The Case for Multi-Version Experimental Evaluation (MVEE)
In the database community, we typically evaluate new methods based on experimental results, which we produce by integrating the proposed method along with a set of baselines in a single benchmarking codebase and measuring the individual runtimes. If …
Authors: Simon Jörz, Felix Schuhknecht
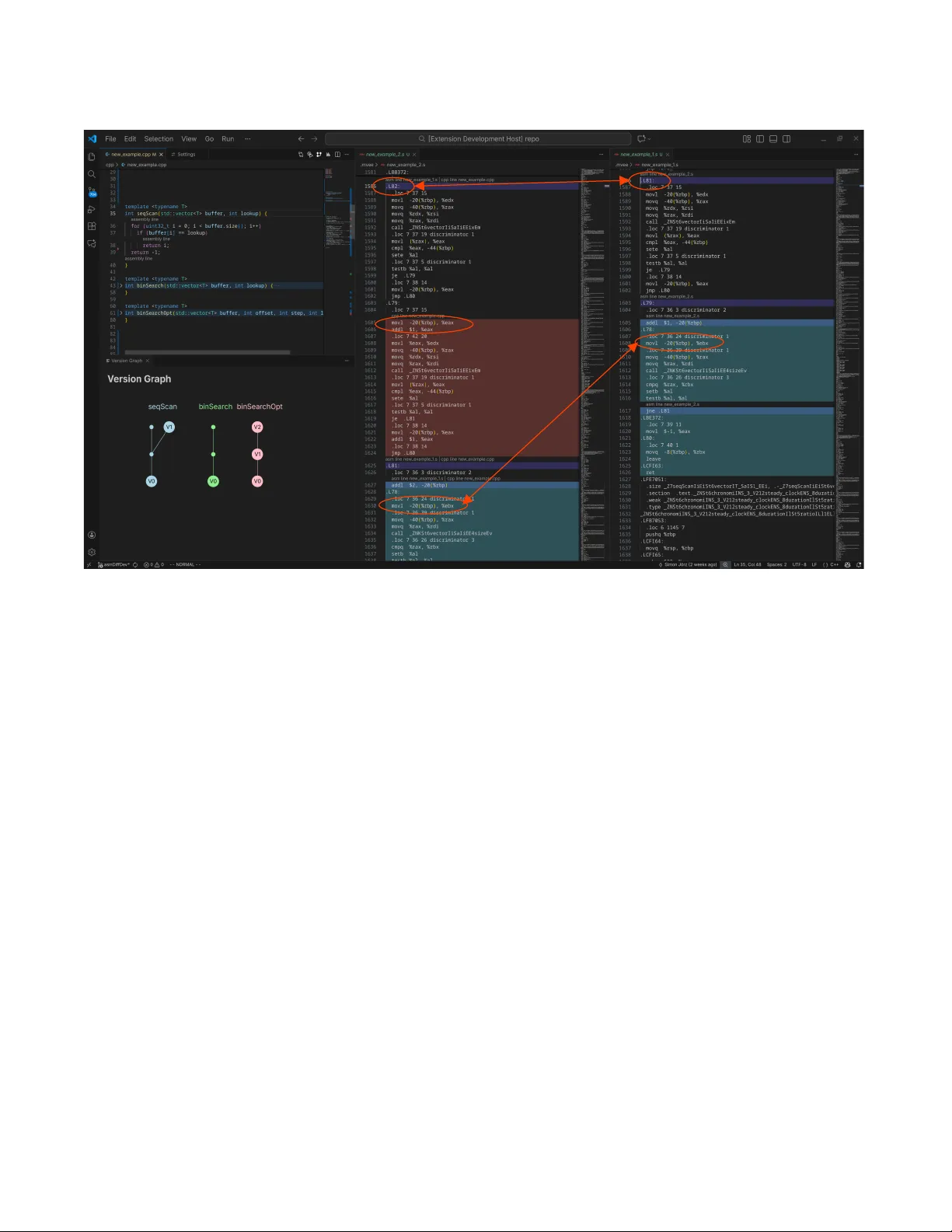
The Case for Multi- V ersion Experimental Evaluation (MVEE) Simon Jörz Johannes Gutenberg University Mainz, Germany joerzsim@uni- mainz.de Felix Schuhknecht Johannes Gutenberg University Mainz, Germany schuhknecht@uni- mainz.de ABSTRA CT In the database community , we typically evaluate new methods based on experimental results, which we produce by integrating the proposed method along with a set of baselines in a single bench- marking codebase and measuring the individual runtimes. If we are unhappy with the p erformance of our method, we gradually improve it while repeatedly comparing to the baselines, until w e outperform them. While this seems like a reasonable approach, it makes one delicate assumption: W e assume that across the opti- mization workow , there exists only a single compiled version of each baseline to compare to. However , we learne d the hard way that in practice, even though the source code remains untouched, general purpose compilers might still generate highly dierent com- piled code across builds, caused by seemingly unrelated changes in other parts of the codebase, leading to awed comparisons and evaluations. T o tackle this problem, we propose the concept of Multi- V ersion Experimental Evaluation (MVEE) . MVEE automati- cally and transparently analyzes subsequent builds on the assembly code level for occurring “build anomalies” and materializes them as new versions of the methods. A s a consequence, all observed ver- sions of the respective methods can be included in the e xperimental evaluation, highly increasing its quality and overall expressiveness. Artifact A vailability: The source code, data, and/or other artifacts have been made available at https://gitlab.rlp.net/mv ee. 1 IN TRODUCTION AND MOTI V A TION Traditionally , database research heavily relies on e xperiments. A typical workow for an evaluation of a new method looks as fol- lows: W e rst integrate the method along with a baseline into a single codebase. Then, we run b oth on the same workload and compare the individual runtimes. If our method is not fast enough, we incrementally try to optimize while re-running the benchmark until we reach our goal. While at rst glance, this looks like a rea- sonable workow , it unfortunately relies on the assumption that the incremental builds of the codebase we compar e with each other are actually comparable . More concretely , we assume that all local modications we apply to our method also remain local in the ac- tual build and do not aect any other parts of the codebase, such as the generated code of the baseline method. Unfortunately , we learned in previous w ork [ 8 ] that this assump- tion cannot be safely made when using a general-purpose compiler such as gcc : After experiencing unexplainable runtime variances across builds in one of our research projects [ 7 ] that evaluated scan-accelerating index structures acr oss dierent selectivities, a deep investigation revealed irregularities across these builds on the assembly level: The generated code of a baseline method B was 0 400 800 1200 1600 Selectivity 100% Runtime [ms] 0 100 200 300 400 Selectivity 4.97% 18.5% 33.6% 55.8% 96.2% Baseline B.V0 (used for selectivities = 100%) Baseline B.V1 (used for selectivities < 100%) Method M 🏆 🏆 🏆 🏆 🏆 🏆 ⚡ ⚡ ⚡ ⚡ ⚡ ⚡ (a) Problem 1: Merging results from dierent builds → false inter- pretation. 0 400 800 1200 1600 Selectivity 100% Runtime [ms] 0 100 200 300 400 Selectivity 4.97% 18.5% 33.6% 55.8% 96.2% Baseline B.V0 (used for all selectivities) Baseline B.V1 (ignored) Method M 🏆 🏆 🏆 ✓ ⚡ 🏆 🏆 🏆 ✓ ✓ ✓ ✓ (b) Problem 2: Showing only the r esults of one build and “forget” about another potentially better build → false interpretation. 0 400 800 1200 1600 Se l e ct i vi t y 100% Runtime [ms] 0 100 200 300 400 Se l e ct i vi t y 4.97% 18.5% 33.6% 55.8% 96.2% Baseline B.V0 Baseline B.V1 Method M B.V1 ! is faster ! than M! B.V0 ! is faster than M! 🏆 🏆 🏆 🏆 🏆 🏆 ✓ ✓ ✓ ✓ ✓ ✓ (c) Solution MVEE: Actively including the results of all seen versions to get the most complete picture → meaningful interpretation. Figure 1: Evaluation workow with and without MVEE. heavily aected by certain changes in completely unrelated code parts within the same compilation unit, pr esumably triggered by one of the many optimization heuristics [ 1 , 4 – 6 ] used within the compiler . This eectively resulted in the unpredictable occurrence of two very dierent versions B.V0 and B.V1 of the same baseline. If these versions go unnoticed one could easily miss comparing to the “right” version. Dep ending on the workow , we have to dierentiate between the following two cases: In the rst case, results from dierent builds are gathered. Figure 1a showcases this with real data from [ 8 ], where the baseline result from one build is used in the plot for a selectivity of 100% , whereas the results from another build are used for the remaining selectivities. As the example shows, if w e are unaware of the existence of the tw o baseline versions B.V0 and B.V1 , we will conclude that M generally outperforms the baseline. In reality , howev er , we just compared against the versions that p erform w orse in the respective situations. Simon Jörz and Felix Schuhkne cht In the second case, all results originate from a single build, but from an arbitrary one, as showcased in Figure 1b. While this at least ensures consistency , we might still draw wrong conclusions as we can miss better versions: In our e xample, this is the case for a selectivity of 100% , where we compare M against the worse version B.V0 , while B.V1 would perform signicantly better . 1.1 Multi- V ersion Experimental Evaluation Unfortunately , as long as we deal with complex black-box compilers, we have to assume that such anomalies occur in practice , even if we try to counter-steer the generation of dierent versions via a stabilization tool [ 2 ]. Howev er , instead of simply ignoring the generated versions, we argue to actively incorporate them into the experimental evaluation workow: If the generated assembly code of a baseline method suddenly changes from one build to the other due to a compilation anomaly without a corresponding change in the source code, we do not ignore this, but treat the anomaly as a new compiled version of the baseline metho d. At the same time, we do not forget ab out the old compiled version, but also keep it, along with the experimental results produced therefrom. As a consequence, as sho wn in Figure 1c, we can include the results from all seen compiled versions to get a complete picture of whether our method actually beats the baseline or not. In the following, we materialize this concept as what we call Multi- V ersion Experimental Evaluation (MVEE) . W e integrated MVEE as a comfortable extension for the VSCode IDE, which we will showcase in this demonstration. During the development w ork- ow , MVEE automatically and transparently analyzes the rele vant compiled code of generate d builds on the x86 assembly level for occurring anomalies. As soon as an anomaly is detected, MVEE does not only report this to the developer for closer inspection by showing the corresponding assembly and sour ce code portions, but automatically registers the change as a newly seen compiled ver- sion of the corresponding source code section, ee ctively building up a version graph that is shown to the user . Additionally , it stores the experimental results of the corresponding run and maps them to this particular version, which allo ws to include these results in the produced plots. Before we jump into the description of the workow , let us clearly dene what we consider as equivalent builds and what as anomalies. W e consider two sequences of assembly code lines 𝑆 1 and 𝑆 2 as equivalent if the following three conditions are all met: (1) Every instruction in 𝑆 1 also exists in 𝑆 2 and vice versa. (2) Every instruction in 𝑆 1 operates on the same data as the corresponding instruction in 𝑆 2 . (3) The control ow of 𝑆 1 is the same as of 𝑆 2 . Consequently , any pair of assembly code line se quences that violates our equivalency denition is considered as an anomaly . Note that within these checks, we currently make the following relaxations for eciency: First, we ignore indirect jumps based on register content. This allows us to che ck for these conditions statically by analyzing the code without requiring any run-time data. Second, we ignor e the register assignment, as anomalies would be detecte d on the instruction and control ow lev el already . 2 MVEE W ORKFLO W T o demonstrate how MVEE operates, we consider an exemplary development workow , where we want to compare the methods M , B0 , and B1 . Method M represents our own method that we optimize incrementally , whereas B0 and B1 r epresent baseline methods. T o bootstrap the system, the user rst communicates to the MVEE extension which code sections are actually relevant for the experimental evaluation and should b e monitored. Further , the user has to introduce an identier for each code section, such that MVEE can later map both active modications as well as occurred anomalies in the code to the corr esponding sections. This is done by packing the code of interest in a run method and surrounding the call to this method by calls to our mark pre-processor denitions gen_begin_mark() and gen_end_mark() , as shown in Listing 1. These mark denitions receive the input, as well as the output of the run method and create a dependency with it. 1 size_t input_B1 = 42; 2 gen_begin_mark(B1, size_t, input_B1); 3 size_t res_B1 = run_B1(input_B1); // monitored for anomalies 4 gen_end_mark(B1, size_t, res_B1); Code Listing 1: Marking the code sections to monitor . After bootstrapping, let us go through the development workow for a couple of steps and see how MVEE handles the occurring eects. Based on the modication and anomaly detection, MVEE builds up a version graph as shown in Figure 2. This version graph keeps track of all o ccurred compiled versions for the individual methods. More importantly it allows to identify at any point in time which versions must currently be considered for a complete result interpretation. M.V0 M.V1 M.V2 M.V3 B0.V0 B0.V2 B0.V1 B1.V0 B1.V1 (2) Developer modified M again. Anomaly in B0 occurred. (3) Developer modified M again. Anomaly in B1 occurred. Anomaly in B0 disappeared. (4) Developer modified B0. (1) Developer modified M. Method M Method B0 Method B1 Change due to modification or anomaly Relevant result data at this point in time Figure 2: The version graph built up by MVEE. Each col- ored circle represents a newly se en compiled version of the method. A source code modication continues respectively merges paths and an anomaly forks the path. W e start with an initial build of the codebase, which creates the initial versions M.V0 , B0.V0 , and B1.V0 . In step (1), the user optimizes method M and rebuild the codebase, which creates the version M.V1 . Since the other methods were not modie d and also did not un- dergo an anomaly , their initial versions and results remain valid, which is indicated by the small black circles in the graph. In step (2), The Case for Multi- V ersion Experimental Evaluation (MVEE) the users optimizes M again and recompiles, resulting in the com- pilation of a new version M.V2 . How ever , the generate d code of B0 changed over the pr evious build, which MVEE detects and classi- es as an anomaly , since the corresponding source code has not been mo died. In the version graph, this anomaly is reected by a fork to version B0.V1 . Due to the fork, both versions B0.V0 and B0.V1 would be considered for result interpretation. In step (3), let us now assume that M is mo died once more, which now causes two side-eects: First, it triggers an anomaly in B1 , resulting in a fork between B1.V0 and B1.V1 . Second, the previously occurred anomaly in B0 disappears and B0 compiles again to the previously seen version B0.V0 . Both versions of B0 still need to be considered for result interpretation. This changes in step (4), when the users actively mo dies the baseline B0 , e.g., to x a bug. This modication obviously creates a new v ersion B0.V2 , which merges the fork, indi- cating that the previous versions B0.V0 and B0.V1 are outdated and should no longer be considered. In summar y , at any point in time, MVEE locates for each method all relevant versions by traversing from top to bottom along all paths until the rst version on each path is visited. These versions in conjunction are considered during result interpretation. In Figure 2, we mark all versions that are relevant after the last step in red boxes. 3 ARCHI TECT URE AND IMPLEMEN T A TION Figure 3 provides a high-level view on the comp onents of our MVEE implementation and how they interact with each other . MVEE itself is split into two components: The VSCode extension and MVEE core, which handles the assembly le analysis. MVEE Visual Studio Code Extension MVEE Core (asmDiff) trueDiff Visual Studio Code Compiler (g++) trigger compilation & run produces new binary and .s file 1 2 Assembly Files compile 3 Result DB Binary run 7 .s trigger equivalence analysis 4 5 equivalence analysis result 7 enter versions visualize anomalies 6 M0 V3 1.52s .s path M1 V2 0.79s .s path M2 V0 1.23s .s path M2 V1 2.31s .s path visualize version graph 8 extends for 86_64 M0.V3 M1.V2 M2.V0 M2.V1 9 include relevant versions in plot 4 Figure 3: High-le vel architecture and interaction. MVEE operates as follows: In 1 , from the IDE, the user tells the MVEE extension to compile the current codebase in order to perform a new experimental run. In 2 , our extension then issues the compilation, which in 3 produces a new binary and the corre- sponding .s le. This assembly le will be stor ed with the pre vious builds in the assembly les directory , named by the timestamp of the run. Next, in 4 , our extension instructs MVEE core to perform an equivalence analysis for all methods that were not modied in the source co de since the last build. This happens based on the corresponding .s les. The core component passes the result of this equivalence analysis for each compared method in 5 to our extension — if anomalies have been detected, they can be inspected by the user in 6 directly in the IDE. In 7 , the extension now trig- gers the actual run of the binary , which produces a new r esult for each method. If an anomaly has b een detected b efore in a method, the new result of that method enters the result database as a new version. Otherwise, the current version is simply replaced by the new version. Additionally , in 8 , the version graph that is displayed in the IDE is update d accordingly . Finally , in 9 , all rele vant ver- sions of the result database are e xtracted from the result database to generate a corresponding results plot. 3.1 Assembly Code Analysis The actual assembly code analysis operates as follows: Given a pair of assembly les to compare, MVEE cor e rst parses each le and computes a corresponding tree-like interme diate representation for the regions of code that are relevant. Then, for the comparison, MVEE core lev erages truedi [ 3 ], a tree based structural ding algorithm which is designed to return concise and type safe edit scripts for typed tree-shape d data. T o be usable in our context, we extended truedi to handle x86 assembly code. As a result of the ding, truedi produces a so-called edit script , which captures all the observed dierences between the analyzed assembly les in a format called truechange . MVEE core then go es through the edit script and identies all dierences that are relevant for our denition of e quivalence (see Se ction 1.1). In the following, we outline the steps in detail: Assembly les → truedi input . MVEE core rst parses all assembly instructions of a le and generates a corresponding inter- mediate representation. This r epresentation is kept general to be able to represent the large backwards-compatible x86 instruction set without having to specify each and every instruction individually . From the intermediate representation, MVEE core next extracts only the code portions that are relevant for the experimental evalu- ation, which relies on the marks placed in the C++ code. Precisely , MVEE core indirectly builds and tra verses the control ow graph from each start mark until the corresponding end mark. T o keep this control ow intact, we group instructions into fallthrough-gr oups. Each fallthr ough-group is a se quence of instructions where one can be executed after another without an unconditional jump or call occurring in-between. Such fallthrough-groups can be reordered without changing the ow of control. Fallthrough-groups → edit script. Next, MVEE core passes the fallthrough-gr oups of both assembly les as source tree and target tree to the truedi algorithm to compute the edit script. This edit script describes how to modify the source to obtain the target. On a high lev el, truedi encodes the structure and literals of all contained subtrees as hashes and identies similarities by comparing these hashes. Subtrees of the source that match with subtrees of the target are reused, while non-matching subtrees are deleted or inserted as needed. In this way the truedi algorithm creates a concise e dit script, while ensuring to use every node exactly once, within linear run-time complexity . Edit script → anomalies . Then, MVEE core analyzes whether the edit script violates our denition of equivalence in three steps: (1) MVEE core che cks whether the script removes or inserts any new instructions, operands or labels. The existence of such signicant structural edits clearly violates e quivalency . (2) MVEE core checks whether the updates do not change any data and are consistent. Simon Jörz and Felix Schuhkne cht Newly build assembly Assembly before C++ source code updated label added instruction reordered instruction Figure 4: The inspection of a detecte d anomaly in our MVEE VSCo de extension. Precisely , it gathers updates to operands (memory references or immediate values). If updates change an immediate or a memory reference this is considered as a violation of the equivalency . If an update changes a label, MVEE cor e veries that all other references to that label are change d as well to the same name. Is that not the case, then the code is as w ell considered to be not equivalent. (3) MVEE core checks whether the reordering of code changes the control ow . Reordering a fallthrough-group does not change the control ow , as jumps remain consistent. But reordering single instructions (or operands) does change the control ow . In the latter case MVEE core consideres a reordering as a violation of the equivalency . Finally , it returns the equivalence result and all edits. 4 USER EXPERIENCE Figure 4 shows how the equivalence result is presented to the user in our VSCode extension. Using CodeLens , our extension links the detected anomaly to the corresponding C++ source code lines, such that the user sees from where the anomaly originates. By clicking on the link, the corresponding assembly le opens, in which all edits are highlighte d in dierent colors depending on their category . Additionally , the MVEE extension continuously visualizes the version graph in a git-style manner . In the demonstration, the audience is able to experience the be- havior of the extension and the benets of MVEE at the example of multiple observed real-world anomalies which hav e been produced during compilation with the general-purpose compiler gcc . These real-world anomalies include the discussed case from our motivat- ing example [ 8 ], but also further observed anomalies — identied by colleagues in their own benchmarking code bases but also found via automated extensive search using AI tools. T o ensure that the audience actually experiences anomalies on site, we prepar e for all code bases in advance a set of snapshots that captur e the state between critical sour ce co de changes that lead to the generation of compilation and performance anomalies. The audience can then (a) obser ve how our MVEE extension automatically detects the anomalies in the respective code parts, and how they are correctly registered as new versions in the version graph. Additionally , (b) the audience is able to analyze the type of anomalies both on the C++ and assembly level in detail, as shown in Figure 4. T o experience the impact on an experimental evaluation, the audience is further able to (c) produce runtime plots that correctly include all identied versions that are rele vant for the experimental evaluation. REFERENCES [1] 2025. https://gcc.gnu.org/onlinedocs/gccint/. (2025). [2] Charlie Curtsinger and Emery D. Berger . 2013. ST ABILIZER: statistically sound performance evaluation. In ASPLOS 2013, Houston, TX, USA, March 16-20, 2013 , Vivek Sarkar and Rastislav Bodík (Eds.). ACM, 219–228. [3] Sebastian Erdweg, T amás Szabó, and André Pacak. 2021. Concise, type-safe, and ecient structural ding. In PLDI ’21: 42nd ACM SIGPLAN, Canada, June 20-25, 2021 , Stephen N. Freund and Eran Y ahav (Eds.). A CM, 406–419. [4] Jan Hubicka. 2005. Pr ole driven optimisations in GCC. Proceedings of the 2005 GCC Developers’ Summit (2005). [5] Jan Hubicka. 2012. Advanced Interprocedural Optimization in GCC. Proceedings of the 2012 GCC Developers’ Summit (2012). [6] Raja Mehrotra et al . 2013. Improving GCC’s loop optimizer . Procee dings of the 2013 GCC Developers’ Summit (2013). [7] Felix Schuhknecht and Justus Henneberg. 2023. Accelerating Main-Memory Table Scans with Partial Virtual Views. In DaMoN 2023, Seattle, W A, USA, June 18-23, 2023 , Norman May and Nesime Tatbul (Eds.). ACM, 89–93. https://doi.org/10. 1145/3592980.3595315 [8] Felix Schuhknecht and Justus Henneberg. 2023. Why Y our Experimental Results Might Be Wrong. In DaMoN 2023, Seattle, W A, USA, June 18-23, 2023 , Norman May and Nesime T atbul (Eds.). ACM, 94–97.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment