Suppression of $^{14}\mathrm{C}$ photon hits in large liquid scintillator detectors via spatiotemporal deep learning
Liquid scintillator detectors are widely used in neutrino experiments due to their low energy threshold and high energy resolution. Despite the tiny abundance of $^{14}$C in LS, the photons induced by the $β$ decay of the $^{14}$C isotope inevitably …
Authors: Junle Li, Zhaoxiang Wu, Gu
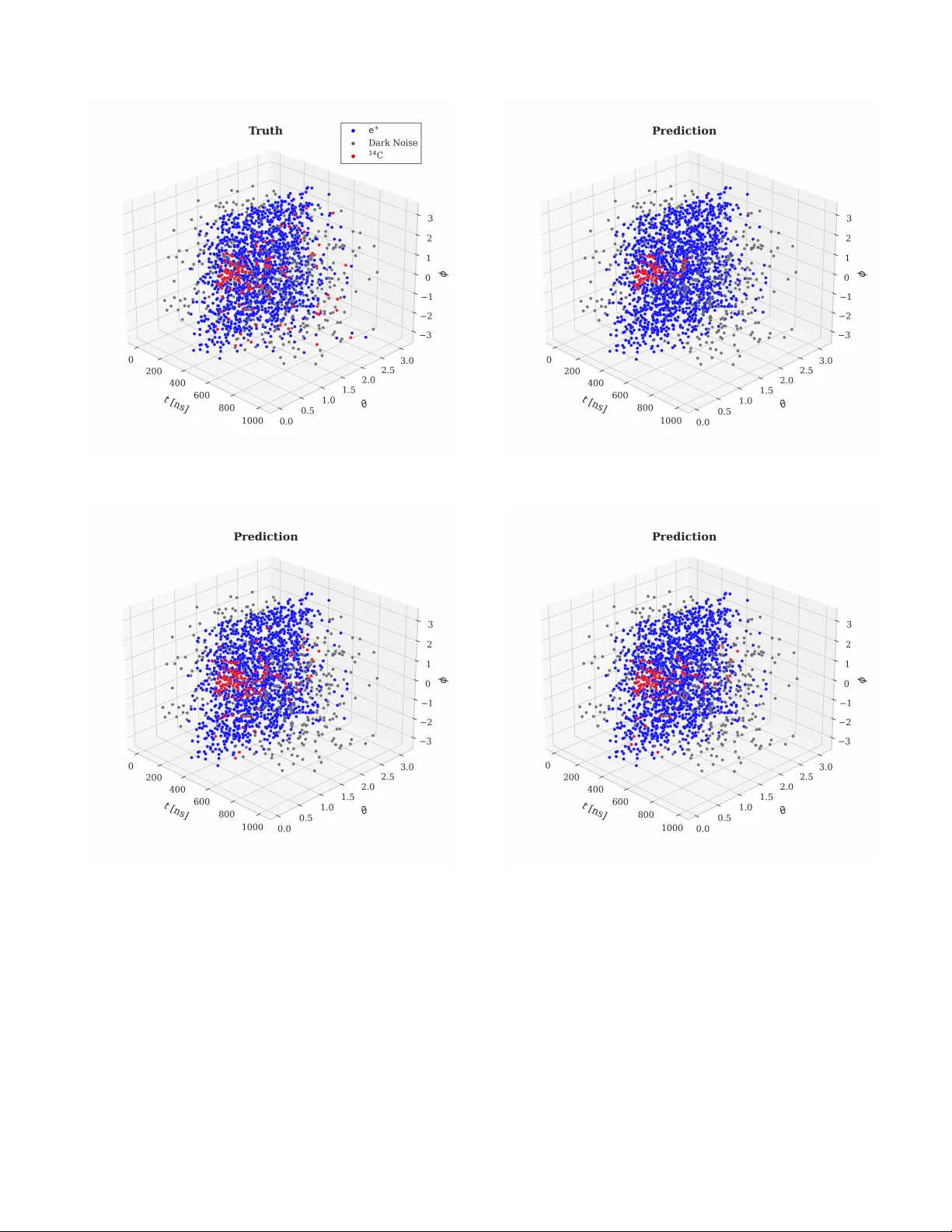
Suppression of 14 C photon hits in large liquid scin tillator detectors via spatiotemp oral deep learning Junle Li , 1 Zhao xiang W u , 2, 3 Guanda Gong , 2 Zhaohan Li , 2 , ∗ W uming Luo , 2 , † Jiah ui W ei , 2 W enxing F ang , 2 and Hehe F an 4 , ‡ 1 Scho ol of A er onautics and Astr onautics, Z hejiang University, Hangzhou 310027, China 2 Institute of High Ener gy Physics, Chinese A cademy of Scienc es, Beijing 100049, China 3 Scho ol of Physic al Scienc es, University of Chinese A c ademy of Scienc e, Beijing 100049, China 4 Col le ge of Computer Scienc e and T echnolo gy, Zhejiang University, Hangzhou 310027, China (Dated: March 29, 2026) Liquid scintillator detectors are widely used in neutrino exp eriments due to their low energy threshold and high energy resolution. Despite the tiny abundance of 14 C in LS, the photons induced b y the β deca y of the 14 C isotope inevitably con taminate the signal, degrading the energy resolution. In this work, we prop ose three mo dels to tag 14 C photon hits in e + ev ents with 14 C pile-up, thereb y suppressing its impact on the energy resolution at the hit level: a gated spatiotemp oral graph neural netw ork and t wo T ransformer-based mo dels with scalar and v ector c harge enco ding. F or a sim ulation dataset in which each ev ent con tains one 14 C and one e + with kinetic energy below 5 MeV, the mo dels achiev e 14 C recall rates of 25%–48% while main taining e + to 14 C misidentification b elo w 1%, leading to a large improv emen t in the resolution of total charge for even ts where e + and 14 C photon hits strongly ov erlap in space and time. I. INTR ODUCTION Pile-up, namely the o verlap of signal and bac kground pro cesses within the same data acquisition windo w, is a w ell-known c hallenge in particle physics exp erimen ts. It can induce fake signal yields or degrade detector reso- lution [ 1 – 5 ], thereb y affecting physics sensitivity . With the adv antages of low energy threshold and high energy resolution, liquid scintillator (LS) detectors [ 6 – 11 ] are widely used in neutrino exp erimen ts. Regardless of the LS recip e, carb on atoms are usually the dominant com- p onen t [ 12 ]. Despite its tiny abundance in LS, the 14 C isotop e decays and induces scintillation photons. When these photons fall within the same data acquisition win- do w as a signal particle, they inevitably contaminate the signal photons. This so-called 14 C pile-up effect worsens the energy resolution or introduces background and is a common challenge for all LS detectors [ 1 , 4 , 13 , 14 ]. This effect becomes even more critical for large-scale detectors suc h as the Jiangmen Underground Neutrino Observ a- tory (JUNO) [ 13 , 15 ], where the large target mass results in a more frequen t o ccurrence of pile-up ev ents. Mean- while the energy resolution is crucial for high-precision neutrino oscillation measurements. While hit-lev el pile- up suppression has b een extensively developed for jet re- construction at the Large Hadron Collider (LHC) [ 16 – 21 ], comparable approac hes are less explored in LS de- tectors. In this paper, we inv estigate the feasibilit y of uti- lizing deep learning metho ds to iden tify and suppress 14 C photon hits in order to mitigate their impact on energy resolution. W e fo cus sp ecifically on 14 C pile-up even ts ∗ Corresponding author: lizhaohan@ihep.ac.cn † Corresponding author: luowm@ihep.ac.cn ‡ Corresponding author: hehefan@zju.edu.cn that contain only a single 14 C pile-up, given that multi- ple 14 C pile-up has a muc h lo w er probability of occurring and a more complex even t top ology . The JUNO exp eri- men t is used as a representativ e case study . JUNO is a 20-kton LS detector designed primarily to determine the neutrino mass ordering, and it requires an unpreceden ted energy resolution of 3% at 1 MeV [ 22 ]. This performance relies on high optical co v erage, pro- vided by appro ximately 17,600 20-inch and 25,600 3-inc h photom ultiplier tub es (PMTs) [ 13 , 23 ], an optimized LS recip e to ac hieve high ligh t yield as w ell as excellent transparency [ 24 ], extensiv e PMT R&D to increase the quan tum efficiency for photon detection, and adv anced reconstruction algorithms [ 23 , 25 – 27 ]. Detailed informa- tion on JUNO can b e found in Refs. [ 13 , 24 ]. JUNO detects reactor ¯ ν e via in verse beta decay (IBD), ¯ ν e + p → n + e + , the av erage dep osited energy of a p ositron is at the MeV scale. In contrast, the p eak and endp oin t energies of the 14 C b eta deca y are 0 . 04 MeV and 0 . 16 MeV, resp ectiv ely , yielding substantially few er scin tillation photons. As a result, when the t w o processes o verlap in time, the 14 C photon con tribution is embedded in the dominant p ositron signal and b ecomes difficult to distinguish at the hit level. The identification of 14 C photon hits can be viewed as a seman tic segmentation task on a sparse p oin t cloud defined on a spherical detector geometry . Compared to p oin t cloud segmentation problems, this task is compli- cated b y the sparsity of the data and the discontin u- ous distribution of photon hits in b oth space and time. T o address these challenges, we inv estigate tw o classes of deep learning arc hitectures: a graph-based mo del implemen ted as a Gated Spatiotemp oral Graph Neu- ral Netw ork (Gated-STGNN)[ 28 ], and tw o T ransformer- based mo dels [ 29 ]: the Spatiotemp oral T ransformer with Scalar Charge Encoding (STT-Scalar) , whic h uses the c harge of eac h PMT hit directly , and the Spatiotem- 2 (a) Large separation (∆ t = 455 . 0 ns) (b) Small separation (∆ t = 2 . 6 ns) FIG. 1. Hit time distributions of pile-up even ts. The curves show the contributions from e + annihilation (blue), 14 C decay (red), and dark noise (gray), along with the total hit count (dashed blac k). (a) With large ∆ t , the 14 C signal app ears as a w eak secondary p eak. (b) With small ∆ t , the 14 C hits are buried within the dominant e + p eak. p oral T ransformer with V ector Charge Enco ding (STT- V ector), whic h incorp orates c harge information aggre- gated from neighboring hits. The graph-based approach emphasizes local spatiotemp oral correlations through structured neighborho o d aggregation, while the T rans- former framework captures global dep endencies via self- atten tion mechanisms. Their p erformance is ev aluated based on hit identification efficiency and the resulting impact on the reconstructed energy resolution. The pap er is organized as follows. Section I I describ es the simulation and data represen tation. Section I I I de- tails the proposed graph and atten tion-based architec- tures. The training proto col and ev aluation metrics are presen ted in Section IV . Finally , Section V discusses the classification p erformance and its impact on energy res- olution, follo wed by conclusions in Section VI . I I. SIMULA TION AND DA T ASET Data samples are simulated based on a configuration similar to the JUNO central detector [ 13 ], including PMT p ositions, LS prop erties, etc. V arious electronic effects, suc h as PMT transit-time smearing, PMT dark noise and PMT single-photo electron charge smearing, were imple- men ted in a toy electronics sim ulation. Moreo ver, as men tioned in the Introduction, the simulation w as cus- tomized such that one 14 C pile-up was enforced for every e + ev ent. With a light yield of 1665 photon hits p er MeV from a previous study [ 23 ], an e + at rest (0 MeV kinetic energy) dep osits around 1 . 022 MeV in the LS and induces approximately 1702 photon hits recorded by the PMTs, with a statistical fluctuation of 41 photons. By con trast, a 14 C deca y produces around 100 photons on a verage, which are easily ov e rwhelmed b y the e + photon hits. In addition, given an av erage rate of 22.7 kHz and 17,600 PMTs, PMT dark noise con tributes about 400 photon hits within the acquisition window of each even t, making the identification of 14 C photons more challeng- ing. The acquisition windo w of an even t is 1000 ns. Each ev ent con tains photon hits induced by three components: one IBD positron (e + ), one 14 C β decay , and uniformly distributed dark noise (DN). F or the i -th hit, the data v ector is defined as s i = ( x i , y i , z i , t i , q i , ℓ i ) , (1) where ( x, y , z ) are the spatial coordinates of the triggered PMT [ 13 ], t is the arriv al time relative to the start of the acquisition window, and q is the c harge. Here ℓ i ∈ { 0 , 1 , 2 } denotes the truth lab el of the hit, represen ting it originating from DN, e + , and 14 C, resp ectiv ely . The photon hit time distributions of tw o example ev ents are shown in Fig. 1 . The difficulty of hit-level dis- crimination dep ends strongly on the relative difference b et w een the 14 C deca y time ( t 14 C ) and the e + time ( t e + ), defined as ∆ t ≡ t 14 C − t e + . (2) F or an even t with large | ∆ t | , as sho wn in Fig. 1a , the tw o comp onen ts are temp orally separated and background 14 C hits can b e rejected using simple timing cuts [ 23 ]. F or even ts with ∆ t ∈ [ − 100 , 300] ns, the 14 C comp onent is em b edded within the dominan t e + p eak, rendering tim- ing information alone insufficient, as indicated in Fig. 1b . A joint analysis of spatial and temp oral correlations is therefore required. The spatiotemp oral structure of a t ypical ev ent in this regime is shown in Fig. 2 . This 3 100 – 200 ns 200 – 300 ns 300 – 400 ns 400 – 500 ns 500 – 600 ns FIG. 2. The spatiotemp oral structure of a pile-up even t with ∆ t = 1 . 9 ns. The truth information for the e + ev ent consists of a kinetic energy E k (e + ) = 1 . 4 MeV and a vertex p osition of ( x, y, z ) = ( − 1 . 9 , 5 . 7 , 11 . 1) m, while that for the 14 C even t consists of a dep osited energy E 14 C = 107 . 4 keV and a vertex p osition of ( x, y , z ) = ( − 5 . 4 , 1 . 9 , − 14 . 8) m. The plots show the spatial distribution of photon hits in 100 ns in terv als. Blue dots represent hits from the p ositron annihilation, red dots from the 14 C deca y , and gray dots indicate dark noise. study fo cuses on ev en ts with ∆ t ∈ [ − 100 , 300] ns, exclud- ing other even ts. Ev ents at a few-MeV scale contain relatively few pho- ton hits. Thus, only a small fraction of all PMTs are trig- gered and register photon hits. Moreo ver, the ma jority of these PMTs will detect no more than 4 photons in the en tire 1000 ns acquisition windo w. Therefore, the data structure manifests inherent sparsit y and spatiotemp oral discon tinuit y . This is very different from the scenario of con ven tional p oint cloud tasks [ 30 – 34 ]. The samples used in this study are as follows. T raining sample: Mo dels are trained on a sample of one million simulated ev en ts with contin uous positron ki- netic energy E k (e + ) ∈ [0 , 5] MeV and vertices distributed uniformly within the LS T est sample: Ev aluation is conducted on 24 inde- p enden t test sets, eac h containing 8 × 10 4 ev ents. These data sets corresp ond to the combinations of six discrete p ositron kinetic energies, E k (e + ) ∈ { 0 , 1 , 2 , 3 , 4 , 5 } MeV , (3) and four exemplary v ertex positions along the detector z -axis: z ∈ { 0 , 6 , 15 , 16 . 5 } m . (4) The datasets at 0 and 6 m characterize mo del p er- formance in the detector’s inner v olume. T o probe p er- formance near the detector b oundary , we also consider datasets at larger radii. In particular, the JUNO central detector exhibits a total reflection region, approximately defined by r ∈ [15 . 6 , 17 . 7] m [ 13 ]. The dataset at 15 m prob es even ts close to the b oundary of this region, while the dataset at 16.5 m corresp onds to even ts well within the total reflection regime and serves as a representativ e sample. 4 I II. METHODOLOGY A. Gated Spatiotemp oral Graph Neural Netw ork (Gated-STGNN) LHC uses Gated-GNN [ 28 ] to suppress the pile-up ef- fect in the jet reconstruction [ 18 , 19 , 35 ]. In this work, w e adapt the Gated-GNN to the 14 C hit-level tagging task and refer to it as Gated-STGNN. Gated-STGNN mo dels even ts as graphs where no des represent hits and edges enco de lo cal spatiotemp oral proximit y . The archi- tecture employs message passing for contextual propaga- tion and a p er-hit classifier for the three target classes. The Gated-STGNN serves as the baseline mo del for this study . Input r epr esentation and b atching. F or an even t with N hits, the input feature vector u i is constructed from the hit vector s i defined in Eq. ( 1 ). The spatial co ordinates r i = ( x i , y i , z i ) are mapp ed to the unit direction vector ˆ x i = r i / ∥ r i ∥ . The hit time t i is transformed into a normalized con- tin uous time ˜ t i ∈ [0 , 1) within the acquisition window [ t min , t max ) to preserv e the precise timing required for mi- croscopic hit-lev el correlations. T o simultaneously cap- ture the macroscopic temp oral evolution of the ev ent, t i is also mapped to a normalized coarse-grained time-bin index ˜ b i ∈ [0 , 1] using a bin width ∆ t bin . The charge q i is used directly . The resulting input v ector for the i -th hit is given by u i = ( ˆ x i , q i , ˜ t i , ˜ b i ) ∈ R 6 . (5) The num b er of hits v aries across ev en ts; how ev er, parallel pro cessing on GPUs requires a uniform sequence length for all even ts within a mini-batch. Even ts are therefore zero-padded so that the num ber of hits in every even t equals L max = max m N m , where N m denotes the v alid hit n umber of the m -th even t in the batch. Since zero- padding can interfere with the hit identification task, a binary mask M is emplo yed to strictly exclude padded en tries from the graph construction and message passing op erations: M mj = ( 1 , if j ≥ N m (padding) , 0 , otherwise (v alid) , (6) where the index m denotes the even t within the mini- batc h, and j ∈ [0 , L max − 1] represen ts the hit index within that sp ecific even t. Window-level c ontext. T o capture the global temp o- ral evolution, aggregate statistics—sp ecifically the hit n umber, the sum and mean of the charges, alongside the mean and v ariance of the unit direction vectors—are computed for eac h discrete time bin b to serve as the bin feature vector w b . The sequence of bin features w b is then pro cessed by a Gated Recurren t Unit (GRU) to generate hidden states c b [ 36 ]. Each hit i is subse- quen tly assigned the state c b i corresp onding to its sp e- cific time bin, where the integer bin index is given by b i = ⌊ ( t i − t min ) / ∆ t bin ⌋ . The initial hit embedding is then obtained by applying an input multila yer p ercep- tron (MLP) to the concatenated hit and context features: h (0) i = MLP in ([ u i ; c b i ]). Gr aph c onstruction and e dge fe atur es. F or each hit i , a lo calized spatiotemp oral neighborho o d is strictly de- fined as the set N i = { j = i | | t j − t i | ≤ ∆ t nb , ∥ x j − x i ∥ ≤ ∆ r nb } . T o main tain a fixed graph degree for batc hed pro- cessing, a multi-set S i of exactly K indices is constructed b y sampling uniformly without replacement from N i . If |N i | < K , the sequence is padded with self-lo ops ( j = i ). The edge features e ij are computed for each j ∈ S i and encompass the F ourier-enco ded absolute time difference, the angular alignmen t cos θ ij , the normalized spatial sep- aration, the charge difference, and the normalized signed time difference. Gate d message p assing. The mo del applies L message-passing lay ers. A t lay er ℓ , messages are com- puted via an MLP on the neighbor states along- side the corresp onding edge features, and then aggre- gated by a mean op erator ov er the K sampled no des: ¯ m ( ℓ ) i = 1 K P j ∈S i MLP ( ℓ ) msg ([ h ( ℓ ) j ; e ij ]). The no de state is subsequently up dated using a GRU cell: h ( ℓ +1) i = GR UCell( ¯ m ( ℓ ) i , h ( ℓ ) i ). Output and implementation. The final latent repre- sen tations h ( L ) i ∈ R H , where H denotes the hidden fea- ture dimension, are pro jected onto the decision space via a p osition-wise output MLP , yielding a vector of class logits s i ∈ R 3 . The three comp onents of s i corresp ond to the confidence scores for the dark noise, p ositron (e + ), and 14 C categories, resp ectively . The baseline configu- ration utilizes H = 128, L = 3 message-passing lay ers, a neighborho o d size of K = 24, spatial and temp oral cutoffs of ∆ r nb = 9000 mm and ∆ t nb = 10 ns, and a bin width of ∆ t bin = 20 ns o ver the acquisition window [0 , 1000) ns. This yields a compact mo del with approx- imately 0.66 million trainable parameters. T raining is p erformed using the AdamW optimizer [ 37 ] with cosine annealing and mixed-precision arithmetic. B. Spatiotemp oral T ransformer with Scalar Charge Enco ding (STT-Scalar) The STT-Scalar treats hits as tokens in a sequence, utilizing global self-atten tion to facilitate information ex- c hange across hits for p er-hit classification. Input r epr esentation. F or batc h size B , the input ten- sor X ∈ R B × L max × 5 comprises observ ables ( x, y , z , t, q ) from Eq. ( 1 ). Similar to the Gated-STGNN, sequences are padded to L max and pro cessed using the binary mask M defined in Eq. ( 6 ) to preven t padded tokens from at- tending to v alid signals in the self-attention mechanism. Sp atiotemp or al fe atur e enc o ding. P osition and time are normalized b y S x = 10 4 mm and S t = 10 3 ns, resp ec- tiv ely , and mapp ed using p erio dic enco dings ψ ( · ) with 5 n pe = 5: ψ ( u ) = u, { sin( k π u ) , cos( k π u ) } n pe k =1 . (7) The scalar charge q is embedded via an MLP to e q ∈ R 32 . These features are concatenated and pro jected to dimension d model : h (0) = Pro j h ψ ( ˜ x ); ψ ( ˜ t ); e q i ∈ R d model . (8) T r ansformer b ackb one and output. A stack of L pre- norm T ransformer enco der lay ers T ( ℓ ) pro cesses the em- b eddings: h ( ℓ +1) = T ( ℓ ) h ( ℓ ) , ℓ = 0 , . . . , L − 1 . (9) The final hidden represen tation of each hit is passed through a m ultila yer p erceptron to pro duce a v ector of classification logits s i ∈ R 3 , corresp onding to the three hit categories: dark noise, p ositron-induced signal, and 14 C bac kground. Implementation details. The architecture uses L = 6, d model = 512, and n head = 4, totaling appro ximately 19.09 million trainable parameters. Optimization em- plo ys AdamW with a cosine-annealing schedule. C. Spatiotemp oral T ransformer with V ector Charge Enco ding (STT-V ector) The STT-V ector mo del, inspired by token-based T ransformer mo dels such as the Particle T rans- former [ 38 ], augments the STT-Scalar by enriching each hit tok en with an 18-dimensional charge feature v ector q i , explicitly enco ding lo cal and global spatiotemp oral c harge density correlations. The ov erall architecture is sho wn in Fig. 3 . V e ctor char ge enc o ding. F or each hit i , the vector q i is constructed based on charge accumulation within defined temp oral frames relative to t i : current ( T (0) i : | ∆ t | ≤ 5 ns), next ( T (+) i : 5 < ∆ t ≤ 15 ns), and previ- ous ( T ( − ) i : − 15 ≤ ∆ t < − 5 ns). W e define the c harge sum op erator S i ( τ , R ) = P j ∈T ( τ ) i ∩B i ( R ) q j o ver frame τ and spatial radius R , and the temp oral asymmetry ∆ S i ( τ ′ , R, R ′ ) = S i (0 , R ) − S i ( τ ′ , R ′ ). The feature vector is structured as: q i = h q i ; v glob ; v (1) loc ; v (2) loc ; v (3) loc ; v (4) loc i ⊤ ∈ R 18 . (10) The global blo c k v glob captures total even t activity ( R → ∞ ): v glob ,i = S i (0) , S i (+) , S i ( − ) , ∆ S i (+) , ∆ S i ( − ) ∞ . (11) The four lo cal blocks v ( k ) loc enco de density at spa- tial scales defined b y radius pairs ( R k , R ′ k ) ∈ { (3 , 5) , (5 , 9) , (10 , 16) , (16 , 23) } m: v ( k ) loc = S i (0 , R k ) , S i (+ , R ′ k ) , ∆ S i (+ , R k , R ′ k ) . (12) This vector is precomputed for every hit, resulting in an input tensor X ∈ R B × L max × 22 . Mo del A r chite ctur e. Spatiotemp oral co ordinates ( x, y , z , t ) are enco ded using the p erio dic function ψ ( · ) as in STT-Scalar. The c harge feature v ector q i is indep enden tly em b edded via an MLP to a dimension of d q = 64. These spatial and charge embeddings are concatenated and pro jected to the T ransformer mo del dimension d model = 512. The sequence is pro cessed by L = 6 T ransformer enco der la yers ( n head = 4), resulting in a total of approximately 19.11 million trainable parameters. The sequence padding, the masking mec h- anism defined in Eq. ( 6 ), and the final output MLP mapping to the three-class logits s i are identical to those emplo yed in the STT-Scalar mo del. D. Computational complexity and practical considerations W e analyze the computational complexit y and memory fo otprin t of the three mo dels to address feasibility for hit m ultiplicities N ∼ O (10 3 –10 4 ). Estimates assume batc h size B , hidden dimension H (which corresp onds to d model in the STT architectures), neighbor count K (graph mo dels), la yer coun t L , and atten tion heads n head (T ransformers). 1. Gated-STGNN: Sp arse neighb orho o d message p assing Gated-STGNN utilizes sparse message passing on a graph with b ounded degree K , yielding an edge set size E ≃ N K . Computational c omplexity. The dominant costs p er la yer are MLP-based message computation and GRU state up dates. With matrix-vector m ultiplications scal- ing quadratically in feature dimension, the p er-la yer cost is O ( B N K H 2 ). The total scaling is linear in N : C Gated − STGNN ∼ O ( L · B N K H 2 ) . (13) Memory fo otprint. T raining memory is dominated b y no de states and edge tensors required for backpropaga- tion. The scaling p er lay er is M lay er ∼ O ( B N K H + B N K d e ) , (14) where d e is the edge-feature dimension. Neighb or c onstruction c ost. Neighbor selection em- plo ys vectorized dense op erations for GPU throughput, incurring a distance computation cost of O ( B N 2 ) in b oth compute and memory . How ev er, b ecause this step in- v olves only low-dimensional geometric distance calcula- tions without dense neural netw ork parameter multipli- 6 Po sitio n al En co d in g No rm Sp atiote mporal Branch Ch ar g e M LP V ec tor Ch arge Bran ch Inp u t Projectio n (L inear + LN + G EL U) T ra nsfo rm er Enco der MLP Head Class DN No rm Multi - Head Atten tio n Norm Feed Forwar d T ra nsfo rm er Enco der FIG. 3. Arc hitecture of STT-V ector. Each hit is processed through tw o parallel enco ding branc hes. The spatiotemp oral branc h (top) maps normalized spatial co ordinates and hit times to a high-dimensional representation using sinusoidal p ositional en- co dings ψ ( · ). The vector c harge branch (b ottom) embeds the 18-dimensional charge feature vector q i , which summarizes m ulti-scale lo cal and global charge accum ulation, using a dedicated multila y er p erceptron. The tw o embeddings are concate- nated, pro jected to the T ransformer mo del dimension d model , and passed through L T ransformer enco der la yers to produce p er-hit class logits for dark noise, e + , and 14 C. cations, its empirical runtime o v erhead is negligible com- pared to the O ( L · B N K H 2 ) netw ork scaling. This pre- pro cessing step is p erformed once p er even t and is inde- p enden t of the message-passing lay ers. 2. STT-Scalar: Glob al self-attention with sc alar char ge STT-Scalar pro cesses hits as tokens with global self- atten tion in each lay er. Computational c omplexity. The cost is dominated by self-atten tion matrix computation and v alue aggregation. The N 2 tok en interactions lead to a total complexity scal- ing of C STT-Scalar ∼ O B L N 2 H . (15) This quadratic dep endence on N limits scalability at high m ultiplicities. Memory fo otprint. T raining memory is dominated b y the storage of attention w eights and intermediate activ a- tions: M attn ∼ O B L n head N 2 . (16) The N 2 atten tion tensor typically constrains the maxi- m um feasible batch size. 3. STT-V e ctor: Glob al self-attention with ve ctor char ge fe atur es STT-V ector shares the T ransformer backbone of STT- Scalar but includes an additional feature-construction step. Computational c omplexity (network). The netw ork complexit y remains identical to STT-Scalar at leading order: C net STT-V ector ∼ O B L N 2 H . (17) The 18-dimensional vector embedding adds a subleading O ( B N ) cost. Char ge-fe atur e c onstruction c ost. Aggregating c harges within spatiotemp oral windo ws inv olv es ev alu- ating hit pairs, scaling as: C feat ∼ O N 2 . (18) In this study , these features are precomputed to decouple the O ( N 2 ) prepro cessing burden from the training lo op. Summary. Although neigh b or construction inher- en tly entails an O ( N 2 ) geometric calculation, the dom- inan t computational cost and b ottlenec k of the Gated- STGNN are go verned by the dense matrix multiplications of the sparse neighborho o d aggregations. Consequently , within the empirical regime of typical even t sizes, the ef- fectiv e training time of the Gated-STGNN scales linearly with the hit num b er N , following O ( N K ). In contrast, the T ransformer mo dels exhibit a quadratic O ( N 2 ) com- plexit y in b oth computation and memory fo otprint due to the global self-attention mechanism. The STT-V ector arc hitecture incurs an additional O ( N 2 ) prepro cessing o verhead required for constructing the pairwise vector features. Benc hmarks on a single NVIDIA A6000 GPU (48 GB VRAM) indicate that the Gated-STGNN re- quires approximately an order of magnitude less training time p er ep och than the STT mo dels. This disparity re- flects the linear v ersus quadratic complexity scaling with 7 the hit n umber N , comp ounded b y memory constraints that necessitate a reduced batc h size for the T ransformers ( B = 12) relativ e to the Gated-STGNN ( B = 16). The p er-epo ch training run times of STT-Scalar and STT- V ector are comparable, as vector feature construction is offloaded to pre-pro cessing. IV. TRAINING AND EV ALUA TION A. T raining ob jectiv e Three mo dels are trained by minimizing the hit-level cross-en tropy loss L CE o ver the set of v alid (non-padding) hits V : L CE = − 1 N V X i ∈V log p i,c i , (19) where N V denotes the total coun t of v alid hits. The term p i,c i represen ts the predicted probability assigned to the truth class c i , derived by applying the softmax function to the output logits s i . The padding masks are applied to exclude inv alid en tries from the loss computation. B. Hit-lev el classification metrics F or each test set, a 3 × 3 confusion matrix is constructed from the aggregated hit-level predictions. The normal- ized matrix is defined as C ab = N ( ˆ y = b, y = a ) P b ′ ∈{ 0 , 1 , 2 } N ( ˆ y = b ′ , y = a ) , (20) where a lab els the true class, b labels the predicted class, and N ( ˆ y = b, y = a ) denotes the num b er of hits with true label a predicted as b . The indices a, b ∈ { 0 , 1 , 2 } corresp ond to the dark noise, p ositron (e + ), and 14 C classes, resp ectiv ely . The diagonal element C 22 defines the 14 C signal efficiency (recall), denoted as R 14 C . The con tamination levels are quantified by the off-diagonal elemen ts C 02 and C 12 , which represen t the misidentifi- cation fractions of dark noise ( f DN → 14 C ) and p ositron hits ( f e + → 14 C ) classified as 14 C. The practical goal is to suppress pile-up from 14 C while minimizing the loss of e + hits, thereby reducing the degradation of the recon- structed energy resolution. T o further elucidate mo del p erformance, the 14 C recall is ev aluated differentially as a function of the time separation ∆ t , as defined in Eq. ( 2 ), and the dep osited energy E 14 C : R 14 C (∆ t, E 14 C ) = N ( ˆ y = 2 , y = 2 | ∆ t, E 14 C ) N ( y = 2 | ∆ t, E 14 C ) . (21) C. Impact on the Energy Resolution The remo v al of 14 C hits will reduce fluctuations in the n umber of detected photons and consequently impro ve the energy resolution. A simple study is p erformed to ev aluate the p erformance of the algorithms in terms of the relative improv emen t of the energy resolution. This study do es not represent the p erformance of the real JUNO detector, which w ould require including the im- pro vemen ts from the well-designed energy- and v ertex- reconstruction pro cedure [ 23 , 24 ]. The improv emen t in the energy resolution is quan ti- tativ ely ev aluated using the total charge Q sum = P i q i , where i runs ov er all the selected hits and q i denotes the c harge of the i -th hit. Hits are selected under different criteria: T otal : all hits are retained. In this case, the Q sum includes the contributions from e + and 14 C, as well as from the dark noise. The av erage num ber of DN hits, ⟨ B dn ⟩ = 400, is subtracted from Q sum to pro vide a more accurate estimate of the total charge induced by the par- ticles. Ho wev er, fluctuations in B dn still propagate to the Q sum resolution. 14 C remov ed (truth) : 14 C hits are remov ed accord- ing to the truth hit lab els. In this case, ⟨ B dn ⟩ is also subtracted from Q sum . It represen ts the ideal scenario in which the mo dels predict the 14 C hits with 100% effi- ciency and purity . 14 C remov ed (predicted) : 14 C hits are remov ed according to the hit lab els predicted by a mo del. Since the mo del will misiden tify DN hits as 14 C hits, the re- mo v al of 14 C hits will change the av erage n umber of DN hits. Instead, (1 − C 02 ) ⟨ B dn ⟩ is subtracted from Q sum , where C 02 is the misidentification fraction of dark noise ( f DN → 14 C ). e + only (truth) : only e + hits are selected according to the truth hit lab els to show the in trinsic resolution of e + hits. Since the DN hits are excluded, ⟨ B dn ⟩ is not subtracted from Q sum . The Q sum distributions are fitted with a Gaussian func- tion. The energy resolution is defined as the ratio of the fitted width to the fitted mean, R = σ /µ . V. RESUL TS AND DISCUSSION Fig. 4 visualizes the hit-lev el classification performance for a representativ e even t with ∆ t = 165 . 0 ns. The pre- dictions from the Gated-STGNN, STT-Scalar, and STT- V ector mo dels are consistent with the truth. The mo dels successfully tag 14 C hits while effectively discriminating against the dense p ositron hits and disp ersed dark noise hits. Since light propagation v aries significan tly with the annihilation v ertex, it is necessary to ev aluate the p er- formance of hit-level tagging for e + annihilation even ts at different p ositions. A t higher p ositron energies, the relativ e contribution of 14 C pile-up to the total light yield is smaller, and its impact on the energy resolution is corresp ondingly reduced. How ev er, 14 C tagging b e- comes more challenging at higher p ositron energies, be- cause the 14 C hits are statistically ov erwhelmed by the 8 T ruth Gated-STGNN STT-Scalar STT-V ector FIG. 4. A visualization of the hit iden tification results of Gated-STGNN, STT-Scalar, and STT-V ector, compared with the truth for a pile-up ev en t with ∆ t = 165 . 0 ns. The truth information for the e + ev ent consists of a kinetic energy E k (e + ) = 0 MeV and a v ertex p osition of ( x, y , z ) = (0 . 03 , − 0 . 02 , − 0 . 08) m, while that for the 14 C ev ent consists of a dep osited energy E 14 C = 82 . 5 k eV and a vertex p osition of ( x, y , z ) = (7 . 65 , 5 . 75 , 11 . 23) m. The plots displa y the ( θ , ϕ, t ) distribution of the hits, where t is the hit time and ( θ , ϕ ) are the p olar and azimuthal angles of the PMT. Blue dots represen t hits from the e + ev ent, red dots from the 14 C decay , and gray dots indicate dark noise. larger e + -induced hit p opulation, which is typically of order 10 4 . Therefore, the identification p erformance ex- hibits distinct b ehavior at low and high p ositron energies. The ev aluation is conducted across the discrete grid of p ositron kinetic energies describ ed in Section II . Unless explicitly stated, all mo dels are ev aluated on the same set. 9 Gated-STGNN STT-Scalar STT-V ector FIG. 5. Normalized confusion matrices for ev ents with z = 0 and E k (e + ) = 0 MeV . The panels display the classification p erformance for Gated-STGNN, STT-Scalar, and STT-V ector. Gated-STGNN STT-Scalar STT-V ector FIG. 6. Normalized confusion matrices for ev ents with z = 0 and E k (e + ) = 5 MeV . The panels display the classification p erformance for Gated-STGNN, STT-Scalar, and STT-V ector. A. Global classification p erformance The global classification p erformance for even ts with E k (e + ) = 0 and 5 MeV at the detector center ( z = 0) is summarized by the normalized confusion matrices in Figs. 5 and 6 . The 14 C recall ( C 22 ) is shown in the b ottom-righ t corner. Two additional metrics are par- ticularly imp ortan t: C 02 and C 12 . They quantify the misiden tification fractions of dark-noise hits and positron hits classified as 14 C, namely f DN → 14 C and f e + → 14 C . The former biases the effective dark noise level after remov al, while the latter reduces the signal light yield. Go o d p er- formance is characterized by high C 22 and low v alues of C 02 and C 12 . A t E k (e + ) = 0 MeV, the STT-V ector mo del achiev es the highest 14 C identification recall of 48.54%, follow ed closely by STT-Scalar at 46.53%. In contrast, Gated- STGNN exhibits a notably low er recall of 37.56%. The primary error mo de is the misidentification of 14 C as e + , whic h is 38.88% for STT-V ector and 47.65% for Gated- STGNN. Across all mo dels, the misidentification of e + as 14 C are less than 1% and the misidentification of dark noise as 14 C are less than 2%. This b ehavior is desirable, indicating that when 14 C hits are remov ed based on the predictions, the signal light yield and the av erage dark- noise lev el are not strongly affected. A t E k (e + ) = 5 MeV, the classification landscap e is dominated b y the e + hits. Contrary to the low-energy regime, the 14 C recall decreases significantly across all mo dels. The STT-V ector mo del maintains the highest re- call, achieving a 14 C identification recall of 27 . 43%, com- pared to 25 . 61% for STT-Scalar and 20 . 69% for Gated- STGNN. The dominant error mo de for all mo dels is the misiden tification of 14 C hits as p ositron-induced, with leak age rates exceeding 70%. This b eha vior indicates that the 14 C hits are statistically ov erwhelmed by the m uch larger p opulation of e + hits, making their iden- tification increasingly challenging. The misidentification 10 e + → 14 C Misidentification DN → 14 C Misidentification 14 C Recall FIG. 7. Classification metrics as functions of p ositron kinetic energy E k (e + ) at z = 0 m. The panels show the dep endence on E k (e + ) of the fraction of e + hits misidentified as 14 C, the fraction of dark noise (DN) hits misidentified as 14 C, and the 14 C recall. e + → 14 C Misidentification DN → 14 C Misidentification 14 C Recall FIG. 8. Classification metrics as functions of the v ertex p osition z (ev aluated at discrete points z ∈ { 0 , 6 , 15 , 16 . 5 } m) for ev ents with a fixed p ositron kinetic energy E k (e + ) = 0 MeV . The panels display the dependence on z of the fraction of e + hits misiden tified as 14 C, the fraction of dark noise (DN) hits misidentified as 14 C, and the 14 C recall. rates of e + as 14 C and of dark noise as 14 C are b oth lo wer than in the low-energy regime. The dependence of the C 02 , C 12 and C 22 on the p ositron kinetic energy E k (e + ) at the detector center ( z = 0) is summarized in Fig. 7 . Figure 8 illustrates the z dep endence of the classification metrics with E k (e + ) = 0 MeV . As shown, the STT-V ector mo del maintains a consistently high 14 C recall and low misidentification rates, demonstrating resilience against changes in ligh t path. B. Timing and energy dep endence of 14 C iden tification When the 14 C decay occurs close in time to the e + , the hit-level tagging performance v aries strongly with ∆ t , since the num b er of e + hits surrounding the 14 C changes rapidly . T o quantify this effect, the 14 C hit identification recall is ev aluated as a function of the relativ e time offset ∆ t and the 14 C dep osited energy E 14 C . Figure 9 displays the differential 14 C recall as a func- tion of ∆ t and E 14 C . The maps corresp ond to even ts at the detector cen ter ( z = 0) with p ositron kinetic ener- gies of 0 and 5 MeV, resp ectively . F or larger | ∆ t | , the 14 C background hits are temp orally decoupled from the prompt e + signal windo w, thereby facilitating high 14 C recall. In con trast, the region with small | ∆ t | corresp onds to strong temp oral ov erlap, where discrimination must rely on subtler correlations among hit timing, geometry , and lo cal charge patterns. When the 14 C deca ys with higher energy , its hits b ecome easier to identify . The o verall 14 C recall is low er at higher positron kinetic en- ergies, since the larger e + hit p opulation makes it harder to disen tangle 14 C hits from the e + signal. C. Energy-resolution recov ery from hit-level denoising The impact of hit-level classification on energy reso- lution is ev aluated through the resolution of Q sum . No- tably , the strict p er-hit classification accuracy does not directly translate to energy resolution p erformance. F or example, consider a p ositron hit that is spatially and tem- p orally close to a 14 C hit. If a mo del classifies this hit 11 (a) E k (e + ) = 0 MeV (b) E k (e + ) = 5 MeV FIG. 9. Differential 14 C recall R 14 C (∆ t, E 14 C ) of STT-V ector, ev aluated at z = 0 for E k (e + ) = 0 MeV and E k (e + ) = 5 MeV, resp ectiv ely . FIG. 10. Distributions of the total c harge of selected hits ( Q sum ) at the detector cen ter for even ts with E k (e + ) = 0 MeV (left) and E k (e + ) = 5 MeV (right). The gray dotted line represents Q sum of all hits, b efore applying hits remov al. The green dashed line shows the ideal distribution with 14 C pile-up remov ed by truth lab el. The solid purple line represents Q sum after hit remov al based on the STT-V ector mo del prediction. The fitted mean v alue ( µ ), width ( σ ) and corresp onding resolution ( R = σ/µ ) are also shown. as a 14 C hit, it will b e counted as a misidentification, reducing the recall. How ever, from the p ersp ectiv e of en- ergy reconstruction based on the total charge Q sum or the likelihoo d-based reconstruction algorithm [ 13 ], suc h a “mistak e” ma y ha v e negligible impact. This is b ecause, in such cases, the ov erall statistical b ehavior has a more significan t impact on energy resolution than the precise classification of individual hits. The Q sum distribution of an E k (e + ) = 0 MeV , z = 0 m dataset is shown on the left of Fig. 10 . After remov- ing 14 C hits predicted by STT-V ector, the Q sum reso- lution improv es by 18%. The Q sum distribution of an E k (e + ) = 5 MeV , z = 0 m dataset is sho wn on the righ t of Fig. 10 . After removing 14 C hits according to the STT-V ector prediction, the Q sum resolution improv es by 3%. With higher E k (e + ), the discrimination of 14 C hits b ecomes more c hallenging due to the increasing num b er of e + hits. How ev er, the effect of 14 C hits on energy resolution also diminishes, since at high E k (e + ) the reso- lution b ecomes dominated by intrinsic e + photon statis- tics. The p erformances of Gated-STGNN, STT-Scalar, and STT-V ector for the datasets with z = 0 and dif- feren t E k (e + ) are summarized on the left of Fig. 11 . The three mo dels exhibit similar p erformance. In the E k (e + ) = 0 MeV case, the STT-V ector has b etter p er- formance. 12 FIG. 11. Ratios of the resolutions of the charge sum of selected hits ( Q sum ) under different hit-remov al criteria relative to the “T otal” case, in whic h no hit is remo ved. The left plot shows the ratio’s dep endence on E k at the detector center. The right plot shows the ratio’s dependence on z when E k (e + ) = 0 MeV. The p erformances of the three mo dels for the datasets with E k (e + ) = 0 MeV and different z are summarized on the right of Fig. 11 . The b ehaviors of the three mo dels are similar. An improv emen t of ∼ 20% in the resolution is observ ed for all tested samples with different z , indi- cating that the prop osed mo dels remain v alid under more complex ligh t-propagation conditions. VI. CONCLUSION AND OUTLOOK In this w ork, w e prop ose three mo dels to tag 14 C hits in e + ev ents affected by a single 14 C pile-up. By iden tify- ing and suppressing bac kground photon hits, the metho d mitigates the impact of 14 C pile-up on even t reconstruc- tion. The three models are: Gated-STGNN, which repre- sen ts hits as graphs in spacetime and controls information propagation using GRU units; STT-Scalar, which applies atten tion to p oint-wise features; and STT-V ector, which further includes aggregated features of lo cal top ology . In test datasets with E k (e + ) ≤ 5 MeV, all mo dels suc- cessfully tag 14 C hits while k eeping the misidentification of e + as 14 C b elo w 1% and the misidentification of dark noise as 14 C b elo w 2%, thereby limiting signal depletion and shifts in the dark-noise level. 14 C recall ranges from 25% to 48%, generally ordered as Gated-STGNN < STT- Scalar < STT-V ector. Within the studied o v erlap regime of ∆ t ∈ [ − 100 , 300] ns, differential recall maps indicate that the most c hallenging region is ∆ t ∈ [0 , 200] ns, where the temporal ov erlap b et w een 14 C and e + is the strongest. After 14 C-hit remo v al based on mo del predictions, im- pro vemen ts in the resolution of the total c harge Q sum are observ ed across all test datasets with different E k (e + ) and z p ositions, confirming efficacy from the detector cen ter to near-boundary regions under v arying p ositron kinetic energies. In the challenging pile-up regime ∆ t ∈ [ − 100 , 300] ns, the resolution of Q sum impro ves b y ap- pro ximately 5%–20%, with STT-V ector yielding the b est reco very in the low E k (e + ) case. Key limitations include the prioritization of signal re- ten tion ov er aggressive 14 C-hit tagging, and the depen- dence on temp oral ov erlap. F uture work should address: 1. R efinement for highly overlapping events: Incorp o- rating physically motiv ated descriptors (e.g., time- of-fligh t corrections, m ulti-scale context) to im- pro ve p erformance in the ∆ t ∈ [0 , 200] ns region. 2. R obustness and domain shift: Systematically v ali- dating against v arious detector conditions and ex- ploring domain-adaptation strategies to mitigate sim ulation-data discrepancies. 3. Inte gr ation with r e c onstruction: Propagating hit- lev el selections through the full reconstruction c hain to ev aluate impacts on the energy and ver- tex reconstruction. This study fo cuses on the algo- rithmic feasibilit y of hit-level pile-up suppression. The impact on energy resolution is ev aluated using Q sum as an estimator of calorimetric resp onse at the hit lev el. These results should not be in terpreted as a full detector-level p erformance estimate. A com- prehensiv e assessment requires integration of the hit-selection pro cedure in to the complete JUNO en- ergy reconstruction chain. VI I. A CKNO WLEDGMENTS This work w as partly supp orted by National Natu- ral Science F oundation of China (Grants No. 62472381, 13 No. 12575209), by the National Key R&D Program of China (2023YF A1606103). W e would also like to thank the Computing Center of the Institute of High Energy Ph ysics, Chinese Academy of Science for providing the GPU resources. [1] G. Bellini et al. (BOREXINO), Neutrinos from the pri- mary proton–proton fusion pro cess in the Sun, Nature 512 , 383 (2014) . [2] G. Aad et al. (A TLAS), Measurement of the inclusive jet cross-section in proton-proton collisions at √ s = 7 T eV using 4.5 fb − 1 of data with the A TLAS detec- tor, JHEP 02 , 153 , [Erratum: JHEP 09, 141 (2015)], arXiv:1410.8857 [hep-ex] . [3] V. Khachatry an et al. (CMS), Performance of the CMS missing transv erse momen tum reconstruction in pp data at √ s = 8 T eV, JINST 10 (02), P02006, [ph ysics.ins-det] . [4] S. Andringa et al. (SNO+), Current Status and F u- ture Prosp ects of the SNO+ Experiment, Adv. High Energy Phys. 2016 , 6194250 (2016) , [ph ysics.ins-det] . [5] S. Obara, Y. Gando, S. Ieki, H. Ik eda, K. Ishidoshiro, and R. Nak am ura (KamLAND-Zen), A study of self-vetoing ballo on vessel for liquid-scintillator detectors, J. Phys. Conf. Ser. 2374 , 012111 (2022) . [6] C. Arp esella et al. (Borexino), First real time detection of Be-7 solar neutrinos by Borexino, Phys. Lett. B 658 , 101 (2008) , arXiv:0708.2251 [astro-ph] . [7] K. Eguchi et al. (KamLAND), First results from Kam- LAND: Evidence for reactor anti-neutrino disapp ear- ance, Phys. Rev. Lett. 90 , 021802 (2003) , arXiv:hep- ex/0212021 . [8] V. Lozza (SNO+), Scintillator phase of the SNO+ exp erimen t, J. Phys. Conf. Ser. 375 , 042050 (2012) , arXiv:1201.6599 [hep-ex] . [9] F. P . An et al. (Day a Bay), Precision Measuremen t of Re- actor Antineutrino Oscillation at Kilometer-Scale Base- lines by Day a Bay, Phys. Rev. Lett. 130 , 161802 (2023) , arXiv:2211.14988 [hep-ex] . [10] J. K. Ahn et al. (RENO), Observ ation of Reactor Electron Antineutrino Disapp earance in the RENO Exp erimen t, Phys. Rev. Lett. 108 , 191802 (2012) , arXiv:1204.0626 [hep-ex] . [11] Y. Ab e et al. (Double Cho oz), Indication of Reactor ¯ ν e Disapp earance in the Double Cho oz Exp erimen t, Phys. Rev. Lett. 108 , 131801 (2012) , arXiv:1112.6353 [hep-ex] . [12] A. Abusleme et al. (JUNO, Day a Bay), Optimization of the JUNO liquid scin tillator comp osition using a Day a Ba y antineutrino detector, Nucl. Instrum. Meth. A 988 , 164823 (2021) , arXiv:2007.00314 [physics.ins-det] . [13] A. Abusleme et al. (JUNO), JUNO Physics and De- tector, Prog. P art. Nucl. Ph ys. 123 , 103927 (2022) , arXiv:2104.02565 [hep-ex] . [14] G.-M. Chen, X. Zhang, Z.-Y. Y u, S.-Y. Zhang, Y. Xu, W.-J. W u, Y.-G. W ang, and Y.-B. Huang, Discrimination of pp solar neutrinos and 14 C double pile-up even ts in a large-scale LS detector, Nucl. Sci. T ech. 34 , 137 (2023) , arXiv:2303.08512 [hep-ex] . [15] W. F ang, W. Li, W. Luo, Z. W u, and M. He, Deep Learning-Based 14 C Pile-Up Identification in the JUNO Exp erimen t, (2026) , arXiv:2603.01419 [hep-ex] . [16] L. V aughan, M. Rakib, S. P atel, F. Rizatdinov a, A. Khanov, and A. Bagav athi, PileUp Mitigation at the HL-LHC Using A ttention for Ev ent-Wide Context, (2025), arXiv:2503.02860 [hep-ex] . [17] M. Algren, T. Golling, C. Pollard, and J. A. Raine, V ari- ational inference for pile-up remov al at hadron colliders with diffusion mo dels, Phys. Rev. D 111 , 116010 (2025) , arXiv:2410.22074 [hep-ph] . [18] T. Li, S. Liu, Y. F eng, G. P aspalaki, N. V. T ran, M. Liu, and P . Li, Semi-sup ervised graph neural netw orks for pileup noise remov al, Eur. Phys. J. C 83 , 99 (2023) , arXiv:2203.15823 [hep-ex] . [19] J. Arjona Mart ´ ınez, O. Cerri, M. Pierini, M. Spirop- ulu, and J.-R. Vlimant, Pileup mitigation at the Large Hadron Collider with graph neural netw orks, Eur. Ph ys. J. Plus 134 , 333 (2019) , arXiv:1810.07988 [hep-ph] . [20] D. Bertolini, P . Harris, M. Low, and N. T ran, Pileup P er P article Identification, JHEP 10 , 059 , [hep-ph] . [21] G. So yez, G. P . Salam, J. Kim, S. Dutta, and M. Cacciari, Pileup subtraction for jet shap es, Phys. Rev. Lett. 110 , 162001 (2013) , arXiv:1211.2811 [hep-ph] . [22] F. An et al. (JUNO), Neutrino Physics with JUNO, J. Phys. G 43 , 030401 (2016) , [ph ysics.ins-det] . [23] A. Abusleme et al. (JUNO), Prediction of Energy Resolu- tion in the JUNO Exp eriment, Chin. Ph ys. C 49 , 013003 (2025) , arXiv:2405.17860 [hep-ex] . [24] A. Abusleme et al. (JUNO), Initial performance results of the JUNO detector, (2025), arXiv:2511.14590 [hep-ex] . [25] G.-h. Huang, W. Jiang, L.-j. W en, Y.-f. W ang, and W.-M. Luo, Data-driv en simultaneous vertex and energy recon- struction for large liquid scintillator detectors, Nucl. Sci. T ec h. 34 , 83 (2023) , arXiv:2211.16768 [physics.ins-det] . [26] A. T akenak a et al. , Neutron source-based even t recon- struction algorithm in large liquid scintillator detec- tors, Eur. Phys. J. C 85 , 1097 (2025) , [ph ysics.ins-det] . [27] Z. Qian et al. , V ertex and energy reconstruction in JUNO with machine learning metho ds, Nucl. Instrum. Meth. A 1010 , 165527 (2021) , arXiv:2101.04839 [physics.ins-det] . [28] Y. Li, D. T arlow, M. Bro c kschmidt, and R. S. Zemel, Gated graph sequence neural netw orks, ICLR (2016) . [29] A. V asw ani, N. Shazeer, N. P armar, J. Uszk oreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, A ttention Is All Y ou Need, in 31st International Confer- enc e on Neur al Information Pr o c essing Systems (2017) arXiv:1706.03762 [cs.CL] . [30] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, Poin tnet: Deep learning on p oint sets for 3d classification and seg- men tation, in Pr o c. IEEE Conf. Comput. Vis. Pattern R e c o gnit. (CVPR) (2017) pp. 77–85. [31] H. F an, Y. Y ang, and M. Kank anhalli, Poin t 4d trans- former net works for spatio-temp oral modeling in p oin t cloud videos, in Pr o c. IEEE/CVF Conf. Comput. Vis. Pattern R e c o gnit. (CVPR) (2021) pp. 14199–14208. 14 [32] Y. Guo, H. W ang, Q. Hu, H. Liu, L. Liu, and M. Ben- namoun, Deep learning for 3d point clouds: A survey , IEEE T rans. P attern Anal. Mach. In tell. 43 , 4338 (2021) . [33] J. Liu, J. Han, L. Liu, A. I. Aviles-Rivero, C. Jiang, Z. Liu, and H. W ang, Mamba4D: Efficien t 4d point cloud video understanding with disentangled spatial-temp oral state space models, in Pro c. IEEE/CVF Conf. Comput. Vis. Pattern R e c o gnit. (CVPR) (2025) pp. 17626–17636. [34] B. Lv, Y. Zha, T. Dai, Y. Xue, K. Chen, and S.-T. Xia, Adapting pre-trained 3d models for point cloud video un- derstanding via cross-frame spatio-temp oral p erception, in Pr o c. IEEE/CVF Conf. Comput. Vis. Pattern R e c o g- nit. (CVPR) (2025) pp. 12413–12422. [35] J. Shlomi, P . Battaglia, and J.-R. Vliman t, Graph Neural Net works in Particle Physics 10.1088/2632-2153/abbf9a (2020), arXiv:2007.13681 [hep-ex] . [36] K. Cho, B. v an Merrienbo er, C. Gulcehre, D. Bahdanau, F. Bougares, H. Sch w enk, and Y. Bengio, Learning Phrase Representations using RNN Encoder-Deco der for Statistical Mac hine T ranslation, (2014), [cs.CL] . [37] I. Loshchilo v and F. Hutter, Decoupled W eight Deca y Regularization (2017) arXiv:1711.05101 [cs.LG] . [38] H. Qu, C. Li, and S. Qian, Particle T ransformer for Jet T agging, (2022), arXiv:2202.03772 [hep-ph] .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment