TMTE: Effective Multimodal Graph Learning with Task-aware Modality and Topology Co-evolution
Multimodal-attributed graphs (MAGs) are a fundamental data structure for multimodal graph learning (MGL), enabling both graph-centric and modality-centric tasks. However, our empirical analysis reveals inherent topology quality limitations in real-wo…
Authors: Yinlin Zhu, Xunkai Li, Di Wu
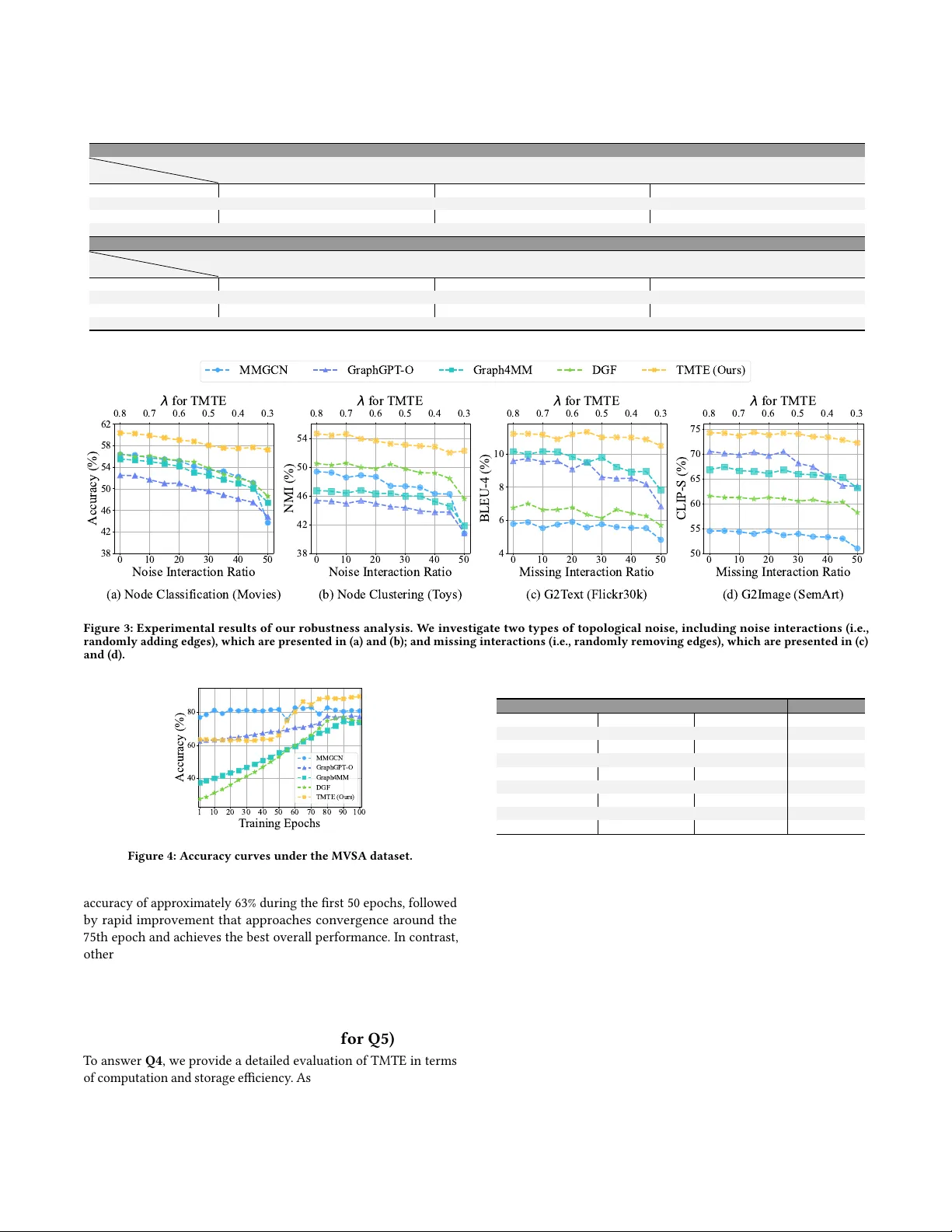
TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and T opology Co-evolution Yinlin Zhu Sun Y at-sen University Guangzhou, China zhuylin27@mail2.sysu.edu.cn Xunkai Li Beijing Institute of T e chnology Beijing, China cs.xunkai.li@gmail.com Di W u ∗ Sun Y at-sen University Guangzhou, China wudi27@mail.sysu.edu.cn W ang Luo Sun Y at-sen University Guangzhou, China luow69@mail2.sysu.edu.cn Miao Hu Sun Y at-sen University Guangzhou, China humiao5@mail.sysu.edu.cn Guocong Quan Sun Y at-sen University Guangzhou, China quangc@mail.sysu.edu.cn Abstract Multimodal-attributed graphs (MA Gs) are a fundamental data struc- ture for multimo dal graph learning (MGL), enabling both graph- centric and modality-centric tasks. However , our empirical anal- ysis reveals inher ent topology quality limitations in real-world MA Gs, including noisy interactions, missing connections, and task- agnostic relational structures. A single graph derived from generic relationships is therefore unlikely to be universally optimal for diverse downstr eam tasks. T o address this challenge, we pr opose T ask-aware M odality and T opology co- E volution (TMTE), a novel MGL framework that jointly and iteratively optimizes graph topol- ogy and multimodal representations toward the target task. TMTE is motivated by the bidirectional coupling between modality and topology: multimodal attributes induce relational structures, while graph topology shapes modality repr esentations. Concretely , TMTE casts topology evolution as multi-perspective metric learning over modality embeddings with an anchor-based approximation, and formulates modality evolution as smoothness-regularized fusion with cross-modal alignment, yielding a closed-loop task-aware co- evolution process. Extensive experiments on 9 MA G datasets and 1 non-graph multimodal dataset across 6 graph-centric and modality- centric tasks show that TMTE consistently achieves state-of-the-art performance. Our code is available at this repository . CCS Concepts • Computing metho dologies → Semi-supervise d learning settings . Ke ywords Multimodal- Attributed Graph; Graph Neural Network; Graph Ma- chine Learning ∗ Corresponding author Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, r equires prior specic permission and /or a fe e. Request permissions from permissions@acm.org. XX, XX © 2026 Copyright held by the owner/author(s). Publication rights licensed to A CM. ACM ISBN 978-x-xxxx-xxxx-x/Y YY Y/MM https://doi.org/10.1145/nnnnnnn.nnnnnnn 1 Introduction Multimodal-attributed graphs (MAGs) r epresent entities as nodes with multimodal attributes (e.g., images and texts) and encode their relational dependencies as edges, which have been widely adopted in various real-world applications, such as nance [ 50 ], biochem- istry [ 25 ], and recommendation systems [ 14 ]. Building upon this expressive data structure, multimodal graph learning (MGL) has attracted growing attention in recent years. On the one hand, MGL enhances graph-centric tasks (e .g., node classication [ 17 ] and link prediction [ 26 ]) by leveraging rich multimodal attributes; on the other hand, it benets modality-centric tasks (e.g., graph-to- text [ 12 ] and graph-to-image [ 23 ] generation) by exploiting graph topology for contextual information [ 30 ]. Despite their notable advances, most existing MGL metho ds rely on a perfect topology assumption , where the real-world graphs are presumed to be suciently well-structured for downstream tasks [ 7 ]. Howe ver , this assumption often does not hold in prac- tice, which can be summarized from three perspectives: (1) Noisy Interactions. Due to inherent modality noise in the MAGs or imperfections in the colle ction process, the graph topology may contain spurious connections [ 54 ]. (2) Missing Interactions. The collected MAGs may overlook potentially informative connections. Moreover , in some practical applications with sequential entities such as audiovisual spee ch recognition [ 20 ] or isolated multimo dal entities like image-text matching [ 36 ], no explicit graph priors are available to characterize the inter-entity relationships. (3) T ask- agnostic Interactions. Both intuitive reasoning and our empirical study (Sec. 3 ) suggest that a single graph structure derived from task-agnostic r elationships ( e.g., co-occurrence patterns) is unlikely to be universally optimal for diverse downstream tasks, since dier- ent tasks often benet from distinct contextual signals. For example, classication tasks emphasize semantic category consistency , while generation tasks may require semantic diversity . Notably , exist- ing methods [ 54 ] prune spurious links based on low cr oss-modal similarity , thereby targeting only noisy interactions while over- looking the other challenges. Conse quently , existing MGL metho ds inevitably depend on multimodal contexts induced by suboptimal topologies, which compromises downstream task performance. How can we adaptively learn graph structures that faithfully cap- ture inter-entity relationships while simultaneously providing task- specic contextual cues for diverse downstr eam tasks, thereby enabling XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu eective MGL? In this work, we address this question by propos- ing a novel MGL framework, termed T ask-aware M odality and T opology co- E volution (TMTE). TMTE jointly and iteratively opti- mizes graph topology and multimodal representations toward the target task. Our key insight lies in the intrinsic coupling between modality and topology in MGL: (1) Modality → T opology . Multi- modal descriptions of entities naturally induce relational structures; for instance, user attributes shape social connections, and molecu- lar properties govern bonding patterns. (2) T opology → Modality . Conversely , graph topology inuences modality representations via message passing or cross-modal alignment, thereby shaping the latent node emb eddings used for downstream tasks. Concretely , TMTE casts top ology evolution as multi-perspective metric learning over modality embeddings with an anchor-based appro ximation, and formulates modality evolution as smoothness-regularized fu- sion with cross-modal alignment. The rened topology provides improved contextual signals tailor ed to each node with respect to the downstream objective and induces enhanced modality represen- tations through message passing or graph contrastive alignment. This proce dure iterates across training epochs and forms a task- aware modality-topology co-evolution process, converging when the learned structure suciently approximates a topology opti- mized for the target task. Our Contributions: (1) In-depth Investigation. W e provide an in-depth empirical analysis to demonstrate the inherent topology quality limitations of MA Gs, as dierent downstream tasks often require distinct graph topologies to provide appropriate contextual signals. (2) Novel Metho d. W e propose TMTE, a novel MGL frame- work that jointly and evolutionarily optimizes the graph topology and modality attributes toward the downstream task. (3) State-of- the-art Performance. Extensive experimental results on 9 MA G datasets and 1 non-graph multimodal dataset demonstrate that TMTE consistently outperforms the state-of-the-art baselines on 3 graph-centric and 3 modality-centric downstream tasks. 2 Problem Formulation A MAG is denote d as G = ( V , E , { X ( 𝑚 ) } 𝑚 ∈ M ) , where V is the set of no des with 𝑁 = | V | , E is the set of e dges, and M indexes the available modalities (e.g., text and images). For each node 𝑣 𝑖 under modality 𝑚 , we associate a modality-specic feature vector x ( 𝑚 ) 𝑖 ∈ R 𝑑 𝑚 , obtained by enco ding the raw mo dality data with a pre-trained modality encoder (e.g., Sentence-BERT [ 38 ] and T5 [ 37 ] for text; ViT [ 45 ] and DINOv2 [ 34 ] for images). For each modality 𝑚 , the embeddings of all no des are organized into a feature matrix X ( 𝑚 ) ∈ R 𝑁 × 𝑑 𝑚 . All modalities share a common relational structure represented by the adjacency matrix A ∈ R 𝑁 × 𝑁 , with the corre- sponding degree matrix D , where D 𝑖𝑖 = Í 𝑗 A 𝑖 𝑗 and D 𝑖 𝑗 = 0 for 𝑖 ≠ 𝑗 . T o capture structural smoothness, the symmetrically nor- malized adjacency matrix and Laplacian of G are represented by ˜ A = D − 1 / 2 AD − 1 / 2 and L = I − ˜ A , respectively . In this paper , we consider three Graph-centric T asks , includ- ing (1) Node Classication : assigning category labels to unlabele d nodes; (2) Link Prediction : estimating whether an e dge ( 𝑢, 𝑣 ) should exist in E ; (3) No de Clustering : grouping nodes into clusters by applying standard clustering algorithms to the learned node embed- dings; and three Modality-centric T asks , including (1) Modality Retrieval : given a quer y from one modality (e.g., text), retrieving its corresponding representation in another mo dality; (2) Graph- to- T ext Generation (G2T ext) : producing textual outputs conditioned on a target node along with task instructions and its graph neigh- borhood; (3) Graph-to-Image Generation (G2Image) : synthesizing images using diusion models conditione d on the node’s textual descriptions and the associated graph context. Further discussion of these tasks is presented in Appendix D . 3 Empirical Investigation In this section, we conduct a comprehensive analysis of the topology quality limitations of MA Gs (as discussed in Sec. 1 ). Our goal is to systematically examine the following r esearch questions, including Q1 : Are the original MA Gs optimal for downstream tasks? Q2 : Do dierent downstream tasks r equire distinct contextual multimodal semantics induced by dierent graph topologies? and Q3 : Can TMTE learn task-adaptive graph topologies that better align with downstream objectives? Datasets, Methods, and T asks. The controlled study is conducte d to compare the proposed TMTE and MM-GCN [ 44 ] on the T oys [ 31 ] dataset. W e consider two representative downstream tasks, includ- ing a graph-centric task (no de classication) and a modality-centric task (G2Image). For each task, we evaluate three dierent topology congurations. All other experimental settings are kept consis- tent across methods. Detailed dataset, baselines, and pipelines of both the node classication and G2Image tasks are presented in Appendices F , G and D , respectively . 75 80 85 90 Accuracy (%) 55 60 65 70 CLIPS (%) (a) Node Classification (b) G2Image MMGCN (OT) TMTE (OT) MMGCN (CPT) TMTE (CPT) MMGCN (MOT) TMTE (MOT) 1 Figure 1: Exp erimental results of our empirical study. W e compare the proposed TMTE and MM-GCN (representative MGL baseline) on the T oys dataset. (a) No de classication performance under three topology settings. (b) G2Image performance under three topology settings. All results are presented as p ercentages. T opology V ariants. W e construct the following three graph struc- tures, thereby pro viding dierent local context semantics for each node: (1) Original T op ology . The raw graph structure provided by the T oys dataset. (2) Cross-category Pruned T opology . The original graph with cross-category e dges removed. This op eration aims to suppress potentially noisy context arising from conne ctions between semantically inconsistent categories, thereby impro ving performance on node classication tasks. (3) Modality-Optimized T opology . The original graph is rened according to image-text cross-modal similarity . More details are presented in Appendix D . The original topology is not optimal (Answer for Q1). W e rst obser ve that the original graph structure does not yield the best performance for either task. For the node classication (Fig. 1 TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and Topology Co-ev olution XX, XX, XX (a)), the cross-category prune d top ology ( i.e., CPT ) consistently outperforms the original topology ( i.e., OT ). This suggests that the original graph contains noisy inter-categor y connections that dilute discriminative category-specic contexts required for classication. Similarly , for the G2Image task (Fig. 1 ( b)), the modality-optimized topology ( i.e., MOT ) surpasses the original topology , indicating that the original graph fails to provide suciently aligned multimodal contexts for high-quality image generation. Dierent tasks prefer dierent topologies (Answer for Q2). More importantly , the optimal topology varies across tasks. For the node classication task, the cross-categor y pruned topology achieves higher performance than the modality-optimized topol- ogy for the MMGCN and TMTE methods. This implies that classi- cation primarily benets from cleaner , label-consistent structural neighborhoods. In contrast, for the G2Image task, the modality- optimized topology signicantly outperforms the cross-category pruned topology . This demonstrates that modality-centric genera- tion tasks rely more heavily on ne-grained cross-modal semantic alignment than strict category homophily . These results indicate that a single task-agnostic topology is unlikely to be universally optimal, as dierent downstr eam objectives require distinct topo- logical priors to pr ovide appropriate multimodal contextual signals. Therefore, naiv ely conducting MGL on these top ologies yields sub- optimal performance. TMTE can learn task-adaptive topologies (Answer for Q3). Finally , we analyze the performance of TMTE across dierent top ol- ogy congurations. Figure 1 r eveals the follo wing two trends: (1) Under all three topology settings, TMTE consistently outp erforms MM-GCN on both node classication and G2Image tasks. (2) The performance variation of TMTE across dierent input topologies is relatively smaller compared with MM-GCN. These results indicate that TMTE is less sensitive to the quality and conguration of the input graph structure, while MM-GCN exhibits more noticeable per- formance uctuations when the topology changes. This improved robustness indicates that the task-aware topology and modality co-evolution mechanism can optimize the structural dependencies during training rather than relying solely on a xed input graph. 4 Methodology In this section, we introduce TMTE, a novel MGL framework that jointly and evolutionarily optimizes both graph topology and modal- ity representations to ward downstream tasks. W e rst present an overview of TMTE in Fig. 2 . W e then elaborate on the key com- ponents in detail. Specically , we describe the top ology evolution process in Sec. 4.1 , the modality evolution mechanism in Sec. 4.2 , and nally , the task-aware co-evolution strategy that integrates both processes in Sec. 4.3 . 4.1 T opology Evolution from Original Modality Feature Space As discussed in Sec. 1 , the topology of the original MA G may contain noisy connections while omitting informativ e ones. T o address this issue, TMTE rst encourages the topology to preserve intrinsic inter-entity relationships within the original modality feature space, serving as the starting point for top ology evolution. Multimodal and Multi-perspective Similarity Metric Learn- ing. W e formulate topology evolution as a similarity metric learning problem driven by multimo dal semantics from multiple perspec- tives. Specically , given a MA G G = ( V , E , X ( 𝑚 ) 𝑚 ∈ M ) , we rst compute the fused representation as ¯ X = 1 | M | Í 𝑚 ∈ M X ( 𝑚 ) and ex- tend the mo dality index set as ¯ M = M ∪ { | M | + 1 } . For each 𝑚 ∈ ¯ M , we introduce 𝐾 learnable parameter vectors w ( 𝑚, 1 ) , . . . , w ( 𝑚,𝐾 ) to capture pair wise similarities from distinct perspectives using weighted cosine similarity . The similarity between no des 𝑣 𝑖 and 𝑣 𝑗 under modality 𝑚 is computed by aggregating these perspectives: 𝑎 ( 𝑚,𝑝 ) 𝑖 𝑗 = cos w ( 𝑚,𝑝 ) ⊙ x ( 𝑚 ) 𝑖 , w ( 𝑚,𝑝 ) ⊙ x ( 𝑚 ) 𝑗 , 𝑠 ( 𝑚 ) 𝑖 𝑗 = 1 𝐾 𝐾 𝑝 = 1 𝑎 ( 𝑚,𝑝 ) 𝑖 𝑗 , (1) where ⊙ denotes the Hadamard product. Finally , the overall pair- wise similarity b etween nodes 𝑣 𝑖 and 𝑣 𝑗 is obtained via a convex combination of | M | + 1 modality-sp ecic similarities: A 𝐸 1 𝑖 𝑗 = 𝑚 ∈ ¯ M somax ( 𝛽 ) 𝑚 𝑠 ( 𝑚 ) 𝑖 𝑗 , (2) where 𝛽 ∈ R | M | + 1 is jointly optimized with the model parameters to adaptively balance these modality-specic semantics. W e dene A 𝐸 1 as the starting point for topology evolution. Since A 𝐸 1 𝑖 𝑗 ∈ [ − 1 , 1 ] , we further apply a non-negative threshold 𝜖 by setting elements below 𝜖 to zero, forming a symmetric, sparse, and non-negative weighted adjacency matrix A 𝐸 1 ∈ R | V | × | V | . Node-anchor Anity Matrix for Scalability . Howev er , comput- ing full pairwise similarities would require O ( | ¯ M | · | V | 2 ) time and memory and is prohibitive for large MA Gs. Inspired by studies in large-scale graph learning [ 29 ], we adopt an anchor-based scalable formulation. Specically , let U ⊆ V denote an anchor set with | U | randomly sampled nodes. W e compute a node-anchor anity matrix R 𝐸 1 ∈ R | V | × | U | using the same weighted cosine scheme as in Eqs. ( 1 ) and ( 2 ) . This preserves O ( | ¯ M | · | V | · | U | ) complexity , where | U | ≪ | V | holds. R 𝐸 1 serves as the starting point of topology evolution across a bipartite graph B between V and U , which can further induce the global topology evolution term A 𝐸 1 ∈ R | V | × | V | that renes pairwise relations V × V , formulated as: A 𝐸 1 = ∆ 𝐸 1 − 1 R 𝐸 1 Λ 𝐸 1 − 1 R 𝐸 1 ⊤ , (3) where Λ 𝐸 1 ∈ R | U | × | U | ( Λ 𝐸 1 𝑗 𝑗 = Í | N | 𝑖 = 1 R 𝐸 1 𝑖 𝑗 ) and ∆ 𝐸 1 ∈ R | V | × | V | ( ∆ 𝐸 1 𝑖𝑖 = Í | U | 𝑗 = 1 R 𝐸 1 𝑖 𝑗 ) are both diagonal matrices. Importantly , Eq. ( 3 ) does not nee d to be computed explicitly . Instead, the contextual se- mantics are diuse d o ver the evolv ed topology through a two-stage smoothing operation induced by B , which is detailed in Se c. 4.2 . T o employ structural priors encoded in the initial top ology , the learned pairwise relations A 𝐸 1 serve as residual structural rene- ments, corr ecting rather than replacing the original graph. For intu- ition, the topology evolution essentially leads to the symmetrically normalized adjacency matrix Q 𝐸 1 : Q 𝐸 1 = 𝜆 ˜ A + ( 1 − 𝜆 ) A 𝐸 1 , (4) where ˜ A denotes the symmetrically normalized adjacency matrix of the original topology , and 𝜆 ∈ ( 0 , 1 ) is a trade-o parameter to balance the original topology and evolved ones. XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu … … … … … … Visua l Represe nta tio n Textual Representation Fused Represent ati on … Mul t i mod al & Mul t i - Perspective Node - Anc hor Simi la rit y Lear nin g Anch or Nod e Oth er No de … … … … AAACAHicbVDLSsNAFJ34rPUVdeHCzWARXJVEpLosunHhooJ9QBPCZDpph04ezNyIJWTjr7hxoYhbP8Odf+OkzUJbD1w4nHMv997jJ4IrsKxvY2l5ZXVtvbJR3dza3tk19/Y7Kk4lZW0ai1j2fKKY4BFrAwfBeolkJPQF6/rj68LvPjCpeBzdwyRhbkiGEQ84JaAlzzx0QgIjSkR2m3sOsEfIgKhx7pk1q25NgReJXZIaKtHyzC9nENM0ZBFQQZTq21YCbkYkcCpYXnVSxRJCx2TI+ppGJGTKzaYP5PhEKwMcxFJXBHiq/p7ISKjUJPR1Z3GumvcK8T+vn0Jw6WY8SlJgEZ0tClKBIcZFGnjAJaMgJpoQKrm+FdMRkYSCzqyqQ7DnX14knbO63ag37s5rzasyjgo6QsfoFNnoAjXRDWqhNqIoR8/oFb0ZT8aL8W58zFqXjHLmAP2B8fkD4HaXQQ== L task Task Loss … … … … … … … … … … … … … … Evolved Topology AAAB/HicbVDLSsNAFL2pr1pf0S7dDBahbkoiUl0W3bisYB/QxDKZTtqhkwczEyGE+ituXCji1g9x5984abPQ1gMDh3Pu5Z45XsyZVJb1bZTW1jc2t8rblZ3dvf0D8/CoK6NEENohEY9E38OSchbSjmKK034sKA48Tnve9Cb3e49USBaF9yqNqRvgcch8RrDS0tCsOgFWE8/PnPaEzR6yun02G5o1q2HNgVaJXZAaFGgPzS9nFJEkoKEiHEs5sK1YuRkWihFOZxUnkTTGZIrHdKBpiAMq3WwefoZOtTJCfiT0CxWaq783MhxImQaensyjymUvF//zBonyr9yMhXGiaEgWh/yEIxWhvAk0YoISxVNNMBFMZ0VkggUmSvdV0SXYy19eJd3zht1sNO8uaq3roo4yHMMJ1MGGS2jBLbShAwRSeIZXeDOejBfj3fhYjJaMYqcKf2B8/gBOmpSP (1) AAAB/HicbVDLSsNAFL3xWesr2qWbYBHqpiRFqsuiG5cV7AOaWCbTSTt0MgkzEyGE+ituXCji1g9x5984abPQ1gMDh3Pu5Z45fsyoVLb9baytb2xubZd2yrt7+weH5tFxV0aJwKSDIxaJvo8kYZSTjqKKkX4sCAp9Rnr+9Cb3e49ESBrxe5XGxAvRmNOAYqS0NDQrbojUxA8ytz2hs4es1jifDc2qXbfnsFaJU5AqFGgPzS93FOEkJFxhhqQcOHasvAwJRTEjs7KbSBIjPEVjMtCUo5BIL5uHn1lnWhlZQST048qaq783MhRKmYa+nsyjymUvF//zBokKrryM8jhRhOPFoSBhloqsvAlrRAXBiqWaICyozmrhCRIIK91XWZfgLH95lXQbdadZb95dVFvXRR0lOIFTqIEDl9CCW2hDBzCk8Ayv8GY8GS/Gu/GxGF0zip0K/IHx+QNQIJSQ (2) … … … … Ori gin al Topology Mul t i mod al - attribu ted G raph Smooth Fu sed Lat ent Re p. V. Late nt Rep. T. Latent Rep. AAAB/3icbVDLSsNAFJ3UV62vqODGTbAIrkoiUl0W3bhwUcE+oAlhMpm0QycPZm7EErPwV9y4UMStv+HOv3HSZqGtBwYO59zLPXO8hDMJpvmtVZaWV1bXquu1jc2t7R19d68r41QQ2iExj0Xfw5JyFtEOMOC0nwiKQ4/Tnje+KvzePRWSxdEdTBLqhHgYsYARDEpy9QM7xDAimGc3uWsDfYAsjP3c1etmw5zCWCRWSeqoRNvVv2w/JmlIIyAcSzmwzAScDAtghNO8ZqeSJpiM8ZAOFI1wSKWTTfPnxrFSfCOIhXoRGFP190aGQyknoacmi7Ry3ivE/7xBCsGFk7EoSYFGZHYoSLkBsVGUYfhMUAJ8oggmgqmsBhlhgQmoymqqBGv+y4uke9qwmo3m7Vm9dVnWUUWH6AidIAudoxa6Rm3UQQQ9omf0it60J+1Fe9c+ZqMVrdzZR3+gff4AA82WxA== L mod Mod al i t y Alig nment Loss AAAB/XicbVDLSsNAFL2pr1pf8bFzM1iEChISkeqy6MZlBfuANpbJdNIOnTyYmQg1BH/FjQtF3Pof7vwbJ20X2npg4HDOvdwzx4s5k8q2v43C0vLK6lpxvbSxubW9Y+7uNWWUCEIbJOKRaHtYUs5C2lBMcdqOBcWBx2nLG13nfuuBCsmi8E6NY+oGeBAynxGstNQzD7oBVkPPT1vZfVpxTi3LOsl6Ztm27AnQInFmpAwz1HvmV7cfkSSgoSIcS9lx7Fi5KRaKEU6zUjeRNMZkhAe0o2mIAyrddJI+Q8da6SM/EvqFCk3U3xspDqQcB56ezLPKeS8X//M6ifIv3ZSFcaJoSKaH/IQjFaG8CtRnghLFx5pgIpjOisgQC0yULqykS3Dmv7xImmeWU7Wqt+fl2tWsjiIcwhFUwIELqMEN1KEBBB7hGV7hzXgyXox342M6WjBmO/vwB8bnD82nlCk= W (1 ,... ) AAACAnicbVDLSsNAFJ3UV62vqCtxM1iEChISkeqy6MZlhb6giWUynbRDJ5MwMxFKCG78FTcuFHHrV7jzb5y0WWj1wIXDOfdy7z1+zKhUtv1llJaWV1bXyuuVjc2t7R1zd68jo0Rg0sYRi0TPR5IwyklbUcVILxYEhT4jXX9ynfvdeyIkjXhLTWPihWjEaUAxUloamAduiNTYD1K3NSYKZXdpzTm1LOskG5hV27JngH+JU5AqKNAcmJ/uMMJJSLjCDEnZd+xYeSkSimJGsoqbSBIjPEEj0teUo5BIL529kMFjrQxhEAldXMGZ+nMiRaGU09DXnfnBctHLxf+8fqKCSy+lPE4U4Xi+KEgYVBHM84BDKghWbKoJwoLqWyEeI4Gw0qlVdAjO4st/SefMcupW/fa82rgq4iiDQ3AEasABF6ABbkATtAEGD+AJvIBX49F4Nt6M93lryShm9sEvGB/fs/iWVg== ⇥ (1 ,... ) AAACAnicbVDLSsNAFJ3UV62vqCtxM1iEChKSItVl0Y3LCn1BE8tkOmmHTiZhZiKUENz4K25cKOLWr3Dn3zhpu9DWAxcO59zLvff4MaNS2fa3UVhZXVvfKG6WtrZ3dvfM/YO2jBKBSQtHLBJdH0nCKCctRRUj3VgQFPqMdPzxTe53HoiQNOJNNYmJF6IhpwHFSGmpbx65IVIjP0jd5ogolN2nleq5ZVlnWd8s25Y9BVwmzpyUwRyNvvnlDiKchIQrzJCUPceOlZcioShmJCu5iSQxwmM0JD1NOQqJ9NLpCxk81coABpHQxRWcqr8nUhRKOQl93ZkfLBe9XPzP6yUquPJSyuNEEY5ni4KEQRXBPA84oIJgxSaaICyovhXiERIIK51aSYfgLL68TNpVy6lZtbuLcv16HkcRHIMTUAEOuAR1cAsaoAUweATP4BW8GU/Gi/FufMxaC8Z85hD8gfH5A7WCllc= ⇥ (2 ,... ) AAAB/XicbVDLSsNAFL2pr1pf8bFzEyxCBQlJkeqy6MZlBfuANpbJdNIOnUzCzESoIfgrblwo4tb/cOffOGm70OqBgcM593LPHD9mVCrH+TIKS8srq2vF9dLG5tb2jrm715JRIjBp4ohFouMjSRjlpKmoYqQTC4JCn5G2P77K/fY9EZJG/FZNYuKFaMhpQDFSWuqbB70QqZEfpO3sLq1UT23bPsn6ZtmxnSmsv8SdkzLM0eibn71BhJOQcIUZkrLrOrHyUiQUxYxkpV4iSYzwGA1JV1OOQiK9dJo+s461MrCCSOjHlTVVf26kKJRyEvp6Ms8qF71c/M/rJiq48FLK40QRjmeHgoRZKrLyKqwBFQQrNtEEYUF1VguPkEBY6cJKugR38ct/SatquzW7dnNWrl/O6yjCIRxBBVw4hzpcQwOagOEBnuAFXo1H49l4M95nowVjvrMPv2B8fAPPMZQq W (2 ,... ) AAAB/XicbVDLSsNAFL2pr1pf8bFzM1iEChISleqy6MZlBfuANpbJdNIOnTyYmQg1BH/FjQtF3Pof7vwbJ20XWj0wcDjnXu6Z48WcSWXbX0ZhYXFpeaW4Wlpb39jcMrd3mjJKBKENEvFItD0sKWchbSimOG3HguLA47Tlja5yv3VPhWRReKvGMXUDPAiZzwhWWuqZe90Aq6Hnp63sLq2cHluWdZT1zLJt2ROgv8SZkTLMUO+Zn91+RJKAhopwLGXHsWPlplgoRjjNSt1E0hiTER7QjqYhDqh000n6DB1qpY/8SOgXKjRRf26kOJByHHh6Ms8q571c/M/rJMq/cFMWxomiIZke8hOOVITyKlCfCUoUH2uCiWA6KyJDLDBRurCSLsGZ//Jf0jyxnKpVvTkr1y5ndRRhHw6gAg6cQw2uoQ4NIPAAT/ACr8aj8Wy8Ge/T0YIx29mFXzA+vgHQu5Qr W (3 ,... ) AAACAnicbVDLSsNAFJ3UV62vqCtxM1iEChISleqy6MZlhb6giWUynbRDJ5MwMxFKCG78FTcuFHHrV7jzb5y0XWjrgQuHc+7l3nv8mFGpbPvbKCwtr6yuFddLG5tb2zvm7l5LRonApIkjFomOjyRhlJOmooqRTiwICn1G2v7oJvfbD0RIGvGGGsfEC9GA04BipLTUMw/cEKmhH6RuY0gUyu7TyvmpZVknWc8s25Y9AVwkzoyUwQz1nvnl9iOchIQrzJCUXceOlZcioShmJCu5iSQxwiM0IF1NOQqJ9NLJCxk81kofBpHQxRWcqL8nUhRKOQ593ZkfLOe9XPzP6yYquPJSyuNEEY6ni4KEQRXBPA/Yp4JgxcaaICyovhXiIRIIK51aSYfgzL+8SFpnllO1qncX5dr1LI4iOARHoAIccAlq4BbUQRNg8AiewSt4M56MF+Pd+Ji2FozZzD74A+PzB7cMllg= ⇥ (3 ,... ) Figure 2: O verview of TMTE, which jointly and evolutionarily optimizes the top ology and modality toward the downstream task. 4.2 Modality Evolution from Evolved T opology After the topology evolution, we further perform modality ev olu- tion on the rened structure. Motivated by prior work in graph signal processing (GSP) [ 9 ], a well-learned node representation should be smooth over the graph top ology . Accordingly , we model modality evolution as a two-step pr ocess: (1) learning node repre- sentations that capture all modality information while b eing smooth with respect to the graph, and (2) aligning each modality with the learned node embe ddings. Learning Smo oth Fused Representations. Formally , for the 𝑚 - th mo dality , we project its raw feature space X ( 𝑚 ) into a latent space H ( 𝑚 ) via a linear transformation Φ ( 𝑚 ) : H ( 𝑚 ) = X ( 𝑚 ) Φ ( 𝑚 ) . (5) The initial fused node repr esentation is then obtained by averaging across modalities, i.e., ¯ H = 1 | M | Í 𝑚 ∈ M H ( 𝑚 ) . As our goal is to enforce representation smoothness over the ev olved topology Q 𝐸 1 , we further minimize the following optimization objective 𝑓 ( ˆ H ) : min ˆ H ∈ R | 𝑉 | × 𝑑 𝑓 ( ˆ H ) = | | ˆ H − ¯ H | | 2 𝐹 + 𝛼 · tr ( ˆ H ⊤ ( I − Q 𝐸 1 ) ˆ H ) , (6) where 𝛼 > 0 controls the smoothness strength, and the Laplacian regularizer I − Q 𝐸 1 encourages neighb oring nodes to have simi- lar embe ddings. The delity term | | ˆ H − ¯ H | | 2 𝐹 ensures the learned embeddings ˆ H remain close to the initial fused representation ¯ H . By setting 𝜕 𝑓 ( ˆ H ) 𝜕 ˆ H = 0 and further obtaining a 𝑇 -step truncation closed-form solution, we yield the power series appr oximation of ˆ H , whose full derivation is provided in Theorem B.1 : ˆ H = 1 𝛼 + 1 𝑇 𝑡 = 0 𝛼 𝜆 𝛼 + 1 ˜ A + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 A 𝐸 1 𝑡 ¯ H . (7) Importantly , TMTE does not require explicitly constructing A 𝐸 1 . Instead, Eq. ( 7 ) can be eciently computed through recursive mul- tiplications. For example, the multiplication A 𝐸 1 ¯ H can be decom- posed as a two-stage smo othing operator (node-to-anchor-to-no de transformation): Z U = Λ 𝐸 1 − 1 R 𝐸 1 ⊤ ¯ H , Z V = ∆ 𝐸 1 − 1 R 𝐸 1 Z U , (8) where Z V = A 𝐸 1 ¯ H . Proofs and pseudo code refer to The orem B.2 and Appendix C , respectively . Modality Alignment. T o induce modality evolution while main- taining cross-modality consistency , we align each modality emb ed- ding H ( 𝑚 ) with other modalities and the fuse d representation ˆ H via a unied contrastive loss, which can be formulated as follows: L mod = − | M | 𝑚 = 1 | M | + 1 𝑛 = 1 ,𝑛 ≠ 𝑚 𝑢 log exp cos ( h ( 𝑚 ) 𝑢 , csg ( h ( 𝑛 ) 𝑢 ) ) / 𝜏 Í 𝑣 exp cos ( h ( 𝑚 ) 𝑢 , csg ( h ( 𝑛 ) 𝑣 ) ) / 𝜏 , (9) where h ( | M | + 1 ) 𝑢 denotes the fused node embedding ˆ h 𝑢 , csg ( ·) is the conditioned stop-gradient (i.e., applie d only to the smooth fused representation), and 𝜏 is the temperature parameter . 4.3 T ask-aware Modality and T opology Co-evolution Optimization toward Downstream T asks. The framework is task-agnostic and can be optimized for arbitrary downstream objec- tives with corresponding task-specic heads. For graph-centric tasks (e.g., node classication, link prediction, node clustering), we use the smooth fused r epresentation ˆ H in Eq. ( 7 ) as the topology-aware node embedding. For modality-centric tasks (e.g., mo dality retrie val, G2T ext, G2Image), we adopt the modality-specic latent embed- dings H ( 𝑚 ) in Eq. ( 5 ) , which preserve modality characteristics while being aligned via L mod . W e denote the unied downstream objective as L task , which is instantiated according to the specic task. The overall optimization objective of TMTE is formulated as follows: L = L mod + 𝜂 L task , (10) where 𝜂 balances mo dality alignment and task obje ctive (More details are presented in Appendix D ). TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and Topology Co-ev olution XX, XX, XX Modality and T op ology Co-evolution. T opology and modality evolution in TMTE form a closed-loop co-evolution pr ocess. The evolved top ology Q 𝐸 𝑡 guides modality evolution via the smoothness constraints in Eqs. ( 6 ) and ( 7 ) , while the updated representations ˆ H and H ( 𝑚 ) provide rened similarity signals for topology recon- struction. Thus, representation learning and topology renement mutually enhance each other . Specically , at the 𝑡 -th round, we update topology using the smooth fused embedding in Eq. ( 7 ) and mo dality emb eddings in Eq. ( 5 ) . Similar to Eqs. ( 1 ) and ( 2 ) , multi-channel similarities are ag- gregated via [ 𝜃 ( 𝑚,𝑘 ) ] 𝑚 ⩽ | M | + 1 , 𝑘 ⩽ 𝐾 and 𝛾 to obtain R ( 𝐸 𝑡 ) , yielding an implicitly symmetrically normalized adjacency matrix Q 𝐸 𝑡 , which can be calculated as follows: Q 𝐸 𝑡 = 𝜆 ˜ A + ( 1 − 𝜆 ) A 𝐸 𝑡 (11) Modality evolution then replaces Q 𝐸 1 with Q 𝐸 𝑡 in Eqs. ( 6 ) and ( 7 ) , producing ˆ H ( 𝑡 ) and H ( 𝑚,𝑡 ) . W e repeat this process for at most 𝑇 rounds, and stop early when top ology changes are smaller than a threshold 𝛿 , which is formulated as follows: | R ( 𝐸 𝑡 ) − R ( 𝐸 𝑡 − 1 ) | 2 𝐹 | R ( 𝐸 𝑡 ) | 2 𝐹 ⩽ 𝛿 , (12) This iterative co-evolution progressively renes topology and mo dal- ity representations in a task-aware and mutually adaptive manner . The overall procedure of TMTE is presented in Appendix C . 5 Experiments In this section, we rst describe the experimental setup , with full reproducibility details deferr ed to Appendix F and Appendix D . W e then conduct comprehensive empirical evaluations to answer the following research questions: Q1 : Does TMTE outperform existing unimodal GNNs and MGL methods on MA G datasets? Q2 : What are the individual contributions of each module in TMTE? Q3 : How robust is TMTE under noisy settings? Q4 : Does TMTE outp erform existing unimodal GNNs and MGL methods on non-graph multi- modal datasets? Q5 : What are the time and memory overheads, and how ecient is convergence? Q6 : How robust is TMTE to variations in hyperparameters? Moreover , we provide additional experimental results on additional MA G datasets in App endix A . 5.1 Experimental Setup Datasets. W e evaluate TMTE on 9 publicly MAG datasets and 1 non-graph multimodal dataset, co vering diverse domains including social networks, recommendation systems, art, vision-language, and literature. Specically , the graph datasets include RedditS [ 8 ] (social network), Movies [ 31 ] (movie network), two r ecommenda- tion networks (Gr ocery , Ele-fashion) [ 19 , 31 ], two video networks (D Y , Bili Dance) [ 53 ], SemArt [ 13 ] (art network), Flickr30k [ 35 ] (image-text network), and Goodreads [ 42 , 43 ] (bo ok network). The non-graph dataset is MVSA [ 33 ]. Due to space limitations, detaile d statistics and dataset descriptions are provided in Appendix F . Baselines. W e consider two categories of methods: (1) Unimodal GNNs : GCN [ 24 ], GCNII [ 6 ], GA T [ 40 ], and GA T v2 [ 4 ]. (2) MGL methods : MMGCN [ 44 ], MGA T [ 39 ], LGMRe c [ 14 ], MLaGA [ 11 ], GraphGPT -O [ 12 ], Graph4MM [ 32 ], InstructG2I [ 23 ], DMGC [ 15 ], DGF [ 54 ], MIG-GT [ 22 ], NTSFormer [ 21 ], and UniGraph2 [ 17 ]. The details of these baselines are provided in Appendix G . Downstream T asks. W e conduct comprehensiv e evaluations of these methods on: (1) Graph-centric tasks : node classication, link prediction, and node clustering, and (2) Modality-centric tasks : cross- modal retrieval, G2T ext, and G2Image. Given the complexity of evaluation pipelines, hyperparameter congurations, and metrics, we provide full details in Appendix D . 5.2 Main Results (Answ er for Q1) T o answer Q1 , we report results on three graph-centric tasks in T able 1 and three modality-centric tasks in T able 2 . W e further evaluate these methods on a non-graph dataset in Appendix ?? . Graph T asks . TMTE consistently achieves the best performance across all datasets and evaluation metrics, demonstrating stable superiority over existing methods. Specically , for node classica- tion, TMTE improv es over the second-best method by up to +3.83% in Accuracy and +7.34% in F1-score. For link prediction, TMTE achieves improv ements of +3.39% in MRR and +2.06% in Hits@3 over the runner-up; for node clustering, TMTE improves NMI and ARI by +4.16% and +5.51% compared with the second-best results. Notably , although MGL methods generally surpass unimodal GNNs, none maintains consistent dominance across all tasks and metrics. Modality T asks . Our mo dality-centric tasks include retrieval and generation, where TMTE consistently achieves state-of-the-art results. On Ele-fashion retrieval, TMTE reaches MRR 95.22 and Hits@3 86.48, surpassing UniGraph2 by 2.70% and 1.23%. On Flickr30k G2T ext, it outperforms Graph4MM by 1.05% BLEU-4 and 2.68% CIDEr . For SemArt G2Image, TMTE exceeds InstructG2I by 3.63% CLIP-S and 1.87% DINOv2-S, and GraphGPT -O by 3.74% CLIP-S and 3.61% DINOv2-S. These results highlight that xed, task-agnostic graph topologies often fail in MGL, as dier ent generation objec- tives require distinct semantic cues, making suboptimal structures inevitable in existing methods. TMTE performs task-aware modality-topology co-evolution, where the procedure induces an adaptive graph structur e tailored to the downstream objective , and the rened topology in turn en- hances contextual multimodal representations. The consistent su- periority of TMTE across all graph-centric and modality-centric tasks further conrms that dynamically evolving topology toward task-specic objectives is essential for eective MGL. 5.3 Ablation Study (Answ er for Q2) T o address Q2 , we conduct an ablation study to assess the contribu- tion of each TMTE module. As described in Se c. 1 and Sec. 4 , TMTE comprises three core mechanisms: topology evolution, mo dality evolution, and task-aware optimization. Due to the complex interactions among these mechanisms, in- dividual modules cannot be simply removed. Therefore, we dene three variants to evaluate their eects: (1) One-shot T opology Evolu- tion (One-shot TE) : The MA G topology ev olves only once per epoch based on the original modality features, without co-evolving with latent modality representations; (2) Only Mo dality Evolution (Only ME) : The topology evolution is r emoved, and modality evolution re- lies solely on the original topology rather than the evolved one; and XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu T able 1: Performance comparison on three graph-centric downstream tasks. The best, second best and third b est results are highlighte d in red , blue and orange , respectively . T asks Node Classication Link Prediction Node Clustering Movies DY T oys Methods Datasets ACC F1-Score MRR Hits@3 NMI ARI GCN 52 . 24 ± 0 . 15 41 . 80 ± 0 . 13 70 . 22 ± 0 . 35 83 . 80 ± 0 . 37 46 . 50 ± 0 . 15 31 . 66 ± 1 . 21 GCNII 52 . 05 ± 0 . 28 42 . 62 ± 0 . 30 71 . 17 ± 0 . 20 85 . 69 ± 0 . 33 48 . 72 ± 0 . 20 32 . 84 ± 1 . 33 GA T 51 . 92 ± 0 . 32 41 . 47 ± 0 . 29 70 . 35 ± 0 . 24 81 . 92 ± 0 . 52 47 . 34 ± 0 . 22 31 . 13 ± 1 . 22 GA Tv2 50 . 31 ± 0 . 43 39 . 62 ± 0 . 34 70 . 18 ± 0 . 36 83 . 72 ± 0 . 39 48 . 45 ± 0 . 18 32 . 72 ± 1 . 29 MMGCN 56 . 32 ± 0 . 18 44 . 52 ± 0 . 20 72 . 53 ± 0 . 42 85 . 78 ± 0 . 51 49 . 37 ± 0 . 28 33 . 42 ± 1 . 41 MGA T 55 . 51 ± 0 . 33 43 . 95 ± 0 . 47 72 . 19 ± 0 . 38 85 . 47 ± 0 . 52 48 . 78 ± 0 . 28 32 . 89 ± 1 . 35 LGMRec 55 . 44 ± 0 . 27 42 . 78 ± 0 . 24 73 . 55 ± 0 . 18 86 . 28 ± 0 . 34 48 . 82 ± 0 . 29 32 . 63 ± 2 . 28 MLaGA 56 . 25 ± 0 . 40 44 . 67 ± 0 . 51 72 . 11 ± 0 . 42 85 . 23 ± 0 . 29 49 . 20 ± 0 . 32 33 . 26 ± 1 . 48 GraphGPT -O 52 . 48 ± 0 . 21 38 . 35 ± 0 . 42 70 . 04 ± 0 . 62 81 . 22 ± 1 . 36 45 . 34 ± 0 . 31 30 . 85 ± 1 . 72 Graph4MM 55 . 48 ± 0 . 27 42 . 95 ± 0 . 26 74 . 31 ± 0 . 30 86 . 59 ± 0 . 19 46 . 74 ± 0 . 32 32 . 17 ± 1 . 21 InstructG2I 54 . 37 ± 0 . 19 42 . 55 ± 0 . 34 72 . 38 ± 0 . 24 86 . 11 ± 0 . 26 47 . 41 ± 0 . 59 31 . 26 ± 2 . 14 DMGC 52 . 26 ± 0 . 64 42 . 54 ± 0 . 71 75 . 22 ± 0 . 38 91 . 14 ± 0 . 40 48 . 50 ± 0 . 30 31 . 95 ± 1 . 30 DGF 56 . 48 ± 0 . 30 46 . 14 ± 0 . 27 74 . 95 ± 0 . 35 87 . 60 ± 0 . 52 50 . 50 ± 0 . 28 34 . 62 ± 1 . 32 MIG-GT 54 . 93 ± 0 . 47 43 . 12 ± 0 . 58 72 . 63 ± 0 . 50 84 . 74 ± 0 . 57 47 . 86 ± 0 . 38 31 . 94 ± 1 . 52 NTSFormer 56 . 37 ± 0 . 25 43 . 83 ± 0 . 18 72 . 15 ± 0 . 36 85 . 50 ± 0 . 42 49 . 42 ± 0 . 38 34 . 01 ± 1 . 35 UniGraph2 54 . 51 ± 0 . 59 42 . 53 ± 0 . 42 71 . 23 ± 0 . 46 83 . 31 ± 0 . 29 47 . 17 ± 0 . 29 31 . 81 ± 1 . 30 TMTE (Ours) 60 . 31 ± 0 . 24 53 . 48 ± 0 . 18 78 . 61 ± 0 . 24 93 . 20 ± 0 . 42 54 . 66 ± 0 . 30 39 . 52 ± 1 . 01 T able 2: Performance comparison on three mo dality-centric downstream tasks. The b est, second best and third b est results are highlighted in red , blue and orange , respectively . T asks Modality Retrieval G2T ext G2Image Ele-fashion Flickr30k SemArt Methods Datasets MRR Hits@3 BLEU-4 CIDEr CLIP-S DINOv2-S GCN 76 . 40 ± 0 . 44 68 . 55 ± 0 . 52 5 . 62 ± 0 . 23 38 . 43 ± 1 . 27 50 . 05 ± 0 . 18 35 . 52 ± 0 . 21 GCNII 77 . 41 ± 0 . 36 70 . 56 ± 0 . 48 5 . 27 ± 0 . 19 39 . 52 ± 1 . 11 49 . 51 ± 0 . 24 35 . 22 ± 0 . 17 GA T 78 . 12 ± 0 . 57 70 . 35 ± 0 . 39 5 . 12 ± 0 . 21 39 . 48 ± 1 . 09 51 . 26 ± 0 . 33 36 . 24 ± 0 . 42 GA Tv2 78 . 24 ± 0 . 33 70 . 79 ± 0 . 58 5 . 28 ± 0 . 25 39 . 81 ± 1 . 36 51 . 48 ± 0 . 46 36 . 41 ± 0 . 90 MMGCN 81 . 41 ± 0 . 52 73 . 56 ± 0 . 43 5 . 78 ± 0 . 17 43 . 52 ± 1 . 08 54 . 51 ± 0 . 37 39 . 46 ± 0 . 55 MGA T 81 . 70 ± 0 . 38 74 . 39 ± 0 . 49 6 . 49 ± 0 . 22 46 . 34 ± 1 . 47 55 . 38 ± 0 . 41 40 . 24 ± 0 . 63 LGMRec 89 . 45 ± 0 . 41 80 . 26 ± 0 . 55 5 . 90 ± 0 . 18 60 . 40 ± 1 . 25 60 . 28 ± 0 . 52 44 . 87 ± 0 . 66 MLaGA 87 . 45 ± 0 . 59 79 . 22 ± 0 . 46 9 . 26 ± 0 . 31 70 . 94 ± 1 . 18 68 . 23 ± 0 . 73 52 . 88 ± 0 . 84 GraphGPT -O 87 . 84 ± 0 . 47 80 . 12 ± 0 . 42 9 . 57 ± 0 . 28 72 . 26 ± 1 . 09 70 . 47 ± 0 . 69 53 . 68 ± 0 . 77 Graph4MM 85 . 94 ± 0 . 35 78 . 13 ± 0 . 53 10 . 15 ± 0 . 33 74 . 46 ± 1 . 26 66 . 85 ± 0 . 58 51 . 28 ± 0 . 69 InstructG2I 88 . 47 ± 0 . 48 80 . 76 ± 0 . 57 9 . 42 ± 0 . 29 71 . 25 ± 1 . 31 70 . 58 ± 0 . 75 55 . 42 ± 0 . 88 DMGC 91 . 34 ± 0 . 39 85 . 22 ± 0 . 44 7 . 41 ± 0 . 27 60 . 95 ± 1 . 19 60 . 87 ± 0 . 56 46 . 35 ± 0 . 71 DGF 90 . 84 ± 0 . 42 82 . 59 ± 0 . 36 6 . 75 ± 0 . 47 62 . 17 ± 1 . 20 61 . 53 ± 1 . 20 46 . 02 ± 1 . 14 MIG-GT 91 . 33 ± 0 . 51 83 . 27 ± 0 . 47 8 . 30 ± 0 . 22 64 . 27 ± 1 . 33 63 . 45 ± 0 . 67 47 . 62 ± 0 . 78 NTSFormer 91 . 42 ± 0 . 37 83 . 50 ± 0 . 41 8 . 41 ± 0 . 24 65 . 29 ± 1 . 28 62 . 88 ± 0 . 63 47 . 81 ± 0 . 74 UniGraph2 92 . 52 ± 0 . 35 85 . 25 ± 0 . 41 8 . 52 ± 0 . 26 64 . 38 ± 1 . 42 63 . 48 ± 0 . 58 47 . 53 ± 0 . 61 TMTE (Ours) 95 . 22 ± 0 . 33 86 . 48 ± 0 . 37 11 . 20 ± 0 . 15 77 . 14 ± 1 . 33 74 . 21 ± 0 . 44 57 . 29 ± 0 . 52 (3) T ask-agnostic Evolution (T ask-agnostic E) : Modality and top ol- ogy co-evolution ignores do wnstream task objectives, performing task-agnostic evolution follow ed by ne-tuning on the tasks. Based on this, T able 3 conrms the importance of these core mechanisms. Each variant induces a noticeable performance drop. Notably , Only Modality Evolution generally causes the largest degra- dation, highlighting the critical role of topology evolution. The performance drop from One-shot T opology Evolution is often more pronounced than that of Task-agnostic Evolution , indicating that multi-round co-evolution of modality and topology progressiv ely guides the learning of better structures, which single-round evolu- tion based on the original modality space cannot achieve . Finally , the decrease under T ask-agnostic Evolution demonstrates the neces- sity of incorporating downstream objectives into the co-evolution process. Overall, all components are essential for TMTE’s perfor- mance and contribute signicantly to its overall eectiveness. 5.4 Robustness Analysis (Answ er for Q3) T o answer Q3 , we investigate the robustness of TMTE under topol- ogy noise scenarios, including noise interaction and missing in- teraction, which stem from the inherent topological limitations of real-world MA Gs discussed in Se c. 1 . As illustrated in Fig. 3 , when the level of topological noise gradually increases, TMTE maintains remarkable r obustness and stable performance by appropriately ad- justing the 𝜆 parameter (Eqs. ( 4 ) and ( 11 ) ), which eectively controls the weight of the original graph topology during the top ological evolution process and ensur es a balanced integration of evolving structural information. In contrast, the baseline method exhibits a signicant performance decline as the noise level increases. 5.5 Performances on Non-graph Datasets ( Answer for Q4) T o further evaluate TMTE on multimodal data without explicitly constructed topological structures, we conduct experiments on the non-graph MVSA dataset [ 33 ], with details provided in App endix F . The results are sho wn in Fig. 4 . As observed, TMTE maintains an TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and Topology Co-ev olution XX, XX, XX T able 3: Ablation study on 6 MA G datasets with graph-centric and modality-centric tasks. T asks Node Classication Link Prediction Node Clustering Movies DY T oys Methods Datasets ACC F1-Score MRR Hits@3 NMI ARI One-shot TE 57 . 44 ± 0 . 24 47 . 10 ± 0 . 19 77 . 15 ± 0 . 40 92 . 47 ± 0 . 29 48 . 33 ± 0 . 24 33 . 27 ± 1 . 25 Only ME 56 . 31 ± 0 . 29 44 . 27 ± 0 . 30 73 . 45 ± 0 . 19 88 . 57 ± 0 . 42 48 . 40 ± 0 . 14 32 . 24 ± 0 . 82 T ask-agnostic E 58 . 75 ± 0 . 32 49 . 61 ± 0 . 24 76 . 18 ± 0 . 13 91 . 52 ± 0 . 38 52 . 30 ± 0 . 25 36 . 49 ± 1 . 44 TMTE (Ours) 60 . 31 ± 0 . 24 53 . 48 ± 0 . 18 78 . 61 ± 0 . 24 93 . 20 ± 0 . 42 54 . 66 ± 0 . 30 39 . 52 ± 1 . 01 T asks Modality Retrieval G2T ext G2Image Ele-fashion Flickr30k SemArt Methods Datasets MRR Hits@3 BLEU-4 CIDEr CLIP-S DINOv2-S One-shot TE 91 . 27 ± 0 . 42 84 . 09 ± 0 . 23 9 . 61 ± 0 . 30 72 . 48 ± 0 . 17 73 . 22 ± 0 . 48 54 . 30 ± 0 . 38 Only ME 87 . 95 ± 0 . 42 82 . 26 ± 0 . 29 8 . 32 ± 0 . 35 67 . 42 ± 0 . 25 66 . 42 ± 0 . 35 52 . 24 ± 0 . 84 T ask-agnostic E 94 . 10 ± 0 . 27 85 . 75 ± 0 . 30 10 . 82 ± 0 . 33 76 . 42 ± 1 . 58 72 . 37 ± 0 . 22 55 . 81 ± 0 . 61 TMTE (Ours) 95 . 22 ± 0 . 33 86 . 48 ± 0 . 37 11 . 20 ± 0 . 15 77 . 14 ± 1 . 33 74 . 21 ± 0 . 44 57 . 29 ± 0 . 52 0 10 20 30 40 50 Noise Interaction Ratio 38 42 46 50 54 58 62 Accuracy (%) (a) Node Classification (Movies) 0.8 0.7 0.6 0.5 0.4 0.3 f o r T M T E 0 10 20 30 40 50 Noise Interaction Ratio 38 42 46 50 54 NMI (%) (b) Node Clustering (T oys) 0.8 0.7 0.6 0.5 0.4 0.3 f o r T M T E 0 10 20 30 40 50 Missing Interaction Ratio 4 6 8 10 BLEU-4 (%) (c) G2T ext (Flickr30k) 0.8 0.7 0.6 0.5 0.4 0.3 f o r T M T E 0 10 20 30 40 50 Missing Interaction Ratio 50 55 60 65 70 75 CLIP-S (%) (d) G2Image (SemArt) 0.8 0.7 0.6 0.5 0.4 0.3 f o r T M T E MMGCN GraphGPT -O Graph4MM DGF TMTE (Ours) Figure 3: Exp erimental results of our robustness analysis. W e investigate two types of topological noise, including noise interactions (i.e., randomly adding edges), which are presented in (a) and (b); and missing interactions (i.e., randomly removing e dges), which are presented in (c) and (d). 1 10 20 30 40 50 60 70 80 90 100 T raining Epochs 40 60 80 Accuracy (%) MMGCN GraphGPT -O Graph4MM DGF TMTE (Ours) Figure 4: Accuracy cur ves under the MVSA dataset. accuracy of approximately 63% during the rst 50 epochs, followed by rapid improvement that approaches convergence around the 75th epoch and achieves the best overall performance. In contrast, other methods exhibit less favorable optimization behavior , either converging more slowly ( e.g., DGF) or quickly plateauing at subopti- mal lev els ( e.g., MMGCN), demonstrating the superior convergence and robustness of TMTE without predened top ological structures. 5.6 Eciency Analysis (Answ er for Q5) T o answer Q4 , we provide a detailed evaluation of TMTE in terms of computation and storage eciency . As shown in T able 4 , TMTE’s per-epoch training time ( 0 . 4225 s) and inference time ( 0 . 1099 s) are T able 4: Per-ep och eciency on Movies. Method E- Train. (s) E-Infer . (s) Param. MMGCN 0 . 0891 0 . 0352 15 . 8 M GraphGPT -O 1 . 8257 0 . 5167 48 . 7 M Graph4MM 0 . 1599 0 . 5311 33 . 2 M InstructG2I 24 . 9133 0 . 8211 62 . 3 M DMGC 0 . 1362 0 . 0441 0 . 85 M DGF 0 . 1599 0 . 0391 0 . 9 M N TSFormer 0 . 0611 0 . 0206 0 . 7 M Unigraph2 0 . 4933 0 . 0646 36 . 6 M TMTE (Ours) 0 . 4225 0 . 1099 0 . 5 M higher than the fastest baselines such as N TSFormer ( 0 . 0611 s) and MMGCN ( 0 . 0891 s), reecting a moderate additional computational cost per batch. Notably , despite this overhead, TMTE maintains a very small parameter fo otprint ( 0 . 5 M). This mo dest increase in train- ing and inference time is acceptable considering TMTE’s consistent performance advantages in b oth graph-centric and mo dality-centric tasks. In summar y , TMTE achieves superior eectiveness while remaining deployable, pr oviding a favorable trade-o between ef- ciency and task performance. Moreover , we provide additional theoretical analysis of TMTE on large-scale graphs in terms of stability and convergence guarantee (Theorems B.3 and B.4 ). XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu 0.0 0.1 1.0 10.0 S m o o t h n e s s R a t e 5 10 15 20 T u n c a t i o n S t e p T 59.30 58.76 59.49 58.71 61.46 60.73 60.54 60.89 59.83 60.04 60.39 60.00 58.98 58.54 59.10 58.65 (a) Node Classification (Movies) 59 60 61 Accuracy (%) 0.0 0.1 1.0 10.0 S m o o t h n e s s R a t e 5 10 15 20 T u n c a t i o n S t e p T 51.98 50.87 50.65 50.22 52.35 54.39 53.03 53.68 53.03 52.40 53.37 52.45 49.44 51.40 50.81 52.36 (b) Node Clustering (T oys) 50 52 54 NMI (%) 0.0 0.1 1.0 10.0 S m o o t h n e s s R a t e 5 10 15 20 T u n c a t i o n S t e p T 10.84 10.72 1 1.25 10.68 10.01 10.37 10.55 9.57 10.13 10.12 10.09 10.20 10.00 10.28 9.79 9.90 (c) G2T ext (Flickr30k) 10.0 10.5 1 1.0 BLEU-4 (%) 0.0 0.1 1.0 10.0 S m o o t h n e s s R a t e 5 10 15 20 T u n c a t i o n S t e p T 73.03 73.51 72.89 73.12 73.94 73.77 74.10 73.76 74.17 73.62 74.17 73.99 73.47 73.33 73.10 72.99 (d) G2Image (SemArt) 73.0 73.5 74.0 CLIP-S (%) Figure 5: Hyp erparameter analysis for 𝛼 and 𝑇 on four datasets and tasks. T able 5: Impact of 𝐾 on Movies. 𝐾 A CC F1-Score 1 57 . 59 ± 0 . 17 48 . 23 ± 0 . 35 4 60 . 31 ± 0 . 24 53 . 48 ± 0 . 18 8 59 . 40 ± 0 . 32 51 . 26 ± 0 . 53 16 57 . 38 ± 0 . 29 47 . 96 ± 0 . 33 5.7 Hyperparameter Analysis (Answ er for Q6) In this section, we investigate the impacts of key hyperparameters in TMTE. Specically , our evaluations focus on: (1) the number of perspectives for similarity metric learning (i.e., 𝐾 in Eq. ( 1 ) ); (2) the trade-o parameter between the original top ology and the evolved topology (i.e., 𝜆 in Eqs. ( 4 ) and ( 11 ) ); (3) the smoothness rate for modality representation (i.e., 𝛼 in Eq. ( 6 ) ); and (4) the numb er of truncation steps for power series appro ximation (i.e., 𝑇 in Eq. ( 7 ) ). For any TMTE hyperparameters not discussed, we describe their xed values or search ranges in Appendix D . Hyperparameters for T opology Evolution ( 𝐾 and 𝜆 ). For 𝐾 , which denotes the number of persp ectives in similarity metric learning (Eq. ( 1 ) ), it controls the div ersity of learned perspectives during topology evolution. A small 𝐾 may limit the model’s ability to capture heterogeneous structural patterns, while an excessively large 𝐾 can introduce redundancy and overtting. As shown in T able 5 , performance rst improves and then de- clines as 𝐾 increases. Specically , increasing 𝐾 from 1 to 4 signi- cantly boosts p erformance on Movies (A CC improves from 57.59% to 60.31%, and F1-Score from 48.23% to 53.48%), demonstrating that multi-perspective similarity learning ee ctively enhances the qual- ity of learned topology . However , when 𝐾 further increases to 8 or 16, p erformance slightly drops. This suggests that too many perspectives may introduce noisy or redundant similarity channels, weakening discriminative ability . Therefore, a mo derate number of perspectives (e.g., 𝐾 = 4 ) achieves the best trade-o b etween expressiveness and r obustness. For 𝜆 , which balances the original topology and the evolved topology (Eqs. ( 4 ) and ( 11 ) ), we have discussed its eect in Sec. 5.4 . As shown in Fig. 3 , 𝜆 plays a crucial role in noisy topology scenar- ios. When topological noise increases, appropriately adjusting 𝜆 enables TMTE to reduce reliance on corrupted original structures while leveraging the evolved topology . This adaptive weighting mechanism ensures stable performance under var ying noise levels. Hyperparameters for Mo dality Evolution ( 𝛼 and 𝑇 ). As illus- trated in Fig. 5 , we analyze the smoothness rate 𝛼 (Eq. ( 6 ) ) and the truncation step 𝑇 (Eq. 7 ) across four datasets and tasks, includ- ing Movies (node classication), T oys (node clustering), Flickr30k (G2T ext), and SemArt (G2Image). For 𝛼 , which controls the strength of mo dality representation smoothing, we obser ve that var ying 𝛼 across a wide range has relatively limite d impact on the nal performance. As shown in Fig. 5 , although extremely small or large values may lead to slight uctuations, the overall performance remains consistently stable across dierent datasets. This indicates that TMTE is not sensitive to the choice of 𝛼 . In other words, the modality evolution mechanism maintains eectiveness under dierent smoothing strengths. For 𝑇 , it determines the approximation depth of the p ower series expansion. Small 𝑇 values (e.g., 5) may under-appr oximate higher- order propagation. Incr easing 𝑇 to moderate levels ( e.g., 10 or 15) generally improves performance , as higher-order interactions are better captured. However , further increasing 𝑇 (e.g., 20) slightly degrade performance and increase computational complexity . 6 Related W orks Graph Neural Networks (GNNs). Earlier research on deep graph learning extends convolution to handle graphs [ 5 ] but comes with notable parameter counts. T o this end, GCN [ 24 ] simplies graph convolution by utilizing a rst-order Chebyshev lter to capture local neighborho od information. Moreover , GA T [ 40 ] adopts graph attention, allowing weighted aggregation. GraphSA GE [ 16 ] intro- duces a variety of learnable aggregation functions for perform- ing message aggregation. Moreover , recent studies extend GNN optimization from the centralized setting to the decentralized set- ting [ 1 , 27 , 56 – 59 ]. More GNN research can be found in surveys and benchmarks [ 28 , 46 , 47 , 55 ]. Multimodal Graph Learning (MGL). Multimodal graph learning (MGL) [ 10 , 41 ] aims to integrate heterogeneous modalities (e.g., vision, language, audio) within unied graph structures, enabling joint modeling of semantic and structural dependencies. Existing approaches generally extend classical graph learning techniques to multimodal settings, such as graph convolutions, attention mech- anisms, hypergraph modeling, and contrastive objectives. In rec- ommendation scenarios, prior studies [ 14 , 22 , 39 , 44 ] focus on con- structing modality-aware interaction graphs and designing adap- tive fusion strategies to disentangle collaborative and modality- specic signals. These methods improve r obustness under sparse or noisy interactions by enhancing high-order propagation and long-range dependency modeling. Beyond recommendation, se v- eral works [ 15 , 17 , 21 , 54 ] investigate more general multimodal TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and Topology Co-ev olution XX, XX, XX attributed graph learning problems, including heterophily-awar e modeling, feature denoising, cold-start node classication, and cross-domain representation learning. They typically emphasize structural ltering, contrastive alignment, and unied embedding spaces to obtain discriminative and transferable representations. With the rapid development of large language models (LLMs), re- cent eorts [ 11 , 12 , 23 , 32 , 49 , 51 ] explore graph-augmented mul- timodal reasoning and generation. These appr oaches align multi- modal embeddings with top ology and incorporate structural priors into foundation models, enabling structure-aware infer ence, con- trollable generation, and systematic benchmarking. 7 Conclusion In this paper , we revisit the role of graph topology in multimodal- attributed graphs and identify its inherent limitations, including noisy connections, missing connections, and task-agnostic interac- tions. Motivated by the bidirectional coupling b etween modalities and topology , w e propose a novel MGL frame work, TMTE, enabling task-aware co-evolution of graph structure and multimodal rep- resentations. TMTE iteratively renes the initial topology using evolving modality embeddings, which in turn guide representation learning toward downstream obje ctives. Exp eriments show that TMTE eectively mitigates topology noise, consistently improving performance on both graph-centric and modality-centric tasks. References [1] Y uming Ai, Xunkai Li, Jiaqi Chao, Bowen Fan, Zhengyu Wu, Yinlin Zhu, Rong-Hua Li, and Guoren Wang. 2025. Federated Graph Unlearning. arXiv: 2508.02485 [cs.LG] https://ar xiv .org/abs/2508.02485 [2] T akuya Akiba, Shotaro Sano, T oshihiko Y anase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A next-generation hyperparameter optimization frame- work. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD . [3] Jinze Bai, Shuai Bai, Shusheng Y ang, Shijie W ang, Sinan T an, Peng W ang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A versatile vision-language model for understanding, localization. T ext Reading, and Beyond 2, 1 (2023), 1. [4] Shaked Brody , Uri Alon, and Eran Y ahav . 2022. How attentive are graph attention networks? International Conference on Learning Representations, ICLR (2022). [5] Joan Bruna, W ojcie ch Zaremba, Arthur Szlam, and Yann LeCun. 2013. Spectral net- works and locally connected networks on graphs. arXiv preprint (2013). [6] Ming Chen, Zhewei W ei, Zengfeng Huang, Bolin Ding, and Y aliang Li. 2020. Simple and deep graph convolutional networks. In International Conference on Machine Learning, ICML . [7] Y u Chen, Lingfei Wu, and Mohamme d J. Zaki. 2020. Iterativ e Deep Graph Learning for Graph Neural Networks: Better and Robust No de Embeddings. arXiv: 2006.13009 [cs.LG] https://ar xiv .org/abs/2006.13009 [8] Karan Desai, Gaurav Kaul, Zubin Trivadi A ysola, and Justin Johnson. 2021. Re d- Caps: W eb-curated image-text data created by the pe ople, for the pe ople. In Advances in Neural Information Processing Systems, NeurIPS, Datasets and Bench- marks Track, NeurIPS DB Track . [9] Xiaowen Dong, Dorina Thanou, Pascal Frossard, and Pierre Vanderghe ynst. 2016. Learning Laplacian matrix in smooth graph signal representations. IEEE Transactions on Signal Processing 64, 23 (2016), 6160–6173. [10] Y asha Ektefaie, George Dasoulas, A yush Noori, Maha Farhat, and Marinka Zitnik. 2023. Multimo dal learning with graphs. Nature Machine Intelligence 5, 4 (2023), 340–350. [11] Dongzhe Fan, Yi Fang, Jiajin Liu, Djellel Difallah, and Qiaoyu T an. 2025. Mlaga: Multimodal large language and graph assistant. arXiv preprint (2025). [12] Yi Fang, Bowen Jin, Jiacheng Shen, Sirui Ding, Qiaoyu T an, and Jiawei Han. 2025. Graphgpt-o: Synergistic multimodal comprehension and generation on graphs. In Proceedings of the Computer Vision and Pattern Re cognition Conference . 19467–19476. [13] Noa Garcia and George V ogiatzis. 2018. How to read paintings: semantic art un- derstanding with multi-modal r etrieval. In Proceedings of the European Conference on Computer Vision W orkshops, ECCV . [14] Zhiqiang Guo, Jianjun Li, Guohui Li, Chaoyang W ang, Si Shi, and Bin Ruan. 2024. Lgmrec: Local and global graph learning for multimodal recommendation. In Proceedings of the AAAI conference on articial intelligence , V ol. 38. 8454–8462. [15] Zhaochen Guo, Zhixiang Shen, Xuanting Xie, Liangjian W en, and Zhao Kang. 2025. Disentangling homophily and heterophily in multimodal graph clustering. In Proceedings of the ACM International Conference on Multimedia, MM . [16] Will Hamilton, Zhitao Ying, and Jure Leskov ec. 2017. Inductive representation learning on large graphs. Advances in Neural Information Processing Systems, NeurIPS (2017). [17] Y ufei He, Y uan Sui, Xiaoxin He, Yue Liu, Yifei Sun, and Bryan Hooi. 2025. Un- igraph2: Learning a unied emb edding space to bind multimodal graphs. In Proceedings of the ACM on W eb Conference 2025 . 1759–1770. [18] Roger A Horn and Charles R Johnson. 2012. Matrix analysis . Cambridge university press. [19] Y upeng Hou, Jiacheng Li, Zhankui He, An Y an, Xiusi Chen, and Julian McAuley . 2024. Bridging language and items for retrieval and recommendation. arXiv preprint arXiv:2403.03952 (2024). [20] Di Hu, Xuelong Li, et al . 2016. T emporal multimodal learning in audiovisual speech recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . 3574–3582. [21] Jun Hu, Yufei He, Y uan Li, Bryan Ho oi, and Bingsheng He. 2025. N TSFormer: A Self-T eaching Graph Transformer for Multimo dal Isolated Cold-Start Node Classication. In Proce edings of the AAAI Conference on A rticial Intelligence, AAAI . [22] Jun Hu, Bryan Hooi, Bingsheng He, and Yinwei W ei. 2025. Modality-Indep endent Graph Neural Networks with Global T ransformers for Multimodal Recommen- dation. In Proceedings of the AAAI Conference on Articial Intelligence, AAAI . [23] Bowen Jin, Ziqi Pang, Bingjun Guo, Yu-Xiong W ang, Jiaxuan Y ou, and Jiawei Han. 2024. Instructg2i: Synthesizing images from multimodal attributed graphs. Advances in Neural Information Processing Systems 37 (2024), 117614–117635. [24] Thomas N Kipf and Max W elling. 2017. Semi-supervise d classication with graph convolutional networks. In International Conference on Learning Representations, ICLR . [25] Bingjun Li and Sheida Nabavi. 2024. A multimodal graph neural network frame- work for cancer molecular subtype classication. BMC bioinformatics 25, 1 (2024), XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu 27. [26] Xunkai Li, Zhengyu Wu, Zekai Chen, Henan Sun, Daohan Su, Guang Zeng, Hongchao Qin, Rong-Hua Li, and Guoren W ang. 2026. LION: A Cliord Neural Paradigm for Multimodal-Attributed Graph Learning. arXiv preprint arXiv:2601.21453 (2026). [27] Xunkai Li, Zhengyu Wu, W entao Zhang, Yinlin Zhu, Rong-Hua Li, and Guoren W ang. 2023. Fe dGT A: T opology-A ware A veraging for Federate d Graph Learning. Proceedings of the VLDB Endowment (2023). [28] Xunkai Li, Yinlin Zhu, Boyang Pang, Guochen Y an, Y eyu Y an, Zening Li, Zhengyu Wu, W entao Zhang, Rong-Hua Li, and Guoren W ang. 2024. Openfgl: A compre- hensive benchmark for federated graph learning. arXiv preprint (2024). [29] W ei Liu, Junfeng He, and Shih-Fu Chang. 2010. Large graph construction for scal- able semi-supervised learning. In Proceedings of the 27th international conference on machine learning (ICML-10) . 679–686. [30] Sijie Mai, Songlong Xing, Jiaxuan He, Ying Zeng, and Haifeng Hu. 2023. Multi- modal graph for unaligned multimo dal sequence analysis via graph convolution and graph pooling. ACM T ransactions on Multimedia Computing, Communications and A pplications 19, 2 (2023), 1–24. [31] Jianmo Ni, Jiacheng Li, and Julian McA uley . 2019. Justifying recommendations using distantly-labeled reviews and ne-grained aspe cts. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) . 188–197. [32] Xuying Ning, Dongqi Fu, Tianxin W ei, Wujiang Xu, and Jingrui He. 2025. Graph4MM: W eaving multimodal learning with structural information. In Pro- ceedings of the International Conference on Machine Learning, ICML . [33] T eng Niu, Shiai Zhu, Lei Pang, and Ab dulmotaleb El Saddik. 2016. Sentiment analysis on multi-view social data. In International conference on multimedia modeling . Springer , 15–27. [34] Maxime Oquab, Timothée Dar cet, Théo Moutakanni, Huy V o, Marc Szafraniec, V asil Khalidov , Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby , et al . 2023. Dinov2: Learning robust visual features without super vision. arXiv preprint arXiv:2304.07193 (2023). [35] Bryan A Plummer, Liwei W ang, Chris M Cervantes, Juan C Caicedo, Julia Ho ck- enmaier , and Svetlana Lazebnik. 2015. Flickr30 k entities: Collecting region-to- phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE International Conference on Computer Vision, ICCV . [36] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, et al . 2021. Learning transferable visual models from natural language super vision. In International conference on machine learning . PmLR, 8748–8763. [37] Colin Rael, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Y anqi Zhou, W ei Li, and P eter J Liu. 2020. Exploring the limits of transfer learning with a unied text-to-text transformer . Journal of machine learning research 21, 140 (2020), 1–67. [38] Nils Reimers and Ir yna Gurevych. 2019. Sentence-bert: Sentence embe ddings using siamese bert-networks. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) . 3982–3992. [39] Zhulin T ao, Yinwei W ei, Xiang W ang, Xiangnan He, Xianglin Huang, and T at- Seng Chua. 2020. Mgat: Multimodal graph attention network for recommendation. Information Processing & Management 57, 5 (2020), 102277. [40] Petar V eličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero , Pietro Lio, and Y oshua Bengio. 2018. Graph attention networks. In International Confer- ence on Learning Representations, ICLR . [41] Chenxi W an, Xunkai Li, Yilong Zuo, Haokun Deng, Sihan Li, Bowen Fan, Hongchao Qin, Ronghua Li, and Guoren W ang. 2026. Op enMAG: A Comprehen- sive Benchmark for Multimodal-Attributed Graph. arXiv preprint (2026). [42] Mengting Wan and Julian McA uley . 2018. Item recommendation on monotonic behavior chains. In Proceedings of the 12th ACM conference on recommender systems . 86–94. [43] Mengting W an, Rishabh Misra, Ndapandula Nakashole, and Julian McAuley . 2019. Fine-grained spoiler detection from large-scale review corpora. In Proceedings of the 57th A nnual Meeting of the Association for Computational Linguistics . 2605– 2610. [44] Yinwei W ei, Xiang W ang, Liqiang Nie, Xiangnan He , Richang Hong, and T at-Seng Chua. 2019. MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. In Proceedings of the 27th ACM international conference on multimedia . 1437–1445. [45] Bichen Wu, Chenfeng Xu, Xiaoliang Dai, Alvin W an, Peizhao Zhang, Zhicheng Y an, Masayoshi T omizuka, Joseph Gonzalez, Kurt Keutzer , and Peter V ajda. 2020. Visual transformers: T oken-based image representation and processing for com- puter vision. arXiv preprint arXiv:2006.03677 (2020). [46] Zhengyu Wu, Xunkai Li, Yinlin Zhu, Zekai Chen, Guochen Y an, Yanyu Y an, Hao Zhang, Y uming Ai, Xinmo Jin, Rong-Hua Li, et al . 2025. A comprehensive data- centric overview of federated graph learning. arXiv preprint (2025). [47] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu P hilip. 2020. A comprehensive sur vey on graph neural networks. IEEE transactions on neural networks and learning systems 32, 1 (2020), 4–24. [48] Zhengyu Wu, Yinlin Zhu, Xunkai Li, Ziang Qiu, Rong-Hua Li, Guoren Wang, and Chenghu Zhou. 2025. FedBook: A Unied Federated Graph Founda- tion Codebook with Intra-domain and Inter-domain Knowledge Mo deling. arXiv: 2510.07755 [cs.LG] https://ar xiv .org/abs/2510.07755 [49] Hao Y an, Chaozhuo Li, Jun Yin, Zhigang Yu, W eihao Han, Mingzheng Li, Zhengxin Zeng, Hao Sun, and Senzhang W ang. 2025. When graph meets multi- modal: benchmarking and meditating on multimodal attributed graph learning. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2 . 5842–5853. [50] Xiao- Yang Liu Y anglet, Yupeng Cao, and Li Deng. 2025. Multimodal nancial foundation models (MFFMs): Progress, prospects, and challenges. arXiv preprint arXiv:2506.01973 (2025). [51] Minji Y o on, Jing Yu Koh, Bryan Hooi, and Ruslan Salakhutdinov . 2023. Multimodal graph learning for generative tasks. arXiv preprint arXiv:2310.07478 (2023). [52] Hao Zhang, Xunkai Li, Yinlin Zhu, and Lianglin Hu. 2025. Rethinking Federate d Graph Learning: A Data Condensation Perspective. arXiv: 2505.02573 [cs.LG] https://arxiv .org/abs/2505.02573 [53] Jiaqi Zhang, Y u Cheng, Y ongxin Ni, Yunzhu Pan, Zheng Y uan, Junchen Fu, Y ouhua Li, Jie W ang, and Fajie Yuan. 2024. Ninerec: A benchmark dataset suite for evaluating transferable recommendation. IEEE Transactions on Pattern A nalysis and Machine Intelligence (2024). [54] Haoran Zheng, Renchi Yang, Hongtao Wang, and Jianliang Xu. 2025. Cross- contrastive clustering for multimodal attributed graphs with dual graph ltering. arXiv preprint arXiv:2511.20030 (2025). [55] Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Y ang, Zhiyuan Liu, Lifeng W ang, Changcheng Li, and Maosong Sun. 2020. Graph neural networks: A review of methods and applications. AI Open 1 (2020), 57–81. [56] Yinlin Zhu, Miao Hu, and Di W u. 2025. Federate d continual graph learning. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2 . 4203–4213. [57] Yinlin Zhu, Xunkai Li, Jishuo Jia, Miao Hu, Di Wu, and Meikang Qiu. 2025. T owards Eective Federated Graph Foundation Model via Mitigating Knowledge Entanglement. arXiv: 2505.12684 [cs.LG] [58] Yinlin Zhu, Xunkai Li, Zhengyu W u, Di Wu, Miao Hu, and Rong-Hua Li. 2024. Fedtad: T op ology-aware data-free knowledge distillation for subgraph federated learning. arXiv preprint arXiv:2404.14061 (2024). [59] Yinlin Zhu, Di Wu, Xianzhi Zhang, Y uming Ai, Xunkai Li, Miao Hu, and Guocong Quan. 2026. Rethinking Federated Graph Foundation Models: A Graph-Language Alignment-based Approach. arXiv: 2601.21369 [cs.LG] https://arxiv .org/abs/2601. 21369 TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and Topology Co-ev olution XX, XX, XX A Performances on Additional MA G Datasets W e provide evaluations on additional MAG datasets in T able 6 . As observed, TMTE consistently outperforms all baselines on the Grocery , Bili Dance , and RedditS datasets acr oss node classication, link prediction, and node clustering metrics. Specically , for no de classication on Grocery , TMTE improves over the second-best method by +1.96% in Accuracy and +6.36% in F1-score. For link prediction on Bili Dance, it achie ves gains of +2.24% in MRR and +5.98% in Hits@3. In node clustering on Re dditS, TMTE b oosts NMI and ARI by +3.19% and +3.49% compar ed with the next-best approach. These results highlight that, while some multimodal graph methods (e.g., DGF , DMGC) outperform unimodal GNNs on certain tasks, TMTE demonstrates stable and consistent superiority across all datasets and evaluation metrics. B Theoretical Proofs Theorem B.1 (Smooth Fused Represent ations of MA G). For a MAG with fused representation ¯ H = 1 M Í 𝑚 ∈ M H ( 𝑚 ) and a sym- metrically normalize d adjacency matrix of evolved topology Q 𝐸 1 = 𝜆 ˜ A + ( 1 − 𝜆 ) A 𝐸 1 , the smooth fused representations can be approxi- mated as: ˆ H = 1 𝛼 + 1 𝑇 𝑡 = 0 𝛼 𝜆 𝛼 + 1 ˜ A + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 A 𝐸 1 𝑡 ¯ H . (13) Proof. The fused representation that maintains smoothness over the ev olved topology is obtained by minimizing: ˆ H = arg min ˆ H 𝑓 ( ˆ H ) = arg min ˆ H ∥ ˆ H − ¯ H ∥ 2 𝐹 + 𝛼 · tr ˆ H ⊤ ( I − Q 𝐸 1 ) ˆ H , (14) where 𝛼 ∈ ( 0 , 1 ) controls the smoothness strength, and the Lapla- cian regularizer I − Q 𝐸 1 encourages neighboring nodes to have similar embeddings. The delity term ∥ ˆ H − ¯ H ∥ 2 𝐹 ensures that the learned embeddings r emain close to the initial fused representation. Setting 𝜕 𝑓 ( ˆ H ) 𝜕 ˆ H = 0 yields: ˆ H = 1 𝛼 + 1 ( I − 𝛼 𝛼 + 1 Q 𝐸 1 ) − 1 ¯ H . (15) Notably , Q 𝐸 1 is a linear combination of two symmetrically nor- malized adjacency matrices, ˜ A and A 𝐸 1 , with weights summing to 1. Both matrices are symmetric, and their eigenvalues are real and bounded by 1. The maximum eigenvalue of a symmetric matrix can be characterized by the Rayleigh quotient: 𝜆 max ( Q 𝐸 1 ) = max 𝑥 ≠ 0 𝑥 ⊤ Q 𝐸 1 𝑥 𝑥 ⊤ 𝑥 . By convexity of the maximum Rayleigh quotient over symmetric matrices, we have 𝜆 max ( Q 𝐸 1 ) ≤ 𝜆 𝜆 max ( ˜ A ) + ( 1 − 𝜆 ) 𝜆 max ( A 𝐸 1 ) ≤ 1 . Thus, the dominant eigenvalue of Q 𝐸 1 is guaranteed to b e ≤ 1 , ensuring stability in spectral-based operations such as graph convolution. As sho wn in [ 18 ], when the dominant eigenvalue is less than 1, the inverse ( I − Q 𝐸 1 ) − 1 can be expressed as a Neumann series: ( I − Q 𝐸 1 ) − 1 = ∞ 𝑡 = 0 Q 𝐸 1 𝑡 . (16) Truncating the series at 𝑇 steps gives the power series appr oxi- mation: ˆ H = 1 𝛼 + 1 𝑇 𝑡 = 0 𝛼 𝜆 𝛼 + 1 ˜ A + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 A 𝐸 1 𝑡 ¯ H . (17) □ Theorem B.2 (Recursive P ower Exp ansion of Smooth Fused Represent ations). For the smo oth fuse d representation dened in Eq. ( 7 ) , let H ( 0 ) = ¯ H and dene the recursive se quence H ( 𝑡 + 1 ) = 𝛼 𝜆 𝛼 + 1 ˜ A H ( 𝑡 ) + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 A 𝐸 1 H ( 𝑡 ) . Then for any 𝑇 ≥ 0 , the truncate d power series satises ˆ H = 1 𝛼 + 1 Í 𝑇 𝑡 = 0 H ( 𝑡 ) , and each term H ( 𝑡 ) can b e recur- sively compute d without explicitly forming A 𝐸 1 . Proof. Re call from Eq. ( 7 ) that ˆ H = 1 𝛼 + 1 𝑇 𝑡 = 0 𝛼 𝜆 𝛼 + 1 ˜ A + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 A 𝐸 1 𝑡 ¯ H . (18) Dene the linear operator S = 𝛼 𝜆 𝛼 + 1 ˜ A + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 A 𝐸 1 . (19) Let H ( 0 ) = ¯ H , and recursively dene H ( 𝑡 + 1 ) = SH ( 𝑡 ) . W e prove by induction that H ( 𝑡 ) = S 𝑡 ¯ H for all 𝑡 ≥ 0 . (20) Base case: For 𝑡 = 0 , H ( 0 ) = ¯ H = S 0 ¯ H . (21) Inductive step: Assume that H ( 𝑡 ) = S 𝑡 ¯ H . (22) Then H ( 𝑡 + 1 ) = SH ( 𝑡 ) = S ( S 𝑡 ¯ H ) = S 𝑡 + 1 ¯ H . (23) Thus, by mathematical induction, H ( 𝑡 ) = S 𝑡 ¯ H ∀ 𝑡 ∈ 0 , 1 , . . . , 𝑇 . (24) Substituting this result back into the truncated series gives ˆ H = 1 𝛼 + 1 𝑇 𝑡 = 0 H ( 𝑡 ) . (25) Next, we show that each recursive step can be expanded without constructing A 𝐸 1 . By denition, A 𝐸 1 = ∆ 𝐸 1 − 1 R 𝐸 1 Λ 𝐸 1 − 1 R 𝐸 1 ⊤ . Thus, for any H ( 𝑡 ) , A 𝐸 1 H ( 𝑡 ) = ∆ 𝐸 1 − 1 R 𝐸 1 Λ 𝐸 1 − 1 R 𝐸 1 ⊤ H ( 𝑡 ) . Using associativ- ity of matrix multiplication, we regroup terms: A 𝐸 1 H ( 𝑡 ) = ∆ 𝐸 1 − 1 R 𝐸 1 Λ 𝐸 1 − 1 R 𝐸 1 ⊤ H ( 𝑡 ) . (26) Dene Z ( 𝑡 ) U = Λ 𝐸 1 − 1 R 𝐸 1 ⊤ H ( 𝑡 ) , and Z ( 𝑡 ) V = ∆ 𝐸 1 − 1 R 𝐸 1 Z ( 𝑡 ) U . Then Z ( 𝑡 ) V = A 𝐸 1 H ( 𝑡 ) . (27) Therefore, for e very 𝑡 = 0 , 1 , . . . , 𝑇 − 1 , the recursive update H ( 𝑡 + 1 ) = 𝛼 𝜆 𝛼 + 1 ˜ AH ( 𝑡 ) + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 Z ( 𝑡 ) V (28) is algebraically equivalent to H ( 𝑡 + 1 ) = SH ( 𝑡 ) , (29) and thus exactly reproduces the truncated power e xpansion up to order 𝑇 . □ XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu T able 6: Additional performance comparison on Grocery , Bili Dance and RedditS datasets. The best, second b est and third best results are highlighted in red , blue and orange , respectively . T asks Node Classication Link Prediction Node Clustering Grocery Bili Dance RedditS Methods Datasets ACC F1-Score MRR Hits@3 NMI ARI GCN 80 . 19 ± 0 . 30 72 . 25 ± 0 . 43 37 . 50 ± 0 . 22 47 . 30 ± 0 . 50 75 . 15 ± 0 . 25 71 . 08 ± 2 . 43 GCNII 78 . 32 ± 0 . 24 70 . 12 ± 0 . 30 37 . 42 ± 0 . 26 47 . 41 ± 0 . 58 76 . 76 ± 0 . 30 72 . 29 ± 2 . 55 GA T 80 . 22 ± 0 . 37 72 . 38 ± 0 . 46 36 . 74 ± 0 . 31 46 . 62 ± 0 . 34 75 . 32 ± 0 . 27 70 . 98 ± 3 . 48 GA Tv2 80 . 33 ± 0 . 42 73 . 05 ± 0 . 28 37 . 64 ± 0 . 28 47 . 41 ± 0 . 56 77 . 12 ± 0 . 28 72 . 33 ± 2 . 28 MMGCN 82 . 12 ± 0 . 38 74 . 91 ± 0 . 22 38 . 29 ± 0 . 27 48 . 94 ± 0 . 46 77 . 59 ± 0 . 32 72 . 67 ± 2 . 53 MGA T 82 . 48 ± 0 . 42 75 . 43 ± 0 . 34 38 . 96 ± 0 . 33 49 . 19 ± 0 . 58 77 . 31 ± 0 . 29 73 . 14 ± 2 . 52 LGMRec 80 . 06 ± 0 . 39 73 . 21 ± 0 . 49 39 . 55 ± 0 . 27 47 . 62 ± 0 . 51 73 . 41 ± 0 . 61 74 . 02 ± 3 . 34 MLaGA 81 . 52 ± 0 . 36 74 . 83 ± 0 . 32 39 . 14 ± 0 . 88 49 . 82 ± 1 . 34 77 . 69 ± 0 . 33 73 . 12 ± 2 . 64 GraphGPT -O 78 . 27 ± 0 . 21 70 . 72 ± 0 . 55 37 . 22 ± 0 . 48 46 . 54 ± 0 . 24 75 . 42 ± 0 . 61 71 . 15 ± 3 . 04 Graph4MM 79 . 36 ± 0 . 24 72 . 15 ± 0 . 28 38 . 48 ± 0 . 24 47 . 45 ± 0 . 31 75 . 28 ± 0 . 14 70 . 47 ± 1 . 88 InstructG2I 80 . 42 ± 0 . 28 73 . 54 ± 0 . 20 39 . 12 ± 0 . 39 49 . 83 ± 0 . 27 75 . 36 ± 0 . 52 71 . 42 ± 2 . 18 DMGC 81 . 55 ± 0 . 40 71 . 32 ± 0 . 48 41 . 37 ± 0 . 26 55 . 63 ± 0 . 19 79 . 31 ± 0 . 32 75 . 10 ± 3 . 14 DGF 82 . 22 ± 0 . 15 74 . 24 ± 0 . 57 39 . 80 ± 0 . 32 50 . 10 ± 0 . 35 78 . 50 ± 0 . 30 74 . 47 ± 2 . 55 MIG-GT 80 . 88 ± 0 . 41 72 . 26 ± 0 . 39 37 . 82 ± 0 . 44 48 . 31 ± 0 . 69 76 . 34 ± 0 . 42 71 . 58 ± 2 . 73 NTSFormer 81 . 85 ± 0 . 30 74 . 10 ± 0 . 32 38 . 73 ± 0 . 34 49 . 27 ± 0 . 49 77 . 25 ± 0 . 32 72 . 81 ± 2 . 46 UniGraph2 80 . 52 ± 0 . 36 72 . 19 ± 0 . 43 37 . 47 ± 0 . 32 47 . 78 ± 0 . 38 75 . 92 ± 0 . 44 71 . 84 ± 2 . 58 TMTE (Ours) 84 . 18 ± 0 . 30 80 . 80 ± 0 . 45 43 . 61 ± 0 . 24 60 . 61 ± 0 . 31 82 . 28 ± 0 . 21 78 . 59 ± 1 . 44 Theorem B.3 (St ability under inexact large-scale prop - aga tion). Assume the practical recursion on large-scale graphs is computed inexactly: e H ( 𝑡 + 1 ) = S e H ( 𝑡 ) + E ( 𝑡 ) , e H ( 0 ) = ¯ H , (30) where ∥ E ( 𝑡 ) ∥ 𝐹 ≤ 𝜀 𝑡 . Under the assumptions of Theorem B.4 , ∥ e H ( 𝑡 ) − H ( 𝑡 ) ∥ 𝐹 ≤ 𝑡 − 1 𝑘 = 0 𝛽 𝑡 − 1 − 𝑘 𝜀 𝑘 . (31) In particular , if 𝜀 𝑘 ≤ ¯ 𝜀 for all 𝑘 , then sup 𝑡 ∥ e H ( 𝑡 ) − H ( 𝑡 ) ∥ 𝐹 ≤ ¯ 𝜀 1 − 𝛽 , (32) which gives a uniform stability guarantee. Proof. Let D ( 𝑡 ) : = e H ( 𝑡 ) − H ( 𝑡 ) . Then D ( 𝑡 + 1 ) = SD ( 𝑡 ) + E ( 𝑡 ) , D ( 0 ) = 0 . (33) Unrolling recursion yields D ( 𝑡 ) = 𝑡 − 1 𝑘 = 0 S 𝑡 − 1 − 𝑘 E ( 𝑘 ) . (34) Therefore, ∥ D ( 𝑡 ) ∥ 𝐹 ≤ 𝑡 − 1 𝑘 = 0 ∥ S ∥ 𝑡 − 1 − 𝑘 2 ∥ E ( 𝑘 ) ∥ 𝐹 ≤ 𝑡 − 1 𝑘 = 0 𝛽 𝑡 − 1 − 𝑘 𝜀 𝑘 . (35) If 𝜀 𝑘 ≤ ¯ 𝜀 , then ∥ D ( 𝑡 ) ∥ 𝐹 ≤ ¯ 𝜀 𝑡 − 1 𝑗 = 0 𝛽 𝑗 ≤ ¯ 𝜀 1 − 𝛽 . (36) □ Theorem B.4 (Contra ction, uniqeness, and convergence ra te on large-scale graphs). Let S = 𝛼 𝜆 𝛼 + 1 ˜ A + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 A 𝐸 1 , 𝛽 : = 𝛼 𝛼 + 1 ∈ ( 0 , 1 ) , (37) and assume ∥ ˜ A ∥ 2 ≤ 1 and ∥ A 𝐸 1 ∥ 2 ≤ 1 (true for symmetric normal- ized adjacency operators). Then: ∥ S ∥ 2 ≤ 𝛽 < 1 , (38) so ( I − S ) is invertible and the smooth fused representation ˆ H ★ = 1 𝛼 + 1 ( I − S ) − 1 ¯ H (39) is unique. Moreover , for the recursion H ( 𝑡 + 1 ) = SH ( 𝑡 ) with H ( 0 ) = ¯ H , ˆ H ★ − 1 𝛼 + 1 𝑇 𝑡 = 0 H ( 𝑡 ) 𝐹 ≤ 𝛽 𝑇 + 1 ( 𝛼 + 1 ) ( 1 − 𝛽 ) ∥ ¯ H ∥ 𝐹 , (40) i.e., the truncation error decays geometrically . Proof. By triangle ine quality and sub-multiplicativity , ∥ S ∥ 2 ≤ 𝛼 𝜆 𝛼 + 1 ∥ ˜ A ∥ 2 + 𝛼 ( 1 − 𝜆 ) 𝛼 + 1 ∥ A 𝐸 1 ∥ 2 ≤ 𝛼 𝛼 + 1 = 𝛽 < 1 . (41) Hence 𝜌 ( S ) ≤ ∥ S ∥ 2 < 1 , so Neumann series applies: ( I − S ) − 1 = ∞ 𝑡 = 0 S 𝑡 , (42) and ˆ H ★ is unique. Also, ˆ H ★ − 1 𝛼 + 1 𝑇 𝑡 = 0 H ( 𝑡 ) = 1 𝛼 + 1 ∞ 𝑡 = 𝑇 + 1 S 𝑡 ¯ H . (43) T aking Frobenius norm and using ∥ S 𝑡 ¯ H ∥ 𝐹 ≤ ∥ S ∥ 𝑡 2 ∥ ¯ H ∥ 𝐹 ≤ 𝛽 𝑡 ∥ ¯ H ∥ 𝐹 , ˆ H ★ − 1 𝛼 + 1 𝑇 𝑡 = 0 H ( 𝑡 ) 𝐹 ≤ 1 𝛼 + 1 ∞ 𝑡 = 𝑇 + 1 𝛽 𝑡 ∥ ¯ H ∥ 𝐹 = 𝛽 𝑇 + 1 ( 𝛼 + 1 ) ( 1 − 𝛽 ) ∥ ¯ H ∥ 𝐹 . (44) □ C Pseudocode of TMTE W e provide the detailed procedure for TMTE in Algorithm 1 . TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and Topology Co-ev olution XX, XX, XX Algorithm 1: O verall Procedure of TMTE Input: MAG G = ( V , E , { X ( 𝑚 ) } 𝑚 ∈ M ) ; anchor size | U | ; maximum epochs 𝐸 ; threshold 𝛿 . Output: Fused embedding ˆ H and modality embeddings { H ( 𝑚 ) } . /* Initialization */ 1 initialize model parameters; 2 compute normalized original adjacency ˜ A ; 3 for 𝑒 = 1 to 𝐸 do /* Anchor Resampling */ 4 randomly sample anchor set U ⊆ V ; /* Step 1: Topology Evolution from Original Modality Space */ 5 compute node-anchor anity matrix R 𝐸 1 using { X ( 𝑚 ) } via Eqs. ( 1 – 2 ); 6 construct implicit topology Q 𝐸 1 = 𝜆 ˜ A + ( 1 − 𝜆 ) A 𝐸 1 ; /* Step 2: Modality Evolution */ 7 compute modality embeddings { H ( 𝑚 ) } via Eq. ( 5 ); 8 compute fused embedding ˆ H 𝐸 1 via Eq. ( 7 ) using Q 𝐸 1 ; /* Step 3: Task-aware Co-evolution */ 9 set 𝑘 = 2 ; 10 while 𝑘 ⩽ 𝑇 and ∥ R 𝐸 𝑘 − R 𝐸 𝑘 − 1 ∥ 2 𝐹 ∥ R 𝐸 𝑘 ∥ 2 𝐹 > 𝛿 do 11 update node-anchor anity R 𝐸 𝑘 + 1 using { H ( 𝑚 ) } ; 12 update topology Q 𝐸 𝑘 + 1 ; 13 update modality embeddings H ( 𝑚 ) ; 14 update fused embedding ˆ H 𝐸 𝑘 + 1 ; 15 optimize objective L = L 𝑚𝑜𝑑 + 𝜂 L 𝑡 𝑎𝑠 𝑘 ; 16 𝑘 ← 𝑘 + 1 ; 17 end 18 end 19 return ˆ H , { H ( 𝑚 ) } ; D Detailed Exp erimental Setups Empirical Study Details. For the Modality-optimized T opology set- ting, we compute cross-modality similarity between two nodes on the T oys dataset and select the top-5 similar nodes to connect e dges, which can provide semantic-related knowledge for the G2Image task. T ask Objective Details. As TMTE is designed to leverage the downstream task optimization objective to guide the co-ev olution between topology and modality (Eq. ( 10 ) ), we select dierent loss functions L loss for dierent tasks. Specically , for node classica- tion, we adopt the cross-entropy loss; for link prediction, we adopt the binary cross-entropy loss; for no de clustering, we adopt the community-aware (i.e., cluster ) cross-modality contrastive loss pro- posed in DGF [ 54 ]. For the three modality-centric tasks, we adopt the cross-modality contrastive loss as the loss function. Algorithm Hyp erparameters. For our proposed TMTE, we x the topology evolution trade-o 𝜆 to 0 . 8 for all datasets and tasks. The number of perspe ctives 𝐾 is searched within [ 1 , 2 , 4 , 8 , 16 , 32 ] , the hidden dimension of the similarity metric learning is searched within [ 32 , 64 , 128 , 256 , 512 ] , smoothness rate 𝛼 is searched within [ 10 − 2 , 10 − 1 , 1 , 10 , 100 ] , the maximum evolution rounds are xed to 10 , the stop-evolution threshold 𝜂 is searched within [ 1 × 10 − 6 , 1 × 10 − 5 ] , the truncation step 𝑇 is xed to 10 , and the modality evolu- tion trade-o 𝜂 is searched within [ 10 − 3 , 10 − 2 , 10 − 1 ] . For the base- lines, we adopt the hyperparameter congurations reported in their original papers whenever available. When unspecied, we employ automated hyperparameter optimization using the Optuna frame- work [ 2 ]. T ask Hyperparameters and Metrics. T o ensure a fair comparison across diverse MA G learning models, w e employ unied experimen- tal protocols for three graph-centric downstream tasks: super vised node classication, supervise d link prediction, and unsupervised node clustering. For node classication and clustering, we set the learning rate to 5 × 10 − 3 , with a batch size of 512 and weight decay of 1 × 10 − 5 . Node classication is trained for 100 epochs, which is suf- cient for convergence, while node clustering is optimized for 500 epochs to stabilize the self-sup ervised objective. For link prediction, we adopt a learning rate of 1 × 10 − 3 and increase the batch size to 2048 to eciently accommodate large-scale edge-pair samples. T o ensure architectural consistency , we use Qwen2- VL-7B-Instruct [ 3 ] as a frozen feature enco der and x the feature dimensionality to 768 across all tasks. Each experiment is r epeated three times with dierent random seeds, and we report the mean performance to mitigate variance due to initialization. Node Classication is a super vised task where each node in a MAG is encoded into a low-dimensional embe dding, followed by a projection head and a Softmax layer to produce class prob- abilities. The model is optimized via cross-entropy loss against ground-truth lab els. Performance is evaluated using Accuracy (Acc) and F1-score. Specically , Acc = 1 𝑁 Í 𝑁 𝑖 = 1 I ( ˆ 𝑦 𝑖 = 𝑦 𝑖 ) , where 𝑁 is the sample size, 𝑦 𝑖 the ground-truth label, ˆ 𝑦 𝑖 the prediction, and I ( ·) the indicator function. The F1-score, dened as F1 = 2 ( · Precision · Recall ) / ( Precision + Recall ) , captures robustness un- der class imbalance. Link Prediction evaluates the ability to infer missing or p otential edges. The model assigns similarity scores (e.g., dot product) to node pairs, encouraging higher scores for positive edges than neg- atives. In multimodal graphs, this requires aligning structural prox- imity with cross-modal semantics. W e adopt ranking-based met- rics: Mean Reciprocal Rank (MRR) and Hits@K. Formally , MRR = 1 | 𝑄 | Í | 𝑄 | 𝑖 = 1 1 rank 𝑖 , where rank 𝑖 is the rank of the rst correct target for query 𝑖 . Hits@K = 1 | 𝑄 | Í | 𝑄 | 𝑖 = 1 I ( rank 𝑖 ≤ 𝐾 ) measures recall at cuto 𝐾 . Node Clustering assesses representation quality in an unsuper- vised setting following [ 15 ]. The model disentangles homophilous and heterophilous views, fuses dual-frequency signals, and is trained with a joint objective comprising reconstruction, contrastive, and clustering losses. Performance is measured by NMI and ARI. NMI ( 𝑌 , 𝐶 ) = 2 · 𝐼 ( 𝑌 , 𝐶 ) / ( 𝐻 ( 𝑌 ) + 𝐻 ( 𝐶 ) ) quanties mutual dependence between predicted clusters 𝐶 and ground-truth labels 𝑌 . ARI is computed as: ARI = Í 𝑖 𝑗 𝑛 𝑖 𝑗 2 − [ Í 𝑖 𝑎 𝑖 2 Í 𝑗 𝑏 𝑗 2 ] / 𝑛 2 1 2 [ Í 𝑖 𝑎 𝑖 2 + Í 𝑗 𝑏 𝑗 2 ] − [ Í 𝑖 𝑎 𝑖 2 Í 𝑗 𝑏 𝑗 2 ] / 𝑛 2 , (45) where 𝑛 𝑖 𝑗 denotes the overlap between ground-truth cluster 𝑖 and predicted cluster 𝑗 . Modality Retrieval projects queries and candidates from dierent modalities into a shared latent space and ranks them by similarity . W e optimize a contrastive objective with temperature 𝜏 = 0 . 07 , train for 500 ep ochs using learning rate 1 × 10 − 3 and batch size 256, and apply early stopping with patience 10–25 epochs. Evaluation uses MRR and Hits@K. Graph-to- T ext (G2T ext) generates textual descriptions condi- tioned on multimodal graph inputs. Following MMGL [ 51 ], the XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu pipeline includes: (1) neighbor enco ding into a unied embe dding space; (2) graph structure encoding via GNNs or Laplacian posi- tional encodings; and (3) integration into a pre-trained LLM. W e train with learning rate 1 × 10 − 3 , weight decay 1 × 10 − 2 , batch size 8 for 15 ep ochs. SA -E samples four multimodal neighb ors, and GNNs encode structure. The decoder backbone is Facebook OPT - 125M, adapted via Prex T uning or LoRA ( 𝑟 = 64 ). Performance is measured by BLEU-4, ROUGE-L, and CIDEr . Spe cically , BLEU-4 evaluates lexical accuracy and uency by calculating the geometric mean of modied 𝑛 -gram precisions ( 𝑝 𝑛 ) up to length 4: BLEU-4 = BP · exp 4 𝑛 = 1 𝑤 𝑛 log 𝑝 𝑛 ! . (46) ROUGE-L measures sentence-le vel recall based on the longest com- mon subsequence, ensuring the output covers the compr ehensive information content of the ground truth: ROUGE-L = ( 1 + 𝛽 2 ) 𝑅 𝑙 𝑐 𝑠 𝑃 𝑙 𝑐 𝑠 𝑅 𝑙 𝑐 𝑠 + 𝛽 2 𝑃 𝑙 𝑐 𝑠 . (47) CIDEr measur es the consensus between generated captions and hu- man references using TF-IDF weighting, emphasizing the semantic importance and distinctiveness of the generated terms: CIDEr ( 𝑐 , 𝑟 ) = 1 𝑀 𝑀 𝑖 = 1 𝑔 𝑛 ( 𝑐 ) · 𝑔 𝑛 ( 𝑟 𝑖 ) | 𝑔 𝑛 ( 𝑐 ) | | 𝑔 𝑛 ( 𝑟 𝑖 ) | . (48) Graph-to-Image (G2Image) synthesizes images conditioned on MA G. Following InstructG2I [ 23 ], we adopt: (1) semantic PPR-based sampling (0–6 neighbors); (2) Graph-QFormer enco ding; and (3) latent diusion with graph classier-free guidance. T raining uses learning rate 1 × 10 − 4 , batch size 16 for 20 epochs, and image res- olution 256. Evaluation employs CLIP-Score and DINO v2-Score. Specically , CLIP-Score quanties cross-modal semantic consis- tency . Building upon the textual encoder ( 𝐸 𝑇 ) and visual encoder ( 𝐸 𝐼 ) in pre-trained CLIP, this metric determines whether generated images faithfully preserve the semantic content of corresponding graph descriptions: CLIP-Score ( 𝐼 , 𝑇 ) = max ( 100 · cos ( 𝐸 𝐼 ( 𝐼 ) , 𝐸 𝑇 ( 𝑇 ) ) , 0 ) . (49) DINOv2-Score assesses visual delity and structural consistency using feature embeddings from a pre-trained DINOv2 enco der , ensuring high perceptual quality and structural resemblance to reference samples: DINOv2-Score ( 𝐼 gen , 𝐼 ref ) = cos ( DINO ( 𝐼 gen ) , DINO ( 𝐼 ref ) ) . (50) E Experimental Environment Experiments are conducted on a workstation equipped with Intel Xeon Scalable processors and NVIDIA RTX 6000 Ada Generation GP Us with 96 GB of VRAM, supporte d by 256 GB of system RAM. The computational environment utilizes CUD A 12.9, while softwar e implementations are developed using Python 3.10.18 and Py T orch 2.8. F Dataset Details Detailed statistical information on the datasets is presented in T a- ble 7 , with textual descriptions as follows. Movies [ 31 ] is sourced from Amazon’s Movies and TV categor y . Nodes correspond to D VD/Blu-ray products, and edges reect con- sumer co-purchasing behavior . Node attributes include textual plot synopses and customer reviews, alongside visual features derived from ocial cover art. Grocery [ 31 ] is sourced from Amazon’s Grocery and Gourmet Food category . Nodes are foo d and household products, and edges indi- cate complementary purchasing habits derived from ”also-bought” lists. T extual attributes are encoded from product titles and nu- tritional descriptions, while visual attributes are extracted from packaging images. This dataset is primarily utilized for Node Clas- sication, where labels correspond to ne-grained product sub- categories (e.g., Be verages, Snacks). D Y [ 53 ] is sourced from Douyin, a leading short-vide o platform. The graph contains short-video no des linked by co-interaction pat- terns (e.g., liked by the same user). Given the multimodal nature of short videos, textual features are constructed from user captions and hashtags, while visual features are extracted from vide o frames, capturing the fast-paced visual dynamics typical of the platform. Preprocessing involv ed ltering low-frequency items to maintain graph connectivity . This dataset is primarily utilized for Link Pre- diction tasks. Bili Dance [ 53 ] originates from the dance section of Bilibili. No des represent dance performance or tutorial videos. Co-viewing edges capture the trend similarity or sequential learning patterns of vie w- ers (e .g., users watching consecutive tutorials). T extual attributes are derived from dense video descriptions and hashtags, while visual attributes are obtained from keyframes of the dance movements to encode choreographic dynamics. This dataset is primarily utilized for Link Prediction tasks. T oys [ 31 ] originates from Amazon’s T oys and Games category . The graph connects toy product nodes via co-purchasing edges. T extual features are derived from product sp ecications and age recommendations, and visual features are obtained from pr oduct photos to identify visual variants. This dataset is primarily utilize d for Node Classication, where labels represent specic toy types or game genres. RedditS [ 8 ] is a so cial network from Reddit where nodes r epresent posts and edges denote threading relationships (e.g., comments and replies). T extual features are encode d from titles and body content, while visual features are extracted from emb edded images. This dataset is primarily used for node classication and node clustering. Ele-fashion [ 19 , 31 ] is a heterogeneous graph merging Amazon’s Electronics and Fashion categories. Nodes are connected via cross- category co-purchasing links, revealing latent consumer prefer- ences across disparate domains. Features combine technical specs with style descriptions and product imagery . Flickr30k [ 35 ] is a canonical image-text reasoning dataset. In the OpenMAG setting, we construct a graph where nodes represent image regions and caption phrases, linked by semantic grounding annotations. This dataset is utilize d for Graph-to- T ext (G2T ext) tasks, evaluating the mo del’s ability to generate descriptive captions by traversing grounded visual-textual relationships. SemArt [ 13 ] is a ne-art dataset where nodes represent paint- ings and edges are established based on shared metadata such as artist, period, or school. Node features include expert historical TMTE: Eective Multimodal Graph Learning with T ask-aware Modality and Topology Co-ev olution XX, XX, XX T able 7: The statistical information of the experimental datasets. Datasets # Modalities # Nodes # Edges # Classes Domain Movies T ext, Image 16,672 218,390 20 Movie Network Grocery T ext, Image 17,074 171,340 20 E-Commerce Network D Y T ext, Image 8,299 35,627 - Vide o Network Bili Dance T ext, Image 2,307 9,127 - Vide o Network T oys T ext, Image 20,695 126,886 18 E-Commerce Network RedditS T ext, Image 15,894 566,160 20 Social Network Ele-fashion T ext, Image 97,766 199,602 12 Co-purchase Network Flickr30k T ext, Image 31,783 181,151 - Image Netw ork SemArt T ext, Image 21,382 1,216,432 - Art Network MVSA T ext, Image 2,122 17,790 2 KNN Sentiment Graph commentary and stylistic visual attributes from digital images. Se- mArt serves as a benchmark for Graph-to-Image (G2Image) tasks, requiring the reconciliation of abstract historical descriptions with complex visual aesthetics. MVSA [ 33 ] is a multi-view sentiment analysis dataset where each sample consists of a paired image and its corresponding tweet text collected from T witter . The dataset is designed to facilitate research on multimodal sentiment classication, where the goal is to predict users’ attitudes (e.g., positive , negative, or neutral) by jointly mod- eling visual and textual information. Notably , since the sentiment labels corresponding to images and text may dier , we only retain samples where both the image and text are simultane ously negative or simultaneously positive, thus constituting a binary classication task. Furthermore, we calculate the similarity between samples based on the average of the image and te xt modality embeddings, constructing a KNN graph ( 𝐾 = 5 ). G Baseline Details GCN [ 24 ] employs a rst-order appr oximation of spectral convo- lutions combined with a renormalization te chnique. It performs message passing in a lay er-wise manner , producing node embed- dings that jointly reect the local graph top ology and node features, with computation cost scaling linearly with the number of edges. GCNII [ 6 ] enhances standard GCNs by introducing initial residual connections and identity mapping. These additions implicitly sim- ulate lazy random walks, mitigating over-smoothing and enabling deeper network architectures without sacricing representation quality . GA T [ 40 ] leverages self-attention on graph nodes to compute learn- able weights for each neighbor during aggregation. This mechanism allows the network to dierentiate the importance of neighboring nodes, thereby capturing diverse local structur es without relying on a xed Laplacian matrix. GA T v2 [ 4 ] extends GA T by introducing a dynamic attention func- tion that rearranges operations in the attention computation. This adjustment enhances the model’s expressive pow er , enabling it to better approximate complex functions and remain robust against noisy or irrelevant edges. MMGCN [ 44 ] introduces a multimodal framework for micro-video recommendation by modeling user prefer ences across visual, acous- tic, and textual channels. It builds separate modality-specic bi- partite graphs, captures high-or der interactions within each, and fuses them via a structured integration layer , eectively reecting user-item dynamics in each sensory modality . MGA T [ 39 ] applies gated attention over parallel multimo dal in- teraction graphs for personalized recommendation. By adaptively weighting dierent modalities, it disentangles ne-grained user interests and lters out noisy or conicting signals, enhancing preference modeling robustness. MLaGA [ 11 ] enables LLMs to reason ov er MA Gs through a two- stage alignment process. It rst aligns visual and textual embed- dings with graph structures using contrastive pre-training, and then performs instruction tuning to inject graph connectivity priors into the model’s generative reasoning. LGMRec [ 14 ] is a multimodal recommender that models both lo- cal and global user interests through graph learning. It separates collaborative and multimodal signals in user embeddings and ad- dresses sparsity in local interest modeling. A lo cal graph embe dding module learns collaborative and modality-specic emb eddings in- dependently , while a global hyp ergraph module captures overall dependencies among users and items. Combining these decouple d local and global embeddings improves recommendation accuracy and robustness. GraphGPT -O [ 12 ] is a multimodal LLM for joint understanding and generation over MA Gs. It addresses non-Euclidean dependencies and scalability by combining personalized PageRank sampling with a hierarchical alignment mechanism that links node- and graph- level repr esentations to the LLM semantic space. Graph4MM [ 32 ] integrates multi-hop structural cues into atten- tion via a hop-diused strategy . A dedicated MM-QFormer per- forms cross-modal fusion, demonstrating that incorp orating graph topology as an activ e interaction modality outperforms approaches treating it only as auxiliary input. InstructG2I [ 23 ] presents a graph-conditioned diusion model for MA Gs. It constructs contextual prompts through semantic neigh- bor sampling and encodes them with a Graph-QFormer , oering controllable generation via a graph-aware classier-free guidance mechanism. XX, XX, XX Yinlin Zhu, Xunkai Li, Di Wu, W ang Luo, Miao Hu, Di Wu DMGC [ 15 ] models hybrid neighborhood patterns by separating cross-modality homophily-enhanced components from modality- specic heterophily-aware ones. Its dual-frequency fusion mech- anism acts as coupled low- and high-pass lters, capturing b oth intra-class smoothness and inter-class distinctions simultaneously . DGF [ 54 ] proposes cross-contrastive clustering with dual graph ltering to denoise MAG features. A tri-cross contrastiv e objective across modalities, neighborhood structures, and semantic com- munities enables learning of discriminative and robust clustering representations. MIG-GT [ 22 ] uses modality-independent GNNs with adaptive re- ceptive elds to handle diverse propagation needs and noise levels. It complements local aggregation with a sampling-based global transformer to capture long-range semantic dependencies that con- ventional message passing may miss. N TSFormer [ 21 ] introduces a self-teaching graph transformer for cold-start node classication. A stochastic attention mask su- pervises student predictions (self-information only) with teacher predictions (neighbor-aware), ensuring stable performance when structural links or attributes are partially missing. UniGraph2 [ 17 ] is a cross-domain graph foundation model inte- grating multiple modalities into a shared embe dding space. It com- bines frozen pre-trained encoders with a mixture-of-experts module for alignment, followed by a universal GNN for structure-aware aggregation, producing transferable representations for diverse downstream tasks. H Limitations and Broader Impact. Limitations. Our framework primarily focuses on modality-topology co-evolution grounded in graph signal pr ocessing theor y . Integra- tion of TMTE with existing advance d MGL metho ds is not ex- plored and may require additional adaptation. Moreover , while the anchor-based mechanism of TMTE improves scalability , eciency on ultra-large multimodal relational datasets remains to be vali- dated, beneting from distribute d learning (e.g., federated graph learning [ 48 , 52 ]) in future work. Broader Impacts. TMTE oers a generalizable paradigm for learn- ing task-specic graph structures in multimo dal settings. By reduc- ing reliance on manually curated or task-agnostic topologies, TMTE may enable more robust and adaptiv e multimodal graph learning in practical applications, potentially promoting fairer and more ecient MA G-based AI systems in domains such as healthcare, education, and social ser vices.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment