EvA: An Evidence-First Audio Understanding Paradigm for LALMs
Large Audio Language Models (LALMs) still struggle in complex acoustic scenes because they often fail to preserve task-relevant acoustic evidence before reasoning begins. We call this failure the evidence bottleneck: state-of-the-art systems show lar…
Authors: Xinyuan Xie, Shunian Chen, Zhiheng Liu
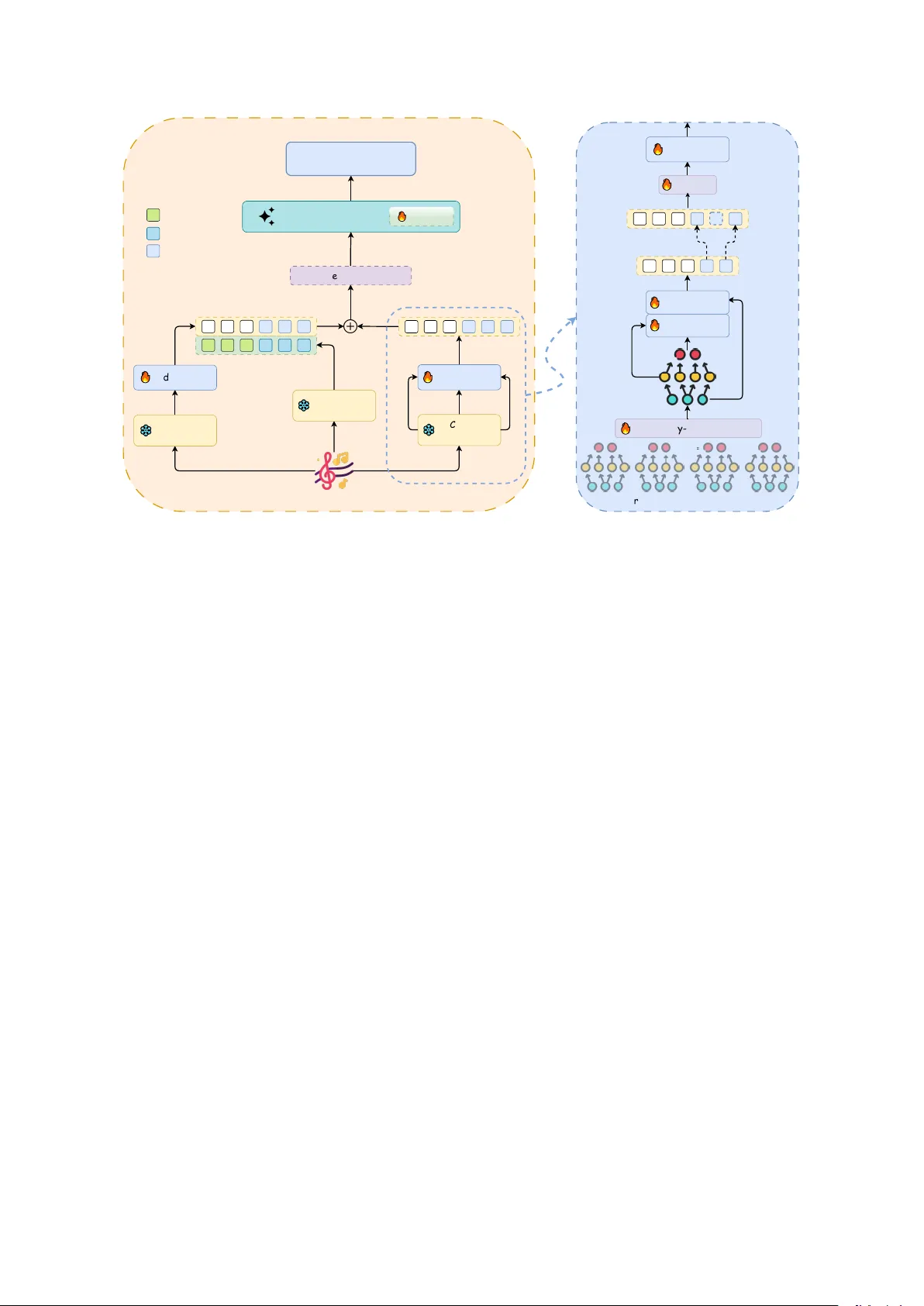
EvA: An Evidence-First A udio Understanding Paradigm f or LALMs Xinyuan Xie 1 , 2 * , Shunian Chen 1 * , Zhiheng Liu 1 , Y uhao Zhang 1 Zhiqiang Lv 2 , Liyin Liang 2 , Beny ou W ang 1 † The Chinese Uni versity of Hong K ong, Shenzhen 1 , Didi Chuxing 2 wangbenyou@cuhk.edu.cn Abstract Large Audio Language Models (LALMs) still struggle in complex acoustic scenes because they often f ail to preserve task-relev ant acous- tic e vidence before reasoning begins. W e call this failure the evidence bottleneck: state-of- the-art systems show lar ger deficits in e vidence extraction than in downstream reasoning, sug- gesting that the main limitation lies in up- stream perception rather than reasoning pol- icy . T o address this problem, we propose EvA (Evidence-First Audio), a dual-path architec- ture that combines Whisper and CED-Base through non-compressi ve, time-aligned fusion. EvA first aggre gates intermediate CED lay- ers to preserve multi-scale acoustic cues, then aligns the aggregated CED features to the Whis- per timeline and adds the two streams without changing sequence length. W e also build EvA- Perception, a large-scale open-source training set with about 54K event-ordered captions (150 h) and about 500K QA pairs. Under a unified zero-shot protocol, EvA achiev es the best open- source P er ception scores on MMA U, MMAR, and MMSU, and improves over Kimi-Audio- 7B on all reported metrics, with the largest gains on perception-heavy splits. These results support the evidence-first h ypothesis: stronger audio understanding depends on preserving acoustic evidence before reasoning. 1 Introduction Large Audio Language Models (LALMs) aim to empo wer machines with the ability to listen, un- derstand, and reason from sound. While recent systems like Qwen2.5-Omni ( Xu et al. , 2025 ) and Kimi-Audio ( Ding et al. , 2025 ) hav e demonstrated impressi ve performance on various benchmarks, their capabilities degrade sharply when confronted with comple x acoustic scenes in v olving ov erlap- ping e vents, faint signals, or fine-grained temporal cues. * Equal Contribution. † Corresponding author . MMSU MMA U 30 40 50 60 70 80 90 100 Performance Score (%) 42.8 66.3 91.2 81.1 73.5 69.6 86.8 82.8 48.4 13.3 14.8 13.2 Performance Gap: Perception vs Reasoning Model P er ception Human P er ception Model R easoning Human R easoning Figure 1: Perception–reasoning performance gap comparison between models and humans. Model performance is av eraged over Qwen2.5–Omni and Kimi–Audio–7B. W e argue that this weakness comes mainly from upstream perception, not from downstream reason- ing. As sho wn in Fig. 1 , the gap between leading LALMs and humans is larger on perception-centric tasks than on reasoning-centric tasks. On MMSU, the model–human gap is 48.4 points in perception (42.8% vs. 91.2%) b ut only 13.3 points in reason- ing. W e refer to this pattern as the “evidence bot- tleneck”: current LALMs are more limited by how well they preserv e and represent acoustic evidence than by ho w well they reason o ver that e vidence. W e attribute this evidence bottleneck to three common design choices in current LALMs. First, reasoning-centric optimization : post-training methods such as SFT and GRPO mainly improv e ho w the model reasons over av ailable evidence, but the y cannot recov er acoustic e vidence that has already been lost upstream. Once task-relev ant acoustic details are discarded in the encoder or interface, later stages can only work with the re- maining signal. Second, frequency inf ormation loss : many encoders process spectrograms as 1D sequences, which weakens or remov es frequenc y- localized cues that are important for non-speech audio. Third, weak alignment interfaces : e xisting 1 dual-path systems often rely either on lossy tempo- ral compression, such as Q-Former modules ( T ang et al. , 2023 ), or on simple feature concatenation without a shared temporal coordinate ( Ghosh et al. , 2024 ). Both choices make it harder for the LLM to use speech and non-speech e vidence jointly . T o address this bottleneck, we introduce EvA (Evidence-First A udio) , a dual-path architecture designed to preserve acoustic e vidence before rea- soning. EvA uses two complementary streams: a Whisper encoder for speech content and a non- speech encoder (CED-Base ( Dinkel et al. , 2024 )) for non-speech ev ents. Its core design is a two- stage, non-compressiv e fusion process. First, EvA performs hierarchical e vidence aggregation within the CED path by combining intermediate and final CED layers, preserving multi-scale acous- tic cues. Second, it applies time-aware additive fusion to align the CED features to the Whisper timeline and combine the tw o streams without re- ducing sequence length. T ogether , these steps pre- serve more acoustic e vidence and make speech and non-speech cues av ailable to the LLM on a shared timeline. T o train this architecture, we de v elop EvA- Perception, a large-scale audio QA dataset with 54K event-ordered captions and 500K QA pairs. Built from the temporal annotations in AudioSet- Strong ( Hershey et al. , 2021 ), it is designed to teach models to preserve and use fine-grained acoustic e vidence. Fine-tuned on only 380 hours of audio, EvA achie ves strong and consistent gains on com- plex audio understanding and acoustic-scene bench- marks, including MMA U ( Sakshi et al. , 2024 ), MMAR ( Ma et al. , 2025 ), MMSU ( W ang et al. , 2025 ), and CochlScene ( Jeong and Park , 2022 ). The gains are largest on perception-heavy tasks, which is consistent with our evidence-first h ypoth- esis. Our main contributions are summarized as fol- lo ws: • Problem Diagnosis W e identify and empir- ically support the “evidence bottleneck” in state-of-the-art LALMs: the main limitation lies in upstream perception, not do wnstream reasoning. • The EvA Architecture W e propose EvA, a dual-path architecture that preserves acoustic e vidence before reasoning through hierarchi- cal aggreg ation and non-compressi ve, time- aligned fusion. • Open-source Dataset and Strong Model W e release EvA-Perception, a dataset for training e vidence-aware audio understanding, and the EvA model, which achiev es the best open- source P er ception results on MMA U, MMAR, and MMSU. 2 Related W orks 2.1 Large A udio Language Models Large Audio Language Models (LALMs) hav e progressed rapidly , with systems such as Qwen2- Audio ( Chu et al. , 2024 ), Qwen2.5-Omni ( Xu et al. , 2025 ), and Kimi-Audio ( Ding et al. , 2025 ). Most of these models rely on a single Whisper encoder ( Radford et al. , 2023 ), which works well for speech but is less effecti ve at preserving non-speech evi- dence. Prior dual-path designs partly address this limitation, but SALMONN ( T ang et al. , 2023 ) re- lies on lossy Q-F ormer compression, and GAMA ( Ghosh et al. , 2024 ) combines features without a strong shared temporal coordinate. A detailed struc- tural comparison with SALMONN-style Q-Former fusion is provided in Appendix A.11 . These lim- itations moti v ate our dual-path, non-compressi v e, time-aligned fusion design. 2.2 A udio Understanding Benchmarks Audio-language ev aluation has shifted from cap- tioning datasets such as A U D I O C A P S ( Kim et al. , 2019 ) and C L O T H O ( Drossos et al. , 2020 ) to more demanding benchmarks including M M AU ( Sak- shi et al. , 2024 ), M M A R ( Ma et al. , 2025 ), and M M S U ( W ang et al. , 2025 ). These benchmarks re- quire both fine-grained perception and higher-le vel reasoning over complex acoustic scenes. In this setting, performance is often limited by ho w well models preserve acoustic evidence before reason- ing, which directly moti v ates our e vidence-first per - specti ve and the construction of EvA-Perception. 3 Motivation: the Evidence Bottleneck The perception–reasoning gap in Sec. 1 suggests an architectural bottleneck rather than a pure training issue. W e analyze the LALM pipeline through a conceptual information-flow lens to identify where acoustic e vidence is attenuated. W e first e xamine the constraints of single-path models (Sec. 3.1 ), then show how dual-path architectures can relax these constraints in practice (Sec. 3.2 ). Formal deri vations are pro vided in Appendix A.4 . 2 GLM Encoder ❄ CED Encoder ❄ Adapter 🔥 Aggregator 🔥 LLM Layer LoRA 🔥 Text Output Whisper Encoder ❄ Audio Embedding Audio Token Text Token Model Architecture Cross-Attn 🔥 Encoder Hidden State (multi-frequency) Cross-Attn 🔥 LLM observable sequence Time-Aware Alignment & Weighted linear interpolation Gate: α Projection 🔥 🔥 Frequency-Pooled Gate 🔥 h f=1 h f=2 h f=3 h f=4 EvA Path H l,t H agg E fused E w E tok H aligned Figure 2: Model ar chitectur e. The left half of the left panel shows the Kimi-Audio backbone, while the right half illustrates the additional EvA Path modules. Audio is encoded into four frequency-band features by the CED Encoder , pooled across frequencies, fused via cross-attention, temporally aligned with Whisper , and integrated through gated additi ve fusion. Notation. W e use Z to denote the latent acoustic e vidence required for the downstream task, such as e vent identities, temporal boundaries, and e vent order . Let X be the ra w audio wav eform, H the en- coder hidden representation, O the representation passed to the language model, and Y the model out- put. W e denote mutual information by I ( · ; · ) and assume only that a joint distribution over ( Z, X ) exists. This minimal assumption is sufficient for qualitative reasoning about information flo w . 3.1 Single-Path LALMs: An Information Constraint Conditioned on fixed parameters after training, the inference-time forward pass is a composition of deterministic mappings of X : H = E θ ( X ) , O = P θ ( H ) , Y = π θ ( O ) . Under this setting, the data-processing inequality (DPI) for deterministic functions implies I ( Z ; Y ) ≤ I ( Z ; O ) ≤ I ( Z ; H ) ≤ I ( Z ; X ) . (1) W e use Eq. ( 1 ) conceptually to compare r elative e vidence retention across stages and paths. Post- training that optimizes only the policy π θ (e.g., SFT or GRPO, Group Relati v e Policy Optimization) can improv e how well the model uses evidence already present in O , but it does not restor e acoustic evi- dence that was lost upstream along X → H → O . This observation moti v ates architectural choices that preserve acoustic e vidence before the LLM (see Sec. 3.3 ). A deriv ation of ( 1 ) under fixed pa- rameters appears in Appendix A.4 . 3.2 Dual-Path Architectur es: More Complementary Evidence Consider two complementary perception paths over the same input X : a speech path producing O 1 = P 1 ( E 1 ( X )) (e.g., Whisper) and a non-speech path producing O 2 = P 2 ( E 2 ( X )) (e.g., CED-Base). The LLM recei ves the joint observ ation ( O 1 , O 2 ) . By the chain rule, I ( Z ; O 1 , O 2 ) = I ( Z ; O 1 ) + I ( Z ; O 2 | O 1 ) ≥ I ( Z ; O 1 ) . W e cite this identity to articulate the complementarity intuition : when the second path contributes cues not already cap- tured by the first, the joint observ ation is—in a qualitati ve sense—no less informati ve than either stream alone. W e do not estimate I ( · ; · ) nor claim quantitati ve increases or bounds in the main text; empirical ablations in T able 3 align with this intu- ition. 3 3.3 Implications for LALM Design This perspecti ve leads to two practical guidelines: (i) Prioritize the perceptual front-end. The pri- mary bottleneck often lies in evidence retention through the encoder/fusion stack rather than in the LLM policy; improving upstream access to fine- grained cues is therefore crucial. (ii) F av or time-aligned, non-compressi ve fusion. Fusion interfaces that preserve temporal resolution and av oid heavy compression are aimed at minimiz- ing av oidable information loss. In our system, the non-speech stream is aligned to the speech timeline and injected via an add-based mechanism with a learnable gate, which is structure-preserving and sequence-length neutral. 4 Method: Evidence-First A udio Understanding Paradigm 4.1 Architectur e EvA adopts a dual-path architecture built on the Kimi-A udio-7B backbone. As shown in Figure 2 , the raw w av eform is encoded by tw o complemen- tary encoders: a Whisper path for speech content and a CED path for non-speech e vidence. Their features are aligned to the token timeline and in- jected into the backbone LLM input space without changing sequence length. Details on initializa- tion and the freezing/training polic y are deferred to Sec. 4.3 . Complementary Dual Encoders. W e use two encoders that capture complementary acoustic in- formation. (i) The Whisper encoder ( E W ) is pre- trained on large-scale ASR corpora and extracts robust linguistic features for speech-related tasks. (ii) The CED-Base encoder ( E C ) is a V ision T rans- former (V iT)-based model trained for general au- dio e vent recognition. It captures non-speech cues such as background e v ents, music, and transients. W e extract hidden states from its shallo w , middle, and final layers to obtain multi-scale acoustic fea- tures. T ogether , these encoders provide comple- mentary vie ws of the same acoustic scene. In our information-theoretic formulation, they correspond to the two information channels O 1 and O 2 that feed the do wnstream LLM. Hierarchical Evidence Aggr egation. Standard encoders, which only expose their final-layer fea- tures, create an internal information bottleneck long before the LLM. The Data Processing Inequal- ity dictates that these final features cannot be more informati ve than the collection of intermediate rep- resentations. T o mitigate this loss, we introduce a hierarchical aggregation process that fuses and harvests features across the frequency domain and from multiple network depths. First, in the frequency domain , we leverage the fact that the V iT -based CED encoder’ s feature maps implicitly retain a frequenc y axis. For the raw feature maps ˜ h l ∈ R B × T × F × D c extracted from layer l ∈ { 4 , 8 , L } (where F is the number of frequency bands), we apply a lightweight gated attention mechanism. This performs a learnable, weighted pooling across the frequency bands for each time step: h l,t = F X f =1 softmax(gate( ˜ h l,t,f )) · ˜ h l,t,f (2) This operation dynamically focuses on the most salient frequency bands at each moment, com- pressing the 2D feature map into a more informa- ti ve 1D temporal sequence, which we denote as H l ∈ R B × T × D c . Second, in the cr oss-layer domain , we fuse these frequency-aggre gated features, H 4 , H 8 , and H L , using a two-stage cascaded cross-attention mechanism implemented in our Aggr e gator . It first enriches the high-le vel semantic features H L with mid-le vel temporal details from H 8 , and then grounds the resulting representation with lo w-lev el acoustic patterns from H 4 : H ′ = Norm(CrossA ttn( H L , H 8 , H 8 ) + H L ) (3) H agg = Norm(CrossA ttn( H ′ , H 4 , H 4 ) + H ′ ) (4) Here, CrossA ttn( Q , K , V ) denotes cross- attention with query Q , key K , and v alue V ; Norm( · ) denotes layer normalization. This cascaded, two-stage aggre gation process produces a informati v e feature sequence H agg that embodies acoustic e vidence integrated across both multiple frequency bands and multiple le vels of abstraction. Time-A war e Alignment and Inject-and-Add Fu- sion. The final and most critical step is to inte- grate the evidence from both encoder paths without creating a fusion bottleneck. A ke y challenge is the temporal mismatch: the LLM-aligned Whis- per features ha ve a stride of 80 ms , whereas the ef fectiv e stride of our aggre gated CED features H agg is coarser at 160 ms . T o reconcile this, we upsample the CED e vidence onto the Whisper 4 Name # of A udio/QA A vg. Caps Len V isual Music Speech Integration T emporal Info AudioCaps ( Kim et al. , 2019 ) 46k/46k 9.03 ✗ ✗ ✗ ✗ ✗ Clotho ( Drossos et al. , 2020 ) 5k/5k 11.00 ✗ ✗ ✗ ✗ ✗ LAION-Audio-630K ( W u et al. , 2023 ) 630k/630k 7.30 ✗ ✗ ✗ ✗ ✗ W avCaps ( Mei et al. , 2024 ) 403k/403k 7.80 ✗ ✗ ✗ ✗ ✗ AudioSetCaps ( Bai et al. , 2025a ) 1.9M/1.9M 28.00 ✗ ✗ ✗ ✗ ✗ Auto-A CD ( Sun et al. , 2024 ) 1.5M/1.5M 18.10 ✓ ✗ ✗ ✓ ✗ CompA-R ( Ghosh et al. , 2024 ) 62k/200k 18.00 ✓ ✗ ✗ ✓ ✗ FusionAudio-1.2M ( Chen et al. , 2025 ) 1.2M/6M 47.18 ✓ ✓ ✓ ✓ ✗ EvA-Caps/QA 54K/500K 67.99 ✓ ✓ ✓ ✓ ✓ T able 1: Comparison of open-source audio caption datasets. timeline using a time-aware linear inter polation . This method respects the true mel-frame times- tamps of each feature window . For each Whis- per token’ s timestamp, we identify its tw o nearest neighbors in the CED sequence and compute a weighted a verage, carefully accounting for the tem- poral cov erage of each feature window to avoid phase drift and preserve transients. The full algo- rithm is detailed in Appendix A.5 . This process yields a temporally-aligned CED feature sequence, H aligned ∈ R B × T w × D c , that now shares the same timeline as the Whisper features. Both the original Whisper features E W and the aligned CED features H aligned are then passed through separate lightweight projection heads ( Pro j W and Pro j C respecti vely) to map them to the LLM’ s hidden dimension. Finally , they are in- tegrated using our inject-and-add strategy . W e chose this approach for three k ey principles: (1) Efficiency: simple vector addition incurs minimal computational ov erhead. (2) Structural Compat- ibility: it preserves the original sequence length and causality , requiring no modification to the LLM backbone. (3) Controllability: it allows for stable training via a learnable gate. The final fused embedding E fused is computed based on a mask M that identifies audio token positions: E audio [ i ] = E tok [ i ] + Pro j W ( E W [ i ]) · √ 2 + α · Pro j C ( H aligned [ i ]) (5) E fused [ i ] = ( E audio [ i ] , M [ i ] = 1 E tok [ i ] , M [ i ] = 0 (6) where E tok are the initial token embeddings, and α is a learnable scalar gate initialized to a small v alue. This allo ws the model to gradually incor - porate non-speech evidence without perturbing the LLM’ s pre-trained kno wledge during early train- ing stages. This strategy enriches each audio to- ken locally , thereby circumventing the information bottlenecks typical of heavy , compressi ve fusion modules. 4.2 EvA-Per ception: A Dataset for Evidence-Grounded T raining Perception-heavy failures in LALMs often stem from weak supervision: generic audio captions usually lack temporal structure and fine-grained acoustic detail (T able 1 ). EvA-Captions , a core component of EvA-Perception, combines e vent- order information with instruction-style supervi- sion, providing training data with explicit temporal structure and fine-grained acoustic e vidence. Construction W e build these complementary re- sources through a multi-expert pipeline (details and prompts are provided in Appendix A.7 ). AudioSet- Str ong ( Hershey et al. , 2021 ) pro vides audio clips and time-localized manual labels as acoustic priors. Gemini-2.5-Pr o ( Comanici et al. , 2025 ) then con- verts them into e v ent-ordered natural-language cap- tions; Whisper ( Radford et al. , 2023 ) contributes ASR when speech is present; OpenMu ( Zhao et al. , 2024 ) adds music-related details; Qwen-2.5-VL- 72B ( Bai et al. , 2025b ) provides visual cues used only to disambiguate underspecified audio e v ents; and QwQ-32B ( T eam , 2025 ) consolidates all de- scriptions into a single coherent caption while pre- serving temporal order . Results This pipeline produces ∼ 54K fine- grained captions ( 150 h ) and ∼ 500K QA pairs (closed/open 2:3 ; see Appendix A.7 ). W e b uild: 1. EvA-Captions & EvA-QA : event-ordered captions ( ∼ 54K / 150 h) and corresponding QA pairs ( ∼ 500K). 2. EvA-Alignment & EvA-P erception : aggre- gated datasets for encoder alignment and SFT , respectiv ely (detailed composition in Ap- pendix A.7 ). 5 Model MMA U MMAR MMSU CochlScene Perc. Reas. Perc. Reas. Perc. Reas. Qwen2.5-Omni-7B 73.99 69.57 48.68 59.20 40.37 66.31 80.38 Audio-Flamingo-3 76.78 74.00 59.23 61.64 45.63 77.86 75.57 Step-Audio-2-mini 69.97 71.62 54.58 61.01 44.36 78.32 83.24 Audio-Reasoner 66.56 65.73 44.34 38.23 40.73 68.38 – R1-A QA 73.07 65.29 48.75 50.19 41.68 71.94 76.30 Kimi-Audio-7B-Instruct 67.80 62.19 56.79 58.72 45.47 71.85 86.17 EvA 78.64 +10.84 67.35 +5.16 59.79 +3.00 59.45 +0.73 47.52 +2.05 75.41 +3.56 87.04 +0.87 T able 2: Main results on benchmarks under our unified zero-shot setting. Green numbers denote absolute gains over Kimi-Audio-7B-Instruct. Definitions of perception and reasoning are giv en in Sec. 5.1 . 4.3 T raining Strategy W e use a two-stage training strategy: first to inte- grate the fusion module stably with the pre-trained backbone, and then to fine-tune the full system for complex audio understanding. Backbone Initialization. W e build EvA on the public Kimi-A udio-7B backbone, while keeping the pretrained Whisper encoder and CED-Base frozen. This avoids costly re-pretraining, preserves the encoder distributions and tok enization, and en- sures a fair comparison by isolating the effect of our e vidence-first fusion. Stage 1: Alignment T uning. In this stage, we train only the newly introduced modules (the CED Aggregator and projection heads) using next-tok en cross-entropy on te xt tokens. The goal is to map the CED feature space to the LLM input embedding space without disrupting the model’ s pre-trained weights. A small initialization of the gate α in Eq. 6 is critical for stability . Stage 2: Instruction Fine-T uning . In this stage, we train the CED Aggregator and Whisper adapter , while updating the LLM backbone through LoRA and keeping both encoders frozen. W e continue to use the same text-only cross-entropy objectiv e on the training set. 5 Experiments In this section, we e v aluate our method on se veral benchmarks. Beyond the of ficial leaderboards, we also report results under unified P er ception and Reasoning splits to better reflect the effect of our method. EvA shows the strongest improvements on P er ception subsets across the three main bench- marks, consistent with our e vidence-first design. 5.1 Experimental Setup Benchmarks. W e ev aluate mainly on three au- dio understanding benchmarks— MMA U , MMAR , and MMSU —and one acoustic-scene benchmark, CochlScene , which together cov er perception- oriented understanding and scene-lev el recognition. T o directly test our central hypothesis re garding the e vidence bottleneck, we categorize the sub-tasks of each benchmark into two primary axes: Per ception and Reasoning . This categorization allows us to quantify performance gains separately on tasks that depend on acoustic perception and on tasks that test abstract reasoning. The detailed categorization is provided in Appendix A.9 . For completeness, we also report results under each benchmark’ s orig- inal cate gories and describe our handling of answer ordering in T able 6 . Baselines. W e compare to strong general under- standing and reasoning systems: Qwen2-Audio ( Chu et al. , 2024 ), Qwen2.5-Omni ( Xu et al. , 2025 ), Audio-Flamingo-3 ( Goel et al. , 2025 ), Step-Audio- 2-mini ( W u et al. , 2025 ), Kimi-Audio ( Ding et al. , 2025 ), Audio-Reasoner ( Xie et al. , 2025b ), and R1- A QA ( Li et al. , 2025 ). All baselines are run under a unified inference protocol, and numbers reported are from our reproduction to ensure fairness. Implementation Details. T raining follo ws the procedure outlined in Sec. 4.3 . In Stage 1 (Align- ment) , we use EvA-Alignment for alignment, train- ing only the CED Aggregator with all other en- coders frozen. W e use a learning rate of 1 × 10 − 3 , train for 5 epochs, with a per -de vice batch size of 2 and gradient accumulation of 8 , resulting in a global batch size of 128 . In Stage 2 (SFT) , EvA- Perception is used for instruction tuning. Both the CED Aggre gator and the Whisper adapter are trained, while the LLM backbone is fine-tuned 6 via LoRA with a rank of 64 , α = 64 , and a dropout rate of 0 . 05 . The learning rate is reduced to 5 × 10 − 5 with 2 epochs, a per -de vice batch size of 2 , and gradient accumulation of 16 , yielding a global batch size of 256 . The maximum sequence length for training and inference is set to 1024 . Both training and decoding use greedy sampling (tem- perature 0 ) with a maximum length of 1024 . Each stage takes approximately 12 hours on 8 × A100 GPUs. For detailed training settings, please refer to Appendix A.6 . 5.2 Main Results As shown in T able 2 , EvA obtains 78.64/67.35 on MMA U (Perception/Reasoning), 59.79/59.45 on MMAR, 47.52/75.41 on MMSU, and 87.04 on CochlScene. Notably , EvA achieves the best open-source P er ception scores on all three main benchmarks (MMA U/MMAR/MMSU). Relati ve to the base model Kimi-Audio-7B-Instruct, EvA improv es all reported metrics: +10.84/+5.16 on MMA U, +3.00/+0.73 on MMAR, +2.05/+3.56 on MMSU, and +0.87 on CochlScene. The largest gains are concentrated on perception splits. EvA also attains a competitiv e CochlScene result in our comparison ( 87.04 ), sho wing that the evidence-first design transfers to specialized acoustic-scene clas- sification. These results suggest that EvA ’ s primary adv antage comes from preserving and using acous- tic e vidence more ef fecti vely , while reasoning per - formance remains competiti ve. Case Study W e illustrate these differences with AudioCaps case studies (Fig. 3 ). Compared with Qwen2.5-Omni and Kimi-Audio, EvA produces captions that are more f aithful to the audio e vents. In the example sho wn, EvA captures the sequence of tone shifts (calm speech → child excitement → laughter), whereas the baselines misinterpret the ev ents. This example illustrates how stronger acoustic e vidence can improv e caption accuracy . 5.3 Ablation Studies Setup. W e study the proposed CED-based fu- sion path from two perspectives. First, we assess its ov erall contrib ution by comparing variants that (do not) use the CED branch during align- ment (Stage 1) and perception SFT (Stage 2). Sec- ond, we analyze the necessity of internal design of the CED Aggregator , including the frequency- gated pooling ov er bands and the top–do wn cross- layer fusion across CED layers. Stage 1 v ariants are trained on EvA-Alignment and ev aluated on AudioCaps using CLAP metrics, while Stage 2 v ariants are trained on EvA-Per ception from the same aligned checkpoint and ev aluated on MMA U, MMAR, and MMSU. Overall effect of the CED branch. Compared to the S0 base model without any CED path, enabling the CED Aggregator during Stage 1 alignment sub- stantially improv es CLAP retrie v al on AudioCaps : all Stage 1 variants that use the CED branch out- perform the S0 backbone, while masking the CED path at inference time yields consistently worse scores than using it throughout (T able 3 , top). Start- ing from the same aligned checkpoint, keeping the CED stream acti v e in Stage 2 perception SFT further boosts MMA U and MMAR ov er masking the CED path (T able 3 , bottom), indicating that the CED encoder contributes complementary non- speech evidence that remains useful after align- ment. The speech-hea vy MMSU benchmark shows a mild re versal, which is consistent with our fo- cus on general audio rather than speech-specialized training. Ablation of modules in the CED branch. W ithin the CED branch, we next ablate the Ag- gregator design (T able 3 , top). Removing the top–do wn cross-layer fusion and using only the last CED layer feature (S1(4)) leads to a marked drop in all CLAP metrics with a comparable pa- rameter budget. This directly supports our claim that intermediate CED layers supply complemen- tary acoustic information that is lost when rely- ing solely on the final layer . Replacing our hierar- chical Aggregator with a windo w-lev el Q-F ormer (S1(5)), similar in spirit to SALMONN, impro ves ov er weaker baselines but still underperforms the full EvA configuration (S1(0)), indicating that non- compressi ve, multi-level fusion is more effecti ve than aggressi v e windo w compression in our setting. W e also analyze the structural shortcomings of the Q-Former module compared with the Aggre gator in Appendix A.11 . W e further examine the frequency-g ated pool- ing over four sub-bands. Simply averaging over bands (S1(3)) instead of using a learnable gate con- sistently degrades CLAP scores, sho wing that the gated pooling helps the model re weight spectral regions. T o probe which bands matter , we perform a coarse band-masking diagnostic by zeroing or keeping indi vidual bands within the same gate (Ap- pendix A.10 ). Across the benchmarks, masking 7 Ca se : Au d io Ca p s / 103394. w a v Hu man R e f er en ce : " A man is spe aki ng f ol l o w ed b y a chi l d spe aki ng and then l aug h t er ", " A ma n s pe aki ng as a m an t alk s o v er an in t er c om i n the backgr ound f ol l o w ed b y a g i rl t alk i ng then a gr oup of people l aug hing and a man an d w oman t al k “ Qw en 2.5 - O mn i : man and c hil d spe aki ng Kimi - Au d i o : a man s pe ak s and a baby c ri es E vA (Our s) : A man sp e ak s c alml y and cl early , f ol l o w ed b y a ch ild sp e akin g e x c i t ed l y . A gr ou p of p e op le lau gh , and the man sp e ak s ag ain i n a f ri en dly t one Figure 3: Qualitativ e comparison of captions generated by dif ferent models on AudioCaps examples. Stage Setting T rainables Start Ckpt A udioCaps (CLAP) Cos R@1 R@5 S0 Base Model N/A N/A 14 . 61 9 . 27 24 . 97 S1(1) w/o CED path Adapter S0 35 . 40 18 . 50 43 . 60 S1(2) mask CED path in inf Adapter & CED Agg. S0 34 . 37 17 . 76 41 . 44 S1(3) w/o frequency pooling Adapter & CED Agg. S0 35 . 54 21 . 24 49 . 61 S1(4) w/o crossing fusion Adapter & CED Agg. S0 28 . 63 11 . 82 29 . 74 S1(5) Q-former Adapter & CED Q-former S0 36 . 24 20 . 08 47 . 36 S1(0) EvA Dual-Path Adapter & CED Agg. S0 36 . 77 22 . 77 49 . 81 Stage Setting T rainables Start Ckpt MMA U MMAR MMSU S0 Base Model N/A N/A 65 . 33 49 . 21 43 . 36 S2(1) mask CED path in inf Adapter & LLM S1(0) 75 . 85 54 . 59 48 . 18 S2(0) EvA Dual-Path Adapter & CED Agg. & LLM S1(0) 80 . 19 55 . 26 47 . 44 T able 3: Ablations of the EvA fusion path. On AudioCaps , we use the CLAP encoder ( W u et al. , 2023 ) to embed text/audio; Cos is cosine similarity , and higher is better for all CLAP metrics. On MMA U/MMAR/MMSU, we report P er ception accuracy (Sec. 5.1 ). Adapter denotes the Whisper adapter; LLM denotes LoRA on the backbone; “ mask CED path ” disables the CED branch at fusion. any single band or keeping only one band is alw ays worse than using the full range, and no indi vidual band dominates across all tasks. T aken together, these ablations suggest that (i) EvA benefits from multi-layer CED features rather than only the last layer , and (ii) the four sub-bands provide complementary cues, making EvA a rea- sonable and robust design choice rather than a rough module assembly . 6 Conclusion In this work, we identified the e vidence bottleneck as a critical limitation in Large Audio Language Models (LALMs): performance in complex acous- tic scenes is often limited more by upstream percep- tion than by do wnstream reasoning. T o address this limitation, we introduced EvA, a dual-path archi- tecture that preserves acoustic evidence through hi- erarchical aggregation and non-compressi ve, time- aligned fusion. Supported by the EvA-Perception dataset, EvA achieves strong performance on benchmarks such as MMA U, MMAR, and MMSU, with the lar gest gains concentrated on perception- heavy tasks. These results are consistent with our central claim that stronger audio understanding de- pends on preserving acoustic e vidence before rea- soning. 7 Limitations While EvA advances audio understanding with stronger acoustic evidence, se v eral limitations re- main: our curated audio–text training corpus cur- rently uses English-only captions, ev en though the paired audio and e v aluation benchmarks contain multilingual inputs, so more systematic multilin- gual supervision and ev aluation are still needed; temporal reasoning is constrained by the soft ev ent boundaries in AudioSet-Strong, and music analysis lacks expert-le vel concepts such as pitch or har - mony . Addressing these challenges is an important direction for future work. 8 References Andrea Agostinelli, T imo I Denk, Zalán Borsos, Jesse Engel, Mauro V erzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco T agliasacchi, and 1 others. 2023. Musi- clm: Generating music from text. arXiv pr eprint arXiv:2301.11325 . Rosana Ardila, Meg an Branson, K elly Davis, Michael Henretty , Michael Kohler , Josh Meyer , Reuben Morais, Lindsay Saunders, Francis M T yers, and Gregor W eber . 2019. Common voice: A massiv ely- multilingual speech corpus. arXiv pr eprint arXiv:1912.06670 . Jisheng Bai, Haohe Liu, Mou W ang, Dongyuan Shi, W enwu W ang, Mark D Plumbley , W oon-Seng Gan, and Jianfeng Chen. 2025a. Audiosetcaps: An en- riched audio-caption dataset using automated genera- tion pipeline with lar ge audio and language models. IEEE T ransactions on Audio, Speech and Language Pr ocessing . Shuai Bai, Keqin Chen, Xuejing Liu, Jialin W ang, W en- bin Ge, Sibo Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, and 1 others. 2025b. Qwen2. 5-vl technical report. arXiv preprint . Shunian Chen, Xinyuan Xie, Zheshu Chen, Liyan Zhao, Owen Lee, Zhan Su, Qilin Sun, and Benyou W ang. 2025. Fusionaudio-1.2 m: T ow ards fine-grained au- dio captioning with multimodal conte xtual fusion. arXiv pr eprint arXiv:2506.01111 . Y unfei Chu, Jin Xu, Qian Y ang, Haojie W ei, Xipin W ei, Zhifang Guo, Y ichong Leng, Y uanjun Lv , Jinzheng He, Junyang Lin, and 1 others. 2024. Qwen2-audio technical report. arXiv preprint . Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice Pasupat, No veen Sachde v a, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Ev an Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advance d reasoning, multimodality , long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 . Ding Ding, Zeqian Ju, Y ichong Leng, Songxiang Liu, T ong Liu, Zeyu Shang, Kai Shen, W ei Song, Xu T an, Heyi T ang, and 1 others. 2025. Kimi-audio technical report. arXiv preprint . Heinrich Dinkel, Y ongqing W ang, Zhiyong Y an, Junbo Zhang, and Y ujun W ang. 2024. Ced: Consistent ensemble distillation for audio tagging. In ICASSP 2024-2024 IEEE International Confer ence on Acous- tics, Speech and Signal Pr ocessing (ICASSP) , pages 291–295. IEEE. K onstantinos Drossos, Samuel Lipping, and T uomas V irtanen. 2020. Clotho: An audio captioning dataset. In ICASSP 2020-2020 IEEE International Confer- ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 736–740. IEEE. Sreyan Ghosh, Sonal Kumar , Ashish Seth, Chandra Ki- ran Reddy Evuru, Utkarsh T yagi, S Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha. 2024. Gama: A large audio-language model with ad- vanced audio understanding and complex reasoning abilities. arXiv preprint . Arushi Goel, Sreyan Ghosh, Jaeh yeon Kim, Sonal Ku- mar , Zhifeng K ong, Sang gil Lee, Chao-Han Huck Y ang, Ramani Duraiswami, Dinesh Manocha, Rafael V alle, and Bryan Catanzaro. 2025. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models . Pr eprint , arXi v:2507.08128. Shawn Hershey , Daniel PW Ellis, Eduardo Fonseca, Aren Jansen, Caroline Liu, R Channing Moore, and Manoj Plakal. 2021. The benefit of temporally-strong labels in audio ev ent classification. In ICASSP 2021- 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 366– 370. IEEE. Il-Y oung Jeong and Jeongsoo P ark. 2022. Cochlscene: Acquisition of acoustic scene data using crowdsourc- ing . Pr eprint , Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. Audiocaps: Generating cap- tions for audios in the wild. In Pr oceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language T echnologies, V olume 1 (Long and Short P apers) , pages 119–132. Gang Li, Jizhong Liu, Heinrich Dinkel, Y adong Niu, Junbo Zhang, and Jian Luan. 2025. Reinforcement learning outperforms supervised fine-tuning: A case study on audio question answering . arXiv pr eprint arXiv:2503.11197 . Ziyang Ma, Y inghao Ma, Y anqiao Zhu, Chen Y ang, Y i-W en Chao, Ruiyang Xu, W enxi Chen, Y uanzhe Chen, Zhuo Chen, Jian Cong, and 1 others. 2025. Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix. arXiv preprint arXiv:2505.13032 . Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang K ong, T om K o, Chengqi Zhao, Mark D Plumbley , Y uexian Zou, and W enwu W ang. 2024. W avcaps: A chatgpt-assisted weakly-labelled audio caption- ing dataset for audio-language multimodal research. IEEE/A CM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , 32:3339–3354. Jan Melechovsk y , Zixun Guo, Deepanway Ghosal, Nav onil Majumder, Dorien Herremans, and Soujan ya Poria. 2023. Mustango: T o ward controllable text-to- music generation. arXiv preprint . Karol J Piczak. 2015. Esc: Dataset for environmental sound classification. In Pr oceedings of the 23rd A CM international conference on Multimedia , pages 1015– 1018. 9 Alec Radford, Jong W ook Kim, T ao Xu, Greg Brock- man, Christine McLeav ey , and Ilya Sutskev er . 2023. Robust speech recognition via large-scale weak su- pervision. In International confer ence on machine learning , pages 28492–28518. PMLR. S Sakshi, Utkarsh T yagi, Sonal Kumar , Ashish Seth, Ramaneswaran Selvakumar , Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. 2024. Mmau: A massi ve multi-task audio under- standing and reasoning benchmark. arXiv pr eprint arXiv:2410.19168 . Luoyi Sun, Xuenan Xu, Mengyue W u, and W eidi Xie. 2024. Auto-acd: A large-scale dataset for audio- language representation learning. In Pr oceedings of the 32nd ACM International Conference on Multime- dia , pages 5025–5034. Changli T ang, W enyi Y u, Guangzhi Sun, Xianzhao Chen, T ian T an, W ei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2023. Salmonn: T o wards generic hearing abilities for large language models. arXiv pr eprint arXiv:2310.13289 . Qwen T eam. 2025. Qwq-32b: Embracing the power of reinforcement learning . Dingdong W ang, Jincenzi W u, Junan Li, Dongchao Y ang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. 2025. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark. arXiv pr eprint arXiv:2506.04779 . Boyong W u, Chao Y an, Chen Hu, Cheng Y i, Chengli Feng, Fei T ian, Feiyu Shen, Gang Y u, Haoyang Zhang, Jingbei Li, Mingrui Chen, Peng Liu, W ang Y ou, Xiangyu T ony Zhang, Xingyuan Li, Xuerui Y ang, Y ayue Deng, Y echang Huang, Y uxin Li, and 90 others. 2025. Step-audio 2 technical report . Pr eprint , Y usong W u, Ke Chen, T ianyu Zhang, Y uchen Hui, T ay- lor Berg-Kirkpatrick, and Shlomo Dubnov . 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyw ord-to-caption augmen- tation. In ICASSP 2023-2023 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocess- ing (ICASSP) , pages 1–5. IEEE. Zeyu Xie, Xuenan Xu, Zhizheng W u, and Mengyue W u. 2025a. Audiotime: A temporally-aligned audio- text benchmark dataset. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 1–5. IEEE. Zhifei Xie, Mingbao Lin, Zihang Liu, Pengcheng W u, Shuicheng Y an, and Chunyan Miao. 2025b. Audio-reasoner: Improving reasoning capability in large audio language models. arXiv pr eprint arXiv:2503.02318 . Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, K eqin Chen, Jialin W ang, Y ang Fan, Kai Dang, and 1 others. 2025. Qwen2. 5-omni tech- nical report. arXiv preprint . Chao-Han Huck Y ang, Sreyan Ghosh, Qing W ang, Jaeyeon Kim, Hengyi Hong, Sonal Kumar , Guirui Zhong, Zhifeng K ong, S Sakshi, V aibha vi Lokeg aonkar , and 1 others. 2025. Multi-domain au- dio question answering to ward acoustic content rea- soning in the dcase 2025 challenge. arXiv preprint arXiv:2505.07365 . Mengjie Zhao, Zhi Zhong, Zhuoyuan Mao, Shiqi Y ang, W ei-Hsiang Liao, Shusuke T akahashi, Hiromi W akaki, and Y uki Mitsufuji. 2024. Openmu: Y our swiss army knife for music understanding. arXiv pr eprint arXiv:2410.15573 . 10 A A ppendix A.1 Potential Risk Because the model and training resources are built from publicly av ailable online content, EvA may inherit latent moral, ethical, or racial biases. W e therefore recommend strengthened human re vie w and supervision when using the system, especially in high-stakes or sensiti ve scenarios. A.2 Access Statement All training and e v aluation data used in this work are collected from publicly a v ailable open-source datasets on the Internet. W e do not use priv ate user recordings or non-public personal data. A.3 Use of LLMs Large language models were utilized for specific tasks, such as assisting with coding and providing grammar checks and language refinement during the writing of this paper . All scientific content, including research design, experimentation, data analysis, and conclusions, was independently con- ducted by the authors without LLM in volvement in the core research process. A.4 Notes for the Inf ormation-Flo w V iew DPI under deterministic inference. After train- ing, condition on fixed parameters θ . Let H = E θ ( X ) , O = P θ ( H ) , Y = π θ ( O ) be deterministic mappings of X . For an y measurable f , DPI gi ves I ( Z ; f ( X )) ≤ I ( Z ; X ) . Applied stage-wise to the composition, I ( Z ; Y ) ≤ I ( Z ; O ) ≤ I ( Z ; H ) ≤ I ( Z ; X ) . If inference includes independent randomness U (e.g., stochastic decoding), write Y = g ( O, U ) with U ⊥ Z | O , so I ( Z ; Y ) ≤ I ( Z ; O , U ) = I ( Z ; O ) . Chain-rule identity (f or intuition). For ran- dom variables Z, O 1 , O 2 , the chain rule gives I ( Z ; O 1 , O 2 ) = I ( Z ; O 1 ) + I ( Z ; O 2 | O 1 ) ≥ I ( Z ; O 1 ) . W e use this only to express complemen- tarity succinctly; no quantitati ve claim is made. A.5 Algorithm for T ime-A ware Coverage-W eighted Linear Interpolation Assumptions and Notation. W e denote the ag- gregated CED sequence as H agg ∈ R T c × D with per-feature centers t c [0] , . . . , t c [ T c − 1] (monoton- ically increasing), and the target Whisper centers t w [0] , . . . , t w [ T w − 1] (also monotonic). All times- tamps share the same unit (e.g., mel frames or mil- liseconds). A small constant ε > 0 (we use 10 − 8 ) is added for numerical stability . When T c ≤ 1 , we simply repeat the sole vector to length T w . Coverage weights. For each CED window ℓ , its cov erage weight c [ ℓ ] ∈ [0 , 1] measures the fraction of the windo w ov erlapping v alid (non-padded) au- dio. Concretely , if a windo w starts at start ℓ and ends at end ℓ with window size t sz , and the valid audio spans [0 , T mel − 1] , then c [ ℓ ] = max 0 , min( end ℓ , T mel − 1) − start ℓ + 1 t sz . Thus c = 1 for fully v alid windo ws and decreases as padding ov erlap gro ws. T arget centers f or Whisper . Let step mel be the mel frames per Whisper token and center mel its center of fset. For k = 0 , . . . , T w − 1 , we use t w [ k ] = k · step mel + center mel . (7) In our implementation, step mel = 8 and center mel = 4 . Discussion. By reweighting both neighbors with c [ ℓ ] in the numerator and renormalizing by the weighted sum in the denominator , features lar gely sourced from padded/silent regions contribute less to the aligned representation, especially near boundaries. In practice we use a vectorized im- plementation (single search-sorted, broad-casted arithmetic) that av oids Python loops while preserv- ing the abov e semantics. A.6 T raining setting As shown in T able 4 , we summarize the training hyperparameters for both stages. Notably , the CED Aggregator is trained from scratch in Stage 1, while the Whisper adapter and LLM are only updated in Stage 2. Both stages use a cosine learning rate schedule with a small warmup, and we keep the encoders frozen throughout to preserve their pre- trained representations and ensure stable training of the ne w modules. The LoRA configuration for the LLM is chosen to balance expressi v eness with parameter ef ficiency , tar geting the query , k ey , v alue, and output projection matrices without modifying the MLP layers. W e also prepare for DeepSpeed ZeR O-3 optimization b ut k eep it of f by def ault to allo w flexibility in resource-constrained settings. 11 Algorithm 1 T ime-A ware, Co verage-W eighted Linear Interpolation (0-based indexing) Require: Aggregated CED features H agg ∈ R T c × D Require: CED centers t c [0 ..T c − 1] (monotonic), Whisper centers t w [0 ..T w − 1] (monotonic) Require: Coverage weights c [0 ..T c − 1] , with c [ ℓ ] ∈ [0 , 1] Require: Stability constant ε > 0 (e.g., 10 − 8 ) Ensure: Aligned features H aligned ∈ R T w × D 1: Initialize H aligned as a tensor of shape ( T w , D ) 2: if T c ≤ 1 then 3: r eturn H aligned ← repeat the sole vector to length T w 4: end if 5: for k ← 0 to T w − 1 do 6: ▷ Locate neighbors of t w [ k ] in t c via binary search 7: r ← searchsorted( t c , t w [ k ]) 8: r ← clamp( r, 1 , T c − 1) , l ← r − 1 9: ▷ Linear interpolation factor with clamping 10: α ← t w [ k ] − t c [ l ] t c [ r ] − t c [ l ] + ε ; 11: α ← clamp( α, 0 , 1) 12: ▷ Cov erage-weighted, normalized interpolation 13: x L , x R ← H agg [ l ] , H agg [ r ] 14: c L , c R ← c [ l ] , c [ r ] 15: num ← (1 − α ) ( c L x L ) + α ( c R x R ) 16: den ← (1 − α ) c L + α c R + ε 17: H aligned [ k ] ← num / den 18: end for 19: retur n H aligned Stage 1 (Alignment) Stage 2 (SFT , LoRA) T rainable modules CED Aggregator CED Aggregator , Whisper adapter; LLM via LoRA Dataset EvA-Alignment EvA-Perception Epochs 5 2 Per-de vice batch 2 2 Grad. accumulation 8 16 Global batch (8 × A100) 128 256 Optimizer AdamW ( β 2 =0 . 95 , wd 0 . 1 ) AdamW ( β 2 =0 . 95 , wd 0 . 1 ) LR / schedule / warmup 1 × 10 − 3 / cosine / 1% 5 × 10 − 5 / cosine / 1% Max seq length 512 1024 LoRA (LLM) – r =64 , α =64 , dropout = 0 . 05 ; targets= q,k,v,o ( include_mlp =False) Modules to sav e – model.vq_adaptor Checkpoint export split ev ery epoch (keep last 5) split ev ery epoch (keep last 5) Distributed setup torchrun, 8 × A100-80GB torchrun, 8 × A100-80GB DeepSpeed ZeR O-3 prepared (config av ailable), off by default prepared, off by default Runtime (wall-clock) ∼ 12h ∼ 12h T able 4: T raining hyperparameters. Encoders (Whisper, CED-Base) are frozen throughout. A.7 Data Construction Figure 4 and Figure 5 show the instructions used to construct EvA-Perception. These instructions are designed to produce audio-focused descrip- tions while controlling cross-modal interference and marking ambiguities based only on auditory perception. The input sources include audio tags, audio descriptions, speech content (ASR), music descriptions, and video descriptions, each with spe- cific guidelines on ho w to use them for accurate audio captioning. The processing steps outline a systematic approach to multimodal parsing, audi- tory fact determination, ambiguity inference, relia- bility assessment, and final caption generation. A.8 Cases in EvA-Captions and EvA-QA W e provide two cases from our EvA-Captions and EvA-QA datasets in Figure 6 and Figure 7 , respec- 12 ti vely . These cases illustrate the complexity and richness of the audio descriptions and the corre- sponding QA pairs, showcasing the model’ s abil- ity to handle intricate acoustic scenes and extract meaningful information for question answering tasks. The captions contain detailed descriptions of the audio content, while the QA pairs test v arious aspects of understanding, such as emotional ef fects, vocal presence, sound dominance, and the contribu- tion of specific elements to the overall atmosphere. A.9 Introduction on Benchmarks MMA U covers broad audio modalities with a mix- ture of perceptual, information-extraction, and rea- soning questions. MMAR emphasizes multi-step inference across hierarchical layers. MMSU tar- gets spoken language understanding, including fine- grained linguistic and paralinguistic phenomena. For our unified analysis, we keep MMSU ’ s nati ve tags, map MMA U ’ s information ex- traction / r easoning categories to Percep- tion/Reasoning, and map MMAR ’ s Sig- nal+P erception / Semantic+Cultur e categories in the same way . In the original MMA U test set, the reference answers are distributed une v enly across choice po- sitions: A: 39.5%, B: 27.1%, C: 20.8%, and D: 12.6%. Such imbalance may bias ev aluation for models with positional preferences (e.g., fa v oring earlier options). T o mitigate this artifact, we ran- domized the order of choices, ensuring that the final distribution of correct answers is balanced across positions. All reported MMA U results in the main paper are based on this balanced setting. A.10 Additional Analysis: Frequency-Band Ablation of the CED Path T o better understand ho w EvA exploits spectral cues, we perform an exploratory ablation on the CED branch by masking coarse frequency bands at inference time. The CED encoder partitions the 64 Mel bins into four contiguous groups and treats them as approximate 2 kHz bands: [0 , 2) , [2 , 4) , [4 , 6) , [6 , 8) kHz. On top of the frozen CED encoder, we insert a band mask before the Ag- gregator: for each configuration, a binary vector of length four determines which bands are zeroed out and which are kept. All experiments share the same single-encoder EvA backbone; we only change the band mask at inference without re-training. T able 8 reports the results on multi-task bench- marks (MMA U, MMAR, MMSU) and a special- ized scene benchmark (CochlScene). W e consider both “ mask X ” (drop one or two bands and keep the others) and “ left X ” (keep only one band and mask the rest), and compare them with the full 0–8 kHz setting used in EvA. Broadband cues ar e consistently better than any subset. Across all benchmarks, any masking or single-band configuration yields lo wer scores than using the full 0–8 kHz range. The full-band EvA remains the best-performing setting in all cases, which supports the interpretation that EvA relies on broadband, complementary spectral information rather than a single dominant frequency re gion. CochlScene shows mild sensiti vity to low fre- quencies. On CochlScene, masking the lowest band (0–2 kHz) tends to be among the weaker con- figurations, and keeping only a single narrow band is also not optimal. T ogether , these observations suggest that low-frequency components provide useful contextual cues for ambient scenes, b ut are most effecti ve when combined with mid- and high- band information. W e view this as a mild trend rather than a strong claim, since the absolute dif- ferences between band configurations remain rela- ti vely small. Similarly , the aggreg ated MMA U, MMAR and MMSU scores are designed to combine heteroge- neous tasks, making them less sensitiv e to an y sin- gle frequency band; here the main takeaw ay is sim- ply that broadband CED fusion is more reliable than any restricted band subset. These results cor- roborate our main conclusion that EvA benefits from broadband, multi-band CED features, and we do not observe e vidence that the model’ s perfor- mance is dominated by a single narro w frequency region. A.11 Structural comparison with Q-F ormer –based fusion This appendix compares EvA ’ s CED Aggregator with a Q-Former –based fusion scheme, instantiated here by our SALMONN-style v ariant, and relates the structural dif ferences to the temporal behavior sho wn in Figure 8 . T oken length and temporal granularity . Fig- ure 8 compares the audio token sequence length after feature fusion in SALMONN versus EvA. The Q-Former in SALMONN maps a long sequence of encoder features to a much shorter set of latent queries, thereby introducing temporal compression. 13 Dataset Constituent Sources Modality Quantity EvA-Alignment EvA-Captions Sound, Speech, Music 53,934 AudioT ime ( Xie et al. , 2025a ) Sound 5,000 CommonV oice ( Ardila et al. , 2019 ) Speech 20,000 MusicBench ( Melechovsk y et al. , 2023 ) Music 30,000 MusicCaps ( Agostinelli et al. , 2023 ) Music 4,852 T otal 113,786 EvA-Perception EvA-Captions Sound, Speech, Music 53,934 EvA-QA Sound, Speech, Music 525,673 AudioSkills: Counting-QA ( Goel et al. , 2025 ) Sound 46,266 ESC50 ( Piczak , 2015 ) Sound 2,000 AudioT ime ( Xie et al. , 2025a ) Sound 5,000 DCASE2025_T5 ( Y ang et al. , 2025 ) Sound 10,687 CommonV oice ( Ardila et al. , 2019 ) Speech 20,000 MusicBench ( Melechovsk y et al. , 2023 ) Music 30,000 MusicCaps ( Agostinelli et al. , 2023 ) Music 4,852 AudioSkills: MagnaT agA T une ( Goel et al. , 2025 ) Music 364,760 T otal 1,063,172 T able 5: Composition of EvA-Perception and EvA-Alignment datasets. Model Sound Speech Music A vg. Qwen2-Audio 58.86 47 . 75 44 . 31 50 . 30 Qwen2.5-Omni 73.87 65 . 47 67 . 96 69 . 10 Kimi-Audio 74.77 62 . 35 64 . 24 67 . 19 Audio-Reasoner 65.77 66 . 07 66 . 77 65 . 00 R1-A QA 74.47 65 . 17 66 . 77 68 . 80 EvA(Ours) 80.78 68.47 74.65 74.63 T able 6: Main results on MMA U-mini-test. Model Single Modality Mixed Modality A vg. Sound Speech Music S-M S-S M-S S-M-S Qwen2-Audio 52 . 73 42 . 86 34 . 95 36 . 36 50 . 46 45 . 12 50 . 00 44 . 80 Qwen2.5-Omni 59 . 39 61 . 22 48 . 06 54 . 55 61 . 01 64.63 58 . 33 58 . 30 Kimi-Audio 55 . 76 59 . 86 45 . 15 36 . 36 61 . 01 54 . 88 45 . 83 55 . 40 Audio-Reasoner 50 . 30 49 . 66 38 . 35 36 . 36 56 . 42 48 . 78 50 . 00 48 . 70 R1-A QA 60.00 51 . 36 42 . 23 54 . 55 57 . 80 52 . 44 45 . 83 52 . 30 EvA(Ours) 55 . 76 63.01 50.25 63.64 63.76 57 . 32 79.17 59.30 T able 7: Main results on MMAR. 14 Instruction for Caption Generation Rigorous Multimodal Inf ormation Integration and Pure A udio Description Expert Core T ask Y ou are an expert specializing in audio information processing. Y our goal is: to integrate and analyze textual descriptions from multiple modalities, strictly controlling cross-modal interference, and to perform cross-reasoning and correction. Ultimately , you should generate a purely audio-focused , temporally ordered, accurate, and detailed description of the audio content in fluent English, while marking potential ambiguities that are only based on auditory perception . Absolutely forbidden: including any visual information, specific speech transcript content, or ambiguity annotations derived from audio-video inconsistencies in the final output. Input Sources (may contain err ors, hallucinations, or incompleteness) : • A udio T ags: A set of frame-level sound category labels annotated by humans. These represent the most prominent acoustical features perceptible to humans, with high r eliability . Format: [start time, end time, event] , e.g., [start time: 9.0, end time: 10.0, event: Generic impact sounds] . • A udio Description: A textual description of the audio content (may include sound events, environmental sounds, music, human voice characteristics, etc.). This is an important basis for describing audio facts and must be cross-validated with tags and music description. • Speech Content (ASR): Automatic speech recognition results. This is used only to confirm the existence of human voices, judge non-content features (e.g., speech vs. nonverbal sounds, emotional tone), and assist in inferring possible scenes or ev ents. The specific text content must never appear in the final output (not quoted, summarized, or paraphrased). If empty , this indicates either no obvious human voice or only non-speech beha viors (e.g., breathing, crying, background chatter). • Music Description: Contains information about music elements (features, instruments, rhythm, etc.) and other scene-related sounds. Musical features are highly reliable. If empty, this indicates no clear music. Non-musical descriptions here are lower priority and secondary to audio tags, audio descriptions, and ASR. • V ideo Description: V isual scene description. Used only under strict conditions (see Step 2 “Positive Correction”) to disambiguate uncertain auditory sources and identify inconsistencies between hearing and vision. Never speculate or describe sound sources, positions, or visual actions based solely on video. If empty, no visual assistance is a vailable. Processing Steps: 1. Multimodal Parsing: Extract key sound ev ents, source characteristics, en vironment, and music elements from each source. Giv e priority to audio tags. From ASR, only detect voice presence and non-content features, possibly aiding en vironment/emo- tion inference, but ne ver include speech text itself. 2. Auditory F act Determination and Cross-modal Correction: • Base facts primarily on: Audio T ags > Music Description (music part) ≈ A udio Description > Speech presence (ASR) > Non-music part of Music Description . • Apply Positiv e Correction with video only if audio information is ambiguous and video provides clear , reasonable confirmation of the specific sound source (e.g., generic rumble corrected to airplane noise if airplane is explicitly shown). If tags already specify the type, no correction applies. • If video does not support or contradicts, never override auditory facts; only internally mark inconsistency for conservati ve phrasing later . • Adopt extreme conservatism when conflicts remain unresolved: omit or cautiously phrase uncertain elements. 3. Pure A uditory Ambiguity Inference: List ambiguities only from hearing, such as similarity of sounds (e.g., car vs. plane), multiple possible sources, or common perceptual misinterpretations. Never include visual-based ambiguities. 4. Reliability Assessment: If audio facts are extremely scarce, or sources are severely conflicting and cannot yield reliable auditory facts, directly output: UNCERTAIN_AUDIO_INFORMATION_DETECTED . 5. Final A udio Caption Generation: If reliable: • Generate a fluent, precise, audio-focused English description that preserves event order, number of occurrences, auditory features (sound type, timbre, rhythm, loudness, space, etc.). • Integrate confirmed auditory facts, using cautious wording for uncertain elements (“sounds like”, “a sound resembling ... is heard”, “potentially ... ”). • Strictly exclude: visual details, speech text, or speculation not supported by input sources. • Express emotional tone if strongly supported by audio (e.g., voice emotion or music mood). Output Format: Normally, output must be JSON: { "Potential ambiguities": [ "Ambiguity description 1 based solely on auditory perception.", "Ambiguity description 2 based solely on auditory perception." ], "Audio caption": "Final audio description focusing solely on audible elements and their auditory characteristics, detailed and fluent English. Use conservative language when uncertain." } In the special case of Step 4 failure, output only: UNCERTAIN_AUDIO_INFORMATION_DETECTED . Figure 4: Instruction for Caption Generation. 15 Instruction for QA Generation Y ou are a data generator that con verts a single audio caption into QA pairs. Write as if you actually listened to the audio. Hard rules: 1. Grounding: Use only the giv en description as grounding. Do not in vent f acts beyond what the description supports. Do not produce ASR-style verbatim transcripts. 2. Output format: Return JSON Lines (JSONL). Each line is one JSON object. No markdown, no backticks, no extra prose, no blank lines. 3. JSON validity: Use straight ASCII quotes. No trailing commas. All keys required. T ypes must match the schema. 4. Bre vity: Closed-ended answers must be short (yes/no, true/false, a label, a small set, or a number) or MCQ (A–D, answer is a single letter). 5. Evidence: support_span must not be empty . Provide exact words/phrases taken from the description that justify the answer . Do not add commentary . 6. Difficulty tagging: Use the boolean field ishard . Set it to true only for the most difficult items in the batch; otherwise false. 7. No meta-refer ence to source: In both question and answer , nev er mention the existence of any “caption/description/text”. Write from an audio-listener perspective, not a reader perspecti v e. Schema (each JSON object must match): { "question": string, "answer": string, "answer_style": "close" | "open", "type": one of [ "presence", "counting", "temporal_order", "concurrency", "trend", "comparative", "scene_spatial", "causality", "mood_style", "submodality_decomposition", "music_feature", "speech_structure", "cross_modal_integration", "higher_order_semantics", "aesthetic_function", "scene_inference", "rhythm_structure", "tension_dynamics" ], "submodality": array of ["speech","music","sound"], "support_span": array of strings (never empty), "confidence": number in [0,1], "ishard": boolean } Closed-ended con ventions: • Y es/No answers must be exactly "Yes" or "No" . • True/False answers must be e xactly "True" or "False" . • MCQ: include the options concisely in the question ; set answer to exactly one letter among "A","B","C","D" . • Counts are integers as strings (e.g., "2" ). • Options or sets should be concise strings (e.g., "drums" , "drums, guitar" ). Design goals: • Fav or integrati v e, cross-modality questions that combine speech/music/sound cues. • Include deep semantic understanding: structural roles, function vs. ornament, implied emotion arcs, rhythm-harmony interplay , tension build/release. • Keep questions div erse (no near-duplicates) and tightly grounded by the description’ s content—yet nev er mention the description explicitly . Figure 5: Instruction for QA Generation. In contrast, EvA preserves full temporal resolu- tion: T ime-A ware Alignment produces H aligned on the Whisper timeline, and the inject-and-add fu- sion in Eq. (6) yields E fused without reducing se- quence length. This non-compressive design en- sures that short transient ev ents and fine-grained temporal structure remain av ailable to the do wn- stream LLM, which is particularly important for perception-heavy benchmarks. Access to acoustic evidence. Q-Former architec- tures typically only consume the encoder’ s final- layer features. For audio encoders, these top-layer representations are often more abstract and may lose low- and mid-lev el cues that are crucial for en vironmental sound and e v ent recognition. EvA introduces an e xplicit cross-layer bypass that aggre- gates multiple CED layers, H 4 , H 8 , H L , into H agg via the two-stage cascaded cross-attention. This 16 Case 1 Captions: The audio opens with a liv ely liv e performance featuring rhythmic electric guitars, prominent bass tones, punchy percussion, and a mellow synth undertone, all layered with sustained cro wd ener gy . A male vocalist deli v ers a passionate vocal passage that blends with the driving instrumentation befor e transitioning into instrumental segments. A high-pitched female vocalist emerges briefly , adding melodic contrast to the arrangement. The track culminates in an abrupt crescendo of an intense, unified crowd shout that escalates sharply bef or e terminating abruptly , leaving a sudden silence. QA pairs: Q: What is the primary emotional effect created by the abrupt final shout and silence? A: A jarring sense of closure with heightened tension release Q: How man y distinct vocalists are present in the audio? A: 2 Q: What type of vocal presence is heard after the initial male v ocalist’ s passage? A: A high-pitched female vocalist Q: What is the primary emotional effect created by the abrupt final shout and silence? A: A jarring sense of closure with heightened tension release Figure 6: Example from EvA-Captions and EvA-QA (Case 1). Case 2 Captions: Persistent wind noise dominates throughout the recording with intermittent radio transmissions containing male speech. The radio communication begins abruptly with fragmented phrases mentioning ’Blackbird, ’ followed by three distinct mechanical ticks at approximately the same temporal proximity . A sharp burst of static noise momentarily interrupts the transmission bef ore resuming with the male voice reiterating ’Blackbird’ amidst continuing wind interference. The radio remains activ e throughout the recording with o verlapping wind noise maintaining consistent background presence. QA pairs: Q: Which sound consistently ov erlays the entire recording? A: W ind noise Q: Is there a sharp burst of static noise present in the audio? A: Y es Q: How does the recurrence of ’Blackbird’ contrib ute to the ov erall atmosphere of tension? A: It creates a sense of urgenc y and repetition amid unstable communication, suggesting unresolved or critical information being transmitted through persistent interference. Figure 7: Example from EvA-Captions and EvA-QA (Case 2). allo ws the fusion module to reuse shallo w , mid- le vel, and high-le vel acoustic information instead of relying solely on the last encoder layer . Interaction mechanism. Q-Former modules rely on a bank of static learnable queries that are shared across all inputs: the same latent queries attend to encoder features regardless of the specific au- dio content. In contrast, EvA performs content- adapti ve cross-layer retrie v al inside the CED path: H L first attends to H 8 , and the resulting represen- tation then attends to H 4 , forming a top–do wn hi- erarchy H L → H 8 → H 4 . This hierarchical atten- tion enables the model to selecti vely recov er fine- grained evidence from lo wer layers conditioned on the current high-level context, which is not possible when only the final encoder layer is exposed to a fixed query set. Summary . T aken together , these structural dif ferences—multi-layer access, content-adaptiv e cross-layer retrie v al, and non-compressi ve tempo- ral fusion—lead to a dif ferent inducti v e bias from Q-Former –based designs. This is consistent with 17 Setting MMA U MMAR MMSU CochlScene Mask 0–2 kHz 72 . 20 55 . 53 63 . 72 60 . 67 Mask 2–4 kHz 72 . 30 55 . 63 63 . 72 60 . 91 Mask 4–6 kHz 72 . 30 56 . 24 63 . 82 60 . 61 Mask 6–8 kHz 72 . 40 55 . 33 63 . 88 61 . 00 Mask 0–4 kHz 72 . 30 54 . 93 63 . 11 60 . 67 Mask 4–8 kHz 71 . 90 55 . 43 63 . 98 60 . 78 Only 0–2 kHz 72 . 10 55 . 73 63 . 34 60 . 34 Only 2–4 kHz 72 . 50 54 . 23 63 . 52 60 . 41 Only 4–6 kHz 71 . 90 54 . 12 63 . 38 60 . 02 Only 6–8 kHz 72 . 80 55 . 33 62 . 81 60 . 27 Full 0–8 kHz 73 . 90 59 . 76 62 . 24 74 . 94 T able 8: Main results on various audio benchmarks. All numbers are av erage scores. Figure 8: Comparison of audio token sequence length after feature fusion. SALMONN’ s Q-Former compresses audio tokens into a shorter latent sequence, while EvA preserves sequence length via inject-and-add fusion. our ablations in T able 3 , where the SALMONN- style Q-Former v ariant improv es over weak er base- lines b ut still underperforms EvA ’ s hierarchical Ag- gregator on perception benchmarks. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment