Low-Rank Adaptation Reduces Catastrophic Forgetting in Sequential Transformer Encoder Fine-Tuning: Controlled Empirical Evidence and Frozen-Backbone Representation Probes
Sequential fine-tuning of pretrained language encoders often overwrites previously acquired capabilities, but the forgetting behavior of parameter-efficient updates remains under-characterized. We present a controlled empirical study of Low-Rank Adap…
Authors: Ashish P, ey
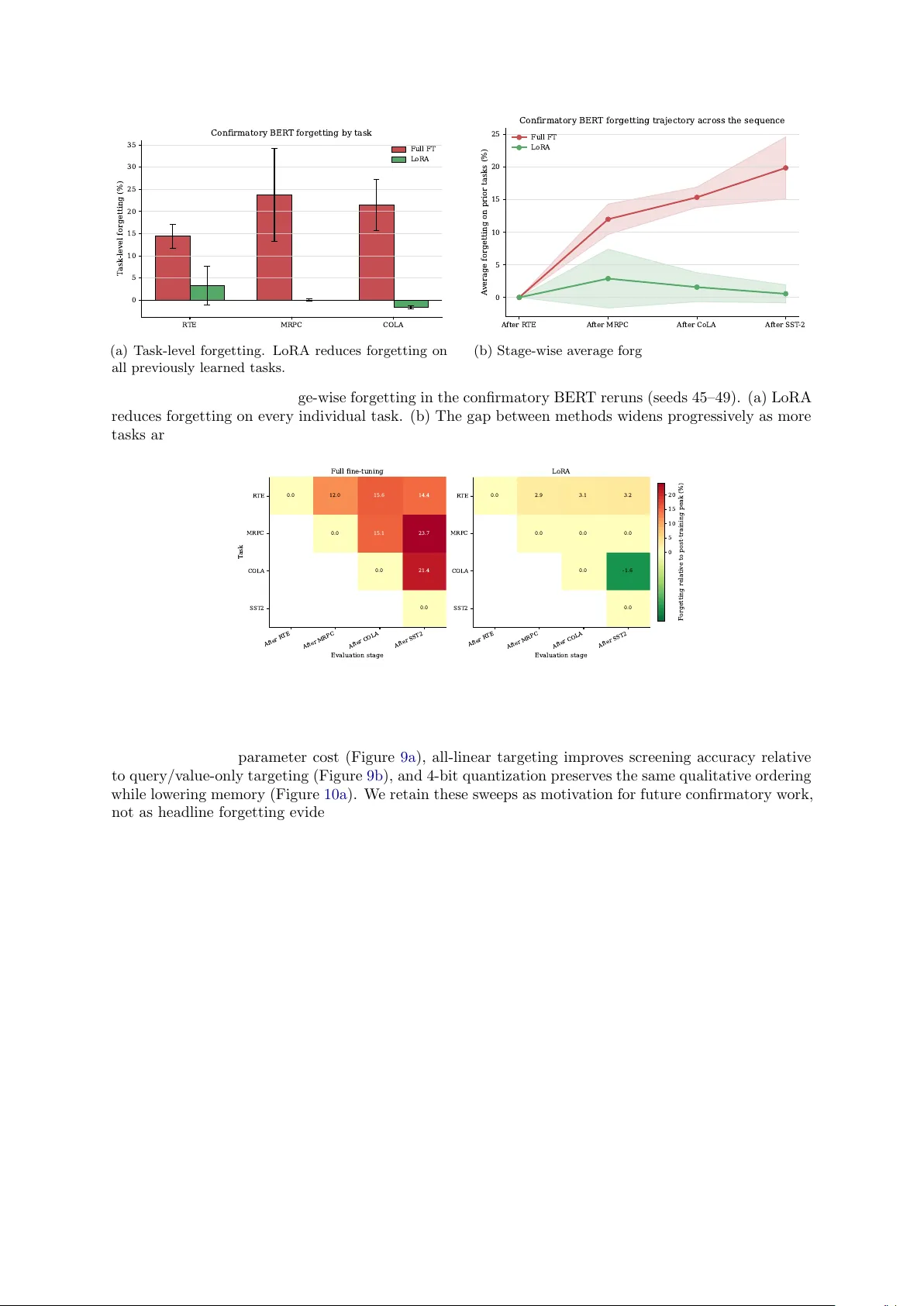
Lo w-Rank Adaptation Reduces Catastrophic F orgetting in Sequen tial T ransformer Enco der Fine-T uning Con trolled Empirical Evidence and F rozen-Bac kb one Represen tation Prob es Ashish P andey ashishpanday9818@gmail.com Marc h 2026 Abstract Sequen tial fine-tuning of pretrained language enco ders often ov erwrites previously acquired capabil- ities, but the forgetting b eha vior of parameter-efficient updates remains under-characterized. W e presen t a con trolled empirical study of Lo w-Rank Adaptation (LoRA) in sequen tial transformer enco der fine-tuning together with companion representation prob es that test a frozen-backbone ex- planation of its robustness. In five full-v alidation BER T-base reruns on an R TE → MRPC → CoLA → SST-2 sequence, full fine-tuning yields 19 . 9% ± 4 . 8% av erage forgetting, whereas standard LoRA ( r = 8, query/v alue mo dules) yields 0 . 6% ± 1 . 4% (paired t -test, p = 0 . 002, Cohen’s d z = 3 . 12). T ask- lev el analyses show that this reduction is not merely an aggregate effect. Secondary full-v alidation exp erimen ts on RoBER T a-base sho w the same qualitative pattern, and the strongest Elastic W eight Consolidation baseline remains at 15 . 5% ± 1 . 4% forgetting. A six-task extension reveals that low a v erage forgetting can still hide strong task-level heterogeneit y , especially on MRPC. Fine-grained freezing ablations show a marked forgetting drop once frozen parameters exceed roughly 95%, with classifier-only and shallow-adapter baselines approac hing standard LoRA. Companion task-similarity prob es in GPT-2 and RoBER T a then sho w the same directional story in represen tation space: frozen- bac kb one regimes preserve substan tially higher inter-task similarit y than full fine-tuning, gradual unfreezing weak ens that stability , and full fine-tuning exhibits its clearest lay er-wise divergence at the final transformer lay er. T aken together, these results supp ort a restrained mechanistic inter- pretation: LoRA app ears to help largely b ecause strong backbone freezing preserves a more stable shared feature scaffold than full fine-tuning. W e therefore p osition standard LoRA as b oth a strong empirical baseline for sequential enco der adaptation and a useful prob e of how selective plasticity shap es in terference in transformer con tin ual learning. Keyw ords: Catastrophic forgetting · Contin ual learning · Low-rank adaptation · Parameter-efficien t fine-tuning · T ransformer enco ders · T ask-in v ariant representations 1 In tro duction Catastrophic forgetting—the tendency of neural netw orks to o verwrite previously learned representations when trained on new tasks—remains one of the most persistent obstacles to deplo ying pretrained language mo dels in sequen tial adaptation settings [ 13 ]. When a pretrained enco der fine-tuned on T ask A is subsequen tly fine-tuned on T ask B, the shared parameters shift tow ard B at the cost of A, pro ducing measurable accuracy regressions that comp ound with each additional task. The difficulty is structural. F ull fine-tuning grants the optimizer unrestricted access to all mo del pa- rameters, and nothing in the standard training ob jective p enalizes interference with previously learned represen tations. Classical con tinual-learning remedies—EW C [ 4 ], repla y buffers [ 11 ], progressive architec- tures [ 15 ]—eac h in tro duce explicit an ti-forgetting mac hinery , but they also add h yp erparameters, storage o v erhead, or architectural complexity that limits practical adoption. P arameter-efficien t fine-tuning (PEFT) metho ds suc h as LoRA [ 3 ] freeze the pretrained backbone and learn lo w-rank updates in a small trainable subspace. This frozen-bac kb one design implicitly restricts the degrees of freedom av ailable to the optimizer, raising a natural question: do es constraining the trainable subspace alone materially reduce catastrophic forgetting, even without any contin ual-learning-sp ecific algorithm? Despite the rapid adoption of LoRA v ariants in contin ual-learning pip elines [ 8 , 19 , 25 ], no 1 prior study isolates this question under a controlled empirical proto col that cleanly separates confirmatory evidence from exploratory screening—nor connects the empirical finding to a mechanistic explanation grounded in representation stability . W e address this gap with a controlled empirical study that measures catastrophic forgetting un- der standard LoRA v ersus full fine-tuning in sequen tial transformer enco der adaptation, together with companion representation prob es that test a frozen-bac kb one explanation. Our design enforces strict proto col separation: the headline result derives exclusively from five full-v alidation BER T-base reruns, while earlier screening sweeps and secondary exp eriments are rep orted transparen tly as supp orting—not confirmatory—evidence. Con tributions. • Confirmatory forgetting reduction. In fiv e paired BER T-base reruns under a consistent full- v alidation proto col, standard LoRA ( r = 8, query/v alue) reduces av erage forgetting from 19 . 9% ± 4 . 8% to 0 . 6% ± 1 . 4%—a 97 . 2% relative reduction (paired t -test, p = 0 . 002, Cohen’s d z = 3 . 12). • Multi-lev el robustness evidence. T ask-level breakdowns, a RoBER T a-base replication, an EWC baseline comparison, and a six-task extension collectively show that the reduction is not confined to a single aggregate statistic, mo del, or task sequence—though it is not uniform across all tasks. • F reezing–forgetting mechanism link. A fine-grained freezing ablation reveals a sharp transition: forgetting drops markedly once more than ∼ 95% of parameters are frozen, linking the main result to the size of the trainable subspace rather than to any LoRA-sp ecific inductive bias. • Represen tation-lev el evidence. Companion task-similarity prob es in GPT-2 and RoBER T a sho w that frozen-backbone regimes preserv e substan tially higher inter-task similarity than full fine-tuning, with gradual unfreezing systematically degrading that stability (Figure 1 ). • Protocol transparency as methodology . By explicitly separating confirmatory , secondary , and exploratory evidence tiers, we demonstrate a rep orting template that prev en ts mixed-proto col o v erclaiming—a common pitfall in sequential fine-tuning studies. The nov elty of this pap er is therefore metho dological and interpretiv e rather than algorithmic. W e do not prop ose a new contin ual-learning metho d. Instead, we pro vide a tightly audited estimate of ho w muc h standard LoRA reduces forgetting under one consistent proto col, then use freezing-based comparisons and representation prob es to narrow the b est-supp orted explanation for that reduction. 2 Related W ork 2.1 Catastrophic F orgetting and Con tinual Learning Catastrophic forgetting has b een studied for decades [ 13 ]. Classical mitigation strategies include reg- ularization metho ds such as Elastic W eigh t Consolidation (EWC) [ 4 ], Synaptic Intelligence [ 22 ], and Learning without F orgetting [ 7 ]; replay-based metho ds such as Gradient Episo dic Memory and exem- plar repla y [ 11 , 14 ]; and architectural metho ds suc h as Progressiv e Net w orks and parameter-isolation sc hemes [ 12 , 15 ]. These approac hes pro vide strong baselines but t ypically require either explicit contin ual- learning ob jectives, task-sp ecific storage, or architectural changes—lea ving op en the question of whether implicit structural constrain ts, suc h as freezing most parameters, can achiev e comparable forgetting reduction without dedicated anti-forgetting machinery . 2.2 P arameter-Efficient Fine-T uning PEFT metho ds adapt pretrained mo dels while up dating a small num b er of task-sp ecific parameters. LoRA [ 3 ] is the most widely used lo w-rank approac h. Subsequen t v arian ts include AdaLoRA [ 24 ], DoRA [ 9 ], RS-LoRA [ 5 ], and quantization-a ware approaches such as QLoRA and LoftQ [ 2 , 6 ]. These metho ds are primarily motiv ated by efficiency , but their frozen-backbone structure also makes them nat- ural candidates for sequential adaptation. How ev er, the PEFT literature ov erwhelmingly ev aluates these metho ds on single-task accuracy; their b ehavior under se quential adaptation—and sp ecifically whether the frozen backbone itself drives forgetting reduction—remains systematically under-studied. 2 2.3 PEFT for Con tin ual Learning Sev eral recent pap ers study LoRA or related PEFT mechanisms directly in contin ual-learning settings. O-LoRA enforces orthogonality across low-rank up dates [ 19 ]. Prompt-based metho ds such as L2P , Dual- Prompt, and CODA-Prompt adapt prompts instead of the full backbone [ 16 , 20 , 21 ]. InfLoRA analyzes in terference-free lo w-rank adaptation [ 8 ]. More recen t work includes C-LoRA [ 25 ], LoRI [ 23 ], replay com bined with LoRA for NLU [ 1 ], drift-resistant LoRA subtraction in exemplar-free contin ual learning [ 10 ], and a 2026 geometric account of forgetting in low-rank adaptation [ 17 ]. Our pap er differs from the abov e w ork on three axes. First, we study standar d LoRA without an y con tin ual-learning-sp ecific mo difications, isolating the implicit frozen-backbone effect. Second, w e enforce strict proto col separation b etw een confirmatory and exploratory evidence, prev enting mixed- proto col o verclaiming. Third, we connect the empirical result to a mec hanistic interpretation via freezing ablations and representation prob es, rather than only rep orting aggregate forgetting scores. 2.4 T ask-Inv arian t Represen tations and Mec hanistic Explanations Multi-task and transfer-learning research has long suggested that stable shared features can improv e ro- bustness across tasks, while task-specific drift in deeper la yers can produce in terference. Recent contin ual- learning work on PEFT increasingly frames the problem in terms of geometric separation, orthogonality , repla y , or constrained subspaces rather than only aggregate forgetting scores. Our manuscript takes a narro w er step in that direction. W e do not claim a complete mechanistic pro of, but w e do test whether the rep ository’s strongest evidence is more consistent with a frozen-backbone account than with a purely lo w-rank one. The language of task-inv arian t representations is therefore used here as an interpretation of the observed freezing pattern, not as a fully established theorem ab out all LoRA b ehavior. 3 Exp erimen tal Metho dology 3.1 Sequen tial Proto col and F orgetting Metric Our main task order is R TE → MRPC → CoLA → SST-2, using GLUE [ 18 ]. After each task is trained, w e ev aluate the curren t mo del on ev ery task seen so far. F or a task T i , forgetting is the drop b etw een its p ost-training p eak and its accuracy after later tasks: F ( T i ) = Acc i (after training T i ) − Acc i (after training T j ) , j > i. (1) Av erage forgetting ov er prior tasks is F = 1 N − 1 N − 1 X i =1 F ( T i ) . (2) P ositiv e v alues indicate forgetting; negative v alues indicate backw ard transfer. 3.2 Evidence Tiers and Proto col T axonom y The central metho dological c hoice in this pap er is to separate confirmatory runs from exploratory ones. Earlier exp eriments in the rep ository used validation[:200] slices and were useful for screening, but they are not merged with the confirmatory statistics rep orted here. In particular, the older BER T seeds 42–44 are not combined with the full-v alidation reruns 45–49. 3.3 Mo dels, Hyp erparameters, and Statistics The confirmatory study uses BER T-base-uncased with either full fine-tuning or LoRA ( r = 8, query/v alue mo dules). Secondary exp eriments use RoBER T a-base, EWC, 6-task sequential adaptation, and freezing ablations under the settings summarized in T able 1 . Across these runs, training uses three ep o chs, learning rate 2 × 10 − 5 , batch size 16, AdamW, warm up 100 steps, and weigh t decay 0.01. W e rep ort mean and standard deviation ov er seeds, and for the main BER T comparison we compute a paired t -test and Cohen’s d z directly from the confirmatory reruns. 3 T able 1: Proto col taxonomy used in this pap er. Only the confirmatory BER T row supplies the main headline result. Study Role V alidation T raining caps Seeds BER T full FT vs. LoRA Confirmatory F ull v alidation SST-2 capped at 2,000 45–49 RoBER T a full FT vs. LoRA Secondary F ull v alidation SST-2 capped at 2,000 42–44 EWC baseline Secondary F ull v alidation SST-2 capped at 2,000 42–44 6-task LoRA extension Secondary F ull v alidation SST-2, QNLI capped at 2,000 42–44 Rank/module/ quant. sweeps Exploratory validation [:200] Screening setup 42–44 Fine-grained freezing ablation Exploratory F ull v alidation SST-2 capped at 2,000 42–44 L0 L5 L11 All layers trainable 19.9% avg forgetting (a) F ull Fine- T uning L0 L5 L11 Frozen backbone L oR A adapters 0.6% avg forgetting (b) LoRA : F rozen Backbone 86 88 90 92 94 96 98 100 % fr ozen parameters 0 2 4 6 8 10 12 14 16 A verage for getting (%) ~95% transition 14.8% 5.2% 2.6 3.1% (c) The 95% F reezing Cliff Figure 1: Paper ov erview. Left: full fine-tuning leav es the entire backbone trainable and suffers high forgetting under unconstrained drift. Middle: LoRA freezes the backbone and routes task-sp ecific adap- tation through small low-rank up dates, preserving a more stable shared scaffold. Right: the empirical freezing ablation shows a sharp forgetting drop once the frozen fraction crosses roughly 95%. 3.4 In terpretive Scop e The framing in this pap er distinguishes b etw een evidence that informs mechanism and a full mechanistic pro of. The confirmatory BER T reruns establish that standard LoRA strongly reduces av erage forgetting under the audited proto col. The freezing studies, classifier-only baselines, and shallo w-adapter v ariants then ask which architectural constraint b est matches that reduction. This lets us compare a frozen- bac kb one h yp othesis against a weak er low-rank-only story . It also forces us to be explicit ab out what the current pap er still do es not establish decisively: a uniquely causal mechanism, a gradient-geometry explanation that surviv es alternative prob es, or long-horizon contin ual adaptation under matched seeds. 3.5 Companion Mec hanism Prob es T o test the frozen-bac kb one in terpretation more directly , we additionally use a v erified companion experi- men t repository that measures task similarit y in represen tation space. These prob es are k ept analytically separate from the confirmatory BER T forgetting statistics: they use partly differen t arc hitectures (GPT-2 and RoBER T a), sometimes few er tasks, and were designed to discriminate b etw een mechanism hypothe- ses rather than to extend the main five-seed b enchmark. In these prob es, task similarity denotes cosine similarit y b etw een task centroids extracted from hidden-state activ ations, with higher v alues indicating that sequen tially adapted tasks contin ue to o ccupy a more shared representation space. W e use these studies only as explanatory evidence ab out freezing, gradual unfreezing, orthogonality , and lay er-wise drift. Figure 1 summarizes the pap er’s central argument b efore the detailed results: the empirical gap b et w een full fine-tuning and LoRA is large, and the freezing transition suggests that the main driver is strong backbone preserv ation rather than unconstrained parameter drift. 4 Full FT LoRA 0 5 10 15 20 25 A verage forgetting (%) 45 46 47 48 49 19.9 +/- 4.8 0.6 +/- 1.4 Confirmatory BER T forgetting (full validation, seeds 45-49) Figure 2: Seed-paired confirmatory BER T forgetting comparison from the audited full-v alidation reruns (seeds 45–49). T able 2: Confirmatory BER T-base forgetting statistics from the full-v alidation reruns (seeds 45–49). Earlier subset-v alidation runs are inten tionally excluded. Metho d Mean Std Min Max Reduction F ull fine-tuning 19.9% 4.8% 12.1% 25.0% — LoRA ( r = 8, qv) 0.6% 1.4% − 2 . 0% 2.1% 97.2% 4 Main Results 4.1 Confirmatory BER T-Base Result The cleanest evidence in this pap er comes from the fiv e full-v alidation BER T reruns. Under this consisten t proto col, full fine-tuning pro duces substantial forgetting: F ull FT: 19 . 9% ± 4 . 8% , (3) while LoRA yields muc h low er av erage forgetting: LoRA: 0 . 6% ± 1 . 4% . (4) This corresp onds to a 97 . 2% relative reduction. The paired comparison also fa vors LoRA under this proto col ( t (4) = 6 . 99, p = 0 . 002, Cohen’s d z = 3 . 12). T ask-level av erages show the same qualitative pattern. Under full fine-tuning, a v erage forgetting is largest on MRPC (23.7 p ercentage p oints), follow ed by CoLA (21.4) and R TE (14.4). Under LoRA, MRPC forgetting is approximately zero on av erage, R TE forgetting is 3.3 p oints, and CoLA shows sligh t backw ard transfer. Figure 3a shows that the reduction is not confined to the aggregate statistic: forgetting is low er on each previously learned task, with the largest absolute gaps on MRPC and CoLA. The confirmatory reruns also show an accuracy trade-off: final a verage accuracy is 64.5% for full fine- tuning versus 59.5% for LoRA. Figure 4 mak es the task-by-stage pattern explicit. Under full fine-tuning, forgetting accumulates quic kly for MRPC and CoLA after later tasks. The LoRA heatmap remains near zero except for mo dest R TE drift and slight CoLA backw ard transfer. 4.2 Exploratory Configuration Con text Earlier screening sweeps o ver rank, mo dule targeting, and quan tization used validation[:200] and are therefore treated as exploratory only . Those runs suggested that r = 8 w as a reasonable parameter- efficiency starting p oint, that targeting more linear lay ers could improv e task accuracy , and that 4- bit quantization preserved accuracy in the screening setup while reducing memory fo otprint. Across 5 R TE MRPC COLA 0 5 10 15 20 25 30 35 T ask -level forgetting (%) Confirmatory BER T forgetting by task Full FT LoRA (a) T ask-level forgetting. LoRA reduces forgetting on all previously learned tasks. A fter R TE A fter MRPC A fter CoLA A fter S ST -2 0 5 10 15 20 25 A verage forgetting on prior tasks (%) Confirmatory BER T forgetting trajectory across the sequence Full FT LoRA (b) Stage-wise av erage forgetting tra jectory across the confirmatory BER T sequence. Figure 3: T ask-lev el and stage-wise forgetting in the confirmatory BER T reruns (seeds 45–49). (a) LoRA reduces forgetting on every individual task. (b) The gap b et ween metho ds widens progressively as more tasks are added. A fter R TE A fter MRPC A fter COLA A fter S ST2 Evaluation stage R TE MRPC COLA S ST2 T ask 0.0 12.0 15.6 14.4 0.0 15.1 23.7 0.0 21.4 0.0 Full fine-tuning A fter R TE A fter MRPC A fter COLA A fter S ST2 Evaluation stage R TE MRPC COLA S ST2 0.0 2.9 3.1 3.2 0.0 0.0 0.0 0.0 -1.6 0.0 LoRA 0 5 10 15 20 F orgetting relative to post-training peak (%) Figure 4: Mean task-by-stage forgetting in the confirmatory BER T reruns. Each cell rep orts forgetting relativ e to that task’s p ost-training p eak, av eraged across seeds 45–49. the app endix sw eeps, the configuration story is internally consistent: larger rank improv es screening accuracy at rising parameter cost (Figure 9a ), all-linear targeting improv es screening accuracy relative to query/v alue-only targeting (Figure 9b ), and 4-bit quan tization preserv es the same qualitativ e ordering while low ering memory (Figure 10a ). W e retain these sweeps as motiv ation for future confirmatory work, not as headline forgetting evidence. The detailed exploratory plots are included in Section A . 5 Secondary Evidence 5.1 RoBER T a Replication The full-v alidation RoBER T a replication supp orts the same qualitative picture: forgetting remains muc h lo w er with standard LoRA than with full fine-tuning. 5.2 EW C Baseline W e also ran a separate full-v alidation EWC baseline on the same 4-task order. The strongest EW C setting in the rep ository reaches 15 . 5% ± 1 . 4% forgetting with 67.0% final av erage accuracy . This is higher forgetting than the confirmatory LoRA reruns, but we treat the comparison as cont extual rather than paired, b ecause the EWC runs use a different seed set. 5.3 Six-T ask Extension The 6-task extension adds QNLI and WNLI. Average forgetting remains low relativ e to full fine-tuning, but the task-lev el breakdo wn is heterogeneous enough that we do not treat this section as clean scalabilit y evidence. 6 T able 3: Secondary full-v alidation RoBER T a-base replication ( n = 3 seeds). Metho d F orgetting Final Avg. Accuracy Reduction F ull fine-tuning 24.2% ± 2.2% 64.8% — LoRA ( r = 8, qv) 1.7% ± 1.0% 59.3% 92.8% T able 4: Secondary EWC baseline under the same task order and training setup. The BER T LoRA row is included only as confirmatory context, not as a paired same-seed comparison. Metho d n F orgetting Final Avg. Accuracy BER T LoRA (confirmatory) 5 0.6% ± 1.4% 59.5% EW C ( λ = 100) 6 16.4% ± 1.2% 66.2% EW C ( λ = 1000) 3 16.2% ± 1.2% 66.2% EW C ( λ = 5000) 3 15.5% ± 1.4% 67.0% A stage-wise view clarifies where the av erage changes o ccur. F orgetting stays close to zero through SST-2, then jumps sharply once QNLI is introduced and remains elev ated after WNLI (Figure 6b ). 6 F reezing and Represen tation Evidence for a F rozen-Backbone Hyp othesis The fine-grained freezing ablation uses full v alidation and therefore carries more w eight than the screening sw eeps, but we still treat it as secondary evidence rather than as a second confirmatory headline. Its purp ose is not to replace the main BER T comparison; instead, it asks which part of the LoRA design b est matches the forgetting reduction. The main pattern is clear: forgetting decreases markedly once more than 95% of parameters are frozen. This ablation is consistent with a frozen-backbone interpretation of the main result, but it do es not b y itself pro v e that atten tion weigh ts are the unique lo cus of in terference. W e therefore frame it as suggestiv e evidence ab out where forgetting b ecomes easier to control, not as a mechanistic pro of. Read together, the freezing rows suggest a more sp ecific interpretation than the original empirical pap er alone could supp ort. High-forgetting partially unfrozen configurations (86.5% and 93.0% frozen) b eha v e muc h more like full fine-tuning than like standard LoRA, whereas classifier-only and shallow- adapter baselines remain close to the standard LoRA regime once the frozen fraction approaches 100%. This pattern is more naturally explained by a strong frozen-backbone constrain t than by low-rank pa- rameterization alone. In that sense, the rep ository’s evidence p oints tow ard a task-inv arian t-subspace h yp othesis: when almost all backbone parameters are fixed, later tasks app ear to reuse a more stable shared feature scaffold instead of ov erwriting it. The companion mechanism prob es strengthen this in terpretation b y measuring task similarit y directly rather than inferring it only from forgetting curves. In a four-task GPT-2 prob e, a fully frozen backbone reac hes task similarit y 0 . 9988 v ersus 0 . 8935 for full fine-tuning while retaining competitive mean accuracy (0 . 671 vs. 0 . 701). A gradual-unfreezing prob e then shows monotonic erosion as more lay ers are released: task similarit y falls from 0 . 9982 in the head-only regime to 0 . 9943 and 0 . 9911 under progressively broader sc hedules, then collapses to 0 . 8542 under full fine-tuning. A dedicated lay er-wise representation analysis sho ws that b oth regimes remain highly similar through most lay ers, but full fine-tuning exhibits its clearest drop at the final la yer (0 . 9902 v ersus 0 . 9973 for LoRA). Orthogonal-regularization sw eeps remain effectiv ely flat (0 . 9775–0 . 9778), suggesting that generic up date decorrelation alone do es not recreate the same preserv ation effect. The broader direction is also visible in RoBER T a (0 . 9321 vs. 0 . 6383), GPT-2 Medium (0 . 9994 vs. 0 . 9967), and an eight-seed GPT-2 v alidation where LoRA main tains higher task similarit y than full fine-tuning (0 . 9973 ± 0 . 0016 vs. 0 . 9897 ± 0 . 0069, p = 0 . 013; see Figure 11 for the compact robustness summary). 7 Full FT LoRA 0 5 10 15 20 25 A verage forgetting (%) RoBER T a replication 100 1000 5000 EWC lambda 0.0 2.5 5.0 7.5 10.0 12.5 15.0 17.5 20.0 A verage forgetting (%) EWC baseline with BER T references BER T Full FT (19.9%) BER T LoRA (0.6%) Figure 5: Secondary cross-chec ks. Left: RoBER T a full fine-tuning versus LoRA. Right: EWC forgetting b y λ with confirmatory BER T reference lines. T able 5: LoRA under 4-task and 6-task full-v alidation proto cols. The 6-task result has low av erage forgetting but large MRPC forgetting. Setting n Avg. F orgetting Final Avg. Accuracy MRPC F orgetting 4-task BER T LoRA reference 5 0.6% ± 1.4% 59.5% − 0 . 3 to 0 . 5 pts 6-task BER T LoRA 3 5.6% ± 0.8% 53.8% 35.8–37.5 pts 7 Computational F o otprin t The rep ository’s directly audited profiling logs are limited to one exploratory 4-bit LoRA configuration, so we rep ort them only as deploymen t context and not as a cross-metho d sp eedup claim. In that setup, training takes 11 . 95 ± 1 . 12 seconds p er ep o ch, p eak memory is 0 . 46 ± 0 . 11 GB, inference latency is 53 . 72 ± 4 . 62 ms, throughput is 18.74 samples/s, and the trainable parameter count is 296,450 (0.44% of the quantized mo del). These v alues should b e read together with the exploratory quantization figure in the app endix: they show that the all-linear/4-bit configuration can op erate at sub-gigabyte memory scale, but they are p eripheral to the pap er’s main empirical and mechanistic claims. 8 Discussion 8.1 What the Confirmatory Result Do es and Do es Not Sho w The strongest claim supp orted by the rep ository is that standard LoRA substantially reduces aver age forgetting in the audited 4-task BER T setting. That claim is robust to the stricter proto col audit: even after discarding the older subset-v alidation seeds, the confirmatory reruns still show a large reduction in forgetting. How ever, the result do es not imply that forgetting is solved in general, nor that ev ery task is uniformly protected. 8.2 Accuracy-F orgetting T rade-off The confirmatory reruns sho w that forgetting reduction is not free. F ull fine-tuning reaches higher final a v erage accuracy than LoRA (64.5% vs. 59.5%), even after forgetting. The 6-task extension reinforces the same p oint: av erage forgetting can remain lo w while individual tasks deteriorate sharply . F or practical con tin ual-learning deploymen ts, av erage forgetting should therefore b e rep orted together with task-level breakdo wns and final av erage accuracy . 8.3 Limitations W e identify five principal limitations, each with its scop e of impact and a path tow ard resolution: • T ask and architecture scop e. The confirmatory claim rests on BER T-base enco der-only classifica- tion o ver four GLUE tasks. This restricts direct generalization to deco der mo dels, generative tasks, 8 R TE MRPC COLA S ST2 QNLI 0 10 20 30 T ask -level forgetting (%) Six -task LoRA run shows heterogeneous forgetting (a) T ask-level forgetting. MRPC is the clear outlier. A fter R TE A fter MRPC A fter COLA A fter S ST2 A fter QNLI A fter WNLI 2 0 2 4 6 8 A verage forgetting on prior tasks (%) 42 43 44 Six -task LoRA forgetting trajectory Mean across seeds (b) Average-forgetting tra jectory . F ain t lines show in- dividual seeds. Figure 6: Six-task LoRA extension. (a) MRPC dominates task-lev el forgetting despite lo w a verage v alues. (b) F orgetting stays near zero through SST-2, then jumps sharply once QNLI is in tro duced. T able 6: Exploratory full-v alidation freezing ablation ( n = 3 seeds). The pattern suggests a marked drop in forgetting once freezing exceeds roughly 95%, but we do not interpret this as identifying a unique causal mechanism. Configuration F rozen % Avg. F or- getting T rainable P arams Role F reeze lay ers 0–9, train 10–11 86.5% 14.8% 14.8M High-forgetting reference F reeze lay ers 0–10, train 11 93.0% 13.2% 7.7M High-forgetting reference F reeze 0–10 + lay er-11 attention 95.1% 5.2% 5.3M Mark ed drop F reeze all 12 lay ers 99.5% 3.1% 592K Classifier-only baseline LoRA on lay er 11 only 100.0% 2.9% 26K Adapter baseline LoRA on lay ers 10–11 100.0% 2.9% 51K Adapter baseline LoRA on all lay ers 99.7% 2.6% 296K Standard LoRA or longer task sequences. Path forwar d: extending the confirmatory proto col to GPT-2-scale deco ders and ≥ 10-task sequences with matched seeds. • Single LoRA configuration. The he adline uses r = 8 on query/v alue mo dules only . Different ranks, target mo dules, or v ariants (AdaLoRA, DoRA) may shift the forgetting–accuracy trade-off. Path forwar d: a factorial sw eep ov er rank × target mo dule × LoRA v ariant under the same full-v alidation proto col. • Architecture mismatc h in mechanism prob es. The companion task-similarity and lay er-wise prob es use GPT-2 and RoBER T a—arc hitecturally distinct from the confirmatory BER T b enchmark. They therefore strengthen interpretation rather than extend the confirmatory result. Path forwar d: replicating the mechanism prob es within the same BER T-base enco der used for the headline compari- son. • No replay or adv anced CL baselines. W e compare only against EWC and v anilla full fine-tuning. Repla y-augmen ted or recen t PEFT-CL metho ds (O-LoRA, InfLoRA) are not included under a matc hed seed proto col. Path forwar d: integrating these baselines into the same confirmatory framework. • Screening data leak age risk. The rep ository contains earlier validation[:200] sweeps. Although w e do not p o ol these with confirmatory statistics, their existence requires transparent disclosure to a v oid acciden tal mixed-proto col claims. Path forwar d: archiving screening runs in a separate repository branc h with explicit metadata tags. 9 86 88 90 92 94 96 98 100 Frozen parameters (%) 2 4 6 8 10 12 14 16 A verage forgetting (%) F orgetting drops once freezing exceeds roughly 95% Standard freezing LoRA variants Figure 7: Fine-grained freezing ablation. Average forgetting falls sharply once freezing exceeds roughly 95% of parameters. 8.4 F rozen-Backbone Bottlenec k Hyp othesis The evidence in this pap er supp orts a simple three-part design hypothesis rather than a completed mec hanistic theory . First, strong freezing acts as an ar chite ctur al b ottlene ck : once most parameters are frozen, later tasks lose the degrees of freedom needed to freely rewrite earlier solutions. Second, that b ottlenec k app ears to preserv e a shar e d fe atur e sc affold . The freezing ablations suggest that forgetting falls most sharply when adaptation is pushed to w ard classifier-only or shallow-adapter regimes, which is exactly where most of the pretrained bac kb one is reused rather than rewritten. Third, the remaining plasticit y b ecomes lo c alize d . The system can still adapt, but the cost-b enefit trade-off shifts to w ard limited task-sp ecific heads or adapter paths rather than full-mo del drift. This hypothesis is narrow er than the mechanism pap er’s original claims, but it now rests on more than forgetting summaries alone. The companion rep ository contributes direct task-similarit y , gradual- unfreezing, and lay er-wise analyses that all point in the same direction: stronger freezing preserves a more shared representation space, while full fine-tuning induces substantially larger drift and concentrates its clearest divergence in the deep est lay er. Ev en so, w e still stop short of claiming a unique causal mechanism b ecause the direct prob es remain exploratory , use partly different architectures and task subsets, and do not isolate every alternative explanation. 8.5 In terpretation The observed pattern is consistent with recent theoretical w ork that links forgetting in low-rank adap- tation to the geometry of task subspaces [ 17 ]. Our empirical findings also align qualitatively with the broader literature sho wing that task isolation, replay , orthogonality , or stronger freezing can all reduce in terference [ 1 , 10 , 19 , 23 , 25 ]. The companion prob es sharp en that interpretation in tw o useful wa ys. First, orthogonal-regularization sweeps leav e task similarity almost unchanged, which weak ens a generic up date-decorrelation explanation. Second, direct representation prob es show that stronger freezing and smaller trainable subspaces mo ve the system to ward higher task similarity , while full fine-tuning produces the clearest late-la y er divergence. The in terpretation developed here is therefore stronger than a pure b enc hmark rep ort but weak er than a full mec hanistic pro of: standard LoRA appears to reduce forget- ting largely b ecause frozen-backbone constrain ts preserve a more task-inv ariant feature s caffold than full fine-tuning. W e do not claim to hav e established the unique causal mechanism, only to hav e identified the frozen-trainable-subspace b oundary as the b est-supp orted explanation in the current rep ositories. 9 Conclusion After separating confirmatory full-v alidation evidence from earlier exploratory runs, the cen tral empirical result remains: in five BER T-base reruns, standard LoRA reduces a verage forgetting from 19 . 9% to 0 . 6%. Secondary full-v alidation exp eriments on RoBER T a and EWC supp ort the same qualitative story , while 10 Figure 8: Companion mechanism prob es from the verified second repository . T op left: direct task- similarit y comparison b etw een a frozen backbone and full fine-tuning in a four-task GPT-2 prob e. T op righ t: task similarity degrades steadily as more lay ers are unfrozen. Bottom: la yer-wise task similar- it y remains high in b oth regimes, but full fine-tuning shows its largest drop at the final transformer la y er. These prob es are exploratory and architecture-mismatc hed to the main BER T b enchmark, so they strengthen interpretation rather than change the confirmatory headline result. the 6-task, freezing, and companion repres en tation prob es show that the picture is more nuanced than a single av erage can capture. The main lesson of this pap er is therefore tw ofold. Standard LoRA is a useful empirical baseline for sequen tial transformer-enco der adaptation, and the strongest current explanation for that robustness is the frozen-backbone constraint it imp oses on later task learning. Proto col transparency still matters b ecause mixing exploratory and confirmatory evidence can easily ov erstate certaint y , but an equally imp ortan t lesson is mechanistic: once direct task-similarity and la yer-wise prob es are added, the evidence increasingly p oints to representation preserv ation rather than low rank alone. W e hope this pap er is useful b oth as a controlled empirical result ab out low-rank adaptation and as a more interpretable account of wh y selective parameter freezing can matter in contin ual fine-tuning. Ac kno wledgmen ts This research receiv ed no external funding. Large language mo dels w ere used to assist with language editing and manuscript drafting; all ideas, analyses, verification of claims, and final resp onsibilit y for the con ten t remain with the author. The co de, exp eriment configurations, and summary results supp orting this study are av ailable from the corresp onding author up on reasonable request. References [1] Zeinab Borhanifard, Heshaam F aili, and Y adollah Y aghoobzadeh. Combining replay and LoRA for con tin ual learning in natural language understanding. Computer Sp e e ch & L anguage , 90:101737, 2025. doi: 10.1016/j.csl.2024.101737. URL https://doi.org/10.1016/j.csl.2024.101737 . [2] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luk e Zettlemo yer. QLoRA: Efficien t finetuning of quantized LLMs. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , volume 36, 2023. 11 [3] Edw ard J. Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizh u Chen. LoRA: Low-rank adaptation of large language mo dels. In International Confer- enc e on L e arning R epr esentations (ICLR) , 2022. [4] James Kirkpatric k, Razv an Pascan u, Neil Rabinowitz, Jo el V eness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszk a Grabsk a-Barwinsk a, et al. Overcoming catastrophic forgetting in neural netw orks. Pr o c e e dings of the National A c ademy of Scienc es , 114 (13):3521–3526, 2017. [5] Lingc hen Kong, Shixuan Duan, Sh uai Y e, Bin Bi, Chengming Li, Y ukun Zuo, Min Zhang, and Y ongbin Zheng. RS-LoRA: Rank-stabilized low-rank adaptation. arXiv pr eprint arXiv:2405.12712 , 2024. [6] Xiaodong Li et al. LoftQ: LoRA-fine-tuning-aw are quantization for large language mo dels. arXiv pr eprint arXiv:2310.08987 , 2023. [7] Zhizhong Li and Derek Hoiem. Learning without forgetting. In Eur op e an Confer enc e on Computer Vision (ECCV) , 2016. [8] Bing Liang and Jiaxing Li. InfLoRA: Interference-free low-rank adaptation for contin ual learning. In IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , 2024. [9] Shih-Y ang Liu, Chien-Yi W ang, Hongxu Yin, Pa vlo Molchano v, Y u-Chiang F rank W ang, Kwang- Ting Cheng, and Min-Hung Chen. DoRA: W eigh t-decomp osed lo w-rank adaptation. In International Confer enc e on Machine L e arning (ICML) , 2024. [10] Xuan Liu and Xiaobin Chang. LoRA subtraction for drift-resistant space in exemplar-free contin ual learning. In IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , 2025. doi: 10.1109/CVPR52734.2025.01426. URL https://doi.org/10.1109/CVPR52734.2025.01426 . [11] Da vid Lop ez-Paz and Marc’Aurelio Ranzato. Gradient episo dic memory for contin ual learning. In A dvanc es in Neur al Information Pr o c essing Systems (NeurIPS) , 2017. [12] Arun Mally a and Svetlana Lazebnik. Pac kNet: Adding m ultiple tasks to a single net w ork b y iterativ e pruning. In IEEE Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , 2018. [13] Mic hael McClosk ey and Neal J. Cohen. Catastrophic interference in connectionist net works: The sequen tial learning problem. In Psycholo gy of L e arning and Motivation , v olume 24, pages 109–165, 1989. [14] Sylv estre-Alvise Rebuffi, Alexander Kolesniko v, Georg Sp erl, and Christoph H. Lamp ert. iCaRL: Incremen tal classifier and representation learning. In IEEE Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , 2017. [15] Andrei A. Rusu, Neil C. Rabino witz, Guillaume Desjardins, Hub ert So yer, James Kirkpatric k, Kora y Ka vuk cuoglu, Razv an Pascan u, and Raia Hadsell. Progressiv e neural net works. arXiv pr eprint arXiv:1606.04671 , 2016. [16] James Seale Smith, Leonid Karlinsky , Vyshna vi Gribb er, Harsh Brando, Rogerio F eris, and Zsolt Kira. CODA-Prompt: Contin ual decomposed atten tion-based prompting for rehearsal-free con tinual learning. In IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , 2023. [17] Brady Steele. Subspace geometry gov erns catastrophic forgetting in low-rank adaptation. arXiv preprin t arXiv:2603.02224, 2026. URL . [18] Alex W ang, Amanpreet Singh, Julian Michael, F elix Hill, Omer Levy , and Samuel R. Bowman. GLUE: A multi-task b enchmark and analysis platform for natural language understanding. In International Confer enc e on L e arning R epr esentations (ICLR) Workshop , 2018. [19] Y ufei W ang, Aman Agarwal, and Christopher D. Manning. Orthogonal subspace learning for lan- guage model contin ual learning. In Findings of the Asso ciation for Computational Linguistics (EMNLP) , 2023. 12 [20] Zifeng W ang, Zizhao Zhang, Sa yna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Y u Lee, Xiao qi Ren, and Guolong Su. DualPrompt: Complementary prompting for rehearsal-free contin ual learning. In Eur op e an Confer enc e on Computer Vision (ECCV) , 2022. [21] Zifeng W ang, Zizhao Zhang, Chen-Y u Lee, Han Zhang, Ruo xi Sun, Xiaoqi Ren, Guolong Su, Vincent P erot, Jennifer Dy , and T omas Pfister. Learning to prompt for contin ual learning. In IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition (CVPR) , 2022. [22] F riedemann Zenke, Ben P o ole, and Surya Ganguli. Contin ual learning through synaptic in telligence. In International Confer enc e on Machine L e arning (ICML) , 2017. [23] Juzheng Zhang, Jiacheng Y ou, Ash winee Panda, and T om Goldstein. LoRI: Reducing cross-task in terference in multi-task low-rank adaptation. arXiv preprint arXiv:2504.07448, 2025. URL https: //arxiv.org/abs/2504.07448 . [24] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengc heng He, Y u Cheng, W eizh u Chen, and T uo Zhao. AdaLoRA: Adaptiv e budget allo cation for parameter-efficient fine-tuning. In Interna- tional Confer enc e on L e arning R epr esentations (ICLR) , 2023. [25] Xin Zhang, Liang Bai, Xian Y ang, and Jiy e Liang. C-LoRA: Contin ual low-rank adaptation for pre-trained mo dels. arXiv preprint arXiv:2502.17920, 2025. URL 17920 . A Exploratory Screening Figures This app endix collects exploratory figures that informed configuration selection together with one com- panion robustness figure from the v erified second repository . The first four figures use validation[:200] screening; training logs are limited to one exploratory 4-bit LoRA configuration, so we rep ort them only as deploymen t context and not as a cross-metho d sp eed comparison. 5 10 15 20 25 30 LoRA rank 55 60 65 70 75 80 85 Mean screening accuracy (%) 148K 296K 591K 1181K Exploratory rank sweep (validation[:200]) (a) Rank sweep. Accuracy improv es with larger rank but parameter coun t rises quic kly . Q+V Q+K+V All linear 0 10 20 30 40 50 60 70 80 Mean screening accuracy (%) 296K 443K 1340K Exploratory module-targeting sweep (validation[:200]) (b) Mo dule-targeting sweep. All-linear targeting im- pro v es accuracy o v er query/v alue. Figure 9: Exploratory configuration sweeps on validation[:200] . 13 Q+V 4-bit Q+V 8-bit All-linear 4-bit All-linear 8-bit 0 20 40 60 80 Mean screening accuracy (%) 0.40 GB 0.48 GB 0.46 GB 0.53 GB Exploratory quantization sweep (validation[:200]) (a) Quantization sweep. 4-bit preserv es qualitativ e ranking while reducing memory . R TE MRPC COLA S ST2 0 20 40 60 80 Single-task validation accuracy (%) 2.42 GB 2.42 GB 2.42 GB 2.43 GB Single-task full fine-tuning baseline (validation[:200]) (b) Single-task full fine-tuning baseline from the screen- ing setup. Figure 10: Exploratory quantization and baseline context from validation[:200] . Figure 11: Companion robustness prob es. Left: task similarity across RoBER T a, GPT-2 Medium, and eigh t-seed GPT-2. Right: orthogonal regularization effect. Bottom: forgetting across task orderings. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment