Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism
To generate synthetic datasets, e.g., in domains such as healthcare, the literature proposes approaches of two main types: Probabilistic Graphical Models (PGMs) and Deep Learning models, such as LLMs. While PGMs produce synthetic data that can be use…
Authors: Antheas Kapenekakis, Bent Thomsen, Katja Hose
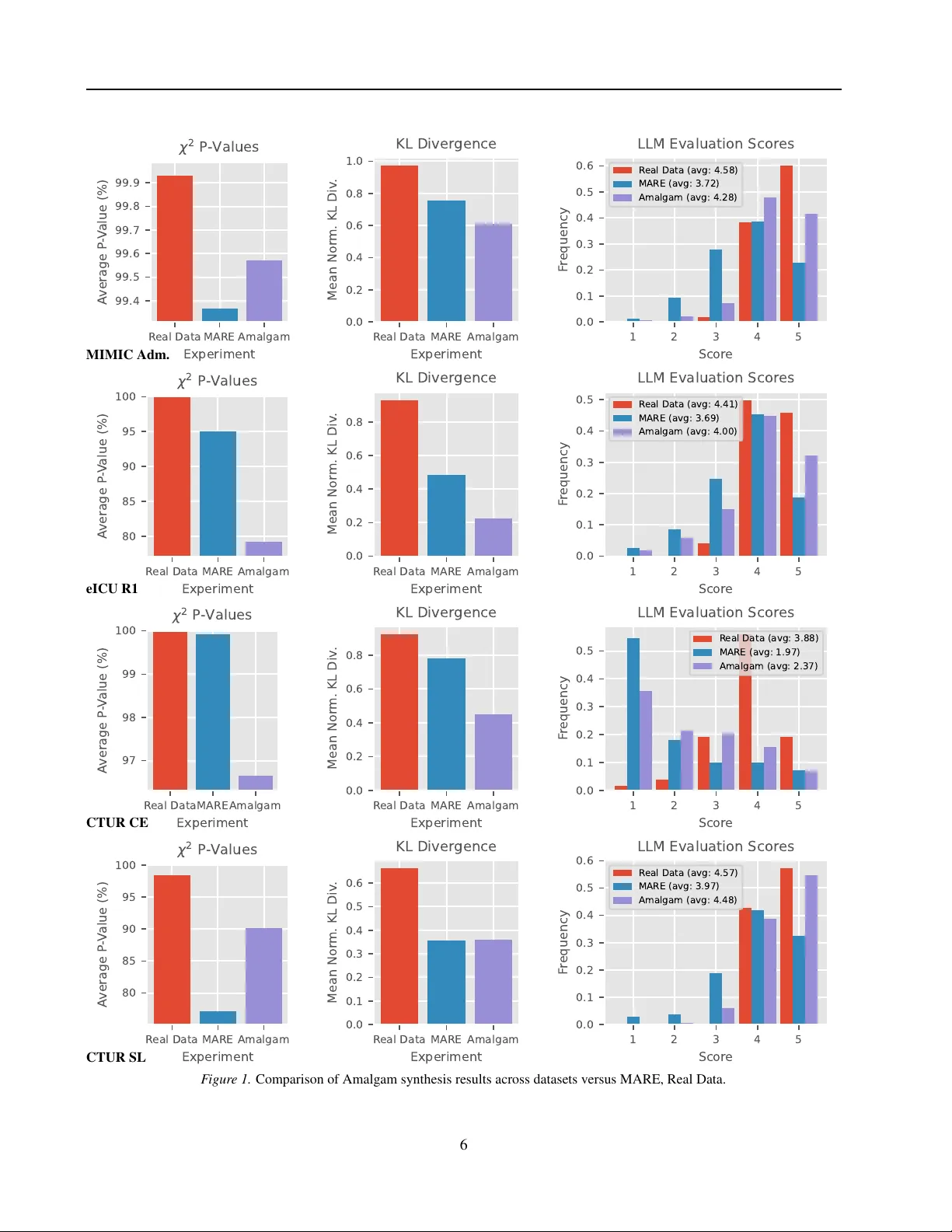
Amalgam: Hybrid LLM-PGM Synthesis Algorithm f or Accuracy and Realism Antheas Kapenekakis 1 Bent Thomsen 1 Katja Hose 2 Michele Albano 1 Abstract T o generate synthetic datasets, e.g., in domains such as healthcare, the literature proposes ap- proaches of two main types: Probabilistic Graph- ical Models (PGMs) and Deep Learning mod- els, such as LLMs. While PGMs produce syn- thetic data that can be used for advanced analyt- ics, they do not support complex schemas and datasets. LLMs on the other hand, support com- plex schemas b ut produce ske wed dataset distrib u- tions, which are less useful for advanced analytics. In this paper , we therefore present Amalgam, a hybrid LLM-PGM data synthesis algorithm sup- porting both advanced analytics, realism, and tan- gible priv ac y properties. W e show that Amalgam synthesizes data with an av erage 91 % χ 2 P v alue and scores 3.8/5 for realism using our proposed metric, where state-of-the-art is 3.3 and real data is 4.7. 1. Introduction Data synthesis is the process of generating artificial data that mimics the properties of a real dataset. It is widely used in multiple domains, with two main purposes: augmenting training data for machine learning and sharing data in a priv ac y-preserving manner . In this paper, we focus on the latter , which is especially relev ant in domains that handle confidential data, such as healthcare and finance. In these domains, algorithms focus on two approaches: Probabilistic Graphical Models (PGMs) and Deep Learning Networks. Probabilistic Graphical Models (PGMs) ( Cai et al. , 2023 ; 2021 ; McKenna et al. , 2022 ) are lo w parameter statistical models that learn the joint distrib ution of a dataset. Because of their structure, they are interpretable and the resulting data has strong analytical properties (e.g., Kullback-Leiber div ergence is minimal). In addition, due to their lo w param- eter count, the y hav e excellent priv ac y properties, especially when combined with methods such as Dif ferential Pri vac y 1 Aalborg Univ ersity , Aalborg, Denmark 2 TU Wien, V ienna, Austria. Correspondence to: Antheas Kapenekakis < anth- eas@cs.aau.dk > . Pr eprint. Marc h 31, 2026. (DP) ( Dwork , 2006 ), and through work such as the sys- tem Pasteur ( Kapenekakis et al. , 2026 ), they are sho wn to scale to very large datasets. Ho wev er , PGMs do not scale to complex datasets, with most work focusing on tabular data ( Cai et al. , 2021 ; McKenna et al. , 2022 ; Zhang et al. , 2017 ; McKenna et al. , 2021 ). On the other hand, Deep Learning models ( Jordon et al. , 2018 ; Guo et al. , 2023 ), especially Large Language Mod- els (LLMs) ( Goyal & Mahmoud , 2025 ; Chan et al. ; Y ang et al. , 2024 ), due to their high parameter count and being pre-trained on a lar ge corpus of data, ha ve the potential to handle complex datasets, which may contain sequences or complex relational structures. Howe ver , due to their high parameter count, if the input dataset is used for training, it is hard to ensure that the model does not expose the training dataset and that it is pri vac y-preserving without sacrificing accuracy ( Song et al. , 2013 ). Moreov er , the resulting data tends to capture a less accurate distribution ( T ao et al. , 2021 ) These approaches appear complimentary: PGMs provide accurate analytics and pri v acy , while LLMs provide the abil- ity to handle complex datasets. Howe ver , combining them and retaining these qualities remains an unanswered ques- tion. Evaluating the result for realism and analytics accurac y without a human in the loop remains an open question as well. In this paper, we aim to answer the following research questions: ( RQ1): How do we combine a PGM and an LLM to produce synthetic data where the following are met: ( Sub-RQ1): W e preserve the accurac y of analytics from the PGM? (accuracy) ( Sub-RQ2): The foundational kno wledge of an LLM is used to handle and enhance complex dataset? (com- plexity) ( Sub-RQ3): The resulting data features quantified priv acy properties? (priv acy) ( Sub-RQ4): The computational complexity remains reason- able to perform locally? (efficienc y) ( RQ2): Giv en a relational dataset as a result, how do we e valu- ate the synthetic data for: ( Sub-RQ1): Realism, i.e., ho w lifelike is the data?, in an unattended fashion, i.e., without revie w by a 1 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism human (realism) ( Sub-RQ2): Accuracy of analytics, i.e., ho w well key statis- tics are preserved?, across tables in a standard- ized manner (accuracy) In this paper , we aim to combine the benefits of PGMs and LLMs, through introducing Amalgam, a hybrid LLM-PGM synthesis algorithm. Amalgam uses a PGM to learn the joint distribution of the dataset and generate summary statistics which are priv acy-preserving and accurate. The summary statistics are used to condition an LLM, along similar sam- ples from the original dataset, to generate synthetic samples in a zero-shot manner . The resulting data features a fav or- able combination of the qualities of priv ac y-preservation, accuracy , complexity of input data, and computational effi- ciency over state-of-the-art. Then, we present an unattended ev aluation method for dataset realism, where an LLM is used to reason and then score ho w lifelike each sample is. Finally , we present experiments where we compare Amalgam against state-of-the-art on two public datasets for accuracy and realism. W e show that Amalgam presents a fa vorable combination of qualities over state-of-the-art (i.e., higher priv acy and accuracy than LLMs, handling higher complexity with higher realism than PGMs). 2. Related W ork W ork on data synthesis spans multiple domains and data types, where foundation of this paper is relational data syn- thesis and priv acy-aw are synthesis. F or structured data, most work focuses on tabular datasets and on two ap- proaches. The first one is PGM models ( McK enna et al. , 2022 ; Cai et al. , 2021 ; Zhang et al. , 2017 ; McKenna et al. , 2021 ; Mckenna et al. , 2019 ), which feature the Dif ferential Priv ac y technique ( Dwork , 2006 ) to ensure priv ac y . The second one is Deep Learning models ( Jordon et al. , 2018 ; Guo et al. , 2023 ; Xu et al. , 2019 ). Most of these works in volv e the use of a Generativ e Adversarial Netw ork (GAN) or a V ariational Autoencoder (V AE). In benchmarks ( T ao et al. , 2021 ), PGM models tend to outperform Deep Learn- ing models in terms of distributional accuracy on tabular datasets. Moreover , training Deep Learning models via Dif- ferential Pri v acy tends to result in a significant accurac y loss as sho wn in those papers ( Jordon et al. , 2018 ; Guo et al. , 2023 ; Xu et al. , 2019 ) and since tabular datasets are triv- ial, the ability of Deep Learning models to handle complex datasets is not lev eraged. Recently , two PGM works ha ve attempted to synthesize re- lational data ( Cai et al. , 2023 ; Kapenekakis et al. , 2024 ) using PGMs. Pri vLav a ( Cai et al. , 2023 ) deri ves from PrivMRF ( Cai et al. , 2021 ) to allow generating multiple disjoint tables together , without inter -table dependencies (e.g., two subsequent patient admissions in a medical dataset are generated independently). MARE ( Kapenekakis et al. , 2024 ) is PGM algorithm agnostic and models a relational dataset as a template representation graph ( K oller & Fried- man , 2009 ). This graph can model three types of child-to- parent table relationships: sequential (via Markov Chains), associativ e (via a technique called unrolling), and indepen- dent, where generated rows can reference all previously generated v alues (e.g., an admission column can reference the patient’ s sex). Both of these approaches are limited to simple relational datasets and scaling to more complex dataset requires significant engineering. This is similar to early attempts at computer vision, which used complex rule- sets to e.g., recognize faces before being obsoleted by Deep Learning. LLM models are used in general for generation pur- poses ( V aswani et al. , 2017 ), and for synthetic data ( Goyal & Mahmoud , 2025 ). Recently , great strides hav e been made on models that can run on-premises, in secure infrastruc- ture ( Lin et al. , 2024 ; et al. , 2024 ; GemmaT eam , 2025 ). These models can be ef fectiv ely run on a single GPU with an adequate token generation speed (hundreds of tokens per second). Howe ver , small models are regarded as having a lower quality output than higher end proprietary models. T o aid in augmenting data quality , recent works suggest a grammar based approach ( Ugare et al. ; T uccio et al. , 2025 )to limit the output tokens of the models to a specific schema (e.g., SQL, JSON, XML). Both local LLM inference frame- works (e.g., llamma cpp, vllm) and online providers (e.g., OpenAI) provide an approach to limit the output tokens with a specific grammar . 3. Amalgam Algorithm In this section, we present the algorithm Amalgam. First, we present the two main steps of the algorithm: structure learning (i.e., training the PGM and preparing the LLM), and sampling (i.e., generating synthetic data). Then, we present an ev aluation method for determining the realism of synthetic data based on an assessment by an LLM agent. 3.1. Structure Lear ning Structure learning begins by collecting metadata per entity in the dataset to form a tabular dataset distilling their an- alytics. An entity is defined as a single ro w in the main table of the dataset. F or example, in a medical dataset, an entity may be a patient or an admission in the intensive care unit (ICU) if the dataset does not link to patients. In such cases, the main table is the patient table or the admission table, respectiv ely . The analytics are defined as k ey statistics that we want to preserv e in the synthetic data (e.g., the age distribution, treatment length, or medicine distrib ution). T o create the tabular dataset of analytics, first, the relational dataset is discretized to ensure all columns are cate gorical. 2 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism Numerical columns are binned into a set of discrete ranges. Integers are used, selecting the smallest unsigned integer width that fits the domain of the column (e.g., uint8 for values between 0 and 255). The core of the analytics table is formed by the main table of the dataset. Then, through a series of left joins, other tables in the dataset are merged into the main table, selecting one ro w per entity . If the relation- ship between the tables is sequential (e.g., admissions sorted by date), the first ro w is selected. Otherwise, an arbitrary row is chosen. Moreover , a count column is added per child table to indicate how man y ro ws the original entity had. The analytics tabular dataset is used to train a PGM model, e.g., PrivBayes ( Zhang et al. , 2017 ) or Pri vMRF ( Cai et al. , 2021 ), which learns the joint distribution of the analytics. T o ensure priv ac y when generating analytics, privac y-aw are al- gorithms utilize the mechanism Differential Priv acy ( Dwork , 2006 ). By using a low pri v acy b udget parameter ϵ , e.g., 2, the algorithms ensure the analytics, which reference the whole dataset, are protected from inference. The resulting PGM is used to generate samples of the analytics, which will be used to condition the LLM during sampling. By av oiding the use of fine tuning or LLMs during structure learning, we av oid the priv ac y and performance implications these processes carry . 3.2. Sampling During sampling, the PGM generates conditioning values (e.g., age, sex). These values are used with a similarity function to collect a number of top samples in the original data to be provided as a reference for synthesis. Then, the analytics are con verted into a list of human readable values (e.g., “age: 45”, “entry time: 10:30”) and provided along-side the similar samples in a JSON format. These two components are used to form the prompt for the LLM, which is bound by a grammar to generate a JSON object that mirrors the dataset schema. The output of the LLM is parsed and returned as the synthetic sample. Similarity Function. W e define the similarity function as a function that receiv es as input the single column his- tograms of the analytics dataset, measured during the fitting of the PGM, and two samples, a , b . It can be formulated as follows: similar ( a, b ) = n X i =1 ( a i = b i ) · 1 p i (1) Where n is the number of columns, a i and b i are the values of column i in samples a and b respectiv ely , and p i is the probability of the value a i in the marginal of column i . An alternate representation of a single-column marginal is a histogram of the value counts of a column. This heuristic representation increases the perceiv ed similarity between two samples proportionally to the number of values they hav e common and how rare these v alues are. The similarity scores are generated per conditioning sample and ro w in the original data (complexity O ( M N ) , where N is the number of ro ws in the original and M is the number of conditioning samples). If M = N , this would result in a complexity of O ( N 2 ) . Howe ver , as we show in the e xperi- mental section, the computational cost of each sampled row requires running the LLM, where the cost is O ( M F LLM ) , where F LLM is the cost of running the LLM per sample. As F LLM is significantly higher than N similarity function calculations, M << N must hold for synthesis to finish in a realistic timeframe. Therefore, the complexity of the sim- ilarity function is not a bottleneck in the overall synthesis process. LLM Synthesis. First, the original dataset schema is con- verted into a JSON schema. This is done by mapping each row of the dataset to a dictionary , and modelling depen- dencies between tables as lists of those dictionaries. The con version is performed by parsing the dataset schema recur- siv ely . Then, the n samples are con verted into this schema, by using human-readable values where possible (e.g., time value “5” becomes “4:00”). The samples and the conditioning values are used to form the prompt for the LLM as follows: ( 1): Identifier to the LLM: The LLM is told it is a domain expert (e.g., a doctor for medical data) and that it is provided n reference samples. ( 2): Reference Samples: Then, the n reference samples are provided in JSON format. ( 3): Conditioning V alues: Next, the conditioning values are provided in human-readable format (e.g., “age: 45”, “entry time: 10:30”). ( 4): Generation Instruction: The LLM is instructed to generate a sample in JSON format that is similar to the conditioning values and reference samples. ( 5): Guiding Instructions: Finally , if necessary , the LLM can be giv en a set of instructions to improve its output (e.g., “If the generated patient would be unrealistic, adjust the values slightly”). The structure of the prompt is designed to minimize context contamination while aiding the model to generate similar data. While providing reference samples is not required, not doing so could cause the synthetic output to not be similar to real data since the model would miss queues that come from observing the real data. Then, by placing the reference samples before the conditioning values and ha ving the instructions last, we ensure that the model focuses on the conditioning values and remembers the guiding instructions 3 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism clearly . A different approach could optimize token caching by placing the guiding instructions first, and then the context, loweri ng the computational cost. W e delegate the e valuation of such an approach to future work. The LLM is then bound by the JSON schema of the dataset to ensure the output data is parseable through using a grammar-based approach ( Ugare et al. ; T uccio et al. , 2025 ). This ensures that the output is always valid JSON, which is especially important for complex schemas and when using local small models. Finally , the output JSON is parsed and con verted to the relational format of the original data. 3.3. Realism Evaluation A challenge that was faced by this work is the ev aluation of the realism of synthetic data. As realism is a subjecti ve metric, it is hard to quantify mechanically , via e.g., statis- tical metrics. For this reason, we introduce an unattended ev aluation method for realism based on an LLM agent. This method re-uses the core aspects of Amalgam’ s sam- pling process. Gi ven a sample, the top n similar samples are collected from the original dataset using the similarity function defined in Section 3.2 . Then, all n + 1 samples (the synthetic and the n original) are con verted into JSON. Next, a prompt is formed for the LLM as follo ws: ( 1): Identifier to the LLM: The LLM is told it is a domain expert and that it is pro vided n real samples. ( 2): Real Samples: The n samples are provided as JSON. ( 3): T ask: The model is told to e valuate the realism of an additional sample provided to it and score it from 1 to 5 for realism. ( 4): Evaluation Sample: Finally , the e v aluated sample is provided to the LLM. The LLM is expected to return a score from 1 to 5 and bound by grammar to ensure the output is parsable. The score is collected and av eraged across multiple samples to pro vide an ov erall realism score for the synthetic dataset. Then, the ev aluation is re-run using a hold-out set of real data samples that were not used for synthesis or eligible for selection as similar samples. This provides a realism score for real data, which can be used as a baseline for the synthetic data. 4. Experiments W e compare Amalgam against state-of-the-art in two experiments. First, we compare Amalgam against MARE ( Kapenekakis et al. , 2024 ), a PGM relational data synthesis algorithm, on four datasets. Then, we compare Amalgam’ s performance when using different local LLMs on one of the datasets. 4.1. Comparison with State-of-the-Art In the first experiment, we compare Amalgam against the state-of-the-art algorithm MARE ( Kapenekakis et al. , 2024 ), which is an orchestration algorithm for relational data us- ing multiple PGMs, according to which each relationship is classified as independent, associati ve, or sequential. W e compare to MARE across four datasets: MIMIC-IV Admis- sions, eICU R1, CTUR SL, and CTUR CE. MIMIC-IV Admissions is a dataset that consists of three ta- bles in the core set of MIMIC-IV ( Johnson et al. ): “patients”, “admissions”, and “transfers”. The tables “admissions” and “transfers” hav e a sequential relationship, where “transfers” is a child of “admissions”. eICU R1 is a dataset that consists of four tables in the eICU dataset ( Pollard et al. , 2019 ): “pa- tients”, “admissiondx”, “vitalaperiodic”, and “medication”, with an assortment of columns. All tables have a child rela- tionship to “patients”. The datasets CTUR SL and CTUR CE are sourced from The CTU Prague Relational Learning Repository ( Motl & Schulte , 2024 ), where SL is the Student- Loans dataset, and CE is the ConsumerExpenditures dataset. CTUR SL contains key-only tables that show an attribute for a student (e.g., “disabled”). W e merge those tables to the main “person” table to form a three table dataset with “person”, “enrolled”, and “enlist”, where “enrolled” and “en- list” are associativ e child tables of “person”. For CTUR CE, the tables “household”, “person”, and “expenditure” form a three table dataset. A dataset overvie w is sho wn in T able 1 . It lists the number of tables, total number of columns, total number of v alues (i.e., ro ws multiplied by columns per ta- ble), number of entities (i.e., rows in the main table), and the av erage ratio of values to entities. Dataset Tbls Cols V als N V als/N MIMIC Adm. 3 25 16.6M 180.7k 91.6 eICU R1 4 25 141.3M 200.9k 703.5 CTUR CE 3 20 13.3M 56.8k 234.5 CTUR SL 3 10 9.2k 1.0k 9.2 T able 1. Dataset summary statistics. In the experiments, we use the same PGM as MARE, PrivBayes ( Zhang et al. , 2017 ), with a total priv acy bud- get of ϵ = 2 . W e retain a 20% hold-out set for accuracy and realism e v aluation. For accuracy , we collect an aggre- gated Kullback-Leibler (KL) di ver gence metric as shown in MARE ( Kapenekakis et al. , 2024 ) and a χ 2 metric. Then, for realism, we use our proposed LLM-based evaluation method. W e use Qwen3 8B ( Y ang et al. , 2025 ) as the LLM for both synthesis and realism ev aluation. For the aggregated KL metric, we collect column pairs in three categories: intra-table pairs (both columns from the same table), inter-table pairs (columns from dif ferent tables that have a foreign key relationship), and sequential inter- 4 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism table pairs (with up to two pre vious ro ws). For each pair in the dataset, we calculate KL diver gence between the original and synthetic (or real) data for each table and normalize them with the formula f ( x ) = 1 / (1 + x ) , which maps [0 , ∞ ) to (0 , 1] . Then, we av erage the results per cate gory , per-table, and finally we a verage the three categories to form the aggregated KL metric. For the χ 2 metric, we collect the χ 2 P value per column between the original and synthetic (or real) data, average them per-table, and finally average the per-table results to form the final χ 2 metric. χ 2 P value s indicate the likelihood that two distributions were drawn from the same underlying distribution, with 100% being identical distributions. Due to the higher computational demand of Amalg am and realism ev aluation, we limit the number of samples that are generated and e v aluated for realism to 2000 per dataset (excl. CTUR SL where it is 800 total). MARE always generates the same number of samples as the original dataset, and accuracy metrics (KL, χ 2 ) are computed on all produced samples. The results are shown in Figure 1 . Finally , we collect the synthesis time of Amalgam versus MARE for two steps: structure learning and sampling, shown in T able 2 . MARE Amalgam Dataset Fit Sample Fit Sample MIMIC Adm. 1m29s 3s 1m1s 8h26m eICU R1 4m7s 3m33s 25s 12h30m CTUR CE 14.8s 1s 13s 6h49m CTUR SL 11s 0.3s 4s 7m7s T able 2. Time comparison between MARE and Amalgam. 4.2. LLM Comparison and Efficiency In the second experiment, we compare Amalgam using four different LLMs for synthesis: Qwen3 8B ( Y ang et al. , 2025 ), Gemma3 12B ( GemmaT eam , 2025 ), GPT -OSS 20B ( Agar - wal et al. , 2025 ), and Meta Llama 3.1 8B Instruct ( Grattafiori et al. , 2024 ). Qwen3 8B is used to ev aluate realism in all four cases. W e generate 250 samples. W e use the MIMIC- IV Admissions dataset for this experiment and collect the same metrics as before. Then, we collect per-second energy and utilization data from the GPU, running the experiments back to back and recording the relative experiment time (wall time). The metrics results are shown in Figure 2 and the energy analysis in Figure 3 . 4.3. Hardwar e Setup The experiments are e xecuted on units of Nvidia DGX Spark Founder Edition that contain a GB10, 128GB of RAM, and 4TB of SSD, using their stock operating system that mirrors Ubuntu 24.04, with Python 3.12. PGM models use the CPU and LLM inference the GPU. F or each e xperiment, we collect per-second ener gy data from the GPU using “nvidia- smi” and the timing intervals of each synthesis step. 4.4. Implementation W e implement Amalgam by extending the data synthesis system Pasteur ( Kapenekakis et al. , 2026 ), which is written in Python. Pasteur pro vides the reference implementation of the algorithm MARE ( Kapenekakis et al. , 2024 ) using PrivBayes ( Zhang et al. , 2017 ), which is our state-of-the-art reference model. W e implement the structure learning phase by re-using the fitting process of PrivBayes from Pasteur . Then, we implement the sampling phase by integrating the LLM inference framework “Llama.cpp” under the library “llama-cpp-python” and use the library “outlines” ( W illard & Louf , 2023 ) to perform grammar-based generation. W e attempted to use online inference providers through OpenRouter but found that the structured generation via grammar f ailed when provided comple x schemas for synthe- sis (e.g., the pro vider Groq only performed post-inference validation and discarded more than half of the samples) and had varying support per provider . The library “outlines” was also pushed to its limits, requiring around 1–3 minutes to prime the grammar for comple x schemas and having around a 30% GPU throughput degradation compared to normal generation (shown in Figure 3 po wer drop). W e source local open-source models from Hugging- Face ( W olf et al. , 2020 ). Specifically , we opt to use the model Qwen3 8B ( Y ang et al. , 2025 ) quantized to 4-bit (“Qwen/Qwen3-8B-GGUF”, filename “Qwen3-8B- Q4 K M.gguf ”) for its balance of quality and perfor- mance. For comparison, we compare it with models Gemma3 12B ( GemmaT eam , 2025 ) (“unsloth/gemma-3- 12b-it-GGUF”, filename “gemma-3-12b-it-Q4 K M.gguf ”), GPT -Oss 20B ( Agarwal et al. , 2025 ) (“unsloth/gpt-oss- 20b-GGUF”, filename “gpt-oss-20b-Q4 K M.gguf ”), and Meta Llama 3.1 8B Instruct ( Grattafiori et al. , 2024 ) (“MaziyarPanahi/Meta-Llama-3.1-8B-Instruct-GGUF”, file- name “Meta-Llama-3.1-8B-Instruct.Q4 K M.gguf ”). At the time of this writing, only Qwen3 8B provided an official 4-bit GGUF quantization, so for the other models we used popular community provided quantizations. 5. Results In the first experiment (Figure 1 ), we observ e that Amalg am provides significantly higher realism than MARE across all datasets, closing the gap to real data. Overall, the average re- alism score across datasets for Amalgam is 3.8/5 compared to MARE’ s 3.3/5 and real data’ s 4.4/5. This is expected, as the LLM is able to le verage its foundational knowledge to generate more lifelike samples. Specifically , on MIMIC Admissions and CTUR SL, the Amalgam score distribution 5 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism R eal Data MARE Amalgam Experiment 99.4 99.5 99.6 99.7 99.8 99.9 A verage P - V alue (%) 2 P - V a l u e s R eal Data MARE Amalgam Experiment 0.0 0.2 0.4 0.6 0.8 1.0 Mean Nor m. KL Div . KL Diver gence 1 2 3 4 5 Scor e 0.0 0.1 0.2 0.3 0.4 0.5 0.6 F r equency LLM Evaluation Scor es R eal Data (avg: 4.58) MARE (avg: 3.72) Amalgam (avg: 4.28) MIMIC Adm. R eal Data MARE Amalgam Experiment 80 85 90 95 100 A verage P - V alue (%) 2 P - V a l u e s R eal Data MARE Amalgam Experiment 0.0 0.2 0.4 0.6 0.8 Mean Nor m. KL Div . KL Diver gence 1 2 3 4 5 Scor e 0.0 0.1 0.2 0.3 0.4 0.5 F r equency LLM Evaluation Scor es R eal Data (avg: 4.41) MARE (avg: 3.69) Amalgam (avg: 4.00) eICU R1 R eal Data MARE Amalgam Experiment 97 98 99 100 A verage P - V alue (%) 2 P - V a l u e s R eal Data MARE Amalgam Experiment 0.0 0.2 0.4 0.6 0.8 Mean Nor m. KL Div . KL Diver gence 1 2 3 4 5 Scor e 0.0 0.1 0.2 0.3 0.4 0.5 F r equency LLM Evaluation Scor es R eal Data (avg: 3.88) MARE (avg: 1.97) Amalgam (avg: 2.37) CTUR CE R eal Data MARE Amalgam Experiment 80 85 90 95 100 A verage P - V alue (%) 2 P - V a l u e s R eal Data MARE Amalgam Experiment 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Mean Nor m. KL Div . KL Diver gence 1 2 3 4 5 Scor e 0.0 0.1 0.2 0.3 0.4 0.5 0.6 F r equency LLM Evaluation Scor es R eal Data (avg: 4.57) MARE (avg: 3.97) Amalgam (avg: 4.48) CTUR SL F igur e 1. Comparison of Amalgam synthesis results across datasets versus MARE, Real Data. 6 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism Experiment 98.8 99.0 99.2 99.4 99.6 99.8 100.0 A verage P - V alue (%) 2 P - V a l u e s Experiment 0.0 0.2 0.4 0.6 0.8 1.0 Mean Nor m. KL Div . KL Diver gence 1 2 3 4 5 Scor e 0.0 0.1 0.2 0.3 0.4 0.5 0.6 F r equency LLM Evaluation Scor es R eal Data (avg: 4.59) GPT OSS 20B (avg: 3.94) Gemma3 12b (avg: 4.34) Llama3.1 8B It (avg: 3.98) Qwen3 8B (avg: 4.28) F igur e 2. Comparison of Amalgam synthesis for different LLMs on MIMIC-IV Admissions. from 1 to 5 overlaps significantly with real data, sho wing that the synthetic data is hard to distinguish from real data. On CTUR CE, the realism is improved significantly ov er MARE, but there is a significant number of unrealistic sam- ples for both MARE and Amalgam. This is likely an effect of the dataset, which uses a lot of arbitrary product keys under “expenditures” that ha ve lo w semantic meaning. On accuracy , Amalgam is grounded in reality , with χ 2 scores very close to 100%, sho wing high histogram quality . The exception is eICU R1, where the very large number of rows per entity causes the LLM to struggle to generate accurate counts for child tables. The histogram quality was additionally verified manually by observing histogram plots of the produced columns. The KL div ergence scores are lower , showing that the joint distributions between columns are not as well preserved. As the LLM only has access to first ro w statistics (Section 3.1 ) and not follo w-up ro w statis- tics, which would be required to preserve joint distributions, this is expected. Overall, the χ 2 score across datasets for Amalgam is 91%, compared to MARE’ s 92%, and for KL div ergence, Amalg am scores 0.40 with MARE at 0.60. Revi ewing the times on T able 2 , we observe that Amalgam’ s structure learning is slightly faster than MARE’ s, as Amal- gam only fits a single PGM. Howe ver , the sampling time is significantly higher , as sampling uses an LLM. In the second e xperiment (Figure 2 ), we observ e that Qwen3 8B and Gemma3 12B provide the best realism scores, with GPT -OSS and Meta Llama 3.1 8B Instruct lagging behind. On accuracy , all models provide similar χ 2 scores, with Qwen3 8B ha ving a slight edge. Due to the lo wer number of samples (250), the KL diver gence score is negativ ely affected compared to the pre vious experiment, as rare com- binations of values may not appear in the synthetic data. On the energy axis, we observe that Qwen3 8B uses sig- nificantly less ener gy than Gemma3 12B while producing slightly better results (Figure 3 ), making it the best choice for synthesis. GPT -OSS is surprisingly ef ficient, using two fifths of the energy and runtime of Qwen3 8B through its Mixture-of-Experts architecture with 3B parameters, but it performs worse. MARE runs on CPU only and only re- quires 1–5m to generate as many samples as in the original data, so its energy usage is negligible compared to LLMs. All models, including real data, are ev aluated using Qwen3 8B for realism, so energy values for e v aluation are the same across all models and real data (hold-out set). 6. Discussion The results sho w that Amalgam is able to generate synthetic data that is significantly more realistic than PGM-based syn- thesis while preserving high accurac y . This is achie ved by lev eraging the foundational kno wledge of LLMs to generate lifelike samples, while using PGMs to ground the generation in reality . Through combining these approaches, Amalgam handles complex datasets that PGM-based synthesis strug- gles to be realistic with, while a voiding the priv ac y and performance issues of LLM fine-tuning. As Amalgam uses Differential Priv acy in the PGM, it en- sures that each synthetic sample is traceable to a fixed num- ber of original samples, which can be used to audit the synthetic data for priv acy violations. This is a significant advantage o ver pure LLM-based synthesis with fine-tuning, where the lack of traceability can lead to pri v acy concerns. Methods for automated screening of LLM outputs for pri- vac y violations is a natural next step for future w ork. Moreov er , Amalgam runs comfortably on-premises, with all the experiments in this paper being performed on edge devices (DGX Sparks) with acceptable runtimes ( ∼ 7 hours for 2000 samples), while representing the whole dataset, which is an excellent attribute for sensitiv e data synthesis. Due to its PGM foundation, Amalgam can scale to very large datasets and fit them in minutes, with its generated 7 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism 0 20 40 60 80 100 GPU Utilization (%) 0 1 2 3 4 W all T ime (hours) 20 40 60 80 P ower Draw (W, total 0.29 kWh) R eal Data Eval (per run, 8 Wh) GPT OSS 20B Gen ( 23 Wh) GPT OSS 20B Eval ( 8 Wh) Gemma3 12b Gen ( 92 Wh) Gemma3 12b Eval ( 7 Wh) Llama3.1 8B It Gen ( 52 Wh) Llama3.1 8B It Eval ( 7 Wh) Qwen3 8B Gen ( 57 Wh) Qwen3 8B Eval ( 8 Wh) F igur e 3. Energy usage comparison across different LLMs on MIMIC-IV Admissions dataset. data being representativ e of the entire input dataset and, if on-demand generation is needed, Amalgam can begin generating synthetic data a few minutes after cold-start. Howe v er , Amalgam has limitations in certain use-cases where PGMs would be preferable. For example, if the goal is purely analytical and the data will not be used for human consumption, PGM-based synthesis can produce comparable analytics while being significantly faster and more energy efficient. In that re gard, if the data will be used to stress test systems (e.g., databases), PGM-based synthesis is a better fit. In summary , Amalgam has a complementary use-case to PGM-based synthesis, being preferable when the data will be used for human consumption (e.g., application testing) and a large amount of output data is not required. When analytics are the main goal and large amounts of data are required, PGM-based synthesis remains preferable. As an algorithm, Amalgam’ s resource requirements are relativ ely low , allo wing it to run on-premises or on edge de vices. In sum, we envision that Amalgam can be used by organiza- tions in combination with a PGM algorithm, where Amal- gam is used to generate a small set of realistic samples (in the thousands) for UI stand-ins and PGM synthesis to gen- erate large amounts of accurate samples (in the hundreds of millions) for e.g., database stress-testing. 7. Conclusion In this paper , we presented Amalgam, a hybrid LLM-PGM synthesis algorithm that leverages the strengths of LLMs and PGMs to generate lifelike synthetic data. Amalgam uses PGMs to learn the joint distrib ution of ke y analytics in the dataset, ensuring that the synthetic data is grounded in real- ity , while using pre-trained LLMs to generate samples that are similar to real data. This combination allows Amalgam to handle complex datasets that PGMs struggle with, while av oiding the pri v acy and performance issues of LLM fine- tuning. Through experiments on multiple datasets, we show that Amalgam produces synthetic data that is significantly more realistic than PGM-based synthesis while preserving high accuracy . Moreover , Amalgam runs comfortably on- premises, making it suitable for sensitiv e data synthesis. A. Acknowledgments This work w as supported by the VILLUM F oundation under project “T eaching AI Green Coding” (VIL70090); by ITEA4 and the Innovation Fund Denmark for projects “GreenCode” (2306) and “MAST” (22035). 8 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism B. LLM Prompts In this appendix, we provide the prompts used for LLM syn- thesis for each dataset, for synthesis and realism ev aluation. In code, the placeholders , , , and are replaced with the number of samples, the reference samples in JSON format, the condi- tioning values in human-readable format, and the ev aluated sample in JSON format respectiv ely . B.1. MIMIC-IV Admissions Synthesis Prompt You are a doctor working at a hospital. Reference the following example patients: And derive a JSON patient using: Guidelines: • the provided values are for the first admission/transfer, generate the rest in a realistic manner • for provided ranges use a random value that is within the range • Reason about the key events in this patient’s admission; they should make sense • If a value would cause an unrealistic patient, adjust it slightly for realism Evaluation Pr ompt You are a medical doctor. You are given the following real patients as a reference: Then, you are asked to comment on how real the following patient is with a rating from 1 to 5 (5 being very real): B.2. eICU R1 Synthesis Prompt You are a doctor working at a hospital. Reference the following example patients: And derive a JSON patient using: Guidelines: • the provided values are for the first admissions etc, generate the rest in a realistic manner • for provided ranges use a random value that is within the range • Reason about the key events in this patient’s admission; they should make sense • If a value would cause an unrealistic patient, adjust it slightly for realism Evaluation Pr ompt You are a medical doctor. You are given the following real patients as a reference: Then, you are asked to comment on how real the following patient is with a rating from 1 to 5 (5 being very real): B.3. CTUR CE Synthesis Prompt You are a tax accountant. Reference the following households: And derive a new JSON household using: Guidelines: • the provided values are for the first expense/member, generate the rest in a realistic manner • for provided ranges use a random value that is within the range and 4 decimal places • If a value would cause an unrealistic household, adjust it slightly for realism Evaluation Pr ompt You are a tax accountant. You are given the following real households as a reference: Then, you are asked to comment on how real the following household is with a rating from 1 to 5 (5 being very real): 9 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism B.4. CTUR SL Synthesis Prompt You are a school administrator. Reference the following student profiles: And derive a new JSON student using: Guidelines: • the provided values are for the first enrollment/enlistment, generate the rest in a realistic manner • for provided ranges use a random value that is within the range and 4 decimal places • If a value would cause an unrealistic student, adjust it slightly for realism Evaluation Pr ompt You are a school administrator. You are given the following real students as a reference: Then, you are asked to comment on how real the following student is with a rating from 1 to 5 (5 being very real): References Agarwal, S., Ahmad, L., Ai, J., Altman, S., et al. gpt-oss- 120b & gpt-oss-20b model card, 2025. URL https: //arxiv.org/abs/2508.10925 . Cai, K., W ei, J., Lei, X., and Xiao, X. Data Synthesis via Differentially Priv ate Markov Random Fields. VLDB , 2021. Cai, K., Xiao, X., and Cormode, G. Privla v a: Synthesizing relational data with foreign ke ys under differential priv acy . Pr oc. A CM Manag. Data , 1(2):142:1–142:25, 2023. Chan, Y .-C., Pu, G., Shanker , A., Suresh, P ., Jenks, P ., Heyer , J., and Denton, S. Balancing Cost and Effecti veness of Synthetic Data Generation Strategies for LLMs. Dwork, C. Differential pri vac y . 2006. et al., D.-A. Deepseek-v3 technical report. 12 2024. URL https://arxiv.org/pdf/2412.19437 . GemmaT eam. Gemma 3 technical report. 3 2025. URL https://arxiv.org/pdf/2503.19786 . Goyal, M. and Mahmoud, Q. H. An LLM-Based Frame- work for Synthetic Data Generation. 2025 IEEE 15th Annual Computing and Communication W orkshop and Confer ence, CCWC 2025 , pp. 340–346, 2025. doi: 10.1109/CCWC62904.2025.10903878. Grattafiori, A., Dubey , A., Jauhri, A., et al. The llama 3 herd of models, 2024. URL abs/2407.21783 . Guo, K., Chen, J., Qiu, T ., Guo, S., Luo, T ., Chen, T ., and Ren, S. Medgan: An adapti v e GAN approach for medical image generation. Comput. Biol. Medicine , 163:107119, 2023. Johnson, A., Bulgarelli, L., Pollard, T ., Horng, S., Celi, L. A., and Mark, R. MIMIC-IV. Jordon, J., Y oon, J., and V an Der Schaar , M. Pate-gan: Gen- erating synthetic data with dif ferential pri v acy guarantees. In International confer ence on learning r epr esentations , 2018. Kapenekakis, A., Dell’aglio, D., V esteghem, C., Poulsen, L., Bøgsted, M., Garofalakis, M., and Hose, K. Synthesizing accurate relational data under dif ferential priv ac y . IEEE BigData 2024 , 2024. Kapenekakis, A., Dell’Aglio, D., Bøgsted, M., Garofalakis, M., and Hose, K. Pasteur: Scaling priv acy-aw are data synthesis. In Chrysanthis, P . K., Nørv ˚ ag, K., Stefanidis, K., and Zhang, Z. (eds.), Advances in Databases and Information Systems , pp. 164–180, Cham, 2026. Springer Nature Switzerland. ISBN 978-3-032-05281-0. K oller , D. and Friedman, N. Structure learning in bayesian networks. Pr obabilistic Graphical Models: Principles and T echniques , pp. 783–848, 2009. Lin, J., T ang, J., T ang, H., Y ang, S., Chen, W .-M., W ang, W .-C., Xiao, G., Dang, X., Gan, C., and Han, S. A wq: Activ ation-a ware weight quantization for on-de vice llm compression and acceleration. Pr oceedings of Machine Learning and Systems , 6:87–100, 5 2024. URL https: //github.com/mit- han- lab/llm- awq . Mckenna, R., Sheldon, D., and Miklau, G. Graphical-model based estimation and inference for differential pri vac y . In Pr oceedings of the 36th International Confer ence on Machine Learning , pp. 4435–4444. PMLR, May 2019. McKenna, R., Miklau, G., and Sheldon, D. Winning the NIST Contest: A scalable and general approach to differ- entially priv ate synthetic data, August 2021. McKenna, R., Mullins, B., Sheldon, D., and Miklau, G. AIM: An Adaptiv e and Iterativ e Mechanism for Differen- tially Priv ate Synthetic Data, January 2022. 10 Amalgam: Hybrid LLM-PGM Synthesis Algorithm for Accuracy and Realism Motl, J. and Schulte, O. The ctu prague relational learning repository , 2024. URL 1511.03086 . Pollard, T ., Johnson, A., Raf fa, J., Celi, L. A., Badawi, O., and Mark, R. eICU Collaborativ e Research Database, April 2019. URL https://doi.org/10.13026/ C2WM1R . V ersion 2.0. Song, S., Chaudhuri, K., and Sarwate, A. D. Stochastic gradient descent with dif ferentially pri vate updates. In 2013 IEEE Global Confer ence on Signal and Information Pr ocessing , 2013. T ao, Y ., McK enna, R., Hay , M., Machana v ajjhala, A., and Miklau, G. Benchmarking Differentially Priv ate Syn- thetic Data Generation Algorithms. December 2021. T uccio, G., Bulla, L., Madonia, M., Gangemi, A., and Mongiovi’, M. Grammar-llm: Grammar-constrained natural language generation. pp. 3412–3422, 8 2025. doi: 10.18653/V1/2025.FINDINGS- A CL. 177. URL https://aclanthology.org/2025. findings- acl.177/ . Ugare, S., Suresh, T ., Kang, H., Misailovic, S., and Singh, G. Syncode: Llm generation with grammar augmen- tation. T ransactions on Machine Learning Resear ch . ISSN 2835-8856. URL https://github.com/ uiuc- focal- lab/syncode . V aswani, A., Brain, G., Shazeer , N., Parmar , N., Uszkoreit, J., Jones, L., Gomez, A. N., Ł ukasz Kaiser , and Polo- sukhin, I. Attention is all you need. Advances in Neural Information Pr ocessing Systems , 30, 2017. W illard, B. T . and Louf, R. Ef ficient guided generation for large language models. arXiv preprint , 2023. W olf, T ., Deb ut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P ., Rault, T ., Louf, R., Funto w- icz, M., Da vison, J., Shleifer , S., v on Platen, P ., Ma, C., Jernite, Y ., Plu, J., Xu, C., Le Scao, T ., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. Hugging- face’ s transformers: State-of-the-art natural language pro- cessing. arXiv pr eprint arXiv:1910.03771 , 2020. doi: 10.48550/arXiv .1910.03771. URL https://arxiv. org/abs/1910.03771 . Xu, L., Skoularidou, M., Cuesta-Infante, A., and V eera- machaneni, K. Modeling T ab ular data using Conditional GAN. 2019. Y ang, A., Li, A., Y ang, B., Zhang, B., Hui, B., Zheng, B., Y u, B., Gao, C., Huang, C., Lv , C., Zheng, C., Liu, D., Zhou, F ., Huang, F ., Hu, F ., Ge, H., W ei, H., Lin, H., T ang, J., Y ang, J., T u, J., Zhang, J., Y ang, J., Y ang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Y ang, K., Y u, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P ., W ang, P ., Zhu, Q., Men, R., Gao, R., Liu, S., Luo, S., Li, T ., T ang, T ., Y in, W ., Ren, X., W ang, X., Zhang, X., Ren, X., Fan, Y ., Su, Y ., Zhang, Y ., Zhang, Y ., W an, Y ., Liu, Y ., W ang, Z., Cui, Z., Zhang, Z., Zhou, Z., and Qiu, Z. Qwen3 technical report, 2025. URL https: //arxiv.org/abs/2505.09388 . Y ang, D., Monaikul, N., Ding, A., T an, B., Mosaliganti, K., and Iyengar , G. Enhancing T able Representations with LLM-po wered Synthetic Data Generation. nov 2024. URL . Zhang, J., Cormode, G., Procopiuc, C. M., Sriv astav a, D., and Xiao, X. Pri vBayes: Pri v ate Data Release via Bayesian Networks. ACM T ransactions on Database Systems , 42(4):25:1–25:41, October 2017. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment