Bidirectional Multimodal Prompt Learning with Scale-Aware Training for Few-Shot Multi-Class Anomaly Detection
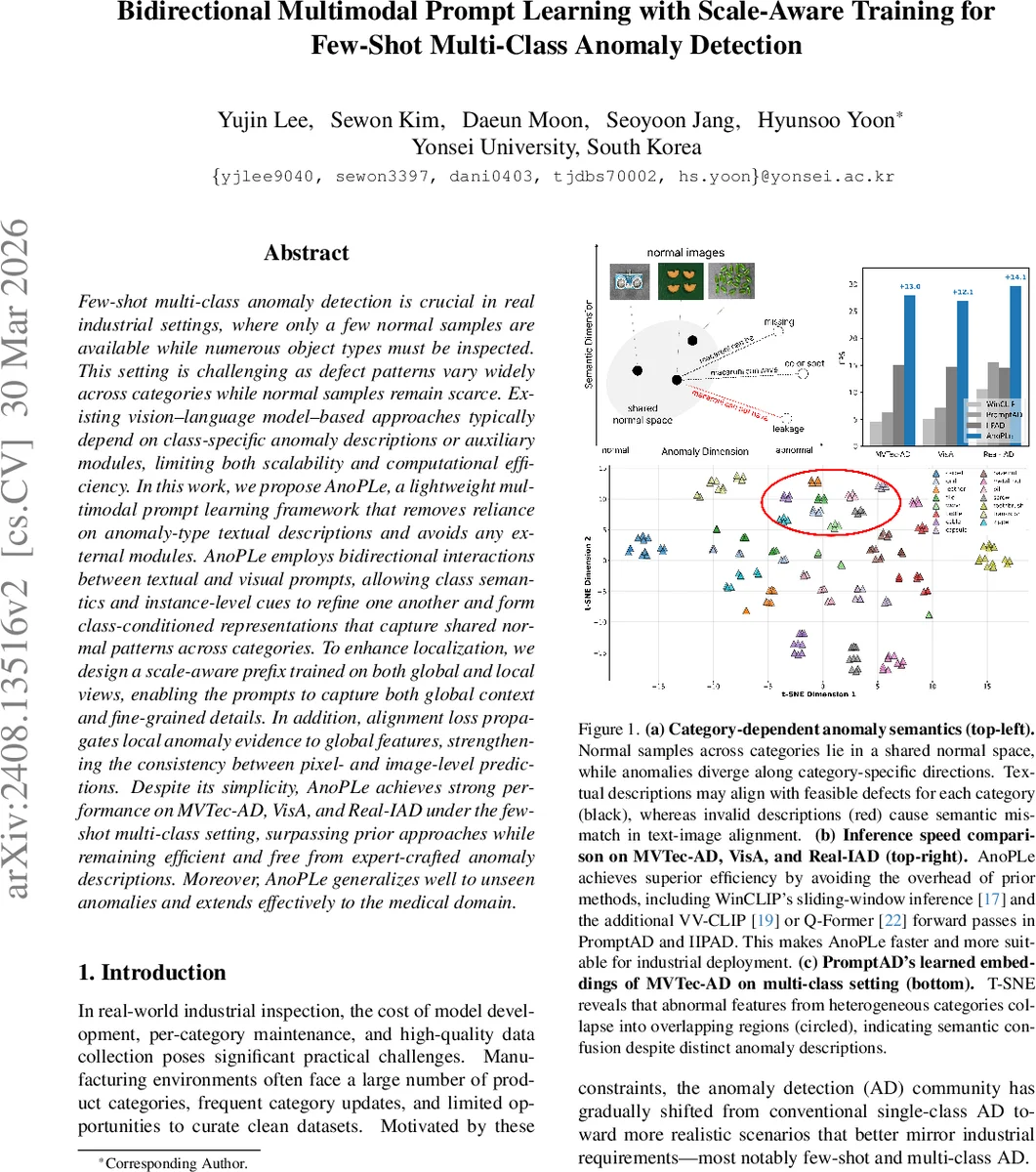
Few-shot multi-class anomaly detection is crucial in real industrial settings, where only a few normal samples are available while numerous object types must be inspected. This setting is challenging as defect patterns vary widely across categories while normal samples remain scarce. Existing vision-language model-based approaches typically depend on class-specific anomaly descriptions or auxiliary modules, limiting both scalability and computational efficiency. In this work, we propose AnoPLe, a lightweight multimodal prompt learning framework that removes reliance on anomaly-type textual descriptions and avoids any external modules. AnoPLe employs bidirectional interactions between textual and visual prompts, allowing class semantics and instance-level cues to refine one another and form class-conditioned representations that capture shared normal patterns across categories. To enhance localization, we design a scale-aware prefix trained on both global and local views, enabling the prompts to capture both global context and fine-grained details. In addition, alignment loss propagates local anomaly evidence to global features, strengthening the consistency between pixel- and image-level predictions. Despite its simplicity, AnoPLe achieves strong performance on MVTec-AD, VisA, and Real-IAD under the few-shot multi-class setting, surpassing prior approaches while remaining efficient and free from expert-crafted anomaly descriptions. Moreover, AnoPLe generalizes well to unseen anomalies and extends effectively to the medical domain.
💡 Research Summary
The paper tackles the practical problem of few‑shot multi‑class anomaly detection (FS‑MCAD), where only a handful of normal images per product category are available and no textual descriptions of defects exist. Existing vision‑language model (VLM) approaches either rely on handcrafted class‑specific anomaly prompts (e.g., “broken fabric”) or introduce heavyweight auxiliary modules such as Q‑Former to generate instance‑level prompts. Both strategies hinder scalability: textual descriptions can be ambiguous or missing, and extra modules increase inference latency, which is undesirable for real‑time industrial inspection.
AnoPLe (Anomaly Prompt Learning) proposes a lightweight, description‑free framework that leverages only class names as textual anchors. The core idea is bidirectional multimodal prompt learning: textual prompts encode class semantics together with a unified “abnormal” token, while visual prompts consist of learnable context vectors prepended to the patch embeddings of the image. At each transformer layer, the textual and visual contexts are projected into each other’s embedding space via linear maps (f_{v→t} and f_{t→v}) and fused. This mutual refinement allows class‑level semantics to guide visual feature formation and, conversely, instance‑level visual cues to enrich the textual representation. Consequently, the model learns class‑conditioned normal representations that are defect‑agnostic, avoiding the need for explicit anomaly descriptions.
To address the localization requirement, the authors introduce a scale‑aware prefix. During training, each batch contains the full‑resolution image and several non‑overlapping crops, exposing the prompt sequence to both global context and fine‑grained details. The same prefix is used for both scales, so at test time only the global prefix is needed, preserving efficiency. Additionally, an alignment loss enforces consistency between pixel‑level logits (produced by a lightweight decoder) and the global image‑level logits, propagating local anomaly evidence to the whole image representation even when normal data are extremely scarce.
AnoPLe is evaluated on three industrial anomaly detection benchmarks—MVTec‑AD, VisA, and Real‑IAD—under a one‑shot setting (one normal image per class). It achieves AUROC scores of 94.5 %, 86.0 %, and 81.2 % respectively, and PRO (pixel‑level) scores of 90.8 %, 87.5 %, and 88.8 %, outperforming prior state‑of‑the‑art methods that rely on textual descriptions or auxiliary modules. Inference speed reaches 27–30 FPS on a single GPU, markedly faster than methods such as WinCLIP (which uses sliding windows) or PromptAD/IIP‑AD (which require extra forward passes). The approach also generalizes to unseen anomaly types and transfers to a medical imaging scenario, demonstrating robustness beyond the training domains.
Key contributions are:
- A unified FS‑MCAD framework that eliminates handcrafted anomaly prompts and heavy external modules.
- Bidirectional interaction between textual and visual prompts, yielding class‑aware yet defect‑agnostic embeddings.
- Scale‑aware prefix learning and alignment loss that jointly capture global context and fine‑grained local cues without extra inference cost.
- State‑of‑the‑art performance in few‑shot settings with high computational efficiency, confirming practicality for real‑world deployment.
Overall, AnoPLe shows that leveraging the latent normality/abnormality priors of large VLMs through carefully designed multimodal prompts can solve the few‑shot multi‑class anomaly detection problem in an elegant, scalable, and efficient manner. Future work may explore further prompt compression, integration with newer VLMs, or adaptation to other domains such as autonomous driving or satellite imagery.
Comments & Academic Discussion
Loading comments...
Leave a Comment