Optimizing Coverage and Difficulty in Reinforcement Learning for Quiz Composition
Quiz design is a tedious process that teachers undertake to evaluate the acquisition of knowledge by students. Our goal in this paper is to automate quiz composition from a set of multiple choice questions (MCQs). We formalize a generic sequential de…
Authors: Ricardo Pedro Querido Andrade Silva, Nassim Bouarour, Dina Fettache
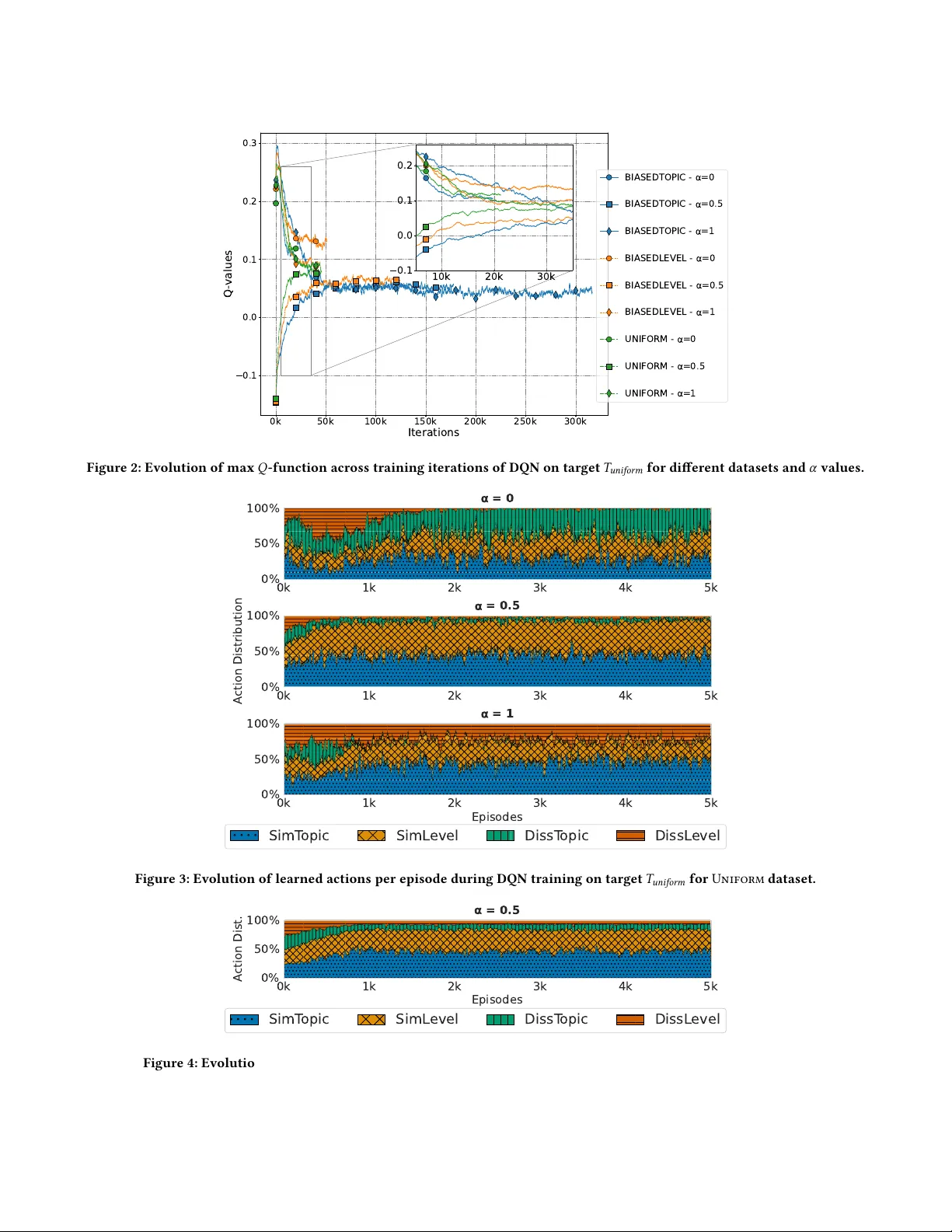
Optimizing Cov erage and Diiculty in Reinforcement Learning for iz Composition Ricardo Pedro Querido Andrade Silva CNRS, Univ . Grenoble Alpes Grenoble, France Nassim Bouarour CNRS, Univ . Grenoble Alpes Grenoble, France Dina Fettache CNRS, Univ . Grenoble Alpes Grenoble, France Sarab Boussouar CNRS, Univ . Grenoble Alpes Grenoble, France Noha Ibrahim Université Grenoble Alpes Grenoble, France Sihem Amer- Y ahia CNRS, Univ . Grenoble Alpes Grenoble, France Abstract Quiz design is a tedious process that teachers undertake to evaluate the acquisition of knowledge by students. Our goal in this paper is to automate quiz composition from a set of multiple choice ques- tions (MCQs). W e formalize a generic sequential decision-making problem with the goal of training an agent to compose a quiz that meets the desired topic coverage and diculty levels. W e inves- tigate DQN, SARSA and A2C/A3C, three reinforcement learning solutions to solve our pr oblem. W e run e xtensive experiments on synthetic and real datasets that study the ability of RL to land on the best quiz. Our results reveal subtle dierences in agent behav- ior and in transfer learning with dierent data distributions and teacher goals. This was supporte d by our user study , paving the way for automating various teachers’ pedagogical goals. 1 Introduction T eachers spend considerable time crafting quizzes to evaluate their students’ knowledge acquisition [ 11 , 12 , 18 ]. They usually follo w a stepwise decision-making process starting from a mix of previ- ously used quizzes and newly designe d Multiple-Choice Questions (MCQs). At each step, they seek to ensure that the MCQs forming a quiz cover desired topics and diculty level distributions. In this paper , our aim is to help teachers automate quiz composition. Context and motivating example . Quiz creation has recently moved from manual editing to smarter , learning-based systems. T eachers used to spend a lot of time adjusting questions one by one to create a good quiz. K ey concerns like topic cov erage, diculty balance, and rele vance to the material are still essential for build- ing high-quality quizzes. Consider the six Multi-Choice Questions provided in Figure 1 where the topic, diculty level, and correct solution of each MCQ are highlighted in bold. A teacher seeking to build a 3-MCQ quiz to test students on two topics, e.g. Statistics and Probabilities, would choose MCQs with var ying diculties, e.g., MCQs 1, 5, and 6 (this answer is not unique). A teacher who aims to vary topics and maintain the same diculties would choose MCQs 1, 4 and 5, that constitute the only solution in this case. In practice, teachers proceed either by creating MCQs from scratch, or by replacing some MCQs by others until they r each a satisfactory quiz. T o reduce human eort in composing quizzes from large MCQ pools, early systems use d rule-based methods with predened tem- plates and constraints (e.g., “include two geometry questions”), oering limited exibility and generalization [ 1 , 6 ]. Later work au- tomated quiz generation using diculty prediction via lexical and syntactic features [ 4 ], or clustering and topic modeling to group or diversify questions [ 9 ]. However , these metho ds target single objectives—such as topic relevance or redundancy reduction—and do not balance multiple pedagogical criteria. Challenges. Sele cting 𝑘 MCQs from a large pool is dicult be- cause the system must incrementally choose questions that best meet target topic coverage and diculty . As demonstrate d in recent work [ 20 ], this sequential decision process naturally suits RL. How- ever , how dierent RL methods handle varying data distributions and teacher goals remains unclear . K ey challenges include design- ing the MDP—esp ecially re wards that reect teacher objectives and actions that mimic quiz-design operations—and determining how to train agents for reusable performance across future quiz-design tasks. Contributions. W e dene izComp , a constrained bi-objective optimization problem that takes MCQs and target topic and dif- culty distributions and outputs a satisfying quiz. W e design an MDP where each state is a quiz, transitions r eplace it with one that improves topic or diculty (reected in the reward), and actions operate via similarity or dissimilarity on each objective. W e im- plement three RL solutions: DQN, SARSA, and A2C/A3C. DQN serves as the benchmark and has prior use in quiz composition. SARSA enables comparison within temporal dierence metho ds and has shown multitask potential. A2C/A3C provide a structurally dierent RL approach, combining policy and value networks with potential GP U eciency b enets. Empirical validation. Our experiments evaluate multiple RL algo- rithms across varied input samples and topic/diculty distributions using synthetic data and the real Med and Ma th datasets. Results conrm that agents can mimic teacher behavior using only MCQ similarity and dissimilarity . All algorithms use all actions, converge quickly , and tend to favor small gains, showing a bias toward topic and diculty similarity . This leads to local exploration of MCQ neighborhoods, with larger jumps taken only when similar op- tions are exhausted, mirroring human quiz design. On real datasets, all metho ds nd quizzes highly aligned with targets, with DQN performing best. W e further test transferability acr oss target types, uniform and biased, and datasets, nding strong cross-domain and cross-target transfer . Agents trained on one dataset transfer well to the other , and those trained on biased targets transfer ee ctively other targets. 1 MCQ4 [T opic Linear Algebra - Difficulty Easy] Compute the determinant of A=( [ 1 -3 1 2; -2 1 2 1; 0 0 -1 0; 2 4 2 1 ]) a. 11 b. -1 c. 35 d. impossible, the determinant is undefined MCQ2 [T opic Linear Algebra - Difficulty Hard] Solve the linear system x + y + z = 1 3x - y - z = 4 x + 5y + 5z = -1 a. The system has (x, x, -2x+1) as solution for every x ∈ℝ . b. The system has no solution. c. The system has (5/4, y, z) as solution for every y,z ∈ℝ . d. The system has (0, 0, 1) as its unique solution. MCQ1 [T opic Statistics - Difficulty Easy] A sample of 8 medical institutions in the country, found these monthly expenses for stationery (in eur os): 69, 48, 99, 87, 93, 84, 80, and 98. The expenses of the Red Cross hospital, which was not in the sample, were 1.5 stand ard deviation below the sample mean. What were the e xpenses of the Red Cross hospital? a. 56.75 b. 58.40 c. 106.10 d. 107.75 MCQ3 [T opic Statistics - Difficulty Hard] F or the summary of a sample given below, ident ify the possible outliers using the inter quartile range. [ MIN Q_1 Median Q_3 MAX; 10 17 18 23 78; ] a. The outlier is 30. b. The outliers are 17, 18 and 23. c. The outliers are 10 and 78. d. The outlier is 78. MCQ5 [T opic Pr obabilities - Difficulty Easy] In how many different ways can you arr ange 8 guests around a circular table? a. 720 b. 120 c. 1024 d. 5040 MCQ6 [T opic Pr obabilities - Difficulty Hard] A team of 4 people is to be f ormed from a gr oup of 7 women and 5 men. How many different teams might be formed? a. 495 b. 11880 c. 24 d. 479001600 Figure 1: MCQs used to generate quizzes. Our user study with 28 qualied participants resulted in higher satisfaction and lower eort, conrming the nee d for automating quiz generation. 2 Problem and Solutions W e consider a set of knowledge topics 𝑇 and a set 𝑀 of MCQs. W e associate to each MCQ 𝑚𝑐𝑞 ∈ 𝑀 a topic 𝑡 ∈ 𝑇 and a categorical value 𝑙 that reects its diculty level. Following common practice, we consider the diculty levels in the Bloom taxonomy [ 7 , 11 , 16 ]. Our framew ork accommodates a variable numb er of diculty levels, which dep end on the dataset. W e dene a quiz as a subset 𝑍 ⊆ 𝑀 of MCQs of a xed size 𝑘 . W e asso ciate with each quiz 𝑍 , a topic vector of a xed size, where each entr y 𝑖 is computed as the proportion of MCQs in 𝑍 with topic 𝑡 𝑖 ∈ 𝑇 (recall that each MCQ has a single topic). W e also associate to 𝑍 a diculty vector of xed size, where each entr y is compute d as the proportion of MCQs in 𝑍 that are associated with a given diculty level in the taxonomy . A teacher wishing to compose a quiz has in mind topics and diculty levels to cover . Those are expressed as two target vectors: 𝑇 𝐶 , a distribution of proportions of MCQs in the quiz with desired topics, and 𝑇 𝐷 , a distribution of proportions of MCQs in the quiz of desired diculty levels. For e xample, < 0 , 0 , 0 , 0 , 0 , 0 . 5 , 0 , 0 , 0 . 5 , 0 > is a biased topic vector where half the MCQs cov er one topic and the other half another , and < 0 . 2 , 0 . 2 , 0 . 2 , 0 . 2 , 0 . 2 > represents a uniform vector of diculties. W e dene topicMatch ( Z , T C ) and diMatch ( Z , T D ) , two func- tions that reect to what extent a quiz 𝑍 reects the desired distri- butions. Our formalization is agnostic to ho w these functions are dened. In our implementation, we use Cosine similarity . Problem 1 (The izComp Problem). Given a set 𝑀 of MCQs, two target vectors 𝑇 𝐶 and 𝑇 𝐷 , and an integer 𝑘 , our goal is to compose a quiz 𝑍 ⊆ 𝑀 of 𝑘 MCQs s.t.: argmax 𝑍 ⊆ 𝑀 topicMatch ( 𝑍 , 𝑇 𝐶 ) argmax 𝑍 ⊆ 𝑀 diMatch ( 𝑍 , 𝑇 𝐷 ) (1) 2.1 Markov Decision Process Formalization W e assume a Discr ete Markov Decision Process (MDP) dened by a triplet {S , A , R } : State space S is a set of states of the environment; Action space A is a set of actions from which the agent selects an action at each step; A reward function R that computes the reward of an action 𝑎 𝑖 from state 𝑠 𝑖 to 𝑠 ′ 𝑖 , 𝑅 𝑖 = 𝑟 ( 𝑠 𝑖 , 𝑎 𝑖 , 𝑠 ′ 𝑖 ) . States and actions. W e dene an explorator y agent’s environment as a set of distinct quizzes, each containing 𝑘 MCQs. Although our model is not restricted to pre-existing quizzes, in our implemen- tation, we materialize the space of all possible quizzes to achieve eciency . The state space represents a quiz 𝑍 as a set of 𝑘 MCQs, and each state is the concatenation of its quiz-level topic and dif- culty distribution vectors. When an agent visits a state 𝑠 (i.e., a quiz 𝑍 ), it seeks a better state 𝑠 ′ (a quiz 𝑍 ′ ) by applying one of four actions: SimT opic, SimLevel, DissT opic, or DissLevel . Each action transforms a quiz 𝑍 into a new quiz 𝑍 ′ that is either similar or dierent with respect to topics or diculty . Section 3.1 details how each action is eciently implemented. Reward design. As izComp is a multi-objective problem, we propose to dene our reward using scalarization, a common ap- proach that transforms the problem into a single obje ctive via a weighted linear sum. Given a quiz 𝑍 , we can compute how close it is to the target coverage and diculty: targetMatch ( 𝑍 , 𝑇 𝐶 , 𝑇 𝐷 ) = 𝛼 · topicMatch ( 𝑍 , 𝑇 𝐶 ) + ( 1 − 𝛼 ) · diMatch ( 𝑍 , 𝑇 𝐷 ) , where 𝛼 ∈ [ 0 , 1 ] . W e dene the re ward of taking an action 𝑎 at a state 𝑠 : R ← targetMatch ( 𝑠 ′ .𝑍 , 𝑇 𝐶 , 𝑇 𝐷 ) − targetMatch ( 𝑠 .𝑍 , 𝑇 𝐶 , 𝑇 𝐷 ) . 2 A state 𝑠 ∈ S contains a quiz 𝑍 , and applying action (a) yields a new state (s’) with quiz 𝑍 ′ . The reward captures the agent’s pro- gression: if 𝑠 ′ .𝑍 is farther from the target than 𝑠 .𝑍 , the reward is negative, penalizing the action and discouraging its future use in similar situations. If 𝑠 ′ .𝑍 is closer to the target, the agent receives a positive reward and is encouraged to reuse action 𝑎 . Exploration session. An agent learns to navigate in the environ- ment. In each step 𝑖 , a new quiz 𝑍 𝑖 + 1 is composed based on the previous one 𝑍 𝑖 by taking an action 𝑎 𝑖 . An exploration session 𝑆 , starting at state 𝑠 1 (i.e., denes a quiz 𝑍 1 ), of length 𝑛 , is a sequence of exploration states and actions: 𝑆 = [ ( 𝑠 1 , 𝑎 1 ) , . . . , ( 𝑠 𝑛 , 𝑎 𝑛 ) ] . Reinforcement Learning. Model-free RL [ 21 ] addresses sequen- tial optimization by having an agent interact with an environment and maximize cumulative reward. W e use this frame work for iz- Comp , where the agent composes the best quiz (Z) (the best state (s)) by maximizing search pr ogression. RL includes four elements: policy , reward, value function, and environment. A policy maps perceived states (quizzes) to actions, sometimes via simple functions and sometimes via search, as in izComp . The rewar d function denes the task objectiv e. Maximizing total reward drives policy updates. While rewards capture immediate benet, the value function reects long-term desirability . Here, the agent starts from a random quiz 𝑍 1 and moves closer to target topics and diculties 𝑇 𝐶 and 𝑇 𝐷 at each step. Although RL can include a model predicting next states and rewards, w e focus on model-free methods. Policy 𝜋 . A policy 𝜋 : S × A → [ 0 , 1 ] of an RL agent maps the probability of taking action 𝑎 ∈ A in state 𝑠 ∈ S , that is, 𝜋 ( 𝑠 , 𝑎 ) = 𝑃 𝑟 ( 𝑎 𝑡 = 𝑎 | 𝑠 𝑡 = 𝑠 ) . W e can rewrite the denition of a session as 𝑆 𝜋 = [ ( 𝑠 1 , 𝜋 ( 𝑠 1 ) ) , . . . , ( 𝑠 𝑛 , 𝜋 ( 𝑠 𝑛 ) ) ] . By replacing each state by its respective quiz, w e rewrite the session 𝑆 as 𝑆 𝜋 = [ ( 𝑍 1 , 𝜋 ( 𝑍 1 ) ) , . . . , ( 𝑍 𝑛 , 𝜋 ( 𝑍 𝑛 ) ) ] . Optimal Policy 𝜋 ∗ . A policy 𝜋 ∗ is optimal if its expecte d cu- mulative rewar d is greater than or equal to the expected cumu- lative reward of all other policies 𝜋 . The optimal policy has an associated optimal state-value function and optimal Q-function: 𝑄 ∗ ( 𝑠 , 𝑎 ) ← max 𝜋 𝑄 𝜋 ( 𝑠 , 𝑎 ) . Problem 2 (Revisited izComp Problem). Given a session 𝑆 , we dene sessionMatch ( . ) to measure the agent’s progress to ward nding a quiz that matches the target distributions, discounted by 𝛾 ∈ [ 0 , 1 ] : sessionMatch ( 𝑆 , 𝑇 𝐶 , 𝑇 𝐷 ) = (2) ( 𝑠 𝑖 ,𝑎 𝑖 ) ∈ 𝑆 𝛾 𝑖 targetMatch ( 𝑠 𝑖 + 1 .𝑍 , 𝑇 𝐶 , 𝑇 𝐷 ) − (3) targetMatch ( 𝑠 𝑖 .𝑍 , 𝑇 𝐶 , 𝑇 𝐷 ) (4) Hence, the problem is to nd an optimal policy 𝜋 ∗ = 𝑎𝑟 𝑔𝑚𝑎𝑥 𝜋 sessionMatch ( 𝑆 𝜋 , 𝑇 𝐶 , 𝑇 𝐷 ) . 2.2 Reinforcement Learning Solutions W e explore three RL solutions to solve izComp . Deep Q-Network (DQN) [ 21 ] extends Q-learning using deep net- works to approximate Q-values, estimating expe cted cumulative reward for each ⟨ 𝑠 , 𝑎 ⟩ pair . It iteratively up dates Q-values to bal- ance exploration and exploitation with learning rate 𝛼 and discount factor 𝛾 : 𝑄 ( 𝑠 , 𝑎 ) ← 𝑄 ( 𝑠 , 𝑎 ) + 𝛼 𝑅 + 𝛾 max 𝑎 ′ ∈ 𝐴 𝑄 ( 𝑠 ′ , 𝑎 ′ ) − 𝑄 ( 𝑠 , 𝑎 ) . (5) W e adopt PER [19] to enrich training experience. SARSA [ 21 ] is an on-policy variant of Q-learning, SARSA updates Q-values using the action the agent actually takes: 𝑄 ( 𝑠 , 𝑎 ) ← 𝑄 ( 𝑠 , 𝑎 ) + 𝛼 [ 𝑅 + 𝛾 𝑄 ( 𝑠 ′ , 𝑎 ′ ) − 𝑄 ( 𝑠 , 𝑎 ) ] . (6) A2C/A3C [ 13 ] are actor–critic methods that combine policy gra- dients with value estimation. The actor updates action pr obabilities while the critic estimates advantages: Advantage ( 𝑠 , 𝑎 ) ≈ 𝑅 ( 𝑠 , 𝑎, 𝑠 ′ ) + 𝛾 𝑉 ( 𝑠 ′ ) − 𝑉 ( 𝑠 ) . (7) A3C extends A2C with parallel asynchronous workers, each interacting with its own envir onment copy to stabilize learning and update shared actor–critic networks. 3 Experiments 3.1 Setup Datasets. W e use three Synthetic and two real datasets ( MeD and Ma th , T able 1). While Math has human-crafted MCQs, we generate MCQs for MeD using MedGemma 9B, p erforming com- parably to GPT -4o. Synthetic datasets control data distributions (uniform or biase d) to study agent behavior (T able 2), sampling topic and diculty vectors via a multivariate Dirichlet (parame- ters 1 for uniform, 0.5 for biased). Our real datasets have median similarity 0.67 ( Ma th ) and 0.69 ( MeD ), indicating generally similar quizzes. High-similarity quizzes ( > 0 . 80 ) are far fewer for biased targets; e.g., in MeD , 3860 quizzes match 𝑇 uniform vs. 86 for 𝑇 bias . T eacher targets. W e consider two typ es of target distributions. 𝑇 uniform represents uniform coverage of all topics and diculty levels, while 𝑇 bias and 𝑇 ′ bias represent biased targets, focusing on specic topics and diculty levels. Agents. W e instantiate ve dierent agents for each RL algo- rithm described in Section 2.2 by var ying the weight of the reward 𝛼 in { 0, 0.25, 0.5, 0.75, 1 } . Each instance of an algorithm focuses on giving more or less importance to optimizing one of the objec- tives based on its spe cic value of 𝛼 (e.g., an instance with 𝛼 = 0 optimizes only for the diculty le vel and ignores topic distribution). Implementation of environment and actions. W e build the environment from MCQs by ltering those covering a random subset of 𝑘 = 10 topics yielding a universe to 10 4 quizzes. MDP actions use Cosine similarity to modify a quiz 𝑍 into 𝑍 ′ , sampling the 25 most similar or dissimilar quizzes from the pre-sampled quizzes, while avoiding similarity greater than 0 . 95 . Training setup. W e set the numb er of episo des to 5000 and the maximum number of iterations per episode to 100. W e set the reward target threshold 𝛽 to 0 . 85 . This means that if the agent nds a quiz 𝑍 with a similarity to the target that is equal to or higher than 0 . 85 , it considers it as a go od result and stops the navigation. W e used a 𝜖 -greedy decay strategy for exploitation/exploration with 𝜖 _ 𝑑 𝑒𝑐 𝑎𝑦 = 0 . 995 , 𝜖 _ 𝑚𝑖 𝑛 = 0 . 05 . W e set the value of 𝛾 to 0 . 95 , the learning rate to 0 . 005 , and the batch size to 128 . 3 Dataset Description #MCQs #T opics #Di. levels MeD generated using MedGemma 9B 1 based on medical documents from the UNESS https://entrainement- ecn.uness.fr/ platform for training medical professionals. 1500+ 111 topics from which w e sampled 10 topics, e.g., Car- diology , Rhumatology . The diculty level of each MCQ has a numerical scale within [ 1 , 5 ] , 1 being the easiest. Ma th [2] collected from MathE https://mathe. ipb.pt/ an e-learning platform for enhancing mathematical skills in higher e ducation and supporting au- tonomous MCQ-based learning. 1900+ 15 topics from which we sampled 10 topics, e.g., Lin- ear Algebra, Probabilities. The diculty level of each MCQ on a increasing scale within [ 1 , 6 ] . T able 1: Description of real datasets. Dataset Description Example quiz representation Uniform Uniformly drawn MCQs 𝑇 𝐶 = <0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1> 𝑇 𝐷 = <0.2, 0.2, 0.2, 0.2, 0.2> BiasedT opic Biased topics and uniform diculties 𝑇 𝐶 = <0, 0, 0, 0, 0, 0.5, 0, 0, 0.5, 0> 𝑇 𝐷 = <0.2, 0.2, 0.2, 0.2, 0.2> BiasedLevel Biased diculties and uniform topics 𝑇 𝐶 = <0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1> 𝑇 𝐷 = <0.5, 0, 0, 0, 0.5> T able 2: Description of Synthetic datasets. Oracle. W e assume access to an oracle that always nds the closest quiz to the target, used to assess our agents’ ability to reach the ground truth. The oracle scans all 10,000 quizzes, but in real scenarios, the full quiz set may be unavailable, as quizzes are gen- erated by the agent. Thus, the oracle serves only as an accuracy baseline. Measures. W e report measures for training: (1) evolution of Q- values across episodes to verify conv ergence, (2) action distribution, and for inference: (3) similarity to the b est quiz, (4) #iterations to reach it, and (5) avg time. All results are an aggregation over 10 runs. 3.2 Summary of results Our results show that agents converge regardless of 𝛼 values or dataset bias. The learned action distribution depends on 𝛼 and the target but not the dataset: for 𝑇 uniform , agents favor similarity actions ( SimT opic , SimLevel ) and av oid dissimilarity actions, staying risk- averse, while for 𝑇 bias , they explore more using dissimilarity actions. In synthetic inference, RL agents nd go od quizzes independently of 𝛼 or data bias, though matching topics is harder than diculties due to their larger number . Real-world results conrm these ndings: agents achie ve goo d quizzes 100 × faster than Oracle and reach high quiz similarity ( . 925 ) when increasing the reward thr eshold, likely due to replay buers. Transfer learning is eective acr oss datasets and from 𝑇 bias to 𝑇 uniform , and between biased targets ( 𝑇 bias and 𝑇 ′ bias ), though the reverse transfer is har der . 3.3 Synthetic environments W e r eport the DQN evaluation results with dierent values of 𝛼 and dierent datasets. The other RL algorithms exhibit similar trends. The training is performed on 𝑇 uniform as it reects real settings. In the following, we report empirical results on both the training and inference phases. Training P hase. Figure 2 shows that all DQN agents converge around ∼ 30 k steps across datasets and 𝛼 values, despite early instability for 𝛼 = 0 . 5 and biases like those in BiasedT opic . Maximum Q-values vary with data bias and 𝛼 , but convergence remains consistent, highlighting agent stability without theoretical guarantees [14]. Figure 3 shows that for target 𝑇 uniform , agents primarily select sim- ilarity actions ( SimT opic , SimLevel ) and avoid dissimilarity actions ( DissT opic , DissLevel ) due to negative rewar ds, a pattern consistent across datasets and driven by 𝛼 rather than data bias. For biased targets 𝑇 bias (Figure 4), agents use more dissimilarity actions, re- ecting exploratory behavior . O verall, learned policies depend on both the target type and the optimized obje ctives. Algos 𝛼 Uniform BiasedT opic BiasedLevel DQN 0 0.896 0.903 0.888 0.25 0.877 0.880 0.885 0.5 0.870 0.870 0.862 0.75 0.868 0.860 0.860 1 0.877 0.851 0.869 Oracle 0 0.998 0.997 1.000 0.25 0.957 0.995 0.983 0.5 0.944 0.994 0.975 0.75 0.944 0.994 0.967 1 0.973 0.999 0.974 T able 3: A verage similarity with target 𝑇 uniform for all Syn- thetic datasets. 4 0k 50k 100k 150k 200k 250k 300k Iterations 0.1 0.0 0.1 0.2 0.3 Q - values 10k 20k 30k 0.1 0.0 0.1 0.2 BIASEDTOPIC - =0 BIASEDTOPIC - =0.5 BIASEDTOPIC - =1 BIASEDLEVEL - =0 BIASEDLEVEL - =0.5 BIASEDLEVEL - =1 UNIFORM - =0 UNIFORM - =0.5 UNIFORM - =1 Figure 2: Evolution of max 𝑄 -function across training iterations of DQN on target 𝑇 uniform for dierent datasets and 𝛼 values. 0k 1k 2k 3k 4k 5k 0% 50% 100% = 0 0k 1k 2k 3k 4k 5k 0% 50% 100% A ction Distribution = 0.5 0k 1k 2k 3k 4k 5k Episodes 0% 50% 100% = 1 SimT opic SimL evel DissT opic DissL evel Figure 3: Evolution of learned actions per episode during DQN training on target 𝑇 uniform for Uniform dataset. 0k 1k 2k 3k 4k 5k Episodes 0% 50% 100% A ction Dist . α = 0.5 SimT opic SimL evel DissT opic DissL evel Figure 4: Evolution of learned actions per episode during DQN training on target 𝑇 bias for Uniform dataset. 5 = 0.25 = 0.75 T rajectory Start End Oracle 0.6 0.8 Similarity Figure 5: Examples of agent trajectories in Uniform dataset using UMAP 2D projection. Inference Phase. T able 3 shows the average similarity of the found quizzes to the target 𝑇 uniform using dierent 𝛼 values on all Syn- thetic datasets. O verall, the trained agents succee d in nding good quizzes close to the target 𝑇 uniform as they reach the 0 . 85 similarity threshold. The agents seem to nd it more challenging to optimize for topics than for diculty levels, as the similarity with 𝑇 uniform slightly decreases when 𝛼 increases (i.e., the increase obser ved with 𝛼 = 1 is due to the fact that the agent optimizes only topic cover- age). This can also be se en in Figure 5, which depicts the inference trajectory that an agent takes to nd 𝑇 uniform . The agent tends to use more actions with 𝛼 = 0 . 75 than with 𝛼 = 0 . 25 . W e explain this by the fact that ther e ar e mor e topics than diculties, which makes it more challenging to match the desired topic distribution. 3.4 Real environments Data Algos 𝛼 0 0.25 0.5 0.75 1 MeD DQN 0.918 0.878 0.871 0.860 0.893 SARSA 0.911 0.880 0.876 0.870 0.852 A2C 0.907 0.877 0.869 0.861 0.886 A3C 0.910 0.880 0.869 0.866 0.899 Oracle 1.000 0.978 0.977 0.988 1.000 Ma th DQN 0.875 0.859 0.860 0.858 0.886 SARSA 0.870 0.856 0.862 0.852 0.906 A2C 0.870 0.859 0.855 0.861 0.899 A3C 0.879 0.856 0.859 0.852 0.913 Oracle 0.913 0.913 0.913 0.936 1.000 T able 4: A verage similarity with target for all agents in real datasets when nding 𝑇 uniform . T able 4 shows all algorithms achieve quiz similarity above 0.85. Dierences b etween RL metho ds are small, showing they lo cate the target region eectively . RL nds goo d quizzes (e.g., 𝛼 = 0 . 5 , SARSA 0.876 vs. 0.977 best). Extreme 𝛼 values improve similarity by focusing on a single objective, and no algorithm consistently outperforms others across datasets and 𝛼 values. Data Algos # Iterations Time (sec) MeD DQN 20 0.04 SARSA 29 0.07 A2C 25 0.05 A3C 17 0.04 Oracle 10000 5.22 Ma th DQN 31 0.07 SARSA 30 0.06 A2C 33 0.06 A3C 33 0.08 Oracle 10000 4.99 T able 5: A verage #iterations and time to nd target 𝑇 uniform . T able 5 shows avg iterations and inference times for 𝑇 uniform . On Ma th , algorithms perform similarly , while DQN and A3C slightly outperform on MeD , likely due to DQN’s replay buer [ 8 ] and A3C’s asynchronous exploration [ 13 ]. Oracle nds the most similar quiz but scales poorly; e.g., on MeD , DQN reaches 91.4% of Oracle’s similarity about 100x faster . Small p erformance dierences in Tables 4 may stem from the 0.85 reward threshold used in training and inference. Figure 6 shows that for thresholds below 0.925, DQN, SARSA, and A3C achieve similar similarity , while ab ove 0.925, DQN outperforms due to stable learning with experience replay [ 8 ]; SARSA is conservative and A3C requires careful tuning [ 3 ]. High-similarity quizzes ( > 0 . 90 ) often satisfy at least one criterion, limiting gains, and iteration counts rise with thresholds, justifying the 0.85 threshold for faster convergence and generalization. 3.5 Transfer Learning W e evaluate the transfer capabilities of a trained RL model across dierent targets ( 𝑇 uniform , 𝑇 bias , and 𝑇 ′ bias ) and across datasets ( MeD 6 Figure 6: Evolution of number of iterations and similarity to target based on reward threshold for MeD dataset. and Ma th ). W e set the value of 𝛼 to 0 . 5 to have an equi-balanced bi-objective optimization and rely only on real-world datasets. Training target Inference target Algos Similarity w/target #Iter 𝑇 uniform 𝑇 bias DQN 0.756 100 SARSA 0.791 100 A2C 0.800 83 A3C 0.775 95 Oracle 0.888 10000 𝑇 bias 𝑇 uniform DQN 0.866 24 SARSA 0.855 62 A2C 0.852 67 A3C 0.833 97 Oracle 0.913 10000 𝑇 bias 𝑇 ′ bias DQN 0.856 48 SARSA 0.851 84 A2C 0.866 52 A3C 0.866 50 Oracle 0.927 10000 T able 6: A verage similarity and # Iter (iterations) for trans- ferring the learning of agents across targets on Ma th with 𝛼 = 0 . 5 . T able 6 shows transfer results on Ma th . Transferring from a biased target to a uniform one works well, with agents reaching 0.85 similarity in few iterations. The re verse is harder: from 𝑇 uniform to 𝑇 bias , agents either hit the iteration limit (DQN, SARSA) or need many iterations (A3C, 95). Biased targets require more exploration; agents trained on 𝑇 uniform favor similarity actions and local search, while those trained on 𝑇 bias use dissimilarity actions. T raining on one biased target also transfers to another (e.g., 𝑇 ′ bias ), with all agents reaching 0.85 similarity , showing a general policy for uniform or biased quizzes. T able 7 shows the results of transferring the learning of agents across datasets using 𝑇 uniform as a target. In both cases the similarity of the found quizzes is high ev en if the transfer is performed across two types of knowledge. This benets from our formalization (Sec- tion 2.1), which makes our agents agnostic to the typ es of MCQs or quizzes. Training data Inference data Algos Similarity w/target #Iter MeD Ma th DQN 0.877 12 SARSA 0.881 8 A2C 0.865 16 A3C 0.864 11 Oracle 0.956 10000 Ma th MeD DQN 0.868 20 SARSA 0.874 12 A2C 0.867 9 A3C 0.874 12 Oracle 0.977 10000 T able 7: A verage similarity and # Iter (Iterations) for trans- ferring the learning of agents across datasets on 𝑇 uniform with 𝛼 = 0 . 5 . 3.6 Qualitative Study W e launched a pilot user study with 28 participants to assess per- ceived workload using the NASA Task Load Index (NASA- TLX). 2 Participants were selected to have teaching experience at the uni- versity or se condary level and hold a Master’s or PhD degree in mathematics or a closely related quantitative eld. After using our system to build quizzes, participants reporte d moderate mental demand and eort, low perceived controllability reected in lower perceived performance and higher frustration, and low temporal demand, with moderate perceived accomplish- ment and slightly positive satisfaction. Finally , 57% of participants indicated they would use the system again, opening new opportu- nities for larger studies. 4 Related W ork Standard quiz generation. Early rule-based quiz generation use d templates and simple rules, such as “include two geometr y ques- tions, ” oering automation but limited generalizability [ 1 , 6 ]. Later , NLP and ML methods predicted question diculty [ 4 ] and use d clustering or topic modeling to group or diversify questions [ 9 ]. These methods focus on single-objective optimization and do not sup- port balancing multiple pedagogical criteria. Multi-objective quiz composition. With a high-quality MCQ bank, focus shifts from generation to comp osition. MOEPG [ 20 ] frames exam generation as multi-objective RL. In our work, we tar- get varie d topic and diculty distributions allowing us to train agents that capture dierent p edagogical goals. Additionally , we evaluate multiple RL algorithms. LLMs for quiz generation. LLMs like GPT -4 generate MCQs text [ 11 , 12 ], using prompt engineering or chain-of-thought [ 22 ], and can generate and evaluate quizzes [ 12 , 15 ], though irrelevant con- tent may appear . Knowledge Tracing and RAG adapt quizzes to learners [ 10 ], while concept-based methods improve grounding [ 5 ]. W e use LLMs to generate MCQs but rely on RL for quiz compo- sition to mimic a teacher balancing multiple objectives across data distributions. 2 https://en.wikipedia.org/wiki/NASA- TLX 7 5 Conclusion W e inv estigated RL-base d approaches for quiz composition and pro- vided an extensive performance comparison of DQN, SARSA, and A2C/A3C. Our work investigated and demonstrated ee ctiveness of transfer learning across datasets and p edagogical targets. Our future work will broaden the action space and study trade-os between on-the-y MCQ generation with language mo dels and me eting teacher objectives. W e will compare the cost of prompt engineering and model calls to the cost of training an RL agent, including in transfer-learning settings, formalizing b oundaries between training and reuse in line with recent work on ML reusability [17]. Impact Statement This paper advances Online RL by studying its application to teacher- facing services. Our work has notable societal implications, partic- ularly in empowering teachers to understand their materials and generate personalized tests. References [1] T ahani Alsubait, Bijan Parsia, and Ulrike Sattler . Ontology-based multiple choice question generation. KI - Künstliche Intelligenz , 30(2):183–188, 2016. [2] Beatriz Flamia Azevedo, Florb ela P. Fernandes, Maria F. Pacheco, and Ana I. Pereira. Dataset for Assessing Mathematics Learning in Higher Education, 2024. [3] Neil De La Fuente and Daniel A Vidal Guerra. A comparative study of deep reinforcement learning mo dels: Dqn vs ppo vs a2c. arXiv preprint , 2024. [4] W . Feng, P. Tran, S. Sireci, and A. Lan. Reasoning and sampling-augmente d mcq diculty prediction via llms. arXiv preprint , arXiv:2503.08551, 2025. [5] Yicheng Fu, Zikui W ang, Liuxin Y ang, Meiqing Huo, and Zhongdongming Dai. Conquer: A framework for concept-based quiz generation, 2025. [6] Michael Heilman and Noah A. Smith. Good question! statistical ranking for question generation. In Proceedings of the NAACL-HLT , 2010. [7] Kevin Hwang, Sai Challagundla, Mar yan M. Alomair , and Lujie Karen Chen. T owards ai-assisted multiple choice question generation and quality evaluation at scale: Aligning with blo om’s taxonomy . In Generative AI for Education (GAIED): Advances, Opportunities, and Challenges. NeurIPS2023 , 2023. [8] Gonzalo Aguilar Jiménez, Arturo de la Escalera Hueso, and Maria J Gómez-Silva. Reinforcement learning algorithms for autonomous mission accomplishment by unmanned aerial vehicles: A comparative view with dqn, sarsa and a2c. Sensors , 23(21):9013, 2023. [9] Ghader Kurdi, Jared Leo, Bijan Parsia, Uli Sattler , and Salam Al-Emari. A system- atic review of automatic question generation for educational purposes. Interna- tional Journal of A rticial Intelligence in Education , 30(1):121–204, 2020. ERIC: EJ1247652. [10] Zhaoxing Li, V ahid Y azdanpanah, Jindi W ang, W en Gu, Lei Shi, Alexandra I. Cristea, Sarah Kiden, and Sebastian Stein. Tutorllm: Customizing learning r ec- ommendations with knowledge tracing and retrieval-augmented generation, 2025. [11] Subhankar Maity , Aniket Deroy , and Sudeshna Sarkar. Exploring the capabilities of prompted large language models in educational and assessment applications, 2024. [12] N. Meißner , S. Speth, J. Kieslinger , and S. Becker. Evalquiz — llm-base d automate d generation of self-assessment quizzes in se education. In SEUH 2024 , 2024. [13] V olodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timo- thy P. Lillicrap, Tim Harley , David Silver , and Koray K avukcuoglu. Asynchronous methods for deep reinforcement learning. CoRR , abs/1602.01783, 2016. [14] V olodymyr Mnih, Koray Kavukcuoglu, David Silver , Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller . P laying atari with deep reinforcement learning. CoRR , abs/1312.5602, 2013. [15] Sérgio Silva Mucciaccia, Thiago Meireles Paixão, Filipe W all Mutz, Claudine Santos Badue, Alberto Ferreira de Souza, and Thiago Oliveira-Santos. Automatic multiple-choice question generation and evaluation systems based on LLM: A study case with university resolutions. In Proceedings of the 31st International Conference on Computational Linguistics , pages 2246–2260, Abu Dhabi, U AE, January 2025. [16] Deepak Subramani Nicy Scaria, Suma Dharani Chenna. Automated educational question generation at dierent bloom’s skill levels using large language models: Strategies and evaluation. In A rticial Intelligence in Education. AIED 2024 , 2024. [17] Sepideh Nikookar , Sohrab Namazi Nia, Senjuti Basu Roy , Sihem Amer-Y ahia, and Behrooz Omidvar- Tehrani. Model reusability in reinforcement learning. VLDB J. , 34(2):283–304, 2025. [18] Andrew M. Olney . Generating multiple choice questions from a textbook: Llms match human performance on most metrics. In Procee dings of the W orkshop on Empowering Education with LLMs, co-located with AIED 2023, T okyo, Japan, July 7, 2023, volume 3487, pages 111–128. , 2023. [19] T om Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay . In Y oshua Bengio and Yann LeCun, editors, 4th International Conference on Learning Representations, ICLR 2016, Puerto Rico, May 2-4, 2016 , 2016. [20] Y . Shang, X. Luo, L. W ang, H. Peng, X. Zhang, Y. Ren, and K. Liang. Reinforce- ment learning guided multi-objective exam paper generation. arXiv preprint , arXiv:2303.01042, 2023. [21] R. S. Sutton and A. G. Barto. Reinforcement learning: A n introduction . MI T Press, Cambridge, MA, 2018. [22] Z. Y ao, C. Zhang, J. Gu, J. Yin, Z. Yin, and M. Tan. Mcqg-srene: Multiple choice question generation with iterative self-critique and correction. arXiv preprint , arXiv:2410.13191, 2024. 8 Unifor m / α=0. 5 Bi asedT opic w / α =1 Bi asedL evel w / α =0 0.6 0.8 t ar getMatch Figure 7: Projection of high-dimensional states in 2D with UMAP: a) Uniform dataset with 𝛼 = 0 . 5 ; b) BiasedT opic dataset with 𝛼 = 1 ; c) BiasedLevel dataset with 𝛼 = 0 . A Additional Synthetic Experiments and Qualitative Diagnostics This appendix complements the main experimental section with additional material focused on the synthetic setting: (i) the distribution of the generated synthetic data, (ii) reward stabilization during training, and (iii) qualitative visualizations of the agent navigation in the quiz space. A.1 Synthetic data generation and distributions Synthetic environments. W e generate three synthetic datasets ( Uniform , BiasedT opic , and BiasedLevel ) to study agent behavior under controlled data distributions. W e sample topic and diculty vectors from a Dirichlet distribution, with concentration parameters 𝜇 = 1 for Uniform data and 𝜇 = 0 . 5 for biased data. T able 2 in the main paper reports the denition of the three synthetic datasets, while Figure 7 provides a qualitative visualization of their structure using a 2D UMAP projection. Reward Denitions. W e report results under two reward schemes. The rst reward, denoted 𝑅 1 , is a direct similarity reward baseline where the agent is rewar ded according to the absolute similarity between the current quiz and the target distributions: 𝑅 1 ( 𝑠 , 𝑎, 𝑠 ′ ) = targetMatch ( 𝑍 ′ , 𝑇 𝐶 , 𝑇 𝐷 ) , (8) with targetMatch ( 𝑍 , 𝑇 𝐶 , 𝑇 𝐷 ) = 𝛼 · topicMatch ( 𝑍 , 𝑇 𝐶 ) + ( 1 − 𝛼 ) · diMatch ( 𝑍 , 𝑇 𝐷 ) , (9) where 𝛼 ∈ [ 0 , 1 ] controls the relative importance of topic cov erage versus diculty alignment. The second reward, denoted 𝑅 2 , is a progress-based rewar d that captures the agent’s improv ement between consecutive quizzes: 𝑅 2 ( 𝑠 , 𝑎, 𝑠 ′ ) = targetMatch ( 𝑍 ′ , 𝑇 𝐶 , 𝑇 𝐷 ) − targetMatch ( 𝑍 , 𝑇 𝐶 , 𝑇 𝐷 ) . (10) Positive rewards indicate progress toward the target, while negative rewards penalize regressions. Unlike 𝑅 1 , 𝑅 2 explicitly encourages exploratory trajectories by rewarding incremental impro vements rather than absolute similarity . A.2 Reward stabilization during training Figure 8 shows the evolution of topicMatch and diMatch across training episodes under the direct rewar d baseline R 1 , illustrating early stabilization and limited improvement. A.3 Agent trajectories in the quiz space W e provide qualitative visualizations of agent navigation both in the state space ( UMAP) and in the objective space ( topicMatch , diMatch ). UMAP trajectories. Figures 9 and 10 show example inference trajectories under R 1 and R 2 , respectively . Trajectories in objective space . Figures 11 and 12 show the same type of analysis projected in the 2D plane dened by ( topicMatch , diMatch ). 9 0 1k 2k 3k 4k 5k Episodes 0.56 0.58 0.60 0.62 0.64 t o p i c M a t c h = 0 = 0.25 = 0.5 = 0.75 = 1 0 1k 2k 3k 4k 5k Episodes d i f f M a t c h Figure 8: Evolution of topicMatch and diMatch across training episodes of DQN on target 𝑇 uniform for Uniform dataset, with smoothing window of size 100. α = 0.25 α = 0.75 T rajectory Start End Oracle 0.6 0.8 targetMatch Figure 9: Examples of agent trajectories in Uniform dataset using UMAP 2D projection following reward R 1 (direct similarity reward); the colors of the agent trajectory represent the inference timeline, wher e time shifts from lighter to darker colors. 10 = 0.25 = 0.75 T rajectory Start End Oracle 0.6 0.8 Similarity Figure 10: Examples of agent trajectories in Uniform dataset using UMAP 2D projection following reward R 2 (progress-based reward). 0.45 0.60 0.75 0.90 topicMatch 0.45 0.60 0.75 0.90 diffMatch α = 0.25 T rajectory Start End Oracle 0.45 0.60 0.75 0.90 α = 0.75 0.6 0.8 targetMatch Figure 11: Examples of agent traje ctories in Uniform dataset using 2D projection with topicMatch and diMatch following reward R 1 (direct similarity re ward). 11 0.45 0.60 0.75 0.90 topicMatch 0.45 0.60 0.75 0.90 diffMatch α = 0.25 T rajectory Start End Oracle 0.45 0.60 0.75 0.90 α = 0.75 0.6 0.8 targetMatch Figure 12: Examples of agent traje ctories in Uniform dataset using 2D projection with topicMatch and diMatch following reward R 2 (progress-based rewar d). 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment