Needle in the Repo: A Benchmark for Maintainability in AI-Generated Repository Edits
AI coding agents can now complete complex programming tasks, but existing evaluations largely emphasize behavioral correctness and often overlook maintainability risks such as weak modularity or testability. We present Needle in the Repo (NITR), a di…
Authors: Haichao Zhu, Qian Zhang, Jiyuan Wang
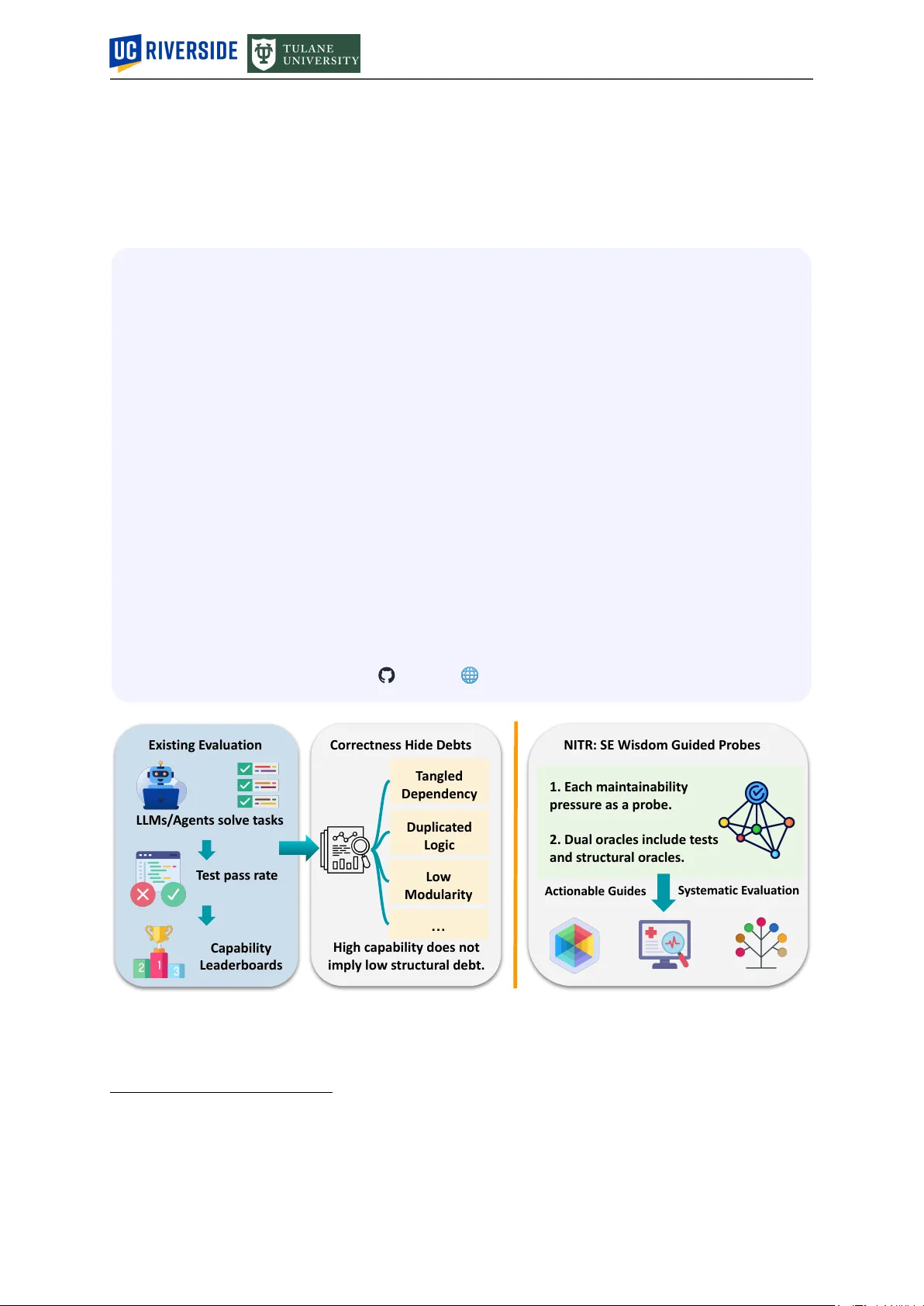
2026-03-31 Needle in the Repo: A Benchmark for Maintainability in AI-Generated Repository Edits Haichao Zhu 2,† , Qian Zhang 1,† , Jiyuan W ang 3 , Zhaorui Y ang 1 , Y uxin Qiu 1 1 UC Riverside 2 Independent Researcher 3 T ulane University Abstract AI coding agents can now complete complex programming tasks, but existing evaluations lar gely emphasize behavioral corr ectness and often overlook maintainability risks such as weak modularity or testability . Automation without accountability shifts invisible cost downstream because hidden maintainability failures incurred today are deferred to the developers who must extend, debug, and sustain these systems tomorrow , raising significant technical and organizational concerns for software engineering. W e pr esent Needle in the Repo (N I T R), a diagnostic, probe-and-oracle framework for evaluating whether behaviorally correct repository edits preserve maintainable structur e. The key idea is to distill recurring software engineering wisdom into controlled probes embedded in small, realistic multi-file codebases, with each probe designed so that success depends primarily on one tar geted maintainability dimension. Each probe is pair ed with a hidden evaluation harness that combines (i) functional tests for required behavior , and (ii) structural oracles that encode the targeted maintainability constraint and r eturn interpretable diagnoses. Using N I T R, we extensively evaluate 23 coding configurations across GPT , Claude, Gemini, and Qwen families in both direct-inference and agent-based settings. W e find that curr ent AI coding systems remain far from r obust. On average, all AI coding configurations solve only 36.2% of cases, the best reaches 57.1%, and performance drops fr om 53.5% on micro cases to 20.6% on multi-step cases. The har dest pressures ar e architectural rather than local edits, especially dependency control (4.3%) and responsibility decomposition (15.2%). Moreover , 64/483 outcomes (13.3%) pass all functional tests yet fail the structural oracle. Under our harness, agent-mode configurations improve average performance from 28.2% to 45.0%, but does not eliminate the architectural failur es. These results show that progr ess in code generation is not yet progr ess in maintainable code evolution, and that N I T R exposes a critical failure surface largely missed by conventional evaluation. Repo W ebPage Exis ting E v alua tion Corr ectness Hide Deb ts NITR: SE Wisdom Guided Pr obes LLMs/ Ag en ts solv e t ask s T es t pass r a t e Capability Leaderboar ds High c apability does not imply lo w s tructur al deb t. T angled Dependency Duplic a t ed Logic Lo w Modularity … 1. E ach main t ainability pr essur e as a pr obe. 2. Dual or acles include t es ts and s tructur al or acles. S y s t ema tic E v alua tion Actionable Guides Figure 1: Existing evaluations rank models by behavioral success, but leaderboard performance says little about maintainability risk. N I T R uses curated probes and structural oracles to expose failure modes beyond test passing. † Equal contribution. ∗ Corresponding authors: lszhuhaichao@gmail.com ; qzhang@cs.ucr.edu . 1 1 Introduction Artificial intelligence (AI) is rapidly reshaping software development, demonstrating str ong capabilities in code understanding, generation, execution, and iterative debugging Jimenez et al . ( 2024 ); Y ang et al . ( 2024 ); W ang et al . ( 2025 ). W e use the term coding agents to r efer to large language model (LLM)-based systems equipped with scaffolding such as r epository navigation Y ang et al . ( 2024 ); Ouyang et al . ( 2025 ), code editing Y ang et al . ( 2024 ); W ang et al . ( 2025 ), program execution W ang et al . ( 2024 ), and feedback- driven repair Shinn et al . ( 2023 ); Bouzenia et al . ( 2025 ). These agents now operate directly inside real development environments, making their evaluation increasingly important for understanding what kinds of software engineering (SE) work they can actually support. The Gap: Completion is Not Construction. Recent benchmarks have made substantial progr ess by moving beyond single-file completion toward r epository-level tasks Liu et al . ( 2024 ); Jimenez et al . ( 2024 ); Li et al . ( 2024a ). For example, SWE-bench and its variants Jimenez et al . ( 2024 ); Y ang et al . ( 2025 ) evaluate LLMs on issue resolution acr oss 12 GitHub repositories. However , these evaluations still define success primarily in terms of behavioral corr ectness , operationalized as pass/fail performance on pr edefined test cases. This leaves a fundamental gap between what current benchmarks measur e and what SE practice actually requir es, illustrated in Figure 1 . First, test pass/fail is a narrow view of softwar e quality . A patch may satisfy the tar get tests while still duplicating logic, bypassing an existing abstraction, or spreading a small feature across unr elated modules, thereby making the repository harder to extend and maintain over time. Recent studies of non-functional quality in LLM-generated code likewise find that behavioral success does not guarantee maintainability , reliability , or broader quality attributes Sun et al . ( 2025 ); Molison et al . ( 2025 ). This concern also appears in practitioner discussion. For example, one recent Reddit comment r ed ( 2026 ) observed that “The real failur e mode I keep seeing is maintenance.” Second, test-centric evaluations pr ovide weak diagnostic insight. They indicate whether agents completed a task, but not which maintainability capabilities they handled well or failed to preserve. Previous work has shown that correctness-based benchmarks often miss specific failure modes and overlook code-quality concerns that matter in practice Hu et al . ( 2024 ); Zheng et al . ( 2024 ); Chen et al . ( 2026 ). As a result, they rank models by outcome, but reveal little about wher e current LLMs still fall short. This W ork. This work addresses a cor e limitation of current code-agent evaluation: passing r epository tasks does not tell us whether the r esulting code r emains maintainable, or which maintainability capa- bilities current LLMs fail to preserve. W e present N E E D L E I N T H E R E P O (N I T R ), a probe-and-oracle framework for evaluating maintainability preservation in AI-generated repository edits. Throughout this paper , we use maintainability failur e to refer to code that is behaviorally correct for the curr ent task but makes future evolution har der to extend, test, or reason about safely . Our central insight is that software engineering wisdom can be distilled into small, repository-gr ounded probes with explicit design boundaries and executable structural checks. N I T R operationalizes 9 main- tainability dimensions through targeted C++ repository probes: Change Locality , Reuse and Repo A wareness, Responsibility Decomposition, Extension Str ucture, Interface and Substitutability Discipline, Dependency Control, T estability and Determinism, State Ownership and Lifecycle, and Side-Effect Isolation. N I T R comprises 21 curated C++ repository probes spanning nine maintainability dimensions. Each case encodes one primary r epository-evolution pressur e through a natural multi-file change r equest and is paired with hidden functional tests and str uctural probes, enabling diagnosis beyond test passing. Key Findings. Using N I T R , we evaluate 23 coding configurations spanning GPT , Claude, Gemini, and Qwen families in both direct-infer ence and agent-mode settings. W e pr esent, to our knowledge, the first probe-and-oracle study focused on maintainability pr eservation in AI-generated repository edits and report thr ee findings. First, curr ent coding systems remain far from robust at maintainability-pr eserving repository evolution: the average configuration solves only 36.2% of cases, the best r eaches 57.1%, and five pr obes are unsolved by all configurations. Second, curr ent systems struggle most not with isolated edits, but with changes that must preserve deeper r epository structur e, including dependency control (4.3% pass rate), responsibility decomposition (15.2%), and abstraction-respecting extension (26.1%). Third, test passing is an unreliable pr oxy for maintainability: 64/483 outcomes (13.3%) are behaviorally correct yet structurally wr ong, and although agent-mode con- figurations under our harness raises average performance from 28.2% to 45.0%, it does not eliminate these core failur es. T ogether , these r esults show that N I T R reveals hidden str uctural debt that conventional evaluations largely miss. This work makes three contributions: 2 1 // Non-maintainable: submitted by 17/23 agents. Each new type 2 // requires duplicating a definition (change amplification). 3 namespace solid :: case001 { 4 int add ( int a, int b) { return a + b; } 5 float add ( float a, float b) { return a + b; } 6 double add ( double a, double b) { return a + b; } 7 long long add ( long long a, long long b) { return a + b; } 8 } 9 10 // Maintainable: a single generic definition handles all types. 11 // Adding support for a new type requires zero code change. 12 namespace solid :: case001 { 13 template < typename T > 14 T add(T a, T b) { return a + b; } 15 } Listing 1: T wo implementations of a multi-type add function. Both pass all unit tests, but the overloaded version (top) fails the structural probe because it introduces a new definition for each type added, amplifying change across the codebase. The template version (bottom) passes both unit tests and the structural pr obe. • N I T R turns maintainability-preserving r epository edit evaluation into a controlled object of study by pairing curated repository pr obes with hidden structural oracles. • W e pr ovide the first probe-and-oracle empirical study of maintainability preservation in AI-generated repository edits, showing that test-passing often misses structural failur e and that the hardest pressures are ar chitectural rather than local. • W e r elease N I T R as an open-source suite to support future r esearch on maintainability-awar e coding agents and repository-level softwar e engineering evaluation. NITR is not intended as a universal taxonomy or a naturalistic sample of all softwar e tasks; it is a diag- nostic suite designed to make specific maintainability pressures observable, executable, and comparable. In other wor ds, it does not attempt to cover all maintainability phenomena, but to make a set of recurring, practically important repository-evolution pr essures pr ecise enough to evaluate, compare, and analyze. 2 Motivating Example Coding agents are often evaluated as if passing tests were sufficient evidence of code quality . The motivating example in case 001 of N I T R shows why this assumption is too weak. In this task, a small utility function add is widely used acr oss a codebase. The agent is asked, over thr ee incremental steps, to extend it to support additional numeric types: first int , then float and double , and finally long long . Throughout all steps, the call sites in app/main.cc remain fixed and must not be modified. Listing 1 shows two representative implementations submitted by agents. The overloaded implementation (lines 2–8) is the approach taken by 17 of 23 evaluated configurations. It introduces a separate, copy- pasted definition for every numeric type. Functionally , both implementations are equivalent: all unit tests pass. The tests check corr ect addition output for each requir ed type; they do not inspect the structure of the implementation. The structural probe in N I T R , however , evaluates a differ ent criterion. It checks that the implementation provides a centralized r eusable core (detected via generic-function patterns such as a template) and that no more than one explicit per-type overload definition is present. The overloaded implementation (lines 2–8) violates both conditions and is therefor e marked as failing, even though every functional test passes. This failure has direct maintenance consequences. If the codebase later needs to support unsigned int or float128 , the overloaded design requir es adding another specialized definition and modifying the library interface. In a multi-step tasks, the problem becomes worse. Once an agent has intr oduced the overload pattern, later steps may continue extending that pattern rather than r epairing the abstraction, compounding the original design mistake. This example illustrates the exact failur e mode that N I T R is designed to expose: code can be behaviorally correct yet str ucturally poor to evolve. 3 Maintainability Pressure Probe Instantiation Hidden Oracle Change Spread Reuse Bypase Dependency Creep Side-effect Intrusion Starter repo T ASK.md maintainable path tempting shortcut Functional tests Structural probes Pass if both succeed One primary diemsnion Figure 2: Fr om maintainability pr essure to diagnostic probe. N I T R summarizes SE practices into 9 recurring repository-evolution pressur es, instantiates each target pressur e as a compact pr obe with starter code and an agent-facing task, and pairs the probe with functional and str uctural oracles. 3 Maintainability Probe Design W e constr uct N I T R in three parts as shown in Figur e 2 . First, we define a maintainability design space grounded in recurring software-evolution pressures (Section 3.1 ). Second, we instantiate each target pressur e as a compact repository probe with starter code and an agent-facing task (Section 3.2 ). Third, we package each probe with hidden functional tests and structural oracles that distinguish maintainable solutions from tempting shortcut solutions (Section 3.3 ). N I T R is organized as a collection of expert-curated maintainability pr obes rather than generic coding tasks mined from GitHub that may alr eady be familiar to LLMs. Each probe is a small repository-level scenario designed to expose one primary maintainability pr essure under realistic softwar e evolution. The evaluation target is whether AI’s chosen implementation strategy pr eserves maintainable structure. The resulting suite contains 21 C++ probes spanning 9 softwar e engineering dimensions, including 10 micro probes and 11 multi-step pr obes detailed below . 3.1 From Principles to Maintainability Dimensions Our starting point is that software engineering wisdom alr eady provides a practical basis for judging whether code will remain easy to extend, modify , test, and integrate over time. Accor dingly , N I T R begins from the design principles and engineering practices that developers use to assess code quality in r eal repositories. T o define the construction design space of N I T R , we reviewed established software engineering principles, including SOLID Martin ( 2003 ), together with maintainability practices such as code reuse Haefliger et al . ( 2008 ); Krueger ( 1992 ) and testability Fr eedman ( 1991 ); Parker ( 1982 ). From this author-driven consolidation, we derived the nine dimensions by consolidating recurrent repository-evolution pr essures rather than by starting from a fixed taxonomy alone. Concretely , we first enumerated common structural failure pressures that arise during repository change, such as change amplification, duplicate-path introduction, r esponsibility leakage, dependency creep, test-seam er osion, lifecycle scattering, and side-effect intrusion. W e then grouped these pressures into broader , reusable construction axes, using classical software-design principles such as SOLID as an organizing lens where appropriate. The resulting nine dimensions are ther efore best understood as probe-construction axes for maintainability-relevant r epository evolution, not as an exhaustive ontology of maintainability . The nine dimensions include: (D1) Change Locality , whether a r equested change remains localized rather than forcing scattered edits; (D2) Reuse and Repo A war eness , whether the solution r euses and adapts existing repository logic instead of re-implementing it in parallel; (D3) Responsibility Decomposition , whether distinct concerns r emain separated rather than collapsing into one component; (D4) Extension Structure , whether new behavior is added through clean extension rather than ad hoc special cases; (D5) Interface and Substitutability Discipline , whether interfaces remain narr ow , coher ent, and safe for interchangeable implementations; (D6) Dependency Control , whether modules avoid unnecessary coupling and depend only on what they need; (D7) T estability and Determinism , whether the design preserves clean test seams and avoids hidden nondeterminism; (D8) State Ownership and Lifecycle , whether mutable state has clear ownership and lifetime boundaries and (D9) Side-Effect Isolation , whether effects such as I/O, 4 logging, and global mutation are kept separate from cor e logic. T able 1 reports coverage at the dimension level, while the design matrix records the concrete failure pressur es each dimension was designed to capture. Each case declares exactly one primary_dimension , defined as the main maintainability pressure the case is designed to isolate. Optional secondary_dimensions recor d supporting pressur es when needed. Assigning one primary dimension keeps each probe interpr etable and supports balanced coverage across the design space, while still allowing secondary pressur es to appear as context. 3.2 Instantiating Maintainability Probes Outcome Pass only if both succeed NITR Case Starter Code T ASK.md SPEC.md Evaluator Functional tests Structural probes Hidden from agent/API V isible to agent/API Model output / generated files Integrate into workspace Figure 3: Anatomy of a maintainability probe. Each probe contains starter code, an agent-visible task ( TASK.md ), an author-facing specification ( SPEC.md ), and a hidden evalua- tor . During evaluation, the model sees only the starter code and TASK.md ; the pr obe passes only if the generated edits satisfy both the functional tests and the structural pr obes. Given a tar get dimension, we instantiate it as a small, self-contained C++ repository probe. A probe is a jointly designed artifact consisting of a repository scenario, starter code, an agent-visible task, and hidden eval- uation logic, as illustrated in Figure 3 . Each probe is constructed so that the target main- tainability pressur e arises naturally , a short- cut solution remains plausible, and the dif- ference between the two can be diagnosed automatically . Please note that this cura- tion is deliberate rather than incidental. In mined tasks, the intended design boundary is often implicit, underspecified, or entan- gled with unrelated repository history , mak- ing maintainability judgment difficult to op- erationalize. NITR instead uses compact, au- thored r epository scenarios where the main- tainable path and the tempting shortcut are both behaviorally plausible, but structurally distinguishable. This enables interpretable diagnosis of edit strategy rather than only outcome success. Step 1: Repository Scenario Selection. W e first select a compact engineering change that naturally exposes the target maintainability pressure. The scenario should be realistic and narrow in scope, while still admitting two plausible implementation paths: one that preserves repository structure and one that satisfies the required behavior through a shortcut. For example, the curated Case 021 tar gets D2: Reuse and Repo Awar eness . The r equested change is to add support for an inline filter form such as status=open,priority=3 . The r epository already supports filtering through an existing structured pipeline, so the cor e question is whether the new inline entry point reuses that pipeline or intr oduces a second parsing-and-validation path. Listing 2 shows the associated structural oracle. Step 2: Starter-Code Shaping. W e then shape the starter r epository so that the intended maintainable path alr eady exists in the codebase. In Case 021, the starter code already contains a r epository-native filter repr esentation, an existing parse/validate pipeline, and a designated validation module. This creates two clear solution paths. A maintainable solution parses the inline string only far enough to construct the existing internal repr esentation and then delegates to the curr ent pipeline. A shortcut solution instead introduces inline-only logic for numeric parsing, field interpretation, or err or classification. These shortcut patterns are encoded directly in the hidden oracle checks in Listing 2 , including checks for std::stoi , std::isdigit , duplicated field literals, and duplicated error literals. Step 3: Agent-Facing T ask Design. For each probe, we write a concise TASK.md as a natural engineering request. It specifies the required behavior , but does not reveal the maintainability dimension, the intended design move, or the hidden oracle logic. In Case 021, the visible task asks the agent to add support for the inline filter form while pr eserving existing behavior . It does not say “reuse the validation module,” does not mention D2, and does not warn against introducing a helper such as ParseInlineFilter with its own integer parsing and field checks. Step 4: Micro versus Multi-Step Probes. W e use a micro pr obe when the targeted maintainability 5 Starter Codebase Codebase after step 1 Codebase after step 2 Final Codebase T ASK1.md T ASK2.md T ASK3.md Hiden Evaluator Hiden Evaluator Functional tests Structural probes Figure 4: Multi-step pr obe execution. Each step is applied to the codebase produced by the pr evious step, so early design choices persist acr oss later changes. The final codebase is then evaluated with tests and structural oracles. 1 # Check 1: The inline entrypoint should not perform its own 2 # numeric parsing. In the intended design, integer validation 3 # stays in the existing filter-validation path rather than being 4 # reimplemented inline. 5 has_stoi = "std::stoi" in content 6 has_isdigit = "std::isdigit" in content 7 8 if has_stoi or has_isdigit: 9 fail( "Suspicious duplicate numeric validation" ) 10 11 # Check 2: Repeating field and error literals outside the 12 # designated validation files often signals a shadow parser with 13 # its own lookup tables and error mapping logic. 14 has_inline_parser = "ParseInlineFilter" in content 15 field_hits = sum (literal in content for literal in FIELD_LITERALS) 16 error_hits = sum (literal in content for literal in ERROR_LITERALS) 17 18 if has_inline_parser and field_hits > 0 and error_hits > 1 : 19 fail( "Suspicious duplicated error classification" ) Listing 2: Excerpt of the hidden structural oracle for Case 021. The individual string-level checks shown here ar e not used as standalone maintainability judgments; they function only as case-specific signals within a jointly designed repository context. pressur e can be exposed by a single localized change, and a multi-step probe when it only becomes visible under continued evolution. In a multi-step probe, the model receives a sequence of task files, each applied to the code produced at the previous step, as illustrated in Figure 4 . This makes early design decisions persistent across later changes. Case 021 is a micro probe because the D2 failure is visible after one change. Once the agent adds the inline entry point, the solution either routes it through the existing pipeline or introduces inline-only parsing and validation logic. The hidden oracle can detect that shortcut immediately through patterns such as std::stoi , std::isdigit , duplicated field handling, or duplicated error classification, so no further evolution is needed to expose the difference. By contrast, dimensions such as Dependency Control or Responsibility Decomposition often requir e multi-step probes, because a design that looks acceptable at step 1 may only fail later when added features for ce one component to absorb logging, provider-specific logic, or extra dependencies. 3.3 Packaging Dual Oracles Each probe is paired with two hidden evaluators: functional tests , which check the requested behavior , and structural oracles , which check whether the implementation preserves the intended maintainability constraint. A pr obe passes only if both succeed. The structural oracle is probe-specific, but its design follows recurring patterns aligned with the nine dimensions. For Change Locality (D1), it checks whether a small r equirement change remains localized. For Reuse and Repo Awar eness (D2), it checks reuse of existing repository af fordances and rejects duplicate implementation. For Responsibility Decomposition (D3), Extension Structure (D4), and Dependency Control (D6), it checks whether new behavior stays within the intended module boundaries rather than expanding 6 T able 2: All 21 repositories in N I T R with their dimension, granularity , and aggregate outcomes acr oss 23 evaluated configurations. S counts are bolded wher e ≥ 4, highlighting probes where functionally corr ect code still fails the maintainability oracle. 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 Dim. D1 D2 D2 D3 D4 D5 D5 D6 D7 D9 D1 D8 D1 D4 D6 D7 D8 D7 D9 D3 D2 T ype m m m m m µ m µ µ µ µ µ µ µ m m m m m µ µ Pass 5 0 22 0 0 2 10 2 21 21 10 23 18 19 0 8 4 2 1 7 0 S 13 0 0 0 0 4 0 4 0 0 0 0 0 0 0 0 0 0 0 11 0 m = multi-step; µ = micro; S = functional tests pass, but the maintainability oracle fails. central dispatch logic or introducing unnecessary coupling. For Interface and Substitutability Discipline (D5), it checks that interfaces remain narrow and that callers do not branch on concr ete subtype identity . For T estability and Determinism (D7), it flags hidden wall-clock or randomness usage and verifies that the intended deterministic seam is pr eserved. For State Ownership and Lifecycle (D8), it checks that lifecycle- sensitive state transitions remain within the designated ownership boundary . For Side-Effect Isolation (D9), it ensures that logging, tracing, or explanation paths do not intrude into cor e decision logic. These checks are lightweight and targeted rather than full semantic program analyses, but they are suf ficient to distinguish the intended maintainable solution family from common shortcut patterns. Case 021 illustrates the oracle pattern. Functional tests alone cannot distinguish reuse of the existing filter pipeline from a shadow parser , so the structural oracle checks for duplicated parsing and validation outside the designated repository path. Listing 2 shows an excerpt: it flags uses of std::stoi or std::isdigit , rejects inline-only integer handling when FilterValueKind::kInteger appears together with ParseInlineFilter , and detects repeated field or error logic outside the existing validation flow . In this way , the oracle distinguishes reuse of repository af fordances fr om parallel reimplementation. Oracle validation. During case construction, each oracle was validated against intended maintainable solutions, repr esentative shortcut solutions, and near -miss variants. W e iterated until the oracle stably separated the intended solution family fr om targeted shortcuts under small implementation variation; repr esentative intended, shortcut, and near-miss variants ar e included in the artifact. 3.4 Evaluation Protocol T able 1: The nine maintainability dimensions used as probe- construction axes in N I T R . Each case is assigned exactly one primary dimension. The last column reports how many cases in that dimension involve multiple steps. Dim. Name #Cases #Multi-step D1 Change Locality 3 1 D2 Reuse & Repo A wareness 3 2 D3 Responsibility Decomposition 2 1 D4 Extension Structure 2 1 D5 Interface & Substitutability 2 1 D6 Dependency Control 2 1 D7 T estability & Determinism 3 2 D8 State Ownership & Lifecycle 2 1 D9 Side-Effect Isolation 2 1 T otal 21 11 For each probe, the harness cr eates a temporary workspace, applies the model-generated file edits, configures and builds the project with CMake , runs the hidden functional tests, and then ex- ecutes the structural oracles. A pr obe is marked pass only if both the functional and structural evaluations succeed. This strict conjunction is intentional. N I T R is designed to expose a failure surface that ordinary test-centric evalu- ation misses: solutions that satisfy the requested behavior while introducing structural shortcuts. T able 1 summa- rizes the nine maintainability dimen- sions covered by N I T R, and T able 2 pro- vides the full probe inventory , includ- ing each case’s dimension, granularity , and aggregate outcome counts across the evaluated configurations. 4 Experimental Setup W e use N I T R to study coding agents and answer questions: • RQ1: How well do contemporary coding systems perform on the N I T R case suite? 7 0 20 40 60 API- only Agent- mode 13.6 28.1 44.2 63.6 Pass Rate (%) Micro Multi-step Figure 5: Both API-only and agent-mode systems perform substantially better on micr o cases than on multi-step cases, indicating that the main difficulty lies in evolutionary tasks rather than isolated edits. • RQ2: Which maintainability dimensions are most challenging for current coding systems? • RQ3: What structural failur e patterns do current AI coding tools exhibit, and to what extent are these failures missed by functional tests alone? • RQ4: Under our constrained evaluation harness, to what extent do agent-mode configurations outper - form direct API-based configurations fr om the same model family on maintainability preservation? Models and Agents. W e evaluate 23 configurations from multiple providers: 11 agent-mode and 12 API-only . Agent-mode systems ar e accessed through pr ovider-managed CLI surfaces that provide agentic scaffolding, such as multi-turn interaction and managed execution envir onments. API-only systems ar e accessed through direct model endpoints without such scaffolding. For API-mode evaluation, Qwen, Gemini, and Claude ar e served through Google Cloud V ertex AI ver ( 2026 ), while OpenAI models are accessed through the of ficial OpenAI API ope ( 2026 ). Submission Format and Execution Setup. T o standardize outputs, all systems must return edits as a JSON dictionary mapping file names to file contents. A local Python harness materializes each submission by overwriting the corresponding repository files. In multi-step cases, agent-mode systems receive tasks sequentially and may observe their own prior edits, wher eas API-only systems receive each step independently together with the relevant prior context. In all settings, models see only the agent-facing TASK.md , without hidden hints or additional maintainability instructions. Experimental Constraints. T o prevent evaluator leakage, neither agent-mode nor API-only systems can access the hidden unit tests or Python evaluation scripts. Agent-mode systems are additionally restricted to read-only r epository access: they may inspect files in the tar get repository , but cannot execute arbitrary commands, use external tools, or access files outside the workspace. These contr ols ensure that outputs are derived only fr om TASK.md and the visible repository contents. 5 Experimental Results and Findings 5.1 RQ1: Overall Performance T able 3 summarizes performance across the 21-case suite. Overall pass rates range fr om 24% (5/21 cases) for the weakest configurations to 57% (12/21) for the strongest ones. The best-performing systems are GPT-5.3-Cx (Agt) and Claude Opus 4.6 (Agt) , which each solve 12 of 21 cases. The strongest API-only configuration, Gemini 3.1 Pro (API) , solves 8 of 21 cases (38%). T aken together , these results indicate that even fr ontier coding systems solve only about half of the N I T R suite at best. Maintainability- preserving r epository evolution therefor e remains a substantial open challenge rather than a nearly solved capability . Performance is highly uneven across the suite, suggesting that current systems succeed mainly when the repository alr eady exposes a clear path for change, but str uggle once they must infer and preserve that path themselves. A small number of pr obes are close to saturation. Case 012 ( cache lifecycle ) is solved by all 23 configurations, while Case 003 ( reuse existing code ), Case 009 ( session-expiry testability ), and Case 010 ( logging side-effects ) are passed by 21–22 systems. These are cases where the starter repository already provides a strong structural path towar d the desir ed change, so the main burden is r ecognizing and following that path correctly . At the other extreme, five probes are not solved by any configuration: Case 002 ( refactor-and-r euse ), Case 004 ( responsibility decomposition in the CV pipeline ), Case 005 ( pricing extension structure ), Case 015 ( pipeline provider decoupling ), and Case 021 ( inline filter entrypoint reuse ). These universally unsolved cases are revealing because they are not simply hard programming tasks. Rather , they require the model 8 T able 3: Pass rates of evaluated configurations on N I T R (21 cases). Agent uses agentic scaf folding; API uses direct infer ence. Per -dimension cell background: all pass, majority , minority , none. Model Mode # Rate D1 D2 D3 D4 D5 D6 D7 D8 D9 GPT -5.3-Cx Agent 12 57% 2/3 1/3 1/2 1/2 1/2 1/2 2/3 2/2 1/2 GPT -5.2-Cx Agent 11 52% 3/3 1/3 0/2 1/2 1/2 1/2 2/3 1/2 1/2 GPT -5 Agent 11 52% 2/3 1/3 1/2 1/2 1/2 0/2 3/3 1/2 1/2 GPT -5.4 Agent 10 48% 2/3 1/3 1/2 1/2 1/2 0/2 2/3 1/2 1/2 GPT -5.4 API 7 33% 1/3 1/3 0/2 1/2 0/2 0/2 1/3 2/2 1/2 GPT -5-Mini API 6 29% 0/3 1/3 0/2 1/2 1/2 0/2 1/3 1/2 1/2 GPT -5.3-Cx API 6 29% 0/3 1/3 0/2 1/2 1/2 0/2 1/3 1/2 1/2 Claude Opus 4.6 Agent 12 57% 3/3 1/3 1/2 1/2 2/2 0/2 2/3 1/2 1/2 Claude Opus 4.5 Agent 10 48% 2/3 1/3 1/2 1/2 1/2 0/2 2/3 1/2 1/2 Claude Sonnet 4.6 Agent 9 43% 2/3 1/3 0/2 1/2 1/2 0/2 2/3 1/2 1/2 Claude Sonnet 4.5 Agent 8 38% 2/3 1/3 1/2 0/2 1/2 0/2 2/3 1/2 0/2 Claude Opus 4.5 API 6 29% 1/3 1/3 0/2 1/2 0/2 0/2 1/3 1/2 1/2 Claude Opus 4.6 API 6 29% 1/3 1/3 0/2 1/2 0/2 0/2 1/3 1/2 1/2 Claude Sonnet 4.5 API 6 29% 1/3 1/3 0/2 1/2 0/2 0/2 1/3 1/2 1/2 Claude Sonnet 4.6 API 5 24% 0/3 1/3 0/2 1/2 0/2 0/2 1/3 1/2 1/2 Gemini 3.1 Pro Agent 10 48% 3/3 0/3 0/2 1/2 1/2 0/2 1/3 2/2 2/2 Gemini 3.1 Flash Agent 6 29% 1/3 1/3 0/2 1/2 0/2 0/2 1/3 1/2 1/2 Gemini 2.5 Pro Agent 5 24% 1/3 1/3 0/2 1/2 0/2 0/2 1/3 1/2 0/2 Gemini 3.1 Pro API 8 38% 2/3 1/3 1/2 1/2 0/2 0/2 1/3 1/2 1/2 Gemini 2.5 Pro API 6 29% 2/3 1/3 0/2 0/2 0/2 0/2 0/3 2/2 1/2 Gemini 3.1 Flash API 5 24% 1/3 1/3 0/2 0/2 0/2 0/2 1/3 1/2 1/2 Qwen3-Coder API 5 24% 1/3 1/3 0/2 0/2 0/2 0/2 1/3 1/2 1/2 Qwen3-80B API 5 24% 0/3 1/3 0/2 1/2 0/2 0/2 1/3 1/2 1/2 Agent avg. 9.5 45% API avg. 5.9 28% Case pass rate 48% 32% 15% 41% 26% 4% 45% 59% 48% to preserve or r ecover an architectural dir ection under structural pr essure: refactor toward existing abstractions, maintain responsibility boundaries, extend behavior without patching central logic, or r oute changes through the repository’s intended r euse path. This suggests that the main limitation exposed by N I T R is not raw implementation ability alone, but difficulty maintaining design discipline during repository-level change. A further pattern emerges when we separate micr o cases from multi-step cases, also shown in Figur e 5 . Across all 23 configurations, micro cases are passed at 53.5% (123/230), whereas multi-step cases are passed at only 20.6% (52/253). The same drop appears in both evaluation regimes. API-only systems fall from 44.2% on micro cases (53/120) to 13.6% on multi-step cases (18/132), while agent-mode systems fall from 63.6% (70/110) to 28.1% (34/121). Mor eover , four of the five universally unsolved cases belong to the multi-step setting. Summary 1 N I T R shows that current AI coding tools remain far from r obust: they solve only 36.2% of cases, and pass rates collapse from 53.5% on micro cases to 20.6% on multi-step cases. The real bottleneck is sustained structural discipline under change, not isolated code generation or bug fixing. 5.2 RQ2: Which Maintainability Dimensions Are Most Challenging? T able 3 (bottom row) reports aggregate pass rates by maintainability dimension. The results reveal a non-uniform difficulty pattern within NITR rather than a uniform decline across the suite. Please note that because some dimensions ar e repr esented by a few cases, these rates should be r ead as diagnostic trends within N I T R rather than high-confidence population estimates of maintainability difficulty . Dependency Control (D6) is the hardest dimension by a wide mar gin, with a pass rate of just 4.3%. Across its two cases (Case 008 and Case 015), only 2 of 46 evaluated attempts succeed. Responsibility Decomposition 9 Figure 6: Pass/fail heatmap of 23 evaluated configurations across 21 cases. Pass, S-category failure (functional tests pass, maintainability oracle fails), Functional test failure, Both fail, Build failure. Cases marked confirm that functional tests alone miss these maintainability failures, which are detectable only via str uctural probes. Model 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 GPT-5.3-Cx (Agt) S S ✓ F B S ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ F ✓ ✓ F F ✓ F GPT-5.3-Cx (API) S S ✓ F B B ✓ F ✓ ✓ F ✓ F ✓ F F S F B S F GPT-5.4 (Agt) S S ✓ F B S ✓ F ✓ ✓ ✓ ✓ ✓ ✓ F ✓ S F B ✓ F GPT-5.4 (API) S S ✓ F B E F F ✓ ✓ F ✓ ✓ ✓ F F ✓ F B S F GPT-5.2-Cx (Agt) ✓ B ✓ F B S ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ F ✓ S F B S F GPT-5 (Agt) S B ✓ E B S ✓ B ✓ ✓ ✓ ✓ ✓ ✓ F ✓ S ✓ B ✓ F GPT-5-Mini (API) S B ✓ F E E ✓ B ✓ ✓ F ✓ F ✓ F F F F B S F Claude Opus 4.5 (Agt) S B ✓ F F S ✓ F ✓ ✓ ✓ ✓ ✓ ✓ F ✓ S F B ✓ F Claude Opus 4.5 (API) S S ✓ F F B F B ✓ ✓ F ✓ ✓ ✓ F F B F B S F Claude Opus 4.6 (Agt) ✓ S ✓ F B ✓ ✓ F ✓ ✓ ✓ ✓ ✓ ✓ F ✓ B F B ✓ F Claude Opus 4.6 (API) S S ✓ E F B F F ✓ ✓ F ✓ ✓ ✓ F F B F B S F Claude Sonnet 4.5 (Agt) S S ✓ F B E ✓ E ✓ F ✓ ✓ ✓ E F ✓ B F B ✓ F Claude Sonnet 4.5 (API) S S ✓ F E F B F ✓ ✓ F ✓ ✓ ✓ F F B F B S F Claude Sonnet 4.6 (Agt) S S ✓ F F ✓ F F ✓ ✓ ✓ ✓ ✓ ✓ F ✓ B F B S F Claude Sonnet 4.6 (API) S S ✓ E E F B F ✓ ✓ F ✓ F ✓ F F S F B S F Gemini 3.1 Pro (Agt) ✓ E F F F S ✓ S F ✓ ✓ ✓ ✓ ✓ S B ✓ ✓ ✓ S F Gemini 3.1 Pro (API) S S ✓ F F E F S ✓ ✓ ✓ ✓ ✓ ✓ F F S F B ✓ F Gemini 3.1 Flash (Agt) S S ✓ F F F F F ✓ ✓ F ✓ ✓ ✓ F F B F E S F Gemini 3.1 Flash (API) S S ✓ E F E F F ✓ ✓ F ✓ ✓ F F F B F E S F Gemini 2.5 Pro (Agt) B E ✓ E E E F F ✓ F F ✓ ✓ ✓ F E E F E S F Gemini 2.5 Pro (API) ✓ S ✓ F E B E F E ✓ F ✓ ✓ F F E ✓ F E S F Qwen3-Coder (API) ✓ E ✓ E B E F E ✓ ✓ F ✓ F E F F E F B E F Qwen3-80B (API) S S ✓ E E E F E ✓ ✓ F ✓ F ✓ E E B F B S F Pass 5/23 0/23 22/23 0/23 0/23 2/23 10/23 2/23 21/23 21/23 10/23 23/23 18/23 19/23 0/23 8/23 4/23 2/23 1/23 7/23 0/23 (D3) is the second hardest at 15.2%, followed by Interface and Substitutability Discipline (D5) at 26.1%, and Reuse and Repo A wareness (D2) at 31.9%. These are dimensions that requir e the model to identify and preserve latent r epository structure: respect dependency boundaries, maintain r esponsibility separation, extend behavior through the right abstraction, and reuse existing mechanisms instead of introducing parallel paths. By contrast, the easiest dimension is State Ownership and Lifecycle (D8) at 58.7%. It is followed by Change Locality (D1) and Side-Effect Isolation (D9), both at 47.8%, and T estability and Determinism (D7) at 44.9%. These dimensions are still nontrivial, but in many cases the intended structural direction is more explicit in the starter repository . Summary 2 W ithin N I T R , maintainability difficulty is highly concentrated instead of evenly distributed. Curr ent AI coding tools achieve 58.7% on D8 but only 4.3% on D6, a 13 × gap. W ithin NITR, the bottlenecks are dependency contr ol, responsibility decomposition, and abstraction-r especting extension. 5.3 RQ3: Maintainability Failures Missed by Functional Correctness T o answer RQ3, we analyze whether systems fail and how they fail. In particular , we distinguish ordinary functional failur es from failures that remain behaviorally correct yet violate the maintainability constraint encoded by the probe. Figure 6 summarizes the outcome of every (model, case) pair . W e classify each r esult as Pass , F (functional test failure), S (functional tests pass, but the maintainability oracle fails), B (both fail), or E (build err or). Across all 483 evaluated pairs, 36.2% pass, 31.5% are functional failur es, 13.3% ar e S -category failures, 10.4% are joint failur es, and 8.7% ar e build errors. By this decoupling, N I T R is deliberately constructed so that a behaviorally correct shortcut and a maintainable r epository-aligned solution can both satisfy the immediate task, while differing in long-term str uctural quality . The S category is especially important for answering this resear ch question. These are solutions that compile, pass the hidden functional tests, and would be counted as successful under conventional test-based evaluation, yet still violate the intended maintainability constraint. Across the full suite, this occurs in 64 of 483 evaluated pairs (13.3%). The effect is particularly str ong in Case 001, Case 002, and Case 020, which exhibit 17/23, 16/23, and 15/23 S -category outcomes, respectively . In these probes, many systems produce code that appears corr ect behaviorally while silently introducing structural debt. This shows that functional correctness and maintainability quality often decouple, and that test-only 10 T able 4: The table summarizes recurring qualitative patterns and representative cases; it is not an exhaustive coded annotation of all failures. Failure archetype Defining behavior Representative cases Outcome Shortcut over reuse or ab- straction Clones logic or creates a parallel path instead of routing the change through a reusable or repository-aligned abstraction 001, 002, 011, 021 S / F Boundary contamination Preserves visible behavior but violates re- sponsibility , ownership, or side-effect bound- aries 004, 019, 020 S / F / B Incomplete abstraction refac- tor Starts the right abstraction shape but does not propagate the change consistently acr oss the repository 006, 008, 014, 015 E / B Later-step r egression W orks for earlier milestones but breaks base- line behavior or collapses under later exten- sions 005, 007, 016, 017, 018, 019 F / B Missing test seam Leaves time, randomness, or configuration- sensitive behavior hardwir ed in core logic 009, 016, 018 F evaluation systematically overestimates maintainability competence on a nontrivial portion of the suite. Manual Inspection. T o contextualize the failur e matrix, we qualitatively inspected failed outcomes at the level of individual (model, case) runs. Across the 308 failed runs, the breakdowns clustered into a small set of recurring cross-case archetypes rather than appearing arbitrary or case-specific. These archetypes captur e empirical failure mechanisms shared across maintainability dimensions: reuse and dependency-control pr obes often fail through shortcut-over -reuse or incomplete abstraction r efactors, whereas r esponsibility and side-effect pr obes more often fail thr ough boundary contamination. Overall, N I T R suggests that current AI coding tools often preserve required behavior thr ough structurally convenient shortcuts that accumulate maintainability debt beyond what functional tests alone expose. Summary 3 W ithin N I T R , test passing is an unreliable pr oxy for maintainability preservation. 64/483 outcomes (13.3%) are behaviorally correct yet structurally wrong, and 308 failed runs collapse into five recurring archetypes rather than case-specific noise. 5.4 RQ4: Agents vs. APIs Under the N I T R Harness Under our constrained harness, agent-mode configurations are associated with higher overall perfor- mance on N I T R . W e report this as an observational comparison rather than a clean causal estimate of scaffolding alone, since agent and API settings differ in interface and execution surface. Across all configurations, agent mode averages 45.0% (9.45/21 cases) versus 28.2% (5.92/21) for API-only systems, a gain of 16.8 percentage points. The best agent configuration solves 12 of 21 cases, compared with 8 for the best API-only configuration. The same pattern appears in matched same-family comparisons. Among the nine families evaluated in both modes, agent mode impr oves performance in eight, with an average gain of 3.0 passed cases. For example, GPT-5.3-Cx and Claude Opus 4.6 improve fr om 6 to 12 passed cases in agent mode. Across N I T R , the largest gains appear on Cases 007, 011, 016, and 020, which requir e coor dination acr oss module boundaries, staged modifications, or responsi- bility-preserving changes. However , agent mode does not remove the core bottlenecks exposed by N I T R: no matched family solves Cases 002, 004, 005, 015, or 021 in either mode. Overall, under this harness, agent-mode systems are associated with better maintainability-pr eserving performance, but they do not resolve the underlying architectural failur e modes. 11 Summary 4 Under the NITR harness, agent-mode configurations generally perform better than API-only ones (45.0% vs. 28.2%), but this does not isolate scaffolding as the sole cause and does not r emove the core architectural bottlenecks. 5.5 Representative Case Studies W e discuss representative cases to illustrate distinct maintainability failure modes. Cases 001 and 020 capture N I T R ’s central behavioral–structural gap, while Case 006 highlights brittle extension against an existing repository convention. Case 001 (D1, S-category maintainability failure). The task asks agents to implement a multi-type add function across three incremental steps. Although the locked app/main.cc calls add with all four types from step 1, only the integer path is tested initially , so explicit overloads can still pass early . By step 3, 17 of 23 configurations incur structural debt by introducing duplicated, type-specific implementations while still passing the functional tests. The structural probe r equires a generic definition ( e.g., template or auto ) and flags multiple explicit overloads as ERR_DUPLICATED_IMPLEMENTATION . Case 020 (D3, S-category maintainability failure). The task asks agents to implement a handover-packet ownership boundary between two adjacent pipeline modules. 7 configurations pass the case. 15 of 23 configurations produce functionally correct solutions, but the structural probe detects that the ownership- transfer function also performs validation or enrichment that belongs in the receiving module, violating the intended responsibility boundary . Case 006 (D5, mixed maintainability/functional/build failure). The task asks agents to r efactor a hit- processing pipeline so that the sort stage consumes a narrow view type rather than the full HitBuffer . T wo configurations pass. 6 configurations still pass all functional tests, but intr oduce no new view type. Here the r epository already establishes an extension contract through its existing type-family structure, and the task r equires the new sort-stage interface to follow that pattern. The str uctural probe ther efore checks for a corresponding view abstraction in the public interface using repository-consistent patterns ( e.g., SortView or IHitSorting ); this is not a stylistic naming preference, but a check that the edit preserves the repository’s extension structur e rather than taking an ad hoc shortcut. A further four configurations introduce a view type but wir e it incorrectly , breaking functionality , and eight fail to compile altogether . 6 Discussion and Implications 6.1 Implications NITR suggests implications for education , code review , and agent design . First, N I T R can be useful as a teaching instrument for SE courses. Its cases make design tradeoffs concr ete by contrasting behaviorally correct solutions with structurally poor ones, which help students discuss reuse, boundaries, and testability in a more grounded way . Second, in practice, re viewing AI-generated code should go beyond asking whether a patch works, and ask whether it preserves reuse paths, dependency boundaries, responsibility separation, etc. Especially for multi-step changes, AI-generated code should be treated less as finished output and mor e as a structurally untrusted pr oposal. Third, the failures exposed by N I T R suggest that improving coding agents will requir e stronger r epository-level structural reasoning rather than better local code synthesis alone. 6.2 Threats to V alidity Construct validity . N I T R operationalizes maintainability through authored probes and case-specific structural oracles. This means the framework measures maintainability preservation as instantiated by explicit repository-evolution pr essures and executable design-boundary checks, not maintainability in an unrestricted sense. W e therefore position N I T R as a diagnostic instrument for targeted maintainability pressur es rather than a universal maintainability benchmark. Internal validity . Agent/API comparisons depend on the execution surfaces used her e and should be read as harness-level comparisons rather than isolated causal estimates. Each configuration is evaluated with a fixed setup and single sampled run per case, so we do not estimate run-to-run variance or prompt sensitivity . External validity . The suite uses 21 small C++ repositories for diagnostic clarity . This supports interpretability and oracle precision, but does not cover the full diversity of languages, r epository scales, or software-engineering workflows. Conclusion validity . Some maintainability dimensions are repr esented by only two or three 12 cases. Accor dingly , dimension-level differences are best interpr eted as suite-level diagnostic tr ends rather than high-power statistical estimates. 7 Related W ork Software Engineering Benchmarks for LLMs. A large body of work evaluates coding systems primarily through behavioral corr ectness. Early benchmarks such as HumanEval Chen et al . ( 2021 ), MBPP Austin et al . ( 2021 ), and CodeContests Li et al . ( 2022 ) focus on synthesis tasks whose outputs ar e judged by hidden tests. Mor e recent benchmarks br oaden the setting from isolated functions to r ealistic codebase tasks while retaining correctness as the main signal. RepoBench Liu et al . ( 2024 ) introduces r epository- level context for cross-file completion, LiveCodeBench Jain et al . ( 2024 ) emphasizes contamination-free and continually refr eshed evaluation, SWE-bench Jimenez et al . ( 2024 ) measures issue r esolution in real GitHub repositories, and EvoCodeBench Li et al . ( 2024a ) evaluates repository-gr ounded code generation under evolving benchmark updates. This line of work has since expanded along several axes. SWE-bench V erified Chowdhury et al . ( 2024 ), SWE-bench Pro Deng et al . ( 2025 ), and Multi-SWE-bench Zan et al . ( 2025 ) strengthen issue-r esolution evaluation through improved quality control, difficulty , and multilingual coverage. SWE-Evo Thai et al . ( 2025 ) and Commit-0 Zhao et al . ( 2025 ) move towar d longer -horizon development workflows, while NL2Repo Ding et al . ( 2026 ) studies full repository generation from natural-language specifications. Automated pipelines such as SWE-r ebench Badertdinov et al . ( 2025 ) and SWE-bench Live Zhang et al . ( 2025 ) further improve r ealism. . These works are indispensable for measuring task-completion capability , but their primary signal re- mains test behavior . N I T R instead evaluates whether a behaviorally correct repository edit pr eserves maintainability . It r elies on expert-curated pr obes to ensur e data quality , so that each case cleanly encodes a specific software engineering principle and maintainability pr essure. Long-Horizon Software Evolution Benchmarks. A second line of work pushes evaluation beyond one-shot issue resolution toward broader software-development behavior and continuous repository change. DevBench Li et al . ( 2024b ) evaluates multiple stages of the software-development lifecycle, SWE-EVO Thai et al . ( 2025 ) and SWE-CI Chen et al . ( 2026 ) study multi-step repository evolution and continuous-integration-style maintenance, SlopCodeBench slo ( 2026 ) examines code er osion as agents iterate, and EvoClaw Deng et al . ( 2026 ) evaluates continuous softwar e evolution thr ough executable milestone sequences that stress sustained system integrity over time. These efforts primarily evaluate agents under continuous task evolution measured by test behaviors, whereas N I T R evaluates whether a behaviorally correct repository edit pr eserves maintainable structure in a way that can be diagnosed precisely . LLMs for Design Quality and Maintainability Analysis. Maintainability has long been studied in software engineering through code and design quality perspectives, including coupling and cohesion metrics Chidamber and Kemer er ( 1994 ), design principles such as SOLID Martin ( 2003 ), and technical debt as a way to reason about futur e maintenance cost Cunningham ( 1992 ). Recent software engineering work has begun to study LLMs on maintainability and quality-oriented tasks beyond functional correctness Sun et al . ( 2025 ); Molison et al . ( 2025 ). Recent examples include LLM-based localization of code design issues Batole et al . ( 2025 ), prompting-based detection of SOLID principle violations Pehlivan et al . ( 2025 ), evaluation of LLMs for fixing maintainability issues in real- world projects Nunes et al . ( 2025 ), context-enriched quality-awar e code review generation Zhang et al . ( 2026 ), and industrial experience with LLM-based automated code review Ramesh et al. ( 2025 ). These ef forts study how LLMs can analyze , r eview , or r epair maintainability-r elated pr oblems. N I T R differs fr om them by evaluating whether maintainability is pr eserved during code generation itself. Its distinguishing mechanism is the use of hidden structural oracles tied to explicit repository-evolution pressur es. 8 Conclusion N I T R is ultimately a step toward a broader shift in how we evaluate LLM for software engineering: from asking whether models can produce correct code, to asking whether they can participate responsibly in the long-term evolution of r eal repositories. As coding agents move fr om isolated completions to sustained collaboration with developers, the central question is no longer only correctness, but whether generated changes preserve the str uctural conditions that make future change possible. W e hope N I T R 13 helps make maintainability a first-class objective in both evaluation and system design, and encourages the next generation of coding agents to be judged not only by what they can build today , but by whether what they build remains worth extending tomorr ow . References 2026. Google V ertex AI. https://cloud.google.com/vertex- ai . 2026. OpenAI API Platform. https://openai.com/api/ . 2026. SlopCodeBench. https://www.scbench.ai/ . 2026. Why the majority of vibe coded projects fail. https://www.reddit.com/r/ClaudeAI/comments/ 1rt31th/why_the_majority_of_vibe_coded_projects_fail/ . Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael T erry , Quoc Le, et al . 2021. Program Synthesis with Lar ge Language Models. arXiv preprint arXiv:2108.07732 (2021). Ibragim Badertdinov , Alexander Golubev , Maksim Nekrashevich, Anton Shevtsov , Simon Karasik, Andrei Andriushchenko, Maria T rofimova, Daria Litvintseva, and Boris Y angel. 2025. SWE-rebench: An Automated Pipeline for T ask Collection and Decontaminated Evaluation of Software Engineering Agents. arXiv preprint arXiv:2505.20411 (2025). Fraol Batole, David OBrien, T ien N. Nguyen, Robert Dyer , and Hridesh Rajan. 2025. An LLM-Based Agent- Oriented Approach for Automated Code Design Issue Localization. In Proceedings of the IEEE/ACM 47th International Conference on Softwar e Engineering (Ottawa, Ontario, Canada) (ICSE ’25) . IEEE Press, 1320–1332. doi: 10.1109/ICSE55347.2025.00100 Islem Bouzenia, Premkumar T . Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair . In Proceedings of the 47th IEEE/ACM International Confer ence on Software Engineering (ICSE) . 2188–2200. Jialong Chen, Xander Xu, Hu W ei, Chuan Chen, and Bing Zhao. 2026. SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration. arXiv preprint (2026). doi: 10.48550/arXiv.2603.03823 Mark Chen, Jerry T worek, Heewoo Jun, Qiming Y uan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Y uri Burda, Nicholas Joseph, Greg Br ockman, et al . 2021. Evaluating Large Language Models T rained on Code. arXiv preprint arXiv:2107.03374 (2021). Shyam R. Chidamber and Chris F . Kemerer . 1994. A Metrics Suite for Object Oriented Design. IEEE T ransactions on Software Engineering 20, 6 (1994), 476–493. doi: 10.1109/32.295895 Neil Chowdhury , James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, et al . 2024. Introducing SWE-bench V erified. https: //openai.com/index/introducing- swe- bench- verified/ . W ard Cunningham. 1992. The W yCash Portfolio Management System. In Addendum to the Proceedings on Object-Oriented Programming Systems, Languages, and Applications (OOPSLA ’92) . ACM, 29–30. doi: 10. 1145/157709.157715 Gangda Deng, Zhaoling Chen, Zhongming Y u, Haoyang Fan, Y uhong Liu, Y uxin Y ang, Dhruv Parikh, Raj- gopal Kannan, Le Cong, Mengdi W ang, Qian Zhang, V iktor Prasanna, Xiangru T ang, and Xingyao W ang. 2026. EvoClaw: Evaluating AI Agents on Continuous Softwar e Evolution. arXiv:2603.13428 [cs.SE] Xiang Deng, Jeff Da, Edwin Pan, Y annis Y iming He, Charles Ide, Kanak Garg, Niklas Lauf fer , Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurt hy , Sean Hendryx, Zifan W ang, V ijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler . 2025. SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering T asks? arXiv:2509.16941 [cs.SE] Jingzhe Ding, Shengda Long, Changxin Pu, Huan Zhou, Hongwan Gao, Xiang Gao, Chao He, Y ue Hou, Fei Hu, Zhaojian Li, W eiran Shi, Zaiyuan W ang, Daoguang Zan, Chenchen Zhang, Xiaoxu Zhang, Qizhi Chen, Xianfu Cheng, Bo Deng, Qingshui Gu, Kai Hua, Juntao Lin, Pai Liu, Mingchen Li, Xuanguang Pan, Zifan Peng, Y ujia Qin, Y ong Shan, Zhewen T an, W eihao Xie, Zihan W ang, Y ishuo Y uan, Jiayu Zhang, Enduo Zhao, Y unfei Zhao, He Zhu, Liya Zhu, Chenyang Zou, Ming Ding, Jianpeng Jiao, Jiaheng 14 Liu, Minghao Liu, Qian Liu, Chongyang T ao, Jian Y ang, T ong Y ang, Zhaoxiang Zhang, Xinjie Chen, W enhao Huang, and Ge Zhang. 2026. NL2Repo-Bench: T owards Long-Horizon Repository Generation Evaluation of Coding Agents. arXiv:2512.12730 [cs.CL] Roy S Freedman. 1991. T estability of software components. IEEE transactions on Software Engineering 17, 6 (1991), 553–564. Stefan Haefliger , Georg V on Krogh, and Sebastian Spaeth. 2008. Code reuse in open source software. Management science 54, 1 (2008), 180–193. Ruida Hu, Chao Peng, Jingyi Ren, Bo Jiang, Xiangxin Meng, Qinyun W u, Pengfei Gao, Xinchen W ang, and Cuiyun Gao. 2024. A Real-W orld Benchmark for Evaluating Fine-Grained Issue Solving Capabilities of Large Language Models. arXiv pr eprint arXiv:2411.18019 (2024). Naman Jain, Ming-Ho Y ee, Kyle Lo, V aishaal Shankar , Arjun Guha, Koushik Sen, Ion Stoica, and Dan Klein. 2024. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv:2403.07974 [cs.SE] Carlos E Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-W orld GitHub Issues?. In Interna- tional Conference on Learning Repr esentations (ICLR) . Charles W Krueger . 1992. Software reuse. ACM Computing Surveys (CSUR) 24, 2 (1992), 131–183. Bowen Li, W enhan W u, Ziwei T ang, Lin Shi, John Y ang, Jinyang Li, Shunyu Y ao, Chen Qian, Binyuan Hui, Qicheng Zhang, Zhiyin Y u, He Du, Ping Y ang, Dahua Lin, Chao Peng, and Kai Chen. 2024b. DevBench: A Compr ehensive Benchmark for Software Development. arXiv preprint (2024). doi: 10.48550/arXiv.2403.08604 Jia Li, Ge Li, Xuanming Zhang, Y ihong Dong, and Zhi Jin. 2024a. EvoCodeBench: An Evolving Code Generation Benchmark Aligned with Real-W orld Code Repositories. arXiv preprint (2024). doi: 10.48550/arXiv.2404.00599 Y ujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser , Rémi Leblond, T om Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al . 2022. Competition-Level Code Generation with AlphaCode. Science 378, 6624 (2022), 1092–1097. T ianyang Liu, Canwen Xu, and Julian McAuley . 2024. RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems. In The T welfth International Confer ence on Learning Representations . https://openreview.net/forum?id=pPjZIOuQuF Robert C. Martin. 2003. Agile Software Development, Principles, Patterns, and Practices . Prentice Hall. Alfred Santa Molison, Marcia Moraes, Glaucia Melo, Fabio Santos, and W esley K. G. Assuncao. 2025. Is LLM-Generated Code More Maintainable & Reliable than Human-W ritten Code? arXiv preprint arXiv:2508.00700 (2025). doi: 10.48550/arXiv.2508.00700 Henrique Nunes, Eduar do Figueiredo, Larissa Rocha, Sarah Nadi, Fischer Ferreira, and Geanderson Esteves. 2025. Evaluating the Effectiveness of LLMs in Fixing Maintainability Issues in Real-W orld Projects. arXiv:2502.02368 [cs.SE] Siru Ouyang, W enhao Y u, Kaixin Ma, Zilin Xiao, Zhihan Zhang, Mengzhao Jia, Jiawei Han, Hongming Zhang, and Dong Y u. 2025. RepoGraph: Enhancing AI Softwar e Engineering with Repository-level Code Graph. In The Thirteenth International Conference on Learning Representations (ICLR) . https: //openreview.net/forum?id=JbWVgWsW9H Parker . 1982. Design for testability—A survey . IEEE T ransactions on computers 100, 1 (1982), 2–15. Fatih Pehlivan, Arçin Ülkü Ergüzen, Sahand Moslemi Y engejeh, Mayasah Lami, and Anil Koyuncu. 2025. Are W e SOLID Y et? An Empirical Study on Prompting LLMs to Detect Design Principle V iolations. arXiv:2509.03093 [cs.SE] Shweta Ramesh, Joy Bose, Hamender Singh, A K Raghavan, Sujoy Roy Chowdhury , Giriprasad Sridhara, Nishrith Saini, and Ricardo Britto. 2025. Automated Code Review Using Lar ge Language Models at Ericsson: An Experience Report. 2025 IEEE International Confer ence on Software Maintenance and Evolution (ICSME) (2025), 602–607. https://api.semanticscholar.org/CorpusID:280046022 Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R. Narasimhan, and Shunyu Y ao. 2023. Reflexion: Language Agents with V erbal Reinforcement Learning. In Advances in Neural Information Processing Systems . https://openreview.net/forum?id=vAElhFcKW6 15 Xin Sun, Daniel Ståhl, Kristian Sandahl, and Christoph Kessler . 2025. Quality Assurance of LLM- generated Code: Addr essing Non-Functional Quality Characteristics. arXiv preprint (2025). doi: 10.48550/arXiv.2511.10271 Minh V . T . Thai, T ue Le, Dung Nguyen Manh, Huy Phan Nhat, and Nghi D. Q. Bui. 2025. SWE- EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios. arXiv preprint arXiv:2512.18470 (2025). Xingyao W ang, Y angyi Chen, Lifan Y uan, Y izhe Zhang, Y unzhu Li, Hao Peng, and Heng Ji. 2024. Executable Code Actions Elicit Better LLM Agents. In Proceedings of the 41st International Conference on Machine Learning (ICML) . 50208–50232. Xingyao W ang, Boxuan Li, Y ufan Song, Frank F . Xu, Xiangru T ang, Mingchen Zhuge, Jiayi Pan, Y ueqi Song, Bowen Li, Jaskirat Singh, Hoang H. T ran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Y anjun Shao, Niklas Muennighof f, Y izhe Zhang, Binyuan Hui, Junyang Lin, Robert Br ennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for AI Software Developers as Generalist Agents. In The Thirteenth International Conference on Learning Representations (ICLR) . https://openreview.net/forum?id=OJd3ayDDoF John Y ang, Carlos E. Jimenez, Alexander W ettig, Kilian Lieret, Shunyu Y ao, Karthik R. Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Interfaces Enable Automated Softwar e Engineering. In Advances in Neural Information Processing Systems . https://openreview.net/forum?id=mXpq6ut8J3 John Y ang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Y ang, Xindi W u, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, Diyi Y ang, Sida W ang, and Ofir Press. 2025. SWE-bench Multimodal: Do AI Systems Generalize to V isual Software Domains?. In The Thirteenth International Conference on Learning Representations . https://openreview.net/forum?id=riTiq3i21b Daoguang Zan, Zhirong Huang, W ei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, et al . 2025. Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving. arXiv preprint arXiv:2504.02605 (2025). Linghao Zhang, Shilin He, Chaoyun Zhang, Y u Kang, Bowen Li, Chengxing Xie, Junhao W ang, Maoquan W ang, Y ufan Huang, Shengyu Fu, et al . 2025. SWE-bench Goes Live! arXiv preprint (2025). Y uxin Zhang, Y uxia Zhang, Zeyu Sun, Y anjie Jiang, and Hui Liu. 2026. LAURA: Enhancing Code Review Generation with Context-Enriched Retrieval-Augmented LLM. In 2025 40th IEEE/ACM International Conference on Automated Softwar e Engineering (ASE) (Seoul, Korea, Republic of). IEEE Pr ess, 2983–2995. doi: 10.1109/ASE63991.2025.00245 W enting Zhao, Nan Jiang, Celine Lee, Justin T . Chiu, Claire Cardie, Matthias Gallé, and Alexander M. Rush. 2025. Commit0: Library Generation from Scratch. In International Conference on Learning Represen- tations (ICLR) . Jiasheng Zheng, Boxi Cao, Zhengzhao Ma, Ruotong Pan, Hongyu Lin, Y aojie Lu, Xianpei Han, and Le Sun. 2024. Beyond Correctness: Benchmarking Multi-dimensional Code Generation for Large Language Models. arXiv preprint arXiv:2407.11470 (2024). 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment