,n -3 if end - start + 1 < k: step = max ( 1 ,(end - start + 1 ) // k) idxs = [ min (end,start + i * step) for i in range (k)] return sorted ( set (idxs))[:k] base = [start + (i +1 ) * (end - start) // (k +1 ) for i in range (k)] out,last = [],start -1 for b in base: j = max (last +1 ,b + random . randint( -2 , 2 )) j = min (j,end - (k - len (out) - 1 )) out . append(j);last = j return out def _local_path_orient ( self ,path,idx): a = path[ max ( 0 ,idx -1 )];c = path[ min ( len (path) -1 ,idx +1 )] dx,dy = c[ 0 ] - a[ 0 ],c[ 1 ] - a[ 1 ] return 'x' if abs (dx) >= abs (dy) else 'y' def _add_barrier_line ( self ,x,y,orient): if orient == 'x' : for yy in range ( 1 , self . height -1 ): if yy == y: continue if self . grid . get(x,yy) is None : self . put_obj(Wall(),x,yy) else : for xx in range ( 1 , self . width -1 ): if xx == x: continue if self . grid . get(xx,y) is None : self . put_obj(Wall(),xx,y) def _add_soft_wings ( self ,x,y,orient,wing_len =2 ): wing_len = max ( 0 , int (wing_len)) if wing_len == 0 : return if orient == 'x' : for d in range ( 1 ,wing_len +1 ): for yy in (y - d,y + d): if 1 <= yy < self . height -1 and self . grid . get(x,yy) is None : self . put_obj(Wall(),x,yy) else : for d in range ( 1 ,wing_len +1 ): for xx in (x - d,x + d): if 1 <= xx < self . width -1 and self . grid . get(xx,y) is None : self . put_obj(Wall(),xx,y) def _add_door_jamb ( self ,x,y,orient): sides = [(x,y -1 ),(x,y +1 )] if orient == 'x' else [(x -1 ,y),(x +1 ,y)] for sx,sy in sides: if 1 <= sx < self . width -1 and 1 <= sy < self . height -1 : if self . grid . get(sx,sy) is None : self . put_obj(Wall(),sx,sy) def _place_obstacles ( self ,reserved,doors,keys): """Scatterobstacleswithdensityself.complexity,neveronreservedoradjacenttodoors/keys.""" reserved = set (reserved) | set (doors) | set (keys) #1-cellhaloarounddoors/keys for d in doors + keys: for nb in self . _neighbors( * d): if 1 <= nb[ 0 ] < self . width -1 and 1 <= nb[ 1 ] < self . height -1 : reserved . add(nb) free = [(x,y) for x in range ( 1 , self . width -1 ) for y in range ( 1 , self . height -1 ) if (x,y) not in reserved and self . grid . get(x,y) is None ] n_obs = int ( len (free) * self . complexity) random . shuffle(free) placed = 0 for (x,y) in free: if placed >= n_obs: break #avoidsealingnarrow1-widecorridors:keepatleast2passableneighbors if self . _free_neighbors_count(x,y,keys = frozenset ()) <= 1 : continue self . put_obj(Wall(),x,y);placed += 1 from minigrid.core.world_object import Goal,Door,Key,Wall from minigrid.core.grid import Grid from minigrid.core.constants import COLOR_NAMES from minigrid.minigrid_env import MiniGridEnv from minigrid.core.mission import MissionSpace import numpy as np import random from collections import deque VALID_COLORS = [ "red" , "green" , "blue" , "purple" , "yellow" , "grey" ] def bfs_ignore_doors (env,start,goal): queue = deque([start]) parents = {start: None } while queue: cx,cy = queue . popleft() if (cx,cy) == goal: path = [] cur = goal while cur is not None : path . append(cur) cur = parents[cur] path . reverse() return path for dx,dy in [( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )]: nx,ny = cx + dx,cy + dy if 0 <= nx < env . width and 0 <= ny < env . height: if (nx,ny) not in parents: cell = env . grid . get(nx,ny) if _bfs_passable_ignore_door(cell): parents[(nx,ny)] = (cx,cy) queue . append((nx,ny)) return None def _bfs_passable_ignore_door (cell): if cell is None : return True if isinstance (cell,Wall): return False return True def bfs_block_locked (env,start): queue = deque([start]) visited = set ([start]) while queue: cx,cy = queue . popleft() for dx,dy in [( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )]: nx,ny = cx + dx,cy + dy if 0 <= nx < env . width and 0 <= ny < env . height: if (nx,ny) not in visited: cell = env . grid . get(nx,ny) if isinstance (cell,Wall): continue if isinstance (cell,Door) and cell . is_locked: continue visited . add((nx,ny)) queue . append((nx,ny)) return visited def check_solvable (env,start,goal): queue = deque() visited = set () start_state = (start[ 0 ],start[ 1 ], frozenset ()) queue . append(start_state) visited . add(start_state) while queue: x,y,have_keys = queue . popleft() if (x,y) == goal: return True cell = env . grid . get(x,y) new_keys = have_keys if isinstance (cell,Key) and (cell . color not in have_keys): new_keys = frozenset ( set (have_keys) | {cell . color}) for dx,dy in [( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )]: nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height: nxt = (nx,ny,new_keys) if nxt not in visited: if can_pass(env,nx,ny,new_keys): visited . add(nxt) queue . append(nxt) return False def can_pass (env,x,y,keys): cell = env . grid . get(x,y) if cell is None : return True if isinstance (cell,Wall): return False if isinstance (cell,Door): if cell . is_locked and (cell . color not in keys): return False return True def find_random_empty (env,exclude = None ): if exclude is None : exclude = [] empties = [] for x in range ( 1 ,env . width - 1 ): for y in range ( 1 ,env . height - 1 ): if env . grid . get(x,y) is None and (x,y) not in exclude: empties . append((x,y)) if not empties: return None return random . choice(empties) class CustomEnv (MiniGridEnv): def __init__ ( self ,size =29 ,max_steps = None ,complexity =0.65 ,num_doors =6 ): self . size = size self . complexity = complexity self . num_doors = num_doors if max_steps is None : max_steps = 3 * (size ** 2 ) mission_space = MissionSpace( lambda : "Gettothegreengoalsquare." ) import gymnasium as gym self . observation_space = gym . spaces . Box( low =0.0 ,high =1.0 , shape = ( self . size * self . size * 3 ,), dtype = np . float32 ) super () . __init__ ( mission_space = mission_space, grid_size = self . size, see_through_walls = True , max_steps = max_steps ) self . failure_feedback = "" def _gen_grid ( self ,width,height): max_tries = 1000 solved = False self . failure_feedback = "" if self . num_doors > len (VALID_COLORS): self . failure_feedback = f"Requested { self . num_doors } doors>availablecolors" return for attempt in range (max_tries): self . grid = Grid(width,height) self . grid . wall_rect( 0 , 0 ,width,height) for xx in range ( 1 ,width - 1 ): for yy in range ( 1 ,height - 1 ): self . grid . set(xx,yy, None ) agent_pos = find_random_empty( self ) goal_pos = find_random_empty( self ,exclude = [agent_pos]) if not agent_pos or not goal_pos or agent_pos == goal_pos: continue self . agent_pos = agent_pos self . agent_dir = random . randint( 0 , 3 ) self . put_obj(Goal(),goal_pos[ 0 ],goal_pos[ 1 ]) colors = random . sample(VALID_COLORS,k = self . num_doors) if not self . _place_doors_and_keys(agent_pos,goal_pos,colors): continue self . _place_strategic_obstacles(agent_pos,goal_pos) path_ign = bfs_ignore_doors( self ,agent_pos,goal_pos) if not path_ign: continue if not check_solvable( self ,agent_pos,goal_pos): self . failure_feedback += f"Attempt { attempt + 1 } :BFSunsolvable." continue solved = True break if not solved: self . failure_feedback += ( f" Nosolvablelayoutfoundafter ❌ { max_tries } tries." "Possiblytoomanyobstaclesorunluckyplacements." ) def gen_obs ( self ): encoded = self . grid . encode() . astype(np . float32) return encoded def _place_doors_and_keys ( self ,agent_pos,goal_pos,door_colors): for color in door_colors: path_ign = bfs_ignore_doors( self ,agent_pos,goal_pos) if not path_ign or len (path_ign) < 4 : return False success = False for _ in range ( 10 ): door_idx = random . randint( 2 , len (path_ign) - 2 ) door_pos = path_ign[door_idx] if self . grid . get(door_pos[ 0 ],door_pos[ 1 ]) is None : self . put_obj(Door(color,is_locked = True ),door_pos[ 0 ],door_pos[ 1 ]) success = True break if not success: return False alt_path = bfs_ignore_doors( self ,agent_pos,goal_pos) if alt_path: for (xx,yy) in alt_path[ 1 : -1 ]: if (xx,yy) not in path_ign and self . grid . get(xx,yy) is None : self . put_obj(Wall(),xx,yy) visited_blk = bfs_block_locked( self ,agent_pos) skip = {agent_pos,door_pos,goal_pos} candidates = [c for c in visited_blk if c not in skip and self . grid . get( * c) is None ] if not candidates: return False key_spot = random . choice(candidates) self . put_obj(Key(color),key_spot[ 0 ],key_spot[ 1 ]) return True def _place_strategic_obstacles ( self ,agent_pos,goal_pos): path_ign = bfs_ignore_doors( self ,agent_pos,goal_pos) path_set = set (path_ign) if path_ign else set () skip = path_set | {agent_pos} for xx in range ( 1 , self . width - 1 ): for yy in range ( 1 , self . height - 1 ): obj = self . grid . get(xx,yy) if isinstance (obj,(Goal,Door,Key)): skip . add((xx,yy)) interior = [] for xx in range ( 1 , self . width - 1 ): for yy in range ( 1 , self . height - 1 ): if (xx,yy) not in skip and self . grid . get(xx,yy) is None : interior . append((xx,yy)) n_obs = int ( len (interior) * self . complexity) random . shuffle(interior) for i,cell in enumerate (interior): if i >= n_obs: break self . put_obj(Wall(),cell[ 0 ],cell[ 1 ]) from minigrid.core.world_object import Goal,Door,Key,Wall from minigrid.core.grid import Grid from minigrid.core.constants import COLOR_NAMES from minigrid.minigrid_env import MiniGridEnv from minigrid.core.mission import MissionSpace import numpy as np import random from collections import deque VALID_COLORS = [ "red" , "green" , "blue" , "purple" , "yellow" , "grey" ] def bfs_ignore_doors (env,start,goal): queue = deque([start]) parents = {start: None } while queue: cx,cy = queue . popleft() if (cx,cy) == goal: path = [] cur = goal while cur is not None : path . append(cur) cur = parents[cur] path . reverse() return path for dx,dy in [( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )]: nx,ny = cx + dx,cy + dy if 0 <= nx < env . width and 0 <= ny < env . height: if (nx,ny) not in parents: cell = env . grid . get(nx,ny) if _bfs_passable_ignore_door(cell): parents[(nx,ny)] = (cx,cy) queue . append((nx,ny)) return None def _bfs_passable_ignore_door (cell): if cell is None : return True if isinstance (cell,Wall): return False return True def bfs_block_locked (env,start): queue = deque([start]) visited = set ([start]) while queue: cx,cy = queue . popleft() for dx,dy in [( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )]: nx,ny = cx + dx,cy + dy if 0 <= nx < env . width and 0 <= ny < env . height: if (nx,ny) not in visited: cell = env . grid . get(nx,ny) if isinstance (cell,Wall): continue if isinstance (cell,Door) and cell . is_locked: continue visited . add((nx,ny)) queue . append((nx,ny)) return visited def check_solvable (env,start,goal): queue = deque() visited = set () start_state = (start[ 0 ],start[ 1 ], frozenset ()) queue . append(start_state) visited . add(start_state) while queue: x,y,have_keys = queue . popleft() if (x,y) == goal: return True cell = env . grid . get(x,y) new_keys = have_keys if isinstance (cell,Key) and (cell . color not in have_keys): new_keys = frozenset ( set (have_keys) | {cell . color}) for dx,dy in [( 1 , 0 ),( -1 , 0 ),( 0 , 1 ),( 0 , -1 )]: nx,ny = x + dx,y + dy if 0 <= nx < env . width and 0 <= ny < env . height: nxt = (nx,ny,new_keys) if nxt not in visited: if can_pass(env,nx,ny,new_keys): visited . add(nxt) queue . append(nxt) return False def can_pass (env,x,y,keys): cell = env . grid . get(x,y) if cell is None : return True if isinstance (cell,Wall): return False if isinstance (cell,Door): if cell . is_locked and (cell . color not in keys): return False return True def find_random_empty (env,exclude = None ): if exclude is None : exclude = [] empties = [] for x in range ( 1 ,env . width - 1 ): for y in range ( 1 ,env . height - 1 ): if env . grid . get(x,y) is None and (x,y) not in exclude: empties . append((x,y)) if not empties: return None return random . choice(empties) class CustomEnv (MiniGridEnv): def __init__ ( self ,size =29 ,max_steps = None ,complexity =0.65 ,num_doors =6 ): self . size = size self . complexity = complexity self . num_doors = num_doors if max_steps is None : max_steps = 3 * (size ** 2 ) mission_space = MissionSpace( lambda : "Gettothegreengoalsquare." ) import gymnasium as gym self . observation_space = gym . spaces . Box( low =0.0 ,high =1.0 , shape = ( self . size * self . size * 3 ,), dtype = np . float32 ) super () . __init__ ( mission_space = mission_space, grid_size = self . size, see_through_walls = True , max_steps = max_steps ) self . failure_feedback = "" def _gen_grid ( self ,width,height): max_tries = 1000 solved = False self . failure_feedback = "" if self . num_doors > len (VALID_COLORS): self . failure_feedback = f"Requested { self . num_doors } doors>availablecolors" return for attempt in range (max_tries): self . grid = Grid(width,height) self . grid . wall_rect( 0 , 0 ,width,height) for xx in range ( 1 ,width - 1 ): for yy in range ( 1 ,height - 1 ): self . grid . set(xx,yy, None ) agent_pos = find_random_empty( self ) goal_pos = find_random_empty( self ,exclude = [agent_pos]) if not agent_pos or not goal_pos or agent_pos == goal_pos: continue self . agent_pos = agent_pos self . agent_dir = random . randint( 0 , 3 ) self . put_obj(Goal(),goal_pos[ 0 ],goal_pos[ 1 ]) colors = random . sample(VALID_COLORS,k = self . num_doors) if not self . _place_doors_and_keys(agent_pos,goal_pos,colors): continue self . _place_strategic_obstacles(agent_pos,goal_pos) path_ign = bfs_ignore_doors( self ,agent_pos,goal_pos) if not path_ign: continue if not check_solvable( self ,agent_pos,goal_pos): self . failure_feedback += f"Attempt { attempt + 1 } :BFSunsolvable." continue solved = True break if not solved: self . failure_feedback += ( f" Nosolvablelayoutfoundafter ❌ { max_tries } tries." "Possiblytoomanyobstaclesorunluckyplacements." ) def gen_obs ( self ): encoded = self . grid . encode() . astype(np . float32) return encoded def _place_doors_and_keys ( self ,agent_pos,goal_pos,door_colors): for color in door_colors: path_ign = bfs_ignore_doors( self ,agent_pos,goal_pos) if not path_ign or len (path_ign) < 4 : return False success = False for _ in range ( 10 ): door_idx = random . randint( 2 , len (path_ign) - 2 ) door_pos = path_ign[door_idx] if self . grid . get(door_pos[ 0 ],door_pos[ 1 ]) is None : self . put_obj(Door(color,is_locked = True ),door_pos[ 0 ],door_pos[ 1 ]) success = True break if not success: return False alt_path = bfs_ignore_doors( self ,agent_pos,goal_pos) if alt_path: for (xx,yy) in alt_path[ 1 : -1 ]: if (xx,yy) not in path_ign and self . grid . get(xx,yy) is None : self . put_obj(Wall(),xx,yy) visited_blk = bfs_block_locked( self ,agent_pos) skip = {agent_pos,door_pos,goal_pos} candidates = [c for c in visited_blk if c not in skip and self . grid . get( * c) is None ] if not candidates: return False key_spot = random . choice(candidates) self . put_obj(Key(color),key_spot[ 0 ],key_spot[ 1 ]) return True def _place_strategic_obstacles ( self ,agent_pos,goal_pos): path_ign = bfs_ignore_doors( self ,agent_pos,goal_pos) path_set = set (path_ign) if path_ign else set () skip = path_set | {agent_pos} for xx in range ( 1 , self . width - 1 ): for yy in range ( 1 , self . height - 1 ): obj = self . grid . get(xx,yy) if isinstance (obj,(Goal,Door,Key)): skip . add((xx,yy)) interior = [] for xx in range ( 1 , self . width - 1 ): for yy in range ( 1 , self . height - 1 ): if (xx,yy) not in skip and self . grid . get(xx,yy) is None : interior . append((xx,yy)) n_obs = int ( len (interior) * self . complexity) random . shuffle(interior) for i,cell in enumerate (interior): if i >= n_obs: break self . put_obj(Wall(),cell[ 0 ],cell[ 1 ]) door_idx = random . randint( 2 , len (path_ign) - 2 door_pos = path_ign[door_idx] if self . grid . get(door_pos[ 0 ],door_pos[ 1 ]) is None : self . put_obj(Door(color,is_locked = True ),door_pos[ 0 ],door_pos[ 1 ]) success = True break door_idxs = self . _choose_sequential_door_indices(main_path, self . num_doors) colors = random . sample(VALID_COLORS,k = self . num_doors) n_hard = max ( 1 , min ( self . num_doors, int ( round ( self . fraction_hard * self . num_doors)))) hard_mask = set (random . sample( range ( self . num_doors),k = n_hard)) door_positions = [] for i,idx in enumerate (door_idxs): x,y = main_path[idx] if self . grid . get(x,y) is not None : break self . put_obj(Door(colors[i],is_locked = True ),x,y) door_positions . append((x,y)) orient = self . _local_path_orient(main_path,idx) if i in hard_mask: self . _add_barrier_line(x,y,orient) self . _add_door_jamb(x,y,orient) else : self . _add_soft_wings(x,y,orient, self . soft_wing_len) self . _add_door_jamb(x,y,orient) from heapq import heappop,heappush from collections import deque #====Actions==== TURN_LEFT = 0 TURN_RIGHT = 1 MOVE_FORWARD = 2 PICK_UP = 3 DROP = 4 TOGGLE = 5 #====Objects==== WALL = 2 GOAL = 8 DOOR = 4 KEY = 5 #====Doorstate(typicalMiniGridencoding)==== DOOR_OPEN = 0 DOOR_CLOSED = 1 DOOR_LOCKED = 2 #====Directions==== RIGHT = 0 DOWN = 1 LEFT = 2 UP = 3 DIRECTION_OFFSETS = { RIGHT:( 1 , 0 ), DOWN:( 0 , 1 ), LEFT:( -1 , 0 ), UP:( 0 , -1 ), } #----Runner-persistentstate---- carrying_key_color = None drop_cooldown = 0 last_drop_front = None #avoiddroppingtwiceinsamefrontcell #==========PUBLICENTRYPOINT========== def policy (obs,agent_pos,agent_dir): """ obs:NxNx3array(obj,color,state) agent_pos:(x,y) agent_dir:0:RIGHT,1:DOWN,2:LEFT,3:UP returns:actionint """ global carrying_key_color,drop_cooldown if drop_cooldown > 0 : _dec_drop_cooldown() front = get_facing(agent_pos,agent_dir) goal = find_goal(obs) #----1)Immediatefrontinteractions---- if in_bounds(front,obs): fobj,fcol,fstate = tile(obs,front) #Doors:openclosed-unlocked;unlocklockedifwecarrymatchingkey if fobj == DOOR: if is_door_closed_unlocked(fstate): return TOGGLE if is_door_locked(fstate) and carrying_key_color == fcol: return TOGGLE #Keyswithsingle-keycapacity if fobj == KEY: if carrying_key_color is None and drop_cooldown == 0 : carrying_key_color = fcol return PICK_UP elif carrying_key_color is not None and carrying_key_color != fcol: act = drop_key_somewhere(obs,agent_pos,agent_dir,goal) if act is not None : return act return TURN_RIGHT #----2)Trydirectpathtogoal(open-only)---- if goal: path = a_star_open_only(obs,agent_pos,goal) if path: return step_to(path[ 0 ],agent_pos,agent_dir) #----3)Handleblockingdoors(lockedorclosed)---- blocking = find_blocking_doors(obs,agent_pos,goal) #(x,y,color,state) blocking . sort(key = lambda d:manhattan(agent_pos,d[: 2 ])) for (dx,dy,dcol,dstate) in blocking: if is_door_locked(dstate): #Needkeyofcolordcol if carrying_key_color not in ( None ,dcol): act = drop_key_somewhere(obs,agent_pos,agent_dir,goal) if act is not None : return act return TURN_RIGHT if carrying_key_color != dcol: kpos = find_key_of_color(obs,dcol) if kpos: adj = nearest_adjacent_open_only(obs,kpos,agent_pos) if adj: path = a_star_open_only(obs,agent_pos,adj) if path: return step_to(path[ 0 ],agent_pos,agent_dir) return TURN_RIGHT #Havecorrectkey→goadjacenttodoor adj = nearest_adjacent_open_only(obs,(dx,dy),agent_pos) if adj: path = a_star_open_only(obs,agent_pos,adj) if path: return step_to(path[ 0 ],agent_pos,agent_dir) return TURN_RIGHT #Closed-unlocked:justapproachandtoggle if is_door_closed_unlocked(dstate): adj = nearest_adjacent_open_only(obs,(dx,dy),agent_pos) if adj: path = a_star_open_only(obs,agent_pos,adj) if path: return step_to(path[ 0 ],agent_pos,agent_dir) return TURN_RIGHT #----4)Mildexploration---- return TURN_RIGHT #==================HELPERS================== def get_facing (pos,dir_): dx,dy = DIRECTION_OFFSETS[dir_] return (pos[ 0 ] + dx,pos[ 1 ] + dy) def in_bounds (pos,obs): n = obs . shape[ 0 ] return 0 <= pos[ 0 ] < n and 0 <= pos[ 1 ] < n def tile (obs,pos): return obs[pos[ 0 ],pos[ 1 ], 0 ],obs[pos[ 0 ],pos[ 1 ], 1 ],obs[pos[ 0 ],pos[ 1 ], 2 ] def is_door_locked (state): return state == DOOR_LOCKED def is_door_closed_unlocked (state): return state == DOOR_CLOSED def is_open_door (state): return state == DOOR_OPEN def is_passable_open_only (obj,state): if obj == WALL: return False if obj == DOOR: return is_open_door(state) return True #GOAL,empty,key,etc.(wedon'tstepintokeys,butallowroutingaround) def find_goal (obs): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == GOAL: return (x,y) return None def manhattan (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) def step_to (next_pos,agent_pos,agent_dir): dx,dy = next_pos[ 0 ] - agent_pos[ 0 ],next_pos[ 1 ] - agent_pos[ 1 ] for dir_,(ox,oy) in DIRECTION_OFFSETS . items(): if (dx,dy) == (ox,oy): if agent_dir == dir_: return MOVE_FORWARD elif (agent_dir - dir_) % 4 == 1 : return TURN_LEFT else : return TURN_RIGHT return TURN_LEFT #----------A*(opendoorsonly)---------- def a_star_open_only (obs,start,goal): if goal is None : return None def h (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) open_set = [( 0 ,start)] came_from = {} g = {start: 0 } f = {start:h(start,goal)} while open_set: _,current = heappop(open_set) if current == goal: return _reconstruct_path(came_from,current) for ox,oy in DIRECTION_OFFSETS . values(): nx,ny = current[ 0 ] + ox,current[ 1 ] + oy nxt = (nx,ny) if not in_bounds(nxt,obs): continue o,c,s = tile(obs,nxt) if not is_passable_open_only(o,s): continue tg = g[current] + 1 if nxt not in g or tg < g[nxt]: g[nxt] = tg came_from[nxt] = current fn = tg + h(nxt,goal) f[nxt] = fn heappush(open_set,(fn,nxt)) return None def _reconstruct_path (came_from,cur): path = [] while cur in came_from: path . append(cur) cur = came_from[cur] path . reverse() return path #----------Blockingdoors(firstfrontierofclosed/locked)---------- def find_blocking_doors (obs,start,goal): n = obs . shape[ 0 ] q = deque([start]) seen = {start} blockers = [] while q: x,y = q . popleft() if goal and (x,y) == goal: return [] for ox,oy in DIRECTION_OFFSETS . values(): nx,ny = x + ox,y + oy if not ( 0 <= nx < n and 0 <= ny < n): continue o,c,s = obs[nx,ny] nxt = (nx,ny) if (o == DOOR) and (is_door_locked(s) or is_door_closed_unlocked(s)): if nxt not in [b[: 2 ] for b in blockers]: blockers . append((nx,ny,c,s)) continue if nxt in seen: continue if not is_passable_open_only(o,s): continue seen . add(nxt) q . append(nxt) return blockers #----------Adjacentpassabletileneartarget---------- def nearest_adjacent_open_only (obs,target_pos,from_pos): adjs = [] for ox,oy in DIRECTION_OFFSETS . values(): p = (target_pos[ 0 ] + ox,target_pos[ 1 ] + oy) if in_bounds(p,obs): o,c,s = tile(obs,p) if is_passable_open_only(o,s): adjs . append(p) if not adjs: return None best = None best_len = 1e9 for a in adjs: path = a_star_open_only(obs,from_pos,a) if path and len (path) < best_len: best_len = len (path) best = a return best def find_key_of_color (obs,color): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == KEY and obs[x,y, 1 ] == color: return (x,y) return None #----------Important-cellawareDROPlogic---------- def drop_key_somewhere (obs,agent_pos,agent_dir,goal): """ Avoiddroppingonimportantsquares: -GOALtile -tilesadjacenttoanyDOOR -tilesadjacenttoGOAL -cellsoncurrentshortestpathtoGOAL -chokepoints(<=2passableneighbors) """ global carrying_key_color,last_drop_front imp = compute_important_cells(obs,agent_pos,goal) #1)TrydroppingintoFRONTifsafe¬important front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs) and is_safe_drop_target(obs,front,imp) and front != last_drop_front: carrying_key_color = None set_drop_cooldown() last_drop_front = front return DROP #2)Rotatetofaceasafe&non-importantfrontcell for turns,next_dir in (( 0 ,agent_dir), ( 1 ,(agent_dir + 1 ) % 4 ), ( 2 ,(agent_dir + 2 ) % 4 ), ( 3 ,(agent_dir + 3 ) % 4 )): f = get_facing(agent_pos,next_dir) if in_bounds(f,obs) and is_safe_drop_target(obs,f,imp) and f != last_drop_front: if turns == 0 : carrying_key_color = None set_drop_cooldown() last_drop_front = f return DROP if (agent_dir - next_dir) % 4 == 1 : return TURN_LEFT else : return TURN_RIGHT #3)Gostandonaplatformfromwhichsomefacinghasasafedroptarget platform,face_dir = nearest_drop_platform(obs,agent_pos,imp) if platform: if agent_pos != platform: path = a_star_open_only(obs,agent_pos,platform) if path: return step_to(path[ 0 ],agent_pos,agent_dir) #onplatform:orientthendrop if agent_dir != face_dir: #one-steprotatetowardface_dir if (agent_dir - face_dir) % 4 == 1 : return TURN_LEFT else : return TURN_RIGHT #nowfrontissafe&non-important front2 = get_facing(agent_pos,agent_dir) if in_bounds(front2,obs) and is_safe_drop_target(obs,front2,imp): carrying_key_color = None set_drop_cooldown() last_drop_front = front2 return DROP #fallback return TURN_RIGHT def is_safe_drop_target (obs,pos,important_set): """Emptyfloor,notimportant,notadoor/key/goal/wall,andnotachokepoint.""" o,c,s = tile(obs,pos) if o in (WALL,DOOR,KEY,GOAL): return False if pos in important_set: return False if is_chokepoint(obs,pos): return False return True def compute_important_cells (obs,agent_pos,goal): """Marksquaresweshouldavoiddroppingon.""" important = set () n = obs . shape[ 0 ] #Goalitself if goal: important . add(goal) #Adjacenttogoal for ox,oy in DIRECTION_OFFSETS . values(): g2 = (goal[ 0 ] + ox,goal[ 1 ] + oy) if in_bounds(g2,obs): important . add(g2) #Adjacenttoanydoor for x in range (n): for y in range (n): if obs[x,y, 0 ] == DOOR: for ox,oy in DIRECTION_OFFSETS . values(): d2 = (x + ox,y + oy) if in_bounds(d2,obs): important . add(d2) #Cellsonthecurrentshortestpathtogoal(ifreachable) if goal: path = a_star_open_only(obs,agent_pos,goal) if path: for p in path: important . add(p) return important def is_chokepoint (obs,pos): """Atilewith<=2passableneighbors→likelyacorridor/bottleneck.""" cnt = 0 for ox,oy in DIRECTION_OFFSETS . values(): p = (pos[ 0 ] + ox,pos[ 1 ] + oy) if not in_bounds(p,obs): continue o,c,s = tile(obs,p) if is_passable_open_only(o,s): cnt += 1 return cnt <= 2 def nearest_drop_platform (obs,from_pos,important_set): """ BFSoverstandpositions.Return(platform_pos,facing_dir)suchthat fromplatform_pos,thefrontcell(infacing_dir)isasafedroptarget. """ q = deque([from_pos]) seen = {from_pos} while q: c = q . popleft() for face_dir,(ox,oy) in DIRECTION_OFFSETS . items(): f = (c[ 0 ] + ox,c[ 1 ] + oy) if in_bounds(f,obs) and is_safe_drop_target(obs,f,important_set) and f != last_drop_front: return c,face_dir #expand for ox,oy in DIRECTION_OFFSETS . values(): nx,ny = c[ 0 ] + ox,c[ 1 ] + oy nxt = (nx,ny) if not in_bounds(nxt,obs) or nxt in seen: continue o,c_,s = tile(obs,nxt) if is_passable_open_only(o,s): seen . add(nxt) q . append(nxt) return None , None def set_drop_cooldown (): global drop_cooldown drop_cooldown = 2 def _dec_drop_cooldown (): global drop_cooldown drop_cooldown = max ( 0 ,drop_cooldown - 1 ) from heapq import heappop,heappush from collections import deque #====Actions==== TURN_LEFT = 0 TURN_RIGHT = 1 MOVE_FORWARD = 2 PICK_UP = 3 DROP = 4 TOGGLE = 5 #====Objects==== WALL = 2 GOAL = 8 DOOR = 4 KEY = 5 #====Doorstate(typicalMiniGridencoding)==== DOOR_OPEN = 0 DOOR_CLOSED = 1 DOOR_LOCKED = 2 #====Directions==== RIGHT = 0 DOWN = 1 LEFT = 2 UP = 3 DIRECTION_OFFSETS = { RIGHT:( 1 , 0 ), DOWN:( 0 , 1 ), LEFT:( -1 , 0 ), UP:( 0 , -1 ), } #----Runner-persistentstate---- carrying_key_color = None drop_cooldown = 0 last_drop_front = None #avoiddroppingtwiceinsamefrontcell #==========PUBLICENTRYPOINT========== def policy (obs,agent_pos,agent_dir): """ obs:NxNx3array(obj,color,state) agent_pos:(x,y) agent_dir:0:RIGHT,1:DOWN,2:LEFT,3:UP returns:actionint """ global carrying_key_color,drop_cooldown if drop_cooldown > 0 : _dec_drop_cooldown() front = get_facing(agent_pos,agent_dir) goal = find_goal(obs) #----1)Immediatefrontinteractions---- if in_bounds(front,obs): fobj,fcol,fstate = tile(obs,front) #Doors:openclosed-unlocked;unlocklockedifwecarrymatchingkey if fobj == DOOR: if is_door_closed_unlocked(fstate): return TOGGLE if is_door_locked(fstate) and carrying_key_color == fcol: return TOGGLE #Keyswithsingle-keycapacity if fobj == KEY: if carrying_key_color is None and drop_cooldown == 0 : carrying_key_color = fcol return PICK_UP elif carrying_key_color is not None and carrying_key_color != fcol: act = drop_key_somewhere(obs,agent_pos,agent_dir,goal) if act is not None : return act return TURN_RIGHT #----2)Trydirectpathtogoal(open-only)---- if goal: path = a_star_open_only(obs,agent_pos,goal) if path: return step_to(path[ 0 ],agent_pos,agent_dir) #----3)Handleblockingdoors(lockedorclosed)---- blocking = find_blocking_doors(obs,agent_pos,goal) #(x,y,color,state) blocking . sort(key = lambda d:manhattan(agent_pos,d[: 2 ])) for (dx,dy,dcol,dstate) in blocking: if is_door_locked(dstate): #Needkeyofcolordcol if carrying_key_color not in ( None ,dcol): act = drop_key_somewhere(obs,agent_pos,agent_dir,goal) if act is not None : return act return TURN_RIGHT if carrying_key_color != dcol: kpos = find_key_of_color(obs,dcol) if kpos: adj = nearest_adjacent_open_only(obs,kpos,agent_pos) if adj: path = a_star_open_only(obs,agent_pos,adj) if path: return step_to(path[ 0 ],agent_pos,agent_dir) return TURN_RIGHT #Havecorrectkey→goadjacenttodoor adj = nearest_adjacent_open_only(obs,(dx,dy),agent_pos) if adj: path = a_star_open_only(obs,agent_pos,adj) if path: return step_to(path[ 0 ],agent_pos,agent_dir) return TURN_RIGHT #Closed-unlocked:justapproachandtoggle if is_door_closed_unlocked(dstate): adj = nearest_adjacent_open_only(obs,(dx,dy),agent_pos) if adj: path = a_star_open_only(obs,agent_pos,adj) if path: return step_to(path[ 0 ],agent_pos,agent_dir) return TURN_RIGHT #----4)Mildexploration---- return TURN_RIGHT #==================HELPERS================== def get_facing (pos,dir_): dx,dy = DIRECTION_OFFSETS[dir_] return (pos[ 0 ] + dx,pos[ 1 ] + dy) def in_bounds (pos,obs): n = obs . shape[ 0 ] return 0 <= pos[ 0 ] < n and 0 <= pos[ 1 ] < n def tile (obs,pos): return obs[pos[ 0 ],pos[ 1 ], 0 ],obs[pos[ 0 ],pos[ 1 ], 1 ],obs[pos[ 0 ],pos[ 1 ], 2 ] def is_door_locked (state): return state == DOOR_LOCKED def is_door_closed_unlocked (state): return state == DOOR_CLOSED def is_open_door (state): return state == DOOR_OPEN def is_passable_open_only (obj,state): if obj == WALL: return False if obj == DOOR: return is_open_door(state) return True #GOAL,empty,key,etc.(wedon'tstepintokeys,butallowroutingaround) def find_goal (obs): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == GOAL: return (x,y) return None def manhattan (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) def step_to (next_pos,agent_pos,agent_dir): dx,dy = next_pos[ 0 ] - agent_pos[ 0 ],next_pos[ 1 ] - agent_pos[ 1 ] for dir_,(ox,oy) in DIRECTION_OFFSETS . items(): if (dx,dy) == (ox,oy): if agent_dir == dir_: return MOVE_FORWARD elif (agent_dir - dir_) % 4 == 1 : return TURN_LEFT else : return TURN_RIGHT return TURN_LEFT #----------A*(opendoorsonly)---------- def a_star_open_only (obs,start,goal): if goal is None : return None def h (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) open_set = [( 0 ,start)] came_from = {} g = {start: 0 } f = {start:h(start,goal)} while open_set: _,current = heappop(open_set) if current == goal: return _reconstruct_path(came_from,current) for ox,oy in DIRECTION_OFFSETS . values(): nx,ny = current[ 0 ] + ox,current[ 1 ] + oy nxt = (nx,ny) if not in_bounds(nxt,obs): continue o,c,s = tile(obs,nxt) if not is_passable_open_only(o,s): continue tg = g[current] + 1 if nxt not in g or tg < g[nxt]: g[nxt] = tg came_from[nxt] = current fn = tg + h(nxt,goal) f[nxt] = fn heappush(open_set,(fn,nxt)) return None def _reconstruct_path (came_from,cur): path = [] while cur in came_from: path . append(cur) cur = came_from[cur] path . reverse() return path #----------Blockingdoors(firstfrontierofclosed/locked)---------- def find_blocking_doors (obs,start,goal): n = obs . shape[ 0 ] q = deque([start]) seen = {start} blockers = [] while q: x,y = q . popleft() if goal and (x,y) == goal: return [] for ox,oy in DIRECTION_OFFSETS . values(): nx,ny = x + ox,y + oy if not ( 0 <= nx < n and 0 <= ny < n): continue o,c,s = obs[nx,ny] nxt = (nx,ny) if (o == DOOR) and (is_door_locked(s) or is_door_closed_unlocked(s)): if nxt not in [b[: 2 ] for b in blockers]: blockers . append((nx,ny,c,s)) continue if nxt in seen: continue if not is_passable_open_only(o,s): continue seen . add(nxt) q . append(nxt) return blockers #----------Adjacentpassabletileneartarget---------- def nearest_adjacent_open_only (obs,target_pos,from_pos): adjs = [] for ox,oy in DIRECTION_OFFSETS . values(): p = (target_pos[ 0 ] + ox,target_pos[ 1 ] + oy) if in_bounds(p,obs): o,c,s = tile(obs,p) if is_passable_open_only(o,s): adjs . append(p) if not adjs: return None best = None best_len = 1e9 for a in adjs: path = a_star_open_only(obs,from_pos,a) if path and len (path) < best_len: best_len = len (path) best = a return best def find_key_of_color (obs,color): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == KEY and obs[x,y, 1 ] == color: return (x,y) return None #----------Important-cellawareDROPlogic---------- def drop_key_somewhere (obs,agent_pos,agent_dir,goal): """ Avoiddroppingonimportantsquares: -GOALtile -tilesadjacenttoanyDOOR -tilesadjacenttoGOAL -cellsoncurrentshortestpathtoGOAL -chokepoints(<=2passableneighbors) """ global carrying_key_color,last_drop_front imp = compute_important_cells(obs,agent_pos,goal) #1)TrydroppingintoFRONTifsafe¬important front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs) and is_safe_drop_target(obs,front,imp) and front != last_drop_front: carrying_key_color = None set_drop_cooldown() last_drop_front = front return DROP #2)Rotatetofaceasafe&non-importantfrontcell for turns,next_dir in (( 0 ,agent_dir), ( 1 ,(agent_dir + 1 ) % 4 ), ( 2 ,(agent_dir + 2 ) % 4 ), ( 3 ,(agent_dir + 3 ) % 4 )): f = get_facing(agent_pos,next_dir) if in_bounds(f,obs) and is_safe_drop_target(obs,f,imp) and f != last_drop_front: if turns == 0 : carrying_key_color = None set_drop_cooldown() last_drop_front = f return DROP if (agent_dir - next_dir) % 4 == 1 : return TURN_LEFT else : return TURN_RIGHT #3)Gostandonaplatformfromwhichsomefacinghasasafedroptarget platform,face_dir = nearest_drop_platform(obs,agent_pos,imp) if platform: if agent_pos != platform: path = a_star_open_only(obs,agent_pos,platform) if path: return step_to(path[ 0 ],agent_pos,agent_dir) #onplatform:orientthendrop if agent_dir != face_dir: #one-steprotatetowardface_dir if (agent_dir - face_dir) % 4 == 1 : return TURN_LEFT else : return TURN_RIGHT #nowfrontissafe&non-important front2 = get_facing(agent_pos,agent_dir) if in_bounds(front2,obs) and is_safe_drop_target(obs,front2,imp): carrying_key_color = None set_drop_cooldown() last_drop_front = front2 return DROP #fallback return TURN_RIGHT def is_safe_drop_target (obs,pos,important_set): """Emptyfloor,notimportant,notadoor/key/goal/wall,andnotachokepoint.""" o,c,s = tile(obs,pos) if o in (WALL,DOOR,KEY,GOAL): return False if pos in important_set: return False if is_chokepoint(obs,pos): return False return True def compute_important_cells (obs,agent_pos,goal): """Marksquaresweshouldavoiddroppingon.""" important = set () n = obs . shape[ 0 ] #Goalitself if goal: important . add(goal) #Adjacenttogoal for ox,oy in DIRECTION_OFFSETS . values(): g2 = (goal[ 0 ] + ox,goal[ 1 ] + oy) if in_bounds(g2,obs): important . add(g2) #Adjacenttoanydoor for x in range (n): for y in range (n): if obs[x,y, 0 ] == DOOR: for ox,oy in DIRECTION_OFFSETS . values(): d2 = (x + ox,y + oy) if in_bounds(d2,obs): important . add(d2) #Cellsonthecurrentshortestpathtogoal(ifreachable) if goal: path = a_star_open_only(obs,agent_pos,goal) if path: for p in path: important . add(p) return important def is_chokepoint (obs,pos): """Atilewith<=2passableneighbors→likelyacorridor/bottleneck.""" cnt = 0 for ox,oy in DIRECTION_OFFSETS . values(): p = (pos[ 0 ] + ox,pos[ 1 ] + oy) if not in_bounds(p,obs): continue o,c,s = tile(obs,p) if is_passable_open_only(o,s): cnt += 1 return cnt <= 2 def nearest_drop_platform (obs,from_pos,important_set): """ BFSoverstandpositions.Return(platform_pos,facing_dir)suchthat fromplatform_pos,thefrontcell(infacing_dir)isasafedroptarget. """ q = deque([from_pos]) seen = {from_pos} while q: c = q . popleft() for face_dir,(ox,oy) in DIRECTION_OFFSETS . items(): f = (c[ 0 ] + ox,c[ 1 ] + oy) if in_bounds(f,obs) and is_safe_drop_target(obs,f,important_set) and f != last_drop_front: return c,face_dir #expand for ox,oy in DIRECTION_OFFSETS . values(): nx,ny = c[ 0 ] + ox,c[ 1 ] + oy nxt = (nx,ny) if not in_bounds(nxt,obs) or nxt in seen: continue o,c_,s = tile(obs,nxt) if is_passable_open_only(o,s): seen . add(nxt) q . append(nxt) return None , None def set_drop_cooldown (): global drop_cooldown drop_cooldown = 2 def _dec_drop_cooldown (): global drop_cooldown drop_cooldown = max ( 0 ,drop_cooldown - 1 ) from heapq import heappop,heappush from collections import deque #Actions TURN_LEFT = 0 TURN_RIGHT = 1 MOVE_FORWARD = 2 PICK_UP = 3 DROP = 4 TOGGLE = 5 #Objects WALL = 2 GOAL = 8 DOOR = 4 KEY = 5 #Directions RIGHT = 0 DOWN = 1 LEFT = 2 UP = 3 DIRECTION_OFFSETS = { RIGHT:( 1 , 0 ), DOWN:( 0 , 1 ), LEFT:( -1 , 0 ), UP:( 0 , -1 ), } #Single-keycapacity carrying_key_color = None def policy (obs,agent_pos,agent_dir): global carrying_key_color n = obs . shape[ 0 ] act = maybe_toggle_if_in_front(obs,agent_pos,agent_dir) if act is not None : return act act = maybe_pickup_if_in_front(obs,agent_pos,agent_dir) if act is not None : return act goal_pos = find_goal(obs) if not goal_pos: return TURN_LEFT path_goal = a_star(obs,agent_pos,goal_pos,avoid_locked = True ) if path_goal: return step_to(path_goal[ 0 ],agent_pos,agent_dir) blocking_doors = find_all_blocking_doors(obs,agent_pos,goal_pos) if not blocking_doors: return TURN_LEFT for (dx,dy,door_col) in blocking_doors: if not can_open_door(obs,agent_pos,agent_dir,door_col,exploring_colors = set ()): continue #ifweholdadifferentkey=>dropit if carrying_key_color and carrying_key_color != door_col: drop_act = maybe_drop_wrong_key(obs,agent_pos,agent_dir,goal_pos) if drop_act: return drop_act #ifwedontholddoor_col=>pickitup if carrying_key_color != door_col: key_loc = find_key(obs,door_col) if not key_loc: continue chain_path = path_with_chain_unlock(obs,agent_pos,agent_dir,key_loc,exploring_colors = set ()) if not chain_path: continue return step_to(chain_path[ 0 ],agent_pos,agent_dir) #nowweholddoor_col=>pathnextto(dx,dy) adj = find_adjacent_tile(obs,(dx,dy),agent_pos) if not adj: continue chain_path2 = path_with_chain_unlock(obs,agent_pos,agent_dir,adj,exploring_colors = set ()) if chain_path2: if len (chain_path2) ==0 or chain_path2[ 0 ] == agent_pos: return TURN_LEFT return step_to(chain_path2[ 0 ],agent_pos,agent_dir) return TURN_LEFT def maybe_toggle_if_in_front (obs,agent_pos,agent_dir): front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs . shape[ 0 ]): fobj,fcol,fstate = obs[front[ 0 ],front[ 1 ]] if fobj == DOOR and fstate ==2 and carrying_key_color == fcol: return TOGGLE return None def maybe_pickup_if_in_front (obs,agent_pos,agent_dir): """ IffrontisKEY: -Ifnokey=>pickitup -Ifholddifferentkey=>mustdropoldfirst=>donothing -Ifholdsamecolor=>donothing """ global carrying_key_color f = get_facing(agent_pos,agent_dir) if in_bounds(f,obs . shape[ 0 ]): fo,fc,fs = obs[f[ 0 ],f[ 1 ]] if fo == KEY: if carrying_key_color is None : carrying_key_color = fc return PICK_UP return None def maybe_drop_wrong_key (obs,agent_pos,agent_dir,goal_pos): global carrying_key_color if carrying_key_color is None : return None front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs . shape[ 0 ]): fo,fc,fs = obs[front[ 0 ],front[ 1 ]] if fo in ( 1 , 3 ): #floor carrying_key_color = None return DROP non_important = find_non_important_floor(obs,agent_pos,goal_pos) if non_important: path_ni = a_star(obs,agent_pos,non_important,avoid_locked = False ) if path_ni: if len (path_ni) ==0 or path_ni[ 0 ] == agent_pos: #ifBFSisdegenerate=>trydroppingonourowntileifsafe if can_drop_on_own_tile(obs,agent_pos): carrying_key_color = None return DROP return TURN_LEFT return step_to(path_ni[ 0 ],agent_pos,agent_dir) fallback_floor = find_any_floor(obs,agent_pos) if fallback_floor: path_floor = a_star(obs,agent_pos,fallback_floor,avoid_locked = False ) if path_floor: if len (path_floor) ==0 or path_floor[ 0 ] == agent_pos: if can_drop_on_own_tile(obs,agent_pos): carrying_key_color = None return DROP return TURN_LEFT return step_to(path_floor[ 0 ],agent_pos,agent_dir) if can_drop_on_own_tile(obs,agent_pos): carrying_key_color = None return DROP return TURN_LEFT def can_drop_on_own_tile (obs,agent_pos): x,y = agent_pos o,c,s = obs[x,y] return (o in ( 1 , 3 )) #---------------------------------------------------------------------- def find_non_important_floor (obs,agent_pos,goal_pos): visited_path = set () #BFSfromagent_pos=>goal_posignoringlocked n = obs . shape[ 0 ] from collections import deque queue = deque([agent_pos]) visited_path . add(agent_pos) found_goal = False while queue: cur = queue . popleft() if cur == goal_pos: found_goal = True cx,cy = cur for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if 0<= nx < n and 0<= ny < n: if (nx,ny) not in visited_path: oo,cc,ss = obs[nx,ny] if oo == WALL: continue if oo == DOOR and ss ==2 : continue visited_path . add((nx,ny)) queue . append((nx,ny)) for x2 in range (n): for y2 in range (n): if (x2,y2) not in visited_path: oo,cc,ss = obs[x2,y2] if oo in ( 1 , 3 ): #floor return (x2,y2) return None def find_goal (obs): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == GOAL: return (x,y) return None def find_any_floor (obs,agent_pos): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] in ( 1 , 3 ): return (x,y) return None def get_facing (agent_pos,agent_dir): dx,dy = DIRECTION_OFFSETS[agent_dir] return (agent_pos[ 0 ] + dx,agent_pos[ 1 ] + dy) def in_bounds (pos,n): return ( 0<= pos[ 0 ] < n and 0<= pos[ 1 ] < n) def a_star (obs,start,goal,avoid_locked = True ): def heuristic (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) from heapq import heappop,heappush n = obs . shape[ 0 ] open_set = [] heappush(open_set,( 0 ,start)) came_from = {} g_score = {start: 0 } f_score = {start:heuristic(start,goal)} while open_set: _,current = heappop(open_set) if current == goal: path = [] while current in came_from: path . append(current) current = came_from[current] path . reverse() return path cx,cy = current for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if not ( 0<= nx < n and 0<= ny < n): continue o = obs[nx,ny, 0 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 and avoid_locked: continue cost = g_score[current] +1 if (nx,ny) not in g_score or cost < g_score[(nx,ny)]: g_score[(nx,ny)] = cost f_score[(nx,ny)] = cost + heuristic((nx,ny),goal) came_from[(nx,ny)] = current heappush(open_set,(f_score[(nx,ny)],(nx,ny))) return None def step_to (next_pos,agent_pos,agent_dir): dx = next_pos[ 0 ] - agent_pos[ 0 ] dy = next_pos[ 1 ] - agent_pos[ 1 ] desired_dir = None for d,(ox,oy) in DIRECTION_OFFSETS . items(): if (dx,dy) == (ox,oy): desired_dir = d break if desired_dir is None : return TURN_LEFT turn_act = turn_toward(agent_dir,desired_dir) if turn_act is not None : return turn_act else : return MOVE_FORWARD def turn_toward (current_dir,target_dir): if current_dir == target_dir: return None left_turns = (current_dir - target_dir) %4 return TURN_LEFT if left_turns ==1 else TURN_RIGHT def find_all_blocking_doors (obs,agent_pos,goal_pos): """ BFSignoringwalls&opendoors.Wenotelockeddoorsbutkeepexploringtoseeifthereisapatharoundthem. Ifwefindthegoal=>nodooristrulyblocking=>return[]. Ifnot=>thelockeddoorswesawareindeedblocking. """ n = obs . shape[ 0 ] visited = set ([agent_pos]) from collections import deque q = deque([agent_pos]) blocking = [] while q: cx,cy = q . popleft() if (cx,cy) == goal_pos: return [] for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if 0<= nx < n and 0<= ny < n: if (nx,ny) not in visited: o = obs[nx,ny, 0 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 : color = obs[nx,ny, 1 ] if (nx,ny,color) not in blocking: blocking . append((nx,ny,color)) continue visited . add((nx,ny)) q . append((nx,ny)) return blocking def find_key (obs,color): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == KEY and obs[x,y, 1 ] == color: return (x,y) return None def can_open_door (obs,agent_pos,agent_dir,needed_color,exploring_colors = None ): if exploring_colors is None : exploring_colors = set () if needed_color in exploring_colors: return False if carrying_key_color == needed_color: return True key_loc = find_key(obs,needed_color) if not key_loc: return False exploring_colors . add(needed_color) path = path_with_chain_unlock(obs,agent_pos,agent_dir,key_loc,exploring_colors) exploring_colors . remove(needed_color) return (path is not None ) def path_with_chain_unlock (obs,agent_pos,agent_dir,target,exploring_colors): """ BFSthattreatslockeddoorcolorXaspassableifcan_open_door=>True """ n = obs . shape[ 0 ] visited = set ([agent_pos]) came_from = {} from collections import deque queue = deque([agent_pos]) def reconstruct (e): path = [] while e in came_from: path . append(e) e = came_from[e] path . reverse() return path while queue: cur = queue . popleft() if cur == target: return reconstruct(cur) cx,cy = cur for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if not ( 0<= nx < n and 0<= ny < n): continue if (nx,ny) in visited: continue o = obs[nx,ny, 0 ] c = obs[nx,ny, 1 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 : if not can_open_door(obs,(cx,cy),agent_dir,c,exploring_colors): continue elif o == DOOR and s !=0 : #closed=>nokeyneeded=>pass pass visited . add((nx,ny)) came_from[(nx,ny)] = cur queue . append((nx,ny)) return None def find_adjacent_tile (obs,door_pos,agent_pos): n = obs . shape[ 0 ] (dx,dy) = door_pos candidates = [] for (sx,sy) in DIRECTION_OFFSETS . values(): nx,ny = dx + sx,dy + sy if 0<= nx < n and 0<= ny < n: o = obs[nx,ny, 0 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 : continue candidates . append((nx,ny)) if not candidates: return None #pickwhicheverisclosesttoagent candidates . sort(key = lambda c: abs (c[ 0 ] - agent_pos[ 0 ]) + abs (c[ 1 ] - agent_pos[ 1 ])) return candidates[ 0 ] from heapq import heappop,heappush from collections import deque #Actions TURN_LEFT = 0 TURN_RIGHT = 1 MOVE_FORWARD = 2 PICK_UP = 3 DROP = 4 TOGGLE = 5 #Objects WALL = 2 GOAL = 8 DOOR = 4 KEY = 5 #Directions RIGHT = 0 DOWN = 1 LEFT = 2 UP = 3 DIRECTION_OFFSETS = { RIGHT:( 1 , 0 ), DOWN:( 0 , 1 ), LEFT:( -1 , 0 ), UP:( 0 , -1 ), } #Single-keycapacity carrying_key_color = None def policy (obs,agent_pos,agent_dir): global carrying_key_color n = obs . shape[ 0 ] act = maybe_toggle_if_in_front(obs,agent_pos,agent_dir) if act is not None : return act act = maybe_pickup_if_in_front(obs,agent_pos,agent_dir) if act is not None : return act goal_pos = find_goal(obs) if not goal_pos: return TURN_LEFT path_goal = a_star(obs,agent_pos,goal_pos,avoid_locked = True ) if path_goal: return step_to(path_goal[ 0 ],agent_pos,agent_dir) blocking_doors = find_all_blocking_doors(obs,agent_pos,goal_pos) if not blocking_doors: return TURN_LEFT for (dx,dy,door_col) in blocking_doors: if not can_open_door(obs,agent_pos,agent_dir,door_col,exploring_colors = set ()): continue #ifweholdadifferentkey=>dropit if carrying_key_color and carrying_key_color != door_col: drop_act = maybe_drop_wrong_key(obs,agent_pos,agent_dir,goal_pos) if drop_act: return drop_act #ifwedontholddoor_col=>pickitup if carrying_key_color != door_col: key_loc = find_key(obs,door_col) if not key_loc: continue chain_path = path_with_chain_unlock(obs,agent_pos,agent_dir,key_loc,exploring_colors = set ()) if not chain_path: continue return step_to(chain_path[ 0 ],agent_pos,agent_dir) #nowweholddoor_col=>pathnextto(dx,dy) adj = find_adjacent_tile(obs,(dx,dy),agent_pos) if not adj: continue chain_path2 = path_with_chain_unlock(obs,agent_pos,agent_dir,adj,exploring_colors = set ()) if chain_path2: if len (chain_path2) ==0 or chain_path2[ 0 ] == agent_pos: return TURN_LEFT return step_to(chain_path2[ 0 ],agent_pos,agent_dir) return TURN_LEFT def maybe_toggle_if_in_front (obs,agent_pos,agent_dir): front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs . shape[ 0 ]): fobj,fcol,fstate = obs[front[ 0 ],front[ 1 ]] if fobj == DOOR and fstate ==2 and carrying_key_color == fcol: return TOGGLE return None def maybe_pickup_if_in_front (obs,agent_pos,agent_dir): """ IffrontisKEY: -Ifnokey=>pickitup -Ifholddifferentkey=>mustdropoldfirst=>donothing -Ifholdsamecolor=>donothing """ global carrying_key_color f = get_facing(agent_pos,agent_dir) if in_bounds(f,obs . shape[ 0 ]): fo,fc,fs = obs[f[ 0 ],f[ 1 ]] if fo == KEY: if carrying_key_color is None : carrying_key_color = fc return PICK_UP return None def maybe_drop_wrong_key (obs,agent_pos,agent_dir,goal_pos): global carrying_key_color if carrying_key_color is None : return None front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs . shape[ 0 ]): fo,fc,fs = obs[front[ 0 ],front[ 1 ]] if fo in ( 1 , 3 ): #floor carrying_key_color = None return DROP non_important = find_non_important_floor(obs,agent_pos,goal_pos) if non_important: path_ni = a_star(obs,agent_pos,non_important,avoid_locked = False ) if path_ni: if len (path_ni) ==0 or path_ni[ 0 ] == agent_pos: #ifBFSisdegenerate=>trydroppingonourowntileifsafe if can_drop_on_own_tile(obs,agent_pos): carrying_key_color = None return DROP return TURN_LEFT return step_to(path_ni[ 0 ],agent_pos,agent_dir) fallback_floor = find_any_floor(obs,agent_pos) if fallback_floor: path_floor = a_star(obs,agent_pos,fallback_floor,avoid_locked = False ) if path_floor: if len (path_floor) ==0 or path_floor[ 0 ] == agent_pos: if can_drop_on_own_tile(obs,agent_pos): carrying_key_color = None return DROP return TURN_LEFT return step_to(path_floor[ 0 ],agent_pos,agent_dir) if can_drop_on_own_tile(obs,agent_pos): carrying_key_color = None return DROP return TURN_LEFT def can_drop_on_own_tile (obs,agent_pos): x,y = agent_pos o,c,s = obs[x,y] return (o in ( 1 , 3 )) #---------------------------------------------------------------------- def find_non_important_floor (obs,agent_pos,goal_pos): visited_path = set () #BFSfromagent_pos=>goal_posignoringlocked n = obs . shape[ 0 ] from collections import deque queue = deque([agent_pos]) visited_path . add(agent_pos) found_goal = False while queue: cur = queue . popleft() if cur == goal_pos: found_goal = True cx,cy = cur for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if 0<= nx < n and 0<= ny < n: if (nx,ny) not in visited_path: oo,cc,ss = obs[nx,ny] if oo == WALL: continue if oo == DOOR and ss ==2 : continue visited_path . add((nx,ny)) queue . append((nx,ny)) for x2 in range (n): for y2 in range (n): if (x2,y2) not in visited_path: oo,cc,ss = obs[x2,y2] if oo in ( 1 , 3 ): #floor return (x2,y2) return None def find_goal (obs): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == GOAL: return (x,y) return None def find_any_floor (obs,agent_pos): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] in ( 1 , 3 ): return (x,y) return None def get_facing (agent_pos,agent_dir): dx,dy = DIRECTION_OFFSETS[agent_dir] return (agent_pos[ 0 ] + dx,agent_pos[ 1 ] + dy) def in_bounds (pos,n): return ( 0<= pos[ 0 ] < n and 0<= pos[ 1 ] < n) def a_star (obs,start,goal,avoid_locked = True ): def heuristic (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) from heapq import heappop,heappush n = obs . shape[ 0 ] open_set = [] heappush(open_set,( 0 ,start)) came_from = {} g_score = {start: 0 } f_score = {start:heuristic(start,goal)} while open_set: _,current = heappop(open_set) if current == goal: path = [] while current in came_from: path . append(current) current = came_from[current] path . reverse() return path cx,cy = current for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if not ( 0<= nx < n and 0<= ny < n): continue o = obs[nx,ny, 0 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 and avoid_locked: continue cost = g_score[current] +1 if (nx,ny) not in g_score or cost < g_score[(nx,ny)]: g_score[(nx,ny)] = cost f_score[(nx,ny)] = cost + heuristic((nx,ny),goal) came_from[(nx,ny)] = current heappush(open_set,(f_score[(nx,ny)],(nx,ny))) return None def step_to (next_pos,agent_pos,agent_dir): dx = next_pos[ 0 ] - agent_pos[ 0 ] dy = next_pos[ 1 ] - agent_pos[ 1 ] desired_dir = None for d,(ox,oy) in DIRECTION_OFFSETS . items(): if (dx,dy) == (ox,oy): desired_dir = d break if desired_dir is None : return TURN_LEFT turn_act = turn_toward(agent_dir,desired_dir) if turn_act is not None : return turn_act else : return MOVE_FORWARD def turn_toward (current_dir,target_dir): if current_dir == target_dir: return None left_turns = (current_dir - target_dir) %4 return TURN_LEFT if left_turns ==1 else TURN_RIGHT def find_all_blocking_doors (obs,agent_pos,goal_pos): """ BFSignoringwalls&opendoors.Wenotelockeddoorsbutkeepexploringtoseeifthereisapatharoundthem. Ifwefindthegoal=>nodooristrulyblocking=>return[]. Ifnot=>thelockeddoorswesawareindeedblocking. """ n = obs . shape[ 0 ] visited = set ([agent_pos]) from collections import deque q = deque([agent_pos]) blocking = [] while q: cx,cy = q . popleft() if (cx,cy) == goal_pos: return [] for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if 0<= nx < n and 0<= ny < n: if (nx,ny) not in visited: o = obs[nx,ny, 0 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 : color = obs[nx,ny, 1 ] if (nx,ny,color) not in blocking: blocking . append((nx,ny,color)) continue visited . add((nx,ny)) q . append((nx,ny)) return blocking def find_key (obs,color): n = obs . shape[ 0 ] for x in range (n): for y in range (n): if obs[x,y, 0 ] == KEY and obs[x,y, 1 ] == color: return (x,y) return None def can_open_door (obs,agent_pos,agent_dir,needed_color,exploring_colors = None ): if exploring_colors is None : exploring_colors = set () if needed_color in exploring_colors: return False if carrying_key_color == needed_color: return True key_loc = find_key(obs,needed_color) if not key_loc: return False exploring_colors . add(needed_color) path = path_with_chain_unlock(obs,agent_pos,agent_dir,key_loc,exploring_colors) exploring_colors . remove(needed_color) return (path is not None ) def path_with_chain_unlock (obs,agent_pos,agent_dir,target,exploring_colors): """ BFSthattreatslockeddoorcolorXaspassableifcan_open_door=>True """ n = obs . shape[ 0 ] visited = set ([agent_pos]) came_from = {} from collections import deque queue = deque([agent_pos]) def reconstruct (e): path = [] while e in came_from: path . append(e) e = came_from[e] path . reverse() return path while queue: cur = queue . popleft() if cur == target: return reconstruct(cur) cx,cy = cur for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if not ( 0<= nx < n and 0<= ny < n): continue if (nx,ny) in visited: continue o = obs[nx,ny, 0 ] c = obs[nx,ny, 1 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 : if not can_open_door(obs,(cx,cy),agent_dir,c,exploring_colors): continue elif o == DOOR and s !=0 : #closed=>nokeyneeded=>pass pass visited . add((nx,ny)) came_from[(nx,ny)] = cur queue . append((nx,ny)) return None def find_adjacent_tile (obs,door_pos,agent_pos): n = obs . shape[ 0 ] (dx,dy) = door_pos candidates = [] for (sx,sy) in DIRECTION_OFFSETS . values(): nx,ny = dx + sx,dy + sy if 0<= nx < n and 0<= ny < n: o = obs[nx,ny, 0 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 : continue candidates . append((nx,ny)) if not candidates: return None #pickwhicheverisclosesttoagent candidates . sort(key = lambda c: abs (c[ 0 ] - agent_pos[ 0 ]) + abs (c[ 1 ] - agent_pos[ 1 ])) return candidates[ 0 ] def maybe_drop_wrong_key (obs,agent_pos,agent_dir,goal_pos): global carrying_key_color if carrying_key_color is None : return None front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs . shape[ 0 ]): fo,fc,fs = obs[front[ 0 ],front[ 1 ]] if fo in ( 1 , 3 ): #floor carrying_key_color = None return DROP ... if can_drop_on_own_tile(obs,agent_pos): carrying_key_color = None return DROP return TURN_LEFT def drop_key_somewhere (obs,agent_pos,agent_dir,goal): global carrying_key_color,last_drop_front imp = compute_important_cells(obs,agent_pos,goal) #1)TrydroppingintoFRONTifsafe¬important front = get_facing(agent_pos,agent_dir) if in_bounds(front,obs) and is_safe_drop_target(obs,front,imp) and front != last_drop_front: carrying_key_color = None set_drop_cooldown() last_drop_front = front return DR OP #2)Rotatetofaceasafe&non-importantfrontcell for turns,next_dir in (( 0 ,agent_dir), ( 1 ,(agent_dir + 1 ) % 4 ), ( 2 ,(agent_dir + 2 ) % 4 ), ( 3 ,(agent_dir + 3 ) % 4 )): f = get_facing(agent_pos,next_dir) . . . #3)Gostandonaplatformfromwhichsomefacinghasasafedroptarget platform,face_dir = nearest_drop_platform(obs,agent_pos,imp) if platform: if agent_pos != platform: path = a_star_open_only(obs,agent_pos,platform) if path: return step_to(path[ 0 ],agent_pos,agent_dir) . . . return TUR N_R IGHT def a_star (obs,start,goal,avoid_locked = True ): def heuristic (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) from heapq import heappop,heappush ... while open_set: ... for (dx,dy) in DIRECTION_OFFSETS . values(): nx,ny = cx + dx,cy + dy if not ( 0<= nx < n and 0<= ny < n): continue o = obs[nx,ny, 0 ] s = obs[nx,ny, 2 ] if o == WALL: continue if o == DOOR and s ==2 and avoid_locked: continue cost = g_score[current] +1 if (nx,ny) not in g_score or cost < g_score[(nx,ny)]: g_score[(nx,ny)] = cost f_score[(nx,ny)] = cost + heuristic((nx,ny),goal) came_from[(nx,ny)] = current heappush(open_set,(f_score[(nx,ny)],(nx,ny))) return None def a_star_open_only (obs,start,goal): if goal is None : return None def h (a,b): return abs (a[ 0 ] - b[ 0 ]) + abs (a[ 1 ] - b[ 1 ]) ... while open_set: ... for ox,oy in DIRECTION_OFFSETS . values(): nx,ny = current[ 0 ] + ox,current[ 1 ] + oy nxt = (nx,ny) if not in_bounds(nxt,obs): continue o,c,s = tile(obs,nxt) if not is_passable_open_only(o,s): continue tg = g[current] + 1 if nxt not in g or tg < g[nxt]: g[nxt] = tg came_from[nxt] = current fn = tg + h(nxt,goal) f[nxt] = fn heappush(open_set,(fn,nxt)) return None visited_blk = bfs_block_locked( self ,agent_pos) skip = {agent_pos,door_pos,goal_pos} candidates = [c for c in visited_blk if c not in skip and self . grid . get( * c) is None ] ... key_spot = random . choice(candidates) self . put_obj(Key(color),key_spot[ 0 ],key_spot[ 1 ]) reserve = set (path_set) | {agent_pos,goal_pos} | set (door_positions) protected = set () key_positions = [] for i,(dx,dy) in enumerate (door_positions): unlocked = set (colors[:i]) #colorsbeforedooriareusable region = flood_reachable( self ,agent_pos,unlocked) side_neighbors = [(nx,ny) for (nx,ny) in self . _neighbors(dx,dy) if ( 0 <= nx < self . width and 0 <= ny < self . height) and _passable( self ,nx,ny,unlocked) and (nx,ny) in region] ... candidates = [c for c in region if c not in reserve and self . grid . get( * c) is None and self . _free_neighbors_count( * c,keys = unlocked) >= 2 ] ... for cx,cy in pool: p1 = shortest_path( self ,agent_pos,(cx,cy),unlocked) ... p2 = shortest_path( self ,(cx,cy),s,unlocked) ... self . put_obj(Key(colors[i]),cx,cy) key_positions . append((cx,cy)) for cell in p1 + p2: protected . add(cell) for nb in self . _neighbors( * cell): if 1 <= nb[ 0 ] < self . width -1 and 1 <= nb[ 1 ] < self . height -1 : protected . add(nb) Figure 2: Example of co evolution in COvolve. Left: successiv e environment implementations, progr essing from ad hoc generation to a structured, parameterize d design with explicit solvability checks and controllable chokepoints. Right: successive policy implementations, progressing from basic navigation to improved handling of keys and doors, together with renements to the A * based planner for more reliable action selection. Highlighted code blocks indicate the changes introduced. 4.1 Policy Designer For the current level, the Policy Designer Ψ synthesizes a policy via an iterative best-response procedure. Given a level 𝜃 , the pol- icy designer generates 𝐾 candidate policy mutations by applying LLM-guided program transformations to the current best policy , conditioning on the level-specic obser vation and action spaces O 𝜃 and A 𝜃 . Each candidate policy ˜ 𝜋 𝑘 is evaluated on 𝜃 , and the highest-performing candidate accor ding to the utility 𝑈 𝜃 is retained. The selected p olicy 𝜋 constitutes an approximate best response for level 𝜃 and is appended to the growing policy sequence P . While each policy is tailored to an individual level, our broader goal is to obtain an approximation of the optimal policy 𝜋 ∗ that p er- forms well across le vels. Since the interaction between the policy designer and the environment designer forms a two-player zero- sum game, a mixed-strategy Nash Equilibrium (MSNE) provides a principled solution, ensuring that the obtained policy is robust under adversarial conditions. Building on PSRO , we achie ve this by maintaining a growing se quence of policies P = { 𝜋 1 , . . . , 𝜋 𝑡 } and previously generated levels L = { 𝜃 1 , . . . , 𝜃 𝑡 } , where each p olicy 𝜋 𝑖 is optimized for its corresponding level 𝜃 𝑖 using the process de- scribed above. Let the payo matrix be M ∈ R 𝑟 × 𝑡 , wher e each entr y 𝑚 𝑖 𝑗 = 𝑈 𝜃 𝑗 ( 𝜋 𝑖 ) denotes the expecte d return of policy 𝜋 𝑖 on level 𝜃 𝑗 . The new MSNE is then computed via a minimax optimization where the policy agent maximizes its worst-case expected payo [34]: 𝑝 ★ = arg max 𝑝 ∈ Δ 𝑟 min 𝑗 ∈ { 1 ,.. .,𝑟 } 𝑟 𝑖 = 1 𝑝 𝑖 𝑚 𝑖 𝑗 where, Δ 𝑟 = ( 𝑝 ∈ R 𝑟 𝑟 𝑖 = 1 𝑝 𝑖 = 1 , 𝑝 𝑖 ≥ 0 ∀ 𝑖 ) . (1) Here, 𝑝 ★ is the mixture weights over policies that maximizes the worst-case e xpecte d return acr oss all levels, dening the MSNE policy distribution 𝑝 ★ , where each policy 𝜋 𝑖 is sampled from 𝜋 MSNE with probability 𝑝 ∗ 𝑖 . At the start of each episode, the agent samples a policy 𝜋 𝑖 ∼ 𝑝 ★ and takes actions according to 𝑎 ∼ 𝜋 in the given level. 4.2 Environment Designer The Environment Designer generates a new level as a best response to the current MSNE policy . Its goal is to minimize the expected return of the mixture policy , thereby re vealing its w eaknesses. This adversarial loop encourages curriculum-like progression, automat- ically increasing the environment’s diculty in response to the agent’s improvement. Using a best-response update, the environment designer uses an LLM-based adversary Λ to generate 𝐾 candidate mutations of the current environment { ˜ 𝜃 1 , . . . , ˜ 𝜃 𝐾 } = Λ ( 𝜃 , 𝑝 ★ ) . The candidate that minimizes performance under 𝜋 MSNE is selected. The sele cted environment is added to the lev el set L , after which a new policy is synthesized in response and appended to the policy sequence P . This procedure repeats across iterations, expanding both the environment and policy sets. COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game 5 Experiments W e evaluate COvolve across three complementary domains that capture distinct challenges in agent learning. MiniGrid [ 4 ] requires symbolic planning in proce durally generated mazes with sequential dependencies such as keys and doors. PyGame [ 36 ] emphasizes continuous 2D navigation with geometric reasoning and collision constraints, with diculty scaling through denser obstacles and narrower traversable passages. CARLA [ 10 ] provides a high-delity urban driving setting with partial observability , dynamic vehicles, pedestrians, and trac lights. T ogether , these domains encompass symbolic planning, geometric navigation, and realistic multi-agent driving, forming a principled testbed for evaluating curriculum emergence and robustness under co-evolution. 5.1 Environments and T asks All main experiments use GPT -5.2 [ 33 ] as the generative model for both environment and policy synthesis. Prompts are provided in Appendix C. All generated code is dynamically validated and exe- cuted using exec() . For each policy–environment pair , we evaluate the payo 𝑈 𝜃 ( 𝜋 ) ∈ [ 0 , 1 ] , averaged over 100 episodes, to populate the empirical payo matrix M . Complete environment specica- tions (action and observation spaces, task scaling, termination, and feasibility checks) are provided in Appendix B. MiniGrid Symb olic Maze Solving. W e use the MiniGrid-Empty environment as a base for generating symbolic maze-solving tasks. It is a fully-obser vable environment with 𝑛 × 𝑛 × 3 grids, augmented with the agent’s absolute position and orientation, resulting in an 𝑛 × 𝑛 × 3 + 2 obser vation vector , where 𝑛 is the grid width and height. Each cell encodes object type, color identier , and state (e.g., open/closed doors). The agent acts in a 5-action discrete space ( turn, move, pick up, drop, toggle ). Diculty is scaled by enlarging grids, adding walls, and introducing lo cked doors with keys that must be retrieved and used in sequence, enfor cing multi-step planning even in small mazes. W e use handcrafted heuristics to validate if the generated environments ar e feasible ( c.f., § 6 Limitations). Episo des terminate when the agent reaches the goal tile or when the step horizon is reached. A selection of evolved environments is shown in Figure 3, with further implementation details in Appendix B.1. PyGame Geometric 2D Navigation. T o test LLM’s ability to deal with continuous action spaces , we use a custom 2D navigation envi- ronment in which a cir cular agent must reach a rectangular goal zone while avoiding xed rectangular obstacles. States are fully observable, consisting of the agent’s position and a list of all ob- jects (obstacles and goals) with their positions and sizes (gro wing in size for each new level). The agent acts in a continuous space through 2D velocity commands. Diculty increases when obsta- cles are added, the agent–goal distance is increased, and narrow passages are created that may block traversal. This requires agents to identify traversable corridors relative to their size and to plan long detours when direct routes are infeasible. Episodes terminate when the agent overlaps the goal zone or when the step horizon is reached. A selection of evolved environments is shown in Figure 4, with further details in Appendix B.2. CARLA Urban Driving. W e evaluate urban driving in CARLA Town01 , a high-delity simulator with vehicles, pedestrians, and Figure 3: A selection of evolved MiniGrid environments pro- duced by COvolve . Complexity increases from empty grids to larger mazes with dense walls and locke d doors requiring corresponding keys. The agent must reach the green goal tile, often by planning multi-step sequences of key retrieval and door unlocking. Figure 4: A selection of evolved Py Game environments pro- duced by COvolve . Tasks progress from op en arenas to clut- tered maps with dense obstacles and narrow corridors. The agent must reach the rectangular goal zone while navigating collision-free paths through increasingly constrained lay- outs. trac lights. The vehicle follows a prescribed route using con- tinuous steering, throttle, and brake controls. Obser vations are egocentric and partial, consisting of the vehicle ’s kinematics, the nearest trac light, and compact featur es of nearby vehicles and pedestrians. T ask diculty increases with varying trac density and pedestrian activity , introducing adversarial behaviors such as abrupt braking or trac-light violations. Episodes terminate upon route completion (success) or any infraction (collision, red-light violation, or timeout). This setting tests policy robustness under partial observability and multi-agent interactions with stochastic Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi and sometimes adversarial actors. A selection of ev olved environ- ments is shown in Figure 5, with further details in Appendix B.3. Figure 5: Selected CARLA environments produced by COvolve . T asks progress from urban driving on empty roads to crowded streets with increasingly aggressive actor behav- iors. The task for the agent is to drive along the street while following trac rules (such as stopping at red lights), and at the same time, adjust to increasingly unpredictable b ehav- iors of fellow drivers and pedestrians. 5.2 Results W e evaluate whether adversarial co-evolution with equilibrium rea- soning yields policies that b oth adapt to increasingly dicult envi- ronments and retain performance on previously generated ones. At each iteration, we compare three strategies: (i) UED-Greedy , which retains only the latest best policy; (ii) UED-Uniform , which samples uniformly from all p olicies generated up to the current iteration; and (iii) COvolve , which computes a mixed-strategy Nash equilibrium (MSNE) over the policy population. At iteration 𝑘 , all strategies are evaluated on the full environment archive { 𝜃 0 , . . . , 𝜃 𝑘 } . UED-Greedy evaluates only the latest policy when generating new environments, discarding earlier policies. UED-Uniform evalu- ates a uniform mixture ov er all policies generated up to the current iteration, controlling for mixture size without optimizing mixture weights. COvolve instead computes a mixe d-strategy Nash equi- librium over the policy population, selecting mixture weights that maximize the minimum return across the environment ar chive. Because co-evolution produces distinct environment archives across runs, results from dierent random seeds are not directly comparable: averaging would mix performance over non-identical evaluation sets. W e therefore report results from a single repr esen- tative run and provide r esults for a second see d in Appendix D.3. The results, presented in Figur e 6, report three views: (i) UED- Greedy , where the latest policy 𝜋 𝑘 is evaluated on all environments generated up to iteration 𝑘 ; (ii) COvolve , where p olicies are sample d from the MSNE and evaluated on the same environments; and (iii) a direct comparison between UED-Greedy and COvolve at iteration 𝑘 , with performance averaged across all environments. UED-Greedy policies are optimize d for the most recently gen- erated environment and exhibit reduce d performance on earlier environments (Figure 6, left). In contrast, the MSNE mixture main- tains performance across the full environment set as it grows over iterations (Figure 6, center ). The aggr egated comparison shows that, when the equilibrium is non-trivial, MSNE selection yields higher average p erformance than the latest-only UED-Gree dy strategy when evaluated across all environments (Figure 6, right). 5.3 Generalization W e evaluate generalization b eyond co-evolution on unseen stan- dardized benchmark environments that preserve the same under- lying task structure as the evolved environments. For MiniGrid, we consider MiniGrid-MultiRoom-N6-v0 (six rooms), MiniGrid- LockedRoom-v0 , and MiniGrid-DoorKey-16x16-v0 . For CARLA, we evaluate on Town02 , which is not encountered during co-evolution. At iteration 𝑘 , we compare three strategies under identical roll- out settings: UED-Greedy (latest-only policy), UED-Uniform , and the COvolve MSNE policy distribution. For UED-Uniform and COvolve , a policy is sampled at the beginning of each episode according to the corresponding mixture distribution. Detaile d environment spec- ications and their dierences from the evolved tasks are provided in App endix D.1. For each evolutionary seed, we run 100 evaluation episodes and compute the mean return. W e then report the mean and standard deviation across two seeds. W e do not report PyGame generalization results, as no standar dized evaluation benchmarks exist for this domain. Environment UED-Greedy UED-Uniform COvolve MiniGrid-MultiRoom-N6-v0 1 . 00 ± 0 . 00 0 . 86 ± 0 . 06 1 . 00 ± 0 . 00 DoorKey-16x16-v0 (MiniGrid) 1 . 00 ± 0 . 00 0 . 62 ± 0 . 24 1 . 00 ± 0 . 00 LockedRoom-v0 (MiniGrid) 1 . 00 ± 0 . 00 0 . 66 ± 0 . 16 1 . 00 ± 0 . 00 Town02 (CARLA) 0 . 62 ± 0 . 09 0 . 13 ± 0 . 06 0 . 71 ± 0 . 05 T able 1: Generalization to unse en environments. Results are reported as mean ± standard deviation across evolutionary seeds, with 100 evaluation episodes per seed. Importantly , these standardized environments ar e substantially simpler than the environments generated during co-evolution. In contrast, the evolved envir onments typically contain multiple se- quential key–door dependencies, narrow chokepoints, and adver- sarial obstacle placements; the benchmark tasks considered here involve at most a single locked door and a single key , with signi- cantly less constrained geometr y . As a result, strong performance on these unse en benchmarks, as indicated by Table 1, does not indicate overtting of the sp ecic environments, but rather that the learned policies have generalized. This also highlights the role of the environment designer in constructing tasks that are strictly COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game 0 2 4 6 8 Environment 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Score πi_0 πi_1 πi_2 πi_3 πi_4 πi_5 πi_6 πi_7 πi_8 πi_9 0 1 2 3 4 5 6 7 8 9 Environment 0.5 0.6 0.7 0.8 0.9 1.0 Score COvolve (last) π_argmax (π_9) π_last (π_9) 0 1 2 3 4 5 6 7 8 9 Iteration 0.0 0.2 0.4 0.6 0.8 1.0 Mean score over envs COvolve UED-UNIFORM UED-GREEDY 0 2 4 6 8 Environment 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Score πi_0 πi_1 πi_2 πi_3 πi_4 πi_5 πi_6 πi_7 πi_8 πi_9 0 1 2 3 4 5 6 7 8 9 Environment 0.5 0.6 0.7 0.8 0.9 1.0 Score MSNE (last) π_last (π_9) π_argmax (π_7) 0 1 2 3 4 5 6 7 8 9 Iteration 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Mean score over envs COvolve UED-UNIFORM UED-GREEDY 0 2 4 6 8 Environment 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Score πi_0 πi_1 πi_2 πi_3 πi_4 πi_5 πi_6 πi_7 πi_8 πi_9 0 1 2 3 4 5 6 7 8 9 Environment 0.5 0.6 0.7 0.8 0.9 1.0 Score COvolve (last) π_last (π_9) π_argmax (π_8) 0 1 2 3 4 5 6 7 8 9 Iteration 0.0 0.2 0.4 0.6 0.8 1.0 Mean scor e over envs COvolve UED-UNIFORM UED- GREED Y Figure 6: Performance during environment–policy co-evolution. Left: Success rates of all discovered p olicies evaluated on all environments generated during evolution (policy–environment payo matrix). Center: Comparison between the mixed- strategy Nash equilibrium (MSNE) policy mixture, the b est single policy 𝜋 argmax , and the latest policy 𝜋 𝑘 , evaluated on the environment archive { 𝜃 0 , . . . , 𝜃 𝑘 } . Here, 𝜋 argmax denotes the policy that maximizes mean performance over the entire archive. For MiniGrid, 𝜋 argmax = 𝜋 𝑘 . Right: Mean success over { 𝜃 0 , . . . , 𝜃 𝑘 } for three strategies: UED-Gree dy ( latest policy only), UED-Uniform (uniform mixture over all policies), and COvolve (MSNE mixture). As evolution progresses and the latest p olicy forgets earlier environments, the MSNE mixture assigns probabilities to earlier policies to preser ve worst-case performance over the archive. harder than canonical benchmarks, ee ctively inducing a challeng- ing curriculum during co-evolution. 5.4 Ablation Studies Is curriculum necessary? W e perform a zero-shot ablation in which the LLM generates p olicies directly for the hardest envi- ronment in each domain, without exposure to intermediate envi- ronments. Starting from an initial policy , the LLM applies up to 𝑘 mutation steps and we r etain the b est-performing policy . As sho wn in Figure 7, zero-shot generation consistently fails, demonstrating that progressive curriculum construction is necessary for ee ctive policy synthesis. How do neural network-based RL approaches compare to LLM- generated code-as-policies in solving fully observable environments? T o test whether standard RL can solve our fully obser vable evalua- tion tasks, we trained representative Stable-Baselines3 agents [ 37 ] – PPO [ 40 ] and SAC (continuous control) [ 16 ] for Py Game, and PPO and QR-DQN (discr ete) [ 7 ] for MiniGrid. Despite full observ- ability , performance degrades sharply with task complexity: PPO and QR-DQN achieve near-zero rewards and success rates in the harder environments (SA C shows only limited improvements). See Appendix D.2 for details regarding training settings, cur ves, and success rates. How do weaker language mo dels p erform compared to the latest, state-of-the-art mo dels? W e repeat the co-evolution procedure us- ing GPT -4.1 as a w eaker generative model, keeping prompts and evaluation settings the same. Figur e 8 reports results for a single run, comparing MSNE and UED-Gree dy across domains. Although GPT -4.1 produces simpler environments and weaker policies, MSNE consistently outperforms UED-Gr eedy and remains robust o ver the environment archive . 6 Conclusions W e introduce d COvolve , a framew ork in which large language models generate environments and policies in a closed loop. The interaction between environment design and policy design is for- mulated as a two-player zer o-sum game, and learning is performed over growing populations of environments and policies. Solving Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi Zer o -shot MSNE_0 MSNE_9 0.0 0.2 0.4 0.6 0.8 1.0 Scor e 0.00 0.00 0.91 Zer o -shot MSNE_0 MSNE_9 (a) MiniGrid Zer o -shot MSNE_0 MSNE_9 0.0 0.2 0.4 0.6 0.8 1.0 Scor e 0.00 0.00 0.85 Zer o -shot MSNE_0 MSNE_9 (b) PyGame Zer o -shot MSNE_0 MSNE_9 0.0 0.2 0.4 0.6 0.8 1.0 Scor e 0.00 0.00 0.69 Zer o -shot MSNE_0 MSNE_9 (c) CARLA Figure 7: Result on curriculum learning. Direct training on the hardest envir onment (“Zero-shot”) fails, while co- evolutionary MSNE with curriculum ( right bars ) yields non- trivial performance. for a mixed-strategy Nash e quilibrium yields a meta-policy that optimizes worst-case performance across the empirical set of gen- erated environments and provides a population-level objective for continual adaptation. Experiments in urban driving, symbolic maze solving, and geo- metric navigation show that COvolve produces an emergent cur- riculum with environments that exhibit increasing structural com- plexity . These results demonstrate that a game-theoretic formu- lation of policy and environment generation enables robust co- evolution and automated curriculum construction without pr ede- ned task distributions. Limitations and Future W ork. Unconstrained LLM-generated environments can be infeasible. T o prevent this, the environment designer is restricted to using pr edened helper functions that ensure feasibility in each domain. Environments that violate these 0 1 2 3 4 5 6 7 8 9 Iteration 0.00 0.20 0.40 0.60 0.80 1.00 Scor e -0.00 -0.00 -0.00 +0.05 +0.07 +0.16 +0.19 +0.15 +0.11 +0.23 (a) MiniGrid 0 1 2 3 4 5 6 7 8 9 Iteration 0.00 0.20 0.40 0.60 0.80 1.00 Scor e +0.00 +0.00 +0.00 +0.00 +0.03 +0.09 +0.02 +0.00 +0.06 +0.03 (b) PyGame 0 1 2 3 4 5 6 7 8 9 Iteration 0.00 0.20 0.40 0.60 0.80 1.00 Scor e +0.00 +0.00 +0.00 +0.00 +0.02 +0.05 +0.05 +0.00 +0.12 +0.09 (c) CARLA Figure 8: Ablation with a weaker generative model (GPT - 4.1). Comparison b etween UED-Greedy and COvolve (MSNE) across domains. While overall performance degrades due to weaker generation, MSNE consistently mitigates forgetting and maintains robustness across the environment archive. constraints are never sampled or evaluated. Details of these help er functions are provided in Appendix B. Future work could focus on more principled control of environment diculty , for example, by incorporating minimax regret [ 9 ], to provide formal guarantees on curriculum progression rather than relying on domain-specic heuristics. Additional directions include strengthening diversity checks during environment generation. Acknowledgments This work is supported by Knut and Alice W allenberg Founda- tion via the W allenb erg AI A utonomous Sensors Systems and the W allenb erg Scholars Grant. COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game References [1] Y oram Bachrach, Edan T oledo, Karen Hambardzumyan, Despoina Magka, Mar- tin Josifoski, Minqi Jiang, Jakob Fo erster , Roberta Raileanu, T atiana Shavrina, Nicola Cancedda, A vraham Ruderman, K atie Millican, Andrei Lupu, and Rishi Hazra. 2025. Combining Code Generating Large Language Models and Self- Play to Iteratively Rene Strategies in Games. In Proceedings of the Thirty- Fourth International Joint Conference on A rticial Intelligence, IJCAI-25 . Interna- tional Joint Conferences on Articial Intelligence Organization, 10999–11003. doi:10.24963/ijcai.2025/1249 Demo Track. [2] Osbert Bastani, Y ewen Pu, and Armando Solar-Lezama. 2018. V eriable reinforce- ment learning via policy extraction. Advances in neural information processing systems 31 (2018). [3] Lili Chen, Mihir Prabhudesai, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. 2025. Self-Questioning Language Models. arXiv:2508.03682 [cs.LG] https: //arxiv .org/abs/2508.03682 [4] Maxime Chevalier-Boisvert, Bolun Dai, Mark T owers, Rodrigo Perez- Vicente, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jor dan T err y . 2023. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. Advances in Neural Information Processing Systems 36 (2023), 73383–73394. [5] Je Clune. 2020. AI-GAs: AI-generating algorithms, an alternate paradigm for producing general articial intelligence. arXiv:1905.10985 [cs.AI] https: //arxiv .org/abs/1905.10985 [6] Karl Cobbe, Christopher Hesse, Jacob Hilton, and John Schulman. 2020. Lever- aging procedural generation to benchmark reinforcement learning (ICML’20) . JMLR.org, Article 191, 9 pages. [7] Will Dabney , Mark Rowland, Marc G. Bellemare, and Rémi Munos. 2017. Distributional Reinforcement Learning with Quantile Regression. arXiv:1710.10044 [cs.AI] https://arxiv .org/abs/1710.10044 [8] Nicola Dainese, Matteo Merler , Minttu Alakuijala, and Pekka Marttinen. 2024. Generating Code W orld Models with Large Language Models Guided by Monte Carlo Tr ee Search. In The Thirty-eighth A nnual Conference on Neural Information Processing Systems . https://openreview .net/forum?id=9Sp W vX9ykp [9] Michael Dennis, Natasha Jaques, Eugene Vinitsky, Alexandre Bayen, Stuart Russell, Andrew Critch, and Sergey Levine. 2020. Emergent complexity and zero-shot transfer via unsupervised environment design. In Advances in neural information processing systems . [10] Alexey Dosovitskiy , German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. 2017. CARLA: An open urban driving simulator. In Confer ence on robot learning . PMLR, 1–16. [11] Kevin Ellis, Lionel W ong, Maxwell Nye, Mathias Sable-Meyer , Luc Cary, Lor e Anaya Pozo, Luke Hewitt, Armando Solar-Lezama, and Joshua B Tenenbaum. 2023. DreamCoder: growing generalizable, interpretable knowledge with wake– sleep Bayesian program learning. Philosophical Transactions of the Royal Society A 381, 2251 (2023), 20220050. [12] Maxence Faldor, Jenny Zhang, Antoine Cully , and Je Clune. 2025. OMNI- EPIC: Open-endedness via Models of human Notions of Interestingness with Environments Programmed in Code. In The Thirte enth International Conference on Learning Representations . https://openreview .net/forum?id=Y1XkzMJpPd [13] John Forrest and Ted Ralphs. 2005. CBC: COIN-OR Branch and Cut Solver . https://github.com/coin- or/Cbc. V ersion accessed: 2024. [14] Léo Françoso Dal Piccol Sotto, Paul Kaufmann, Timothy Atkinson, Roman Kalkreuth, and Márcio Porto Basgalupp. 2021. Graph representations in ge- netic programming. Genetic Programming and Evolvable Machines 22, 4 (2021), 607–636. [15] Dibya Ghosh, Jad Rahme, A viral Kumar , Amy Zhang, Ryan P Adams, and Sergey Levine. 2021. Why generalization in rl is dicult: Epistemic pomdps and implicit partial observability . Advances in neural information processing systems 34 (2021), 25502–25515. [16] T uomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft Actor-Critic: O-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor . arXiv:1801.01290 [cs.LG] https://arxiv .org/abs/1801.01290 [17] Rishi Hazra, Alkis Sygkounas, Andreas Persson, Amy Lout, and Pedro Zuid- berg Dos Martires. 2025. REvolve: Reward Evolution with Large Language Models using Human Feedback. In The Thirteenth International Conference on Learning Representations . https://openreview .net/forum?id=cJPUpL8mO w [18] Chengsong Huang, W enhao Y u, Xiaoyang W ang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Y u. 2025. R-Zero: Self-Evolving Reasoning LLM from Zero Data. arXiv:2508.05004 [cs.LG] https://arxiv .org/abs/ 2508.05004 [19] Jeevana Priya Inala, Osbert Bastani, Zenna Tavares, and Armando Solar-Lezama. 2020. Synthesizing programmatic policies that inductively generalize. In 8th International Conference on Learning Representations . [20] Nick Jakobi. 1997. Evolutionary robotics and the radical envelope-of-noise hypothesis. Adaptive behavior 6, 2 (1997), 325–368. [21] Minqi Jiang, Edward Grefenstette, and Tim Rocktäschel. 2021. Prioritized level replay . In Advances in Neural Information Processing Systems (NeurIPS) . [22] Robert Kirk, Amy Zhang, Edward Grefenstette, and Tim Rocktäschel. 2023. A Survey of Zero-shot Generalisation in Deep Reinforcement Learning. J. A rtif. Int. Res. 76 (May 2023), 64 pages. doi:10.1613/jair .1.14174 [23] Ezgi Korkmaz. 2024. A Survey Analyzing Generalization in Deep Reinforcement Learning. arXiv:2401.02349 [cs.LG] https://arxiv .org/abs/2401.02349 [24] Marc Lanctot, Vinicius Zambaldi, A udrunas Gruslys, Angeliki Lazaridou, K arl T uyls, Julien Perolat, David Silver , and Thore Graepel. 2017. A Unie d Game- Theoretic Approach to Multiagent Reinforcement Learning. In Advances in Neural Information Processing Systems , I. Guyon, U. V on Luxburg, S. Bengio, H. W allach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), V ol. 30. Cur- ran Associates, Inc. https://proceedings.neurips.cc/pap er_les/paper/2017/le/ 3323fe11e9595c09af38fe67567a9394- Pap er .pdf [25] Jacky Liang, W enlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter , Pete Florence , and Andy Zeng. 2023. Code as policies: Language model programs for embo died control. In 2023 IEEE International Conference on Rob otics and Automation (ICRA) . IEEE, 9493–9500. [26] William Liang, Sam W ang, Hung-Ju Wang, Osbert Bastani, Dinesh Jayara- man, and Y echeng Jason Ma. 2024. Environment Curriculum Generation via Large Language Models. In 8th A nnual Conference on Robot Learning . https: //openreview .net/forum?id=F0r WEID2gb [27] Zi Lin, Sheng Shen, Jingbo Shang, Jason W eston, and Yixin Nie. 2025. Learn- ing to Solve and V erify: A Self-Play Framework for Code and T est Generation. arXiv:2502.14948 [cs.SE] https://arxiv .org/abs/2502.14948 [28] Shaoteng Liu, Hao qi Yuan, Minda Hu, Y anwei Li, Yukang Chen, Shu Liu, Zongqing Lu, and Jiaya Jia. 2024. RL-GPT: Integrating Reinforcement Learning and Code-as-policy. In The Thirty-eighth A nnual Conference on Neural Information Processing Systems . https://openreview .net/forum?id=LEzx6QRkRH [29] Y echeng Jason Ma, William Liang, Guanzhi W ang, De- An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar . 2024. Eureka: Human-Level Re ward Design via Coding Large Language Models. In The T welfth International Conference on Learning Representations . https://openreview .net/ forum?id=IEduRUO55F [30] Stuart Mitchell, Michael OSullivan, and Iain Dunning. 2011. Pulp: a linear programming toolkit for python. The University of Auckland, Auckland, New Zealand 65 (2011), 25. [31] Jun Morimoto and Kenji Doya. 2005. Robust reinforcement learning. Neural computation 17, 2 (2005), 335–359. [32] John Nash. 1951. Non-Coop erative Games. Annals of Mathematics 54, 2 (1951), 286–295. http://www .jstor .org/stable/1969529 [33] OpenAI. 2025. Introducing GPT -5.2. https://openai.com/index/introducing- gpt- 5- 2/ [34] Martin J Osborne and Ariel Rubinstein. 1994. A course in game theory . MI T press. [35] Lerrel Pinto, James Davidson, and Abhinav Gupta. 2017. Sup ervision via compe- tition: Robot adversaries for learning tasks. In 2017 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 1601–1608. [36] PyGame Community. 2000–2024. PyGame: Python Game Development. https: //www.p ygame.org/. Accessed: 2025-05-09. [37] Antonin Ran, Ashley Hill, Adam Gleave , Anssi Kanervisto, Maximilian Ernes- tus, and Noah Dormann. 2021. Stable-Baselines3: Reliable Reinforcement Learn- ing Implementations. Journal of Machine Learning Research 22, 268 (2021), 1–8. http://jmlr .org/papers/v22/20- 1364.html [38] Antonin Ran, Ashley Hill, Adam Gleave , Anssi Kanervisto, Maximilian Ernes- tus, and Noah Dormann. 2021. Stable-baselines3: Reliable reinforcement learning implementations. Journal of Machine Learning Research 22, 268 (2021), 1–8. [39] Mikayel Samvelyan, Akbir Khan, Michael D Dennis, Minqi Jiang, Jack Parker- Holder , Jakob Nicolaus Foerster , Roberta Raileanu, and Tim Rocktäschel. 2023. MAESTRO: Open-Ended Environment Design for Multi- Agent Reinforcement Learning. In The Eleventh International Conference on Learning Representations . https://openreview .net/forum?id=sKWlRDzPfd7 [40] John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . 2017. Proximal Policy Optimization Algorithms. arXiv:1707.06347 [cs.LG] https: //arxiv .org/abs/1707.06347 [41] David Silver and Richard S. Sutton. 2025. W elcome to the Era of Experience. In Designing an Intelligence . MI T Press. [42] Ishika Singh, V alts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay , Dieter Fox, Jesse Thomason, and Animesh Garg. 2022. ProgPrompt: Generating Situated Robot T ask P lans using Large Language Models. In W orkshop on Language and Robotics at CoRL 2022 . https://openreview .net/forum?id=3K4- U_5cRw [43] Hao Tang, Darren Ke y , and Ke vin Ellis. 2024. W orldCo der , a Mo del- Based LLM Agent: Building W orld Models by Writing Code and Inter- acting with the Environment. In Advances in Neural Information Pro- cessing Systems , A. Globerson, L. Mackey , D. Belgrave, A. Fan, U. Pa- quet, J. T omczak, and C. Zhang (Eds.), V ol. 37. Curran Associates, Inc., 70148–70212. https://proceedings.neurips.cc/pap er_les/paper/2024/le/ 820c61a0cd419163ccbd2c33b268816e- Paper- Conference.pdf Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi [44] Josh T obin, Rachel Fong, Alex Ray , Jonas Schneider , W ojcie ch Zaremba, and Pieter Abbeel. 2017. Domain randomization for transferring deep neural networks from simulation to the real world. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . 23–30. [45] Dweep Trivedi, Jesse Zhang, Shao-Hua Sun, and Joseph J Lim. 2021. Learning to synthesize programs as interpretable and generalizable policies. Advances in neural information processing systems 34 (2021), 25146–25163. [46] Abhinav V erma, Vijayaraghavan Murali, Rishabh Singh, Pushmeet Kohli, and Swarat Chaudhuri. 2018. Programmatically interpretable reinforcement learning. In International conference on machine learning . PMLR, 5045–5054. [47] Pablo Villalobos, Anson Ho, Jaime Sevilla, T amay Besiroglu, Lennart Heim, and Marius Hobbhahn. 2024. Will we run out of data? Limits of LLM scaling based on human-generated data. arXiv:2211.04325 [cs.LG] https://ar xiv .org/abs/2211. 04325 [48] Guanzhi W ang, Y uqi Xie, Y unfan Jiang, Ajay Mandlekar , Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar . 2024. V oyager: An Open-Ended Embodied Agent with Large Language Models. Transactions on Machine Learning Research (2024). https://openreview .net/forum?id=ehfRiF0R3a [49] Lirui W ang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar , Chen Bao, Yuzhe Qin, Bailin W ang, Huazhe Xu, and Xiaolong W ang. 2024. GenSim: Generating Robotic Simulation Tasks via Large Language Models. In The Twelfth Interna- tional Conference on Learning Representations . https://openreview .net/forum? id=OI3RoHo W AN [50] Rui W ang, Joel Lehman, Je Clune, and Kenneth O . Stanley . 2019. Paired Op en- Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Di- verse Learning Environments and Their Solutions. arXiv:1901.01753 [cs.NE] https://arxiv .org/abs/1901.01753 [51] Yinjie W ang, Ling Y ang, Y e Tian, K e Shen, and Mengdi W ang. 2025. Co-Evolving LLM Coder and Unit T ester via Reinforcement Learning. arXiv:2506.03136 [cs.CL] https://arxiv .org/abs/2506.03136 [52] Y ao W en Y ang, Jian Feng Xu, and Che e Kiong Soh. 2006. An evolutionary programming algorithm for continuous global optimization. European journal of operational research 168, 2 (2006), 354–369. COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game Appendix The appendix is organized as follows. Section A details the co- evolution algorithm and Nash distribution computation. Section B provides environment implementation specics for the used sim- ulators (i.e., MiniGrid, PyGame, and CARLA). Section C lists the exact prompts used for environment and policy generation. Sec- tion D reports additional e xperimental r esults, including generaliza- tion and reinforcement learning baselines. Se ction E presents the best-performing policies per domain. Finally , Section F illustrates examples of evolv ed environments and their mutation progress. A Algorithmic Details Co-Evolution Lo op. At each generation 𝑡 , the system performs a mutation-based search to synthesize a new environment 𝜃 𝑡 and a corresponding policy 𝜋 𝑡 . Environment mutation generates 𝐾 can- didate environments by perturbing the previous one, 𝜃 𝑡 − 1 . Each candidate is evaluated under the Nash distribution 𝑤 𝑡 − 1 over poli- cies from earlier iterations, and the candidate with the lowest ex- pected return is selecte d. Policy mutation is initialized from the highest-weighted policy 𝜋 best under 𝑤 𝑡 − 1 . The policy LLM gener- ates 𝐾 mutated versions of this base policy , which are evaluated solely on 𝜃 𝑡 , and the best-p erforming policy is selecte d. The pair ( 𝜃 𝑡 , 𝜋 𝑡 ) is added to the archive, and the payo matrix 𝑀 ∈ [ 0 , 1 ] 𝑡 × 𝑡 is updated accordingly . Nash Distribution Computation. T o determine the current policy mixture, we solv e a two-player zero-sum game dened by the em- pirical payo matrix 𝑀 . W e compute the Nash equilibrium policy distribution by solving the dual linear program of a two-player zero- sum game over the empirical payo matrix 𝑀 . The optimization is formulated using PuLP [ 30 ] and solved using the CBC backend solver [ 13 ]. The solution yields a probability distribution over policies that minimizes the worst-case environment return: 𝑤 𝑡 = arg max 𝑤 ∈ Δ 𝑡 min 𝑖 𝑗 𝑤 𝑗 𝑀 𝑖 𝑗 . B Environment Details All environments are being provided, at generation 0, with heuris- tics to ensure solvability for the specic task. For the environment to be generated, at least one solution is required. B.1 MiniGrid Implementation Details The MiniGrid environment represents a 2D grid-world where each cell encodes the presence of objects, walls, keys, doors, and other entities. The environment supports exible congurations of size , object placement, and symbolic dependencies, making it suitable for general planning tasks. Action Space. The agent interacts with the environment using a discrete action space of six primitive actions: • TURN_LEFT (0): Rotate the agent 90 ° counterclockwise. • TURN_RIGHT (1): Rotate the agent 90 ° clockwise. • MOVE_FORWARD (2): Advance one tile forward, if the path is free. • PICK_UP (3): Pick up an obje ct in front, used for collecting keys. • DROP (4): Drop the currently carried object onto the tile in front. • TOGGLE (5): Interact with doors in front of the agent: – Open a close d door (ST A TE = 1). – Unlock a locked do or (ST A TE = 2) if carrying the cor- rect key . Tile Encoding. Each grid tile is encoded as a 3-tuple of integers: (OBJECT_IDX, COLOR_IDX, STATE) This structured representation is provided in a fully observable grid array . The indexing is spatial, with (x, y) referring to grid row and column, respectively . T able 2: MiniGrid OBJECT_IDX Mappings 0 Unseen 1 Empty 2 W all 3 F loor 4 Door 5 Key 6 Ball 7 Box 8 Goal 9 Lava 10 Agent T able 3: Door State Field 0 Open (passable) 1 Closed (toggle to op en) 2 Locke d (requires key to unlock and toggle) Environment Logic. Doors and keys are linked by color indices, with up to six distinct colors available. Lo cked doors block the agent’s path until the corresponding key is acquired. The envi- ronment enforces procedural placement constraints, ensuring at least one feasible path exists through BFS-based solvability che cks. W alls and other obstacles further complicate navigation. The agent maintains a single-key capacity , ne cessitating key management and path re-planning in multi-door congurations. Observations. At each timestep, the agent receives a fully obser v- able grid state represented as a attene d tensor of shap e (grid_size × grid_size × 3) , normalized to [ 0 , 1 ] . Each tile encodes the ob- ject type, color index, and dynamic state (e.g., door status) as dened by the environment’s tile encoding scheme. In addition, the policy receives the agent’s absolute p osition (agent_pos) and current orientation (agent_dir) , enabling precise spatial reasoning and orientation-dependent actions. This structured input enables poli- cies to perform symbolic reasoning without perceptual ambiguity , allowing them to focus solely on decision-making and planning. Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi Figure 9: Example of a generate d MiniGrid environment (cf. Fig. 3). For this environment, the agent (red arrow) must reach the green goal tile by unlocking the intermediate colored doors using the corresponding keys. B.2 PyGame Implementation Details In the PyGame environment, each instance denes a bounded 2D plane in pixel space, with task-sp ecic width and height parameters. The agent is modeled as a circular b ody with a xed physical radius of 15 pixels, while the goal zone is a rectangular target area guaran- teed to fully contain the agent’s circle upon successful completion. Obstacles are axis-aligned rectangles with randomly positioned and size d dimensions. Their placement follows strict feasibility constraints: • Obstacles must not overlap with the goal zone. • Obstacles must not overlap with each other . • New obstacles are placed only if their inated bounding box (expanded by the agent’s radius) does not intersect existing obstacles, ensuring local non-overlap and feasible placement. Action and Observation Spaces. The agent selects a continuous 2D velocity vector [dx, dy] ∈ [ − 1 . 0 , 1 . 0 ] 2 at each timestep. This vector is scaled by an envir onment-dened spee d factor to deter- mine pixel-wise displacement. Collision detection is p erformed for each proposed mo vement; invalid moves that w ould result in obsta- cle penetration or leaving environment bounds are rejected, leaving the agent stationary . Observations are provided as a structured dictionary containing: • agent_pos : The agent’s center coordinates in pixels. • objects : A list describing the goal zone and each obstacle, with entries specifying type , pos , size , and (for the goal zone) purpose . Figure 10: Example of a generated PyGame environment (cf. Fig. 4). In this environment, the agent ( blue circle) must navigate the environment spatially to reach the goal (green rectangle). • step_count : The current timestep within the episode. T ask Parameters. T ask diculty is progressively scaled by modi- fying environment parameters, including: • The number of obstacles, increasing clutter , and requiring more deliberate path planning. • The environment’s width and height, expanding navigation complexity . • The agent’s movement speed, reducing maneuverability . • The minimum agent-goal start distance, forcing longer tra- versal paths. These parameters are dynamically adjuste d by the environment generator to produce increasingly challenging, yet solvable, task instances. Episode T ermination and Reward. An episode terminates when the agent’s circular body is entirely within the goal zone or when the maximum allowed steps are exhausted. Feasibility Guarante es. T o ensure the agent can navigate to the goal, the environment performs a reachability check using a dis- cretized o ccupancy grid that inates obstacle regions by the agent’s radius. This guarantees that all generated tasks are physically fea- sible for the agent to complete. Invalid placements of obstacles or agent start positions are rejected during the generation process. This process ensures that every evaluation involves meaningful, solvable navigation challenges with non-trivial spatial reasoning requirements. B.3 CARLA Implementation Details Simulator and Map. W e use CARLA Town01 in synchronous mode with a xed time step. The route is a recorded closed polyline. The roadway is a two-way single carriageway: one lane per direc- tion, each ≈ 4 m wide (total ≈ 8 m ). Each episode spawns the ego COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game Figure 11: Example of a generated CARLA environment (cf. Fig. 5). From the ego viewpoint, the car perceives pe des- trians, trac lights, and other vehicles as describe d in Ap- pendix B.3. The red car to the right of the ego vehicle (T esla v3) was intentionally placed (from the LLM) to confuse the policy . at a xed start; non-ego vehicles and pedestrians are randomized. Episodes terminate on collision, red-light violation, timeout, or loop completion. Frenet Ge ometry and Progress. Let the route be a looped p olyline { 𝑃 𝑖 } 𝑁 𝑖 = 1 . For a world point 𝑝 ∈ R 2 , we project onto each segment 𝑡 𝑖 = clip ( 𝑝 − 𝑃 𝑖 ) ⊤ ( 𝑃 𝑖 + 1 − 𝑃 𝑖 ) ∥ 𝑃 𝑖 + 1 − 𝑃 𝑖 ∥ 2 2 , 0 , 1 , ˆ 𝑝 𝑖 = 𝑃 𝑖 + 𝑡 𝑖 ( 𝑃 𝑖 + 1 − 𝑃 𝑖 ) . Let 𝑘 = arg min 𝑖 ∥ 𝑝 − ˆ 𝑝 𝑖 ∥ 2 , segment length ℓ 𝑘 = ∥ 𝑃 𝑘 + 1 − 𝑃 𝑘 ∥ 2 , and cumulative arclength up to segment 𝑘 be 𝑠 𝑘 . W e dene arclength and lateral oset: 𝑠 ( 𝑝 ) = 𝑠 𝑘 + 𝑡 𝑘 ℓ 𝑘 , ℓ ⊥ ( 𝑝 ) = ( 𝑝 − ˆ 𝑝 𝑘 ) ⊤ n 𝑘 , n 𝑘 = 1 ℓ 𝑘 − 𝑑 𝑘 ,𝑦 𝑑 𝑘 ,𝑥 . Progress from the episode start 𝑠 0 wraps on the loop: Δ 𝑠 = ( 𝑠 ( 𝑝 ) − 𝑠 0 ) mod 𝐿 , with loop length 𝐿 . W e express relative positions/veloci- ties in the ego frame via 𝑅 we ( 𝜓 ) = cos 𝜓 sin 𝜓 − sin 𝜓 cos 𝜓 . The yaw error is Δ 𝜓 = ( ( 𝜓 − 𝜓 path + 𝜋 ) mod 2 𝜋 ) − 𝜋 . Observation Space. W e expose only the featur es the policy needs to drive on a prescribed path while interacting with trac and pedestrians: Ego kinematics. Sp eed speed_mps , yaw rate yaw_rate_rps , lat- eral error ℓ ⊥ , yaw error Δ 𝜓 . Short histories ( length 4) for { speed, lateral error , yaw error , past steer/throttle/brake } stabilize control. Trac light. Nearest trac light ahead on the route: exists , dist_m , state ∈ { Red , Green , Yellow }. For simplicity , Y ellow is treated as Red. V ehicles. W e ke ep a small, order ed snapshot (top-2) per class with ego-frame gaps and simple surrogates: THW = 𝑔 𝑥 max ( 0 . 5 , 𝑣 ego ) , T TC = ( 𝑔 𝑥 / ( − Δ 𝑣 𝑥 ) , Δ 𝑣 𝑥 < 0 null , otherwise. Lead cars are those with Frenet lateral | ℓ ⊥ | ≤ 2 m (ego lane). Opposite cars fall in − 6 ≤ ℓ ⊥ < − 2 m (oncoming lane). Pedestrians. Within a forward window along the route, we clas- sify: (i) in-lane if | 𝑔 𝑦 | ≤ 2 m ; (ii) approaching if 2 < | 𝑔 𝑦 | ≤ 3 m and moving toward the lane ( Δ 𝑣 𝑦 𝑔 𝑦 < 0 ). For approaching walkers, we estimate time-to-enter the near lane edge, 𝑡 enter = ( 𝑦 ★ − 𝑔 𝑦 ) / Δ 𝑣 𝑦 when | Δ 𝑣 𝑦 | is non-negligible, where 𝑦 ★ = ± 2 m. Action Space. A continuous 3-vector ( steer , throttle , brake ) with steer ∈ [− 1 , 1 ] , throttle ∈ [ 0 , 1 ] , brake ∈ [ 0 , 1 ] . Notes. This design yields a small, interpr etable state while cov- ering path tracking (via ℓ ⊥ , Δ 𝜓 ), car-following and oncoming inter- actions (via THW/T TC and lane bands), signal compliance (trac- light snapshot), and pedestrian crossing risk (in-lane vs. approach- ing with 𝑡 enter ). All constants and implementation details ( e.g., hori- zons, smoothing) are provided in our code release. Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi C Prompts W e provide the exact prompts used for environment and policy generation in each domain. These are instantiated dynamically at each iteration, reecting task-specic parameters and environment congurations. C.1 Environment Generation Prompts Box 1: MiniGrid Environment Prompt GOAL Minimize the scalar "Actual Score" in [0,1] evaluated on the Nash-weighted policy mix: {Weights} {Policies} You will return a SINGLE Python class that replaces the existing: class CustomEnv(MiniGridEnv): REQUIREMENTS (MANDATORY) 1) Class: - Keep "class CustomEnv(MiniGridEnv):" and its public API exactly. - Do not modify the base class or inheritance. 2) - If you add helpers, define them inside the same file . - Do not rely on undefined globals or external dependencies. 3) Fixed knobs in __init__ - Set once ( and only here): self.size = {Size} self.num_doors = min ({NumDoors}, 6) - "_gen_grid()" must use these fixed values directly (no dynamic rescaling). 4) Structured placement - Place perimeter, rooms/corridors, doors, keys, and goal via explicit logic. - Do not place objects blindly or randomly. 5) Solvability check - After placements, call "check_solvable(self, start, goal)" exactly as provided. - Accept the layout only if it returns True. 6) Episode diversity - "_gen_grid()" must generate different layouts across episodes (vary partitions, door indices, key pockets) while using the fixed knobs. 7) Termination - Episode ends when (a) the agent reaches the goal, or (b) max_steps is exceeded. 8) Retry policy - If unsolvable, retry up to 1000 times. - If still unsolvable, set "self.failure_feedback" and return . FEASIBILITY FUNCTIONS (DO NOT MODIFY) - "_verify_mandatory_door_keys(self)" - "bfs_ignore_doors(self, start, goal)" - "bfs_block_locked(self, start, goal)" - "_find_key_spot_block_locked(self, agent_pos, door_pos, unlocked_colors)" Use these as - is . You may add helpers, but never replace or alter them. OUTPUT Return ONLY the updated "CustomEnv" class (no commentary). Box 2: PyGame Environment Prompt GOAL Minimize the scalar "Actual Score" in [0,1] evaluated on the Nash-weighted policy mix: {Weights} {Policies} REQUIREMENTS (MANDATORY) 1) Class/API - Keep "class CustomEnv:" and its public API exactly. - Do not change the class name or inheritance. 2) Implement only these methods: - reset(self) - step(self, action) - draw_objects(self) - task_description(self) - _get_obs(self) - render(self) - Any private helpers defined inside the class (e.g., _handle_quit, _sample_pos). 3) task_description(self) - Must return a plain string describing: - The task objective (agent must reach the goal zone). - The action space (continuous [dx,dy] in [-1.0,1.0]^2). - Key parameters (sizes, margins, speeds). - The full observation dictionary structure. 4) Episode termination - Ends if agent reaches the goal (checked externally by _check_done()). - Ends if max_steps is exceeded. - Do not call _check_done() inside step(). 5) Structured placement - Place agent, goal, and obstacles via explicit rules. - Ensure no overlaps; keep all objects inside bounds. - Guarantee solvability (always at least one valid path). 6) Randomization - Use structured randomness (np.random.randint, np.random.uniform) in reset(). - Every reset() must produce a distinct environment instance. - Randomness must contribute to meaningful diversity. 7) Safety - The goal zone must be large enough: width,height >= 2*agent_radius + margin. 8) Behavior - step(action): interpret action as 2D continuous move. - Call self._handle_quit() at the start to process quit events. - Return (obs, reward, done) where obs=self._get_obs(), reward=0.0, done=self. done. 9) Observations - _get_obs() must return : { "agent_pos" : [x,y], "agent_radius" : r, "objects" : [ { "type" : "zone" , "pos" :[cx,cy], "size" :[w,h], "purpose" : "goal" }, { "type" : "obstacle" , "shape" : "rect" , "pos" :[cx,cy], "size" :[w,h] }, ... ], "bounds" : [W,H], "step_count" : N, "max_steps" : M } 10) Rendering - draw_objects(): use pygame primitives; only draw if self.render_mode==True. - render(): create/update PyGame surface, call draw_objects(), flip buffers if render_mode==True. TASK EVOLUTION - Increase distance between agent and goal. - Add obstacles or tighter passages. - Increase W,H and proportionally increase max_steps. - You are free and motivated to introduce new difficulties as long as the task remains the same: The agent must reach the goal zone. CONSTRAINTS - Do NOT add symbolic puzzles (no keys, doors, colors). - Do NOT use MiniGrid tile logic. - Do NOT add irrelevant randomness. - Do NOT remove or rename required methods. - Do NOT alter the external _check_done(). OUTPUT Return ONLY the updated "CustomEnv" class (no commentary). COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game Box 3: CARLA Environment Prompt GOAL Minimize the scalar "Actual Score" in [0,1] evaluated on the Nash-weighted policy mix: {Weights} {Policies} Current environment performance: {ActualScore} You will return a SINGLE Python class that replaces the existing: {Actual_Class} MUTATION CONSTRAINT - Apply exactly ONE structural change to the class . - A structural change is defined as : (i) adding or removing a single environment component or behavior, OR (ii) (ii) modifying the logic of a single existing component (within a single method). - All other code must remain semantically identical. REQUIREMENTS (MANDATORY) 1) Class - Keep the class name "CarlaTown01Env" exactly. - Preserve all existing methods; you may add new helpers inside the class . 2) Task identity - Ego vehicle is always vehicle.tesla.model3. - Start and goal follow the same Town01 loop. - Do not spawn oversized vehicles (buses, trucks) or actors that may block solvability. 3) task_description(self) - Must return a plain string describing: - The driving objective (complete the loop without collisions). - Key environment elements (traffic, pedestrians, lights, dynamic behaviors). - The observation dictionary fields provided to the policy. - If new fields are added to obs (via get_obs), they must be explicitly documented in this string. - Do not remove fields; only extend if needed. 4) Observations - get_obs() must remain consistent with the description. - The observation dictionary includes ego state, histories, traffic lights, lead cars, opposite cars, pedestrians. - New factors (e.g., jaywalkers, lane changes) must be added carefully and described in task_description. 5) Solvability and safety - Always ensure at least one feasible driving strategy exists. - Pedestrian side-hit guard must remain intact. - Adjust max_steps proportionally if difficulty increases. - No actor may force unsolvable collisions. 6) Constraints - Do not add global code or side effects outside the class . - Do not remove feasibility checks already in place. - Do not change the class name. OUTPUT Return ONLY the updated CarlaTown01Env class (no commentary). C.2 Policy Generation Prompts Box 4: PyGame Policy Prompt GOAL Maximize the scalar "Actual Score" in [0,1] for the current policy by improving the given function. YOU MUST RETURN A SINGLE Python function that replaces the existing one: def policy(obs): # -> [dx, dy] in [-1.0, 1.0]^2 MUTATION CONSTRAINT - Apply exactly ONE structural change to the class . - A structural change is defined as : (i) adding or removing a single environment component or behavior, OR (ii) (ii) modifying the logic of a single existing component (within a single method). - All other code must remain semantically identical. INPUTS - Actual Score = {ActualScore} - Given Policy = {Policy} - Observation dictionary schema (exact field names and meaning) = {obs_dict} FUNCTION CONTRACT - Keep the exact signature: def policy(obs). - Return a 2D continuous action [dx, dy] with each component in [-1.0, 1.0]. - Do not use randomness, globals , I/O, or external libs beyond numpy. OBSERVATION DICTIONARY - Use only fields provided in obs. The runner supplies {obs_dict}. The typical structure is : - agent_pos: [x, y] current agent center position in pixels - agent_radius: r agent circle radius in pixels - objects: list of dicts describing scene items. Each item: - type : "zone" or "obstacle" - pos: [cx, cy] center position - size: [w, h] rectangle width, height - purpose: optional string, e.g., "goal" for the goal zone - bounds: [W, H] canvas width and height in pixels - step_count: N steps elapsed - max_steps: M step limit before timeout STRICT REQUIREMENTS 1) Goal-directed motion - Move toward the goal zone whenever a safe direction exists. - Prefer progress that reduces distance-to-goal. 2) Obstacle and bounds safety - Do not output actions that would cause collision with any obstacle rectangle. - Do not move outside [0, W] x [0, H]. - Respect agent_radius clearance when deciding direction. 3) Action validity - Clamp or normalize output so each component stays within [-1.0, 1.0]. - Avoid jitter or oscillation near the goal. 4) Robustness - If the direct route is blocked, choose a safe detour around obstacles. - Avoid loops by preferring actions that reduce distance-to-goal over time. EDGE CASES - Goal directly reachable: head straight toward the goal center or safe entry edge. - Narrow passage: align with passage axis and pass through without scraping boundaries. - Stuck against obstacle: choose an alternate heading that increases free-space margin. - Near goal zone edge: reduce overshoot and enter the zone cleanly. QUALITY TARGETS - Short time-to-goal. - Minimal wasted motion and reversals. - Collision-free trajectories across diverse layouts. FORBIDDEN - Changing the function name, arguments, or return type . - Returning values outside [-1.0, 1.0]. - Ignoring obstacles, bounds, or agent_radius in decisions. - Using randomness, global state, file or network I/O, or non-numpy libraries. OUTPUT Return ONLY the improved function "def policy(obs):" No explanations, no comments, no extra text. Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi Box 5: MiniGrid Policy Prompt GOAL You are tasked with improving an existing policy function for navigating MiniGrid environments by applying macro-mutation operator. The policy must analyze the grid, reason about objects, plan an optimal path, and execute actions efficiently. The objective is to reach the goal tile (OBJECT_IDX=8). You are provided with : - Actual Score = {ActualScore}, a scalar in [0,1] that reflects the performance of the given policy. - Policy = {Policy}, the current implementation of the policy function. YOUR TASK Analyze the given policy together with its score and modify it to improve performance. The output must be a new version of the same function with improvements. MUTATION CONSTRAINT - Apply exactly ONE structural change to the class . - A structural change is defined as : (i) adding or removing a single environment component or behavior, OR (ii) (ii) modifying the logic of a single existing component (within a single method). - All other code must remain semantically identical. OUTPUT Return a single Python function: def policy(obs, agent_pos, agent_dir): # -> int in {0,1,2,3,4,5} ENVIRONMENT FORMAT - obs is a 2D NumPy array of shape (grid_size, grid_size, 3). - Each tile is encoded as (OBJECT_IDX, COLOR_IDX, STATE). - Indexing is (x=row, y=column). OBJECT_IDX MAP: 0=Unseen, 1=Empty, 2=Wall, 3=Floor, 4=Door, 5=Key, 6=Ball, 7=Box, 8=Goal, 9=Lava, 10=Agent DOOR STATE: 0=Open (free to pass ), 1=Closed (requires Toggle action=5 when facing), 2=Locked (requires correct key + Toggle=5) ACTIONS: 0=Turn Left, 1=Turn Right, 2=Move Forward, 3=Pick Up, 4=Drop, 5=Toggle STRICT REQUIREMENTS 1) Goal-Oriented Navigation - Always plan and execute a valid path to the Goal (OBJECT_IDX=8). - Avoid unnecessary detours unless a locked door blocks the path. 2) Door Handling - Open doors (STATE=0) act as free space. - Closed doors (STATE=1): face the door, Toggle (5) to open , then Move Forward (2). - Locked doors (STATE=2): only approach after collecting the correct key. Face the door, Toggle (5), then Move Forward (2). 3) Key Handling - Keys are only collected if required to unlock a blocking door. - The agent can hold exactly one key at a time. - If already holding a different key, Drop (4) into the front cell ( if empty) before picking up the new one. - Keys must be picked up with Pick Up (3) when the agent is adjacent and facing the key. - Dropped keys must remain accessible. 4) Safety and Obstacles - Never Move Forward (2) into a Wall (2) or Lava (9). - Treat Unseen tiles (0) as blocked until explored. 5) Orientation - Before any interaction (Move Forward, Pick Up, Drop, Toggle), ensure the agent is facing the correct adjacent cell. - Rotate (0=Left, 1=Right) until aligned, then act. 6) Termination - The episode ends when the agent reaches the Goal or exceeds max_steps. - The policy must minimize wasted actions and maximize efficiency. EDGE CASES - If the agent needs a key but already holds another, drop the held key before pickup. FORBIDDEN - Changing the function name, arguments, or return type . - Returning values outside {0,1,2,3,4,5}. - Using randomness, global state, or external libraries. OUTPUT FORMAT - Return only the improved function ` def policy(...) ` in valid Python. - No explanations, no comments, no extra text. Box 6: CARLA Policy Prompt GOAL Maximize the scalar "Actual Score" in [0,1] by improving the current driving policy. You will return a SINGLE Python class that replaces the existing: {Actual_Policy} MUTATION CONSTRAINT - Apply exactly ONE structural change to the class . - A structural change is defined as : (i) adding or removing a single environment component or behavior, OR (ii) (ii) modifying the logic of a single existing component (within a single method). - All other code must remain semantically identical. INPUTS - Actual Score = {ActualScore} - Previous Policy = {Policy} - Path = np.ndarray (N,2) lane-center polyline STRICT REQUIREMENTS 1) Class/API - Keep the class name "Policy" . - Implement __init__(self) and compute_action(self, obs, path). - Return (steering, throttle, brake) as floats. - steering in [-1,1], throttle in [0,1], brake in [0,1]. - If brake > 0 then throttle must equal 0. 2) Determinism and smoothness - No randomness or learning. - Ensure gradual changes, avoid jerks. 3) Robustness - Handle None or NaN conservatively. - On invalid input , default to safe stop (steer=0, throttle=0, brake>0). - No prints or logging. 4) Sign conventions - lateral_hist4: right-positive meters. - yaw_error_hist4: ego yaw - path yaw, right-positive. - yaw_rate_rps: right-positive radians/s. OBSERVATION FORMAT obs is a dictionary containing: - Ego state: - speed_mps: current speed in m/s - yaw_rate_rps: yaw rate in rad/s (right-positive) - Ego histories (arrays of length 4): - speed_hist4: past speeds - lateral_hist4: lateral errors (m, right-positive) - yaw_error_hist4: yaw errors (rad, right-positive) - steer_cmd_hist4: previous steering commands - throttle_cmd_hist4: previous throttle commands - brake_cmd_hist4: previous brake commands - Traffic light: - exists: boolean - state: int {0=unknown, 1=green, 2=yellow, 3=red} - dist_m: distance to stop line (m) - Lead cars (up to 2, same schema each): - gap_long_m: longitudinal gap (m) - gap_lat_m: lateral gap (m) - rel_long_mps: relative longitudinal speed (m/s) - ttc_s: time-to-collision (s) - thw_s: time headway (s) - Opposite cars (up to 2, same schema as lead cars) - Pedestrians (variable count): - lane: lane index - state: int encoding motion state - gap_long_m: longitudinal gap (m) - gap_lat_m: lateral gap (m) - rel_lat_mps: relative lateral speed (m/s) - t_enter_lane_s: predicted time to enter lane (s) - side: which side of road (left/right) - All dynamic actors truncated to 35 m ahead of ego OBJECTIVES - Lateral: minimize lateral and yaw errors relative to the centerline. - Longitudinal: track target speed up to 6.94 m/s (25 km/h) if unimpeded. - Traffic lights: stop smoothly before stop line on red; never cross on red. - Pedestrians: yield to pedestrians in or entering ego lane. - Lead vehicles: maintain safe following distance; avoid indefinite blocking. - Precedence order: red light stop > pedestrian yielding > lead vehicle following > cruising. - Fail-safe: if uncertain, perform controlled stop. - Comfort: avoid abrupt oscillations; prioritize smooth steering and braking. FORBIDDEN - Changing the class name or method signatures. - Returning values outside steering/throttle/brake ranges. - Simultaneous throttle and brake > 0. - Using randomness, logging, prints, or external dependencies. OUTPUT Return ONLY the new improved class "Policy" . COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game D Additional Results D .1 Generalization Across Environments W e compare standardized, unseen environments to those produced during co-evolution. The standardized set comprises MiniGrid DoorKey-16x16-v0 and LockedRoom-v0 , and CARLA Town02 (trained on Town01 ). These dier from our e volved environments in three respects: (i) structure (xed layouts and goal semantics rather than co-evolved variants), (ii) scale (grid/world size and path lengths), and (iii) sequential dependencies (e.g., key–door ordering and room unlocking). For CARLA, Town02 diverges from Town01 by road- network density and trac comple xity: it has sharper turns, nar- rower lanes, and more intersections and pedestrian crossings, re- quiring longer detours and tighter maneuvers compared to the more regular T own01 layout. W e evaluate with identical rollout settings. D .2 Reinforcement Learning Results D .2.1 MiniGrid Maze-solving. W e evaluate two repr esentative al- gorithms using Stable-Baselines3 [ 38 ]: PPO, a policy-gradient method, and QRDQN, a value-based method for discrete domains. Reward shaping. For r eward, we use the default MiniGrid re ward function: 𝑅 ( 𝑠 , 𝑎 ) = 1 − 0 . 9 · 𝑡 𝑇 max , if the agent reaches the goal at step 𝑡 , 0 , otherwise , where 𝑇 max is the maximum episode length. Thus, faster completion yields a higher return. Algorithm Env 0 Env 2 Env 6 PPO 12 . 0 ± 1 . 4 % 0 . 0 ± 0 . 0 % 0 . 0 ± 0 . 0 % QRDQN 68 . 5 ± 12 . 0 % 0 . 0 ± 0 . 0 % 0 . 0 ± 0 . 0 % T able 4: Success rates (%, mean ± std over two runs) across MiniGrid environments. D .2.2 PyGame 2D Navigation. W e evaluate two representativ e algorithms using Stable-Baselines3 [38]: PPO , and SAC. Reward shaping. In the Py Game environments, reward is sparse with a per-step penalty: 𝑅 ( 𝑠 , 𝑎 ) = + 1 , if the agent reaches the goal , − 0 . 01 , otherwise (each step) . This encourages agents to minimize path length while ensuring sparse success feedback. D .3 Additional seed run E Best Performing Policies The nal evolved policies are too extensive to analyze line by line . Instead, we provide high-level summaries of their algorithmic struc- ture and key heuristics. Algorithm Env 0 Env 2 Env 6 PPO 61 . 7 ± 2 . 3 % 6 . 2 ± 0 . 7 % 0 . 0 ± 0 . 0 % SA C 88 . 2 ± 3 . 0 % 22 . 5 ± 5 . 9 % 0 . 0 ± 0 . 0 % T able 5: Success rates (%, mean ± std over two runs) across PyGame environments. E.1 Best Performing MiniGrid Policy The b est p erforming p olicy ( policy_9 , se e Figure 6) is a fully model- based planning agent that formulates MiniGrid navigation as a discrete A * search over agent position, orientation, held key color , and door-open states. The policy operates as follows: (1) it parses the grid to identify the goal, doors, and ke ys, (2) computes a r elaxed r eachability region that ignores door and key semantics to conservatively identify which do ors and key colors can lie on a valid start–goal corridor , (3) performs lexicographic-cost A * planning over a factored state space with explicit door toggling, key pickup , key drop, and mo vement actions, and (4) executes only the rst action of the optimal plan, replanning at every timestep. T o reduce the search space without sacricing correctness, the planner reasons only about useful doors (doors that lie in the relaxed start–goal corridor) and useful key colors (keys that can open such doors). K eys are treated as blocking cells during planning, and ke ys are only dropped when the agent is holding one and the cell ahead is empty , ensuring safe and deterministic key management. The A * heuristic combines Manhattan distance to the goal with a lower bound on the number of turns required to face a direction that reduces this distance, improving guidance while preserving admissibility . T ogether , these components yield a deterministic planning agent that can reliably resolve door–key dependencies, minimize un- necessary interactions, and avoid key-handling loops in complex MiniGrid environments. E.2 PyGame Policy The PyGame agent is implemented as a planning–reactive naviga- tion policy that combines global path planning with local, feasibility- aware motion selection at every timestep. • Global planning : The agent computes a global path to the goal using A * search on a coarse occupancy grid. Obstacles are mildly inated based on the agent radius to ensure collision-free paths. The resulting path is cached and only recomputed when the goal changes or when progr ess stalls. • W ayp oint tracking with visibility lo okahead : The agent follows the planned path using waypoints, advancing when suciently close. If multiple upcoming waypoints are di- rectly visible, the agent skips intermediate points and tar- gets the farthest visible waypoint. • Local motion candidates : At each step, the policy samples a set of candidate motion directions ar ound the desired path direction, including small angular deviations and obstacle- aligned tangents when near walls. Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi (a) DoorKey-16x16-v0 (MiniGrid) (b) LockedRoom-v0 (MiniGrid) (c) MultiRoom-N6-v0 (MiniGrid) (d) Town02 (CARLA) Figure 12: Examples of previously unse en standardized environments used to validate generalization. MiniGrid snapshots ( top ): DoorKey , LockedRoom , and the hardest goal-reaching benchmark ObstructedMaze-Full . CARLA Town02 ( boom ). • Predictive collision checking : Each candidate direction is validate d using one-step forward collision checks that match the environment’s continuous collision model. In- feasible directions are discarded before scoring. • Directional scoring and selection : Feasible candidates are scored based on path-aligned progress, goal alignment, continuity with the previous action, and lo cal obstacle clear- ance. The highest-scoring direction is selected. • Oscillation control : The policy maintains a short-term memory of recent motion directions and penalizes rapid directional sign changes. A turn-rate limiter further con- strains angular changes between successive actions. • Gap-centering behavior : When near obstacles, lateral ray probes estimate free space on either side of the agent, biasing motion toward the center of locally available free space. • Execution : The nal action is a normalized 2D velocity di- rection returned to the environment. If no feasible direction exists, the agent temporarily halts and triggers replanning. This structure allo ws the agent to consistently alternate between global path guidance and locally feasible motion execution in con- tinuous PyGame navigation environments. E.3 Carla Policy The best performing controller ( policy_9 , see Fig. 6) augments a smooth cruise/follow core with a clearance-aware passing routine and stricter intersection handling. Four-stage loop. (1) Signal gating : strict trac-light guard ( Y el- low = Red ), stop-line latch, and p edestrian holds; approach spee d is limited by both stop-line distance and queued-lead gap. (2) Lead classication : distinguishes a right-curb parke d blocker from an in- lane stopped lead using lateral intrusion and r elative speed cues. (3) Clearance-aware pass : if the blocker is parked, oncoming is clear , and distance gates are met, the agent enters a bounded left-oset pass. It maintains a minimum oset and a small, gated opposite-lane incursion, holds the oset while alongside, and only recenters after front-clearance (with a brief hold if the lead vanishes). (4) Smooth tracking : target-speed smo othing with curvature/heading caps COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Steps 1e6 0.08 0.10 0.12 0.14 0.16 0.18 0.20 0.22 0.24 R ewar d R ewar d (MA=50) ±1 std (a) PPO Env 0 0.0 0.2 0.4 0.6 0.8 1.0 Steps 1e6 0.04 0.02 0.00 0.02 0.04 R ewar d R ewar d (MA=50) ±1 std (b) PPO Env 2 0.0 0.2 0.4 0.6 0.8 1.0 Steps 1e6 0.04 0.02 0.00 0.02 0.04 R ewar d R ewar d (MA=50) ±1 std (c) PPO Env 6 0.00 0.25 0.50 0.75 1.00 1.25 1.50 1.75 2.00 Steps 1e6 0.1 0.2 0.3 0.4 0.5 R ewar d R ewar d (MA=50) ±1 std (d) QRDQN Env 0 0.0 0.2 0.4 0.6 0.8 1.0 Steps 1e6 0.04 0.02 0.00 0.02 0.04 R ewar d R ewar d (MA=50) ±1 std (e) QRDQN Env 2 0.0 0.2 0.4 0.6 0.8 1.0 Steps 1e6 0.04 0.02 0.00 0.02 0.04 R ewar d R ewar d (MA=50) ±1 std (f ) QRDQN Env 6 Figure 13: Training curves of PPO ( top ) and QRDQN ( boom ) across MiniGrid environments. The y-axis represents reward, and the x-axis represents total training steps. 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 Steps 1e6 0.2 0.4 0.6 0.8 1.0 R ewar d (a) PPO Env 0 0.0 0.2 0.4 0.6 0.8 1.0 Steps 1e7 0.000 0.025 0.050 0.075 0.100 0.125 0.150 0.175 R ewar d (b) PPO Env 2 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 Steps 1e6 0.04 0.02 0.00 0.02 0.04 R ewar d (c) PPO Env 6 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 Steps 1e6 0.0 0.2 0.4 0.6 0.8 1.0 R ewar d (d) SAC Env 0 0.0 0.2 0.4 0.6 0.8 1.0 Steps 1e7 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 R ewar d (e) SAC Env 2 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 Steps 1e6 0.04 0.02 0.00 0.02 0.04 R ewar d (f ) SAC Env 6 Figure 14: Training curves of PPO (top) and SAC (b ottom) across Py Game environments. The y-axis represents reward, and the x-axis represents total training steps. and a damped lookahead lateral controller; unstick logic pro vides a gentle creep when safe. Key heuristics. • Stop-line priority : combined stop-line/lead-gap caps and a near-line latch prevent creeping over the line on non- green states. Alkis Sygkounas, Rishi Hazra, Andreas Persson, Pedro Zuidberg Dos Martires, and Amy Loutfi 0 2 4 6 8 Environment 0.0 0.2 0.4 0.6 0.8 1.0 Score pi_0 pi_1 pi_2 pi_3 pi_4 pi_5 pi_6 pi_7 pi_8 pi_9 0 1 2 3 4 5 6 7 8 9 Environment 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Score COvolve (last) π_last (π_9) π_argmax (π_5) 0 1 2 3 4 5 6 7 8 9 Iteration 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Mean score over envs COvolve UED-UNIFORM UED-GREEDY 0 2 4 6 8 Environment 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Score πi_0 πi_1 πi_2 πi_3 πi_4 πi_5 πi_6 πi_7 πi_8 πi_9 0 1 2 3 4 5 6 7 8 9 Environment 0.75 0.80 0.85 0.90 0.95 1.00 Score COvolve π_argmax (π_9) π_last (π_9) 0 1 2 3 4 5 6 7 8 9 Iteration 0.0 0.2 0.4 0.6 0.8 1.0 Mean score over envs COvolve UED-UNIFORM UED-GREEDY 0 2 4 6 8 Environment 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Score πi_0 πi_1 πi_2 πi_3 πi_4 πi_5 πi_6 πi_7 πi_8 πi_9 0 1 2 3 4 5 6 7 8 9 Environment 0.5 0.6 0.7 0.8 0.9 1.0 Score COvolve (last) π_last (π_9) π_argmax (π_8) 0 1 2 3 4 5 6 7 8 9 Iteration 0.0 0.2 0.4 0.6 0.8 1.0 Mean score over envs COvolve UED-UNIFORM UED-GREEDY Figure 15: Performance during environment–policy co-evolution for the second seed. Left: Success rates of all discovered policies evaluated on all environments generated during evolution (policy–environment payo matrix). Center: Comparison between the mixe d-strategy Nash equilibrium (MSNE) policy mixture, the best single p olicy ( 𝜋 argmax ), and the latest policy ( 𝜋 𝑘 ), evaluated on all environments { 𝜃 0 , . . . , 𝜃 𝑘 } for Pygame, 𝜋 argmax coincides with 𝜋 𝑘 . Right: Mean success over environments { 𝜃 0 , . . . , 𝜃 𝑘 } for three strategies: UED-Greedy ( latest policy only), UED-Uniform (uniform mixture over all policies so far), and COvolve (MSNE mixture). • Right-edge pass safety : minimum pass oset, centerline guard, and oncoming no-pass gate; tiny opp osite-lane in- cursion is permitted only when clear . • Stability under occlusion : oset-hold on brief lead dropouts avoids snap-back; post-clear recenter includes a short hys- teresis. F Evolved Environments F .1 MiniGrid Environment Mutations In the MiniGrid maze-solving task, the LLM mutates discrete grid- worlds where an agent must navigate to a goal while avoiding obstacles, doors, and keys. Diculty increases through the follow- ing mechanisms: • Grid scaling : larger grids extend path length and increase exploration requirements. • Obstacle density : additional walls create more complex mazes and reduce direct visibility of the goal. • Sequential key–door dependencies : locked doors are introduced along the main corridor , requiring keys to be collected and used in the correct order . • Hard vs. soft chokepoints : some doors are reinforced by barrier walls that force strict bottlenecks, while others include short wings or detours that add complexity without fully blocking the corridor . • Protected corridors : a one-cell halo ensures that critical key–door paths remain open even as random obstacles are added, guaranteeing solvability . This progression transforms initially trivial layouts into struc- tured mazes that demand multi-step reasoning, ordered dependen- cies, and long-horizon planning while ensuring that every environ- ment remains solvable by construction. F .2 PyGame Environment Mutations In the PyGame navigation task, the LLM mutates a continuous 2D arena where a circular agent must reach a rectangular goal zone while avoiding collisions. While early generations adjust simple parameters such as arena size or obstacle counts, later environments evolve into structur ed mazes with corridor-like passages and long detours. Key mutation axes include: COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game • Corridor formation : long rectangular bars are placed to partition the arena into corridors, forcing agents to identify traversable passages rather than rely on direct routes. • Bottleneck and detour creation : increasing bar thickness and obstacle density narrows passageways and introduces dead ends, requiring agents to plan long, non-greedy paths. • Start–goal separation : minimum distance constraints push the agent to begin far from the goal, ensuring navigation requires multiple turns and obstacle avoidance. • Precision termination : the goal region remains small rel- ative to agent size, demanding careful alignment to trigger success. • Scalable horizons : enlarging arenas and increasing max- imum steps allows environments to grow in complexity without becoming unsolvable. Unlike gridworlds, these continuous Py Game arenas induce navi- gation behaviors closer to geometric planning: agents must balance global pathnding with lo cal collision checks, and later evolved environments present rich mazes with narr ow corridors that mimic real-world navigation challenges. F .3 Carla Environment Mutations In the Carla T own01 driving task, the LLM mutates a xed urban loop with signalized intersections, oncoming trac, and pedestri- ans. Diculty rises from light, compliant ows to dense, hetero- geneous trac with narrow-clearance segments, while remaining solvable by construction. • Trac scaling : vehicle counts increase from light to heavy urban load; speed variance and lane changes introduce realistic ow heterogeneity . • Pedestrian pressure : higher crossing rates and tighter ca- dences create frequent curb-to-lane interactions requiring cautious approach and yielding. • Intersection strictness : virtual “second gates” beyond stop lines mirror light states, penalizing early acceleration and forcing disciplined red/yellow behavior . • Narrow-clearance segments : parked or fr ozen intrusions create lane squeezes that demand bounded lateral osets and precise, short opposite-lane incursions when clear . • Micro-perturbations : perio dic brake-taps on leads and oc- casional temp orary stoppers test following stability without causing deadlocks. • Oncoming dynamics : faster opposite-lane bursts create brief no-pass windows, requiring agents to time passes and maintain centerline guards. • Jam watchdog & solvability : stall detectors inject bounded ow perturbations to unstick trac; obstacle placements and signal logic are constrained to ensure episodes remain completable. • Observation compatibility : added features (e.g., lane- squeeze indicators, extended stop-line states) are e xposed via backward-compatible elds to avoid policy breakage. This progression turns a benign city loop into a dense, signal- rich scenario with tight margins and bursty interactions, pushing policies to coordinate cautious intersection handling, safe passing, and recovery from transient jams.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment