Prototype-Aligned Federated Soft-Prompts for Continual Web Personalization
Continual web personalization is essential for engagement, yet real-world non-stationarity and privacy constraints make it hard to adapt quickly without forgetting long-term preferences. We target this gap by seeking a privacy-conscious, parameter-ef…
Authors: Canran Xiao, Liwei Hou
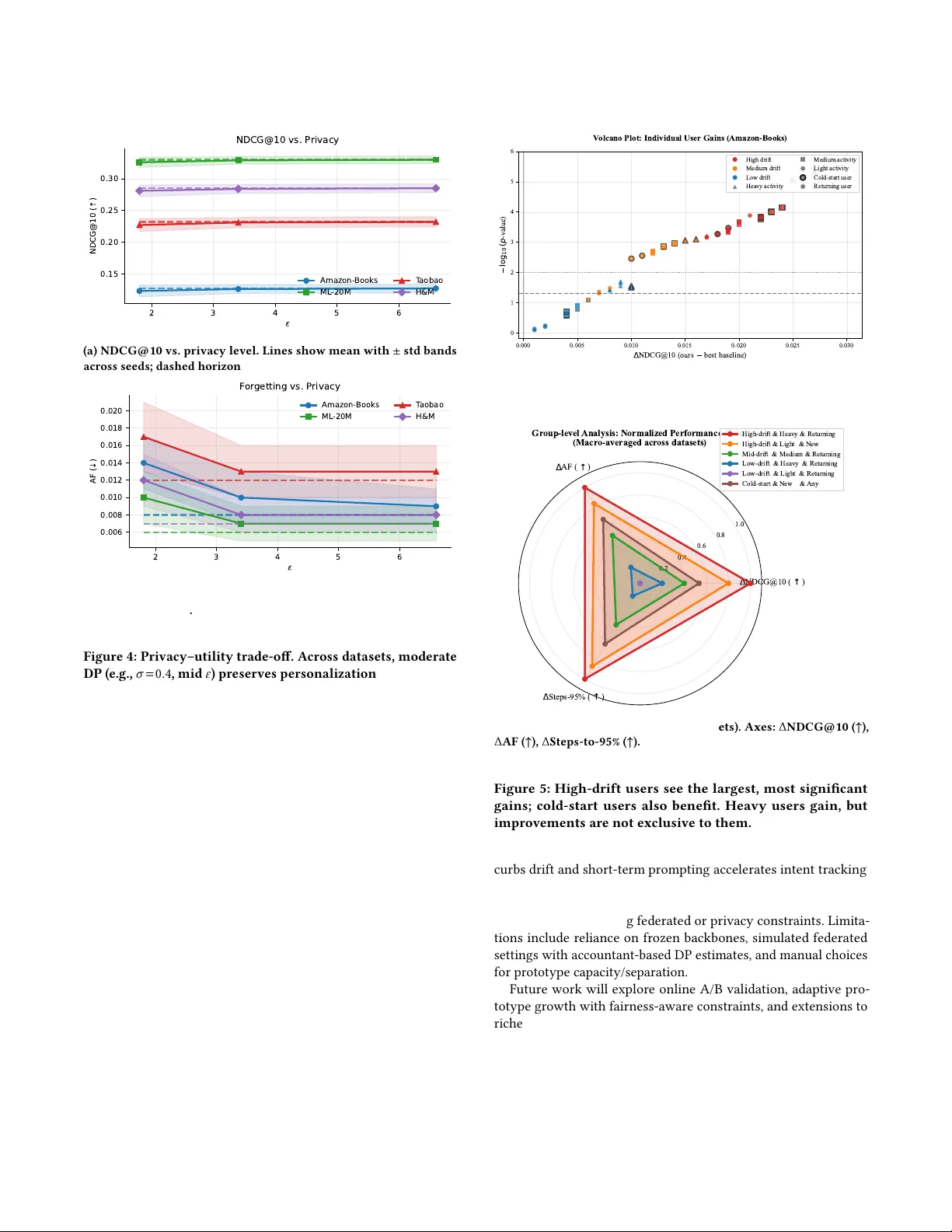
Prototype- Aligned Federate d So-Prompts for Continual W eb Personalization Canran Xiao xiaocr3@mail.sysu.edu.cn Shenzhen Campus of Sun Y at-sen University Shenzhen, Guangdong, China Liwei Hou ∗ houliwei@hnu.edu.cn Hunan University Changsha, Hunan, China Abstract Continual W eb personalization is essential for engagement, yet real-world non-stationarity and privacy constraints make it hard to adapt quickly without forgetting long-term preferences. W e target this gap by seeking a privacy-conscious, parameter-ecient inter- face that controls stability–plasticity at the user/session level while tying user memory to a shared semantic prior . W e propose ProtoFed- SP, a prompt-based framework that injects dual-timescale soft prompts into a frozen backbone: a fast, sparse short-term pr ompt tracks session intent, while a slow long-term prompt is anchored to a small server-side prototype library that is continually refreshed via dierentially private federated aggregation. Queries are routed to T op- 𝑀 prototypes to compose a personalized prompt. Across eight benchmarks, ProtoFed-SP improves NDCG@10 by +2.9% and HR@10 by +2.0% over the strongest baselines, with notable gains on Amazon-Books (+5.0% NDCG vs. INFER), H&M ( +2.5% vs. Dual- LoRA), and T aobao (+2.2% vs. Fe dRAP). It also lowers forgetting (AF) and Steps-to-95% and preserves accuracy under practical DP budgets. Our contribution is a unifying, privacy-aware prompting interface with prototype anchoring that delivers robust continual personalization and oers a transparent, controllable mechanism to balance stability and plasticity in deployment. CCS Concepts • Computing methodologies → Distributed algorithms ; Arti- cial intelligence . Ke ywords Continual personalization, federated recommendation, parameter- ecient prompting, dierential privacy , stability–plasticity trade- o A CM Reference Format: Canran Xiao and Liwei Hou. 2026. Prototype- Aligned Federated Soft-Prompts for Continual W eb Personalization. In Proceedings of the A CM W eb Confer- ence 2026 (W WW ’26), A pril 13–17, 2026, Dubai, United Arab Emirates . ACM, New Y ork, NY, USA, 12 pages. https://doi.org/10.1145/3774904.3792626 ∗ Corresponding author . This work is licensed under a Creative Commons Attribution 4.0 International License. WW W ’26, Dubai, United Arab Emirates © 2026 Copyright held by the owner/author(s). ACM ISBN 979-8-4007-2307-0/2026/04 https://doi.org/10.1145/3774904.3792626 1 Introduction Personalized W eb experiences—from recommendations[ 21 , 23 , 27 ] to on-site search and feeds[ 5 , 43 ]—operate in non-stationar y en- vironments where user interests, item supply , and platform rules evolve continually . This non-stationarity makes accurate, timely adaptation indispensable for engagement and safety at scale, yet exposes a classic stability–plasticity dilemma: models must absorb fresh signals quickly without erasing long-term prefer ences. At the same time, modern deployments increasingly require on-device adaptation and privacy-preserving training, challenging conven- tional full retraining pipelines[24, 32, 34, 37]. Recent advancements in continuous recommendation cover self- correction, regularization, federated personalization, and parameter- ecient prompting—showing that models are capable of adapting under non-stationary conditions [ 3 , 9 , 11 , 14 , 15 , 17 – 19 , 31 , 33 , 41 ]. Y et across these lines, three high-level limitations remain. First, adaptation is typically governed at the global or loss level, with no portable, shareable semantic anchor that tethers per-user memor y to population structure—leaving stability–plasticity largely uncon- trolled at the user granularity [ 20 , 28 ]. Second, practical deploy- ments must respect privacy and bandwidth: replay and interaction- derived signals can be costly or sensitive, while federated meth- ods often personalize via extra weights without a lightweight, prompt-level memory and explicit DP accounting [ 17 , 18 , 26 , 29 ]. Third, although PEFT/LLM approaches enable low-overhead adap- tation, they rarely couple fast session plasticity with a r efreshable global prior that is update d in a privacy-aware, federated man- ner [ 3 , 11 , 15 , 19 , 33 , 40 , 42 ]. In short, the eld lacks a privacy- conscious, parameter-ecient personalization interface that (i) provides per-user control of stability–plasticity and (ii) binds user memor y to a shared semantic prior that can be continually refreshed under federated constraints (with fairness monitored over time [16, 30, 36]). This paper addresses that gap by studying a pr ompt-based con- tinual personalization interface that unies per-user , dual-timescale adaptation with a small population semantic prior maintained in federated form under dierential privacy . W e give the answer to the following question: Can we achieve fast session-level plasticity and long-term stability per user , while privately refreshing a global anchor that resists drift? Our contributions can be summarized as follows: (1) Insight. W e articulate and operationalize a stability–plasticity control interface for continual personalization: fast session updates are decoupled from slow preference memory , and slow memor y is anchored to a compact, federated semantic prior—yielding a con- crete mechanism to reason about drift, forgetting, and adaptation across users. WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Canran Xiao and Liwei Hou (2) Performance. Across eight benchmarks, the proposed inter- face attains consistent gains over strong SoT A, while preser ving utility under practical DP budgets. (3) Capability . The design is parameter- and communication- ecient , supp orts federate d and multi-modal settings, and improves cold-start and high-drift segments—demonstrating that privacy- conscious, anchored prompting is a viable path toward robust con- tinual W eb personalization. 2 Related W ork 2.1 Continual adaptation in recommender systems Early industrial CL for RS emphasized self-correction and error re-use. ReLoop [ 4 ] encourages each model version to reduce the predecessor’s errors; ReLoop2 [ 44 ] extends this line by coupling slow (parametric) and fast (non-parametric err or memory) learners for responsive adaptation. Replay has evolved from reservoir or frequency heuristics to inuence-base d selection (INFER) that prior- itizes exemplars with higher training impact [ 41 ]. On the regulariza- tion side, SAIL-PIW learns user-wise imitation weights to balance recency vs. history , hinting at per-user stability–plasticity [ 31 ]; CCD co-evolves teacher–student via continual distillation [ 14 ]. Despite their progr ess, these methods typically (a) treat stabil- ity–plasticity at the algorithm or global level rather than at the prompt/memory level for each user; (b) rely on storing interactions or logits (privacy/cost); and ( c) lack an explicit, shareable anchor that tethers long-term user memory to population semantics. Our approach diers by (1) repr esenting user memory as dual-timescale soft prompts , (2) aligning the slow (long-term) prompt to a fe derated prototype library to curb drift, and (3) avoiding raw-data replay through DP aggregation of compressed prompt embeddings. 2.2 Federated and privacy-preser ving personalization Foundational FL work like FedProx establishe d communication- ecient aggr egation and robustness to statistical heterogeneity [ 18 , 26 ]. Personalize d FL (PFL) then introduced per-client objectives (e.g., Ditto) to reconcile accuracy , robustness and fairness [ 7 , 17 ]. T aobao’s CTNet formalized continual transfer between time-evolving domains, showing the value of preserving historical parameters under dynamics [ 25 ]. However , most PFL/CTL metho ds do not expose a prompt-level memory for fast personalization, rarely pro- vide DP guarantees on uploaded signals, and do not unify p er-user stability–plasticity control with a server-side semantic prior [ 12 ]. W e bridge these gaps by (i) learning user prompts (fast & slow ) on device, (ii) up dating population prototypes via DP-aware ag- gregation, and (iii) routing queries to a small set of pr ototypes for parameter-ecient, privacy-conscious adaptation. 2.3 Parameter-ecient prompting and LLM-based recommendation PEFT replaces full ne-tuning with small trainable modules: pr e- x/prompt tuning learn continuous prompts for frozen LMs [ 8 , 15 , 19 ]; LoRA inje cts low-rank adapters [ 11 ]. Recent LLM4Rec studies tailor PEFT/ICL to dynamics: Re cICL adapts to recency purely via in-context e xemplars without weight updates [ 3 ]; PCL treats prompts as external memory to mitigate forgetting in con- tinual user mo deling [ 33 ]. While comp elling, these approaches either lack a shareable semantic prior (each user/task learns its own prompt/adapters), or trade o fast session-level adaptation against long-term stability without an explicit anchor or fe derated privacy [ 35 ]. Our method complements PEFT/LLM4Rec by tying user prompts to a prototype manifold: a small, DP-refreshed li- brary that stabilizes long-term memor y , while short-term prompts provide rapid session-level plasticity . This yields a concrete me cha- nism for per-user stability–plasticity control that coexists with FL constraints. 3 Method: Prototype-Aligned Federated Soft-Prompts (ProtoFed-SP) ProtoFed-SP treats soft prompts as user-spe cic, parameter-ecient memories and prototypes as server-side, fe derated anchors of stable population knowledge. Each client 𝑢 maintains a dual-timescale prompt state ( 𝑝 long 𝑢 , 𝑝 short 𝑢,𝑡 ) for slow/fast preference dynamics and queries a global prototype library C = { 𝑐 𝑘 } 𝐾 𝑘 = 1 to compose a routed prompt ˜ 𝑝 𝑢,𝑡 for inference. The long-term prompt is explicitly aligned to prototypes via an alignment loss, while the prototype library is federate dly updated by dierentially private (DP) aggregation of compressed client-side prompt embeddings. The overall objec- tive balances recommendation accuracy , alignment (stability ), and sparsity (plasticity), as shown in Fig. 1. 3.1 Notation and Setting Let U be the user set. At time 𝑡 ∈ N , user 𝑢 ∈ U issues a request with query/session context 𝑞 𝑢,𝑡 and local interaction buer D 𝑢,𝑡 . A frozen backbone recommender 𝑓 𝜃 (sequence/ranking model with parameters 𝜃 ) consumes item features 𝑥 𝑢,𝑡 , while a soft prompt ˜ 𝑝 𝑢,𝑡 ∈ R 𝐿 𝑝 × 𝑑 is injected at the emb edding layer . Each client keeps a long- term prompt 𝑝 long 𝑢 ∈ R 𝐿 𝑝 × 𝑑 and a short-term prompt 𝑝 short 𝑢,𝑡 ∈ R 𝐿 𝑝 × 𝑑 . The server maintains a prototype library C = { 𝑐 𝑘 } 𝐾 𝑘 = 1 , 𝑐 𝑘 ∈ R 𝐿 𝑝 × 𝑑 (or an equivalent latent r epresentation). W e denote by 𝜙 : R 𝐿 𝑝 × 𝑑 → R 𝑑 𝜙 a prompt enco der used for alignment/aggregation (e.g., average pooling followed by an MLP), and by 𝑔 : Q → R 𝑑 𝜙 a query encoder for routing. 3.2 Client: Dual- Timescale Personalized Prompting Users exhibit both slowly evolving preferences (genres, brands) and rapidly changing intents (session-level topics). A single prompt state either o verts to r ecent noise (plasticity dominates) or forgets old habits (stability dominates). W e separate the temporal roles. The composed prompt used for inference is ˜ 𝑝 𝑢,𝑡 = 𝑝 long 𝑢 + 𝛼 𝑢,𝑡 𝑝 short 𝑢,𝑡 + 𝑘 ∈ T op- 𝑀 ( 𝑞 𝑢,𝑡 ) 𝑤 𝑘 ( 𝑞 𝑢,𝑡 ) 𝑐 𝑘 , (1) where 𝛼 𝑢,𝑡 ∈ R ≥ 0 scales short-term inuence, 𝑤 𝑘 ( 𝑞 𝑢,𝑡 ) ≥ 0 are routing weights with Í 𝑘 𝑤 𝑘 = 1 , and 𝑐 𝑘 are prototypes. The pr ompt injection concatenates ˜ 𝑝 𝑢,𝑡 with token embe ddings: if 𝐸 ( ·) maps tokens to R 𝑑 , we form Inject ( 𝐸 ( 𝑥 𝑢,𝑡 ) , ˜ 𝑝 𝑢,𝑡 ) = [ ˜ 𝑝 𝑢,𝑡 ; 𝐸 ( 𝑥 𝑢,𝑡 ) ] and feed into 𝑓 𝜃 . Prototype- Aligned Federated So-Prompts for Continual W eb Personalization WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Frozen Query/ history Candidate items Query Encoder pooled embedding Top-M softmax Prototype Router Prototype Composer Frozen Backbone Loss : BCE/BPR Upload ( compress + clip + DP noise ) Download Assign Aggregate mean point add noise momentum update Sepa ration / Prune Separation Prune low use Client side Server side Input tokens ( historical/item ) long term prompt tokens short term prompt tokens prototypes (server) prototype mixture prompt Trainable Figure 1: ProtoFed-SP: Prototype- Aligned Federated Soft-Prompt Personalization. Le (Client side). Given a user quer y or interaction history , the client encodes the context into a pooled emb edding and routes it to a small set of T op- 𝑀 population prototypes via similarity-base d retrieval. A dual-timescale prompt state is maintained locally: a long-term prompt capturing stable preferences and a short-term prompt modeling session-level intent. The routed prompt is composed by summing the long-term prompt, a drift-adaptive short-term prompt, and a weighted mixture of retrieved prototypes, and is injected into a frozen backb one for ranking. Gradients from the recommendation loss (BCE/BPR) update only the prompt parameters, with sparse proximal updates for the short-term prompt and prototype-aligned updates for the long-term prompt. Right (Server side). Clients periodically upload compressed long-term prompt embeddings protected by clipping and Gaussian noise. The server performs dierentially private aggregation (e.g., DP-FedKMeans or robust alternatives) to update a compact prototype librar y , with momentum updates, prototype separation, and pruning to prevent collapse. The refreshed prototypes are broadcast back to clients, enabling privacy-conscious, parameter-ecient continual personalization with explicit stability–plasticity control. Short-term update (fast, sparse). T o avoid prompt sprawl, we promote sparsity in 𝑝 short 𝑢,𝑡 via an ℓ 1 penalty and update it with a proximal step: 𝑝 short 𝑢,𝑡 ← Soresh 𝑝 short 𝑢,𝑡 − 𝜂 𝑠 ∇ 𝑝 short 𝑢,𝑡 L rec ( 𝑢, 𝑡 ) , 𝜂 𝑠 𝜆 𝑝 , (2) where 𝜂 𝑠 > 0 is the step size, 𝜆 𝑝 > 0 controls sparsity , and Soresh ( 𝑧, 𝜏 ) = sign ( 𝑧 ) · max { | 𝑧 | − 𝜏 , 0 } is applied element-wise. Here L rec is the recommendation loss (dened in §3.6). Long-term update (slow , aligne d). Long-term prompts incorpo- rate an alignment proximal to prototypes (§3.4): 𝑝 long 𝑢 ← arg min 𝑝 ⟨∇ 𝑝 L rec ( 𝑢, 𝑡 ) , 𝑝 − 𝑝 long 𝑢 ⟩ + 1 2 𝜂 ℓ ∥ 𝑝 − 𝑝 long 𝑢 ∥ 2 𝐹 | {z } quadratic model of L rec + 𝜆 𝑠 A ( 𝜙 ( 𝑝 ) , C ) | {z } prototype alignment , (3) with step size 𝜂 ℓ > 0 , stability weight 𝜆 𝑠 > 0 , Frobenius norm ∥ · ∥ 𝐹 . The alignment term A is detailed below; the pr oximal yields a stability-aware up date that resists drift away from population anchors. Session-adaptive scaling. W e let 𝛼 𝑢,𝑡 = 𝜎 ( 𝑎 ⊤ Δ 𝑢,𝑡 ) with 𝜎 the sig- moid, 𝑎 ∈ R 𝑑 𝜙 learnable, and Δ 𝑢,𝑡 = 𝜓 ( ¯ 𝑒 𝑢,𝑡 − ¯ 𝑒 𝑢,𝑡 − 1 ) a drift summar y (e .g., 𝜓 ( 𝑧 ) = ∥ 𝑧 ∥ 2 , ¯ 𝑒 𝑢,𝑡 are rolling means of query emb eddings). This increases plasticity when session drift is large. 3.3 Prototype Router and Comp osition User intents can be multi-peaked; routing to multiple prototypes lets the prompt attend to several stable themes concurr ently . W e compute ℎ 𝑢,𝑡 = 𝑔 ( 𝑞 𝑢,𝑡 ) ∈ R 𝑑 𝜙 and scores 𝑠 𝑘 = ⟨ ℎ 𝑢,𝑡 , 𝜙 ( 𝑐 𝑘 ) ⟩ / 𝜏 , with temperature 𝜏 > 0 . The routing weights are 𝑤 𝑘 ( 𝑞 𝑢,𝑡 ) = exp ( 𝑠 𝑘 ) Í 𝑗 ∈ Top- 𝑀 ( 𝑞 𝑢,𝑡 ) exp ( 𝑠 𝑗 ) for 𝑘 ∈ T op- 𝑀 ( 𝑞 𝑢,𝑡 ) , 𝑤 𝑘 = 0 other wise , (4) WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Canran Xiao and Liwei Hou and the composition uses (1) . T op- 𝑀 retrieval uses maximum inner product or cosine similarity in R 𝑑 𝜙 . 3.4 Alignment Losses: Stability via Prototype Anchors Without constraints, 𝑝 long 𝑢 may collapse to recent idiosyncratic sig- nals. Prototypes { 𝑐 𝑘 } dene a low-curvature manifold of stable population semantics; aligning 𝜙 ( 𝑝 long 𝑢 ) to that manifold tethers long-term memory . Let 𝑧 𝑢 = 𝜙 ( 𝑝 long 𝑢 ) ∈ R 𝑑 𝜙 and 𝑣 𝑘 = 𝜙 ( 𝑐 𝑘 ) . W e provide a unie d alignment family: A ( 𝑧 𝑢 , C ) = min 𝑘 ∈ [ 𝐾 ] 𝐷 Ψ ( 𝑧 𝑢 ∥ 𝑣 𝑘 ) | {z } Bregman pull + 𝛾 · − log exp ( ⟨ 𝑧 𝑢 , 𝑣 𝜋 ( 𝑢 ) ⟩ / 𝜏 𝑎 ) Í 𝐾 𝑗 = 1 exp ( ⟨ 𝑧 𝑢 , 𝑣 𝑗 ⟩ / 𝜏 𝑎 ) | {z } InfoNCE sharpen , (5) where 𝐷 Ψ ( 𝑥 ∥ 𝑦 ) = Ψ ( 𝑥 ) − Ψ ( 𝑦 ) − ⟨∇ Ψ ( 𝑦 ) , 𝑥 − 𝑦 ⟩ is a Bregman divergence (e.g., Ψ ( 𝑥 ) = 1 2 ∥ 𝑥 ∥ 2 2 gives squared Euclidean), 𝜋 ( 𝑢 ) = arg min 𝑘 𝐷 Ψ ( 𝑧 𝑢 ∥ 𝑣 𝑘 ) is the nearest prototype, 𝛾 ≥ 0 , and 𝜏 𝑎 > 0 is the alignment temperature. The rst term contracts 𝑧 𝑢 toward its closest anchor; the se cond term sharpens assignment against distractor prototypes. When session-level embeddings form a set { ℎ 𝑢,𝜏 } 𝜏 ≤ 𝑡 , we may align empirical measure ˆ 𝜇 𝑢 to the mixture of prototype atoms via a 2- W asserstein term: A W ( ˆ 𝜇 𝑢 , C ) = inf 𝜋 ∈ Π ( ˆ 𝜇 𝑢 ,𝜈 C ) ∫ ∥ 𝑥 − 𝑦 ∥ 2 2 d 𝜋 ( 𝑥 , 𝑦 ) , (6) 𝜈 C = 𝐾 𝑘 = 1 𝜌 𝑘 𝛿 𝑣 𝑘 , (7) with mixture weights 𝜌 𝑘 (learned or uniform). This encourages the distribution of long-term contexts to sit near a prototype mixture , not just the center . 𝐷 Ψ is a Bregman divergence parametrized by a strictly convex Ψ ; 𝜋 ( 𝑢 ) is nearest-anchor assignment; 𝛾 , 𝜏 𝑎 are scalars; ˆ 𝜇 𝑢 is the empirical measure over historical client emb ed- dings; Π ( · , · ) denotes the set of couplings; 𝛿 𝑣 𝑘 is a Dirac at 𝑣 𝑘 . 3.5 Federated Prototype Aggregation with Dierential Privacy W e avoid uploading raw interactions or gradients. Instead, clients periodically send compressed, noised emb eddings: 𝑧 𝑢 = compress ( 𝜙 ( 𝑝 long 𝑢 ) ) + 𝜉 (8) the server updates prototypes using robust, DP-aware aggregation. Each round, the server receives { 𝑧 𝑢 } 𝑢 ∈ B from a mini-batch B of clients. With isotropic Gaussian noise 𝜉 ∼ N ( 0 , 𝜎 2 𝐼 ) calibrated to sensitivity 𝑆 and privacy budget ( 𝜀 , 𝛿 ) , standard mechanisms yield ( 𝜀 , 𝛿 ) -DP for released statistics. W e describe three interchangeable prototype updates in R 𝑑 𝜙 : (i) DP-FedKMeans (assignment + mean with clipping). A 𝑘 = { 𝑢 ∈ B : 𝑘 = arg min 𝑗 ∥ 𝑧 𝑢 − 𝑣 𝑗 ∥ 2 2 } , ¯ 𝑧 𝑘 = 1 | A 𝑘 | 𝑢 ∈ A 𝑘 clip ( 𝑧 𝑢 , 𝑅 ) , 𝑣 𝑘 ← ( 1 − 𝛽 ) 𝑣 𝑘 + 𝛽 ( ¯ 𝑧 𝑘 + 𝜉 𝑘 ) , (9) where 𝑅 > 0 clips per-sample norm to b ound sensitivity , 𝛽 ∈ ( 0 , 1 ] is momentum, and 𝜉 𝑘 is aggregation noise. (ii) Geometric median (robust to outliers). 𝑣 𝑘 ← arg min 𝑣 𝑢 ∈ A 𝑘 ∥ 𝑧 𝑢 − 𝑣 ∥ 2 , (10) solved by W eiszfeld iterations; add DP noise at each xed-p oint update or on the nal estimate. (iii) W asserstein barycenter (distributional prototypes). As- suming each client emits a small set { 𝑧 𝑢,𝑚 } 𝑀 𝑚 = 1 (or a Gaussian ap- prox.), update 𝑣 𝑘 as the 2- W asserstein barycenter of assigned client measures, computed with entropic Sinkhorn and then noised. Prototype pruning and separation. T o prevent prototype collapse , enforce a minimum separation constraint min 𝑖 ≠ 𝑗 ∥ 𝑣 𝑖 − 𝑣 𝑗 ∥ 2 ≥ 𝜌 , (11) via projected updates; prune low-utilization prototypes using a threshold on assignment mass. clip ( 𝑧 , 𝑅 ) rescales 𝑧 to norm ≤ 𝑅 if necessary; 𝛽 is a server mo- mentum; 𝜉 , 𝜉 𝑘 are DP noises; 𝜌 > 0 enforces pair wise prototype spacing. 3.6 Recommendation Loss and End-to-End Objective W e cast recommendation as either pointwise (cross-entr opy) or pairwise (BPR) learning under prompt-injected backb one. For a candidate set I 𝑢,𝑡 with lab els 𝑦 𝑢,𝑡 ,𝑖 ∈ { 0 , 1 } and scores ˆ 𝑠 𝑢,𝑡 ,𝑖 = 𝑓 𝜃 ( 𝑥 𝑢,𝑡 ,𝑖 ; ˜ 𝑝 𝑢,𝑡 ) , a pointwise loss is L rec ( 𝑢, 𝑡 ) = 𝑖 ∈ I 𝑢,𝑡 h − 𝑦 𝑢,𝑡 ,𝑖 log 𝜎 ( ˆ 𝑠 𝑢,𝑡 ,𝑖 ) − ( 1 − 𝑦 𝑢,𝑡 ,𝑖 ) log ( 1 − 𝜎 ( ˆ 𝑠 𝑢,𝑡 ,𝑖 ) ) i , (12) with sigmoid 𝜎 ( ·) . A pairwise BPR alternative uses triplets ( 𝑖 + , 𝑖 − ) : L BPR rec ( 𝑢, 𝑡 ) = ( 𝑖 + ,𝑖 − ) − log 𝜎 ˆ 𝑠 𝑢,𝑡 ,𝑖 + − ˆ 𝑠 𝑢,𝑡 ,𝑖 − . (13) Global objective. Aggregating over users/timestamps and adding stability/plasticity regularization yields J = E ( 𝑢,𝑡 ) h L rec ( 𝑢, 𝑡 ) + 𝜆 𝑠 A 𝜙 ( 𝑝 long 𝑢 ) , C + 𝜆 𝑝 ∥ 𝑝 short 𝑢,𝑡 ∥ 1 i , (14) where 𝜆 𝑠 , 𝜆 𝑝 > 0 control stability and plasticity . Optionally , use the W asserstein alignment A W in (7). User-adaptive stability (optional). Set 𝜆 𝑠 ≡ 𝜆 𝑠 ( 𝑢 ) via a drift-to- stability mapping, e.g., 𝜆 𝑠 ( 𝑢 ) = 𝜆 max · exp − 𝜅 · Δ 𝑢 , (15) Δ 𝑢 = 1 𝑇 𝑢 − 1 𝑇 𝑢 𝑡 = 2 ∥ ¯ 𝑒 𝑢,𝑡 − ¯ 𝑒 𝑢,𝑡 − 1 ∥ 2 , (16) so highly drifting users receive weaker alignment (more plasticity), where 𝜅 > 0 tunes sensitivity and 𝑇 𝑢 is the number of obser ved periods. Prototype- Aligned Federated So-Prompts for Continual W eb Personalization WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates 3.7 Algorithmic O verview ProtoFed-SP decomposes continual personalization into three co- ordinated procedures: (i) ClientUpdate ( Alg. 1) maintains a dual- timescale prompt state per user by performing a sparse, fast update for the short-term prompt and an alignment-aware, slow update for the long-term prompt; (ii) Server Aggregate (Alg. 2) updates the prototype library via dierentially private federated aggregation of compressed client embeddings, with robustness and separation constraints; (iii) OnlineInference (Alg. 3) retriev es T op- 𝑀 proto- types given the current context, composes the routed soft prompt, and ranks candidates with a frozen backbone [ 39 ], performing a lightweight in-session short-term step when immediate feedback is available. Complexity and Memor y Footprint. Let 𝐿 𝑝 be prompt length and 𝑑 the embedding width. Per-client memor y is O ( 𝐿 𝑝 𝑑 ) for 𝑝 long 𝑢 and O ( 𝐿 𝑝 𝑑 ) for 𝑝 short 𝑢,𝑡 (short-term can be ephemeral or capped). Ser ver memory is O ( 𝐾 𝐿 𝑝 𝑑 ) for prototypes. Routing costs O ( 𝐾 𝑑 𝜙 ) per request (before T op- 𝑀 pruning); with ANN indexing in R 𝑑 𝜙 , this becomes sublinear in 𝐾 . 4 Experiment 4.1 Experimental Setup 4.1.1 Datasets. W e evaluate ProtoFed-SP on widely-adopted, re- cent, and method-aligned benchmarks used in continual recom- mendation, federated personalization, and multi-mo dal settings. • Amazon-Books, Amazon-Electronics (sequential, long horizon). Large-scale, high adoption in continual RS; strong concept drift and frequent cold items. W e follow recent works by using implicit feedback (binary) with 1 + 99 nega- tive sampling per evaluation query . • MovieLens-20M (ML-20M). Classic yet still standard for sequence/top- 𝐾 evaluation; we use the timestamped ratings and binarize with threshold ≥ 4 . • Y elp (temporal clicks/reviews). Urban venues with pronounced seasonality; useful for user-drift analysis and stability–plasticity trade-os. • Gowalla / LastFM-1K (check-in / music listening sequences). Popular for drifted sequences and for comparing to contin- ual/distillation baselines. • RetailRocket (clickstream). Session-heavy e-commerce in- teractions with short-term intent spikes. • T aobao User Behavior (large-scale CTR). Used by recent continual/federated CTR papers; provides realism for feder- ated simulation with many clients. • H&M Fashion (multi-modal). Public Kaggle benchmark with product images & metadata. W e freeze ViT/BERT en- coders as backbones to test multi-modal continual personal- ization and prototype routing. For all datasets we keep the canonical 5-core lter (users/items with ≥ 5 interactions), sort interactions chronologically , and parti- tion the stream into 𝑇 ∈ { 8 , 10 , 12 } time-slices (tasks) by wall-clock time so as to avoid leakage. Unless noted, we hold out the last 10% interactions of each time-slice for testing and the previous 10% for validation; candidate sets are top-100 (1 positive + 99 sampled negatives) standard in sequence ranking. 4.1.2 Evaluation Protocol and Metrics. W e follow recent continual- RS practice[ 14 ] and report freshness , r etention/forgetting , and e- ciency : (i) T op- 𝐾 accuracy . HitRate@K (HR@ 𝐾 ), NDCG@ 𝐾 , and MRR@ 𝐾 with 𝐾 ∈ { 5 , 10 , 20 } computed on each time-slice 𝑡 . (ii) Forgetting and transfer . Let 𝐴 𝑡 𝑠 denote NDCG@ 10 on slice 𝑠 after training up to slice 𝑡 . AF = 1 𝑇 − 1 𝑇 − 1 𝑠 = 1 max 𝑡 ′ ≤ 𝑇 − 1 𝐴 𝑡 ′ 𝑠 − 𝐴 𝑇 𝑠 , (17) BWT = 1 𝑇 − 1 𝑇 − 1 𝑠 = 1 𝐴 𝑇 𝑠 − 𝐴 𝑠 𝑠 , (18) FW T = 1 𝑇 − 1 𝑇 𝑠 = 2 𝐴 𝑠 − 1 𝑠 − ¯ 𝐴 scratch 𝑠 . (19) where ¯ 𝐴 scratch 𝑠 is p erformance on slice 𝑠 before se eing it (scratch model). (iii) Adaptation sp eed. Steps-to- 95% : the number of lo cal gradient steps to reach 0 . 95 × the converged NDCG@ 10 on the current slice. (iv) Fairness over time. W e report exposure disparity across head vs. tail items and low-activity vs. high-activity users : Disp item = Exp head − Exp tail , Disp user = Exp hi − Exp lo , tracked across slices to study long-term eects. (v ) Eciency . Trainable parameters (M), on-device memory (GB), wall-clock per slice (min), and communication cost (MB per client per round). For privacy reporting w e provide ( 𝜀 , 𝛿 ) under the Gauss- ian mechanism for the chosen 𝜎 and accountant. 4.1.3 Baselines. W e compare against strong and recent baselines; when methods were originally designed for trainable backbones, we include both their standard implementation and a PEFT variant to normalize training budget. (i) Static / non-continual. FullRetrain (oracle full retraining on cumulative data), Fine Tune-Last (train only on the current slice). (ii) Regularization-based CL. EWC [ 13 ], SI [ 38 ], MAS [ 2 ], LwF [ 22 ], Personalized Imitation (user-wise stability weights; SAIL-PIW - style) [31]. (iii) Replay-based CL. ER-Random [ 6 ], ER-Freq [ 1 ], ReLoop / ReLoop2 [4, 44], INFER [41]. (iv) Distillation / co-evolution. CCD (continual collaborative dis- tillation) [14]. (v ) Parameter-isolation / adapters. Prex-/Prompt- Tuning [ 15 , 19], Adapters [10], Dual-LoRA [11]. (vi) Federated personalization. FedA vg-Finetune [ 26 ], FedProx [ 18 ], Ditto [ 17 ]. For methods without DP , we report both non-DP and DP-wrapped versions for fairness. (vii) LLM4Rec (reference). Re cICL (in-context adaptation without parameter updates) [3] and PCL (prompt-as-memory) [33]. These are included on representative datasets to contextualize prompt- based personalization; their backbones are LLMs and are evaluated under the same candidate protocol. Please refer to §B for the detailed implementations. WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Canran Xiao and Liwei Hou T able 1: O verall T op- 𝐾 accuracy . NDCG@10 / HR@10 on eight benchmarks: Amazon-Books, Amazon-Electronics, MovieLens- 20M, Y elp, RetailRocket, Gowalla, T aobao, and H&M. Books Electronics ML-20M Y elp RetailRocket Gowalla T aobao H&M Method N@10 HR@10 N@10 HR@10 N@10 HR@10 N@10 HR@10 N@10 HR@10 N@10 HR@10 N@10 HR@10 N@10 HR@10 FullRetrain 0.114 0.231 0.133 0.257 0.319 0.644 0.109 0.220 0.244 0.466 0.205 0.514 0.217 0.438 0.262 0.487 Fine T une-Last 0.102 0.208 0.122 0.240 0.302 0.616 0.101 0.206 0.232 0.446 0.195 0.498 0.208 0.421 0.251 0.472 EWC 0.109 0.223 0.128 0.248 0.307 0.625 0.106 0.214 0.236 0.454 0.198 0.505 0.211 0.428 0.255 0.476 SI 0.108 0.221 0.127 0.246 0.306 0.623 0.105 0.213 0.235 0.452 0.197 0.503 0.207 0.420 0.251 0.472 MAS 0.109 0.222 0.127 0.247 0.305 0.622 0.105 0.213 0.235 0.452 0.197 0.504 0.210 0.427 0.254 0.476 LwF 0.110 0.225 0.129 0.249 0.310 0.629 0.106 0.214 0.238 0.457 0.199 0.507 0.212 0.431 0.257 0.480 Personalized Imitation 0.113 0.229 0.132 0.252 0.313 0.633 0.108 0.218 0.241 0.463 0.202 0.511 0.214 0.435 0.259 0.483 ER-Random 0.112 0.228 0.131 0.251 0.314 0.634 0.107 0.216 0.242 0.464 0.203 0.512 0.215 0.437 0.260 0.485 ER-Freq 0.115 0.232 0.134 0.255 0.316 0.637 0.110 0.220 0.245 0.469 0.206 0.517 0.218 0.441 0.263 0.489 ReLoop 0.116 0.233 0.134 0.256 0.317 0.638 0.111 0.222 0.246 0.471 0.207 0.519 0.219 0.443 0.265 0.492 ReLoop2 0.118 0.234 0.137 0.265 0.320 0.645 0.113 0.226 0.248 0.472 0.210 0.521 0.221 0.446 0.268 0.495 INFER 0.120 0.239 0.136 0.263 0.318 0.642 0.115 0.229 0.251 0.478 0.209 0.520 0.222 0.448 0.270 0.497 CCD 0.117 0.235 0.134 0.257 0.317 0.639 0.112 0.223 0.247 0.471 0.212 0.525 0.220 0.444 0.267 0.494 Prex/Prompt- Tuning 0.116 0.233 0.132 0.252 0.315 0.636 0.111 0.222 0.244 0.467 0.206 0.517 0.216 0.440 0.271 0.497 AdapterCL 0.115 0.232 0.133 0.254 0.316 0.637 0.111 0.221 0.245 0.469 0.207 0.518 0.217 0.441 0.268 0.494 Dual-LoRA (LSA T) 0.117 0.235 0.135 0.263 0.323 0.647 0.114 0.225 0.247 0.472 0.208 0.519 0.220 0.445 0.277 0.503 FedA vg-Finetune 0.111 0.226 0.129 0.249 0.309 0.628 0.106 0.214 0.240 0.460 0.201 0.509 0.219 0.442 0.261 0.486 FedProx 0.112 0.227 0.130 0.251 0.311 0.631 0.107 0.215 0.241 0.462 0.202 0.510 0.223 0.447 0.262 0.487 Ditto 0.113 0.228 0.131 0.252 0.312 0.632 0.108 0.217 0.243 0.466 0.203 0.512 0.223 0.447 0.263 0.489 FedRAP 0.114 0.231 0.133 0.256 0.314 0.635 0.110 0.219 0.246 0.471 0.206 0.517 0.226 0.451 0.266 0.492 RecICL 0.113 0.232 0.128 0.250 0.311 0.628 0.110 0.221 0.242 0.468 0.203 0.514 0.214 0.435 0.266 0.492 PCL 0.117 0.236 0.133 0.257 0.316 0.636 0.112 0.224 0.246 0.472 0.205 0.518 0.219 0.443 0.269 0.494 ProtoFed-SP (ours) 0.126 0.248 0.142 0.271 0.329 0.658 0.119 0.233 0.257 0.487 0.216 0.534 0.231 0.461 0.284 0.512 64 128 256 K prototypes 0.12 0.15 0.18 0.20 0.23 0.25 0.28 0.30 0.33 NDCG@10 2 4 8 M T op-M routing 0.12 0.15 0.18 0.20 0.23 0.25 0.28 0.30 0.33 0.1 0.5 1.0 s (stability weight) 0.12 0.15 0.18 0.20 0.23 0.25 0.28 0.30 0.33 1 × 1 0 4 5 × 1 0 4 1 × 1 0 3 p (sparsity) 0.12 0.15 0.18 0.20 0.23 0.25 0.28 0.30 0.33 0.2 0.4 0.8 (DP noise scale) 0.12 0.15 0.18 0.20 0.23 0.25 0.28 0.30 0.33 Amazon-Books ML-20M T aobao H&M Figure 2: Core hyperparameter sensitivity (NDCG@10, mean ± std). One parameter varie d p er blo ck; others xed at defaults. 4.2 Main Results W e report T op- 𝐾 ranking accuracy on eight widely-used bench- marks. Across all eight benchmarks, ProtoFed-SP attains the highest NDCG@10 and HR@10 (T ab. 1). A veraged over datasets, it improves NDCG@10 by +2.9% and HR@10 by +2.0% over the strongest com- peting baseline. The margins are largest on A mazon-Books (+5.0% NDCG vs. INFER) and H&M (+2.5% NDCG vs. Dual–LoRA), evi- dencing the benets of prototype alignment and dual-timescale prompting under long-tailed and multi-modal drift. On T aobao , ProtoFed-SP exceeds FedRAP by +2.2% NDCG and +2.2% HR, indicating that DP prototype aggregation preserves per- sonalization quality . Although INFER and ReLoop2 are the strongest prior methods on session/sequence data, Dual–LoRA excels on multi-mo dal H&M and FedRAP on federated CTR; ProtoFed-SP nevertheless consistently outperforms all alternatives. 4.3 Ablation and Analysis Single-factor ablations. W e disable one design at a time and keep all other components/Hyperparameters xed. W e report NDCG@10 / HR@10 on four representative datasets covering long-tail (Amazon- Books), classic sequence (ML-20M), federated CTR (T aobao), and multi-modal drift (H&M). Blue numb ers denote the drop relative to our full model (§4.2). T able 2 shows each component contributes measurably: (i) Long- term prompt is critical for stability . Removing 𝑝 long 𝑢 yields the largest drops, conrming its role in retaining long-horizon pref- erences. (ii) Prototype alignment mitigates drift. Disabling A degrades performance, supporting the stability benet of anchoring 𝑝 long 𝑢 to C . (iii) Short-term prompt accelerates intent tracking. Removing 𝑝 short 𝑢 , 𝑡 hurts more on interaction-dense or multi-modal settings, aligning with its rapid session adaptation design. (iv) Fed- erated prototype updates matter . Freezing prototypes causes uniform degradation, evidencing the value of continually refr esh- ing population anchors. (v) A ggregator choice is secondar y but Prototype- Aligned Federated So-Prompts for Continual W eb Personalization WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates T able 2: Single-factor ablations. NDCG@10 / HR@10 on four representative datasets. ( Δ ) is the decrease w .r .t. ProtoFed-SP (Full). Amazon-Books ML-20M T aobao H&M Method N@10 HR@10 N@10 HR@10 N@10 HR@10 N@10 HR@10 ProtoFed-SP (Full) 0.126 0.248 0.329 0.658 0.231 0.461 0.284 0.512 w/o Prototype Alignment A 0.120 (-0.006) 0.238 (-0.010) 0.324 (-0.005) 0.649 (-0.009) 0.225 (-0.006) 0.451 (-0.010) 0.277 (-0.007) 0.501 (-0.011) w/o Short-term prompt ( 𝛼 = 0 ) 0.122 (-0.004) 0.241 (-0.007) 0.325 (-0.004) 0.652 (-0.006) 0.227 (-0.004) 0.454 (-0.007) 0.279 (-0.005) 0.504 (-0.008) w/o Long-term prompt (short only ) 0.116 (-0.010) 0.232 (-0.016) 0.320 (-0.009) 0.644 (-0.014) 0.223 (-0.008) 0.448 (-0.013) 0.274 (-0.010) 0.496 (-0.016) Static Prototypes (no federated update) 0.121 (-0.005) 0.240 (-0.008) 0.326 (-0.003) 0.653 (-0.005) 0.226 (-0.005) 0.453 (-0.008) 0.278 (-0.006) 0.502 (-0.010) Alt. Aggregator: Geom. Median 0.124 (-0.002) 0.245 (-0.003) 0.328 (-0.001) 0.656 (-0.002) 0.230 (-0.001) 0.460 (-0.001) 0.282 (-0.002) 0.509 (-0.003) Alt. Aggregator: 2- W asserstein Bary . 0.123 (-0.003) 0.244 (-0.004) 0.327 (-0.002) 0.655 (-0.003) 0.229 (-0.002) 0.459 (-0.002) 0.281 (-0.003) 0.508 (-0.004) non-negligible. Replacing DP-FedKMeans with Geometric Median or 2- W asserstein Barycenter changes accuracy by ≤ 0 . 003 NDCG, indicating our gains are not tied to a specic aggregation rule. Parameter Sensitivity . W e analyze the ve most inuential hy- perparameters while xing all others to the defaults in §B. Figure 2 shows stable optima near the defaults. 1 2 3 4 5 6 7 8 S l i c e t 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 A F ( ) Amazon-Books 1 2 3 4 5 6 7 8 S l i c e t 0.000 0.005 0.010 0.015 0.020 0.025 A F ( ) H&M 180 200 220 240 260 280 300 320 S t e p s - t o - 9 5 % ( ) 200 220 240 260 280 300 320 S t e p s - t o - 9 5 % ( ) AF and Steps-to-95% acr oss slices Full AF Full Steps w/o align AF w/o align Steps w/o short AF w/o short Steps w/o long AF w/o long Steps (a) Time-series verication: AF ↓ (left axis) and Steps-to-95% ↓ (right axis) across slices on A mazon-Bo oks ( left panel) and H&M (right panel). 1 2 3 4 5 6 7 8 S l i c e t 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 A F ( ) Amazon-Books: AF vs NDCG@10 Method Full w/o align w/o short w/o long Metric AF NDCG@10 Metric AF NDCG@10 0.1 16 0.1 18 0.120 0.122 0.124 0.126 0.128 N D C G @ 1 0 ( ) (b) Dual-axis view (Amazon-Books): AF ↓ (left axis) vs. NDCG@10 ↑ (right axis) across slices for Full and ablations. Figure 3: Stability–plasticity verication. Prototype align- ment consistently lowers forgetting, while short-term prompts markedly reduce the steps nee ded to adapt; combin- ing both yields the best AF–NDCG frontier . Stability–Plasticity V erication. This experiment verify that dual timescales (long/short prompts) and prototype alignment jointly reduce forgetting (AF ↓ ) and spee d adaptation (Steps-to-95% ↓ ). For each time slice 𝑡 ∈ { 1 , . . . , 8 } we compute cumulative forgetting AF ( 𝑡 ) and the steps needed to reach 95% of the converged NDCG@10 on the same slice. W e compare ProtoFed-SP (Full) with three abla- tions: w/o align (drop A ), w/o short ( 𝛼 = 0 ), and w/o long (remove 𝑝 long ). From Fig. 3, we can observe: (i) Forgetting. The Full mo del main- tains uniformly low AF across slices on both datasets; removing alignment increases AF monotonically (e.g., Books 𝑡 = 8 : 0 . 024 vs. 0 . 009 ), evidencing the anchoring eect of pr ototypes. (ii) Adapta- tion. Steps-to-95% is lowest for the Full model and largest without the short-term prompt (Bo oks 𝑡 = 8 : 170 vs. 270 ), conrming that 𝑝 short accelerates session adaptation. (iii) AF–NDCG frontier . On Books, the Full model achiev es a superior Pareto front: NDCG rises steadily while AF remains below 0 . 01 ; ablations trade accuracy for either slower adaptation (w/o short) or larger forgetting (w/o align / w/o long). T ogether , the cur ves validate that alignment A reduces drift-induced forgetting and short-term prompting cuts adap- tation steps . Their combination yields the b est stability–plasticity balance. Does Privacy Hurt Personalization? Does adding dierential pri- vacy (DP) to federated prototype aggregation signicantly degrade personalization quality? W e compare Non-DP versus DP with Gaussian noise scales 𝜎 ∈ { 0 . 2 , 0 . 4 , 0 . 8 } applied to uploaded prompt embeddings 𝑧 𝑢 = compress ( 𝜙 ( 𝑝 long 𝑢 ) ) + 𝜉 , 𝜉 ∼ N ( 0 , 𝜎 2 𝐼 ) . As shown in Fig. 4: (i) Moderate DP preser ves personalization. At 𝜎 = 0 . 4 ( 𝜀 ≈ 3 . 4 ), NDCG remains within the Non-DP error bands on all datasets while AF increases marginally . (ii) Stronger DP degrades gracefully . 𝜎 = 0 . 8 ( 𝜀 ≈ 1 . 8 ) reduces NDCG by ∼ 1 – 2 . 5 points but does not induce catastrophic forgetting (AF rises mo destly). (iii) T ask de- pendence. T aobao (dense CTR) is the most sensitive to 𝜀 , whereas ML-20M is the most robust—consistent with their noise–signal ratios. Overall, DP prototype aggregation does not undermine per- sonalization at practical privacy levels. Who Benets from Personalization? Is the gain concentrated on heavy users, or do high-drift and cold-start users also benet? W e stratify users along three axes: (i) drift (Low/Mid/High, estimated by rolling embedding shift), (ii) activity (Light/Me dium/Heavy , by interactions per slice), and (iii) cold-start (New vs. Returning). WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Canran Xiao and Liwei Hou 2 3 4 5 6 0.15 0.20 0.25 0.30 NDCG@10 ( ) NDCG@10 vs. P rivacy Amazon- Books ML -20M T aobao H&M (a) NDCG@10 vs. privacy level. Lines show mean with ± std bands across seeds; dashe d horizontal lines indicate the Non-DP baselines. 2 3 4 5 6 0.006 0.008 0.010 0.012 0.014 0.016 0.018 0.020 AF ( ) F or getting vs. P rivacy Amazon- Books ML -20M T aobao H&M (b) AF (forgetting) vs. privacy level. Lower is better; dashed lines are Non-DP references. Figure 4: Privacy–utility trade-o. Across datasets, moderate DP (e.g., 𝜎 = 0 . 4 , mid 𝜀 ) preserves personalization: NDCG stays within the Non-DP band while AF increases only slightly; very strong DP ( 𝜎 = 0 . 8 ) degrades gracefully rather than cata- strophically . From Figure 5, we can observe that: (i) Not just heav y users. High-drift users—both heav y and light—cluster in the upp er-right of the volcano (large Δ , low 𝑝 ), indicating signicant, substantive gains. (ii) Cold-start gains. New users exhibit positive Δ on all radar axes (accuracy , forgetting, and adaptation), showing that prompt- based personalization shortens the cold-start vacuum. (iii) Drift matters most. Radar polygons expand with drift level mor e than with activity , matching the method’s design: prototype alignment stabilizes long-term memory , while short-term prompts accelerate adaptation irrespective of activity . 5 Conclusion W e addressed continual W eb personalization under non-stationarity and privacy by introducing a privacy-aware, parameter-ecient prompting interface that couples dual-timescale user prompts with a federated, prototype-anchored semantic prior . Our framework delivers consistent gains acr oss diverse benchmarks while reducing forgetting and adaptation latency , and it preserves utility under practical DP budgets; ablations and analyses clarify how alignment 0.000 0.005 0.010 0.015 0.020 0.025 0.030 N D C G @ 1 0 ( o u r s b e s t b a s e l i n e ) 0 1 2 3 4 5 6 l o g 1 0 ( p - v a l u e ) V olcano Plot: Individual User Gains (Amazon-Books) High drift Medium drift Low drift Heavy activity Medium activity Light activity Cold-start user Returning user (a) V olcano (Amazon-Books). Per-user eect size ( Δ NDCG@10) vs. − log 10 𝑝 . Points are colored by (drift, activity , cold-start) strata; hori- zontal line marks 𝑝 = 0 . 05 . N D C G @ 1 0 ( ) A F ( ) S t e p s - 9 5 % ( ) 0.2 0.4 0.6 0.8 1.0 Gr oup-level Analysis: Normalized Performance Gains (Macr o-averaged acr oss datasets) High-drift & Heavy & Returning High-drift & Light & New Mid-drift & Medium & Returning Low-drift & Heavy & Returning Low-drift & Light & Returning Cold-start & New & Any (b) Group radar (macro-avg across datasets). Axes: Δ NDCG@10 ( ↑ ), Δ AF ( ↑ ), Δ Steps-to-95% ( ↑ ). Figure 5: High-drift users see the largest, most signicant gains; cold-start users also benet. Heav y users gain, but improvements are not exclusive to them. curbs drift and short-term pr ompting accelerates intent tracking. For the community , these results suggest that anchored prompting is a viable recipe for balancing stability–plasticity at the user/session level without sacricing federated or privacy constraints. Limita- tions include reliance on frozen backb ones, simulated federated settings with accountant-based DP estimates, and manual choices for prototype capacity/separation. Future work will explore online A/B validation, adaptive pro- totype growth with fairness-aware constraints, and extensions to richer multi-modal and cross-domain personalization scenarios. Acknowledgments W e would like to thank Hunan Airon T echnology Co., Ltd. for providing computing resour ces for this project. Prototype- Aligned Federated So-Prompts for Continual W eb Personalization WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates References [1] Kian Ahrabian, Yishi Xu, Yingxue Zhang, Jiapeng Wu, Yuening W ang, and Mark Coates. 2021. Structure aware experience replay for incremental learning in graph-based recommender systems. In Procee dings of the 30th ACM International Conference on Information & Knowledge Management . 2832–2836. [2] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny , Marcus Rohrbach, and Tinne T uytelaars. 2018. Memory aware synapses: Learning what (not) to forget. In Proceedings of the European conference on computer vision (ECCV) . 139–154. [3] Keqin Bao, Ming Y an, Yang Zhang, Jizhi Zhang, W enjie Wang, Fuli Feng, and Xiangnan He. 2024. Real-Time Personalization for LLM-based Recommendation with Customized In-Context Learning. arXiv preprint arXiv:2410.23136 (2024). [4] Guohao Cai, Jieming Zhu, Quanyu Dai, Zhenhua Dong, Xiuqiang He , Ruiming T ang, and Rui Zhang. 2022. Reloop: A self-correction continual learning loop for recommender systems. In Proceedings of the 45th International A CM SIGIR Conference on Research and Development in Information Retrieval . 2692–2697. [5] Hongru Cai, Y ongqi Li, W enjie W ang, Fengbin Zhu, Xiaoyu Shen, W enjie Li, and T at-Seng Chua. 2025. Large language mo dels empowered personalized web agents. In Proceedings of the ACM on W eb Conference 2025 . 198–215. [6] Arslan Chaudhry , Marcus Rohrbach, Mohamed Elhoseiny , Thalaiyasingam Ajan- than, Puneet K Dokania, Philip HS T orr, and Marc’ Aurelio Ranzato. 2019. On tiny episodic memories in continual learning. arXiv preprint arXiv:1902.10486 (2019). [7] Chaochao Chen, Xiaohua Feng, Yuyuan Li, Lingjuan Lyu, Jun Zhou, Xiaolin Zheng, and Jianwei Yin. 2024. Integration of large language models and federated learning. Patterns 5, 12 (2024). [8] Chaochao Chen, Yizhao Zhang, Yuyuan Li, Jun W ang, Lianyong Qi, Xiaolong Xu, Xiaolin Zheng, and Jianwei Yin. 2024. Post-training attribute unlearning in recommender systems. ACM Transactions on Information Systems 43, 1 (2024), 1–28. [9] Xiaohong Chen, Canran Xiao, and Y ongmei Liu. 2024. Confusion-resistant federated learning via diusion-based data harmonization on non-IID data. In Proceedings of the 38th International Conference on Neural Information Processing Systems . 137495–137520. [10] Neil Houlsby , Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly . 2019. Parameter-ecient transfer learning for NLP. In International conference on machine learning . PMLR, 2790–2799. [11] Edward J Hu, Y elong Shen, P hillip W allis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean W ang, Lu Wang, W eizhu Chen, et al . 2022. Lora: Low-rank adaptation of large language models. ICLR 1, 2 (2022), 3. [12] Linling Jiang, Xin Wang, Fan Zhang, and Caiming Zhang. 2025. Transform- ing time and space: ecient video super-resolution with hybrid attention and deformable transformers. The Visual Computer (2025), 1–12. [13] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Jo el V eness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al . 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences 114, 13 (2017), 3521– 3526. [14] Gyuseok Lee, SeongKu Kang, W onbin K weon, and Hwanjo Y u. 2024. Continual collaborative distillation for recommender system. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 1495–1505. [15] Brian Lester , Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Ecient Prompt T uning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing . 3045–3059. [16] Muquan Li, Dongyang Zhang, T ao He, Xiurui Xie, Yuan-Fang Li, and Ke Qin. 2024. T owards eective data-free knowledge distillation via diverse diusion augmen- tation. In Proceedings of the 32nd ACM International Conference on Multimedia . 4416–4425. [17] Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. 2021. Ditto: Fair and robust federated learning through personalization. In International conference on machine learning . PMLR, 6357–6368. [18] Tian Li, Anit Kumar Sahu, Manzil Zaheer , Maziar Sanjabi, Ameet T alwalkar , and Virginia Smith. 2020. Federated optimization in heterogeneous networks. Proceedings of Machine learning and systems 2 (2020), 429–450. [19] Xiang Lisa Li and Percy Liang. 2021. Prex-T uning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th A nnual Meeting of the Associa- tion for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers) . 4582–4597. [20] Y uyuan Li, Chaochao Chen, Yizhao Zhang, W eiming Liu, Lingjuan Lyu, Xiaolin Zheng, Dan Meng, and Jun W ang. 2023. Ultrare: Enhancing receraser for recom- mendation unlearning via error decomposition. Advances in Neural Information Processing Systems 36 (2023), 12611–12625. [21] Y uyuan Li, Yizhao Zhang, W eiming Liu, Xiaohua Feng, Zhong xuan Han, Chaochao Chen, and Chenggang Y an. 2025. Multi-Objective Unlearning in Rec- ommender Systems via Preference Guided Pareto Exploration. IEEE Transactions on Services Computing (2025). [22] Zhizhong Li and Derek Hoiem. 2017. Learning without forgetting. IEEE transac- tions on pattern analysis and machine intelligence 40, 12 (2017), 2935–2947. [23] Ting-Peng Liang, Hung-Jen Lai, and Yi-Cheng Ku. 2006. Personalized content rec- ommendation and user satisfaction: Theoretical synthesis and empirical ndings. Journal of Management Information Systems 23, 3 (2006), 45–70. [24] Junhong Lin, Xinyue Zeng, Jie Zhu, Song W ang, Julian Shun, Jun W u, and Daw ei Zhou. 2025. Plan and Budget: Eective and Ecient T est- Time Scaling on Large Language Model Reasoning. arXiv:2505.16122 [cs.LG] https://arxiv .org/abs/2505. 16122 [25] Lixin Liu, Y anling W ang, Tianming Wang, Dong Guan, Jiawei W u, Jingxu Chen, Rong Xiao, W enxiang Zhu, and Fei Fang. 2023. Continual transfer learning for cross-domain click-through rate prediction at taobao. In Companion Proceedings of the A CM W eb Conference 2023 . 346–350. [26] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-ecient learning of deep net- works from de centralized data. In Articial intelligence and statistics . PMLR, 1273–1282. [27] Arpit Rana, Scott Sanner , Mohamed Reda Bouadjenek, Ronald Di Carlantonio, and Gar y Farmaner. 2024. User experience and the role of p ersonalization in critiquing-based conversational recommendation. ACM Transactions on the W eb 18, 4 (2024), 1–21. [28] Hailin T ao, Jinjiang Li, Zhen Hua, and Fan Zhang. 2023. DUDB: de ep unfolding- based dual-branch feature fusion network for pan-sharpening remote sensing images. IEEE Transactions on Geoscience and Remote Sensing 62 (2023), 1–17. [29] Hua W ang and Fan Zhang. 2024. Computing nodes for plane data points by constructing cubic p olynomial with constraints. Computer Aided Ge ometric Design 111 (2024), 102308. [30] Y uenan Wang, Hua Wang, and Fan Zhang. 2025. A Medical image segmenta- tion model with auto-dynamic convolution and location attention mechanism. Computer Methods and Programs in Biomedicine 261 (2025), 108593. [31] Y uening W ang, Yingxue Zhang, Antonios Valkanas, Ruiming T ang, Chen Ma, Jianye Hao, and Mark Coates. 2023. Structure aware incremental learning with personalized imitation weights for recommender systems. In Proceedings of the AAAI Conference on A rticial Intelligence , V ol. 37. 4711–4719. [32] Zongda Wu, Shigen Shen, Haiping Zhou, Huxiong Li, Chenglang Lu, and Dong- dong Zou. 2021. An eective approach for the protection of user commodity viewing privacy in e-commerce website . Knowledge-Based Systems 220 (2021), 106952. [33] Mingdai Y ang, Fan Y ang, Y anhui Guo, Shaoyuan Xu, Tianchen Zhou, Y etian Chen, Simone Shao, Jia Liu, and Y an Gao. 2025. PCL: Prompt-based continual learning for user modeling in recommender systems. In Companion Proceedings of the ACM on W eb Conference 2025 . 1475–1479. [34] Jiawei Y ao, Chuming Li, Keqiang Sun, Yingjie Cai, Hao Li, W anli Ouyang, and Hongsheng Li. 2023. Ndc-scene: Boost mono cular 3d semantic scene completion in normalized device coordinates space. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV) . IEEE Computer Society , 9421–9431. [35] Jiawei Y ao, Chuming Li, and Canran Xiao . 2024. Swift sampler: Ecient learning of sampler by 10 parameters. Advances in Neural Information Processing Systems 37 (2024), 59030–59053. [36] Hyunsik Y oo, Zhichen Zeng, Jian Kang, Ruizhong Qiu, David Zhou, Zhining Liu, Fei W ang, Charlie Xu, Eunice Chan, and Hanghang T ong. 2024. Ensuring user-side fairness in dynamic recommender systems. In Proceedings of the ACM W eb Conference 2024 . 3667–3678. [37] Xinyue Zeng, Haohui W ang, Junhong Lin, Jun Wu, Tyler Cody , and Dawei Zhou. 2025. LENSLLM: Unveiling Fine-T uning Dynamics for LLM Selection. arXiv:2505.03793 [cs.LG] [38] Friedemann Zenke, Ben Po ole, and Surya Ganguli. 2017. Continual learning through synaptic intelligence. In International conference on machine learning . PMLR, 3987–3995. [39] Fan Zhang, Gongguan Chen, Hua W ang, Jinjiang Li, and Caiming Zhang. 2023. Multi-scale video super-resolution transformer with polynomial approximation. IEEE Transactions on Circuits and Systems for Video T echnology 33, 9 (2023), 4496– 4506. [40] Fan Zhang, Gongguan Chen, Hua Wang, and Caiming Zhang. 2024. CF-DAN: Facial-expression recognition based on cross-fusion dual-attention network. Com- putational Visual Media 10, 3 (2024), 593–608. [41] Xinni Zhang, Y ankai Chen, Chenhao Ma, Yixiang Fang, and Irwin King. 2024. Inuential exemplar r eplay for incremental learning in recommender systems. In Proceedings of the AAAI Conference on Articial Intelligence , V ol. 38. 9368–9376. [42] Xiaofeng Zhang, Fanshuo Zeng, Yihao Quan, Zheng Hui, and Jiawei Y ao. 2025. Enhancing multimodal large language models complex reason via similarity computation. In Proceedings of the AAAI Conference on Articial Intelligence , V ol. 39. 10203–10211. [43] Y ujia Zhou, Qiannan Zhu, Jiajie Jin, and Zhicheng Dou. 2024. Cognitive per- sonalized search integrating large language models with an ecient memory mechanism. In Proceedings of the ACM W eb Conference 2024 . 1464–1473. [44] Jieming Zhu, Guohao Cai, Junjie Huang, Zhenhua Dong, Ruiming T ang, and W einan Zhang. 2023. ReLoop2: Building Self-Adaptive Recommendation Models via Responsive Error Compensation Loop. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 5728–5738. WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Canran Xiao and Liwei Hou Appendix A Algorithm pseudoco de W e present the pseudocode for the training and inference of ProtoFed- SP. Algorithm 1 ProtoFed-SP: ClientUpda te (user 𝑢 at time 𝑡 ) Require: Frozen backbone 𝑓 𝜃 ; prototypes C = { 𝑐 𝑘 } 𝐾 𝑘 = 1 ; encoders 𝜙 (prompt) and 𝑔 (query); local buer D 𝑢,𝑡 , context 𝑞 𝑢,𝑡 ; steps 𝜂 𝑠 , 𝜂 ℓ ; weights 𝜆 𝑝 , 𝜆 𝑠 ; temp eratures 𝜏 , 𝜏 𝑎 ; retrieval size 𝑀 ; upload period 𝑅 , DP noise scale 𝜎 , clip radius 𝑅 clip . Ensure: Updated ( 𝑝 long 𝑢 , 𝑝 short 𝑢,𝑡 ) ; optional upload vector 𝑧 𝑢 . 1: function ClientUpda te ( 𝑢, 𝑡 ) 2: ℎ ← 𝑔 ( 𝑞 𝑢,𝑡 ) ⊲ encode current query/session 3: T opM ← arg max 𝑀 𝑘 ∈ [ 𝐾 ] ⟨ ℎ, 𝜙 ( 𝑐 𝑘 ) ⟩ ⊲ ANN/MIPS retrieval 4: 𝑠 𝑘 ← ⟨ ℎ, 𝜙 ( 𝑐 𝑘 ) ⟩ / 𝜏 for 𝑘 ∈ T opM ; 𝑤 𝑘 ← exp ( 𝑠 𝑘 ) Í 𝑗 ∈ TopM exp ( 𝑠 𝑗 ) 5: ˜ 𝑝 𝑢,𝑡 ← 𝑝 long 𝑢 + 𝛼 𝑢,𝑡 𝑝 short 𝑢,𝑡 + Í 𝑘 ∈ T opM 𝑤 𝑘 𝑐 𝑘 6: Compute scores ˆ 𝑠 on a minibatch from D 𝑢,𝑡 via 𝑓 𝜃 ( · ; ˜ 𝑝 𝑢,𝑡 ) 7: L rec ← RecLoss ( ˆ 𝑠 ) ⊲ e.g., BCE or BPR ⊲ Short-term (fast, sparse) up date 8: 𝐺 𝑠 ← ∇ 𝑝 short 𝑢,𝑡 L rec 9: 𝑝 short 𝑢,𝑡 ← Soresh 𝑝 short 𝑢,𝑡 − 𝜂 𝑠 𝐺 𝑠 , 𝜂 𝑠 𝜆 𝑝 ⊲ Long-term (slow , prototype-aligne d) up date 10: 𝑧 ← 𝜙 ( 𝑝 long 𝑢 ) ; 𝑣 𝑘 ← 𝜙 ( 𝑐 𝑘 ) 11: 𝑘 ★ ← arg min 𝑘 𝐷 Ψ ( 𝑧 ∥ 𝑣 𝑘 ) ⊲ nearest prototype under Bregman 𝐷 Ψ 12: A ← 𝐷 Ψ ( 𝑧 ∥ 𝑣 𝑘 ★ ) + 𝛾 · InfoNCE ( 𝑧, { 𝑣 𝑘 } , 𝜏 𝑎 ) 13: 𝐺 ℓ ← ∇ 𝑝 long 𝑢 ( L rec + 𝜆 𝑠 A ) 14: 𝑝 long 𝑢 ← 𝑝 long 𝑢 − 𝜂 ℓ 𝐺 ℓ ⊲ Periodic/triggered upload with DP protection 15: if 𝑡 mo d 𝑅 = 0 or DriftLarge then 16: 𝑧 𝑢 ← compress 𝜙 ( 𝑝 long 𝑢 ) 17: 𝑧 𝑢 ← 𝑧 𝑢 + 𝜉 , where 𝜉 ∼ N ( 0 , 𝜎 2 𝐼 ) 18: SendT oServer ( 𝑧 𝑢 ) 19: return ( 𝑝 long 𝑢 , 𝑝 short 𝑢,𝑡 ) 20: function SoftThresh ( 𝑧, 𝜏 ) 21: return sign ( 𝑧 ) · max { | 𝑧 | − 𝜏 , 0 } ⊲ element-wise soft-thresholding B Implementation Details Backbone and tokenization. Unless other wise stated we use a frozen SASRec -style Transformer (2 layers, 𝑑 = 256 , 4 heads) for sequence scoring; for H&M we additionally fr eeze ViT -B/16 (im- age) and DistilBERT (text) encoders whose outputs are linearly projected to 𝑑 . A candidate set of 100 items p er quer y is used (1 positive + 99 sampled negatives). Soft prompts and routing. Prompt length 𝐿 𝑝 = 8 tokens (default), dimension 𝑑 = 256 . Prototype count 𝐾 ∈ { 64 , 128 } (default 128), T op- 𝑀 = 4 retrieval. Query encoder 𝑔 ( ·) and prompt encoder 𝜙 ( ·) are 2 -layer MLPs with GELU and LayerNorm, outputting 𝑑 𝜙 = 128 . Router temperature 𝜏 = 0 . 07 ; alignment temperature 𝜏 𝑎 = 0 . 1 . Algorithm 2 ProtoFed-SP: ServerAggrega te (DP-Fe dKMeans variant) Require: Uploads { 𝑧 𝑢 } 𝑢 ∈ B ; current prototype reps { 𝑣 𝑘 } 𝐾 𝑘 = 1 ; mo- mentum 𝛽 ; clip radius 𝑅 clip ; DP noise scale 𝜎 ; separation margin 𝜌 ; utilization threshold 𝜏 util . Ensure: Updated { 𝑣 𝑘 } and prototype librar y C . 1: function ServerAggrega te ( { 𝑧 𝑢 } , { 𝑣 𝑘 } ) 2: Assign: A 𝑘 ← { 𝑢 ∈ B : 𝑘 = arg min 𝑗 ∥ 𝑧 𝑢 − 𝑣 𝑗 ∥ 2 2 } for 𝑘 = 1 , . . . , 𝐾 3: for 𝑘 = 1 to 𝐾 do 4: ¯ 𝑧 𝑘 ← 1 | A 𝑘 | Í 𝑢 ∈ A 𝑘 clip ( 𝑧 𝑢 , 𝑅 clip ) 5: 𝑣 𝑘 ← ( 1 − 𝛽 ) 𝑣 𝑘 + 𝛽 ( ¯ 𝑧 𝑘 + 𝜉 𝑘 ) , with 𝜉 𝑘 ∼ N ( 0 , 𝜎 2 𝐼 ) 6: EnforceSepara tion ( { 𝑣 𝑘 } , 𝜌 ) ⊲ project to the minimum-spacing feasible set 7: PruneOrReinit ( { 𝑣 𝑘 } , { A 𝑘 } , 𝜏 util ) 8: return { 𝑣 𝑘 } 9: function EnforceSepara tion ( { 𝑣 𝑘 } , 𝜌 ) 10: for 𝑖 < 𝑗 do 11: if ∥ 𝑣 𝑖 − 𝑣 𝑗 ∥ 2 < 𝜌 then 12: 𝛿 ← 𝜌 − ∥ 𝑣 𝑖 − 𝑣 𝑗 ∥ 2 2 · 𝑣 𝑖 − 𝑣 𝑗 ∥ 𝑣 𝑖 − 𝑣 𝑗 ∥ 2 + 𝜖 13: 𝑣 𝑖 ← 𝑣 𝑖 + 𝛿 ; 𝑣 𝑗 ← 𝑣 𝑗 − 𝛿 14: function PruneOrReinit ( { 𝑣 𝑘 } , { A 𝑘 } , 𝜏 util ) 15: 𝑁 ← Í 𝑘 | A 𝑘 | 16: for 𝑘 = 1 to 𝐾 do 17: if | A 𝑘 | / 𝑁 < 𝜏 util then 18: ReinitFromMass ( 𝑣 𝑘 ) ⊲ e.g., KMeans++ seeding on recent uploads Algorithm 3 ProtoFed-SP: OnlineInference (routing and rank- ing) Require: User 𝑢 , context 𝑞 𝑢,𝑡 , candidate set I 𝑢,𝑡 ; current ( 𝑝 long 𝑢 , 𝑝 short 𝑢,𝑡 ) , prototypes C ; enco ders 𝑔, 𝜙 ; temp erature 𝜏 ; re- trieval size 𝑀 ; optional step size 𝜂 𝑠 , sparsity weight 𝜆 𝑝 . Ensure: Ranked list over I 𝑢,𝑡 . 1: function OnlineInference ( 𝑢 , 𝑡 ) 2: ℎ ← 𝑔 ( 𝑞 𝑢,𝑡 ) ; T opM ← arg max 𝑀 𝑘 ⟨ ℎ, 𝜙 ( 𝑐 𝑘 ) ⟩ 3: 𝑤 𝑘 ← somax ( ⟨ ℎ, 𝜙 ( 𝑐 𝑘 ) ⟩ / 𝜏 ) for 𝑘 ∈ T opM 4: ˜ 𝑝 𝑢,𝑡 ← 𝑝 long 𝑢 + 𝛼 𝑢,𝑡 𝑝 short 𝑢,𝑡 + Í 𝑘 ∈ T opM 𝑤 𝑘 𝑐 𝑘 5: Compute scores ˆ 𝑠 𝑖 ← 𝑓 𝜃 ( 𝑥 𝑢,𝑡 ,𝑖 ; ˜ 𝑝 𝑢,𝑡 ) for 𝑖 ∈ I 𝑢,𝑡 6: return RankBy ( ˆ 𝑠 ) 7: if HasImmediateFeedba ck then 8: L rec ← RecLoss 9: 𝐺 𝑠 ← ∇ 𝑝 short 𝑢,𝑡 L rec 10: 𝑝 short 𝑢,𝑡 ← Soresh 𝑝 short 𝑢,𝑡 − 𝜂 𝑠 𝐺 𝑠 , 𝜂 𝑠 𝜆 𝑝 Optimization. Short-term step size 𝜂 𝑠 = 5 × 10 − 3 with proximal soft-threshold 𝜆 𝑝 ∈ { 10 − 4 , 10 − 3 } ; long-term step size 𝜂 ℓ = 1 × 10 − 3 ; alignment weight 𝜆 𝑠 ∈ [ 0 . 1 , 1 . 0 ] (user-adaptive via Eq. (16) unless specied); InfoNCE weight 𝛾 = 0 . 5 . W e train for 3 epochs per slice on each client with batch size 𝐵 = 256 and sequence length 𝐿 = 50 . AdamW with weight decay 10 − 4 , cosine schedule, and gradient clipping at 1 . 0 . Prototype- Aligned Federated So-Prompts for Continual W eb Personalization WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Federated schedule and privacy . W e simulate 𝑁 𝑐 ∈ { 1 k , 5 k } clients, sample 5% per round. Uploads occur every 𝑅 = 500 lo cal steps or when drift exceeds a threshold (Sec. 3): 𝑧 𝑢 = compress ( 𝜙 ( 𝑝 long 𝑢 ) ) + 𝜉 , where compression is PCA to 64-d followed by 8-bit product quantization. Clipping radius 𝑅 clip = 1 . 0 , server momentum 𝛽 = 0 . 5 . DP noise 𝜎 ∈ { 0 . 2 , 0 . 4 , 0 . 8 } ; we report the resulting ( 𝜀 , 𝛿 = 10 − 5 ) using a moments accountant for 𝑇 rounds. Prototype separation margin 𝜌 = 0 . 5 with projection; low-utilization threshold 𝜏 util = 0 . 01 for pruning. Hardware and libraries. Exp eriments run on 8 × A100-80GB GP Us (BF16), Py T orch 2.2, CUDA 12.1, F AISS 1.8 for ANN retrieval, and a federated simulator based on Flower/FedML. Multi-modal encoders are preloaded and kept frozen. W e x three random seeds and report mean ± std. Hyperparameter selection. For each dataset we grid-search 𝜆 𝑠 ∈ { 0 . 1 , 0 . 3 , 0 . 5 , 0 . 8 , 1 . 0 } , 𝜆 𝑝 ∈ { 1e − 4 , 1e − 3 } , 𝐾 ∈ { 64 , 128 , 256 } , 𝑀 ∈ { 2 , 4 , 8 } on the rst two slices’ validation sets and ke ep the best for the remainder . Candidate generation and negatives. T o decouple ranking from retrieval, all methods shar e the same candidate set; at evaluation we sample 99 negatives uniformly fr om items not interacted with by the user in the current slice. Items that appear for the rst time in slice 𝑡 are eligible for the positive of slice 𝑡 only (no leakage). C Dynamic Regret and Anchor-Induce d Drift Contraction W e study the client-side update of ProtoFed-SP through a convex surrogate that conditions on the router-selected anchor 𝑐 𝑡 and replaces the nonconvex min 𝑘 /InfoNCE alignment with a quadratic prototype tether , enabling sharp dynamic-regret and drift-control guarantees. Setup: Prompt as an Online De cision V ariable. W e analyze one user/client. Let 𝑤 ∈ R 𝑑 denote the attene d prompt parameters, partitioned as 𝑤 = ( 𝑢, 𝑠 ) where 𝑢 ∈ R 𝑑 ℓ is the long-term block and 𝑠 ∈ R 𝑑 𝑠 is the short-term block ( 𝑑 ℓ + 𝑑 𝑠 = 𝑑 ). At round 𝑡 = 1 , 2 , . . . , 𝑇 , the client faces a convex per-round objective 𝐹 𝑡 ( 𝑤 ) : = 𝑓 𝑡 ( 𝑤 ) + 𝜆 𝑝 ∥ 𝑠 ∥ 1 + 𝜆 𝑠 2 ∥ 𝑢 − 𝑐 𝑡 ∥ 2 2 , (20) where 𝑓 𝑡 : R 𝑑 → R is a convex surr ogate for the recommendation loss induced by the local buer (e.g., convexied logistic/square surrogate), 𝑐 𝑡 ∈ R 𝑑 ℓ is the selected prototype anchor , and 𝜆 𝑝 , 𝜆 𝑠 ≥ 0 control plasticity and stability . Let W ⊂ R 𝑑 be a closed convex feasible set ( e.g., reecting bounded prompt energy). Dene the diameter 𝐷 : = sup 𝑤, 𝑤 ′ ∈ W ∥ 𝑤 − 𝑤 ′ ∥ 2 < ∞ . (21) Comparator sequence and variation. For any comparator se quence { 𝑢 𝑡 } 𝑇 𝑡 = 1 ⊂ W (note: here 𝑢 𝑡 denotes a generic comparator point in W , not the long block), dene its path length 𝑉 𝑇 ( { 𝑢 𝑡 }) : = 𝑇 𝑡 = 2 ∥ 𝑢 𝑡 − 𝑢 𝑡 − 1 ∥ 2 . (22) In particular , denote by 𝑤 ★ 𝑡 ∈ arg min 𝑤 ∈ W 𝐹 𝑡 ( 𝑤 ) any per-round minimizer , and write 𝑉 ★ 𝑇 : = 𝑉 𝑇 ( { 𝑤 ★ 𝑡 }) . Algorithm: Regularized Online Proximal Update. W e analyze the following (implicit) proximal update, which captures the stability- aware prompt interface and is the standard “follow-the-regularized- leader with a quadratic stabilizer” form: 𝑤 𝑡 ∈ arg min 𝑤 ∈ W n 𝐹 𝑡 ( 𝑤 ) + 1 2 𝜂 ∥ 𝑤 − 𝑤 𝑡 − 1 ∥ 2 2 o , 𝑡 = 1 , . . . , 𝑇 , (23) with stepsize 𝜂 > 0 and an initialization 𝑤 0 ∈ W . This up date is stability-biased: the quadratic term discourages abrupt changes, while the anchor term 𝜆 𝑠 2 ∥ 𝑢 − 𝑐 𝑡 ∥ 2 tethers the long-term block toward population semantics. Remark 1 (Rela tion to Prot oFed-SP upda tes). Eq. (23) is an idealized update that optimizes the round objective plus a quadratic trust region. In practice, ProtoFed-SP implements a computationally lighter approximation: a proximal step for the ℓ 1 short-term block and an alignment-aware proximal step for the long-term block using a local quadratic model of the recommendation loss. The analysis below characterizes the fundamental stability–plasticity tradeo induced by anchoring; it can b e extended to inexact solves via standard inexact- proximal arguments (omitted for brevity ). Lemma C.1 (Proximal three-point ineqality). Let 𝐹 : W → R ∪ { +∞ } be convex, W closed and convex, and let 𝑥 ∈ W . For 𝜂 > 0 , dene 𝑥 + ∈ arg min 𝑤 ∈ W n 𝐹 ( 𝑤 ) + 1 2 𝜂 ∥ 𝑤 − 𝑥 ∥ 2 2 o . Then for every 𝑢 ∈ W , 𝐹 ( 𝑥 + ) − 𝐹 ( 𝑢 ) ≤ 1 2 𝜂 ∥ 𝑢 − 𝑥 ∥ 2 2 − ∥ 𝑢 − 𝑥 + ∥ 2 2 − ∥ 𝑥 + − 𝑥 ∥ 2 2 . (24) Proof. By optimality of 𝑥 + , 𝐹 ( 𝑥 + ) + 1 2 𝜂 ∥ 𝑥 + − 𝑥 ∥ 2 2 ≤ 𝐹 ( 𝑢 ) + 1 2 𝜂 ∥ 𝑢 − 𝑥 ∥ 2 2 ∀ 𝑢 ∈ W . (25) Rearranging yields 𝐹 ( 𝑥 + ) − 𝐹 ( 𝑢 ) ≤ 1 2 𝜂 ∥ 𝑢 − 𝑥 ∥ 2 2 − ∥ 𝑥 + − 𝑥 ∥ 2 2 . (26) Now expand the squared norm identity ∥ 𝑢 − 𝑥 ∥ 2 2 = ∥ 𝑢 − 𝑥 + ∥ 2 2 + ∥ 𝑥 + − 𝑥 ∥ 2 2 + 2 ⟨ 𝑢 − 𝑥 + , 𝑥 + − 𝑥 ⟩ , and substitute into (26) to get 𝐹 ( 𝑥 + ) − 𝐹 ( 𝑢 ) ≤ 1 2 𝜂 ∥ 𝑢 − 𝑥 + ∥ 2 2 + 2 ⟨ 𝑢 − 𝑥 + , 𝑥 + − 𝑥 ⟩ . Finally , apply polarization 2 ⟨ 𝑢 − 𝑥 + , 𝑥 + − 𝑥 ⟩ = ∥ 𝑢 − 𝑥 ∥ 2 2 − ∥ 𝑢 − 𝑥 + ∥ 2 2 − ∥ 𝑥 + − 𝑥 ∥ 2 2 , which yields (24). □ Theorem C.2 (Dynamic regret bound (pa th-length form)). Assume W has nite diameter 𝐷 as in (21) . Let { 𝑤 𝑡 } 𝑇 𝑡 = 0 be generate d by (23) . Then for any comparator se quence { 𝑢 𝑡 } 𝑇 𝑡 = 1 ⊂ W , 𝑇 𝑡 = 1 𝐹 𝑡 ( 𝑤 𝑡 ) − 𝐹 𝑡 ( 𝑢 𝑡 ) ≤ 1 2 𝜂 ∥ 𝑢 1 − 𝑤 0 ∥ 2 2 + 𝐷 𝜂 𝑉 𝑇 ( { 𝑢 𝑡 }) . (27) WW W ’26, April 13–17, 2026, Dubai, United Arab Emirates Canran Xiao and Liwei Hou In particular , choosing 𝑢 𝑡 = 𝑤 ★ 𝑡 ∈ arg min 𝑤 ∈ W 𝐹 𝑡 ( 𝑤 ) gives 𝑇 𝑡 = 1 𝐹 𝑡 ( 𝑤 𝑡 ) − 𝐹 𝑡 ( 𝑤 ★ 𝑡 ) ≤ 1 2 𝜂 ∥ 𝑤 ★ 1 − 𝑤 0 ∥ 2 2 + 𝐷 𝜂 𝑉 ★ 𝑇 . (28) Proof. Apply Lemma C.1 to each round with 𝐹 ( ·) = 𝐹 𝑡 ( ·) , 𝑥 = 𝑤 𝑡 − 1 , 𝑥 + = 𝑤 𝑡 , and 𝑢 = 𝑢 𝑡 : 𝐹 𝑡 ( 𝑤 𝑡 ) − 𝐹 𝑡 ( 𝑢 𝑡 ) ≤ 1 2 𝜂 ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 − ∥ 𝑢 𝑡 − 𝑤 𝑡 ∥ 2 2 − ∥ 𝑤 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 . (29) Dropping the nonpositive term − ∥ 𝑤 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 yields the relaxed but still valid bound 𝐹 𝑡 ( 𝑤 𝑡 ) − 𝐹 𝑡 ( 𝑢 𝑡 ) ≤ 1 2 𝜂 ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 − ∥ 𝑢 𝑡 − 𝑤 𝑡 ∥ 2 2 . (30) Sum (32) over 𝑡 = 1 , . . . , 𝑇 : 𝑇 𝑡 = 1 𝐹 𝑡 ( 𝑤 𝑡 ) − 𝐹 𝑡 ( 𝑢 𝑡 ) ≤ 1 2 𝜂 𝑇 𝑡 = 1 ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 − ∥ 𝑢 𝑡 − 𝑤 𝑡 ∥ 2 2 = 1 2 𝜂 ∥ 𝑢 1 − 𝑤 0 ∥ 2 2 − ∥ 𝑢 𝑇 − 𝑤 𝑇 ∥ 2 2 + 𝑇 𝑡 = 2 ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 − ∥ 𝑢 𝑡 − 1 − 𝑤 𝑡 − 1 ∥ 2 2 ≤ 1 2 𝜂 ∥ 𝑢 1 − 𝑤 0 ∥ 2 2 + 1 2 𝜂 𝑇 𝑡 = 2 ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 − ∥ 𝑢 𝑡 − 1 − 𝑤 𝑡 − 1 ∥ 2 2 , (31) 𝐹 𝑡 ( 𝑤 𝑡 ) − 𝐹 𝑡 ( 𝑢 𝑡 ) ≤ 1 2 𝜂 ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 − ∥ 𝑢 𝑡 − 𝑤 𝑡 ∥ 2 2 . (32) where we dropped the nonpositive term − ∥ 𝑢 𝑇 − 𝑤 𝑇 ∥ 2 2 . It remains to control the dier ence of squared distances in (31) . Fix any 𝑡 ≥ 2 and write 𝑎 : = ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 , 𝑏 : = ∥ 𝑢 𝑡 − 1 − 𝑤 𝑡 − 1 ∥ 2 . Then 𝑎 2 − 𝑏 2 = ( 𝑎 − 𝑏 ) ( 𝑎 + 𝑏 ) ≤ | 𝑎 − 𝑏 | ( 𝑎 + 𝑏 ) . (33) By the reverse triangle inequality , | 𝑎 − 𝑏 | = ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 − ∥ 𝑢 𝑡 − 1 − 𝑤 𝑡 − 1 ∥ 2 ≤ ∥ 𝑢 𝑡 − 𝑢 𝑡 − 1 ∥ 2 . (34) Moreover , since 𝑢 𝑡 , 𝑢 𝑡 − 1 , 𝑤 𝑡 − 1 ∈ W and W has diameter 𝐷 , ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 ≤ 𝐷 , ∥ 𝑢 𝑡 − 1 − 𝑤 𝑡 − 1 ∥ 2 ≤ 𝐷 ⇒ ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 + ∥ 𝑢 𝑡 − 1 − 𝑤 𝑡 − 1 ∥ 2 ≤ 2 𝐷 . (35) Combining (33)–(35) yields ∥ 𝑢 𝑡 − 𝑤 𝑡 − 1 ∥ 2 2 − ∥ 𝑢 𝑡 − 1 − 𝑤 𝑡 − 1 ∥ 2 2 ≤ 2 𝐷 ∥ 𝑢 𝑡 − 𝑢 𝑡 − 1 ∥ 2 . (36) Substitute (36) into (31): 𝑇 𝑡 = 1 𝐹 𝑡 ( 𝑤 𝑡 ) − 𝐹 𝑡 ( 𝑢 𝑡 ) ≤ 1 2 𝜂 ∥ 𝑢 1 − 𝑤 0 ∥ 2 2 + 1 2 𝜂 𝑇 𝑡 = 2 2 𝐷 ∥ 𝑢 𝑡 − 𝑢 𝑡 − 1 ∥ 2 = 1 2 𝜂 ∥ 𝑢 1 − 𝑤 0 ∥ 2 2 + 𝐷 𝜂 𝑇 𝑡 = 2 ∥ 𝑢 𝑡 − 𝑢 𝑡 − 1 ∥ 2 = 1 2 𝜂 ∥ 𝑢 1 − 𝑤 0 ∥ 2 2 + 𝐷 𝜂 𝑉 𝑇 ( { 𝑢 𝑡 }) , (37) which proves (27). T aking 𝑢 𝑡 = 𝑤 ★ 𝑡 gives (28). □ C.1 Why Anchoring Reduces the Drift T erm: A Contraction Result The dynamic r egret bound in The orem C.2 depends on the compara- tor path length 𝑉 𝑇 ( { 𝑢 𝑡 }) . W e now show , in a standard quadratic (strongly conve x) surrogate model, that anchoring provably con- tracts the optimal trajector y , thereby reducing the drift-controlled term when the anchor itself changes slowly . Long-term quadratic surrogate. Consider a long-term-only surro- gate 𝑓 long 𝑡 ( 𝑢 ) : = 1 2 ∥ 𝐴𝑢 − 𝑏 𝑡 ∥ 2 2 , 𝐻 : = 𝐴 ⊤ 𝐴, 𝜇𝐼 ⪯ 𝐻 ⪯ 𝐿𝐼 , (38) with 𝜇 > 0 (strong conv exity) and 𝐿 ≥ 𝜇 (smoothness). Dene the unanchored minimizer 𝑢 ◦ 𝑡 : = arg min 𝑢 𝑓 long 𝑡 ( 𝑢 ) and the anchored minimizer 𝑢 ★ 𝑡 : = arg min 𝑢 ∈ R 𝑑 ℓ n 𝑓 long 𝑡 ( 𝑢 ) + 𝜆 𝑠 2 ∥ 𝑢 − 𝑐 𝑡 ∥ 2 2 o . (39) Proposition C.3 (Anchor-induced contra ction of the op- timal pa th). Under (38) , the anchored optimum satises ∥ 𝑢 ★ 𝑡 − 𝑢 ★ 𝑡 − 1 ∥ 2 ≤ 𝜅 ( 𝜆 𝑠 ) ∥ 𝑢 ◦ 𝑡 − 𝑢 ◦ 𝑡 − 1 ∥ 2 + 𝛼 ( 𝜆 𝑠 ) ∥ 𝑐 𝑡 − 𝑐 𝑡 − 1 ∥ 2 , (40) where 𝜅 ( 𝜆 𝑠 ) : = ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 𝐻 op ≤ 𝐿 𝜇 + 𝜆 𝑠 , 𝛼 ( 𝜆 𝑠 ) : = 𝜆 𝑠 ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 op ≤ 𝜆 𝑠 𝜇 + 𝜆 𝑠 . (41) Consequently , dening 𝑉 ◦ 𝑇 : = Í 𝑇 𝑡 = 2 ∥ 𝑢 ◦ 𝑡 − 𝑢 ◦ 𝑡 − 1 ∥ 2 and 𝑉 𝑐 𝑇 : = Í 𝑇 𝑡 = 2 ∥ 𝑐 𝑡 − 𝑐 𝑡 − 1 ∥ 2 , we obtain 𝑉 ★ 𝑇 : = 𝑇 𝑡 = 2 ∥ 𝑢 ★ 𝑡 − 𝑢 ★ 𝑡 − 1 ∥ 2 ≤ 𝜅 ( 𝜆 𝑠 ) 𝑉 ◦ 𝑇 + 𝛼 ( 𝜆 𝑠 ) 𝑉 𝑐 𝑇 . (42) Proof. First note the closed forms. The unanchored minimizer solves 𝐻 𝑢 = 𝐴 ⊤ 𝑏 𝑡 , hence 𝑢 ◦ 𝑡 = 𝐻 − 1 𝐴 ⊤ 𝑏 𝑡 . (43) The anchored minimizer solves ( 𝐻 + 𝜆 𝑠 𝐼 ) 𝑢 = 𝐴 ⊤ 𝑏 𝑡 + 𝜆 𝑠 𝑐 𝑡 , hence 𝑢 ★ 𝑡 = ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 𝐴 ⊤ 𝑏 𝑡 + 𝜆 𝑠 𝑐 𝑡 = ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 𝐻 𝑢 ◦ 𝑡 + 𝜆 𝑠 𝑐 𝑡 . (44) Subtract (44) at times 𝑡 and 𝑡 − 1 : 𝑢 ★ 𝑡 − 𝑢 ★ 𝑡 − 1 = ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 𝐻 ( 𝑢 ◦ 𝑡 − 𝑢 ◦ 𝑡 − 1 ) + 𝜆 𝑠 ( 𝑐 𝑡 − 𝑐 𝑡 − 1 ) = ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 𝐻 ( 𝑢 ◦ 𝑡 − 𝑢 ◦ 𝑡 − 1 ) + 𝜆 𝑠 ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 ( 𝑐 𝑡 − 𝑐 𝑡 − 1 ) . (45) T aking norms and applying the operator norm b ound gives (40) with the denitions in (41). It remains to bound 𝜅 ( 𝜆 𝑠 ) and 𝛼 ( 𝜆 𝑠 ) . Diagonalize 𝐻 = 𝑄 Λ 𝑄 ⊤ with Λ = diag ( 𝜆 𝑖 ) and 𝜆 𝑖 ∈ [ 𝜇, 𝐿 ] . Then ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 𝐻 = 𝑄 ( Λ + 𝜆 𝑠 𝐼 ) − 1 Λ 𝑄 ⊤ , whose eigenvalues are 𝜆 𝑖 𝜆 𝑖 + 𝜆 𝑠 ≤ 𝐿 𝜇 + 𝜆 𝑠 , hence 𝜅 ( 𝜆 𝑠 ) ≤ 𝐿 𝜇 + 𝜆 𝑠 . Similarly , 𝜆 𝑠 ( 𝐻 + 𝜆 𝑠 𝐼 ) − 1 = 𝑄 diag 𝜆 𝑠 𝜆 𝑖 + 𝜆 𝑠 𝑄 ⊤ , so its operator norm is at most max 𝑖 𝜆 𝑠 𝜆 𝑖 + 𝜆 𝑠 ≤ 𝜆 𝑠 𝜇 + 𝜆 𝑠 , yielding 𝛼 ( 𝜆 𝑠 ) ≤ 𝜆 𝑠 𝜇 + 𝜆 𝑠 . Summing (40) over 𝑡 = 2 , . . . , 𝑇 yields (42). □
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment