Aligning LLMs with Graph Neural Solvers for Combinatorial Optimization
Recent research has demonstrated the effectiveness of large language models (LLMs) in solving combinatorial optimization problems (COPs) by representing tasks and instances in natural language. However, purely language-based approaches struggle to ac…
Authors: Shaodi Feng, Zhuoyi Lin, Yaoxin Wu
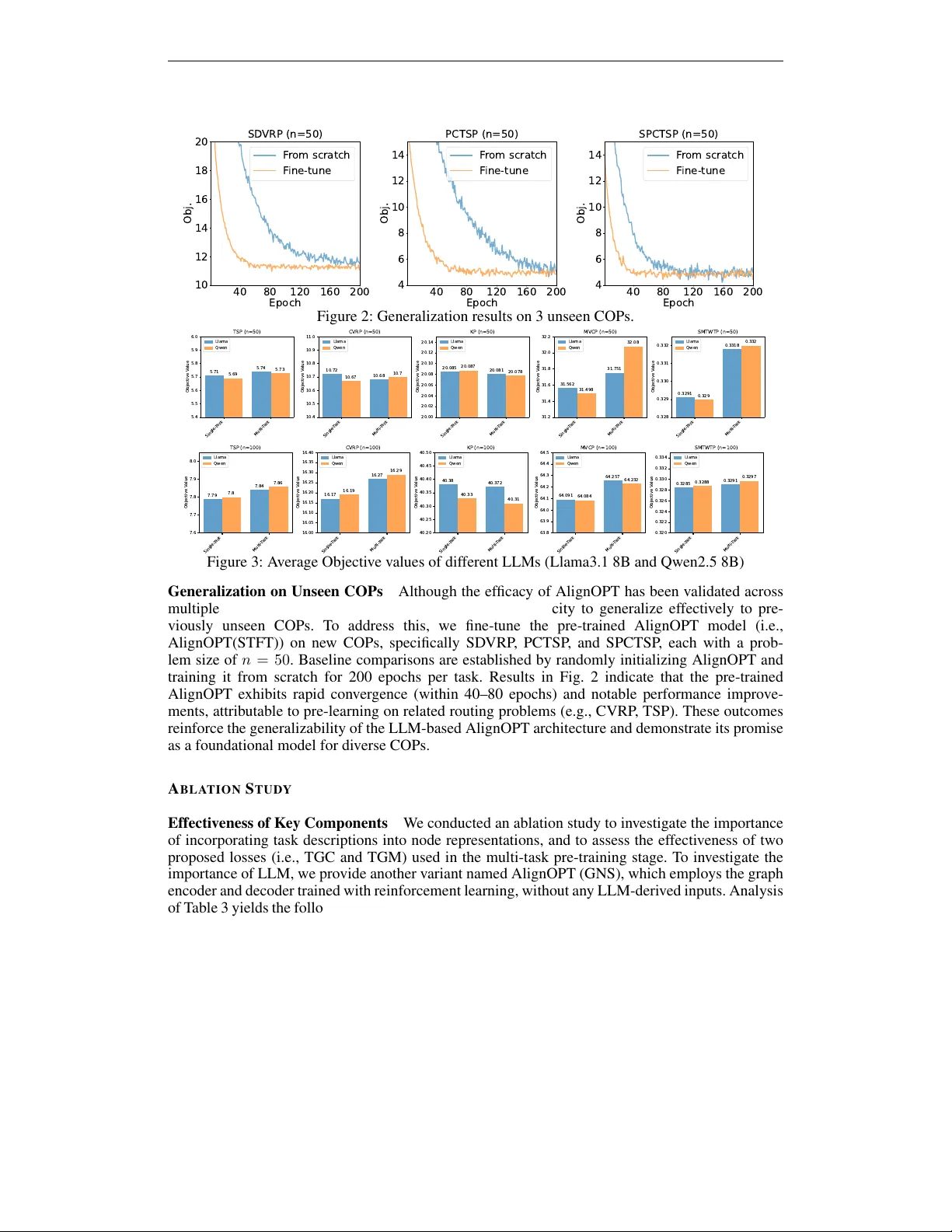
A L I G N I N G L L M S W I T H G R A P H N E U R A L S O L V E R S F O R C O M B I N A T O R I A L O P T I M I Z A T I O N Shaodi Feng 1 , Zhuoyi Lin 2 † , Y aoxin W u 3 , Haiyan Y in 4 , Y an Jin 5 , Senthilnath Jaya velu 2 , 6 , Xun Xu 2 1 National Y ang Ming Chiao T ung University 2 Institute for Infocomm Research (I 2 R), A*ST AR 3 Eindhov en Univ ersity of T echnology Eindhov en 4 Centre for Frontier AI Research, A*ST AR 5 Huazhong Univ ersity of Science and T echnology 6 National Univ ersity of Singapore A B S T R A C T Recent research has demonstrated the ef fectiv eness of large language models (LLMs) in solving combinatorial optimization problems (COPs) by represent- ing tasks and instances in natural language. Howe ver , purely language-based ap- proaches struggle to accurately capture complex relational structures inherent in many COPs, rendering them less effecti ve at addressing medium-sized or larger instances. T o address these limitations, we propose AlignOPT , a nov el approach that aligns LLMs with graph neural solvers to learn a more generalizable neural COP heuristic. Specifically , AlignOPT lev erages the semantic understanding ca- pabilities of LLMs to encode textual descriptions of COPs and their instances, while concurrently exploiting graph neural solvers to explicitly model the under- lying graph structures of COP instances. Our approach facilitates a rob ust inte gra- tion and alignment between linguistic semantics and structural representations, enabling more accurate and sca lable COP solutions. Experimental results demon- strate that AlignOPT achieves state-of-the-art results across div erse COPs, un- derscoring its effecti veness in aligning semantic and structural representations. In particular , AlignOPT demonstrates strong generalization, ef fecti vely e xtending to previously unseen COP instances. I N T R O D U C T I O N Combinatorial optimization problems (COPs), which in volv e finding optimal solutions from finite sets of objects, underpin numerous real-world applications in logistics, scheduling, and network design (Bengio et al., 2021). T ypical COPs, such as the T raveling Salesman Problem (TSP), V ehi- cle Routing Problem (VRP), and Knapsack Problem (KP), are notoriously challenging due to their NP-hard nature, requiring ef ficient heuristic or meta-heuristic solutions (W ang & Sheu, 2019; K on- stantakopoulos et al., 2022; Lin et al., 2024). T raditionally , COPs have been approached through exact optimization methods and domain-specific heuristics. Howe ver , these methods often require extensi ve domain knowledge and manual tuning, making them less adaptable to ne w problem vari- ants or different application conte xts. Recent studies indicate that large language models (LLMs) have emer ged as po werful and versatile tools for tackling a div erse range of COPs. By framing COPs within natural language descriptions, LLM-based methods hav e demonstrated initial success in automatically solving optimization prob- lems. Ne vertheless, despite these advancements, the current capability of LLMs to directly generate solutions remains primarily restricted to relativ ely small-scale problem instances, such as TSP with fewer than 30 nodes (Y ang et al., 2023; Iklasso v et al., 2024). In addition, existing LLM-based solutions still encounter inherent limitations when addressing COPs characterized by complex un- derlying structures, particularly graph problems (Cappart et al., 2023; Bengio et al., 2021; Drakulic † Corresponding author . 1 et al., 2024). Pure language models inherently lack e xplicit structural reasoning capabilities, making it difficult for them to ef fectiv ely capture and represent intricate relational information in graphs. Consequently , these limitations can significantly de grade solution optimality and ov erall quality , substantially limiting the applicability of LLM-driven approaches in realistic, large-scale settings, particularly in fields such as logistics, transportation, and supply chain management, where typical problem instances in volv e hundreds to thousands of nodes (Bengio et al., 2021). T o address these challenges, we propose AlignOPT , a novel frame work designed to integrate the complementary capabilities of LLMs and graph-based neural solvers for COPs. Specifically , LLMs provide robust semantic understanding and fle xible representation of natural language instructions, while graph-based neural solv ers explicitly capture relational structures and topological dependen- cies inherent in COP instances. T o ef fectiv ely align these two modalities, AlignOPT introduces a multi-task pre-training strate gy comprising two novel objecti ves: (1) a T ext-Graph Contrastive (TGC) loss, designed to align semantic node embeddings from LLMs with structural embeddings from graph-based neural solvers, and (2) a T ext-Graph Matching (TGM) loss, facilitating fine- grained multimodal node representation. By jointly optimizing these objecti ves, AlignOPT pro- duces unified representations that enhance the accuracy and richness of COP embeddings. In this way , AlignOPT leverages guidance from LLMs exclusi vely during the pre-training stage to embed optimization kno wledge into the graph neural solver (encoder). In the fine-tuning stage, AlignOPT fine-tunes the graph encoder along with a decoder trained via reinforcement learning to learn ef- fectiv e optimization policy . Consequently , AlignOPT utilizes only the graph encoder and decoder for inference, processing inputs directly as graphs without relying on textual input or an LLM. This approach significantly reduces inference overhead and enhances computational ef ficiency , enabling AlignOPT to achiev e superior generalization and solution quality across di verse COPs. Overall, the main contrib utions of this work to the COPs research can be summarized as follo ws. • W e introduce a nov el frame work AlignOPT , that explicitly aligns LLMs with graph- based neural solvers , bridging the gap between semantic and structural representations in COPs and mo ving be yond the single-modality reliance of current LLM-based models. AlignOPT performs multi-task pre-training across diverse text-attributed COPs , fa- cilitating a more informative encoding process and subsequent fine-tuning. This enables the generation of ef fectiv e and unified solutions for various COPs and adapts ef ficiently to unseen COPs without further reliance on LLMs during inference. • Extensi ve e xperiments on synthetic COP instances and real-world benchmarks demonstrate the effecti veness of our proposed AlignOPT , achie ving high performance gains over state- of-the-art solvers. R E L A T E D W O R K Neural Combinatorial Optimization Constructiv e neural combinatorial optimization (NCO) methods aim to learn policies that iteratively construct solutions in an autoregressi ve manner . Early approaches primarily emplo yed pointer networks (V inyals et al., 2015; Bello et al., 2016), a class of recurrent neural networks (RNNs) that encode inputs and generate outputs through a sequence-to- sequence frame work. Building on the T ransformer architecture (V aswani et al., 2017), the Attention Model (AM) (Kool et al., 2018) was subsequently dev eloped to address vehicle routing problems (VRPs), demonstrating superior performance compared to traditional heuristic methods. Following this, various strategies hav e been proposed to further improve T ransformer-based NCO models by exploiting the inherent symmetries in combinatorial optimization problems (COPs) (Kwon et al., 2020; Kim et al., 2022; Fang et al., 2024) and incorporating efficient acti ve search techniques (Hot- tung et al., 2021; Choo et al., 2022; Qiu et al., 2022). More recently , some work extends constructive NCO to be one-for -all solv ers aiming at multiple COPs by a single model (Zhou et al., 2024; Zheng et al., 2024; Berto et al.; Drakulic et al., 2024; Li et al.). Howe ver , they are constrained by specific problem structures, such as vehicle routing, which limits their representational scope and under- mines the model’ s learning capacity . In contrast, our AlignOPT delves into general text-attributed COPs described in natural language. Lev eraging the unified semantic representations inherent in LLMs, AlignOPT enables a general model to accommodate a wide range of COPs. Compared with GO AL (Drakulic et al., 2024) which proposes a unified encoder that is trained with supervised fine- tuning. AlignOPT goes further by 1). Explicitly aligning this encoder with structured optimization 2 insights derived from LLMs during pre-training. 2) Perform multi-task fine-tuning with reinforce- ment learning, ensuring superior generalization across diverse routing tasks during the fine-tuning stage. These enhancements e xplicitly encode generalized optimization reasoning from LLMs, en- abling the model to robustly generalize to di verse routing problems encountered in practice. LLM for Combinatorial Optimization Recent research on the application of LLMs to COPs has demonstrated promising and impactful results. As early attempts, LLMs operate as black-box solvers that either directly generate feasible solutions with natural language problem descriptions (Abgaryan et al., 2024) or iterativ ely refine initial solutions through guided search mechanisms (Y ang et al., 2023; Liu et al., 2024b). Notably , recent findings indicate that LLMs often exhibit lim- ited generalization capabilities, tending instead to replicate memorized patterns from training data rather than performing robust, adaptable reasoning (Zhang et al., 2024; Iklassov et al., 2024). On the other hand, LLMs can be tasked with generating e xecutable code that implements heuristic al- gorithms for solving COPs (Romera-Paredes et al., 2024; Liu et al., 2024a; Y e et al., 2024). By initializing a code template, LLMs iterativ ely refine algorithmic heuristics through an e volutionary process. While this approach demonstrates promising flexibility , it often requires substantial domain expertise and incurs high token usage for each specific problem instance. The most relev ant w ork to us is LNCS (Jiang et al., 2024), which integrates LLMs with NCO model to unify the solution process across multiple COPs. Howe ver , LNCS sequentially utilizes LLMs and T ransformer archi- tectures, resulting in a notable modality gap when compared to specialized neural solvers designed explicitly for COPs. Moreov er , LNCS heavily depends on the inference ef ficiency of LLMs, which is frequently constrained by significant computational requirements and limited conte xt lengths, thus restricting their scalability when inference on large-scale COPS. Instead, we propose AlignOPT to align LLMs, adept at semantic understanding, with graph-based neural solv ers, proficient in captur- ing structural information, aiming to enhance solution quality and generalization capabilities. Note that after pre-training of AlignOPT , LLMs are no longer required during the fine-tuning and infer- ence stages. This allows inference to be performed rapidly without the latency or cost associated with real-time LLM queries, significantly enhancing practical usability , scalability , and deployment feasibility . P R E L I M I N A R I E S Combinatorial Optimization Pr oblems Solving COPs in volv es identifying the optimal solution from a finite set of feasible candidates. Such problems are defined by their discrete nature, with solutions commonly represented as integers, sets, graphs, or sequences (Blum & Roli, 2003). Most COPs can be defined over a graph G with nodes and edges. Specifically , a COP P = ( S, f ) can be formulated as follows: min X f ( X , P ) s.t. c j ( X, P ) ≤ 0 , j = 0 , 1 , . . . , J. (1) where X = { x i ∈ D i | i = 1 , . . . , n } is a set of discrete variables; f ( X , P ) indicates the objectiv e function of COP and c ( X , P ) denotes the problem-specific constraints for the v ariable X . Note that typical COPs (e.g., TSP , CVRP , KP) are NP-hard problems. As a result, identifying the optimal solution s ∗ is computationally intractable in man y practical scenarios. Therefore, a more tractable approach inv olves searching for a set of feasible solutions S rather than stri ving for e xact optimality . The set S is formally defined as: S = { s = { ( x 1 , v 1 ) , . . . , ( x n , v n ) } | v i ∈ D i , c ( X, P ) ≤ 0 } . (2) where a solution s satisfies f ( s, P ) ≥ f ( s ∗ , P ) , ∀ s ∈ S . Neural Construction Heuristics for COPs Learning construction heuristics has become a widely adopted paradigm for addressing V ehicle Routing Problems (VRPs) (Bello et al., 2016; K ool et al., 2018; Kwon et al., 2020). In this framework, solutions are constructed incrementally by sequentially selecting valid nodes, a process effecti vely modeled as a Markov Decision Process (MDP). At each step, the agent observes a state composed of the problem instance and the current partial solution, and selects a valid node from the remaining candidates. This process continues iterativ ely until a complete and feasible solution is obtained. 3 Task Descriptio n : For a travel salesman problem (TSP), there wi ll be a li st of node s di stributed in a unit square, representing a series of cities … Instance Descr iption : Node (0). Attribution : [0. 6184 , 0. 8962 ]. The 3 nearest nodes and distances : [( 17 ): 0. 1067 , (6): 0. 1451 , (7): 0. 2120 ] ; Node (1). : … Task Des cription : For a knapsack probl em (KP), there will be a list of nodes distributed in an unit square, representing a series of items … Instance Description : Node (0). Attribution : [0. 2667 , 0. 9909 ]. Value - to - weight ratio and importance rank : [3. 7151 , 7]; Node (1). Attribution : [0. 6706 , 0. 1806 ]… LLM Unified Decoder Graph - based Encoder … (a) Pre - training with TGM a nd TGC Graph - based Encoder (b) Fine - tu ning w ithout L LM Codebook Mixed A ttention Add & Norm Feed Forward Output Adapter Add & Norm Input Adapter 𝑸 𝒎 + 𝑸 𝒎𝒏 # 𝑲 𝒎 + 𝑲 𝒎𝒏 # 𝑽 𝒎 MatMul SoftMax MatMul (c) Graph - based Encoder × L × H One - hot COP Representation Constraints Vector First N ode Selected Node 𝒉 𝒙 𝒉 𝒈 𝒉 𝒈 COP Instan ce COP Instan ce TGM los s TGC los s Figure 1: Overall workflow of AlignOPT . (a) AlignOPT first performs multi-task pretraining on div erse COPs to align semantic and structural node representations with TGC and TGM losses. The LLM remains frozen and processes the T AIs to generate semantic node representations. (b) The encoder and decoder are then fine-tuned through reinforcement learning to solve COPs. Notably , LLMs are e xcluded during this phase to ensure computational efficienc y , as the encoder has already been aligned with LLM-deriv ed representations during pre-training. (c) The model architecture of the graph-based encoder , which applies a mixed attention mechanism that enables handling COPs represented by graphs. The solution construction policy is typically parameterized by a neural network, such as a Long Short-T erm Memory (LSTM) or T ransformer, denoted by θ . At each decision step, the polic y in- fers a probability distribution over the valid nodes, from which one is sampled and appended to the partial solution. The ov erall probability of generating a tour π is then factorized as p θ ( π |G ) = Q T t =1 p θ ( π t |G , π 30 ) by leveraging the structural information inherently embedded in their formulations. 7 TSP Method n = 20 n = 50 n = 100 Obj. Gap T ime Obj. Gap T ime Obj. Gap T ime LKH3 3.85 0.00% 0.05s 5.69 2.80% 0.26s 7.76 0.00% 2.05s OR tools 3.85 0.00% 0.36s 5.87 3.07% 0.60s 8.13 4.77% 1.32s Nearest neighbor 3.91 1.45% 0.06s 5.89 3.51% 0.03s 9.69 24.87% 0.10s Farthest insertion 3.96 2.89% 0.21s 5.98 4.97% 4.73s 8.21 5.80% 126s A CO 3.94 2.23% 0.74s 6.54 14.54% 1.53s 9.99 28.74% 2.01s LNCS 3.87 0.55% 0.31s 5.79 1.64% 0.49s 8.10 4.38% 0.81s GOAL 3.86 0.26% 0.012s 5.76 1.23% 0.018s 7.98 2.84% 0.028s AlignOPT(MTFT) 3.85 0.00% 0.048s 5.74 0.53% 0.082s 7.84 1.03% 0.165s AlignOPT(STFT) 3.85 0.00% 0.048s 5.71 0.35% 0.082s 7.79 0.38% 0.165s CVRP HGS 6.10 0.00% 0.2s 10.36 0.00% 0.6s 15.49 0.00% 2.22s OR tools 6.18 1.30% 0.27s 11.05 6.63% 0.48s 17.36 12.07% 1.40s Sweep heuristic 7.51 23.17% 0.01s 15.65 50.95% 0.05s 28.40 83.39% 0.25s Parallel saving 6.33 3.85% < 0.01s 10.90 5.18% < 0.01s 16.42 6.03% 0.03s A CO 7.72 26.56% 0.80s 15.76 52.12% 1.97s 26.66 72.11% 4.90s LNCS 6.25 2.51% 0.315s 10.74 3.62% 0.495s 16.35 5.59% 0.820s GOAL 6.20 1.50% 0.013s 10.73 3.55% 0.019s 16.30 5.30% 0.029s AlignOPT(MTFT) 6.18 1.31% 0.051s 10.72 3.47% 0.087s 16.27 5.048% 0.172s AlignOPT(STFT) 6.13 0.49% 0.051s 10.68 3.09% 0.087s 16.17 4.39% 0.172s KP OR tools 7.948 0.00% < 0.01s 20.086 0.00% < 0.01s 40.377 0.00% < 0.01s Greedy policy 7.894 0.67% < 0.01s 20.033 0.26% < 0.01s 40.328 0.12% < 0.01s A CO 7.947 0.00% 0.72s 20.053 0.15% 2.19s 40.124 0.62% 3.41s LNCS 7.939 0.10% 0.308s 20.071 0.06% 0.485s 40.361 0.03% 0.800s GOAL 7.941 0.09% 0.012s 20.078 0.04% 0.017s 40.370 0.11% 0.027s AlignOPT(MTFT) 7.942 0.08% 0.049s 20.081 0.03% 0.084s 40.372 0.12% 0.168s AlignOPT(STFT) 7.948 0.00% 0.049s 20.085 0.00% 0.084s 40.380 0.00% 0.168s MVCP Gurobi 11.95 0.00% < 0.01s 28.812 0.00% 0.01s 56.191 0.00% 0.02s MVCApprox 14.595 22.13% < 0.01s 34.856 20.98% < 0.01s 68.313 21.57% < 0.01s REH 16.876 41.22% < 0.01s 41.426 43.78% < 0.01s 81.860 45.68% < 0.01s LNCS 12.900 7.93% 0.310s 32.101 11.42% 0.485s 64.893 15.49% 0.800s GOAL 12.750 6.50% 0.012s 31.800 10.40% 0.017s 64.300 14.50% 0.026s AlignOPT(MTFT) 12.703 6.30% 0.048s 31.751 10.20% 0.081s 64.257 14.35% 0.163s AlignOPT(STFT) 12.597 5.41% 0.048s 31.562 9.54% 0.081s 64.091 14.06% 0.163s SMTWTP Gurobi 0.1017 0.00% 0.02s 0.2148 0.00% < 0.01s 0.2438 0.00% 0.35s A CO 0.2967 191.74% 0.35s 1.0471 387.48% 1.35s 6.77 2677% 2.00s LNCS 0.2862 181.41% 0.315s 0.3353 56.10% 0.492s 0.3316 36.01% 0.815s GOAL 0.2848 179.50% 0.013s 0.3335 55.20% 0.019s 0.3298 35.20% 0.029s AlignOPT(MTFT) 0.2835 64.12% 0.052s 0.3328 35.45% 0.089s 0.3291 25.919% 0.175s AlignOPT(STFT) 0.2829 64.05% 0.052s 0.3318 35.26% 0.089s 0.3285 25.78% 0.175s T able 2: Performance comparison on 1K instances. AlignOPT(MTFT) denotes multi-task fine- tuning on di verse COPs, while AlignOPT(STFT) refers to fine-tuning on the target COP . Obj. indi- cates the av erage objectiv e v alues. LNCS uses LLM Encoder + T ransformer Decoder , GO AL uses GNN only , and AlignOPT uses GNN + T ransformer Decoder . Comparison with T raditional and NCO solvers W e present the experimental comparison be- tween AlignOPT and baselines in T able 2. Overall, AlignOPT consistently achiev es competitiv e performance across v arious problem sizes ( n = 20 , 50 , 100 ). Specifically , AlignOPT(STFT), which fine-tunes on task-specific instances, demonstrates superior or comparable results to all baseline methods. F or instance, in TSP , AlignOPT(STFT) achie ves the lo west objecti ve values at all sizes, closely matching the state-of-the-art solver LKH3 and significantly outperforming classical heuris- tics such as Nearest Neighbor and Farthest Insertion, as well as the LNCS baseline. In CVRP , AlignOPT(STFT) substantially outperforms heuristics like Sweep and Parallel Saving, deli vering objectiv e values closely aligned with HGS, the leading solver . For KP , AlignOPT(STFT) achie ves optimal solutions on par with OR tools and keeps outperforming heuristic methods and LNCS. Notably , classical optimization solv ers such as Gurobi consistently perform best for MVCP and SMTWTP , yet AlignOPT(STFT) significantly narro ws the performance gap compared to heuristic methods and the LNCS baseline. Specifically , for MVCP at n = 100 , AlignOPT(STFT) achieves a 14.06% gap, improving ov er REH (45.68%) by 31.62% and slightly outperforming LNCS (15.49%). At n = 50 , it further reduces the gap to 9.54%, compared to REH’ s 43.78% and LNCS’ s 11.42%. For SMTWTP , where A CO struggles to produce feasible solutions across all scales, AlignOPT(STFT) consistently outperforms LNCS, achieving gaps of 25.78%, 35.26%, and 64.05% at n = 100 , 50, and 20, respectiv ely , compared to LNCS’ s 36.01%, 56.10%, and 181.41%. These results underscore AlignOPT’ s rob ust performance and its capability to generalize effecti vely across di verse tasks. AlignOPT (particularly STFT variant) consistently outperforms GO AL across all tested combina- torial optimization problems, while maintaining comparable computational efficiency , with STFT demonstrating superior balance between solution quality and speed. 8 40 80 120 160 200 Epoch 10 12 14 16 18 20 Obj. SD VRP (n=50) F r om scratch F ine-tune 40 80 120 160 200 Epoch 4 6 8 10 12 14 Obj. PCTSP (n=50) F r om scratch F ine-tune 40 80 120 160 200 Epoch 4 6 8 10 12 14 Obj. SPCTSP (n=50) F r om scratch F ine-tune Figure 2: Generalization results on 3 unseen COPs. Single- T ask Multi- T ask 5.4 5.5 5.6 5.7 5.8 5.9 6.0 Objective V alue 5.71 5.74 5.69 5.73 TSP (n=50) Llama Qwen Single- T ask Multi- T ask 10.4 10.5 10.6 10.7 10.8 10.9 11.0 Objective V alue 10.72 10.68 10.67 10.7 CVRP (n=50) Llama Qwen Single- T ask Multi- T ask 20.00 20.02 20.04 20.06 20.08 20.10 20.12 20.14 Objective V alue 20.085 20.081 20.087 20.078 KP (n=50) Llama Qwen Single- T ask Multi- T ask 31.2 31.4 31.6 31.8 32.0 32.2 Objective V alue 31.562 31.751 31.498 32.08 MVCP (n=50) Llama Qwen Single- T ask Multi- T ask 0.328 0.329 0.330 0.331 0.332 Objective V alue 0.3291 0.3318 0.329 0.332 SMTWTP (n=50) Llama Qwen Single- T ask Multi- T ask 7.6 7.7 7.8 7.9 8.0 Objective V alue 7.79 7.84 7.8 7.86 TSP (n=100) Llama Qwen Single- T ask Multi- T ask 16.00 16.05 16.10 16.15 16.20 16.25 16.30 16.35 16.40 Objective V alue 16.17 16.27 16.19 16.29 CVRP (n=100) Llama Qwen Single- T ask Multi- T ask 40.20 40.25 40.30 40.35 40.40 40.45 40.50 Objective V alue 40.38 40.372 40.33 40.31 KP (n=100) Llama Qwen Single- T ask Multi- T ask 63.8 63.9 64.0 64.1 64.2 64.3 64.4 64.5 Objective V alue 64.091 64.257 64.084 64.232 MVCP (n=100) Llama Qwen Single- T ask Multi- T ask 0.320 0.322 0.324 0.326 0.328 0.330 0.332 0.334 Objective V alue 0.3285 0.3291 0.3288 0.3297 SMTWTP (n=100) Llama Qwen Figure 3: A verage Objecti ve values of dif ferent LLMs (Llama3.1 8B and Qwen2.5 8B) Generalization on Unseen COPs Although the ef ficacy of AlignOPT has been v alidated across multiple COPs, an important consideration remains its capacity to generalize ef fecti vely to pre- viously unseen COPs. T o address this, we fine-tune the pre-trained AlignOPT model (i.e., AlignOPT(STFT)) on new COPs, specifically SDVRP , PCTSP , and SPCTSP , each with a prob- lem size of n = 50 . Baseline comparisons are established by randomly initializing AlignOPT and training it from scratch for 200 epochs per task. Results in Fig. 2 indicate that the pre-trained AlignOPT exhibits rapid con vergence (within 40–80 epochs) and notable performance impro ve- ments, attributable to pre-learning on related routing problems (e.g., CVRP , TSP). These outcomes reinforce the generalizability of the LLM-based AlignOPT architecture and demonstrate its promise as a foundational model for div erse COPs. A B L AT I O N S T U D Y Effectiveness of K ey Components W e conducted an ablation study to in vestigate the importance of incorporating task descriptions into node representations, and to assess the effecti veness of two proposed losses (i.e., TGC and TGM) used in the multi-task pre-training stage. T o in vestigate the importance of LLM, we provide another variant named AlignOPT (GNS), which emplo ys the graph encoder and decoder trained with reinforcement learning, without any LLM-deriv ed inputs. Analysis of T able 3 yields the following insights: (1) The substantially lower performance of AlignOPT(GNS) demonstrates that structural reasoning alone (without LLM inputs) cannot account for the improve- ments achie ved by the full model (i.e., AlignOPT(STFT)). (2) Incorporating task descriptions k P into node representations from LLMs consistently improv es the model’ s performance. For example, on TSP with problem size 100, AlignOPT(STFT) achieved an objectiv e v alue of 7.79 compared to 7.87 (w/o T ask Rep.). (3) Both proposed losses, TGC and TGM, play critical roles during the pre-training stage. Specifically , removing either loss individually (w/o TGC or w/o TGM) leads to notably higher objectiv e values and optimality gaps, such as the increase from 5.71 to 6.33 for the TGC loss ablation in TSP size 50. (4) The combined application of the abov e components (i.e., AlignOPT(STFT)) consistently yields the best performance across v arious COPs and problem sizes, underscoring the effecti veness and complementary nature of these components in AlignOPT’ s pre- training process. These findings collectively v alidate the significance of each proposed component in AlignOPT , highlighting their contrib utions to enhancing model performance and generalization capabilities. 9 TSP Method n = 20 n = 50 n = 100 Obj. Gap Time Obj. Gap T ime Obj. Gap T ime AlignOPT (GNS) 4.02 4.41% 0.048s 6.33 11.24% 0.082s 8.37 7.86% 0.165s AlignOPT (w/o TGC) 3.96 2.86% 0.048s 6.18 8.24% 0.082s 8.22 5.52% 0.165s AlignOPT (w/o T ask Rep.) 3.85 0.00% 0.048s 5.76 0.70% 0.082s 7.87 4.38% 0.165s AlignOPT (w/o TGM) 3.85 0.00% 0.048s 5.77 0.52% 0.082s 7.89 0.64% 0.165s AlignOPT(STFT) 3.85 0.00% 0.048s 5.71 0.35% 0.082s 7.79 0.38% 0.165s CVRP AlignOPT (GNS) 6.88 12.79% 0.051s 11.21 8.20% 0.087s 17.11 10.46% 0.172s AlignOPT (w/o TGC) 6.75 10.12% 0.051s 11.05 6.45% 0.087s 16.89 8.24% 0.172s AlignOPT (w/o T ask Rep.) 6.21 0.49% 0.051s 10.73 0.10% 0.087s 16.29 0.13% 0.172s AlignOPT (w/o TGM) 6.19 0.16% 0.051s 10.74 0.18% 0.087s 16.30 0.18% 0.172s AlignOPT(STFT) 6.13 0.49% 0.051s 10.68 3.09% 0.087s 16.17 4.39% 0.172s KP AlignOPT (GNS) 7.552 4.98% 0.049s 19.274 4.04% 0.084s 38.850 3.78% 0.168s AlignOPT (w/o TGC) 7.648 3.77% 0.049s 19.582 2.50% 0.084s 39.425 2.36% 0.168s AlignOPT (w/o T ask Rep.) 7.941 0.11% 0.049s 20.082 0.01% 0.084s 40.375 0.01% 0.168s AlignOPT (w/o TGM) 7.942 0.08% 0.049s 20.081 0.02% 0.084s 40.372 0.02% 0.168s AlignOPT(STFT) 7.948 0.00% 0.049s 20.085 0.00% 0.084s 40.380 0.00% 0.168s MVCP AlignOPT (GNS) 13.410 10.88% 0.048s 34.078 15.45% 0.081s 66.399 15.37% 0.163s AlignOPT (w/o TGC) 13.125 8.52% 0.048s 33.245 12.65% 0.081s 65.782 12.89% 0.163s AlignOPT (w/o T ask Rep.) 12.741 0.30% 0.048s 31.907 0.49% 0.081s 64.438 0.28% 0.163s AlignOPT (w/o TGM) 12.731 0.22% 0.048s 31.872 0.38% 0.081s 64.398 0.22% 0.163s AlignOPT(STFT) 12.597 5.41% 0.048s 31.562 9.54% 0.081s 64.091 14.06% 0.163s SMTWTP AlignOPT (GNS) 0.2954 65.57% 0.052s 0.3550 39.49% 0.089s 0.3469 29.72% 0.175s AlignOPT (w/o TGC) 0.2912 63.25% 0.052s 0.3485 36.78% 0.089s 0.3412 27.45% 0.175s AlignOPT (w/o T ask Rep.) 0.2843 0.28% 0.052s 0.3335 0.21% 0.089s 0.3295 0.12% 0.175s AlignOPT (w/o TGM) 0.2839 0.14% 0.052s 0.3332 0.12% 0.089s 0.3296 0.15% 0.175s AlignOPT(STFT) 0.2829 64.05% 0.052s 0.3318 35.26% 0.089s 0.3285 25.78% 0.175s T able 3: Ablation studies of key designs across 1K instances for 5 representati ve COPs. Analysis of Different LLMs T o inv estigate the influence of different LLMs on AlignOPT during the pre-training stage, we conducted a comparativ e analysis between Llama3.1 8B and Qwen2.5 8B, focusing on problem sizes 50 and 100 under both single-task and multi-task fine-tuning scenarios. As shown in Fig. 3, Qwen slightly outperforms Llama on all fiv e COPs at size 50 in single-task scenarios, while Llama demonstrates better performance on multi-task KP , CVRP , and SMTWTP scenarios. For the larger size 100 instances, Llama consistently achiev es better results on TSP , and CVRP across both scenarios. Con versely , Qwen notably excels at MVCP and SMTWTP for both single-task and multi-task scenarios at size 100. These results suggest that model performance de- pends significantly on the specific COP , problem size, and fine-tuning strategy . C O N C L U S I O N S In this work, we propose AlignOPT , a nov el frame work that addresses the limitations of LLM- only approaches, which struggle to accurately capture the complex relational structures of COPs. By combining the semantic understanding of LLMs with the relational modeling capabilities of graph-based neural solv ers, AlignOPT ef fectiv ely aligns textual descriptions with structural repre- sentations. Extensi ve experiments show that AlignOPT consistently achie ves state-of-the-art perfor- mance. Ablation studies further v alidate the ke y design components, highlighting the effecti veness of our multi-task alignment strategy . Moreover , AlignOPT demonstrates strong generalization, suc- cessfully solving previously unseen COP instances with minimal fine-tuning and without further reliance on LLMs. Future work will focus on refining the alignment mechanisms between LLMs and graph-based solvers, particularly through dynamic integration during inference, to further en- hance adaptability and performance. R E F E R E N C E S Henrik Abgaryan, Ararat Harutyunyan, and T ristan Cazenave. Llms can schedule. arXiv pr eprint arXiv:2408.06993 , 2024. Reuven Bar-Y ehuda and Shimon Even. A local-ratio theorem for approximating the weighted v ertex cov er problem. In North-Holland Mathematics Studies , volume 109, pp. 27–45. Else vier, 1985. Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning. arXiv pr eprint arXiv:1611.09940 , 2016. 10 Y oshua Bengio, Andrea Lodi, and Antoine Prouv ost. Machine learning for combinatorial opti- mization: a methodological tour d’horizon. European Journal of Operational Resear ch , 290(2): 405–421, 2021. Federico Berto, Chuanbo Hua, Nayeli Gast Zepeda, Andr ´ e Hottung, Niels W ouda, Leon Lan, Ke vin T ierney , and Jinkyoo Park. Routefinder: T owards foundation models for vehicle routing problems. In ICML 2024 W orkshop on F oundation Models in the W ild . Christian Blum and Andrea Roli. Metaheuristics in combinatorial optimization: Overvie w and con- ceptual comparison. A CM computing surve ys (CSUR) , 35(3):268–308, 2003. Quentin Cappart, Didier Ch ´ etelat, Elias B Khalil, Andrea Lodi, Christopher Morris, and Petar V eli ˇ ckovi ´ c. Combinatorial optimization and reasoning with graph neural netw orks. Journal of Machine Learning Resear ch , 24(130):1–61, 2023. T ing Chen, Simon K ornblith, Mohammad Norouzi, and Geoffre y Hinton. A simple framework for contrastiv e learning of visual representations. In International confer ence on mac hine learning , pp. 1597–1607. PmLR, 2020. Jinho Choo, Y eong-Dae Kw on, Jihoon Kim, Jeongwoo Jae, Andr ´ e Hottung, K e vin Tierne y , and Y oungjune Gwon. Simulation-guided beam search for neural combinatorial optimization. Ad- vances in Neural Information Pr ocessing Systems , 35:8760–8772, 2022. Darko Drakulic, Sofia Michel, and Jean-Marc Andreoli. Goal: A generalist combinatorial optimiza- tion agent learner . arXiv pr eprint arXiv:2406.15079 , 2024. Han F ang, Zhihao Song, Paul W eng, and Y utong Ban. In vit: A generalizable routing problem solver with in v ariant nested view transformer . arXiv preprint , 2024. Andr ´ e Hottung, Y eong-Dae Kwon, and Ke vin Tierne y . Efficient activ e search for combinatorial optimization problems. arXiv pr eprint arXiv:2106.05126 , 2021. Zangir Iklassov , Y ali Du, Farkhad Akimo v , and Martin T akac. Self-guiding exploration for com- binatorial problems. Advances in Neural Information Pr ocessing Systems , 37:130569–130601, 2024. James R Jackson. Scheduling a production line to minimize maximum tardiness. 1955. Xia Jiang, Y aoxin W u, Y uan W ang, and Y ingqian Zhang. Bridging large language models and optimization: A unified framework for text-attrib uted combinatorial optimization. arXiv pr eprint arXiv:2408.12214 , 2024. Minsu Kim, Junyoung Park, and Jink yoo Park. Sym-nco: Lev eraging symmetricity for neural com- binatorial optimization. Advances in Neural Information Pr ocessing Systems , 35:1936–1949, 2022. Grigorios D Konstantakopoulos, Sotiris P Gayialis, and Evripidis P Kechagias. V ehicle routing problem and related algorithms for logistics distribution: A literature re view and classification. Operational r esearc h , 22(3):2033–2062, 2022. W outer Kool, Herke V an Hoof, and Max W elling. Attention, learn to solv e routing problems! arXiv pr eprint arXiv:1803.08475 , 2018. Y eong-Dae Kwon, Jinho Choo, Byoungjip Kim, Iljoo Y oon, Y oungjune Gw on, and Seungjai Min. Pomo: Policy optimization with multiple optima for reinforcement learning. Advances in Neural Information Pr ocessing Systems , 33:21188–21198, 2020. Han Li, Fei Liu, Zhi Zheng, Y u Zhang, and Zhenkun W ang. Cada: Cross-problem routing solver with constraint-aware dual-attention. In F orty-second International Confer ence on Machine Learning . Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre- training for unified vision-language understanding and generation. In International conference on machine learning , pp. 12888–12900. PMLR, 2022. 11 Zhuoyi Lin, Y aoxin W u, Bangjian Zhou, Zhiguang Cao, W en Song, Y ingqian Zhang, and Senthilnath Jayav elu. Cross-problem learning for solving vehicle routing problems. In Proceedings of the Thirty-Thir d International J oint Confer ence on Artificial Intelligence , pp. 6958–6966, 2024. Fei Liu, Xialiang T ong, Mingxuan Y uan, and Qingfu Zhang. Algorithm e volution using large lan- guage model. arXiv pr eprint arXiv:2311.15249 , 2023. Fei Liu, Xialiang T ong, Mingxuan Y uan, Xi Lin, Fu Luo, Zhenkun W ang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: to wards ef ficient automatic algorithm design using large language model. In Pr oceedings of the 41st International Conference on Machine Learning , ICML ’24. JMLR.org, 2024a. Shengcai Liu, Caishun Chen, Xinghua Qu, Ke T ang, and Y ew-Soon Ong. Large language models as ev olutionary optimizers. In 2024 IEEE Congress on Evolutionary Computation (CEC) , pp. 1–8. IEEE, 2024b. Leonard Brian Pitt. A simple pr obabilistic appr oximation algorithm for vertex cover . Y ale Univ er- sity , Department of Computer Science, 1985. Ruizhong Qiu, Zhiqing Sun, and Y iming Y ang. Dimes: A dif ferentiable meta solver for combina- torial optimization problems. Advances in Neural Information Processing Systems , 35:25531– 25546, 2022. Jussi Rasku, T ommi K ¨ arkk ¨ ainen, and Nysret Musliu. Meta-survey and implementations of classical capacitated v ehicle routing heuristics with reproduced results. T owar d A utomatic Customization of V ehicle Routing Systems , pp. 133–260, 2019. Bernardino Romera-P aredes, Mohammadamin Barekatain, Alexander Noviko v , Matej Balog, M Pawan Kumar , Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming W ang, Omar Fa wzi, et al. Mathematical discoveries from program search with large language models. Natur e , 625(7995):468–475, 2024. Ashish V aswani, Noam Shazeer, Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. Attention is all you need. Advances in neural information pr ocessing systems , 30, 2017. Oriol V inyals, Meire F ortunato, and Navdeep Jaitly . Pointer networks. Advances in neural informa- tion pr ocessing systems , 28, 2015. Zheng W ang and Jiuh-Biing Sheu. V ehicle routing problem with drones. T ransportation r esear ch part B: methodological , 122:350–364, 2019. Ronald J Williams. Simple statistical gradient-follo wing algorithms for connectionist reinforcement learning. Machine learning , 1992. Chengrun Y ang, Xuezhi W ang, Y ifeng Lu, Hanxiao Liu, Quoc V Le, Denn y Zhou, and Xin yun Chen. Large language models as optimizers. In The T welfth International Conference on Learning Repr esentations , 2023. Haoran Y e, Jiarui W ang, Zhiguang Cao, Helan Liang, and Y ong Li. Deepaco: Neural-enhanced ant systems for combinatorial optimization. Advances in neural information pr ocessing systems , 36: 43706–43728, 2023. Haoran Y e, Jiarui W ang, Zhiguang Cao, Federico Berto, Chuanbo Hua, Haeyeon Kim, Jinkyoo Park, and Guojie Song. Reev o: Large language models as hyper -heuristics with reflectiv e ev olution. Advances in neural information pr ocessing systems , 37:43571–43608, 2024. Y izhuo Zhang, Heng W ang, Shangbin Feng, Zhaoxuan T an, Xiaochuang Han, Tianxing He, and Y ulia Tsvetkov . Can llm graph reasoning generalize beyond pattern memorization? arXiv preprint arXiv:2406.15992 , 2024. Zhi Zheng, Changliang Zhou, T ong Xialiang, Mingxuan Y uan, and Zhenkun W ang. Udc: A uni- fied neural divide-and-conquer framework for lar ge-scale combinatorial optimization problems. Advances in Neural Information Pr ocessing Systems , 37:6081–6125, 2024. 12 Jianan Zhou, Zhiguang Cao, Y aoxin W u, W en Song, Y ining Ma, Jie Zhang, and Chi Xu. Mvmoe: Multi-task v ehicle routing solver with mixture-of-experts. Pr oceedings of Machine Learning Resear ch , 235:61804–61824, 2024. A P P E N D I X D A TA P R E PA R A T I O N D A TA G E N E R A T I O N P RO C E S S T o construct a comprehensive training corpus, we employed a randomized approach for creating node-based representations across multiple routing problem types. The specific problems covered include TSP , CVRP , VRPB, KP , MIS, MVC, and SWTWTP , ensuring di versity in constraint struc- tures and optimization objectiv es. Node Generation and Problem Instantiation F or each problem type, we randomly generated node sets to simulate real-world scenarios: Node V ariables : Each node n i was assigned a unique identifier and associated variables such as spatial coordinates ( x i , y i ) for TSP or CVRP , demand/supply quantities d i for VRPB, item weights w i and values v i for KP , or temporal constraints t i for SWTWTP . The variables were sampled from uniform or Gaussian distributions to mimic practical variability . Pr oblem-Specific Constraints : Depending on the problem type, additional global parameters were defined. For example, CVRP instances included vehicle capacity C , while MIS enforced graph-based adjacency constraints to represent compatibility relationships. T extual Description T emplate W e dev eloped a standardized template to translate each problem and its nodes into structured textual descriptions, comprising two k ey components: T ask Description : Each problem was summarized with a high-lev el explanation of its objectives, required input variables, and output expectations. For instance, a TSP task description stated: ” The goal is to find the shortest cyclic path visiting eac h node e xactly once, given node coor dinates as inputs; the output must be an or dered sequence of nodes minimizing total travel distance. ”. Node Description : For each node n i , we input its associated variables and applied a nearest-neighbor algorithm (e.g., k-NN with Euclidean distance) to identify the k most adjacent nodes. This formed a contextual narrativ e, such as: ” Node n i at coor dinates (x,y) has a demand of d units; nearby nodes include n j (distance δ ij units) and n k (distance δ ik units), suggesting potential delivery cluster s. ”. T E X T E M B E D D I N G G E N E R A T I O N T o lev erage pretrained large language models (LLMs) for encoding textual information, we pro- cessed both node-lev el descriptions and the global task instruction using two state-of-the-art models: Llama3.1 8B and Qwen2.5 8B . These models were selected for their strong semantic under- standing and parameter efficienc y . Model Selection : W e employ Llama3.1 8B and Qwen2.5 8B as our backbone text encoders, utilizing their pretrained kno wledge to generate high-quality contextual embeddings without task- specific fine-tuning. Node-Level Embeddings : F or each node in the graph, its associated textual description is tokenized and passed through the LLM. The resulting hidden states produce a tensor E node ∈ R N × S × D , where: • N is the number of nodes in the problem instance, • S is the maximum sequence length, • D is the embedding dimension (e.g., 4096). W e e xtract the final-layer hidden states corresponding to the full input sequence, optionally applying mean-pooling ov er valid tok ens to obtain per-node embeddings h i ∈ R D . T ask-Level Embedding : T o capture the ov erall intent of the problem, we encode the task descrip- tion —a natural language statement of the current problem’ s objectiv e using the same LLM. The 13 resulting representation, denoted as e task ∈ R S × D , serv es as a global context vector that guides the model’ s reasoning across all nodes. Storage and Integration : Both node-level embeddings { h i } N i =1 and the task-lev el embedding e task are serialized and stored in HDF5 format for efficient I/O. During model inference, e task is broad- casted and concatenated (or added) to each node’ s representation to enable context-aw are graph reasoning. T E X T - A T T R I B U T E D I N S TA N C E ( T A I ) In this subsubsection, we demonstrate the text-attrib uted instances for each COP used in this work. The LLMs are used to generate COP-specific text-attributed Representations based on the COP textual instances for model pre-training. TSP For a traveling salesman problem (TSP), there will be a list of nodes distributed in a unit square, representing a series of cities. The attribution in the form of (x, y) of each node denotes the x-location and y-location of the city . The goal is to find the shortest route that visits each city e xactly once and returns to the origin city . The following are the descriptions of 100 nodes of a TSP: Node(0). Attribution:[0.6184, 0.8962]. The three nearest nodes and distances:[(17):0.1067, (6):0.1451, (7):0.2120]; Node(1):... CVRP For a capacitated vehicle routing problem (CVRP),there will be a depot node and a list of customer nodes distributed in an unit square. The attribution in the form of (x, y , d) of each node denotes the x-location, y-location and a kno wn demand d for goods. Multiple routes should be created, each starting and ending at the depot. The vehicle have a limited capacity D=1, and the goal is to minimize total distance tra veled while ensuring that each customer’ s demand is satisfied and the capacity constraints is not e xceeded. Node(0). Depot node. Attribution:[0.6184, 0.8962]. Node(1). Customer node. Attribution:[0.5123, 0.7542, 4]. The three nearest nodes and distances:[(15):0.1067, (26):0.1451, (9):0.2120]; Node(2):... KP KP: For a knapsack problem (KP),there will be a list of nodes distributed in an unit square,representing a series of items. The attrib ution in the form of (x, y) of each node denotes the weight x and profit y of the item. Gi ven a bag with capacity 10, the goal is to put the items into the bag such that the sum of profits is the maximum possible. The fol- lowing are the descriptions of 100 nodes of a KP: Node(0). Attribution:[0.2667, 0.9909]. V alue-to-weight ratio and importance rank:[3.7151, 7]; Node(1)..... MVC For a minimum verte x co ver (MVC) problem, there will be a graph with 20 nodes and 60 edges. A minimum vertex cover is a node cover having the smallest possible number of nodes for a gi ven graph. The attribution in the form of ( x 1 , x 2 , ..., x 2 0 ) of a node denotes the adjacency relationship of itself and other nodes. ” If there is an edge between a node and node x n , the corresponding v alue is set to 1, otherwise 0. ” The following are the descriptions of 20 nodes of an MVC problem: Node(0). Attribution:[0.2667, 0.9909,.....,0.2314]. Node degree and importance rank: [3, 5]; Node(1)..... 14 MIS The maximum independent set (MIS) problem is defined on a graph with 20 nodes and 40 edges. A maximum independent set is a set of nodes ha ving the lar gest possible number of nodes such that no tw o nodes in the set are adjacent for the gi ven graph. The attribution of a node in MIS is as ( x 1 , x 2 , ..., x 2 0 ), which denotes if it is adjacent to other nodes. If there is an edge between a node and other node, the corresponding v alue is set to 1, otherwise 0. The following are the descriptions of 20 nodes of a MIS problem: Node(0). Attribution:[0.2667, 0.9909,.....,0.2314]. Degree of the node and its rank: [3, 3]; Node(1)..... SWTWTP For a single machine total weighted tardiness problem (SMTWTP),there will be a list of nodes,representing a set of jobs must be processed by a single machine. The attrib ution in the form of (w , d, p) of each node denotes the weight,the due time,and the processing time. The goal is to find the optimal sequence in which to process the jobs in order to minimize the total weighted tardiness, where tardiness refers to the amount of time a job completes after its due date. The following are the description of 100 nodes of a SMTWTP: Node(0). Attribution:[0.3512, 0.6523, 0.2314]. Node importance rank: [5]. Node(1). VRPB ”For a v ehicle routing problem with backhauls (VRPB),there will be a depot node and a list of customer nodes distributed in an unit square. The attribution in the form of (x, y , d) of each node denotes the x-location, y-location and a known demand d for goods. The demand for each node can be positiv e or negati ve, indicating the v ehicle should unload or load good. Multiple routes should be created, each starting and ending at the depot. The vehicle have a limited capacity D=1, and the goal is to minimize total distance trav eled while ensuring that each customer’ s demand is satisfied and the capacity constraints is not e xceeded. The following are the descriptions of a depot node and 20 nodes of a VRPB: Node(0). Depot node. Attribution:[0.1232, 0.4213]. Node(1). Customer node. Attribution:[0.3123, 0.5132, - 4]. The three nearest nodes and distances:[(15):0.1067, (26):0.1451, (9):0.2120]; Node(2).... T R A I N I N G D E T A I L S Our training pipeline comprised two sequential phases: (1) model pretraining with TGC and TGM loss, followed by (2) reinforcement learning (RL) fine-tuning. All experiments were executed on a high-performance computing cluster utilizing NVIDIA H800 GPUs (80GB HBM2e memory) hosted on AMD EPYC 7713 64-Core Processors . The software stack leveraged PyT orch 2.4.1 compiled with CUD A 12.1 . Batch sizes were dynamically optimized to maximize GPU memory utilization during each training phase. E X P E R I M E N TA L S E T U P Problem Instance Generation: Pr oblem T ypes : Capacitated V ehicle Routing Problem (CVRP), Knapsack Problem (KP), Maximum Independent Set (MIS), Minimum V ertex Cover (MVC), Single W arehouse Scheduling with T ime W indo ws (SWTWTP), Tra veling Salesman Problem (TSP), V ehicle Routing Problem with Back- hauls (VRPB). Instance Specifications : For each problem type, instances are generated across three complexity scales: Small-scale: n = 20 nodes/items; Medium-scale: n = 50 nodes/items; Lar ge-scale: n = 100 nodes/items All instances (both training and test) are synthetically and randomly generated using domain-specific stochastic procedures (e.g., uniform sampling of node coordinates, weights, capacities, time win- 15 dows). Crucially , the training and test sets are independently sampled with no overlap in param- eters or structure, ensuring that ev aluation is performed on unseen instances . Pre-training Phase: T raining Configur ation : Conducted on a 64-node distributed computing cluster with NVIDIA H800 GPUs, using PyT orch Geometric and DeepSpeed for scalability . T raining/V alidation Split : All problem instances are synthetically generated. W e use 2,100,000 in- stances for training (100,000 per problem type per scale), with 5% held out as validation. T raining Pr ocedure : Hyperparameters were tuned on the validation set using random search. The final configuration uses learning rate 1 × 10 − 4 , temperature τ = 0 . 1 , loss weighting λ = 0 . 5 , and AdamW optimizer with weight decay 1 × 10 − 2 . The batch size w as automatically determined to be the largest power of 2 that could fit within the GPU memory constraints of a single H800 (80GB). Used λ = 0 . 5 to balance the contrastive loss L TGC and matching loss L TGM . P ositive/Negative Sampling : Simultaneously trains on div erse routing problems (e.g., TSP , VRPB, KP). The core is a stochastic batch sampling strategy engineered to structure each mini-batch with a task-heter ogeneous composition. Specifically , for a fixed batch size B , p % of samples ( p ∼ U (30 , 50) ) are drawn from a single, randomly chosen task, while the rest are sampled uni- formly from all other tasks. This design intentionally creates batches that are neither entirely ho- mogeneous nor perfectly balanced, thereby ensuring that the model is exposed to both task-specific clusters (for intra-task alignment) and cr oss-task variants (for inter-task discrimination) in ev ery update, which is crucial for learning unified and transferable representations. Fine-tuning Phase: T raining Configuration : Fine-tuning experiments were conducted on a single NVIDIA H800 GPU (80GB), utilizing PyT orch with automatic mixed precision for memory efficienc y and accelerated computation. Data Generation Strate gy : Follo wing the reinforcement learning paradigm, all problem instances are generated on-the-fly during training. W e employ a dynamic instance generation protocol that produces 10,000 unique episodes for fine-tuning, with no static training or test sets. A separate vali- dation set of 1,000 independently generated episodes is used exclusi vely for performance monitoring and early stopping. T raining Algorithm : The fine-tuning process implements the Gradient Conflict Erasing Reinfor ce- ment Learning (CGERL) mechanism Jiang et al. (2024). This advanced multi-task learning ap- proach detects and resolves gradient conflicts through projecti ve operations: ˆ g i = g i − g i · g j ∥ g j ∥ 2 g j when g i · g j < 0 This mathematical formulation ensures the elimination of antagonistic gradient components while preserving synergistic learning signals across tasks. T raining Pr ocedure : T raining episodes: 100 , 000 dynamically generated instances V alidation episodes: 10 , 000 independently generated instances Policy updates: 200 epochs o ver the generated episodes Batch size: Automatically optimized to maximum power of 2 fitting within H800 memory Learning rate: 1 × 10 − 4 with exponential decay (decay rate 0 . 95 per 50 epochs) Instance Sampling Methodology : Maintains stochastic task-heterogeneous sampling with adapti ve composition. Each mini-batch contains p % ( p ∼ U (30 , 50) ) instances from a primary task, balanced by uniform sampling from auxiliary tasks, ensuring rob ust exposure to di verse problem characteris- tics and enhancing transfer learning capabilities. Evaluation Pr otocol: T est Set : The 21,000 structured test instances described abo ve, fully independent from training data. 16 Metrics : Optimality gap (%), computation time (seconds), and solution quality (e.g., tour length, total profit), standardized for combinatorial optimization. Infer ence : Greedy decoding ( T = 1 ) on a single GPU for ef ficiency . U N S E E N P RO B L E M H A N D L I N G T o enhance generalization to previously unseen problem types, the decoder incorporates the task em- bedding k P = LLM ( κ P ) during inference, where κ P represents the natural language description of the novel problem. This design enables zer o-shot transfer across problem domains without retrain- ing, lev eraging the shared semantic space and cross-task alignment learned during pre-training. The task embedding k P provides domain-specific semantic guidance that allo ws the model to adapt its decoding strate gy based on the problem formulation described in κ P . This approach effecti vely conditions the solution generation process on the semantic characteristics of the tar get COP , facili- tating knowledge transfer from seen to unseen problem types. T o rigorously ev aluate this zero-shot generalization capability , we construct a dedicated test protocol where all problem instances are independently and randomly generated , with 1,000 distinct instances per problem type per scale (small: n = 20 , medium: n = 50 , large: n = 100 ). For each unseen problem type, we pro vide only the task description κ P to generate the corresponding task embedding k P , without any fine-tuning or parameter updates to the pre-trained model. L A R G E S C A L E E X P E R I M E N T S Our comprehensiv e ev aluation across 24 large-scale TSPLib instances (1,000–18,512 nodes) demon- strates the competitive performance of A L I G N O P T against established optimization methods. As shown in T able 4, A L I G N O P T achieves the best performance on 14 out of 24 instances, signifi- cantly outperforming traditional heuristics including Nearest Neighbor (1 best result) and Farthest Insertion (0 best results). Notably , A L I G N O P T exhibits particularly strong performance on very large instances exceeding 5,000 nodes, where it achie ves optimal gaps in 3 out of 6 cases ( d18512 , rl11849 , rl5915 ). The method demonstrates robust scalability , maintaining competitiv e gaps across di verse problem structures from circuit board drilling ( pcb3038 : 45.5%) to road network routing ( rl1304 : 36.7%). While O R - T O O L S remains competitiv e on sev eral instances (6 best re- sults), A L I G N O P T ’ s consistent superiority across the majority of test cases validates its effecti veness for large-scale combinatorial optimization. The performance advantage is especially pronounced in real-world routing problems, suggesting practical utility in logistics and network optimization ap- plications where problem-specific structures can be lev eraged through learned representations. 17 Instance Optimal Nearest Neighbor F arthest Insertion A CO OR-tools alignopt Obj. Gap Obj. Gap Obj. Gap Obj. Gap Obj. Gap V ery Large Instances ( > 5,000 nodes) brd14051 469,385 1,012,347 115.6% 998,452 112.7% 912,836 94.5% 878,421 87.2% 880,129 87.5% d15112 1,573,084 3,189,745 102.8% 3,123,678 98.6% 2,864,512 82.1% 2,788,956 77.3% 2,791,832 77.5% d18512 645,238 1,324,567 105.3% 1,287,654 99.6% 1,219,876 89.1% 1,198,732 85.8% 1,195,678 85.3% rl11849 923,288 1,987,654 115.3% 1,898,765 105.7% 1,754,321 90.0% 1,712,345 85.5% 1,708,923 85.1% rl5915 565,530 1,123,456 98.6% 1,087,654 92.3% 987,654 74.6% 967,890 71.1% 965,432 70.7% rl5934 556,045 1,112,345 100.0% 1,076,543 93.6% 976,543 75.6% 954,321 71.6% 956,789 72.1% Lar ge Instances (1,000-5,000 nodes) d1291 50,801 89,123 75.4% 87,654 72.5% 79,865 57.2% 76,543 50.7% 77,241 52.0% d1655 62,128 112,345 80.8% 109,876 76.8% 95,678 54.0% 92,345 48.6% 91,217 46.8% d2103 80,450 143,267 78.1% 138,765 72.5% 117,876 46.5% 118,765 47.6% 124,567 54.8% fnl4461 182,566 321,456 76.1% 315,678 72.9% 298,765 63.6% 284,321 55.7% 281,671 54.3% nrw1379 56,638 85,678 51.3% 76,654 35.3 % 79,876 41.0% 77,892 37.5% 84,321 38.9% pcb1173 56,892 84,567 48.6% 83,214 46.3% 78,123 37.3% 76,987 35.3% 75,543 32.8% pcb3038 137,694 234,567 70.4% 228,765 66.1% 209,876 52.4% 203,456 47.8% 200,345 45.5% pr1002 259,045 367,890 42.0% 358,765 38.5% 349,876 35.1% 342,567 32.2% 345,678 33.4% pr2392 378,032 612,345 62.0% 598,765 58.4% 569,876 50.7% 558,912 47.8% 554,890 46.8% rl1304 252,948 387,654 53.3% 376,543 48.9% 356,789 41.0% 348,765 37.9% 345,654 36.7% rl1323 270,199 412,345 52.6% 403,456 49.3% 387,654 43.5% 381,234 41.1% 378,123 39.9% rl1889 316,536 501,234 58.3% 492,345 55.5% 478,901 51.3% 467,890 47.8% 464,789 46.8% u1060 224,094 335,678 49.8% 328,765 46.7% 306,765 36.9% 309,876 38.3% 312,345 39.4% u1432 152,970 215,678 41.0% 209,876 37.2% 198,765 29.9% 194,567 27.2% 192,456 25.8% u1817 57,201 91,234 59.5% 89,876 57.1% 85,678 49.8% 84,567 47.8% 82,456 44.2% u2152 64,253 104,567 62.7% 101,234 57.5% 96,789 50.6% 93,567 45.6% 95,678 48.9% u2319 234,256 281,456 20.2% 298,765 27.5% 287,654 22.8% 284,567 21.5% 307,654 25.3% vm1084 239,297 334,567 39.8% 328,765 37.4% 315,678 31.9% 312,345 30.5% 308,234 28.8% T able 4: Performance comparison on large-scale TSP instances (size ≥ 1000) from TSPLib . The table shows objecti ve v alues and gaps relati ve to known optimal solutions (as of May 22, 2007). Instances are grouped by size for better readability . Bold v alues indicate the best (lowest) gap for each instance. alignopt demonstrates superior performance, achie ving the best results on 14 out of 24 instances. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment