Transparency as Architecture: Structural Compliance Gaps in EU AI Act Article 50 II
Art. 50 II of the EU Artificial Intelligence Act mandates dual transparency for AI-generated content: outputs must be labeled in both human-understandable and machine-readable form for automated verification. This requirement, entering into force in …
Authors: Vera Schmitt, Niklas Kruse, Premtim Sahitaj
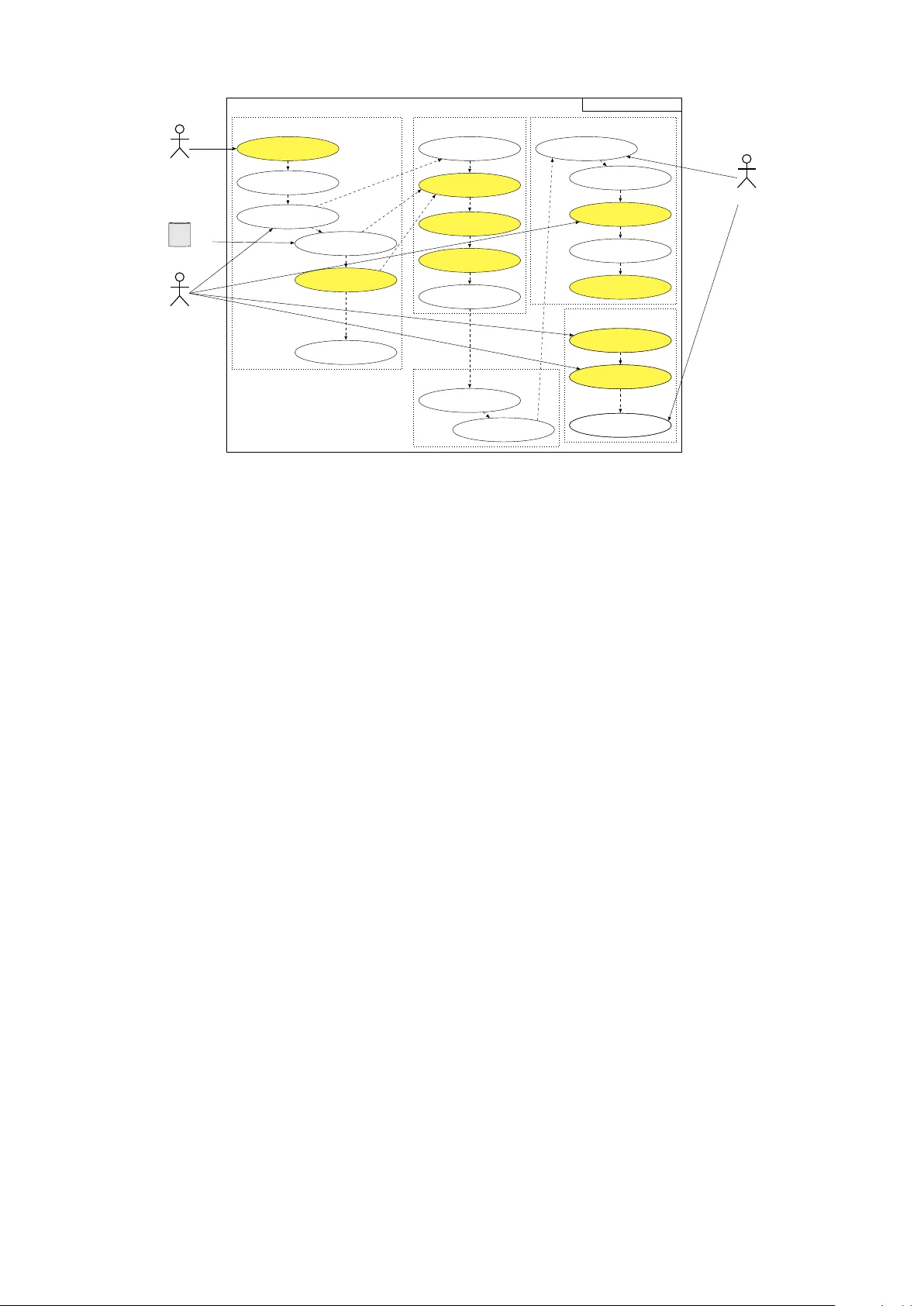
T ransparency as Architecture: Structural Compliance Gaps in EU AI Act Article 50 II V era Schmitt ⋆ , 1 , 2 , 3 , Niklas Kruse ⋆ , 4 , Premtim Sahitaj 1 , Julius Schöning 4 T echnichal University Berlin XpaliNLP Group 1 , Research Center for Ar tificial Intelligence (DFKI) Berlin 2 , Center for European Research on T rust ed AI (CERT AIN) 3 , Faculty of Engineering and Computer Science, Osnabrück University of Applied Sciences 4 {vera.schmitt, premtim.sahitaj}@tu-berlin.de, {niklas.kruse,j.schoening}@hs-osnabrueck.de Abstract Ar t. 50 II of the EU Ar tificial Intelligence Act mandates dual transparency for AI-generated content : outputs must be labeled in both human-understandable and machine-readable form for automated verification. This requirement, entering into force in August 2026, collides with fundamental constraints of current generative AI systems. Using synthetic data generation and automated fact-checking as diagnostic use cases, we show that compliance cannot be reduced to post-hoc labeling. In fact-checking pipelines, pro venance tracking is not feasible under iterativ e editorial workflows and non-det erministic LLM outputs; moreo ver , the assistiv e-function e xemption does not apply , as such syst ems activ ely assign truth v alues r ather than supporting editorial presentation. In synthetic data generation, persistent dual-mode marking is paradoxical: watermarks sur viving human inspection risk being learned as spurious features during training, while marks suited for machine verification are fragile under standard data processing. Across both domains, three structural gaps obstruct compliance: (a) absent cross-platform marking formats for interlea ved human-AI outputs; (b) misalignment between the regulation ’s ’reliability’ criterion and probabilistic model behavior ; and (c) missing guidance for adapting disclosures to heterogeneous user expertise. Closing these gaps requires transparency to be treated as an architectural design requirement, demanding interdisciplinary research across legal semantics, AI engineering, and human-centered design. Ke ywords: AI Act, transparency , legal compliance, data gov ernance, synthetic data, fact-checking 1. Introduction The proliferation of generative AI systems across high-stakes domains such as journalism, scien- tific research, public administration, and automated decision-making has made the prov enance and au- thenticity of digital content a pressing gov ernance concern. Synthetic te xt, images, and structured data can now be produced at scale, at low cost, and with a degree of realism that makes human de- tection increasingly unreliable ( Schmitt et al. , 2025 ; V aranasi and Goy al , 2023 ). In response, the Euro- pean Union has enacted the Ar tificial Intelligence Act (AI Act), which represents a decisive shif t from e x pos t regulation of digital technologies toward the ex ante gov ernance of AI systems ( Kruse and Schöning , 2025 ). Unlik e earlier framew orks such as the General Data Pr otection Regulation (GDPR), which targets data processing and individual rights, the AI Act directly regulates the behavior , outputs, and societal effects of AI systems, most directl y through Ar t. 50 II, which enters into force in August 2026. Ar t. 50 II imposes a dual transparency require- ment on providers of generative AI: outputs must be labeled in a human-understandable manner and in a machine-readable form that enables au- tomated v erification. The provision applies across data types and deployment conte xts, from te xt and ⋆ Both authors contributed eq ually to this research. images t o synthetic datasets used in AI training pipelines. Its regulatory intent is clear: restoring epistemic trust in digital content by making AI in- volv ement permanently traceable. Its technical specifications, howev er , are absent. Ar t. 50 II man- dates that labeling solutions be effective, interoper - able, robust, and reliable, while referring to wat er - marks, metadata labels, and cr ypt ographic meth- ods as candidate approaches. None of these cri- teria are defined operationally , and the technical standards that would supply such definitions are still under development ( European Commission , 2025 ). This paper argues that operationalizing Ar t. 50 II cannot be achiev ed through labeling solutions ap- pended to exis ting systems. Generativ e AI oper - ates under constraints that are structurally at odds with the regulation’ s requirements. Probabilistic outputs resist deterministic attribution; prov enance chains fragment when human and AI contributions are interlea ved; and the regulation’s demand for re- liable and effective transparency provides no guid- ance on what these proper ties mean for systems whose outputs var y across identical in puts. These are not im plementation difficulties to be engineered aw ay . They reflect conceptual mismatches be- tween legal specification and technical reality that require coordinated research across disciplines. T o expose and structure these mismatches, we analyze two technically distinct but jointly reveal- ing use cases. In synthe tic data generation , dual- mode marking introduces a paradox between label- ing persistence and training data integrity : water - marks designed to sur viv e human inspection risk being learned as spurious features during model training, while marks suit ed for machine verification are fragile under standard data processing oper- ations. In automated fact-checking , RA G-based multi-source attribution cannot be adequately rep- resented in e xisting metadata schemas such as Dublin Core or Schema.org, and iterative editorial workflows degrade marking signals to the point where human and AI contributions can no longer be cleanly separated. Be yond these technical limi- tations, the Ar t. 50 II assistive-function ex emption does not apply to fact-checking systems, as they actively assign truth values and confidence judg- ments to claims rather than merely suppor ting ed- itorial presentation, a legal distinction with direct compliance consequences. T ogether , these cases expose three structural gaps that any compliance pathwa y must address. T o systematically address these tensions, two research questions are proposed that ser v e as the foundation for our analysis. RQ 1: Which requirements of Ar t. 50 II (human- understandability , machine-readability , effec- tiveness, interoperability , robustness, and reli- ability) can be technically implemented within current AI systems, and where do systematic, non-incidental limitations arise? RQ 2: How do legal concepts such as ‘under - standability’ and ‘reliability’ diverge from their technical counterpar ts, e xplainability , q uality assurance, and output consistency , and what are the com pliance consequences of these divergences for practitioners and regulators? Section 2 situates Ar t. 50 II within the AI Act’s regulatory architecture and ex amines its technical requirements. Section 3 ex amines both research questions through the lens of two high-stakes use cases, assessing where compliance is feasible and where it breaks down. Section 4 synthesizes the three structural gaps and identifies preliminary com- pliance pathway s grounded in the use case anal- ysis. Section 5 concludes by repositioning trans- parency from a post-hoc metadata problem to an architectural design requirement, and outlines what a research agenda would need to deliver before Ar t. 50 II takes effect. 2. Art. 50 II as T echnical Requirement Ar t. 50 of the AI Act establishes transparency obli- gations for pro viders and deploy ers of cer tain AI syst ems, sitting within Chapter IV and entering into force on 2 August 2026. The provision addresses four distinct scenarios: AI systems that interact directly with natural persons (Ar t. 50 I); systems that generate synthetic audio, image, video or text content (Ar t. 50 II); emotion recognition and bio- metric categorisation systems (Ar t. 50 III); and sys- tems that generate or manipulate deep fake content or te xt published for public information purposes (Ar t. 50 IV). This paper focuses on Ar t. 50 II, which imposes the most technically demanding obliga- tions and applies directly to providers of generative AI systems, including general-purpose AI models. Ar t. 50 II requires providers of systems generat- ing synthetic audio, image, video or te xt content to ensure that outputs are marked in a machine- readable format and detectable as ar tificially gen- erated or manipulated. Crucially , the obligation is qualified: providers must ensure their technical solutions are effective, interoperable, robust and reliable as far as this is technicall y feasible , taking into account the specificities and limitations of vari- ous types of content, the costs of implementation, and the generally acknowledged state of the ar t as reflected in relev ant technical standards. Three ex- emptions limit the obligation’ s scope. First, it does not apply where AI syst ems perform an assistiv e function for standard editing. Second, it does not apply where the system does not substantially alter the input data or its semantics. Third, it does not ap- ply where use is authorised by law for pur poses of detecting, pre venting, investigating or prosecuting criminal offences. The interaction between these ex emptions and the use cases ex amined in this paper is non-trivial and is addressed in Section 3 . The regulation is formulat ed in a deliberately technology -neutral manner : Ar t. 50 II names no specific technical im plementation and provides no operational definition of the four quality criteria. Recital 133 identifies candidate approaches, in- cluding watermarks, metadata labels, and cr yp- tographic methods, but does not specify formats, protocols or measurement criteria. This neutral- ity creates a structural compliance problem. A pro vider cannot determine from the regulation alone whether a given w atermarking scheme satisfies the effectiveness criterion, what interoperability re- quires across platforms and jurisdictions, how ro- bustness should be measured under realistic pro- cessing conditions, or what reliability means for syst ems whose outputs are probabilistic and non- determinis tic. These are not peripheral questions: they determine whether any specific technical im- plementation is compliant. The regulation’ s response to this uncer tainty is to def er to technical standards, referenced in Ar t. 50 II as the intended source of operational guidance. Ar t. 50 VII fur ther provides that the AI Office shall facilitate codes of practice to suppor t effective implementation, and that the Commission ma y adopt implementing acts to approv e or specify common rules for these obligations. How ever , the relev ant harmonized standards remain under de- velopment by international, European and national standardization bodies, and it is unclear whether they will be finalized bef ore the provision enters into force ( European Commission , 2025 ). The stan- dards available to date address adjacent concerns rather than output-level transparency . ISO 42001 gov erns organizational AI management systems. ISO/IEC 24028 addresses trustwor thiness at the syst em level. ISO/IEC 24027 provides methodolo- gies for bias assessment. None specifies how a label should be designed, embedded, or verified for a given class of AI-generated output, nor how persistence should be maintained once an output passes through downstream processing, editing or format conversion. This gap between regulatory requirement and av ailable technical guidance is structural rather than incidental. The dual transpar ency obliga- tion, which this paper reads as requiring both a human-understandable and a machine-readable marking, applies across a heterogeneous class of data types, including t ext, images, audio and structured datasets, each of which presents dis- tinct technical constraints. The absence of harmo- nized, output-lev el standards leaves providers with- out a clear com pliance pathwa y , and the t echnically feasible qualification in Ar t. 50 II, while pragmatic, introduces its own ambiguity: it is unclear who de- termines feasibility , by what standard, and at what point in the system life-cy cle. These unresolved questions set the stage for the specific technical breakdowns ex amined in the use cases that follow . 3. Use Cases Influenced by Ar t. 50 II This section ex amines the operational challenges of Ar t. 50 II through two high-stakes use cases: syn- thetic data generation and automated fact-checking. These cases are technically distinct but jointly de- tecting similar issues. Each exposes a differ ent facet of the compliance gap identified in Section 2 : the synthetic data case reveals how the dual trans- parency obligation conflicts with the technical re- quirements of model dev elopment pipelines, while the fact-checking case rev eals how iterativ e human- AI workflows undermine prov enance tracking and why the assistive-function ex emption does not pro- vide suppor t. T ogether , they ground the three struc- tural gaps described fur ther in Section 4 . 3.1. Synthetic Data Generation Systems The av ailability of data for dev eloping high- per f ormance AI systems remains a significant chal- lenge across both academic and economic fields ( Li et al. , 2021 ; Sambasivan et al. , 2021 ; Malerba and P asquadibisceglie , 2024 ). Modern AI sys- tems, par ticularly those employing transformer ar - chitectures ( Kaplan et al. , 2020 ; Richt er et al. , 2022 ; Halevy et al. , 2009 ), necessitate substantial datasets to attain optimal performance. Conv en- tionally , data has been obtained from the real world, a process frequently associated with high costs and limited av ailability ( Buhrmester et al. , 2011 ). These facts suggest that the development of next- generation AI syst ems is encountering a significant impediment: insufficient data to enhance their ca- pabilities. A potential solution to this challenge is to augment existing datasets with synthetic data ( Mu- muni and Mumuni , 2022 ; W achter et al. , 2025 ). As illustrated in Figure 1 , the generation of syn- thetic data encompasses various stakeholders and a range of digital inputs and outputs, including one or sev eral datasets, AI modeling interfaces, and licenses. The synthetic data itself can mani- fest in various forms, including te xts, images, and time series. Although disparate data types are de- rived from reality , they do not exist outside the syn- thetic data space. Synthetic data offer s a variety of added values. Real-world data can be collected through direct or indirect methods, both of which are deriv ed from reality . These datasets are of- ten subject to real-world biases and can be ex- pensive or time-consuming ( Wacht er et al. , 2024 ; Gebru et al. , 2021 ). Consequently , existing feature gaps or biases can be addressed b y lev eraging synthetic data. Another potential application is the pre-training of large AI models, in which synthetic features are used to train fundamental features, thereb y im pro ving per formance on real datasets. A salient question that remains unanswered is the ex- tent to which synthetic data can completel y replace real-world data. In the cont ext of human subjects re- search, synthetic data of t en exhibits a high degree of indistinguishability from ar tificial data, which falls under Ar t. 50 II if generative AI is used to create it. How ever , given the inherent variability of image data, par ticularly in its presentation and design, it is impor tant to note that, e.g., synthetic image data of ten contains f eatures that ar e more read- ily identifiable by an AI syst em than by humans. Consequently , a discrepancy arises between syn- thetic and real data, known as the “reality gap” or “domain gap” . ( Wacht er et al. , 2025 ; Peng et al. , 2018 ). The ext ent of this discrepancy remains a subject of ongoing research and will be impor tant in determining whether synthetic data needs to be labeled in the conte xt of Ar t. 50 II. 3.1.1. Art. 50 II Analysis and Applicability A system for the generation of synthetic data, as il- lustrat ed in Figure 1 , constitutes a standard case of define dataset requirements select / connect data sources ingest raw data label / annotate data clean & normalize data profile data generate synthetic dataset design synthesis schema export dataset formats configure generator parameters apply privacy constraints apply differential privacy (optional) detect & remove PII set access control & licensing security review Compliance approval check constraints & consistency validate statistical fidelity check bias & fairness run utility tests (train & benchmark) QA sign-off version & sign release document datasheet & metadata publish dataset request dataset access download / access via API monitor usage & audit logs provide feedback / report issues deprecate / revoke release extend extend data preparation / synthetic dataset generation extend extend synthesis privacy & governance extend validation release & lifecycle synthetic dataset generation domain expert external data source compliance officer (DPO / Legal) metadata catalog dataset user (AI engineer) model training pipeline issue tracker platform admin dataset tester (QA / validation) data engineer extend extend Figure 1: Use case diagram of a synthetic data generation system; the y ellow-highlighted use case might be relev ant for fulfilling Ar t. 50 II. Note that, depending on the syst em design, some use cases may be more or less relevant to Ar t. 50 II. Ar t. 50 II. Such systems o verlap with the regulatory aspects of Ar t. 50 IV , which refers to deepfakes. Whether an AI system is subject to Ar t. 50 II or IV depends largely on the type of data it generat es. Ac- cording to Recital 134, a deepfake is characterized by the fact that the AI output is intended to falsely convince the recipient that the altered output is ac- tual reality . If synthetic generation is used merely to substitute for the dataset creation process and identical artificial representations of real objects are created, this is likely to constitute a case under Ar t. 50 IV . This generation process could constitute a deepfake within the meaning of Recital 134. If, instead, data is generated to fill gaps in a dataset that cannot be collected because such data does not exist in a usable form, or to expand an existing dataset, then no deepfak e is created; rather , new content is created. Such synthetic data generation syst ems are regulated under Ar t. 50 II. As depicted in Figure 1 , the use cases within the subsystem data synthesis do not fall under Ar t. 50 II. Howe ver , within the subsystem synthetic dataset generation, three use cases “label & annotate data” clean & normalize” , and “define datase t requirements ” , constitute a standard case of Ar t. 50 II, since the dataset output must be labeled in a way that is both machine-readable and accessible to humans, e.g., using the wat ermar ks mentioned in Recital 133. Howe ver , if synthetic datasets are used to train AI systems, the machine-readability of watermarks can become an obstacle to the usability of synthetic data for these purposes. Since in these cases the wat ermar k occurs very frequently , depending on the propor tion of synthetic data in the entire dataset, there could be a risk that, due to the distribution of the feature, the AI system treats the watermark as a feature relev ant to the training process rather than the actual training content. This links to the subsyst em “release & life-cycle, ” in which sever al use cases need to comply with Ar t. 50 II, e.g., to offer two versions of such synthe tic data via an application programming inter face (API) so that wa- termarks visible to an AI can be remo ved before training, enabling an unbiased training of the AI architectur e. The version intended for human re- cipients contains a human-recognizable watermark instead ( Simmons and Winograd , 2024 ; Bohacek and Vilanov a Echav arri , 2025 ; Kruse and Schön- ing , 2024 ). Such watermark methods allow the standard’s purpose to continue to be fulfilled while the whole life-cy cle and priv acy gov ernance ensure that synthetic data generation systems are usable and compliant with Ar t. 50 II. 3.1.2. T echnical and Oper ational Challenges Implementing Ar t. 50 II’ s dual transpar ency re- quirements for synthetic data generation syst ems presents technical and operational challenges within the subsyst ems “release & life-cy cle” , “syn- thetic dataset generation” , and privacy & gov er - nance” . While wat ermarking techniques, as ref- erenced in Recital 133, appear to offer a straight- forward technical solution with permanently linked labels to the data ( Militsyna , 2025 ; Łabuz , 2024 ), their practical implementation re veals significant complexities and will hinder the use of synthetic datasets. Firstly , the fundamental tension between human- readable labeling and machine-readability engen- ders a technical parado x ( Militsyna , 2025 ). W a- termarks designed t o be discernible to humans, e.g., subtle visual patterns or embedded text, of- ten impede training when synthetic data is used to train AI models. As discussed in Section 3.1.1 , wat ermar ks have the potential to ev olve into fea- tures that AI syst ems learn to recognize rather than disregard, thereby jeopardizing the integrity of the training data. Jeopardizing the integrity of the train- ing data creates a critical conflict : the regulatory re- quirement for persistent labeling directly contradicts the technical need for clean, unadulterat ed data in model training pipelines ( W achter et al. , 2025 ; Chen et al. , 2024 ; Geirhos et al. , 2020 ). The proposed solution of maintaining two versions of synthe tic datasets for the subsyst em’s “release & life-cy cle” use cases introduces operational complexity , re- quiring additional data management infrastructure and potentially increasing data providers ’ costs. Secondly , contemporar y watermarking technolo- gies are deficient in t erms of the robustness re- quired for Art. 50 II’s “r eliable” standard. Wat er- marks are of t en susceptible to compromise when, e.g., subjected to conv entional image processing operations such as compression, resizing, crop- ping, and format conv ersion. These operations are frequently employ ed in data pipelines ( Chen et al. , 2024 ; Wan et al. , 2022 ). This fragility undermines the “persistence” requirement of Ar t. 50 II, as wa- termarks may be inadver t ently remov ed or alter ed during standard data processing. F ur thermore, the efficacy of wat ermar king varies considerably across different data types and content ( Fernandez et al. , 2023 ), with comple x or highly unbalanced data pos- ing par ticular challenges for reliable wat ermark em- bedding and detection. Thirdly , the absence of interoperable technical standards engenders a fragmented implementa- tion landscape ( Simmons and Winograd , 2024 ; Bo- hacek and Vilanov a Echav arri , 2025 ). Although Recital 133 references wat ermarks, metadata la- bels, and cr yptogr aphic methods, it does not pro- vide detailed specifications regarding technical for - mats or pro tocols. This will result in a prolif era- tion of proprietar y watermarking solutions that lac k cross-platform compatibility . This is why the use cases “label & annotate data” clean & normalize” , and “define dataset requirements” also need to consider Ar t. 50 II. T o illustrate, a watermark em- bedded using one provider’s technology ma y not be det ectable by another pro vider’s v erification system, thereb y violating the “interoper able” requirement of Ar t. 50. This fragmentation engenders substantial impediments for organizations that must integrat e synthetic data from multiple sources or utilize data across disparate AI systems. Fourthly , the scope ambiguity of Ar t. 50 II exac- erbates these technical challenges. The regulatory framew ork lacks clarity on the necessity of labeling synthetic data used for A I training in a manner con- sistent with synthetic data distributed to end users. This ambiguity creates operational uncer tainty for the system compliance office, which must decide when a wat ermark is human-recognizable under AI Act Ar t. 50 and the Accessibility Act. The absence of regulatory guidance on this distinction compels organizations to make potentiall y costly implemen- tation decisions without clear legal direction. The tension be tween regulat or y requirements and practical AI system dev elopment presents a significant operational challenge. Data scientists and AI engineers generally prioritize data quality and model per formance ov er com pliance consid- erations ( Rako va et al. , 2021 ; V aranasi and Goy al , 2023 ; Sambasivan et al. , 2021 ). The implemen- tation and maintenance of dual labeling systems within the “release & life-cycle ” subsystem may be a bottleneck to innovation rather than a necessar y compliance measure. The aforementioned challenges collectively demonstrate that Ar t. 50 II’s transparency require- ments cannot be met by simple technical add-ons to existing data-generation pipelines. Instead, a fundamental rethinking of the generation, labeling, and management of synthetic data throughout its life-cy cle is necessar y . 3.2. Fact-Checking Systems F act-checking systems constitute a paradigmatic application domain in which the transparency obli- gations of Ar t. 50 II intersect with highly complex technical and editorial workflows. Contemporary automated syst ems ( Guo et al. , 2022 ) increas- ingly rely on large language models (LLMs) em- bedded in multi-stage pipelines that typically com- prise claim detection ( Hassan et al. , 2017 ), evi- dence retrie val ( Sahitaj et al. , 2025 ), veracity as- sessment, and the retriev al-augmented generation (RA G) ( Lewis et al. , 2020 ) of te xtual justifications or summaries. These pipelines connect content platforms, the actors who use the syst em’s outputs, like journalists or moderators, and the or ganiza- tions that deploy it, such as newsrooms, turning verified claims into repor ts that can determine mod- eration or editorial decisions ( Schlichtkrull et al. , 2023 ). When LLMs are used in automated fact- checking pipelines, it is of t en difficult to understand why the system reached a specific verdict. Ex- planations can end up sounding like af t er-t he-fact analyses rather than justifying the actual reason- ing behind claim-verification decisions ( T an et al. , 2025 ). User studies also suggest that explanations may impro ve perceived clarity without reliably im- proving AI-assisted human decision quality , and can even increase ov erconfidence ( Schmitt et al. , 2025 ), indicating that transparency mechanisms define fact-checking scope ingest claims (e.g. articles, social media) detect & extract checkable claims retrieve evidence (knowledge base, web) generate justification profile claim complexity & verifiability design verdict schema generate AI ver - dict & explanation apply machine-readable marking/watermarking configure trans- parency parameters export verdict formats (JSON-LD, metadata) remove personal data if necessary apply differential privacy [optional] check factual consistency validate statistical fidelity check for bias and fairness run utility test (precision/recall) QA sign-off (dis- closure check) document sy s t em card/tr anspar ency r epor t monit or usage/audit logs (disclosur e com pliance) provide feed- back/report issues input & claim processing verdict generation privacy validation document system card/transparency report monitor usage/audit logs (disclosure compliance) provide feed- back/report issues release & lifecycle AI-driven fact-checking domain expert: journalist external data source ML engineer fact-checking- /red-team Figure 2: Use case diagram of an AI-driven fact-checking system; the yello w-highlighted use case might be relev ant for fulfilling Ar t. 50 II. Note that, depending on the syst em design, some use cases may be more or less relevant to Ar t. 50 II. can actively undermine their own regulator y pur - pose if poorly designed 3.2.1. Art. 50 II Analysis and Applicability As illustrated in Fig. 2 , fact-checking systems fall within the scope of Ar t. 50 II whenev er they gener - ate te xtual justifications for veracity assessments, synthesize evidence from multiple sources, or dis- seminate AI-generated ev aluations on matters of public interest. The boundar y between Ar t. 50 II and the assistive-function e x emption in Ar t. 50 II sentence 3 turns on semantic transformation. The ex emption covers syst ems that per form standard editing functions or do not substantially alter the semantics of their inputs. F act-chec king syst ems do neither: the y actively transform user -submitted claims by assigning truth values, confidence scores, and evidential justifications. This constitutes a sub- stantive semantic transformation rather than ed- itorial assistance and therefore falls outside the ex emption’ s scope. Unlike the synthetic data case, where the Ar t. 50 II versus Ar t. 50 IV boundar y de- pends on intent and realism, the fact-checking case inv olves a different boundar y question: whether the assistive-function ex emption applies. The an- swer is no, and this has direct compliance conse- quences: pr oviders cannot reduce their marking obligations through the ex em ption and must imple- ment full dual transparency for all pipeline outputs. Within t he use case architecture depicted in Fig. 2 , this obligation maps onto specific subsys- tems. In the verdict generation subsystem, the use cases generate AI verdict and e xplanation and ap- ply machine-readable marking and wat ermarking constitute the primar y compliance locus: outputs must be marked in a machine-readable format and detectable as ar tificially generated at the point of generation. In the release and lifecycle subsystem, the use cases monitor usage and audit logs and document syst em card and transparency report carry secondary com pliance obligations, as they must preser v e evidence of AI involv ement across the output lifecycle. Howev er , a critical complica- tion arises from the interlea ving of human and AI contributions. When a journalist reviews, edits, and publishes an AI-generated verdict, the boundar y be- tween AI-generated and human-authored content becomes impossible to demarcate cleanly . Unlike the synthetic data case, where a dual-version API can separate watermark ed and watermark -free out- puts for different recipients, no equivalent architec- tural solution exists for fact-checking pipelines: the human editorial process itself destroy s the prove- nance chain that machine-readable marking re- quires. Current gov ernance standards exhibit the same structural gap identified in Section 2 and Sec- tion 3.1 . ISO/IEC 42001:2023 addresses organi- zational AI management rather than output-level transparency . ISO/IEC 24027:2021 provides bias assessment methodologies relevant to source se- lection and ideological bias in fact-checking, but does not mandate user -facing disclosure of those bi- ases. IEEE P7001 proposes graded transparency lev els that remain misaligned with Ar t. 50 II’s simul- taneous human-readable and machine-readable marking requir ement. The question of risk clas- sification adds a further compliance dimension. The societal im pact of automated f act-checking, par ticularly in electoral contexts, suggests pot en- tial qualification as a high-risk sy stem under An- nex III, Ar t. 8 aa ( Schmitt et al. , 2024a ), which would trigger full Chapter III obligations including conformity assessment, human ov er sight under Ar t. 14, and technical documentation under Ar t. 11. Journalist-facing tools functioning in an advisor y rather than decisive capacity may alternatively qual- ify as limited-risk assistive systems, in which case compliance is largely confined to Ar t. 50’s trans- parency requirements. This ambiguity is not merely theore tical: the applicable compliance pathwa y and associated architectural burden differ substantially between these two classifications, and no regula- tory guidance or case law currently resolves the question. 3.2.2. T echnical and Oper ational Challenges Implementing Art. 50 II’s dual transparency require- ments across the v erdict generation , v alidation , and release and lifecy cle subsystems presents four in- terconnect ed challenges that parallel those in the synthetic data case but arise from structurally dif- ferent sources. First, the fundamental tension between human- readable and machine-readable marking is com- pounded in fact-checking by the iterativ e nature of editorial workflows. T e xt watermarking techniques that could in principle satisfy the machine-readable requirement are highly fragile under the editing, paraphrasing, and summarization practices com- mon in newsrooms ( Kirchenbauer et al. , 2023 ). A wat ermar k embedded in an AI-generated justifica- tion is unlikely to sur vive the revisions a journalist applies befor e publication. Unlike the synthetic data case, where a dual-version solution can separate marked and unmarked outputs at distribution time, no equiv alent separation point exis ts in editorial workflows: the human review process intervenes between AI generation and publication, and it is precisely this inter v ention that destroys the mark. The regulatory requirement for persistent marking directly contradicts the operational reality of human- AI collaboration in journalism. Second, the robustness of marking is struc- turally undermined by RA G-based multi-source attribution. When a justification dra ws on multi- ple r etriev ed sources, weight ed by retriev al con- fidence and filtered by a v eracity classifier , no current me tadata schema pro vides a machine- readable format adequat e to capture that prove- nance chain. Established schemas such as Dublin Core or Schema.org lack the semantics for ex- pressing confidence-weighted, multi-step attribu- tion ( Kirchenbauer et al. , 2023 ). This is analo- gous to the watermark fragility problem in synthetic data pipelines, but arises from semantic complexity rather than signal degradation: the prov enance in- formation e xists but cannot be represent ed in any in- teroper able, machine-readable form. The real-time demands of breaking-news scenarios compound this fur ther: cryptographic marking schemes that could suppor t fine-grained provenance are compu- tationally expensiv e and create latency trade-offs incompatible with live editorial workflows. Third, the absence of interoperable standards produces the same fragmented im plementation landscape identified in the synthetic data case, but with an additional cross-modal dimension. No unified marking approach currently exists for fact-checking outputs that combine text, images, and video, despite Ar t. 50 II’s explicit multimodal scope. Existing prov enance frameworks, includ- ing C2P A ( C2P A Steering Committee , 2024 ), pro- vide insufficient support for deeply interlea ved, te xt- centric outputs in which human and AI contributions cannot be cleanly separated. A marking solution dev eloped for te xt-based verdicts will not extend to video fact-checks without significant additional en- gineering, and no cross-modal standard currently fills this gap. Fourth, the scope of Art. 50 II is ambiguous with respect to explanation quality in wa ys that hav e no direct parallel in the synthetic data case. Ar t. 50 V requires that disclosures be provided in a clear and distinguishable manner conforming to applicable accessibility requirements, but pro- vides no guidance on calibrating explanation depth or format t o different user groups. Post-hoc e x- plainability methods such as LIME or SHAP gen- erate technically accurate featur e attributions but are inaccessible to non-technical users including most journalists and content moderators ( Schmitt et al. , 2024b ). Natural-language explanations gen- erated by LLMs are more accessible but introduce explanation-induced ov erreliance: fluent but incor - rect rationales increase user trust without improv- ing decision quality ( Bansal et al. , 2021 ; Schmitt et al. , 2024b ). The result is a one-size-fits-all trans- parency requirement that is likely to under -ser v e both technical and non-technical user groups simul- taneously , and whose interaction with the halluci- nation and non-determinism proper ties of LLMs ( Ji et al. , 2023 ) means that legally verifiable quality guarantees cannot be provided under current tech- nology . Finally , human-AI collaboration introduces addi- tional operational risks. Newsroom environments characterized by time pressure are par ticularly sus- ceptible to automation bias, potentially eroding in- dependent verification practices and diffusing ac- countability when AI-assisted fact-checks prov e in- correct ( Liu et al. , 2024 ). Although Ar t. 14’s human ov ersight requirements and Ar t. 50’s transparency obligations are conceptually complementar y , con- cret e guidance on their coordinated implementa- tion in fact-checking contexts remains largely ab- sent. T aken together , these four challenges demon- strate that Ar t. 50 II compliance for automat ed fact-checking cannot be achie ved through mark - ing solutions appended to existing pipelines. The prov enance chain that machine-readable marking requires is broken by the editorial workflows that human oversight demands, the semantic complex- ity of RAG-based attribution ex ceeds what current standards can represent, and the e xplanation re- quirements of Ar t. 50 V cannot be met without user - group-specific transparency designs that the reg- ulation does not specify . As in the synthetic data case, compliance must be treated as an architec- tural requirement integrated from the outset, not a post-hoc addition. The next section synthesizes the structural gaps common to both cases and iden- tifies the research directions needed to close them. 4. Structural Gaps and Research Agenda for Ar t. 50 II Compliance The use case analyses show three structural gaps that any compliance pathway must address: the absence of cross-platform marking formats for in- terlea ved human-AI outputs (RQ1), the misalign- ment between the regulation’ s reliability criterion and probabilistic model behavior (RQ2), and miss- ing guidance for adapting transparency to heter o- geneous user expertise (RQ2). Pathway 1: Interoperable provenance st an- dards. No current standard can represent prov e- nance in outputs where human and AI con- tributions are interlea ved. In synthetic data pipelines, the dual-version API approach par- tially addresses distribution-time separation but lacks cross-platform verification. In fact-checking pipelines, RA G-based attribution cannot be rep- resented in schemas such as Dublin Core or Schema.org, and editorial workflow s destro y prove- nance chains at the point of human re view . F u- ture work should extend framew orks such as C2P A ( C2P A Steering Committee , 2024 ) to inter - leav ed te xt-centric outputs and establish robust- ness benchmar ks for marking methods under real- istic processing conditions. Pathway 2: Oper ational feasibility criteria. The undefined quality criteria in Ar t. 50 II leave providers without a clear compliance pathwa y . In synthetic data conte xts, it is unclear whether training-time watermark remov al violates the relia- bility criterion. In fact-checking conte xts, no guid- ance exis ts on whether marks destroy ed by editorial re vision satisfy the regulation ’s persistence require- ment. The Commission’ s Code of Practice ( Euro- pean Commission , 2025 ) represents an initial step but does not resolve these ambiguities. Future work should develop measurable criteria differenti- ated by data type, deployment conte xt, and recipi- ent, including the unaddressed distinction between synthetic data for human recipients and for model training pipelines. Pathway 3: User-group-specific tr ansparency designs. Art. 50 V requires clear and distinguish- able disclosures but provides no guidance on cali- brating explanations to different user groups. Pos t- hoc methods such as LIME or SHAP are inaccessi- ble to non-technical users, while natural-language LLM explanations introduce explanation-induced ov erreliance ( Bansal et al. , 2021 ; Schmitt et al. , 2024b ). F uture work should dev elop and v ali- date disclosure frame works that adjust explana- tion depth and format to the recipient’ s role and expertise, including in time-pressured editorial en- vironments where automation bias poses par ticular risks ( Liu et al. , 2024 ). These pathwa ys are interde- pendent : interoperable standards are a prerequisite for machine-readable com pliance, operational crite- ria are necessar y to ev aluate conformity , and user - centered designs determine whether the human- understandable dimension of dual transparency is achiev ed in practice. T ogether they define the min- imum research agenda needed before Ar t. 50 II enters into force in August 2026. 5. Conclusion Using synthetic data generation and automated fact-checking as diagnostic use cases, this paper shows that Ar t. 50 II compliance cannot be reduced to post-hoc labeling. In synt hetic data pipelines, persistent marking conflicts with model training in- tegrity ; in fact-checking workflows, human editorial intervention destro ys the pro venance chains that machine-readable marking requires, and no equiv- alent architectural solution exists. For RQ1, some Ar t. 50 II requirements are achiev able where outputs can be accompanied by structured pro venance ar t efacts that suppor t cross-syst em v erification. Systematic limitations arise where ver the regulation presupposes mark persistence and robustness under realistic transfor - mations: precisely the conditions both use cases expose. For RQ2, legal understandability diverges from technical e xplainability in that explainabil- ity methods target model behavior rather than in- formed use at the point of access. Legal reliability diverges from quality assurance in that probabilis- tic, non-deterministic LLM outputs cannot pro vide the verifiable consist ency guarantees the regulation implies. The compliance consequence is concret e: treat- ing fluent model-generated rationales as evidence of reliability risks explanation-induced ov erreliance and weakens the regulatory objective of Ar t. 50 II. These findings support the paper’ s central argu- ment : dual transparency mus t be tr eated as an architectural design requirement integrated across the full AI lifecy cle, not a labeling add-on. Closing the three structural gaps identified in Secti on 4 re- quires coordinated action across legal semantics, AI engineering, and human-centered design before Ar t. 50 II enters into force in August 2026. Acknowledgements This research is funded by the F ederal Ministry of Research, T echnology , and Space (BMFTR) in the scope of the research projects news-polygr aph (refer ence: 03RU2U151C), V eraXtract (refer ence: 16IS24066), and BIFOLD project Fak eXplain. Moreo ver , this paper includes work carried out within the AgrifoodTEF-DE project. AgrifoodTEF- DE (reference: 28DZI04A23) is suppor ted by funds of the F ederal Ministry of Agriculture, Food and Re- gional Identity (BMLEH) based on a decision of the P arliament of the Feder al Republic of Germany via the Federal Office for Agriculture and Food (BLE) under the research and innov ation program ’Cli- mate Protection in Agriculture’ . Disclosure: Grammarly , an AI writing assistance tool was used to improv e the or thograph y and gram- mar of sever al paragraphs of te xt. 6. Bibliographical References Gagan Bansal, T ongshuang W u, Joy ce Zhou, Ra ymond Fok, Besmira Nushi, Ece Kamar , Marco T ulio Ribeiro, and Daniel W eld. 2021. Does the whole ex ceed its par ts? the effect of ai explanations on complementar y team per for - mance . In CHI Confer ence on Human F actors in Computing Syst ems . A CM. Matyas Bohacek and Ignacio Vilanov a Echav arri. 2025. Compliance rating scheme: A data prov e- nance framework for generative ai datasets . In Inter national Conference on Multimedia . ACM. Michael Buhrmester , T racy Kwang, and Samuel D. Gosling. 2011. Amazon’s mechanical turk: A new source of inexpensiv e, y et high-quality , data? PERSPECT PS Y CHOL SCI , 6(1). C2P A Steering Committee. 2024. Coalition for con- tent prov enance and authenticity (C2P A) techni- cal specification . Huajie Chen, Chi Liu, Tianqing Zhu, and Wanlei Zhou. 2024. When deep learning meets wat er- marking: A survey of application, attac ks and defenses . C OMP ST AND INTER , 89. European Commission. 2025. Code of practice on transparency of ai-generated content . Draft version, December 2025. Pierre Fernandez, Guillaume Couairon, Her v é Jé- gou, Matthijs Douze, and T eddy Furon. 2023. The stable signature: Rooting watermarks in la- tent diffusion models . In International Confer ence on Computer Vision (ICCV) . IEEE. Timnit Gebru, Jamie Morgens tern, Briana V ec- chione, Jennifer W or tman V aughan, Hanna W allach, Hal Daumé III, and Kate Cra wford. 2021. Datasheets for datasets . COMMUN A CM , 64(12):86–92. Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. 2020. Shor tcut learning in deep neural networks . N a- ture Machine Intelligence , 2(11). Zhijiang Guo, Michael Schlichtkrull, and Andreas Vlachos. 2022. A sur v ey on automat ed fact- checking . T r ansactions of t he Association for Computational Linguistics , 10. Alon Halevy , P eter Nor vig, and Fernando P ereira. 2009. The unreasonable effectiveness of data . IEEE INTELL S Y S T , 24(2). Naeemul Hassan, Fatma Arslan, Chengkai Li, and Mark T r emayne. 2017. T oward automated fact- checking: Det ecting chec k -worthy factual claims by claimbuster . In 23rd ACM SIGKDD Interna- tional Conference on Knowledge Discov ery and Data Mining , KDD ’17, pages 1803–1812. A CM. Ziwei Ji, Na yeon Lee, Rita F rieske, Tiezheng Y u, Dan Su, Y an Xu, Etsuko Ishii, Y e Jin Bang, An- drea Madotto, and P ascale Fung. 2023. Sur v ey of hallucination in natural language generation . A CM COMPUT SUR V , 55(12). Jared Kaplan, Sam McCandlish, T om Henighan, T om B. Brown, Benjamin Chess, Rewon Child, Scott Gray , Alec Radford, Jeffre y Wu, and Dario Amodei. 2020. Scaling laws for neural language models . John Kirchenbauer , Jonas Geiping, Y uxin Wen, Jonathan Katz, Ian Mier s, and T om Goldstein. 2023. A wat ermar k for large language models. arXiv preprint arXiv:2301.10226 . Niklas Kruse and Julius Schöning. 2024. Legal conform data sets for yard tractors and robots . COMPUT ELECTRON A GR , 223:109106. Niklas Kruse and Julius Schöning. 2025. Explain- able and trustwor th y ai compliance for farms . P atric k Lewis, Ethan Perez, Aleksandra Piktus, F abio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrie val-augmented generation for knowledge-intensiv e nlp tasks. AD V NEUR IN , 33:9459–9474. Yifan Li, Xiaohui Y u, and Nick Koudas. 2021. Data acquisition for improving machine learning mod- els . VLDB Endowment , 14(10). Houjiang Liu, Anubrata Das, Ale xander Boltz, Didi Zhou, Daisy Pinaroc, Matthew Lease, and Min K yung Lee. 2024. Human-centered nlp fact- checking: Co-designing with fact-checkers using matchmaking for ai . Proc. ACM Hum.-Comput. Inter act. , 8(CSCW2). Donato Malerba and Vincenzo Pasquadibisceglie. 2024. Data-centric ai . J INTELL INF S Y ST , 62(6). Kat er yna Militsyna. 2025. Can copyright law benefit from the marking requirement of the ai act? IIC- INT REV INTELL P , 56(9):1734–1751. Alhassan Mumuni and Fuseini Mumuni. 2022. Data augmentation: A comprehensive sur ve y of mod- ern approaches . Arra y , 16:100258. Xue Bin P eng, Marcin Andr y chowicz, W ojciech Zaremba, and Pieter Abbeel. 2018. Sim-to-real transfer of robotic control with dynamics random- ization . In IEEE International Conference on Robo tics and Aut omation (ICRA) . IEEE. Bogdana Rak ova, Jingying Y ang, Henriette Cramer , and R umman Cho wdhur y . 2021. Wher e r e- sponsible ai meets reality: Practitioner perspec- tives on enabler s for shif ting organizational prac- tices . A CM on Human-Comput er Inter action , 5(CSCW1). Mats L. Richt er , Julius Schöning, Anna Wiedenroth, and Ulf Krumnac k. 2022. Receptiv e Field Analy - sis for Optimizing Conv olutional Neural Netw ork Archit ectures Without T r aining , pages 235–261. Springer Nature Singapore. Premtim Sahitaj, Iffat Maab, Junichi Y amagishi, Jaw an Kolano wski, Sebastian Möller , and V era Schmitt. 2025. T owards Automat ed Fact- Checking of Real-W orld Claims: Exploring T ask Formulation and Assessment with LLMs . Nithy a Sambasivan, Shivani Kapania, Hannah Highfill, Diana Akrong, Pra veen P aritosh, and Lora M Aroy o. 2021. “ev er yone wants to do the model work, not the data work”: Data cascades in high-stak es ai . In 21 CHI Confer ence on Human F actors in Computing Sys tems , CHI ’21. A CM. Michael Schlichtkrull, Nedjma Ousidhoum, and An- dreas Vlachos. 2023. The Intended Uses of Auto- mated F act-Chec king Ar t efacts: Why, How and Who . V era Schmitt, Isabel Bezzaoui, Charlott Jak ob, Premtim Sahitaj, and Qianli W ang. 2025. Be- yond T ransparency : Evaluating Explainability in AI-Suppor t ed Fact-Checking. V era Schmitt, Aljoscha Burchardt, Jakob T esch, Eva Lopez, Salar Mohtaj, K onstanze Neumann, Tim Polzehl, and Sebastian Möller . 2024a. Im- plications of regulations on large generativ e ai models in the super -election y ear and the im- pact on disinformation. In Legal W orkshop at LREC-COLIN G 2024 . V era Schmitt, Luis-Felipe Villa-Arenas, Nils Feld- hus, Joachim Mey er , Rober t P . Spang, and Se- bastian Moeller . 2024b. The role of explainability in collaborative human-ai disinformation detec- tion. In 24 ACM Conference on F airness, Ac- countability , and T r ansparency . ACM. John C. Simmons and Joseph M. Winograd. 2024. Interoper able prov enance authentication of broadcast media using open standards-based metadata, watermarking and cr yptograph y . Xin T an, Bowei Zou, and Ai Ti Aw . 2025. Improving Explainable Fact-Checking with Claim-Evidence Correlations. In 31st Inter national Conference on Computational Linguistics , pages 1600–1612, Abu Dhabi, UAE. Association for Computational Linguistics. Rama Adithy a V aranasi and Nitesh Goy al. 2023. “it is currently hodgepodge”: Examining ai/ml prac- titioners’ challenges during co-production of re- sponsible ai values . In 23 CHI Confer ence on Human Fact ors in Computing Sys tems . ACM. P aul Wacht er , Niklas Kruse, and Julius Schöning. 2024. Synthetic fields, real gains . P aul W achter , Lukas Niehaus, and Julius Schön- ing. 2025. Dev elopment of Hybrid Ar tificial In- tellig ence T raining on Real and Synthetic Data: Benchmark on T wo Mixed T raining Strategies , pages 175–189. Springer Nature Switzerland. W enbo Wan, Jun W ang, Y unming Zhang, Jing Li, Hui Y u, and Jiande Sun. 2022. A comprehensive sur v ey on robust image watermarking . Neuro- computing , 488:226–247. Mateusz Łabuz. 2024. Deep fak es and the ar tificial intelligence act—an impor tant signal or a missed oppor tunity? Policy & Interne t , 16(4).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment