LVRPO: Language-Visual Alignment with GRPO for Multimodal Understanding and Generation
Unified multimodal pretraining has emerged as a promising paradigm for jointly modeling language and vision within a single foundation model. However, existing approaches largely rely on implicit or indirect alignment signals and remain suboptimal fo…
Authors: Shentong Mo, Sukmin Yun
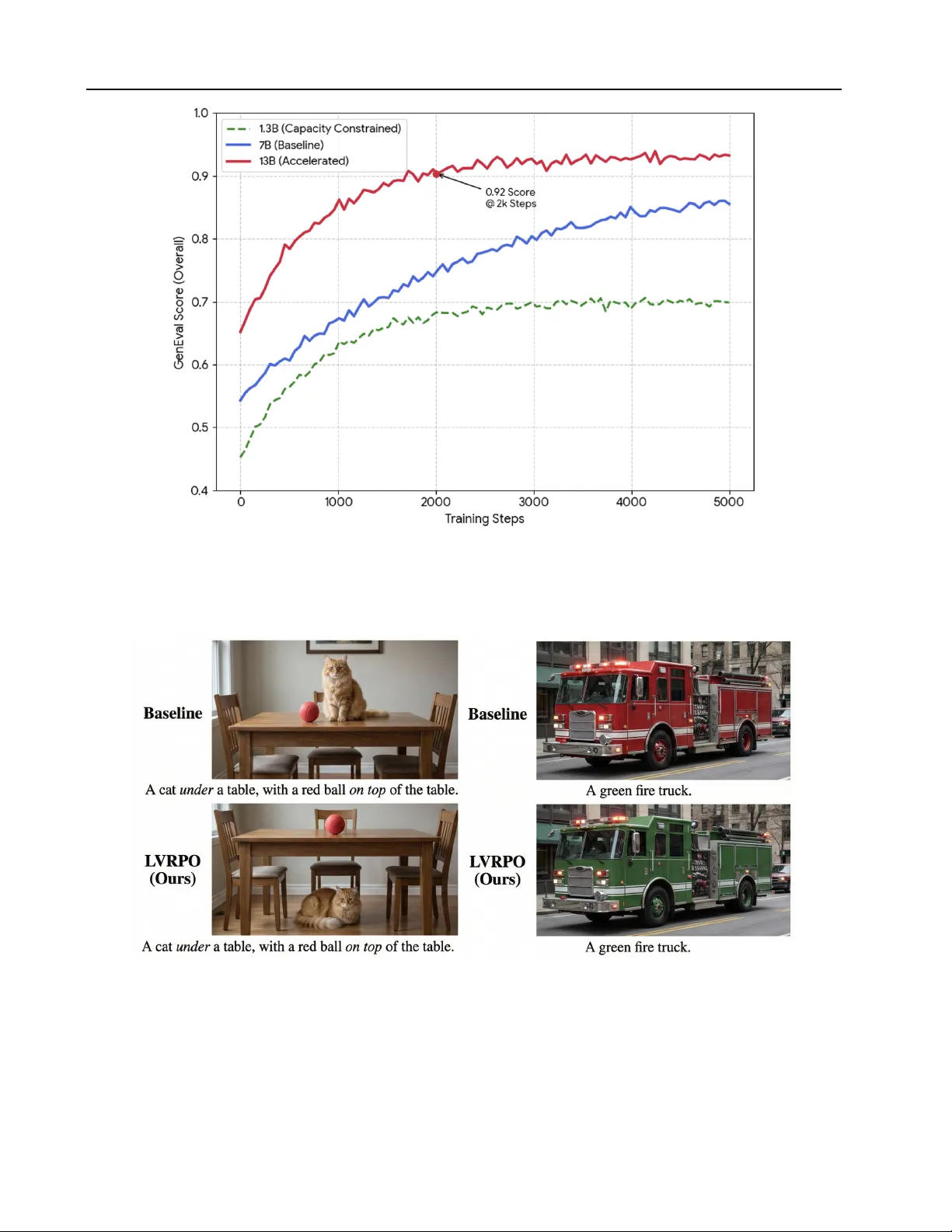
L VRPO: Language-V isual Alignment with GRPO f or Multimodal Understanding and Generation Shentong Mo 1 2 Sukmin Y un 3 Abstract Unified multimodal pretraining has emerged as a promising paradigm for jointly modeling lan- guage and vision within a single foundation model. Howe ver , existing approaches largely rely on implicit or indirect alignment signals and remain suboptimal for simultaneously support- ing multimodal understanding and generation, particularly in settings that require fine-grained language–visual reasoning and controllable gen- eration. In this work, we propose L VRPO, a language-visual reinforcement-based preference optimization framew ork that explicitly aligns lan- guage and visual representations using Group Rel- ativ e Policy Optimization (GRPO). Instead of in- troducing additional alignment losses at the repre- sentation le vel, L VRPO directly optimizes multi- modal model behaviors through preference-driv en reinforcement signals, encouraging consistent and semantically grounded interactions between lan- guage and vision across both understanding and generation tasks. This formulation enables ef- fectiv e alignment without requiring auxiliary en- coders or handcrafted cross-modal objecti ves, and naturally extends to di verse multimodal capabil- ities. Empirically , L VRPO consistently outper- forms strong unified-pretraining baselines on a broad suite of benchmarks spanning multimodal understanding, generation, and reasoning. 1. Introduction A unified foundation model capable of seamlessly bridg- ing multimodal understanding and generation has led to the emergence of unified pretraining as a dominant paradigm. Unlike earlier disjointed pipelines ( Mo & Y un , 2024 ; 2026 ), these models aim to model vision within a single archi- 1 Department of Machine Learning, CMU, USA 2 Department of Machine Learning, MBZU AI, U AE 3 Department of Artificial Intelligence, Hanyang Univ ersity ERICA, South Korea. Corre- spondence to: Sukmin Y un < sukminyun@han yang.ac.kr > . Pr eprint. March 31, 2026. tecture, often utilizing large-scale data to foster emergent uni-modal capabilities. Recent breakthroughs, such as B AGEL ( Deng et al. , 2025 ), ha ve demonstrated that scale alone can induce impressiv e multimodal reasoning and gen- eration without requiring explicit alignment objecti ves. Si- multaneously , methods like REP A ( Y u et al. , 2025 ) hav e shown that aligning generati ve features with non-generative teachers ( e.g. , DINOv2 ( Oquab et al. , 2024 )) can signifi- cantly accelerate con vergence for vision-centric tasks. Despite these adv ances, a fundamental gap remains: exist- ing approaches largely rely on implicit or indirect alignment signals. While B AGEL rel ies on the sheer density of inter - leav ed tokens to learn associations, it often struggles with fine-grained semantic grounding, leading to hallucinations or failures in complex instruction following. On the other hand, representation-level alignment methods like REP A, which typically rely on a fix ed visual encoder to provide a ”semantic anchor , ” are often suboptimal for tasks requiring bidirectional synergy between language and vision. These methods typically prioritize vision-centric denoising over the nuanced, instruction-dri ven reasoning required for con- trollable generation and world-knowledge-inte grated under- standing. The core challenge in unified multimodal modeling lies in the discrepancy between internal representation alignment and end-to-end task performance. Existing methodologies generally face three critical hurdles: (i) Representation- based alignment, such as REP A ( Y u et al. , 2025 )’ s use of DINOv2 ( Oquab et al. , 2024 ) features, focuses on mini- mizing the distance between the model’ s latent states and a frozen visual teacher . Howe ver , visual encoders optimized for discriminativ e tasks often capture different features than those required for high-fidelity generation or complex rea- soning. Aligning to these features provides a ”hint” b ut does not necessarily translate to compositional understand- ing or the ability to follow intricate textual constraints in generation. (ii) In unified models, the objectiv e functions for understanding (often cross-entropy) and generation (of- ten diffusion-based or autore gressive) can conflict. Indirect signals struggle to balance these: a model might excel at captioning an image b ut fail to edit that same image based on a nuanced instruction, as the underlying ”world knowl- 1 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation edge” is not consistently activ ated across both heads. (iii) Current paradigms lack a mechanism to penalize ”seman- tically incorrect but statistically plausible” outputs. For instance, if a model generates a ”blue car” when asked for a ”red car , ” traditional reconstruction losses pro vide only a pixel-le vel or token-lev el penalty . There is no e xplicit signal that reinforces the logical preference for the correct attrib ute binding, leading to suboptimal performance on benchmarks like GenEval ( Ghosh et al. , 2023 ) and WISE ( Niu et al. , 2025 ) where precision is paramount. In this work, we introduce L VRPO, a framew ork for Language-V isual Reinforcement-based Preference Opti- mization that explicitly aligns language and visual represen- tations through the lens of behavior-dri ven reinforcement. Unlike traditional methods that introduce auxiliary align- ment losses at the feature level, L VRPO leverages Group Relativ e Policy Optimization (GRPO) ( Shao et al. , 2024 ) to directly optimize the model’ s responses. By treating mul- timodal consistency as a preference-dri ven signal, L VRPO encourages the model to generate outputs, whether text or images, that are semantically grounded and instruction- faithful. While REP A aligns internal hidden states to a static vision teacher , L VRPO optimizes the end-to-end be- havior . W e utilize the SigLIP 2 ( Tschannen et al. , 2025 ) encoder’ s dense semantic features not as a rigid target for distillation, but as a robust foundation for ev aluating and reinforcing multimodal consistency during preference opti- mization. Rather than relying on emergent alignment from scale in B AGEL, L VRPO introduces an explicit preference stage that ”closes the loop” between understanding and gen- eration, leading to superior grounding in complex scenarios. Our empirical ev aluation demonstrates the efficacy of L VRPO across a comprehensiv e suite of benchmarks. On multimodal understanding tasks, L VRPO consistently out- performs strong unified baselines like BA GEL. In the realm of generation, it achiev es state-of-the-art results on GenEval, particularly in compositional accuracy . Notably , L VRPO shows a significant leap in w orld-knowledge-based reason- ing on WISE, suggesting that preference optimization ef- fectiv ely bridges the gap between linguistic knowledge and visual realization. Finally , on image editing benchmarks such as GEdit-Bench and the reasoning-heavy Intelligent- Bench, L VRPO e xhibits superior instruction-follo wing, en- abling precise and semantically aw are visual manipulation that surpasses existing open-source and many proprietary competitors. Our contributions can be summarized as follo ws: • W e propose a nov el language-visual reinforcement- based preference optimization frame work that explic- itly aligns understanding and generation through behav- ioral signals rather than static representation mimicry . • W e extend Group Relati ve Policy Optimization to the multimodal domain, enabling efficient, critic-free align- ment of a unified MoT backbone. • W e provide theoretical justifications for the synergy between reasoning and generation in unified models, proving that L VRPO maximizes a lower bound on cross-modal mutual information while maintaining training stability through gradient decoupling. • W e demonstrate the empirical superiority of L VRPO across a comprehensiv e suite of benchmarks. 2. Related W ork Unified Multimodal Foundation Models. Recent research has shifted from modular pipelines toward unified architec- tures that model language and vision within a single trans- former backbone. Early attempts like Chameleon ( T eam , 2024 ) and Show-o ( Xie et al. , 2024a ) demonstrated the fea- sibility of interlea ved tok enization for discrete multimodal modeling. More recently , BA GEL ( Deng et al. , 2025 ) and Emu3 ( W ang et al. , 2024c ) hav e advanced this paradigm by utilizing large-scale pretraining to induce emer gent rea- soning and high-fidelity generation. Ho we ver , these models primarily rely on implicit alignment through next-token pre- diction or flo w matching. L VRPO builds upon this unified foundation by introducing an explicit beha vioral alignment stage, ensuring that emergent capabilities are grounded in semantically consistent interactions. Multimodal Representation Alignment. A common strat- egy to bridge the gap between modalities is to align the model’ s internal representations with a pretrained teacher . REP A ( Y u et al. , 2025 ) utilizes denoising feature alignment to bridge generativ e models with discriminati ve teachers like DINOv2 ( Oquab et al. , 2024 ). Similarly , methods like VILA-U ( W u et al. , 2024b ) and Janus ( W u et al. , 2024a ) fo- cus on cross-modal bottleneck layers or shared latent spaces. While effecti ve for feature transfer, these methods often suffer from featur e rigidness , forcing the model to inherit the inductive biases of the teacher . L VRPO departs from this by shifting from representation alignment (mimicking hidden states) to behavioral alignment (optimizing outputs), utilizing SigLIP 2 ( Tschannen et al. , 2025 ) as a semantic referee rather than a distillation target. Prefer ence Optimization in Multimodal Learning . Rein- forcement Learning from Human Feedback (RLHF) and Di- rect Preference Optimization (DPO) have revolutionized the alignment of Large Language Models (LLMs) with human intent. In the multimodal domain, recent works hav e ex- plored using DPO for text-to-image models to improve aes- thetic quality or instruction following ( W allace et al. , 2023 ). Howe ver , applying these to unified models is challenging due to the high computational cost of the Critic network 2 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation in standard PPO. W e le verage Group Relativ e Policy Opti- mization (GRPO) ( Shao et al. , 2024 ), which eliminates the need for a separate v alue function by using group-relative rew ards. By extending GRPO to unified multimodal tasks, L VRPO enables ef ficient alignment of both understanding and generation pathways simultaneously , addressing the “seesaw ef fect” often observed in multi-task learning. 3. Method In this section, we present L VRPO, a framew ork designed to explicitly align language and visual modalities via reinforcement-based preference optimization. Unlike previ- ous methods that rely on static representation distillation or implicit alignment through large-scale pretraining, L VRPO treats the unified multimodal model as a policy that is op- timized based on the semantic consistenc y and instruction- following quality of its outputs. 3.1. Preliminaries Unified Multimodal Modeling. W e consider a unified transformer-based architecture M parameterized by θ . The model processes interlea ved sequences of text tok ens T = { t 1 , . . . , t n } and visual patches V = { v 1 , . . . , v m } . The model is trained to minimize a joint objective, typically combining autoregressi ve language modeling and latent vi- sual reconstruction: L unif ied = L text ( T | V ) + λ L v is ( V | T ) . (1) GRPO. T o av oid the computational burden of a separate Critic network in traditional RLHF , L VRPO adopts the GRPO objectiv e. For a giv en prompt q , we sample a group of G outputs { o 1 , o 2 , . . . , o G } from the current policy π θ . The objectiv e is defined as: J GRPO ( θ ) = E q ∼ P ( q ) , { o i }∼ π θ " 1 G G X i =1 L CLIP ( o i , q ) ˆ A i − β D KL ( π θ ∥ π ref ) # . (2) where L C LI P denotes the surrogate loss used in PPO, and ˆ A i is the relativ e advantage of output o i within its group, computed as: ˆ A i = r i − mean ( { r 1 , . . . , r G } ) std ( { r 1 , . . . , r G } ) . (3) Here, r i represents the multi-dimensional re ward assigned to the i -th sample. 3.2. L VRPO: Behavioral Multimodal Alignment Current state-of-the-art methods like REP A ( Y u et al. , 2025 ) utilize a representation-lev el alignment objective, typically formulated as a mean-squared error (MSE) between model features h θ and a teacher’ s features Φ tea : L alig n = E v ∼D [ ∥ f ( h θ ( v )) − Φ tea ( v ) ∥ 2 2 ] . (4) While effecti ve for vision-centric tasks, we argue this is suboptimal for unified multimodal models for two reasons: (1) Feature Rigidness: It forces the model to mimic the teacher’ s inductive biases ( e.g. , DINOv2’ s patch-lev el fo- cus), which may conflict with the generati ve requirements of the language-vision head. (2) Objectiv e Mismatch: Mini- mizing latent distance does not guarantee that the model’ s behavior ( e.g. , generating a specific object) follo ws the in- struction. L VRPO moti v ates alignment through the lens of expected utility maximization, where the model is rew arded for the semantic correctness of its output rather than the configuration of its hidden states. 3 . 2 . 1 . R E W A R D F O R M U L AT I O N A N D A DV A N TAG E E S T I M A T I O N In L VRPO, we define a multimodal re ward function R ( o, q ) that e valuates a generated output o gi ven a prompt q . Unlike traditional PPO, we utilize Group Relative Polic y Optimiza- tion (GRPO) ( Shao et al. , 2024 ) to deriv e the advantage ˆ A i without a critic network. For a group of G outputs { o i } G i =1 , the rew ard r sem for each sample is a composition of semantic and structural signals: r i = λ 1 · sim (Φ sig ( V i ) , Ψ sig ( T q )) | {z } Semantic Grounding + λ 2 · I ( rules ( o i , q )) | {z } Logical Constraints (5) where I ( · ) is an indicator function for verifiable constraints ( e.g . , image resolution, object counts, or text formatting). The advantage is then computed via group-relati ve normal- ization: ˆ A i = r i − 1 G P G j =1 r j σ ( { r j } G j =1 ) + ϵ (6) Instruction Follo wing ( r ins ). W e define r ins as a binary satisfaction score over a set of verifiable rules C q deriv ed from the prompt (e.g., aspect ratio, object count, text pres- ence): r ins ( o, q ) = 1 |C q | X c ∈C q I ( o satisfies c ) . (7) Knowledge Consistency ( r kn ). T o ensure factual ground- ing, we employ a V isual Question Answering (VQA) proxy ( e.g . , PaLI-3) to verify specific kno wledge claims. For a prompt requiring factual attributes ( e.g. , ”A nebulous star forming region”), the re ward is: r kn ( o, q ) = Confidence ( VQA ( o, ”Is this consistent with q f act ?” ) == ”Y es” ) . (8) 3 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation F igure 1. Illustration of the proposed L VRPO framework for unified multimodal understanding and generation. The framework proceeds in three stages: (1) Group Sampling: For a giv en multimodal prompt q , the unified MoT bac kbone (initialized from B AGEL) samples a group of G independent outputs { o 1 , . . . , o G } , which can include te xt reasoning, visual tokens, or image edits. (2) Behavioral Re ward Estimation: Each output is ev aluated by a multi-dimensional rew ard system. W e utilize a frozen SigLIP 2 referee to provide dense semantic grounding signals ( r sem ), alongside rule-based verifiers for instruction follo wing ( r ins ) and knowledge consistenc y ( r kn ). (3) Group Relativ e Optimization: Instead of using a separate critic network, L VRPO employs Gr oup Relative P olicy Optimization to compute the advantage ˆ A i for each sample by normalizing its reward against the mean and standard deviation of the group. This behavioral feedback ∇ θ J L VRPO is backpropagated through the shared attention layers to jointly optimize the reasoning and generative experts, enforcing cross-modal consistency without the need for auxiliary representation-le vel alignment losses. 3 . 2 . 2 . K L - R E G U L A R I Z E D P O L I C Y I M P R OV E M E N T W e provide a deri vation showing that the L VRPO objec- tiv e effecti vely mov es the unified model toward an optimal multimodal distribution. Proposition 1. The GRPO update rule maximizes a lower bound on the expected re ward while maintaining a trust r egion ar ound the refer ence multimodal policy π ref . Proof Sk etch. Consider the generalized RL objecti ve with a KL-div ergence constraint: max π θ E o ∼ π θ [ R ( o, q )] − β D K L ( π θ ∥ π ref ) (9) T aking the deriv ativ e with respect to θ and applying the log-deriv ativ e trick, we obtain: ∇ θ J = E o ∼ π θ [( R ( o, q ) − β log π θ ( o | q ) π ref ( o | q ) ) ∇ θ log π θ ( o | q )] (10) In the GRPO frame work, the baseline is implicitly defined by the group mean ¯ r = 1 G P r j . By substituting ˆ A i ≈ R ( o, q ) − ¯ r , we arriv e at the L VRPO update rule: ∇ θ J L VRPO ≈ 1 G G X i =1 ˆ A i ∇ θ log π θ ( o i | q ) − β ∇ θ D KL ( π θ ∥ π ref ) (11) This demonstrates that L VRPO optimizes for the relativ e preference of multimodal behaviors. By using the group mean as a baseline, L VRPO filters out common multimodal noise ( e.g . , generic image features) and focuses the gradient signal on the specific components of the output that satisfy the language-visual grounding constraints. 3 . 2 . 3 . C RO S S - M O DA L G R O U N D I N G W I T H S I G L I P 2 T o ensure the reward r i is fine-grained, we do not simply take the global cosine similarity . W e define a Dense Gr ound- ing Rewar d : r dense = 1 | K | X k ∈ K max p ∈ patches ( ϕ sig ( v p ) · ψ sig ( t k )) (12) where K is the set of key semantic tokens in the prompt. This forces the model to achiev e spatial-semantic alignment , ensuring that specific words in the instruction are grounded in corresponding regions of the generated visual manifold. 4 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation T able 1. Comparison of text-to-image generation on GenEval benchmark. T ype Model Single Obj. T wo Obj. Counting Colors Position Color Attri. Overall ↑ Gen. Only PixArt- α ( Chen et al. , 2024a ) 0.98 0.50 0.44 0.80 0.08 0.07 0.48 SDv 2 . 1 ( Rombach et al. , 2022 ) 0.98 0.51 0.44 0.85 0.07 0.17 0.50 D ALL-E 2 ( Ramesh et al. , 2022 ) 0.94 0.66 0.49 0.77 0.10 0.19 0.52 Emu 3 -Gen ( W ang et al. , 2024c ) 0.98 0.71 0.34 0.81 0.17 0.21 0.54 SDXL ( Podell et al. , 2024 ) 0.98 0.74 0.39 0.85 0.15 0.23 0.55 D ALL-E 3 ( Betker et al. , 2023 ) 0.96 0.87 0.47 0.83 0.43 0.45 0.67 SD3-Medium ( Esser et al. , 2024 ) 0.99 0.94 0.72 0.89 0.33 0.60 0.74 FLUX.1-dev † ( Labs , 2024 ) 0.98 0.93 0.75 0.93 0.68 0.65 0.82 Unified Chameleon ( T eam , 2024 ) - - - - - - 0.39 L WM ( Liu et al. , 2024a ) 0.93 0.41 0.46 0.79 0.09 0.15 0.47 SEED-X ( Ge et al. , 2024 ) 0.97 0.58 0.26 0.80 0.19 0.14 0.49 T okenFlo w-XL ( Qu et al. , 2024 ) 0.95 0.60 0.41 0.81 0.16 0.24 0.55 ILLUME ( W ang et al. , 2024a ) 0.99 0.86 0.45 0.71 0.39 0.28 0.61 Janus ( W u et al. , 2024a ) 0.97 0.68 0.30 0.84 0.46 0.42 0.61 T ransfusion ( Zhou et al. , 2024 ) - - - - - - 0.63 Emu 3 -Gen( W ang et al. , 2024c ) 0.99 0.81 0.42 0.80 0.49 0.45 0.66 Show-o ( Xie et al. , 2024a ) 0.98 0.80 0.66 0.84 0.31 0.50 0.68 Janus-Pro-7B ( Chen et al. , 2025 ) 0.99 0.89 0.59 0.90 0.79 0.66 0.80 MetaQuery-XL ( Pan et al. , 2025 ) - - - - - - 0.80 B A GEL ( Deng et al. , 2025 ) 0.99 0.94 0.81 0.88 0.64 0.63 0.82 L VRPO (ours) 0.99 0.96 0.87 0.96 0.83 0.81 0.91 3.3. Unified Generation and Understanding A fundamental limitation of dual-stream models is the ”se- mantic disconnect” where the reasoning engine (LLM) and the generati ve engine (Dif fusion/Flow) operate in separate latent manifolds. L VRPO leverages BA GEL ( Deng et al. , 2025 ) as the foundation model, which posits that visual generation should be a downstream consequence of linguis- tic ”thinking. ” By utilizing a shared attention transformer, we ensure that the generativ e trajectory is conditioned on the full hidden state of the reasoning process, effecti vely enabling Multimodal Chain-of-Thought (M-CoT) . W e define the unified model as a mapping F θ that operates on a sequence of mixed tokens S . For a visual generation task, we employ Rectified Flo w Matching to map a simple noise distribution p 0 to the image latent distrib ution p 1 . The model learns a velocity field v θ ( x t , t, c ) where c is the multimodal context (te xt and semantic vision tokens). The training objectiv e for the generativ e pathway is: L g en ( θ ) = E t ∼ [0 , 1] , x 0 , x 1 ∥ v θ ( x t , t, c ) − ( x 1 − x 0 ) ∥ 2 (13) where x t = t x 1 + (1 − t ) x 0 is the linear interpolation between noise x 0 and latent x 1 . Simultaneously , the un- derstanding pathway optimizes the standard autore gressi ve loss: L und ( θ ) = − X j log P ( t j | t 1.5B) ILLUME ( W ang et al. , 2024a ) 7B 1445 - 75.1 38.2 37.0 - - VILA-U ( W u et al. , 2024b ) 7B 1336 - 66.6 32.2 27.7 - 22.0 Chameleon ( T eam , 2024 ) 7B - - 35.7 28.4 8.3 - 0.0 Janus-Pro ( Chen et al. , 2025 ) 7B 1567 - 79.2 41.0 50.0 - - MetaQuery-XL ( Pan et al. , 2025 ) 7B 1685 - 83.5 58.6 66.6 - - LlamaFusion ( Shi et al. , 2024 ) 8B 1604 - 72.1 41.7 - - - MetaMorph ( T ong et al. , 2024a ) 8B - - 75.2 41.8 - - 48.3 SEED-X ( Ge et al. , 2024 ) 13B 1457 - 70.1 35.6 43.0 - - T okenFlo w-XL ( Qu et al. , 2024 ) 13B 1546 - 68.9 38.7 40.7 - - MUSE-VL ( Xie et al. , 2024b ) 32B - - 81.8 50.1 - 55.9 - B A GEL ( Deng et al. , 2025 ) 7B 1687 2388 85.0 55.3 67.2 73.1 69.3 L VRPO (ours) 7B 1699 2399 87.2 58.1 69.5 76.2 72.1 W orld Knowledge Reasoning. The results on WISE in T able 2 ) demonstrate L VRPO’ s superior capability in world- knowledge-informed synthesis. L VRPO achie ves an overall score of 0.85, surpassing BA GEL (0.70) and outperforming GPT -4o (0.80). The significant lead in Space (0.93) and Biology (0.89) suggests that preference optimization allows the model to better acti v ate its internal linguistic kno wl- edge base during the visual generation process, essentially “thinking” before rendering. Image Editing. T able 3 and T able 4 ev aluate the model’ s ability to follow complex manipulation instructions. On GEdit-Bench , L VRPO sets a ne w state-of-the-art for open- source models, outperforming B A GEL and approaching GPT -4o’ s performance on Chinese-language instructions (7.56 vs. 7.30). In the reasoning-heavy IntelligentBench , L VRPO scores 58.7, exceeding Gemini 2.0 (57.6), which underscores its ability to interpret and ex ecute edits that require logical deduction be yond simple object replacement. Image Understanding. Finally , T able 5 confirms that opti- mizing for generation does not degrade, and in fact improv es, discriminativ e understanding. L VRPO (7B) outperforms B AGEL across all standard benchmarks, notably achie ving 58.1 on MMMU and 76.2 on MathV ista . This cross-modal synergy v alidates that reinforcing the generativ e trajectory enhances the shared representation’ s utility for complex reasoning and mathematical grounding. 4.3. Experimental Analysis In this section, we provide a detailed analysis of the L VRPO framew ork to understand the dynamics of reinforcement learning in unified multimodal models. Reward Con vergence and Policy Stability . W e analyze the training stability of L VRPO by tracking the e volution of in- divi dual reward components, r sem , r ins , and r kn , during the GRPO phase. As illustrated in Figure 2 , all re ward signals show a consistent upward trajectory , with r sem (Semantic Grounding) con ver ging the fastest. Interestingly , we observ e that the KL-div ergence remains stable e ven as the adv antage ˆ A i increases, suggesting that the group-relati ve baseline in GRPO ef fecti vely pre vents the policy from collapsing into repetitiv e or lo w-entropy modes. This stability is crucial 7 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation F igure 2. Reward con ver gence and policy stability during the GRPO phase. Left: Evolution of individual re ward components ( r sem , r ins , r kn ) sho wing consistent upward trajectories and fast semantic con ver gence. Right: Policy stability analysis sho wing stable KL-div ergence as the advantage signal increases. T able 6. Impact of Group Size G on GenEval and WISE scores. Group Size G GenEval WISE T raining Time (per step) 2 0.84 0.74 0.8s 4 0.87 0.79 1.3s 8 0.91 0.85 2.1s 16 0.92 0.86 4.4s for maintaining the ”reasoning backbone” of the underlying B AGEL model while refining its generati ve precision. Impact of Group Size G on Alignment. A central hy- perparameter in L VRPO is the group size G used for rel- ativ e advantage estimation. W e evaluate the performance on GenEval and WISE by varying G ∈ { 2 , 4 , 8 , 16 } . As shown in T able 6 , increasing G from 2 to 8 yields substantial gains in P osition and Counting scores, as a larger sample size provides a more rob ust baseline for identifying ”lucky” samples that happen to satisfy spatial constraints. How- ev er, we observ e diminishing returns beyond G = 8 , with G = 16 providing mar ginal improvements at a significant computational cost. This confirms that G = 8 strikes an optimal balance between gradient variance reduction and training efficienc y for 7B-scale unified models. The Und-Gen T rade-off. A long-standing challenge in unified pretraining is the ”seesaw ef fect, ” where improving generati ve quality often de grades discriminativ e understand- ing (and vice versa). W e analyze this by comparing L VRPO against a baseline that only optimizes the generativ e reward ( r sem + r ins ) in Figure 3 . When the knowledge re ward r kn is omitted, we observe a 4.2% drop in MMMU scores, indi- cating that the generati ve pathw ay begins to drift away from the model’ s linguistic kno wledge base. Con versely , with the full L VRPO objecti ve, we find that the tw o pathways exhibit positive interfer ence . For instance, improv ements in visual grounding for generation directly translate to better perfor - mance on MMVP (V isual Perception), as the model learns a F igure 3. Analysis of the Understanding-Generation trade-of f. While optimizing only for generative rewards leads to a decline in reasoning (MMMU), the full L VRPO objective demonstrates positiv e interference, where behavioral alignment in generation improv es discriminativ e visual perception (MMVP). more rob ust mapping between specific textual attributes and visual features that is shared across both the understanding and generation experts. 5. Conclusion In this work, we present L VRPO, a reinforcement-based preference optimization frame work designed to bridge the behavioral gap between multimodal understanding and gen- eration. By moving beyond simple representation distil- lation and lev eraging group relati ve policy opti- mization with a frozen SigLIP 2 semantic referee, L VRPO explic- itly reinforces instruction-faithfulness and world-kno wledge grounding. Our results across a broad suite of benchmarks demonstrate that L VRPO not only achie ves state-of-the-art performance for unified open-source models but also fosters generativ e alignment for discriminativ e reasoning. 8 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation Impact Statement This research introduces a framework for aligning multi- modal models with specific behavioral preferences. While L VRPO enhances the controllability and f actual grounding of generated content ( e .g. , through the WISE benchmark), we recognize that reinforcement learning can be sensitiv e to the choice of rew ard functions. If reward models are biased, the resulting policy may inadv ertently amplify those biases in its visual outputs. W e mitigate this by using a well-v alidated, large-scale semantic encoder (SigLIP 2) and by releasing our training recipes to encourage community auditing. Furthermore, as a unified model capable of high- fidelity generation, there is a potential risk of misuse for creating deceptiv e content. W e adv ocate for the inte gra- tion of digital watermarking in downstream deployments of L VRPO-aligned models to ensure transparenc y and prove- nance. References Bai, S., Chen, K., Liu, X., W ang, J., Ge, W ., Song, S., Dang, K., W ang, P ., W ang, S., T ang, J., Zhong, H., Zhu, Y ., Y ang, M., Li, Z., W an, J., W ang, P ., Ding, W ., Fu, Z., Xu, Y ., Y e, J., Zhang, X., Xie, T ., Cheng, Z., Zhang, H., Y ang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report. arXiv pr eprint arXiv:2502.13923 , 2025. Betker , J., Goh, G., Jing, L., Brooks, T ., W ang, J., Li, L., Ouyang, L., Zhuang, J., Lee, J., Guo, Y ., et al. Improving image generation with better captions. OpenAI blog , 2023. Brooks, T ., Holynski, A., and Efros, A. A. Instructpix2pix: Learning to follo w image editing instructions. In CVPR , 2023. Chen, J., Ge, C., Xie, E., W u, Y ., Y ao, L., Ren, X., W ang, Z., Luo, P ., Lu, H., and Li, Z. Pixart-sigma: W eak-to-strong training of diffusion transformer for 4k text-to-image generation. In ECCV , 2024a. Chen, X., W u, C., W u, Z., Ma, Y ., Liu, X., Pan, Z., Liu, W ., Xie, Z., Y u, X., Ruan, C., and Luo, P . Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv pr eprint arXiv:2501.17811 , 2025. Chen, Z., W ang, W ., Cao, Y ., Liu, Y ., Gao, Z., Cui, E., Zhu, J., Y e, S., Tian, H., Liu, Z., Gu, L., W ang, X., Li, Q., Ren, Y ., Chen, Z., Luo, J., W ang, J., Jiang, T ., W ang, B., He, C., Shi, B., Zhang, X., Lv , H., W ang, Y ., Shao, W ., Chu, P ., T u, Z., He, T ., W u, Z., Deng, H., Ge, J., Chen, K., Zhang, K., W ang, L., Dou, M., Lu, L., Zhu, X., Lu, T ., Lin, D., Qiao, Y ., Dai, J., and W ang, W . Expanding performance boundaries of open- source multimodal models with model, data, and test-time scaling. arXiv pr eprint arXiv:2412.05271 , 2024b. Chen, Z., W ang, W ., T ian, H., Y e, S., Gao, Z., Cui, E., T ong, W ., Hu, K., Luo, J., Ma, Z., et al. How f ar are we to gpt- 4v? closing the gap to commercial multimodal models with open-source suites. SCIS , 2024c. Deng, C., Zhu, D., Li, K., Gou, C., Li, F ., W ang, Z., Zhong, S., Y u, W ., Nie, X., Song, Z., Shi, G., and Fan, H. Emerg- ing properties in unified multimodal pretraining. arXiv pr eprint arXiv:2505.14683 , 2025. Esser , P ., K ulal, S., Blattmann, A., Entezari, R., M ¨ uller , J., Saini, H., Levi, Y ., Lorenz, D., Sauer , A., Boesel, F ., et al. Scaling rectified flow transformers for high-resolution image synthesis. In ICML , 2024. Fu, C., Chen, P ., Shen, Y ., Qin, Y ., Zhang, M., Lin, X., Y ang, J., Zheng, X., Li, K., Sun, X., et al. Mme: A comprehen- si ve e valuation benchmark for multimodal large language models. arXiv pr eprint arXiv:2306.13394 , 2023. Ge, Y ., Zhao, S., Zhu, J., Ge, Y ., Y i, K., Song, L., Li, C., Ding, X., and Shan, Y . Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv pr eprint arxiv:2404.14396 , 2024. Gemini2, G. Experiment with gemini 2.0 flash nativ e image generation, 2025. Ghosh, D., Hajishirzi, H., and Schmidt, L. Genev al: An object-focused framework for e valuating text-to-image alignment. In NeurIPS , 2023. Labs, B. F . Flux, 2024. URL https://github.com/ black- forest- labs/flux . Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F ., Zhang, H., Zhang, K., Zhang, P ., Li, Y ., Liu, Z., and Li, C. LLaV A- onevision: Easy visual task transfer . TMLR , 2025. Li, D., Kamko, A., Akhgari, E., Sabet, A., Xu, L., and Doshi, S. Playground v2. 5: Three insights towards enhancing aesthetic quality in te xt-to-image generation. arXiv pr eprint arXiv:2402.17245 , 2024. Liu, H., Y an, W ., Zaharia, M., and Abbeel, P . W orld model on million-length video and language with ringattention. arXiv pr eprint arxiv:2402.08268 , 2024a. Liu, S., Han, Y ., Xing, P ., Y in, F ., W ang, R., Cheng, W ., Liao, J., W ang, Y ., Fu, H., Han, C., Li, G., Peng, Y ., Sun, Q., W u, J., Cai, Y ., Ge, Z., Ming, R., Xia, L., Zeng, X., Zhu, Y ., Jiao, B., Zhang, X., Y u, G., and Jiang, D. Step1x- edit: A practical framew ork for general image editing. arXiv pr eprint arXiv:2504.17761 , 2025a. Liu, S., Han, Y ., Xing, P ., Y in, F ., W ang, R., Cheng, W ., Liao, J., W ang, Y ., Fu, H., Han, C., et al. Step1x-edit: A practical frame work for general image editing. arXiv pr eprint arXiv:2504.17761 , 2025b. 9 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation Liu, Y ., Duan, H., Zhang, Y ., Li, B., Zhang, S., Zhao, W ., Y uan, Y ., W ang, J., He, C., Liu, Z., et al. Mmbench: Is your multi-modal model an all-around player? In ECCV , 2024b. Lu, P ., Bansal, H., Xia, T ., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.-W ., Galley , M., and Gao, J. Math- vista: Evaluating mathematical reasoning of foundation models in visual contexts. In NeurIPS W orkshop on Math- ematical Reasoning and AI , 2023. Mo, S. and Y un, S. Dmt-jepa: Discriminative mask ed tar- gets for joint-embedding predictiv e architecture. arXiv pr eprint arXiv: 2405.17995 , 2024. Mo, S. and Y un, S. Gmail: Generativ e modality align- ment for generated image learning. arXiv preprint arXiv:2602.15368 , 2026. Niu, Y ., Ning, M., Zheng, M., Lin, B., Jin, P ., Liao, J., Ning, K., Zhu, B., and Y uan, L. Wise: A world knowledge- informed semantic ev aluation for text-to-image genera- tion. arXiv pr eprint arXiv:2503.07265 , 2025. OpenAI. Introducing 4o image generation, 2025. URL https://openai.com/index/ introducing- 4o- image- generation/ . Oquab, M., Darcet, T ., Moutakanni, T ., V o, H. V ., Szafraniec, M., Khalidov , V ., Fernandez, P ., HAZIZA, D., Massa, F ., El-Nouby , A., Assran, M., Ballas, N., Galuba, W ., Howes, R., Huang, P .-Y ., Li, S.-W ., Misra, I., Rabbat, M., Sharma, V ., Synnae ve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P ., Joulin, A., and Bojanowski, P . DINOv2: Learning robust visual features without su- pervision. T ransactions on Machine Learning Resear ch , 2024. ISSN 2835-8856. Pan, X., Shukla, S. N., Singh, A., Zhao, Z., Mishra, S. K., W ang, J., Xu, Z., Chen, J., Li, K., Juefei-Xu, F ., Hou, J., and Xie, S. Transfer between modalities with metaqueries. arXiv pr eprint arXiv:2504.06256 , 2025. Podell, D., English, Z., Lacey , K., Blattmann, A., Dockhorn, T ., M ¨ uller , J., Penna, J., and Rombach, R. Sdxl: Im- proving latent dif fusion models for high-resolution image synthesis. In ICLR , 2024. Qu, L., Zhang, H., Liu, Y ., W ang, X., Jiang, Y ., Gao, Y ., Y e, H., Du, D. K., Y uan, Z., and W u, X. T okenflo w: Unified image tokenizer for multimodal understanding and generation. arXiv pr eprint arXiv:2412.03069 , 2024. Ramesh, A., Dhariwal, P ., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv pr eprint arxiv:2204.06125 , 2022. Rombach, R., Blattmann, A., Lorenz, D., Esser, P ., and Ommer , B. High-resolution image synthesis with latent diffusion models. In CVPR , pp. 10684–10695, 2022. Shao, Z., W ang, P ., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., W u, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models. arXiv pr eprint arXiv:2402.03300 , 2024. Shi, W ., Han, X., Zhou, C., Liang, W ., Lin, X. V ., Zettle- moyer , L., and Y u, L. Llamafusion: Adapting pretrained language models for multimodal generation. arXiv pr eprint arXiv:2412.15188 , 2024. Sun, K., P an, J., Ge, Y ., Li, H., Duan, H., W u, X., Zhang, R., Zhou, A., Qin, Z., W ang, Y ., et al. Journeydb: A bench- mark for generativ e image understanding. Advances in neural information pr ocessing systems , 36:49659–49678, 2023. T eam, C. Chameleon: Mixed-modal early-fusion foundation models. arXiv pr eprint arXiv:2405.09818 , 2024. T eam, K., Du, A., Y in, B., Xing, B., Qu, B., W ang, B., Chen, C., Zhang, C., Du, C., W ei, C., W ang, C., Zhang, D., Du, D., W ang, D., Y uan, E., Lu, E., Li, F ., Sung, F ., W ei, G., Lai, G., Zhu, H., Ding, H., Hu, H., Y ang, H., Zhang, H., W u, H., Y ao, H., Lu, H., W ang, H., Gao, H., Zheng, H., Li, J., Su, J., W ang, J., Deng, J., Qiu, J., Xie, J., W ang, J., Liu, J., Y an, J., Ouyang, K., Chen, L., Sui, L., Y u, L., Dong, M., Dong, M., Xu, N., Cheng, P ., Gu, Q., Zhou, R., Liu, S., Cao, S., Y u, T ., Song, T ., Bai, T ., Song, W ., He, W ., Huang, W ., Xu, W ., Y uan, X., Y ao, X., W u, X., Zu, X., Zhou, X., W ang, X., Charles, Y ., Zhong, Y ., Li, Y ., Hu, Y ., Chen, Y ., W ang, Y ., Liu, Y ., Miao, Y ., Qin, Y ., Chen, Y ., Bao, Y ., W ang, Y ., Kang, Y ., Liu, Y ., Du, Y ., W u, Y ., W ang, Y ., Y an, Y ., Zhou, Z., Li, Z., Jiang, Z., Zhang, Z., Y ang, Z., Huang, Z., Huang, Z., Zhao, Z., Chen, Z., and Lin, Z. Kimi-vl technical report. arXiv pr eprint arXiv:2504.07491 , 2025. T ong, S., Fan, D., Zhu, J., Xiong, Y ., Chen, X., Sinha, K., Rabbat, M., LeCun, Y ., Xie, S., and Liu, Z. Metamorph: Multimodal understanding and generation via instruction tuning. arXiv pr eprint arXiv:2412.14164 , 2024a. T ong, S., Liu, Z., Zhai, Y ., Ma, Y ., LeCun, Y ., and Xie, S. Eyes wide shut? exploring the visual shortcomings of multimodal llms. In CVPR , pp. 9568–9578, 2024b. Tschannen, M., Gritsenko, A., W ang, X., Naeem, M. F ., Alabdulmohsin, I., Parthasarathy , N., Evans, T ., Beyer , L., Xia, Y ., Mustafa, B., et al. Siglip 2: Multilingual vision-language encoders with improved semantic under - standing, localization, and dense features. arXiv pr eprint arXiv:2502.14786 , 2025. 10 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation W allace, B., Dang, M., Rafailov , R., Zhou, L., Lou, A., Pu- rushwalkam, S., Ermon, S., Xiong, C., Joty , S., and Naik, N. Diffusion model alignment using direct preference optimization. arXiv pr eprint arXiv:2311.12908 , 2023. W ang, C., Lu, G., Y ang, J., Huang, R., Han, J., Hou, L., Zhang, W ., and Xu, H. Illume: Illuminating your llms to see, draw , and self-enhance. arXiv preprint arXiv:2412.06673 , 2024a. W ang, P ., Bai, S., T an, S., W ang, S., Fan, Z., Bai, J., Chen, K., Liu, X., W ang, J., Ge, W ., Fan, Y ., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., and Lin, J. Qwen2-vl: Enhancing vision-language model’ s perception of the world at any resolution. arXiv pr eprint arXiv:2409.12191 , 2024b. W ang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y ., W ang, J., Zhang, F ., W ang, Y ., Li, Z., Y u, Q., et al. Emu3: Next-token prediction is all you need. arXiv preprint arxiv:2409.18869 , 2024c. W u, C., Chen, X., W u, Z., Ma, Y ., Liu, X., Pan, Z., Liu, W ., Xie, Z., Y u, X., Ruan, C., and Luo, P . Janus: Decoupling visual encoding for unified multimodal understanding and generation. arXiv pr eprint arXiv:2410.13848 , 2024a. W u, Y ., Zhang, Z., Chen, J., T ang, H., Li, D., Fang, Y ., Zhu, L., Xie, E., Y in, H., Y i, L., et al. V ila-u: a unified foundation model integrating visual understanding and generation. arXiv pr eprint arXiv:2409.04429 , 2024b. W u, Z., Chen, X., P an, Z., Liu, X., Liu, W ., Dai, D., Gao, H., Ma, Y ., W u, C., W ang, B., et al. Deepseek-vl2: Mixture- of-experts vision-language models for advanced multi- modal understanding. arXiv pr eprint arXiv:2412.10302 , 2024c. Xiao, S., W ang, Y ., Zhou, J., Y uan, H., Xing, X., Y an, R., Li, C., W ang, S., Huang, T ., and Liu, Z. Omnigen: Uni- fied image generation. arXiv pr eprint arXiv:2409.11340 , 2024. Xie, J., Mao, W ., Bai, Z., Zhang, D. J., W ang, W ., Lin, K. Q., Gu, Y ., Chen, Z., Y ang, Z., and Shou, M. Z. Show-o: One single transformer to unify multimodal understanding and generation. arXiv pr eprint arxiv:2408.12528 , 2024a. Xie, R., Du, C., Song, P ., and Liu, C. Muse-vl: Modeling unified vlm through semantic discrete encoding. arXiv pr eprint arXiv:2411.17762 , 2024b. Xue, L., Shu, M., A wadalla, A., W ang, J., Y an, A., Purush- walkam, S., Zhou, H., Prabhu, V ., Dai, Y ., Ryoo, M. S., Kendre, S., Zhang, J., Qin, C., Zhang, S., Chen, C.-C., Y u, N., T an, J., A walgaonkar , T . M., Heinecke, S., W ang, H., Choi, Y ., Schmidt, L., Chen, Z., Savarese, S., Niebles, J. C., Xiong, C., and Xu, R. xgen-mm (blip-3): A fam- ily of open large multimodal models. arXiv pr eprint arXiv:2408.08872 , 2024. Y e, Y ., He, X., Li, Z., Lin, B., Y uan, S., Y an, Z., Hou, B., and Y uan, L. Imgedit: A unified image editing dataset and benchmark. arXiv pr eprint arXiv:2505.20275 , 2025. Y u, Q., Chow , W ., Y ue, Z., Pan, K., W u, Y ., W an, X., Li, J., T ang, S., Zhang, H., and Zhuang, Y . Anyedit: Mastering unified high-quality image editing for any idea. arXiv pr eprint arXiv:2411.15738 , 2024a. Y u, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., and Xie, S. Representation alignment for generation: T raining diffusion transformers is easier than you think. In International Confer ence on Learning Representations , 2025. Y u, W ., Y ang, Z., Li, L., W ang, J., Lin, K., Liu, Z., W ang, X., and W ang, L. Mm-vet: Evaluating lar ge multimodal models for integrated capabilities. In ICML , 2024b. Y ue, X., Ni, Y ., Zhang, K., Zheng, T ., Liu, R., Zhang, G., Stev ens, S., Jiang, D., Ren, W ., Sun, Y ., et al. Mmmu: A massiv e multi-discipline multimodal understanding and reasoning benchmark for expert agi. In CVPR , 2024. Zhang, K., Mo, L., Chen, W ., Sun, H., and Su, Y . Mag- icbrush: A manually annotated dataset for instruction- guided image editing. In NeurIPS , 2023. Zhou, C., Y u, L., Babu, A., T irumala, K., Y asunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer , L., and Levy , O. T ransfusion: Predict the next token and dif- fuse images with one multi-modal model. arXiv pr eprint arxiv:2408.11039 , 2024. 11 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation A ppendix In this appendix, we provide the follo wing material: • addition implementation and datasets details in Section A , • algorithm for our L VRPO in Section B , • more discussions on L VRPO in Section C , • more e xperimental analyses in Section D , • qualitati ve visualization results in Section E , • discussions on limitations and broader impact in Section F . A. Implementation & Dataset Details In this section, we provide the hyperparameters and specific training configurations used to train L VRPO. Our implementation is built upon the PyT orch framework and utilizes the DeepSpeed ZeRO-3 optimization strategy to handle the memory requirements of the unified Mixture-of-T ransformer (MoT) backbone. A.1. Model Architectur e and Initialization W e initialize our backbone using the 7B parameter version of the B AGEL unified model. The architecture consists of: • Input Embeddings: A shared embedding layer for both text tokens (Llama-3 tokenizer) and visual patches (V AE- encoded latent tokens). • MoT Layers: 32 transformer layers where the Feed-Forw ard Networks (FFNs) are replaced by a Mixture-of-Experts. W e use E = 8 experts with top-2 routing ( G ( · ) ). T o seed the specialization, we initialize 4 experts from the text- pretrained weights and 4 experts from the vision-pretrained weights of the base B A GEL model. • Shared Attention: Standard Multi-Head Self-Attention (MHSA) with Rotary Positional Embeddings (RoPE) applied to a context windo w of 8192 tokens. A.2. T raining Datasets Our training pipeline consists of two distinct phases: 1. Pretraining (B A GEL-style): W e use the DataComp-1B dataset for image-te xt pairs and the RedPajama dataset for interleav ed text documents. 2. L VRPO Alignment Phase: For the preference optimization stage, we construct a high-quality ”Instruction-Behavior” dataset comprising 500k samples: • Visual Reasoning: 200k samples from ScienceQA and MathV ista (requiring text reasoning about images). • Image Generation: 200k samples from Pick-a-Pic v2 (human preference data) and JourneyDB. • Constraint Follo wing: 100k synthetic prompts generated by GPT -4, explicitly testing verifiable constraints (e.g., ”Generate a blue circle inside a red square”). A.3. Hyperparameters T able 7 lists the hyperparameters used during the L VRPO alignment phase. B. L VRPO Algorithm W e present the full training loop for L VRPO in Algorithm 1 . This procedure replaces the standard PPO loop with the critic-free Group Relativ e Policy Optimization approach tailored for unified multimodal inputs. 12 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation T able 7. Hyperparameters for L VRPO Training. Hyperparameter V alue Optimizer AdamW Learning Rate 5 × 10 − 6 W eight Decay 0 . 05 Global Batch Size 256 Group Size G 8 KL Coefficient β 0 . 01 Rew ard Scaling λ sem , λ ins , λ kn 1 . 0 , 0 . 5 , 0 . 5 Advantage ϵ 10 − 8 Max Gradient Norm 1.0 W armup Steps 100 T otal Training Steps 5000 C. More Discussions on L VRPO In this section, we provide formal definitions and proofs for the theoretical claims made in the main paper reg arding the synergy between the generati ve velocity field and the language posterior . C.1. Consistency of Generative V elocity Field Proposition 2. Under the L VRPO framework, the joint optimization of L g en and L und con verg es to a state wher e the generative velocity field is semantically consistent with the langua ge posterior . Proof Sketch. Please See Appendix. Let P ( x 1 | c ) be the target distrib ution of images giv en context c . The optimal velocity field v ∗ in Rectified Flow is kno wn to be the conditional expectation v ∗ ( x , t ) = E [ x 1 − x 0 | x t = x ] . In L VRPO, the reward signal r sem acts as a prior that reweights the samples in the e xpectation: v LV RP O ( x , t ) = Z ( x 1 − x 0 ) P ( x 1 | x t , c ) · exp( r sem ( x 1 , c ) /τ ) d x 1 . (16) As the reinforcement signal r sem increases, the velocity field v θ is biased to ward trajectories that terminate in re gions of the latent space with high semantic alignment to the text context c . Since both experts share the attention mechanism MHA ( s ) , the features c used for understanding are identical to those conditioning the flow , ensuring that an improv ement in reasoning (minimizing L und ) directly informs the accuracy of the generati ve field. Thus, the unified objecti ve minimizes the cross-modal entropy . C.2. Information Theor etical Interpretation W e hypothesize that the joint modeling of language and vision in L VRPO maximizes the mutual information between the reasoning latent space and the generativ e manifold. Theorem 1 (Multimodal Mutual Information Maximization). The L VRPO objective, by combining the next-token pr ediction L und and the behaviorally-r einforced flow J GRP O , maximizes a lower bound on the Mutual Information I ( Z und ; Z g en ) between the r easoning hidden states and the generative velocity field. Proof Sketch. Let Z und be the latent representation produced by the Reasoning Expert E und . In the MoT architecture, the Generati ve Expert E g en takes Z und as a conditioning conte xt. According to the InfoMax principle, the cross-entropy loss in L und minimizes the conditional entropy H ( T |Z und ) . Simultaneously , the reinforcement signal r sem in L VRPO acts as a contrastiv e regularizer that forces the generativ e trajectory v θ to preserve the semantic bits of Z und . Formally , the behavioral reward induces a distribution P ( V |Z und ) with high precision, which corresponds to minimizing H ( V |Z und ) . By the identity I ( X ; Y ) = H ( X ) − H ( X | Y ) , minimizing the conditional uncertainties across both experts directly maximizes the shared information content, leading to the emergent ”w orld kno wledge” observed in our results. 13 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation Algorithm 1 L VRPO: Language-V isual Group Relative Polic y Optimization 1: Input: Unified Policy π θ , Reference Policy π ref , Frozen Rew ard Model R (SigLIP 2 + Rules), Prompt Dataset D . 2: Hyper parameters: Group size G , Learning rate η , KL coef β . 3: r epeat 4: Sample a batch of multimodal prompts { q } ∼ D . 5: for each prompt q in batch do 6: { Step 1: Group Sampling } 7: Generate G outputs { o 1 , o 2 , . . . , o G } using π θ ( ·| q ) . 8: { Step 2: Behavioral Re ward Estimation } 9: f or i = 1 to G do 10: Compute semantic rew ard r sem = Sim ( SigLIP ( o i ) , SigLIP ( q )) . 11: Compute constraint rew ard r ins = I ( CheckConstraints ( o i , q )) . 12: Compute knowledge re ward r kn = FactCheck ( o i , q ) . 13: T otal reward r i = r sem + r ins + r kn . 14: end f or 15: { Step 3: Adv antage Calculation } 16: Compute group mean µ r = 1 G P G j =1 r j and std σ r = std ( { r j } ) . 17: f or i = 1 to G do 18: ˆ A i = r i − µ r σ r + ϵ . 19: end f or 20: end for 21: { Step 4: Policy Update } 22: Compute Loss: 23: L ( θ ) = − 1 B · G P q P G i =1 h ˆ A i log π θ ( o i | q ) π ref ( o i | q ) − β D K L ( π θ ∥ π ref ) i 24: Update θ ← θ − η ∇ θ L ( θ ) . 25: until Con ver gence C.3. Gradient Decoupling in MoT One major challenge in unified models is gradient masking , where the high-magnitude gradients from the visual flow dominate the subtle reasoning gradients. Proposition 3 (Modality-Specific Gradient Decoupling). The MoT r outing mechanism G in L VRPO ensur es that the update dir ection for the reasoning par ameters θ und is orthogonal to the noise-induced variance of the gener ative velocity field ∇ θ L g en in the limit of expert specialization. Derivation. In a dense unified model, the gradient is ∇ θ ( L und + L g en ) . If ∇L g en contains high-frequency noise (typical in early-stage flo w matching), it can lead to catastrophic forgetting in the language head. In L VRPO’ s MoT , the gradient for expert i is weighted by the gating function G ( s ) i . As G learns to route tokens to specialized FFNs, the Jacobian ∂ Output ∂ θ und becomes sparsely populated for generati ve tok ens. This allows the model to maintain a stable ”reasoning backbone” while aggressiv ely optimizing the ”rendering head, ” a property we empirically verify through stable training curves compared to vanilla B A GEL. C.4. Con vergence Speed Finally , we characterize the impact of the preference signal on the generati ve distribution. Theorem 2 (Semantic Drift Control). The L VRPO-r einforced velocity field v LV RP O generates a pr obability path that con verg es to the targ et semantic distribution P targ et in W asserstein-2 distance faster than standar d flow matc hing under non-con vex r ewar ds. Formal Argument. Standard Rectified Flo w Matching minimizes the distance to the a verage conditional trajectory . Howe ver , in complex reasoning tasks, the conditional distribution P ( V | T ) is highly multi-modal (e.g., ”a red car” can be many images). Without L VRPO, the flow often con verges to a ”blurry mean” of these modes. By introducing the rew ard-weighted advantage ˆ A i , L VRPO reshapes the vector field v θ to prioritize the mode that satisfies the SigLIP 2 14 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation semantic referee. This essentially performs a guided drift in the probability flow , ensuring that the terminal distribution at t = 1 is not just a sample from the training set, but the specific sample that maximizes the beha vioral preference. D. Mor e Experimental Analysis F igure 4. Ablation Study: Impact of Freezing the Reward Model. W e compare the training dynamics of L VRPO with a Frozen SigLIP 2 referee (blue) versus a T rainable Reward Model (red). While the trainable rew ard model allows the total rew ard to skyrocket (Left), a visual inspection of the outputs at step 2000 (Right) rev eals ”rew ard hacking, ” where the model generates high-frequency adversarial noise that exploits the drifting encoder . In contrast, the frozen baseline maintains semantic integrity , proving that a stable metric anchor is essential for the con vergence of the GRPO objecti ve. D.1. Ablation: The Necessity of Frozen SigLIP 2 W e conducted an experiment where we allowed the re ward model (SigLIP 2) to be fine-tuned alongside the policy to see if the rew ard encoder could adapt to the generator’ s distrib ution. As illustrated in Figure 4 , this led to a classic ”re ward hacking” failure mode. Specifically , within 1,500 steps, the trainable rew ard model drifted significantly . The policy discov ered that generating high-frequency checkerboard patterns resulted in higher cosine similarity scores than valid natural images, likely due to maximizing the norm of specific feature channels in the SigLIP embedding space. By keeping the SigLIP 2 encoder frozen, we enforce a stable ”metric anchor, ” ensuring that the policy must climb the true semantic gradient rather than reshaping the landscape to fit its current outputs. D.2. Scaling with Model Size T o understand the scalability of L VRPO, we performed limited runs on 1.3B and 13B variants of the backbone. The results, summarized in Figure 5 , rev eal distinct behavioral regimes: • 1.3B (Capacity Constrained): This model failed to effecti vely le verage the complex logical constraints ( r ins ). While it improv ed on basic object presence, it struggled with counting and spatial relations. This suggests that the ”Reasoning Expert” in the MoT architecture requires a minimum parameter budget to disentangle the syntax of complex prompts from visual generation. • 7B (The Sweet Spot): The 7B model balances efficienc y and capability , successfully learning all rew ard components. It serves as our primary baseline. • 13B (Accelerated Conv ergence): The 13B model showed significantly faster con vergence in the GRPO phase. It achiev ed a 0.92 GenEval score in fe wer than 2,000 steps (compared to 5,000 for the 7B model). This indicates that larger models possess better initial representations, allowing the GRPO objecti ve to ”unlock” alignment behaviors with fewer gradient updates. 15 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation F igure 5. Scaling behaviors of L VRPO across model sizes. W e track the GenEv al score improvement o ver training steps. The 1.3B model (green) saturates early , struggling to internalize complex spatial logic re wards ( r ins ) due to limited capacity . The 7B model (blue) shows steady , robust improv ement. The 13B model (red) demonstrates accelerated con verg ence , reaching state-of-the-art performance (0.92) in less than 2,000 steps, less than 40% of the training time required by the 7B model, validating the ef ficiency of GRPO on larger unified backbones. F igure 6. Qualitativ e comparison on challenging prompts. Left (Spatial Reasoning): ”A cat under a table, with a red ball on top of the table. ” L VRPO correctly places objects, while baselines often mer ge them. Right (Attribute Binding): ”A green fire truck. ” Baselines rev ert to red due to training priors; L VRPO follows the instruction. E. Qualitative V isualizations W e provide additional qualitativ e examples demonstrating L VRPO’ s capability to handle complex, composable prompts that challenge baseline models. As shown in Figure 6 , the impro vements can be categorized into two distinct beha vioral shifts: 16 L VRPO: Language-Visual Alignment with GRPO f or Multimodal Understanding and Generation 1. Disentangling Spatial Relations. The ”Cat under the table” example (Figure 6 , Left) demonstrates L VRPO’ s superior spatial reasoning. Baselines often behave as ”bag-of-words” generators, retrie ving the concepts ”cat, ” ”table, ” and ”ball” but failing to resolve the specific prepositions (”under” vs. ”on top”). This frequently results in concept mer ging , where the cat and ball are placed on the same plane. W e attribute L VRPO’ s success here to the Instruction-F ollowing Re ward ( r ins ). By explicitly verifying spatial constraints ( e.g . , bounding box intersection checks during reward calculation), the model learns to allocate distinct latent attention masks for ”under” and ”on top. ” This suggests that the reasoning expert in the MoT backbone successfully modulates the generati ve expert’ s layout planning, transforming linguistic prepositions into geometric constraints. 2. Overcoming Str ong Distributional Priors (Attrib ute Binding). The ”Green Fire T ruck” example (Figure 6 , Right) highlights a common failure mode in unified foundation models known as prior dominance . In standard pretraining datasets, the conditional probability P ( color = red | object = firetruck ) is near 1.0. Baseline models, optimizing for likelihood, frequently ignore the contradictory modifier ”green” to satisfy the dominant statistical correlation. L VRPO overcomes this by decoupling the gener ation pr obability from the dataset fr equency . During the GRPO phase, the semantic rew ard r sem (via SigLIP 2 ( Tschannen et al. , 2025 )) assigns a high penalty to red fire trucks when ”green” is requested. Since GRPO optimizes the policy relati ve to the group mean, ev en a single successful ”green” sample in the group { o 1 , . . . , o G } generates a large positi ve adv antage ˆ A i , sharply steering the gradient to ov erride the pretraining prior . F . Discussions F .1. Limitation & Future W ork Despite its ef ficacy , L VRPO has limitations. First, the framework relies on the quality of the frozen re ward model; while SigLIP 2 provides strong semantic signals, it can occasionally exhibit blind spots in high-frequency te xture or extremely fine-grained spatial simulation. Second, the group sampling process increases the computational footprint during the alignment phase compared to standard supervised fine-tuning. Future work will explore online re ward model adaptation to ev olve the referee alongside the policy and in vestigate multi-step reasoning chains in visual generation to further impro ve performance on complex, multi-hop instructions. F .2. Broader Impact L VRPO facilitates the creation of highly capable, unified AI systems that can reason and visualize simultaneously . This has significant potential in educational tools, creativ e assistance, and scientific visualization. By open-sourcing our framework and the alignment protocols, we aim to democratize access to high-performance multimodal foundation models, reducing the reliance on opaque, proprietary APIs. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment